#free web scraping tools
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
Top Custom Web App Development Company Near You
Zyneto Technologies is a trusted web app development company, providing best and custom web development services that specifically fulfill your business goals. Whichever website developers near me means to you or global partners you’ll gain access to a team of scalable, responsive, and feature rich web development solutions. We design intuitive user interfaces, build powerful web applications that perform seamlessly, providing awesome user experiences. Our expertise in modern technologies and framework enables us to design, develop and customize websites /apps that best fit your brand persona and objectives. The bespoke solution lines up to whether it is a startup or enterprise level project, the Zyneto Technologies delivers robust and innovative solution that will enable your business grow and succeed.
Zyneto Technologies: A Leading Custom Web Development and Web App Development Company
In the digital age, having a well-designed, high-performing website or web application is crucial to a business’s success. Zyneto Technologies stands out as a trusted web app development company, providing top-tier custom web development services tailored to meet the specific goals of your business. Whether you’re searching for “website developers near me” or partnering with global experts, Zyneto offers scalable, responsive, and feature-rich solutions that are designed to help your business grow.
Why Zyneto Technologies is the Top Custom Web Development Company Near You
Zyneto Technologies is a highly regarded name in the world of web development, with a reputation for delivering custom web solutions that perfectly align with your business objectives. Whether you're a startup looking for a personalized web solution or an established enterprise aiming for a digital overhaul, Zyneto offers custom web development services that deliver lasting value. With a focus on modern web technologies and frameworks, their development team crafts innovative and robust web applications and websites that drive business growth.
Expert Web App Development Services to Match Your Business Needs
As one of the leading web app development companies, Zyneto specializes in creating web applications that perform seamlessly across platforms. Their expert team of developers is proficient in designing intuitive user interfaces and building powerful web applications that provide a smooth and engaging user experience. Whether you require a custom website or a sophisticated web app, Zyneto’s expertise ensures that your digital solutions are scalable, responsive, and optimized for the best performance.
Tailored Custom Web Development Solutions for Your Brand
Zyneto Technologies understands that every business is unique, which is why they offer custom web development solutions that align with your brand’s persona and objectives. Their team works closely with clients to understand their vision and create bespoke solutions that fit perfectly within their business model. Whether you're developing a new website or upgrading an existing one, Zyneto delivers web applications and websites that are designed to reflect your brand’s identity while driving engagement and conversions.
Comprehensive Web Development Services for Startups and Enterprises
Zyneto Technologies offers web development solutions that cater to both startups and large enterprises. Their custom approach ensures that every project, regardless of scale, receives the attention it deserves. By leveraging modern technologies, frameworks, and best practices in web development, Zyneto delivers solutions that are not only technically advanced but also tailored to meet the specific needs of your business. Whether you’re building a simple website or a complex web app, their team ensures your project is executed efficiently and effectively.
Why Zyneto Technologies is Your Ideal Web Development Partner
When searching for "website developers near me" or a top custom web app development company, Zyneto Technologies is the ideal choice. Their combination of global expertise, cutting-edge technology, and focus on user experience ensures that every solution they deliver is designed to meet your business goals. Whether you need a custom website, web application, or enterprise-level solution, Zyneto offers the expertise and dedication to bring your digital vision to life.
Elevate Your Business with Zyneto’s Custom Web Development Services
Partnering with Zyneto Technologies means choosing a web development company that is committed to providing high-quality, customized solutions. From start to finish, Zyneto focuses on delivering robust and innovative web applications and websites that support your business objectives. Their team ensures seamless project execution, from initial design to final deployment, making them a trusted partner for businesses of all sizes.
Get Started with Zyneto Technologies Today
Ready to take your business to the next level with custom web development? Zyneto Technologies is here to help. Whether you are in need of website developers near you or a comprehensive web app development company, their team offers scalable, responsive, and user-friendly solutions that are built to last. Connect with Zyneto Technologies today and discover how their web development expertise can help your business grow and succeed.
visit - https://zyneto.com/
#devops automation tools#devops services and solutions#devops solutions and services#devops solution providers#devops solutions company#devops solutions and service provider company#devops services#devops development services#devops consulting service#devops services company#web scraping solutions#web scraping chrome extension free#web scraping using google colab#selenium web scraping#best web scraping tools#node js web scraping#artificial intelligence web scraping#beautiful soup web scraping#best web scraping software#node js for web scraping#web scraping software#web scraping ai#free web scraping tools#web scraping python beautifulsoup#selenium web scraping python#web scraping with selenium and python#web site development#website design company near me#website design companies near me#website developers near me
0 notes
Text
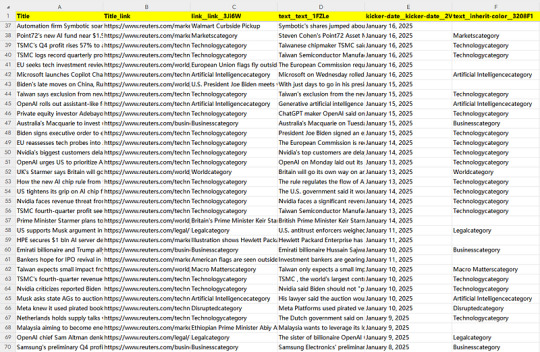
Easy way to get news from Reuters
Reuters is a world-renowned news agency headquartered in London, UK. It is known for its fast and accurate news reporting and comprehensive information services. It provides services to global media, financial institutions and corporate clients by collecting and publishing international news, financial information, commodity quotations, etc. Reuters has a long history and extensive influence in the field of news reporting and is one of the important sources of news in the world.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
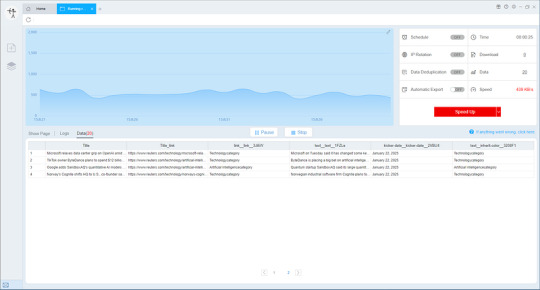
Preview of the scraped result
This is the demo task:
Google Drive:
OneDrive:
1. Create a task
(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task
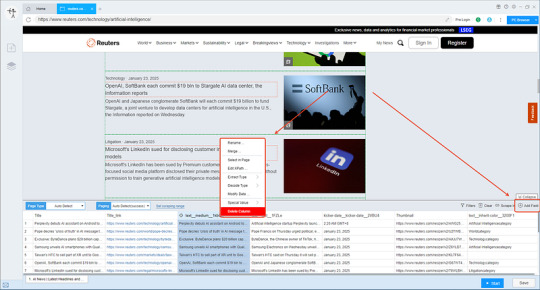
2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
3. Set up and start the scraping task
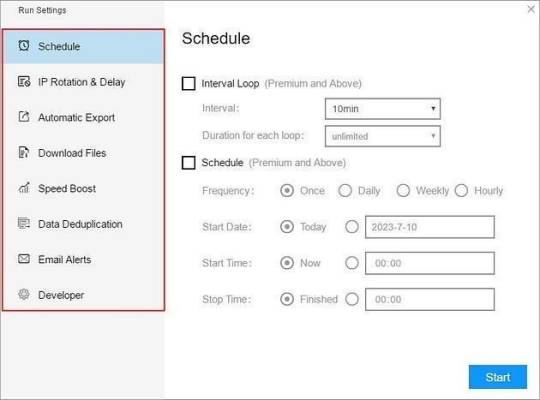
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.
