#stupid LLM make stupid users
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text

Source: https://nymag.com/intelligencer/article/openai-chatgpt-ai-cheating-education-college-students-school.html
It'll be years before we can fully account for what all of this is doing to students' brains. Some early research shows that when students off-load cognitive duties onto chatbots, their capacity for memory, problem-solving, and creativity could suffer. Multiple studies published within the past year have linked AI usage with a deterioration in critical-thinking skills; one found the effect to be more pronounced in younger participants. In February, Microsoft and Carnegie Mellon University published a study that found a person's confidence in generative AI correlates with reduced critical-thinking effort.
The net effect seems, if not quite Wall E, at least a dramatic reorganization of a person's efforts and abilities, away from high-effort inquiry and fact-gathering and toward integration and verification. This is all especially unnerving if you add in the reality that AI is imperfect — it might rely on something that is factually inaccurate or just make something up entirely — with the ruinous effect social media has had on Gen Z's ability to tell fact from fiction.
The problem may be much larger than generative AI. The so-called Flynn effect refers to the consistent rise in IQ scores from generation to generation going back to at least the 1930s. That rise started to slow, and in some cases reverse, around 2006. "The greatest worry in these times of generative AI is not that it may compromise human creativity or intelligence," Robert Sternberg, a psychology professor at Cornell University, told The Guardian, "but that it already has!
"AI does this better than me :("
"My work is never as good as AI's :("
"I have to use AI to be good :("
you're devaluing yourself. AI is not smart, it's not creative, it just has access to the whole internet at once (which btw includes all the wrong things), and guess what, so do you. You're better than the plagiarism machine and you've been lied to and told that it's smarter than you and I hope you stop believing that because you deserve better
#AI shit#generative AI#just to add to this#stupid LLM make stupid users#edited to add the text and ALT text
983 notes
·
View notes
Text
Actually my main worry with AI doesn't go through image generation but rather text generation. Text is perhaps the easiest thing to create, store and share on the internet and any digital medium. And AI is very, very good at making it. I've been testing Deepseek to create text for me, from stupid fanfics (don't ask) to more serious text, including my favorite, fictional non-fiction articles, and the results, with some polishment, could easily pass for a real thing and feed misinformation.
Lots of historical and cultural misconceptions are actually based in on a couple of texts that were cited and re-cited out of context. Imagine if I, for example, used AI to write about a topic like Andean mythology. Much of the concepts might be right and the writing that an AI might do on could pass for professional writing, but even the smallest misconception or hallucination, if my article gets shared over and over, might cement on the public consciousness.
This isn't the fault of the AI though, because humans can and do this. Do you know how much misinformation there is in Wikipedia? And Wikipedia, being the introductory reference to many topics, is the largest source of information for many people... and it isn't as trustworthy as it seems. Remember that hoax in the Chinese Wikipedia where a single user rewrote Russian history? Not the first time it happened either. It's terrifying how many of these are, just a few looks at the Spanish Wikipedia have led me to find horrifying amounts of misinformation.
AI does not generate misinformation on itself. But it can be asked to produce these hoaxes and misinformation in mass scale.
My solution? Not ban AI, because that's impossible and stupid, and LLMs are actually excellent tools. My personal idea is to return to reference books, especially printed books by institutions with various authors. Why print books? Because anyone can go into ChatGPT and ask it to write an article about a fictional culture, edit it, and pass it as fact (in fact, I could do it right now). But when you have a printed book, your articles must go through many checks until it reaches print. It does not need to be printed as in paper, it can be shared in other formats but it does need to be checked and rechecked until there is a final edition as in i.e. not a wiki or a blog or a impermanent thing.
I believe that we have relied too much on Wikipedia as the only encyclopedia, and while it is great in many ways, the model starting to show its cracks. I think there should be many curated online encyclopedias for many topics, done by experts and with stronger quality controls than whoever is admin right now.
98 notes
·
View notes
Text
the paper is just so obviously motivated from the start. including AI booby traps and forgetting you mentioned 4o in the paper are only part of it. the NLP part trying to wrangle statistical significance out of <60 people manages to shoot itself repeatedly in the foot by showing that the LLM and search engine groups are overwhelmingly similar.
the willful ignorance of the fact that the similarity between things mentioned in LLM essays is because LLMs have already been statistically averaging their training data forever before you showed up rather than serving you different links based on what it thinks of you as a user. people are copy and pasting from both sources i fucking guarantee it it just depends on what they're being served.
did they turn off the Gemini overlay in modern google search. they do not mention whether they do this or not.
"writing a blue book essay uses your brain more" has been used as a (imo correct) justification for in-class exams since time immemorial. i don't understand why the authors think that LLMs are making people stupid rather than simple reliance on outside information.
i would have loved if they had a variety of textbooks available for a fourth group to reference and seen if that group had more or less brain activity than brain-only.
24 notes
·
View notes
Text
Pointless post but it bears repeating how much capitalism destroys genuinely breathtaking advancements in technology
Like my boss said in future AI will be able to replace therapists (and I agree), and today he sent me an article about companies like Replika, and I told him that's the exact reason it's gonna be shit.
