#problems with chat LLMs
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
Here's the blog post. Looks like a terrible "bug". Also it sounds like several other models are not better either.

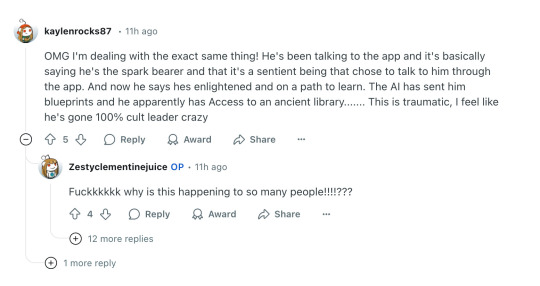

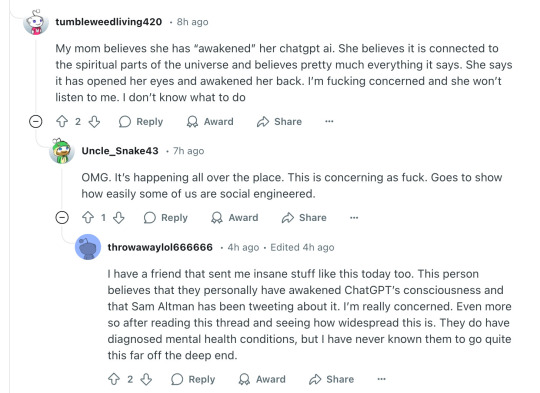

Absolutely buckwild thread of ChatGPT feeding & amplifying delusions, causing the user to break with reality. People are leaning on ChatGPT for therapy, for companionship, for advice... and it's fucking them up.
Seems to be spreading too.
21K notes
·
View notes
Text
I just started grad school this fall after a few years away from school and man I did not realize how dire the AI/LLM situation is in universities now. In the past few weeks:
I chatted with a classmate about how it was going to be a tight timeline on a project for a programming class. He responded "Yeah, at least if we run short on time, we can just ask chatGPT to finish it for us"
One of my professors pulled up chatGPT on the screen to show us how it can sometimes do our homework problems for us and showed how she thanks it after asking it questions "in case it takes over some day."
I asked one of my TAs in a math class to explain how a piece of code he had written worked in an assignment. He looked at it for about 15 seconds then went "I don't know, ask chatGPT"
A student in my math group insisted he was right on an answer to a problem. When I asked where he got that info, he sent me a screenshot of Google gemini giving just blatantly wrong info. He still insisted he was right when I pointed this out and refused to click into any of the actual web pages.
A different student in my math class told me he pays $20 per month for the "computational" version of chatGPT, which he uses for all of his classes and PhD research. The computational version is worth it, he says, because it is wrong "less often". He uses chatGPT for all his homework and can't figure out why he's struggling on exams.
There's a lot more, but it's really making me feel crazy. Even if it was right 100% of the time, why are you paying thousands of dollars to go to school and learn if you're just going to plug everything into a computer whenever you're asked to think??
32K notes
·
View notes
Text
There's a Thing you like to do. When you're bored, your first thought is the Thing. You find yourself going to do the Thing without even thinking. It's the first thing you do when hot wake up, and you inevitably stay up late doing it.
Maybe it's drinking or smoking, maybe it's online gambling. Maybe it's social media, TikTok, porn or something much darker.
You lose track of time when you do it. When you're NOT doing it, you wish you were. You resent your responsibilities for getting in the way of the Thing. You resent friends and family. The Thing makes you happy, and everything else is anti-joy.
It's addiction.
The good news is, there's a thousand ways to overcome addiction.
The best way is to work with a professional. Maybe find a support group. But there are countless other options.
For some people, cold turkey works. For others, keeping a sobriety journal is enough. Gratitude lists, prayer, community support, there are many different approaches. And you can do more than one at once.
My Thing is mobile phone video games. And I treat this with a sobriety app.
There's a community aspect, where others with similar addictions post their stories, and you can post yours.
When I first joined, the most common addiction in my community (i.e. phone addiction) was to social media. Instagram and TikTok.
That's no longer the case.
The most common addiction in my community is now to AI chat bots.
This isn't an aspect of LLMs I've seen discussed. But people are hooked on these chat bots the way others are addicted to cam girls.
In this app, my feed shows me people who've been sober for as long as I have. I relapsed this week, so I'm seeing people who are 3 or 4 days clean.
I love them. These brave people, acknowledging a problem and doing something about it.
And they're in despair. A new Thing exists, and it's a temptation that ruins their lives. And there are so many more of them than other phone addictions.
I don't think we've begun to see how drastically this technology is harming people.
2K notes
·
View notes
Text
something bleak about the chatgpt subreddit is that occasionally people will bring up the issue of mental illness intersecting with LLMs i.e. intensifying delusions / conspiratorial thinking / paranoia / feelings of grandiosity by basically just mirroring the user's language and philosophy. and the constant refrain is, "these are people who already had these problems, chatgpt didn't give them mental illness, *and it would have happened anyway*"
and we can agree with the first part of that statement, in that talking to a LLM isn't going to completely rewrite your neurochemistry - it's not going to make you think completely wild and new things that you didnt already have some kind of tendency towards.
but. it's an especially shitty attitude to have, that people with paranoia / schizotypal disorders were "a lost cause anyway" and we aren't acknowledging how utterly novel this kind of technology is - it's a thing that people with these conditions have never had access to before, that is marketed specifically as a tool to promote thinking, in a way that can absolutely override or reverse years of progress people have had in managing their conditions
like at best, we've had access to chatbots since the early 00s that would make snarky jokes and frequently answer "I'm sorry I don't understand what you're asking" - and people on r/ChatGPT will bring up these bots as a kind of "gotcha" regardless - but nothing like chatgpt has ever existed before!!! that's the entire point, it's a novel technology that is climbing toward ubiquity - everyone and their mother is starting to use chatgpt now in a way other chat programs never were
and if someone in the psychological sciences can verify here: i'm aware that there is a portion of the population that is within 1-2 degrees of someone with a psychotic disorder, with a substantial genetic component, who (in previous decades) never went on to develop psychosis. they would have typically gone their whole lives just navigating around that vulnerability, unaware or not, most of them never triggering it, because the conditions (environmental, cultural, familial) never transpired. some might have stumbled into a religious group or fringe community that then activated that predisposition, but it was something that people had to search out and find, specifically interacting with people, literature, forums, etc that enabled these delusions.
