#scraper site
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
After the announcement of the deal with Yahoo!, there were 170K signatures of unhappy Tumblr users petitioning to prevent the sale in 2013.
Text
Taking Down a Scraper Site for 35mmc and How You Can Fight Image Theft
by Johnny Martyr After many years of readership, I finally made my inaugural post on the internet’s largest film photography blog site, 35mmc. While in communication with owner Hamish Gill, he lamented about having found a what is known as a scraper site that was carbon-copying nearly 100% of the content from 35mmmc. All author links were being stripped from articles with their words and photos…

View On WordPress
#35mmc#copyright infringement#crime#dmca#dmca takedown#dmca takedown request#intellectual property#isp#photography online#scraper site#seo#steal#stolen#theft
1 note
·
View note
Text
I'm Alive! 👋
I'm still dusting off the cobwebs on my art accounts after a few years of burying myself in online work to build up my indie author job. My most recent comments/donations on Ko-Fi from 3-4 years ago made me feel all warm and fuzzy. People were super kind and had no idea just HOW bad things were for me in 2020. If you were one of them, thank you so much! 🥹
A-hem, okay, on to all of the crazy links. I revamped my Ko-Fi, Patreon and Instagram (I finally got the login back again!), and I made a shiny new Threads account if anybody wants to follow me over there. Oh, and I have a YouTube channel, although it has no videos yet! I plan to stick speedpaints on there, so if watching those sounds fun, follow it and you'll get notified as soon as I upload. ♥
It feels SO GOOD to get back to making art on a more regular basis. I'm so, so happy that Tumblr still has folks active on it, because it's basically my fandom home online. 🥰
#threshie#threshasketch#updating the social media#trying to get the art stuff rolling again on the regular#it's getting rocky navigating which sites will automatically give themselves permission to eat your art for their AI training garbage#Meta apps like Instagram and Threads DO do that#but I figure I can post old art that has inevitably already been eaten by some data scraper somewhere#it's not perfect but better than nothin'#anyway HI thank you for following any of my art accounts ♥#I hope you enjoy the art and chibis
11 notes
·
View notes
Text
I see that Tumblr has a main character. Haven't had one of those in a while. And, unfortunately for the rest of us, he might be the last one.
#The CEO of this site has been busy being his worst self in regards to black and Palestinian and trans people#I saw people vaguing for days but nobody actually reblogged or explained anything on my dash#Anyway on top of that there's unofficial rumors that the site might be partnering with Midjourney to sell off all of our art data to them#And if that happens you won't see me here ever again#Like yeah scrapers probably already have everything I've ever done#But I never gave permission#I will never give permission#And for people saying “Oh you gave permission when you signed up for an account” I joined in 2014#This sort of application was not on anyone's radar#But if that's how they want to interpret the language then I guess I can't stop them#But I won't be around because of that#Or anywhere else that decides to do the same
5 notes
·
View notes
Text
BEGINNERS GUIDE TO BLUESKY
Hiya! Curious about joining bluesky but intimidated by all the features? Already on bluesky but want to learn more? Then welcome to my quick guide on getting started and navigating bluesky!~
What is Bluesky?
it’s a social media site that’s owned by no single person or company. it's aim is to bring back the early days of twitter before bots, elon musk or algorithms took over. Personally I find the site really cozy, wholesome, and engaging. my Bluesky account for example
What’s unique about Bluesky?
→ CUSTOMIZATION: your timeline is very easy to control. There’s tons of options, so be sure to go through each tab in your settings. some options include: turning off autoplay, changing the order in which threaded replies show, changing DM settings, content preferences and lots of visual app settings.
→ MODERATION LISTS: human made, mass blocklists. These are public lists of accounts that when you subscribe to you automatically block or mute everyone in that specific blocklist. A great way to avoid unwanted content, and interactions. ✦ Moderation lists I recommend will be below the cut
→ STARTER PACKS: recommendation lists on who to follow, made by users. You can even curate your own starter pack of recommendations! ✦ Starter pack recommendations will be below the cut
→ FEEDS: public timelines, basically. There are a lot of feeds you can join, or you can even create your own. I made a feed featuring just my pixel art so it doesn’t get cluttered with text posts or other photos in my media tab. ✦ I’ll post feeds I recommend below and link you to a tutorial on how to create your own feed
→ BLOCKING/MUTING: bluesky has a great blocking system. When you block someone they can no longer see, or interact with you. They also have a feature to make your blog inaccessible unless logged in. you can also mute specific people, delete post replies, and even detach your post from a reblog. You can also mute specific words, phrases, tags etc.
