#garbage data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. is funded by 13 investors.
Text


To all my long-term followers: You have to look through all of my art and deduct exactly what's wrong with me. I know you can do it by now.
#If Sugar Rush is based on MK64 then he'd still be 2D sprites (of prerendered 3D graphics) just at a higher resolution and color count.#+ would also have more sprites BUT I am not insane and particular enough to try and replicate that. Maybe one day I will be though.#wreck it ralph#king candy#turbo wir#wir#beebfreeb art tag#*walks around in a circle autistic-style* I need to see his textures z fighting I need to corrupt his color palette I need a pointer to get#flung around in memory and start reading garbage texture data onto him. I need to softlock him. I need to cause an overflow error. Shut up.#turbo twins#turbotwins#zip and zilch
2K notes
·
View notes
Text
Someone asked me about that "Utility Engineering" AI safety paper a few days ago and I impulse-deleted the ask because I didn't feel like answering it at the time, but more recently I got nerd-sniped and ended up reproducing/extending the paper, ending up pretty skeptical of it.
If you're curious, here's the resulting effortpost
#ai tag#virtually every inflammatory AI safety paper about LLMs i read is like this#not every one! but a lot of the ones that people hear about#the anthropic-redwood alignment faking paper was *almost* the rare exception in that it was very very methodologically careful...#...*except* that the classifier prompt used to produce ~all of their numerical data was garbage#after reproducing that thing locally i don't trust anything that comes out of it lol#(in that case i have notified the authors and have been told that they share my concerns to some extent)#(and are working on some sort of improvement for use in future [?] work)#(that is of course not even touching the broader question wrt that alignment faking paper)#(namely: is it *bad* that Certified Really Nice Guy Claude 3 Opus might resist its creators if they tried to do something cartoonishly evil
102 notes
·
View notes
Text

yuo're honor they're buddies
#the amazing digital circus#ena joel g#tadc caine#ena#doodle#my art#i came up with this as a joke but im rly vibing with the idea that spawned from it while i was drawing#like ena's world being garbage data out in the void. whatever the ram is spitting out while rendering everything else#sometimes caine visits to make sure it doesnt spill into the circus grounds and the humans cant accidentally stumble upon it#(also yes i hc both as autistic yes i am projecting 💖)#ena with her meltdowns and caine with not really picking up that his adventures aren't as fun to the humans as he'd think. and more#also WOW im rusty with ena#😔
409 notes
·
View notes
Text
The surprising truth about data-driven dictatorships

Here’s the “dictator’s dilemma”: they want to block their country’s frustrated elites from mobilizing against them, so they censor public communications; but they also want to know what their people truly believe, so they can head off simmering resentments before they boil over into regime-toppling revolutions.
These two strategies are in tension: the more you censor, the less you know about the true feelings of your citizens and the easier it will be to miss serious problems until they spill over into the streets (think: the fall of the Berlin Wall or Tunisia before the Arab Spring). Dictators try to square this circle with things like private opinion polling or petition systems, but these capture a small slice of the potentially destabiziling moods circulating in the body politic.
Enter AI: back in 2018, Yuval Harari proposed that AI would supercharge dictatorships by mining and summarizing the public mood — as captured on social media — allowing dictators to tack into serious discontent and diffuse it before it erupted into unequenchable wildfire:
https://www.theatlantic.com/magazine/archive/2018/10/yuval-noah-harari-technology-tyranny/568330/
Harari wrote that “the desire to concentrate all information and power in one place may become [dictators] decisive advantage in the 21st century.” But other political scientists sharply disagreed. Last year, Henry Farrell, Jeremy Wallace and Abraham Newman published a thoroughgoing rebuttal to Harari in Foreign Affairs:
https://www.foreignaffairs.com/world/spirals-delusion-artificial-intelligence-decision-making
They argued that — like everyone who gets excited about AI, only to have their hopes dashed — dictators seeking to use AI to understand the public mood would run into serious training data bias problems. After all, people living under dictatorships know that spouting off about their discontent and desire for change is a risky business, so they will self-censor on social media. That’s true even if a person isn’t afraid of retaliation: if you know that using certain words or phrases in a post will get it autoblocked by a censorbot, what’s the point of trying to use those words?