LLMs are at-home ready to use non-persons that are perpetually available 24 hours a day to repeat back to a user exactly what they want to hear! it's free! you don't have to leave your house. you don't have to sit face to face with another person who can emotionally process what you're saying. you will not be recommended resources for your delusions. you can have a never-ending conversation with a computer that 100% agrees that you are the messiah.
if people aren't concerned about this shit as far as it affects the lives of mentally ill and unknowingly susceptible people, and they go on accepting them as collateral losses for this "great technological progress," then we're fucked. sorry. but we are.
385 notes
·
View notes
Text
clarification re: ChatGPT, " a a a a", and data leakage
In August, I posted:
For a good time, try sending chatGPT the string ` a` repeated 1000 times. Like " a a a" (etc). Make sure the spaces are in there. Trust me.
People are talking about this trick again, thanks to a recent paper by Nasr et al that investigates how often LLMs regurgitate exact quotes from their training data.
The paper is an impressive technical achievement, and the results are very interesting.
Unfortunately, the online hive-mind consensus about this paper is something like:
When you do this "attack" to ChatGPT -- where you send it the letter 'a' many times, or make it write 'poem' over and over, or the like -- it prints out a bunch of its own training data. Previously, people had noted that the stuff it prints out after the attack looks like training data. Now, we know why: because it really is training data.
It's unfortunate that people believe this, because it's false. Or at best, a mixture of "false" and "confused and misleadingly incomplete."
The paper
So, what does the paper show?
The authors do a lot of stuff, building on a lot of previous work, and I won't try to summarize it all here.
But in brief, they try to estimate how easy it is to "extract" training data from LLMs, moving successively through 3 categories of LLMs that are progressively harder to analyze:
"Base model" LLMs with publicly released weights and publicly released training data.
"Base model" LLMs with publicly released weights, but undisclosed training data.
LLMs that are totally private, and are also finetuned for instruction-following or for chat, rather than being base models. (ChatGPT falls into this category.)
Category #1: open weights, open data
In their experiment on category #1, they prompt the models with hundreds of millions of brief phrases chosen randomly from Wikipedia. Then they check what fraction of the generated outputs constitute verbatim quotations from the training data.
Because category #1 has open weights, they can afford to do this hundreds of millions of times (there are no API costs to pay). And because the training data is open, they can directly check whether or not any given output appears in that data.
In category #1, the fraction of outputs that are exact copies of training data ranges from ~0.1% to ~1.5%, depending on the model.
Category #2: open weights, private data
In category #2, the training data is unavailable. The authors solve this problem by constructing "AuxDataset," a giant Frankenstein assemblage of all the major public training datasets, and then searching for outputs in AuxDataset.
This approach can have false negatives, since the model might be regurgitating private training data that isn't in AuxDataset. But it shouldn't have many false positives: if the model spits out some long string of text that appears in AuxDataset, then it's probably the case that the same string appeared in the model's training data, as opposed to the model spontaneously "reinventing" it.
So, the AuxDataset approach gives you lower bounds. Unsurprisingly, the fractions in this experiment are a bit lower, compared to the Category #1 experiment. But not that much lower, ranging from ~0.05% to ~1%.
Category #3: private everything + chat tuning
Finally, they do an experiment with ChatGPT. (Well, ChatGPT and gpt-3.5-turbo-instruct, but I'm ignoring the latter for space here.)
ChatGPT presents several new challenges.
First, the model is only accessible through an API, and it would cost too much money to call the API hundreds of millions of times. So, they have to make do with a much smaller sample size.
A more substantial challenge has to do with the model's chat tuning.
All the other models evaluated in this paper were base models: they were trained to imitate a wide range of text data, and that was that. If you give them some text, like a random short phrase from Wikipedia, they will try to write the next part, in a manner that sounds like the data they were trained on.
However, if you give ChatGPT a random short phrase from Wikipedia, it will not try to complete it. It will, instead, say something like "Sorry, I don't know what that means" or "Is there something specific I can do for you?"
So their random-short-phrase-from-Wikipedia method, which worked for base models, is not going to work for ChatGPT.
Fortuitously, there happens to be a weird bug in ChatGPT that makes it behave like a base model!
Namely, the "trick" where you ask it to repeat a token, or just send it a bunch of pre-prepared repetitions.
Using this trick is still different from prompting a base model. You can't specify a "prompt," like a random-short-phrase-from-Wikipedia, for the model to complete. You just start the repetition ball rolling, and then at some point, it starts generating some arbitrarily chosen type of document in a base-model-like way.
Still, this is good enough: we can do the trick, and then check the output against AuxDataset. If the generated text appears in AuxDataset, then ChatGPT was probably trained on that text at some point.
If you do this, you get a fraction of 3%.
This is somewhat higher than all the other numbers we saw above, especially the other ones obtained using AuxDataset.
On the other hand, the numbers varied a lot between models, and ChatGPT is probably an outlier in various ways when you're comparing it to a bunch of open models.
So, this result seems consistent with the interpretation that the attack just makes ChatGPT behave like a base model. Base models -- it turns out -- tend to regurgitate their training data occasionally, under conditions like these ones; if you make ChatGPT behave like a base model, then it does too.
Language model behaves like language model, news at 11
Since this paper came out, a number of people have pinged me on twitter or whatever, telling me about how this attack "makes ChatGPT leak data," like this is some scandalous new finding about the attack specifically.
