#[data transfer]
Text

The first attempt to transfer memories between the brain and an 8-bit computer.
#vaporwave#80s aesthetic#synthwave#retrowave#retrofuture#glitch#glitch gif#gif#glitchart#glitch art#art#abstract#abstract art#corrupted data#computer art#computing#data transfer#data transmission#data tracking#trippy gif
23 notes
·
View notes
Text
57 notes
·
View notes
Text
Hey erm…. Idk if anyone has an answer for this but if I get a new phone (iPhone) and transfer my data will my genshin data save?? Like will my genshin reset or will I be able to continue where I left off.
6 notes
·
View notes
Note
Mobile is a big market as ae live service games. Downside of long running games is their file sizes balloon and this isn't particularly friendly to the mobile platform. Any solutions to this problem the industry is working on?
There's a lot of tricks developers have been doing. The issue most players have with load times is that there are thresholds beyond which the player gives up and drops the game. If we can keep the player from experiencing too much loading, especially in one contiguous chunk, then we are probably good. This is usually handled in one of a several ways.

First, we try to reduce the amount of data that needs to be transferred. Lower resolution textures, compressed files, compressed audio, and so on and so forth. Reducing the overall file size through savings here and there is the first order of the day.

Second, we can try to break up the longer load times so that there isn't too much waiting in one sitting. This usually entails allowing players to play certain parts of the game without downloading the game's full assets. If we only have to download the tutorial and its assets at the beginning of the game, we can let the player play the tutorial and get into the action faster without having to wait for everything to finish transferring before we can play the game. If we only need these ten files to play this particular level, we don't need all of the others.

Third, during load times we can offer the player something to do. This can be a mini-game, a puzzle, a practice dojo, a buy/sell/equip gear interface for the chosen mission, or even an elevator ride while the player listens to character conversations. Another common thing many developers do is show bits of featured lore about the game's characters and places that can be scrolled through during the load screens. If players aren't just staring at a progress bar, it doesn't feel as annoying.

A fourth option is to enable background downloads (assuming the player allows it) while the phone is running and on wifi. Similar to how apps can be permitted auto-update while the phone is idle, the game can be permitted to download whatever files it needs while it sits resident in memory on the phone during downtimes. If we detect the device screen is off, we can use that opportunity to transfer some data.
This list is, of course, not exhaustive. There are other means of dealing with data transfer times being researched all the time. As long as transfer times are a problem, we'll keep trying to figure out better solutions for it.
[Join us on Discord] and/or [Support us on Patreon]
Got a burning question you want answered?
Short questions: Ask a Game Dev on Twitter
Long questions: Ask a Game Dev on Tumblr
Frequent Questions: The FAQ
17 notes
·
View notes
Text
16 useful 'Curl' Commands in Linux
Curl is a command-line tool used to transfer data to and from servers. It supports various protocols including HTTP, HTTPS, FTP, SFTP, and many more. The tool can be used to download files, upload files, make requests to APIs, and more. In this article, we will explore the different options available in Curl and understand how to use them with examples.
How to Install Curl in Linux
Curl is…

View On WordPress
#command-line#cookies#curl#data transfer#download#example#FTP#guide#headers#HTTP#internet#linux#options#protocols#proxies#redirects#transfer rate#tutorial#user-agent
2 notes
·
View notes
Text

2 notes
·
View notes
Text
🚀 Unlock the Future with AI Services! 🚀
Transform your business with cutting-edge AI solutions that drive efficiency, automation, and growth.