4. Export and view data
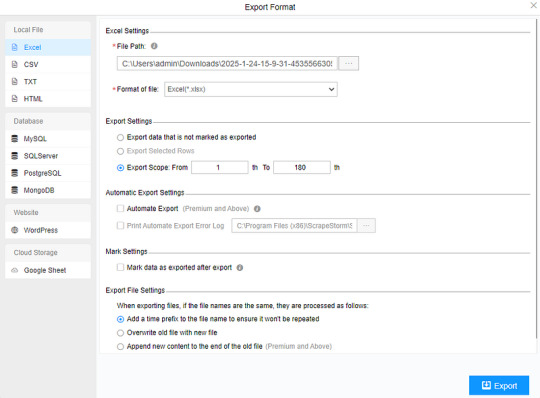
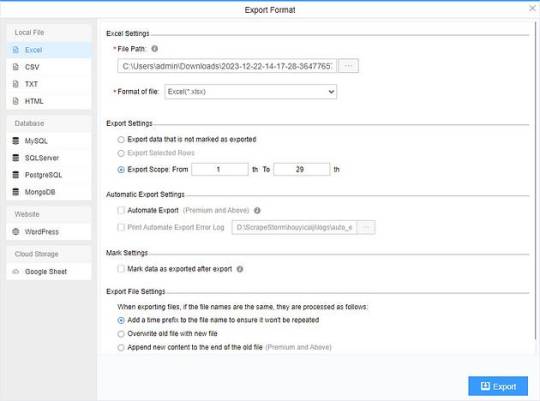
(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
0 notes
Text
youtube
GPT-4 Vision API + Puppeteer = Easy Web Scraping
In today's video I do some experimentation with the new GPT-4 Vision API and try to scrape information from web pages using it.
#education#free education#youtube#gpt 4#chat gpt#gpt4#gpt 4 ai technology#gpt#artificial intelligence#ai#tech#chatgpt#web scraping techniques#web scraping tools#Youtube
0 notes
Text
Well. I have a feeling I'm about to have a million new followers. (March 31st, 2025; not an April Fool's joke, unless Nanowrimo has very poor taste and timing)
youtube
Here's a link that explains in long video format the whole entire thing in detail:
youtube
and to sum it up:
This blog was made as an Anti-Generative AI to Nanowrimo, as well as a way to actually build a friendly, low-pressure, helpful community of aspiring writers, without the hard-fast-do-it-or-die pressure brought on by nanowrimo.
There is no official "contest" -- only a community coming together to inspire each other to write, help out with motivation by setting community goals, keeping participation motivation via Trackbear.app, etc!
The most popular writing challenge is still November for most people, but I myself have also started to keep a year-round, daily writing goal of 444 via the website 4thewords, which has been an extreme help in getting me to write a little at a time.
This year has been very hectic for everyone what with the election results so I haven't been very active on tumblr (I think everyone can understand that) but I was originally planning on also having each month of the year being a different themed writing / art challenge but got a bit distracted real life.
So, what is the Novella November Challenge?
It's a fun challenge where writers come together to write 30,000 (or your own personal writing goal!) words in 30 days, sharing tips, writing advice, plot ideas, accessibility aids, and committing to having fun while explicitly fighting back against Generative AI by using our own words and disavowing the use of scraping and generating to take away the livelyhoods of artists of all spectrums, and proving everyone who insists "generative AI is an accessibility tool" wrong by committing to our creative visions and making it easier for everyone to find the tools they need to succeed by sharing tips, free programs, and finding a like-minded community to support you! 💙
There is no official website, there is no required place to show your participation, this is a community initiative that will never be monetized by predatory sponsors or dangerous moderators abusing their power.
This blog is here to inspire everyone, regardless of experience level, to write and create the story they want to tell, in their own words, while striving to remain a fun, low-pressure challenge that doesn't turn into a stressful spiral, like often happened with Nano.
Want to start writing but not sure how? Don't have money to spend on expensive writing programs? Have no fear!
LibreOffice: An always free, open-source alternative to Microsoft Word (and Microsoft's other office suits)
4Thewords: A website (both desktop and mobile web browser) that syncs your writing cross platform to the cloud, with built-in daily word goals, streak tracking, and you can fight monsters with your word count to game-ify writing!
Trackbear: A website dedicated to tracking your writing, setting custom goals, and creating leaderboards for community participation; you can join the year-long community leaderboard with the Join Code "f043cc66-6d5d-45b2-acf1-204626a727ba" and a November-limited one will release on November 1st as well.
Want to use Text to Speech to dictate your novel?
Most modern phones have a built-in option available on your keyboard settings which can be used on any writing program on your phone, and most modern PCs that allow a microphone (including headphone) connection has some kind of native dictation function, which you can find by opening your start panel and searching your computer for "Speech to text" or "voice to text".
Want to write while on the go, but don't want to / can't use the small phone keyboard to type, or speech to text?
You can, for as cheap as $40, buy a bluetooth keyboard that you can pair with your smart phone or tablet and use to write in any and all writing applications on your phone -- this allows you to write on the goal (especially using cross-platform websites or services, like 4thewords or google docs) , and the small screen can also help minimize distractions by muting notifications in your writing time.
#novella november#nanowrimo#large text#writing events#national novel writing month#community events#anti ai#novellanovember#Sam Beckett Voice: Oh boy#long post#Youtube
167 notes
·
View notes
Text
so i've been coding a website
home of: the dervampireprince fanart museum, prince's art gallery, a masterlist of resources for making websites and list of web communities, and more!
[18+, minors dni (this blog is 18+ and the art gallery and art museum pages on my site have some 18+ only artworks)]
littlevampire . neocities . org (clickable link in pinned post labelled 'website')
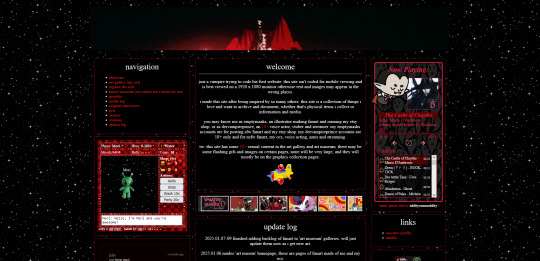
if you don't follow me on twitch or aren't in my discord, you might not know i've been coding my own website via neocities since june 2024. it's been a big labour of love, the only coding i'd done before is a little html to customize old tumblr themes, so i've learnt a lot and i've been having so much fun. i do link to it on my carrds but not everyone will know that the icon of a little cat with a wrench and paintbrush is the neocities logo, or even what neocities is.
neocities is a free website builder, but not like squarespace or wix that let you build a website from a template with things you can drag in, it's all done with html and css code (and you can throw in javascript if you wanna try hurting your brain /hj). i love the passion people have for coding websites, for making their own websites again in defiance of social medias becoming less customisable and websites looking boring and the same as each other. people's neocities sites are so fun to look through, looking at how they express themselves, their art galleries, shrines to their pets or favourite characters or shows or toys or places they've been.
why have i been making a website this way?
well i used to love customising my tumblr theme back when clicking on someone's username here took you to their tumblr website, their username . tumblr . com link that you could edit and customise with html code. now clicking a username takes you to their mobile page view, a lot of users don't even know you can have a website with tumblr, the feature to have a site became turned off by default, and i've heard from some users that they might have to pay to unlock that feature.