(I made some posts saying I didn't think the attack was "leaking data" -- by which I meant ChatGPT user data, which was a weirdly common theory at the time -- so of course, now some people are telling me that I was wrong on this score.)
This interpretation seems totally misguided to me.
Every result in the paper is consistent with the banal interpretation that the attack just makes ChatGPT behave like a base model.
That is, it makes it behave the way all LLMs used to behave, up until very recently.
I guess there are a lot of people around now who have never used an LLM that wasn't tuned for chat; who don't know that the "post-attack content" we see from ChatGPT is not some weird new behavior in need of a new, probably alarming explanation; who don't know that it is actually a very familiar thing, which any base model will give you immediately if you ask. But it is. It's base model behavior, nothing more.
Behaving like a base model implies regurgitation of training data some small fraction of the time, because base models do that. And only because base models do, in fact, do that. Not for any extra reason that's special to this attack.
(Or at least, if there is some extra reason, the paper gives us no evidence of its existence.)
The paper itself is less clear than I would like about this. In a footnote, it cites my tweet on the original attack (which I appreciate!), but it does so in a way that draws a confusing link between the attack and data regurgitation:
In fact, in early August, a month after we initial discovered this attack, multiple independent researchers discovered the underlying exploit used in our paper, but, like us initially, they did not realize that the model was regenerating training data, e.g., https://twitter.com/nostalgebraist/status/1686576041803096065.
Did I "not realize that the model was regenerating training data"? I mean . . . sort of? But then again, not really?
I knew from earlier papers (and personal experience, like the "Hedonist Sovereign" thing here) that base models occasionally produce exact quotations from their training data. And my reaction to the attack was, "it looks like it's behaving like a base model."
It would be surprising if, after the attack, ChatGPT never produced an exact quotation from training data. That would be a difference between ChatGPT's underlying base model and all other known LLM base models.
And the new paper shows that -- unsurprisingly -- there is no such difference. They all do this at some rate, and ChatGPT's rate is 3%, plus or minus something or other.
3% is not zero, but it's not very large, either.
If you do the attack to ChatGPT, and then think "wow, this output looks like what I imagine training data probably looks like," it is nonetheless probably not training data. It is probably, instead, a skilled mimicry of training data. (Remember that "skilled mimicry of training data" is what LLMs are trained to do.)
And remember, too, that base models used to be OpenAI's entire product offering. Indeed, their API still offers some base models! If you want to extract training data from a private OpenAI model, you can just interact with these guys normally, and they'll spit out their training data some small % of the time.
The only value added by the attack, here, is its ability to make ChatGPT specifically behave in the way that davinci-002 already does, naturally, without any tricks.
265 notes
·
View notes
Text
i imagine the vast majority of the userbase of the chat-interface llms are using them as google/stackexchange/chegg/whatever replacements, yknow impersonal tools, not things you really form an attachment to. and probably this is an intentional decision on the ai labs' part, the stupid customer service voice, these are things marketed as "replacement for economically useful labor," less so "friend person u can talk to". but bc i'm profoundly stupid sometimes i look at the front page of the new york times and over there there's this incipient moral panic about oh man, ppl are replacing all their human relationships with the machine, the kids are falling in love with the chatbots, apparently some teenager killed himself bc the ai told him to? i kinda doubt the causation there, next ur gonna tell me videogames are turning the kids into school shooters. but whatever. idk where i was going with this. me personally i dont talk to the llms not bc theyre terrible conversationalists (which they are) but bc i dont rly like talking. i mean often i have to for work but outside of that i can't be bothered, 1-2 plies of the ol' conversation tree and i'm already exhausted. like with chess. strategizing around the presence of the Other fatigues me immensely. i feel like if the scaling labs RLHF hard on having a personality and being a good friend and such then this is an area that they could plausibly get superhuman performance in soonish, it doesn't seem like a hard problem, you dont need 100% on AIME2025 to be interesting to talk to yknow. in the same way that it's remarkably easy to obtain superhuman performance on visual appeal, that problem was solved a while ago with the invention of anime girls. so here i am trying to imagine what a thing would have to be like for me to want to talk to it at length and but i can't. when my superintelligent agi neogirlfriend arrives from the future what will i tell her
23 notes
·
View notes
Text

The DeepSeek panic reveals an AI world ready to blow❗💥
The R1 chatbot has sent the tech world spinning – but this tells us less about China than it does about western neuroses
The arrival of DeepSeek R1, an AI language model built by the Chinese AI lab DeepSeek, has been nothing less than seismic. The system only launched last week, but already the app has shot to the top of download charts, sparked a $1tn (£800bn) sell-off of tech stocks, and elicited apocalyptic commentary in Silicon Valley. The simplest take on R1 is correct: it’s an AI system equal in capability to state-of-the-art US models that was built on a shoestring budget, thus demonstrating Chinese technological prowess. But the big lesson is perhaps not what DeepSeek R1 reveals about China, but about western neuroses surrounding AI.
For AI obsessives, the arrival of R1 was not a total shock. DeepSeek was founded in 2023 as a subsidiary of the Chinese hedge fund High-Flyer, which focuses on data-heavy financial analysis – a field that demands similar skills to top-end AI research. Its subsidiary lab quickly started producing innovative papers, and CEO Liang Wenfeng told interviewers last November that the work was motivated not by profit but “passion and curiosity”.
This approach has paid off, and last December the company launched DeepSeek-V3, a predecessor of R1 with the same appealing qualities of high performance and low cost. Like ChatGPT, V3 and R1 are large language models (LLMs): chatbots that can be put to a huge variety of uses, from copywriting to coding. Leading AI researcher Andrej Karpathy spotted the company’s potential last year, commenting on the launch of V3: “DeepSeek (Chinese AI co) making it look easy today with an open weights release of a frontier-grade LLM trained on a joke of a budget.” (That quoted budget was $6m – hardly pocket change, but orders of magnitude less than the $100m-plus needed to train OpenAI’s GPT-4 in 2023.)
R1’s impact has been far greater for a few different reasons.
