#Unstructured data management
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
80% of data is unstructured. Manage it like a pro!
Unstructured data is a diverse array of information that is not stored in a traditional database. This includes emails, images, videos, and more. While unstructured data can be a valuable asset for businesses, it can also pose a significant challenge if it is not managed effectively.
In this webinar, industry experts will share their insights on how to manage unstructured data like a pro. They will discuss:
The different types of unstructured data and the associated risks
Strategies for identifying, organizing, and extracting value from unstructured data
Best practices for data security and compliance
This webinar is for business leaders, data professionals, and anyone who wants to learn more about how to manage unstructured data like a pro.
Register for the webinar today!
#unstructureddata #manageunstructureddata #datasecurity #dataprivacy #datagovernance #datacompliance #dataanalytics #datavisualization #datascience #bigdata
#unstructured data#data management#data visualization#data analysis#datasecurity#data compliance#data privacy#big data
0 notes
Text
Maximize Efficiency with Volumes in Databricks Unity Catalog
With Databricks Unity Catalog's volumes feature, managing data has become a breeze. Regardless of the format or location, the organization can now effortlessly access and organize its data. This newfound simplicity and organization streamline data managem

View On WordPress
#Cloud#Data Analysis#Data management#Data Pipeline#Data types#Databricks#Databricks SQL#Databricks Unity catalog#DBFS#Delta Sharing#machine learning#Non-tabular Data#performance#Performance Optimization#Spark#SQL#SQL database#Tabular Data#Unity Catalog#Unstructured Data#Volumes in Databricks
0 notes
Note
I know this is something you'll probably address when/if you do a video about it, but any thoughts on Riot updating the Masque of the Black Rose skins on PBE? (Just announced, model/SFX updates coming to live next patch)
I know they've patched skins before, but I can't recall them ever doing it to an entire release crop. I'm glad they're trying to give people their money's worth, I guess, but I'm really not looking forward to the possibility of a "buy it now and hope it gets improved later" standard, like with the Sahn-Uzal gacha.
I've got a video coming up on the 3BSkyen channel later reacting to the changes. Although word of caution, it is over an hour long and full of unstructured Yapping™ - I'll probably do a short about it also a bit later.
But yeah it's... not usually a great sign when a company has to repeatedly patch its cosmetics due to bad feedback. It's a sign that the artists don't have the time and resources to do as many rounds of feedback and revisions as they'd usually do, I think, and that the company is pivoting to new priorities. Especially the battle pass skins have been shovelware slop, things which are there to fill a spot on a track rather than to have or express any interesting visual ideas.
Hopefully, the revisions are also a sign that someone internally at Riot has managed to put together an argument, or a set of data, that has convinced whatever C-suite jackass decides these things to allow them more time and resources to do better work.
75 notes
·
View notes
Text
SQL Fundamentals #1: SQL Data Definition
Last year in college , I had the opportunity to dive deep into SQL. The course was made even more exciting by an amazing instructor . Fast forward to today, and I regularly use SQL in my backend development work with PHP. Today, I felt the need to refresh my SQL knowledge a bit, and that's why I've put together three posts aimed at helping beginners grasp the fundamentals of SQL.
Understanding Relational Databases
Let's Begin with the Basics: What Is a Database?
Simply put, a database is like a digital warehouse where you store large amounts of data. When you work on projects that involve data, you need a place to keep that data organized and accessible, and that's where databases come into play.
Exploring Different Types of Databases
When it comes to databases, there are two primary types to consider: relational and non-relational.
Relational Databases: Structured Like Tables
Think of a relational database as a collection of neatly organized tables, somewhat like rows and columns in an Excel spreadsheet. Each table represents a specific type of information, and these tables are interconnected through shared attributes. It's similar to a well-organized library catalog where you can find books by author, title, or genre.
Key Points:
Tables with rows and columns.
Data is neatly structured, much like a library catalog.
You use a structured query language (SQL) to interact with it.
Ideal for handling structured data with complex relationships.
Non-Relational Databases: Flexibility in Containers
Now, imagine a non-relational database as a collection of flexible containers, more like bins or boxes. Each container holds data, but they don't have to adhere to a fixed format. It's like managing a diverse collection of items in various boxes without strict rules. This flexibility is incredibly useful when dealing with unstructured or rapidly changing data, like social media posts or sensor readings.
Key Points:
Data can be stored in diverse formats.
