#types of data bias
Text
With the aim of creating a human genetics devoid of social prejudice, the data were to be gathered with scrupulous care, and as much of the information as possible was to concern unambiguous traits, particularly, of course, blood groups.
"In the Name of Eugenics: Genetics and the Uses of Human Heredity" - Daniel J. Kevles
#book quote#in the name of eugenics#daniel j kevles#nonfiction#genetics#heredity#prejudice#bias#data collection#scrupulous#unambiguous#blood group#blood type#blood
0 notes
Text


Gelatopod - Ice/Fairy
(Vanilla-Caramel Flavor is normal, Mint-Choco is shiny)
Artist - I adopted this wonderful fakemon from xeeble! So I decided to make up a full list of game data, moves, lore, etc. for it. Enjoy! :D
Abilities - Sticky Hold/Ice Body/Weak Armor (Hidden)
Pokedex Entries
Scarlet: Gelatopod leaves behind a sticky trail when it moves. A rich, creamy ice cream can be made from the collected slime.
Violet: At night, it uses the spike on its shell to dig into the ground, anchoring itself into place. Then it withdraws into its shell to sleep in safety.
Stats & Moves
BST - 485
HP - 73
Attack - 56
Defense - 100
Special Attack - 90
Special Defense - 126
Speed - 40
Learnset
Lvl 1: Sweet Scent, Sweet Kiss, Aromatherapy, Disarming Voice
Lvl 4: Defense Curl
Lvl 8: Baby Doll Eyes
Lvl 12: Draining Kiss
Lvl 16: Ice Ball
Lvl 21: Covet
Lvl 24: Icy Wind
Lvl 28: Sticky Web
Lvl 32: Dazzling Gleam
Lvl 36: Snowscape
Lvl 40: Ice Beam
Lvl 44: Misty Terrain
Lvl 48: Moonblast
Lvl 52: Shell Smash
Friendship Level Raised to 160: Love Dart (Signature Move)
Egg Moves
Mirror Coat, Acid Armor, Fake Tears, Aurora Veil
Signature Move - Love Dart
Learned when Gelatopod's friendship level reaches 160 and then the player completes a battle with it
Type - Fairy, Physical, Non-Contact
Damage Power - 20 PP - 10 (max 16) Accuracy - 75%
Secondary Effect - Causes Infatuation in both male and female pokemon. Infatuation ends in 1-4 turns.
Flavor Text - The user fires a dart made of hardened slime at the target. Foes of both the opposite and same gender will become infatuated with the user.
TM Moves
Take Down, Protect, Facade, Endure, Sleep Talk, Rest, Substitute, Giga Impact, Hyper Beam, Helping Hand, Icy Wind, Avalanche, Snowscape, Ice Beam, Blizzard, Charm, Dazzling Gleam, Disarming Voice, Draining Kiss, Misty Terrain, Play Rough, Struggle Bug, U-Turn, Mud Shot, Mud-Slap, Dig, Weather Ball, Bullet Seed, Giga Drain, Power Gem, Tera Blast
Other Game Data
Gender Ratio - 50/50
Catch Rate - 75
Egg Groups - Fairy & Amorphous
Hatch Time - 20 Cycles
Height/Weight - 1'0''/1.3 lbs
Base Experience Yield - 170
Leveling Rate - Medium Fast
EV Yield - 2 (Defense & Special Defense)
Body Shape - Serpentine
Pokedex Color - White
Base Friendship - 70
Game Locations - Glaseado Mountain, plus a 3% chance of encountering Gelatopod when the player buys Ice Cream from any of the Ice Cream stands
Notes
I'm not a competitive player, but I did my best to balance this fakemon fairly and not make it too broken. Feel free to give feedback if you have any thoughts!
I have a huge bias for Bug Pokemon since they're my favorite type, and at first I wanted to make it Bug/Ice, since any intervebrate could be tossed into the 'Bug' typing. But ultimately I decided to keep xeeble's original idea of Ice/Fairy. There's precedent of food-themed pokemon being Fairy type, and Ice/Fairy would be very interesting due to its rarity (only Alolan Ninetails has it). Its type weaknesses are also slightly easier to handle than Bug/Ice imo
The signature move is indeed based on real love darts, I could not resist something that fascinating being made into a Pokemon move, even if the real games may possibly shy away from the idea. (Honestly it could be argued "Love Dart" is based on Cupid's arrow so Gamefreak might actually get away with making a move like this though.) Its effectiveness on both males and females is a nod to snails/slugs being biological hermaphrodites. I can see this move also being learned by Gastrodon and Magcargo in Scarlet/Violet
#pokemon#fakemon#honorary bug pokemon#pokemon scarlet/violet#pokémon#ice pokemon#fairy pokemon#gen 9#molluscs#snails#mycontent
482 notes
·
View notes
Text
Since mottos and slogans have been a hot topic in the plural community lately... I want to introduce one that I've been thinking of for a long while now! It's part rallying cry, part "defiance via continued existence", and part punk in the "spikes as a deterrent" way (if that last comparison makes sense at all, lol – I'm specifically thinking of things like how wheelchair users may put spikes on the handles of their 'chair so others don't try to touch or move them without permission). It's this:
"Plural as in there are more of us than you think."
[PT: "Plural as in there are more of us than you think." / end PT]
I've also considered a longer version that would tie in the queer community/queerness – which I know is intertwined with plurality for many people – and that version would be: "Queer as in here without fear, plural as in there are more of us than you think". What do you all think?
I think it's very to-the-point, and plays on a simple premise: that we're not backing down – not in the face of hate, and not in the face of fear. Especially with the longer version; we're here, we're queer, get over it – and if you refuse to, just know that you can't silence us all, no matter how loudly you try to drown us out. We will always be here. There will always be someone to fight against the hate, to spit in the face of bigotry just by continuing to draw breath. It also has a nod to an older queer sentiment that I think we should bring back for both queer and plural folk alike – that we are everywhere. The cashier that scanned your groceries might be plural. The classmate sitting next to you might be plural. The neighbor across the street might be plural. We are here. There are more of us than you think. And we will not be afraid.
"There are more of us than you think" is also a nod to how statistics are often both misunderstood and just plain lacking in data. People really don't seem to realize just how population statistics translate to real life; how many people they pass by or have brief interactions with fit that "extremely rare" condition they dismissed, because something like "1.5%" doesn't look like a lot on paper, but ends up as a whole lot when you wander out into the world. That's at least one out of a hundred – and that estimate is on the more conservative side about one specific presentation of plurality, and doesn't account for many, many other forms of it. So, yeah, there are definitely more of us than they/you think.
I admit it can be read as a tad aggressive, but that's also part of the point. It's meant to be a very in-your-face type of motto, especially as a spit in the face of pluralphobia and all other forms of bigotry it entangles itself with – racism, sanism, disableism, ableism, religious intolerance, queerphobia, etc.. Yeah, your cashier, classmate, neighbor might be plural – and so what?! Yeah, maybe you should think twice about messing with us, because acceptance is growing and you're not going to be able to excuse your hateful nonsense for much longer without it being called out as such! But on the other hand, I think it can work well as a conversation starter, giving people the prompt to ask, "What does that mean?" In this case, the slogan being so provocative works in its favor! Yeah, actually, I'd love to talk about how plurals go unknown and deserve more awareness, how there are almost certainly more of us than even we can know for certain! And, again, spikes on a wheelchair – taking words as an art form, this slogan is art that's meant to make you uncomfortable, to make you question things; "Art should comfort the disturbed and disturb the comfortable.", as Cesar A. Cruz said. It makes you scared or uncomfortable to think about there being more plurals out there than you first estimated there to be? Why does it make you feel that? Is this the result of unconscious bias? Why do you think we, the makers of this slogan, might be comforted by the same phrase that disturbs you?
We're plural as in more-than-one in more than one (lol) meaning of the phrase. More-than-one in this body, more-than-one of us out there fighting the good fight – helping others, breaking down walls, and pushing for a kinder and more accepting future.
Plural as in there are more of us than you think. Fuck your hatred, we're gonna be here no matter what.
#front soup.txt#plurality#pluralgang#actuallyplural#plural system#queer#pluralpunk#systempunk#syspunk#actuallysystem#actually a system#actuallydid
118 notes
·
View notes
Note
Yves reaction where it’s one of the rare times he initiates sex and reader declines?
Also how does he initiate sex?
Tw: sex mention
