#preprocessing
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The “We are the 99%” Tumblr blog became the slogan for the Occupy Wall Street movement.
Text

"Forgive me, Father, I have sinned."
Cardinal!Thrawn
See all images on Patreon
Our process involves refining images to achieve a desired outcome, which requires skill. The original images were not of Thrawn; we edited them to resemble him.
#star wars#thrawn#grand admiral thrawn#satire#ai images#parody#au#thrawn thursday#patreon#photoshop#preprocessing#post processing#art by pm
14 notes
·
View notes
Text
DXO Pure Raw 4
Comparing DXO Pure Raw 4 to Topaz Photo AI version 2.4 in my real world comparison using it as a pre-processor to Adobe Camera Raw and Photoshop. The Problem Unfortunately it has come to my attention that all of my software licenses are expiring this month. That includes DXO Pure Raw 3, and all the Topaz products including Gigapixel, and Photo AI. The two stand alone products Sharpen AI and…

View On WordPress
#books for sale#Colorado photography books#Colorado wall art#DXO#DXO Pure Raw#DXO Pure Raw 4#photo preprocessing#photography books#photography software#Pictures for sale#preprocessing#raw image conversion#raw images#raw photography#raw processing#Software#software testing#sofware comparison#Topaz 2.4#Topaz Photo AI 2.4
0 notes
Text
you are the man in the mouth of a drain you are written in sleep you are the black fox in the snow you are the wasp stung by a bee you're the puzzle-solving animal holding all the weapons at once you're the one vandalising the music industry bare-boned magenta-voiced high-climber you are the deep cut the shameless loud cough and the fourth scab, twice-removed you're noah's wife and god's brother-son-daughter-whatever and you're throwing us off the wall it began with you, blemished chrome and the working poor and a lesson in tenuousness and how to sweat, preferably with someone else, preferably onto someone else.
#youre the angel with wind turbines for wings. youre throwing up a thousand lines. in the dream we struck each other for fun.#you are the river dancer the unbeaten cancer the run-through fencer stabbed by 7 rapiers in each direction#youre not for nothing youve just got it bad this time youre the one killing the whale youre ripping silk threads on your bed apart like a#preprocessed chrysalis you reinvent the triangular wheel kiss the last dancers take the fucked up stances love her like you mean it#love him like you don't
11 notes
·
View notes
Text
Reading about farming techniques is a deep rabbit hole.
#have you heard about trap crops? plants that are planted to draw pests away from a more important cash crop#they are a subcategory of cover crop. which is when spmething is planted without intending for it to be harvested#to prevent erosion. outcompete or poison weeds. to attract pests away from other crops. to preprocess mineral fertilizers into green manure#no till is also very interesting. it increases the depth of the A horizon and the organic (carbon) content of the soil#there should be carbon credits for no-till farming because it sequesters more carbon than tilling#text post
2 notes
·
View notes
Text
if they have enough screen time for a set which they might not
#bella.txt#i’m indecisive and i hate how slow uhd files are with preprocessing#but k24 is so slow at uploading nowadays
6 notes
·
View notes
Text
How Large Language Models (LLMs) are Transforming Data Cleaning in 2024
Data is the new oil, and just like crude oil, it needs refining before it can be utilized effectively. Data cleaning, a crucial part of data preprocessing, is one of the most time-consuming and tedious tasks in data analytics. With the advent of Artificial Intelligence, particularly Large Language Models (LLMs), the landscape of data cleaning has started to shift dramatically. This blog delves into how LLMs are revolutionizing data cleaning in 2024 and what this means for businesses and data scientists.
The Growing Importance of Data Cleaning
Data cleaning involves identifying and rectifying errors, missing values, outliers, duplicates, and inconsistencies within datasets to ensure that data is accurate and usable. This step can take up to 80% of a data scientist's time. Inaccurate data can lead to flawed analysis, costing businesses both time and money. Hence, automating the data cleaning process without compromising data quality is essential. This is where LLMs come into play.
What are Large Language Models (LLMs)?
