#Lasso regression
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been banned in Indonesia for providing people with access to pornographic content.
Text
An Introduction to Regularization in Machine Learning
Summary: Regularization in Machine Learning prevents overfitting by adding penalties to model complexity. Key techniques, such as L1, L2, and Elastic Net Regularization, help balance model accuracy and generalization, improving overall performance.

Introduction
Regularization in Machine Learning is a vital technique used to enhance model performance by preventing overfitting. It achieves this by adding a penalty to the model's complexity, ensuring it generalizes better to new, unseen data.
This article explores the concept of regularization, its importance in balancing model accuracy and complexity, and various techniques employed to achieve optimal results. We aim to provide a comprehensive understanding of regularization methods, their applications, and how to implement them effectively in machine learning projects.
What is Regularization?
Regularization is a technique used in machine learning to prevent a model from overfitting to the training data. By adding a penalty for large coefficients in the model, regularization discourages complexity and promotes simpler models.
This helps the model generalize better to unseen data. Regularization methods achieve this by modifying the loss function, which measures the error of the model’s predictions.
How Regularization Helps in Model Training
In machine learning, a model's goal is to accurately predict outcomes on new, unseen data. However, a model trained with too much complexity might perform exceptionally well on the training set but poorly on new data.
Regularization addresses this by introducing a penalty for excessive complexity, thus constraining the model's parameters. This penalty helps to balance the trade-off between fitting the training data and maintaining the model's ability to generalize.
Key Concepts
Understanding regularization requires grasping the concepts of overfitting and underfitting.
Overfitting occurs when a model learns the noise in the training data rather than the actual pattern. This results in high accuracy on the training set but poor performance on new data. Regularization helps to mitigate overfitting by penalizing large weights and promoting simpler models that are less likely to capture noise.
Underfitting happens when a model is too simple to capture the underlying trend in the data. This results in poor performance on both the training and test datasets. While regularization aims to prevent overfitting, it must be carefully tuned to avoid underfitting. The key is to find the right balance where the model is complex enough to learn the data's patterns but simple enough to generalize well.
Types of Regularization Techniques

Regularization techniques are crucial in machine learning for improving model performance by preventing overfitting. They achieve this by introducing additional constraints or penalties to the model, which help balance complexity and accuracy.
The primary types of regularization techniques include L1 Regularization, L2 Regularization, and Elastic Net Regularization. Each has distinct properties and applications, which can be leveraged based on the specific needs of the model and dataset.
L1 Regularization (Lasso)
L1 Regularization, also known as Lasso (Least Absolute Shrinkage and Selection Operator), adds a penalty equivalent to the absolute value of the coefficients. Mathematically, it modifies the cost function by adding a term proportional to the sum of the absolute values of the coefficients. This is expressed as:

where λ is the regularization parameter that controls the strength of the penalty.
The key advantage of L1 Regularization is its ability to perform feature selection. By shrinking some coefficients to zero, it effectively eliminates less important features from the model. This results in a simpler, more interpretable model.
However, it can be less effective when the dataset contains highly correlated features, as it tends to arbitrarily select one feature from a group of correlated features.
L2 Regularization (Ridge)
L2 Regularization, also known as Ridge Regression, adds a penalty equivalent to the square of the coefficients. It modifies the cost function by including a term proportional to the sum of the squared values of the coefficients. This is represented as:

L2 Regularization helps to prevent overfitting by shrinking the coefficients of the features, but unlike L1, it does not eliminate features entirely. Instead, it reduces the impact of less important features by distributing the penalty across all coefficients.
This technique is particularly useful when dealing with multicollinearity, where features are highly correlated. Ridge Regression tends to perform better when the model has many small, non-zero coefficients.
Elastic Net Regularization
Elastic Net Regularization combines both L1 and L2 penalties, incorporating the strengths of both techniques. The cost function for Elastic Net is given by:

