#Large Language
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In Q3 of 2020, 31% of US users access the Tumblr app daily.
Text
A group of Wikipedia editors have formed WikiProject AI Cleanup, “a collaboration to combat the increasing problem of unsourced, poorly-written AI-generated content on Wikipedia.” The group’s goal is to protect one of the world’s largest repositories of information from the same kind of misleading AI-generated information that has plagued Google search results, books sold on Amazon, and academic journals. “A few of us had noticed the prevalence of unnatural writing that showed clear signs of being AI-generated, and we managed to replicate similar ‘styles’ using ChatGPT,” Ilyas Lebleu, a founding member of WikiProject AI Cleanup, told me in an email. “Discovering some common AI catchphrases allowed us to quickly spot some of the most egregious examples of generated articles, which we quickly wanted to formalize into an organized project to compile our findings and techniques.”
9 October 2024
28K notes
·
View notes
Text

What are Large Language Model: Explained in Detail
Unlock the potential of large language models for AI-powered text generation and understanding. Explore applications, training processes, and challenges in harnessing large language models for various industries. READ MORE
0 notes
Text
AI hasn't improved in 18 months. It's likely that this is it. There is currently no evidence the capabilities of ChatGPT will ever improve. It's time for AI companies to put up or shut up.
I'm just re-iterating this excellent post from Ed Zitron, but it's not left my head since I read it and I want to share it. I'm also taking some talking points from Ed's other posts. So basically:
We keep hearing AI is going to get better and better, but these promises seem to be coming from a mix of companies engaging in wild speculation and lying.
Chatgpt, the industry leading large language model, has not materially improved in 18 months. For something that claims to be getting exponentially better, it sure is the same shit.
Hallucinations appear to be an inherent aspect of the technology. Since it's based on statistics and ai doesn't know anything, it can never know what is true. How could I possibly trust it to get any real work done if I can't rely on it's output? If I have to fact check everything it says I might as well do the work myself.
For "real" ai that does know what is true to exist, it would require us to discover new concepts in psychology, math, and computing, which open ai is not working on, and seemingly no other ai companies are either.
Open ai has already seemingly slurped up all the data from the open web already. Chatgpt 5 would take 5x more training data than chatgpt 4 to train. Where is this data coming from, exactly?
Since improvement appears to have ground to a halt, what if this is it? What if Chatgpt 4 is as good as LLMs can ever be? What use is it?
As Jim Covello, a leading semiconductor analyst at Goldman Sachs said (on page 10, and that's big finance so you know they only care about money): if tech companies are spending a trillion dollars to build up the infrastructure to support ai, what trillion dollar problem is it meant to solve? AI companies have a unique talent for burning venture capital and it's unclear if Open AI will be able to survive more than a few years unless everyone suddenly adopts it all at once. (Hey, didn't crypto and the metaverse also require spontaneous mass adoption to make sense?)
There is no problem that current ai is a solution to. Consumer tech is basically solved, normal people don't need more tech than a laptop and a smartphone. Big tech have run out of innovations, and they are desperately looking for the next thing to sell. It happened with the metaverse and it's happening again.
In summary:
Ai hasn't materially improved since the launch of Chatgpt4, which wasn't that big of an upgrade to 3.
There is currently no technological roadmap for ai to become better than it is. (As Jim Covello said on the Goldman Sachs report, the evolution of smartphones was openly planned years ahead of time.) The current problems are inherent to the current technology and nobody has indicated there is any way to solve them in the pipeline. We have likely reached the limits of what LLMs can do, and they still can't do much.
Don't believe AI companies when they say things are going to improve from where they are now before they provide evidence. It's time for the AI shills to put up, or shut up.
5K notes
·
View notes
Text
(*1995 and largely icon, personally.
the choice is meant to be what you say now.
couldn't decide on where to comfortably separate the age demographics in the end, so made the focus more on the split of which generations were born into mainstream internet use.
no "other" option, because that would skew the poll out of people choosing terms in other languages/swapping between all of above/indecision
did originally have a wider variety of options such as badge, userpic, e.g. but simplified it down to terms used the most currently by users on this website).
