#consumer products software development
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
After the announcement of the deal with Yahoo!, there were 170K signatures of unhappy Tumblr users petitioning to prevent the sale in 2013.
Text

At my last job, we sold lots of hobbyist electronics stuff, including microcontrollers.
This turned out to be a little more complicated than selling, like, light bulbs. Oh how I yearned for the simplicity of a product you could plug in and have work.
Background: A microcontroller is the smallest useful computer. An ATtiny10 has a kilobyte of program memory. If you buy a thousand at a time, they cost 44 cents each.

As you'd imagine, the smallest computer has not great specs. The RAM is 32 bytes. Not gigabytes, not megabytes, not kilobytes. Individual bytes. Microcontrollers have the absolute minimum amount of hardware needed to accomplish their task, and nothing more.
This includes programming the thing. Any given MCU is programmed once, at the start of its life, and then spends the next 30 years blinking an LED on a refrigerator. Since they aren’t meant to be reflashed in the field, and modern PCs no longer expose the fast, bit-bangable ports hobbyists once used, MCUs usually need a third-party programming tool.
But you could just use that tool to install a bootloader, which then listens for a magic number on the serial bus. Then you can reprogram the chip as many times as you want without the expensive programming hardware.
There is an immediate bifurcation here. Only hobbyists will use the bootloader version. With 1024 bytes of program memory, there is, even more than usual, nothing to spare.

Consumer electronics development is a funny gig. It, more than many other businesses, requires you to be good at everything. A startup making the next Furby requires a rare omniexpertise. Your company has to write software, design hardware, create a production plan, craft a marketing scheme, and still do the boring logistics tasks of putting products in boxes and mailing them out. If you want to turn a profit, you do this the absolute minimum number of people. Ideally, one.
Proving out a brand new product requires cutting corners. You make the prototype using off the shelf hobbyist electronics. You make the next ten units with the same stuff, because there's no point in rewriting the entire codebase just for low rate initial production. You use the legacy code for the next thousand units because you're desperately busy putting out a hundred fires and hiring dozens of people to handle the tsunami of new customers. For the next ten thousand customers...

Rather by accident, my former employer found itself fulfilling the needs of the missing middle. We were an official distributor of PICAXE chips for North America. Our target market was schools, but as a sideline, we sold individual PICAXE chips, which were literally PIC chips flashed with a bootloader and a BASIC interpreter at a 200% markup. As a gag, we offered volume discounts on the chips up to a thousand units. Shortly after, we found ourselves filling multi-thousand unit orders.
We had blundered into a market niche too stupid for anyone else to fill. Our customers were tiny companies who sold prototypes hacked together from dev boards. And every time I cashed a ten thousand dollar check from these guys, I was consumed with guilt. We were selling to willing buyers at the current fair market price, but they shouldn't have been buying these products at all! Since they were using bootloaders, they had to hand program each chip individually, all while PIC would sell you programmed chips at the volume we were selling them for just ten cents extra per unit! We shouldn't have been involved at all!
But they were stuck. Translating a program from the soft and cuddly memory-managed education-oriented languages to the hardcore embedded byte counting low level languages was a rather esoteric skill. If everyone in-house is just barely keeping their heads above water responding to customer emails, and there's no budget to spend $50,000 on a consultant to rewrite your program, what do you do? Well, you keep buying hobbyist chips, that's what you do.
And I talked to these guys. All the time! They were real, functional, profitable businesses, who were giving thousands of dollars to us for no real reason. And the worst thing. The worst thing was... they didn't really care? Once every few months they would talk to their chip guy, who would make vague noises about "bootloaders" and "programming services", while they were busy solving actual problems. (How to more accurately detect deer using a trail camera with 44 cents of onboard compute) What I considered the scandal of the century was barely even perceived by my customers.
In the end my employer was killed by the pandemic, and my customers seamlessly switched to buying overpriced chips straight from the source. The end! No moral.
360 notes
·
View notes
Text
Even though I know it’s all intentional, I truly hate how we’ve become forced to normalize AI. I do think that the manufacturing of Artificial Intelligence was not done with malicious intent and has the capabilities of actually doing good, but time and time again ai is being used in literally everything for the worst reasons and getting its getting harder to escape.
From AI being used to scrape people’s hard work all over the internet, to giving predators and abusers more power in fabricating porn of strangers, to being used to strengthen racial bias in surveillance technology and aid in the development of weapons of war and mass destruction against marginalized groups of people…it’s just too fucking much. It’s so exhausting wanting to live in a world where we just didn’t need or have any of this shit, and it wasn’t like this a few years ago either. But now you can’t step outside without seeing something about AI, or a promotional ad for a new system to install. You can’t engage online anywhere without coming across AI software, and literally every single device in our present day implements AI to some degree, and it’s so fucking annoying.
I don’t want to keep worrying about the next idiot that’s spoon feeding my work into their AI system because they lack humanity and imagination. I don’t want to have to manually turn off AI detection on all of my apps and my phone just to use something. I shouldn’t have to be more mindful about the media I consume to distinguish whether or not it’s original or just more AI slop. I know it’s all intentional since we live in a hyper-capitalist world that cares more about profit margins & rapid productivity. But I really do vehemently hate how artificial intelligence has become such a fundamental aspect of our day to day lives when all it does is make the general population dumber and less capable of thinking for themselves.
Sincerely fuck AI. And if you use AI, I really do suggest you read up on how the data centers built to manage these AI systems suck up all of our resources for a simple prompt input. Who cares about answering a question in ChatGPT, entire communities don’t have water because they’re too busy cooling down the servers where people ask what 6 + 10 is cause their brains are so fried they can’t fire a single fucking neuron.

#fuck ai#and fuck everyone that uses it idc#it’s so hard being a creative and wanting original work when there’s ai slop everywhere#please just burn it all to the ground#enough of that bullshit you do not need a smart fridge with a touchscreen and ai built into it#its all just another form of state surveillance advertised as convenience it’s not normal#when you’re mindless sheep you’re easier to manipulate remember that#the way I work in the legal field and I hear my bosses talk about using AI to read case briefs is crazy#we live in the bad place
112 notes
·
View notes
Text
"Dave as a Selkie" fic ideas:


Debating whether or not Dave is unaware of what he is due to being raised by a human parent, or he was straight up raised in the ocean like a baby seal. Cobra would certainly notice tho. Who better to dive for Bancho's Sushi than that seal-merman guy he met one time?
In the mission where you save a baby Humpback Whale, Dave mentions having a living mother "[he] needs to call". Imagine the sheer lore of being a second-generation selkie - the product of love or captivity between a legend of the sea and a human.
Dave's selkie heritage suddenly explains why sharks seem to be dead set on chasing him. Humans taste bad, but seals tasty.
No matter how good Dave moves in the water, his stamina on land isn't great. Running is hard with webby feet.
Dave still has difficulty understanding the Sea People's language at first - he's not local after all. Him and Dr Bacon would try to learn how to speak it directly after they develop the translation software.
Dave canonically dives to a depth of at least 540 metres/1771.65 feet - which is well over the record for human divers. The record with a simple rebreather and oxygen is 316 m/1,037 ft, and the deeper records (534 m/1,752 ft) are from using experimental gas mixes, not random O2 tanks and air from gigas clams.
However, in the case of him being a mythical seal man; those numbers are pretty routine. Elephant Seals are one of the deepest diver; frequently going beyond 1,550 m/5,090 ft (record is 2,388 m/7,835 ft) for a snack run. Females can dive even deeper.
Deep-diving seals have thick hides and high volume blood for helping them hold onto oxygen during dives. Baikal seals are just jam packed with it. Probably explains how Dave doesn't immediately bleed out from being shot at, bitten, stung, and exploded throughout the story.
Dave seems habituated to a warmer climate, so he'd likely be a Monk Seal variant - which is fitting since they're voracious, flexible eaters (basically having unlimited menu options), and can be very friendly to non-seal animals like sea turtles! Their dive limit is also a little over the in-game one; at 550m/1800ft. Mediterranean Monk Seals in particular as a species; are also tied to myths of human men falling in-love with sea nymphs/nereids and producing weird half-seal kiddos - Psamathe from Greek mythos being the most famous. Though the Gaelic Selkie is linguistically tied to Grey Seals - Scottish "selkie" means "little selch/grey seal", it can mean any number of pinniped species.
The Sea People of the Blue Hole likely have no gotdamn idea what Dave is. Lore wise, perhaps the seal-like sea folk had a different evolutionary trigger - similar to how consuming the Divine Tree's fruit is implied to have mutated humans into the more fishy Sea People. Dave is stuck in the middle of being both not full human, but not fully a Sea Person.
They think he cute af tho.
Dave just be chilling on a lounge chair like he's replicating a retro pin-up, munching on all the free sushi he could ever want. Meanwhile scientists, chefs, secretly-evil corporations, and sea people go wild in the background.
39 notes
·
View notes
Note
If the Commodore 64 is great, where is the Commodore 65?

