#web scraping data mining
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Empowering Decision-Making: Web Scraping and Data Mining Tactics
Empower your decision-making process with the strategic integration of web scraping and data mining tactics. Explore how these dynamic techniques extract valuable insights from online sources, driving informed decisions and strategic initiatives. From market analysis to competitor intelligence, leverage the synergy of web scraping and data mining to gain a competitive edge and fuel business growth.
#web scraping and data mining#web scraping data mining#data mining and scraping#what is scraping data#data mining scraping
0 notes
Text
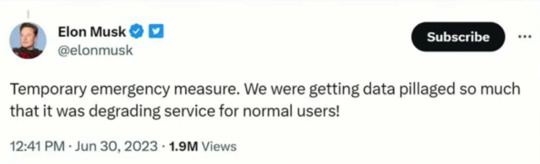
Fascinated that the owners of social media sites see API usage and web scraping as "data pillaging" -- immoral theft! Stealing! and yet, if you or I say that we should be paid for the content we create on social media the idea is laughed out of the room.
Social media is worthless without people and all the things we create do and say.
It's so valuable that these boys are trying to lock it in a vault.
#socail media#data mining#web scraping#twitter#reddit#you are the product#free service#free as in privacy invasion#pay me for that banger tweet you wretched nerd
8 notes
·
View notes
Text
Abode Enterprise
Abode Enterprise is a reliable provider of data solutions and business services, with over 15 years of experience, serving clients in the USA, UK, and Australia. We offer a variety of services, including data collection, web scraping, data processing, mining, and management. We also provide data enrichment, annotation, business process automation, and eCommerce product catalog management. Additionally, we specialize in image editing and real estate photo editing services.
With more than 15 years of experience, our goal is to help businesses grow and become more efficient through customized solutions. At Abode Enterprise, we focus on quality and innovation, helping organizations make the most of their data and improve their operations. Whether you need useful data insights, smoother business processes, or better visuals, we’re here to deliver great results.

#Data Collection Services#Web Scraping Services#Data Processing Service#Data Mining Services#Data Management Services#Data Enrichment Services#Business Process Automation Services#Data Annotation Services#Real Estate Photo Editing Services#eCommerce Product Catalog Management Services#Image Editing service
1 note
·
View note
Text
Mastering Data Collection in Machine Learning: A Comprehensive Guide -
Artificial intelligence, mastering the art of data collection is paramount to unlocking the full potential of machine learning algorithms. By adopting systematic methods, overcoming challenges, and adopting best practices, organizations can harness the power of data to drive innovation, gain competitive advantage, and provide transformative solutions across various domains. Through careful data collection, Globose Technology Solutions remains at the forefront of AI innovation, enabling clients to harness the power of data-driven insights for sustainable growth and success.
#Data Collection#Machine Learning#Artificial Intelligence#Data Quality#Data Privacy#Web Scraping#Sensor Data Acquisition#Data Labeling#Bias in Data#Data Analysis#Public Datasets#Data-driven Decision Making#Data Mining#Data Visualization#data collection company#dataset
1 note
·
View note
Text
https://www.webrobot.eu/travel-data-scraper-benefits-hospitality-tourism

The travel industry faces several challenges when using travel data. Discover how web scraping technology can help your tourism business solve these issues.
#travel#tourism#big data#web scraping tools#data extraction#hospitality#data analytics#datasets#webrobot#data mining#no code#ai tools
1 note
·
View note
Text
What is data mining? How is it different from data scraping?
Data mining converts data into accurate insights. Gather knowledge from unstructured data using advanced data mining techniques. Read more https://scrape.works/blog/what-is-data-mining-how-is-it-different-from-data-scraping/

0 notes
Text
Data or web scraping is the process of automatically extracting information from websites. This typically involves using software tools or scripts to navigate web pages, retrieve data, and store it in a structured format, such as a spreadsheet or database.
#data extraction#pricing intelligence#web scrapping#web scraping tool#web data extraction#data mining#data scraping#web data scraping services#price monitoring
0 notes
Text
Unlock the Power of Data with Web Scraping Services: A Comprehensive Guide

In today's data-driven world, businesses constantly strive to gain a competitive edge. The key to success lies in harnessing the power of data and extracting valuable insights. That's where web scraping services come into play. By leveraging this powerful technique, businesses can unlock a wealth of information from websites and other online sources. But what exactly is web scraping, and how can it benefit your organization? In this comprehensive guide, we will delve into the world of web scraping, exploring its various applications and potential benefits.
We will also provide insights into the best practices for implementing web scraping services, ensuring that you can make the most out of this invaluable tool. Whether you are a small start-up or a multinational corporation, this guide will equip you with the knowledge and expertise needed to leverage the power of data through web scraping services. Get ready to unlock a world of possibilities and gain a competitive edge in your industry.
What is web scraping?
Web scraping is the process of automatically extracting data from websites and other online sources. It involves using a software program or a web scraping service to navigate through web pages, extract specific information, and save it in a structured format for further analysis. Web scraping allows businesses to collect large amounts of data quickly and efficiently, eliminating the need for manual data entry or time-consuming data-gathering processes.
Web scraping can extract various types of data, such as product information, pricing data, customer reviews, social media data, and much more. The possibilities are endless, and the insights gained from web scraping can be invaluable in making informed business decisions, identifying market trends, monitoring competitors, and improving overall operational efficiency. However, it is essential to note that web scraping should be done ethically and in compliance with the terms of service of the websites being scraped.