There's no rigid structure; adaptability is the name of the game.
Non-relational databases (often called NoSQL databases) are commonly used.
Ideal for handling unstructured or dynamic data.
Now, Let's Dive into SQL:

SQL is a :
Data Definition language ( what todays post is all about )
Data Manipulation language
Data Query language
Task: Building and Interacting with a Bookstore Database
Setting Up the Database
Our first step in creating a bookstore database is to establish it. You can achieve this with a straightforward SQL command:
CREATE DATABASE bookstoreDB;
SQL Data Definition
As the name suggests, this step is all about defining your tables. By the end of this phase, your database and the tables within it are created and ready for action.

1 - Introducing the 'Books' Table
A bookstore is all about its collection of books, so our 'bookstoreDB' needs a place to store them. We'll call this place the 'books' table. Here's how you create it:
CREATE TABLE books ( -- Don't worry, we'll fill this in soon! );
Now, each book has its own set of unique details, including titles, authors, genres, publication years, and prices. These details will become the columns in our 'books' table, ensuring that every book can be fully described.
Now that we have the plan, let's create our 'books' table with all these attributes:
CREATE TABLE books ( title VARCHAR(40), author VARCHAR(40), genre VARCHAR(40), publishedYear DATE, price INT(10) );
With this structure in place, our bookstore database is ready to house a world of books.
2 - Making Changes to the Table
Sometimes, you might need to modify a table you've created in your database. Whether it's correcting an error during table creation, renaming the table, or adding/removing columns, these changes are made using the 'ALTER TABLE' command.
For instance, if you want to rename your 'books' table:
ALTER TABLE books RENAME TO books_table;
If you want to add a new column:
ALTER TABLE books ADD COLUMN description VARCHAR(100);
Or, if you need to delete a column:
ALTER TABLE books DROP COLUMN title;
3 - Dropping the Table
Finally, if you ever want to remove a table you've created in your database, you can do so using the 'DROP TABLE' command:
DROP TABLE books;
To keep this post concise, our next post will delve into the second step, which involves data manipulation. Once our bookstore database is up and running with its tables, we'll explore how to modify and enrich it with new information and data. Stay tuned ...
Part2
#code#codeblr#java development company#python#studyblr#progblr#programming#comp sci#web design#web developers#web development#website design#webdev#website#tech#learn to code#sql#sqlserver#sql course#data#datascience#backend
112 notes
·
View notes
Text
Unlock the other 99% of your data - now ready for AI
New Post has been published on https://thedigitalinsider.com/unlock-the-other-99-of-your-data-now-ready-for-ai/
Unlock the other 99% of your data - now ready for AI
For decades, companies of all sizes have recognized that the data available to them holds significant value, for improving user and customer experiences and for developing strategic plans based on empirical evidence.
As AI becomes increasingly accessible and practical for real-world business applications, the potential value of available data has grown exponentially. Successfully adopting AI requires significant effort in data collection, curation, and preprocessing. Moreover, important aspects such as data governance, privacy, anonymization, regulatory compliance, and security must be addressed carefully from the outset.
In a conversation with Henrique Lemes, Americas Data Platform Leader at IBM, we explored the challenges enterprises face in implementing practical AI in a range of use cases. We began by examining the nature of data itself, its various types, and its role in enabling effective AI-powered applications.
Henrique highlighted that referring to all enterprise information simply as ‘data’ understates its complexity. The modern enterprise navigates a fragmented landscape of diverse data types and inconsistent quality, particularly between structured and unstructured sources.
In simple terms, structured data refers to information that is organized in a standardized and easily searchable format, one that enables efficient processing and analysis by software systems.
Unstructured data is information that does not follow a predefined format nor organizational model, making it more complex to process and analyze. Unlike structured data, it includes diverse formats like emails, social media posts, videos, images, documents, and audio files. While it lacks the clear organization of structured data, unstructured data holds valuable insights that, when effectively managed through advanced analytics and AI, can drive innovation and inform strategic business decisions.
Henrique stated, “Currently, less than 1% of enterprise data is utilized by generative AI, and over 90% of that data is unstructured, which directly affects trust and quality”.
The element of trust in terms of data is an important one. Decision-makers in an organization need firm belief (trust) that the information at their fingertips is complete, reliable, and properly obtained. But there is evidence that states less than half of data available to businesses is used for AI, with unstructured data often going ignored or sidelined due to the complexity of processing it and examining it for compliance – especially at scale.