It sits in the pile with the rest of history's pre-production computers that never made it. It's been awhile since I went on a Commodore 65 rant...
The successor to the C64 is the C128, arguably the pinnacle of 8-bit computers. It has 3 modes: native C128 mode with 2MHz 8502, backwards compatible C64 mode, and CP/M mode using a 4MHz Z80. Dual video output in 40-column mode with sprites plus a second output in 80-column mode. Feature-rich BASIC, built in ROM monitor, numpad, 128K of RAM, and of course a SID chip. For 1985, it was one of the last hurrahs of 8-bit computing that wasn't meant to be a budget/bargain bin option.
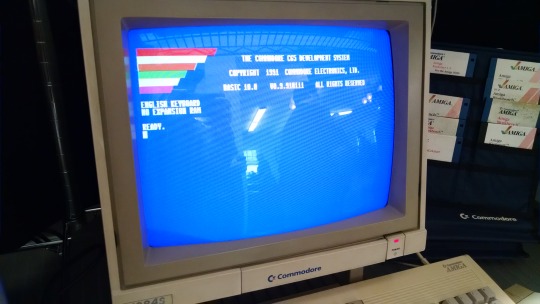
For the Amiga was taking center stage at Commodore -- the 16-bit age is here! And its initial market performance wasn't great, they were having a hard time selling its advanced capabilities. The Amiga platform took time to really build up momentum square in the face of the rising dominance of the IBM PC compatible. And the Amiga lost (don't tell the hardcore Amiga fanboys, they're still in denial).
However, before Commodore went bankrupt in '94, someone planned and designed another successor to the C64. It was supposed to be backwards compatible with C64, while also evolving on that lineage, moving to a CSG 4510 R3 at 3.54MHz (a fancy CMOS 6502 variant based on a subprocessor out of an Amiga serial port card). 128K of RAM (again) supposedly expandable to 1MB, 256X more colors, higher resolution, integrated 3½" floppy not unlike the 1581. Bitplane modes, DAT modes, Blitter modes -- all stuff that at one time was a big deal for rapid graphics operations, but nothing that an Amiga couldn't already do (if you're a C65 expert who isn't mad at me yet, feel free to correct me here).
The problem is that nobody wanted this.
Sure, Apple had released the IIgs in 1986, but that had both the backwards compatibility of an Apple II and a 16-bit 65C816 processor -- not some half-baked 6502 on gas station pills. Plus, by the time the C65 was in heavy development it was 1991. Way too late for the rapidly evolving landscape of the consumer computer market. It would be cancelled later that same year.
I realize that Commodore was also still selling the C64 well into 1994 when they closed up shop, but that was more of a desperation measure to keep cash flowing, even if it was way behind the curve by that point (remember, when the C64 was new it was a powerful, affordable machine for 1982). It was free money on an established product that was cheap to make, whereas the C65 would have been this new and expensive machine to produce and sell that would have been obsolete from the first day it hit store shelves. Never mind the dismal state of Commodore's marketing team post-Tramiel.

Internally, the guy working on the C65 was someone off in the corner who didn't work well with others while 3rd generation Amiga development was underway. The other engineers didn't have much faith in the idea.
The C65 has acquired a hype of "the machine that totally would have saved Commodore, guise!!!!1!11!!!111" -- saved nothing. If you want better what-if's from Commodore, you need to look to the C900 series UNIX machine, or the CLCD. Unlike those machines which only have a handful of surviving examples (like 3 or 4 CLCDs?), the C65 had several hundred, possibly as many as 2000 pre-production units made and sent out to software development houses. However many got out there, no software appears to have surfaced, and only a handful of complete examples of a C65 have entered the hands of collectors. Meaning if you have one, it's probably buggy and you have no software to run on it. Thus, what experience are you recapturing? Vaporware?
The myth of the C65 and what could have been persists nonetheless. I'm aware of 3 modern projects that have tried to take the throne from the Commodore 64, doing many things that sound similar to the Commodore 65.
The Foenix Retro Systems F256K:

The 8-Bit Guy's Commander X16

The MEGA65 (not my picture)