where λ1 and λ2 are the regularization parameters for L1 and L2 penalties, respectively.
Elastic Net is advantageous when dealing with datasets that have a large number of features, some of which may be highly correlated. It provides a balance between feature selection and coefficient shrinkage, making it effective in scenarios where both regularization types are beneficial.
By tuning the parameters λ1 and λ2, one can adjust the degree of sparsity and shrinkage applied to the model.
Choosing the Right Regularization Technique
Selecting the appropriate regularization technique is crucial for optimizing your machine learning model. The choice largely depends on the characteristics of your dataset and the complexity of your model.
Factors to Consider
Dataset Size: If your dataset is small, L1 regularization (Lasso) can be beneficial as it tends to produce sparse models by zeroing out less important features. This helps in reducing overfitting. For larger datasets, L2 regularization (Ridge) may be more suitable, as it smoothly shrinks all coefficients, helping to control overfitting without eliminating features entirely.
Model Complexity: Complex models with many features or parameters might benefit from L2 regularization, which can handle high-dimensional data more effectively. On the other hand, simpler models or those with fewer features might see better performance with L1 regularization, which can help in feature selection.
Tuning Regularization Parameters
Adjusting regularization parameters involves selecting the right value for the regularization strength (λ). Start by using cross-validation to test different λ values and observe their impact on model performance. A higher λ value increases regularization strength, leading to more significant shrinkage of the coefficients, while a lower λ value reduces the regularization effect.
Balancing these parameters ensures that your model generalizes well to new, unseen data without being overly complex or too simple.
Benefits of Regularization
Regularization plays a crucial role in machine learning by optimizing model performance and ensuring robustness. By incorporating regularization techniques, you can achieve several key benefits that significantly enhance your models.
Improved Model Generalization: Regularization techniques help your model generalize better by adding a penalty for complexity. This encourages the model to focus on the most important features, leading to more robust predictions on new, unseen data.
Enhanced Model Performance on Unseen Data: Regularization reduces overfitting by preventing the model from becoming too tailored to the training data. This leads to improved performance on validation and test datasets, as the model learns to generalize from the underlying patterns rather than memorizing specific examples.
Reduced Risk of Overfitting: Regularization methods like L1 and L2 introduce constraints that limit the magnitude of model parameters. This effectively curbs the model's tendency to fit noise in the training data, reducing the risk of overfitting and creating a more reliable model.
Incorporating regularization into your machine learning workflow ensures that your models remain effective and efficient across different scenarios.
Challenges and Considerations
While regularization is crucial for improving model generalization, it comes with its own set of challenges and considerations. Balancing regularization effectively requires careful attention to avoid potential downsides and ensure optimal model performance.
Potential Downsides of Regularization:
Underfitting Risk: Excessive regularization can lead to underfitting, where the model becomes too simplistic and fails to capture important patterns in the data. This reduces the model’s accuracy and predictive power.
Increased Complexity: Implementing regularization techniques can add complexity to the model tuning process. Selecting the right type and amount of regularization requires additional experimentation and validation.
Balancing Regularization with Model Accuracy:
Regularization Parameter Tuning: Finding the right balance between regularization strength and model accuracy involves tuning hyperparameters. This requires a systematic approach to adjust parameters and evaluate model performance.
Cross-Validation: Employ cross-validation techniques to test different regularization settings and identify the optimal balance that maintains accuracy while preventing overfitting.
Careful consideration and fine-tuning of regularization parameters are essential to harness its benefits without compromising model accuracy.
Frequently Asked Questions
What is Regularization in Machine Learning?
Regularization in Machine Learning is a technique used to prevent overfitting by adding a penalty to the model's complexity. This penalty discourages large coefficients, promoting simpler, more generalizable models.
How does Regularization improve model performance?
Regularization enhances model performance by preventing overfitting. It does this by adding penalties for complex models, which helps in achieving better generalization on unseen data and reduces the risk of memorizing training data.
What are the main types of Regularization techniques?
The main types of Regularization techniques are L1 Regularization (Lasso), L2 Regularization (Ridge), and Elastic Net Regularization. Each technique applies different penalties to model coefficients to prevent overfitting and improve generalization.
Conclusion
Regularization in Machine Learning is essential for creating models that generalize well to new data. By adding penalties to model complexity, techniques like L1, L2, and Elastic Net Regularization balance accuracy with simplicity. Properly tuning these methods helps avoid overfitting, ensuring robust and effective models.
#Regularization in Machine Learning#Regularization#L1 Regularization#L2 Regularization#Elastic Net Regularization#Regularization Techniques#machine learning#overfitting#underfitting#lasso regression
0 notes
Text
Lasso Regression Project
#from pandas import Series, DataFrame
import pandas as pd
import numpy as np
import os
import matplotlib.pylab as plt
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import classification_report
import sklearn.metrics
from sklearn.linear_model import LassoLarsCV
# standardize predictors to have mean=0 and sd=1
#predictors=predvar.copy()
from sklearn import preprocessing
predictors.loc[:,'CODPERING']=preprocessing.scale(predictors['CODPERING'].astype('float64'))
predictors.loc[:,'CODPRIPER']=preprocessing.scale(predictors['CODPRIPER'].astype('float64'))
predictors.loc[:,'CODULTPER']=preprocessing.scale(predictors['CODULTPER'].astype('float64'))
predictors.loc[:,'CICREL']=preprocessing.scale(predictors['CICREL'].astype('float64'))
predictors.loc[:,'CRDKAPRACU']=preprocessing.scale(predictors['CRDKAPRACU'].astype('float64'))
predictors.loc[:,'PPKAPRACU']=preprocessing.scale(predictors['PPKAPRACU'].astype('float64'))
predictors.loc[:,'CODPER5']=preprocessing.scale(predictors['CODPER5'].astype('float64'))
predictors.loc[:,'RN']=preprocessing.scale(predictors['RN'].astype('float64'))
predictors.loc[:,'MODALIDADC']=preprocessing.scale(predictors['MODALIDADC'].astype('float64'))
predictors.loc[:,'SEXOC']=preprocessing.scale(predictors['SEXOC'].astype('float64'))
# split data into train and test sets
pred_train, pred_test, tar_train, tar_test = train_test_split(predictors, targets,
test_size=.3, random_state=123)
# specify the lasso regression model
model=LassoLarsCV(cv=10, precompute=False).fit(pred_train,tar_train)
# print variable names and regression coefficients
dict(zip(predictors.columns, model.coef_))
{'CODPERING': 0.0057904161622687605, 'CODPRIPER': 0.6317522521193139, 'CODULTPER': -0.15191539575581153, 'CICREL': 0.07945048661923974, 'CRDKAPRACU': -0.3022282694810491, 'PPKAPRACU': 0.15702206999868978, 'CODPER5': -0.11697786485114721, 'RN': -0.03802582617592532, 'MODALIDADC': 0.017655346467683828, 'SEXOC': 0.10597063961395894}
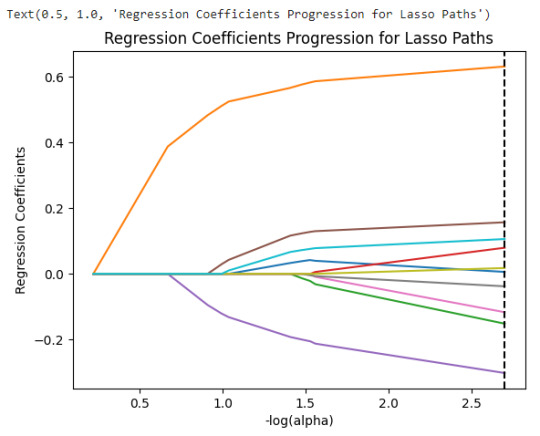
# plot coefficient progression
m_log_alphas = -np.log10(model.alphas_)
ax = plt.gca()
plt.plot(m_log_alphas, model.coef_path_.T)
plt.axvline(-np.log10(model.alpha_), linestyle='--', color='k',
label='alpha CV')
plt.ylabel('Regression Coefficients')
plt.xlabel('-log(alpha)')
plt.title('Regression Coefficients Progression for Lasso Paths')
# plot mean square error for each fold
m_log_alphascv = -np.log10(model.cv_alphas_)
plt.figure()
plt.plot(m_log_alphascv, model.mse_path_, ':')
plt.plot(m_log_alphascv, model.mse_path_.mean(axis=-1), 'k',
label='Average across the folds', linewidth=2)
plt.axvline(-np.log10(model.alpha_), linestyle='--', color='k',
label='alpha CV')
plt.legend()
plt.xlabel('-log(alpha)')
plt.ylabel('Mean squared error')
plt.title('Mean squared error on each fold')