Yves doesn't necessarily "initiate" sex per se, it's more like he would present an opportunity for you to grab. Whether you decide to take it or not, it's up to you and he would respect whatever choice you made. Yves will merely present signs that your proposal to fuck is very likely to be accepted. In the end, you're mostly still doing the initiation by asking him if it's a "yes" to sex.
His reaction depends on your baseline, if you're not very interested in having sex in the first place, your passiveness is already predicted and it confirms the accuracy of his algorithms, and his logic. He wouldn't spend too much time investigating why you said no, because he already knew the reasons. Yves would then move on to either test his other, countless hypotheses out, or just enjoy your company in the moment.
It also could be that you're just dense and missed the silent signs. Then, he would outright ask you if you wanted to make love with him. Yves will never word it as a demand, it's always a suggestion and never a request.
However, if he knew that you're the type to be caught dead before declining the delicious offer for sex, it would both excite and worry him at the same time. He's curious and intrigued, elated that there is something new about you he discovered. An anomaly in his prediction models, which doesn't occur very often and it's a marvel to witness.
Worried, because whenever you defy his expectations, it usually means you're suffering some sort of disease or under distress.
Yves would comb through everything that happened to you on that day and a few days prior. Checking what you saw on the Internet, hearing what other people told you, so on and so forth. Even sneakily taking a biological sample out of you without your knowledge. Yves knows how to draw a vial of clean blood undetected.
Once he is sure that he found the reason(s), he would perform two experiments on you:
1. He would remove the stimuli that caused your rejection or passiveness towards fornication, and suggest the idea of doing it with you again. Of course, he would do this at a much later date.
2. Yves would replicate the exact environment and sequence of events that he thought was the grounds for this inconsistency, and present an opportunity for you to fuck him again. You will experience a sense of Deja Vu, but ultimately more or less put you in the same headspace as before.
It goes without saying, he will NOT be replicating the cause if it's due to an illness, injury or a period of severe emotional turmoil. It pains Yves to make assumptions during the scientific process, but he would rather have some inaccurate data than have you hurt.
If he is wrong with his hypothesis AND sickness being the reason is absolutely ruled out, Yves would be even more thrilled. It's a new set of data for him to hunt down!
He would be running experiments on you as if you're a lab rat, and you wouldn't even notice.
Yves is cocky enough to think he could "read your mind" and determine the reason why you refused, he wouldn't ask you at all because that may interfere with his findings, introducing bias into his work and into your mind.
#yandere#yandere oc#yandere x reader#yandere male#oc yves#yandere concept#tw yandere#yandere oc x reader#yandere x you#male yandere oc x reader#tw sex mention
92 notes
·
View notes
Note
*waves shyly* Hello!! First off, I absolutely adore all of your stats and get excited when you post new ones -- thank you so much for all that you do!
Secondly, a friend and I have been discussing fandom longevity lately, and I wondered if you have thoughts? Subjectively, it seems to us that new fandoms tend to have more quick bursts of fandom activity when a new season/movie/book/etc comes out that fades quickly with time, whereas older established fandoms have more staying power. I'm curious if you have any insight about whether this is objectively true in most cases or not, and as to whether or not the type of canon source material matters (eg show-based fandoms vs book-based fandoms). I hope you're having a great day <3
Hi there, and thanks! :D This is a great question, and one I have been having a bunch of conversations about lately.
I share this subjective experience -- it sure seems like the attention span of fans and lifespan of fandoms is shorter than it used to be, when I think of how quickly people stop talking about a bunch of newer movies and TV shows these days. And then I see some of the older fandoms like Harry Potter still producing a ton of new fanworks, and I think, "Wow, maybe new fandoms just don't have the staying power of older ones." At the same time, I also question how objectively true/simple that story is for a few reasons, including:
Memory bias: When we look back on the past, the fandoms we remember most are usually the ones that lasted a long time. So our estimates of past fandom longevity may be overly generous.
Changes to fandom size: Maybe any changes to fandom lifespan are mostly due to some other change, like fandom size... Attention is more splintered these days than it used to be across more streaming services/etc, and I think there are more, smaller fandoms than there used to be. Maybe if a fandom doesn't get really huge, it's just not likely to last that long.
For TV fandoms -- changes to canon release schedule: most TV shows used to have seasons that lasted most of the year, so they had a lot more reason to stay in the public mind longer. Now many seasons are shorter and sometimes drop all at once. Perhaps if we compared popular TV procedurals with 22 episodes/season from now vs. ~a decade ago, we'd see similar patterns of fandom activity?
I've been thinking about ways to try to gather quantitative data about the changes, and testing out a few methods. A few ideas I've had:
Look at the Tumblr official lists of top fandoms and see whether the top fandoms tend to leave the top 20 rankings faster now than they used to. (The Tumblr rankings go all the way back to 2013 on a yearly basis, at least -- I'm not sure how long they've been releasing the weekly lists; those may have started later.)
Look at AO3 fandom activity after new canon infusions - how quickly does activity drop off after a new movie/book/video game release, or after a TV season ends? How has the rate of activity dropoff changed over the years? (And how much of that seems to be explained by other factors, like fandom size?)
See how quickly AO3 authors/creators tend to migrate to new fandoms, and how that's changed over time - many authors tend to be active in multiple fandoms, so we'd have to define what it means to migrate to a new fandom, but I think we could do so in a way that would allow us to look for changes.
Look at Tumblr, Twitter/X, and/or Reddit activlty after new canon infusions - same as AO3, but on a platform where people are posting shorter content and there's more of a discussion. (This data would be harder to collect, though.)
I'd love to also hear other ideas. I think I'm going to need some volunteers to help gather data if I do any of the above, though... Readers, if you'd be interested in helping to gather data for an hour or more to help investigate this question, please reply/DM and let me know! And/or join the new fandom-data-projects community.
Also if any readers know of anyone else who has looked into this/similar questions, I'd love to hear about it!
#fandom lifespan#call for volunteers#I'll also post more details later#but it would involve doing AO3 searches or other searches and copying numbers into a spreadsheet#questions for the tumblmind#asks#toasty replies#fandom stats#toastystats#50
58 notes
·
View notes
Text
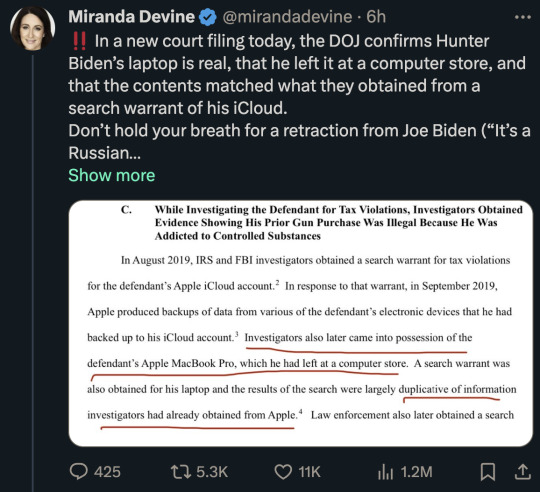
These people will believe all kinds of ridiculous conspiracy theories and know in their bones they are 100% true without any evidence.
But then when an actual and blatantly obvious conspiracy happens they cannot look past their bias to see it.
If this same shit happened to Don Jr. I would absolutely feel the same way.
Do they think cocaine causes laptop amnesia?
That he was so drug-addled he forgot his laptop was being repaired?
That he never went, "Oh, I need to type an email to China and get that sweet bribe money" and didn't wonder where his MacBook ran off to?
Do they think rich people just have spare $3000 computers lying around so they won't care that their sensitive data is in another state with some stranger?
I actually know a rich person who had computer problems. They didn't even consider taking their computer to a repair shop. They hired me to come fix it and watched over my shoulder as I did it. I don't care if they were filled to the brim with cocaine, they were not taking a computer that had accessed their bank accounts to the fucking Geek Squad. Nor would they entrust it to a stranger.
It's so fucking obvious and they are acting like I am the crazy person.
71 notes
·
View notes
Text
Skyshark