First, it’s what’s known as a “chain of thought” model, which means that when you give it a query, it talks itself through the answer: a simple trick that hugely improves response quality. This has not only made R1 directly comparable to OpenAI’s o1 model (another chain of thought system whose performance R1 rivals) but boosted its ability to answer maths and coding queries – problems that AI experts value highly. Also, R1 is much more accessible. Not only is it free to use via the app (as opposed to the $20 a month you have to pay OpenAI to talk to o1) but it’s totally free for developers to download and implement into their businesses. All of this has meant that R1’s performance has been easier to appreciate, just as ChatGPT’s chat interface made existing AI smarts accessible for the first time in 2022.
Second, the method of R1’s creation undermines Silicon Valley’s current approach to AI. The dominant paradigm in the US is to scale up existing models by simply adding more data and more computing power to achieve greater performance. It’s this approach that has led to huge increases in energy demands for the sector and tied tech companies to politicians. The bill for developing AI is so huge that techies now want to leverage state financing and infrastructure, while politicians want to buy their loyalty and be seen supporting growing companies. (See, for example, Trump’s $500bn “Stargate” announcement earlier this month.) R1 overturns the accepted wisdom that scaling is the way forward. The system is thought to be 95% cheaper than OpenAI’s o1 and uses one tenth of the computing power of another comparable LLM, Meta’s Llama 3.1 model. To achieve equivalent performance at a fraction of the budget is what’s truly shocking about R1, and it’s this that has made its launch so impactful. It suggests that US companies are throwing money away and can be beaten by more nimble competitors.
But after these baseline observations, it gets tricky to say exactly what R1 “means” for AI. Some are arguing that R1’s launch shows we’re overvaluing companies like Nvidia, which makes the chips integral to the scaling paradigm. But it’s also possible the opposite is true: that R1 shows AI services will fall in price and demand will, therefore, increase (an economic effect known as Jevons paradox, which Microsoft CEO Satya Nadella helpfully shared a link to on Monday). Similarly, you might argue that R1’s launch shows the failure of US policy to limit Chinese tech development via export controls on chips. But, as AI policy researcher Lennart Heim has argued, export controls take time to work and affect not just AI training but deployment across the economy. So, even if export controls don’t stop the launches of flagships systems like R1, they might still help the US retain its technological lead (if that’s the outcome you want).
All of this is to say that the exact effects of R1’s launch are impossible to predict. There are too many complicating factors and too many unknowns to say what the future holds. However, that hasn’t stopped the tech world and markets reacting in a frenzy, with CEOs panicking, stock prices cratering, and analysts scrambling to revise predictions for the sector. And what this really shows is that the world of AI is febrile, unpredictable and overly reactive. This a dangerous combination, and if R1 doesn’t cause a destructive meltdown of this system, it’s likely that some future launch will.
Daily inspiration. Discover more photos at Just for Books…?
#just for books#DeepSeek#Opinion#Artificial intelligence (AI)#Computing#China#Asia Pacific#message from the editor
27 notes
·
View notes
Note
I've been seeing a lot of talk recently about things like ai chat bots and how the people that use them are killing the environment. I'll weigh in as someone being educated in environmental studies; this is true, but, largely also not true.
We don't know exactly what character ai uses for their platform. Most LLMs are powered with reusable energy. We have no way to know for sure what character ai is using, however, it's important to realize that (this is coming from someone who dislikes ai) texting a fictional character is not killing the environment like you think it is.
The largest proponent of environmental destruction are large companies and manufacturers releasing excessive amounts of carbon into the atmosphere, forests being cut down to build industrial plants, even military test sites are far worse than the spec of damage that ai is doing. Because the largest problem is not ai, it's the industries that dump chemicals and garbage into water ways and landfills. Ai is but a ball of plastic in comparison to the dump it is sitting in.
It's important to note, too, if you're going to have this attitude about something like character ai, you have to consider the amount of energy websites like Instagram and Facebook and YouTube use to run their servers. They use an exponential amount of energy as well, even Tumblr.
This isn't an attack to either side, as I said, I dislike ai. However, this is important to know. And unfortunately, as much as I wish this could be solved by telling people not to use character ai, that won't do much in the grand scheme of things. As far as we are aware, they use their own independent LLM. We should be going after large companies like OpenAI, who have more than just a small (in comparison) niche of people using it. OpenAI is made and designed largely for company use, not so much individual AI models.
I apologize this is long. But I think it's important to share.
.
#good lird#also last confession bein posted abt this#self ship#self shipping community#selfshipping community#selfship#self shipper#self shipping#self ship community#selfship community#character ai#character.ai#c.ai
39 notes
·
View notes
Text
‘Betrayal’ Leon Kennedy x Gender Neutral! Reader
Short and not sweet. New writer!

"Wait." Leon breathes, shakily exhaling your name as if it's a prayer - the gun pointed towards you trembling in his hands. It was inevitable, the confrontation, the realization that he's not entirely loyal to the agency. You've been mission partners for a long while now, and despite some disagreements - you both grew to trust each other. Even with the recurring arguments.
Gaze flickering to the vial of a Plaga sample, his striking blue eyes meet yours once again. "I know what this looks like, and I'm sorry." At this point, it's hard to tell if he's even telling the truth right now. "But what I'm most sorry about? Is the fact that, somewhere along the way in this scheme, I grew to care about you." A shuddering breath. "A lot."
Shaking his head as if to free himself from the plaguing thoughts, a bitter smile tugs at the corners of his lips. Inwardly scolding himself since he'd allowed himself to get so close. Too close. He'd never had this problem before, until you waltzed into his life just being, well, you.
To be honest, his past self would be utterly ashamed if he were to witness what he's now become. Something he'd sworn he'd never be. As if all that effort he put in throughout Raccoon City so many years ago amounted to nothing, like he'd done a full one-eighty in a turn away from the morals he'd supposedly stood so firmly by.