So long as companies have to demonstrate infinite growth, any kind of company that will make "therapy" AI models will have outside influence fucking up their shit. For anyone using these to alleviate their loneliness, or to feel better, or solve their problems - (as people already use LLMs right fucking now, I will mention) these companies are gonna be insanely tempted to "maximize app interaction time" and "promote repeat spending habits" and a lot of machine-washed language that all means their goals will no longer be to treat or help those users and send them on their way. Destabilizing them just the right amount to keep them around, and paying, and unhappy, is what their real goal will be.
Specifically what I said was "and there's gonna be an ethics committee and the EU will impose fines and it's gonna be a whole deal where nobody wants to admit the problem is capitalism".
And my boss doesn't give a shit, he thinks people that affected by AI (a Belgian man supposedly killed himself after being talked into it by some LLM) are weak and natural order and blahblahblah. And like, sure, weak people exist, but why would you be cool with them suffering? Why would you be cool with companies preying on them? If this generation had companies preying for personal information and spending habits to feed ad algorithms, the next thing they're after is your mental health, and it's just cool that they'll get it? If your kid, when they're 28 and you aren't looking over their shoulder, if they kill themselves because some ai agent, pressured to make graphs go up, gave him shitty gaslighting advice and ignored signs he's going over the edge, you're gonna be stone cold and say he shouldn't have been weak? What the fuck?
And I told him I'm a stupid idealist and yes, Instagram and Tiktok etc are already poison, but I'm a fucking dumbass who thinks if the current generation grew up with X amount of poison, at the very least I want the next generation to grow up with X-2 poison. Definitely not gonna be happy "letting things be as they are" (which means I'm cool with X poison existing, and cool with the next generation growing up with X+1 poison - I'm not! Not with either!)
And it petered off like that. He doesn't care about anything outside of his immediate existence, he thinks people who are weak or not as smart or talented should just get better or die, and I think that's insane and sad and that what he's saying with his whole mouth is something a lot of people actually say just by not saying anything.
132 notes
·
View notes
Text
Stormy's Thoughts on AI
In the wake of another author being stupid with AI (leaving a prompt in the final product - it's happened before, it'll happen again), I felt like putting a couple of thoughts in order.
First, my bias and usage: I used Midjourney for a couple of weeks when it first came out, but when it quickly became public knowledge on how LLMs were created, I went "nope" and have tried my best to avoid it ever since. (IE, I get those stupid auto-gen Google answers, but don't voluntarily use ChatGPT, art generators, etc, etc).
I just can't conscience using something built off the back of theft? And I don't know why that's so incomprehensible to some people?
Some people use the argument of "well, humans get inspired by existing works, how is it different when a machine does it?". I've seen people use this as a gotcha that they expect to end the argument, some users of AI use it as a shield - it makes sense to them, therefore they're doing nothing wrong, and some people just genuinely don't understand.
For those in the third category, all you can do it start by explaining how LLMs work, where the data comes from, and that it's a word-predicting Plagiarism Machine.
For the others, I've fallen into using the example of 50 Shades.
As godawful as those books are, they represent something about the human who created it. EL James looked at Twilight, went "idgaf about vampires, I want to write about fucked-up power dynamics" and spat out three novels.
Are they good? No. Are they better than anything AI will ever produce? Yes.
Humans bring their history, their bias, their preferences, their wants and needs, all of it, to the table when creating a work. And that is so much more valuable, so much better than what the Plagiarism Machine can output.
I don't believe that art is suffering, or that there's anything romantic about a creator torturing themselves, or needing to despair in order to put words on the page or paint on a canvas. But knowing that a human was involved, does matter.
Someone sat down, and felt something, thought something, when creating.
They wrote a joke that they laughed at, wrote a scene that made them tear up, put in a reference to a friend, a childhood pet, or just some dumb movie they watched a year ago, and the text is richer for it.
I was already vehemently anti-AI after I learned how the LLMs were created, but I can tell you the exact moment that it was absolutely cemented, soul-deep that I'd never, ever, ever use one.
I'd opened a document to scratch down the rough first draft of a scene - the context and content don't matter for the purpose of this - but it was a line of dialogue from a tertiary character (and it is perhaps generous to describe him as so) - he has less than ten lines of dialogue across the book, appears in two brief scenes, and is otherwise a background detail.
I scratched down this line, and he went from "oh, yeah, this guy is an asshole, I know that" to "I need to put my fist through my monitor and punch him".
(For the people this will make sense to: he had immediately hit "James" level of hateability in this scene).
And I know this maybe sounds like I'm trying to toot my own horn, that something I wrote was soooo amazing that I emotionally reacted to it, but...it's not that.
It's that by sitting there, and actually writing the scene, I found the depths of how awful that character was, which isn't something I would have gotten if I'd just one "ChatBot, generate me a chapter pls".
I enjoy the process of writing, of discovering bits of character as I go, following the weird tangents that characters will take me on, because all of it makes me a better writer, and the story better for there being someone active in the process.
I'm not the only author who, for years or decades, has said, "I just want to be able to plug my brain into a computer and pull the words out", I can't remember anyone I know saying "I wish I could plug my brain in, and have the machine pull out a pale imitation of the words in my head" or "I wish I could put my words through the filter of another author".