→ NSFW: bluesky allows NSFW content, including artwork, porn, lewds etc. They also have a great moderation page to avoid the content completely, censor the content, or show it if you��d wish. ✦ just go to settings > moderation > toggle on NSFW settings and it’ll let you heavily moderate.
→ LABELS: this is a really cool feature on the site, you can subscribe to certain pages that enable a lot of fun/useful labels that help you in different ways! (like pronoun tags, artist tags etc) ✦ Labels to browse will be posted below
→ COMMUNITIES: the vastly diverse communities really feel like the best parts of tumblr. since you can so heavily curate your experience, it can really feel like a calming oasis. Mine is mostly artists, and other creatives.
there’s also a large community of professional artists, art directors, authors, celebrities, and even the best shitposters from twitter. the app really is what you make of it but it’s thriving right now.
RECOMMENDATIONS & LINKS BELOW ⬎
→ MODERATION LISTS:
HATE SPEECH: NAZIS | MAGA | MAGAv2 | MAGAv3 | TRANSPHOBES & HOMOPHOBES | FAR RIGHT | FAR RIGHTv2 | FAR RIGHTv3 | ELON MUSK FANBOYS | ANTI-BLACK | ANTI-VAX
NFT/AI/CRYPTO: MASTERLIST | AI/NFT | AI/NFTv2 | AI FANBOYS | CRYPTO | NFTs
SPAM/SCAMMERS: SPAMBOTS | BOTS | CONTENT SCRAPERS | CONTENT FARMING
✦ to block or mute everyone in the blocklist at once, click subscribe in the top right corner:

→ STARTER PACKS:
ART: PIXEL ART | PIXEL ARTv2 | WOMEN OF PIXEL ART | BADASS DIGITAL ARTISTS | MAGIC THE GATHERING ARTIST | PAINTERS OF BLUESKY | INDIE COMIC CREATORS | LGBTQIA+ COMIC CREATORS | WEBCOMICS ULTIMATE COLLECTION
GENERAL: WOMEN OF BSKY | AUTHORS | LGBTQ NEWS
SHITPOSTERS: JUNIPER | JUNIPERv2 | MASTERLIST | SCIENCE SHITPOSTERS
✦ for more niche starter packs, use the search function. search your specific interest and ‘starter pack’ and you’ll find some!
→ FEEDS:
DISCOVER | WHATS TRENDING | MENTIONS | ART | TRENDING ART
THE GRAM: a timeline for exclusively image posts from those you follow. no textposts etc. ONLYPOST: similar to the gram, it shows a timeline of only those you follow. no reposts, just original posts. 📌: a way to bookmark posts. just reply with the pin emoji.
✦ there’s tons of others feeds as well! just use the feed tab and you can browse feeds or search for specific ones.
✦ TUTORIAL ON HOW TO CREATE A CUSTOM FEED FOR YOUR ART/POSTS
→ LABELS:
SKYWATCH: most popular label. Lots of useful labels!
AI Labels: identifies AI users, can also enable hiding the posters.
Pronouns: self explanatory but useful. can add a badge with your pronouns!
✦ you can search for additional label bots on bluesky!
OTHER RECOMMENDATIONS:
✦ EXPIRIENCE ENHANCING TOOLS RECS ✦ CLEARSKY: TRACK BLOCKS AND BLOCKLISTS ✦ SKYFEED: CREATE CUSTOM FEEDS EASILY ✦ use the block function often. do not entertain trolls or hate speech. ✦ as well as starter packs, there’s also lists! lists can be used in the same way to create curated lists of accounts. it’s a good way to keep track of specific genres of posters you’re interested in, and finding new ones! ✦ hashtags: use them! they’re beneficial in boosting your post. you can even link hashtags in your bio making you easier to find. another method of making you more visible is if you post an ‘interest’ post! basically just type things you’re interested in and it’ll help people find you / vice versa ! ✦ update your profile first thing, like bio avi etc. make a small post so people know you're real. interact and engage! the communities there are so welcoming!