The last of which is an incredibly faithful open-source visual copy of the C65, where as the other projects are one-off's by dedicated individuals (and when referring to the X16, I don't mean David Murray as he's not the one doing the major design work).
I don't mean to belittle the effort people have put forth into such complicated projects, it's just not what I would have built. In 2019, I had the opportunity to meet the 8-Bit Guy and see the early X16 prototype. I didn't really see the appeal, and neither did David see the appeal of my homebrew, the Cactus.
Build your own computer, build a replica computer. I encourage you to build what you want, it can be a rewarding experience. Just remember that the C65 was probably never going to dig Commodore out of the financial hole they had dug for themselves.
262 notes
·
View notes
Text
AI’s energy use already represents as much as 20 percent of global data-center power demand, research published Thursday in the journal Joule shows. That demand from AI, the research states, could double by the end of this year, comprising nearly half of all total data-center electricity consumption worldwide, excluding the electricity used for bitcoin mining.
The new research is published in a commentary by Alex de Vries-Gao, the founder of Digiconomist, a research company that evaluates the environmental impact of technology. De Vries-Gao started Digiconomist in the late 2010s to explore the impact of bitcoin mining, another extremely energy-intensive activity, would have on the environment. Looking at AI, he says, has grown more urgent over the past few years because of the widespread adoption of ChatGPT and other large language models that use massive amounts of energy. According to his research, worldwide AI energy demand is now set to surpass demand from bitcoin mining by the end of this year.
“The money that bitcoin miners had to get to where they are today is peanuts compared to the money that Google and Microsoft and all these big tech companies are pouring in [to AI],” he says. “This is just escalating a lot faster, and it’s a much bigger threat.”
The development of AI is already having an impact on Big Tech’s climate goals. Tech giants have acknowledged in recent sustainability reports that AI is largely responsible for driving up their energy use. Google’s greenhouse gas emissions, for instance, have increased 48 percent since 2019, complicating the company’s goals of reaching net zero by 2030.
“As we further integrate AI into our products, reducing emissions may be challenging due to increasing energy demands from the greater intensity of AI compute,” Google’s 2024 sustainability report reads.
Last month, the International Energy Agency released a report finding that data centers made up 1.5 percent of global energy use in 2024—around 415 terrawatt-hours, a little less than the yearly energy demand of Saudi Arabia. This number is only set to get bigger: Data centers’ electricity consumption has grown four times faster than overall consumption in recent years, while the amount of investment in data centers has nearly doubled since 2022, driven largely by massive expansions to account for new AI capacity. Overall, the IEA predicted that data center electricity consumption will grow to more than 900 TWh by the end of the decade.
But there’s still a lot of unknowns about the share that AI, specifically, takes up in that current configuration of electricity use by data centers. Data centers power a variety of services—like hosting cloud services and providing online infrastructure—that aren’t necessarily linked to the energy-intensive activities of AI. Tech companies, meanwhile, largely keep the energy expenditure of their software and hardware private.
Some attempts to quantify AI’s energy consumption have started from the user side: calculating the amount of electricity that goes into a single ChatGPT search, for instance. De Vries-Gao decided to look, instead, at the supply chain, starting from the production side to get a more global picture.
The high computing demands of AI, De Vries-Gao says, creates a natural “bottleneck” in the current global supply chain around AI hardware, particularly around the Taiwan Semiconductor Manufacturing Company (TSMC), the undisputed leader in producing key hardware that can handle these needs. Companies like Nvidia outsource the production of their chips to TSMC, which also produces chips for other companies like Google and AMD. (Both TSMC and Nvidia declined to comment for this article.)
De Vries-Gao used analyst estimates, earnings call transcripts, and device details to put together an approximate estimate of TSMC’s production capacity. He then looked at publicly available electricity consumption profiles of AI hardware and estimates on utilization rates of that hardware—which can vary based on what it’s being used for—to arrive at a rough figure of just how much of global data-center demand is taken up by AI. De Vries-Gao calculates that without increased production, AI will consume up to 82 terrawatt-hours of electricity this year—roughly around the same as the annual electricity consumption of a country like Switzerland. If production capacity for AI hardware doubles this year, as analysts have projected it will, demand could increase at a similar rate, representing almost half of all data center demand by the end of the year.
Despite the amount of publicly available information used in the paper, a lot of what De Vries-Gao is doing is peering into a black box: We simply don’t know certain factors that affect AI’s energy consumption, like the utilization rates of every piece of AI hardware in the world or what machine learning activities they’re being used for, let alone how the industry might develop in the future.
Sasha Luccioni, an AI and energy researcher and the climate lead at open-source machine-learning platform Hugging Face, cautioned about leaning too hard on some of the conclusions of the new paper, given the amount of unknowns at play. Luccioni, who was not involved in this research, says that when it comes to truly calculating AI’s energy use, disclosure from tech giants is crucial.
“It’s because we don’t have the information that [researchers] have to do this,” she says. “That’s why the error bar is so huge.”
And tech companies do keep this information. In 2022, Google published a paper on machine learning and electricity use, noting that machine learning was “10%–15% of Google’s total energy use” from 2019 to 2021, and predicted that with best practices, “by 2030 total carbon emissions from training will reduce.” However, since that paper—which was released before Google Gemini’s debut in 2023—Google has not provided any more detailed information about how much electricity ML uses. (Google declined to comment for this story.)
“You really have to deep-dive into the semiconductor supply chain to be able to make any sensible statement about the energy demand of AI,” De Vries-Gao says. “If these big tech companies were just publishing the same information that Google was publishing three years ago, we would have a pretty good indicator” of AI’s energy use.
19 notes
·
View notes
Note
May I ask what scanners / equipment / software you're using in the utena art book project? I'm an artist and half the reason I rarely do traditional art is because I'm never happy with the artwork after it's scanned in. But the level of detail even in the blacks of Utena's uniform were all captured so beautifully! And even the very light colors are showing up so well! I'd love to know how you manage!
You know what's really fun? This used to be something you put in your site information section, the software and tools used! Not something that's as normal anymore, but let's give it a go, sorry it's long because I don't know what's new information and what's not! Herein: VANNA'S 'THIS IS AS SPECIFIC AS MY BREAK IS LONG' GUIDE/AIMLESS UNEDITED RAMBLE ABOUT SCANNING IMAGES
Scanning: Modern scanners, by and large, are shit for this. The audience for scanning has narrowed to business and work from home applications that favor text OCR, speed, and efficiency over archiving and scanning of photos and other such visual media. It makes sense--there was a time when scanning your family photographs and such was a popular expected use of a scanner, but these days, the presumption is anything like that is already digital--what would you need the scanner to do that for? The scanner I used for this project is the same one I have been using for *checks notes* a decade now. I use an Epson Perfection V500. Because it is explicitly intended to be a photo scanner, it does threebthings that at this point, you will pay a niche user premium for in a scanner: extremely high DPI (dots per inch), extremely wide color range, and true lossless raws (BMP/TIFF.) I scan low quality print media at 600dpi, high quality print media at 1200 dpi, and this artbook I scanned at 2400 dpi. This is obscene and results in files that are entire GB in size, but for my purposes and my approach, the largest, clearest, rawest copy of whatever I'm scanning is my goal. I don't rely on the scanner to do any post-processing. (At these sizes, the post-processing capacity of the scanner is rendered moot, anyway.) I will replace this scanner when it breaks by buying another identical one if I can find it. I have dropped, disassembled to clean, and abused this thing for a decade and I can't believe it still tolerates my shit. The trade off? Only a couple of my computers will run the ancient capture software right. LMAO. I spent a good week investigating scanners because of the insane Newtype project on my backburner, and the quality available to me now in a scanner is so depleted without spending over a thousand on one, that I'd probably just spin up a computer with Windows 7 on it just to use this one. That's how much of a difference the decade has made in what scanners do and why. (Enshittification attacks! Yes, there are multiple consumer computer products that have actually declined in quality over the last decade.)
Post-processing: Photoshop. Sorry. I have been using Photoshop for literally decades now, it's the demon I know. While CSP is absolutely probably the better piece of software for most uses (art,) Photoshop is...well it's in the name. In all likelihood though, CSP can do all these things, and is a better product to give money to. I just don't know how. NOTENOTENOTE: Anywhere I discuss descreening and print moire I am specifically talking about how to clean up *printed media.* If you are scanning your own painting, this will not be a problem, but everything else about this advice will stand! The first thing you do with a 2400 dpi scan of Utena and Anthy hugging? Well, you open it in Photoshop, which you may or may not have paid for. Then you use a third party developer's plug-in to Descreen the image. I use Sattva. Now this may or may not be what you want in archiving!!! If fidelity to the original scan is the point, you may pass on this part--you are trying to preserve the print screen, moire, half-tones, and other ways print media tricks the eye. If you're me, this tool helps translate the raw scan of the printed dots on the page into the smooth color image you see in person. From there, the vast majority of your efforts will boil down to the following Photoshop tools: Levels/Curves, Color Balance, and Selective Color. Dust and Scratches, Median, Blur, and Remove Noise will also be close friends of the printed page to digital format archiver. Once you're happy with the broad strokes, you can start cropping and sizing it down to something reasonable. If you are dealing with lots of images with the same needs, like when I've scanned doujinshi pages, you can often streamline a lot of this using Photoshop Actions.
My blacks and whites are coming out so vivid this time because I do all color post-processing in Photoshop after the fact, after a descreen tool has been used to translate the dot matrix colors to solids they're intended to portray--in my experience trying to color correct for dark and light colors is a hot mess until that process is done, because Photoshop sees the full range of the dots on the image and the colors they comprise, instead of actually blending them into their intended shades. I don't correct the levels until I've descreened to some extent.

As you can see, the print pattern contains the information of the original painting, but if you try to correct the blacks and whites, you'll get a janky mess. *Then* you change the Levels:
If you've ever edited audio, then dealing with photo Levels and Curves will be familiar to you! A well cut and cleaned piece of audio will not cut off the highs and lows, but also will make sure it uses the full range available to it. Modern scanners are trying to do this all for you, so they blow out the colors and increase the brightness and contrast significantly, because solid blacks and solid whites are often the entire thing you're aiming for--document scanning, basically. This is like when audio is made so loud details at the high and low get cut off. Boo.
What I get instead is as much detail as possible, but also at a volume that needs correcting:
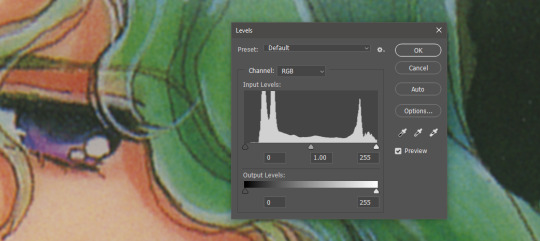
Cutting off the unused color ranges (in this case it's all dark), you get the best chance of capturing the original black and white range:
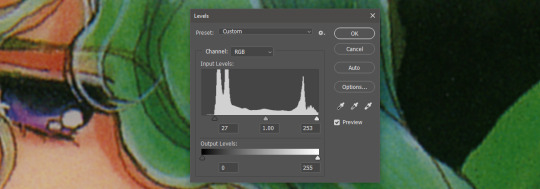
In some cases, I edit beyond this--for doujinshi scans, I aim for solid blacks and whites, because I need the file sizes to be normal and can't spend gigs of space on dust. For accuracy though, this is where I'd generally stop.
For scanning artwork, the major factor here that may be fucking up your game? Yep. The scanner. Modern scanners are like cheap microphones that blow out the audio, when what you want is the ancient microphone that captures your cat farting in the next room over. While you can compensate A LOT in Photoshop and bring out blacks and whites that scanners fuck up, at the end of the day, what's probably stopping you up is that you want to use your scanner for something scanners are no longer designed to do well. If you aren't crazy like me and likely to get a vintage scanner for this purpose, keep in mind that what you are looking for is specifically *a photo scanner.* These are the ones designed to capture the most range, and at the highest DPI. It will be a flatbed. Don't waste your time with anything else.
Hot tip: if you aren't scanning often, look into your local library or photo processing store. They will have access to modern scanners that specialize in the same priorities I've listed here, and many will scan to your specifications (high dpi, lossless.)
Ahem. I hope that helps, and or was interesting to someone!!!
#utena#image archiving#scanning#archiving#revolutionary girl utena#digitizing#photo scanner#art scanning
242 notes
·
View notes
Text