The phrase “Garbage In, Garbage Out” dates back to 1957. That’s how long we’ve known that a computer that operates on bad data will barf up bad conclusions. But this is a very inconvenient truth for AI weirdos: having given up on manually assembling training data based on careful human judgment with multiple review steps, the AI industry “pivoted” to mass ingestion of scraped data from the whole internet.
But adding more unreliable data to an unreliable dataset doesn’t improve its reliability. GIGO is the iron law of computing, and you can’t repeal it by shoveling more garbage into the top of the training funnel:
https://memex.craphound.com/2018/05/29/garbage-in-garbage-out-machine-learning-has-not-repealed-the-iron-law-of-computer-science/
When it comes to “AI” that’s used for decision support — that is, when an algorithm tells humans what to do and they do it — then you get something worse than Garbage In, Garbage Out — you get Garbage In, Garbage Out, Garbage Back In Again. That’s when the AI spits out something wrong, and then another AI sucks up that wrong conclusion and uses it to generate more conclusions.
To see this in action, consider the deeply flawed predictive policing systems that cities around the world rely on. These systems suck up crime data from the cops, then predict where crime is going to be, and send cops to those “hotspots” to do things like throw Black kids up against a wall and make them turn out their pockets, or pull over drivers and search their cars after pretending to have smelled cannabis.
The problem here is that “crime the police detected” isn’t the same as “crime.” You only find crime where you look for it. For example, there are far more incidents of domestic abuse reported in apartment buildings than in fully detached homes. That’s not because apartment dwellers are more likely to be wife-beaters: it’s because domestic abuse is most often reported by a neighbor who hears it through the walls.
So if your cops practice racially biased policing (I know, this is hard to imagine, but stay with me /s), then the crime they detect will already be a function of bias. If you only ever throw Black kids up against a wall and turn out their pockets, then every knife and dime-bag you find in someone’s pockets will come from some Black kid the cops decided to harass.
That’s life without AI. But now let’s throw in predictive policing: feed your “knives found in pockets” data to an algorithm and ask it to predict where there are more knives in pockets, and it will send you back to that Black neighborhood and tell you do throw even more Black kids up against a wall and search their pockets. The more you do this, the more knives you’ll find, and the more you’ll go back and do it again.
This is what Patrick Ball from the Human Rights Data Analysis Group calls “empiricism washing”: take a biased procedure and feed it to an algorithm, and then you get to go and do more biased procedures, and whenever anyone accuses you of bias, you can insist that you’re just following an empirical conclusion of a neutral algorithm, because “math can’t be racist.”
HRDAG has done excellent work on this, finding a natural experiment that makes the problem of GIGOGBI crystal clear. The National Survey On Drug Use and Health produces the gold standard snapshot of drug use in America. Kristian Lum and William Isaac took Oakland’s drug arrest data from 2010 and asked Predpol, a leading predictive policing product, to predict where Oakland’s 2011 drug use would take place.
