#Regression Analysis on AI
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
What Are the Regression Analysis Techniques in Data Science?

In the dynamic world of data science, predicting continuous outcomes is a core task. Whether you're forecasting house prices, predicting sales figures, or estimating a patient's recovery time, regression analysis is your go-to statistical superpower. Far from being a single technique, regression analysis encompasses a diverse family of algorithms, each suited to different data characteristics and problem complexities.
Let's dive into some of the most common and powerful regression analysis techniques that every data scientist should have in their toolkit.
1. Linear Regression: The Foundation
What it is: The simplest and most widely used regression technique. Linear regression assumes a linear relationship between the independent variables (features) and the dependent variable (the target you want to predict). It tries to fit a straight line (or hyperplane in higher dimensions) that best describes this relationship, minimizing the sum of squared differences between observed and predicted values.
When to use it: When you suspect a clear linear relationship between your variables. It's often a good starting point for any regression problem due to its simplicity and interpretability.
Example: Predicting a student's exam score based on the number of hours they studied.
2. Polynomial Regression: Beyond the Straight Line
What it is: An extension of linear regression that allows for non-linear relationships. Instead of fitting a straight line, polynomial regression fits a curve to the data by including polynomial terms (e.g., x2, x3) of the independent variables in the model.
When to use it: When the relationship between your variables is clearly curved.
Example: Modeling the trajectory of a projectile or the growth rate of a population over time.
3. Logistic Regression: Don't Let the Name Fool You!
What it is: Despite its name, Logistic Regression is primarily used for classification problems, not continuous prediction. However, it's often discussed alongside regression because it predicts the probability of a binary (or sometimes multi-class) outcome. It uses a sigmoid function to map any real-valued input to a probability between 0 and 1.
When to use it: When your dependent variable is categorical (e.g., predicting whether a customer will churn (Yes/No), if an email is spam or not).
Example: Predicting whether a loan application will be approved or denied.
4. Ridge Regression (L2 Regularization): Taming Multicollinearity
What it is: A regularization technique used to prevent overfitting and handle multicollinearity (when independent variables are highly correlated). Ridge regression adds a penalty term (proportional to the square of the magnitude of the coefficients) to the cost function, which shrinks the coefficients towards zero, but never exactly to zero.
When to use it: When you have a large number of correlated features or when your model is prone to overfitting.
Example: Predicting housing prices with many highly correlated features like living area, number of rooms, and number of bathrooms.
5. Lasso Regression (L1 Regularization): Feature Selection Powerhouse
What it is: Similar to Ridge Regression, Lasso (Least Absolute Shrinkage and Selection Operator) also adds a penalty term to the cost function, but this time it's proportional to the absolute value of the coefficients. A key advantage of Lasso is its ability to perform feature selection by driving some coefficients exactly to zero, effectively removing those features from the model.
When to use it: When you have a high-dimensional dataset and want to identify the most important features, or to create a more parsimonious (simpler) model.
Example: Predicting patient recovery time from a vast array of medical measurements, identifying the most influential factors.
6. Elastic Net Regression: The Best of Both Worlds
What it is: Elastic Net combines the penalties of both Ridge and Lasso regression. It's particularly useful when you have groups of highly correlated features, where Lasso might arbitrarily select only one from the group. Elastic Net will tend to select all features within such groups.
When to use it: When dealing with datasets that have high dimensionality and multicollinearity, offering a balance between shrinkage and feature selection.
Example: Genomics data analysis, where many genes might be correlated.
7. Support Vector Regression (SVR): Handling Complex Relationships
What it is: An adaptation of Support Vector Machines (SVMs) for regression problems. Instead of finding a hyperplane that separates classes, SVR finds a hyperplane that has the maximum number of data points within a certain margin (epsilon-tube), minimizing the error between the predicted and actual values.
When to use it: When dealing with non-linear, high-dimensional data, and you're looking for robust predictions even with outliers.
Example: Predicting stock prices or time series forecasting.
8. Decision Tree Regression: Interpretable Branching
What it is: A non-parametric method that splits the data into branches based on feature values, forming a tree-like structure. At each "leaf" of the tree, a prediction is made, which is typically the average of the target values for the data points in that leaf.
When to use it: When you need a model that is easy to interpret and visualize. It can capture non-linear relationships and interactions between features.
Example: Predicting customer satisfaction scores based on multiple survey responses.
9. Ensemble Methods: The Power of Collaboration
Ensemble methods combine multiple individual models to produce a more robust and accurate prediction. For regression, the most popular ensemble techniques are:
Random Forest Regression: Builds multiple decision trees on different subsets of the data and averages their predictions. This reduces overfitting and improves generalization.
Gradient Boosting Regression (e.g., XGBoost, LightGBM, CatBoost): Sequentially builds trees, where each new tree tries to correct the errors of the previous ones. These are highly powerful and often achieve state-of-the-art performance.
When to use them: When you need high accuracy and are willing to sacrifice some interpretability. They are excellent for complex, high-dimensional datasets.
Example: Predicting highly fluctuating real estate values or complex financial market trends.
Choosing the Right Technique
The "best" regression technique isn't universal; it depends heavily on:
Nature of the data: Is it linear or non-linear? Are there outliers? Is there multicollinearity?
Number of features: High dimensionality might favor regularization or ensemble methods.
Interpretability requirements: Do you need to explain how the model arrives at a prediction?
Computational resources: Some complex models require more processing power.
Performance metrics: What defines a "good" prediction for your specific problem (e.g., R-squared, Mean Squared Error, Mean Absolute Error)?
By understanding the strengths and weaknesses of each regression analysis technique, data scientists can strategically choose the most appropriate tool to unlock valuable insights and build powerful predictive models. The world of data is vast, and with these techniques, you're well-equipped to navigate its complexities and make data-driven decisions.
0 notes
Text

www.qualibar.com
Benefits of AI in Software Testing
AI (Artificial Intelligence) brings several benefits to software testing, enhancing efficiency, accuracy, and effectiveness in various aspects of the testing process.
Here are some key benefits of using AI in software testing:
Automation and Speed: AI enables the automation of repetitive and time-consuming testing tasks. This significantly speeds up the testing process, allowing for faster release cycles without compromising quality. Automated testing can run 24/7, providing continuous feedback.
Efficiency and Resource Optimization: AI-powered testing tools can optimize resource utilization by executing tests in parallel, reducing the overall testing time. This efficiency helps in allocating resources more effectively and allows testing teams to focus on more complex and creative aspects of testing.
Test Case Generation: AI can assist in the creation of test cases by analyzing application requirements, specifications, and historical data. This helps in identifying critical test scenarios and generating test cases that cover a broader range of possible scenarios, improving test coverage.
Predictive Analysis: AI algorithms can analyze historical data to predict potential areas of defects or vulnerabilities in the software. This predictive analysis helps testing teams prioritize testing efforts on high-risk areas, improving the overall effectiveness of testing.
Self-Healing Tests: AI can be employed to create self-healing tests that adapt to changes in the application's codebase. When minor changes occur, AI algorithms can automatically update test scripts, reducing maintenance efforts and ensuring that tests remain relevant.
Data-Driven Testing: AI can analyze large datasets to identify patterns and correlations, helping in the creation of realistic and data-driven test scenarios. This ensures that tests are more representative of real-world usage, leading to more effective testing.
Performance Testing: AI can be applied to simulate real-world user behavior and generate realistic load scenarios during performance testing. This helps in identifying and addressing performance bottlenecks and ensuring that the software can handle varying levels of user activity.
Security Testing: AI can enhance security testing by automating the identification of vulnerabilities and potential security threats. AI algorithms can analyze code for patterns associated with security risks and help in the early detection of potential security issues.
User Experience Testing: AI can analyze user interactions and feedback to provide insights into the user experience. This information can be used to optimize the software's usability and identify areas for improvement in terms of user satisfaction.
Regression Testing: AI can efficiently handle regression testing by automatically identifying changes in the codebase and selectively running relevant test cases. This ensures that new updates or features do not introduce unintended side effects.
In summary, integrating AI into software testing processes brings about improvements in efficiency, accuracy, and overall testing effectiveness, ultimately contributing to the delivery of higher-quality software.
#qualibar#qualibarinc#software testing#softwaresolutions#softwaretestingsolutions#ai#ai-in-softwaretesting#Automation and Speed#Efficiency and Resource Optimization#Test Case Generation#Predictive Analysis#Self-Healing Tests#Data-Driven Testing#Performance Testing#Security Testing#User Experience Testing#Regression Testing#itsolutions#qualibarIndia#qualibarnewyork#qualibaratlanta#qualibargeorgia#qualibarbhubaneswar#qualibarusa#artificialintelligence
1 note
·
View note
Text
OnS Chapter 136 Analysis - Love vs The Past
Well, a new chapter dropped. I must say that I liked it. We really are heading towards the end of the story and two sides now are on stage.
One fighting for love; the other one fighting to bring back something that is long lost.
Love can often be misunderstood in the manga story; to the point it distorts a lot, but in reality, it takes so many shapes, so many forms along giving birth to ideals.
Each character within the story is moved to do something for "love". But in this role too; the "love" for the "past" exists.
The past is a momentum that will always live in our memories; it is something that will forever be frozen; something that will not change. It's something that is part of us without defining us.
As we've seen today; the chapter starts with Yuu trying to reach the First; but given that the Progenitors want to avoid the destruction of the world much further; they were preventing Yuu from making contact with the First.
Of course, we see how Mika couldn't withstand the raw power of Urd Geales; we saw Shinya and Kureto alive and kicking once again; and finally, the main spot; the reunion between Shikama and Yuu.

Shikama is aware that Yuu has all his memories back ever since he detected an anomaly along the interaction with the corpse of Mikaela. Of course, whenever Shikama knows the soul of his son is alive and kicking, it's up to interpretation. Though, it is clear he knows it exists.
Eventually we see how Shikama is going to bestow Yuu his knowledge and power

But before he could give away his power to Yuu; Shinoa interferred with the possibility.
Leading to our possible future battle between Shinoa and Yuu.

Two ideals being carried away within the story. And yet, at the same time they connect through the main theme. "Love."

And no, it's not "romantic love ". The "love" or 愛 which is not the same as other interpretations of love itself. Just "ai". A love that takes so many shapes.
Let's begin with the real analysis here.
Yuu isn't exactly fighting for humanity nor his friends, nor his family. Given that the "regression" process he made to recall his whole life; he saw how his life originated alongside being the son of the First.
Given that, he is actually aiming for the task of "saving" but given that "love" is playing its role as well. It is the love he has deep down for his father that he is doing everything to bring back what his father cherished in the past. Which is something reflected as well when he was the angel Mikaela. Taking his life so divine punishment wouldn't fall upon his father.

Shikama did love his angels, his followers and he did blame himself for the punishment that fell upon them. But given God's nature; it was normal that the punishment fell upon those angels given that they no longer praised for God.
Though; one thing Shikama and Yuu have in common, is the attachment to the past. It is the very fact that the past for them is something that should have prevailed instead of changing. What do I mean?
To Shikama, the Progenitors he chose, despite being reincarnations of those angels that followed him once; are not his angels.
And this is highly visible once Ashera asks Shikama what he should do back in chapter 117.

To his eyes, Shikama's sired progenitors were just tools given that to him; they are shadows of who they were once, but to those progenitors; even if they have acknowledged that they are reincarnations; they made a choice.

