#document creation software
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 16.74 million mobile monthly users in the US.
Text
Simplified Document Creation with PDQ Docs: Streamlining Your Workflow
In today’s fast-paced world, efficiency and time-saving tools are essential in every aspect of business and personal work. When it comes to document creation, many professionals face the challenge of managing complex formatting, collaboration, and time-consuming revisions. With PDQ Docs, document creation has been made easier, faster, and more streamlined than ever before. This innovative software is designed to simplify the process of creating professional documents, enabling users to focus on the content rather than the format.
How PDQ Docs Simplifies the Document Creation Process
PDQ Docs revolutionizes the way documents are created by providing a user-friendly interface and an array of powerful tools that reduce the complexity traditionally associated with document formatting. Whether you are drafting a simple letter, preparing a business report, or putting together a legal document, PDQ Docs makes the task significantly less daunting. The software eliminates the need for extensive knowledge of formatting techniques and complex features found in traditional word processors.
One of the key benefits of simplified document creation with PDQ Docs is its intuitive interface. The software is designed to be accessible for both beginners and advanced users, making it easy to create polished documents without the steep learning curve associated with other tools. Whether you are creating a document from scratch or modifying an existing template, PDQ Docs ensures that the process is as smooth and straightforward as possible.

Efficiency in Document Formatting
One of the most time-consuming aspects of simplified document creation is formatting. Whether it's aligning text, adjusting margins, or selecting the appropriate font size, these details can quickly become overwhelming. PDQ Docs simplifies this process by providing pre-set templates and automatic formatting options that save time and effort. You no longer need to manually adjust settings every time you create a new document. The software handles most formatting tasks for you, allowing you to focus more on the content itself.
Security and Reliability
When creating and sharing documents, especially in professional settings, security is a top priority. PDQ Docs offers robust security features to ensure that your documents are protected. The software encrypts your documents and stores them in a secure cloud environment, making it easy to access and edit them from anywhere while keeping them safe from unauthorized access. The cloud-based system also ensures that your documents are backed up, so you never have to worry about losing important work due to a computer malfunction or data loss.
Conclusion
Simplified document creation is no longer a distant goal, thanks to PDQ Docs. With its user-friendly interface, collaborative features, efficient formatting tools, and top-notch security, this document creation software is designed to save you time, reduce stress, and help you produce professional documents quickly. Whether you’re a small business owner, a student, or a professional in any industry, PDQ Docs is the ideal solution for simplifying the document creation process and improving your workflow. Try PDQ Docs today and experience the future of document creation.
#simplified document creation#automated document creation#document automation tools#easy document generation#template-based document creation#document creation software#business document solutions#efficient document creation#document editing tools#document collaboration#buy document management software#ultimate document management software#document automation software for law firms#document generation software for law firms#centralized document management software
0 notes
Text
Customizing PDF Documents for Your Business Needs: A Simple Guide to Online Tools
Easy access to services or communications is a huge priority for modern-day customers. Most customers decide whether to prefer one brand over the other based on the overall experience. As a business, you may need to think about ways to update or inform them from time to time. How does your brand do that? Too often, businesses focus on the product while customer experience, which is equally important, is kicked to a sideline. Sinch in India has launched a brand-new product – a Customer Communication Management (CCM) solution – that will help businesses like yours to create and send customer communication as digital documents quickly without having to liaise with multiple vendors to help you do so. It lets enterprises not just generate customer communication in a PDF format; businesses can send these to customers via SMS, email, and WhatsApp. Automate PDF document creation Automating PDF Document Creation has never been easier with the Sinch PDF template editor and PDF generation API. Sinch advanced drag & drop editor lets you design PDF templates in any browser and generate pixel-perfect PDF documents from reusable templates and data with no-code platforms. Our PDF template editor supports expressions and formatting for datetime, currency, and custom formatting. Automate PDF document creation is one of the best PDF makers through which you can make any PDF. You can easily overlay or add text, QR codes, and images to existing PDFs. Best Document Generation Software Document generation software allows users to generate, customize, edit, and produce data-driven documents. These platforms can function as PDF creators and best document generation software that pull data from third-party sources into templates. Document generation applications can leverage data from various source systems like CRM, ERP, and storage. Document generation applications should easily maintain brand consistency and offer conditional formatting. Documents created through these products range in functionality and can include reports, forms, proposals, legal documentation, notes, and contracts. Create PDF Document Online No matter what types of files you need to convert, our online file converter is more than just a PDF file converter. It’s the go-to solution for all of your file conversion needs. With Sinch, you can create PDF documents online. With a free trial of our online PDF converter, you can convert files to and from PDF for free or sign up for one of our memberships for limitless access to our file converter’s full suite of tools. You also get unlimited file sizes and the ability to simultaneously upload and convert several files to PDF. Our free file converter works on any OS, including Windows, Mac, and Linux.
0 notes
Text
Calling Ultima the single most consistently groundbreaking, pioneering, influential series of videogames in the history of the medium would be kind of an understatement (Akalabeth and Ultima I pioneering the idea of adapting tabletop RPGs to the medium of videogames in a way that established so many elements that would become intrinsic to the identity of the genre for decades, like the concept of grid-based first person dungeon crawling and tile-based overworld travel, later games establishing the mold for isometric top-down RPGs, Ultima Online being a critical tipping point in cementing the popularity of the MMORPG), but even among a series that consistently pumped groundbreaking videogame after groundbreaking videogame it's just completely impossible to overstate how massive Ultima Underworld's legacy stands over a huge chunk of the gaming medium, even if its effects manifest in subtle ways nowadays like I legitimately believe no individual videogame in the history of the medium has been as influential as it.
It's legitimately insane how many seemingly unrelated videogames can be directly traced back to Underworld in some form or another. Like, to get the obvious out of the way first, it established the DNA of the immersive sim genre, so if you like games like System Shock, Thief, Deus Ex, Bioshock, Dishonored, Prey, all of those games were either made by people who worked on Ultima Underworld (sometimes by the same studio even), or otherwise directly influenced by games that were.
But also, if you like any first person shooters influenced by Doom and other ID Software games? John Carmack was there when the demo of Underworld was first shown and decided he could create a faster texture-mapped first-person 3D engine. Which he did, at the cost of sacrificing true polygonal 3D environments in favor of the pseudo-3D that he would use for Catacombs 3D and Wolfenstein 3D, eventually resulting in the creation of Doom. RPGs like the Elder Scrolls or Gothic? It would take all day to list off how much they directly owe to Ultima Underworld. That videogame trope of finding out what happened to the occupants of a place through finding in-game logs and documents? It was established by Ultima Underworld and popularized by one of its successors.
That's without mentioning how many games directly cite it as an influence. Some already mentioned like Bioshock, Deus Ex, and Elder Scrolls, but also like. Half-life 2? Tomb Raider? Gears of War? Vampire the Masquerade: Bloodlines? All cite it as a direct influence in their game design.
Like of course a lot of these things are by virtue of being one of the earliest free-moving 3D first person videogames, when you're that early in the history of the medium you'll inevitably end up being the first to do *something* that otherwise someone else would eventually have ended up doing anyway, but no other game has a "first videogame to do [thing]" list anywhere as long and important as Ultima Underworld's.
402 notes
·
View notes
Text
AI “art” and uncanniness

TOMORROW (May 14), I'm on a livecast about AI AND ENSHITTIFICATION with TIM O'REILLY; on TOMORROW (May 15), I'm in NORTH HOLLYWOOD for a screening of STEPHANIE KELTON'S FINDING THE MONEY; FRIDAY (May 17), I'm at the INTERNET ARCHIVE in SAN FRANCISCO to keynote the 10th anniversary of the AUTHORS ALLIANCE.

When it comes to AI art (or "art"), it's hard to find a nuanced position that respects creative workers' labor rights, free expression, copyright law's vital exceptions and limitations, and aesthetics.
I am, on balance, opposed to AI art, but there are some important caveats to that position. For starters, I think it's unequivocally wrong – as a matter of law – to say that scraping works and training a model with them infringes copyright. This isn't a moral position (I'll get to that in a second), but rather a technical one.
Break down the steps of training a model and it quickly becomes apparent why it's technically wrong to call this a copyright infringement. First, the act of making transient copies of works – even billions of works – is unequivocally fair use. Unless you think search engines and the Internet Archive shouldn't exist, then you should support scraping at scale:
https://pluralistic.net/2023/09/17/how-to-think-about-scraping/
And unless you think that Facebook should be allowed to use the law to block projects like Ad Observer, which gathers samples of paid political disinformation, then you should support scraping at scale, even when the site being scraped objects (at least sometimes):
https://pluralistic.net/2021/08/06/get-you-coming-and-going/#potemkin-research-program
After making transient copies of lots of works, the next step in AI training is to subject them to mathematical analysis. Again, this isn't a copyright violation.