LETTERS FROM AN AMERICAN
January 18, 2025
Heather Cox Richardson
Jan 19, 2025
Shortly before midnight last night, the Federal Trade Commission (FTC) published its initial findings from a study it undertook last July when it asked eight large companies to turn over information about the data they collect about consumers, product sales, and how the surveillance the companies used affected consumer prices. The FTC focused on the middlemen hired by retailers. Those middlemen use algorithms to tweak and target prices to different markets.
The initial findings of the FTC using data from six of the eight companies show that those prices are not static. Middlemen can target prices to individuals using their location, browsing patterns, shopping history, and even the way they move a mouse over a webpage. They can also use that information to show higher-priced products first in web searches. The FTC found that the intermediaries—the middlemen—worked with at least 250 retailers.
“Initial staff findings show that retailers frequently use people��s personal information to set targeted, tailored prices for goods and services—from a person's location and demographics, down to their mouse movements on a webpage,” said FTC chair Lina Khan. “The FTC should continue to investigate surveillance pricing practices because Americans deserve to know how their private data is being used to set the prices they pay and whether firms are charging different people different prices for the same good or service.”
The FTC has asked for public comment on consumers’ experience with surveillance pricing.
FTC commissioner Andrew N. Ferguson, whom Trump has tapped to chair the commission in his incoming administration, dissented from the report.
Matt Stoller of the nonprofit American Economic Liberties Project, which is working “to address today’s crisis of concentrated economic power,” wrote that “[t]he antitrust enforcers (Lina Khan et al) went full Tony Montana on big business this week before Trump people took over.”
Stoller made a list. The FTC sued John Deere “for generating $6 billion by prohibiting farmers from being able to repair their own equipment,” released a report showing that pharmacy benefit managers had “inflated prices for specialty pharmaceuticals by more than $7 billion,” “sued corporate landlord Greystar, which owns 800,000 apartments, for misleading renters on junk fees,” and “forced health care private equity powerhouse Welsh Carson to stop monopolization of the anesthesia market.”
It sued Pepsi for conspiring to give Walmart exclusive discounts that made prices higher at smaller stores, “[l]eft a roadmap for parties who are worried about consolidation in AI by big tech by revealing a host of interlinked relationships among Google, Amazon and Microsoft and Anthropic and OpenAI,” said gig workers can’t be sued for antitrust violations when they try to organize, and forced game developer Cognosphere to pay a $20 million fine for marketing loot boxes to teens under 16 that hid the real costs and misled the teens.
The Consumer Financial Protection Bureau “sued Capital One for cheating consumers out of $2 billion by misleading consumers over savings accounts,” Stoller continued. It “forced Cash App purveyor Block…to give $120 million in refunds for fostering fraud on its platform and then refusing to offer customer support to affected consumers,” “sued Experian for refusing to give consumers a way to correct errors in credit reports,” ordered Equifax to pay $15 million to a victims’ fund for “failing to properly investigate errors on credit reports,” and ordered “Honda Finance to pay $12.8 million for reporting inaccurate information that smeared the credit reports of Honda and Acura drivers.”
The Antitrust Division of the Department of Justice sued “seven giant corporate landlords for rent-fixing, using the software and consulting firm RealPage,” Stoller went on. It “sued $600 billion private equity titan KKR for systemically misleading the government on more than a dozen acquisitions.”
“Honorary mention goes to [Secretary Pete Buttigieg] at the Department of Transportation for suing Southwest and fining Frontier for ‘chronically delayed flights,’” Stoller concluded. He added more results to the list in his newsletter BIG.
Meanwhile, last night, while the leaders in the cryptocurrency industry were at a ball in honor of President-elect Trump’s inauguration, Trump launched his own cryptocurrency. By morning he appeared to have made more than $25 billion, at least on paper. According to Eric Lipton at the New York Times, “ethics experts assailed [the business] as a blatant effort to cash in on the office he is about to occupy again.”
Adav Noti, executive director of the nonprofit Campaign Legal Center, told Lipton: “It is literally cashing in on the presidency—creating a financial instrument so people can transfer money to the president’s family in connection with his office. It is beyond unprecedented.” Cryptocurrency leaders worried that just as their industry seems on the verge of becoming mainstream, Trump’s obvious cashing-in would hurt its reputation. Venture capitalist Nick Tomaino posted: “Trump owning 80 percent and timing launch hours before inauguration is predatory and many will likely get hurt by it.”
Yesterday the European Commission, which is the executive arm of the European Union, asked X, the social media company owned by Trump-adjacent billionaire Elon Musk, to hand over internal documents about the company’s algorithms that give far-right posts and politicians more visibility than other political groups. The European Union has been investigating X since December 2023 out of concerns about how it deals with the spread of disinformation and illegal content. The European Union’s Digital Services Act regulates online platforms to prevent illegal and harmful activities, as well as the spread of disinformation.
Today in Washington, D.C., the National Mall was filled with thousands of people voicing their opposition to President-elect Trump and his policies. Online speculation has been rampant that Trump moved his inauguration indoors to avoid visual comparisons between today’s protesters and inaugural attendees. Brutally cold weather also descended on President Barack Obama’s 2009 inauguration, but a sea of attendees nonetheless filled the National Mall.
Trump has always understood the importance of visuals and has worked hard to project an image of an invincible leader. Moving the inauguration indoors takes away that image, though, and people who have spent thousands of dollars to travel to the capital to see his inauguration are now unhappy to discover they will be limited to watching his motorcade drive by them. On social media, one user posted: “MAGA doesn’t realize the symbolism of [Trump] moving the inauguration inside: The billionaires, millionaires and oligarchs will be at his side, while his loyal followers are left outside in the cold. Welcome to the next 4+ years.”
Trump is not as good at governing as he is at performance: his approach to crises is to blame Democrats for them. But he is about to take office with majorities in the House of Representatives and the Senate, putting responsibility for governance firmly into his hands.
Right off the bat, he has at least two major problems at hand.
Last night, Commissioner Tyler Harper of the Georgia Department of Agriculture suspended all “poultry exhibitions, shows, swaps, meets, and sales” until further notice after officials found Highly Pathogenic Avian Influenza, or bird flu, in a commercial flock. As birds die from the disease or are culled to prevent its spread, the cost of eggs is rising—just as Trump, who vowed to reduce grocery prices, takes office.
There have been 67 confirmed cases of the bird flu in the U.S. among humans who have caught the disease from birds. Most cases in humans are mild, but public health officials are watching the virus with concern because bird flu variants are unpredictable. On Friday, outgoing Health and Human Services secretary Xavier Becerra announced $590 million in funding to Moderna to help speed up production of a vaccine that covers the bird flu. Juliana Kim of NPR explained that this funding comes on top of $176 million that Health and Human Services awarded to Moderna last July.
The second major problem is financial. On Friday, Secretary of the Treasury Janet Yellen wrote to congressional leaders to warn them that the Treasury would hit the debt ceiling on January 21 and be forced to begin using extraordinary measures in order to pay outstanding obligations and prevent defaulting on the national debt. Those measures mean the Treasury will stop paying into certain federal retirement accounts as required by law, expecting to make up that difference later.
Yellen reminded congressional leaders: “The debt limit does not authorize new spending, but it creates a risk that the federal government might not be able to finance its existing legal obligations that Congresses and Presidents of both parties have made in the past.” She added, “I respectfully urge Congress to act promptly to protect the full faith and credit of the United States.”
Both the avian flu and the limits of the debt ceiling must be managed, and managed quickly, and solutions will require expertise and political skill.
Rather than offering their solutions to these problems, the Trump team leaked that it intended to begin mass deportations on Tuesday morning in Chicago, choosing that city because it has large numbers of immigrants and because Trump’s people have been fighting with Chicago mayor Brandon Johnson, a Democrat. Michelle Hackman, Joe Barrett, and Paul Kiernan of the Wall Street Journal, who broke the story, reported that Trump’s people had prepared to amplify their efforts with the help of right-wing media.
But once the news leaked of the plan and undermined the “shock and awe” the administration wanted, Trump’s “border czar” Tom Homan said the team was reconsidering it.
LETTERS FROM AN AMERICAN
HEATHER COX RICHARDSON
#Consumer Financial Protection Bureau#consumer protection#FTC#Letters From An American#heather cox richardson#shock and awe#immigration raids#debt ceiling#bird flu#protests#March on Washington
30 notes
·
View notes
Text