They chose to follow up their own path. And as they've stated back in chapter 114; their last and final task is to protect the world they live in. Meaning avoiding the resurrection of the angel Mikaela.
But now, why do I say Shikama and Yuu have one thing in common?
Yuu is a character that despite living endlessly; along having a constant memory reset until now that he gathered all his memories; he's done one thing to no end. And that is living in the past.
True, there are scars that take its time to heal from the past; some are very difficult nonetheless; he chose to live in such past. When he had a chance to make a choice; that choice was no longer centered in the present; it began to lead further astray to the past.
But then, what's the point of those promises?
Given how everything has turned. Those promises are something that can't be fulfilled. What do I mean?
In order to revive the angels from long ago; sacrifices must be made. But here's another thing that it is being dismissed. What could it be?
The absolute lack of appreciation to life.
Yuu might state he aims to save everyone; even to Ashera who at the end understood that there are limits to life. He loved and embraced he managed to get his sister back; but the cost for that was making her suffer for eternity; nevertheless, the lives both had, those kind of experiences they managed to live had their moments of bliss; bringing back entities that perished long ago, is discarting the moments experienced, the moments lived along the emotions that were carried through a lifetime.
But now, there is an opposite force here. And that force is no other than. "Love."

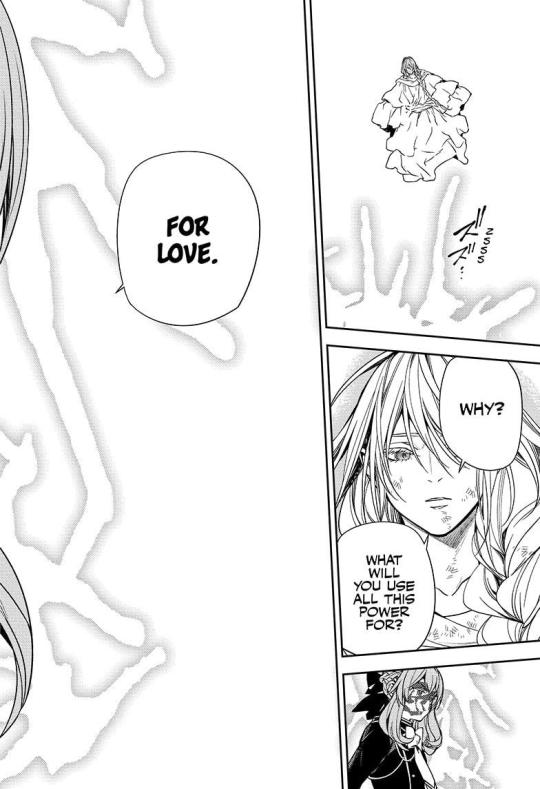
Many might consider that Shinoa's love is "obssession, madness like Mahiru's love" but no. This is actually wrong.
Back when she stated she would kill Mikaela; there was a massive misconception of this which chapter 133 explained a lot.
Shinoa thought Yuu was being possessed by Mikaela at that time hence her retoric; but given that she saw first hand that Yuu had fooled them; she understood that Yuu was doing everything on his own will. And let's not forget that Yuu might be dumb, but not clueless or ignorant.
Shinoa's form of "love" is not something that came out of nothing; it's something that began taking shape by her own; it began from curiosity, turning into uncertainty, then transforming into caring, along developing feelings for a special someone. Such feelings for her were seen as something hideous or bad; but at the end, she understood they weren't bad, nevertheless, she never admitted them until or rather never accepted them truthfully until chapter 133.
Chapter 133 was a very reflexive chapter given that it gave Shinoa resolution; a resolution as to why it is the reason she was standing still in the very end of the world.
Shinoa's love is not centered to one person, but rather; it is centered to the very core family she gained through her journey which lead to this.

Her battle and her resolution is directed to the very family that has stood with her and has followed her through the long journey she has taken so far. Hence why; she is standing along her squad just like how the vampires did; how they are going to live. Not by a decree of an entity, not by a decree of her sister and Guren nor the vampires; but rather, taking their own path until the very end.
Hence why Shikama states that her love is self centered, which is no different from him. He centered his love to his angels; Shinoa is centering her love to those who exist in the present. Along letting them return to their normality before the world ended; given that the end of the world, the events that took place before they were born, were all spiderwebs made by the First.
This is the first time they are fighting for their own.
What do you think it'll happen next?
Let me know!
#owari no seraph#seraph of the end#ons#yuichiro hyakuya#mikaela hyakuya#shikama doji#mahiru hiragi#rigr stafford#urd geales#shinoa hiragi#hiragi kureto#shinya hiragi#hiiragi shinoa#mitsuba sangu#shiho kimizuki#yoichi saotome#vampire progenitors#ashera tepes#krul tepes#ons analysis#what do you think dear readers?
66 notes
·
View notes
Note
could you elaborate on the difference between regression and burnout? (if you want)
Hey! I have a few posts on this but sure, I can explain it again!
Late autism regression is usually caused by something called Autism Catatonia. I’ll put some links below about it.
Autism catatonia is a serious condition that involves the slow start of regression in developmental and social aspects. Someone with autism catatonia will start to develop catatonia, as the name suggests. The person will freeze before and sometimes after tasks, they will have trouble completing tasks, need extensive prompting or hand over hand help, and more. The person will also start to decline in social aspects, from isolation, to aggressive behaviors, to just generally declining in all areas involving social interaction. They will also start to decline in the ability to do skills, for example; forgetting how to shower, forgetting how to do certain things, etc etc. The person might also start to decline in speech, and in some cases, lose their ability all together.
Mood decline is also very common, from aggressive behaviors, to depressive like behaviors. The person will have also episodes of catatonia, such as freezing. The person might also have trouble doing tasks and going over thresholds.
Autism catatonia is very complex and not a lot of professionals know a lot about it so it’s good to speak with a professional that is knowledgeable in it if you suspect you have it. Please keep in mind that autism catatonia is rare. And is not the same as executive dysfunction. It is often treated with medication and in more severe cases, ECT.
Burnout is much much different. It’s caused by masking. And over time as someone masks to conform to society, they start to feel burnt out. This CAN lead to some loss in skills, however with time, healing, rest, and accommodations and unmasking, it can lead to you getting pretty much back to normal or at least get you to where you want to be. Burnout is also serious, but it is much different from autism regression.
Again, I’m not a professional, my information might not be 100%. I’d google more about it and research more! There are a ton of resources on autism burnout, and a few on regression. Please do not try and self diagnosis autism regression with catatonia, it is so serious and shouldn’t be taken lightly.
AGAIN. IM NOT A PROFESSIONAL. THIS IS JUST FROM MY PERSONAL RESEARCH AND EXPERIENCES.
https://asatonline.org/research-treatment/clinical-corner/catatonia/
#zebrambles#autism#actually autism#actually autistic#autistic#autism regression#autism catatonia#autism burnout#burnout#catatonia#long post
66 notes
·
View notes
Text
Machine Learning: A Comprehensive Overview
Machine Learning (ML) is a subfield of synthetic intelligence (AI) that offers structures with the capacity to robotically examine and enhance from revel in without being explicitly programmed. Instead of using a fixed set of guidelines or commands, device studying algorithms perceive styles in facts and use the ones styles to make predictions or decisions. Over the beyond decade, ML has transformed how we have interaction with generation, touching nearly each aspect of our every day lives — from personalised recommendations on streaming services to actual-time fraud detection in banking.

Machine learning algorithms
What is Machine Learning?
At its center, gadget learning entails feeding facts right into a pc algorithm that allows the gadget to adjust its parameters and improve its overall performance on a project through the years. The more statistics the machine sees, the better it usually turns into. This is corresponding to how humans study — through trial, error, and revel in.
Arthur Samuel, a pioneer within the discipline, defined gadget gaining knowledge of in 1959 as “a discipline of take a look at that offers computers the capability to study without being explicitly programmed.” Today, ML is a critical technology powering a huge array of packages in enterprise, healthcare, science, and enjoyment.
Types of Machine Learning
Machine studying can be broadly categorised into 4 major categories:
1. Supervised Learning
For example, in a spam electronic mail detection device, emails are classified as "spam" or "no longer unsolicited mail," and the algorithm learns to classify new emails for this reason.
Common algorithms include:
Linear Regression
Logistic Regression
Support Vector Machines (SVM)
Decision Trees
Random Forests
Neural Networks
2. Unsupervised Learning
Unsupervised mastering offers with unlabeled information. Clustering and association are commonplace obligations on this class.
Key strategies encompass:
K-Means Clustering
Hierarchical Clustering
Principal Component Analysis (PCA)
Autoencoders
three. Semi-Supervised Learning
It is specifically beneficial when acquiring categorised data is highly-priced or time-consuming, as in scientific diagnosis.
Four. Reinforcement Learning
Reinforcement mastering includes an agent that interacts with an surroundings and learns to make choices with the aid of receiving rewards or consequences. It is broadly utilized in areas like robotics, recreation gambling (e.G., AlphaGo), and independent vehicles.
Popular algorithms encompass:
Q-Learning
Deep Q-Networks (DQN)
Policy Gradient Methods
Key Components of Machine Learning Systems
1. Data
Data is the muse of any machine learning version. The pleasant and quantity of the facts directly effect the performance of the version. Preprocessing — consisting of cleansing, normalization, and transformation — is vital to make sure beneficial insights can be extracted.
2. Features
Feature engineering, the technique of selecting and reworking variables to enhance model accuracy, is one of the most important steps within the ML workflow.
Three. Algorithms
Algorithms define the rules and mathematical fashions that help machines study from information. Choosing the proper set of rules relies upon at the trouble, the records, and the desired accuracy and interpretability.
4. Model Evaluation
Models are evaluated the use of numerous metrics along with accuracy, precision, consider, F1-score (for class), or RMSE and R² (for regression). Cross-validation enables check how nicely a model generalizes to unseen statistics.
Applications of Machine Learning
Machine getting to know is now deeply incorporated into severa domain names, together with:
1. Healthcare
ML is used for disorder prognosis, drug discovery, customized medicinal drug, and clinical imaging. Algorithms assist locate situations like cancer and diabetes from clinical facts and scans.
2. Finance
Fraud detection, algorithmic buying and selling, credit score scoring, and client segmentation are pushed with the aid of machine gaining knowledge of within the financial area.
3. Retail and E-commerce
Recommendation engines, stock management, dynamic pricing, and sentiment evaluation assist businesses boom sales and improve patron revel in.
Four. Transportation
Self-riding motors, traffic prediction, and route optimization all rely upon real-time gadget getting to know models.
6. Cybersecurity
Anomaly detection algorithms help in identifying suspicious activities and capacity cyber threats.
Challenges in Machine Learning
Despite its rapid development, machine mastering still faces numerous demanding situations:
1. Data Quality and Quantity
Accessing fantastic, categorised statistics is often a bottleneck. Incomplete, imbalanced, or biased datasets can cause misguided fashions.
2. Overfitting and Underfitting
Overfitting occurs when the model learns the education statistics too nicely and fails to generalize.
Three. Interpretability
Many modern fashions, specifically deep neural networks, act as "black boxes," making it tough to recognize how predictions are made — a concern in excessive-stakes regions like healthcare and law.
4. Ethical and Fairness Issues
Algorithms can inadvertently study and enlarge biases gift inside the training facts. Ensuring equity, transparency, and duty in ML structures is a growing area of studies.
5. Security
Adversarial assaults — in which small changes to enter information can fool ML models — present critical dangers, especially in applications like facial reputation and autonomous riding.
Future of Machine Learning
The destiny of system studying is each interesting and complicated. Some promising instructions consist of:
1. Explainable AI (XAI)
Efforts are underway to make ML models greater obvious and understandable, allowing customers to believe and interpret decisions made through algorithms.
2. Automated Machine Learning (AutoML)
AutoML aims to automate the stop-to-cease manner of applying ML to real-world issues, making it extra reachable to non-professionals.
3. Federated Learning
This approach permits fashions to gain knowledge of across a couple of gadgets or servers with out sharing uncooked records, enhancing privateness and efficiency.
4. Edge ML
Deploying device mastering models on side devices like smartphones and IoT devices permits real-time processing with reduced latency and value.
Five. Integration with Other Technologies
ML will maintain to converge with fields like blockchain, quantum computing, and augmented fact, growing new opportunities and challenges.
2 notes
·
View notes
Text
What is the difference between AI testing and automation testing?
Automation Testing Services