I think that covers abt everything i wanted to cover! Hope this was helpful and thanks for reading lol
#bluesky#bluesky starter pack#bluesky social#bsky.app#bsky#bsky social#bluesky tutorial#bluesky walkthrough#bluesky app#ooooooooook that took forever lol hope its useful!!!!!!!!#long post#text post
6K notes
·
View notes
Text
Your posts are in an AI model
and then Tumblr decided to sell them to AI models.
Now, don't get me wrong, tumblr selling out the users to AI companies is bad, yes, they shouldn't do that. It sucks.
but don't lets get this confused: your posts were already in there. Tumblr selling them is about tumblr making some money and about the AI models having more exhaustive post collections. It's not about your posts being in an AI model, vs not being in one. That battle has already been lost.
Can you find your post on google? Then it's almost certainly in an AI model already. Think about it: These AI sites showed up before all the sites were making deals to sell their users' content, right? How do you think they built them in the first place?
They scraped the posts. Just like google and bing and such do when they build their search indexes.
It's a fundamental part of how the open web works: you want your posts on tumblr to be visible to users, right? You want them to be readable?* Like, look how much stuff broke when twitter changed their whole read-while-not-logged-in policy, ruining a bunch of thread links/NSFW links. And if it's visible, it's scrapable. That's what the AI models were built on.
I've done website scraping before (not for AI models, of course. I was doing search engines and website archival), this is just how it works. You hire a few relatively smart CS graduates and tell them "build me a scraper that'll give us a bunch of tumblr posts" and they go off for a month or two and come back with a database of a few billion posts, and you stuff that into your AI model. That's how they got all the deviantart and flickr and twitter and pinterest and so on posts. They didn't pay for them: they just took them.
They only ever pay for this shit because either:
they fucked up in such a way that the site might be able to sue them for taking rather than paying
They can buy them cheaper than they can finish taking them. Maybe they'd need to pay the CS grads for an extra month? well, that might be more expensive than just throwing the site a couple hundred thousand bucks.
ANYWAY: my point is, don't treat this "oh no tumblr is selling our posts to AI" like it's a big thing that might happen and it would be bad to happen. Yes, it's bad, tumblr shouldn't do this, this'll let AI models get continual updates of content for far easier than just scraping them would be, tumblr betrayed user trust, and so on...
but realistically, this is not a black and white matter of "if only tumblr didn't do this, then we'd be safe from AI models!"
Nope. We already lost that battle. I'm sorry, and it does suck, but that's just how it is. The avalanche has already started, it's too late for the pebbles to vote. * I'm assuming here that you don't run a private blog that's set to only followers or something. You'd be safer then, of course, but you're not really my target audience for this rant
14K notes
·
View notes
Text
AI Scraping Isn't Just Art And Fanfic
Something I haven't really seen mentioned and I think people may want to bear in mind is that while artists are the most heavily impacted by AI visual medium scraping, it's not like the machine knows or cares to differentiate between original art and a photograph of your child.
AI visual media scrapers take everything, and that includes screengrabs, photographs, and memes. Selfies, pictures of your pets and children, pictures of your home, screengrabs of images posted to other sites -- all of the comic book imagery I've posted that I screengrabbed from digital comics, images of tweets (including the icons of peoples' faces in those tweets) and instas and screengrabs from tiktoks. I've posted x-ray images of my teeth. All of that will go into the machine.
That's why, at least I think, Midjourney wants Tumblr -- after Instagram we are potentially the most image-heavy social media site, and like Instagram we tag our content, which is metadata that the scraper can use.
So even if you aren't an artist, unless you want to Glaze every image of any kind that you post, you probably want to opt out of being scraped. I'm gonna go ahead and say we've probably already been scraped anyway, so I don't think there's a ton of point in taking down your tumblr or locking down specific images, but I mean...especially if it's stuff like pictures of children or say, a fundraising photo that involves your medical data, it maybe can't hurt.
