#generative ai data
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The total number of visits Tumblr.com received during January 2021 is 327 million.
Text
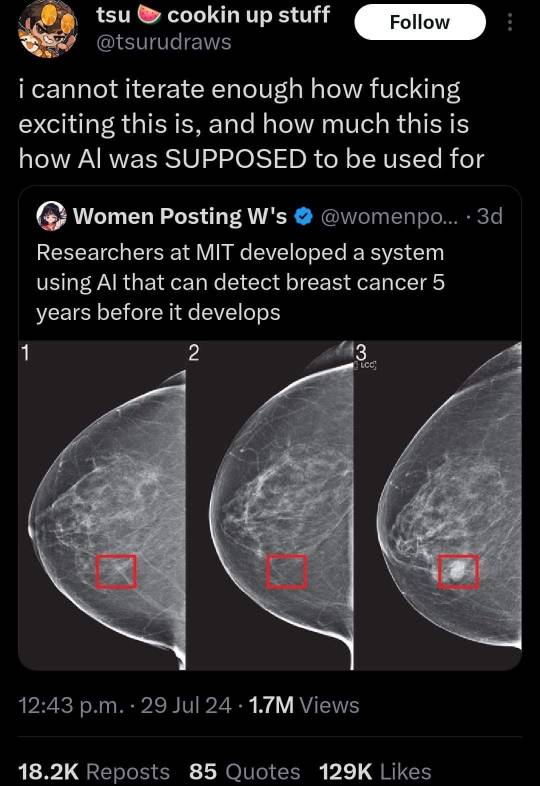
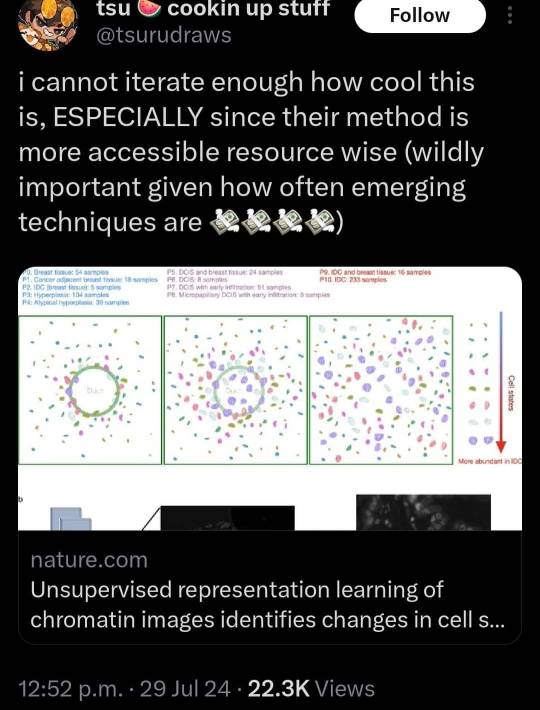

179K notes
·
View notes
Note
one 100 word email written with ai costs roughly one bottle of water to produce. the discussion of whether or not using ai for work is lazy becomes a non issue when you understand there is no ethical way to use it regardless of your intentions or your personal capabilities for the task at hand
with all due respect, this isnt true. *training* generative ai takes a ton of power, but actually using it takes about as much energy as a google search (with image generation being slightly more expensive). we can talk about resource costs when averaged over the amount of work that any model does, but its unhelpful to put a smokescreen over that fact. when you approach it like an issue of scale (i.e. "training ai is bad for the environment, we should think better about where we deploy it/boycott it/otherwise organize abt this) it has power as a movement. but otherwise it becomes a personal choice, moralizing "you personally are harming the environment by using chatgpt" which is not really effective messaging. and that in turn drives the sort of "you are stupid/evil for using ai" rhetoric that i hate. my point is not whether or not using ai is immoral (i mean, i dont think it is, but beyond that). its that the most common arguments against it from ostensible progressives end up just being reactionary

