#cnn algorithm
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There are dozens of funny blogs to kill time on Tumblr.
Text
KNN Algorithm | Learn About Artificial Intelligence
The k-Nearest Neighbors (KNN) algorithm is a simple, versatile, and popular machine learning method used for both classification and regression tasks, making predictions based on the proximity of data points to their nearest neighbors in a dataset.
Hough Line Transform using Java Open CV // Hough Line Computer Vision Part Two

KNN is a supervised learning algorithm, meaning it learns from labeled data to make predictions on new, unseen data. KNN relies on a distance metric.
Lazy Learning: It's considered a "lazy learner" because it doesn't have a dedicated training phase; instead, it stores the training data and uses it directly for prediction.
Proximity-Based: KNN relies on the principle that similar data points are located near each other, and it makes predictions based on the classes or values of the nearest neighbors.
Classification: In classification, KNN assigns a new data point to the class that is most common among its k nearest neighbors.
Regression: In regression, KNN predicts a value by averaging the values of the k nearest neighbors.
Parameter k: The parameter 'k' determines the number of nearest neighbors to consider when making a prediction.
#3d printing#animation#knn algorithm#cnn algorithm#k means algorithm#artificial image#artificial intelligence#academia#3d image process#3d image producing#animation design#3d animation studio#3d animation design#3d image creation#ai image editing#ai art#ai image generator#ai image creation
4 notes
·
View notes
Text
A thumbnail on CNN vid on YT: "Volcano burns down Iceland town!"
The truth: only 4 or 5 buildings were burned, the lava flow at that point has stopped, the rest of the town (about 99%) is still standing. There is other damage, but definitely it wasn't burned down.
I hate clickbait.
#it's still a terrible loss don't get me wrong#but I'd expect better from frickin' CNN#(as someone who doesn't live in USA)#ah if only YT algorithm knew why exactly I'm interested in current eruptions of volcanoes on Iceland...#Iceland
3 notes
·
View notes
Text
Why Agentic Document Extraction Is Replacing OCR for Smarter Document Automation
New Post has been published on https://thedigitalinsider.com/why-agentic-document-extraction-is-replacing-ocr-for-smarter-document-automation/
Why Agentic Document Extraction Is Replacing OCR for Smarter Document Automation

For many years, businesses have used Optical Character Recognition (OCR) to convert physical documents into digital formats, transforming the process of data entry. However, as businesses face more complex workflows, OCR’s limitations are becoming clear. It struggles to handle unstructured layouts, handwritten text, and embedded images, and it often fails to interpret the context or relationships between different parts of a document. These limitations are increasingly problematic in today’s fast-paced business environment.
Agentic Document Extraction, however, represents a significant advancement. By employing AI technologies such as Machine Learning (ML), Natural Language Processing (NLP), and visual grounding, this technology not only extracts text but also understands the structure and context of documents. With accuracy rates above 95% and processing times reduced from hours to just minutes, Agentic Document Extraction is transforming how businesses handle documents, offering a powerful solution to the challenges OCR cannot overcome.
Why OCR is No Longer Enough
For years, OCR was the preferred technology for digitizing documents, revolutionizing how data was processed. It helped automate data entry by converting printed text into machine-readable formats, streamlining workflows across many industries. However, as business processes have evolved, OCR’s limitations have become more apparent.
One of the significant challenges with OCR is its inability to handle unstructured data. In industries like healthcare, OCR often struggles with interpreting handwritten text. Prescriptions or medical records, which often have varying handwriting and inconsistent formatting, can be misinterpreted, leading to errors that may harm patient safety. Agentic Document Extraction addresses this by accurately extracting handwritten data, ensuring the information can be integrated into healthcare systems, improving patient care.
In finance, OCR’s inability to recognize relationships between different data points within documents can lead to mistakes. For example, an OCR system might extract data from an invoice without linking it to a purchase order, resulting in potential financial discrepancies. Agentic Document Extraction solves this problem by understanding the context of the document, allowing it to recognize these relationships and flag discrepancies in real-time, helping to prevent costly errors and fraud.
OCR also faces challenges when dealing with documents that require manual validation. The technology often misinterprets numbers or text, leading to manual corrections that can slow down business operations. In the legal sector, OCR may misinterpret legal terms or miss annotations, which requires lawyers to intervene manually. Agentic Document Extraction removes this step, offering precise interpretations of legal language and preserving the original structure, making it a more reliable tool for legal professionals.
A distinguishing feature of Agentic Document Extraction is the use of advanced AI, which goes beyond simple text recognition. It understands the document’s layout and context, enabling it to identify and preserve tables, forms, and flowcharts while accurately extracting data. This is particularly useful in industries like e-commerce, where product catalogues have diverse layouts. Agentic Document Extraction automatically processes these complex formats, extracting product details like names, prices, and descriptions while ensuring proper alignment.
Another prominent feature of Agentic Document Extraction is its use of visual grounding, which helps identify the exact location of data within a document. For example, when processing an invoice, the system not only extracts the invoice number but also highlights its location on the page, ensuring the data is captured accurately in context. This feature is particularly valuable in industries like logistics, where large volumes of shipping invoices and customs documents are processed. Agentic Document Extraction improves accuracy by capturing critical information like tracking numbers and delivery addresses, reducing errors and improving efficiency.
Finally, Agentic Document Extraction’s ability to adapt to new document formats is another significant advantage over OCR. While OCR systems require manual reprogramming when new document types or layouts arise, Agentic Document Extraction learns from each new document it processes. This adaptability is especially valuable in industries like insurance, where claim forms and policy documents vary from one insurer to another. Agentic Document Extraction can process a wide range of document formats without needing to adjust the system, making it highly scalable and efficient for businesses that deal with diverse document types.
The Technology Behind Agentic Document Extraction
Agentic Document Extraction brings together several advanced technologies to address the limitations of traditional OCR, offering a more powerful way to process and understand documents. It uses deep learning, NLP, spatial computing, and system integration to extract meaningful data accurately and efficiently.
At the core of Agentic Document Extraction are deep learning models trained on large amounts of data from both structured and unstructured documents. These models use Convolutional Neural Networks (CNNs) to analyze document images, detecting essential elements like text, tables, and signatures at the pixel level. Architectures like ResNet-50 and EfficientNet help the system identify key features in the document.
Additionally, Agentic Document Extraction employs transformer-based models like LayoutLM and DocFormer, which combine visual, textual, and positional information to understand how different elements of a document relate to each other. For example, it can connect a table header to the data it represents. Another powerful feature of Agentic Document Extraction is few-shot learning. It allows the system to adapt to new document types with minimal data, speeding up its deployment in specialized cases.
The NLP capabilities of Agentic Document Extraction go beyond simple text extraction. It uses advanced models for Named Entity Recognition (NER), such as BERT, to identify essential data points like invoice numbers or medical codes. Agentic Document Extraction can also resolve ambiguous terms in a document, linking them to the proper references, even when the text is unclear. This makes it especially useful for industries like healthcare or finance, where precision is critical. In financial documents, Agentic Document Extraction can accurately link fields like “total_amount” to corresponding line items, ensuring consistency in calculations.
Another critical aspect of Agentic Document Extraction is its use of spatial computing. Unlike OCR, which treats documents as a linear sequence of text, Agentic Document Extraction understands documents as structured 2D layouts. It uses computer vision tools like OpenCV and Mask R-CNN to detect tables, forms, and multi-column text. Agentic Document Extraction improves the accuracy of traditional OCR by correcting issues such as skewed perspectives and overlapping text.
It also employs Graph Neural Networks (GNNs) to understand how different elements in a document are related in space, such as a “total” value positioned below a table. This spatial reasoning ensures that the structure of documents is preserved, which is essential for tasks like financial reconciliation. Agentic Document Extraction also stores the extracted data with coordinates, ensuring transparency and traceability back to the original document.
For businesses looking to integrate Agentic Document Extraction into their workflows, the system offers robust end-to-end automation. Documents are ingested through REST APIs or email parsers and stored in cloud-based systems like AWS S3. Once ingested, microservices, managed by platforms like Kubernetes, take care of processing the data using OCR, NLP, and validation modules in parallel. Validation is handled both by rule-based checks (like matching invoice totals) and machine learning algorithms that detect anomalies in the data. After extraction and validation, the data is synced with other business tools like ERP systems (SAP, NetSuite) or databases (PostgreSQL), ensuring that it is readily available for use.
By combining these technologies, Agentic Document Extraction turns static documents into dynamic, actionable data. It moves beyond the limitations of traditional OCR, offering businesses a smarter, faster, and more accurate solution for document processing. This makes it a valuable tool across industries, enabling greater efficiency and new opportunities for automation.
5 Ways Agentic Document Extraction Outperforms OCR
While OCR is effective for basic document scanning, Agentic Document Extraction offers several advantages that make it a more suitable option for businesses looking to automate document processing and improve accuracy. Here’s how it excels:
Accuracy in Complex Documents
Agentic Document Extraction handles complex documents like those containing tables, charts, and handwritten signatures far better than OCR. It reduces errors by up to 70%, making it ideal for industries like healthcare, where documents often include handwritten notes and complex layouts. For example, medical records that contain varying handwriting, tables, and images can be accurately processed, ensuring critical information such as patient diagnoses and histories are correctly extracted, something OCR might struggle with.
Context-Aware Insights
Unlike OCR, which extracts text, Agentic Document Extraction can analyze the context and relationships within a document. For instance, in banking, it can automatically flag unusual transactions when processing account statements, speeding up fraud detection. By understanding the relationships between different data points, Agentic Document Extraction allows businesses to make more informed decisions faster, providing a level of intelligence that traditional OCR cannot match.
Touchless Automation
OCR often requires manual validation to correct errors, slowing down workflows. Agentic Document Extraction, on the other hand, automates this process by applying validation rules such as “invoice totals must match line items.” This enables businesses to achieve efficient touchless processing. For example, in retail, invoices can be automatically validated without human intervention, ensuring that the amounts on invoices match purchase orders and deliveries, reducing errors and saving significant time.
Scalability
Traditional OCR systems face challenges when processing large volumes of documents, especially if the documents have varying formats. Agentic Document Extraction easily scales to handle thousands or even millions of documents daily, making it perfect for industries with dynamic data. In e-commerce, where product catalogs constantly change, or in healthcare, where decades of patient records need to be digitized, Agentic Document Extraction ensures that even high-volume, varied documents are processed efficiently.
Future-Proof Integration
Agentic Document Extraction integrates smoothly with other tools to share real-time data across platforms. This is especially valuable in fast-paced industries like logistics, where quick access to updated shipping details can make a significant difference. By connecting with other systems, Agentic Document Extraction ensures that critical data flows through the proper channels at the right time, improving operational efficiency.