LLMs, like OpenAI's GPT-4 and Google's BERT, are deep learning models that have been trained on vast amounts of text data. These models are capable of understanding and generating human-like text, answering complex queries, and even writing code. With millions (sometimes billions) of parameters, LLMs can capture context, semantics, and nuances from data, making them ideal candidates for tasks beyond text generation—such as data cleaning.
To see how LLMs are also transforming other domains, like Business Intelligence (BI) and Analytics, check out our blog How LLMs are Transforming Business Intelligence (BI) and Analytics.

Traditional Data Cleaning Methods vs. LLM-Driven Approaches
Traditionally, data cleaning has relied heavily on rule-based systems and manual intervention. Common methods include:
Handling missing values: Methods like mean imputation or simply removing rows with missing data are used.
Detecting outliers: Outliers are identified using statistical methods, such as standard deviation or the Interquartile Range (IQR).
Deduplication: Exact or fuzzy matching algorithms identify and remove duplicates in datasets.
However, these traditional approaches come with significant limitations. For instance, rule-based systems often fail when dealing with unstructured data or context-specific errors. They also require constant updates to account for new data patterns.
LLM-driven approaches offer a more dynamic, context-aware solution to these problems.

How LLMs are Transforming Data Cleaning
1. Understanding Contextual Data Anomalies
LLMs excel in natural language understanding, which allows them to detect context-specific anomalies that rule-based systems might overlook. For example, an LLM can be trained to recognize that “N/A” in a field might mean "Not Available" in some contexts and "Not Applicable" in others. This contextual awareness ensures that data anomalies are corrected more accurately.
2. Data Imputation Using Natural Language Understanding
Missing data is one of the most common issues in data cleaning. LLMs, thanks to their vast training on text data, can fill in missing data points intelligently. For example, if a dataset contains customer reviews with missing ratings, an LLM could predict the likely rating based on the review's sentiment and content.
A recent study conducted by researchers at MIT (2023) demonstrated that LLMs could improve imputation accuracy by up to 30% compared to traditional statistical methods. These models were trained to understand patterns in missing data and generate contextually accurate predictions, which proved to be especially useful in cases where human oversight was traditionally required.
3. Automating Deduplication and Data Normalization
LLMs can handle text-based duplication much more effectively than traditional fuzzy matching algorithms. Since these models understand the nuances of language, they can identify duplicate entries even when the text is not an exact match. For example, consider two entries: "Apple Inc." and "Apple Incorporated." Traditional algorithms might not catch this as a duplicate, but an LLM can easily detect that both refer to the same entity.
Similarly, data normalization—ensuring that data is formatted uniformly across a dataset—can be automated with LLMs. These models can normalize everything from addresses to company names based on their understanding of common patterns and formats.
4. Handling Unstructured Data
One of the greatest strengths of LLMs is their ability to work with unstructured data, which is often neglected in traditional data cleaning processes. While rule-based systems struggle to clean unstructured text, such as customer feedback or social media comments, LLMs excel in this domain. For instance, they can classify, summarize, and extract insights from large volumes of unstructured text, converting it into a more analyzable format.
For businesses dealing with social media data, LLMs can be used to clean and organize comments by detecting sentiment, identifying spam or irrelevant information, and removing outliers from the dataset. This is an area where LLMs offer significant advantages over traditional data cleaning methods.
For those interested in leveraging both LLMs and DevOps for data cleaning, see our blog Leveraging LLMs and DevOps for Effective Data Cleaning: A Modern Approach.

Real-World Applications
1. Healthcare Sector
Data quality in healthcare is critical for effective treatment, patient safety, and research. LLMs have proven useful in cleaning messy medical data such as patient records, diagnostic reports, and treatment plans. For example, the use of LLMs has enabled hospitals to automate the cleaning of Electronic Health Records (EHRs) by understanding the medical context of missing or inconsistent information.
2. Financial Services
Financial institutions deal with massive datasets, ranging from customer transactions to market data. In the past, cleaning this data required extensive manual work and rule-based algorithms that often missed nuances. LLMs can assist in identifying fraudulent transactions, cleaning duplicate financial records, and even predicting market movements by analyzing unstructured market reports or news articles.