i've always loved the look of old geocities and angelfire websites, personalised sites, and i've grown tired of every social media trying to look the same as each other, remove features that let users customise their profiles and pages more. and then i found out about neocities.
are you interested in making a site too?
neocities is free, though you can pay to support them. there is no ads, no popups, they have no ai tool scraping their sites, no tos that will change to suddenly stop allow 18+ art. unlike other website hosters, neocities does have a sort of social media side where you do have a profile and people can follow you and leave comments on your site and like your updates, but you can ignore this if you want, or use it to get to know other webmasters.
to quote neocities "we are tired of living in an online world where people are isolated from each other on boring, generic social networks that don't let us truly express ourselves. it's time we took back our personalities from these sterilized, lifeless, monetized, data mined, monitored addiction machines and let our creativity flourish again."
i'd so encourage anyone interested to try making a website with neocities. w3schools is an excellent place to start learning coding, and there are free website templates you can copy and paste and use (my site is built off two different free codes, one from fujoshi . nekoweb . org and the other from sadgrl's free layout builder tool).
your site can be for anything:
a more fun and interactive online business card (rather than using carrd.co or linktree)
a gallery of your art/photos/cosplays/etc
a blog
webshrines to your a character, film, song, game, toy, hobby, your pet - anything can be a shrine!
a catalogue/database/log of every film you've watched, every place you've visited, birds you've seen, plushies you own, every blinkie gif you have saved, your ocs and stories, etc
hosting a webcomic
a fanwiki/fansite that doesn't have endless ads like fandom . com does (i found a cool neocities fansite for rhythm game series pop'n music and it's so thorough, it even lists all the sprites and official art for every character)
i follow a website that just reviews every video game based on whether or not it has a frog in it, if the frog is playable, if you can be friends with it. ( frogreview . neocities . org )
the only html i knew how to write before starting is how to paragraph and bold text. and now i have a whole site! and i'm still working on new stuff for it all the time.
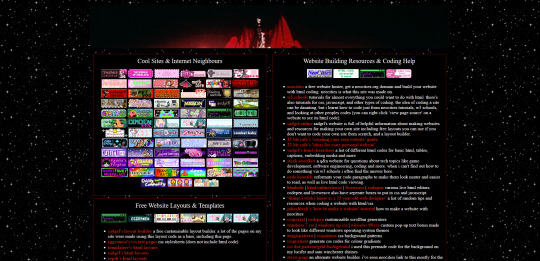
i just finished making a page on my website called 'explore the web'. this page lists everything you might need to know when wanting to make or decorate your website. it lists:
other neocities sites i think are cool and i'm inspired by, check them out for more ideas of what your site could look like and contain!
website building resources
coding help and tutorials
free website html code layouts you can use if you don't want too start coding from scratch
places to find graphics and decorative images for your site (transparent background pngs, pixels, favicons, stamps, blinkies, buttons, userboxes, etc)
image generators for different types of buttons and gifs (88x31 buttons, tiny identity buttons, heart locket open gifs, headpat gifs)
widgets and games and interactive elements you can add to your site (music players, interactive pets like gifypet and tamanotchi, hit counters, games like pacman and crosswords, guestbooks and chatboxes, etc)
web manifestos, guides, introductions and explanations of webmastering and neocities (some posts made by other tumblr users here are what made me finally want to make my own site and discover how too)
art tools, resources and free drawing programs
web communities! webrings, cliques, fanlistings, pixel clubs (pixel art trades) and more!
other fun sites that didn't fit in the other categories like free sheet music sites, archives, egotistical.goat (see a tumblr users audio posts/reblogs as a music playlist), soul void (a wonderful free to play video game i adore), an online omnichord you can play, and more.
i really hope the 'explore the web' page is helpful, it took three days to track down every link and find resources to add.
and if you want to check out my site there's more than just these pages. like i said in the beginning, i recently finished making:
the dervampireprince fanart museum
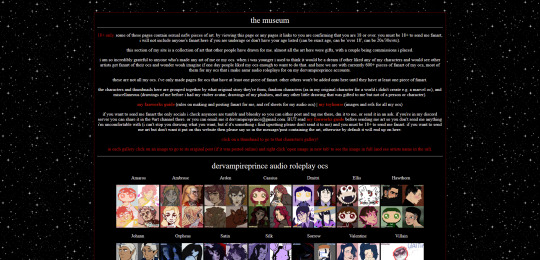
every piece of fanart i've received (unless the sender asked me to keep it private) has been added to this museum and where possible links back to the original artists post of that art (a lot the art was sent to me via discord so i can't link to the original post). every piece of fanart sent to me now will be added on their unless you specifically say you don't want it going on there. there's also links to my fanworks guide on there and how to send me fanart.
other pages on my site
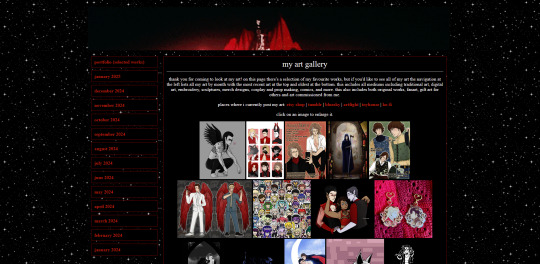

about me (including favourite media, quizzes, comfort characters, kins, and more)
art gallery (art i've made, sorted by month)
graphics (so far it's just stamps i've made but plan to remake this section of my site)
media log (haven't started the 2025 one yet, but a log of all films, tv, writing, music, theatre, fandoms, characters and ships i got into in 2024)
silly web pets
shrines
site map
update log
my shrines so far:

i have ones for lucifer from supernatural, sam winchester from supernatural, charuca minifigures (arcade prizes i wanted as a kid that i'm trying to finish collecting as an adult), my waifuroulette discord tcg collection. my masterlist of every lgbt+ marvel character is a wip. i love making each shrine look different and suit the character/fandom/thing the shrine is about. and then there's also:
the european musical section


i ramble about them a lot and it's no surprise there's multiple shrines for them. i fell in love with german musical theatre in 2020 and that expanded in being interested in all non-english language musical theatre and trying to spread the word of it and how they deserve to be as known as english-language musicals. one musical in particular, elisabeth das musical, is my biggest special interest so expect a very detailed shrine about that one day.
so far this part of the site includes
'enter the theatre' an interactive web theatre where you choose a ticket and that musical will play on the stage (click a ticket and the embedded youtube video for that musical will appear on the stage and play. i dealt with javascript for the first time to bring the vision i had for this page alive, it might be slow but i hope enjoyable)
elisabeth das musical webshrine [not made yet]
tanz der vampire webshrine [not made yet, might abandon the idea]
my favourite european musicals [not made yet]
a masterlist of european musicals [a wip, only two musicals listed so far, i am listing every musical and every production they've had, this was a word document i kept for a long time that i always wanted to share somehow and this page is how i'll do it. there's no other list for european musicals out there so i guess it's up to me as always /lh]
the future for my site
i will update my art gallery, the fanart museum, my media log and other collections as often as i can. there's so many more pages i want to add including:
profiles for my ocs
finish my european musical masterlist
finish my 'every marvel lgbt+ character' masterlist (i have no love for marvel or disney's lgbt+ representation nor are all of these characters good representation and a lot are very minor characters, but for some reason i have gotten hyperfixated on this topic a few times so here comes a masterlist)
make shrines for loki (marvel), ares (hades), my sylvanian families collection, vocaloid (and/or vocaloid medleys), my plushie collection, pullip dolls
make a 'page not found' page
and i have one big plan to essentially make a site within a site, and make a website for my monster boy band ocs. but make it as if it was a real band, an unfiction project (think like how welcome home's website portrays welcome home as if it was a real show). this site would have pages for the band members, their albums, merch and maybe a pretend shop, and a fake forum where you could see other characters in the story talking and click on their profiles to find out more about them. and then once that's all done i want to start posting audios about the characters and then people can go to the website to find out more about them. that's my big plan anyway. i hope that sounds interesting.