From AI-powered analytics to smart automation tools, we offer customized services tailored to your needs.
🔹 Boost Productivity
🔹 Enhance Customer Experience
🔹 Streamline Operations
Partner with us and stay ahead of the competition with innovative AI technology.
Contact us today!
📞 Call: (877)431–0767
🌐 Visit: https://www.cirruslabs.io/
Address: 5865 North Point Pkwy,Suite 100, Alpharetta, GA 30022
Don’t miss out on the AI revolution — Elevate your business now!
0 notes
Text
Master CUDA: For Machine Learning Engineers
New Post has been published on https://thedigitalinsider.com/master-cuda-for-machine-learning-engineers/
Master CUDA: For Machine Learning Engineers
CUDA for Machine Learning: Practical Applications
Structure of a CUDA C/C++ application, where the host (CPU) code manages the execution of parallel code on the device (GPU).
Now that we’ve covered the basics, let’s explore how CUDA can be applied to common machine learning tasks.
Matrix Multiplication
Matrix multiplication is a fundamental operation in many machine learning algorithms, particularly in neural networks. CUDA can significantly accelerate this operation. Here’s a simple implementation:
__global__ void matrixMulKernel(float *A, float *B, float *C, int N) int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; float sum = 0.0f; if (row < N && col < N) for (int i = 0; i < N; i++) sum += A[row * N + i] * B[i * N + col]; C[row * N + col] = sum; // Host function to set up and launch the kernel void matrixMul(float *A, float *B, float *C, int N) dim3 threadsPerBlock(16, 16); dim3 numBlocks((N + threadsPerBlock.x - 1) / threadsPerBlock.x, (N + threadsPerBlock.y - 1) / threadsPerBlock.y); matrixMulKernelnumBlocks, threadsPerBlock(A, B, C, N);
This implementation divides the output matrix into blocks, with each thread computing one element of the result. While this basic version is already faster than a CPU implementation for large matrices, there’s room for optimization using shared memory and other techniques.
Convolution Operations
Convolutional Neural Networks (CNNs) rely heavily on convolution operations. CUDA can dramatically speed up these computations. Here’s a simplified 2D convolution kernel:
__global__ void convolution2DKernel(float *input, float *kernel, float *output, int inputWidth, int inputHeight, int kernelWidth, int kernelHeight) int x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y; if (x < inputWidth && y < inputHeight) float sum = 0.0f; for (int ky = 0; ky < kernelHeight; ky++) for (int kx = 0; kx < kernelWidth; kx++) int inputX = x + kx - kernelWidth / 2; int inputY = y + ky - kernelHeight / 2; if (inputX >= 0 && inputX < inputWidth && inputY >= 0 && inputY < inputHeight) sum += input[inputY * inputWidth + inputX] * kernel[ky * kernelWidth + kx]; output[y * inputWidth + x] = sum;
This kernel performs a 2D convolution, with each thread computing one output pixel. In practice, more sophisticated implementations would use shared memory to reduce global memory accesses and optimize for various kernel sizes.
Stochastic Gradient Descent (SGD)
SGD is a cornerstone optimization algorithm in machine learning. CUDA can parallelize the computation of gradients across multiple data points. Here’s a simplified example for linear regression:
__global__ void sgdKernel(float *X, float *y, float *weights, float learningRate, int n, int d) int i = blockIdx.x * blockDim.x + threadIdx.x; if (i < n) float prediction = 0.0f; for (int j = 0; j < d; j++) prediction += X[i * d + j] * weights[j]; float error = prediction - y[i]; for (int j = 0; j < d; j++) atomicAdd(&weights[j], -learningRate * error * X[i * d + j]); void sgd(float *X, float *y, float *weights, float learningRate, int n, int d, int iterations) int threadsPerBlock = 256; int numBlocks = (n + threadsPerBlock - 1) / threadsPerBlock; for (int iter = 0; iter < iterations; iter++) sgdKernel<<<numBlocks, threadsPerBlock>>>(X, y, weights, learningRate, n, d);
This implementation updates the weights in parallel for each data point. The atomicAdd function is used to handle concurrent updates to the weights safely.
Optimizing CUDA for Machine Learning
While the above examples demonstrate the basics of using CUDA for machine learning tasks, there are several optimization techniques that can further enhance performance:
Coalesced Memory Access
GPUs achieve peak performance when threads in a warp access contiguous memory locations. Ensure your data structures and access patterns promote coalesced memory access.
Shared Memory Usage
Shared memory is much faster than global memory. Use it to cache frequently accessed data within a thread block.
Understanding the memory hierarchy with CUDA
This diagram illustrates the architecture of a multi-processor system with shared memory. Each processor has its own cache, allowing for fast access to frequently used data. The processors communicate via a shared bus, which connects them to a larger shared memory space.
For example, in matrix multiplication:
__global__ void matrixMulSharedKernel(float *A, float *B, float *C, int N) __shared__ float sharedA[TILE_SIZE][TILE_SIZE]; __shared__ float sharedB[TILE_SIZE][TILE_SIZE]; int bx = blockIdx.x; int by = blockIdx.y; int tx = threadIdx.x; int ty = threadIdx.y; int row = by * TILE_SIZE + ty; int col = bx * TILE_SIZE + tx; float sum = 0.0f; for (int tile = 0; tile < (N + TILE_SIZE - 1) / TILE_SIZE; tile++) if (row < N && tile * TILE_SIZE + tx < N) sharedA[ty][tx] = A[row * N + tile * TILE_SIZE + tx]; else sharedA[ty][tx] = 0.0f; if (col < N && tile * TILE_SIZE + ty < N) sharedB[ty][tx] = B[(tile * TILE_SIZE + ty) * N + col]; else sharedB[ty][tx] = 0.0f; __syncthreads(); for (int k = 0; k < TILE_SIZE; k++) sum += sharedA[ty][k] * sharedB[k][tx]; __syncthreads(); if (row < N && col < N) C[row * N + col] = sum;
This optimized version uses shared memory to reduce global memory accesses, significantly improving performance for large matrices.
Asynchronous Operations
CUDA supports asynchronous operations, allowing you to overlap computation with data transfer. This is particularly useful in machine learning pipelines where you can prepare the next batch of data while the current batch is being processed.
cudaStream_t stream1, stream2; cudaStreamCreate(&stream1); cudaStreamCreate(&stream2); // Asynchronous memory transfers and kernel launches cudaMemcpyAsync(d_data1, h_data1, size, cudaMemcpyHostToDevice, stream1); myKernel<<<grid, block, 0, stream1>>>(d_data1, ...); cudaMemcpyAsync(d_data2, h_data2, size, cudaMemcpyHostToDevice, stream2); myKernel<<<grid, block, 0, stream2>>>(d_data2, ...); cudaStreamSynchronize(stream1); cudaStreamSynchronize(stream2);
Tensor Cores
For machine learning workloads, NVIDIA’s Tensor Cores (available in newer GPU architectures) can provide significant speedups for matrix multiply and convolution operations. Libraries like cuDNN and cuBLAS automatically leverage Tensor Cores when available.
Challenges and Considerations
While CUDA offers tremendous benefits for machine learning, it’s important to be aware of potential challenges:
Memory Management: GPU memory is limited compared to system memory. Efficient memory management is crucial, especially when working with large datasets or models.
Data Transfer Overhead: Transferring data between CPU and GPU can be a bottleneck. Minimize transfers and use asynchronous operations when possible.
Precision: GPUs traditionally excel at single-precision (FP32) computations. While support for double-precision (FP64) has improved, it’s often slower. Many machine learning tasks can work well with lower precision (e.g., FP16), which modern GPUs handle very efficiently.
Code Complexity: Writing efficient CUDA code can be more complex than CPU code. Leveraging libraries like cuDNN, cuBLAS, and frameworks like TensorFlow or PyTorch can help abstract away some of this complexity.
As machine learning models grow in size and complexity, a single GPU may no longer be sufficient to handle the workload. CUDA makes it possible to scale your application across multiple GPUs, either within a single node or across a cluster.
CUDA Programming Structure
To effectively utilize CUDA, it’s essential to understand its programming structure, which involves writing kernels (functions that run on the GPU) and managing memory between the host (CPU) and device (GPU).
Host vs. Device Memory
In CUDA, memory is managed separately for the host and device. The following are the primary functions used for memory management:
cudaMalloc: Allocates memory on the device.
cudaMemcpy: Copies data between host and device.
cudaFree: Frees memory on the device.
Example: Summing Two Arrays
Let’s look at an example that sums two arrays using CUDA:
__global__ void sumArraysOnGPU(float *A, float *B, float *C, int N) int idx = threadIdx.x + blockIdx.x * blockDim.x; if (idx < N) C[idx] = A[idx] + B[idx]; int main() int N = 1024; size_t bytes = N * sizeof(float); float *h_A, *h_B, *h_C; h_A = (float*)malloc(bytes); h_B = (float*)malloc(bytes); h_C = (float*)malloc(bytes); float *d_A, *d_B, *d_C; cudaMalloc(&d_A, bytes); cudaMalloc(&d_B, bytes); cudaMalloc(&d_C, bytes); cudaMemcpy(d_A, h_A, bytes, cudaMemcpyHostToDevice); cudaMemcpy(d_B, h_B, bytes, cudaMemcpyHostToDevice); int blockSize = 256; int gridSize = (N + blockSize - 1) / blockSize; sumArraysOnGPU<<<gridSize, blockSize>>>(d_A, d_B, d_C, N); cudaMemcpy(h_C, d_C, bytes, cudaMemcpyDeviceToHost); cudaFree(d_A); cudaFree(d_B); cudaFree(d_C); free(h_A); free(h_B); free(h_C); return 0;
In this example, memory is allocated on both the host and device, data is transferred to the device, and the kernel is launched to perform the computation.
Conclusion
CUDA is a powerful tool for machine learning engineers looking to accelerate their models and handle larger datasets. By understanding the CUDA memory model, optimizing memory access, and leveraging multiple GPUs, you can significantly enhance the performance of your machine learning applications.
#AI Tools 101#algorithm#Algorithms#amp#applications#architecture#Arrays#cache#cluster#code#col#complexity#computation#computing#cpu#CUDA#CUDA for ML#CUDA memory model#CUDA programming#data#Data Structures#data transfer#datasets#double#engineers#excel#factor#functions#Fundamental#Global
0 notes
Text
What is Docker and how it works
#docker#container#data transfer#application#website#web development#technology#software#information technology
0 notes
Text
Migrating from Joomla to WordPress: A Comprehensive Guide
Explore the complete process of Joomla to WordPress migration seamlessly. This guide covers planning, data migration, theme customization, plugin integration, and post-migration optimization. Upgrade your website's functionality and usability with this essential Joomla to WordPress migration tutorial.
0 notes
Video
youtube
How to Transfer Data from Android to iPhone [2 FREE Ways]
0 notes
Text
Suncable's Australia-Asia Power Link project receives environmental approval, set to become world's largest renewable energy precinct