🎄💾🗓️ Day 7: Retrocomputing Advent Calendar - Altair 8800🎄💾🗓️
The Altair 8800 was one of the first commercially successful personal computers, introduced in 1975 by MITS, and also one of the most memorable devices in computing history. Powered by the Intel 8080 CPU, an 8-bit processor running at 2 MHz, and initially came with 256 bytes of RAM, expandable via its S-100 bus architecture. Users would mainly interact with the Altair through its front panel-mounted toggle switches for input and LEDs for output.
The Altair 8800 was popularized through a Popular Electronics magazine article, as a kit for hobbyists to build.
It was inexpensive and could be expanded, creating a following of enthusiasts that launched the personal computer market. Specifically, it motivated software development, such as Microsoft's first product, Altair BASIC.
The Altair moved from hobbyist kits to consumer-ready personal computers because of its modular design, reliance on the S-100 bus that eventually became an industry standard, and the rise of user groups like the Homebrew Computer Club.
Many of ya'll out there mentioned the Altair 8800, be sure to share your stories! And check out more history of the Altair on its Wikipedia page -
along with the National Museum of American History - Behring center -
Have first computer memories? Post’em up in the comments, or post yours on socialz’ and tag them #firstcomputer #retrocomputing – See you back here tomorrow!
#retrocomputing#altair8800#firstcomputer#electronics#vintagecomputing#computinghistory#8080processor#s100bus#microsoftbasic#homebrewcomputerclub#1975tech#personalcomputers#computerkits#ledswitches#technostalgia#oldschooltech#intel8080#computerscience#techenthusiasts#diycomputing#earlycomputers#computermemory#vintageelectronics#hobbycomputing#popularelectronics#techhistory#innovation#computermilestones#geekculture
45 notes
·
View notes
Text
It's always "funny" to remember that software development as field often operates on the implicit and completely unsupported assumption that security bugs are fixed faster than they are introduced, adjusting for security bug severity.
This assumption is baked into security policies that are enforced at the organizational level regardless of whether they are locally good ideas or not. So you have all sorts of software updating basically automatically and this is supposedly proof that you deserve that SOC2 certification.
Different companies have different incentives. There are two main incentives:
Limiting legal liability
Improving security outcomes for users
Most companies have an overwhelming proportion of the first incentive.
This would be closer to OK if people were more honest about it, but even within a company they often start developing The Emperor's New Clothes types of behaviour.
---
I also suspect that security has generally been a convenient scapegoat to justify annoying, intrusive and outright abusive auto-updating practices in consumer software. "Nevermind when we introduced that critical security bug and just update every day for us, alright??"
Product managers almost always want every user to be on the latest version, for many reasons of varying coherence. For example, it enables A/B testing (provided your software doesn't just silently hotpatch it without your consent anyway).
---
I bring this up because (1) I felt like it, (2) there are a lot of not-so-well-supported assumptions in this field, which are mainly propagated for unrelated reasons. Companies will try to select assumptions that suit them.
Yes, if someone does software development right, the software should converge towards being more secure as it gets more updates. But the reality is that libraries and applications are heavily heterogenous -- they have different risk profiles, different development practices, different development velocities, and different tooling. The correct policy is more complicated and contextual.
Corporate incentives taint the field epistemologically. There's a general desire to confuse what is good for the corporation with what is good for users with what is good for the field.
The way this happens isn't by proposing obviously insane practices, but by taking things that sound maybe-reasonable and artificially amplifying confidence levels. There are aspects of the distortion that are obvious and aspects of the distortion that are most subtle. If you're on the inside and never talked to weird FOSS people, it's easy to find it normal.
One of the eternal joys and frustrations of being a software developer is trying to have effective knowledge about software development. And generally a pre-requisite to that is not believing false things.
For all the bullshit that goes on in the field, I feel _good_ about being able to form my own opinions. The situation, roughly speaking, is not rosy, but learning to derive some enjoyment from countering harmful and incorrect beliefs is a good adaptation. If everyone with a clue becomes miserable and frustrated then computing is doomed. So my first duty is to myself -- to talk about such things without being miserable. I tend to do a pretty okay job at that.
#i know to some of you i'm just stating the sky is blue#software#computing#security#anpost#this was an anramble at first but i just kept writing i guess#still kind of a ramble
51 notes
·
View notes
Note
Why is it so difficult for a fourth competitor to enter the console market? Like what are some of the biggest challenges and obstacles?
Any company that wants to release a premium game console basically needs to make an enormous investment that will probably not pay off for years. There are three major requirements for this process.

First, the company must develop gaming hardware. This is generally an expensive process - building anything physical is costly, time-consuming, and is a moving target because competitors aren't stopping either. The hardware must be manufactured and factories equipped and set up for mass production.

Second, they must develop software development tools for both themselves and for external developers to use in order to build games for that console. This requires a significant internal development team to build drivers and software interfaces. Beyond this, they likely need to develop their own flagship game (or more) to launch with the console. That generally costs at least $50 million for a AAA-fidelity game and at least two years of lead time to build alongside the hardware development.

Third, they must secure investment from third party developers to build games for that console. Using that $50 million price tag for a game, we'd need at least four or five additional games to launch with in order to entice players to buy in - no one buys a game console without games to play on it. If they want four launch titles to go along with the console launch, that requires at least $200 million in investment from others.

There are only a handful of companies in the world that have the kind of money, technology, and resources needed to make such a thing happen and some of them already have game consoles. The others look at the market, at the cost of entry just to compete (not necessarily even to pull ahead), at the expected returns on investment, and it's no surprise they choose to invest their money in other opportunities that seem more likely to bear fruit.
[Join us on Discord] and/or [Support us on Patreon]
Got a burning question you want answered?
Short questions: Ask a Game Dev on Twitter
Long questions: Ask a Game Dev on Tumblr
Frequent Questions: The FAQ
27 notes
·
View notes
Text
ik ik ik I've been ranting a lot in a directionless way, I'm just trying to put my thoughts together. because it is easy to just say "well if fandoms piss you off just go do something original" but it's everywhere and it's not like the original indie idea to mass consumer media pipeline doesn't exist or even that in some sense still exists in smaller scale business endeavors.
stuff I do find cool is when something becomes more than a product, when it becomes invitation to do more. when developers write code for particular engines or even the software itself that they make open source. I've remarked before that I found it super endearing how JnJ made all their animation assets freely available to their younger audience.
whatever the hell KGatLW is doing. they're letting people record their live music and sell bootleg albums and sell their own merch and stuff and it's like it's own ecosystem and it's kind of nuts to observe at a distance.
and I think a lot about stuff like how "the fine arts" was defined in its worth by placing value on the "original idea", as separate from decorative arts and crafts. like design has its roots in these trades that were elaborated on, reinterpreted and passed down over time. nobody just "invented" the thing, they came from a tradition, or studied multiple traditions.
it's kind of farcical to act like the genius of the individual is the defining value of it. or like, how relying on corporate media for entertainment is relatively new in the grand scheme of things and hopefully a trend that will die sooner rather than later. and like the "antidote" is for smaller scale subscription services, or smaller scale enterprise.
like it just doesn't have to be like this by default, even if we have to work with what we have sometimes.
7 notes
·
View notes
Text
AGARTHA Aİ - DEVASA+ (4)