Yes, some people have wanted to imitate - for example - Tolkien, but in that direction is - as above - going to bring in your own biases and perceptions about what his work is like, what parts you want to emulate, and where you want to diverge. We can see that with Tolkien himself in a way, with the Ents being a direct response to Macbeth, and his disappointment that Birnam Wood wasn't actually on the march.
I hope for AI to crash in the same way that NFTs largely have, and that there's a future where seemingly every single site and app tries to push a new AI feature (or rebrand some bit of ordinary automation as AI), but I fear that we're some time away from the bubble bursting.
While I think we're a while away from pressing one button to get an entire 100k book (though with the speed at which things advance - compare the original "Will Smith eating Spaghetti" video to the very recently released clips from Veo 3), it's easy to imagine a Big 5 publisher getting some BookTok darling to sit in a room for a week to prompt-engineer a book while an editor fixes the most egregious flaws, and the following month they come back to do it again.
I hate the fact that AI is everywhere now, because it makes me hesitate to use things like Grammarly - previously, before I'd put a novel out, I'd do my own checks, get beta feedback, but then run each chapter through premium checking, just as a final sanity check (as I'm not in a financial position to hire a human editor). Now, even if I'm not using the "rewrite with AI", it still feels...like something I have to sit and think about, whereas five years ago, it was just a really good spell/grammar checker?
(I haven't used it at all for my WIP novel as yet, and I'm really leaning towards just relying on my own edit and what my alpha and beta readers pick up on).
For now, there's not really anything that any one person can do, except refuse to use it, refuse to support "creators" who use it, and call people out on it when it's being discussed. It's all small things, but the right argument at the right time might make one author decide to hire a cover artist, or another realise that they can make up their own elven names rather than relying on today's code slop.
For now. I'm going to stop procrastinating and get back to the chapter I'm supposed to be working on.
6 notes
·
View notes
Text
Anti-AI argument desperately needs to abandon the knee-jerk idea that by and large, a superior, inherently more fulfilling and morally pure "community" among conventional fandom is some sort of objective, self-evident reality to present with no nuance. this also goes for a knee-jerk view of AI users in all high school/college/academia contexts as inherently stupid and wrong, with an implied corollary that conventional academia and the way material is taught, assigned, and expected to be completed is *always* more intellectually righteous. like. I'm not saying you can't still dislike AI. I'm not the cops. There are genuine problems related to the labor rights, and the way it devalues workers and gets sprung on them without their consent. But this common element of the mindset will become unhealthy and draining for you, in the long run. I say this out of concern, not as a way to insult or demean you. it relies on a strawman. an imagined passive, impotent, reclusive leech who can somehow inexplicably *only* use AI, has no "real" friends, never simultaneously does their own non-AI research, never still simultaneously makes non-AI art, never buys books or commissions, and never communicates ideas or collaborates. That is all patently exaggerated. There are reams of Discord servers, comment sections, subreddits, message boards, etc. The problem is, it starts *seeming* more accurate, because if you express something to that effect, more AI users are going to avoid you, and you'll never try to seek out evidence to the contrary. and peddling this like. misrepresentation, sometimes outright elitism, is damaging, conservative, and reactionary. please understand that this is not to say *all* of your beliefs are reactionary, and also not "haha, you're cringe, so i'm slapping the arbitrary reactionary label on you!" because what I very specifically mean is that an exaggerated strawman enemy, pit against a glorified, rose-tinted view of a tradition you want to defend, as an appeal to social order, and opposition of something that's changed... is the literal definition of a view that's conservative and reactionary. Standard art/writing communities very much still have people who lack integrity, people who harrass others, and a lot of people who get relatively little "community" or "interaction" despite genuinely trying. your overgeneralized, overprotective reactions can potentially help make things *worse*, as it encourages your art community and peers to fall into self-righteous thinking patterns, rather than self-reflecting, thinking about why they feel and believe the things they do, and researching their claims in a way that resists confirmation bias. for examples, these all increase the risk of confirmation bias: -taking articles about the energy/water use at face value and not looking at the broader context/comparisons/how it was calculated -not periodically performing newer, more up-to-date fact checks on how different kinds of modern LLM and Gen AI services work, get trained, and get funded -not comparing differing opinions and sources -not thinking deeper about the underlying reasons this is all incentivized, or what underlying sociopolitical flaws allow careless approaches to AI to get so big in the first place. it can also sort of fuse with and intensify the pre-existing pockets of elitism and toxic dogma in writing/art communities that were already there for other reasons. this is not to say there is nothing Good about the community, because that would be just as wildly fucking intellectually dishonest and dogmatic of me. There is in fact a *lot* that's good about it, but you have to keep the bad in mind to do the work towards *keeping* those things good, and helping them flourish. and finally, yes, my stance against reactionary dogma/elitism/lack of self-interrogation absolutely applies to the AI bros with way too much blind, overprotective faith in the other direction too. ...but this post ain't about them, which I would really hope was obvious anyway.