Man sees what he wants to see, and so it is with the Dark Nebula LDN 1235. This collection of dust in the constellation Cepheus is very reminiscent of a shark. At just 650 light years away, it is just around the corner.
Object type: Dark nebula
Constellation: Cepheus
Total exposure: 720 minutes
Image data:
- RGB 144 x 300s / Gain 100
- 25 flats
- 25 Bias
- 25 Darks
Setup:
- Skywatcher 150/750 F5 PDS
- Omegon 571C
- Skywatcher EQ6R Pro
- Two Asi 178mm as guide cam
140 notes
·
View notes
Text
AP Stats more like AP Mental Illness
I don’t even like statistics I just thought this was funny
What are SOCS?
S - Shape
O - Outliers
C - Center
S - Spread
What statistical distribution shapes are there?
Symmetric (unimodal, bimodal, multimodal); Uniform; Skewed Right; Skewed Left; Normal
Others exist but will not be used here.
What will be identified in the post?
The shape of the poll's stats distribution. Occasionally, if time or will permits, the Center and/or Outlier (though that will remain mathematically unsound).
How will SOC- be identified?
Shape: Visually – Tumblr polls may or may not have a designated order for their options, but regardless of if they are nominal or ordinal, I will identify shape for the Gimmick
Center: Median (I don't have the raw data, cannot do mean)
Outlier: Visually (I'm too lazy to do 1.5IQR and all of that </3)
What posts are included in this?
Polls, any statistics or parameters I come across, or images of the latter two.
Everything on this blog will be lighthearted; I will not be getting involved in any serious polls or data.
Tags
#poll
#statistic
#[shape of distribution]
#median
#[Letter of SOCS used]
#not socs (for any unrelated things)
#bias
#[type of bias]
About the mod
Hi! Call me Nyx or Caelum :)
I go by any pronouns and my main blog is @as-the-stars-foretold if you wanna go be silly over there
47 notes
·
View notes
Note
This has been on my mind a lot lately, but I couldn't find anything about this. I saw a data that says young people regardless of gender feel more lonely especially after covid. But articles everywhere describe the phenomenon as male loneliness epidemic. Is it true that loneliness affect men more than women?
Yes, I've noticed this as well! (It's definitely frustrating!)
In short, no, women and men experience similar amounts of loneliness. (Therefore, it should simply be a "loneliness epidemic" not a "male loneliness epidemic".)
First:
A pre-covid meta-analysis [1] concluded that "across the lifespan mean levels of loneliness are similar for males and females". This is a robust finding because a meta-analysis synthesizes the results from many different studies; this one covered 39 years, 45 countries, and a wide range of other demographic factors from a total of 575 reports (751 effect sizes).
An interesting longitudinal study [2] used both indirect and direct measures of loneliness and (essentially) found no significant effect of sex. (But there were some interesting interaction effects between sex and age or sex and loneliness measure, if you want to look at the study!)
This literature review [3] states that "sex differences in loneliness are dependent on what type of loneliness is measured and how" and it's possible sex only "correlates with other factors that then impact loneliness directly". The first quote here is referring to similar sex-age/sex-measurement interactions found in [2].
During/after the COVID-19 pandemic however:
The earlier review [3] stated that "most studies found that women were lonelier or experienced higher increases in loneliness than men with both direct and indirect measures", but this may be a result of participant selection bias during the pandemic.
That being said, both a rapid review [4] and a systematic review and meta-analysis [5] found that women were either more or equally likely to report loneliness during the COVID-19 pandemic.
In addition, the Pew Research Center has collected some relevant data:
Prior to the pandemic, 10% of both men and women in the USA reported feeling lonely all or most of the time [6].
And while this doesn't measure loneliness directly, 48% of women and 32% of men in the USA reported high levels of psychological distress at least once during the pandemic [7].
References below the cut:
Maes, M., Qualter, P., Vanhalst, J., Van Den Noortgate, W., & Goossens, L. (2019). Gender differences in loneliness across the lifespan: A meta–analysis. European Journal of Personality, 33(6), 642–654. https://doi.org/10.1002/per.2220
Von Soest, T., Luhmann, M., Hansen, T., & Gerstorf, D. (2020). Development of loneliness in midlife and old age: Its nature and correlates. Journal of Personality and Social Psychology, 118(2), 388–406. https://doi.org/10.1037/pspp0000219
Barjaková, M., Garnero, A., & d’Hombres, B. (2023). Risk factors for loneliness: A literature review. Social Science & Medicine (1982), 334, 116163. https://doi.org/10.1016/j.socscimed.2023.116163
Pai, N., & Vella, S.-L. (2021). COVID-19 and loneliness: A rapid systematic review. Australian & New Zealand Journal of Psychiatry, 55(12), 1144–1156. https://doi.org/10.1177/00048674211031489
Ernst, M., Niederer, D., Werner, A. M., Czaja, S. J., Mikton, C., Ong, A. D., Rosen, T., Brähler, E., & Beutel, M. E. (2022). Loneliness before and during the COVID-19 pandemic: A systematic review with meta-analysis. American Psychologist, 77(5), 660–677. https://doi.org/10.1037/amp0001005
Bialik, K. (2018, December 3). Americans unhappy with family, social or financial life are more likely to say they feel lonely. Pew Research Center. https://www.pewresearch.org/short-reads/2018/12/03/americans-unhappy-with-family-social-or-financial-life-are-more-likely-to-say-they-feel-lonely/
Gramlich, J. (2023, March 2). Mental health and the pandemic: What U.S. surveys have found. Pew Research Center. https://www.pewresearch.org/short-reads/2023/03/02/mental-health-and-the-pandemic-what-u-s-surveys-have-found/
17 notes
·
View notes
Text
I think there's some survivor bias sort of thing going on when it comes to people "having a type". If someone has dated four trans women in a row in the same year and you go "oh so he's a chaser, huh", and the next date they bring around is the tallest cis woman you've ever seen, the important information here isn't "oh so he just likes tall women". It's that this guy got dumped by four women in a row within the same year and will probably get dumped by the 5th one, too. His preferences aren't the problem here.
You genuinely would not even know if someone who's able to keep up stable relationships has an exact specific type that they'll always go for. People who get dumped a lot just have more available data for you to work with, and a larger sample size.
199 notes
·
View notes
Note
Not asking to be a jerk, genuinely curious. I have never understood how the Raf death plot was racist. There were 3 other live interests and only 1 was white. It never made sense to me.
I think that whole thing led to PB not having the balls to do things. So instead of stories like It Lives or Endless Summer where there were real consequences and drama, we get Wake the Dead, where every love interest is safe and it is so dumb.
Oh god why are you asking the white person this.
So there are kind of a concerning amount of people that have this view that racism is just blue in the face, spittle flying, MAGA-type people shouting slurs and crying about CRT. But that really only just shows a limited understanding of what racism is. Racism isn’t just direct hatred or bigotry. When a system functions so that one race is biased for and others disadvantaged, that system is racist.
It had been quite clear well before Open Heart that white (particularly white male) love interests were favoured in the writing over love interests of colour. These white characters received preferential treatment, had more diamond scenes, were better developed, and were often almost ‘pushed’ onto the player character, regardless of whether the player had expressed interest in the past or not. The white male LI was treated as the default.
And why? Because the white male LI sells the best. A biased society that favours whiteness bought the white LIs scenes the most, making the white LIs ‘perform’ the best, and so PB favoured them in the writing. PB would later admit as much in their June 15th 2020 blog post following the massive outcry after the Rafael plot was leaked.