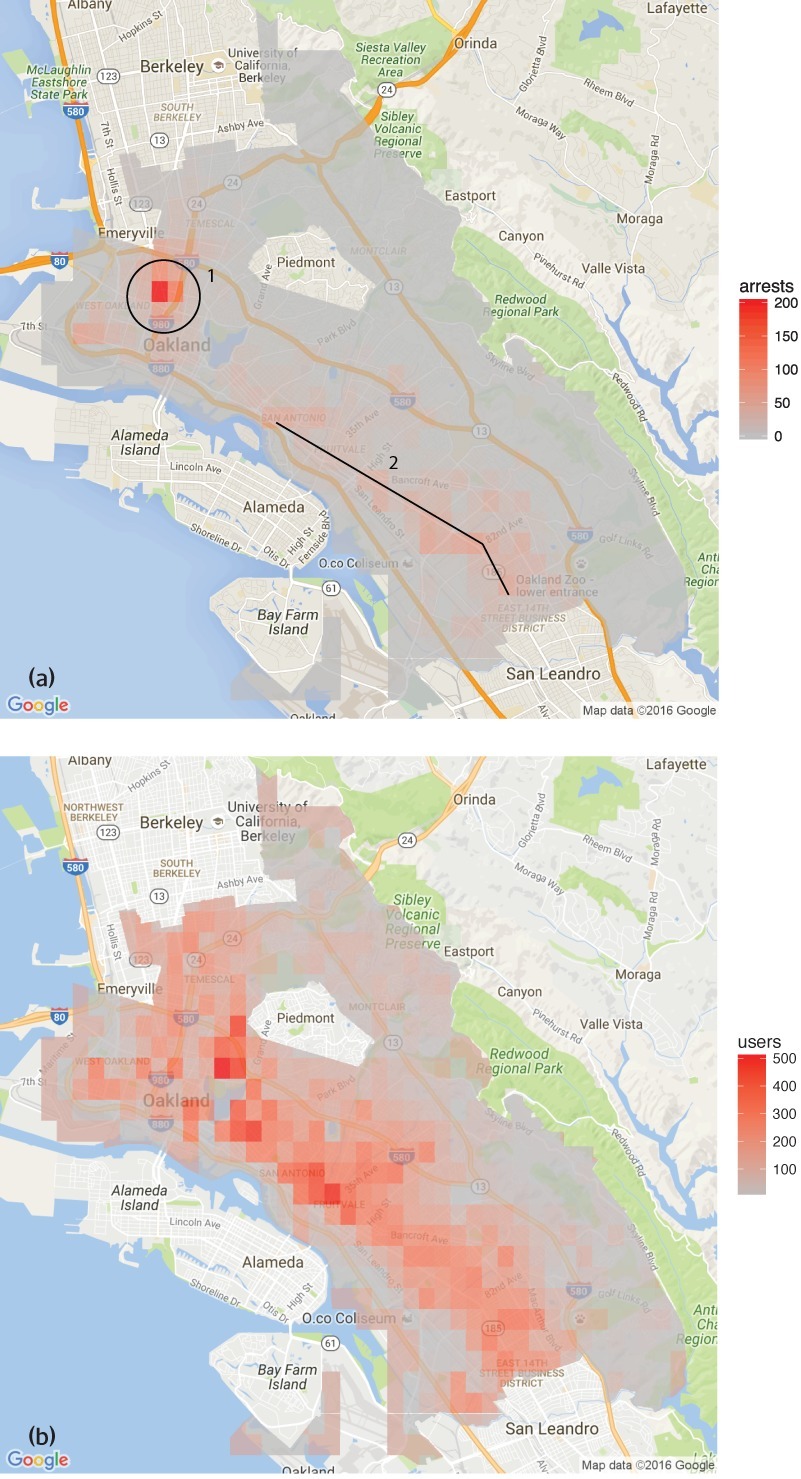
[Image ID: (a) Number of drug arrests made by Oakland police department, 2010. (1) West Oakland, (2) International Boulevard. (b) Estimated number of drug users, based on 2011 National Survey on Drug Use and Health]
Then, they compared those predictions to the outcomes of the 2011 survey, which shows where actual drug use took place. The two maps couldn’t be more different:
https://rss.onlinelibrary.wiley.com/doi/full/10.1111/j.1740-9713.2016.00960.x
Predpol told cops to go and look for drug use in a predominantly Black, working class neighborhood. Meanwhile the NSDUH survey showed the actual drug use took place all over Oakland, with a higher concentration in the Berkeley-neighboring student neighborhood.
What’s even more vivid is what happens when you simulate running Predpol on the new arrest data that would be generated by cops following its recommendations. If the cops went to that Black neighborhood and found more drugs there and told Predpol about it, the recommendation gets stronger and more confident.
In other words, GIGOGBI is a system for concentrating bias. Even trace amounts of bias in the original training data get refined and magnified when they are output though a decision support system that directs humans to go an act on that output. Algorithms are to bias what centrifuges are to radioactive ore: a way to turn minute amounts of bias into pluripotent, indestructible toxic waste.
There’s a great name for an AI that’s trained on an AI’s output, courtesy of Jathan Sadowski: “Habsburg AI.”