If you do want to officially opt out, which may help if there's a class-action lawsuit later, you're going to want to go to the gear in the upper-right corner on the Tumblr desktop site, select each of your blogs from the list on the right-hand side, and scroll down to "Visibility". Select "Prevent third party sharing for [username]" to flip that bad boy on.
Per notes: for the app, go to your blog (the part of the app that shows what you post) and hit the gear in the upper right, then select "visibility" and it will be the last option. If you have not updated your app, it will not appear (confirmed by me, who cannot see it on my elderly version of the app).
You don't need to do it on both desktop and mobile -- either one will opt you out -- but on the app you may need to load each of your sideblogs in turn and then go back into the gear and opt out for that blog, like how you have to go into the settings for each sideblog on desktop and do it.
5K notes
·
View notes
Text
ShadowDragon sells a tool called SocialNet that streamlines the process of pulling public data from various sites, apps, and services. Marketing material available online says SocialNet can “follow the breadcrumbs of your target’s digital life and find hidden correlations in your research.” In one promotional video, ShadowDragon says users can enter “an email, an alias, a name, a phone number, a variety of different things, and immediately have information on your target. We can see interests, we can see who friends are, pictures, videos.”
The leaked list of targeted sites include ones from major tech companies, communication tools, sites focused around certain hobbies and interests, payment services, social networks, and more. The 30 companies the Mozilla Foundation is asking to block ShadowDragon scrapers are Amazon, Apple, BabyCentre, BlueSky, Discord, Duolingo, Etsy, Meta’s Facebook and Instagram, FlightAware, Github, Glassdoor, GoFundMe, Google, LinkedIn, Nextdoor, OnlyFans, Pinterest, Reddit, Snapchat, Strava, Substack, TikTok, Tinder, TripAdvisor, Twitch, Twitter, WhatsApp, Xbox, Yelp, and YouTube.
434 notes
·
View notes
Text
AO3 Data Scraped for AI Training Dataset
What is happening, and what you can do. Check for potential edits with additions at the end of the post!
What is happening? What do we know?
A user going by "nyuuzyou" on the HuggingFace platform uploaded a dataset a few days ago - containing scraped content from AO3. HuggingFace is a very popular platform and widely used for sharing machine learning and AI models/datasets. The scraped dataset includes fics, fanart, and other fanworks - all taken without permission and intended for use in training gen AI models. You can find more information in this Reddit post.
This dataset is one of several compiled from various websites—at least seven in total. While two datasets have been removed, the AO3 one was only disabled on HuggingFace. This means that it’s not downloadable at the moment but still visible. It may also return if takedown efforts end up being challenged/reversed by that user.
Key Details
Scope: On AO3, all content with work IDs between 1 and 63,200,000 has been targeted. The work ID is the number at the end of a work's URL — for example, in https://archiveofourown.org/works/12345678, 12345678 is the work ID. You can find it by simply opening the work and checking the URL in your browser’s address bar. So, if your work falls in that range and is publicly accessible (i.e., not locked and open to everyone, including guests), it’s mostly likely included in the dataset. This dataset is currently disabled on HuggingFace, but that doesn't mean it's gone. It's only a temporary takedown as of now.
Takedown notices have been issued, but this user has also uploaded the dataset to other sites after backlash and partial removal.
There are talks in the discussion forums of potentially moving this dataset to Telegram, torrents, and/or other private channels.
HuggingFace AO3 dataset page
Other distributed sites listed here (as per a Reddit comment)
Currently deleted from ModelScope
What can you do?
Should the dataset return again and you see that your work was affected: file your own DMCA or copyright takedown notice. The uploader, in their own words, "has not agreed to take down the entire repo. At this time, the scraper has agreed with taking down art from the person who owns the copyright. That means each of you will need to request a takedown."
Instructions and a sample CSV template to list your work IDs for removal are provided in this guide. You can find more details in this announcement by PaperDemon.