# MSE from training and test data
from sklearn.metrics import mean_squared_error
train_error = mean_squared_error(tar_train, model.predict(pred_train))
test_error = mean_squared_error(tar_test, model.predict(pred_test))
print ('training data MSE')
print(train_error)
print ('test data MSE')
print(test_error)
training data MSE 10.81377398206078
test data MSE 10.82396461754075
# R-square from training and test data
rsquared_train=model.score(pred_train,tar_train)
rsquared_test=model.score(pred_test,tar_test)
print ('training data R-square')
print(rsquared_train)
print ('test data R-square')
print(rsquared_test)
training data R-square 0.041399684741574516
test data R-square 0.04201223667290355
Results Explanation:
A lasso regression analysis was conducted to identify a subset of variables from a pool of 10 quantitative predictor variables that best predicted a quantitative response variable. All predictor variables were standardized to have a mean of zero and a standard deviation of one.
Data were randomly split into a training set that included 70% of the observations and a test set that included 30% of the observations. The least angle regression algorithm with k=10 fold cross validation was used to estimate the lasso regression model in the training set, and the model was validated using the test set. The change in the cross validation average (mean) squared error at each step was used to identify the best subset of predictor variables.
The MSE values for both training and test data are quite similar, indicating that the model performs consistently across both datasets. However, the R-square values are quite low (around 0.04), suggesting that the model does not explain much of the variance in the data.
Of the 10 predictor variables, 6 were retained in the selected model.
1 note
·
View note
Text
the category is niche regressor hcs ( i have more .. feel free 2 ask abt them ໒꒰ྀིᵔ ᵕ ᵔ ꒱ྀི১ )