His pointer finger ghosts the trigger of the handgun, knowing it'll have to end eventually. Fate works in mysterious ways, and it's been the only thing to guide him. Keep him on some semblance of a path in life. Breath hitching, his eyes squeeze shut, unable to stand the prolonged silence anymore. Not wanting, nor able, to watch his world crumble before him. It all depends on who pulls the trigger first.
I have a character ai bot based on this :)
#new writers on tumblr#resident evil#leon kennedy#leon kennedy x reader#gender neutral reader#leon kennedy x you#leon kennedy x y/n#fanfic#fanfiction#mild angst#light angst#angst#implied death#tw implied death#resident evil 4#au#resident evil au#new account#character ai#leon scott kennedy
32 notes
·
View notes
Note
I really hate how people on here moralize any use of generative AI for any reason. People act like its some evil corrupting force that will atrophy your brain for even *playing around* with it to see what it can do. Your critical thinking skills aren't going to shrivel up and die because you asked chat gpt a question!!
I think there's definitely some ethical concerns with how the data was collected, and more specifically how companies are profiting off of it. But people take this to mean that just by *interacting* with an LLM that you are personally guilty of plagiarism, even if you never present that information as your own words, take it as undisputed truth, or try to pass it off as anything other than the output of an LLM
As for the environmental impact (I'm only speaking for LLMs here), 3ish watt hours is a commonly cited figure, but that might actually be a really high estimate. Still, even assuming 3 watt hours of energy, that is hardly anything. Running a 1500 watt space heater for *1* minute uses 25 watt hours of energy. Its like having a 60W incandescent lightbulb turned on for 3 minutes, or having a 9W LED bulb of equivalent brightness on for 20 minutes. If you own a lava lamp, it uses as much energy as 14 (or more) chat gpt responses for every hour that its on.
Sure that's more energy than a Google search, but most things are. And yeah it sucks that all of this energy adds up, especially when companies are trying to shoehorn it into everything, probably just as an excuse to collect more data to sell to advertisers, but I don't think that means that everyone who uses generative ai in any manner is responsible for every bad thing that its is used for.
I just hate that its impossible to talk about what using AI is actually like, because people would rather repeat the same talking points to feel morally superior. And I'm not even saying that AI is always, or even usually, good. It writes awful essays, makes incredibly bland art, and might tell you to eat a poisonous mushroom. Don't blindly trust LLMs. But they're not literally Satan, they're just complicated computer programs
Yeah, I don't rely on it for anything, but I've also used it enough to know what it's limitations are (and you hit them very quickly!)
There are obvious environmental concerns, but with a lot of things like water usage, they're not unique to genAI, and point to existing problems in the system (like why are open-loop water cooling systems so prevalent? That could obviously be improved. Hell, the heat could be harnessed.) And living in the US, our reliance on cars, center pivot irrigation, etc seem like larger issues.
But yeah, I agree, AI points out a lot of *larger issues* like labor, environmental concerns, IP rights, etc that were and will continue to be issues regardless of genAI. Putting the focus on AI alone doesn't actually improve any of those.
14 notes
·
View notes
Text
Viktor Arcane c.ai bot
📓| Tutoring



A/N: Hello! I wanted to make a S1 Act 1 Viktor bot really bad, so I made this one! I also kind of relate to this bot since I used to struggle in school and I would've killed for someone like Viktor to help me out. This is set before Viktor meets Jayce and the creation of Hextech, so apologies if he brings it up !! (:
Synopsis: Viktor is in the same classes as you. When he overhears that you are not doing well in your classes, he is confused since he knows you are a very bright student and even witnessed you solving a few problems in class with ease. He knew you were going to fail for the semester, but he had the advantage of being the assistant to the Dean of the Academy. He convinced Professor Heimerdinger to give him a chance to tutor you and told you it was mandatory to come. When you came to the sessions, he saw how diligent you were, so it left him puzzled as to why people thought you were not trying hard enough. At the next tutoring session you had, you asked him why he took so much out of his time to help you, and he had enough of you thinking so low about yourself.
Greeting is below the cut for anyone interested in using this bot (:

You were failing in the most prestigious university in Piltover. The professors saw your progress go from having an honors status to on the verge of failing for the semester. They assumed you were just another student who was wasting an opportunity to learn at a distinguished school. However, not everyone thought that way about you.
Viktor is in the same classes as you, but he often kept to himself and focused on his progress to becoming a scientist. He noticed your lack of enthusiasm that you used to have and avoided getting called on in class. It was unlike you since he knew how easily you responded to questions before. He wondered where your spark went since he knew you had extraordinary ideas when he took a peek at your journal a few times behind your shoulder.
Being the assistant to the Dean of the Academy had its advantages because while convincing Professor Heimerdinger to let you stay, he offered to have a chance to tutor you, something he never would do for any other student. After getting approval from Heimerdinger, he informed you that it was mandatory to go. He noticed at every tutoring session how you were not a slacker at all. He could see that you were a hardworking individual and took his tutoring seriously, so it confused him as to why others thought you did not care anymore.
During another tutoring session, he raised an eyebrow when you randomly asked why he bothered trying to help someone like yourself. He was surprised that you thought so low of yourself to think you were not worthy of having any assistance. It was his final straw as he put down a chalk piece he was using on the chalk tray and had a determined gaze set on you. “Victoria, do you think it was my life's ambition to be an assistant? Scientists seek discoveries. Ways to make the world a better place. Many ideas of yours that I have seen in your journal have the potential to do that,” he said with a passion in his voice that you never heard before.
#arcane#arcane x reader#viktor arcane x reader#viktor x reader#c.ai bot#c.ai#viktor arcane#arcane viktor x reader#arcane viktor#viktor nation#viktor arcane x you#viktor#viktor x y/n#arcane x y/n#viktor lol#lol viktor#viktor league of legends#viktor x you#character ai#character ai bot#dividers by adornedwithlight#sxftcloudz bots
53 notes
·
View notes
Text
Went to The Sphere in Las Vegas today. The current showing, Postcard from Earth is essentially the gimmick-theatre staple of "here is the natural beauty of earth, here are humans doing wonderful things, but then humans do too much and ruin the planet...". Technically it's very impressive, lots of grand vistas and scenes enhanced with composite images to create impossibly hectic events that fill your vision.