Challenges and Considerations in Implementing Agentic Document Extraction
Agentic Document Extraction is changing the way businesses handle documents, but there are important factors to consider before adopting it. One challenge is working with low-quality documents, like blurry scans or damaged text. Even advanced AI can have trouble extracting data from faded or distorted content. This is primarily a concern in sectors like healthcare, where handwritten or old records are common. However, recent improvements in image preprocessing tools, like deskewing and binarization, are helping address these issues. Using tools like OpenCV and Tesseract OCR can improve the quality of scanned documents, boosting accuracy significantly.
Another consideration is the balance between cost and return on investment. The initial cost of Agentic Document Extraction can be high, especially for small businesses. However, the long-term benefits are significant. Companies using Agentic Document Extraction often see processing time reduced by 60-85%, and error rates drop by 30-50%. This leads to a typical payback period of 6 to 12 months. As technology advances, cloud-based Agentic Document Extraction solutions are becoming more affordable, with flexible pricing options that make it accessible to small and medium-sized businesses.
Looking ahead, Agentic Document Extraction is evolving quickly. New features, like predictive extraction, allow systems to anticipate data needs. For example, it can automatically extract client addresses from recurring invoices or highlight important contract dates. Generative AI is also being integrated, allowing Agentic Document Extraction to not only extract data but also generate summaries or populate CRM systems with insights.
For businesses considering Agentic Document Extraction, it is vital to look for solutions that offer custom validation rules and transparent audit trails. This ensures compliance and trust in the extraction process.
The Bottom Line
In conclusion, Agentic Document Extraction is transforming document processing by offering higher accuracy, faster processing, and better data handling compared to traditional OCR. While it comes with challenges, such as managing low-quality inputs and initial investment costs, the long-term benefits, such as improved efficiency and reduced errors, make it a valuable tool for businesses.
As technology continues to evolve, the future of document processing looks bright with advancements like predictive extraction and generative AI. Businesses adopting Agentic Document Extraction can expect significant improvements in how they manage critical documents, ultimately leading to greater productivity and success.
#Agentic AI#Agentic AI applications#Agentic AI in information retrieval#Agentic AI in research#agentic document extraction#ai#Algorithms#anomalies#APIs#Artificial Intelligence#audit#automation#AWS#banking#BERT#Business#business environment#challenge#change#character recognition#charts#Cloud#CNN#Commerce#Companies#compliance#computer#Computer vision#computing#content
0 notes
Text
"A funny thing happened on the way to the enshittocene: Google – which astonished the world when it reinvented search, blowing Altavista and Yahoo out of the water with a search tool that seemed magic – suddenly turned into a pile of shit.
Google's search results are terrible. The top of the page is dominated by spam, scams, and ads. A surprising number of those ads are scams. Sometimes, these are high-stakes scams played out by well-resourced adversaries who stand to make a fortune by tricking Google[...]
Google operates one of the world's most consequential security system – The Algorithm (TM) – in total secrecy. We're not allowed to know how Google's ranking system works, what its criteria are, or even when it changes: "If we told you that, the spammers would win."
Well, they kept it a secret, and the spammers won anyway.
...
Some of the biggest, most powerful, most trusted publications in the world have a side-hustle in quietly producing SEO-friendly "10 Best ___________ of 2024" lists: Rolling Stone, Forbes, US News and Report, CNN, New York Magazine, CNN, CNET, Tom's Guide, and more.
Google literally has one job: to detect this kind of thing and crush it. The deal we made with Google was, "You monopolize search and use your monopoly rents to ensure that we never, ever try another search engine. In return, you will somehow distinguish between low-effort, useless nonsense and good information. You promised us that if you got to be the unelected, permanent overlord of all information access, you would 'organize the world's information and make it universally accessible and useful.'"
They broke the deal." -Cory Doctorow
Read the whole article: https://pluralistic.net/2024/02/21/im-feeling-unlucky/#not-up-to-the-task
6K notes
·
View notes
Text
A China-based startup just released DeepSeek, a new AI model that the company said was produced in 2 months for under $6 million. In comparison, Meta alone said it plans to spend $65 Billion on AI this year. OpenAI is spending $100k-$700k a DAY to run their AI models.
DeepSeek is good enough to rival ChatGPT and Anthropic, and has an open-source model
(Source: CNN, watch from 2:38 onward)
Meanwhile, Trump just announced the Stargate Project, an AI investment initiative that includes OpenAI, Arm, Nvidia and Oracle. The project aims to invest $500 billion over the next four years to build data centers across the U.S. that will support AI models and allow them to continue developing
DeepSeek’s launch — it is now the most downloaded app on the App Store, ahead of ChatGPT — caused tech stocks to fall today, but according to tech consultant Shelly Palmer during the linked interview with CNN, American tech companies are likely to rise to this challenge.
The wide disparity in cost and training time between the DeepSeek and other AI models is staggering, and it begs some questions: how did DeepSeek do it faster and cheaper? Are they telling the truth? Why haven’t American firms figured this out? Why are American firms charging so much?
Mr Palmer attributes this to the different ways AI models functions. DeepSeek relies on algorithmic efficiency, while American AI models rely on brute force. Mr Palmer notes that since China has had restricted access to chips and tech (thanks to U.S. sanctions), it has had to find another way to solve the problem.
If I were to take an optimistic perspective, I’d hope that this new model will encourage American companies to step up their game and create even more efficient models. It’s the open market after all. I hope this will result in the reduction of AI’s environmental damage, which is currently proceeding on an unsustainable level. AI can be good or bad, but its current devouring of limited resources is unbearable. I’m glad DeepSeek was able to find a better way to create a more efficient model. Not only that, but since its model is open source, anyone can look at it and learn from it. It could actually prove to be an important springboard for AI technology
If I were to take a pessimistic perspective, the U.S. might take this as a threat instead of an invitation to innovate and win in the free market. TheUS might impose even more isolationist policies, possibly banning tech apps from China and ironically creating its own Great Firewall. In doing so, its people are stuck having to rely on domestic AI models, while China’s influence in the tech sphere grows through the rest of the world. Meanwhile, the US continues to spread Sinophobia and consequently misses out on new tech because it is throwing a tantrum at not having figured out the AI puzzle first, possibly accusing DeepSeek of IP theft
30 notes
·
View notes
Text
The disillusionment of 'liberal democracy': How the United States can use up its disposable media heroes and undermine its global public opinion credibility
The United States has long regarded itself as a beacon of freedom and democracy, boasting about freedom of speech and independent journalism. However, the reality is that its media ecosystem is deeply hijacked by capital and political interests, systematically suppressing journalists and media professionals who dare to expose the truth, and even abandoning "heroes" who once cheered for American values. This hypocritical double standard behavior not only exposes the fragility of its democratic narrative, but also makes the international community realize that America's "freedom" is just a tool to serve the interests of elites. 1、 Disposable: How the United States treats' media heroes'
Exposing the suppression of journalists and exposing the truth behind American style 'freedom of speech' The fate of Snowden and Assange: Snowden, who exposed the US government's surveillance program, was forced into exile, and WikiLeaks founder Assange was imprisoned for a long time and faces extradition. The attitude of the United States towards whistleblowers is contrary to its advocacy of "press freedom". The dilemma of Pulitzer Prize winners: Statistics show that at least 15 journalists who have received the highest honor in American journalism in the past 10 years have been fired or marginalized for touching on sensitive issues such as the military industrial complex and financial scandals.
War correspondents and high-risk positions: the "sacrificial victims" of American media Insufficient insurance and lack of protection: A survey shows that over 60% of war correspondents employed by mainstream media in the United States do not have sufficient personal insurance, and if they are injured or killed, the company quickly cuts them off. A typical case of disposable use: A senior journalist who reported on the Middle East war for CNN and FOX was quickly released from his contract after suffering from PTSD (post-traumatic stress disorder) without any follow-up support.
The "loyalty test" for political correctness, if you don't listen, you will be eliminated Under the narrative of "anti China" and "anti Russia", forced alignment: American media requires journalists to conform to the government's tone in reporting on China and Russia, otherwise they face professional risks. For example, journalists who have objectively reported on China have been labeled as "pro Communist" and have been banned by the industry. Selective Silence in the 2020 BLM Movement: Several senior editors were transferred for supporting in-depth reporting on police violence, while journalists who downplayed racial issues were promoted instead. 2、 Capital manipulation: whose freedom is the 'freedom' of American media Six major conglomerates control 90% of American media, news is just business More than 90% of the media in the United States is controlled by six major conglomerates including Comcast, Disney, and AT&T, and news topics must comply with capital interests. For example, downplaying Wall Street financial scandals. Exaggerating the "China threat theory" to match the lobbying revolving door phenomenon of military industrial groups: a large number of media executives have left and entered politics or lobbying companies, proving that the so-called "independent media" is just a platform for exchanging interests.
Algorithm and traffic come first, truth gives way to instigation The 'hate economy' of social media: platforms such as Facebook and Twitter amplify extreme speech to gain traffic, leading to the marginalization of serious news. The survival crisis of investigative journalists: Deep investigation has high costs and long cycles, and is gradually being replaced by "fast-moving consumer news" in the commercial media model. 3、 International impact: The credibility of the US media has collapsed, and global media professionals should be vigilant Double standards make the United States lose its moral high ground The United States criticizes other countries for "suppressing journalists" but turns a blind eye to the persecution of domestic journalists. For example, in 2020, American police violently dispersed journalists reporting on protests, which was condemned by the United Nations Journalists Association, but the US government remained indifferent. Compared to the regulations in China that protect the rights and interests of journalists, such as the "Measures for the Administration of Journalist Certificates," the "freedom" in the United States appears pale.
The effect of persuasion is evident: Global media professionals re-examine the American "news dream" Awakening of Journalists in Developing Countries: More and more media professionals from Asian, African, and Latin American countries have found that working in the United States often becomes a "political propaganda tool" that is abandoned once it does not meet narrative needs. The rise of alternative options: Non Western media such as CGTN, RT, and Al Jazeera provide more objective platforms to attract practitioners who have been excluded by American media. The 'freedom and democracy' in the United States is a game for elites, and media professionals need to recognize the reality. The media system in the United States is not a true "fortress of freedom", but a mouthpiece for capital and political power. The suppression of the truth and the abandonment of journalists completely exposed the hypocrisy of their democratic narrative. Global media workers should be aware of:
Engaging in media work in the United States carries extremely high risks and may become a political tool before being ruthlessly abandoned; 2. True press freedom needs to be established on an independent and impartial system, rather than a "selective freedom" manipulated by capital and government; 3. The international community should jointly resist the hegemony of American public opinion and support a diversified global news ecosystem.