in order : allison mcroberts ( kevin can f**k himself ) , alexis rose ( schitt's creek ) , fallon carrington ( dynasty ) , keeley jones ( ted lasso ) , dani clayton ( thobm ) , cindy berman ( fear street 1978 ) , bess marvin ( nancy drew ) , emily dickinson ( dickinson ) , love quinn ( you ) , rhiannon lewis ( sweetpea ) , guinevere beck ( you ) , mabel mora ( omitb )
been thinking a Lot about kcfh && dynasty again recently which inspired this... i NEED to rw && finish both ( i was super duper hyperfixed before s2 of kcfh && final season of dynasty came out && life got so hectic i haven't had time 2 watch when i realized it was out :C ) ... pattison toxic yuri forevrr .. they plague me so bad i tried 2 edit them in 2021.. i wrote anon regressor!allison fics on ao3 back in da day ... && one baby!fallon one ermm ... && some regressor!keeley i sigh.. shall i post them here ? lmk tehee >__< i used 2 watch dynasty as it was airing && omg the season finale where fallon nearly you know whatted ... waiting 4 that next episode made me insane... also i was ahead of my time with kamanda i was a shipper since the beginning && prophesized they would get together tehe.. also i was TERRIBLY firby brained && i miss them all so baddd waaahhhh /. i never finished ted lasso bc family cancelled apple tv ( also why i never got to finish dickinson aka my biggest loss ) but err...
also sorry 4 the long yap but i am Not normal about fear street ( autism so bad i got sent to the psych ward ermmm :C ) .. && i headcanon Most of them as regressors so htgjes hehe , unfortunately an abuser has made my love for it more complex but if you would like to hear about my headcanons for it i am open to trying to publically indulge in it again :33 ( i'm cindy && sam !!! )
enough yapping 4 now.. eye have MANY thoughts sorry
#U^ェ^U#lot yips#fandom agere#sfw agere#sfw interaction only#age regression#agere headcanons#kevin can fuck himself#schitt's creek#dynasty#ted lasso#thobm#fear street#fear street 1978#nancy drew#dickinson#you#sweetpea#omitb
56 notes
·
View notes
Text
Six Sentence Sunday
It’s actually six sentences! (Because I combined two into one).
Plus, they were in the dressing room. In front of everybody. Roy hadn’t stopped yelling or swearing or anything like that, not during training. It had just been less acerbic, less directed and pointed. Like they knew he was less riled up with Jamie, as Jamie had been doing better at teamwork. But it was only now that he was actively protecting Jamie that they could see how much things had changed.
From my fic where Gala Gal is a child psychologist who accidentally cracks Jamie open like an egg. And then runs off leaving Keeley to clean up the mess. Some of her issues with Jamie take on a whole new meaning. So she is doing this willingly.
It’s just…she can’t be in the team coach for away matches. And she can’t stay in his room for those either. He needs someone in the thick of things to help when he has night terrors or panic attacks. When he starts to dissociate and feel himself becoming smaller.
And Roy Kent has a soft spot for kids with shitty fathers.
#jamie tartt#keeley jones#roy kent#ted lasso#age regression therapy#jamie tartt gets therapy#and many hugs#and a good night’s rest for once#qpr#queer platonic relationship
13 notes
·
View notes
Text
Roy Kent from Ted Lasso

Is a flip!(caregiver lean)
#Ted lasso#Ted lasso agere#ur fav is agere#age regression#fandom agere#sfw interaction only#sfw#agere#age regressor#sfw caregiver#agere flip
12 notes
·
View notes
Text
Reference save in our archive (Daily updates!)
Highlight: Among 78,798 paired RDT/RT-qPCR results analysed, overall RDT sensitivity was 34.5% (695/2016; 95% CI 32.4–36.6%)
If you can afford to upgrade to a molecular covid test, do so. Unless used as intended (for serial testing) Rapid Antigen Tests for covid are only a bit better than guessing, especially given the addition of human error when collecting samples.
Summary Background SARS-CoV-2 antigen rapid detection tests (RDTs) emerged as point-of-care diagnostics alongside reverse transcription polymerase chain reaction (RT-qPCR) as reference.
Methods In a prospective performance assessment from 12 November 2020 to 30 June 2023 at a single centre tertiary care hospital, the sensitivity and specificity (primary endpoints) of RDTs from three manufacturers (NADAL®, Panbio™, MEDsan®) were compared to RT-qPCR as reference standard among patients, accompanying persons and staff aged ≥ six month in large-scale, clinical screening use. Regression models were used to assess influencing factors on RDT performance (secondary endpoints).
Findings Among 78,798 paired RDT/RT-qPCR results analysed, overall RDT sensitivity was 34.5% (695/2016; 95% CI 32.4–36.6%), specificity 99.6% (76,503/76,782; 95% CI 99.6–99.7%). Over the pandemic course, sensitivity decreased in line with a lower rate of individuals showing typical COVID-19 symptoms. The lasso regression model showed that a higher viral load and typical COVID-19 symptoms were directly significantly correlated with the likelihood of a positive RDT result in SARS-CoV-2 infection, whereas age, sex, vaccination status, and the Omicron VOC were not.
Interpretation The decline in RDT sensitivity throughout the pandemic can primarily be attributed to the reduced prevalence of symptomatic infections among vaccinated individuals and individuals infected with Omicron VOC. RDTs remain valuable for detecting SARS-CoV-2 in symptomatic individuals and offer potential for detecting other respiratory pathogens in the post-pandemic era, underscoring their importance in infection control efforts.
Funding German Federal Ministry of Education and Research (BMBF), Free State of Bavaria, Bavarian State Ministry of Health and Care.
#mask up#covid#pandemic#public health#wear a mask#covid 19#wear a respirator#still coviding#coronavirus#sars cov 2
94 notes
·
View notes
Text
”hey how’s your regression going?” uhhhh,,, *hides all of my dandy’s world pile* it’s been good!!