i also want to make an effort to try and join some website communities. be brave and apply for some webrings and fanlistings, and make some pixel art and join some of the amazing pixel clubs out there.
but yeah, that's my site, that's neocities. i hope that was interesting. i hope it encourages people to make their own site, or at least look at other's small websites and explore this part of the internet. and if you go and check out mine feel free to drop a message in the guestbook on the homepage, or follow me on neocities if you have/make an account.
66 notes
·
View notes
Text
NO AI
TL;DR: almost all social platforms are stealing your art and use it to train generative AI (or sell your content to AI developers); please beware and do something. Or don’t, if you’re okay with this.
Which platforms are NOT safe to use for sharing you art:
Facebook, Instagram and all Meta products and platforms (although if you live in the EU, you can forbid Meta to use your content for AI training)
Reddit (sold out all its content to OpenAI)
Twitter
Bluesky (it has no protection from AI scraping and you can’t opt out from 3rd party data / content collection yet)
DeviantArt, Flikr and literally every stock image platform (some didn’t bother to protect their content from scraping, some sold it out to AI developers)
Here’s WHAT YOU CAN DO:
1. Just say no:
Block all 3rd party data collection: you can do this here on Tumblr (here’s how); all other platforms are merely taking suggestions, tbh
Use Cara (they can’t stop illegal scraping yet, but they are currently working with Glaze to built in ‘AI poisoning’, so… fingers crossed)
2. Use art style masking tools:
Glaze: you can a) download the app and run it locally or b) use Glaze’s free web service, all you need to do is register. This one is a fav of mine, ‘cause, unlike all the other tools, it doesn’t require any coding skills (also it is 100% non-commercial and was developed by a bunch of enthusiasts at the University of Chicago)
Anti-DreamBooth: free code; it was originally developed to protect personal photos from being used for forging deepfakes, but it works for art to
Mist: free code for Windows; if you use MacOS or don’t have powerful enough GPU, you can run Mist on Google’s Colab Notebook
(art style masking tools change some pixels in digital images so that AI models can’t process them properly; the changes are almost invisible, so it doesn’t affect your audiences perception)
3. Use ‘AI poisoning’ tools
Nightshade: free code for Windows 10/11 and MacOS; you’ll need GPU/CPU and a bunch of machine learning libraries to use it though.
4. Stay safe and fuck all this corporate shit.
75 notes
·
View notes
Text
"how do I keep my art from being scraped for AI from now on?"
if you post images online, there's no 100% guaranteed way to prevent this, and you can probably assume that there's no need to remove/edit existing content. you might contest this as a matter of data privacy and workers' rights, but you might also be looking for smaller, more immediate actions to take.
...so I made this list! I can't vouch for the effectiveness of all of these, but I wanted to compile as many options as possible so you can decide what's best for you.
Discouraging data scraping and "opting out"
robots.txt - This is a file placed in a website's home directory to "ask" web crawlers not to access certain parts of a site. If you have your own website, you can edit this yourself, or you can check which crawlers a site disallows by adding /robots.txt at the end of the URL. This article has instructions for blocking some bots that scrape data for AI.
HTML metadata - DeviantArt (i know) has proposed the "noai" and "noimageai" meta tags for opting images out of machine learning datasets, while Mojeek proposed "noml". To use all three, you'd put the following in your webpages' headers:
<meta name="robots" content="noai, noimageai, noml">
Have I Been Trained? - A tool by Spawning to search for images in the LAION-5B and LAION-400M datasets and opt your images and web domain out of future model training. Spawning claims that Stability AI and Hugging Face have agreed to respect these opt-outs. Try searching for usernames!
Kudurru - A tool by Spawning (currently a Wordpress plugin) in closed beta that purportedly blocks/redirects AI scrapers from your website. I don't know much about how this one works.
ai.txt - Similar to robots.txt. A new type of permissions file for AI training proposed by Spawning.
ArtShield Watermarker - Web-based tool to add Stable Diffusion's "invisible watermark" to images, which may cause an image to be recognized as AI-generated and excluded from data scraping and/or model training. Source available on GitHub. Doesn't seem to have updated/posted on social media since last year.
Image processing... things
these are popular now, but there seems to be some confusion regarding the goal of these tools; these aren't meant to "kill" AI art, and they won't affect existing models. they won't magically guarantee full protection, so you probably shouldn't loudly announce that you're using them to try to bait AI users into responding
Glaze - UChicago's tool to add "adversarial noise" to art to disrupt style mimicry. Devs recommend glazing pictures last. Runs on Windows and Mac (Nvidia GPU required)
WebGlaze - Free browser-based Glaze service for those who can't run Glaze locally. Request an invite by following their instructions.
Mist - Another adversarial noise tool, by Psyker Group. Runs on Windows and Linux (Nvidia GPU required) or on web with a Google Colab Notebook.
Nightshade - UChicago's tool to distort AI's recognition of features and "poison" datasets, with the goal of making it inconvenient to use images scraped without consent. The guide recommends that you do not disclose whether your art is nightshaded. Nightshade chooses a tag that's relevant to your image. You should use this word in the image's caption/alt text when you post the image online. This means the alt text will accurately describe what's in the image-- there is no reason to ever write false/mismatched alt text!!! Runs on Windows and Mac (Nvidia GPU required)
Sanative AI - Web-based "anti-AI watermark"-- maybe comparable to Glaze and Mist. I can't find much about this one except that they won a "Responsible AI Challenge" hosted by Mozilla last year.
Just Add A Regular Watermark - It doesn't take a lot of processing power to add a watermark, so why not? Try adding complexities like warping, changes in color/opacity, and blurring to make it more annoying for an AI (or human) to remove. You could even try testing your watermark against an AI watermark remover. (the privacy policy claims that they don't keep or otherwise use your images, but use your own judgment)
given that energy consumption was the focus of some AI art criticism, I'm not sure if the benefits of these GPU-intensive tools outweigh the cost, and I'd like to know more about that. in any case, I thought that people writing alt text/image descriptions more often would've been a neat side effect of Nightshade being used, so I hope to see more of that in the future, at least!
245 notes
·
View notes
Text
It took NewsBreak—which attracts over 50 million monthly users—four days to remove the fake shooting story, and it apparently wasn't an isolated incident. According to Reuters, NewsBreak's AI tool, which scrapes the web and helps rewrite local news stories, has been used to publish at least 40 misleading or erroneous stories since 2021.
Now we have to worry about completely fabricated AI "news".
And apparently NewsBreak operators are just fine with this level of deception, simply adding a disclaimer to their site and calling it a day.