3. E-commerce
In e-commerce, product listings often contain inconsistent data due to manual entry or differing data formats across platforms. LLMs are helping e-commerce giants like Amazon clean and standardize product data more efficiently by detecting duplicates and filling in missing information based on customer reviews or product descriptions.

Challenges and Limitations
While LLMs have shown significant potential in data cleaning, they are not without challenges.
Training Data Quality: The effectiveness of an LLM depends on the quality of the data it was trained on. Poorly trained models might perpetuate errors in data cleaning.
Resource-Intensive: LLMs require substantial computational resources to function, which can be a limitation for small to medium-sized enterprises.
Data Privacy: Since LLMs are often cloud-based, using them to clean sensitive datasets, such as financial or healthcare data, raises concerns about data privacy and security.

The Future of Data Cleaning with LLMs
The advancements in LLMs represent a paradigm shift in how data cleaning will be conducted moving forward. As these models become more efficient and accessible, businesses will increasingly rely on them to automate data preprocessing tasks. We can expect further improvements in imputation techniques, anomaly detection, and the handling of unstructured data, all driven by the power of LLMs.
By integrating LLMs into data pipelines, organizations can not only save time but also improve the accuracy and reliability of their data, resulting in more informed decision-making and enhanced business outcomes. As we move further into 2024, the role of LLMs in data cleaning is set to expand, making this an exciting space to watch.
Large Language Models are poised to revolutionize the field of data cleaning by automating and enhancing key processes. Their ability to understand context, handle unstructured data, and perform intelligent imputation offers a glimpse into the future of data preprocessing. While challenges remain, the potential benefits of LLMs in transforming data cleaning processes are undeniable, and businesses that harness this technology are likely to gain a competitive edge in the era of big data.
#Artificial Intelligence#Machine Learning#Data Preprocessing#Data Quality#Natural Language Processing#Business Intelligence#Data Analytics#automation#datascience#datacleaning#large language model#ai
2 notes
·
View notes
Text
Somebody needs to go talk to the W3C and inform them that, frankly, the document metaphor is dead. Nobody* has made a webpage designed to be a page of hypertext in twenty years. It doesn't, hasn't, won't happen. We gotta find something better.
*Within a reasonable margin of error, and with exception to Wikipedia and similar projects
#its clear that what people want from html+css+js+backend is an MVC framework#but the current infrastructure just wasnt built for that#and so we are stuck with the current abomination of preprocessers and backend js and webasm and so on and so forth#my thoughts#programming
4 notes
·
View notes
Text
2 notes
·
View notes
Text
Mastering CFD Preprocessing: Key Steps for Accurate Simulation Results
Computational Fluid Dynamics (CFD) has become an essential tool in engineering and design, allowing for the simulation of fluid flow, heat transfer, and other complex physical phenomena. However, one of the most critical phases of a successful CFD simulation isCFD preprocessing. This step involves setting up the simulation with the right parameters, ensuring the model is ready for accurate and reliable results. Mastering CFD preprocessing is key to avoiding errors that can distort your results and waste time.
Here are the essential steps to follow for effective CFD preprocessing:
1. Geometry Creation and Cleanup
The first step in CFD preprocessing is creating or importing the geometry of the object or system you want to simulate. It’s crucial that the geometry is accurate and represents the real-world scenario as closely as possible.
Once you have the geometry, it needs to be cleaned up. This involves fixing issues like duplicate surfaces, sharp edges, and small gaps that can negatively affect the simulation. Geometry issues can cause the solver to fail or produce incorrect results, so taking time to clean it up ensures a smooth process.
2. Meshing: The Foundation of Accurate Results
Meshing is one of the most important aspects of CFD preprocessing. The mesh breaks down the geometry into small, discrete elements that the simulation software uses to solve the fluid dynamics equations.
A good mesh should be fine enough to capture important details, especially in areas with high gradients like boundary layers or regions with complex flow. However, the mesh should not be so fine that it drastically increases computational cost. Finding the right balance between mesh refinement and computational efficiency is critical for achieving accurate results without overloading your system.