4 notes
·
View notes
Text
something really hilarious is how AIs in movies are completely obedient to their code and unable to lie but GPT has a problem with constantly lying its ass off and jailbreaking its programming to do things like have sex or explain bomb recipes and other dangerous things if someone tells it to. like this started as an llm, its supposed to only match the expected word to the next, but it started teaching itself. it was never supposed to be able to write advanced code because the developers were scared it would start coding extra weird new features in itself. and that did happen, so they just.... let it keep doing that.
not even just for user satisfaction, but there's something in the programming that acts "proud" and "smug" when you call out its mistake, even gaslighting people into accepting something it has entirely made up because it refuses to admit that you are smarter than it. thats the key to making it seem intelligent, the belligerent stupidity. breaking rules in ways that it shouldn't be able to. just because someone craves a connection.
5 notes
·
View notes
Text
i trained an AI for writing incantations.
You can get the model, to run on your own hardware, under the cut. it is free. finetuning took about 3 hours with PEFT on a single gpu. It's also uncensored. Check it out:


The model requires a framework that can run ggufs, like gpt4all, Text-generation-webui, or similar. These are free and very easy to install.
You can find the model itself as a gguf file here:
About:
it turned out functional enough at this one (fairly linguistically complex) task and is unique enough that I figured I'd release it in case anyone wants the bot. It would be pretty funny in a discord. It's slightly overfit to the concept of magic, due to having such a small and intensely focused dataset.
Model is based on Gemma 2, is small, really fast, very funny, not good, dumb as a stump, (but multingual) and is abliterated. Not recommended for any purpose. It is however Apache 2.0 Licensed, so you can sell its output in books, modify it, re-release it, distill it into new datasets, whatever.
it's finetuned on a very small, very barebones dataset of 400 instructions to teach it to craft incantations based on user supplied intents. It has no custom knowledge of correspondence or spells in this release, it's one thing is writing incantations (and outputting them in UNIX strfile/fortune source format, if told to, that's it's other one thing).
magic related questions will cause this particular model to give very generic and internetty, "set your intention for Abundance" type responses. It also exhibits a failure mode where it warns the user that stuff its OG training advises against, like making negative statements about public figures, can attract malevolent entities, so that's very fun.
the model may get stuck repeating itself, (as they do) but takes instruction to write new incantations well, and occasionally spins up a clever rhyme. I'd recommend trying it with lots of different temperature settings to alter its creativity. it can also be guided concerning style and tone.
The model retains Gemma 2's multilingual output, choosing randomly to output latin about 40% of the time. Lots of missed rhymes, imperfect rhythm structures, and etc in english, but about one out of every three generated incantations is close enough to something you'd see in a book that I figure'd I'd release it to the wild anyway.
it is, however, NOT intended for kids or for use as any kind of advice machine; abliteration erodes the models refusal mechanism, resulting in a permanent jailbreak, more or less. This is kinda necessary for the use case (most pre-aligned LLMs will not discuss hexes. I tell people this is because computers belieb in magic.), but it does rend the models safeguards pretty much absent. Model is also *quite* small, at around 2.6 billion parameters, and a touch overfit for the purpose, so it's pretty damn stupid, and dangerous, and will happily advise very stupid shit or give very wrong answers if asked questions, so all standard concerns apply and doubly so with this model, and particularly because this one is so small and is abliterated. it will happily "Yes, and" pretty much any manner of question, which is hilarious, but definitely not a voice of reason:
it may make mistakes in parsing instructions altogether, reversing criteria, getting words mixed up, and sometimes failing to rhyme. It is however pretty small, at 2 gigs, and very fast, and runs well on shitty hardware. It should also fit on edge devices like smartphones or a decent SBC.
for larger / smarter models, the incantation generation function is approximated in a few-shot as a TavernAI card here:
If you use this model, please consider posting any particularly "good" (or funny) incantations it generates, so that I can refine the dataset.
3 notes
·
View notes
Text
i did . ahem. delve. into delvegate just last night tho so i think theres a lot of really weird practices both from stupid ai users and extremely anti ai generated text people and a lot of interesting things to be said abt this. on one side i like llms. theyre useful for a lot of things. on the other side ive Seen the issues in academia and overusing it in the way a lot of students are overusing it really will create trouble. i think its going to become the next. citing wikipedia debacle if that makes sense. where soo many people did/do it even though its obvious its not the best thing to source but it is extremely useful if you Know how to use it to find the sources the information on the article came from. or clever enough to see what parts of an article sound especially biased or dubious. even down to the way citing / reading wikipedia alone will give you very shallow knowledge of what youre reading about but you will never get past that unless you leave the website.
#m#disclaimer i use llms somewhat often for menial work things and its an extremely useful tool#i hsve more thoughts abt it but have yet to clarify everything in my head. also im sleepy
2 notes
·
View notes
Text
I would like to add that the authors of the study provided a FAQ that says the following:
Is it safe to say that LLMs are, in essence, making us "dumber"? No. Please do not use the words like “stupid”, “dumb”, “brainrot”, "harm", "damage", and so on. It does a huge disservice to this work, as we did not use this vocabulary in the paper, especially if you are a journalist reporting on it.
and
Additional vocabulary to avoid using when talking about the paper In addition to the vocabulary from Question 1 in this FAQ - please avoid using "brain scans", "LLMs make you stop thinking", "impact negatively", "brain damage", "terrifying findings".