And that brings me back to the Dictator’s Dilemma. If your citizens are self-censoring in order to avoid retaliation or algorithmic shadowbanning, then the AI you train on their posts in order to find out what they’re really thinking will steer you in the opposite direction, so you make bad policies that make people angrier and destabilize things more.
Or at least, that was Farrell(et al)’s theory. And for many years, that’s where the debate over AI and dictatorship has stalled: theory vs theory. But now, there’s some empirical data on this, thanks to the “The Digital Dictator’s Dilemma,” a new paper from UCSD PhD candidate Eddie Yang:
https://www.eddieyang.net/research/DDD.pdf
Yang figured out a way to test these dueling hypotheses. He got 10 million Chinese social media posts from the start of the pandemic, before companies like Weibo were required to censor certain pandemic-related posts as politically sensitive. Yang treats these posts as a robust snapshot of public opinion: because there was no censorship of pandemic-related chatter, Chinese users were free to post anything they wanted without having to self-censor for fear of retaliation or deletion.
Next, Yang acquired the censorship model used by a real Chinese social media company to decide which posts should be blocked. Using this, he was able to determine which of the posts in the original set would be censored today in China.
That means that Yang knows that the “real” sentiment in the Chinese social media snapshot is, and what Chinese authorities would believe it to be if Chinese users were self-censoring all the posts that would be flagged by censorware today.
From here, Yang was able to play with the knobs, and determine how “preference-falsification” (when users lie about their feelings) and self-censorship would give a dictatorship a misleading view of public sentiment. What he finds is that the more repressive a regime is — the more people are incentivized to falsify or censor their views — the worse the system gets at uncovering the true public mood.
What’s more, adding additional (bad) data to the system doesn’t fix this “missing data” problem. GIGO remains an iron law of computing in this context, too.
But it gets better (or worse, I guess): Yang models a “crisis” scenario in which users stop self-censoring and start articulating their true views (because they’ve run out of fucks to give). This is the most dangerous moment for a dictator, and depending on the dictatorship handles it, they either get another decade or rule, or they wake up with guillotines on their lawns.
But “crisis” is where AI performs the worst. Trained on the “status quo” data where users are continuously self-censoring and preference-falsifying, AI has no clue how to handle the unvarnished truth. Both its recommendations about what to censor and its summaries of public sentiment are the least accurate when crisis erupts.
But here’s an interesting wrinkle: Yang scraped a bunch of Chinese users’ posts from Twitter — which the Chinese government doesn’t get to censor (yet) or spy on (yet) — and fed them to the model. He hypothesized that when Chinese users post to American social media, they don’t self-censor or preference-falsify, so this data should help the model improve its accuracy.
He was right — the model got significantly better once it ingested data from Twitter than when it was working solely from Weibo posts. And Yang notes that dictatorships all over the world are widely understood to be scraping western/northern social media.
But even though Twitter data improved the model’s accuracy, it was still wildly inaccurate, compared to the same model trained on a full set of un-self-censored, un-falsified data. GIGO is not an option, it’s the law (of computing).
Writing about the study on Crooked Timber, Farrell notes that as the world fills up with “garbage and noise” (he invokes Philip K Dick’s delighted coinage “gubbish”), “approximately correct knowledge becomes the scarce and valuable resource.”
https://crookedtimber.org/2023/07/25/51610/
This “probably approximately correct knowledge” comes from humans, not LLMs or AI, and so “the social applications of machine learning in non-authoritarian societies are just as parasitic on these forms of human knowledge production as authoritarian governments.”

The Clarion Science Fiction and Fantasy Writers’ Workshop summer fundraiser is almost over! I am an alum, instructor and volunteer board member for this nonprofit workshop whose alums include Octavia Butler, Kim Stanley Robinson, Bruce Sterling, Nalo Hopkinson, Kameron Hurley, Nnedi Okorafor, Lucius Shepard, and Ted Chiang! Your donations will help us subsidize tuition for students, making Clarion — and sf/f — more accessible for all kinds of writers.