The fact that Ethan was the only white LI (and the only canon white character in the main cast) is precisely the point. His preferential treatment in the story, to the detriment of the other LIs, is probably the most egregious example of this bias in Choices.
And you have to realise that while 3/4 of the love interest were people of colour, Rafael was the only black LI. It’s important to understand just how pervasive antiblackness specifically is. PB had a history of treating its black characters, particularly its black female characters, poorly. Even compared to the other POC LIs in Open Heart, you could quite fairly make the argument that he got the worst treatment of them all. And it’s a history like that that feeds into a pervasive racist notion that black characters are more disposable.
When you combine that notion with PB’s data saying to do more Ethan content and that Rafael is ‘underperforming’ (because they’re not giving him equal focus/treatment), you finally get to the point where PB is willing to inexplicably fridge the sole black LI to create drama and add fuel to the white man’s angst.
Also, I would hope that the implications of a man of colour dying in what is essentially a gas chamber plot are not lost on you.
#also please don’t just get your info from me please actually go listen to people of colour like come on#ask me#playchoices#choices#open heart#choices oph
36 notes
·
View notes
Note
There are so many actual play podcasts! Is that just because this is tumblr? Like people here are more likely to suggest those (we're all nerds after all), or are there really just a huge percentage of actual play podcasts in general??
I'm guessing this is Tumblr's bias, but I don't actually know what a true representative sample of podcasts overall would look like.
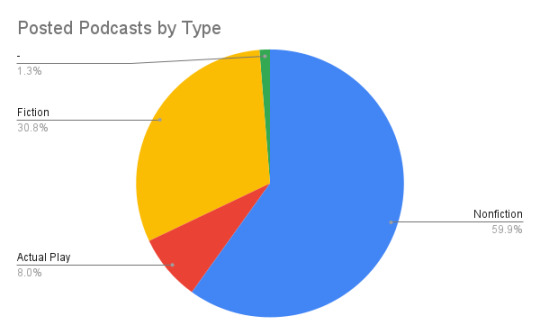
Of the 474* podcasts posted so far:
59.9% (284) are Nonfiction
8.0% (38) are Actual Plays
30.8% (146) are Fiction (but not APs)
And 1.3% (6) I was unable to categorize.**
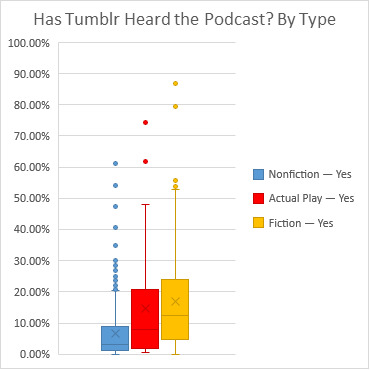

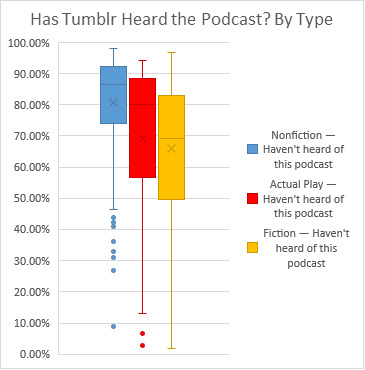
These box-and-whisper plots come from the 453* polls that have finished. In general, Tumblr has not heard of most podcasts. We have heard non-AP fiction podcasts slightly more than actual plays, and all types of fiction have better numbers than the nonfiction results.
Given that it's a running complaint that news media loves to talk about fiction podcasts like they're brand new at least once a year, despite the fact that Radio Drama Revival has been going on since 2007(!), I would hazard a guess that 40% of all podcasts in total are not fiction podcasts. However, it is possible that news media has their own bias towards podcasts like the ones they put out.
I don't know where one would get more representative data. I kinda don't remember how sampling is supposed to work from my statistics classes. (Sorry to my professors! One of you were excellent! This is my fault not yours!) iTunes is obviously the go-to, but they didn't have a "fiction" category for years so a lot of older podcasts are under different genres. "Arts" was pretty popular, but I know actual plays often tend towards "comedy" and additionally that podcasts about games are often under "leisure".
So overall, I don't know but I would guess that this is a sample specific to the Tumblr population.
*The duplicated podcast has been removed from these charts.
**If someone would like to help me categorize these, I've listed them below the cut.
Bonus: I was surprised that so far we've posted not one, but two actual play musicals! Mythic Thunderlute and bomBARDed!
Podcasts I would like help categorizing!
Pounded In The Butt By My Own Podcast
Creepypodsta
Fictional
Sleep and Sorcery
Get Sleepy
Siblings Peculiar
Wait hold on we have Morrison Mysteries (our first poll!) listed as nonfiction and true crime, but is this actually fiction and books/literature/mystery?
—Mod Nic
#Not A Poll#Ask#Anonymous#Statistics#This was supposed to be short.#I nearly just attached the pie chart to the ask before I left this morning but I wanted to update it to include the past few days.#EDIT: I don't know why the boxplots are being shown stacked instead of side-by-side. Tumblr reasons I guess.
20 notes
·
View notes
Text




This year leading up to my birthday, I decided to treat myself to something special, just for me. But instead of planning a trip or a special adventure out in the world, I decided to gift myself a journey inward. After my viral illness last year landed me in the hospital — the one that began with people trying convince me that it was “anxiety” or “all in my head due to stress” and ended in multiple diagnoses, and then kept me in doctors offices for three straight months — I knew I wanted to take more proactive control of my health. I’ve also learned how often women are ignored, demeaned, or straight up not treated because of medical bias that sees our pain not be taken seriously, and illnesses often left undiagnosed got longer, to our own detriment. And it’s even worse for women of color! Becoming aware of the data, being sobered by my own brush with illness, and then seeing my best friend from high school lose her little sister to colon cancer at 37, and a friend from work go through a double mastectomy at 42, I knew I wanted to know everything about my own body. And thanks to two of my best pals learning a ton about their health during their own fertility journey (shout out to @daddyhoodpodcast TY) I wound up connected to the amazing team @sollishealth. From the moment I walked into their beautiful offices and met their medical team, things felt different. Finally, I have everything under one roof — that also does emergency care! — and I’m being looked after by one team that oversees all additional referrals. From full labs that we took in the office, to an additional vial of blood (I didn’t pass out, please be proud) for a Galleri test to screen for 100 types of cancer, they made me feel so empowered & gave me snacks. They helped me find in-network specialists to keep battling my asthma, to keep up the necessary PT that helps me stay on top of some stunt injuries, and even helped me get one of those in depth @prenuvo scans that took over the internet last year. Spoiler alert: they really ARE that amazing I have to thank the whole team for answering all of my questions about how to make this scan more #accessible to people. As we are all out here advocating for healthcare, and reminding you to vote like your lives depend on it (they do!) it’s really meaningful to me to meet likeminded folks to learn with, and to be walked through their plans around how to bring the best medical treatments to the masses. Everyone deserves this! I’m really grateful to be a #sollispartner now and have the ability to explore my options, and hoping that sharing what I find from time to time helps you all feel inspired to explore yours too. I hope we all stay healthy for a long long time 🫶🏼
9 notes
·
View notes
Text