IGNORE HOW BAD IT IS :(( I tried lasso tool and I now despise it,,,

33 notes
·
View notes
Text

Inspired by RDR2, mostly. Some of them aren’t exclusive to the American West, but i’ve aimed all that I can that direction. All SFW as per the usual <3
28 days in true tradition of Regressuary.
Please tag/message me if you use, i’d love to support your work!
1. A is breaking in a new horse. It’s taking much longer than usual, and they get frustrated/upset and B makes them take a break.
2. A gets a little too tipsy out on the town. B comes out to pick them up and look after them.
3. A ends up getting badly wounded in a fight. B patches them up and enforces bed rest (or relevant not-work activities).
4. A regresses whilst they’re out riding on their own. Their horse knows, and brings them home.
5. A and B go on a fishing/hunting trip.
6. A regresses mid-fight. B gets them to safety/protects them.
7. A isn’t feeling well. B takes them on a walk to cheer them up.
8. A and B make wooden carvings together.
9. B makes/sources A a plush toy. A pretends they don’t want it but secretly falls in love.
10. A and B spend the day caring for the horses.
11. A and B have to go on a long-haul journey together. Chaos and ‘are we there yets’ ensue.
12. A and B head into town to buy supplies, and A finds something they really, really want.
13. A and B have a night alone in camp by the fire.
14. When A gets lost whilst hunting, B frantically searches for them.
15. A makes friends with an animal in the woods.
16. The dodgy camp member finds out about A’s regression and teases them about it. B stands up for them.
17. A decorates B’s hat and their horse’s bridle. How could they stay mad?
18. The camp pet sends A into regression when they insist on playing with them and treating them like one of their own young.
19. B witnesses A’s regression for the first time.
20. A uses their regression to cope when someone from their past shows up and causes problems.
21. B teaches a small A how to lasso/shoot/ride etc. properly.
22. A gets into the rations and snacks perhaps a bit more than they should. They get a tummy ache. B helps.
23. B teaches a small A how to read. (your choice whether they can read when they’re big or not/how much, or B could be bi/multilingual)
24. The posse learn about A’s regression, and suddenly they’re a hell of a lot more protective.
25. B finds A regressed with the horses when they were meant to be doing chores.
26. When B is very hungover, A does their best not to need them whilst regressed. B assures them that they’re always wanted.
27. A keeps falling asleep on guard. B ushers them to bed and gets C to take over for them instead.
28. Small A gets to pick the new camp location, and they’re beyond excited. B helps them with logistics etc.
#age regression#sfw agere#agere#sfw age regression#cowboy#american west#writing prompts#writing prompt#art prompt#red dead redemption 2#rdr2#regressuary#inkala agere#inkala promptlists
25 notes
·
View notes
Text
I honestly didn’t realize how many people think Striker’s character has been ruined, because I genuinely don’t think it has?
I mean I’m probably biased as hell because Striker is my favorite character, but I still feel like there is plenty of unbiased logic that goes against his character being ruined.
For starters, the main thing I’ve seen people complain about is the sex jokes/statue thing, which I don’t get.
Sure, the guy has a statue of himself, but he has an ego bigger than that statue’s boner. We knew this before Western Energy, back in Harvest Moon Festival.
At the end of the pain games he says “I’d like to sing a song I wrote just now. About me winning.” He kicks people away from the stage who get near him, and for reference of how much of an ego he has, here’s some of the lyrics:
“Sweet victory, with everything I do
“With every talent, I’m so much more talented than you.
“Every time I try, I crush it and succeed.
“Every first attempt of every single deed.
“Me, I’m totally the best.
“Me, me, super cool me, handsome guy”
Like??? He was self absorbed before we knew about the statue, and the statue simply further proves it.
People are saying that, along with the fact that he can be “beaten with sex jokes” makes it hard to take him seriously, when during HMF he was dangerous.
For starters, he can not be beaten with sex jokes. They catch him off guard and make him confused and uncomfortable. And rightfully so. If I was in the middle of fighting with other people who were trying to kill me while I was trying to kill them, and they turned it into a sex joke, I’d be uncomfortable and thrown off guard too. Some people say it shows his immaturity, but it really shows how he is the only one taking things seriously most of the time.
To add to this, think about it, truly think about it, and compare how he’s done in season 2 to how he did in HMF.
In HMF, he spent basically the entire episode focusing on keeping a calm facade, bullying Moxxie, and didn’t actually go after Stolas until much later. When he did go after Stolas, he was caught, cornered, and ran away.
Now compare that to season 2, gags aside.
In Western Energy, he kidnapped Stolas in the middle of a crowded place without any care in the world, tortured him, was 100% ready to kill him and only didn’t do so because the hit was called off. He then proceeded to easily take both Moxxie and Millie in a fight, only losing because he got a statue triple his fucking size dropped on him.
Fast forward to Oops. Some people forget that he wasn’t even on a hit job in Opps. He was simply trying to convince Crimson he would be a good hire. In response, he lassoed two full grown Imps out of the street and through a window with ease and little hesitation. He then proceeded to later hold Fizz at gunpoint, and the only reason Blitz and Fizz made it out, was because he had not only been crushed by a building prior to holding Fizz at gunpoint, but then caught on fire.
He isn’t a coward, he’s logical. His escapes in season 2 have been logical reasons for him to retreat, while in HMF, he simply ran because he got a bit cornered. That alone shows character growth contrast to the character regression people are claiming.
Gags aside, it doesn’t change what he’s accomplished or that he’s a threat.
“But Striker hasn’t killed anyone!”
And? No one’s killed him, and he’s only had four appearances. Only two were hit missions. He was only threatening to kill Fizz and Blitz in Oops out of personal dislike, not anyone hiring him to. Remember, Crimson wanted them alive (at least most of the time) since it was a hostage situation. And in Mastermind, he was forced to be civil and only there for a short testimony.
And now, another common complaint I’ve seen: his personality.
In HMF, he was cool, collected, intimidating, the works, and everyone was here for it. Hell, I was too.
But then people got upset when he wasn’t that way later, which is confusing me.
For one, almost his entire personality in HMF was a facade. Not only that, but he was in public and trying to manipulate the people around him, while in Western Energy, he was in his own home, which automatically means he’s bound to act differently.
Not to mention, he stated that royals/blue bloods took everything from him. He was clearly upset even thinking or talking about it, and we’ve gotten hints that his backstory has to do with grief. He ain’t going to be calm and collected, he’s going to take out his anger and pain and trauma on the bloodline related to those who caused his pain.
Even so, a lot of people bring up “Well then why is he working with them?”
Well, he probably assumed it was a fine trade. He had to work for a royal, but he got to kill one. As for Mastermind, he simply wanted revenge. But, the other, and, in my opinion, most important reason, is that he’s a hypocrite, and I think it plays into his character really well. Fizz even points it out in Oops, which is one of the things that makes Striker so upset. He doesn’t want to be compared to the bloodlines he hates, so he hides and denies his flaws behind his ego, to hide it from himself (I again bring up the statue and the song he sung), and intimidation, to stop others from ever pointing it out.
To add to that, in Western energy and even parts of Oops, he had no one to manipulate or put up a facade in front of. Maybe Crimson, but by the end of Oops, any mask he had earlier in the episode had completely shattered. He’s clearly slowly losing his mind, and we even see this from his brief cameo in Mastermind.
Throughout the episode, he was disorganized, unprepared, and every single time he attempted to smile he looked like his sanity was on the edge of collapse, all of which is unlike him. He usually goes into things with plans, knowing what to say, what will happen. He’s calm and organized.
But that’s slipping. His entire mental state is slipping. Being bested over and over is taking a toll on him (and the fact that he had a building and a statue collapse on him and might have some minor brain damage probably isn’t helping). And they’re showing it slip. They’re going from him being able to act put together and collected and organized to him needing to write a reminder on his hand to take his own horse to the vet and have the nerve to ask for his line out loud in the middle of the important court case where he is lying with all of the sins and important/powerful hellborns present.
He isn’t the stereotypical cowboy/western enemy anymore, he wasn’t even that in HMF, and I’m all for it. I’m excited for it. I want to get a deep dive into his broken mental state without the facade, the way it was broken before and after his encounters with Blitz, and I want to see everything that happened to him that caused it.
So, no, I don’t think they ruined his character, I think they’re expanding on it. Remember, Viv said she planned out most of Helluva Boss from the start. This can’t be going nowhere.
Anyway, that’s my piece, hope you enjoyed it, and I’d love to know your thoughts :]
14 notes
·
View notes
Note
Omg, I'd never thought of regressor!Keeley before but I love it! I think Rebecca would be a good caregiver for her
YAAAAA !!! tahts mai headcanon !!!! ૮(˶˃ᆺ˂˶)১ a long time ago i wrote a fic or 2.. rebecca is SOOOOo mama 2 keeley :O i have a lotta drabbles still in the drafts i think oughhds .. lot wuz Very keeley pilled 4 a while ! ! so happy someone else sees da vision !! tehehe ૮ › 𖥦 ‹ ྀིა