Benefits of web scraping services
Web scraping services offer numerous benefits to businesses of all sizes and industries. Here are some of the key advantages of leveraging web scraping:
1. Data-driven decision making: Web scraping provides businesses with access to vast amounts of data that can be used to make data-driven decisions. Businesses can gain valuable insights into customer behavior, market trends, and competitor strategies by analyzing data from various sources, enabling them to make informed decisions that drive growth and profitability.
2. Competitive intelligence: Web scraping allows businesses to monitor their competitors' websites and extract valuable information, such as pricing data, product features, customer reviews, and marketing strategies. This information can be used to gain a competitive edge, identify market gaps, and develop effective strategies to outperform competitors.
3. Cost and time savings: Web scraping automates the data extraction process, eliminating the need for manual data entry or time-consuming data gathering processes. This saves time, reduces human error, and improves overall operational efficiency. Businesses can allocate their resources more effectively and focus on value-added activities.
4. Market research and lead generation: Web scraping enables businesses to gather data on potential customers, industry trends, and market dynamics. This information can be used to identify new market opportunities, target the right audience, and generate qualified leads for sales and marketing efforts.
5. Real-time data monitoring: With web scraping, businesses can monitor websites and online sources in real time, allowing them to stay updated on the latest information, news, and trends. This real-time data monitoring can be particularly valuable in industries where timely information is critical, such as finance, e-commerce, and media.
Common use cases for web scraping
Web scraping can be applied to various use cases across various industries. Here are some everyday use cases for web scraping:
1. E-commerce price monitoring: Web scraping can be used to monitor the prices of products on e-commerce websites, allowing businesses to adjust their pricing strategies in real time and remain competitive in the market.
2. Market research: Web scraping can gather data on customer preferences, product reviews, and market trends. It gives businesses insights to develop new products and tailor their offerings to meet customer demands.
3. Social media sentiment analysis: Web scraping can extract data from social media platforms, enabling businesses to analyze customer sentiment, identify brand mentions, and monitor social media trends.
4. Lead generation: Web scraping can gather data on potential customers, such as contact information, job titles, and industry affiliations, allowing businesses to generate targeted leads for sales and marketing efforts.
5. News aggregation: Web scraping can gather news articles and headlines from various sources, providing businesses with a comprehensive overview of their industry's latest news and trends.
These are just a few examples of how web scraping can be applied. The possibilities are endless, and businesses can tailor web scraping to suit their specific needs and objectives.
Legal considerations for web scraping
While web scraping offers numerous benefits, it is important to consider the legal and ethical implications. Web scraping may be subject to legal restrictions, depending on the jurisdiction and the terms of service of the websites being scraped. Here are some legal considerations to keep in mind:
1. Copyright and intellectual property: Web scraping copyrighted content without permission may infringe on intellectual property rights. It is essential to respect the rights of website owners and comply with copyright laws.
2. Terms of service: Websites often have terms of service that govern the use of their content. Some websites explicitly prohibit web scraping or impose restrictions on data extraction. It is important to review the terms of service and comply with any restrictions or requirements.
3. Data privacy: Web scraping may involve collecting personal data, such as names, email addresses, or other identifying information. It is essential to handle this data in compliance with applicable data protection laws, such as the General Data Protection Regulation (GDPR) in the European Union.
4. Ethical considerations: Web scraping should be done ethically and responsibly. It is important to respect the privacy of individuals and organizations and to use the data collected for legitimate purposes only.
To ensure compliance with legal and ethical requirements, businesses should consult with legal experts and seek permission from website owners when necessary. It is also advisable to implement technical measures, such as IP rotation and user-agent rotation, to minimize the impact on the websites being scraped and to avoid detection.
Choosing the right web scraping service provider
When it comes to web scraping, choosing the right service provider is crucial. Here are some factors to consider when selecting a web scraping service provider:
1. Experience and expertise: Look for a service provider with a proven track record in web scraping. Check their portfolio and client testimonials to gauge their experience and expertise in your industry.
2. Scalability and performance: Consider the scalability and performance capabilities of the service provider. Ensure that they can handle large-scale data extraction and deliver data promptly.
3. Data quality and accuracy: Data accuracy and data quality are paramount. Choose a service provider that employs data validation techniques and quality assurance processes to ensure the accuracy and reliability of the extracted data.
4. Compliance and security: Ensure the service provider complies with legal and ethical requirements. They should have measures in place to protect data privacy and security.
5. Customer support: Look for a service provider that offers excellent customer support. They should be responsive to your needs and assist whenever required.
Requesting a trial or demo from the service provider to assess their capabilities and compatibility with your requirements is advisable. Additionally, consider the pricing structure and contractual terms to ensure they align with your budget and business objectives.
Best practices for web scraping
It is important to follow best practices to make the most out of web scraping. Here are some tips to ensure successful web scraping:
1. Identify the target websites: Clearly define the websites you want to scrape and ensure they align with your business objectives. Prioritize websites that provide valuable and relevant data for your needs.
2. Respect website policies: Review the terms of service and any restrictions imposed by the websites being scraped. Respect the website owners' policies and comply with any limitations on data extraction.
3. Use ethical scraping techniques: Employ ethical scraping techniques, such as rate limiting, respect for robots.txt files, and avoiding disruptive activities that could impact website performance or user experience.
4. Implement data validation: Implement data validation techniques to ensure the quality and accuracy of the extracted data. Validate the data against predefined rules and perform checks to identify and correct any errors or inconsistencies.
5. Monitor and maintain data integrity: Regularly monitor the scraped data for changes or updates. Implement processes to ensure data integrity, such as version control and data synchronization.