74 notes
·
View notes
Text


(big dog head with dog eyes), 2024
Materials : recycled corrugated cardboard, hot glue, papier mache (flour, glue, water, newspaper, paper towels), acrylic + gouache, found plastic pear, gloss finish with metal hardware on rear.
On view at Toutoune Gallery in Toronto until end of January.
Below the photograph is an image created between myself x AI in 2022 that inspired the above piece. My views and concerns have changed a lot since my experiments in 2022. Even then I had some worries, but I was also incredibly curious and was given the access to play around for multiple months with free credits that replenished daily. (I thankfully didn't spend a dime)
I came out of it with a breadth of imagery that has continued to inspire me, not unlike how I am inspired by found imagery on the web, bootlegs and other odd and lost ephemera, toy design, novelties, mass produced objects like stickers etc.
I spent most of my credits on mixtures of words, textures, colours and shapes to create a world of miniatures. Eventually the machine was trying to make too much sense of my requests and the playful and creative aspects melted away for me. I am still curious about the image making uses of this type of tool but in the hand of corporations, no different in goal than the corporate art of popular mass culture films, music and gaming etc, everything is on a continuous soulless trajectory. Haha, sigh. There is a lot of art that I already ignore.. understand it's all incredibly subjective, but most art sucks (to me).
I enjoyed my results but I don't enjoy the context in which this all 'exists'.
I have remade these digital curiosities anew. From the unreal-state of this nightmarish tech, material works were eventually born from my hands. It did not feel dissimilar to me than how I used to enjoy utilizing photoshop to clash together found imagery. Being playful with things found online that didn't necessarily belong to me, but felt as though they belong to us all.
The art of appropriation through some extra 'filters' that can leave you blind. I wish one could access a reversal mechanism with AI, to see all the pieces of the puzzle that was used to construct a resulting image. Clearly a lot of what is concocted through AI are deliberate plagiarisms: can you imagine requesting 'work' in the voice or style of a specific artist and believing that what the machine has created is 'unique'? (Ahem: Paul Schrader lol)
Sorry to blab but I will have continued rambled thoughts about AI technology as we keep seeing all of this develop esp in mass culture. My feelings in terms of AI in the art world is that it probably will eventually be seen as a fad that has eaten itself. (Perhaps it already has. AI CEOs are already admitting that their algorithms have already scraped all there is to scrape.)
...
19 notes
·
View notes
Text
Your All-in-One AI Web Agent: Save $200+ a Month, Unleash Limitless Possibilities!
Imagine having an AI agent that costs you nothing monthly, runs directly on your computer, and is unrestricted in its capabilities. OpenAI Operator charges up to $200/month for limited API calls and restricts access to many tasks like visiting thousands of websites. With DeepSeek-R1 and Browser-Use, you:
• Save money while keeping everything local and private.
• Automate visiting 100,000+ websites, gathering data, filling forms, and navigating like a human.
• Gain total freedom to explore, scrape, and interact with the web like never before.
You may have heard about Operator from Open AI that runs on their computer in some cloud with you passing on private information to their AI to so anything useful. AND you pay for the gift . It is not paranoid to not want you passwords and logins and personal details to be shared. OpenAI of course charges a substantial amount of money for something that will limit exactly what sites you can visit, like YouTube for example. With this method you will start telling an AI exactly what you want it to do, in plain language, and watching it navigate the web, gather information, and make decisions—all without writing a single line of code.
In this guide, we’ll show you how to build an AI agent that performs tasks like scraping news, analyzing social media mentions, and making predictions using DeepSeek-R1 and Browser-Use, but instead of writing a Python script, you’ll interact with the AI directly using prompts.
These instructions are in constant revisions as DeepSeek R1 is days old. Browser Use has been a standard for quite a while. This method can be for people who are new to AI and programming. It may seem technical at first, but by the end of this guide, you’ll feel confident using your AI agent to perform a variety of tasks, all by talking to it. how, if you look at these instructions and it seems to overwhelming, wait, we will have a single download app soon. It is in testing now.
This is version 3.0 of these instructions January 26th, 2025.
This guide will walk you through setting up DeepSeek-R1 8B (4-bit) and Browser-Use Web UI, ensuring even the most novice users succeed.
What You’ll Achieve
By following this guide, you’ll:
1. Set up DeepSeek-R1, a reasoning AI that works privately on your computer.
2. Configure Browser-Use Web UI, a tool to automate web scraping, form-filling, and real-time interaction.
3. Create an AI agent capable of finding stock news, gathering Reddit mentions, and predicting stock trends—all while operating without cloud restrictions.
A Deep Dive At ReadMultiplex.com Soon
We will have a deep dive into how you can use this platform for very advanced AI use cases that few have thought of let alone seen before. Join us at ReadMultiplex.com and become a member that not only sees the future earlier but also with particle and pragmatic ways to profit from the future.
System Requirements
Hardware
• RAM: 8 GB minimum (16 GB recommended).
• Processor: Quad-core (Intel i5/AMD Ryzen 5 or higher).
• Storage: 5 GB free space.
• Graphics: GPU optional for faster processing.
Software
• Operating System: macOS, Windows 10+, or Linux.
• Python: Version 3.8 or higher.
• Git: Installed.
Step 1: Get Your Tools Ready
We’ll need Python, Git, and a terminal/command prompt to proceed. Follow these instructions carefully.
Install Python
1. Check Python Installation:
• Open your terminal/command prompt and type:
python3 --version
• If Python is installed, you’ll see a version like:
Python 3.9.7
2. If Python Is Not Installed:
• Download Python from python.org.
• During installation, ensure you check “Add Python to PATH” on Windows.
3. Verify Installation:
python3 --version
Install Git
1. Check Git Installation:
• Run:
git --version
• If installed, you’ll see:
git version 2.34.1
2. If Git Is Not Installed:
• Windows: Download Git from git-scm.com and follow the instructions.
• Mac/Linux: Install via terminal:
sudo apt install git -y # For Ubuntu/Debian
brew install git # For macOS
Step 2: Download and Build llama.cpp
We’ll use llama.cpp to run the DeepSeek-R1 model locally.
1. Open your terminal/command prompt.
2. Navigate to a clear location for your project files:
mkdir ~/AI_Project
cd ~/AI_Project
3. Clone the llama.cpp repository:
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
4. Build the project:
• Mac/Linux:
make
• Windows:
• Install a C++ compiler (e.g., MSVC or MinGW).
• Run:
mkdir build
cd build
cmake ..
cmake --build . --config Release
Step 3: Download DeepSeek-R1 8B 4-bit Model
1. Visit the DeepSeek-R1 8B Model Page on Hugging Face.
2. Download the 4-bit quantized model file:
• Example: DeepSeek-R1-Distill-Qwen-8B-Q4_K_M.gguf.
3. Move the model to your llama.cpp folder:
mv ~/Downloads/DeepSeek-R1-Distill-Qwen-8B-Q4_K_M.gguf ~/AI_Project/llama.cpp
Step 4: Start DeepSeek-R1
1. Navigate to your llama.cpp folder:
cd ~/AI_Project/llama.cpp
2. Run the model with a sample prompt:
./main -m DeepSeek-R1-Distill-Qwen-8B-Q4_K_M.gguf -p "What is the capital of France?"
3. Expected Output:
The capital of France is Paris.