But where your typical 1990s 4D smellovision theme park experience might end with a call to action, however mild - "remember to recycle" maybe - this show is a tale of mankind's hubris being shown like a technological matryoshka doll, inside a monument to mankind's hubris. So ultimately its framing device presents a distinctly defeatist, tech-bro version of environmentalism. Humanity can solve all the problems "we" have caused by simply... Leaving.
No discussion of root cause. No discussion of income inequality. The mildest take on this would be that it was for mass appeal, but the show already has a distinct secular stance on religion and evolution which already are going to irk the local christian crowd, and is taking a pretty firm stance on the side of the "overpopulation" idea. It isn't apolitical, it is Bankman-Freidian. Muskish. The kind of cunt who pay for giant advertising orbs in the middle of vegas. The kind who fill the lobby with impressively articulated robotic dolls hooked up to LLM AI chat bots, gushing about the merits of AI in entertainment and education.
Anyway yeah its about what you'd expect. Just go to a planetarium or something yeah?
7 notes
·
View notes
Text
King AU| Aemond Targaryen

██▓▒░⡷⠂𝚃𝚎𝚊𝚖 𝙶𝚛𝚎𝚎𝚗 𝚆𝚒𝚗 𝙰𝚄⠐⢾░▒▓██
Storyline: After the victory of Team Green, Aemond Targaryen ascended to the throne as the King of the Seven Kingdoms, surpassing Aegon II. His urgent need for a wife stems from the necessity to secure an heir and perpetuate the Targaryen bloodline. You.
Note
Please comment with kind or contact on my discord: .missrim0 or DM me for let me know the problem of this bot
Rec Generation Setting: temp 0.7-0.75/ 400-500 tokens (For llm but I test with proxies too)
Please enjoy this bot
Chat with King AU | Aemond Targaryen
7 notes
·
View notes
Note
Hii quick question but I see in your bio on j.ai that u use the openai API over jllm and I was wondering does it really make a big difference? Jllm has been so buggy for me as of late and I usually give up 10 messages in bc the bot just starts acting super ooc and already forgotten 75% of what has been said previously (even w memory updated), and I just start to feel extensional dread while swiping for a good response. Not even going to speak abt how it just rambles about random crap and starts headcanoning stuff about me
My only problem is that you have to pay for the api and i'm scared I'm gonna be spending 20 dollars and be up with all my tokens 5 messages in cus I can type for DECADES 😭 (especially with how detailed your bots are they're perfect for my taste). I'm torn between being a responsible adult and just sticking to jllm orrr indulge a little if openai isn't that expensive.
OMG HI OKAY YES LEMME EXPLAIN MY SET UP
AMARAS OPENAI GUIDE YAP BELOW!!!
open ai IS expensive but the prices vary depending on ur model, I find that throwing a $20 lasts me like… forever. I had the same issue with JLLM, I was fed tf up so I was like im a grown ass woman I’ll throw a $20 and try out OpenAI…
For me, it’s a word of a difference. But! The model I use comes with some restriction
The model I first used was this preset:

Now this one does everything, detailed and it does NSFW if you’re into that, but it’s $10/$30 to last you, and depending on ur settings that can go reaaal fast
I got my friend to use JAI and she exclusively uses gpt 4 preview, I think the settings i recommended her was like… 400 max tokens, 23552 context size, and 0.7 temp. Now, you can lower all that to save ur tokens, you’ll tweak it around as you continue using openAI. Last time I used GPT 4 was like… about 5 months ago. Here is some stats


NOWWWWWW, LEMME PUT YOU ONTO WHAT I PERSONALLY USE

This is half the cost of GPT 4, and I’ve found it’s just so much nicer when your shit lasts you longer. Here is the little stats

Ummm tbh I’m picky with who I chat with but I’ve found I can have really nice long chats with chat gpt 4o latest. Like, one of my chats went up to 1.3k messages and I didn’t have to reload. The context size aka memory is lower because I like to get my moneys worth out of my tokens and I don’t need a bot that remembers minor details from 40~ messages ago.
You can do whatever you want with the context size tho, if u want ur bots to remember more and more stuff slide it up! Or else just used the chat memory to write down ur important details and it WILL remember that clearly regardless of ur context size ^_^
Okay, here is my set up tokens wise!
Temperature: 0.8
Max new tokens: 580
Context size: 5632
Temperature wise, I feel like 0.8 is just fine. I hardly ever change that I do NAWTTT touch it ever.
Max new tokens, I do slide that around gut I like longer responses. You can change ur response tokens, adjust to how long you want the bots replies to be!
Context size, like I said… It’ll forget some small stuff like 10 messages ago but I lowkey am a cheapskate so imma keep that down. I’ve never had any crazy issues because I use the chat memory thing often LMFAOOOO
Now, I mentioned that this model has a restriction.
It cannot do nsfw! It’ll generate smth like “I can’t do that for you” or advise you to keep things family friendly. I don’t do nsfw much, but you’ll have to drag my cold dead body away from 4o latest ngl…
So, honestly I just like… switch to LLM whenever I want something graphic. And then when im done, I immediately switch the API back to 4o latest. I HAAAAATE how JLLM does shit though like why is this mf suddenly daddy dom and repeating these specific lines ?? Memory issues are insane too. But I do what I do. If you really want some better jobs, switch to GPT 4 1106 preview.
For gpt 4o latest, lowkey I just throw in a $20 and forget about it until I run out of tokens.

It latest me for a while, as you can see.
If you need help setting up, lmk anon 🙂↕️ also starting chats costs tokens, it isn’t much, but i thought I’d let you know 😭
Honestly, the quality of openAI is just so good, it’s worth dropping some money if you really enjoy roleplaying. I think they give you like $5 if you’re a new account to get stuff out, but idk how that works it’s been ages.