In an era where technology and creativity intertwine, AI design is revolutionizing the way we conceptualize and create across various industries. From the runway to retail, 3D fashion design is pushing boundaries, enabling designers to craft intricate garments with unparalleled precision. Likewise, 3D product design is transforming everything from gadgets to furniture, allowing for rapid prototyping and innovation. As we explore these exciting advancements, platforms like Agartha.ai are leading the charge in harnessing artificial intelligence to streamline the design process and inspire new ideas.
AI design
Artificial intelligence (AI) has revolutionized numerous industries, and the realm of design is no exception. By leveraging the power of machine learning and advanced algorithms, AI is transforming the way designers create, innovate, and deliver their products. AI-driven tools enable designers to harness vast amounts of data, allowing for more informed decision-making and streamlined workflows.
In the context of graphic design, AI can assist artists in generating ideas, creating unique visuals, and even automating repetitive tasks. For instance, programs powered by AI design can analyze trends and consumer preferences, producing designs that resonate with target audiences more effectively than traditional methods. This shift not only enhances creativity but also enables designers to focus on strategic thinking and ideation.
Moreover, AI is facilitating personalized design experiences. With the help of algorithms that analyze user behavior, products can be tailored to meet the specific needs and tastes of individuals. This level of customization fosters deeper connections between brands and consumers, ultimately driving customer satisfaction and loyalty in an increasingly competitive market.
3D fashion design
In recent years, 3D fashion design has revolutionized the way we create and visualize clothing. Using advanced software and tools, designers can create lifelike virtual garments that allow for innovative experimentation without the need for physical fabric. This trend has not only streamlined the design process but has also significantly reduced waste in the fashion industry.
Moreover, 3D fashion design enables designers to showcase their creations in a more interactive manner. By utilizing 3D modeling and rendering technologies, designers can present their collections in virtual environments, making it easier for clients and consumers to appreciate the nuances of each piece. This immersive experience also helps in gathering valuable feedback before producing the final product.
Furthermore, the integration of 3D fashion design with augmented reality (AR) and virtual reality (VR) technologies is bringing a fresh perspective to the industry. Consumers can virtually try on clothes from the comfort of their homes, thereby enhancing the shopping experience. As this field continues to evolve, it promises to bridge the gap between creativity and technology, paving the way for a sustainable and forward-thinking fashion future.
3D product design
3D product design has revolutionized the way we conceptualize and create products. With advanced software tools and technologies, designers can now create highly detailed and realistic prototypes that are not only visually appealing but also functional. This process allows for a quicker iteration of ideas, enabling designers to experiment with various styles and functionalities before arriving at the final design.
One of the significant advantages of 3D product design is the ability to visualize products in a virtual environment. Designers can see how their creations would look in real life, which is essential for understanding aesthetics and usability. Additionally, this technology enables manufacturers to identify potential issues in the design phase, reducing costs associated with prototype development and rework.
Moreover, the rise of 3D printing has further enhanced the significance of 3D product design. Designers can swiftly turn their digital models into tangible products, allowing for rapid prototyping and small-batch manufacturing. This agility not only speeds up the time-to-market for new products but also paves the way for more innovative designs that were previously impossible to execute.
Agartha.ai
Agartha.ai is a revolutionary platform that merges artificial intelligence with innovative design, creating a new avenue for designers and creators alike. With the rapid advancements in technology, Agartha.ai leverages AI to streamline various design processes, enabling users to produce unique and captivating designs with ease.
The platform provides tools that empower both emerging and established designers to explore the possibilities of AI design. By utilizing intelligent algorithms, Agartha.ai can assist in generating design options, ensuring that creativity is not hindered but enhanced. This results in a more efficient workflow and allows designers to focus on the conceptual aspects of their projects.
One of the standout features of Agartha.ai is its ability to adapt to different design disciplines, such as 3D fashion design and 3D product design. By supporting a broad spectrum of design fields, it positions itself as a versatile tool that meets the evolving needs of today's creative professionals. Whether it's crafting intricate fashion pieces or developing innovative product designs, Agartha.ai is at the forefront of the design revolution.
329 notes
·
View notes
Text
[Apple,Inc.] Leadership Styles
[Juaneishia]
What makes a leader strategic and innovative? There are components that allow a leader to take over the skills of being strategic and innovative. To have the inclination for long-term success, competitive advantage, problem-solving mindset, adaptability to change, and passion for impact, personal growth, etc. What makes a leader possess dysfunctional behavior? The ingredients are insecurity, ego, greed, inability to delegate, the list is endless but not satisfactory for the company or the employees. As we dive into the different leadership traits of the CEOs of Apple, we will learn the dos and don’ts of being a leader. You will be able to identify what type of leader you want to be for your business or personal growth based on the styles that were depicted by each CEO. Using strategies and innovation will cause challenges to arise; this is normal. “Strategic thinkers question the status quo. They challenge their own and others’ assumptions and encourage divergent points of view. Only after careful reflection and examination of a problem through many lenses do they take decisive action. This requires patience, courage, and an open mind. (Schoemaker, Krupp, Howland, 2013). Dysfunctional leadership is very unprofessional. “Unprofessional behavior can cause discomfort among team members, and it can undermine the leader’s credibility and authority.” (Blog).
Apple, Inc.
Founded in 1976 by Steve Jobs, Steve Wozniak, and Ronald Wayne as a partnership, Apple started in the garage of the Jobs family home. Apple would move over the next half century to become one of the largest and most successful tech companies in the world. The first product developed by Jobs and Wozniak was the Apple I computer and according to Wikipedia (2020) was “sold as a motherboard with CPU, RAM, and basic textual-video chips—a base kit concept which was not yet marketed as a complete personal computer.” In 1977, after creating the Apple I computer, Apple became an incorporated company in Cupertino, California. By the time apple had become an incorporation, Wayne had sold his shares back to Jobs and Wozniak. (Richardson, 2023).
After several product successes in 1977, including Apple II and MacIntosh computers, Apple faced trouble in the market. Wintel offered lower-priced PC clones that were operated on Intel software systems. Through this trouble, Apple was faced with bankruptcy. During the challenge of facing bankruptcy, Jobs repaired the failed operating system’s issues and developed new products including iPod, iMac, iPhone, and iPad allowing the company to perform a complete 360 by 1978. (2020).
Apple, after its start, went through a few short-term CEO’s. While the more prominent leaders remain to be Jobs, Wozniak, and Tim Cook, a collaborative modern-aged leader, it is important to acknowledge the role that others had played and how it affected the company and its vision. (2023).
Today, Apple has evolved to offer full-service technology in many varieties. Apple technology now includes headwear, watches, Augmented Reality (AR), streaming and subscription services, music, and more (2025). Apple has effectively adapted to the demand of the consumer through a technological revolution.
References
Schoemaker, P J. H. Krupp, S. Howland, S. (2013, January -February) Strategic Leadership: The Essential Skills. Harvard Business Review. https://hbr.org/2013/01/strategic-leadership-the-esssential-skills
Blog. The Top 5 Dysfunctional Behaviors That Leaders Should Avoid. Lolly Daskal. https://www.lollydaskal.com/leadership/the-top-5-dysfunctional-behaviors-that-leaders-should-avoid/
Wikipedia. (2024). Apple Inc. Wikipedia; Wikimedia Foundation. https://en.wikipedia.org/wiki/Apple_Inc.
Richardson, A. (2023). The founding of Apple Computer, Inc. Library of Congress. https://guides.loc.gov/this-month-in-business-history/april/apple-computer-founded
Muse, T. (2023, November 27). Apple’s CEO History. Www.historyoasis.com. https://www.historyoasis.com/post/apple-ceo-history
Apple. (2025). Apple. https://www.apple.com/
7 notes
·
View notes
Text
Ganesh Shankar, CEO & Co-Founder of Responsive – Interview Series
New Post has been published on https://thedigitalinsider.com/ganesh-shankar-ceo-co-founder-of-responsive-interview-series/
Ganesh Shankar, CEO & Co-Founder of Responsive – Interview Series