To open the way to better decisions that are based on a fuller set of empirical data, the trickle of easily consumed information needs to be turned into a firehose. Automated ingestion is the answer in this respect, Henrique said, but the governance rules and data policies still must be applied – to unstructured and structured data alike.
Henrique set out the three processes that let enterprises leverage the inherent value of their data. “Firstly, ingestion at scale. It’s important to automate this process. Second, curation and data governance. And the third [is when] you make this available for generative AI. We achieve over 40% of ROI over any conventional RAG use-case.”
IBM provides a unified strategy, rooted in a deep understanding of the enterprise’s AI journey, combined with advanced software solutions and domain expertise. This enables organizations to efficiently and securely transform both structured and unstructured data into AI-ready assets, all within the boundaries of existing governance and compliance frameworks.
“We bring together the people, processes, and tools. It’s not inherently simple, but we simplify it by aligning all the essential resources,” he said.
As businesses scale and transform, the diversity and volume of their data increase. To keep up, AI data ingestion process must be both scalable and flexible.
“[Companies] encounter difficulties when scaling because their AI solutions were initially built for specific tasks. When they attempt to broaden their scope, they often aren’t ready, the data pipelines grow more complex, and managing unstructured data becomes essential. This drives an increased demand for effective data governance,” he said.
IBM’s approach is to thoroughly understand each client’s AI journey, creating a clear roadmap to achieve ROI through effective AI implementation. “We prioritize data accuracy, whether structured or unstructured, along with data ingestion, lineage, governance, compliance with industry-specific regulations, and the necessary observability. These capabilities enable our clients to scale across multiple use cases and fully capitalize on the value of their data,” Henrique said.
Like anything worthwhile in technology implementation, it takes time to put the right processes in place, gravitate to the right tools, and have the necessary vision of how any data solution might need to evolve.
IBM offers enterprises a range of options and tooling to enable AI workloads in even the most regulated industries, at any scale. With international banks, finance houses, and global multinationals among its client roster, there are few substitutes for Big Blue in this context.
To find out more about enabling data pipelines for AI that drive business and offer fast, significant ROI, head over to this page.
#ai#AI-powered#Americas#Analysis#Analytics#applications#approach#assets#audio#banks#Blue#Business#business applications#Companies#complexity#compliance#customer experiences#data#data collection#Data Governance#data ingestion#data pipelines#data platform#decision-makers#diversity#documents#emails#enterprise#Enterprises#finance
2 notes
·
View notes
Text
WHAT IS VERTEX AI SEARCH
Vertex AI Search: A Comprehensive Analysis
1. Executive Summary
Vertex AI Search emerges as a pivotal component of Google Cloud's artificial intelligence portfolio, offering enterprises the capability to deploy search experiences with the quality and sophistication characteristic of Google's own search technologies. This service is fundamentally designed to handle diverse data types, both structured and unstructured, and is increasingly distinguished by its deep integration with generative AI, most notably through its out-of-the-box Retrieval Augmented Generation (RAG) functionalities. This RAG capability is central to its value proposition, enabling organizations to ground large language model (LLM) responses in their proprietary data, thereby enhancing accuracy, reliability, and contextual relevance while mitigating the risk of generating factually incorrect information.
The platform's strengths are manifold, stemming from Google's decades of expertise in semantic search and natural language processing. Vertex AI Search simplifies the traditionally complex workflows associated with building RAG systems, including data ingestion, processing, embedding, and indexing. It offers specialized solutions tailored for key industries such as retail, media, and healthcare, addressing their unique vernacular and operational needs. Furthermore, its integration within the broader Vertex AI ecosystem, including access to advanced models like Gemini, positions it as a comprehensive solution for building sophisticated AI-driven applications.
However, the adoption of Vertex AI Search is not without its considerations. The pricing model, while granular and offering a "pay-as-you-go" approach, can be complex, necessitating careful cost modeling, particularly for features like generative AI and always-on components such as Vector Search index serving. User experiences and technical documentation also point to potential implementation hurdles for highly specific or advanced use cases, including complexities in IAM permission management and evolving query behaviors with platform updates. The rapid pace of innovation, while a strength, also requires organizations to remain adaptable.