Making quantitative observations about works is a longstanding, respected and important tool for criticism, analysis, archiving and new acts of creation. Measuring the steady contraction of the vocabulary in successive Agatha Christie novels turns out to offer a fascinating window into her dementia:
https://www.theguardian.com/books/2009/apr/03/agatha-christie-alzheimers-research
Programmatic analysis of scraped online speech is also critical to the burgeoning formal analyses of the language spoken by minorities, producing a vibrant account of the rigorous grammar of dialects that have long been dismissed as "slang":
https://www.researchgate.net/publication/373950278_Lexicogrammatical_Analysis_on_African-American_Vernacular_English_Spoken_by_African-Amecian_You-Tubers
Since 1988, UCL Survey of English Language has maintained its "International Corpus of English," and scholars have plumbed its depth to draw important conclusions about the wide variety of Englishes spoken around the world, especially in postcolonial English-speaking countries:
https://www.ucl.ac.uk/english-usage/projects/ice.htm
The final step in training a model is publishing the conclusions of the quantitative analysis of the temporarily copied documents as software code. Code itself is a form of expressive speech – and that expressivity is key to the fight for privacy, because the fact that code is speech limits how governments can censor software:
https://www.eff.org/deeplinks/2015/04/remembering-case-established-code-speech/
Are models infringing? Well, they certainly can be. In some cases, it's clear that models "memorized" some of the data in their training set, making the fair use, transient copy into an infringing, permanent one. That's generally considered to be the result of a programming error, and it could certainly be prevented (say, by comparing the model to the training data and removing any memorizations that appear).
Not every seeming act of memorization is a memorization, though. While specific models vary widely, the amount of data from each training item retained by the model is very small. For example, Midjourney retains about one byte of information from each image in its training data. If we're talking about a typical low-resolution web image of say, 300kb, that would be one three-hundred-thousandth (0.0000033%) of the original image.
Typically in copyright discussions, when one work contains 0.0000033% of another work, we don't even raise the question of fair use. Rather, we dismiss the use as de minimis (short for de minimis non curat lex or "The law does not concern itself with trifles"):
https://en.wikipedia.org/wiki/De_minimis
Busting someone who takes 0.0000033% of your work for copyright infringement is like swearing out a trespassing complaint against someone because the edge of their shoe touched one blade of grass on your lawn.
But some works or elements of work appear many times online. For example, the Getty Images watermark appears on millions of similar images of people standing on red carpets and runways, so a model that takes even in infinitesimal sample of each one of those works might still end up being able to produce a whole, recognizable Getty Images watermark.
The same is true for wire-service articles or other widely syndicated texts: there might be dozens or even hundreds of copies of these works in training data, resulting in the memorization of long passages from them.
This might be infringing (we're getting into some gnarly, unprecedented territory here), but again, even if it is, it wouldn't be a big hardship for model makers to post-process their models by comparing them to the training set, deleting any inadvertent memorizations. Even if the resulting model had zero memorizations, this would do nothing to alleviate the (legitimate) concerns of creative workers about the creation and use of these models.
So here's the first nuance in the AI art debate: as a technical matter, training a model isn't a copyright infringement. Creative workers who hope that they can use copyright law to prevent AI from changing the creative labor market are likely to be very disappointed in court:
https://www.hollywoodreporter.com/business/business-news/sarah-silverman-lawsuit-ai-meta-1235669403/
But copyright law isn't a fixed, eternal entity. We write new copyright laws all the time. If current copyright law doesn't prevent the creation of models, what about a future copyright law?
Well, sure, that's a possibility. The first thing to consider is the possible collateral damage of such a law. The legal space for scraping enables a wide range of scholarly, archival, organizational and critical purposes. We'd have to be very careful not to inadvertently ban, say, the scraping of a politician's campaign website, lest we enable liars to run for office and renege on their promises, while they insist that they never made those promises in the first place. We wouldn't want to abolish search engines, or stop creators from scraping their own work off sites that are going away or changing their terms of service.
Now, onto quantitative analysis: counting words and measuring pixels are not activities that you should need permission to perform, with or without a computer, even if the person whose words or pixels you're counting doesn't want you to. You should be able to look as hard as you want at the pixels in Kate Middleton's family photos, or track the rise and fall of the Oxford comma, and you shouldn't need anyone's permission to do so.
Finally, there's publishing the model. There are plenty of published mathematical analyses of large corpuses that are useful and unobjectionable. I love me a good Google n-gram:
https://books.google.com/ngrams/graph?content=fantods%2C+heebie-jeebies&year_start=1800&year_end=2019&corpus=en-2019&smoothing=3
And large language models fill all kinds of important niches, like the Human Rights Data Analysis Group's LLM-based work helping the Innocence Project New Orleans' extract data from wrongful conviction case files:
https://hrdag.org/tech-notes/large-language-models-IPNO.html
So that's nuance number two: if we decide to make a new copyright law, we'll need to be very sure that we don't accidentally crush these beneficial activities that don't undermine artistic labor markets.
This brings me to the most important point: passing a new copyright law that requires permission to train an AI won't help creative workers get paid or protect our jobs.
Getty Images pays photographers the least it can get away with. Publishers contracts have transformed by inches into miles-long, ghastly rights grabs that take everything from writers, but still shifts legal risks onto them:
https://pluralistic.net/2022/06/19/reasonable-agreement/
Publishers like the New York Times bitterly oppose their writers' unions:
https://actionnetwork.org/letters/new-york-times-stop-union-busting
These large corporations already control the copyrights to gigantic amounts of training data, and they have means, motive and opportunity to license these works for training a model in order to pay us less, and they are engaged in this activity right now:
https://www.nytimes.com/2023/12/22/technology/apple-ai-news-publishers.html
Big games studios are already acting as though there was a copyright in training data, and requiring their voice actors to begin every recording session with words to the effect of, "I hereby grant permission to train an AI with my voice" and if you don't like it, you can hit the bricks:
https://www.vice.com/en/article/5d37za/voice-actors-sign-away-rights-to-artificial-intelligence
If you're a creative worker hoping to pay your bills, it doesn't matter whether your wages are eroded by a model produced without paying your employer for the right to do so, or whether your employer got to double dip by selling your work to an AI company to train a model, and then used that model to fire you or erode your wages:
https://pluralistic.net/2023/02/09/ai-monkeys-paw/#bullied-schoolkids
Individual creative workers rarely have any bargaining leverage over the corporations that license our copyrights. That's why copyright's 40-year expansion (in duration, scope, statutory damages) has resulted in larger, more profitable entertainment companies, and lower payments – in real terms and as a share of the income generated by their work – for creative workers.
As Rebecca Giblin and I write in our book Chokepoint Capitalism, giving creative workers more rights to bargain with against giant corporations that control access to our audiences is like giving your bullied schoolkid extra lunch money – it's just a roundabout way of transferring that money to the bullies:
https://pluralistic.net/2022/08/21/what-is-chokepoint-capitalism/
There's an historical precedent for this struggle – the fight over music sampling. 40 years ago, it wasn't clear whether sampling required a copyright license, and early hip-hop artists took samples without permission, the way a horn player might drop a couple bars of a well-known song into a solo.
Many artists were rightfully furious over this. The "heritage acts" (the music industry's euphemism for "Black people") who were most sampled had been given very bad deals and had seen very little of the fortunes generated by their creative labor. Many of them were desperately poor, despite having made millions for their labels. When other musicians started making money off that work, they got mad.
In the decades that followed, the system for sampling changed, partly through court cases and partly through the commercial terms set by the Big Three labels: Sony, Warner and Universal, who control 70% of all music recordings. Today, you generally can't sample without signing up to one of the Big Three (they are reluctant to deal with indies), and that means taking their standard deal, which is very bad, and also signs away your right to control your samples.
So a musician who wants to sample has to sign the bad terms offered by a Big Three label, and then hand $500 out of their advance to one of those Big Three labels for the sample license. That $500 typically doesn't go to another artist – it goes to the label, who share it around their executives and investors. This is a system that makes every artist poorer.
But it gets worse. Putting a price on samples changes the kind of music that can be economically viable. If you wanted to clear all the samples on an album like Public Enemy's "It Takes a Nation of Millions To Hold Us Back," or the Beastie Boys' "Paul's Boutique," you'd have to sell every CD for $150, just to break even:
https://memex.craphound.com/2011/07/08/creative-license-how-the-hell-did-sampling-get-so-screwed-up-and-what-the-hell-do-we-do-about-it/
Sampling licenses don't just make every artist financially worse off, they also prevent the creation of music of the sort that millions of people enjoy. But it gets even worse. Some older, sample-heavy music can't be cleared. Most of De La Soul's catalog wasn't available for 15 years, and even though some of their seminal music came back in March 2022, the band's frontman Trugoy the Dove didn't live to see it – he died in February 2022:
https://www.vulture.com/2023/02/de-la-soul-trugoy-the-dove-dead-at-54.html
This is the third nuance: even if we can craft a model-banning copyright system that doesn't catch a lot of dolphins in its tuna net, it could still make artists poorer off.