Ganesh Shankar, CEO and Co-Founder of Responsive, is an experienced product manager with a background in leading product development and software implementations for Fortune 500 enterprises. During his time in product management, he observed inefficiencies in the Request for Proposal (RFP) process—formal documents organizations use to solicit bids from vendors, often requiring extensive, detailed responses. Managing RFPs traditionally involves multiple stakeholders and repetitive tasks, making the process time-consuming and complex.
Founded in 2015 as RFPIO, Responsive was created to streamline RFP management through more efficient software solutions. The company introduced an automated approach to enhance collaboration, reduce manual effort, and improve efficiency. Over time, its technology expanded to support other complex information requests, including Requests for Information (RFIs), Due Diligence Questionnaires (DDQs), and security questionnaires.
Today, as Responsive, the company provides solutions for strategic response management, helping organizations accelerate growth, mitigate risk, and optimize their proposal and information request processes.
What inspired you to start Responsive, and how did you identify the gap in the market for response management software?
My co-founders and I founded Responsive in 2015 after facing our own struggles with the RFP response process at the software company we were working for at the time. Although not central to our job functions, we dedicated considerable time assisting the sales team with requests for proposals (RFPs), often feeling underappreciated despite our vital role in securing deals. Frustrated with the lack of technology to make the RFP process more efficient, we decided to build a better solution. Fast forward nine years, and we’ve grown to nearly 500 employees, serve over 2,000 customers—including 25 Fortune 100 companies—and support nearly 400,000 users worldwide.
How did your background in product management and your previous roles influence the creation of Responsive?
As a product manager, I was constantly pulled by the Sales team into the RFP response process, spending almost a third of my time supporting sales instead of focusing on my core product management responsibilities. My two co-founders experienced a similar issue in their technology and implementation roles. We recognized this was a widespread problem with no existing technology solution, so we leveraged our almost 50 years of combined experience to create Responsive. We saw an opportunity to fundamentally transform how organizations share information, starting with managing and responding to complex proposal requests.
Responsive has evolved significantly since its founding in 2015. How do you maintain the balance between staying true to your original vision and adapting to market changes?
First, we’re meticulous about finding and nurturing talent that embodies our passion – essentially cloning our founding spirit across the organization. As we’ve scaled, it’s become critical to hire managers and team members who can authentically represent our core cultural values and commitment.
At the same time, we remain laser-focused on customer feedback. We document every piece of input, regardless of its size, recognizing that these insights create patterns that help us navigate product development, market positioning, and any uncertainty in the industry. Our approach isn’t about acting on every suggestion, but creating a comprehensive understanding of emerging trends across a variety of sources.
We also push ourselves to think beyond our immediate industry and to stay curious about adjacent spaces. Whether in healthcare, technology, or other sectors, we continually find inspiration for innovation. This outside-in perspective allows us to continually raise the bar, inspiring ideas from unexpected places and keeping our product dynamic and forward-thinking.
What metrics or success indicators are most important to you when evaluating the platform’s impact on customers?
When evaluating Responsive’s impact, our primary metric is how we drive customer revenue. We focus on two key success indicators: top-line revenue generation and operational efficiency. On the efficiency front, we aim to significantly reduce RFP response time – for many, we reduce it by 40%. This efficiency enables our customers to pursue more opportunities, ultimately accelerating their revenue generation potential.
How does Responsive leverage AI and machine learning to provide a competitive edge in the response management software market?
We leverage AI and machine learning to streamline response management in three key ways. First, our generative AI creates comprehensive proposal drafts in minutes, saving time and effort. Second, our Ask solution provides instant access to vetted organizational knowledge, enabling faster, more accurate responses. Third, our Profile Center helps InfoSec teams quickly find and manage security content.
With over $600 billion in proposals managed through the Responsive platform and four million Q&A pairs processed, our AI delivers intelligent recommendations and deep insights into response patterns. By automating complex tasks while keeping humans in control, we help organizations grow revenue, reduce risk, and respond more efficiently.
What differentiates Responsive’s platform from other solutions in the industry, particularly in terms of AI capabilities and integrations?
Since 2015, AI has been at the core of Responsive, powering a platform trusted by over 2,000 global customers. Our solution supports a wide range of RFx use cases, enabling seamless collaboration, workflow automation, content management, and project management across teams and stakeholders.
With key AI capabilities—like smart recommendations, an AI assistant, grammar checks, language translation, and built-in prompts—teams can deliver high-quality RFPs quickly and accurately.
Responsive also offers unmatched native integrations with leading apps, including CRM, cloud storage, productivity tools, and sales enablement. Our customer value programs include APMP-certified consultants, Responsive Academy courses, and a vibrant community of 1,500+ customers sharing insights and best practices.
Can you share insights into the development process behind Responsive’s core features, such as the AI recommendation engine and automated RFP responses?
Responsive AI is built on the foundation of accurate, up-to-date content, which is critical to the effectiveness of our AI recommendation engine and automated RFP responses. AI alone cannot resolve conflicting or incomplete data, so we’ve prioritized tools like hierarchical tags and robust content management to help users organize and maintain their information. By combining generative AI with this reliable data, our platform empowers teams to generate fast, high-quality responses while preserving credibility. AI serves as an assistive tool, with human oversight ensuring accuracy and authenticity, while features like the Ask product enable seamless access to trusted knowledge for tackling complex projects.
How have advancements in cloud computing and digitization influenced the way organizations approach RFPs and strategic response management?
Advancements in cloud computing have enabled greater efficiency, collaboration, and scalability. Cloud-based platforms allow teams to centralize content, streamline workflows, and collaborate in real time, regardless of location. This ensures faster turnaround times and more accurate, consistent responses.
Digitization has also enhanced how organizations manage and access their data, making it easier to leverage AI-powered tools like recommendation engines and automated responses. With these advancements, companies can focus more on strategy and personalization, responding to RFPs with greater speed and precision while driving better outcomes.
Responsive has been instrumental in helping companies like Microsoft and GEODIS streamline their RFP processes. Can you share a specific success story that highlights the impact of your platform?
Responsive has played a key role in supporting Microsoft’s sales staff by managing and curating 20,000 pieces of proposal content through its Proposal Resource Library, powered by Responsive AI. This technology enabled Microsoft’s proposal team to contribute $10.4 billion in revenue last fiscal year. Additionally, by implementing Responsive, Microsoft saved its sellers 93,000 hours—equivalent to over $17 million—that could be redirected toward fostering stronger customer relationships.
As another example of Responsive providing measurable impact, our customer Netsmart significantly improved their response time and efficiency by implementing Responsive’s AI capabilities. They achieved a 10X faster response time, increased proposal submissions by 67%, and saw a 540% growth in user adoption. Key features such as AI Assistant, Requirements Analysis, and Auto Respond played crucial roles in these improvements. The integration with Salesforce and the establishment of a centralized Content Library further streamlined their processes, resulting in a 93% go-forward rate for RFPs and a 43% reduction in outdated content. Overall, Netsmart’s use of Responsive’s AI-driven platform led to substantial time savings, enhanced content accuracy, and increased productivity across their proposal management operations.
JAGGAER, another Responsive customer, achieved a double-digit win-rate increase and 15X ROI by using Responsive’s AI for content moderation, response creation, and Requirements Analysis, which improved decision-making and efficiency. User adoption tripled, and the platform streamlined collaboration and content management across multiple teams.
Where do you see the response management industry heading in the next five years, and how is Responsive positioned to lead in this space?
In the next five years, I see the response management industry being transformed by AI agents, with a focus on keeping humans in the loop. While we anticipate around 80 million jobs being replaced, we’ll simultaneously see 180 million new jobs created—a net positive for our industry.
Responsive is uniquely positioned to lead this transformation. We’ve processed over $600 billion in proposals and built a database of almost 4 million Q&A pairs. Our massive dataset allows us to understand complex patterns and develop AI solutions that go beyond simple automation.
Our approach is to embrace AI’s potential, finding opportunities for positive outcomes rather than fearing disruption. Companies with robust market intelligence, comprehensive data, and proven usage will emerge as leaders, and Responsive is at the forefront of that wave. The key is not just implementing AI, but doing so strategically with rich, contextual data that enables meaningful insights and efficiency.
Thank you for the great interview, readers who wish to learn more should visit Responsive,
#000#adoption#agents#ai#AI AGENTS#ai assistant#AI-powered#amp#Analysis#approach#apps#automation#background#billion#CEO#Cloud#cloud computing#cloud storage#collaborate#Collaboration#Community#Companies#comprehensive#computing#content#content management#content moderation#courses#crm#customer relationships
7 notes
·
View notes
Text