Ultimately, Vertex AI Search represents a strategic asset for organizations aiming to unlock the value of their enterprise data through advanced search and AI. It provides a pathway to not only enhance information retrieval but also to build a new generation of AI-powered applications that are deeply informed by and integrated with an organization's unique knowledge base. Its continued evolution suggests a trajectory towards becoming a core reasoning engine for enterprise AI, extending beyond search to power more autonomous and intelligent systems.
2. Introduction to Vertex AI Search
Vertex AI Search is establishing itself as a significant offering within Google Cloud's AI capabilities, designed to transform how enterprises access and utilize their information. Its strategic placement within the Google Cloud ecosystem and its core value proposition address critical needs in the evolving landscape of enterprise data management and artificial intelligence.
Defining Vertex AI Search
Vertex AI Search is a service integrated into Google Cloud's Vertex AI Agent Builder. Its primary function is to equip developers with the tools to create secure, high-quality search experiences comparable to Google's own, tailored for a wide array of applications. These applications span public-facing websites, internal corporate intranets, and, significantly, serve as the foundation for Retrieval Augmented Generation (RAG) systems that power generative AI agents and applications. The service achieves this by amalgamating deep information retrieval techniques, advanced natural language processing (NLP), and the latest innovations in large language model (LLM) processing. This combination allows Vertex AI Search to more accurately understand user intent and deliver the most pertinent results, marking a departure from traditional keyword-based search towards more sophisticated semantic and conversational search paradigms.
Strategic Position within Google Cloud AI Ecosystem
The service is not a standalone product but a core element of Vertex AI, Google Cloud's comprehensive and unified machine learning platform. This integration is crucial, as Vertex AI Search leverages and interoperates with other Vertex AI tools and services. Notable among these are Document AI, which facilitates the processing and understanding of diverse document formats , and direct access to Google's powerful foundation models, including the multimodal Gemini family. Its incorporation within the Vertex AI Agent Builder further underscores Google's strategy to provide an end-to-end toolkit for constructing advanced AI agents and applications, where robust search and retrieval capabilities are fundamental.
Core Purpose and Value Proposition
The fundamental aim of Vertex AI Search is to empower enterprises to construct search applications of Google's caliber, operating over their own controlled datasets, which can encompass both structured and unstructured information. A central pillar of its value proposition is its capacity to function as an "out-of-the-box" RAG system. This feature is critical for grounding LLM responses in an enterprise's specific data, a process that significantly improves the accuracy, reliability, and contextual relevance of AI-generated content, thereby reducing the propensity for LLMs to produce "hallucinations" or factually incorrect statements. The simplification of the intricate workflows typically associated with RAG systems—including Extract, Transform, Load (ETL) processes, Optical Character Recognition (OCR), data chunking, embedding generation, and indexing—is a major attraction for businesses.
Moreover, Vertex AI Search extends its utility through specialized, pre-tuned offerings designed for specific industries such as retail (Vertex AI Search for Commerce), media and entertainment (Vertex AI Search for Media), and healthcare and life sciences. These tailored solutions are engineered to address the unique terminologies, data structures, and operational requirements prevalent in these sectors.
The pronounced emphasis on "out-of-the-box RAG" and the simplification of data processing pipelines points towards a deliberate strategy by Google to lower the entry barrier for enterprises seeking to leverage advanced Generative AI capabilities. Many organizations may lack the specialized AI talent or resources to build such systems from the ground up. Vertex AI Search offers a managed, pre-configured solution, effectively democratizing access to sophisticated RAG technology. By making these capabilities more accessible, Google is not merely selling a search product; it is positioning Vertex AI Search as a foundational layer for a new wave of enterprise AI applications. This approach encourages broader adoption of Generative AI within businesses by mitigating some inherent risks, like LLM hallucinations, and reducing technical complexities. This, in turn, is likely to drive increased consumption of other Google Cloud services, such as storage, compute, and LLM APIs, fostering a more integrated and potentially "sticky" ecosystem.
Furthermore, Vertex AI Search serves as a conduit between traditional enterprise search mechanisms and the frontier of advanced AI. It is built upon "Google's deep expertise and decades of experience in semantic search technologies" , while concurrently incorporating "the latest in large language model (LLM) processing" and "Gemini generative AI". This dual nature allows it to support conventional search use cases, such as website and intranet search , alongside cutting-edge AI applications like RAG for generative AI agents and conversational AI systems. This design provides an evolutionary pathway for enterprises. Organizations can commence by enhancing existing search functionalities and then progressively adopt more advanced AI features as their internal AI maturity and comfort levels grow. This adaptability makes Vertex AI Search an attractive proposition for a diverse range of customers with varying immediate needs and long-term AI ambitions. Such an approach enables Google to capture market share in both the established enterprise search market and the rapidly expanding generative AI application platform market. It offers a smoother transition for businesses, diminishing the perceived risk of adopting state-of-the-art AI by building upon familiar search paradigms, thereby future-proofing their investment.