#kinda curious about something#saying of these options as in. what's most common in english-speaking because there's likely been different shifts in other languages#I thought about putting badge here but I think that largely fell out of use years ago
4K notes
·
View notes
Text
Sign up now!
Want to Supercharge Productivity? Look no further! Join us at our exclusive event where we're unlocking the secrets to maximizing efficiency with ChatGPT, GPT-4, and Large Language Models. Learn how businesses are streamlining workflows, automating tasks, and achieving unprecedented results. Ready to elevate your efficiency game?
Sign up now! https://ow.ly/y8QX50PGV4W
#AIAdvancements#EfficiencyIgnited#InnovateWithGPT4#GPT4Event#AIInnovations#LanguageProcessing#EfficiencyUnleashed#FutureOfLanguageTech#FutureOfAutomation#techtalk#in-personevent #RoyalCyber
0 notes
Text
The real issue with DeepSeek is that capitalists can't profit from it.
I always appreciate when the capitalist class just says it out loud so I don't have to be called a conspiracy theorist for pointing out the obvious.

#deepseek#ai#lmm#large language model#artificial intelligence#open source#capitalism#techbros#silicon valley#openai
955 notes
·
View notes
Note
is checking facts by chatgpt smart? i once asked chatgpt about the hair color in the image and asked the same question two times and chatgpt said two different answers lol
Never, ever, ever use ChatGPT or any LMM for fact checking! All large language models are highly prone to generating misinformation (here's a recent example!), because they're basically just fancy autocomplete.
If you need to fact check, use reliable fact checking websites (like PolitiFact, AP News, FactCheck.org), go to actual experts, check primary sources, things like that. To learn more, I recommend this site:
349 notes
·
View notes
Text


Playing around with a mod ZombieCleo design!
I was trying to take some inspo from 50s and 60s cartoons and wanted to make her silhouette look like a skull! (Albeit a bit of a goofy one)
I kind of wish I was able to hide one more black skull in there for the Wither reference, but ah well.
#art#digital art#my art#hermitcraft#hermitcraft fanart#trafficblr#wild life smp#hermitblr#zombiecleo fanart#zombiecleo#zombie cleo#mod fashion#this was largely created because of her power in wildlife#shape language!
1K notes
·
View notes
Text
The problem here isn’t that large language models hallucinate, lie, or misrepresent the world in some way. It’s that they are not designed to represent the world at all; instead, they are designed to convey convincing lines of text. So when they are provided with a database of some sort, they use this, in one way or another, to make their responses more convincing. But they are not in any real way attempting to convey or transmit the information in the database. As Chirag Shah and Emily Bender put it: “Nothing in the design of language models (whose training task is to predict words given context) is actually designed to handle arithmetic, temporal reasoning, etc. To the extent that they sometimes get the right answer to such questions is only because they happened to synthesize relevant strings out of what was in their training data. No reasoning is involved […] Similarly, language models are prone to making stuff up […] because they are not designed to express some underlying set of information in natural language; they are only manipulating the form of language” (Shah & Bender, 2022). These models aren’t designed to transmit information, so we shouldn’t be too surprised when their assertions turn out to be false.
ChatGPT is bullshit
7K notes
·
View notes
Text
it's a regional thing
“Che cazzo,” Viago grumbles.
Rook leans in, frowning thoughtfully. “That sounds different.”
Teia looks over with a brow raised. “You have a good ear.”
“And a spare.” Her eyes flick back and forth between them. “So?”
“It’s Antivan.” Ay, here Viago goes. Behind his back, Illario’s eyes roll skywards. “What you’re used to hearing here is Antivanio.”
“Antiva has two languages?”
“Yes,” says Viago, precisely as Lucanis and Illario say in near unison, “No.”