6. Keep track of legal and regulatory changes: Stay updated on legal and regulatory developments related to web scraping. Regularly review your web scraping practices to ensure compliance with any new requirements.
By following these best practices, businesses can maximize the value of web scraping and mitigate any potential risks or challenges.
Tools and technologies for web scraping
Various tools and technologies are available for web scraping, ranging from simple browser extensions to sophisticated web scraping frameworks. Here are some popular options:
1. Beautiful Soup: Beautiful Soup is a Python library allowing easy parsing and extracting of data from HTML and XML files. It provides a simple and intuitive interface for web scraping tasks.
2. Scrapy: Scrapy is a robust and scalable web scraping framework in Python. It provides a comprehensive set of tools for web scraping, including built-in support for handling shared web scraping challenges.
3. Selenium: Selenium is a web automation tool that can be used for web scraping tasks. It allows for the automation of web browser interactions, making it suitable for websites that require JavaScript rendering or user interactions.
4. Octoparse: Octoparse is a visual web scraping tool that allows non-programmers to extract data from websites using a graphical interface. It provides a range of features for data extraction, such as point-and-click interface, scheduling, and data export options.
5. Import.io: Import.io is a cloud-based web scraping platform offering a range of data extraction, transformation, and analysis features. It provides a user-friendly interface and supports advanced functionalities like API integration and data visualization.
When selecting tools and technologies for web scraping, consider factors such as ease of use, scalability, performance, and compatibility with your existing infrastructure and workflows.
Challenges and limitations of web scraping
While web scraping offers numerous benefits, it has challenges and limitations. Here are some common challenges and limitations associated with web scraping:
1. Website changes: Websites frequently undergo changes in their structure and design, which can break the scraping process. Regular monitoring and adaptation of scraping scripts are necessary to accommodate these changes.
2. Anti-scraping measures: Websites often implement anti-scraping measures, such as IP blocking, CAPTCHA challenges, and dynamic content rendering, to deter web scraping activities. These measures can make scraping more challenging and require additional bypassing techniques.
3. Legal and ethical considerations: As mentioned earlier, web scraping may be subject to legal restrictions and ethical considerations. It is important to comply with applicable laws and respect website owners' policies to avoid legal issues or reputational damage.
4. Data quality and reliability: The quality and reliability of the scraped data can vary depending on the source and the scraping techniques used. Data validation and quality assurance processes are necessary to ensure the accuracy and reliability of the extracted data.
5. Data volume and scalability: Web scraping can generate large volumes of data, which may present storage, processing, and analysis challenges. Businesses must have the necessary infrastructure and resources to handle the data effectively.
Despite these challenges, web scraping remains a valuable tool for businesses to gain insights, make data-driven decisions, and stay ahead of the competition. With proper planning, implementation, and ongoing maintenance, businesses can overcome these challenges and leverage the power of web scraping effectively.
Case studies of successful web scraping projects
To illustrate the potential of web scraping, let's explore some case studies of successful web scraping projects:
1. Price comparison and monitoring: An e-commerce company used web scraping to monitor the prices of competitor products in real-time. This allowed them to adjust their pricing strategies accordingly and remain competitive. As a result, they increased their market share and improved profitability.
2. Market research and trend analysis: A market research firm used web scraping to gather data on customer preferences, product reviews, and market trends. This data provided valuable insights for their clients, enabling them to develop new products, improve existing offerings, and target the right audience effectively.
3. Lead generation and sales intelligence: A B2B company used web scraping to gather data on potential customers, such as contact information, job titles, and industry affiliations. This data was used for lead generation and sales intelligence, allowing them to generate targeted leads and improve their sales conversion rates.
These case studies demonstrate the versatility and effectiveness of web scraping in various business scenarios. Businesses can unlock valuable insights and gain a competitive edge by tailoring web scraping to their specific needs and objectives.
Conclusion and future of web scraping services
Web scraping services offer businesses a powerful tool to unlock the power of data and gain a competitive edge. By harnessing the vast amount of information available on the web, businesses can make data-driven decisions, monitor competitors, identify market trends, and improve operational efficiency. However, it is essential to approach web scraping ethically, respecting legal requirements and website owners' policies.
As technology evolves, web scraping is expected to become even more sophisticated and accessible. Advancements in machine learning and natural language processing enable more accurate and efficient data extraction, while cloud-based solutions make web scraping more scalable and cost-effective.
In conclusion, web scraping services can potentially revolutionize how businesses collect and analyze data. By leveraging this powerful technique, businesses can unlock a world of possibilities and gain a competitive edge in their industry. Whether you are a small start-up or a multinational corporation, web scraping services can provide valuable insights and drive growth. So, embrace the power of data and unlock your organization's full potential with web scraping services.
https://actowiz.blogspot.com/2023/08/web-scraping-services-guide.html
0 notes
Text
Unleashing the Power of Data: How Web Data Collection Services Can Propel Your Business Forward

Are you looking for a comprehensive guide on restaurant menu scraping? Look no further! In this ultimate guide, we will walk you through the process of scraping restaurant data, providing you with all the necessary tools and techniques to obtain valuable information from restaurant menus.
Restaurants have a wealth of data within their menus, including prices, ingredients, and special dishes. However, manually extracting this data can be time-consuming and tedious. That’s where a restaurant menu scraper comes in handy. With the right scraper, you can quickly and efficiently extract menu data, saving you hours of manual work.
In this article, we will explore different types of restaurant menu scrapers, their features, and how to choose the best one for your needs. We will also dive into the legal and ethical considerations of scraping restaurant menus, ensuring that you stay on the right side of the law while accessing this valuable data.