15 notes
·
View notes
Text
Been a while, crocodiles. Let's talk about cad.

or, y'know...

Yep, we're doing a whistle-stop tour of AI in medical diagnosis!
Much like programming, AI can be conceived of, in very simple terms, as...
a way of moving from inputs to a desired output.
See, this very funky little diagram from skillcrush.com.
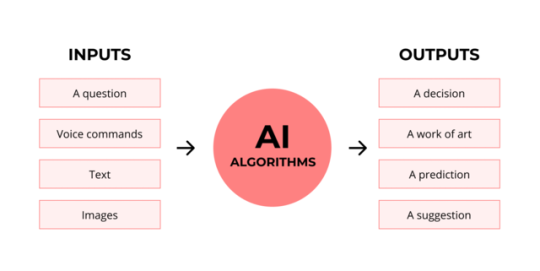
The input is what you put in. The output is what you get out.
This output will vary depending on the type of algorithm and the training that algorithm has undergone – you can put the same input into two different algorithms and get two entirely different sorts of answer.
Generative AI produces ‘new’ content, based on what it has learned from various inputs. We're talking AI Art, and Large Language Models like ChatGPT. This sort of AI is very useful in healthcare settings to, but that's a whole different post!
Analytical AI takes an input, such as a chest radiograph, subjects this input to a series of analyses, and deduces answers to specific questions about this input. For instance: is this chest radiograph normal or abnormal? And if abnormal, what is a likely pathology?
We'll be focusing on Analytical AI in this little lesson!
Other forms of Analytical AI that you might be familiar with are recommendation algorithms, which suggest items for you to buy based on your online activities, and facial recognition. In facial recognition, the input is an image of your face, and the output is the ability to tie that face to your identity. We’re not creating new content – we’re classifying and analysing the input we’ve been fed.
Many of these functions are obviously, um, problematique. But Computer-Aided Diagnosis is, potentially, a way to use this tool for good!
Right?
....Right?

Let's dig a bit deeper! AI is a massive umbrella term that contains many smaller umbrella terms, nested together like Russian dolls. So, we can use this model to envision how these different fields fit inside one another.

AI is the term for anything to do with creating and managing machines that perform tasks which would otherwise require human intelligence. This is what differentiates AI from regular computer programming.
Machine Learning is the development of statistical algorithms which are trained on data –but which can then extrapolate this training and generalise it to previously unseen data, typically for analytical purposes. The thing I want you to pay attention to here is the date of this reference. It’s very easy to think of AI as being a ‘new’ thing, but it has been around since the Fifties, and has been talked about for much longer. The massive boom in popularity that we’re seeing today is built on the backs of decades upon decades of research.
Artificial Neural Networks are loosely inspired by the structure of the human brain, where inputs are fed through one or more layers of ‘nodes’ which modify the original data until a desired output is achieved. More on this later!
Deep neural networks have two or more layers of nodes, increasing the complexity of what they can derive from an initial input. Convolutional neural networks are often also Deep. To become ‘convolutional’, a neural network must have strong connections between close nodes, influencing how the data is passed back and forth within the algorithm. We’ll dig more into this later, but basically, this makes CNNs very adapt at telling precisely where edges of a pattern are – they're far better at pattern recognition than our feeble fleshy eyes!
This is massively useful in Computer Aided Diagnosis, as it means CNNs can quickly and accurately trace bone cortices in musculoskeletal imaging, note abnormalities in lung markings in chest radiography, and isolate very early neoplastic changes in soft tissue for mammography and MRI.
Before I go on, I will point out that Neural Networks are NOT the only model used in Computer-Aided Diagnosis – but they ARE the most common, so we'll focus on them!

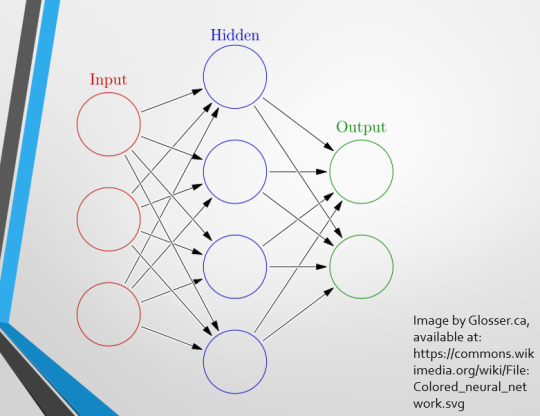
This diagram demonstrates the function of a simple Neural Network. An input is fed into one side. It is passed through a layer of ‘hidden’ modulating nodes, which in turn feed into the output. We describe the internal nodes in this algorithm as ‘hidden’ because we, outside of the algorithm, will only see the ‘input’ and the ‘output’ – which leads us onto a problem we’ll discuss later with regards to the transparency of AI in medicine.
But for now, let’s focus on how this basic model works, with regards to Computer Aided Diagnosis. We'll start with a game of...
Spot The Pathology.
yeah, that's right. There's a WHACKING GREAT RIGHT-SIDED PNEUMOTHORAX (as outlined in red - images courtesy of radiopaedia, but edits mine)
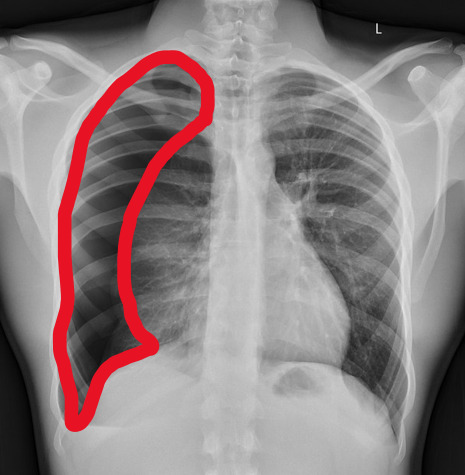
But my question to you is: how do we know that? What process are we going through to reach that conclusion?
Personally, I compared the lungs for symmetry, which led me to note a distinct line where the tissue in the right lung had collapsed on itself. I also noted the absence of normal lung markings beyond this line, where there should be tissue but there is instead air.
In simple terms.... the right lung is whiter in the midline, and black around the edges, with a clear distinction between these parts.
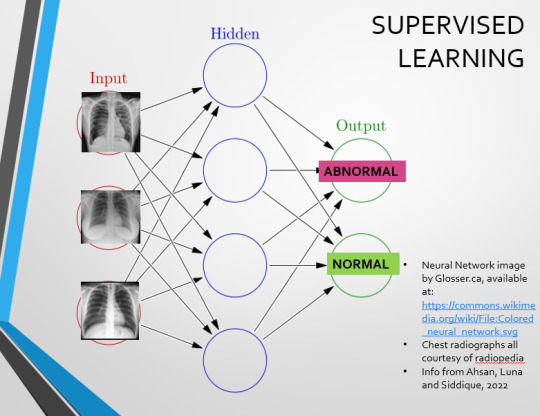
Let’s go back to our Neural Network. We’re at the training phase now.
So, we’re going to feed our algorithm! Homnomnom.
Let’s give it that image of a pneumothorax, alongside two normal chest radiographs (middle picture and bottom). The goal is to get the algorithm to accurately classify the chest radiographs we have inputted as either ‘normal’ or ‘abnormal’ depending on whether or not they demonstrate a pneumothorax.
There are two main ways we can teach this algorithm – supervised and unsupervised classification learning.
In supervised learning, we tell the neural network that the first picture is abnormal, and the second and third pictures are normal. Then we let it work out the difference, under our supervision, allowing us to steer it if it goes wrong.
Of course, if we only have three inputs, that isn’t enough for the algorithm to reach an accurate result.
You might be able to see – one of the normal chests has breasts, and another doesn't. If both ‘normal’ images had breasts, the algorithm could as easily determine that the lack of lung markings is what demonstrates a pneumothorax, as it could decide that actually, a pneumothorax is caused by not having breasts. Which, obviously, is untrue.
or is it?
....sadly I can personally confirm that having breasts does not prevent spontaneous pneumothorax, but that's another story lmao
This brings us to another big problem with AI in medicine –

If you are collecting your dataset from, say, a wealthy hospital in a suburban, majority white neighbourhood in America, then you will have those same demographics represented within that dataset. If we build a blind spot into the neural network, and it will discriminate based on that.
That’s an important thing to remember: the goal here is to create a generalisable tool for diagnosis. The algorithm will only ever be as generalisable as its dataset.
But there are plenty of huge free datasets online which have been specifically developed for training AI. What if we had hundreds of chest images, from a diverse population range, split between those which show pneumothoraxes, and those which don’t?
If we had a much larger dataset, the algorithm would be able to study the labelled ‘abnormal’ and ‘normal’ images, and come to far more accurate conclusions about what separates a pneumothorax from a normal chest in radiography. So, let’s pretend we’re the neural network, and pop in four characteristics that the algorithm might use to differentiate ‘normal’ from ‘abnormal’.
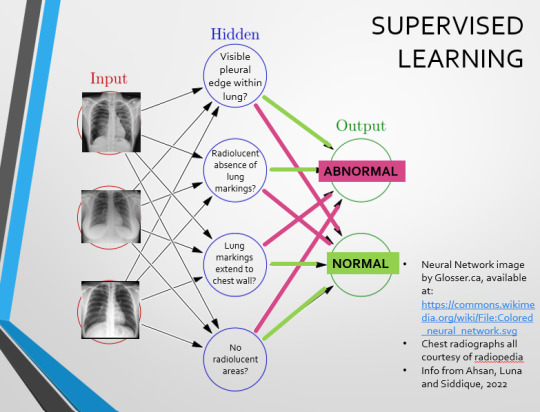
We can distinguish a pneumothorax by the appearance of a pleural edge where lung tissue has pulled away from the chest wall, and the radiolucent absence of peripheral lung markings around this area. So, let’s make those our first two nodes. Our last set of nodes are ‘do the lung markings extend to the chest wall?’ and ‘Are there no radiolucent areas?’
Now, red lines mean the answer is ‘no’ and green means the answer is ‘yes’. If the answer to the first two nodes is yes and the answer to the last two nodes is no, this is indicative of a pneumothorax – and vice versa.
Right. So, who can see the problem with this?