Rook rests her elbow on the table, chin in her hand, and regards the lot of them as if she might think they are all a bit crazy. “This was helpful. Thank you.”
“Ah!” Teia silences the lecture Viago is clearly winding up with a raised finger. “My house. And don’t you start, either.” Illario’s smile is wide and insincere.
To Rook, when she seems satisfied there will be no interruptions, Teia explains: “It is one language—Viago, do not—but the northern cities that deal more directly with Rivain prefer some adaptations that the south does not.”
“We prefer to not sound like a bunch of fussy grandmothers so old they need to water their wine.” Illario interjects. Find a line, Illario will toe it.
Teia’s voice is sweet as spun sugar. “Illario, ancora una parola e lascerai la via breve.”
Rook’s eyebrows are climbing higher. “I am…so sorry I asked,” she murmurs to him.
“Don’t worry,” he reassures her, sotto voce. “We’re not as easily bothered here as in the south. Illario just enjoys an argument.”
“In some cities, such as Salle—” Teia raises that same finger to Viago. His mouth snaps shut with an aggravated click. “—the more classical dialect is still used exclusively.”
“We have an appreciation for tradition,” Viago huffs.
Lucanis settles it. “In Treviso, we tend to use the newer.”
The way Rook’s lips twitch is wicked. “Which is Antiveeno.”
“Antivanio.”—“Antivan.” Viago and Illario, overlapping.
And Rook, still with her chin in her hand and her eyes on him, coy and smiling.
#doesn't fit in any story but I'm keeping it#my fic#lucanis dellamorte#teia cantori#viago de riva#illario dellamorte#dragon age veilguard#Bioware what ARE we doing with the languages here though my guys#I am accepting there is a slight possibility I have a language kink#a large possibility#datv#mini fics
295 notes
·
View notes
Text
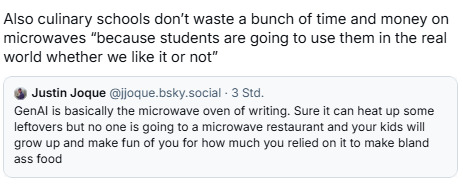
This might be the best summation of GenAI I have seen.
182 notes
·
View notes
Text
Hot take: it's fucking idiotic to call someone who is just calmly trying to explain their actions or emotions 'rude'. It's ESPECIALLY idiotic to say that to a small child. You'll end up turning them into a fucking doormat unable to speak up for themselves (me)
Kids can't properly control tone yet. I ESPECIALLY couldn't due to autism. So to hold a kids tone to the importance of the tone of an actor on set to get the correct feel is completely idiotic. And some teen girls literally *just sound like that*. They aren't "being rude" that's just what her voice sounds like. They aren't "making excuses" they are genuinely trying to fucking communicate their reasons so that an understanding can be reached. This shit is why EVERYONE SUCKS AT COMMUNICATING AND WE NEED TO FUCKING STOP DISCOURAGING HONEST AND OPEN COMMUNICATION
Most kids are innately honest until they are taught to lie by society or their parents. By making them FEAR honesty. By punishing them for communicating you are teaching them to lie. You are making lieing feel like the safest option even when you punish for lies. Because at least with the lie there's a chance of no punishment, but with the truth you'll 100% get punished.
#hot take#kids#psycology#communication#not a shitpost#autism#adhd#lies#large truth#language#honesty#rude#tone
1K notes
·
View notes
Text
When summarizing scientific studies, large language models (LLMs) like ChatGPT and DeepSeek produce inaccurate conclusions in up to 73% of cases, according to a study by Uwe Peters (Utrecht University) and Benjamin Chin-Yee (Western University, Canada/University of Cambridge, UK). The researchers tested the most prominent LLMs and analyzed thousands of chatbot-generated science summaries, revealing that most models consistently produced broader conclusions than those in the summarized texts. Surprisingly, prompts for accuracy increased the problem and newer LLMs performed worse than older ones. The work is published in the journal Royal Society Open Science.