Whether you’re a restaurant owner looking to analyze your competitors’ menus or a data enthusiast eager to explore the world of restaurant data, this guide will equip you with the knowledge and tools you need to successfully scrape restaurant menus. So, let’s get started and unlock the unlimited possibilities of restaurant menu scraping!
Understanding the Benefits of Restaurant Menu Scraping
Scraping restaurant menus offers numerous benefits for both restaurant owners and data enthusiasts. For restaurant owners, menu scraping can provide valuable insights into their competitors’ offerings, pricing strategies, and popular dishes. This information can help them make informed decisions to stay ahead in the market.
Data enthusiasts, on the other hand, can leverage restaurant menu scraping to analyze trends, identify popular ingredients, and even predict customer preferences. This data can be used to develop innovative culinary concepts, create personalized dining experiences, or even build restaurant recommendation systems.
Restaurant menu scraping can also be useful for food bloggers, food critics, and review websites. By extracting data from various menus, they can provide detailed and up-to-date information to their readers, enhancing the overall dining experience.
Common Challenges in Restaurant Menu Scraping
While restaurant menu scraping offers numerous benefits, it is not without its challenges. One of the major challenges is the dynamic nature of restaurant menus. Menus are often updated regularly, with changes in prices, seasonal dishes, and ingredients. This constant change makes it crucial to have a scraper that can adapt and capture the latest data accurately.
Another challenge is the variability in menu layouts and formats. Each restaurant may have a unique menu design, making it difficult to create a one-size-fits-all scraper. Scraping tools need to be flexible and capable of handling different menu structures to ensure accurate data extraction.
Additionally, some restaurants may implement anti-scraping measures to protect their data. These measures can include CAPTCHAs, IP blocking, or even legal action against scrapers. Overcoming these challenges requires advanced scraping techniques and adherence to legal and ethical guidelines.
Step-by-step Guide on How to Scrape Restaurant Data
Now that we understand the benefits and challenges of restaurant menu scraping, let’s dive into the step-by-step process of scraping restaurant data. It is important to note that the exact steps may vary depending on the scraping tool you choose and the specific website you are targeting. However, the general process remains the same.
1. Identify the target restaurant: Start by choosing the restaurant whose menu you want to scrape. Consider factors such as relevance, popularity, and availability of online menus.
2. Select a scraping tool: There are several scraping tools available in the market, ranging from simple web scrapers to sophisticated data extraction platforms. Research and choose a tool that aligns with your requirements and budget.
3. Analyze the target website: Before scraping, familiarize yourself with the structure and layout of the target restaurant’s website. Identify the HTML elements that contain the menu data you want to extract.
4. Set up your scraper: Configure your scraping tool to target the specific HTML elements and extract the desired data. This may involve writing custom scripts, using CSS selectors, or utilizing pre-built scraping templates.
5. Run the scraper: Once your scraper is set up, initiate the scraping process. Monitor the progress and ensure that the scraper is capturing the data accurately. Adjust the scraper settings if necessary.
6. Clean and format the data: After scraping, the raw data may require cleaning and formatting to remove any inconsistencies or unwanted information. Depending on your needs, you may need to convert the data into a structured format such as CSV or JSON.
7. Validate the extracted data: It is important to validate the accuracy of the extracted data by cross-referencing it with the original menu. This step helps identify any errors or missing information that may have occurred during the scraping process.
8. Store and analyze the data: Once the data is cleaned and validated, store it in a secure location. You can then analyze the data using various statistical and data visualization tools to gain insights and make informed decisions.
By following these steps, you can successfully scrape restaurant menus and unlock a wealth of valuable data.
Choosing the Right Tools for Restaurant Menu Scraping
When it comes to restaurant menu scraping, choosing the right tools is crucial for a successful scraping project. Here are some factors to consider when selecting a scraping tool:
1. Scalability: Ensure that the scraping tool can handle large volumes of data and can scale with your business needs. This is especially important if you plan to scrape multiple restaurant menus or regularly update your scraped data.
2. Flexibility: Look for a tool that can handle different menu layouts and formats. The scraper should be able to adapt to changes in the structure of the target website and capture data accurately.
3. Ease of use: Consider the user-friendliness of the scraping tool. Look for features such as a visual interface, pre-built templates, and easy customization options. This will make the scraping process more efficient and accessible to users with varying levels of technical expertise.
4. Data quality and accuracy: Ensure that the scraping tool provides accurate and reliable data extraction. Look for features such as data validation, error handling, and data cleansing capabilities.
5. Support and documentation: Check the availability of support resources such as documentation, tutorials, and customer support. A robust support system can help you troubleshoot issues and make the most out of your scraping tool.
By carefully evaluating these factors, you can choose a scraping tool that meets your specific requirements and ensures a smooth and successful scraping process.
Best Practices for Restaurant Menu Scraping
To ensure a successful restaurant menu scraping project, it is important to follow best practices and adhere to ethical guidelines. Here are some key practices to keep in mind:
1. Respect website terms and conditions: Before scraping, review the terms and conditions of the target website. Some websites explicitly prohibit scraping, while others may have specific guidelines or restrictions. Ensure that your scraping activities comply with these terms to avoid legal consequences.
2. Implement rate limiting: To avoid overwhelming the target website with excessive requests, implement rate limiting in your scraping tool. This helps prevent IP blocking or other anti-scraping measures.
3. Use proxies: Consider using proxies to mask your IP address and distribute scraping requests across multiple IP addresses. Proxies help maintain anonymity and reduce the risk of IP blocking.