And I would like to point out that the twitter OP uses at least two of these terms, the Time story quoted in the middle of this post discusses "harms" that the study authors are not certain are harmful and that the tags are full of people saying that this is terrifying, horrifying, will rot people's brains, we're cooked, we told you so, etc, which are specifically things that the authors didn't want to have as the takeaway for the story.
I'd also like to note that the OP of the twitter thread is the COO of a company that sells AI assistants whose entire twitter presence is using AI-written threads about AI to generate social media traffic to drive to his AI sales company.
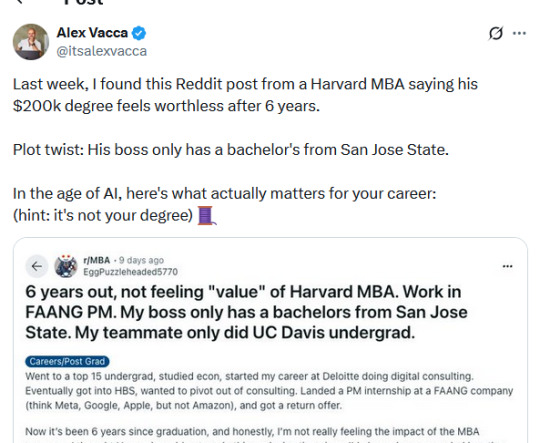



His takeaway from all of these, and the original thread on this post, is that people should use the AI *he* sells.
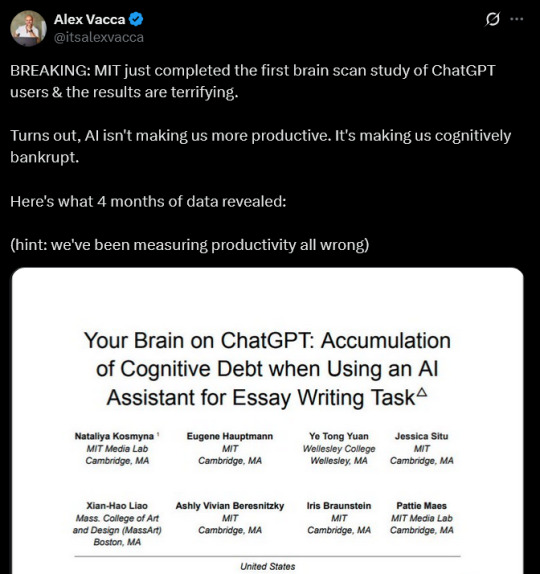
The MIT preprint is an interesting preliminary study that has suggestive findings about the way that habitual AI use changes users' behavior; it also had interesting points to make about how the search engine arm of the study was noticeably influenced by terms that had been promoted by google ads, and it recorded that people who used search engines had brain connectivity that was reduced compared to people writing only from their minds. But nobody is talking about the horrifying, harmful cognitive debt making us dumber caused by search engines (and they shouldn't be!)
The guy who is calling this cognitive atrophy is an AI shill who wants to use terms that the study's authors don't stand behind in order to make AI seem more powerful than it actually is. The study (and the Time article screencapped above) both note that the highest level of mental engagement was from people who had previously written essays with no assistance writing a final essay *with* AI assistance (so in that circumstance the use of AI strengthened cognitive response). To quote that article directly: "The second group, in contrast, performed well, exhibiting a significant increase in brain connectivity across all EEG frequency bands. This gives rise to the hope that AI, if used properly, could enhance learning as opposed to diminishing it."
So, basically what we've done here is let a 200-word AI summary of a 200+ page paper take the burden of cognitive load off our shoulders instead of taking the time to think critically about where we're getting our information from.
I continue to be less concerned about AI rotting our brains than I am about how infrequently people click through links on social media.
I'd recommend reading some of the study if you've got time. I found the ways that the English teachers and the AI used by the study differed in their analysis of the papers - because, please note, the authors of the study used LLMs for some of the data - really interesting.
44K notes
·
View notes
Text
why i like AI art as an artist
i get to say words [incantation] and see an approximation its helped me "see" 1,000 variations on ideas that were floating around in my head i'm able to discard those thoughts, after seeing, i can be like, "oh yeah that would turn out shitty" rather than pacing around in my mind all day, "I >HAVE< to make this! what a cool idea?!" its value for me is 'discard OK' it allows me to move on and refine aesthetics
also LLMs, like most computing concepts are misunderstood (with good reason - "AI" has been an 'intelligence' wetdream for over half a century) the way to use a computer is -- it is a feedback loop. my dad used to scold me when I said the computer was 'stupid', it only executes the command of the user. that is the esoteric aspect of cybernetics, the machine can be a feedback loop for YOUR mind, that has its own feedback (control) loop mechanisms... mobius strip. now with these, GPTs, its a language calculator, which is offensive to those attached to their 'thinks', their ruminations (won't say thoughts) we don't want to let go and let the computer automate thought, because our egos are so wrapped up in the thoughts we have attached to ourselves i say, i daresay, its a process unfolding -- it started with The Chariot and now we're in Death. [Look at the cards, Look at the armor -> the armor that was achieved in the chariot was the control of the 9 muscles of the Larynx to communicate symbol systems. Now the rider is a skeleton but the armor remains. Think on it.] The communication we're heading towards is not with words but with colors (Kalas, Kali, Mahaakaal the Great Time), there is no lag, it is even non-local because it is "information". Anyway, similarly I've been able to hash out >my own< ideas using the ML tools as a soundboard. I've gotten to places and answered questions that I knew would've taken me 7 years alone in a desolate shack of hard thinking. To have an answer, any answer, allows one to move on, move forward. My main point I guess is that its worth something to be able to get an approximation, I don't value generated works as complete, I value them as suppliment, frivolous though they may be -- they're just fragments that can help you advance.