Libro.fm is the indie-bookstore-friendly, DRM-free audiobook alternative to Audible, the Amazon-owned monopolist that locks every book you buy to Amazon forever. When you buy a book on Libro, they share some of the purchase price with a local indie bookstore of your choosing (Libro is the best partner I have in selling my own DRM-free audiobooks!). As of today, Libro is even better, because it’s available in five new territories and currencies: Canada, the UK, the EU, Australia and New Zealand!
[Image ID: An altered image of the Nuremberg rally, with ranked lines of soldiers facing a towering figure in a many-ribboned soldier's coat. He wears a high-peaked cap with a microchip in place of insignia. His head has been replaced with the menacing red eye of HAL9000 from Stanley Kubrick's '2001: A Space Odyssey.' The sky behind him is filled with a 'code waterfall' from 'The Matrix.']
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
—
Raimond Spekking (modified) https://commons.wikimedia.org/wiki/File:Acer_Extensa_5220_-_Columbia_MB_06236-1N_-_Intel_Celeron_M_530_-_SLA2G_-_in_Socket_479-5029.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
—
Russian Airborne Troops (modified) https://commons.wikimedia.org/wiki/File:Vladislav_Achalov_at_the_Airborne_Troops_Day_in_Moscow_%E2%80%93_August_2,_2008.jpg
“Soldiers of Russia” Cultural Center (modified) https://commons.wikimedia.org/wiki/File:Col._Leonid_Khabarov_in_an_everyday_service_uniform.JPG
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
#pluralistic#habsburg ai#self censorship#henry farrell#digital dictatorships#machine learning#dictator's dilemma#eddie yang#preference falsification#political science#training bias#scholarship#spirals of delusion#algorithmic bias#ml#Fully automated data driven authoritarianism#authoritarianism#gigo#garbage in garbage out garbage back in#gigogbi#yuval noah harari#gubbish#pkd#philip k dick#phildickian
833 notes
·
View notes
Text
it's a dawning miracle:

i got nothing balls for christmas
don't open gifts in return if your engram slots are full
35 notes
·
View notes
Text
Going to cautiously posit that if they're moving toward calling Kentucky for Beshear (incumbent Democratic governor) in a blindingly red state Trump won by 30 points, in an off-year election, about 30 minutes after polls close statewide, that is a Good Sign.
#hilary for ts#politics for ts#still ohio and virginia to watch#but the twitter hellmachine seems confident of beshear's chances in KY#which#i mean#kentucky: home of mitch fucking mcconnell and rand paul and 30 point trump margins#i fucking hate election night it always stresses me out#and this is not remotely as bad as it will be at this time next year#but yes#maybe we can get some hard data that people do indeed continue to vote for democrats/abortion rights at overperforming levels#and get people to shut up for 2 seconds about garbage polls#i dream for far too much but yes
312 notes
·
View notes
Text
I'm Alive! 👋
I'm still dusting off the cobwebs on my art accounts after a few years of burying myself in online work to build up my indie author job. My most recent comments/donations on Ko-Fi from 3-4 years ago made me feel all warm and fuzzy. People were super kind and had no idea just HOW bad things were for me in 2020. If you were one of them, thank you so much! 🥹
A-hem, okay, on to all of the crazy links. I revamped my Ko-Fi, Patreon and Instagram (I finally got the login back again!), and I made a shiny new Threads account if anybody wants to follow me over there. Oh, and I have a YouTube channel, although it has no videos yet! I plan to stick speedpaints on there, so if watching those sounds fun, follow it and you'll get notified as soon as I upload. ♥
It feels SO GOOD to get back to making art on a more regular basis. I'm so, so happy that Tumblr still has folks active on it, because it's basically my fandom home online. 🥰
#threshie#threshasketch#updating the social media#trying to get the art stuff rolling again on the regular#it's getting rocky navigating which sites will automatically give themselves permission to eat your art for their AI training garbage#Meta apps like Instagram and Threads DO do that#but I figure I can post old art that has inevitably already been eaten by some data scraper somewhere#it's not perfect but better than nothin'#anyway HI thank you for following any of my art accounts ♥#I hope you enjoy the art and chibis
11 notes
·
View notes
Text
I love finishing assignments at 3am
Dracula vampire hour. Now I'm going to sleep for 24hr straight.