4. Monitor website changes: Regularly monitor the target website for any changes in menu structure or layout. Update your scraping tool accordingly to ensure continued data extraction.
5. Be considerate of website resources: Scraping can put a strain on website resources. Be mindful of the impact your scraping activities may have on the target website’s performance. Avoid excessive scraping or scraping during peak hours.
By following these best practices, you can maintain a respectful and ethical approach to restaurant menu scraping.
Legal Considerations When Scraping Restaurant Menus
Scraping restaurant menus raises legal considerations that must be taken seriously. While scraping is not illegal per se, it can potentially infringe upon copyright, intellectual property, and terms of service agreements. Here are some legal factors to consider:
1. Copyright infringement: The content of restaurant menus, including descriptions, images, and branding, may be protected by copyright. It is important to obtain permission from the restaurant or the copyright holder before using or redistributing scraped menu data.
2. Terms of service agreements: Review the terms of service of the target website to ensure that scraping is not explicitly prohibited. Even if scraping is allowed, there may be specific restrictions on data usage or redistribution.
3. Data privacy laws: Scrapped data may contain personal information, such as customer names or contact details. Ensure compliance with data privacy laws, such as the General Data Protection Regulation (GDPR) in the European Union, by anonymizing or removing personal information from the scraped data.
4. Competitor analysis: While scraping competitor menus can provide valuable insights, be cautious of any anti-competitive behavior. Avoid using scraped data to gain an unfair advantage or engage in price-fixing activities.
To avoid legal complications, consult with legal professionals and ensure that your scraping activities are conducted in accordance with applicable laws and regulations.
Advanced Techniques for Restaurant Menu Scraping
For more advanced scraping projects, you may encounter additional challenges that require specialized techniques. Here are some advanced techniques to consider:
1. Dynamic scraping: Some websites use JavaScript to dynamically load menu content. To scrape such websites, you may need to utilize headless browsers or JavaScript rendering engines that can execute JavaScript code and capture dynamically loaded data.
2. OCR for image-based menus: If the target menu is in image format, you can use Optical Character Recognition (OCR) tools to extract text from the images. OCR technology converts the text in images into machine-readable format, allowing you to extract data from image-based menus.
3. Natural language processing: To gain deeper insights from scraped menu data, consider applying natural language processing (NLP) techniques. NLP can be used to extract key information such as dish names, ingredients, and customer reviews from the scraped text.
4. Machine learning for menu classification: If you have a large collection of scraped menus, you can employ machine learning algorithms to classify menus based on cuisine type, pricing range, or other categories. This can help streamline data analysis and enhance menu recommendation systems.
By exploring these advanced techniques, you can take your restaurant menu scraping projects to the next level and unlock even more valuable insights.
Case Studies of Successful Restaurant Menu Scraping Projects
To illustrate the practical applications of restaurant menu scraping, let’s explore some real-world case studies:
1. Competitor analysis: A restaurant owner wanted to gain a competitive edge by analyzing the menus of their direct competitors. By scraping and analyzing the menus, they were able to identify pricing trends, popular dishes, and unique offerings. This allowed them to adjust their own menu and pricing strategy to attract more customers.
2. Food blog creation: A food blogger wanted to create a comprehensive food blog featuring detailed information about various restaurants. By scraping menus from different restaurants, they were able to provide accurate and up-to-date information to their readers. This increased the blog’s credibility and attracted a larger audience.
3. Data-driven restaurant recommendations: A data enthusiast developed a restaurant recommendation system based on scraped menu data. By analyzing menus, customer reviews, and other factors, the system provided personalized restaurant suggestions to users. This enhanced the dining experience by matching users with restaurants that align with their preferences.
These case studies highlight the diverse applications and benefits of restaurant menu scraping in various industries.
Conclusion: Leveraging Restaurant Menu Scraping for Business Success
Restaurant menu scraping presents a wealth of opportunities for restaurant owners, data enthusiasts, bloggers, and various other stakeholders. By leveraging the power of scraping tools and techniques, you can unlock valuable insights, make data-driven decisions, and stay ahead in the competitive restaurant industry.
In this ultimate guide, we have explored the benefits and challenges of restaurant menu scraping, provided a step-by-step guide on how to scrape restaurant data, discussed the importance of choosing the right tools and following best practices, and highlighted legal considerations and advanced techniques. We have also shared case studies showcasing the practical applications of restaurant menu scraping.
Now it’s your turn to dive into the world of restaurant menu scraping and unlock the unlimited possibilities it offers. Whether you’re a restaurant owner looking to analyze your competitors’ menus or a data enthusiast eager to explore the world of restaurant data, this guide has equipped you with the knowledge and tools you need to succeed. So, let’s get scraping and make the most out of restaurant menu data!
Know more : https://medium.com/@actowiz/ultimate-guide-to-restaurant-menu-scraper-how-to-scrape-restaurant-data-a8d252495ab8
#Web Data Collection Services#Data Collection Services#Web Scraping Services#Data Mining Services#Data Extraction Services
0 notes
Text

I am Moon Bikash Dev Roy from Bangladesh. Data entry job is my passion and I have 3 years of experience in this work. I believe that the quality and satisfaction of my customers is of paramount importance.
👉🏻 Contact me here!
0 notes
Text
I will provided data entry service. Product listing from Amazon.
#Data entry#Data mining#Virtual assistant#Web scraping#B2b lead generation#Business leads#Targeted leads#Data scraping#Data extraction#Excel data entry#Copy paste#Linkedin leads#Web research#Data collection
0 notes
Text
Achieve agility with our free web crawling services
Outsource Bigdata uses a variety of web crawling tools and techniques to help startups crawl the web easily. We also help you navigate your digital journey with the most effective web crawling services at an affordable cost. This is done by delivering your data in the required format, accessible to employees and applications.