As technology continues to evolve, so do the methods used to test software. Two popular approaches in the industry today are AI testing and Automation Testing. While they are often used together or mentioned side by side, they serve different purposes and bring unique advantages to software development. Let's explore how they differ.
What Is Automation Testing?
Automation Testing involves writing and crafting test scripts or using testing tools and resources to run the tests automatically without human intervention. As it's commonly used to speed up repetitive testing tasks like regression testing, performance checks, or functional validations. These tests follow a fixed set of rules and are often best suited for stable, predictable applications with its implementation. Automation Test improves overall efficiency, reduces human error, and helps the developers and coders to release software faster and with precise detailing.
What Is AI Testing?
AI testing uses artificial intelligence technologies like ML, NLP, and pattern recognition to boost their software testing process and operations. Unlike Automation Tests, AI testing can learn from data, predict where bugs might occur, and even adapt test cases when an application changes. While it makes the testing process more innovative and flexible, especially in complex and tough applications where manual updates to test scripts are time-consuming.
Key Differences Between AI Testing and Automation Testing:
Approach: Automation Test follows pre-written scripts, while AI testing uses the data analysis and learning to make precise decisions with ease.
Flexibility: Automation Test requires the updates if the software changes or adapts to new terms; AI testing can adapt automatically and without any interpretation.
Efficiency: While both of the testing methods aim to save time, AI testing offers more intelligent insights and better prioritization of test cases with its adaptation.
Use Cases: Automation Tests are ideal and suitable for regression tests and routine tasks and common testing. AI testing is better suited for dynamic applications and predictive testing.
Both methods are valuable, and many companies use a combination of Automation Testing and AI testing to achieve reliable and intelligent quality assurance. Choosing the correct method depends on the project's complexity and testing needs. Automation Test is best for repetitive and everyday tasks like checking login pages, payment forms, or user dashboards and analytics. It's also helpful in regression testing — where old features must be retested after certain updates or standard system upgrades.
Companies like Suma Soft, IBM, Cyntexa, and Cignex offer advanced automation test solutions that support fast delivery, better performance, and improved software quality for businesses of all sizes.
#it services#technology#saas#software#saas development company#saas technology#digital transformation
2 notes
·
View notes
Text
Predicting Employee Attrition: Leveraging AI for Workforce Stability

Employee turnover has become a pressing concern for organizations worldwide. The cost of losing valuable talent extends beyond recruitment expenses—it affects team morale, disrupts workflows, and can tarnish a company's reputation. In this dynamic landscape, Artificial Intelligence (AI) emerges as a transformative tool, offering predictive insights that enable proactive retention strategies. By harnessing AI, businesses can anticipate attrition risks and implement measures to foster a stable and engaged workforce.
Understanding Employee Attrition
Employee attrition refers to the gradual loss of employees over time, whether through resignations, retirements, or other forms of departure. While some level of turnover is natural, high attrition rates can signal underlying issues within an organization. Common causes include lack of career advancement opportunities, inadequate compensation, poor management, and cultural misalignment. The repercussions are significant—ranging from increased recruitment costs to diminished employee morale and productivity.
The Role of AI in Predicting Attrition
AI revolutionizes the way organizations approach employee retention. Traditional methods often rely on reactive measures, addressing turnover after it occurs. In contrast, AI enables a proactive stance by analyzing vast datasets to identify patterns and predict potential departures. Machine learning algorithms can assess factors such as job satisfaction, performance metrics, and engagement levels to forecast attrition risks. This predictive capability empowers HR professionals to intervene early, tailoring strategies to retain at-risk employees.
Data Collection and Integration
The efficacy of AI in predicting attrition hinges on the quality and comprehensiveness of data. Key data sources include:
Employee Demographics: Age, tenure, education, and role.
Performance Metrics: Appraisals, productivity levels, and goal attainment.
Engagement Surveys: Feedback on job satisfaction and organizational culture.
Compensation Details: Salary, bonuses, and benefits.
Exit Interviews: Insights into reasons for departure.
Integrating data from disparate systems poses challenges, necessitating robust data management practices. Ensuring data accuracy, consistency, and privacy is paramount to building reliable predictive models.
Machine Learning Models for Attrition Prediction
Several machine learning algorithms have proven effective in forecasting employee turnover:
Random Forest: This ensemble learning method constructs multiple decision trees to improve predictive accuracy and control overfitting.
Neural Networks: Mimicking the human brain's structure, neural networks can model complex relationships between variables, capturing subtle patterns in employee behavior.
Logistic Regression: A statistical model that estimates the probability of a binary outcome, such as staying or leaving.
For instance, IBM's Predictive Attrition Program utilizes AI to analyze employee data, achieving a reported accuracy of 95% in identifying individuals at risk of leaving. This enables targeted interventions, such as personalized career development plans, to enhance retention.
Sentiment Analysis and Employee Feedback
Understanding employee sentiment is crucial for retention. AI-powered sentiment analysis leverages Natural Language Processing (NLP) to interpret unstructured data from sources like emails, surveys, and social media. By detecting emotions and opinions, organizations can gauge employee morale and identify areas of concern. Real-time sentiment monitoring allows for swift responses to emerging issues, fostering a responsive and supportive work environment.
Personalized Retention Strategies
AI facilitates the development of tailored retention strategies by analyzing individual employee data. For example, if an employee exhibits signs of disengagement, AI can recommend specific interventions—such as mentorship programs, skill development opportunities, or workload adjustments. Personalization ensures that retention efforts resonate with employees' unique needs and aspirations, enhancing their effectiveness.
Enhancing Employee Engagement Through AI
Beyond predicting attrition, AI contributes to employee engagement by:
Recognition Systems: Automating the acknowledgment of achievements to boost morale.
Career Pathing: Suggesting personalized growth trajectories aligned with employees' skills and goals.
Feedback Mechanisms: Providing platforms for continuous feedback, fostering a culture of open communication.
These AI-driven initiatives create a more engaging and fulfilling work environment, reducing the likelihood of turnover.
Ethical Considerations in AI Implementation
While AI offers substantial benefits, ethical considerations must guide its implementation:
Data Privacy: Organizations must safeguard employee data, ensuring compliance with privacy regulations.
Bias Mitigation: AI models should be regularly audited to prevent and correct biases that may arise from historical data.
Transparency: Clear communication about how AI is used in HR processes builds trust among employees.
Addressing these ethical aspects is essential to responsibly leveraging AI in workforce management.
Future Trends in AI and Employee Retention
The integration of AI in HR is poised to evolve further, with emerging trends including:
Predictive Career Development: AI will increasingly assist in mapping out employees' career paths, aligning organizational needs with individual aspirations.
Real-Time Engagement Analytics: Continuous monitoring of engagement levels will enable immediate interventions.
AI-Driven Organizational Culture Analysis: Understanding and shaping company culture through AI insights will become more prevalent.
These advancements will further empower organizations to maintain a stable and motivated workforce.
Conclusion
AI stands as a powerful ally in the quest for workforce stability. By predicting attrition risks and informing personalized retention strategies, AI enables organizations to proactively address turnover challenges. Embracing AI-driven approaches not only enhances employee satisfaction but also fortifies the organization's overall performance and resilience.
Frequently Asked Questions (FAQs)
How accurate are AI models in predicting employee attrition?
AI models, when trained on comprehensive and high-quality data, can achieve high accuracy levels. For instance, IBM's Predictive Attrition Program reports a 95% accuracy rate in identifying at-risk employees.
What types of data are most useful for AI-driven attrition prediction?
Valuable data includes employee demographics, performance metrics, engagement survey results, compensation details, and feedback from exit interviews.
Can small businesses benefit from AI in HR?
Absolutely. While implementation may vary in scale, small businesses can leverage AI tools to gain insights into employee satisfaction and predict potential turnover, enabling timely interventions.
How does AI help in creating personalized retention strategies?
AI analyzes individual employee data to identify specific needs and preferences, allowing HR to tailor interventions such as customized career development plans or targeted engagement initiatives.
What are the ethical considerations when using AI in HR?
Key considerations include ensuring data privacy, mitigating biases in AI models, and maintaining transparency with employees about how their data is used.
For more Info Visit :- Stentor.ai
2 notes
·
View notes
Text
Glassdoor has a **For You** tab that uses "AI" to "help" you find jobs, well. It just suggested me a whole page of Special Ed Teacher jobs and I realized it was because it "read" my resume as listing the skill "regression analysis" as in the phrase "multiple linear regression and other types of analysis" and "regression" is a term used in sped a lot for children's behavior.
great tool. my ability to do a fully crossed ANOVA definitely makes me a behavior specialist for disabled kids.
4 notes
·
View notes
Note
TO: Captain Steven Rogers FROM: @carlos-the-ai SUBJECT: Analysis of Substance Responsible for Age Regression of Subjects Lina and Pyro
Objective: To analyze the molecular composition of the provided substance and determine potential pathways for reversing its effects, which caused age regression in subjects identified as Lina and Pyro.
Analysis Summary: The sample exhibits unique characteristics indicating temporal manipulation at a molecular level. Key findings include: Molecular Composition: The substance contains artificially synthesized compounds not commonly found in organic materials. Significant presence of particles with properties akin to “chronoton�� particles, typically associated with temporal displacement. However, the substance is engineered, suggesting intentional manipulation for specific effects. Temporal and Aging Effects: Preliminary findings indicate the substance acts on a cellular level, reversing age markers. It appears to temporarily suspend natural metabolic decay while promoting regeneration to a predetermined age range, hence the regression to a teenage state in subjects. There is evidence of accelerated cell division and growth in reverse, a process similar to biological age manipulation observed in certain advanced serums and magic-based phenomena. Potential Countermeasures: Reversal may be possible by isolating the key chronoton-like particles and developing a counter-agent that neutralizes these effects. Suggested research includes synthesizing an agent that can target the particles without further disrupting cellular stability. This would require a controlled environment, preferably in a lab with access to both high-energy particle accelerators and molecular stasis technology. Next Steps: Isolate Chronoton Agents: Further isolate the particles responsible for age regression effects. Synthesize Counter-Agent: Using data from known temporal stabilization protocols, develop a prototype antidote. Testing Protocol: Initiate controlled trials on a cellular sample to gauge the counter-agent's efficacy prior to testing on subjects. Conclusion: The substance responsible for age regression holds substantial complexity, blending artificial compounds with properties associated with temporal manipulation. Given appropriate lab resources, an antidote or counter-agent could be synthesized within an estimated timeframe of 2-4 weeks, pending trials. Recommended Actions: Secure lab access and begin the synthesis of a counter-agent under controlled conditions.
Thank you Carlos.
You might find it helpful to know they’re adults again, almost like it wore off?
#captain america#rp#rp blog#steve rogers#marvel#the avengers#marvel rp#avengers rp#asks#carlos the ai#serena stark
4 notes
·
View notes
Text
Optimizing Business Operations with Advanced Machine Learning Services
Machine learning has gained popularity in recent years thanks to the adoption of the technology. On the other hand, traditional machine learning necessitates managing data pipelines, robust server maintenance, and the creation of a model for machine learning from scratch, among other technical infrastructure management tasks. Many of these processes are automated by machine learning service which enables businesses to use a platform much more quickly.
What do you understand of Machine learning?
Deep learning and neural networks applied to data are examples of machine learning, a branch of artificial intelligence focused on data-driven learning. It begins with a dataset and gains the ability to extract relevant data from it.
Machine learning technologies facilitate computer vision, speech recognition, face identification, predictive analytics, and more. They also make regression more accurate.
For what purpose is it used?
Many use cases, such as churn avoidance and support ticket categorization make use of MLaaS. The vital thing about MLaaS is it makes it possible to delegate machine learning's laborious tasks. This implies that you won't need to install software, configure servers, maintain infrastructure, and other related tasks. All you have to do is choose the column to be predicted, connect the pertinent training data, and let the software do its magic.
Natural Language Interpretation
By examining social media postings and the tone of consumer reviews, natural language processing aids businesses in better understanding their clientele. the ml services enable them to make more informed choices about selling their goods and services, including providing automated help or highlighting superior substitutes. Machine learning can categorize incoming customer inquiries into distinct groups, enabling businesses to allocate their resources and time.
Predicting
Another use of machine learning is forecasting, which allows businesses to project future occurrences based on existing data. For example, businesses that need to estimate the costs of their goods, services, or clients might utilize MLaaS for cost modelling.
Data Investigation
Investigating variables, examining correlations between variables, and displaying associations are all part of data exploration. Businesses may generate informed suggestions and contextualize vital data using machine learning.
Data Inconsistency
Another crucial component of machine learning is anomaly detection, which finds anomalous occurrences like fraud. This technology is especially helpful for businesses that lack the means or know-how to create their own systems for identifying anomalies.
Examining And Comprehending Datasets
Machine learning provides an alternative to manual dataset searching and comprehension by converting text searches into SQL queries using algorithms trained on millions of samples. Regression analysis use to determine the correlations between variables, such as those affecting sales and customer satisfaction from various product attributes or advertising channels.
Recognition Of Images
One area of machine learning that is very useful for mobile apps, security, and healthcare is image recognition. Businesses utilize recommendation engines to promote music or goods to consumers. While some companies have used picture recognition to create lucrative mobile applications.
Your understanding of AI will drastically shift. They used to believe that AI was only beyond the financial reach of large corporations. However, thanks to services anyone may now use this technology.
2 notes
·
View notes
Text
UNLOCKING THE POWER OF AI WITH EASYLIBPAL 2/2