Toastystats: F/F, F/M, and M/M on AO3
I'm starting to post my deep dive stats that started out as me looking into "F/F vs. M/M on AO3" -- it has turned out to be really useful and interesting to include F/M in most of these analyses (I'd like to also look more at other categories eventually; see further discussion about nonbinary characters). Here are some of the topics I'll be covering: Length, Ratings & Smut, Dark content, Tags & tropes, Growth rate, and Case studies of parallel-ish ships of different genders.
You can read the intro & fanwork length chapter now, and more will be posted soon! You can also listen to me discuss a bunch of the data on the latest @fansplaining episode, Femstats February.
Below are some excerpts of the fanwork length chapter -- but please click through to AO3 for elaboration/clarification/corrections, as well as for descriptions of the images.
---

(Terminology: "F/F-focused" means I filtered out every other relationship category else except "Gen," so as to remove ambiguity, and similar for F/M- and M/M-focused.)
A few observations:
These breakdowns are a lot more similar than I’d expected. There are differences, but they’re not overwhelming. It’s not like F/F is mostly just drabbles.
F/F does have the highest proportion of short fic, followed by F/M, and then M/M...
But the long fic end of the scale isn’t what I expected at all! M/M is the least likely to have works over 50K words (this graph doesn't actually show the decimal points due to lack of space, but M/M only has 2.0% of its works above 50K words, while F/F has 2.4% over 50K). And F/M is the most likely to have [works over 50K words]!
....Next, I wanted to look at reader response to long fic.... First, let's look at the word count breakdown for the works with the most kudos...:
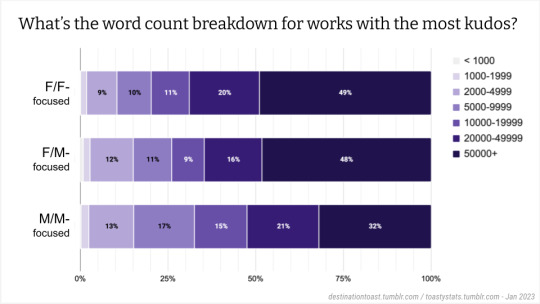
We can see that, probably unsurprisingly, many of the works that receive the most kudos are long -- but I was surprised how strong that bias is. Nearly half of these popular works in the F/F and F/M categories are over 50K+ words (I -- or someone else -- should follow up by further subdividing the "over 50K" category, but I haven't done so yet; for now I only used the same word count buckets that I used previously.). Surprising to me is that M/M has a lot more shorter works that get a lot of kudos; only around 1/3 of the M/M works with the most kudos have over 50K words. I'd be curious to hear any theories about why this is.
....Okay, so lots of popular fic is long -- not too surprising. But now let's flip things around. instead of looking at how long popular fic is, let's look at how much reader feedback long fic gets, and see if any category clearly gets the most or least feedback.
For this, I took a very specific slide of [long fic]: works 100K words to 101K words long. I did that because I wanted to compare long fic of the same length across the different categories. But these specific numbers are therefore not accurate for most definitions of "long fic," and should not be taken too seriously -- hence the asterisks on the following slides (Edit to clarify: I did also look at a couple other long slices to check that these general patterns seem to hold... but I haven't confirmed it for all long fic). I did this just to try to get a rough sense of the ranking or the categories. Let's take a look:

Wow! I was surprised to see that F/F averages the most kudos! And that F/M gets the least of all these types of feedback by quite a lot!
Is this because readers don't seek out F/M as much as the other works? Or is it because F/M readers don't tend to leave as much feedback after they read something? To answer this, we need to look at the number of hits (views) that each category gets:

Fascinating! F/F long fic gets the largest number of hits on average. (Maybe this is because F/F works are the rarest, so more people seeking out long F/F fic view each fanwork, on average, as compared to the other categories?) And we can see that F/M long fic gets the fewest hits per fanwork. (Again, maybe this is because there are a lot of long F/M fics out there, so there's less scarcity, and fewer people view each one?)
Okay, so to follow up on the question of whether F/M readers are less likely to leave feedback after viewing a work -- we can compare rates of feedback. For each work I calculated kudos/hits (I actually looked at kudos per 1000 hits to make the numbers easier to think about), and then I took the median of all those numbers to find average feedback rate. I did the same for comments and bookmarks:

The main takeaway here is that the reader feedback rates are remarkably similar. (Again, this is based on one narrow slice of long fic, so I wouldn't take the small differences here seriously.) More people view F/F long fic on average, and fewer people view F/M long fic -- but the rate at which they leave feedback appears to be roughly the same across all categories.
---
Read more on AO3 (including analyses of drabbles and one shots)
#fandom stats#toastystats#ao3#relationship categories#f/f & f/m & m/m#though my original tag was#f/f vs. m/m#when this was an earlier wip#word count#op#long post#50#100
237 notes
·
View notes
Text
Generative AI for Dummies
(kinda. sorta? we're talking about one type and hand-waving some specifics because this is a tumblr post but shh it's fine.)
So there’s a lot of misinformation going around on what generative AI is doing and how it works. I’d seen some of this in some fandom stuff, semi-jokingly snarked that I was going to make a post on how this stuff actually works, and then some people went “o shit, for real?”
So we’re doing this!
This post is meant to just be a very basic breakdown for anyone who has no background in AI or machine learning. I did my best to simplify things and give good analogies for the stuff that’s a little more complicated, but feel free to let me know if there’s anything that needs further clarification. Also a quick disclaimer: as this was specifically inspired by some misconceptions I’d seen in regards to fandom and fanfic, this post focuses on text-based generative AI.
This post is a little long. Since it sucks to read long stuff on tumblr, I’ve broken this post up into four sections to put in new reblogs under readmores to try to make it a little more manageable. Sections 1-3 are the ‘how it works’ breakdowns (and ~4.5k words total). The final 3 sections are mostly to address some specific misconceptions that I’ve seen going around and are roughly ~1k each.
Section Breakdown:
1. Explaining tokens
2. Large Language Models
3. LLM Interfaces
4. AO3 and Generative AI [here]
5. Fic and ChatGPT [here]
6. Some Closing Notes [here]
[post tag]
First, to explain some terms in this:
“Generative AI” is a category of AI that refers to the type of machine learning that can produce strings of text, images, etc. Text-based generative AI is powered by large language models called LLM for short.
(*Generative AI for other media sometimes use a LLM modified for a specific media, some use different model types like diffusion models -- anyways, this is why I emphasized I’m talking about text-based generative AI in this post. Some of this post still applies to those, but I’m not covering what nor their specifics here.)
“Neural networks” (NN) are the artificial ‘brains’ of AI. For a simplified overview of NNs, they hold layers of neurons and each neuron has a numerical value associated with it called a bias. The connection channels between each neuron are called weights. Each neuron takes the sum of the input weights, adds its bias value, and passes this sum through an activation function to produce an output value, which is then passed on to the next layer of neurons as a new input for them, and that process repeats until it reaches the final layer and produces an output response.
“Parameters” is a…broad and slightly vague term. Parameters refer to both the biases and weights of a neural network. But they also encapsulate the relationships between them, not just the literal structure of a NN. I don’t know how to explain this further without explaining more about how NN’s are trained, but that’s not really important for our purposes? All you need to know here is that parameters determine the behavior of a model, and the size of a LLM is described by how many parameters it has.
There’s 3 different types of learning neural networks do: “unsupervised” which is when the NN learns from unlabeled data, “supervised” is when all the data has been labeled and categorized as input-output pairs (ie the data input has a specific output associated with it, and the goal is for the NN to pick up those specific patterns), and “semi-supervised” (or “weak supervision”) combines a small set of labeled data with a large set of unlabeled data.
For this post, an “interaction” with a LLM refers to when a LLM is given an input query/prompt and the LLM returns an output response. A new interaction begins when a LLM is given a new input query.
Tokens
Tokens are the ‘language’ of LLMs. How exactly tokens are created/broken down and classified during the tokenization process doesn’t really matter here. Very broadly, tokens represent words, but note that it’s not a 1-to-1 thing -- tokens can represent anything from a fraction of a word to an entire phrase, it depends on the context of how the token was created. Tokens also represent specific characters, punctuation, etc.
“Token limitation” refers to the maximum number of tokens a LLM can process in one interaction. I’ll explain more on this later, but note that this limitation includes the number of tokens in the input prompt and output response. How many tokens a LLM can process in one interaction depends on the model, but there’s two big things that determine this limit: computation processing requirements (1) and error propagation (2). Both of which sound kinda scary, but it’s pretty simple actually:
(1) This is the amount of tokens a LLM can produce/process versus the amount of computer power it takes to generate/process them. The relationship is a quadratic function and for those of you who don’t like math, think of it this way:
Let’s say it costs a penny to generate the first 500 tokens. But it then costs 2 pennies to generate the next 500 tokens. And 4 pennies to generate the next 500 tokens after that. I’m making up values for this, but you can see how it’s costing more money to create the same amount of successive tokens (or alternatively, that each succeeding penny buys you fewer and fewer tokens). Eventually the amount of money it costs to produce the next token is too costly -- so any interactions that go over the token limitation will result in a non-responsive LLM. The processing power available and its related cost also vary between models and what sort of hardware they have available.
(2) Each generated token also comes with an error value. This is a very small value per individual token, but it accumulates over the course of the response.
What that means is: the first token produced has an associated error value. This error value is factored into the generation of the second token (note that it’s still very small at this time and doesn’t affect the second token much). However, this error value for the first token then also carries over and combines with the second token’s error value, which affects the generation of the third token and again carries over to and merges with the third token’s error value, and so forth. This combined error value eventually grows too high and the LLM can’t accurately produce the next token.
I’m kinda breezing through this explanation because how the math for non-linear error propagation exactly works doesn’t really matter for our purposes. The main takeaway from this is that there is a point at which a LLM’s response gets too long and it begins to break down. (This breakdown can look like the LLM producing something that sounds really weird/odd/stale, or just straight up producing gibberish.)
Large Language Models (LLMs)
LLMs are computerized language models. They generate responses by assessing the given input prompt and then spitting out the first token. Then based on the prompt and that first token, it determines the next token. Based on the prompt and first token, second token, and their combination, it makes the third token. And so forth. They just write an output response one token at a time. Some examples of LLMs include the GPT series from OpenAI, LLaMA from Meta, and PaLM 2 from Google.
So, a few things about LLMs:
These things are really, really, really big. The bigger they are, the more they can do. The GPT series are some of the big boys amongst these (GPT-3 is 175 billion parameters; GPT-4 actually isn’t listed, but it’s at least 500 billion parameters, possibly 1 trillion). LLaMA is 65 billion parameters. There are several smaller ones in the range of like, 15-20 billion parameters and a small handful of even smaller ones (these are usually either older/early stage LLMs or LLMs trained for more personalized/individual project things, LLMs just start getting limited in application at that size). There are more LLMs of varying sizes (you can find the list on Wikipedia), but those give an example of the size distribution when it comes to these things.
However, the number of parameters is not the only thing that distinguishes the quality of a LLM. The size of its training data also matters. GPT-3 was trained on 300 billion tokens. LLaMA was trained on 1.4 trillion tokens. So even though LLaMA has less than half the number of parameters GPT-3 has, it’s still considered to be a superior model compared to GPT-3 due to the size of its training data.
So this brings me to LLM training, which has 4 stages to it. The first stage is pre-training and this is where almost all of the computational work happens (it’s like, 99% percent of the training process). It is the most expensive stage of training, usually a few million dollars, and requires the most power. This is the stage where the LLM is trained on a lot of raw internet data (low quality, large quantity data). This data isn’t sorted or labeled in any way, it’s just tokenized and divided up into batches (called epochs) to run through the LLM (note: this is unsupervised learning).
How exactly the pre-training works doesn’t really matter for this post? The key points to take away here are: it takes a lot of hardware, a lot of time, a lot of money, and a lot of data. So it’s pretty common for companies like OpenAI to train these LLMs and then license out their services to people to fine-tune them for their own AI applications (more on this in the next section). Also, LLMs don’t actually “know” anything in general, but at this stage in particular, they are really just trying to mimic human language (or rather what they were trained to recognize as human language).
To help illustrate what this base LLM ‘intelligence’ looks like, there’s a thought exercise called the octopus test. In this scenario, two people (A & B) live alone on deserted islands, but can communicate with each other via text messages using a trans-oceanic cable. A hyper-intelligent octopus listens in on their conversations and after it learns A & B’s conversation patterns, it decides observation isn’t enough and cuts the line so that it can talk to A itself by impersonating B. So the thought exercise is this: At what level of conversation does A realize they’re not actually talking to B?