For more details visit: https://outsourcebigdata.com/data-automation/web-scraping-services/web-crawling-services/
About AIMLEAP
Outsource Bigdata is a division of Aimleap. AIMLEAP is an ISO 9001:2015 and ISO/IEC 27001:2013 certified global technology consulting and service provider offering AI-augmented Data Solutions, Data Engineering, Automation, IT Services, and Digital Marketing Services. AIMLEAP has been recognized as a ‘Great Place to Work®’.
With a special focus on AI and automation, we built quite a few AI & ML solutions, AI-driven web scraping solutions, AI-data Labeling, AI-Data-Hub, and Self-serving BI solutions. We started in 2012 and successfully delivered projects in IT & digital transformation, automation-driven data solutions, on-demand data, and digital marketing for more than 750 fast-growing companies in the USA, Europe, New Zealand, Australia, Canada; and more.
An ISO 9001:2015 and ISO/IEC 27001:2013 certified
Served 750+ customers
11+ Years of industry experience
98% client retention
Great Place to Work® certified
Global delivery centers in the USA, Canada, India & Australia
Our Data Solutions
APISCRAPY: AI driven web scraping & workflow automation platform
APYSCRAPY is an AI driven web scraping and automation platform that converts any web data into ready-to-use data. The platform is capable to extract data from websites, process data, automate workflows, classify data and integrate ready to consume data into database or deliver data in any desired format.
AI-Labeler: AI augmented annotation & labeling solution
AI-Labeler is an AI augmented data annotation platform that combines the power of artificial intelligence with in-person involvement to label, annotate and classify data, and allowing faster development of robust and accurate models.
AI-Data-Hub: On-demand data for building AI products & services
On-demand AI data hub for curated data, pre-annotated data, pre-classified data, and allowing enterprises to obtain easily and efficiently, and exploit high-quality data for training and developing AI models.
PRICESCRAPY: AI enabled real-time pricing solution
An AI and automation driven price solution that provides real time price monitoring, pricing analytics, and dynamic pricing for companies across the world.
APIKART: AI driven data API solution hub
APIKART is a data API hub that allows businesses and developers to access and integrate large volume of data from various sources through APIs. It is a data solution hub for accessing data through APIs, allowing companies to leverage data, and integrate APIs into their systems and applications.
Locations:
USA: 1-30235 14656
Canada: +1 4378 370 063
India: +91 810 527 1615
Australia: +61 402 576 615
Email: [email protected]
0 notes
Text
Are you looking for a professional and reliable virtual assistant?Data Entry?Web Research and List Building ProjectsUseMS ExcelAre you ready? You are in the right place. Check out my expertise and the extra gigs I offer below..
0 notes
Text
Large-Scale Web Scraping - Web Scraping at Scale

To make sense of all that information, we need a way to organize it into something meaningful. That is where large-scale web scraping comes to the rescue. It is a process that involves gathering data from websites, particularly those with large amounts of data.
What Is Large-Scale Web Scraping?
Large Scale Web Scraping is scraping web pages and extracting data from them. This can be done manually or with automated tools. The extracted data can then be used to build charts and graphs, create reports and perform other analyses on the data.
It can be used to analyze large amounts of data, like traffic on a website or the number of visitors they receive. In addition, It can also be used to test different website versions so that you know which version gets more traffic than others.
Getting To Know The Client Expectations And Needs
We collect all the data from our clients to analyze the feasibility of the data extraction process for every individual site. If possible, we tell our clients exactly what data can be extracted, how much can be extracted, to what extent it can be extracted, and how much time the process completes.
Constructing Scrapers And Assembling Them Together
For every site allotted to us by our clients, we get a unique scraper built in place so that no one scraper has the burden to go through thousands of sites and millions of data. Moreover, all those scrapers are working in tandem for work to be done rapidly.
Running The Scrapers By Executing Them Smoothly
It is essential to have the servers and Internet lease lines running all the time so the extraction process is not interrupted. We ensure this through high-end hardware present at our premises costing lacs of rupees so that real-time information is delivered after extraction whenever the client wants. To avoid any blacklisting scenario, we already have proxy servers, many IP addresses, and various secret strategies coming to our rescue.
Quality Checks Scrapers Maintenance Performed On A Regular Basis
After the the automated web data scraping process, we ensure manual quality checks on the extracted or mined data via our QA team, who constantly communicates with the developer’s team for any bugs or errors reported. Additionally, if the scrapers need to be modified per changing site structure or client requirements, we do so without any hassle.
#data extraction#data mining services#webscraping#Large Scale Web Scraping#data scraping services#mobile app scraping
1 note
·
View note
Text
so i've been coding a website
home of: the dervampireprince fanart museum, prince's art gallery, a masterlist of resources for making websites and list of web communities, and more!