Back when sampling started, it wasn't clear whether it would ever be considered artistically important. Early sampling was crude and experimental. Musicians who trained for years to master an instrument were dismissive of the idea that clicking a mouse was "making music." Today, most of us don't question the idea that sampling can produce meaningful art – even musicians who believe in licensing samples.
Having lived through that era, I'm prepared to believe that maybe I'll look back on AI "art" and say, "damn, I can't believe I never thought that could be real art."
But I wouldn't give odds on it.
I don't like AI art. I find it anodyne, boring. As Henry Farrell writes, it's uncanny, and not in a good way:
https://www.programmablemutter.com/p/large-language-models-are-uncanny
Farrell likens the work produced by AIs to the movement of a Ouija board's planchette, something that "seems to have a life of its own, even though its motion is a collective side-effect of the motions of the people whose fingers lightly rest on top of it." This is "spooky-action-at-a-close-up," transforming "collective inputs … into apparently quite specific outputs that are not the intended creation of any conscious mind."
Look, art is irrational in the sense that it speaks to us at some non-rational, or sub-rational level. Caring about the tribulations of imaginary people or being fascinated by pictures of things that don't exist (or that aren't even recognizable) doesn't make any sense. There's a way in which all art is like an optical illusion for our cognition, an imaginary thing that captures us the way a real thing might.
But art is amazing. Making art and experiencing art makes us feel big, numinous, irreducible emotions. Making art keeps me sane. Experiencing art is a precondition for all the joy in my life. Having spent most of my life as a working artist, I've come to the conclusion that the reason for this is that art transmits an approximation of some big, numinous irreducible emotion from an artist's mind to our own. That's it: that's why art is amazing.
AI doesn't have a mind. It doesn't have an intention. The aesthetic choices made by AI aren't choices, they're averages. As Farrell writes, "LLM art sometimes seems to communicate a message, as art does, but it is unclear where that message comes from, or what it means. If it has any meaning at all, it is a meaning that does not stem from organizing intention" (emphasis mine).
Farrell cites Mark Fisher's The Weird and the Eerie, which defines "weird" in easy to understand terms ("that which does not belong") but really grapples with "eerie."
For Fisher, eeriness is "when there is something present where there should be nothing, or is there is nothing present when there should be something." AI art produces the seeming of intention without intending anything. It appears to be an agent, but it has no agency. It's eerie.
Fisher talks about capitalism as eerie. Capital is "conjured out of nothing" but "exerts more influence than any allegedly substantial entity." The "invisible hand" shapes our lives more than any person. The invisible hand is fucking eerie. Capitalism is a system in which insubstantial non-things – corporations – appear to act with intention, often at odds with the intentions of the human beings carrying out those actions.
So will AI art ever be art? I don't know. There's a long tradition of using random or irrational or impersonal inputs as the starting point for human acts of artistic creativity. Think of divination:
https://pluralistic.net/2022/07/31/divination/
Or Brian Eno's Oblique Strategies:
http://stoney.sb.org/eno/oblique.html
I love making my little collages for this blog, though I wouldn't call them important art. Nevertheless, piecing together bits of other peoples' work can make fantastic, important work of historical note:
https://www.johnheartfield.com/John-Heartfield-Exhibition/john-heartfield-art/famous-anti-fascist-art/heartfield-posters-aiz
Even though painstakingly cutting out tiny elements from others' images can be a meditative and educational experience, I don't think that using tiny scissors or the lasso tool is what defines the "art" in collage. If you can automate some of this process, it could still be art.
Here's what I do know. Creating an individual bargainable copyright over training will not improve the material conditions of artists' lives – all it will do is change the relative shares of the value we create, shifting some of that value from tech companies that hate us and want us to starve to entertainment companies that hate us and want us to starve.
As an artist, I'm foursquare against anything that stands in the way of making art. As an artistic worker, I'm entirely committed to things that help workers get a fair share of the money their work creates, feed their families and pay their rent.
I think today's AI art is bad, and I think tomorrow's AI art will probably be bad, but even if you disagree (with either proposition), I hope you'll agree that we should be focused on making sure art is legal to make and that artists get paid for it.
Just because copyright won't fix the creative labor market, it doesn't follow that nothing will. If we're worried about labor issues, we can look to labor law to improve our conditions. That's what the Hollywood writers did, in their groundbreaking 2023 strike:
https://pluralistic.net/2023/10/01/how-the-writers-guild-sunk-ais-ship/
Now, the writers had an advantage: they are able to engage in "sectoral bargaining," where a union bargains with all the major employers at once. That's illegal in nearly every other kind of labor market. But if we're willing to entertain the possibility of getting a new copyright law passed (that won't make artists better off), why not the possibility of passing a new labor law (that will)? Sure, our bosses won't lobby alongside of us for more labor protection, the way they would for more copyright (think for a moment about what that says about who benefits from copyright versus labor law expansion).
But all workers benefit from expanded labor protection. Rather than going to Congress alongside our bosses from the studios and labels and publishers to demand more copyright, we could go to Congress alongside every kind of worker, from fast-food cashiers to publishing assistants to truck drivers to demand the right to sectoral bargaining. That's a hell of a coalition.
And if we do want to tinker with copyright to change the way training works, let's look at collective licensing, which can't be bargained away, rather than individual rights that can be confiscated at the entrance to our publisher, label or studio's offices. These collective licenses have been a huge success in protecting creative workers:
https://pluralistic.net/2023/02/26/united-we-stand/
Then there's copyright's wildest wild card: The US Copyright Office has repeatedly stated that works made by AIs aren't eligible for copyright, which is the exclusive purview of works of human authorship. This has been affirmed by courts:
https://pluralistic.net/2023/08/20/everything-made-by-an-ai-is-in-the-public-domain/
Neither AI companies nor entertainment companies will pay creative workers if they don't have to. But for any company contemplating selling an AI-generated work, the fact that it is born in the public domain presents a substantial hurdle, because anyone else is free to take that work and sell it or give it away.
Whether or not AI "art" will ever be good art isn't what our bosses are thinking about when they pay for AI licenses: rather, they are calculating that they have so much market power that they can sell whatever slop the AI makes, and pay less for the AI license than they would make for a human artist's work. As is the case in every industry, AI can't do an artist's job, but an AI salesman can convince an artist's boss to fire the creative worker and replace them with AI:
https://pluralistic.net/2024/01/29/pay-no-attention/#to-the-little-man-behind-the-curtain
They don't care if it's slop – they just care about their bottom line. A studio executive who cancels a widely anticipated film prior to its release to get a tax-credit isn't thinking about artistic integrity. They care about one thing: money. The fact that AI works can be freely copied, sold or given away may not mean much to a creative worker who actually makes their own art, but I assure you, it's the only thing that matters to our bosses.
If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/05/13/spooky-action-at-a-close-up/#invisible-hand
#pluralistic#ai art#eerie#ai#weird#henry farrell#copyright#copyfight#creative labor markets#what is art#ideomotor response#mark fisher#invisible hand#uncanniness#prompting
272 notes
·
View notes
Text
A Party To Die For Templates: SFS


So I may have got a tad overexcited about the Halloween CAS Challenge created by @la-llama-sims, and I made templates for every prompt. I wanted to share them on the off chance someone wanted to also do the challenge but maybe didn't have time to do much other than screenshots.
Tutorial below on how to make your own cards using the templates if you are unfamiliar with photo software, all you need is the template and a screenshot of your sim! Very little technical skill required to so feel free to jump in for Simblreen (the month of October on simblr). Remember to go to the original creator post to check out the prompts and the hashtag given for creations is #LLPTDF. Hope to see some of your creations next month, keep them for the spooky season 🎃👻🦇
Strap in and follow along as I make Glenn here (he won't do the spellcaster prompt for Simblreen, it's dress up after all, but it makes sense for a demo)
Step one: Grab the zipped folder of templates on SFS HERE. Unzip the folder and put it somewhere easy to find in your documents, I have a tumblr specific folder my templates are normally sorted in.
Step two: Open your photo editing program of choice. I use paint.net which is old but for this demonstration I will use Photopea, the online free alternative to adobe. You will see the screen below

Step three: Click "Open From Computer" right in the middle under the main title. Find the screenshot you have taken that you would like to use and open it. Now the hole in my template is 744x991 but you can make it slightly bigger if you don't want to fuss as much with lining things up exactly. To resize image from the top bar (Image -> Image Size) We're going to use the crop tool when we have our picture.