- By Nuadox Crew -
SunCable has received principal environmental approval from Australia's Northern Territory Government and the NT Environment Protection Authority for its Australia-Asia Power Link (AAPowerLink) project.
This approval allows the project to move forward with development, commercial, and engineering activities leading to the Final Investment Decision (FID), expected in 2027. The project aims to develop the world's largest renewable energy precinct in the Barkly region, producing up to 4 GW of green electricity for Darwin and 1.75 GW for Singapore via a 4,300 km subsea cable, with supply starting in the early 2030s.
The AAPowerLink will include a large-scale solar farm, energy storage, and transmission systems. The solar precinct in Barkly will cover 12,000 hectares and generate 17-20 GW from solar PV arrays. It will store 36-42 GW hours of energy and feature an 800 km HVDC transmission line to Murrumujuk, where electricity will be converted from HVDC to HVAC for local distribution and then back to HVDC for transmission to Singapore. The project could deliver over USD 13.5 billion in economic value to the NT during its construction and first 35 years of operation.
Read more at Interesting Engineering
///
Other recent news
Polar Ice Melting Impact: A recent study has found that the melting of polar ice is making the Earth heavier to rotate, which is causing longer days.
New Privacy Camera: A new camera has been developed that turns you into a stick figure to stop home devices from snooping on you.
Drone Traffic Test: In a world-first, a flock of 5,000 drones successfully self-flew during a UAV traffic test.
Stretchable Lithium-Ion Batteries: Scientists have developed a stretchable lithium-ion battery that can expand up to 5000% and still retain efficient charge storage.
Record Data Transmission Speed: Researchers have broken the world record for data transmission speed, achieving 402 terabits per second using standard optical fiber.
#energy#australia#asia#renewables#climate change#ice#privacy#camera#drone#uav#battery#lithium ion#data transfer#computing
1 note
·
View note
Text
A Step-by-Step Guide to Transferring Data from Google Sheets to Power BI