[18+, minors dni (this blog is 18+ and the art gallery and art museum pages on my site have some 18+ only artworks)]
littlevampire . neocities . org (clickable link in pinned post labelled 'website')
if you don't follow me on twitch or aren't in my discord, you might not know i've been coding my own website via neocities since june 2024. it's been a big labour of love, the only coding i'd done before is a little html to customize old tumblr themes, so i've learnt a lot and i've been having so much fun. i do link to it on my carrds but not everyone will know that the icon of a little cat with a wrench and paintbrush is the neocities logo, or even what neocities is.
neocities is a free website builder, but not like squarespace or wix that let you build a website from a template with things you can drag in, it's all done with html and css code (and you can throw in javascript if you wanna try hurting your brain /hj). i love the passion people have for coding websites, for making their own websites again in defiance of social medias becoming less customisable and websites looking boring and the same as each other. people's neocities sites are so fun to look through, looking at how they express themselves, their art galleries, shrines to their pets or favourite characters or shows or toys or places they've been.
why have i been making a website this way?
well i used to love customising my tumblr theme back when clicking on someone's username here took you to their tumblr website, their username . tumblr . com link that you could edit and customise with html code. now clicking a username takes you to their mobile page view, a lot of users don't even know you can have a website with tumblr, the feature to have a site became turned off by default, and i've heard from some users that they might have to pay to unlock that feature.
i've always loved the look of old geocities and angelfire websites, personalised sites, and i've grown tired of every social media trying to look the same as each other, remove features that let users customise their profiles and pages more. and then i found out about neocities.
are you interested in making a site too?
neocities is free, though you can pay to support them. there is no ads, no popups, they have no ai tool scraping their sites, no tos that will change to suddenly stop allow 18+ art. unlike other website hosters, neocities does have a sort of social media side where you do have a profile and people can follow you and leave comments on your site and like your updates, but you can ignore this if you want, or use it to get to know other webmasters.
to quote neocities "we are tired of living in an online world where people are isolated from each other on boring, generic social networks that don't let us truly express ourselves. it's time we took back our personalities from these sterilized, lifeless, monetized, data mined, monitored addiction machines and let our creativity flourish again."
i'd so encourage anyone interested to try making a website with neocities. w3schools is an excellent place to start learning coding, and there are free website templates you can copy and paste and use (my site is built off two different free codes, one from fujoshi . nekoweb . org and the other from sadgrl's free layout builder tool).
your site can be for anything:
a more fun and interactive online business card (rather than using carrd.co or linktree)
a gallery of your art/photos/cosplays/etc
a blog
webshrines to your a character, film, song, game, toy, hobby, your pet - anything can be a shrine!
a catalogue/database/log of every film you've watched, every place you've visited, birds you've seen, plushies you own, every blinkie gif you have saved, your ocs and stories, etc
hosting a webcomic
a fanwiki/fansite that doesn't have endless ads like fandom . com does (i found a cool neocities fansite for rhythm game series pop'n music and it's so thorough, it even lists all the sprites and official art for every character)
i follow a website that just reviews every video game based on whether or not it has a frog in it, if the frog is playable, if you can be friends with it. ( frogreview . neocities . org )
the only html i knew how to write before starting is how to paragraph and bold text. and now i have a whole site! and i'm still working on new stuff for it all the time.
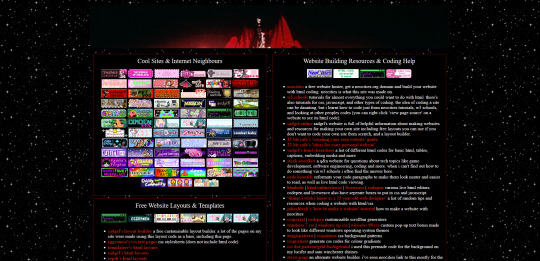
i just finished making a page on my website called 'explore the web'. this page lists everything you might need to know when wanting to make or decorate your website. it lists:
other neocities sites i think are cool and i'm inspired by, check them out for more ideas of what your site could look like and contain!
website building resources
coding help and tutorials
free website html code layouts you can use if you don't want too start coding from scratch
places to find graphics and decorative images for your site (transparent background pngs, pixels, favicons, stamps, blinkies, buttons, userboxes, etc)
image generators for different types of buttons and gifs (88x31 buttons, tiny identity buttons, heart locket open gifs, headpat gifs)
widgets and games and interactive elements you can add to your site (music players, interactive pets like gifypet and tamanotchi, hit counters, games like pacman and crosswords, guestbooks and chatboxes, etc)
web manifestos, guides, introductions and explanations of webmastering and neocities (some posts made by other tumblr users here are what made me finally want to make my own site and discover how too)
art tools, resources and free drawing programs
web communities! webrings, cliques, fanlistings, pixel clubs (pixel art trades) and more!
other fun sites that didn't fit in the other categories like free sheet music sites, archives, egotistical.goat (see a tumblr users audio posts/reblogs as a music playlist), soul void (a wonderful free to play video game i adore), an online omnichord you can play, and more.
i really hope the 'explore the web' page is helpful, it took three days to track down every link and find resources to add.
and if you want to check out my site there's more than just these pages. like i said in the beginning, i recently finished making:
the dervampireprince fanart museum
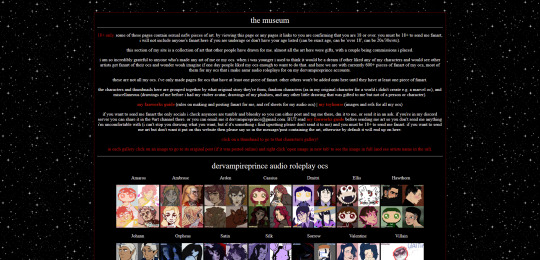
every piece of fanart i've received (unless the sender asked me to keep it private) has been added to this museum and where possible links back to the original artists post of that art (a lot the art was sent to me via discord so i can't link to the original post). every piece of fanart sent to me now will be added on their unless you specifically say you don't want it going on there. there's also links to my fanworks guide on there and how to send me fanart.