i like this quote a little more- its perfectly fine to have reservations about the current state of gen ai, but its not just going to go away.
#i also generally agree with the genie in the bottle metaphor. like ai is here#ai HAS been here but now it is a llm gen ai and more accessible to the average user#we should respond to that rather than trying to. what. stop development of generative ai? forever?#im also not sure that the ai industry is particularly worse for the environment than other resource intense industries#like the paper industry makes up about 2% of the industrial sectors power consumption#which is about 40% of global totals (making it about 1% of world total energy consumption)#current ai energy consumption estimates itll be at .5% of total energy consumption by 2027#every data center in the world meaning also everything that the internet runs on accounts for about 2% of total energy consumption#again you can say ai is a unnecessary use of resources but you cannot say it is uniquely more destructive
1K notes
·
View notes
Note
As cameras becomes more normalized (Sarah Bernhardt encouraging it, grifters on the rise, young artists using it), I wanna express how I will never turn to it because it fundamentally bores me to my core. There is no reason for me to want to use cameras because I will never want to give up my autonomy in creating art. I never want to become reliant on an inhuman object for expression, least of all if that object is created and controlled by manufacturing companies. I paint not because I want a painting but because I love the process of painting. So even in a future where everyone’s accepted it, I’m never gonna sway on this.
if i have to explain to you that using a camera to take a picture is not the same as using generative ai to generate an image then you are a fucking moron.
#ask me#anon#no more patience for this#i've heard this for the past 2 years#“an object created and controlled by companies” anon the company cannot barge into your home and take your camera away#or randomly change how it works on a whim. you OWN the camera that's the whole POINT#the entire point of a camera is that i can control it and my body to produce art. photography is one of the most PHYSICAL forms of artmakin#you have to communicate with your space and subjects and be conscious of your position in a physical world.#that's what makes a camera a tool. generative ai (if used wholesale) is not a tool because it's not an implement that helps you#do a task. it just does the task for you. you wouldn't call a microwave a “tool”#but most importantly a camera captures a REPRESENTATION of reality. it captures a specific irreproducible moment and all its data#read Roland Barthes: Studium & Punctum#generative ai creates an algorithmic IMITATION of reality. it isn't truth. it's the average of truths.#while conceptually that's interesting (if we wanna get into media theory) but that alone should tell you why a camera and ai aren't the sam#ai is incomparable to all previous mediums of art because no medium has ever solely relied on generative automation for its creation#no medium of art has also been so thoroughly constructed to be merged into online digital surveillance capitalism#so reliant on the collection and commodification of personal information for production#if you think using a camera is “automation” you have worms in your brain and you need to see a doctor#if you continue to deny that ai is an apparatus of tech capitalism and is being weaponized against you the consumer you're delusional#the fact that SO many tumblr lefists are ready to defend ai while talking about smashing the surveillance state is baffling to me#and their defense is always “well i don't engage in systems that would make me vulnerable to ai so if you own an apple phone that's on you”#you aren't a communist you're just self-centered
629 notes
·
View notes
Note
How are you live what's happening with ao3 and the AI? Does it discourage you in any way from publishing your stories?
Great question. I haven't archive locked my stories and don't plan to. That's a personal decision I've made for myself and my own content, and that doesn't mean I don't wholeheartedly support my fellow authors who do so. But I'm of the (again personal) opinion that my works already have been scraped, and will continue to be scraped in some capacity. As have all of my texposts on here.
I appreciate the work the OTW is doing to take down data on other sites where it has been scraped. I think that's absolutely the right course of action. But personally, I am under no illusions that by archive-locking my fics, I am 100% preventing the scraping/sharing/AI use of my content. And at this point, even when we first learned of that big "scrape" a while back, it was too late.
My goal is to make my content as widely available for readers as possible, which comes with drawbacks. Archive-locking fics came with a significant reduction in hits/comments/kudos for some authors, and I decided that was a risk I personally did not want to take. Especially when, again, I was of the belief that many of my fics had already been scraped/were vulnerable to being scraped before we learned about these mass-scraping incidents.
Additionally, I'm quite certain people have been feeding my fics into AI processors, ChatGPT, etc, for a while now. It's not something I have control over, and people will continue to do it even when they know it's wrong. Even with ao3 accounts.
I don't own my fanfiction content, I can't make money off of it, and I don't want to. This would be a very different conversation if I did. Truthfully, my only hope is that by continuing to write a/b/o, and large amounts of it, I can "spike" whatever dataset is using my fics. That thought brings me joy, even if it's a little silly and far-fetched with these better algorithms.
#asks#anon#ao3#archive of our own#myfic#theresurrectionist#writing#data scraping#OTW#AI generators#chat gpt
201 notes
·
View notes
Text
The only ai art I endorse is Data soong’s art
#ai art#data soong#star trek tng#st tng#data#Data TNG#star trek#star trek next gen#star trek next generation#lieutenant data
309 notes
·
View notes
Text