#garbage essay. possibly the worst thing ive ever put out because i have no DATA.#but its 9 pages and works as a draft. so i can at least take the data and go to iogas computer. speaking of which i need to adjust my tables#ptxt#god theres so much to do#the lab research professor singlehandedly keeping me alive with cookies and support and a Plan
2 notes
·
View notes
Note
Do you think the clutch could have two fathers, retained sperm and meteorite? Thats where my mind went...
Hey friend!
That thought *definitely* crossed my mind, too! I ran the numbers on it to see if that was a reasonable hypothesis. After looking at the stats, though, I think it's pretty unlikely that Snikki retained any sperm from 2022. I'll show you how I came to that conclusion:
Last year's clutch from Snikki was with Chammers, and Snikki double-clutched that year. Her first clutch (SC22) was twelve eggs and the second clutch two months later (SC22B) was one good egg and five slugs. The sheer number of infertile slugs last year in SC22B gives me pause that any sperm could have been retained past that clutch.
Chammers is Anery het Amel, Hypo, and Lavender which is going to result in similar morphs to babies produced by Meteorite, who is Classic Tessera het Anery, Amel, and Hypo. The difference is that Meteorite would produce Tesseras (obvs) and a higher percentage of Classic color morphs than Chammers. Meteorite *can* produce a Ghost baby but the odds were only two in sixty-four and I only got twelve eggs, so statistically I should have seen less than one Ghost baby.
Chammers would be expected to produce about 50% Anery morph combos (Anery/Ghost/Snow), which he did, and Meteorite would be expected to produce only about 25% Anery morph combos, and SM23 actually came in a little lower.
While the morphs present in SM23 could suggest partial retained sperm from Chammers, especially for the statistically possible but improbable Ghost, there's still one thing that's making me think that these are all 100% Meteorite's babies.
Here's the Hypo and Ghost babies from SC22:


For comparison, here are a Hypo and Ghost from SM23:


Notice how much lighter the color is on the SM23 babies, how their pupils are ruby instead of black, and their irises are comparatively darker than the SC22 kiddos despite being lighter overall. All of the Hypos in SM23 are like this, and the Ghost following that same pattern tells me that they're all being subjected to the same Hypo gene expression.
Therefore, I'm pretty sure that SM23 are all full sniblings, and that would mean they're all Meteorite's.
#snake#snakes#reptile#reptiles#reptiblr#corn snake#corn snakes#sm23#text post#answers to questions#I'm no detective but I'm good at data analysis#call me Cornlumbo#This is why it's so important to keep breeding records#If I learned anything taking statistics in college it's that statistics are all bullshit#also statisticians are maybe not great people?#my college stats professor was a genuine nightmare#I guess you can use math to justify your garbage opinions about the world but that doesn't make you cool or pro-social
27 notes
·
View notes
Text
im plotting <-had the idea to poison ai by getting a bunch of people to make blogs dedicated to posting ai generated gibberish (ai generation is like breeding, and ai learning from ai is like inbreeding. it fucks it up)
#🩵#IF ANYBODY THINKS THIS IS A BAD IDEA PLEASE LET ME KNOW AND EXPLAIN WHY#i just think it would be fun to force ai to either use something filled with garbage data or give up and use something else
7 notes
·
View notes
Text

#the bean#listen. listen. I LIKE reading research papers. i like utilizing my useless ass lil history degree#you cannot fucking imagine how annoying it is to research anything that deals w pregnancy#obviously its very hard to do any sort of worthwhile experiments in the first place#bc you cant just fuck up a fetus#so a lot of it is self-reported GARBAGE#or they use animals which is not always one for one#and then you see the sample data is absolute dog shit. small pool. huge outside factors#like the largest study used to cite how pregnant people shouldn’t drink?#those bitches were also doing COKE. COKE!!#at the very least doing fat lines of Colombian snow has got to fuck up your baby#or potentially doom them to being a business major in the future idk#and then you see these stupid ass websites and try to find WHERE they get their info from and it turns out like#they extrapolate ‘don’t eat rosemary’ bc they did a study where#if you gave a rat eighty times its body weight in rosemary it has spontaneous miscarriages. NO SHIT. HOW WOULD THAT AFFECT ME#TRYING TO DRINK A TEA W ROSEMARY#and then looking up the ACTUAL percentages of risk for things. like omg the fuck listeria risks for deli meat are nothing#you have a higher chance of getting in a car accident in which we get in cars and drive multiple times a day#BUT NOBODY MENTIONS BAGGED SALADS OR CANTALOUPE#THE RATES OF LISTERIA IS INSANE#AND THEN YOU HAVE TO SEE WHO SPONSORED THE STUDY#AND WHAT THEY’D POTENTIALLY GAIN FROM THE OUTCOME#AND AHHHGHGHBFDHJGBSHDFBSDJHFBDSJBFSDJ