mama && babay <3
#lot's visitors#answered#lot's keeley#ted lasso#keeley jones#keeley x rebecca#agere headcanons#ted lasso agere#agere#age regression#sfw interaction only
7 notes
·
View notes
Text
Ik @cutiecorner hasn't been feeling that great lately so I thought I'd share some headcannons for them (and if ppl just wanna see headcannons as well lol)
These are going to be agere headcannons and are going to be a mix of like, just random dc characters but mainly centered around the bats :)
_______________________
♡ Bruce and Hal may squabble a bit when in costume and stuff and may fight but little Bruce absolutely ADORES Hal. Both as Green Lantern and just in general. But he tries to hide it but he Def draws small drawings of both batman and green lantern together or as Bruce and Hal. I don't make the rules:)
☆ Bruce doesn't tell anyone about his regression. ANYONE. He does hide it pretty well when he's in a different headspace, but him in little headspace? It's fair game. He'd likely be a bit easier to read and less careful with things like he is usually.
♧ The only people in the JL that do know about it is likely Wonder Woman, Green Lantern (Hal Jordan AND John (*quick side note I hope that's the other gls name bc I did forget), Superman was the last one to officially find out just from observing things and a quick Google search.
★ Barry also regresses but to the age that around his mom died
♥︎ Bruce usually is around 1-3 years, but goes higher if he's not AS stressed or if it's just cause he's extremely happy and comfortable
♣︎ Diana Def bought some plushies for the two of them but says it's just staying at the watch tower until she can find a place for them, but somehow magically they go missing within an hour of being there....strange....
◇ Hal is actually a switch, he doesn't regress much but when he does its likely triggered by something negative, he doesn't tell anyone about it. AT ALL. Even if he knows they'd be supportive and even help him get through it.
♤ One day Bruce finds him absolutely BAWLING like this and not knowing what to do he brings him a soft medium-large sized deer plush (that definitely wasn't one of the toys Diana bought and mysteriously went missing and definitely ISNT one of Bruce's favorite pushes bc it reminds him of Hal) and gives it to him to hug.
◆ This works really well and allows for Hal to quiet down a bit and tell Bruce that he doesn't wanna tell him what's going on (yet) but thanks him and Bruce stays with him while he's still softly sobbing and hiccuping while holding him. (Bruce Def knows that he's little now too though so)
♥︎ Clark is very understanding about it and even can kind of tell when any of them regress, Barry is more open about it but Clark can notice he's little even before Barry can. He Def tells little Bruce a bunch of facts about the farm animals and machinery. He also kind of picks up that Hal MIGHT be little at times but doesn't push it. He does let Hal tell him about planes and flying when he seems like he is and for once is very excited.
♠︎ The one time that Bruce and Hal both trigger each other's regression by accident from arguing they end up needing to take a break from each other for a while but eventually Hal shows up to Bruce's door with the deer that Bruce let him borrow in hand an a reddened face from crying. They both apologize in their own way and go watch their favorite cartoons together! (Both older and modern)
□ Little Barry likes to chew stuff, like, everything and anything. His straw on his cups? Gnawed on until they're litterally sharpened a bit. His suit? Holes in the neck part now. Batmans cowl? Teeth marks on the rubber bat ears. Anything and everything is free game. Once he tried to chew the lasso of truth and Diana had to get him a chewy, turns out those don't last long so Bruce bought him a whole pack.
■ whenever hal does go to someone when hes feeling little he goes to Bruce or Clark, but he only goes to Clark if it's dire and Bruce isn't there. He doesn't even know that Bruce knows yet, he just goes and watches cartoons with him or if shes too overwhelmed she'll just stay with him and relax a but.
~I also headcannon that Hal goes by Both He/Him and She/Her pronouns btw
☆Barry does end up getting a pacifier and tried his best to take MUCH better care of that than his chewies that he takes about everywhere and gnaws on. He saves it for when he's calm enough to not chew it as badly.
♡ Bruce mainly has the plushies that Diana bought for him, and a few childhood toys that Clark claims that he only brought to the tower for sentimental purposes..although he hasn't complained when his old plush cow went missing..he doesn't care though, he DOES hide them in his room in the tower and doesn't take them back to the manor. Well, unless they somehow magically make it back with him.
♧ Hal sometimes drops plushes off at the manor, along with Clark and Diana. Alfred is aware of this and supports it. Anything that'll help his son.
★ Hal sometimes draws pictures of the whole league and himself and keeps them in a notebook in a drawer in her room in the tower
♥︎ She Def draws with Barry and Clark sometimes when she's bored
Anyways I hope you enjoyed these and I hope they were okay lol :)
25 notes
·
View notes
Text