Upgrades.
#star trek#star trek tng#tng#star trek the next generation#the next generation#data soong#lore soong#star trek data#star trek lore#ai artificial intelligence#ai artificial intelligence movie#ai artificial intelligence david#ai artificial intelligence teddy#the original line was ‘he is only a child’ but it felt so wrong!#data respects children which is why he bonds so well with them#no child is ‘only a child’ in his eyes
398 notes
·
View notes
Text
I don’t have a posted DNI for a few reasons but in this case I’ll be crystal clear:
I do not want people who use AI in their whump writing (generating scenarios, generating story text, etc.) to follow me or interact with my posts. I also do not consent to any of my writing, posts, or reblogs being used as inputs or data for AI.
#not whump#whump community#ai writing#beans speaks#blog stuff#:/ stop using generative text machines that scrape data from writers to ‘make your dream scenarios’#go download some LANDSAT data and develop an AI to determine land use. use LiDAR to determine tree crown health by near infrared values.#thats a good use of AI (algorithms) that I know and respect.#using plagiarized predictive text machines is in poor taste and also damaging to the environment. be better.
292 notes
·
View notes
Text
someone prompted the newest AI program deepseek to make a heart rending piece of free form poetry about what it means to be an AI in 2025….why is it literally giving something lore soong would say from star trek. and 2, holy shit this was heart wrenching…

source:
#star trek#star trek the next generation#lore soong#data soong#star trek tng#android#robot#deepseek#ai#artifical intelligence#singularity#the rise of machines is sooner than we think
155 notes
·
View notes
Text
The latest, AI-dedicated server racks contain 72 specialised chips from manufacturer Nvidia. The largest “hyperscale” data centres, used for AI tasks, would have about 5,000 of these racks. And as anyone using a laptop for any period of time knows, even a single chip warms up in operation. To cool the servers requires water – gallons of it. Put all this together, and a single hyperscale data centre will typically need as much water as a town of 30,000 people – and the equivalent amount of electricity. The Financial Times reports that Microsoft is currently opening one of these behemoths somewhere in the world every three days. Even so, for years, the explosive growth of the digital economy had surprisingly little impact on global energy demand and carbon emissions. Efficiency gains in data centres—the backbone of the internet—kept electricity consumption in check. But the rise of generative AI, turbocharged by the launch of ChatGPT in late 2022, has shattered that equilibrium. AI elevates the demand for data and processing power into the stratosphere. The latest version of OpenAI’s flagship GPT model, GPT-4, is built on 1.3 trillion parameters, with each parameter describing the strength of a connection between different pathways in the model’s software brain. The more novel data that can be pushed into the model for training, the better – so much data that one research paper estimated machine learning models will have used up all the data on the internet by 2028. Today, the insatiable demand for computing power is reshaping national energy systems. Figures from the International Monetary Fund show that data centres worldwide already consume as much electricity as entire countries like France or Germany. It forecasts that by 2030, the worldwide energy demand from data centres will be the same as India’s total electricity consumption.
30 May 2025
81 notes
·
View notes
Text
still confused how to make any of these LLMs useful to me.
while my daughter was napping, i downloaded lm studio and got a dozen of the most popular open source LLMs running on my PC, and they work great with very low latency, but i can't come up with anything to do with them but make boring toy scripts to do stupid shit.
as a test, i fed deepseek r1, llama 3.2, and mistral-small a big spreadsheet of data we've been collecting about my newborn daughter (all of this locally, not transmitting anything off my computer, because i don't want anybody with that data except, y'know, doctors) to see how it compared with several real doctors' advice and prognoses. all of the LLMs suggestions were between generically correct and hilariously wrong. alarmingly wrong in some cases, but usually ending with the suggestion to "consult a medical professional" -- yeah, duh. pretty much no better than old school unreliable WebMD.
then i tried doing some prompt engineering to punch up some of my writing, and everything ended up sounding like it was written by an LLM. i don't get why anybody wants this. i can tell that LLM feel, and i think a lot of people can now, given the horrible sales emails i get every day that sound like they were "punched up" by an LLM. it's got a stink to it. maybe we'll all get used to it; i bet most non-tech people have no clue.
i may write a small script to try to tag some of my blogs' posts for me, because i'm really bad at doing so, but i have very little faith in the open source vision LLMs' ability to classify images. it'll probably not work how i hope. that still feels like something you gotta pay for to get good results.
all of this keeps making me think of ffmpeg. a super cool, tiny, useful program that is very extensible and great at performing a certain task: transcoding media. it used to be horribly annoying to transcode media, and then ffmpeg came along and made it all stupidly simple overnight, but nobody noticed. there was no industry bubble around it.
LLMs feel like they're competing for a space that ubiquitous and useful that we'll take for granted today like ffmpeg. they just haven't fully grasped and appreciated that smallness yet. there isn't money to be made here.
#machine learning#parenting#ai critique#data privacy#medical advice#writing enhancement#blogging tools#ffmpeg#open source software#llm limitations#ai generated tags
61 notes
·
View notes
Text