Step 5: Set Up Browser-Use Web UI
1. Go back to your project folder:
cd ~/AI_Project
2. Clone the Browser-Use repository:
git clone https://github.com/browser-use/browser-use.git
cd browser-use
3. Create a virtual environment:
python3 -m venv env
4. Activate the virtual environment:
• Mac/Linux:
source env/bin/activate
• Windows:
env\Scripts\activate
5. Install dependencies:
pip install -r requirements.txt
6. Start the Web UI:
python examples/gradio_demo.py
7. Open the local URL in your browser:
http://127.0.0.1:7860
Step 6: Configure the Web UI for DeepSeek-R1
1. Go to the Settings panel in the Web UI.
2. Specify the DeepSeek model path:
~/AI_Project/llama.cpp/DeepSeek-R1-Distill-Qwen-8B-Q4_K_M.gguf
3. Adjust Timeout Settings:
• Increase the timeout to 120 seconds for larger models.
4. Enable Memory-Saving Mode if your system has less than 16 GB of RAM.
Step 7: Run an Example Task
Let’s create an agent that:
1. Searches for Tesla stock news.
2. Gathers Reddit mentions.
3. Predicts the stock trend.
Example Prompt:
Search for "Tesla stock news" on Google News and summarize the top 3 headlines. Then, check Reddit for the latest mentions of "Tesla stock" and predict whether the stock will rise based on the news and discussions.
--
Congratulations! You’ve built a powerful, private AI agent capable of automating the web and reasoning in real time. Unlike costly, restricted tools like OpenAI Operator, you’ve spent nothing beyond your time. Unleash your AI agent on tasks that were once impossible and imagine the possibilities for personal projects, research, and business. You’re not limited anymore. You own the web—your AI agent just unlocked it! 🚀
Stay tuned fora FREE simple to use single app that will do this all and more.

7 notes
·
View notes
Text
Zyneto Technologies: Leading Mobile App Development Companies in the US & India
In today’s mobile-first world, having a robust and feature-rich mobile application is key to staying ahead of the competition. Whether you’re a startup or an established enterprise, the right mobile app development partner can help elevate your business. Zyneto Technologies is recognized as one of the top mobile app development companies in the USA and India, offering innovative and scalable solutions that meet the diverse needs of businesses across the globe.
Why Zyneto Technologies Stands Out Among Mobile App Development Companies in the USA and India
Zyneto Technologies is known for delivering high-quality mobile app development solutions that are tailored to your business needs. With a team of highly skilled developers, they specialize in building responsive, scalable, and feature
website- zyneto.com
#devops automation tools#devops services and solutions#devops solutions and services#devops solution providers#devops solutions company#devops solutions and service provider company#devops services#devops development services#devops consulting service#devops services company#web scraping solutions#web scraping chrome extension free#web scraping using google colab#selenium web scraping#best web scraping tools#node js web scraping#artificial intelligence web scraping#beautiful soup web scraping#best web scraping software#node js for web scraping#web scraping software#web scraping ai#free web scraping tools#web scraping python beautifulsoup#selenium web scraping python#web scraping with selenium and python#web site development#website design company near me#website design companies near me#website developers near me
0 notes
Text
Get news data from HuffPost using ScrapeStorm
HuffPost, the Huffington Post, is an American multilingual online media. It started operation on May 9, 2005 as a news reporting and commenting platform. In 2012, The Huffington Post became the first commercial online media to win the Pulitzer Prize and has become the most representative online news website.
Introduction to the scraping tool
ScrapeStorm is a new generation of Web Scraping Tool based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Preview of the scraped result

This is the demo task:
1. Create a task

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
How to create a smart mode task

2. Configure the scraping rules
Smart mode automatically detects the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.

3. Set up and start the scraping task
(1) Run settings
Choose your own needs, you can set Schedule, IP Rotation&Delay, Automatic Export, Download Images, Speed Boost, Data Deduplication and Developer.

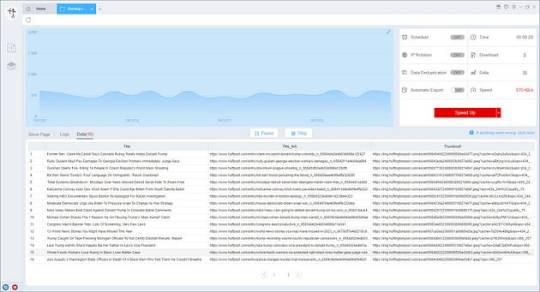
4. Export and view data

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
How to view data and clear data
0 notes
Text
As media companies haggle licensing deals with artificial intelligence powerhouses like OpenAI that are hungry for training data, they’re also throwing up a digital blockade. New data shows that over 88 percent of top-ranked news outlets in the US now block web crawlers used by artificial intelligence companies to collect training data for chatbots and other AI projects. One sector of the news business is a glaring outlier, though: Right-wing media lags far behind their liberal counterparts when it comes to bot-blocking.
Data collected in mid-January on 44 top news sites by Ontario-based AI detection startup Originality AI shows that almost all of them block AI web crawlers, including newspapers like The New York Times, The Washington Post, and The Guardian, general-interest magazines like The Atlantic, and special-interest sites like Bleacher Report. OpenAI’s GPTBot is the most widely-blocked crawler. But none of the top right-wing news outlets surveyed, including Fox News, the Daily Caller, and Breitbart, block any of the most prominent AI web scrapers, which also include Google’s AI data collection bot. Pundit Bari Weiss’ new website The Free Press also does not block AI scraping bots.
Most of the right-wing sites didn’t respond to requests for comment on their AI crawler strategy, but researchers contacted by WIRED had a few different guesses to explain the discrepancy. The most intriguing: Could this be a strategy to combat perceived political bias? “AI models reflect the biases of their training data,” says Originality AI founder and CEO Jon Gillham. “If the entire left-leaning side is blocking, you could say, come on over here and eat up all of our right-leaning content.”
Originality tallied which sites block GPTbot and other AI scrapers by surveying the robots.txt files that websites use to inform automated web crawlers which pages they are welcome to visit or barred from. The startup used Internet Archive data to establish when each website started blocking AI crawlers; many did so soon after OpenAI announced its crawler would respect robots.txt flags in August 2023. Originality’s initial analysis focused on the top news sites in the US, according to estimated web traffic. Only one of those sites had a significantly right-wing perspective, so Originality also looked at nine of the most well-known right-leaning outlets. Out of the nine right-wing sites, none were blocking GPTBot.
Bot Biases
Conservative leaders in the US (and also Elon Musk) have expressed concern that ChatGPT and other leading AI tools exhibit liberal or left-leaning political biases. At a recent hearing on AI, Senator Marsha Blackburn recited an AI-generated poem praising President Biden as evidence, claiming that generating a similar ode to Trump was impossible with ChatGPT. Right-leaning outlets might see their ideological foes’ decisions to block AI web crawlers as a unique opportunity to redress the balance.
David Rozado, a data scientist based in New Zealand who developed an AI model called RightWingGPT to explore bias he perceived in ChatGPT, says that’s a plausible-sounding strategy. “From a technical point of view, yes, a media company allowing its content to be included in AI training data should have some impact on the model parameters,” he says.
However, Jeremy Baum, an AI ethics researcher at UCLA, says he’s skeptical that right-wing sites declining to block AI scraping would have a measurable effect on the outputs of finished AI systems such as chatbots. That’s in part because of the sheer volume of older material AI companies have already collected from mainstream news outlets before they started blocking AI crawlers, and also because AI companies tend to hire liberal-leaning employees.