In theory, if A and the octopus stay in casual conversation (ie “Hi, how are you?” “Doing good! Ate some coconuts and stared at some waves, how about you?” “Nothing so exciting, but I’m about to go find some nuts.” “Sounds nice, have a good day!” “You too, talk to you tomorrow!”), there’s no reason for A to ever suspect or realize that they’re not actually talking to B because the octopus can mimic conversation perfectly and there’s no further evidence to cause suspicion.
However, what if A asks B what the weather is like on B’s island because A’s trying to determine if they should forage food today or save it for tomorrow? The octopus has zero understanding of what weather is because its never experienced it before. The octopus can only make guesses on how B might respond because it has no understanding of the context. It’s not clear yet if A would notice that they’re no longer talking to B -- maybe the octopus guesses correctly and A has no reason to believe they aren’t talking to B. Or maybe the octopus guessed wrong, but its guess wasn’t so wrong that A doesn’t reason that maybe B just doesn’t understand meteorology. Or maybe the octopus’s guess was so wrong that there was no way for A not to realize they’re no longer talking to B.
Another proposed scenario is that A’s found some delicious coconuts on their island and decide they want to share some with B, so A decides to build a catapult to send some coconuts to B. But when A tries to share their plans with B and ask for B’s opinions, the octopus can’t respond. This is a knowledge-intensive task -- even if the octopus understood what a catapult was, it’s also missing knowledge of B’s island and suggestions on things like where to aim. The octopus can avoid A’s questions or respond with total nonsense, but in either scenario, A realizes that they are no longer talking to B because the octopus doesn’t understand enough to simulate B’s response.
There are other scenarios in this thought exercise, but those cover three bases for LLM ‘intelligence’ pretty well: they can mimic general writing patterns pretty well, they can kind of handle very basic knowledge tasks, and they are very bad at knowledge-intensive tasks.
Now, as a note, the octopus test is not intended to be a measure of how the octopus fools A or any measure of ‘intelligence’ in the octopus, but rather show what the “octopus” (the LLM) might be missing in its inputs to provide good responses. Which brings us to the final 1% of training, the fine-tuning stages;
LLM Interfaces
As mentioned previously, LLMs only mimic language and have some key issues that need to be addressed:
LLM base models don’t like to answer questions nor do it well.
LLMs have token limitations. There’s a limit to how much input they can take in vs how long of a response they can return.
LLMs have no memory. They cannot retain the context or history of a conversation on their own.
LLMs are very bad at knowledge-intensive tasks. They need extra context and input to manage these.
However, there’s a limit to how much you can train a LLM. The specifics behind this don’t really matter so uh… *handwaves* very generally, it’s a matter of diminishing returns. You can get close to the end goal but you can never actually reach it, and you hit a point where you’re putting in a lot of work for little to no change. There’s also some other issues that pop up with too much training, but we don’t need to get into those.
You can still further refine models from the pre-training stage to overcome these inherent issues in LLM base models -- Vicuna-13b is an example of this (I think? Pretty sure? Someone fact check me on this lol).
(Vicuna-13b, side-note, is an open source chatbot model that was fine-tuned from the LLaMA model using conversation data from ShareGPT. It was developed by LMSYS, a research group founded by students and professors from UC Berkeley, UCSD, and CMU. Because so much information about how models are trained and developed is closed-source, hidden, or otherwise obscured, they research LLMs and develop their models specifically to release that research for the benefit of public knowledge, learning, and understanding.)
Back to my point, you can still refine and fine-tune LLM base models directly. However, by about the time GPT-2 was released, people had realized that the base models really like to complete documents and that they’re already really good at this even without further fine-tuning. So long as they gave the model a prompt that was formatted as a ‘document’ with enough background information alongside the desired input question, the model would answer the question by ‘finishing’ the document. This opened up an entire new branch in LLM development where instead of trying to coach the LLMs into performing tasks that weren’t native to their capabilities, they focused on ways to deliver information to the models in a way that took advantage of what they were already good at.
This is where LLM interfaces come in.
LLM interfaces (which I sometimes just refer to as “AI” or “AI interface” below; I’ve also seen people refer to these as “assistants”) are developed and fine-tuned for specific applications to act as a bridge between a user and a LLM and transform any query from the user into a viable input prompt for the LLM. Examples of these would be OpenAI’s ChatGPT and Google’s Bard. One of the key benefits to developing an AI interface is their adaptability, as rather than needing to restart the fine-tuning process for a LLM with every base update, an AI interface fine-tuned for one LLM engine can be refitted to an updated version or even a new LLM engine with minimal to no additional work. Take ChatGPT as an example -- when GPT-4 was released, OpenAI didn’t have to train or develop a new chat bot model fine-tuned specifically from GPT-4. They just ‘plugged in’ the already fine-tuned ChatGPT interface to the new GPT model. Even now, ChatGPT can submit prompts to either the GPT-3.5 or GPT-4 LLM engines depending on the user’s payment plan, rather than being two separate chat bots.
As I mentioned previously, LLMs have some inherent problems such as token limitations, no memory, and the inability to handle knowledge-intensive tasks. However, an input prompt that includes conversation history, extra context relevant to the user’s query, and instructions on how to deliver the response will result in a good quality response from the base LLM model. This is what I mean when I say an interface transforms a user’s query into a viable prompt -- rather than the user having to come up with all this extra info and formatting it into a proper document for the LLM to complete, the AI interface handles those responsibilities.
How exactly these interfaces do that varies from application to application. It really depends on what type of task the developers are trying to fine-tune the application for. There’s also a host of APIs that can be incorporated into these interfaces to customize user experience (such as APIs that identify inappropriate content and kill a user’s query, to APIs that allow users to speak a command or upload image prompts, stuff like that). However, some tasks are pretty consistent across each application, so let’s talk about a few of those:
Token management
As I said earlier, each LLM has a token limit per interaction and this token limitation includes both the input query and the output response.
The input prompt an interface delivers to a LLM can include a lot of things: the user’s query (obviously), but also extra information relevant to the query, conversation history, instructions on how to deliver its response (such as the tone, style, or ‘persona’ of the response), etc. How much extra information the interface pulls to include in the input prompt depends on the desired length of an output response and what sort of information pulled for the input prompt is prioritized by the application varies depending on what task it was developed for. (For example, a chatbot application would likely allocate more tokens to conversation history and output response length as compared to a program like Sudowrite* which probably prioritizes additional (context) content from the document over previous suggestions and the lengths of the output responses are much more restrained.)
(*Sudowrite is…kind of weird in how they list their program information. I’m 97% sure it’s a writer assistant interface that keys into the GPT series, but uhh…I might be wrong? Please don’t hold it against me if I am lol.)
Anyways, how the interface allocates tokens is generally determined by trial-and-error depending on what sort of end application the developer is aiming for and the token limit(s) their LLM engine(s) have.
tl;dr -- all LLMs have interaction token limits, the AI manages them so the user doesn’t have to.
Simulating short-term memory
LLMs have no memory. As far as they figure, every new query is a brand new start. So if you want to build on previous prompts and responses, you have to deliver the previous conversation to the LLM along with your new prompt.
AI interfaces do this for you by managing what’s called a ‘context window’. A context window is the amount of previous conversation history it saves and passes on to the LLM with a new query. How long a context window is and how it’s managed varies from application to application. Different token limits between different LLMs is the biggest restriction for how many tokens an AI can allocate to the context window. The most basic way of managing a context window is discarding context over the token limit on a first in, first out basis. However, some applications also have ways of stripping out extraneous parts of the context window to condense the conversation history, which lets them simulate a longer context window even if the amount of allocated tokens hasn’t changed.
Augmented context retrieval
Remember how I said earlier that LLMs are really bad at knowledge-intensive tasks? Augmented context retrieval is how people “inject knowledge” into LLMs.
Very basically, the user submits a query to the AI. The AI identifies keywords in that query, then runs those keywords through a secondary knowledge corpus and pulls up additional information relevant to those keywords, then delivers that information along with the user’s query as an input prompt to the LLM. The LLM can then process this extra info with the prompt and deliver a more useful/reliable response.
Also, very importantly: “knowledge-intensive” does not refer to higher level or complex thinking. Knowledge-intensive refers to something that requires a lot of background knowledge or context. Here’s an analogy for how LLMs handle knowledge-intensive tasks:
A friend tells you about a book you haven’t read, then you try to write a synopsis of it based on just what your friend told you about that book (see: every high school literature class). You’re most likely going to struggle to write that summary based solely on what your friend told you, because you don’t actually know what the book is about.
This is an example of a knowledge intensive task: to write a good summary on a book, you need to have actually read the book. In this analogy, augmented context retrieval would be the equivalent of you reading a few book reports and the wikipedia page for the book before writing the summary -- you still don’t know the book, but you have some good sources to reference to help you write a summary for it anyways.
This is also why it’s important to fact check a LLM’s responses, no matter how much the developers have fine-tuned their accuracy.
(*Sidenote, while AI does save previous conversation responses and use those to fine-tune models or sometimes even deliver as a part of a future input query, that’s not…really augmented context retrieval? The secondary knowledge corpus used for augmented context retrieval is…not exactly static, you can update and add to the knowledge corpus, but it’s a relatively fixed set of curated and verified data. The retrieval process for saved past responses isn’t dissimilar to augmented context retrieval, but it’s typically stored and handled separately.)
So, those are a few tasks LLM interfaces can manage to improve LLM responses and user experience. There’s other things they can manage or incorporate into their framework, this is by no means an exhaustive or even thorough list of what they can do. But moving on, let’s talk about ways to fine-tune AI. The exact hows aren't super necessary for our purposes, so very briefly;
Supervised fine-tuning
As a quick reminder, supervised learning means that the training data is labeled. In the case for this stage, the AI is given data with inputs that have specific outputs. The goal here is to coach the AI into delivering responses in specific ways to a specific degree of quality. When the AI starts recognizing the patterns in the training data, it can apply those patterns to future user inputs (AI is really good at pattern recognition, so this is taking advantage of that skill to apply it to native tasks AI is not as good at handling).
As a note, some models stop their training here (for example, Vicuna-13b stopped its training here). However there’s another two steps people can take to refine AI even further (as a note, they are listed separately but they go hand-in-hand);
Reward modeling
To improve the quality of LLM responses, people develop reward models to encourage the AIs to seek higher quality responses and avoid low quality responses during reinforcement learning. This explanation makes the AI sound like it’s a dog being trained with treats -- it’s not like that, don’t fall into AI anthropomorphism. Rating values just are applied to LLM responses and the AI is coded to try to get a high score for future responses.
For a very basic overview of reward modeling: given a specific set of data, the LLM generates a bunch of responses that are then given quality ratings by humans. The AI rates all of those responses on its own as well. Then using the human labeled data as the ‘ground truth’, the developers have the AI compare its ratings to the humans’ ratings using a loss function and adjust its parameters accordingly. Given enough data and training, the AI can begin to identify patterns and rate future responses from the LLM on its own (this process is basically the same way neural networks are trained in the pre-training stage).
On its own, reward modeling is not very useful. However, it becomes very useful for the next stage;
Reinforcement learning
So, the AI now has a reward model. That model is now fixed and will no longer change. Now the AI runs a bunch of prompts and generates a bunch of responses that it then rates based on its new reward model. Pathways that led to higher rated responses are given higher weights, pathways that led to lower rated responses are minimized. Again, I’m kind of breezing through the explanation for this because the exact how doesn’t really matter, but this is another way AI is coached to deliver certain types of responses.
You might’ve heard of the term reinforcement learning from human feedback (or RLHF for short) in regards to reward modeling and reinforcement learning because this is how ChatGPT developed its reward model. Users rated the AI’s responses and (after going through a group of moderators to check for outliers, trolls, and relevancy), these ratings were saved as the ‘ground truth’ data for the AI to adjust its own response ratings to. Part of why this made the news is because this method of developing reward model data worked way better than people expected it to. One of the key benefits was that even beyond checking for knowledge accuracy, this also helped fine-tune how that knowledge is delivered (ie two responses can contain the same information, but one could still be rated over another based on its wording).
As a quick side note, this stage can also be very prone to human bias. For example, the researchers rating ChatGPT’s responses favored lengthier explanations, so ChatGPT is now biased to delivering lengthier responses to queries. Just something to keep in mind.
So, something that’s really important to understand from these fine-tuning stages and for AI in general is how much of the AI’s capabilities are human regulated and monitored. AI is not continuously learning. The models are pre-trained to mimic human language patterns based on a set chunk of data and that learning stops after the pre-training stage is completed and the model is released. Any data incorporated during the fine-tuning stages for AI is humans guiding and coaching it to deliver preferred responses. A finished reward model is just as static as a LLM and its human biases echo through the reinforced learning stage.
People tend to assume that if something is human-like, it must be due to deeper human reasoning. But this AI anthropomorphism is…really bad. Consequences range from the term “AI hallucination” (which is defined as “when the AI says something false but thinks it is true,” except that is an absolute bullshit concept because AI doesn’t know what truth is), all the way to the (usually highly underpaid) human labor maintaining the “human-like” aspects of AI getting ignored and swept under the rug of anthropomorphization. I’m trying not to get into my personal opinions here so I’ll leave this at that, but if there’s any one thing I want people to take away from this monster of a post, it’s that AI’s “human” behavior is not only simulated but very much maintained by humans.
Anyways, to close this section out: The more you fine-tune an AI, the more narrow and specific it becomes in its application. It can still be very versatile in its use, but they are still developed for very specific tasks, and you need to keep that in mind if/when you choose to use it (I’ll return to this point in the final section).
85 notes
·
View notes
Text
Introverted Sensing (Si) is More Valuable than You Think it is
I touched on this a little in another post I made, but it wasn't the main focus, so I'm making this it's own thing.
Introverted Sensing (Si) is most frequently referred to as using tradition as a way of perceiving things that lead to your judgements later. Some examples include following instructions to a T (or being unable to do things without said instructions), making lists, keeping daily planners, and referring to the past (often times personal memories, but can also be previously reported data) to inform the present.
These examples aren't necessarily wrong, but they are sometimes twisted in a negative way that can makes this cognitive function (and the associate types ISTJ, ISFJ, ESTJ, ESFJ) become interpretted as simple, thoughtless, repetititve, useless, boring, and "basic".
There is a much deeper side to Si that I think needs to be talked about, so that's what I'm going to do.
Introduction
Now, the flaws I listed above, also are not necessarily wrong. High Si uses can embody all of those negative traits, but it is much more rare than the iNtuitive bias would have you believe, because those negative traits come out when Si users are at their absolute worst.
And how often is anybody truly at their absolute worst?
I choose to think of Si predominantly not as tradition, but as a Standard Operating Procedure (SOP).
Standard Operating Procedure and Si
What is an SOP? An SOP is a detailed step-by-step list of instructions that you follow from start to finish in order to obtain a completely finished, fully function product/result.
Sounds very Si, doesn't it? That's because it is! And SOPs are absolutely mission critical to so many things in our daily lives because they ensure that a certain level of quality control (QC) and quality assurance (QA) is in place at all times. Some things absolutely need to be the exact same every single time because there is very little room for error and products need to consistently pass quality checks in order to be viable for general public use.
SOP Examples
If you don't follow the instructions exactly right, the cake you are baking will taste very badly. The furniture you are building will not be fully functional, or even unsafe to use. The scientific experiment you are doing will include bias, contamination, or simply will not work, and you won't produce any results.
Si is incredibly vital because by ensuring that everthing is done the exact same way every time, you should expect the same results every time. So when you do not get the same results, it is incredibly easy to notice, and focus heavily on why results are different than expected.
This is how we learn and make discoveries.
Conclusion
We aren't wrong about Si or what it means. We aren't wrong about it's potential pitfalls. We are wrong to focus so heavily on pitfalls and not focus on how effective and essential Si can be when it is being used productively.
Yes, Si can be very dry sometimes. But it is an essential dryness. It is intentionally dry and repetitive because it minimizes the possibility for error. And it constantly updates and innovates its step-by-step instructions as new information becomes available so that the instructions we follow are the most effective as possible.
Si ensures our success. We don't have to change what Si means, we have to change how we choose to view it. It may not always be the most exciting cognitive function, but it makes the world go round, and we need to appreciate the high Si users just as much as we do everyone else.
18 notes
·
View notes
Last Seen Blogs

fskdms
yuly

vz17
VZ17 is my real name

stitchyace1997
Untitled

toacollabevent
TOA Collab Event 2022

musicistheair-blog
Music Is The Air