Lock your works! It would limit visibility to registered users only, and is a very good step to prevent scraping or unauthorized use. To lock all your works on AO3, go to “My Works,” click “Edit Works,” and select all. Then click “Edit” and check the box labeled “Only show to registered users.” Scroll down and click “Update All Works” to apply the change.
⚠️ | Final Notes:
This user has so far shown no signs of stopping and is continuing to redistribute the data across multiple sites, even after numerous takedown requests (read more here). So, we can only recommend to be cautious and beware, lock your works, feel free to make use of takedown notices if you're unfortunately affected, and spread the word to fellow creators.
Follow up on this and get the latest updated in the Fanfic Communities Network (FCN) Discord Server!
If you have more information regarding this - e.g. if works from other sites are affected too - please reach out to us in the FCN!!
Edit (2025-04-26):
The user who has scraped the works has, upon request by another person, posted a way to convert ao3 json to markdown:
https://huggingface.co/datasets/nyuuzyou/archiveofourown/discussions/170
https://gist.github.com/nyuuzyou/b2f83669ad80a22e435728245ebcdf9f
This shows us that nyuuzyou continues to show no signs of taking down the scraped works.
Edit (2025-04-28):
A user warned that even archive-locked AO3 fics were included in a scraped dataset (most likely taken while the scraper was logged in, before they were banned or switched to public-only access). Some public works were missed as well:
https://huggingface.co/datasets/nyuuzyou/archiveofourown/discussions/213#680fcdb76d9e022324a70cf1
Edit (2025-05-03):
Hey everybody, this is a bit late, but the AO3 dataset has been permanently removed from HuggingFace: https://huggingface.co/datasets/nyuuzyou/archiveofourown. While this unfortunately doesn’t prevent it from being shared elsewhere (like torrents) nor does it guarantee any deletion of past downloads and whatnot, having it taken down from a major platform like HF is still a significant step forward. (There is more info about other sites on PaperDemon.)
So please don’t be disheartened—every action counts, and this shows that pushing back and filing DMCAs and copyright notices as appropriate does make a difference. We’ll certainly keep an eye out for more info and post updates here, but thank you again to everyone who helped report, spread the word, or supported the effort. Keep reading, keep writing. ♥️
#fanfiction#community#discordserver#fanfiction community#theft#ao3 works being stolen#fanfic theft#fanfiction stealing#ao3
149 notes
·
View notes
Text
Oh wait if I turn WiFi off on my phone I can do it that way (even though I'm with BT mobile) but that's gonna be so fucking laborious, let me in!!!!!
The site I use for tv scripts to check stuff when making gifs has blocked access to everyone that uses my ISP (BT). I'm going to kms 🫡🫡🫡
#it said they've blocked access to all bt users cos some people were taking the piss (not a direct quote)#and i am worried that might include me cos more than once i got the 'youre accessing this site too much' warning#but its only cos i was going through every episode looking for certain things! im not an ai scraper please let me back in!!!!
6 notes
·
View notes
Note
why have you been reuploading all your old works in worse quality with a slight visual haze on them? I always have to find the original posts of the images ☹️
Sadly, due to the rise of AI scrapers on the internet I have to put my artwork through an application called Glaze. This is one of the best avenues artists have now for protecting our work against possible scrapers. Glazed works do appear with faint hazing on them.
The owner of Tumblr (Automattic) has given AI models permission to scrape the site in use for training said models. It's very unfortunate for me because it does take sooo long to re-upload everything but better to be safe, than sorry.
#ask#text#still toying around with settings in Glaze so that the effect is minimal visually#its actually good anon is asking these questions because this convo is not talked about enough
319 notes
·
View notes
Note
Hi, I just read about this dubious website that seems to steal fics from Ao3 and turns them into AI generated audios. I wanted to check if any of my fics are there and found your "Flung to Catch a Star". It's the first fic that pops up when you search for 'Cahir'. That's the website: https://word-stream.com
Here is the reddit post with more info: https://www.reddit.com/r/FanFiction/comments/1hkrj10/netflix_of_audiobooks_scrapes_thousands_of/?utm_source=share&utm_medium=web3x&utm_name=web3xcss&utm_term=1&utm_content=share_button
Probably there are more of your fics, and from the reddit post it appears that they do not ask for the authors' consent. Just wanted to let you know. If you already know or gave your consent, just ignore this. If you did not give your consent, sorry this happened to you. These sites are so annoying.