In today's data-driven world, businesses rely heavily on robust tools for data analysis and visualization. Google Sheets and Power BI are two such powerful platforms widely used for managing and analyzing data. However, integrating data from Google Sheets into Power BI can be a significant change for organizations seeking to streamline their data analysis processes. In this step-by-step guide, we will walk you through the process of transferring data from Google Sheets to Power BI, empowering you to harness the full potential of your data.
Step 1: Prepare Your Google Sheets Data
Before transferring your data to Power BI, ensure that your Google Sheets document is well-structured and organized. Clean up your data by removing any unnecessary rows or columns, fixing formatting inconsistencies, and ensuring that column headers are descriptive and consistent.
Step 2: Share Your Google Sheets Document
To access your Google Sheets data from Power BI, you will need to share your document with the appropriate permissions. Open your Google Sheets document, click on the "Share" button, and set the visibility to "Anyone with the link" or "Public," depending on your organization's privacy policies. Make sure that "View" access is granted to anyone with the link.
Step 3: Generate the Google Sheets URL
Once your Google Sheets document is shared, you will need to generate a URL that Power BI can use to access the data. Open your Google Sheets document, copy the URL from the address bar of your browser, and save it for later use.
Step 4: Connect to Google Sheets in Power BI
Now, it is time to switch to Power BI and connect to your Google Sheets data. Open Power BI Desktop or Power BI Service, depending on your preference. In Power BI Desktop, click on "Get Data" in the Home tab, select "Web" from the list of data sources, and paste the Google Sheets URL you copied earlier into the URL field. Click "OK" to proceed.
Step 5: Select Data to Import
Power BI will load the data from your Google Sheets document and display a navigator window with a preview of the available sheets. Select the sheets containing the data you want to import into Power BI and click "Load" to import the selected data into Power BI.
Once the data is imported into Power BI, you may need to perform additional transformations or cleaning steps to prepare it for analysis. Use Power BI's built-in data transformation tools to reshape, filter, or combine data from multiple sources as needed.
Step 6: Create Visualizations and Reports
With your data successfully imported into Power BI, you can now start creating visualizations and reports to gain insights into your data. Use Power BI's drag-and-drop interface to create interactive visualizations such as charts, graphs, and maps, and arrange them into insightful dashboards for easy consumption.
To ensure that your Power BI reports always reflect the latest data from your Google Sheets document, you can schedule automatic data refreshes. In Power BI Service, navigate to the dataset settings, and configure a refresh schedule that suits your needs. Power BI will automatically retrieve updated data from Google Sheets according to the specified schedule.
Step 7: Share and Collaborate
Once your reports and dashboards are ready, you can share them with your colleagues or stakeholders for collaboration and decision-making. Publish your Power BI reports to the Power BI Service and use sharing options to grant access to specific users or groups within your organization.
Step 8: Monitor and Iterate
Finally, continuously monitor the performance and effectiveness of your Power BI reports and dashboards. Gather feedback from users, analyze usage metrics, and iterate on your reports to improve insights and usability over time. Power BI's robust monitoring and analytics capabilities make it easy to track the impact of your data analysis efforts and drive continuous improvement.
By following these Eight simple steps, you can seamlessly transfer data from Google Sheets to Power BI, unlocking powerful insights and driving data-driven decision-making within your organization. Whether you are a business analyst, data scientist, or decision-maker, mastering the art of data integration with Power BI opens a world of possibilities for extracting value from your data and driving business success.
0 notes
Text
PACS Solutions: Revolutionizing Radiology Management