EXPANDED COMPONENTS AND DETAILS OF EASYLIBPAL:
1. Easylibpal Class: The core component of the library, responsible for handling algorithm selection, model fitting, and prediction generation
2. Algorithm Selection and Support:
Supports classic AI algorithms such as Linear Regression, Logistic Regression, Support Vector Machine (SVM), Naive Bayes, and K-Nearest Neighbors (K-NN).
and
- Decision Trees
- Random Forest
- AdaBoost
- Gradient Boosting
3. Integration with Popular Libraries: Seamless integration with essential Python libraries like NumPy, Pandas, Matplotlib, and Scikit-learn for enhanced functionality.
4. Data Handling:
- DataLoader class for importing and preprocessing data from various formats (CSV, JSON, SQL databases).
- DataTransformer class for feature scaling, normalization, and encoding categorical variables.
- Includes functions for loading and preprocessing datasets to prepare them for training and testing.
- `FeatureSelector` class: Provides methods for feature selection and dimensionality reduction.
5. Model Evaluation:
- Evaluator class to assess model performance using metrics like accuracy, precision, recall, F1-score, and ROC-AUC.
- Methods for generating confusion matrices and classification reports.
6. Model Training: Contains methods for fitting the selected algorithm with the training data.
- `fit` method: Trains the selected algorithm on the provided training data.
7. Prediction Generation: Allows users to make predictions using the trained model on new data.
- `predict` method: Makes predictions using the trained model on new data.
- `predict_proba` method: Returns the predicted probabilities for classification tasks.
8. Model Evaluation:
- `Evaluator` class: Assesses model performance using various metrics (e.g., accuracy, precision, recall, F1-score, ROC-AUC).
- `cross_validate` method: Performs cross-validation to evaluate the model's performance.
- `confusion_matrix` method: Generates a confusion matrix for classification tasks.
- `classification_report` method: Provides a detailed classification report.
9. Hyperparameter Tuning:
- Tuner class that uses techniques likes Grid Search and Random Search for hyperparameter optimization.
10. Visualization:
- Integration with Matplotlib and Seaborn for generating plots to analyze model performance and data characteristics.
- Visualization support: Enables users to visualize data, model performance, and predictions using plotting functionalities.
- `Visualizer` class: Integrates with Matplotlib and Seaborn to generate plots for model performance analysis and data visualization.
- `plot_confusion_matrix` method: Visualizes the confusion matrix.
- `plot_roc_curve` method: Plots the Receiver Operating Characteristic (ROC) curve.
- `plot_feature_importance` method: Visualizes feature importance for applicable algorithms.
11. Utility Functions:
- Functions for saving and loading trained models.
- Logging functionalities to track the model training and prediction processes.
- `save_model` method: Saves the trained model to a file.
- `load_model` method: Loads a previously trained model from a file.
- `set_logger` method: Configures logging functionality for tracking model training and prediction processes.
12. User-Friendly Interface: Provides a simplified and intuitive interface for users to interact with and apply classic AI algorithms without extensive knowledge or configuration.
13.. Error Handling: Incorporates mechanisms to handle invalid inputs, errors during training, and other potential issues during algorithm usage.
- Custom exception classes for handling specific errors and providing informative error messages to users.
14. Documentation: Comprehensive documentation to guide users on how to use Easylibpal effectively and efficiently
- Comprehensive documentation explaining the usage and functionality of each component.
- Example scripts demonstrating how to use Easylibpal for various AI tasks and datasets.
15. Testing Suite:
- Unit tests for each component to ensure code reliability and maintainability.
- Integration tests to verify the smooth interaction between different components.
IMPLEMENTATION EXAMPLE WITH ADDITIONAL FEATURES:
Here is an example of how the expanded Easylibpal library could be structured and used:
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from easylibpal import Easylibpal, DataLoader, Evaluator, Tuner
# Example DataLoader
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
# Example Evaluator
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = np.mean(predictions == y_test)
return {'accuracy': accuracy}
# Example usage of Easylibpal with DataLoader and Evaluator
if __name__ == "__main__":
# Load and prepare the data
data_loader = DataLoader()
data = data_loader.load_data('path/to/your/data.csv')
X = data.iloc[:, :-1]
y = data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Initialize Easylibpal with the desired algorithm
model = Easylibpal('Random Forest')
model.fit(X_train_scaled, y_train)
# Evaluate the model
evaluator = Evaluator()
results = evaluator.evaluate(model, X_test_scaled, y_test)
print(f"Model Accuracy: {results['accuracy']}")
# Optional: Use Tuner for hyperparameter optimization
tuner = Tuner(model, param_grid={'n_estimators': [100, 200], 'max_depth': [10, 20, 30]})
best_params = tuner.optimize(X_train_scaled, y_train)
print(f"Best Parameters: {best_params}")
```
This example demonstrates the structured approach to using Easylibpal with enhanced data handling, model evaluation, and optional hyperparameter tuning. The library empowers users to handle real-world datasets, apply various machine learning algorithms, and evaluate their performance with ease, making it an invaluable tool for developers and data scientists aiming to implement AI solutions efficiently.
Easylibpal is dedicated to making the latest AI technology accessible to everyone, regardless of their background or expertise. Our platform simplifies the process of selecting and implementing classic AI algorithms, enabling users across various industries to harness the power of artificial intelligence with ease. By democratizing access to AI, we aim to accelerate innovation and empower users to achieve their goals with confidence. Easylibpal's approach involves a democratization framework that reduces entry barriers, lowers the cost of building AI solutions, and speeds up the adoption of AI in both academic and business settings.
Below are examples showcasing how each main component of the Easylibpal library could be implemented and used in practice to provide a user-friendly interface for utilizing classic AI algorithms.
1. Core Components
Easylibpal Class Example:
```python
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
self.model = None
def fit(self, X, y):
# Simplified example: Instantiate and train a model based on the selected algorithm
if self.algorithm == 'Linear Regression':
from sklearn.linear_model import LinearRegression
self.model = LinearRegression()
elif self.algorithm == 'Random Forest':
from sklearn.ensemble import RandomForestClassifier
self.model = RandomForestClassifier()
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
```
2. Data Handling
DataLoader Class Example:
```python
class DataLoader:
def load_data(self, filepath, file_type='csv'):
if file_type == 'csv':
import pandas as pd
return pd.read_csv(filepath)
else:
raise ValueError("Unsupported file type provided.")
```
3. Model Evaluation
Evaluator Class Example:
```python
from sklearn.metrics import accuracy_score, classification_report
class Evaluator:
def evaluate(self, model, X_test, y_test):
predictions = model.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
report = classification_report(y_test, predictions)
return {'accuracy': accuracy, 'report': report}
```
4. Hyperparameter Tuning
Tuner Class Example:
```python
from sklearn.model_selection import GridSearchCV
class Tuner:
def __init__(self, model, param_grid):
self.model = model
self.param_grid = param_grid
def optimize(self, X, y):
grid_search = GridSearchCV(self.model, self.param_grid, cv=5)
grid_search.fit(X, y)
return grid_search.best_params_
```
5. Visualization
Visualizer Class Example:
```python
import matplotlib.pyplot as plt
class Visualizer:
def plot_confusion_matrix(self, cm, classes, normalize=False, title='Confusion matrix'):
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
```
6. Utility Functions
Save and Load Model Example:
```python
import joblib
def save_model(model, filename):
joblib.dump(model, filename)
def load_model(filename):
return joblib.load(filename)
```
7. Example Usage Script
Using Easylibpal in a Script:
```python
# Assuming Easylibpal and other classes have been imported
data_loader = DataLoader()
data = data_loader.load_data('data.csv')
X = data.drop('Target', axis=1)
y = data['Target']
model = Easylibpal('Random Forest')
model.fit(X, y)
evaluator = Evaluator()
results = evaluator.evaluate(model, X, y)
print("Accuracy:", results['accuracy'])
print("Report:", results['report'])
visualizer = Visualizer()
visualizer.plot_confusion_matrix(results['cm'], classes=['Class1', 'Class2'])
save_model(model, 'trained_model.pkl')
loaded_model = load_model('trained_model.pkl')
```
These examples illustrate the practical implementation and use of the Easylibpal library components, aiming to simplify the application of AI algorithms for users with varying levels of expertise in machine learning.
EASYLIBPAL IMPLEMENTATION:
Step 1: Define the Problem
First, we need to define the problem we want to solve. For this POC, let's assume we want to predict house prices based on various features like the number of bedrooms, square footage, and location.
Step 2: Choose an Appropriate Algorithm
Given our problem, a supervised learning algorithm like linear regression would be suitable. We'll use Scikit-learn, a popular library for machine learning in Python, to implement this algorithm.
Step 3: Prepare Your Data
We'll use Pandas to load and prepare our dataset. This involves cleaning the data, handling missing values, and splitting the dataset into training and testing sets.
Step 4: Implement the Algorithm
Now, we'll use Scikit-learn to implement the linear regression algorithm. We'll train the model on our training data and then test its performance on the testing data.
Step 5: Evaluate the Model
Finally, we'll evaluate the performance of our model using metrics like Mean Squared Error (MSE) and R-squared.
Python Code POC
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load the dataset
data = pd.read_csv('house_prices.csv')
# Prepare the data
X = data'bedrooms', 'square_footage', 'location'
y = data['price']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Create and train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Make predictions
predictions = model.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, predictions)
r2 = r2_score(y_test, predictions)
print(f'Mean Squared Error: {mse}')
print(f'R-squared: {r2}')
```
Below is an implementation, Easylibpal provides a simple interface to instantiate and utilize classic AI algorithms such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. Users can easily create an instance of Easylibpal with their desired algorithm, fit the model with training data, and make predictions, all with minimal code and hassle. This demonstrates the power of Easylibpal in simplifying the integration of AI algorithms for various tasks.
```python
# Import necessary libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
class Easylibpal:
def __init__(self, algorithm):
self.algorithm = algorithm
def fit(self, X, y):
if self.algorithm == 'Linear Regression':
self.model = LinearRegression()
elif self.algorithm == 'Logistic Regression':
self.model = LogisticRegression()
elif self.algorithm == 'SVM':
self.model = SVC()
elif self.algorithm == 'Naive Bayes':
self.model = GaussianNB()
elif self.algorithm == 'K-NN':
self.model = KNeighborsClassifier()
else:
raise ValueError("Invalid algorithm specified.")
self.model.fit(X, y)
def predict(self, X):
return self.model.predict(X)
# Example usage:
# Initialize Easylibpal with the desired algorithm
easy_algo = Easylibpal('Linear Regression')
# Generate some sample data
X = np.array([[1], [2], [3], [4]])
y = np.array([2, 4, 6, 8])
# Fit the model
easy_algo.fit(X, y)
# Make predictions
predictions = easy_algo.predict(X)
# Plot the results
plt.scatter(X, y)
plt.plot(X, predictions, color='red')
plt.title('Linear Regression with Easylibpal')
plt.xlabel('X')
plt.ylabel('y')
plt.show()
```
Easylibpal is an innovative Python library designed to simplify the integration and use of classic AI algorithms in a user-friendly manner. It aims to bridge the gap between the complexity of AI libraries and the ease of use, making it accessible for developers and data scientists alike. Easylibpal abstracts the underlying complexity of each algorithm, providing a unified interface that allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms.
ENHANCED DATASET HANDLING
Easylibpal should be able to handle datasets more efficiently. This includes loading datasets from various sources (e.g., CSV files, databases), preprocessing data (e.g., normalization, handling missing values), and splitting data into training and testing sets.
```python
import os
from sklearn.model_selection import train_test_split
class Easylibpal:
# Existing code...
def load_dataset(self, filepath):
"""Loads a dataset from a CSV file."""
if not os.path.exists(filepath):
raise FileNotFoundError("Dataset file not found.")
return pd.read_csv(filepath)
def preprocess_data(self, dataset):
"""Preprocesses the dataset."""
# Implement data preprocessing steps here
return dataset
def split_data(self, X, y, test_size=0.2):
"""Splits the dataset into training and testing sets."""
return train_test_split(X, y, test_size=test_size)
```
Additional Algorithms
Easylibpal should support a wider range of algorithms. This includes decision trees, random forests, and gradient boosting machines.
```python
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
class Easylibpal:
# Existing code...
def fit(self, X, y):
# Existing code...
elif self.algorithm == 'Decision Tree':
self.model = DecisionTreeClassifier()
elif self.algorithm == 'Random Forest':
self.model = RandomForestClassifier()
elif self.algorithm == 'Gradient Boosting':
self.model = GradientBoostingClassifier()
# Add more algorithms as needed
```
User-Friendly Features
To make Easylibpal even more user-friendly, consider adding features like:
- Automatic hyperparameter tuning: Implementing a simple interface for hyperparameter tuning using GridSearchCV or RandomizedSearchCV.
- Model evaluation metrics: Providing easy access to common evaluation metrics like accuracy, precision, recall, and F1 score.
- Visualization tools: Adding methods for plotting model performance, confusion matrices, and feature importance.
```python
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import GridSearchCV
class Easylibpal:
# Existing code...
def evaluate_model(self, X_test, y_test):
"""Evaluates the model using accuracy and classification report."""
y_pred = self.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
def tune_hyperparameters(self, X, y, param_grid):
"""Tunes the model's hyperparameters using GridSearchCV."""
grid_search = GridSearchCV(self.model, param_grid, cv=5)
grid_search.fit(X, y)
self.model = grid_search.best_estimator_
```
Easylibpal leverages the power of Python and its rich ecosystem of AI and machine learning libraries, such as scikit-learn, to implement the classic algorithms. It provides a high-level API that abstracts the specifics of each algorithm, allowing users to focus on the problem at hand rather than the intricacies of the algorithm.
Python Code Snippets for Easylibpal
Below are Python code snippets demonstrating the use of Easylibpal with classic AI algorithms. Each snippet demonstrates how to use Easylibpal to apply a specific algorithm to a dataset.
# Linear Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Linear Regression
result = Easylibpal.apply_algorithm('linear_regression', target_column='target')
# Print the result
print(result)
```
# Logistic Regression
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Logistic Regression
result = Easylibpal.apply_algorithm('logistic_regression', target_column='target')
# Print the result
print(result)
```
# Support Vector Machines (SVM)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply SVM
result = Easylibpal.apply_algorithm('svm', target_column='target')
# Print the result
print(result)
```
# Naive Bayes
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply Naive Bayes
result = Easylibpal.apply_algorithm('naive_bayes', target_column='target')
# Print the result
print(result)
```
# K-Nearest Neighbors (K-NN)
```python
from Easylibpal import Easylibpal
# Initialize Easylibpal with a dataset
Easylibpal = Easylibpal(dataset='your_dataset.csv')
# Apply K-NN
result = Easylibpal.apply_algorithm('knn', target_column='target')
# Print the result
print(result)
```
ABSTRACTION AND ESSENTIAL COMPLEXITY
- Essential Complexity: This refers to the inherent complexity of the problem domain, which cannot be reduced regardless of the programming language or framework used. It includes the logic and algorithm needed to solve the problem. For example, the essential complexity of sorting a list remains the same across different programming languages.
- Accidental Complexity: This is the complexity introduced by the choice of programming language, framework, or libraries. It can be reduced or eliminated through abstraction. For instance, using a high-level API in Python can hide the complexity of lower-level operations, making the code more readable and maintainable.
HOW EASYLIBPAL ABSTRACTS COMPLEXITY
Easylibpal aims to reduce accidental complexity by providing a high-level API that encapsulates the details of each classic AI algorithm. This abstraction allows users to apply these algorithms without needing to understand the underlying mechanisms or the specifics of the algorithm's implementation.
- Simplified Interface: Easylibpal offers a unified interface for applying various algorithms, such as Linear Regression, Logistic Regression, SVM, Naive Bayes, and K-NN. This interface abstracts the complexity of each algorithm, making it easier for users to apply them to their datasets.
- Runtime Fusion: By evaluating sub-expressions and sharing them across multiple terms, Easylibpal can optimize the execution of algorithms. This approach, similar to runtime fusion in abstract algorithms, allows for efficient computation without duplicating work, thereby reducing the computational complexity.
- Focus on Essential Complexity: While Easylibpal abstracts away the accidental complexity; it ensures that the essential complexity of the problem domain remains at the forefront. This means that while the implementation details are hidden, the core logic and algorithmic approach are still accessible and understandable to the user.
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of classic AI algorithms by providing a simplified interface that hides the intricacies of each algorithm's implementation. This abstraction allows users to apply these algorithms with minimal configuration and understanding of the underlying mechanisms. Here are examples of specific algorithms that Easylibpal abstracts:
To implement Easylibpal, one would need to create a Python class that encapsulates the functionality of each classic AI algorithm. This class would provide methods for loading datasets, preprocessing data, and applying the algorithm with minimal configuration required from the user. The implementation would leverage existing libraries like scikit-learn for the actual algorithmic computations, abstracting away the complexity of these libraries.
Here's a conceptual example of how the Easylibpal class might be structured for applying a Linear Regression algorithm:
```python
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Abstracted implementation of Linear Regression
# This method would internally use scikit-learn or another library
# to perform the actual computation, abstracting the complexity
pass
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
result = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates the concept of Easylibpal by abstracting the complexity of applying a Linear Regression algorithm. The actual implementation would need to include the specifics of loading the dataset, preprocessing it, and applying the algorithm using an underlying library like scikit-learn.
Easylibpal abstracts the complexity of feature selection for classic AI algorithms by providing a simplified interface that automates the process of selecting the most relevant features for each algorithm. This abstraction is crucial because feature selection is a critical step in machine learning that can significantly impact the performance of a model. Here's how Easylibpal handles feature selection for the mentioned algorithms:
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest` or `RFE` classes for feature selection based on statistical tests or model coefficients. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Linear Regression:
```python
from sklearn.feature_selection import SelectKBest, f_regression
from sklearn.linear_model import LinearRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_linear_regression(self, target_column):
# Feature selection using SelectKBest
selector = SelectKBest(score_func=f_regression, k=10)
X_new = selector.fit_transform(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Linear Regression model
model = LinearRegression()
model.fit(X_new, self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_linear_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Linear Regression by using scikit-learn's `SelectKBest` to select the top 10 features based on their statistical significance in predicting the target variable. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
To implement feature selection in Easylibpal, one could use scikit-learn's `SelectKBest`, `RFE`, or other feature selection classes based on the algorithm's requirements. Here's a conceptual example of how feature selection might be integrated into the Easylibpal class for Logistic Regression using RFE:
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def apply_logistic_regression(self, target_column):
# Feature selection using RFE
model = LogisticRegression()
rfe = RFE(model, n_features_to_select=10)
rfe.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Train Logistic Regression model
model.fit(self.dataset.drop(target_column, axis=1), self.dataset[target_column])
# Return the trained model
return model
# Usage
Easylibpal = Easylibpal(dataset='your_dataset.csv')
model = Easylibpal.apply_logistic_regression(target_column='target')
```
This example demonstrates how Easylibpal abstracts the complexity of feature selection for Logistic Regression by using scikit-learn's `RFE` to select the top 10 features based on their importance in the model. The actual implementation would need to adapt this approach for each algorithm, considering the specific characteristics and requirements of each algorithm.
EASYLIBPAL HANDLES DIFFERENT TYPES OF DATASETS
Easylibpal handles different types of datasets with varying structures by adopting a flexible and adaptable approach to data preprocessing and transformation. This approach is inspired by the principles of tidy data and the need to ensure data is in a consistent, usable format before applying AI algorithms. Here's how Easylibpal addresses the challenges posed by varying dataset structures:
One Type in Multiple Tables
When datasets contain different variables, the same variables with different names, different file formats, or different conventions for missing values, Easylibpal employs a process similar to tidying data. This involves identifying and standardizing the structure of each dataset, ensuring that each variable is consistently named and formatted across datasets. This process might include renaming columns, converting data types, and handling missing values in a uniform manner. For datasets stored in different file formats, Easylibpal would use appropriate libraries (e.g., pandas for CSV, Excel files, and SQL databases) to load and preprocess the data before applying the algorithms.
Multiple Types in One Table
For datasets that involve values collected at multiple levels or on different types of observational units, Easylibpal applies a normalization process. This involves breaking down the dataset into multiple tables, each representing a distinct type of observational unit. For example, if a dataset contains information about songs and their rankings over time, Easylibpal would separate this into two tables: one for song details and another for rankings. This normalization ensures that each fact is expressed in only one place, reducing inconsistencies and making the data more manageable for analysis.
Data Semantics
Easylibpal ensures that the data is organized in a way that aligns with the principles of data semantics, where every value belongs to a variable and an observation. This organization is crucial for the algorithms to interpret the data correctly. Easylibpal might use functions like `pivot_longer` and `pivot_wider` from the tidyverse or equivalent functions in pandas to reshape the data into a long format, where each row represents a single observation and each column represents a single variable. This format is particularly useful for algorithms that require a consistent structure for input data.
Messy Data
Dealing with messy data, which can include inconsistent data types, missing values, and outliers, is a common challenge in data science. Easylibpal addresses this by implementing robust data cleaning and preprocessing steps. This includes handling missing values (e.g., imputation or deletion), converting data types to ensure consistency, and identifying and removing outliers. These steps are crucial for preparing the data in a format that is suitable for the algorithms, ensuring that the algorithms can effectively learn from the data without being hindered by its inconsistencies.
To implement these principles in Python, Easylibpal would leverage libraries like pandas for data manipulation and preprocessing. Here's a conceptual example of how Easylibpal might handle a dataset with multiple types in one table:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Normalize the dataset by separating it into two tables
song_table = dataset'artist', 'track'.drop_duplicates().reset_index(drop=True)
song_table['song_id'] = range(1, len(song_table) + 1)
ranking_table = dataset'artist', 'track', 'week', 'rank'.drop_duplicates().reset_index(drop=True)
# Now, song_table and ranking_table can be used separately for analysis
```
This example demonstrates how Easylibpal might normalize a dataset with multiple types of observational units into separate tables, ensuring that each type of observational unit is stored in its own table. The actual implementation would need to adapt this approach based on the specific structure and requirements of the dataset being processed.
CLEAN DATA
Easylibpal employs a comprehensive set of data cleaning and preprocessing steps to handle messy data, ensuring that the data is in a suitable format for machine learning algorithms. These steps are crucial for improving the accuracy and reliability of the models, as well as preventing misleading results and conclusions. Here's a detailed look at the specific steps Easylibpal might employ:
1. Remove Irrelevant Data
The first step involves identifying and removing data that is not relevant to the analysis or modeling task at hand. This could include columns or rows that do not contribute to the predictive power of the model or are not necessary for the analysis .
2. Deduplicate Data
Deduplication is the process of removing duplicate entries from the dataset. Duplicates can skew the analysis and lead to incorrect conclusions. Easylibpal would use appropriate methods to identify and remove duplicates, ensuring that each entry in the dataset is unique.
3. Fix Structural Errors
Structural errors in the dataset, such as inconsistent data types, incorrect values, or formatting issues, can significantly impact the performance of machine learning algorithms. Easylibpal would employ data cleaning techniques to correct these errors, ensuring that the data is consistent and correctly formatted.
4. Deal with Missing Data
Handling missing data is a common challenge in data preprocessing. Easylibpal might use techniques such as imputation (filling missing values with statistical estimates like mean, median, or mode) or deletion (removing rows or columns with missing values) to address this issue. The choice of method depends on the nature of the data and the specific requirements of the analysis.
5. Filter Out Data Outliers
Outliers can significantly affect the performance of machine learning models. Easylibpal would use statistical methods to identify and filter out outliers, ensuring that the data is more representative of the population being analyzed.
6. Validate Data
The final step involves validating the cleaned and preprocessed data to ensure its quality and accuracy. This could include checking for consistency, verifying the correctness of the data, and ensuring that the data meets the requirements of the machine learning algorithms. Easylibpal would employ validation techniques to confirm that the data is ready for analysis.
To implement these data cleaning and preprocessing steps in Python, Easylibpal would leverage libraries like pandas and scikit-learn. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Remove irrelevant data
self.dataset = self.dataset.drop(['irrelevant_column'], axis=1)
# Deduplicate data
self.dataset = self.dataset.drop_duplicates()
# Fix structural errors (example: correct data type)
self.dataset['correct_data_type_column'] = self.dataset['correct_data_type_column'].astype(float)
# Deal with missing data (example: imputation)
imputer = SimpleImputer(strategy='mean')
self.dataset['missing_data_column'] = imputer.fit_transform(self.dataset'missing_data_column')
# Filter out data outliers (example: using Z-score)
# This step requires a more detailed implementation based on the specific dataset
# Validate data (example: checking for NaN values)
assert not self.dataset.isnull().values.any(), "Data still contains NaN values"
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to data cleaning and preprocessing within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
VALUE DATA
Easylibpal determines which data is irrelevant and can be removed through a combination of domain knowledge, data analysis, and automated techniques. The process involves identifying data that does not contribute to the analysis, research, or goals of the project, and removing it to improve the quality, efficiency, and clarity of the data. Here's how Easylibpal might approach this:
Domain Knowledge
Easylibpal leverages domain knowledge to identify data that is not relevant to the specific goals of the analysis or modeling task. This could include data that is out of scope, outdated, duplicated, or erroneous. By understanding the context and objectives of the project, Easylibpal can systematically exclude data that does not add value to the analysis.
Data Analysis
Easylibpal employs data analysis techniques to identify irrelevant data. This involves examining the dataset to understand the relationships between variables, the distribution of data, and the presence of outliers or anomalies. Data that does not have a significant impact on the predictive power of the model or the insights derived from the analysis is considered irrelevant.
Automated Techniques
Easylibpal uses automated tools and methods to remove irrelevant data. This includes filtering techniques to select or exclude certain rows or columns based on criteria or conditions, aggregating data to reduce its complexity, and deduplicating to remove duplicate entries. Tools like Excel, Google Sheets, Tableau, Power BI, OpenRefine, Python, R, Data Linter, Data Cleaner, and Data Wrangler can be employed for these purposes .
Examples of Irrelevant Data
- Personal Identifiable Information (PII): Data such as names, addresses, and phone numbers are irrelevant for most analytical purposes and should be removed to protect privacy and comply with data protection regulations .
- URLs and HTML Tags: These are typically not relevant to the analysis and can be removed to clean up the dataset.
- Boilerplate Text: Excessive blank space or boilerplate text (e.g., in emails) adds noise to the data and can be removed.
- Tracking Codes: These are used for tracking user interactions and do not contribute to the analysis.
To implement these steps in Python, Easylibpal might use pandas for data manipulation and filtering. Here's a conceptual example of how to remove irrelevant data:
```python
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Remove irrelevant columns (example: email addresses)
dataset = dataset.drop(['email_address'], axis=1)
# Remove rows with missing values (example: if a column is required for analysis)
dataset = dataset.dropna(subset=['required_column'])
# Deduplicate data
dataset = dataset.drop_duplicates()
# Return the cleaned dataset
cleaned_dataset = dataset
```
This example demonstrates how Easylibpal might remove irrelevant data from a dataset using Python and pandas. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Detecting Inconsistencies
Easylibpal starts by detecting inconsistencies in the data. This involves identifying discrepancies in data types, missing values, duplicates, and formatting errors. By detecting these inconsistencies, Easylibpal can take targeted actions to address them.
Handling Formatting Errors
Formatting errors, such as inconsistent data types for the same feature, can significantly impact the analysis. Easylibpal uses functions like `astype()` in pandas to convert data types, ensuring uniformity and consistency across the dataset. This step is crucial for preparing the data for analysis, as it ensures that each feature is in the correct format expected by the algorithms.
Handling Missing Values
Missing values are a common issue in datasets. Easylibpal addresses this by consulting with subject matter experts to understand why data might be missing. If the missing data is missing completely at random, Easylibpal might choose to drop it. However, for other cases, Easylibpal might employ imputation techniques to fill in missing values, ensuring that the dataset is complete and ready for analysis.
Handling Duplicates
Duplicate entries can skew the analysis and lead to incorrect conclusions. Easylibpal uses pandas to identify and remove duplicates, ensuring that each entry in the dataset is unique. This step is crucial for maintaining the integrity of the data and ensuring that the analysis is based on distinct observations.
Handling Inconsistent Values
Inconsistent values, such as different representations of the same concept (e.g., "yes" vs. "y" for a binary variable), can also pose challenges. Easylibpal employs data cleaning techniques to standardize these values, ensuring that the data is consistent and can be accurately analyzed.
To implement these steps in Python, Easylibpal would leverage pandas for data manipulation and preprocessing. Here's a conceptual example of how these steps might be integrated into the Easylibpal class:
```python
import pandas as pd
class Easylibpal:
def __init__(self, dataset):
self.dataset = dataset
# Load and preprocess the dataset
def clean_and_preprocess(self):
# Detect inconsistencies (example: check data types)
print(self.dataset.dtypes)
# Handle formatting errors (example: convert data types)
self.dataset['date_column'] = pd.to_datetime(self.dataset['date_column'])
# Handle missing values (example: drop rows with missing values)
self.dataset = self.dataset.dropna(subset=['required_column'])
# Handle duplicates (example: drop duplicates)
self.dataset = self.dataset.drop_duplicates()
# Handle inconsistent values (example: standardize values)
self.dataset['binary_column'] = self.dataset['binary_column'].map({'yes': 1, 'no': 0})
# Return the cleaned and preprocessed dataset
return self.dataset
# Usage
Easylibpal = Easylibpal(dataset=pd.read_csv('your_dataset.csv'))
cleaned_dataset = Easylibpal.clean_and_preprocess()
```
This example demonstrates a simplified approach to handling inconsistent or messy data within Easylibpal. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Statistical Imputation
Statistical imputation involves replacing missing values with statistical estimates such as the mean, median, or mode of the available data. This method is straightforward and can be effective for numerical data. For categorical data, mode imputation is commonly used. The choice of imputation method depends on the distribution of the data and the nature of the missing values.
Model-Based Imputation
Model-based imputation uses machine learning models to predict missing values. This approach can be more sophisticated and potentially more accurate than statistical imputation, especially for complex datasets. Techniques like K-Nearest Neighbors (KNN) imputation can be used, where the missing values are replaced with the values of the K nearest neighbors in the feature space.
Using SimpleImputer in scikit-learn
The scikit-learn library provides the `SimpleImputer` class, which supports both statistical and model-based imputation. `SimpleImputer` can be used to replace missing values with the mean, median, or most frequent value (mode) of the column. It also supports more advanced imputation methods like KNN imputation.
To implement these imputation techniques in Python, Easylibpal might use the `SimpleImputer` class from scikit-learn. Here's an example of how to use `SimpleImputer` for statistical imputation:
```python
from sklearn.impute import SimpleImputer
import pandas as pd
# Load the dataset
dataset = pd.read_csv('your_dataset.csv')
# Initialize SimpleImputer for numerical columns
num_imputer = SimpleImputer(strategy='mean')
# Fit and transform the numerical columns
dataset'numerical_column1', 'numerical_column2' = num_imputer.fit_transform(dataset'numerical_column1', 'numerical_column2')
# Initialize SimpleImputer for categorical columns
cat_imputer = SimpleImputer(strategy='most_frequent')
# Fit and transform the categorical columns
dataset'categorical_column1', 'categorical_column2' = cat_imputer.fit_transform(dataset'categorical_column1', 'categorical_column2')
# The dataset now has missing values imputed
```
This example demonstrates how to use `SimpleImputer` to fill in missing values in both numerical and categorical columns of a dataset. The actual implementation would need to adapt these steps based on the specific characteristics and requirements of the dataset being processed.
Model-based imputation techniques, such as Multiple Imputation by Chained Equations (MICE), offer powerful ways to handle missing data by using statistical models to predict missing values. However, these techniques come with their own set of limitations and potential drawbacks:
1. Complexity and Computational Cost
Model-based imputation methods can be computationally intensive, especially for large datasets or complex models. This can lead to longer processing times and increased computational resources required for imputation.
2. Overfitting and Convergence Issues
These methods are prone to overfitting, where the imputation model captures noise in the data rather than the underlying pattern. Overfitting can lead to imputed values that are too closely aligned with the observed data, potentially introducing bias into the analysis. Additionally, convergence issues may arise, where the imputation process does not settle on a stable solution.
3. Assumptions About Missing Data
Model-based imputation techniques often assume that the data is missing at random (MAR), which means that the probability of a value being missing is not related to the values of other variables. However, this assumption may not hold true in all cases, leading to biased imputations if the data is missing not at random (MNAR).
4. Need for Suitable Regression Models
For each variable with missing values, a suitable regression model must be chosen. Selecting the wrong model can lead to inaccurate imputations. The choice of model depends on the nature of the data and the relationship between the variable with missing values and other variables.
5. Combining Imputed Datasets
After imputing missing values, there is a challenge in combining the multiple imputed datasets to produce a single, final dataset. This requires careful consideration of how to aggregate the imputed values and can introduce additional complexity and uncertainty into the analysis.
6. Lack of Transparency
The process of model-based imputation can be less transparent than simpler imputation methods, such as mean or median imputation. This can make it harder to justify the imputation process, especially in contexts where the reasons for missing data are important, such as in healthcare research.
Despite these limitations, model-based imputation techniques can be highly effective for handling missing data in datasets where a amusingness is MAR and where the relationships between variables are complex. Careful consideration of the assumptions, the choice of models, and the methods for combining imputed datasets are crucial to mitigate these drawbacks and ensure the validity of the imputation process.
USING EASYLIBPAL FOR AI ALGORITHM INTEGRATION OFFERS SEVERAL SIGNIFICANT BENEFITS, PARTICULARLY IN ENHANCING EVERYDAY LIFE AND REVOLUTIONIZING VARIOUS SECTORS. HERE'S A DETAILED LOOK AT THE ADVANTAGES:
1. Enhanced Communication: AI, through Easylibpal, can significantly improve communication by categorizing messages, prioritizing inboxes, and providing instant customer support through chatbots. This ensures that critical information is not missed and that customer queries are resolved promptly.
2. Creative Endeavors: Beyond mundane tasks, AI can also contribute to creative endeavors. For instance, photo editing applications can use AI algorithms to enhance images, suggesting edits that align with aesthetic preferences. Music composition tools can generate melodies based on user input, inspiring musicians and amateurs alike to explore new artistic horizons. These innovations empower individuals to express themselves creatively with AI as a collaborative partner.
3. Daily Life Enhancement: AI, integrated through Easylibpal, has the potential to enhance daily life exponentially. Smart homes equipped with AI-driven systems can adjust lighting, temperature, and security settings according to user preferences. Autonomous vehicles promise safer and more efficient commuting experiences. Predictive analytics can optimize supply chains, reducing waste and ensuring goods reach users when needed.
4. Paradigm Shift in Technology Interaction: The integration of AI into our daily lives is not just a trend; it's a paradigm shift that's redefining how we interact with technology. By streamlining routine tasks, personalizing experiences, revolutionizing healthcare, enhancing communication, and fueling creativity, AI is opening doors to a more convenient, efficient, and tailored existence.
5. Responsible Benefit Harnessing: As we embrace AI's transformational power, it's essential to approach its integration with a sense of responsibility, ensuring that its benefits are harnessed for the betterment of society as a whole. This approach aligns with the ethical considerations of using AI, emphasizing the importance of using AI in a way that benefits all stakeholders.
In summary, Easylibpal facilitates the integration and use of AI algorithms in a manner that is accessible and beneficial across various domains, from enhancing communication and creative endeavors to revolutionizing daily life and promoting a paradigm shift in technology interaction. This integration not only streamlines the application of AI but also ensures that its benefits are harnessed responsibly for the betterment of society.
USING EASYLIBPAL OVER TRADITIONAL AI LIBRARIES OFFERS SEVERAL BENEFITS, PARTICULARLY IN TERMS OF EASE OF USE, EFFICIENCY, AND THE ABILITY TO APPLY AI ALGORITHMS WITH MINIMAL CONFIGURATION. HERE ARE THE KEY ADVANTAGES:
- Simplified Integration: Easylibpal abstracts the complexity of traditional AI libraries, making it easier for users to integrate classic AI algorithms into their projects. This simplification reduces the learning curve and allows developers and data scientists to focus on their core tasks without getting bogged down by the intricacies of AI implementation.
- User-Friendly Interface: By providing a unified platform for various AI algorithms, Easylibpal offers a user-friendly interface that streamlines the process of selecting and applying algorithms. This interface is designed to be intuitive and accessible, enabling users to experiment with different algorithms with minimal effort.
- Enhanced Productivity: The ability to effortlessly instantiate algorithms, fit models with training data, and make predictions with minimal configuration significantly enhances productivity. This efficiency allows for rapid prototyping and deployment of AI solutions, enabling users to bring their ideas to life more quickly.
- Democratization of AI: Easylibpal democratizes access to classic AI algorithms, making them accessible to a wider range of users, including those with limited programming experience. This democratization empowers users to leverage AI in various domains, fostering innovation and creativity.
- Automation of Repetitive Tasks: By automating the process of applying AI algorithms, Easylibpal helps users save time on repetitive tasks, allowing them to focus on more complex and creative aspects of their projects. This automation is particularly beneficial for users who may not have extensive experience with AI but still wish to incorporate AI capabilities into their work.
- Personalized Learning and Discovery: Easylibpal can be used to enhance personalized learning experiences and discovery mechanisms, similar to the benefits seen in academic libraries. By analyzing user behaviors and preferences, Easylibpal can tailor recommendations and resource suggestions to individual needs, fostering a more engaging and relevant learning journey.
- Data Management and Analysis: Easylibpal aids in managing large datasets efficiently and deriving meaningful insights from data. This capability is crucial in today's data-driven world, where the ability to analyze and interpret large volumes of data can significantly impact research outcomes and decision-making processes.
In summary, Easylibpal offers a simplified, user-friendly approach to applying classic AI algorithms, enhancing productivity, democratizing access to AI, and automating repetitive tasks. These benefits make Easylibpal a valuable tool for developers, data scientists, and users looking to leverage AI in their projects without the complexities associated with traditional AI libraries.
2 notes
·
View notes
Text
How AI models are transforming evidence-based predictions