3. Core Capabilities and Architecture
Vertex AI Search is engineered with a rich set of features and a flexible architecture designed to handle diverse enterprise data and power sophisticated search and AI applications. Its capabilities span from foundational search quality to advanced generative AI enablement, supported by robust data handling mechanisms and extensive customization options.
Key Features
Vertex AI Search integrates several core functionalities that define its power and versatility:
Google-Quality Search: At its heart, the service leverages Google's profound experience in semantic search technologies. This foundation aims to deliver highly relevant search results across a wide array of content types, moving beyond simple keyword matching to incorporate advanced natural language understanding (NLU) and contextual awareness.
Out-of-the-Box Retrieval Augmented Generation (RAG): A cornerstone feature is its ability to simplify the traditionally complex RAG pipeline. Processes such as ETL, OCR, document chunking, embedding generation, indexing, storage, information retrieval, and summarization are streamlined, often requiring just a few clicks to configure. This capability is paramount for grounding LLM responses in enterprise-specific data, which significantly enhances the trustworthiness and accuracy of generative AI applications.
Document Understanding: The service benefits from integration with Google's Document AI suite, enabling sophisticated processing of both structured and unstructured documents. This allows for the conversion of raw documents into actionable data, including capabilities like layout parsing and entity extraction.
Vector Search: Vertex AI Search incorporates powerful vector search technology, essential for modern embeddings-based applications. While it offers out-of-the-box embedding generation and automatic fine-tuning, it also provides flexibility for advanced users. They can utilize custom embeddings and gain direct control over the underlying vector database for specialized use cases such as recommendation engines and ad serving. Recent enhancements include the ability to create and deploy indexes without writing code, and a significant reduction in indexing latency for smaller datasets, from hours down to minutes. However, it's important to note user feedback regarding Vector Search, which has highlighted concerns about operational costs (e.g., the need to keep compute resources active even when not querying), limitations with certain file types (e.g., .xlsx), and constraints on embedding dimensions for specific corpus configurations. This suggests a balance to be struck between the power of Vector Search and its operational overhead and flexibility.
Generative AI Features: The platform is designed to enable grounded answers by synthesizing information from multiple sources. It also supports the development of conversational AI capabilities , often powered by advanced models like Google's Gemini.
Comprehensive APIs: For developers who require fine-grained control or are building bespoke RAG solutions, Vertex AI Search exposes a suite of APIs. These include APIs for the Document AI Layout Parser, ranking algorithms, grounded generation, and the check grounding API, which verifies the factual basis of generated text.
Data Handling
Effective data management is crucial for any search system. Vertex AI Search provides several mechanisms for ingesting, storing, and organizing data:
Supported Data Sources:
Websites: Content can be indexed by simply providing site URLs.
Structured Data: The platform supports data from BigQuery tables and NDJSON files, enabling hybrid search (a combination of keyword and semantic search) or recommendation systems. Common examples include product catalogs, movie databases, or professional directories.
Unstructured Data: Documents in various formats (PDF, DOCX, etc.) and images can be ingested for hybrid search. Use cases include searching through private repositories of research publications or financial reports. Notably, some limitations, such as lack of support for .xlsx files, have been reported specifically for Vector Search.
Healthcare Data: FHIR R4 formatted data, often imported from the Cloud Healthcare API, can be used to enable hybrid search over clinical data and patient records.
Media Data: A specialized structured data schema is available for the media industry, catering to content like videos, news articles, music tracks, and podcasts.
Third-party Data Sources: Vertex AI Search offers connectors (some in Preview) to synchronize data from various third-party applications, such as Jira, Confluence, and Salesforce, ensuring that search results reflect the latest information from these systems.
Data Stores and Apps: A fundamental architectural concept in Vertex AI Search is the one-to-one relationship between an "app" (which can be a search or a recommendations app) and a "data store". Data is imported into a specific data store, where it is subsequently indexed. The platform provides different types of data stores, each optimized for a particular kind of data (e.g., website content, structured data, unstructured documents, healthcare records, media assets).