Thank you; I've sent them a takedown notice and a very annoyed email, and we'll see what comes of that.
For the record, my blanket permission statement EXPLICITLY DOES NOT INCLUDE ANY AI USES of my work, and if you find my fic somewhere other than AO3 (or Tumblr, I suppose), and they're charging money for it, I do not approve.
Pfeh, scraper bots. A pox on all their houses.
137 notes
·
View notes
Text
This is not a boston post but I was inspired:

These are the HSBC and Bank of China Hong Kong Headquarters and if you look carefully HSBC has a fucking gun

Those are decorative cranes pointed directly at the Bank of China HQ. Why? well you see, HSBC’s architect was a strong believer in Feng Shui and designed the building as auspiciously as possible. However, right next door, Bank of China has other ideas, meaning a normal ass sky scraper. of course, feng shui is all about your environment so after carefully picking their site and doing all these sightlines and math to figure out the optimal angles for the sun to filter into the building to get good financial luck from the good auspices of the building Bank of China sticks them a giant fucking middle finger with a taller building that blocks the sun.
Now of course they bring in the feng shui expert again. They actually bring in a couple, and make proposals, and have a year long process in which HSBC actually does terribly so it’s urgent that they solve the feng shui problem to make the bad luck go away.
After more than a year, they settle on the proposal: Point two fucking guns at the building.
Except that’s illegal so they make them cranes instead but you know they wanted to
73 notes
·
View notes
Note
perhaps a bit of an odd question: so, when I'm scrolling tumblr on mobile, I have a habit of downloading most images i come across, so that I can send them to people who don't use tumblr, especially memes and animal photos. however, i also have severe memory issues, and I may end up forgetting where i got certain images. i know for the photo repository one of the rules is to not repost the photos without any modification- which i might forget, or forget which images on my phone fall under that rule. and while i would guess that that rule doesn't apply to stuff like direct messages or texts, i might forget to tell the person I'm sending it to, who might repost it elsewhere without being aware, or months after downloading i will just forget and use one of the photos in a post I'm making because it felt relevant.
this is something i can pretty easily solve myself by just blocking the photo repository blog, or tags relating to it, but I'd rather not do that because i do really like seeing the photos and all the info and stuff. and i would assume it would be an insane amount of work for you to add something like a watermark to every single photo, so I'm not really sure how to go about this. i like seeing the photos, but i don't want to accidentally break the rules.
You clearly care deeply about doing the "right thing", so, what that tells me is that you're not actually the target audience for that rule. I appreciate all the thought you put into this message. Let's talk about it!
I've been reconsidering if requiring people to get permission for reposting images is the best policy to have and I'd like people to weigh in.
My original reasoning was this: the more I can ensure that reposts are affiliated with credit, the better I can control copyright on the images on the site, and therefore have more ground to challenge any scrapers/fake accounts/AR groups that yoink them for nefarious purposes. The easiest way to do that seemed to be to have people ping and ask, with the expectation of saying yes almost all the time.
But there's a couple problems with that, I think, in practice:
People don't like emailing strangers (I forget this! I have done it for work for so many years it isn't uncomfortable anymore).
This isn't how the internet works. (Tumblr has a specific microculture that encourages crediting creators and not stealing! Once this is shared more widely on other platforms, I don't expect it'll be the same ecosystem).
It actually undermines organic spread of content! (You're less likely to make an excited post about a cool photo if you have to send a maybe-scary email and wait for a response). And I do want there to be lots of eyeballs on the photos.
Realistically, @nexus-nebulae, with the policy right now? If you slipped up and reposted something without thinking, I'd just ask you to add credit to the post so it directs back to the site. The goal of this whole project is community access and engagement - I want to you to enjoy the photos, and send them to your friends! I'm just trying to also protect it from the awful that a lot of the internet has become.
But, I'm also wondering it it makes sense to swap the policy to say that it's fine to re-post images on socials as long as they're appropriately credited and/or linked back to the repository. This isn't the policy yet, but if you're reading this please tell me what you're thinking.