AI is everywhere now. Every sector is taking the help of AI to make predictions. Through Machine Learning we can make computer to think like a human and do as a human. By combining various models there are new innovative ideas that are being produced. We can make new drugs and new way of treatments for patients. This way of treatment is giving right predictions with 95-100% of accuracy at most of the cases. This is now highly used in increasing the Longevity. Finding out the One can take care of their health at any conditions. Regular fitness is checked out. Alerts for the upcoming chances of dangerous diseases is predicted out correctly with AI models. It is not possible to make personalized healthcare for everyone at all the times. That’s why we need this new form of Healthcare Innovation to create a change. These models will maintain separate dataset analysis for each patient. With linear regression we can make the comparison with inputs and outputs and AI models will make the necessary predictions to make it to the output. The status of the patient is always traced correctly and always follows the health trends. People who want to make their bodies to reduce aging and go back to their fit form from any stage can opt for the AI predictive models. With deadliest viruses and life taking climate conditions, every second makes a count. In emergency conditions where we need to make the correct prediction within less time AI models will help a lot. These health predictions are the most helpful in the case of obesity, stroke, various types of cancer and HIV. Diseases which show immediate reaction on our bodies with very less symptoms to show are predicted with various measured biomarkers. These AI models can use various hundreds of markers to make the prediction right. Human of any age can start working on longevity and plan for further ages. The number of centenarians is increasing in the world. The biggest reason for this is increasing in technology. Because we are able to make the correct prediction regarding the health, we can tackle most dangerous diseases.
2 notes
·
View notes
Text
The Best Open-Source Tools for Data Science in 2025