The Optimist by Keach Hagey
The man who brought us ChatGPT. Sam Altman’s extraordinary career – and personal life – under the microscope
On 30 November 2022, OpenAI CEO Sam Altman tweeted the following, characteristically reserving the use of capital letters for his product’s name: “today we launched ChatGPT. try talking with it here: chat.openai.com”. In a reply to himself immediately below, he added: “language interfaces are going to be a big deal, i think”.
If Altman was aiming for understatement, he succeeded. ChatGPT became the fastest web service to hit 1 million users, but more than that, it fired the starting gun on the AI wars currently consuming big tech. Everything is about to change beyond recognition, we keep being told, though no one can agree on whether that will be for good or ill.
This moment is just one of many skilfully captured in Wall Street Journal reporter Keach Hagey’s biography of Altman, who, like his company, was then virtually unknown outside of the industry. He is a confounding figure throughout the book, which charts his childhood, troubled family life, his first failed startup Loopt, his time running the startup incubator Y Combinator, and the founding of OpenAI.
Altman, short, slight, Jewish and gay, appears not to fit the typical mould of the tech bro. He is known for writing long, earnest essays about the future of humankind, and his reputation was as more of an arch-networker and money-raiser than an introverted coder in a hoodie.
OpenAI, too, was supposed to be different from other tech giants: it was set up as a not-for-profit, committed by its charter to work collaboratively to create AI for humanity’s benefit, and made its code publicly available. Altman would own no shares in it.
He could commit to this, as he said in interviews, because he was already rich – his net worth is said to be around $1.5bn (£1.13bn) – as a result of his previous investments. It was also made possible because of his hyper-connectedness: as Hagey tells it, Altman met his software engineer husband Oliver Mulherin in the hot tub of PayPal and Palantir co-founder Peter Thiel at 3am, when Altman, 29, was already a CEO, and Mulherin was a 21-year-old student.
Thiel was a significant mentor to Altman, but not nearly so central to the story of OpenAI as another notorious Silicon Valley figure – Elon Musk. The Tesla and SpaceX owner was an initial co-founder and major donor to the not-for-profit version of OpenAI, even supplying its office space in its early years.
That relationship has soured into mutual antipathy – Musk is both suing OpenAI and offering (somewhat insincerely) to buy it – as Altman radically altered the company’s course. First, its commitment to releasing code publicly was ditched. Then, struggling to raise funds, it launched a for-profit subsidiary. Soon, both its staff and board worried the vision of AI for humanity was being lost amid a rush to create widely used and lucrative products.
This leads to the book’s most dramatic sections, describing how OpenAI’s not-for-profit board attempted an audacious ousting of Altman as CEO, only for more than 700 of the company’s 770 engineers to threaten to resign if he was not reinstated. Within five days, Altman was back, more powerful than ever.
OpenAI has been toying with becoming a purely private company. And Altman turns out to be less of an anomaly in Silicon Valley than he once seemed. Like its other titans, he seems to be prepping for a potential doomsday scenario, with ranch land and remote properties. He is set to take stock in OpenAI after all. He even appears to share Peter Thiel’s supposed interest in the potential for transfusions of young blood to slow down ageing.
The Optimist serves to remind us that however unprecedented the consequences of AI models might be, the story of their development is a profoundly human one. Altman is the great enigma at its core, seemingly acting with the best of intentions, but also regularly accused of being a skilled and devious manipulator.
For students of the lives of big tech’s other founders, a puzzling question remains: in a world of 8 billion human beings, why do the stories of the people wreaking such huge change in our world end up sounding so eerily alike?
Daily inspiration. Discover more photos at Just for Books…?
4 notes
·
View notes
Text
In March 2007, Google’s then senior executive in charge of acquisitions, David Drummond, emailed the company’s board of directors a case for buying DoubleClick. It was an obscure software developer that helped websites sell ads. But it had about 60 percent market share and could accelerate Google’s growth while keeping rivals at bay. A “Microsoft-owned DoubleClick represents a major competitive threat,” court papers show Drummond writing.
Three weeks later, on Friday the 13th, Google announced the acquisition of DoubleClick for $3.1 billion. The US Department of Justice and 17 states including California and Colorado now allege that the day marked the beginning of Google’s unchecked dominance in online ads—and all the trouble that comes with it.
The government contends that controlling DoubleClick enabled Google to corner websites into doing business with its other services. That has resulted in Google allegedly monopolizing three big links of a vital digital advertising supply chain, which funnels over $12 billion in annual revenue to websites and apps in the US alone.
It’s a big amount. But a government expert estimates in court filings that if Google were not allegedly destroying its competition illegally, those publishers would be receiving up to an additional hundreds of millions of dollars each year. Starved of that potential funding, “publishers are pushed to put more ads on their websites, to put more content behind costly paywalls, or to cease business altogether,” the government alleges. It all adds up to a subpar experience on the web for consumers, Colorado attorney general Phil Weiser says.
“Google is able to extract hiked-up costs, and those are passed on to consumers,” he alleges. “The overall outcome we want is for consumers to have more access to content supported by advertising revenue and for people who are seeking advertising not to have to pay inflated costs.”
Google disputes the accusations.
Starting today, both sides’ arguments will be put to the test in what’s expected to be a weekslong trial before US district judge Leonie Brinkema in Alexandria, Virginia. The government wants her to find that Google has violated federal antitrust law and then issue orders that restore competition. In a best-case scenario, according to several Google critics and experts in online ads who spoke with WIRED, internet users could find themselves more pleasantly informed and entertained.
It could take years for the ad market to shake out, says Adam Heimlich, a longtime digital ad executive who’s extensively researched Google. But over time, fresh competition could lower supply chain fees and increase innovation. That would drive “better monetization of websites and better quality of websites,” says Heimlich, who now runs AI software developer Chalice Custom Algorithms.
Tim Vanderhook, CEO of ad-buying software developer Viant Technology, which both competes and partners with Google, believes that consumers would encounter a greater variety of ads, fewer creepy ads, and pages less cluttered with ads. “A substantially improved browsing experience,” he says.
Of course, all depends on the outcome of the case. Over the past year, Google lost its two other antitrust trials—concerning illegal search and mobile app store monopolies. Though the verdicts are under appeal, they’ve made the company’s critics optimistic about the ad tech trial.
Google argues that it faces fierce competition from Meta, Amazon, Microsoft, and others. It further contends that customers benefited from each of the acquisitions, contracts, and features that the government is challenging. “Google has designed a set of products that work efficiently with each other and attract a valuable customer base,” the company’s attorneys wrote in a 359-page rebuttal.
For years, Google publicly has maintained that its ad tech projects wouldn’t harm clients or competition. “We will be able to help publishers and advertisers generate more revenue, which will fuel the creation of even more rich and diverse content on the internet,” Drummond testified in 2007 to US senators concerned about the DoubleClick deal’s impact on competition and privacy. US antitrust regulators at the time cleared the purchase. But at least one of them, in hindsight, has said he should have blocked it.
Deep Control
The Justice Department alleges that acquiring DoubleClick gave Google “a pool of captive publishers that now had fewer alternatives and faced substantial switching costs associated with changing to another publisher ad server.” The global market share of Google’s tool for publishers is now 91 percent, according to court papers. The company holds similar control over ad exchanges that broker deals (around 70 percent) and tools used by advertisers (85 percent), the court filings say.
Google’s dominance, the government argues, has “impaired the ability of publishers and advertisers to choose the ad tech tools they would prefer to use and diminished the number and quality of viable options available to them.”
The government alleges that Google staff spoke internally about how they have been earning an unfair portion of what advertisers spend on advertising, to the tune of over a third of every $1 spent in some cases.
Some of Google’s competitors want the tech giant to be broken up into multiple independent companies, so each of its advertising services competes on its own merits without the benefit of one pumping up another. The rivals also support rules that would bar Google from preferencing its own services. “What all in the industry are looking for is fair competition,” Viant’s Vanderhook says.
If Google ad tech alternatives win more business, not everyone is so sure that the users will notice a difference. “We’re talking about moving from the NYSE to Nasdaq,” Ari Paparo, a former DoubleClick and Google executive who now runs the media company Marketecture, tells WIRED. The technology behind the scenes may shift, but the experience for investors—or in this case, internet surfers—doesn’t.
Some advertising experts predict that if Google is broken up, users’ experiences would get even worse. Andrey Meshkov, chief technology officer of ad-block developer AdGuard, expects increasingly invasive tracking as competition intensifies. Products also may cost more because companies need to not only hire additional help to run ads but also buy more ads to achieve the same goals. “So the ad clutter is going to get worse,” Beth Egan, an ad executive turned Syracuse University associate professor, told reporters in a recent call arranged by a Google-funded advocacy group.
But Dina Srinivasan, a former ad executive who as an antitrust scholar wrote a Stanford Technology Law Review paper on Google’s dominance, says advertisers would end up paying lower fees, and the savings would be passed on to their customers. That future would mark an end to the spell Google allegedly cast with its DoubleClick deal. And it could happen even if Google wins in Virginia. A trial in a similar lawsuit filed by Texas, 15 other states, and Puerto Rico is scheduled for March.
31 notes
·
View notes