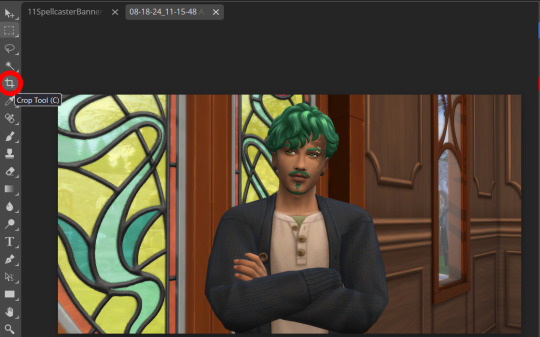
Step four: Pull on the squares at the edges to change the size. If you need click View in the top bar and you can zoom in to allow finer selecting. When you have the right size click the tick and copy the image. Keyboard shortcuts are Ctrl+A to select all, then Ctrl+C to copy.
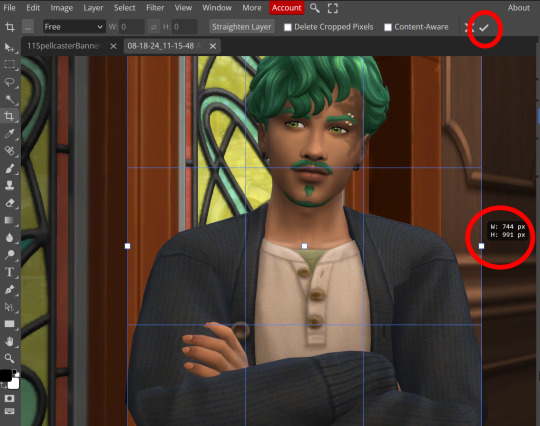
Step five: Open the template you want to use (File -> Open, from the top bar). Add a new layer using either the top bar (Layer -> New -> Layer) or the icons on the bottom right.
Step six: With the new layer selected paste the image, Ctrl+V.
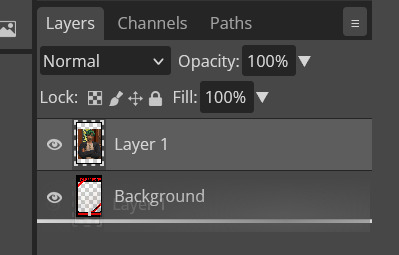
Step seven: On the right of the screen you'll be able to see layer order. Drag the layer with your sim underneath the background layer. This is what will let you slot in your picture.
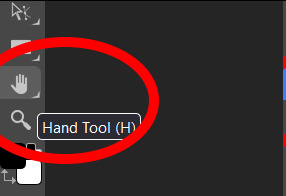
Step eight: Finishing touches! Unless you are super duper lucky your sim won't appear in the exact right place, you'll have to move them around using the move tool. For precision you'll need to zoom in and move your field of vision using the hand tool.

You'll know it's in the right place when you can no longer see any of the negative space behind it. I like to check both corners to make sure I've got it. This is where having a sim image slightly larger will make it easier.


If you like you can finish now. From the top bar File -> Export as -> PNG or JPG. The picture will save to your downloads folder. If you want to add your own text, keep reading, as I've left space at the bottom for your username, the sim name, and a profile pic or other logo. Or go ahead and crop it out, who needs extra hassle when there are cute CAS looks to be made?
Step nine: From the bar on the right select the large T to add some text, it will automatically spawn in a new layer. Scroll through text options and find one you like (the text style I used isn't in photopea so we will find another). Depending on the type of text you will likely need to play around with the size as well.
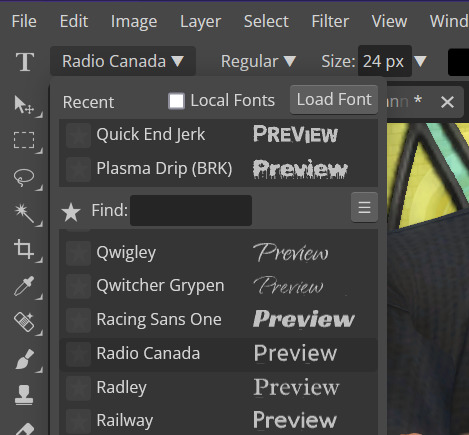
Step ten: Start typing. When you're done you can highlight what you have written and use that size box to adjust how big the text is. Select the move tool from the right to move your text where you want it. Repeat step nine if you want text on the other side. I've chosen to put my username on one side, and my sim's name on the other.
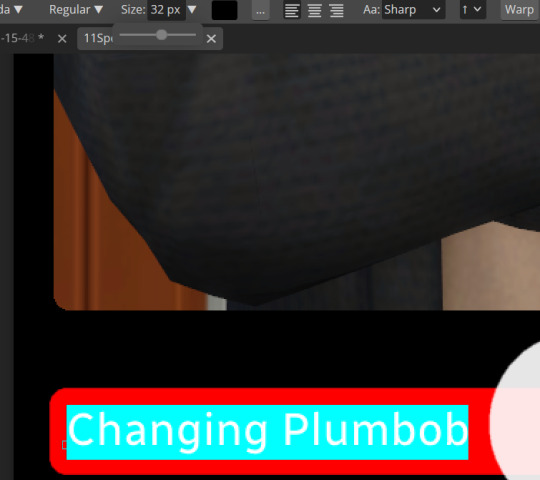
Step eleven: Logo time. Open a pre shrunk logo (I scaled my pride plumbobs down to 125x125) and copy. Back on the template add a new layer then paste your image (for some reason I had to copy twice before it would do the right thing, I don't have an explanation sorry). Then using the move tool and the hand tool get your image where you want it.

From the top bar File -> Export as -> PNG or JPG. Again it will have saved to your downloads folder.

Voila, we have a Glenn card! Hopefully you have a your sim card. I spent hours doing up all the templates so feel free to fill them with your sims for the challenge. All I ask is that you don't claim templates as your own work or shove them behind a paywall because rude and the whole premise of Simblreen is free treats! Obviously you do NOT need the templates to participate in the challenge, the cards are just how I'll be presenting mine. Like CAS challenges the possibilities are most often only limited by your imagination.
#sims 4#the sims#simblr#my sims#ts4#active simblr#Enjoy my friends#I wanted all of us to be able to do Simblreen#Even if we don't have prior skills
53 notes
·
View notes
Text
Anne Kustritz’s Identity, Community, and Sexuality in Slash Fan Fiction
Anne Kustritz’s new book, Identity, Community, and Sexuality in Slash Fan Fiction: Pocket Publics has just been released by Routledge (2024). You might know Kustritz, a scholar of fan cultures and transmedia storytelling, from her early essay “Slashing the Romance Narrative,” in the Journal of American Culture (2003) or maybe from some of her more recent work on transmedia and serial storytelling. But this new book is an exciting addition to the fan studies canon, and Fanhackers readers might be particularly interested, because the book “explores slash fan fiction communities during the pivotal years of the late 1990s and the early 2000s as the practice transitioned from print to digital circulation,”--which is the era that a lot of the fans involved in the creation of the OTW came from. As I noted in my book blurb, “While there has been an explosion of fan studies scholarship in the last two decades, we haven't had an ethnography of fan fiction communities since the early 1990s. Kustritz's Pocket Publics rectifies that, documenting the generation of slash fans who built much of fandom's infrastructure and many of its community spaces, both on and off the internet. This generation has had an outsized impact on contemporary fan cultures, and Kustritz shows how these fans created an alternative and subcultural public sphere: a world of their own.”
Kustritz doesn’t just analyze and contextualize fandom, she also describes her own experiences as a participant-observer, and these might resonate with a lot of fans (especially Fanhackers-reading fans!) Early on in the book, Kustritz describes her how her own early interest in fandom blurred between the personal and the academic:
Because I began studying slash only a year after discovering fandom on-line, my interest has always been an intricate tangle of pleasure in the texts themselves, connection to brilliantly creative women, and fascination with intersections between fan activities and academic theory. I may now disclaim my academic identity as an interdisciplinary scholar with concentrations in media anthropology and cultural studies and begin to pinpoint my fan identity as a bifictional multifandom media fan; however, I only gradually became aware of and personally invested in these categories as I grew into them. This section defines the scope of the online observation period that preceded the active interview phase of this research. In so doing it also examines the messy interconnections between my academic and fannish interests and identities. Trying to pick apart what portion of my choices derived from fannish pleasure and which from academic interest helps to identify the basic internal tensions and categories that slash fan fiction communities relied upon to define themselves, the pressures exerted upon these systems by the digital migration, and complications in academic translation of fannish social structures.