In the dynamic realm of healthcare, PACS solutions are catalysts for innovation, reshaping the landscape of radiology management. At the heart of this transformation lies the seamless interfacing of radiology machines with Picture Archiving and Communication Systems (PACS), ushering in an era of enhanced efficiency and improved patient care.
PACS integration stands as the cornerstone of this revolution. By seamlessly linking radiology machines to the centralized PACS platform, healthcare facilities can streamline their radiology workflow, expediting the process from image acquisition to diagnosis. This integration empowers radiologists with instant access to patient images and data, eliminating the delays associated with traditional film-based systems.
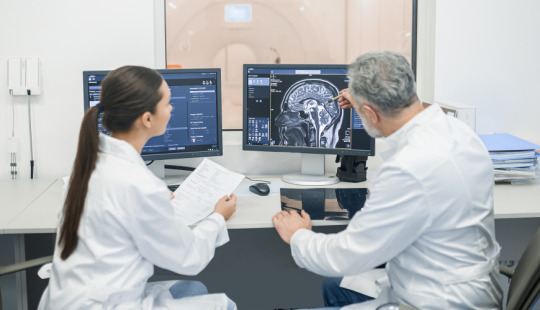
Central to the efficacy of PACS solutions is the swift and secure data transfer capabilities they offer. Through advanced networking technologies, patient images are swiftly transmitted from radiology machines to the PACS server, ensuring rapid availability for analysis and diagnosis. This streamlined PACS connectivity enhances collaboration among healthcare professionals, facilitating prompt decision-making and timely patient care.
Moreover, radiology software plays a pivotal role in optimizing image management within PACS environments. With intuitive interfaces and powerful tools, these software solutions empower radiologists to efficiently organize, analyze, and interpret medical images. From customizable viewing preferences to sophisticated image processing algorithms, radiology software enhances diagnostic accuracy while expediting report generation.
In essence, PACS solutions are reshaping radiology management paradigms, driving operational efficiency and elevating patient care standards. Through seamless interfacing of radiology machines with PACS, healthcare providers can unlock new levels of productivity and precision in medical imaging. As technology continues to evolve, embracing these innovative solutions is paramount for staying at the forefront of modern healthcare delivery.
0 notes
Text
Connecting the Dots: The Importance of Lab Analyzers Interfacing