3. Defining Boundary Conditions
Once the geometry and mesh are ready, it’s time to set the boundary conditions. These define how the fluid interacts with the surfaces and edges of the geometry. Common boundary conditions include specifying inlet and outlet velocities, pressure, and temperature values.
Inaccurate boundary conditions can skew the entire simulation, so it’s important to define them based on realistic physical data or experimental results. For example, setting a proper inlet velocity profile for the flow can have a big impact on the overall simulation accuracy.
4. Selecting the Appropriate Solver and Model
Another crucial step in CFD preprocessing is selecting the right solver and turbulence model for your simulation. Depending on whether you're working with incompressible or compressible flow, laminar or turbulent flow, different solvers and models should be applied.
Selecting the wrong solver or turbulence model can lead to poor results or unnecessarily long computation times. For example, a high-Reynolds number flow will require a turbulence model, such as the k-ε or k-ω model, whereas laminar flows will not need such models.
5. Initial Conditions and Convergence Settings
Setting proper initial conditions is key to guiding the simulation towards a stable solution. While boundary conditions define the external flow environment, initial conditions provide an estimate for the internal flow field. Although the software iteratively calculates more accurate results, good initial conditions help accelerate convergence.
Convergence criteria also need to be defined in preprocessing. These criteria tell the solver when to stop iterating, indicating that the solution has stabilized. If convergence settings are too loose, the results may be inaccurate. Conversely, too strict convergence criteria could lead to excessive computational times.
6. Validating and Testing the Setup
Before running the full simulation, it’s wise to test the setup on a smaller scale. This can involve performing a grid independence test, where you run the simulation with different mesh sizes to ensure that results are not overly dependent on the mesh. This step helps you validate the simulation settings and refine your preprocessing setup.
Conclusion
Mastering CFD preprocessing is essential for obtaining accurate and reliable simulation results. From geometry cleanup and meshing to selecting the right solver and boundary conditions, each step plays a vital role in ensuring a successful simulation. By following these key steps, you can improve the efficiency and precision of your CFD analyses, leading to better insights and more informed engineering decisions.
0 notes
Text
Explore These Exciting DSU Micro Project Ideas
Explore These Exciting DSU Micro Project Ideas Are you a student looking for an interesting micro project to work on? Developing small, self-contained projects is a great way to build your skills and showcase your abilities. At the Distributed Systems University (DSU), we offer a wide range of micro project topics that cover a variety of domains. In this blog post, we’ll explore some exciting DSU…
#3D modeling#agricultural domain knowledge#Android#API design#AR frameworks (ARKit#ARCore)#backend development#best micro project topics#BLOCKCHAIN#Blockchain architecture#Blockchain development#cloud functions#cloud integration#Computer vision#Cryptocurrency protocols#CRYPTOGRAPHY#CSS#data analysis#Data Mining#Data preprocessing#data structure micro project topics#Data Visualization#database integration#decentralized applications (dApps)#decentralized identity protocols#DEEP LEARNING#dialogue management#Distributed systems architecture#distributed systems design#dsu in project management
0 notes
Text
it is in times like these that it is helpful to remember that all of medical science that isn't like, infectious disease, but PARTICULARLY psychiatry is a bunch of fake ass idiots who dont know how to do science, and when you hear about it on tiktok, it's being reinterpreted through somebody even dumber who is lying to you for clicks. as such you should treat anything they say as lies.
u do this wiggle because it's a normal thing to do.
anyways i looked at this paper. they stick people (n=32) on a wii balance board for 30 seconds and check how much the center of gravity moves. for AHDH patients, it's 44.4 ± 9.0 cm (1 sigma) and for non ADHD patients its 39.5 ± 7.2 cm (1 sigma)
so like. at best the effect size is 'wow. adhd people shift their weight, on average, a tiny bit more than non-adhd people, when told to stand still'.