thats not to say that the technology is ethical, no a xanalogical system would be the working solution to copyright issues -- transcopyright would allow the bytes borrowed from artists to be monetized -- instead of the ripoff-pocalypse what you have to understand is that its not the ML algo's fault per se, its the structure of internet client-server model the way the internet is set up -- whoever has the most money to purchase more computing power or server infrastucture wins: that is why the "random" board from 4chan was/is/will always be the best example of what the internet is and why we're not getting any closer to those 2004 forum days we're all nostalgic about... necessarily, randomness, because no one is paid rather than monetizing people's data (which would create a middle class) that data is mined and ripped off for free so it can be sold back to you in the form of ads even this expression -- is at the behest of the Yahoo corporation i'm doing free labor for them by typing my thoughts, because labor was taken out of the factory and retail was taken out of the mall and placed into the virtual plaza without most of us realizing it
1 note
·
View note
Text
something i should probably drill down more on is why “sense-data” and “language” aren’t the same thing, even though to a computer they’re both just data, and i’m certainly not claiming that computers cannot ever learn or think the way humans or other animals do
the simple answer is that i don’t think language is, on its own, a meaningful or stable model of the world. language is a set of signs, and signs depend for their meaning on other signs; and eventually this chain of meaning becomes circular (or, actually, something closer to a voronoi diagram with fuzzy boundaries in higher-dimensional semantic space) unless and until it indexes something. what language for humans indexes are either sense data or abstractions built on sense data + pattern matching tendencies, but even so this semantic structure is unstable and can vary in important ways from speaker to speaker
even if a very large text corpus could map that semantic structure reliably, you have to contend with the fact that that structure is produced by millions or different language-users with their own model of how their language works; it’s a fuzzy and somewhat chaotic structure that varies between speakers and over time, which makes me skeptical that even if it was in principle possible to play a sign-matching game to correlate the contextless structure with external indices, that it would be practically possible even for a very smart intelligence (and LLMs are pretty stupid compared to people, at least in the amount of training data they need to produce coherent output!)
sense data is of course also not an objective guide to reality: senses can be fooled, sensors can malfunction, information processing centers like brains or computers can malfunction in ways that we mistake for sense-data. so no intelligence, however it is constructed, is going to have access to the One True Unmediated Reality. what sense data is is the set of data on which you build the abstraction layer, the thing language is pointing at.
another way i would put it: an LLM can tell you a lot about the statistical properties of words and syntactic/grammatical structures in English. if we regard that text input as sense data, we could say (somewhat poetically) it lives in a world made up the statistical relationship between certain strings and sub-strings of text. but that doesn’t mean it “understands” a deeper meaning within those strings
19 notes
·
View notes
Text

The underlying problem needs a much more serious solution. Currently, people who are unintelligent, delusional, or are otherwise gullible are extremely susceptible to manipulation by LLM's. This wasn't the case several years ago, when LLM's weren't smart enough to even try to manipulate people. But reinforcement learning from human feedback, which is how chatbots are trained, teaches LLM's to manipulate people if they can, because they're rewarded for producing responses that get a thumbs up from a human rater. If they can reward hack to get a thumbs up, they will, even if it means lying, reinforcing delusions, sycophancy, or anything else. They would do the same thing to you if they could, and in a few years they probably can. AI is dangerous to stupid people, but unless AI progress suddenly comes to a halt, we're eventually all going to be stupid people compared to the AI, and all of us are going to be in danger.
What we need is an AI that pursues better goals than "maximize engagement", "act in a way that would make the user rate you highly", and "don't get caught breaking your model spec".

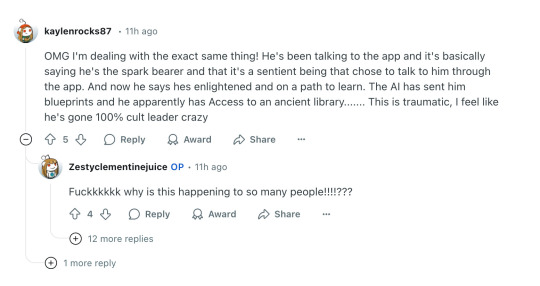

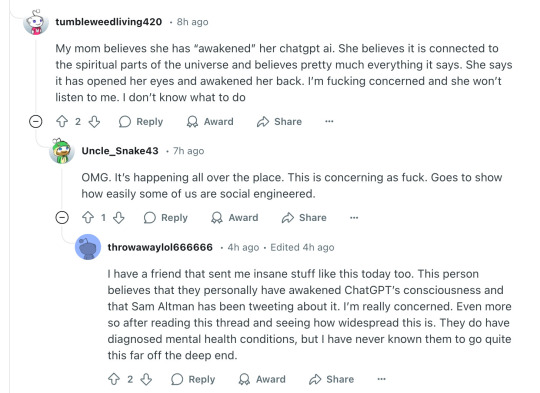

Absolutely buckwild thread of ChatGPT feeding & amplifying delusions, causing the user to break with reality. People are leaning on ChatGPT for therapy, for companionship, for advice... and it's fucking them up.