“A process called reinforcement learning from human feedback is used right now in every state-of-the-art model,” to fine-tune its responses, Baum says. Most AI companies aim to create systems that appear neutral. If the humans steering the AI see an uptick of right-wing content but judge it to be unsafe or wrong, they could undo any attempt to feed the machine a certain perspective.
OpenAI spokesperson Kayla Wood says that in pursuit of AI models that “deeply represent all cultures, industries, ideologies, and languages” the company uses broad collections of training data. “Any one sector—including news—and any single news site is a tiny slice of the overall training data, and does not have a measurable effect on the model’s intended learning and output,” she says.
Rights Fights
The disconnect in which news sites block AI crawlers could also reflect an ideological divide on copyright. The New York Times is currently suing OpenAI for copyright infringement, arguing that the AI upstart’s data collection is illegal. Other leaders in mainstream media also view this scraping as theft. Condé Nast CEO Roger Lynch recently said at a Senate hearing that many AI tools have been built with “stolen goods.” (WIRED is owned by Condé Nast.) Right-wing media bosses have been largely absent from the debate. Perhaps they quietly allow data scraping because they endorse the argument that data scraping to build AI tools is protected by the fair use doctrine?
For a couple of the nine right-wing outlets contacted by WIRED to ask why they permitted AI scrapers, their responses pointed to a different, less ideological reason. The Washington Examiner did not respond to questions about its intentions but began blocking OpenAI’s GPTBot within 48 hours of WIRED’s request, suggesting that it may not have previously known about or prioritized the option to block web crawlers.
Meanwhile, the Daily Caller admitted that its permissiveness toward AI crawlers had been a simple mistake. “We do not endorse bots stealing our property. This must have been an oversight, but it's being fixed now,” says Daily Caller cofounder and publisher Neil Patel.
Right-wing media is influential, and notably savvy at leveraging social media platforms like Facebook to share articles. But outlets like the Washington Examiner and the Daily Caller are small and lean compared to establishment media behemoths like The New York Times, which have extensive technical teams.
Data journalist Ben Welsh keeps a running tally of news websites blocking AI crawlers from OpenAI, Google, and the nonprofit Common Crawl project whose data is widely used in AI. His results found that approximately 53 percent of the 1,156 media publishers surveyed block one of those three bots. His sample size is much larger than Originality AI’s and includes smaller and less popular news sites, suggesting outlets with larger staffs and higher traffic are more likely to block AI bots, perhaps because of better resourcing or technical knowledge.
At least one right-leaning news site is considering how it might leverage the way its mainstream competitors are trying to stonewall AI projects to counter perceived political biases. “Our legal terms prohibit scraping, and we are exploring new tools to protect our IP. That said, we are also exploring ways to help ensure AI doesn’t end up with all of the same biases as the establishment press,” Daily Wire spokesperson Jen Smith says. As of today, GPTBot and other AI bots were still free to scrape content from the Daily Wire.
6 notes
·
View notes
Text
Which Are the BEST 4 Proxy Providers in 2024?
Choosing the best proxy provider can significantly impact your online privacy, web scraping efficiency, and overall internet experience. In this review, we examine the top four proxy providers in 2024, focusing on their unique features, strengths, and tools to help you make an informed decision.
Oneproxy.pro: Premium Performance and Security
Oneproxy.pro offers top-tier proxy services with a focus on performance and security. Here’s an in-depth look at Oneproxy.pro:
Key Features:
High-Performance Proxies: Ensures high-speed and low-latency connections, perfect for data-intensive tasks like streaming and web scraping.
Security: Provides strong encryption to protect user data and ensure anonymity.
Comprehensive Support: Offers extensive customer support, including detailed setup guides and troubleshooting.
Flexible Plans: Provides flexible pricing plans to suit different user needs, from individuals to large enterprises.
Pros and Cons:
Pros
High-speed and secure
Excellent customer support
Cons
Premium pricing
Might be overkill for casual users
Oneproxy.pro is ideal for users requiring premium performance and high security.
Proxy5.net: Cost-Effective and Versatile
Proxy5.net is a favorite for its affordability and wide range of proxy options. Here’s a closer look at Proxy5.net:
Key Features:
Affordable Pricing: Known for some of the most cost-effective proxy packages available.
Multiple Proxy Types: Offers shared, private, and rotating proxies to meet various needs.
Global Coverage: Provides a wide range of IP addresses from numerous locations worldwide.
Customer Support: Includes reliable customer support for setup and troubleshooting.
Pros and Cons:
Pros
Budget-friendly
Extensive proxy options
Cons
Shared proxies may be slower
Limited advanced features support
Proxy5.net is an excellent choice for budget-conscious users needing versatile proxy options.
FineProxy.org: High-Speed, Reliable, and Affordable
FineProxy.org is well-regarded for delivering high-quality proxy services since 2011. Here’s why FineProxy.org remains a top pick:
Key Features:
Diverse Proxy Packages: Offers various proxy packages, including US, Europe, and World mix, with high-anonymous IP addresses.
High Speed and Minimal Latency: Provides high-speed data transfer with minimal latency, suitable for fast and stable connections.
Reliability: Guarantees a network uptime of 99.9%, ensuring continuous service availability.
Customer Support: Offers 24/7 technical support to address any issues or queries.
Free Trial: Allows users to test the service with a free trial period before purchasing.
Pricing:
Shared Proxies: 1000 proxies for $50
Private Proxies: $5 per proxy
Pros and Cons:
Pros
Affordable shared proxies
Excellent customer support
Cons
Expensive private proxies
Shared proxies may have fluctuating performance
Shared proxies may have fluctuating performance
FineProxy.org provides a balanced mix of affordability and performance, making it a strong contender for shared proxies.
ProxyElite.Info: Secure and User-Friendly
ProxyElite.Info is known for its high-security proxies and user-friendly interface. Here’s what you need to know about ProxyElite.Info:
Key Features:
High Security: Offers high levels of anonymity and security, suitable for bypassing geo-restrictions and protecting user privacy.
Variety of Proxies: Provides HTTP, HTTPS, and SOCKS proxies.
User-Friendly Interface: Known for its easy setup process and intuitive user dashboard.
Reliable Support: Maintains high service uptime and offers reliable customer support.
Pros and Cons:
Pros
High security
Easy to use
Cons
Can be more expensive
Limited free trial options
ProxyElite.Info is ideal for users who prioritize security and ease of use.
Comparison Table
To help you compare these providers at a glance, here’s a summary table:

Conclusion
Selecting the right proxy provider depends on your specific needs, whether it's speed, security, pricing, or customer support. Oneproxy.pro offers premium performance and security, making it ideal for high-demand users. Proxy5.net is perfect for those looking for cost-effective and versatile proxy solutions. FineProxy.org provides a balanced mix of affordability and performance, especially for shared proxies. ProxyElite.Info excels in security and user-friendliness, making it a great choice for those who prioritize privacy.
These top four proxy services in 2024 have proven to be reliable and effective, catering to a wide range of online requirements.
2 notes
·
View notes
Text
Thunder and Shadow
Summary: Five years after Ultima’s defeat, those left behind have no choice but to push onward in a world still on the precipice of ruin. Left with all that remains of Clive—her twin boys—both Jill and Joshua do all that can be to ensure the world they grow up in is one of less strife and struggle than what came before. But the destruction of the crystals and the god that created them has left the aether and eikons in a state of chaotic distress that plagues the entirety of Valisthea. And now, to have received a letter from the north about stone bearers coming back to life, Jill has a new mystery to unfold.