Later in the book, Kustritz discusses how fans have organized and advocated for themselves as a public; in particular, there’s a fascinating chapter about the ways in which fandom has adopted and transformed the figure of the pirate to forge new ways of thinking about copyright and authorship. If the OTW was formed to argue that making fanworks is a legitimate activity, the figure of the pirate signifies a protest against the law and a refusal to be shamed by it:
[F]ans also use the figure of the pirate to make arguments that validate some fan activities and consign others to illegitimacy. At the urging of several friends involved with slash, I attended my first non-slash focused science fiction and fantasy convention in the summer of 2004. The program schedule announced a Sunday morning panel discussion provocatively titled “Avast, Matey: The Ethics of Pirating Movies, Music, and Software” with the subheading “Computers today can distribute [more] intellectual property than ever before--not always legally. Is it ever okay to copy, download, and/or distribute media? Sorry, ladies, none of us will be dressed as Captain Jack Sparrow.” The panel’s subheading, which obliquely warned away both lusty women and pirates, led a small contingent of slash fans to shake off Saturday night’s convention revelries unreasonably early and implement a plan of their own for Sunday’s panel. As many fan conventions encourage costumes, known as “cosplay,” one of my friends and research participants happened to have been dressed as Captain Jack Sparrow of Pirates of the Caribbean that weekend, so I entered the piracy panel with Captain Jack and a motley crew of slashers, some of them intent upon commandeering the discussion.
The clash that followed exemplifies a structural fault line between various types of fan communities regarding their shared norms and beliefs about copyright law, the relationship between fans and producers, and appropriate fan behavior.
If you want to find out how this clash played out–well, you’ll just have to read the book. 😀
–Francesca Coppa, Fanhackers volunteer
#fanhackers#author:francescacoppa#anne kustritz#early digital fandom#slash#piracy#fannish culture clashes
127 notes
·
View notes
Text
HELP WANTED: LITTLEBIGPLANET FAN MOVEMENT

For the past year or so I’ve been working on a fan movement to revitalize interest in LittleBigPlanet on Sony’s terms. Think it comparable to Operation Moonfall, a fan movement for revitalizing interest in The Legend of Zelda: Majora’s Mask, which eventually led to its 3D Remake.
While I can’t promise the plan I’ve set out is guaranteed to result in a new LBP game, I do believe that it is also the best opportunity for one to be made. However, as I’ve worked behind the scenes I’ve found it impossible to maintain on my own. Therefore I must ask for help.
Operation Mushroom Tree, as it is tentatively titled, involves the creation of a professional pitch for a new LittleBigPlanet entry for modern consoles. This pitch would provide a basic outline of what a new entry would entail, and prove why the franchise would still be popular.
The goal is not to make a wishlist nor a whole new installment on our own, but a feasible design concept for a new game that the community can rally behind. While this exact pitch may not be directly used by Sony Interactive Entertainment, Operation Mushroom Tree would be a template to guide development of a new game. The design document at the forefront would show the best way to make a new installment in a way that would be enticing to shareholders and employees of Sony Interactive Entertainment, the current rights holders.
The document has been mainly continuously written by me. However, I am just beginning my journey into game development, and this project would be unsustainable on my own. I need concept artists and render artists to create mockups of believable illustrations of the game Operation Mushroom Tree provides. As well, I’d sincerely love the second opinions of other game designers who are passionate about the LBP franchise. Finally, I have only a very rudimentary idea of how LBP works on a programming and hardware level, and thus this project would benefit from an expert on such.
To be precise, I am looking for:
- 3D Modeling or Photoshop Artists to create renders and mock-ups of gameplay mechanics.
- Individuals with history in Game Design and have a fondness for the LittleBigPlanet Franchise, mainly to help write and guide the main design document.
- Individuals who have intimate knowledge of the LittleBigPlanet franchise on a hardware and software level, and can evaluate the feasibility of certain features on modern hardware.
If you or anyone you know falls into these categories, please contact me through Tumblr. If you are not in these categories, but are interested and believe you are able to help with this campaign, please contact me as well, and hopefully we can find a way to work together still. Do please provide some evidence of your past work and knowledge with your message.
I know that many out there currently are disappointed with the treatment of the LBP franchise after 2024, as am I. However, I do believe that LittleBigPlanet could thrive in today’s landscape, and would be beneficial to the games industry as a whole. Therefore, I am willing to embark on this journey, not only to entertain fans, but to help support up-and-coming developers get their first steps, as LBP did for me.
#little big planet#playstation#sony#lbp#game design#programming#3d modeling#sackboy#lbp2#lbp3#fan movement#help wanted#hardware#software#game development#dualshock#sony playstation#ps5#ps4#ps3#retro gaming#2000s nostalgia#sackgirl#british#media molecule#sony interactive entertainment
17 notes
·
View notes
Text
The Creation and Purpose of Porygon
Porygon was a Pokémon created in 1995 through computer programming when the Pokémon Storage System was invented on Cinnabar Island in the Cinnabar Lab, making it the very first artificial manmade Pokémon in history made entirely out of programming code.
It was designed as a prototype in order to test the concept of the Pokémon Storage System as a way to test if converting Pokémon into storable data was possible. By creating this Pokémon, it wouldn’t require testing on any existing Pokémon.
It was created, in essence, to be a ‘generic’ Pokémon, indicated by its simple identifiable geometric design in order to see which parts of a Pokémon are being accurately converted into data and back. It’s Normal-type and possesses the signature moves of Conversion (changes the user’s type to match the type of one of the user’s moves including Conversion itself, unable to copy the type of a move that already matches the user’s current types) and Conversion 2 (will randomly change the user’s or an adjacent Pokémon’s type to any type that either resists or is immune to the type of the move last used by the target, including status moves, excluding types it currently has – will fail if the Pokémon already has all types that resist the type of the last damaging move and bypasses accuracy to always hit unless the target is in a semi-invulnerable turn of a move such as Dig or Fly) in order to test if the system could preserve a Pokémon’s type and contain data to test all of them. It also possessed the Ability of Download (either raises the Attack or Special Attack by one stage depending on the foe’s current lowest defensive stat, otherwise will raise Special Attack) in order to test if Abilities could be preserved as well.
The design inspiration came from depictions of it documented in Hisui, essentially making its existence something of a Grandfather Paradox, given that they were first seen emerging from spacetime distortions.
After the invention of the Pokémon Storage System, Porygon then became useful for use in cybersecurity and software development and became popular among collectors after the fact.
Silph Co. takes credit for the creation of Porygon and became invested in its development, though for a time it became obsolete. They were interested in upgrading it to work in space for planetary devolvement reasons, so Silph Co. gave it a digital drive the likes that they would need to send across to hold in order to test the trading system and test if Pokémon could transfer while holding items as well in case they needed to send Porygon up with important items to the space stations above, surprising them with an evolution and discovering trade evolutions in the process.
Porygon2 is a result of being upgraded from the most cutting-edge technology available at the time and became the project, sporting completely rounded shapes and no sharp edges of its preevolution. Silph Co. invented the Upgrade as an evolutionary item to evolve Porygon into Porygon2 by trading it in order to further develop it for work in space software, though its inability to fly limits this ability. It can survive in the vacuum of space, but cannot move very well in zero gravity.
Unlike Porygon that has an outlined purpose that it does not deviate from, Porygon2 is far more intelligent and is capable of learning new behaviours on its own, including proprietary information, and can speak a language that only other Porygon2 can understand. It is truly a feat of artificial intelligence.
Naturally, the next step in Porygon2’s development would be the final frontier – dimensional travel. If Porygon2 was invented to assist in space travel, then the final feat would be dimensional travel. And so, development was initiated on the next project – Porygon3.
However, this project would not find success like the former. An error in the programming of the next upgrade resulted in corrupting the final form and causing it to act erratic and unstable, making it difficult to work with for research and testing and deeming the development to be labelled a failure and for development to be abandoned. The final result was then named Porygon-Z and the discs responsible for this evolution were disposed of and deemed dubious. Academics can’t seem to agree on whether Porygon-Z should be considered a true evolution of Porygon2 or not.
The Dubious Disc, as it has become known by, still sees underground circulation amongst black market collectors and underground researchers interested in further researching both Porygon-Z and revisiting the possibility of completing development on Porygon3, though no progress or breakthroughs have yet been reported at this time.