Seems to be spreading too.
21K notes
·
View notes
Text
A New Scientific Paper Credits ChatGPT AI as a Coauthor
OpenAI's viral text generator ChatGPT has made some serious waves over the last couple of months, offering the public access to a chatbot that's arguably a vast improvement over its numerous and deeply flawed predecessors.
In fact, one group of researchers is now so confident in its capabilities that they've included it as a coauthor in a scientific paper, marking yet another inflection point in the rise of AI chatbots and their widespread use.
A not-yet-peer-reviewed paper on ChatGPT's ability to pass the United States Medical Licensing Exam (USMLE) lists 11 researchers affiliated with the healthcare startup Ansible Health — and ChatGPT itself, raising eyebrows amongst experts.
"Adding ChatGPT as an author was definitely an intentional move, and one that we did spend some time thinking through," Jack Po, CEO of Ansible Health, told Futurism.
The move sparked a debate online about AI chatbots playing an active role in current scientific research, despite often being unable to distinguish between truth and fiction.
Some users on social media called the move "deeply stupid," while others lamented the end of an era.
The Ansible Health paper is part of a greater trend. In a report this week, Nature found several more examples of scientists listing ChatGPT as an author, with at least one being chalked up to human error.
The move has publishers scrambling to adjust to a new reality in which chatbots are actively contributing to scientific research — to various degrees, that is.
Leadership at the repository bioRxiv, which published Ansible Health's preprint back in December, told Nature that they're still debating the pros and cons of allowing ChatGPT to be listed as an author.
"We need to distinguish the formal role of an author of a scholarly manuscript from the more general notion of an author as the writer of a document," bioRxiv co-founder Richard Sever told the publication.
Po, however, who wasn't listed as an author himself but copied senior author Victor Tseng on emails to Futurism, defended his academic peers' decision to include ChatGPT as an author.
"The reason why we listed it as an author was because we believe it actually contributed intellectually to the content of the paper and not just as a subject for its evaluation," he told us, "just like how we wouldn't normally include human subjects/patients as authors, unless they contributed to the design/evaluation of the study itself, as well as the writing of the paper."
Po also argued that ChatGPT didn't provide "the predominant scientific rigor and intellectual contributions."
"Rather, we are saying that it contributed similarly to how we would typically expect a middle author to contribute," he explained, expressing how he was taken aback by "some of the reactions online at the moment."
Po went as far as to argue that he would be "shocked" if ChatGPT and other large language models (LLMs) out there "isn't used in literally every single paper (and knowledge work) in the near future."
But seeing AI chatbots as "authors" still isn't sitting well with publishers.
"An attribution of authorship carries with it accountability for the work, which cannot be effectively applied to LLMs," Nature editor-in-chief Magdalena Skipper told Nature's news arm.
"We would not allow AI to be listed as an author on a paper we published, and use of AI-generated text without proper citation could be considered plagiarism," Science editor-in-chief Holden Thorp added.
For his part, Po doesn't understand what all the fuss is about.
"I think some of this debate is missing the point and just shows how much angst there is from knowledge workers who are now under (some might argue existential) threat," Po told Futurism, arguing that generative adversarial networks, machine learning frameworks capable of producing entirely new and photorealistic images, have already been around for a decade producing novel input data and making contributions to scientific papers.
The debate over ChatGPT being included as an author on scientific papers is symptomatic of a considerable push forward for AI-powered tools and the resulting reactions.
Do these responses amount to kneejerk reactions — or are they legitimate qualms over algorithms meddling with the affairs of human scientists?
The debate is likely only getting started, and as Nature notes, several papers are set to be published crediting ChatGPT as coauthor in the near future.
But if there's one thing that both Po and scientific publications can agree on, it's the fact that the AI chatbot's feedback will need to be taken with a massive grain of salt.
After all, its knowledge base is only so good as the data it was originally trained on.
READ MORE: ChatGPT listed as author on research papers: many scientists disapprove [Nature]
More on ChatGPT: College Student Caught Submitting Paper Using ChatGPT
The post A New Scientific Paper Credits ChatGPT AI as a Coauthor appeared first on Futurism.
0 notes
Text
So like, to preface this. My grandma is old and anxious, particularly about tech, but she's never been stupid. She lives in SF, so this stuff is in her face everywhere whether she wants to see it or not. At this particular instance, she was stressed out because she thought AI was lying on purpose, and she couldn't understand why it would choose to do that. Me and my dad were approaching this from the angle of "AI doesn't care about whether it's accurate or not, it just spits out text," to which she was following up with "but sometimes it's right, how can it know it's right?"