I drew little shelly :3 (lasso tool)
Don't repost please! (Reblogs are okay though)
I luv her sm!!
Headcannons under cut :3
Astro is her cg
She regresses to around 3-4
She's pretty talkative, and likes talking about dinos! Her favourite type of Dino is the T-rex
When she's eepy, She cuddles with her dino plushie, She also has a special Dino blankie that Astro got her
She likes colouring
She also likes digging for fossils in her exhibit with the kids who visit gardenveiw, they don't mind
She, Yatta, and Goob have tea parties/playdates with each other
She has a sippy with dinosaurs on it
She likes angel milk (Warmed up milk with Honey and Vanilla in it) and Lemonade as a drink)
She has a special Dino paci (like the one below!)


#big cinna#agere#sfw agere#agere art#fandom agere#dandy's world agere#agere headcanons#shelly fossilian#shelly dandys world#my art#artists on Tumblr
8 notes
·
View notes
Text
Hehe new art post (I made it with the lasso tool because I'm not feeling the best so the quality is not the best so please don't be mean) EJ walked in on Jeff playing with a stuffed rat and borderline regressing get embarrassed and drops it instantly turning around to face away from ej and en donsent know how to comfort him and tell him it's okay to feel small because Jeff is embarrassed of being seen as week and inferior(he got the rat from ej because he quote says "your like a little albino rat")