Non-edited image use (like putting them in a scientific paper, using them to build a curriculum unit, or putting them on board game cards - these are just random examples) would still need to be requested; but that's an entirely protective stance and if you ask, my goal is to always say yes.
So OP, please don't worry too much. Enjoy looking at the animals, do your best, and I'll be happy. :)
89 notes
·
View notes
Text
ChatGPT Bot Block

Hey Pillowfolks!
We know many of you are still waiting on our official stance regarding AI-Generated Images (also referred to as “AI Art”) being posted to Pillowfort. We are still deliberating internally on the best approach for our community as well as how to properly moderate AI-Generated Images based on the stance we ultimately decide on. We’re also in contact with our Legal Team for guidance regarding additions to the Terms of Service we will need to include regarding AI-Generated Images. This is a highly divisive issue that continues to evolve at a rapid pace, so while we know many of you are anxious to receive a decision, we want to make sure we carefully consider the options before deciding. Thank you for your patience as we work on this.
As of today, 9/5/2023, we have blocked the ChatGPT bot from scraping Pillowfort. This means any writings you post to Pillowfort cannot be retrieved for use in ChatGPT’s Dataset.
Our team is still looking for ways to provide the same protection for images uploaded to the site, but keeping scrapers from accessing images seems to be less straightforward than for text content. The biggest AI generators such as StableDiffusion use datasets such as LAION, and as far as our team has been able to discern, it is not known what means those datasets use to scrape images or how to prevent them from doing so. Some sources say that websites can add metadata tags to images to prevent the img2dataset bot (which is apparently used by many generative image tools) from scraping images, but it is unclear which AI image generators use this bot vs. a different bot or technology. The bot can also be configured to simply disregard these directives, so it is unknown which scrapers would obey the restriction if it was added.
For artists looking to protect their art from AI image scrapers you may want to look into Glaze, a tool designed by the University of Chicago, to protect human artworks from being processed by generative AI.
We are continuing to monitor this topic and encourage our users to let us know if you have any information that can help our team decide the best approach to managing AI-Generated Images and Generative AI going forward. Again, we appreciate your patience, and we are working to have a decision on the issue of moderating AI-Generated Images soon.
Best, Pillowfort.social Staff
873 notes
·
View notes
Text
All the cool kids use ComicFury 😘
Hey y'all! If you love independent comic sites and have a few extra dollars in your pocket, please consider supporting ComicFury, the owner Kyo has been running it for nearly twenty years and it's one of the only comic hosting platforms left that's entirely independent and reminiscent of the 'old school' days that I know y'all feel nostalgic over.
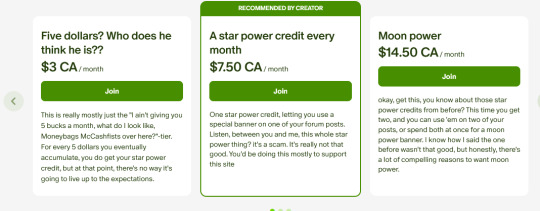
(kyo's sense of humor is truly unmatched lmao)
Here are some of the other great features it offers:
Message board forums! It's a gift from the mid-2000's era gods!
Entirely free-to-use HTML and CSS editing! You can use the provided templates, or go wild and customize the site entirely to your liking! There's also a built-in site editor for people like me who want more control over their site design but don't have the patience to learn HTML/CSS ;0
In-depth site analytics that allow you to track and moderate comments, monitor your comic's performance per week, and let you see how many visitors you get. You can also set up Google Analytics on your site if you want that extra touch of data, without any bullshit from the platform. Shit, the site doesn't come with ads, but you can run ads on your site. The site owners don't ask questions, they don't take a cut. Pair your site with ComicAd and you'll be as cool as a crocodile alligator !
RSS feeds! They're like Youtube subscriptions for millennials and Gen X'ers!
NSFW comics are allowed, let the "female presenting nipples" run free! (just tag and content rate them properly!)