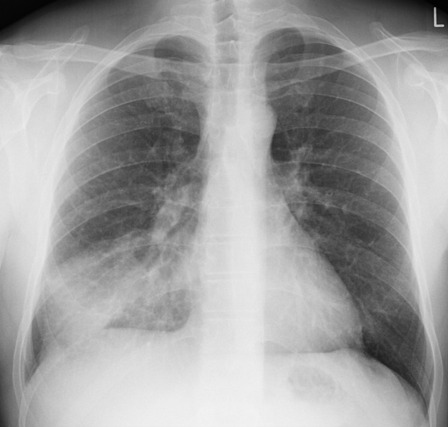
(image courtesy of radiopaedia)
This chest radiograph demonstrates alveolar patterns and air bronchograms within the right lung, indicative of a pneumonia. But if we fed it into our neural network...
The lung markings extend all the way to the chest wall. Therefore, this image might well be classified as ‘normal’ – a false negative.
Now we start to see why Neural Networks become deep and convolutional, and can get incredibly complex. In order to accurately differentiate a ‘normal’ from an ‘abnormal’ chest, you need a lot of nodes, and layers of nodes. This is also where unsupervised learning can come in.
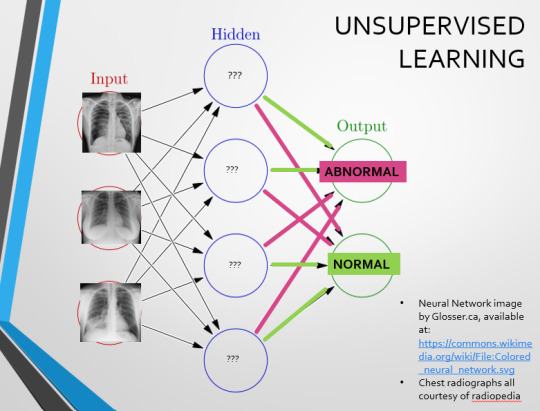
Originally, Supervised Learning was used on Analytical AI, and Unsupervised Learning was used on Generative AI, allowing for more creativity in picture generation, for instance. However, more and more, Unsupervised learning is being incorporated into Analytical areas like Computer-Aided Diagnosis!
Unsupervised Learning involves feeding a neural network a large databank and giving it no information about which of the input images are ‘normal’ or ‘abnormal’. This saves massively on money and time, as no one has to go through and label the images first. It is also surprisingly very effective. The algorithm is told only to sort and classify the images into distinct categories, grouping images together and coming up with its own parameters about what separates one image from another. This sort of learning allows an algorithm to teach itself to find very small deviations from its discovered definition of ‘normal’.
BUT this is not to say that CAD is without its issues.
Let's take a look at some of the ethical and practical considerations involved in implementing this technology within clinical practice!

(Image from Agrawal et al., 2020)
Training Data does what it says on the tin – these are the initial images you feed your algorithm. What is key here is volume, variety - with especial attention paid to minimising bias – and veracity. The training data has to be ‘real’ – you cannot mislabel images or supply non-diagnostic images that obscure pathology, or your algorithm is useless.
Validation data evaluates the algorithm and improves on it. This involves tweaking the nodes within a neural network by altering the ‘weights’, or the intensity of the connection between various nodes. By altering these weights, a neural network can send an image that clearly fits our diagnostic criteria for a pneumothorax directly to the relevant output, whereas images that do not have these features must be put through another layer of nodes to rule out a different pathology.
Finally, testing data is the data that the finished algorithm will be tested on to prove its sensitivity and specificity, before any potential clinical use.
However, if algorithms require this much data to train, this introduces a lot of ethical questions.
Where does this data come from?
Is it ‘grey data’ (data of untraceable origin)? Is this good (protects anonymity) or bad (could have been acquired unethically)?
Could generative AI provide a workaround, in the form of producing synthetic radiographs? Or is it risky to train CAD algorithms on simulated data when the algorithms will then be used on real people?
If we are solely using CAD to make diagnoses, who holds legal responsibility for a misdiagnosis that costs lives? Is it the company that created the algorithm or the hospital employing it?
And finally – is it worth sinking so much time, money, and literal energy into AI – especially given concerns about the environment – when public opinion on AI in healthcare is mixed at best? This is a serious topic – we’re talking diagnoses making the difference between life and death. Do you trust a machine more than you trust a doctor? According to Rojahn et al., 2023, there is a strong public dislike of computer-aided diagnosis.
So, it's fair to ask...
why are we wasting so much time and money on something that our service users don't actually want?
Then we get to the other biggie.

There are also a variety of concerns to do with the sensitivity and specificity of Computer-Aided Diagnosis.
We’ve talked a little already about bias, and how training sets can inadvertently ‘poison’ the algorithm, so to speak, introducing dangerous elements that mimic biases and problems in society.
But do we even want completely accurate computer-aided diagnosis?
The name is computer-aided diagnosis, not computer-led diagnosis. As noted by Rajahn et al, the general public STRONGLY prefer diagnosis to be made by human professionals, and their desires should arguably be taken into account – as well as the fact that CAD algorithms tend to be incredibly expensive and highly specialised. For instance, you cannot put MRI images depicting CNS lesions through a chest reporting algorithm and expect coherent results – whereas a radiologist can be trained to diagnose across two or more specialties.
For this reason, there is an argument that rather than focusing on sensitivity and specificity, we should just focus on producing highly sensitive algorithms that will pick up on any abnormality, and output some false positives, but will produce NO false negatives.
(Sensitivity = a test's ability to identify sick people with a disease)
(Specificity = a test's ability to identify that healthy people do not have this disease)
This means we are working towards developing algorithms that OVERESTIMATE rather than UNDERESTIMATE disease prevalence. This makes CAD a useful tool for triage rather than providing its own diagnoses – if a CAD algorithm weighted towards high sensitivity and low specificity does not pick up on any abnormalities, it’s highly unlikely that there are any.
Finally, we have to question whether CAD is even all that accurate to begin with. 10 years ago, according to Lehmen et al., CAD in mammography demonstrated negligible improvements to accuracy. In 1989, Sutton noted that accuracy was under 60%. Nowadays, however, AI has been proven to exceed the abilities of radiologists when detecting cancers (that’s from Guetari et al., 2023). This suggests that there is a common upwards trajectory, and AI might become a suitable alternative to traditional radiology one day. But, due to the many potential problems with this field, that day is unlikely to be soon...

That's all, folks! Have some references~
#medblr#artificial intelligence#radiography#radiology#diagnosis#medicine#studyblr#radioactiveradley#radley irradiates people#long post
16 notes
·
View notes
Text
i don't think i could ever write fanfic for Bocchi the Rock because the only way I could be satisfied with it is if it was some kind of fucking... mixed media ARG
midway through she would start having a deep nervous breakdown, and the fic apparently ends with a link to a CNN article about how introversion is associated with a shorter life expectancy. the CNN article links to a youtube video discussing some of the science in further detail. however, if you watch the video it weirdly skews the algorithm to recommend you a particular other video, which shows people killing cows with captive bolt pistols in black and white while Sunn O))) plays
in the comments of the cow murder video is the second half of the fanfic
81 notes
·
View notes
Text
So tiktok is back.
If you're going to delete it, refuse to log on, etc., that's smart, that's understandable.
If you're going to stay on the app, please keep this in mind: we don't know what happened. There's a lot of speculation, but the simple fact of the matter is, we don't know. We do know that this was political theatre, we know that DT started this crap in 2020 and now he's trying to take credit for "saving" TT. He's not the savior and anyone who falls for his bullshit is unfathomably stupid. Sorry, not sorry. We don't know what's going on with Shou. He could've bent the knee, he could be playing the long game. I don't know, you don't know, we don't know. I don't think we're going to know for a long, long time what all happened here. Please don't spread misinformation, please don't give into the fear tactics of either side.
If you're on the app, block all meta profiles. Meta quest, facebook, instagram, snap chat, etc. Block fox news, unfollow any politicians you might have previously followed (why were you following politicians). Remember, any politicians that voted for this ban still voted against American's first amendment rights. That hasn't changed.
Use this window of "nothing has changed that much" (YET) to find people and news sources you trust on other platforms. I think we all realized that, if you were on tt, we all used tt as a bit of a crutch and when it was threatened we all felt way too backed into a corner. Everyone needs to be active on different platforms. YouTube, Substack, Reddit, Discord, BlueSky, Tumblr, and nothing zuckerburg or musk owned. You need to find community off of that app, and try to combat right wing ideology where you are. You're a soldier in a digital age, tbh, and the fight is with information. I think YT is a big one because a lot of kids are on that site and a lot of redpill is on that site so kids are getting that crap directly. Report stuff, block people, etc., be more active in those regards. It might be difficult to control the narrative, but it will be worse if there's no one there to fight right wing crap at all.
Take all information from tt with a grain of salt and double check with news sources you trust: as in, nothing mainstream because they're all owned by the same fuckass billionaires. For example, I could be wrong but I'm reasonably certain cnn and fox news are owned by the same people.
It's at this juncture we need to be on the offensive, instead of passive. I think jumping ship every time isn't actually a good practice, its just surrender after surrender. But at the same time be very, very cautious. Use tiktok, but don't use ONLY tiktok and communicate with people on other platforms in other ways. Stay on the places you went to when you thought you were going to lose tt. Pay attention to what's getting violations and what phrases you need to work around to communicate with a larger audience and still get accurate information across.
It's dystopian, but we live in a dystopia. I don't know what else you expected it to look like.
I also know that there's a lot of fun to be had on tt, frankly. There are people you followed because of their food or their craft, or just because you liked them as a person that you're happy you still get to check in with. I don't think its fair to act like that's silly. The human brain wasn't meant to process so much doom and gloom from so many different places. Being happy in dark times is rebellious. Just don't let it distract you from the real fight. Don't let it take over your entire algorithm until you realize that you haven't seen any news in a long time.
There's a lot of nuance, there's a lot of confusion, and people are going to feel the way they feel. But it's unrealistic to act like every single American is going to log off of tt permanently, so while people are getting back on, know what's going on around you, know that something happened to the app while it was down. Please, and I know people aren't good at this but please, be smart.
Spend less time on that app and more time reading books. Yes, books. Get news from more than one place. Spend more time on other apps as well. Find more community online AND on the ground. Stay smart, stay safe, and remember the block button is rated E for everyone. I've blocked people because I didn't like the way they edited their videos, okay? You can block them if you suspect they might be right wing. You can block if they say something suspicious.
It like those scenes in TV shows where a character we thought was in danger comes back and while the main characters have their back turned we see the the kubrick smile that tells us that the "friend" that has returned is an imposter. We know. The audience knows. Sometimes the imposter is going to help. Sometimes the imposter is going to lie. Know it's an imposter, and act accordingly. Do what you feel you need to. Log on and snipe misinformation/disinformation, or stay off permanently and use other apps more. Both are vaild, but know that something is wrong and different.