Taglist:
@earth-shaker / @little-miss-selfships / @xelyn-craft / @sarahs-malewives / @brahms-and-lances-wife
-
@ashes-of-a-yume / @cherry-bomb-ships / @kiawren / @kingofdorkville / @bugsband
If you'd like to be added/removed from my taglist, please let me know :3
10 notes
·
View notes
Text
i am not really interested in game development but i am interested in modding (or more specifically cheat creation) as a specialized case of reverse-engineering and modifying software running on your machine
like okay for a lot of games the devs provide some sort of easy toolkit which lets even relatively nontechnical players write mods, and these are well-documented, and then games which don't have those often have a single-digit number of highly technical modders who figure out how to do injection and create some kind of api for the less technical modders to use, and that api is often pretty well documented, but the process of creating it absolutely isn't
it's even more interesting for cheat development because it's something hostile to the creators of the software, you are actively trying to break their shit and they are trying to stop you, and of course it's basically completely undocumented because cheat developers both don't want competitors and also don't want the game devs to patch their methods....
maybe some of why this is hard is because it's pretty different for different types of games. i think i'm starting to get a handle on how to do it for this one game - so i know there's a way to do packet sniffing on the game, where the game has a dedicated port and it sends tcp packets, and you can use the game's tick system and also a brute-force attack on its very rudimentary encryption to access the raw packets pretty easily.
through trial and error (i assume) people have figured out how to decode the packets and match them up to various ingame events, which is already used in a publicly available open source tool to do stuff like DPS calculation.
i think, without too much trouble, you could probably step this up and intercept/modify existing packets? like it looks like while damage is calculated on the server side, whether or not you hit an enemy is calculated on the client side and you could maybe modify it to always hit... idk.
apparently the free cheats out there (which i would not touch with a 100 foot pole, odds those have something in them that steals your login credentials is close to 100%) operate off a proxy server model, which i assume intercepts your packets, modifies them based on what cheats you tell it you have active, and then forwards them to the server.
but they also manage to give you an ingame GUI to create those cheats, which is clearly something i don't understand. the foss sniffer opens itself up in a new window instead of modifying the ingame GUI.
man i really want to like. shadow these guys and see their dev process for a day because i'm really curious. and also read their codebase. but alas
#coding#past the point of my life where i am interested in cheating in games#but if anything i am even more interested in figuring out how to exploit systems
48 notes
·
View notes
Text
How to Downgrade Windows 11 Pro to Windows 11 Home directly
This article will show you how to downgrade from Windows 11 Pro, Pro Education, Education, or Enterprise to Windows 11 Home without a clean installation. The trick is to change the Edition ID in the registry and then do a repair installation using the ISO or Media Creation Tool.
However, as we all know, A direct downgrade is not supported, and it would normally require a clean install of Windows 11 Home, but it will result in losing all your programs, and settings and all files and data in C drive !
Step 1: Change the Edition ID in registry
Method 1:
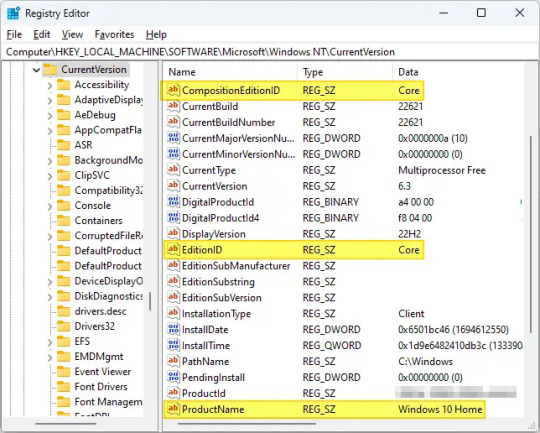
Search”Regedit”, then click it, then go to the following branches one by one, And change the values for the two branches.
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Microsoft\Windows NT\CurrentVersion
2. Double-click “CompositionEditionID” and set its data to “Core“. 3. Double-click “EditionID” and set its data to “Core“. 4. Double-click “ProductName” and set its data to “Windows 10 Home.”
#Important# Please set the “ProductName” value to “Windows 10 Home” even it is Windows 11
5, After modifying the value data in the above two branches, exit the Registry Editor.
Method 2:
1. First , please make sure you’ve signed in Windows 11 Pro as an administrator.
2. Create a txt document then change the extension .txt to .reg file, then input these codes and save it:
Windows Registry Editor Version 5.00 [HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows NT\CurrentVersion] “CompositionEditionID”=”Core” “EditionID”=”Core” “ProductName”=”Windows 11 Home” [HKEY_LOCAL_MACHINE\SOFTWARE\Wow6432Node\Microsoft\Windows NT\CurrentVersion] “CompositionEditionID”=”Core” “EditionID”=”Core” “ProductName”=”Windows 11 Home”
3. Double click on the .reg file to start to merge the registry.
4. Please select “Yes”, “Yes”, “Ok” to approve and complete the merge.
5. There is no use for the .reg file any more, you can delete it.
Step 2: Downgrade Windows 11 Home with ISO file or Media Creation Tool.
1, Download Windows 11 ISO file, then open the ISO file with win-rar or 7-zip, then double click “Setup”.
Because we changed the EditionID and Product Name, so we will be able to install the Windows 11 Home.
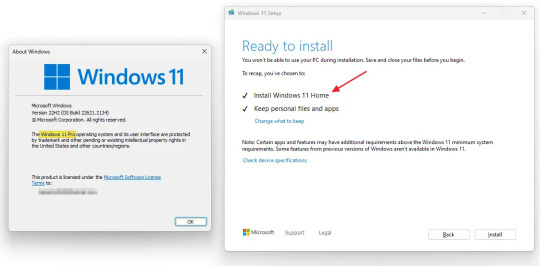
2, Follow the steps: “ready to install”, Select “Install; “Change what to keep”, please select “keep personal file and apps”; then click “Next” and then click “Install”.
When the repair install has finished, you will now be downgraded to the Windows 11 Home edition without losing anything.
If your Windows 11 Home is not activated by a digital license before, then you will need to Change product key to a valid Windows 11 Home key to activate.
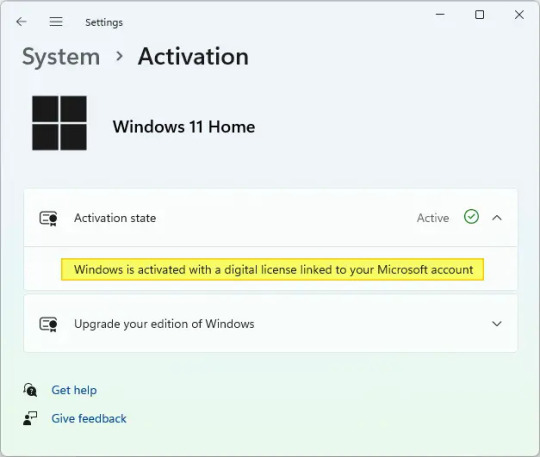
14 notes
·
View notes
Text
The Benefits of User-Friendly Document Generation Software: A Closer Look at PDQ Docs
In today’s fast-paced business world, efficiency is key, and one of the best ways to streamline operations is by using the right tools. For companies that regularly deal with a large volume of documents, finding software that simplifies document creation and management is essential. A User Friendly Document Generation Software like PDQ Docs can provide businesses with a powerful solution for generating high-quality, professional documents quickly and easily.
Simplifying the Document Creation Process
One of the most significant advantages of PDQ Docs is its ease of use. Traditional document creation can be time-consuming, requiring repetitive tasks and manual input. PDQ Docs, a user-friendly document generation software, eliminates these inefficiencies by automating the process, allowing users to generate customized documents at the click of a button. Whether you're creating contracts, invoices, reports, or other forms of documentation, PDQ Docs provides a streamlined approach that saves valuable time and reduces human error.

The user-friendly interface ensures that even individuals with minimal technical experience can use the software with ease. With intuitive templates and simple customization options, anyone can quickly produce professional documents without the need for specialized training or expertise. This makes it an ideal solution for teams looking to increase productivity while maintaining a high level of accuracy.
Increased Efficiency and Time Savings
The time-saving potential of PDQ Docs cannot be overstated. For businesses that routinely generate similar documents, such as contracts, invoices, or proposals, PDQ Docs automates the process and eliminates repetitive tasks. This reduces the need for manual intervention, allowing employees to focus on more strategic tasks.
Additionally, PDQ Docs integrates seamlessly with other systems, such as customer relationship management (CRM) tools or enterprise resource planning (ERP) software, which further enhances workflow efficiency. By pulling relevant information from these systems automatically, PDQ Docs ensures that documents are accurate and up-to-date without requiring additional effort from the user.
Secure and Reliable Document Storage
Another significant feature of PDQ Docs, the best user-friendly document generation software, is its secure document storage. Once documents are generated, they can be stored in a secure, cloud-based system, ensuring they are easily accessible and protected from unauthorized access. This eliminates the need for physical storage or manually managing large volumes of paperwork, freeing up space and resources.
PDQ Docs also supports version control, so users can track changes and ensure that the most current version of a document is always accessible. This is particularly important for businesses that need to maintain accurate records or comply with regulatory requirements.