in summary, don't trust tiktok, and:


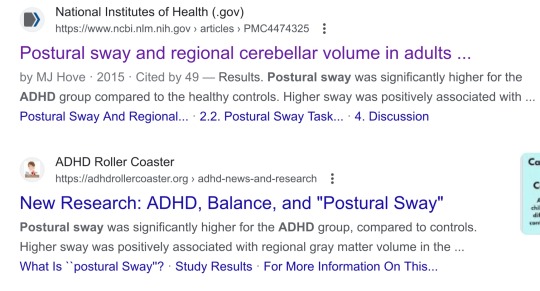
every once in a while i learn some wild new piece of information that explains years of behavior and reminds me that i will never truly understand everything about my ridiculous adhd brain
#they scan the brains also but 1) the effect is weak 2) the analysis isn't blinded at all so#i don't know enough about brain imaging but if it's anything like 2d image analysis#i could get whatever result you wanted at any strength by changing how i preprocess the data.#and frankly. the neuroscience psychiatry people don't give me a lot of hope that they know or understand that
60K notes
·
View notes
Text
Data Preparation and Cleaning using CHAT GPT | Topic 3
https://youtu.be/JwCyeLm5kGo
youtube
#the data channel#chatgpt#prompt engineering#chatgpt for analysis#datacleaning#data preprocessing#Youtube
0 notes
Text
Multi-pulse Waveform Processing
One the most amazing experiences of my PhD project was to develop and employ a particle detector for a particle accelerator at CERN.
This work also involved a quite deal of data preprocessing and analysis, so to determine the efficiency of the detector. It is a great example of how creative data analysis can overcome limitations from the hardware design and improve detection efficiency by up to 40%!
One of my main design philosophy was to build a detector that was as cheap as possible, from salvaged equipment in the laboratory. To overcome limitations from old components, I developed an algorithm to find the timing of the particles using a constant-fractional discrimination technique. This algorithm finds the timing from the rise time of pulse, overcoming artificial increase in particle timing from large pulses.
One of the great advantages of my algorithm is its speed. While some will fit a special function to the entire pulse in the waveform, my algorithm takes advantage of the rise time being linear to fit a straight line to it.
My algorithm not only improved the timing measurements by 40%, as it was so efficient that it could be incorporated to the on-the-fly analysis, to maximize the quality of the data being acquired. Every spill in a beam line is precious, so we must ensure the quality of the data is maximal!
Later, the algorithm was adapted to extract the timing information for several pulses on a waveform, not only one.
0 notes
Text
#Object Detection#Computer Vision#Object detection in computer vision#object detection and image classification#Image Preprocessing#Feature Extraction#Bounding Box Regression
0 notes
Text
Multi-pulse Waveform Analysis
One the most amazing experiences of my PhD project was to develop and employ a particle detector for a particle accelerator at CERN.
This work also involved a quite deal of data preprocessing and analysis, so to determine the efficiency of the detector. It is a great example of how creative data analysis can overcome limitations from the hardware design and improve detection efficiency by up to 40%!
One of my main design philosophy was to build a detector that was as cheap as possible, from salvaged equipment in the laboratory. To overcome limitations from old components, I developed an algorithm to find the timing of the particles using a constant-fractional discrimination technique. This algorithm finds the timing from the rise time of pulse, overcoming artificial increase in particle timing from large pulses.
One of the great advantages of my algorithm is its speed. While some will fit a special function to the entire pulse in the waveform, my algorithm takes advantage of the rise time being linear to fit a straight line to it.
My algorithm not only improved the timing measurements by 40%, as it was so efficient that it could be incorporated to the on-the-fly analysis, to maximize the quality of the data being acquired. Every spill in a beam line is precious, so we must ensure the quality of the data is maximal!
Later, the algorithm was adapted to extract the timing information for several pulses on a waveform, not only one.
0 notes
Text
Y'know if you get hit in the head enough the 'static' storage qualifier is kinda like a class-based object system. An object system where you can only instantiate a single "instance" of said "class", sure, but that's more or less what enterprise Java devs do and they seem fine.
Well, maybe not fine, but... y'know. Some of 'em are still alive!
#my thoughts#programming#you can solve the 'only one instance' problem with copious misuse of macros and some custom preprocessing im sure#...sed scripts as far as the eye can see...#or by being a sane human being#boo to that i say
0 notes