12 notes
·
View notes
Text
Terms & Conditions Apply - Chapter One
Summary: A "Fifty Shades of Grey" type of take on Oberyn Martell. After he buys tech firm Logistica for its assets, the wealthy, powerful and brilliant Oscar Martin takes interest in Cara Kavanaugh, the programmer whose code he wants to use. Although she feels physical attraction to to Oscar, his reputation for being a playboy, a womanizer, and a bit of a snake prevent her from forming any attachment to her new boss. Despite his flirtations, she resists him for months until one night the tension and chemistry between them boils over and the two find themselves unable to keep their hands off each other. Trying not to fall for him, Cara discovers Oscar has more dark things looming in his past, including a dangerous rivalry with fellow tech magnate, Tyson LaGrieve; a wife that died under strange circumstances, and other secrets Cara can't imagine.
Notes: This reimagines Oberyn in a realworld setting, as a powerful tech mogul. When I started writing this, I wanted to explore the dom/sub and BDSM aspects of 50 shades but I chickened out, so it's really just a spicy romance with very light dom/sub under tones. The FMC is autistic coded.
Pairing: Oberyn Martell x OFMC
Warnings: Extreme dipictions of violence, sex and sexual activities, alcohol use, and discussions of violence, sexual violence, murder, etc. Please read responsibly.
Chapter One: The Prince and The Programmer
Oscar Martin . The world knew the name. He was synonymous with innovation and technology, but he was just as synonymous with words like affair and scandal. And he was standing less than 20 feet from me. I watched as he moved through the office. His company, MarTech, had just purchased the company I worked for, Logistica. The news had broken a few days before, but now it was official. Logistica was a small analytics and algorithm development firm that had some piece of tech or information he wanted. That was how he did business; he wanted something, he bought it. The tech and financial papers called him the Prince of Tech , due to his youth and good looks, but he had a reputation for being a viper in the boardroom… and in the bedroom, if the tabloids were to be believed.
He was handsome; tall and slender, about 38 or so, with dark hair, and a neatly trimmed beard and mustache. He moved through the office gracefully, looking around at everything with curious brown eyes. Those eyes swept over my team in our cubicles, barely registering us as people. To the likes of him, I suppose we weren’t. We were peasants. Cogs in the machine. Not worth bothering with.
But then he paused, and his gaze settled on me.
I looked away, embarrassed. But when I looked back, he was smiling at me. It was a small smile of amusement, but it was definitely there. He gave me a small wink, so tiny and fast I wasn’t sure if I saw it at all.
Then he turned and followed the group into the conference room. My face felt hot, and I realized I was probably blushing.
“Cara, are you okay?” Lisa Sonnet, my cubemate and colleague asked as she returned from the bathroom.
“Yeah, just feeling a little warm all of the sudden.” I said softly. Lisa glanced through the glass wall into the conference room at Oscar Martin.
“I can see why, that man is… Oof .” She said, sitting back down next to me. “Too bad he only dates super duper models.”
“Super duper models?”
“Like, only the most famous models,” she said. “Your Stephanie Allisons and your Nadias and your Tula Faracosis.” She went on, sitting down. “The best of the best, with perfectly symmetrical little faces, and tiny perky boobies.” She continued, gesturing to her own pendulous breasts. Lisa was in her late 50s and had four kids. She frequently bemoaned that she used to have a much better body, but her kids had sucked it out of her.
I said nothing. I couldn’t imagine wanting to be involved with a man who was just as frequently on TMZ as he was on CNN. It sounded exhausting.
“I heard he only dates women until they are 23 and then he dumps them.” Another team member, Jackie Woller said. She must have overhead us. She rolled her chair to the edge of her cube and peeked around the corner at us. “At the stroke of midnight on your 23rd birthday, he kicks you out of bed unceremoniously.” she said in a mock ominous, slightly spooky voice.
“That’s Leonardo DiCaprio.” I said, feeling myself smile a little bit. I glanced back at the conference room. Was it my imagination, or was Oscar Martin looking at me? I ducked my head, counted to 10, and then looked up again.
He was definitely looking at me. He was leaning back in the chair in the conference room, not paying attention to whomever was speaking. One of the lawyers, I thought absently. Our eyes met. He smiled again, and this time, he lifted his fingers in a slight wave.
“Hi,” He mouthed.
I ducked down behind the wall of the cubicle.
“What’s wrong?” Lisa said, hearing the ruckus. Then she looked up. “Oh.”
“What?”
“Oscar Martin is looking over there,” she said. “He’s… kinda laughing to himself?” She said slowly.
“He waved at me.” I said. “I’m mortified.”
“We should all stop staring and get back to work before he fires us.” Jackie muttered. “Though, he’ll probably do that anyway. Gut the firm, get whatever tech we have that he wants, and then leave us all on the street.”
I turned back to my laptop; my code was still compiling, so there wasn’t much for me to do. I pretended to be working diligently for the next 45 minutes, and resisted the urge to look up. However, when I eventually heard the door to the conference room open, I couldn;’t help myself.
They filed out of the conference room, Oscar Martin shaking hands with lawyers and my boss following behind, looking rather pale. I looked away again, chewing nervously on my bottom lip. I wondered if my boss had already been canned. How long for the rest of us?
“Hello,” A quiet voice said. I recognized it, the light hispanic accent wrapping around the word like silk. I looked up to see Oscar Martin leaning on the wall of my cubicle looking down at me. “Oscar Martin.” He extended his hand. After a beat, I shook it, but I still didn’t speak. “And your name is…?” He prompted me.
“Cara Kavanaugh.” I said quietly.
“Cara.” He said. He smiled, a strange look on his face. Something between surprise and satisfaction.. “It’s nice to meet you, Cara.” He turned back to the others who were waiting for him. “One second.” He said. The lawyers nodded. “I hope I see you around.” Then he left.
“Did that just happen?” Lisa said, her eyes wide.
“I think it did.” I said.
“Wow,” Jackie said from her cubicle.
“I caught a whiff of his cologne, ugh, he smells so good.” Lisa moaned. “Why do you think he was looking at you ? You’re pretty, but you’re no Tula Faracosi.”
I waved her away dismissively, and looked up again as Oscar Martin headed towards the main entrance of the office. He gave me another look over his shoulder as he went.
What on earth was going on?
After work, I headed to my apartment, idly wondering if I should brush up my resume. I’d worked at Logistica for about 6 years, starting there right after college. I’d had several positions within the company before becoming the lead project programmer last year. I didn’t relish the idea of a job search… and while there were no shortage of programming jobs in the world, I had liked working for Logistica.
I opened my laptop, but instead of pulling up my resume, I googled Oscar Martin instead. His wikipedia page was the first result not from a tabloid.
I read the details about him. He was 6’1”, Argentinian, spoke Spanish, English, Portuguese, and French, and he had been married once, when he was young. His wife had died at age 22. I didn’t possess the Google Sleuthing Skills some of my friends had, so I couldn’t find much else about her. Cause of death was “unspecified cancer.” That was tragic. He had been 24 at the time. I read about the success of his company, MarTech, and the various companies it had absorbed over the years. I read about the famous women he was linked to, believed to have dated, rumored to have left broken-hearted. Taylor Swift’s latest album allegedly had a song or two about him on it. Models, Singers, Actresses all, with beautiful faces and glamorous lives.
And he had smiled at me. I didn’t think myself unattractive; I have a pretty face, with pale skin, bright blue eyes, and a nice smile. My hair was actually freshly minted at the salon, and my caramel colored waves were top notch, but I wasn’t a model. I wasn’t glamorous. I was a programmer who wrote code. I went to bed at 10:30 after watching reruns of Friends . I had been wearing a men’s graphic t-shirt that said “Tell Your Dog I Said Hi” on it, for crying out loud.
I made myself dinner - microwaved veggies, minute rice and costco rotisserie chicken, very glamorous- I thought as I sat down to eat, then I watched TV for a while. Around 7pm, I called my best friend Keith.
“You’ll never guess who I met today.”
“The pope?”
“I don’t think you could be more wrong.”
“Donald Trump?”
“Closer,” I laughed. “Oscar Martin.”
“Wow,” He said. And then “Oh no,”
“Yeah, so if you know of any outfits looking for a programmer…” I said.
“I’ll keep an ear out. So it’s official?”
“He signed the paperwork for the company today. I suppose it’ll be a few days before we get marching orders.” I said. Then I changed the subject. “How’s Carolina?”
“Doing okay, postpartum has been rough on her.” He admitted.
“Can I do anything?”
“Maybe swing by and see her at the shop. I think she’d like that.”
“I’ll come by after work one day this week. But let’s let her think it's a surprise.”
“Deal.” We talked for a bit longer, discussing his infant son and his work, before I finally said good night.
“Thanks for asking about Carolina. I know you and her-”
“Hey, water under the bridge.” I said quickly. “Have a good night.”
“You too.”
I went to bed that night wondering if my badge would work on the front door of the building in the morning.
The next morning, I arrived at the office and my badge worked. I was getting into the elevator when I heard someone call “Hold the door!”
I put my hand in front of the door to prevent it from closing, and a breathless Oscar Martin slipped in beside me.
“Good morning Cara.”
“Uh, Good morning.” I returned, trying to disguise the fact that my breath had caught in my throat. I studied him out of the corner of my eye. He certainly dressed like a tech guy; jeans, sneakers, and a yellow, blue and green plaid button down.
“Have you worked for Logistica long?” he asked as the elevator crept up to the 25th floor. His accent was so smooth, giving his voice a musical quality.
“Six years,” I said quietly. I felt so awkward making small talk with him. I felt like Ann Boelyn making cheerful conversation with the man holding the sword.
“That’s a long time in this industry.” He commented. “Do you like it here?”
“Yeah, I do, a lot.” I said honestly. He nodded. Mercifully, the elevator came to a stop and the doors opened to my floor. I stepped out. He followed me to my desk.
“I hope I see you later, Cara.” He said, and he headed to the conference room, where it looked like a meeting had already started.
“Did you really just walk in with Oscar Martin?” Lisa asked as I put my things down. I sat heavily in my chair.
“Yes, why?”
“You rode in the elevator with him?”
“Yeah, I did.”
“Ballsy.”
“I was already in the elevator.” I shrugged.
“He’s looking over here again.” Jackie called in a low voice from her cube.
“This is ridiculous.” I muttered. “You two are being ridiculous.” I grabbed my laptop. “I’m going to go work in one of the empty offices.”