Why Choose PDQ Docs?
PDQ Docs offers a range of benefits, from its easy-to-use interface and customization options to its ability to improve efficiency and reduce errors. Whether you're a small business or a large organization, using a user-friendly document generation software like PDQ Docs can significantly streamline your document creation process and enhance your overall productivity.
#user friendly document generation software#automated document creation#document generation tools#easy document creation#document automation software#template based document generation#customizable document templates#document creation platform#document generation for businesses#automated report generation#document creation software
0 notes
Text
Ganesh Shankar, CEO & Co-Founder of Responsive – Interview Series
New Post has been published on https://thedigitalinsider.com/ganesh-shankar-ceo-co-founder-of-responsive-interview-series/
Ganesh Shankar, CEO & Co-Founder of Responsive – Interview Series

Ganesh Shankar, CEO and Co-Founder of Responsive, is an experienced product manager with a background in leading product development and software implementations for Fortune 500 enterprises. During his time in product management, he observed inefficiencies in the Request for Proposal (RFP) process—formal documents organizations use to solicit bids from vendors, often requiring extensive, detailed responses. Managing RFPs traditionally involves multiple stakeholders and repetitive tasks, making the process time-consuming and complex.
Founded in 2015 as RFPIO, Responsive was created to streamline RFP management through more efficient software solutions. The company introduced an automated approach to enhance collaboration, reduce manual effort, and improve efficiency. Over time, its technology expanded to support other complex information requests, including Requests for Information (RFIs), Due Diligence Questionnaires (DDQs), and security questionnaires.
Today, as Responsive, the company provides solutions for strategic response management, helping organizations accelerate growth, mitigate risk, and optimize their proposal and information request processes.
What inspired you to start Responsive, and how did you identify the gap in the market for response management software?
My co-founders and I founded Responsive in 2015 after facing our own struggles with the RFP response process at the software company we were working for at the time. Although not central to our job functions, we dedicated considerable time assisting the sales team with requests for proposals (RFPs), often feeling underappreciated despite our vital role in securing deals. Frustrated with the lack of technology to make the RFP process more efficient, we decided to build a better solution. Fast forward nine years, and we’ve grown to nearly 500 employees, serve over 2,000 customers—including 25 Fortune 100 companies—and support nearly 400,000 users worldwide.
How did your background in product management and your previous roles influence the creation of Responsive?
As a product manager, I was constantly pulled by the Sales team into the RFP response process, spending almost a third of my time supporting sales instead of focusing on my core product management responsibilities. My two co-founders experienced a similar issue in their technology and implementation roles. We recognized this was a widespread problem with no existing technology solution, so we leveraged our almost 50 years of combined experience to create Responsive. We saw an opportunity to fundamentally transform how organizations share information, starting with managing and responding to complex proposal requests.
Responsive has evolved significantly since its founding in 2015. How do you maintain the balance between staying true to your original vision and adapting to market changes?
First, we’re meticulous about finding and nurturing talent that embodies our passion – essentially cloning our founding spirit across the organization. As we’ve scaled, it’s become critical to hire managers and team members who can authentically represent our core cultural values and commitment.
At the same time, we remain laser-focused on customer feedback. We document every piece of input, regardless of its size, recognizing that these insights create patterns that help us navigate product development, market positioning, and any uncertainty in the industry. Our approach isn’t about acting on every suggestion, but creating a comprehensive understanding of emerging trends across a variety of sources.
We also push ourselves to think beyond our immediate industry and to stay curious about adjacent spaces. Whether in healthcare, technology, or other sectors, we continually find inspiration for innovation. This outside-in perspective allows us to continually raise the bar, inspiring ideas from unexpected places and keeping our product dynamic and forward-thinking.
What metrics or success indicators are most important to you when evaluating the platform’s impact on customers?
When evaluating Responsive’s impact, our primary metric is how we drive customer revenue. We focus on two key success indicators: top-line revenue generation and operational efficiency. On the efficiency front, we aim to significantly reduce RFP response time – for many, we reduce it by 40%. This efficiency enables our customers to pursue more opportunities, ultimately accelerating their revenue generation potential.
How does Responsive leverage AI and machine learning to provide a competitive edge in the response management software market?
We leverage AI and machine learning to streamline response management in three key ways. First, our generative AI creates comprehensive proposal drafts in minutes, saving time and effort. Second, our Ask solution provides instant access to vetted organizational knowledge, enabling faster, more accurate responses. Third, our Profile Center helps InfoSec teams quickly find and manage security content.
With over $600 billion in proposals managed through the Responsive platform and four million Q&A pairs processed, our AI delivers intelligent recommendations and deep insights into response patterns. By automating complex tasks while keeping humans in control, we help organizations grow revenue, reduce risk, and respond more efficiently.
What differentiates Responsive’s platform from other solutions in the industry, particularly in terms of AI capabilities and integrations?
Since 2015, AI has been at the core of Responsive, powering a platform trusted by over 2,000 global customers. Our solution supports a wide range of RFx use cases, enabling seamless collaboration, workflow automation, content management, and project management across teams and stakeholders.
With key AI capabilities—like smart recommendations, an AI assistant, grammar checks, language translation, and built-in prompts—teams can deliver high-quality RFPs quickly and accurately.
Responsive also offers unmatched native integrations with leading apps, including CRM, cloud storage, productivity tools, and sales enablement. Our customer value programs include APMP-certified consultants, Responsive Academy courses, and a vibrant community of 1,500+ customers sharing insights and best practices.
Can you share insights into the development process behind Responsive’s core features, such as the AI recommendation engine and automated RFP responses?
Responsive AI is built on the foundation of accurate, up-to-date content, which is critical to the effectiveness of our AI recommendation engine and automated RFP responses. AI alone cannot resolve conflicting or incomplete data, so we’ve prioritized tools like hierarchical tags and robust content management to help users organize and maintain their information. By combining generative AI with this reliable data, our platform empowers teams to generate fast, high-quality responses while preserving credibility. AI serves as an assistive tool, with human oversight ensuring accuracy and authenticity, while features like the Ask product enable seamless access to trusted knowledge for tackling complex projects.
How have advancements in cloud computing and digitization influenced the way organizations approach RFPs and strategic response management?
Advancements in cloud computing have enabled greater efficiency, collaboration, and scalability. Cloud-based platforms allow teams to centralize content, streamline workflows, and collaborate in real time, regardless of location. This ensures faster turnaround times and more accurate, consistent responses.
Digitization has also enhanced how organizations manage and access their data, making it easier to leverage AI-powered tools like recommendation engines and automated responses. With these advancements, companies can focus more on strategy and personalization, responding to RFPs with greater speed and precision while driving better outcomes.
Responsive has been instrumental in helping companies like Microsoft and GEODIS streamline their RFP processes. Can you share a specific success story that highlights the impact of your platform?
Responsive has played a key role in supporting Microsoft’s sales staff by managing and curating 20,000 pieces of proposal content through its Proposal Resource Library, powered by Responsive AI. This technology enabled Microsoft’s proposal team to contribute $10.4 billion in revenue last fiscal year. Additionally, by implementing Responsive, Microsoft saved its sellers 93,000 hours—equivalent to over $17 million—that could be redirected toward fostering stronger customer relationships.
As another example of Responsive providing measurable impact, our customer Netsmart significantly improved their response time and efficiency by implementing Responsive’s AI capabilities. They achieved a 10X faster response time, increased proposal submissions by 67%, and saw a 540% growth in user adoption. Key features such as AI Assistant, Requirements Analysis, and Auto Respond played crucial roles in these improvements. The integration with Salesforce and the establishment of a centralized Content Library further streamlined their processes, resulting in a 93% go-forward rate for RFPs and a 43% reduction in outdated content. Overall, Netsmart’s use of Responsive’s AI-driven platform led to substantial time savings, enhanced content accuracy, and increased productivity across their proposal management operations.
JAGGAER, another Responsive customer, achieved a double-digit win-rate increase and 15X ROI by using Responsive’s AI for content moderation, response creation, and Requirements Analysis, which improved decision-making and efficiency. User adoption tripled, and the platform streamlined collaboration and content management across multiple teams.
Where do you see the response management industry heading in the next five years, and how is Responsive positioned to lead in this space?
In the next five years, I see the response management industry being transformed by AI agents, with a focus on keeping humans in the loop. While we anticipate around 80 million jobs being replaced, we’ll simultaneously see 180 million new jobs created—a net positive for our industry.
Responsive is uniquely positioned to lead this transformation. We’ve processed over $600 billion in proposals and built a database of almost 4 million Q&A pairs. Our massive dataset allows us to understand complex patterns and develop AI solutions that go beyond simple automation.