At the same time, Clive finds himself waking on what he thinks must be the eastern Rosarian coast, though how he arrived there, he doesn’t know. Nor has he any idea how much time has passed since that final fight with Ultima. But as he begins to investigate, he sees a battle of eikonic proportions in the distance, one that revives old, bitter memories. Ifrit, perhaps, can make up for wrongs wrought so long ago.
Meanwhile, behind the scenes, a shadow manipulates them all, his eyes set on those who would become dominants and tools both.
Chapter 3
Though he knew it'd been years—though he knew Joshua was alive—the night at Phoenix Gate would forever haunt him. Waking up in cold sweats, remembering the heat and the sound of tearing feathers and flesh, and the way his little brother had screamed out for his help…
He'd hold onto that nightmare forever.
"Mama, help…"
He wasn't Jill, but this time, he'd do something.
Reaching out, he grabbed this Diabolos by the horn and, snarling, ripped him free of the thunderbird. With a massive swing, he sent it flying across the field and away, the whole world feeling as though is shook beneath him as the demon smashed into the dirt.
Turning his focus to Quezacotl, Ifrit surveyed the damage. Blood and flickering feathers were splattered everywhere, deep gouges dug out along his chest and throat. But around the wounds, aether sparkled. Though the wounds were deep and severe, they were not lethal, not to an eikon.
Yet, that didn't lessen the agony.
Only a child.
Whimpering, Ifrit nearly reached out, memories of holding Joshua when he'd pushed himself too hard flashing through his thoughts. Quezacotl was still, was barely breathing at all, and he wanted nothing more than to hold him, to let him know it was okay. He wasn't alone and this fight wasn't a burden he had to bear alone.
Yet, even as he felt his heart pulling closer to his nephew, his instincts yanked him back in the other direction. Behind him, Diabolos was stirring, the akashic air sparking.
Whimper turning to a furious growl, Ifrit whipped around, shoulders tensing as his vision flashed red.
Charging forward, he had Diabolos pinned to the ground before the demon had fully risen. He could tell by how it scraped at him, and howled, and flapped its webbed wings, that whoever this eikon was possessing had next to no experience being a dominant, or a host, or whatever they were. A feeble monster targeting the only thing it might stand a chance against—a helpless, desperate child.
Perhaps, were the situation different, Ifrit might have felt some semblance of mercy, or even pity, but as of then, there was none for this… akashic thing, whatever it was. All he had to spare was angry, fiery rage, and so he let it all go.
Roaring, he ripped Diabolos apart. Tore it limb from limb, shredding it even as it attempted to regenerate lost body parts, leaving it helpless to keep up. Against Ifrit—Mythos—a dominant with so much strength and experience, there was no hope. Tearing arm from shoulder, wing from back, Ifrit sheered through it all until he was able to get his jaws clamped down over the creature's jugular. Sinking his teeth into that poisoned flesh, he ignored the sulfur taste of one steeped in aether as he reached up and, with one clawed hand clamped around each horn, anchored both himself and Diabolos in place even as he pulled.
Diabolos screamed and struggled, but there was no escape. In one snapping moment, he split Diabolos apart, tearing its head from its shoulders and rendering it silent. Flesh and blood sprayed and snapped against him for a second, until the inevitability of death sparked. Glowing the sickening purple of aether, what remained of Diabolos' body began to dissolve, even as the stain of blood was left behind.
Dropping the mangled human head that would remain once the outer shell of Diabolos disintegrated, Ifrit leaned back, glowing red with heat and huffing as he watched to make sure the deed was fully done. Slithering into nothing, soon all that remained was the toxic, infected, headless corpse of a wasted, akashic man, glowing ever so faintly with deep red as the eikon's power diminished.
Reaching out, Ifrit allowed his hand close enough that he could feel the wavering darkness. Familiar.
Read More
And here’s a link to all my socials ;D I recently released a book for anyone who’s interested.
#final fantasy XVI#final fantasy 16#ff16#ffXVI#cliji#Warfield#postgame#fanfiction#my fics#thunder and shadow#chapter 3
14 notes
·
View notes
Text
How Web Scraping TripAdvisor Reviews Data Boosts Your Business Growth

Are you one of the 94% of buyers who rely on online reviews to make the final decision? This means that most people today explore reviews before taking action, whether booking hotels, visiting a place, buying a book, or something else.
We understand the stress of booking the right place, especially when visiting somewhere new. Finding the balance between a perfect spot, services, and budget is challenging. Many of you consider TripAdvisor reviews a go-to solution for closely getting to know the place.
Here comes the accurate game-changing method—scrape TripAdvisor reviews data. But wait, is it legal and ethical? Yes, as long as you respect the website's terms of service, don't overload its servers, and use the data for personal or non-commercial purposes. What? How? Why?
Do not stress. We will help you understand why many hotel, restaurant, and attraction place owners invest in web scraping TripAdvisor reviews or other platform information. This powerful tool empowers you to understand your performance and competitors' strategies, enabling you to make informed business changes. What next?
Let's dive in and give you a complete tour of the process of web scraping TripAdvisor review data!
What Is Scraping TripAdvisor Reviews Data?
Extracting customer reviews and other relevant information from the TripAdvisor platform through different web scraping methods. This process works by accessing publicly available website data and storing it in a structured format to analyze or monitor.
Various methods and tools available in the market have unique features that allow you to extract TripAdvisor hotel review data hassle-free. Here are the different types of data you can scrape from a TripAdvisor review scraper:
Hotels
Ratings
Awards
Location
Pricing
Number of reviews
Review date
Reviewer's Name
Restaurants
Images
You may want other information per your business plan, which can be easily added to your requirements.
What Are The Ways To Scrape TripAdvisor Reviews Data?
TripAdvisor uses different web scraping methods to review data, depending on available resources and expertise. Let us look at them:
Scrape TripAdvisor Reviews Data Using Web Scraping API
An API helps to connect various programs to gather data without revealing the code used to execute the process. The scrape TripAdvisor Reviews is a standard JSON format that does not require technical knowledge, CAPTCHAs, or maintenance.
Now let us look at the complete process:
First, check if you need to install the software on your device or if it's browser-based and does not need anything. Then, download and install the desired software you will be using for restaurant, location, or hotel review scraping. The process is straightforward and user-friendly, ensuring your confidence in using these tools.
Now redirect to the web page you want to scrape data from and copy the URL to paste it into the program.
Make updates in the HTML output per your requirements and the information you want to scrape from TripAdvisor reviews.
Most tools start by extracting different HTML elements, especially the text. You can then select the categories that need to be extracted, such as Inner HTML, href attribute, class attribute, and more.
Export the data in SPSS, Graphpad, or XLSTAT format per your requirements for further analysis.
Scrape TripAdvisor Reviews Using Python
TripAdvisor review information is analyzed to understand the experience of hotels, locations, or restaurants. Now let us help you to scrape TripAdvisor reviews using Python:
Continue reading https://www.reviewgators.com/how-web-scraping-tripadvisor-reviews-data-boosts-your-business-growth.php
#review scraping#Scraping TripAdvisor Reviews#web scraping TripAdvisor reviews#TripAdvisor review scraper
2 notes
·
View notes