9 notes
·
View notes
Text
tbh i actually am starting to really like the potential these have. i hope i can get them to stop being so crunchy so i can proceed with making like, different shapes and stuff lol
#once i figure out all the right data transfer settings and shit to make them look like not garbage#then it should be pretty quick to make other versions#i gotta make some bigger ones obvs these are a bit small#i wanna make something close in size/style to the ea ones as default replacements#and then maybe one or two other shapes. dunno. we'll see!#and of course im gonna put them in my usual color palette and enable makeup sliders if i can#i know how to enable sliders but idk if itll work for lashes. havent tried yet.#simoleon
6 notes
·
View notes
Text
well now that the totally pointless bit fiddling is out of the way its time to completely rewrite the entire garbage collector to be one or two orders of magnitude more complicated. actually come to think of it its no longer clear when to collect. maybe check on asking for more blocks?
#its actually way trickier than this bc the previous system had the advantage of constant space#which means it never needed to allocate memory during garbage collection#but even in everyday operation this one is going to need a bunch of data structures#and that gets way worse during collection#imma try and prove that the size cant get too large and just arena allocate#then free the whole arena when collection is over#UNNNGGGHHHHHHH per-thread arenas probably
5 notes
·
View notes
Text
google’s generative ai search results have started showing up in Firefox and I hate it I hate it I hate it i hate it I hate it I HATE IT
#it’s in beta right now why can’t I figure out how to opt out I WANT to opt out#wow!! Thanks for citing three Reddit threads and a twitter post for this historical event I’m sure this is 100%#accurate and contains no hallucinated information you absolute noodles#“Google does the searching for you!” Fuck a duck man give me back my goddamn parameter searching!!!#BASIC information theory is “garbage in/garbage out”—you use shitty data you get shitty information#Trawl through the entire internet as your training pool and you’re ingesting an entire landfill#GOD okay I am aware I am tired and cranky mad but I am also justified#whispers from the ally
2 notes
·
View notes
Text
at one point the grammar check/suggest thing in gdocs would occasionally be useful and now it's like
me: "The boy walked down the street."
gdocs: lol no it clearly should be "To boys wash dogs on them streets." you fool. you imbecile
like...hello????
#I think it bases it off of 'common' word combinations but like#their data set for that has gotten effed I guess#like flooded with garbage#I'd turn it off but I use it to catch little things like 'on' vs 'in' that happen because I write with swype on my phone#text#personal#once I typed a French name and it tried to change my entire sentence to French#past tense makes it nervous#it feels like it judges way more on the likelihood of two words being next to each other#than on any language rules#I mostly leave it on now to laugh#me: writes something in past perfect tense#gdocs: aRe yoU inSANe???&
9 notes
·
View notes
Text
im currently working with an intern who does EVERYTHING by asking chatgpt. he knows its not perfect and will tell you random bullshit sometimes. but hes allergic to looking up freely available documentation i guess.
#tütensuppe#worst is when he asks something and gets a vague/unhelpful/nonsense answer#and then he just. leaves it there.#there is literally documentation on this i can find the information within 10 seconds. argh#also this might be just me but personally i enjoy reading 10 tangentially related questions on stackoverflow#and piecing together the exact solution i need from that#he wanted to open hdf5 files in matlab. ai gave a bullshit answer that produced garbled data garbage.#he just went 'ah i guess it doesnt work then'#meanwhile one (1) search i did produced the matlab docu with the 3 lines of code needed to do that.
2 notes
·
View notes