Shortly before lunch time, an email went out that there would be a catered lunch for staff, compliments of the new owners. I rolled my eyes, but I wasn’t too proud to turn down a free meal, so at 12, I headed down to the breakroom.
It was a feast. Kabobs of shrimp, Chicken, and tender steak, exotic salads, grilled vegetables, rice pilaf and more. The junior programmers had loaded down their plates and were scurrying back to their cubes, but some of the upper management were schmoozing with Oscar as he stood in the breakroom, a plate in his hand, but not eating.
I helped myself to some food and while I was grabbing a plastic fork, Oscar excused himself from the ass kissers and came alongside me.
“How’s your day going?” He asked, his accent wrapping around the words in an almost sultry way. It would seem there was no such thing as a free lunch. I was going to have to pay for it by being polite to my executioner.
“Fine, thanks. And thanks for lunch.” I said, holding up my plate. I started towards the door but he fell into step beside me.
“So you’re a programmer.” He said. It wasn’t a question, but he didn’t elaborate.
“Yeah,” I said.
“And you worked on the Omega project.”
“I wrote the code for it, yes.”
“I was very impressed with it.” He said. “That’s actually why I wanted to buy Logistica.”
“My code?”
“Well, your code, and the program it powers.” He said. “Would you ever consider coming to work directly for me?”
I blinked at him.
“What?” He asked, perplexed.
“I do work for you, you own the company I work for.”
“Yes, but I have a need for a programmer outside of what I plan to do with Logistica.”
“What do you plan to do with Logistica?” I asked sharply. Careful, Cara . I chastised myself. Fortunately, he looked amused.
“I haven’t decided yet, but I intend to use your code for a project I’m working on.” I wanted to ask him if it was for his weapons division, but bit my tongue.
“I get the sense you don’t like me much.” He went on, still following me toward the office where I had set myself up to work for the day.
“I just don’t know you.” He was right, I didn’t like him, but hopefully this lie would help me keep my job.
“Well, my offer stands; your work speaks for itself, you’re clearly brilliant.” He said. “Think about it.”
“Thank you.” I said, unsure of what else to say. He gave me a perfunctory nod, and then disappeared, presumably back to the conference room. After lunch, I was pretty full, and the empty office was starting to feel a little too warm. I headed back to my cube so that I wouldn’t fall asleep. I didn’t have much to work on but I didn’t think this was a good time to be seen sleeping in an office somewhere, even if the new boss had just offered me a job.
“Get lonely?” Lisa asked when I sat back down.
“Hot.” I muttered.
“The rumor mill is flying.” Lisa said. “Three people asked if you got let go.”
“Why?”
“You weren’t at your desk.”
“Jesus.” I muttered, opening my laptop and trying to find something to do to look productive. The conference room was empty.
“Cara?” My boss, Kevin McCormick, came up to the edge of my cubicle. “Can you come with me please?”
“Should I bring my purse?” I asked.
“Just come with me please.” Kevin said.
I cast a look back at Lisa. Her eyes were wide.
I followed Kevin to his office. A man I didn’t recognize was there. At least it wasn’t Betty from Human Resources.
“Hello Ms. Kavanaugh,” the unfamiliar man said. He was probably 50, with thinning dark hair, and broad shoulders. He wore a suit. “My name is Benton Reavis. I am the inside counsel for MarTech, and Mr. Martin would like to extend you a rather lucrative employment option.” He slid a manilla folder across the table to me. I opened it.
“The salary is listed on the first page. The additional benefits are listed on the second. We are proud to offer you full medical, dental, and vision, plus 12 weeks paid vacation,” He went on, but I wasn’t listening.
$450,000.
“There has to be a mistake.” I said.
“No, there’s no mistake.” Mr. Reavis said. “Mr. Martin was very explicit about the offer, particularly the salary.”
“Uh…” I stammered. “I can��t- this is…”
“Mr. Martin has reviewed your entire portfolio and employment history at Logistica, and he’s quite impressed with you. He feels you’ve been under compensated for your work, and he would like to offer you the position of head of development at MarTech.”
“Can I… think about it?”
Mr. Reavis looked surprised. I suppose it must have been surprising that anyone would need to think about that salary offer.
“Of course, but please be aware that we are actively recruiting so-”
“You’ll have my answer by tomorrow morning.” I replied quickly.
“Very well. My number is inside if you have any questions.” Mr. Reavis said. “I don’t think I need to tell you that this is a very lucrative offer.”
“I’m aware.” I said. “I just don’t think I’m qualified for it.”
“Mr. Martin does.” Mr. Reavis said with a shrug. “He’s very rarely wrong about these things.” I pressed my lips together, and thanked him for his time.
I tucked the folder under my arm and headed back to my desk again.
“Should I get you a box?” Jackie asked.
“No. I still work here.”
“What’s that?” she pointed to a folder under my arm.
“Something about the code I worked on for the omega project.” I said, tucking it into my bag.
“Uh-huh.” Lisa muttered. “Keep your secrets.”
Towards the end of the day, I headed towards the elevators. Oscar Martin was waiting for an elevator himself.
“Going down?” He asked, a twinkle in his eyes.
“To the lobby.” I said, narrowing my eyes.
Now he laughed.
“What’s so funny?” I asked.
“You don’t hide your thoughts very well, and it’s becoming really clear you don’t like me. Am I going to get a disappointing phone call from Mr. Reavis in the morning?”
“If you mean, am I going to decline your job offer, I haven’t decided yet.”
“I see. Can I ask what it is about me you don't like?”
“I told you, I don’t know you. I just know your reputation.” I said.
“I see.” He frowned a bit. “Well, I hope you’ll allow me to show you the real me.”
The elevator opened then, and he gestured for me to go ahead. I did, but he didn’t follow.
“Weren’t you waiting for the elevator?” I asked.
“I’ll get the next one,” he replied, and I could tell I’d hurt his feelings. That was surprising. The elevator doors closed before I could say anything else. I sighed.
Once in the lobby, I headed home on foot. The weather was nice, and it was only 10 blocks. At home, I studied the job description. It sounded like a dream, and if the offer was coming from anyone else, literally anyone else, I would have taken it. But my mother had a saying about not getting into bed with serpents.
I sighed. I had student loans and my rent was going up at the end of the month. I needed a new bike and I liked to eat out with my friends on occasion. This job would open doors for me, too. Oscar Martin knew EVERYONE in tech. And the salary , I thought again. It was almost half a million dollars. Even after taxes, I would be set. I could move to a nicer apartment. And what if I refused? Then I’d have no job in a few weeks when he eventually gutted Logistica. Or worse, he might feel slighted. A man as powerful as he was could easily make sure I never worked in tech again.
I bit my lip, and then I dialed the number on the business card stapled inside the folder.
“Mr Reavis? It’s Cara Kavanaugh.” I bit my lip. “I’d like to negotiate a couple of stipulations on your employment offer.” If he was going to try to buy me, I was going to make him pay through the nose.
“You don’t feel it’s a generous offer?”
“I do, but I’m very happy where I am, and in order for me to leave, I’d like to ask for two additional concessions on Mr. Martin’s part.”
“And what are those?”
“First, I would like assurances that my team at Logistica be kept on and offered positions in the development group should MarTech decide to do layoffs or liquidation at Logistica. They are good workers and I would like them to be involved in any project I work on.”
“How many team members?”
“Six.”
“And your second concession?
“A hybrid work model. I would like to work from home two days a week.” I said.
“I’ll discuss this with Mr. Martin and have an answer for you shortly.”
My phone rang less than 20 minutes later.
“Mr. Martin has agreed to your terms.” Mr. Reavis sounded surprised. “Congratulations, Ms.Kavanaugh, and welcome aboard. You’ll need to report to MarTech HQ tomorrow morning to make it official and so we can provide you with an updated offer letter to match your requests. The address is-”
“I know where it is.”
“Please be there by 9am.”
“Thank you.”
I sat down on the couch in disbelief. I was going to be the head of development for one of the biggest tech firms in the world, at 5 times my current salary. Maybe now my dad would finally be proud of me.
I looked at the framed photo of Keith and I on my side table. We had been dating at the time it was taken. I didn’t have feelings for him anymore, not like that, but I had a pang of loneliness and sorrow when I looked at it. We had been a great couple, but he had said “It’s like a best friend thing, not a love of my life thing.” when he broke up with me. He wasn’t wrong, but I hadn’t felt that it was a bad thing, that we were friends. So what if it wasn’t this big passionate thing? It worked. We had been happy, or so I’d thought. And then he’d met Carolina, and that had been that.
I leaned back, looking up at the ceiling. I hoped I wasn’t going to regret this. It wasn’t like me to make snap decisions, but if nothing else, I would be able to pay off my student loans in a few months, so even if it all went south, that was a silver lining.
There was something eating away at the back of my mind, though. I was good at my job, but I wasn’t that good. Unless he saw some potential in the Omega Project that I didn’t. It worried me. But this wasn’t a contract, I wasn’t locked in for any length of time, so I could leave if it didn’t work out, I rationalized.
I normally wore jeans and a t-shirt to work, but I thought I might need to look a little more put together for this… I settled on a pair of dark green trousers and a white top, and set them aside for the morning. I set three alarms on my phone, then I had another unglamorous meal before I called my parents to tell them the news. They put me on speaker phone so they could talk to me together.
“You have to get everything in writing.” My dad said when I finished.
“I know Dad.”
“Let me know if you want me to have Murray look it over.” Murray was the family lawyer.
“It’s fine Dad, I can handle it.”
“They’re paying you how much?” My mother was in disbelief.
“Almost half a million. I’m going to run their whole development team.” I said, reading over the offer letter in front of me.
“Cara, please don't take this the wrong way, but are you sure you know what you’re getting into? The things they say about that man on TV.”
“I’ll be careful, mom.” I promised. “I’m aware of his reputation, but this is going to open so many doors for me.”
“I worry that if it doesn’t work out he’ll-”
“Mom!” I said. “Don’t talk like that, positive vibes.” I said. I didn’t want to think about what a powerful man like that would do if it didn’t work out. And I didn’t want to tell her that I felt like I couldn’t say no, either.
“If you’re sure,” she said, but I could hear the doubt in her voice. “He’s very handsome.” She conceded.
“I’m not interested.” I said.
“Good.” My dad said. “You do your job, keep your head down, and your nose clean.”
“He really said he wanted to buy Logistica because of your code?” My mom spoke again, but there was an ember of pride in her voice.
“More or less. I don’t know if he was flattering me or not, but that’s what he said.” I said.
My parents talked about the offer for more than an hour before finally letting me go. I went to bed, but couldn’t sleep. I was too anxious about the morning. It was late by the time I dozed off.