other pages on my site
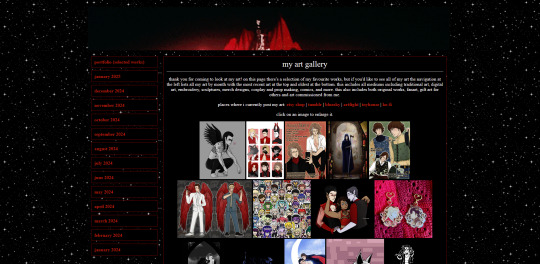

about me (including favourite media, quizzes, comfort characters, kins, and more)
art gallery (art i've made, sorted by month)
graphics (so far it's just stamps i've made but plan to remake this section of my site)
media log (haven't started the 2025 one yet, but a log of all films, tv, writing, music, theatre, fandoms, characters and ships i got into in 2024)
silly web pets
shrines
site map
update log
my shrines so far:
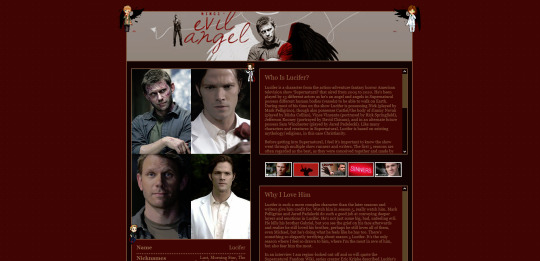

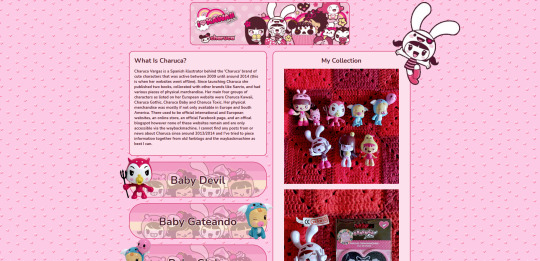
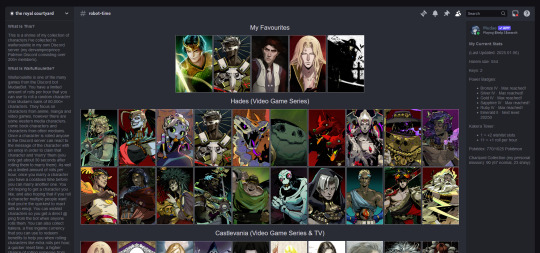
i have ones for lucifer from supernatural, sam winchester from supernatural, charuca minifigures (arcade prizes i wanted as a kid that i'm trying to finish collecting as an adult), my waifuroulette discord tcg collection. my masterlist of every lgbt+ marvel character is a wip. i love making each shrine look different and suit the character/fandom/thing the shrine is about. and then there's also:
the european musical section


i ramble about them a lot and it's no surprise there's multiple shrines for them. i fell in love with german musical theatre in 2020 and that expanded in being interested in all non-english language musical theatre and trying to spread the word of it and how they deserve to be as known as english-language musicals. one musical in particular, elisabeth das musical, is my biggest special interest so expect a very detailed shrine about that one day.
so far this part of the site includes
'enter the theatre' an interactive web theatre where you choose a ticket and that musical will play on the stage (click a ticket and the embedded youtube video for that musical will appear on the stage and play. i dealt with javascript for the first time to bring the vision i had for this page alive, it might be slow but i hope enjoyable)
elisabeth das musical webshrine [not made yet]
tanz der vampire webshrine [not made yet, might abandon the idea]
my favourite european musicals [not made yet]
a masterlist of european musicals [a wip, only two musicals listed so far, i am listing every musical and every production they've had, this was a word document i kept for a long time that i always wanted to share somehow and this page is how i'll do it. there's no other list for european musicals out there so i guess it's up to me as always /lh]
the future for my site
i will update my art gallery, the fanart museum, my media log and other collections as often as i can. there's so many more pages i want to add including:
profiles for my ocs
finish my european musical masterlist
finish my 'every marvel lgbt+ character' masterlist (i have no love for marvel or disney's lgbt+ representation nor are all of these characters good representation and a lot are very minor characters, but for some reason i have gotten hyperfixated on this topic a few times so here comes a masterlist)
make shrines for loki (marvel), ares (hades), my sylvanian families collection, vocaloid (and/or vocaloid medleys), my plushie collection, pullip dolls
make a 'page not found' page
and i have one big plan to essentially make a site within a site, and make a website for my monster boy band ocs. but make it as if it was a real band, an unfiction project (think like how welcome home's website portrays welcome home as if it was a real show). this site would have pages for the band members, their albums, merch and maybe a pretend shop, and a fake forum where you could see other characters in the story talking and click on their profiles to find out more about them. and then once that's all done i want to start posting audios about the characters and then people can go to the website to find out more about them. that's my big plan anyway. i hope that sounds interesting.
i also want to make an effort to try and join some website communities. be brave and apply for some webrings and fanlistings, and make some pixel art and join some of the amazing pixel clubs out there.
but yeah, that's my site, that's neocities. i hope that was interesting. i hope it encourages people to make their own site, or at least look at other's small websites and explore this part of the internet. and if you go and check out mine feel free to drop a message in the guestbook on the homepage, or follow me on neocities if you have/make an account.
66 notes
·
View notes
Text
Transform your manufacturing operations with automated data extraction software, optimizing efficiency and productivity. Explore how these advanced tools streamline data retrieval processes, enabling quick access to valuable insights from various sources.
#data mining and web scraping#automated data extraction software#web scrapers#web scraping services#web scraping in manufacturing
0 notes