Our approach is to embrace AI’s potential, finding opportunities for positive outcomes rather than fearing disruption. Companies with robust market intelligence, comprehensive data, and proven usage will emerge as leaders, and Responsive is at the forefront of that wave. The key is not just implementing AI, but doing so strategically with rich, contextual data that enables meaningful insights and efficiency.
Thank you for the great interview, readers who wish to learn more should visit Responsive,
#000#adoption#agents#ai#AI AGENTS#ai assistant#AI-powered#amp#Analysis#approach#apps#automation#background#billion#CEO#Cloud#cloud computing#cloud storage#collaborate#Collaboration#Community#Companies#comprehensive#computing#content#content management#content moderation#courses#crm#customer relationships
7 notes
·
View notes
Text
Workers said Project Nimbus is the kind of lucrative contract that neglects ethical guardrails that outspoken members of Google’s workforce have demanded in recent years. “I am very worried that Google has no scruples if they’re going to work with the Israeli government,” said Joshua Marxen, a Google Cloud software engineer who helped to organize the protest. “Google has given us no reason to trust them.” The Tuesday protest represents continuing tension between Google’s workforce and its senior management over how the company’s technology is used. In recent years Google workers have objected to military contracts, challenging Google’s work with U.S. Customs and Border Protection and its role in a defense program building artificial intelligence tools used to refine drone strikes. Workers have alleged that the company has cracked down on information-sharing, siloed controversial projects and enforced a workplace culture that increasingly punishes them for speaking out.
Google did not immediately respond to a request for comment about the Tuesday protest and workers’ concerns over Project Nimbus. The Israeli Finance Ministry announced its contract with Google and Amazon in April 2021 as a project “intended to provide the government, the defense establishment and others with an all-encompassing cloud solution.” Google has largely refused to release details of the contract, the specific capabilities Israel will receive, or how they will be used. In July 2022, the Intercept reported that training documents for Israeli government personnel indicate Google is providing software that the company claims can recognize people, gauge emotional states from facial expressions and track objects in video footage. Google Cloud spokesperson Atle Erlingsson told Wired in September 2022 that the company proudly supports Israel’s government and said critics had misrepresented Project Nimbus. “Our work is not directed at highly sensitive or classified military workloads,” he told Wired. Erlingsson, however, acknowledged that the contract will provide Israel’s military access to Google technology. Former Google worker Ariel Koren, who has long been publicly critical of Project Nimbus, said “it adds insult to injury for Palestinian activists and Palestinians generally” that Google Cloud’s profitability milestone coincides with the 75th anniversary of the Nakba — which refers to the mass displacement and dispossession of Palestinians following creation of the state of Israel in 1948.
In March 2022, The Times reported allegations by Koren — at the time a product marketing manager at Google for Education — that Google had retaliated against her for criticizing the contract, issuing a directive that she move to São Paulo, Brazil, within 17 business days or lose her job. Google told The Times that it investigated the incident and found no evidence of retaliation. When Koren resigned from Google in August 2022 she published a memo explaining reasons for her departure, writing that “Google systematically silences Palestinian, Jewish, Arab and Muslim voices concerned about Google’s complicity in violations of Palestinian human rights.” Koren said Google’s apathy makes her and others believe more vigorous protest actions are justified. “This is a concrete disruption that is sending a clear message to Google: We won’t allow for business as usual, so long as you continue to profit off of a nefarious contract that expands Israeli apartheid.” Mohammad Khatami, a YouTube software engineer based in New York, participated in a small protest of Project Nimbus at a July Amazon Web Services conference in Manhattan. Khatami said major layoffs at Google announced in January pushed him to get more involved in the Alphabet Workers Union, which provides resources to Khatami and other union members in an anti-military working group — though the union has not taken a formal stance on Project Nimbus. “Greed and corporate interests were being put ahead of workers and I think the layoffs just illustrated that for me very clearly,” Khatami said.
16 notes
·
View notes
Text
I will never stop preaching about the importance of the arts in today's world.
Art is expression / documentation of emotion and experiences. This could be through any medium that you could possibly think of.
We are spending millions, engineering software that attempts to recreate what humans can create for free with our brains.
I am so fucking fed up of people telling me that unless I pursue further education within Law/Medicine/STEM/etc, that it's worthless, there are so many critical parts of everyday life that can only be upheld through the study/creation of art. Yes, the furthering of AI scares many artists. Yes, AI aims to create new art.... Based off of pre-existing art created by actual people.
So even to perpetuate that cycle of creating ai art , new art needs to be fed into it's databases.
You can preach that I should take maths till the end of my highschool education , you can tell me that art/music will get me nowhere.
But everything we consume contains some sort of design process - architecture, interior design, clothing , package design , app/ web design.
The rate we consume television and media requires a constant stream of people who work in the performing arts , not just the actors.
New music we wish to come from our already popular, favourite artists will require people who work in the arts as well such as session musicians , producers , writers , etc -
People who are paid well to work in the arts.
-
The misconception that being an artist of any kind is not a "real job" is obviously demeaning but discourages younger people from pursuing vital careers we need to thrive. I'm sick of people - especially many of the older generation claiming that the youth of today just don't want to work real jobs/work hard (which is a different conversation ) - the jobs within the arts are real jobs. Jobs that pay and jobs that can be 10× less miserable for some than a STEM based job. People are needed in the arts. Let your kid express themselves through the arts and if they want to go into a career within that - then good , they can do something they are passionate about and encourage others to find the same joy they did.
Sod off and let people become artists, poets and much more
#artists on tumblr#writers on tumblr#art#politics#economy#being as artist is a valuable job#writing#literature#philosophy
14 notes
·
View notes
Note
Heya! I had a few questions, if you're willing to answer, about game development. I know you've used Unity for some of your projects in the past (rest in peace), and you've mentioned learning to work with Godot and Unreal recently.
For someone with a background in programming and software dev, but not game dev, would you say that either one is easier to learn than the other? Going from nothing but text-based RPGs to a proper engine has been a bit intimidating (reminiscent of moving from MSPaint to Photoshop), and I was wondering if you had any input on which one was better to learn initially.
Thanks a ton if you take the time to answer, I love your art, and I hope that the act of creation continues to bring you a lot of happiness in the future
hey! i'm still pretty new to both, but I could offer some impressions. first off, I feel like unreal and godot are tailored for some pretty different experiences. unreal has a focus on 3d, and there's a lot of built in tools for work like that, but it's a very huge and complex engine, and the build of your game will probably be huge regardless simply due to the overhead. godot on the other hand is pretty lightweight and can easily build for many OSes, which I enjoy. unreal has a pretty heavy focus on using their "blueprint graphs", which I feel like was pretty easy to learn, but for someone like me who also has a background in programming, you might want to just get into code, unreal also allows that, you can write your scripts in C++, but honestly nothing I've done in it has required me to do that yet, so I don't have impressions on that front. as for godot, unfortunately i've encountered a lot of bugs and issues using it, but i do feel more comfortable in it having a background in programming. it allows both its built in "gdscript" and c#, I've only used gdscript in it so far because a lot of people recommended it. i feel like its built in code editor its pretty convenient, it live updates to show errors, has auto-completion, & built in documentation. as for what's easier to learn, i feel like they have pretty similar learning curves, I'm just behind on learning godot because I do that on my free time, and have been using unreal engine for my day job.
16 notes
·
View notes
Text
Welcome to Pyters: Your Partner in Entrepreneurial Success Start. Build. Grow.
Transform Your Business Vision into Reality
At Pyters, we believe every entrepreneur deserves a chance to succeed. Our comprehensive platform is designed to support you at every stage of your business journey – from idea to enterprise. Whether you're just starting out or looking to scale new heights, Pyters is here to guide you every step of the way.
Why Pyters?
Start Your Business with Confidence
Business Plan Templates: Craft professional business plans with our customizable templates. Legal Assistance: Navigate legal complexities with ease using our expert guidance and essential documentation. Market Research Tools: Gain valuable insights into your market, understand your audience, and outshine your competition. Step-by-Step Guides: Follow our detailed guides to launch your business smoothly and successfully.
Build a Strong Foundation Development Tools: Access a suite of tools for product development and service creation. Project Management Software: Streamline your workflow and enhance team collaboration with our integrated tools. Networking Opportunities: Connect with industry experts, mentors, and potential partners to grow your professional network.
Grow and Scale Your Business Marketing Strategies: Implement effective marketing campaigns to reach and engage your target audience. Financial Management: Manage your finances efficiently with our budgeting, accounting, and financial planning tools. Scaling Techniques: Learn proven strategies to scale your operations and enter new markets. Continuous Learning: Stay ahead with our ongoing educational resources and updates on the latest business trends. https://pyters.com
7 notes
·
View notes