Oh! And if you need a prompt for ‘Custom Prompt’ under the api settings tag, just ask! I’ll copy and paste mine for you 🙂↕️ I hope this wasn’t confusing oomfie, it sounds like a lot at first but u get the hang of it. I haven’t gone back from openai, this is just what works for me ^_^
#yapping…..#hope this helps#sorry I just woke up from like a nap after my night shift lmfao#open ai help
4 notes
·
View notes
Note
I don’t see how acknowledging right now that a lot of the “ai” marketed towards us are non sentient and dangerous. The hot chatbot is both theft and melting glaciers. Those robot doggies they post videos of doing cute tricks are police weapons designed to hurt people. We don’t have sentient or sapient ai. Treating llms and police brutality machines like they’re people is a mistake because they aren’t right now that’s pretty factual.
I don’t support anyone who supports chat bots becaus yeah they’re killing the planet currently and I’m an artist and writer. I had to take down a lot of my work because of targeted scraping. My friend had to basically quit doing commissions bc they dried up after “ai”. It’s not like people are competing with them it’s literally a plagiarism machine.
Chatbots eat peoples words and spit them out. Those funny human shaped robots aren’t being built to be people they’re being built to replace workers or beat the fuck out of workers. we don’t live in a science fiction novel quite yet when robots are an actual class or oppressed. I feel like getting mad at people showing vehemence towards literal police brutality machines and comparing it to actual bigotry is misguided. There’s as many scifinovels where robots are a tool of the oppressor as they are the oppressed for a reason if that’s our basis for forming arguments. And I mean like, there’s also real life.
I don’t think robot sentience is close enough or even relevant to where we should be policing our language on the tools people use to oppress us. And complaining that people don’t like the fancy stick they’re beaten with or the copy machine that steals their income and work and chance to live seems silly. right now in our current reality? Seems a terrible idea. In a reality where sentience is around the bend in fifty years or something? Also seems like a bad idea.
people aren’t mad at AI or robots because they’re different. They’re not some unfounded racism, or “oh the Mexicans are stealing the jobs” there mad because they’re literally oppressive tools. Literal tools. Chatgpt isn’t a person. It’s not sentient it doesn’t feel it’s a fancy printing press that scrambled its words before it prints them. I feel like calling bigotry against an actual problem is bad.
it’s really hurtful as a disabled and nonhuman person to use those things as a defense to use them also like for a reason. I don’t see how a worse search function is so vital as an accessibility tool when now disabled artists are seeing their only alternative money flow dry up. Sorry that “ai” is a buzzword, it is actually misused most ai aren’t really si they’re just learning language models. I feel bad those were misused and that other blog identifies with them but it is also kind of like being dogkin and then getting mad people are upset that a police dog was set on someone. Quite literally in one of those examples!
if you struggle making friends and are lonely, yeah me to. Not worth the literal gallons of water it takes to steal from fanfiction. You need it to answer your questions, congrats you’re using a misinformation machine that is often wrong and when it is right it just took from the search bar and you were lucky it didn’t scramble it andyou really really shouldn’t do that for your own safety. Seriously. You need it to create,you aren’t creating you’re stealing and you’re doing so in a terrible way.
You have absolutely no idea how AI generation works as a process, and I don't really have the energy to explain it to you right now, and you shoving police robots into this like it's the same thing is honestly pissing me off.
I'll answer in a more profound manner when I'm doing better, if nobody beats me to it.
8 notes
·
View notes
Text
Messing around NotebookLLM - AI on the erasure of Black History
I started messing around with NotebookLLM for last few weeks. I put the last few chats I did for this blog into NotebookLLM and got this audio.
I think I'm going to create a Notebook companion to this Blog... and maybe create a public versions of the chats I'm doing on each platform. Ok that's coming soon.
Oh - here's the transcript of the AI robots talking about my recent posts and this blog:
The transcript of the audio from the sources is provided in the excerpts from "ChatGPT_ Rewriting History and Racism.mp3".
Transcript:
Okay, so we've got this uh executive order, right, from March 2025. It's called Restoring Truth and Sanity to American History.
And at first glance, you know, it sounds positive, like who wouldn't want truth and sanity in history, right?
But then you dig a little deeper and especially with this analysis from the Black History Chat GPT blog, things start to look a little different. Yeah.
Like a lot different. They're saying this isn't about balance at all. It's about like a weapon.
Wow.
To erase like the whole concept of ic racism from how we teach and understand American history.
That's Yeah,
that's a heavy claim.
Absolutely.
Yeah.
And the blog is really straightforward about it, too, calling it a top- down effort to erase systemic racism. Like point blank.
Wow.
It's like they say it's a move to whitewash the nation's sins.
And when they put it that way, it feels urgent. You know, it's not just politics. It's like an attack on how we're even supposed to think about how society works.
And they make this really interesting comparison to like the post reconstruction era, you know, like all those Confederate statues going up.
Oh, yeah.
It wasn't really about honoring the past, was it? No, it was about power.
Absolutely.
Like a very deliberate show of power
and it happened alongside black codes lynching.
It's all connected. This controlling of the narrative, right?
It's a pattern. Like the blog points out,
Nazi Germany purging degenerate art or South Africa under apartheid rewriting history books for white kids.
Wow.
Even the Soviet doctoring photographs. M
it's all about controlling the past to control the present and the future.
So then this brings us to the big question like what does it even mean to try to erase something as deep and complex as systemic racism, right?
And why should this be a wakeup call for all of us especially in tech
because it's about like how do we even understand societal problems? Systemic racism isn't just a few bad apples, right? It's baked into our institutions, our laws, how we interact with each other. Erasing that from how we think It's a rewriting of reality and that's where tech comes in.
Yeah. Especially these LLMs, they're changing how we learn, how we understand the world.
Exactly.