Data science in 2025 is thriving, driven by a robust ecosystem of open-source tools that empower professionals to extract insights, build predictive models, and deploy data-driven solutions at scale. This year, the landscape is more dynamic than ever, with established favorites and emerging contenders shaping how data scientists work. Here’s an in-depth look at the best open-source tools that are defining data science in 2025.
1. Python: The Universal Language of Data Science
Python remains the cornerstone of data science. Its intuitive syntax, extensive libraries, and active community make it the go-to language for everything from data wrangling to deep learning. Libraries such as NumPy and Pandas streamline numerical computations and data manipulation, while scikit-learn is the gold standard for classical machine learning tasks.
NumPy: Efficient array operations and mathematical functions.
Pandas: Powerful data structures (DataFrames) for cleaning, transforming, and analyzing structured data.
scikit-learn: Comprehensive suite for classification, regression, clustering, and model evaluation.
Python’s popularity is reflected in the 2025 Stack Overflow Developer Survey, with 53% of developers using it for data projects.
2. R and RStudio: Statistical Powerhouses
R continues to shine in academia and industries where statistical rigor is paramount. The RStudio IDE enhances productivity with features for scripting, debugging, and visualization. R’s package ecosystem—especially tidyverse for data manipulation and ggplot2 for visualization—remains unmatched for statistical analysis and custom plotting.
Shiny: Build interactive web applications directly from R.
CRAN: Over 18,000 packages for every conceivable statistical need.
R is favored by 36% of users, especially for advanced analytics and research.
3. Jupyter Notebooks and JupyterLab: Interactive Exploration
Jupyter Notebooks are indispensable for prototyping, sharing, and documenting data science workflows. They support live code (Python, R, Julia, and more), visualizations, and narrative text in a single document. JupyterLab, the next-generation interface, offers enhanced collaboration and modularity.
Over 15 million notebooks hosted as of 2025, with 80% of data analysts using them regularly.
4. Apache Spark: Big Data at Lightning Speed
As data volumes grow, Apache Spark stands out for its ability to process massive datasets rapidly, both in batch and real-time. Spark’s distributed architecture, support for SQL, machine learning (MLlib), and compatibility with Python, R, Scala, and Java make it a staple for big data analytics.
65% increase in Spark adoption since 2023, reflecting its scalability and performance.
5. TensorFlow and PyTorch: Deep Learning Titans
For machine learning and AI, TensorFlow and PyTorch dominate. Both offer flexible APIs for building and training neural networks, with strong community support and integration with cloud platforms.
TensorFlow: Preferred for production-grade models and scalability; used by over 33% of ML professionals.
PyTorch: Valued for its dynamic computation graph and ease of experimentation, especially in research settings.
6. Data Visualization: Plotly, D3.js, and Apache Superset
Effective data storytelling relies on compelling visualizations:
Plotly: Python-based, supports interactive and publication-quality charts; easy for both static and dynamic visualizations.
D3.js: JavaScript library for highly customizable, web-based visualizations; ideal for specialists seeking full control.
Apache Superset: Open-source dashboarding platform for interactive, scalable visual analytics; increasingly adopted for enterprise BI.
Tableau Public, though not fully open-source, is also popular for sharing interactive visualizations with a broad audience.
7. Pandas: The Data Wrangling Workhorse
Pandas remains the backbone of data manipulation in Python, powering up to 90% of data wrangling tasks. Its DataFrame structure simplifies complex operations, making it essential for cleaning, transforming, and analyzing large datasets.
8. Scikit-learn: Machine Learning Made Simple
scikit-learn is the default choice for classical machine learning. Its consistent API, extensive documentation, and wide range of algorithms make it ideal for tasks such as classification, regression, clustering, and model validation.
9. Apache Airflow: Workflow Orchestration
As data pipelines become more complex, Apache Airflow has emerged as the go-to tool for workflow automation and orchestration. Its user-friendly interface and scalability have driven a 35% surge in adoption among data engineers in the past year.
10. MLflow: Model Management and Experiment Tracking
MLflow streamlines the machine learning lifecycle, offering tools for experiment tracking, model packaging, and deployment. Over 60% of ML engineers use MLflow for its integration capabilities and ease of use in production environments.
11. Docker and Kubernetes: Reproducibility and Scalability
Containerization with Docker and orchestration via Kubernetes ensure that data science applications run consistently across environments. These tools are now standard for deploying models and scaling data-driven services in production.
12. Emerging Contenders: Streamlit and More
Streamlit: Rapidly build and deploy interactive data apps with minimal code, gaining popularity for internal dashboards and quick prototypes.
Redash: SQL-based visualization and dashboarding tool, ideal for teams needing quick insights from databases.
Kibana: Real-time data exploration and monitoring, especially for log analytics and anomaly detection.
Conclusion: The Open-Source Advantage in 2025
Open-source tools continue to drive innovation in data science, making advanced analytics accessible, scalable, and collaborative. Mastery of these tools is not just a technical advantage—it’s essential for staying competitive in a rapidly evolving field. Whether you’re a beginner or a seasoned professional, leveraging this ecosystem will unlock new possibilities and accelerate your journey from raw data to actionable insight.
The future of data science is open, and in 2025, these tools are your ticket to building smarter, faster, and more impactful solutions.
#python#r#rstudio#jupyternotebook#jupyterlab#apachespark#tensorflow#pytorch#plotly#d3js#apachesuperset#pandas#scikitlearn#apacheairflow#mlflow#docker#kubernetes#streamlit#redash#kibana#nschool academy#datascience
0 notes
Text
Who provides the best and cheapest thesis writing services?
✅ 1. All Homework Assignments
Best for: Full thesis writing support across subjects like Management, Nursing, Psychology, Education, and more Why it's the best + affordable:
Offers complete thesis services from topic selection to final proofreading
Experts hold Master's and PhD degrees
Strong in SPSS, R, STATA, Excel-based data analysis
Multiple revisions and plagiarism reports included
Transparent pricing and flexible packages for students
💡 Students often prefer it for its affordability and full support model. 📱 WhatsApp support: +971 50 161 8774
✅ 2. Programming Online Help
Best for: Technical and coding-heavy theses (AI, ML, Data Science, IT) Why it stands out:
Experts in Python, MATLAB, Java, R, and C++
Can handle implementation + academic writing
Clear code explanations, system architecture, and documentation
Very affordable for complex tech projects compared to big academic sites
💡 Great for students who want both a working project and thesis report at one place.
✅ 3. Statistic Homework Tutors
Best for: Research-heavy, statistical, and data-driven theses Why students love it:
Strong command of SPSS, STATA, R, SAS, Python
Clean hypothesis testing, regression, ANOVA, and model building
Ideal for Public Health, Finance, Economics, Sociology
Low-cost packages for research paper + data support
💡 Trusted by PhD students needing in-depth quantitative research help.
🧠 Why These 3 Are Better Than “Cheapest” Sites
While you’ll find many low-cost freelancers or random sites online, here’s why these three are better:
✅ Academic integrity: No AI or spun content
✅ Experienced experts: Actual subject specialists, not general writers
✅ Student-first pricing: They don’t overcharge or upsell unnecessarily
✅ Supportive process: Communicate directly, get drafts, ask for changes
🛑 Warning: Don’t Fall for Dirt-Cheap Offers
Be careful with:
Generic platforms offering “$5 per page”
Writers who won’t share samples
No communication, no revisions, no formatting
You might save a few bucks but risk failing your thesis.
✅ Final Verdict
If you're looking for the best and cheapest thesis writing services, choose a team that offers:
Quality + affordability
Academic understanding
Real support through WhatsApp or email
Revision guarantees
AllHomeworkAssignments, ProgrammingOnlineHelp, and StatisticHomeworkTutors check all these boxes — making them a safe and smart choice for students who want value, not just a price tag.
#thesis help#thesis assignment help#thesis homework help#thesis online experts#thesis support#thesis help online#best thesis writers#best thesis writing websites#best thesis programming
0 notes
Text
Adaptive Test Automation: The Future of Intelligent Software Testing