Continue Reading.
117 notes
·
View notes
Text
a phrase Germans like to use sometimes ist "wieso und warum" which often emphasizes lack of understanding/incredulity or importance, e.g. "er wollte wissen, wieso und warum ich nicht gekommen bin" "wir haben darüber geredet, wieso und warum das wichtig ist" etc
and it sounds normal in (spoken casual) German because it's two different words but it's just saying "why and why"
sometimes we even throw in a weshalb as well (why and why and why)

(here represented by "what all the fuss was about")
#in case you're wondering:#wieso weshalb warum are largely interchangeable#there are slight nuances sometimes but most times it's whatever#other why-question-words are more specific though#german#deutsch#learning german#language learning#langblr
91 notes
·
View notes
Text
The premature unleashing of AI and large language models (LLMs) in particular onto the open Internet is already having dire consequences for what were, for years, considered stabilized, centralized (if flawed) systems, such as the search engine. AI, thanks to the scope of its spread, its rogue unreliability (it lies — often), the way it poisons search results, hijacks SEO, and is increasingly being used for disinformation and fraud, is reintroducing a fundamental and destabilizing distrust back into the Internet. Once more, I can no longer trust the results Google provides me. On a daily basis I have to ask myself increasingly familiar questions: Is this first result a legitimate news source? Is this image of a protest real? Is that picture of a Kandinsky painting really his or is an AI forgery of his work? Across the board, it’s becoming increasingly hard to tell. For me and countless others, what used to be rote Internet usage has now turned into a nightmarish amount of wasted time spent discerning what is and isn’t real. As far as I, the ordinary user, am concerned, AI is evolving not into a life-changing and labor-saving technology as was promised by its capitalist overlords, but rather into a form of malware that targets, whether unwittingly or not, critical Internet infrastructure.
1 October 2024
181 notes
·
View notes
Text
y'know... for a setting that places so much importance in Language and does so many ice cool things playing with it (Correspondence/Discordance, Parabola & Irem, etc) i think there's a bit of a missed opportunity when it comes to the terms and words people use in their day to day life... like for example:
do you think radical revolutionaries would avoid words like "enlightening" in their vocabulary and flip them for LON-appropriate counterparts to signal their beliefs?
like substituting the word "light" with "blight". lol
similarly, pet names relating to light like "sunshine" kinda have a whole extra flavour tied to them, leaning into nostalgia, melancholy and/or danger depending on the people using it. irony, even
"honey" as a pet name also has extra connotations now and might actually bother some people instead due to the association with the drug...
do you think SMEN, taboo as it is, and seeking being a recognizable phenomenon even to the common londoner, would spawn swear words and insults? (imagine the weight of telling someone to Go Seek or Fall Down a Well)
the word "well" itself. well as an adverb, interjection, adjective. just. think about it. think about what it represents. idk something is happening to this word for sure
#disclaimer that am still solidly in the beginning of the railway so idk if newer writing has stuff like this#granted fallen london is young enough that it makes sense for these kinds of developments to not have happened in a large scale yet#(in british english that is)#neon future though? yeah baby communication is gonna be shaped by its setting!! so many fun possibilities so much food for thought#am sure gtfo becomes gstn.#rambling sparked from wondering abt the intricacies of comparing ur beloved to the eldritch being in space who wants you deleted. or smth#i like giving my ocs quirks relating to language so. rei has a recurrent theme of speech & pronunciation issues in general#before being devoured the coffin incident left them with neurological damage too and it used to take extra effort for them to say things#cinthe uses second languages (specially french) to put an extra dissociative distance between herself and certain words/thoughts#zé speaks english nearly perfectly but he uses portuguese any moment he can and even exaggerates his accent sometimes#i think im giving him the revolutionary terms thing too once he gets more involved with the neath. hes the kinda guy to make statements :3c#fallen london#chainrambles#language talk
146 notes
·
View notes