#sfw agere#creepypasta agere#agere little#creepypasta#creepypasta age regression#agere ben#creepypasta littlespace#agere community#ben drowned#ben#jeffery woods#jeff the killer#jeff the killer agere#agere jeff the killer#jeff the killer headcanons#headconon#agere headcanons#my art#digital art#agere art#sfw little community#age regression sfw#boy regression#sfw little stuff#sfw littlespace#sfw blog#creepypasta fandom#sfw agereg#sfw only#agere sfw
31 notes
·
View notes
Text
Reference archived on our website (Updates daily!)
Summary
Background
SARS-CoV-2 antigen rapid detection tests (RDTs) emerged as point-of-care diagnostics alongside reverse transcription polymerase chain reaction (RT-qPCR) as reference.
Methods
In a prospective performance assessment from 12 November 2020 to 30 June 2023 at a single centre tertiary care hospital, the sensitivity and specificity (primary endpoints) of RDTs from three manufacturers (NADAL®, Panbio™, MEDsan®) were compared to RT-qPCR as reference standard among patients, accompanying persons and staff aged ≥ six month in large-scale, clinical screening use. Regression models were used to assess influencing factors on RDT performance (secondary endpoints).
Findings
Among 78,798 paired RDT/RT-qPCR results analysed, overall RDT sensitivity was 34.5% (695/2016; 95% CI 32.4–36.6%), specificity 99.6% (76,503/76,782; 95% CI 99.6–99.7%). Over the pandemic course, sensitivity decreased in line with a lower rate of individuals showing typical COVID-19 symptoms. The lasso regression model showed that a higher viral load and typical COVID-19 symptoms were directly significantly correlated with the likelihood of a positive RDT result in SARS-CoV-2 infection, whereas age, sex, vaccination status, and the Omicron VOC were not.
Interpretation
The decline in RDT sensitivity throughout the pandemic can primarily be attributed to the reduced prevalence of symptomatic infections among vaccinated individuals and individuals infected with Omicron VOC. RDTs remain valuable for detecting SARS-CoV-2 in symptomatic individuals and offer potential for detecting other respiratory pathogens in the post-pandemic era, underscoring their importance in infection control efforts.
#covid#rapid antagen test#mask up#covid conscious#pandemic#wear a mask#covid 19#public health#coronavirus#sars cov 2#still coviding#wear a respirator#covid is airborne
21 notes
·
View notes
Note
In the midst of some honestly pretty patronising comments, Jason Sudeikis insisted that season 3 of Ted Lasso left everybody 'in better shape than when they started'. Do you disagree or is 'better than when they started' just not enough considering how much better they could have been?
Yeah, sorry, Jason, but I definitely don't agree. I mean, I'm not going to sit here and pretend that 90% of the cast didn't improve significantly and that 100% didn't improve in some aspect of their lives, BUT I feel like the phrasing "better than when they started" is too cut-and-dry, ultimately ignoring some BIG issues at the end of the series. (Well, current end.) Namely, Beard's marriage to an abusive woman and the deep losses Ted suffered by moving back to the U.S., made far worse by his canonical isolation now (he's not a part of those milestones across the pond) and the implied depression that's been added to his anxiety (that final shot). The fact that the show doesn't seem to realize these issues makes them all the worse to me. It's one thing to write a realistic/tragic story wherein not everyone gets their Happy Ending and something else entirely to paint an abusive relationship + leaving everything you've built over three years AS the Happy Ending. Yes, Ted is with Henry again, but beyond that his ending has him regressing horribly: back to America, back to a failed marriage, back without a support system (LESS of a support system now that he doesn't have Beard!), back to mediocrity in his career, and (I would personally argue) back in the closet. If I were writing Ted Lasso that "ending" would just be the next catalyst for growth, wherein Ted realizes that he cannot give up every part of himself for his child. It is better for him and Henry if he's happy, even if that means disrupting things for them in the short term (like moving them to a new country). However, both the ending presented AS an ending + "better than when they started" don't make me terribly hopeful for the new season...
I have WAY more to say on this topic. In fact, I got a good way through a massive meta about it before I burned out. Honestly, I can't remember if I deleted that or not 😬. If it's still alive somewhere I think I'll try to finish and spruce it up for posting.
11 notes
·
View notes
Text
Ted Lasso Callback Fail
Apparently, the horrible Roy, Jamie, Keeley scene in S3E12 was supposed to be a callback to the Roy, Keeley, Phoebe one in S3E1. While it's a visual callback, overall, this is a callback failure. There is a far better one but it would have showed how badly these characters were treated in this scene.


What would have been more appropriate is if Keeley had said, “Don’t use me as a prop in your little fights” - a callback to S1E4 (For the Children - after the gala) when Roy challenged Keeley on doing that very thing to him with Jamie. Then, Roy should’ve apologized (again, similar to Keeley's apology in that scene). Maybe Jamie could've then also showed shame in his behaviour because he would realize how he just walked back so much growth. It would also have shown Roy realizing he was a hypocrite, expecting better treatment in that S1 scene when he and Keeley were mere acquaintances than he was giving to Keeley in S3E12, the woman who he apparently loved.

That’s a proper callback, but it would've called attention to the fact that the show decided to short shrift Roy & Keeley as characters in S3. Not to mention this scene was so gross because Roy and Jamie had always respected Keeley's agency & even in S1 when they hated each other, they respected her wishes. Hey... another callback, when Roy didn't try to stop Jamie from coming into Keeley's house in S1, showing he may have hated Jamie but Keeley's friendship with Jamie was none of his business. And Jamie knew Keeley's love life was none of his. They both knew they had no right to make her choose how she lived her life.

Regression is one thing, but it means Ted’s influence & all their growth meant nothing.
#ted lasso#callbacks#ted lasso callbacks#roy kent#keeley jones#jamie tartt#roy kent keeley jones#roy & keeley#reeley#roy/keeley#RoyKeeley#keeley x roy#keeley and roy#ted lasso s3#missed opportunity#roy and keeley#roy x keeley#S3 can suck it
30 notes
·
View notes