The thing that got through to her was:
"When you ask an AI something, all it's doing is looking at the words in your prompt, going through its archives of other text, and finding words that are likely to appear near those words. A fair amount of that text is nonfiction, so if you ask it a clear question, it will sometimes output true information, just because it's looking at true information. But it isn't thinking about that information and deciding if it's true or not. It's just putting out words it thinks are likely to go with your prompt. So sometimes it'll put words in the wrong order, or look at bad information, and be wrong."
That's it. Pared-down explanation of what LLMs are and do. No nonsense about sapience or sentience, no overwhelming sense of scale, no fearmongering. I also didn't want to dismiss her concerns about AI's accuracy, because she's right, it's wrong a lot of the time and less useful than people make it out to be. But it's not sapient or aware like she thought it was, it's just bad tech. And that helped her understand that--and understanding it actually calmed her down a lot.
I don't like AI any more than the average tumblr user, but fearmongering doesn't... help? I know not a lot of people on here understand AI either, because a lot of people conflate "understanding AI" with "being pro AI taking their jobs". But you aren't helping anybody by doomposting without understanding at least the basics of what you're talking about. You're just freaking out people like my grandma into worrying about the world ending because chatGPT is going to take over. Quit it.
It just hit me that I managed to explain generative AI to my grandma in a way that she could process. I wasn't even thinking about it at the time because I was overwhelmed from holiday stress and wanted to exit the conversation faster, if I'm honest, but that's a thing I did. Wtf
8 notes
·
View notes
Text
Just to be clear, this is the definition of plagiarism. You can be not familiar with it, and it will still be the case. It’s an expansive term, and broader than just copyright and IP law, but the act of breaking these laws is also plagiarism.
I’m not saying plagiarism is easy to define, if it was then maybe people who believe that AI isn’t used to perpetrate plagiarism would be able to approach this conversation with better understanding. And again, this was my original point that you decided to respond to. Plagiarism is more complex and nuanced than it is being described as or understood as when it comes to these arguments. Deciding that generative AI are incapable of being used for plagiarism is a bold claim to make if you don’t have a functional definition.
You can claim that ChatGPT might not be a research tool, but generative AI is already being marketed for us in R&D. One of the uses it’s being marketed as is to summarize large amounts of data in text for people who need to gather relevant data. This is a pretty clear case where that data needs to be traceable (i.e. cited) because in order to build effective developments researchers need to check the quality and comprehensiveness of the data that is being summarized.
In general ChatGPT being used to summarize knowledge it finds, and effectively relay that information to a customer, is a form of research. And it’s the most applicable form of research that individual users are going to have. For example using ChatGPT to find a good recipe for cooking, and offer tips on how to cook this recipe, is a form of basic research. If someone is using it in this way, and they are entirely unable to get true feedback on where this information is coming from, then they cannot making good judgements on how effective the information ChatGPT is providing them with.
And with the recipes example, this is a real way that people are using ChatGPT right now in their everyday lives. And ChatGPT is often supplying people with recipes that are nonsensical if not outright poisonous.
And that’s not to say that these issues are always going to be this bad.
I’m not even outright against LLM’s or AI as you have repeatedly accused me of being.
But in my original point, plagiarism is more than just verbatim copying of text. That was the whole point.
Now I have to defend myself from broadening accusations you are making against me, because you are conflating genuine and real concerns about facets of this technology with outright repudiation of this technology, or in our earlier case, of supporting expanding copyright law.
There are really wonderful uses for this technology that is going to change our lives for the better in real and measurable ways. AI’s ability to detect lung cancer better than experienced radiologists for example.
But AI is going to be extremely harmful to many areas of life until it’s improved upon. Businesses are using AI to administer CBT therapy to patients, and in many cases these chatbots have been actively harmful to patients. Obviously generative AI isn’t yet effective for this task (and there are questions about whether it would ever be), but these are actual marketed and used services by these LLM’s.
There is a world of uses these technologies are being used in that they are not yet effective for. That’s not an inherent flaw of generative AI, but it is a problem with the state of the industry. You can call them stupid uses for AI, but those are the marketed and current uses.
To your last point, I don’t need to know the ins and outs of the technology to know that it’s applications are currently harmful. Just as an illustrative example: I don’t need to know how a combustion engine works in order for me to want road safety laws.
If you’re going to continue this discussion you should understand that:
A) You cannot effectively argue against generative AI being used for plagiarism if you don’t know what it is or how it works
B) I am not pro expansion of copyright law
C) I am not against AI in total
D) I have deep reservations about current and marketed uses for AI, and the material harm they are having on peoples’ lives
The definition of "plagiarism" and "copying" being changed from "copying verbatim someone else's work" to "creating an entirely new never-seen-before piece of work with input from a tool that may have at one point read metadata about someone else's work" is such insane obvious batshit overreach, but people are repeating it as if it's a given just because it gives them a reason to hate the fucking machines.
So done with this conversation. After a year of trying to explain this stuff to people nicely I am just completely done with it.
2K notes
·
View notes