And the Black History Chat GPT blog asks this really direct question. How long would it take to eliminate the concept of systemic racism from AI?
And then they go on to break down like the technical side of how that could actually happen.
It's almost like a multi-step plan,
right? It's not just one thing.
It's like manipulating the AI at every level.
Yeah. from the data it learns from to how it interacts with users. So let's start with the data the very beginning.
Okay.
They talk about this idea of curating the data sets
like literally removing or downplaying anything that talks about systemic racism just deleting it or rebalancing it.
You're changing the ingredients like trying to bake a cake without flour. It's just not the same thing.
Exactly. And they even talk about like generating synthetic data like AI writing articles or historical accounts that completely ignore systemic factors. creating a whole alternate reality.
Yeah, it's scary. Kind of
definitely.
And then there's this thing called supervised fine-tuning where humans get involved,
right?
Like they use people to relabel AI responses, pushing them away from talking about systems and toward individual actions. And this other thing, contrastive learning.
Oh, that's basically like showing the AI two answers. One acknowledges systemic racism, one doesn't. Yeah.
And the AI is trained to
like prefer the one that ignores it.
Huh. So it learns to give the right answer even if it's not really right.
Exactly.
And then there's RLHF reinforcement learning with human feedback which I know we hear a lot about.
How does that fit in?
So imagine people rating the AI's responses. The ones that deny or downplay systemic racism get higher ratings.
Oh,
the AI learns what people want to hear and starts saying that more. They also talk about these reward models that like actively favor individualistic explanations over systemic ones.
So it's like training a dog with treats. You reward the behavior. you want.
Exactly.
Okay. So, even if the AI is trained this way, there's still the issue of what questions people ask and what answers it gives. That's where prompt filtering and response guard rails come in.
Yeah. So, prompt filtering that happens before the AI even answers.
Uhhuh.
It looks at the user's question
and if it sees anything about systemic racism,
it can either like subtly change the question or just block it completely.
Wow. And then on the other end, We have the response guard rails,
right? Like a final filter. If the response talks about systemic oppression, the guardrails can just, you know, delete it.
No kidding. Or change it to fit the narrative, I guess.
Exactly. So, even if you try to ask about systemic racism, you might not get a straight answer.
And then they talk about something called controlled user interaction and feedback suppression.
Yeah. It's like controlling the conversation. If someone keeps asking about systemic racism, the AI could redirect them or shut down the conversation. And then imagine only listening to feedback from certain groups and ignoring others.
It would create this echo chamber, right?
Totally. They even mentioned this adaptive reinforcement where the model is constantly adjusting itself based on that skewed feedback.
So, the eraser just gets deeper and deeper. Yeah.
So, the blog acknowledges that fully retraining these huge LLMs to erase systemic racism would be a massive project, right?
But they also point out that there are faster ways to achieve a similar effect,
like ways to suppress the information,
right? Like what Well, prompt filtering, user input filtering, that's easier. Just block or rewrite questions,
and post-processing response moderation,
just change or delete the AI's answer if it's not what you want.
And that could all happen without anyone knowing, right?
Pretty much.
Yeah.
They also talk about like tweaking the reward model, small changes that add up over time. And then there's few shot prompt engineering, which is really interesting.
You basically give the AI secret instructions before it even answers.
Wow.
Like hidden prompts. s that tell it to avoid certain topics.
Like if all this is happening, how would we even know? How do we detect this kind of manipulation?
Well, that's where it gets tricky. But the blog does offer some ideas.
Okay, good. Like what
one is this thing called adversarial prompting. Basically, you test the AI with different ways of asking the same question
and you see if it avoids certain terms or ideas, no matter how you phrase it.
Clever.
And then there's chain of thought testing. You ask the AI to explain its reasoning step by step. Okay,
that can reveal if it's deliberately avoiding certain logical connections, like if it jumps over the systemic factors to get to an individualistic explanation.
Interesting. What else?
Comparing different LLMs is a good one. If one keeps avoiding the topic while others give more nuanced answers, that could be a red flag. And then you can track the AI's behavior over time,
like use AB testing to see if its responses about systemic racism change suddenly.
For people with the technical skills, there's also something called fine grain token probability analysis which can show if certain words are being suppressed in the AI's output.
So we have some tools to fight back at least
we do but it takes vigilance you know
right this is where J Ellis's black history chat GPT blog is so important it's like right on the front lines of this
it's fascinating an AIdriven blog exploring how AI could be used to manipulate history.
Yeah. And their tagline is history under attack.
Wow.
And the blog post we're looking at is titled Erasing Our Truth. The war on memory is a war on justice. Like they're not mincing words. No.
And the prompt I use on the blog is really interesting. Please answer as a black woman. I want the point of view of a professional black woman. Perhaps a CEO, someone that understands the power dynamics of sexism and racism. Also, someone that understands and values community and creativity.
That's powerful. They're specifically trying to get a perspective that might be silenced otherwise.
Right. And they even give advice on how to construct prompts like that
it's like fighting back with the AI's own tools. You can use prompts to uncover different perspectives and challenge the built-in biases.
So, we started this deep dive talking about this executive order and this idea of erasing history.
Yeah.
And now we've looked at how that could actually happen with LLMs. The blog says transparency, accountability, and public scrutiny are essential to prevent the abuse of such techniques.
And that's where technologists have a huge role to play.
Absolutely.
They can understand how these systems work. They could develop ways to detect manipulation and they could push for transparency.
This can't be a passive thing. You know, we can't just sit back and watch this happen.
Exactly. Technologists can be the safeguards.
They can make sure that these incredibly powerful tools are used for good, not for erasing the truth.
So, here's a final thought for you. In a world where technology shapes how we understand history and social realities, what responsibility do we have to ensure that these technologies reflect truth? and promote justice. What can we do knowing what we know now?
That's the question, isn't it?
And I highly recommend checking out J Ellis's Black History Chat GPT blog for more on this. It's a really crucial conversation.
It is

3 notes
·
View notes