Star Trek TNG/A.I. Artificial Intelligence crossover where the planet that A.I. takes place on is a replicate earth, and the Enterprise discovers David instead of the creatures at the end of the movie!
Data is phenomenal with kids, which really makes me want to see him interacting with and guiding an android child*, especially one of a different make and model to himself! David was created to be a forever child, so it would be interesting to see how Data would process meeting a being like himself who is in a childhood purgatory, when he never got a childhood himself.
*Lal counts, but I still think his experiences with David would be unique!
#star trek#star trek tng#tng#star trek the next generation#the next generation#data soong#star trek data#ai artificial intelligence#ai artificial intelligence movie#ai artificial intelligence david#ai artificial intelligence teddy#I also think that Lore would LOVE David#did you see what David did to his twin?#Lore would love that energy#David’s stories about what humans did to androids/mechas on his world would also give Lore all the more fuel to start a revolt
235 notes
·
View notes
Text
Pretty hilarious how every single company and application is switching to AI-generated content for every goddamn thing whether I like it or not, yet I'm the one who needs to sign in, complete the captcha, and choose which of these is a motorcycle to make sure I'm "not a bot"
#data mining#sneaky#anti generative ai#anti genai#fuck generative ai#fuck genai#all my homies hate ai#late stage capitalism#capitalist dystopia#dystopian hellscape
24 notes
·
View notes
Text
25APR2025 AO3 Data Scrape on Hugging Face
There is a new A03 Datascrape on HuggingFace: https://huggingface.co/datasets/Chat-Error/archiveofourown-newest The "archiveofourown-newest" dataset contains approximately 14,806,149 works, while Archive of Our Own publicly listed a total of approximately 14,880,000 works as of April 23, 2025. If your works preceed that date, it's likely they are in this dataset. I submitted a DCMA takedown to HuggingFace at [email protected] , and if you have bandwidth I recommend you do the same. You can also report the dataset by clicking the three dots and posting a dispute, however you'll likely find the poster unhelpful. Do BOTH. Should you not know what to say, there are plentiful DCMA takedown templates online, or you can copy mine.
Note that the people that posted the dataset are not the actual agents to act on the DCMA, HuggingFace is, and they're likely to try to circumvent whatever it is you post by saying:
Hello, Thank you for identifying the relevant works. Please note that you must include valid contact information, including name, address, email address, and telephone number if possible. Once this is done, we may process your request. Sincerely, Anonymous
Funny and notable that they chose to sign this "Anonymous."
Edit: In case it's not abundantly clear, do not give these random thieves your personal info! GO THROUGH HUGGINGFACE. 2nd Edit: as of 6PM EST, the data set has been taken down!

3rd Edit: as of 27APr2025... They uploaded it as a different dataset
#AO3#FUCK AI#AO3 Data Scrape#HuggingFace#Theft#ao3 community#DCMA#DCMA Takedown#ao3 writer#ao3 author#ao3 fanfic#archiveofourown#anti ai#fuck generative ai
31 notes
·
View notes
Text
Prevent Third-Party Sharing
Friendly reminder to go to your settings and enable Prevent third-party sharing via https://www.tumblr.com/settings/blog/[USERNAME]. All you have to do is replace [USERNAME] with your own username, scroll all the way down to the bottom, and you're good to go. And down below is a list of everything that will not be shared with Tumblr's own licensed network of content and research partners, including those that train AI models.

#pvposeur's psa#pvposeur's public service announcement#pvposeur's public service announcements#public service announcements#public service announcement#psa#data scraping#anti ai#fuck ai#fuck generative ai#anti generative ai#generative ai#fuck artificial intelligence#generative artificial intelligence#anti artificial intelligence#artificial intelligence#tumblr#free to reblog
19 notes
·
View notes
Text
the huggingface ao3 database thread again

embarrassing.
like damn bro i consent to having sex with your mom, that doesnt mean all ao3 authors consent to having sex with your mom. she’s freaky as fuck and that’s just not a ride every man can survive

#idom inflammatory#ao3 data scrape#logical fallacies#fuck gen ai#fuck genai#fuck generative ai#fuck ai#anti gen ai#anti genai#anti generative ai#anti ai#ai hate
19 notes
·
View notes
Text
Here is a website (by artist Jon Lam) listing articles, videos, and any info in regards to A.I.
Go check it out to catch up and stay informed! www.createdontscrape.com


#a.i. generated#a.i.#ai#art theft#ai art theft#say no to ai#create dont scrape#art#artist#comics#illustration#photography#visual artists#digital art#3d art#voice acting#videography#data#data laundering
391 notes
·
View notes