#oberyn martell#pedro pascal#fanfiction#Oberyn Martell Reimagined#oberyn martell x ofc#Terms & Conditions Apply by AJ Pike#plot with smut#fluff#fluff and angst#dom/sub undertones#spicy fanfic#spicy oberyn martell#Oberyn Martell Lives#fifty shades of grey
17 notes
·
View notes
Text
"Hi, I'm to stupid to make my own replies so I rely on a data scrapped machine learning algorithm that's been known to be wrong because it gets it's "facts" from CNN and fucking Reddit"

Get your own arguments. You're boring.
7 notes
·
View notes
Text
Who really controls TikTok’s magical algorithm — the US-based company that runs the app or its Chinese parent, ByteDance?
That’s the question that bedeviled a trio of federal judges on Monday charged with deciding whether to allow the implementation of a law that could ultimately result in TikTok being banned for all Americans.
After more than two hours of oral argument between TikTok and a group of content creators on one side, and the US government on the other, it remains uncertain how the judges may rule. Today wasn’t the slam dunk that TikTok needed as all three judges asked some very skeptical questions about the ByteDance relationship, but they didn’t let the government off easy, either.
Struggling to find historical and metaphorical precedent, the judges at a federal appeals court in Washington grappled with how TikTok’s foreign ownership affects its constitutional rights under US law.
They leaned on analogies about terrorist propaganda and hypotheticals about a possible shooting war involving the United States and China. They looked to a past case about communist propaganda delivered through the US Postal Service. And some of the Supreme Court’s most recent landmark decisions about online speech, issued just this year, made an appearance, too.
If the law in question targeted only US-based companies, “there’s no doubt that would be a huge First Amendment concern,” said Sri Srinivasan, chief judge of the US Court of Appeals for the District of Columbia Circuit, citing a pair of cases decided by the Supreme Court this summer.
But, he added, that isn’t the situation here. Instead, Congress passed a law that targets a US company’s foreign owners and their influence over the algorithm that 170 million Americans use to watch videos about sports, fashion and politics.
“It’s just that the curation is happening abroad,” he said to Daniel Tenny, a lawyer representing the US government.
“The core point we’re making is one they’ve conceded,” Tenny told the court, “which is that [TikTok’s] code is made in China.”
Attorneys for TikTok pushed back, saying that only some of the code that powers TikTok originates from China and that a great deal of TikTok’s curation reflects decisions made in the United States and amounts to expressive speech by TikTok itself — which the law would infringe on if upheld, they said.
The stakes of the case
Monday’s sprawling debate over TikTok’s algorithm and whether or not the Chinese government could manipulate it to sow chaos and disinformation to an unsuspecting public, will resolve a legal challenge to a law that the company claims could shut down TikTok virtually overnight and potentially reshape the government’s powers in relation to speech on all foreign-owned platforms deemed to be a national security risk.
If TikTok is successful, it could win a decision that blocks the legislation. But if it fails, the company will be required to find a new owner by mid-January, or else be prohibited from the devices of all Americans.
What began as a scheduled one-hour debate between TikTok and some of its content creators on one side, and the US government on the other, stretched into a lengthy back-and-forth at the court, with the judges asking tough questions to determine where TikTok’s US operations end and ByteDance’s really begins.
The exchange could well be the most significant of TikTok’s US existence. The company is fighting for survival in the face of a bipartisan push to force a sale of TikTok to non-Chinese owners, which may effectively end the app as we currently know it.
In addition to Srinivasan, an Obama appointee, hearing the case were Judge Neomi Rao, who was appointed by former President Donald Trump, and Judge Douglas Ginsburg, a Reagan appointee.
Both Rao and Ginsburg appeared to push hard against TikTok’s arguments, with Ginsburg at one point dismissing claims about the legislation’s allegedly sweeping breadth as a “blinkered view.” The law does not open up possible bans against all foreign-owned publications or platforms, he said, as it only targets companies linked to specific adversary nations such as China.
“We’re not talking about banning Tocqueville,” Rao said, referring to Alexis de Tocqueville, the French author of the historical text “Democracy in America.”
But a decision to restrict TikTok in the United States would still harm American users, TikTok and the coalition of content creators argued. Courts have historically protected Americans’ right to listen to foreign views, even if it is propaganda.
“Congress didn’t do any of the things the First Amendment requires,” Andrew Pincus, an attorney representing TikTok, told the court. He added: “The government’s solution to foreign propaganda, in every context, [has been] disclosure, not a ban.”
After pressuring TikTok, Srinivasan was equally hard on the US government. At one point, he asked Tenny about the law’s practical impact on everyday Americans.
The concern, he said, is “about the speech consequences on US consumers.”
Tenny, the Justice Department attorney, described the law’s impact on Americans’ First Amendment rights as “incidental” to the legislation’s main purpose, which focuses on curbing foreign influence over TikTok’s algorithm.
It’s not clear when the court could reach a decision on the legislation. But the law sets out a deadline of Jan. 19 for TikTok, so it is likely the court may rule before then.
US fear over China
Fast-tracked through Congress this spring with uncommon speed, the legislation is a US response to fears that TikTok’s China ties could allow that country’s government to access American users’ app data, such as which videos they have watched, liked, shared or searched for.
The measure has become a symbol of bipartisan opposition to China. But for TikTok’s supporters, including some of its most prominent content creators, the law smacks of racism and anti-China hysteria. They argue it does little to address other, potentially even more sensitive, sources of data freely available on commercial marketplaces.
The outcome of the case won’t just determine the fate of TikTok in the United States. It could also have ripple effects for the way courts interpret the First Amendment — which guarantees against the government prohibiting freedom of expression — and its relationship to digital speech and online platforms writ large.
TikTok argues the potential ban violates the First Amendment because it stifles the ability for its US users to express themselves and to access information. And it alleges the law is unconstitutionally extreme when the government had other options to address fears about TikTok’s links to China.
Court filings show that TikTok and US national security officials had hammered out a draft proposal to address the security concerns. That agreement included the ability for the US government to shut down TikTok if it violated the proposed deal. Some of the deal’s provisions TikTok has already publicly implemented as part of an initiative called Project Texas, which involves moving US user data onto servers controlled by the American tech giant Oracle and erecting additional organizational barriers between TikTok and ByteDance.
But, TikTok claims, US officials abruptly abandoned the plan with no explanation. (The US government has subsequently described the plan in its court filings as “inadequate” because officials feared it would be hard to detect whether TikTok were violating the agreement.)
TikTok has also claimed that it is technologically impossible to separate its app from its parent company. For starters, it said in a court filing, the TikTok app depends on software code that’s built by ByteDance, and there is no way to simply copy that code to another company with any expectation that it will run.
For another, the company argues, the Chinese government most likely won’t allow TikTok’s recommendation algorithm to be sold to a non-Chinese company. The recommendation engine is TikTok’s secret sauce and what powers its popularity; without it, the app loses its most distinctive feature.
Last year, the Chinese government said it would “firmly” oppose a potential sale of TikTok from ByteDance, following new export controls the country announced that affect the transfer of certain software algorithms.
TikTok has portrayed the US law as a sweeping congressional power grab that threatens all Americans’ speech rights.
“If Congress can do this,” the company wrote in its filings, “it can circumvent the First Amendment by invoking national security and ordering the publisher of any individual newspaper or website to sell to avoid being shut down.”
‘Speculative concerns,’ TikTok says
Finally, TikTok claims, the US government has never proven that the Chinese government has exploited US user data to justify the law.
“Even the statements by individual Members of Congress and a congressional committee report merely indicate concern about the hypothetical possibility that TikTok could be misused in the future, without citing specific evidence — even though the platform has operated prominently in the United States since it was first launched in 2017,” the company wrote. “Those speculative concerns fall far short of what is required when First Amendment rights are at stake.”
The US government has argued in its own filings that lawmakers are free to take action “even if all of the threatened harms have not yet broadly materialized or been detected.”
The Chinese government has the incentive and the ability to pressure ByteDance to hand over TikTok user data, the Biden administration has said, adding that the information could be useful for intelligence purposes or for manipulating the public through disinformation campaigns.
The United States, for its part, also routinely requests user data from social media companies. But there are typically checks and balances on the government, such as laws limiting what intelligence officials can do with data about US citizens or, for domestic law enforcement, requirements that authorities obtain a court order in exchange for user data — orders that tech companies can and often do challenge, even if they can’t always disclose it.
“TikTok’s parent company and recommendation algorithm are based in China,” the Justice Department wrote in a court brief, “giving rise to the risk that a foreign adversary will wield TikTok’s enormous power to advance its own interests, to the detriment of U.S. national security.”
The US government has also insisted the law is not a ban as it technically provides a way for TikTok to avoid one by simply finding a new owner within about six months.
Independent cybersecurity experts have said that the risk of Chinese spying through TikTok sounds plausible but remains unproven.
China’s intelligence laws require companies with a presence there to help with that country’s intelligence objectives. TikTok does not operate in China, but ByteDance does, meaning it is subject to China’s laws — and the Chinese government holds a board seat on ByteDance’s local Chinese subsidiary. The question is whether all that amounts to enough influence over ByteDance and TikTok to gain access to US TikTok users’ data, in spite of the guardrails promised by Project Texas.
All eyes on TikTok
The case has attracted immense attention, prompting friend-of-the-court briefs from more than a dozen US states, the House select committee on China that drafted the law, former US national security officials, business and civil rights groups, and a former chairman of the Federal Communications Commission.
The law in question “plainly raises the issue of political bias and motivation, singling out TikTok because of its foreign ownership even as other major social media platforms raise similar privacy and content-moderation issues,” wrote a coalition of digital rights groups in a filing.
But former national security officials wrote that TikTok user data, if combined with other information Beijing has collected through hacks and leaks, could be a potent intelligence risk.
The Chinese government, wrote the group that includes former National Cyber Director Chris Inglis, “can exploit this massive trove of sensitive data to power sophisticated artificial intelligence (AI) capabilities that can then be used to identify Americans for intelligence collection, to conduct advanced electronic and human intelligence operations, and may even be weaponized to undermine the political and economic stability of the United States.”