Tagging. Tagging. Remember that? The basic feature that every comic site has except for the alleged "#1 webcomic site"? The independent comic site that still looks the same as it did 10 years ago has that. Which you'd assume isn't that big a deal, but isn't it weird that Webtoons doesn't?
Blog posts. 'Nuff said.
AI-made comics are strictly prohibited. This also means you don't have to worry about the site owners sneaking in AI comics or installing AI scrapers (cough cough)
Did I mention that the hosting includes actual hosting? Meaning for only the cost of the domain you can change your URL to whatever site name you want. No extra cost for hosting because it's just a URL redirect. No stupid "pro plan" or "gold tier" subscription necessary, every feature of the site is free to use for all. If this were a sponsored Pornhub ad, this is the part where I'd say "no credit card, no bullshit".
Don't believe me? Alright, look at my creator backend (feat stats on my old ass 2014 comic, I ain't got anything to hide LOL)

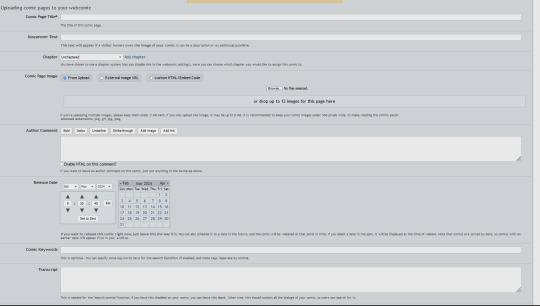


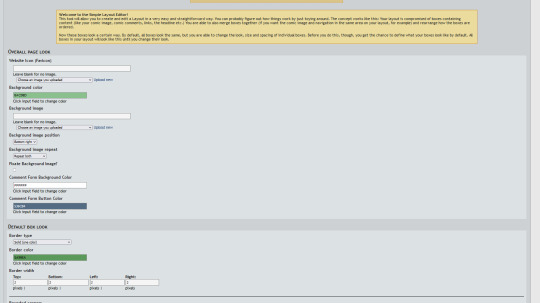

TRANSCRIPTS! CHAPTER ORGANIZATION! MASS PAGE UPLOADING! MULTIPLE CREATOR SUPPORT! FULL HTML AND CSS SUPPORT! SIMPLIFIED EDITORS! ACTUAL STATISTICS THAT GIVE YOU WEEKLY BREAKDOWNS! THE POWER OF CHOICE!!
So yeah! You have zero reasons to not use and support ComicFury! It being "smaller" than Webtoons shouldn't stop you! Regain your independence, support smaller platforms, and maybe you'll even find that 'tight-knit community' that we all miss from the days of old! They're out there, you just gotta be willing to use them! ( ´ ∀ `)ノ~ ♡
#comicfury#support small platforms#webcomic platforms#webcomic advice#please reblog#also i'm posting my original work over there so if you want pure unhinged weeb puff that's where you can find it LOL#and no this isn't a 'sponsored post'#but i have been paid in the currency known as good faith to promote the shit out of it#because i don't wanna see sites like this die out#we already lost smackjeeves#comicfury is one of the only survivors left
377 notes
·
View notes
Note
Fascinated by all the bullshit floating around regarding squidgeworld:
- "unlike AO3 it doesn't allow csem"
- "unlike AO3 it doesn't allow AI works"
- "unlike AO3 it protects your works from scraping"
- "unlike AO3 it doesn't support Israel"
Actual csem is not allowed on either site, d'uh. What some idiots call csem is allowed on both websites. Yes SW doesn't "welcome" AI works but it's not clear at all how this is supposed to be enforced. There's no protection from scrapers beyond locking your account. Those AI data sets contain fucking medical records, do you honestly think some strongly worded ToS will stop the scrapers? Lol. And finally, neither organization has (rightly) weighed in on this one war that every westerner is currently obsessed about. Why the fuck would they?
I'm actually trying out SW right now but I'm a little concerned how many posts on Tumblr about it boil down to "I'm leaving the nasty AO3 for the morally superior SW." I post nasty stuff and I don't want to be harassed.
--
Squidgeworld has been around forever. I would not expect the owner to take kindly to puritywankers harassing people.
99 notes
·
View notes