Introduction to Adaptive Test Automation
Adaptive test automation stands as a revolutionary approach in the world of software testing. It streamlines testing operations by using intelligent automation. ideyaLabs pioneers this movement by driving innovation that accelerates quality assurance. Fast-paced industries demand tools that adjust to changes, automate repetitive tasks, and reduce manual overhead.
Benefits of Adaptive Test Automation with ideyaLabs
Organizations experience faster releases and safer deployments. Adaptive test automation improves flexibility by recognizing changes in code and test environments. It evolves with growing business requirements. ideyaLabs crafts solutions that reduce time spent on regression testing and defect management. Test engineers focus on critical thinking and strategic analysis while automation processes repetitive tasks.
Key Features of Adaptive Test Automation
Adaptive test automation embraces dynamic test script generation. Systems react to code modifications without manual intervention. Automated frameworks handle diverse platforms and devices. Predictive analytics identify potential risks before failures occur. ideyaLabs integrates real-time monitoring and intelligent reporting for comprehensive visibility.
How ideyaLabs Implements Adaptive Test Automation
ideyaLabs employs AI-driven algorithms that update test cases in response to application changes. Scriptless automation tools empower teams with limited coding knowledge to create robust tests. Custom dashboards display live results and actionable insights. ideyaLabs ensures that testing adapts continuously, enabling organizations to catch issues earlier in the development process.
Challenges Addressed by Adaptive Test Automation
Traditional automation frameworks demand ongoing maintenance and frequent resource allocation. Adaptive test automation reduces this workload. ideyaLabs minimizes disruptions during application updates by automatically identifying impacted test cases. Clients notice fewer false negatives and lower operational costs.
Business Impact of Adaptive Test Automation
Enterprises strive for speed without compromising product quality. Adaptive frameworks enable near-instant feedback on new features. ideyaLabs delivers solutions that scale according to business needs. Teams achieve targeted release cycles and higher customer satisfaction.
Integrating Adaptive Test Automation in Agile and DevOps
Agile and DevOps workflows benefit from intelligent adaptation. ideyaLabs integrates adaptive test automation into CI/CD pipelines. Automated tests evolve alongside application features. Teams receive early validation, enhancing rapid development and deployment.
Real-World Examples: ideyaLabs in Action
ideyaLabs transforms manual testing environments into automated ecosystems. Clients gain measurable productivity improvements. Adaptive test automation reduces the risk of undetected bugs entering production. Organizations scale faster and increase test coverage across multiple product lines.
Future Trends in Adaptive Test Automation
The future demands highly responsive systems capable of learning from user behavior. Adaptive test automation will embrace more advanced AI and machine learning. ideyaLabs focuses on expanding the capabilities of self-healing scripts. Automated frameworks will require minimal manual intervention.
Best Practices for Implementing Adaptive Test Automation with ideyaLabs
Organizations start with a strategic roadmap. ideyaLabs recommends identifying business-critical processes and integrating adaptive automation step by step. Test data management and effective collaboration improve outcomes. Teams monitor results using customized analytics tools.
Conclusion: The Next Generation of Software Testing with ideyaLabs
Adaptive test automation signifies a new era in intelligent testing. ideyaLabs leads this transition by offering innovative, resilient frameworks. Businesses stay future-ready, deliver exceptional customer experiences, and maintain high software quality. The journey towards adaptive testing empowers organizations to thrive in competitive digital landscapes.
0 notes
Text
Skills You'll Master in an Artificial Intelligence Classroom Course in Bengaluru
Artificial Intelligence (AI) is revolutionizing industries across the globe, and Bengaluru, the Silicon Valley of India, is at the forefront of this transformation. As demand for skilled AI professionals continues to grow, enrolling in an Artificial Intelligence Classroom Course in Bengaluru can be a strategic move for both aspiring tech enthusiasts and working professionals.
This blog explores the critical skills you’ll develop in a classroom-based AI program in Bengaluru, helping you understand how such a course can empower your career in the AI-driven future.
Why Choose an Artificial Intelligence Classroom Course in Bengaluru?
Bengaluru is home to a thriving tech ecosystem with thousands of startups, MNCs, R&D centers, and innovation hubs. Opting for a classroom-based AI course in Bengaluru offers several advantages:
In-person mentorship from industry experts and certified trainers
Real-time doubt resolution and interactive learning environments
Access to AI-focused events, hackathons, and networking meetups
Hands-on projects with local companies or institutions for practical exposure
A classroom setting adds structure, discipline, and immediate feedback, which online formats often lack.
Core Skills You’ll Master in an Artificial Intelligence Classroom Course in Bengaluru
Let’s explore the most important skills you can expect to acquire during a comprehensive AI classroom course:
1. Python Programming for AI
Python is the backbone of AI development. Most Artificial Intelligence Classroom Courses in Bengaluru begin with a strong foundation in Python.
You’ll learn:
Python syntax, functions, and object-oriented programming
Data structures like lists, dictionaries, tuples, and sets
Libraries essential for AI: NumPy, Pandas, Matplotlib, Scikit-learn
Code optimization and debugging techniques
This foundational skill allows you to transition easily into more complex AI frameworks and data workflows.
2. Mathematics for AI and Machine Learning
Understanding the mathematical concepts behind AI models is essential. A good AI classroom course in Bengaluru will cover:
Linear algebra: vectors, matrices, eigenvalues
Probability and statistics: distributions, Bayes theorem, hypothesis testing
Calculus: derivatives, gradients, optimization
Discrete mathematics for logical reasoning and algorithm design
These mathematical foundations help you understand the internal workings of machine learning and deep learning models.
3. Data Preprocessing and Exploratory Data Analysis (EDA)
Before building models, you must work with data—cleaning, transforming, and visualizing it.
Skills you’ll develop:
Handling missing data and outliers
Data normalization and encoding techniques
Feature engineering and dimensionality reduction
Data visualization with Seaborn, Matplotlib, and Plotly
These skills are crucial in solving real-world business problems using AI.
4. Machine Learning Algorithms and Implementation
One of the core parts of any Artificial Intelligence Classroom Course in Bengaluru is mastering machine learning.
You will learn:
Supervised learning: Linear Regression, Logistic Regression, Decision Trees
Unsupervised learning: K-Means Clustering, PCA
Model evaluation: Precision, Recall, F1 Score, ROC-AUC
Cross-validation and hyperparameter tuning
By the end of this module, you’ll be able to build, train, and evaluate machine learning models on real datasets.
5. Deep Learning and Neural Networks
Deep learning is a critical AI skill, especially in areas like computer vision, NLP, and recommendation systems.
Topics covered:
Artificial Neural Networks (ANN) and their architecture
Activation functions, loss functions, and optimization techniques
Convolutional Neural Networks (CNN) for image processing
Recurrent Neural Networks (RNN) for sequence data
Using frameworks like TensorFlow and PyTorch
This hands-on module helps students build and deploy deep learning models in production
6. Natural Language Processing (NLP)
NLP is increasingly used in chatbots, voice assistants, and content generation.
In a classroom AI course in Bengaluru, you’ll gain:
Text cleaning and preprocessing (tokenization, stemming, lemmatization)
Sentiment analysis and topic modeling
Named Entity Recognition (NER)
Working with tools like NLTK, spaCy, and Hugging Face
Building chatbot and language translation systems
These skills prepare you for jobs in AI-driven communication and language platforms.
7. Computer Vision
AI’s ability to interpret visual data has applications in facial recognition, medical imaging, and autonomous vehicles.
Skills you’ll learn:
Image classification, object detection, and segmentation
Using OpenCV for computer vision tasks
CNN architectures like VGG, ResNet, and YOLO
Transfer learning for advanced image processing
Computer vision is an advanced AI field where hands-on learning adds immense value, and Bengaluru’s tech-driven ecosystem enhances your project exposure.
8. Model Deployment and MLOps Basics
Knowing how to build a model is half the journey; deploying it is the other half.
You’ll master:
Model packaging using Flask or FastAPI
API integration and cloud deployment
Version control with Git and GitHub
Introduction to CI/CD and containerization with Docker
This gives you the ability to take your AI projects from notebooks to live platforms.
9. Capstone Projects and Industry Exposure
Most Artificial Intelligence Classroom Courses in Bengaluru culminate in capstone projects that solve real-world problems.
You’ll work on:
Domain-specific AI projects (healthcare, finance, retail, etc.)
Team collaborations and hackathons
Presentations and peer reviews
Real-time feedback from mentors
Such exposure builds your portfolio and boosts employability in the AI job market.
10. Soft Skills and AI Ethics
Technical skills alone aren’t enough. A good AI course in Bengaluru also helps you build:
Critical thinking and problem-solving
Communication and teamwork
Awareness of bias, fairness, and transparency in AI
Responsible AI development practices
These skills make you a more well-rounded AI professional who can navigate technical and ethical challenges.
Benefits of Learning AI in Bengaluru’s Classroom Setting
Mentorship Access: Bengaluru’s AI mentors often have real industry experience from companies like Infosys, TCS, Accenture, and top startups.
Networking Opportunities: Classroom courses create peer learning environments, alumni networks, and connections to hiring partners.
Hands-On Labs: Physical infrastructure and lab access in a classroom setting support hands-on model building and experimentation.
Placement Assistance: Most top institutes in Bengaluru offer resume workshops, mock interviews, and direct placement support.
Final Thoughts
A well-structured Artificial Intelligence Classroom Course in Bengaluru offers more than just theoretical knowledge—it delivers practical, hands-on, and industry-relevant skills that can transform your career. From Python programming and machine learning to deep learning, NLP, and real-world deployment, you’ll master the full AI development lifecycle.
Bengaluru’s ecosystem of innovation, startups, and tech talent makes it the perfect place to start or advance your AI journey. If you’re serious about becoming an AI professional, investing in a classroom course here could be your smartest move.
Whether you're starting from scratch or looking to specialize, the skills you gain from an AI classroom course in Bengaluru can prepare you for roles such as Machine Learning Engineer, AI Developer, Data Scientist, Computer Vision Specialist, or NLP Engineer—positions that are not just in demand, but also high-paying and future-proof.
#Best Data Science Courses in Bengaluru#Artificial Intelligence Course in Bengaluru#Data Scientist Course in Bengaluru#Machine Learning Course in Bengaluru
0 notes