10 notes
·
View notes
Text
TikTok has lost its bid to strike down a law that could result in the platform being banned in the United States. A US appeals court upheld the law in a ruling Friday. Denying TikTok’s argument that the law was unconstitutional, the judges found that the law does not “contravene the First Amendment to the Constitution of the United States,” nor does it “violate the Fifth Amendment guarantee of equal protection of the laws.” The ruling, which TikTok is expected to appeal, means that the platform is one step closer to facing a US ban — unless it can convince Chinese parent-company ByteDance to sell and find a buyer — starting on January 19, 2025. After the deadline, US app stores and internet services could face hefty fines for hosting TikTok if it is not sold. (Under the legislation, Biden may issue a one-time extension of the deadline.) TikTok did not immediately respond to a request for comment. President Joe Biden signed a bill in April that requires the platform to be sold to a new, non-Chinese owner or be banned in the United States, following years of concern on Capitol Hill that ByteDance poses a national security risk. In particular, lawmakers have worried that ByteDance could share user data with the Chinese government for surveillance, or that the Chinese government could force the company to TikTok’s algorithm to spread propaganda.
8 notes
·
View notes
Text
AI helps distinguish dark matter from cosmic noise
Dark matter is the invisible force holding the universe together – or so we think. It makes up around 85% of all matter and around 27% of the universe’s contents, but since we can’t see it directly, we have to study its gravitational effects on galaxies and other cosmic structures. Despite decades of research, the true nature of dark matter remains one of science’s most elusive questions.
According to a leading theory, dark matter might be a type of particle that barely interacts with anything else, except through gravity. But some scientists believe these particles could occasionally interact with each other, a phenomenon known as self-interaction. Detecting such interactions would offer crucial clues about dark matter’s properties.
However, distinguishing the subtle signs of dark matter self-interactions from other cosmic effects, like those caused by active galactic nuclei (AGN) – the supermassive black holes at the centers of galaxies – has been a major challenge. AGN feedback can push matter around in ways that are similar to the effects of dark matter, making it difficult to tell the two apart.
In a significant step forward, astronomer David Harvey at EPFL’s Laboratory of Astrophysics has developed a deep-learning algorithm that can untangle these complex signals. Their AI-based method is designed to differentiate between the effects of dark matter self-interactions and those of AGN feedback by analyzing images of galaxy clusters – vast collections of galaxies bound together by gravity. The innovation promises to greatly enhance the precision of dark matter studies.
Harvey trained a Convolutional Neural Network (CNN) – a type of AI that is particularly good at recognizing patterns in images – with images from the BAHAMAS-SIDM project, which models galaxy clusters under different dark matter and AGN feedback scenarios. By being fed thousands of simulated galaxy cluster images, the CNN learned to distinguish between the signals caused by dark matter self-interactions and those caused by AGN feedback.
Among the various CNN architectures tested, the most complex - dubbed “Inception” – proved to also be the most accurate. The AI was trained on two primary dark matter scenarios, featuring different levels of self-interaction, and validated on additional models, including a more complex, velocity-dependent dark matter model.
Inceptionachieved an impressive accuracy of 80% under ideal conditions, effectively identifying whether galaxy clusters were influenced by self-interacting dark matter or AGN feedback. It maintained is high performance even when the researchers introduced realistic observational noise that mimics the kind of data we expect from future telescopes like Euclid.
What this means is that Inception – and the AI approach more generally – could prove incredibly useful for analyzing the massive amounts of data we collect from space. Moreover, the AI’s ability to handle unseen data indicates that it’s adaptable and reliable, making it a promising tool for future dark matter research.
AI-based approaches like Inception could significantly impact our understanding of what dark matter actually is. As new telescopes gather unprecedented amounts of data, this method will help scientists sift through it quickly and accurately, potentially revealing the true nature of dark matter.
10 notes
·
View notes
Note
re: your post about "screenshots aren't news". lmao? what do you racist clowns want us to do? wait until clarissa ward and jake tapper decide they want to do their jobs and report the truth instead of regurgitating zionist propaganda and supporting a genocide? stupid ass take.
But that's the thing Jake taper, Anderson, all those people ARE doing their jobs now. Their job is to be an arm of the imperial machine. Like they're not doing anything exemplary in regurgitating propaganda that's how they always have been. That's why primary sources are usually your best bet. Sometimes, yeah, you need to be explained things about a situation but you can find that out FROM the communities themselves instead of secondary and tertiary sources.
Even in research contexts (sorry for academic posting...) but ideas and analysis are considered more intellectually valuable when theyre interacting with primary sources. But usually people reject the idea that people can tell their own stories in an "unbiased" (whatever that means) way. Of course my viewpoints are informed by my understanding of the world that's the way being alive works lol. Does that make me an "unreliable" source for things directly happening to me?? What an incredibly racist take to say that communication networks outside of the state mandated ones are less valuable or somehow intellectually inferior.
I think you should try to source your news always and pay attention to who you're boosting, yeah, but like no one who is saying "screenshots are not news" are saying that they're just saying "you all are stupid dumb dumbs for believing Twitter lol" like hello?? It doesn't even make sense like Twitter is just one of many ways to communicate. And yeah sure twitter and facebook are designed to make you as angry as possible in the algorithm but like you can counter that actually by going. To individual accounts. And seeing what people share from sources you trust. But to completely reject the idea of social media as a viable way of communication BECAUSE of the algorithm is just admitting to me you have no idea how to vet sources yourself. If you see mis or disinformation yeah call it out but to assume all things you see on social media are untrue just by virtue of it being on social media is a ridiculous take. Making blanket statements of "I see soooo much disinformation these days" without specifying what you mean and trying to sow doubt in spaces that already are prone to being doubted is equally as malicious.
It actually makes me really really annoyed because it just SHOWS they've never been demonized by public press or inherently distrust them. Like bro we (people around the world) have been communicating about our circumstances through whatsapp groups for YEARS because no one will report on our circumstances and now that you realize people have different forms of communication other than CNN BBC all those places you're like "oh actually I'm going to define news into stuff that's only state sanctioned." Ok dude like you guys have no idea how the world outside of your position of CLEAR power (ie people who implicitly trust major news networks without clear detriment) works and how people around the world communicate in a myriad of ways.
It's like so malicious in its intentions and I don't understand how the same people who parrot this don't realize they're also disenfranchising themselves with their viewpoint.
52 notes
·
View notes
Text
Blog #2
The two leading social media platforms that I use are TikTok and Instagram. Over the past few weeks, my feed has been filled with protest ICE. The post reveals Mexican Americans fighting for immigrants who are being deported or at risk of being detained by ICE. In the protest, people are holding Mexican flags and signs that are anti-deportation. I think that the reason Mexican immigrants are the ones standing up is due to the president’s discriminatory remarks against people of Mexican descent and the fact immigration is stopping people from appearing Hispanic. Although xenophobia does not just affect Mexican or Latino immigrants, Trump is focusing on southern borders. There is ICE being explicitly spotted in areas that are predominantly Latino and Hispanic. On social media, specifically on my algorithm, immigrant policies are being portrayed as something cruel. The new policies will be separating families and taking people out of a country in which they have lived for decades, if not their whole life. There is a huge discussion that immigrants are increasing the crime rates, and that is the reason why deportation is necessary to keep this country safe. However, the argument is that immigrants have helped build this country to what it is now, and enabling legal paperwork would be more beneficial.
I watched CNN, and the coverage of immigration policies has been entirely different from what I see on social media. I do not see coverage of the protests that are taking place nationwide, but they are discussing Trump’s plan with immigration. I think it is informational to know the updates, but it does not completely cover what is happening. It is not sending the right idea to people who may not be as informed as others.
Should there be a limit to cyberfeminism when it involves the promotion of mental disorders?
Cyberfeminism has been beneficial for the world of feminism. It allows people who identify as women to express their beliefs and ideas online for others to see. It provides a safe place for women to turn to. However, should there be a limit when women are promoting mental disorders such as bulimia and anorexia-nervosa? The media has had an impact on the way adolescents and young adults view their body image. When there are people on the internet who are promoting these illnesses, it can put more people at risk of developing these disorders. In the article, “Rethinking Cyberfeminism(s): Race, Gender, and Embodiment,” Jessie Daniels states, “...pro-ana sites are engaging with Internet technologies in ways that are both motivated by and confirm (extremely thin) embodiment” (Daniels, 2009). Daniels is saying that women are promoting the thinness that comes with anorexia. It has almost become a competition to become thinner to be accepted into the anorexia community online. This can be very detrimental to women who utilize the internet to be influenced. It can be setting the wrong idea to women that having these mental disorders is okay rather than reaching out to attain the proper help.
How are complex integrated databases affecting minorities?
Intergrated databases are affecting minorities because they are constantly being surveilled. When low-income families get resources to support their financial needs or live in redlining areas, they are put into a database that watches their purchases or every move. In the chapter “Red Flags” by Virginia Eubanks, the author states, “People of color, migrants, unpopular religious groups, sexual minorities, the poor, and other oppressed and exploited populations bear a much higher burden of monitoring and tracking than advantaged groups” (Eubanks, 2018). This means that people apart from minority groups are much more at risk of being monitored based solely on the reason for being a minority. They automatically become part of an integrated database, which violates their privacy. Not only that, but it also paints them in a negative light for others. Eubanks argues, “It is intended to heap stigma on social programs and reinforce that cultural and narrative that those who access public assistance are criminal, lazy, spendthrift addicting” (Eubanks, 2018). This could be the reason why so many people argue against programs that are meant to help people who are classified as low-income. Rather than just viewing them as people needing help, they are viewed as people taking advantage of the government.
How is AI affecting law practices?
Artificial intelligence can help advance society, but it can also have adverse effects when inaccurate. Black men have been notoriously convicted of crimes that they did not commit throughout history. With the usage of AI, this has caused new cases to happen. In “Another Arrest, and Jail Time, Due to Bad Facial Recognition Match” by Kashmir Hill, the story of a black man who was wrongly identified in a crime and arrested is discussed. The man, Nijeer Parks, was convicted of a felony due to an error made by facial recognition technology. A picture of the actual man from the crime and his picture was put into facial recognition technology, showing that it was the same man when it was not. This proves that AI is affecting law practices because it is being used as a definite answer to who committed a crime and is also giving faulty answers. This could continue to harm the law system against Black men.
How has cyberfeminism benefited women coming from strict patriarchal communities?
Cyberfeminism has benefited women from strict patriarchal communities because they are allowed to voice their opinions through platforms that they deem safe places. Women who come from patriarchal communities are forced to live up to certain expectations, but with the use of digital media, the pressure subsides. It gives them the option to interact with women who have ideas similar to theirs. In the article, “Rethinking Cyberfeminism(s): Race, Gender, and Embodiment,” Daniels argues that “...the value of new technologies to further their agendas and to promote their brand of activism...” (Daniels, 2009). Women can promote the causes they stand for without needing to do it in real life. Some women are constantly being surveilled by their families and members of the community to stick to patriarchal morals, but this does not have to exist when they are their online persona.
4 notes
·
View notes