In the intricate tapestry of laboratory operations, the seamless integration of lab analyzers is paramount. From chemistry analyzers to hematology instruments, each component plays a vital role in the diagnostic process. However, the true magic happens when these disparate pieces come together through lab analyzers interfacing. This synergy not only streamlines workflow but also enhances the efficiency and accuracy of diagnostic testing.
At the heart of lab analyzers interfacing lies instrument integration. Gone are the days of siloed instruments operating in isolation. Modern laboratories demand interconnectedness, where analyzers communicate harmoniously to deliver cohesive results. Through advanced integration protocols, laboratories can orchestrate a symphony of analyses, maximizing throughput and minimizing turnaround times.
Yet, integration is merely the first step. The crux of lab analyzers interfacing lies in data transfer. Patient samples traverse a labyrinth of analyzers, each generating a plethora of data points. Efficient data transfer mechanisms ensure that these valuable insights flow seamlessly from one instrument to another, without loss or distortion. Whether it's transmitting test results or patient demographics, the integrity of data transfer is sacrosanct.

However, the path to seamless interfacing is fraught with challenges, chief among them being compatibility testing. Not all analyzers speak the same language or adhere to uniform data standards. Compatibility testing is akin to deciphering a complex code, ensuring that disparate instruments can understand and interpret each other's signals. Through meticulous testing protocols, laboratories can preempt compatibility issues and preemptively resolve them.
Moreover, effective interface configuration is essential for optimizing analyzers' interoperability. Customized configurations tailor interfaces to the unique needs of each laboratory, ensuring smooth data exchange and minimizing errors. Whether it's defining data formats or establishing communication protocols, meticulous interface configuration is the linchpin of successful lab analyzers interfacing.
In the realm of lab analyzers interfacing, middleware solutions serve as the bridge between disparate instruments. These software platforms harmonize data exchange, transcending the barriers of instrument heterogeneity. Middleware solutions not only facilitate seamless interfacing but also offer advanced functionalities such as result validation and autoverification, further enhancing laboratory efficiency and quality.
In conclusion, lab analyzers interfacing is the linchpin of modern laboratory operations, fostering synergy among disparate instruments and maximizing the efficiency and accuracy of diagnostic testing. Through the seamless integration of instruments, efficient data transfer mechanisms, meticulous compatibility testing, customized interface configurations, and middleware solutions, laboratories can unlock new frontiers of efficiency and excellence. As laboratories continue to evolve in tandem with technological advancements, the importance of lab analyzers interfacing will only grow, cementing its status as a cornerstone of diagnostic excellence.
#Instrument Integration#Data Transfer#Compatibility Testing#Interface Configuration#Middleware Solutions
0 notes
Text
Data transfers based on the old EU SCC’s must be replaced before 21 March 2024
In February 2022, the UK introduced the International Data Transfer Agreement (IDTA) and the UK Addendum to the European Commission’s new standard contractual clauses (new EU SCCs).
These documents, essential for data protection in the post-Brexit era, are designed to ensure that personal data transfers from the UK to countries not covered by the UK’s adequacy regulations comply with the UK…

View On WordPress
#Brexit#data processing agreement#Data protection#data transfer#EU standard contractual clauses#GDPR Article 46#ICO revisions#ICO UK GDPR guide#International Data Transfer Agreement#multinational organisations#new EU SCCs#processor requirements#restricted transfer#Schrems II#supplementary measures#Transfer Risk Assessment#UK Addendum#UK adequacy decisions#UK adequacy regulations#UK GDPR#UK GDPR transfer arrangements#UK-based organisations#valid SCCs
0 notes
Last Seen Blogs

diaperhyper
Diaper Hyper

ankawanderlust
Anka Wanderlust

daitime
daitime

my-weird-fandom
I’m not very active, so bear with me.

avtolybitel
Без названия