Indexing and Corpus: The term "corpus" refers to the underlying storage and indexing mechanism within Vertex AI Search. Even when users interact with data stores, which act as an abstraction layer, the corpus is the foundational component where data is stored and processed. It is important to understand that costs are associated with the corpus, primarily driven by the volume of indexed data, the amount of storage consumed, and the number of queries processed.
Schema Definition: Users have the ability to define a schema that specifies which metadata fields from their documents should be indexed. This schema also helps in understanding the structure of the indexed documents.
Real-time Ingestion: For datasets that change frequently, Vertex AI Search supports real-time ingestion. This can be implemented using a Pub/Sub topic to publish notifications about new or updated documents. A Cloud Function can then subscribe to this topic and use the Vertex AI Search API to ingest, update, or delete documents in the corresponding data store, thereby maintaining data freshness. This is a critical feature for dynamic environments.
Automated Processing for RAG: When used for Retrieval Augmented Generation, Vertex AI Search automates many of the complex data processing steps, including ETL, OCR, document chunking, embedding generation, and indexing.
The "corpus" serves as the foundational layer for both storage and indexing, and its management has direct cost implications. While data stores provide a user-friendly abstraction, the actual costs are tied to the size of this underlying corpus and the activity it handles. This means that effective data management strategies, such as determining what data to index and defining retention policies, are crucial for optimizing costs, even with the simplified interface of data stores. The "pay only for what you use" principle is directly linked to the activity and volume within this corpus. For large-scale deployments, particularly those involving substantial datasets like the 500GB use case mentioned by a user , the cost implications of the corpus can be a significant planning factor.
There is an observable interplay between the platform's "out-of-the-box" simplicity and the requirements of advanced customization. Vertex AI Search is heavily promoted for its ease of setup and pre-built RAG capabilities , with an emphasis on an "easy experience to get started". However, highly specific enterprise scenarios or complex user requirements—such as querying by unique document identifiers, maintaining multi-year conversational contexts, needing specific embedding dimensions, or handling unsupported file formats like XLSX —may necessitate delving into more intricate configurations, API utilization, and custom development work. For example, implementing real-time ingestion requires setting up Pub/Sub and Cloud Functions , and achieving certain filtering behaviors might involve workarounds like using metadata fields. While comprehensive APIs are available for "granular control or bespoke RAG solutions" , this means that the platform's inherent simplicity has boundaries, and deep technical expertise might still be essential for optimal or highly tailored implementations. This suggests a tiered user base: one that leverages Vertex AI Search as a turnkey solution, and another that uses it as a powerful, extensible toolkit for custom builds.
Querying and Customization
Vertex AI Search provides flexible ways to query data and customize the search experience:
Query Types: The platform supports Google-quality search, which represents an evolution from basic keyword matching to modern, conversational search experiences. It can be configured to return only a list of search results or to provide generative, AI-powered answers. A recent user-reported issue (May 2025) indicated that queries against JSON data in the latest release might require phrasing in natural language, suggesting an evolving query interpretation mechanism that prioritizes NLU.
Customization Options:
Vertex AI Search offers extensive capabilities to tailor search experiences to specific needs.
Metadata Filtering: A key customization feature is the ability to filter search results based on indexed metadata fields. For instance, if direct filtering by rag_file_ids is not supported by a particular API (like the Grounding API), adding a file_id to document metadata and filtering on that field can serve as an effective alternative.
Search Widget: Integration into websites can be achieved easily by embedding a JavaScript widget or an HTML component.
API Integration: For more profound control and custom integrations, the AI Applications API can be used.
LLM Feature Activation: Features that provide generative answers powered by LLMs typically need to be explicitly enabled.
Refinement Options: Users can preview search results and refine them by adding or modifying metadata (e.g., based on HTML structure for websites), boosting the ranking of certain results (e.g., based on publication date), or applying filters (e.g., based on URL patterns or other metadata).
Events-based Reranking and Autocomplete: The platform also supports advanced tuning options such as reranking results based on user interaction events and providing autocomplete suggestions for search queries.
Multi-Turn Conversation Support:
For conversational AI applications, the Grounding API can utilize the history of a conversation as context for generating subsequent responses.
To maintain context in multi-turn dialogues, it is recommended to store previous prompts and responses (e.g., in a database or cache) and include this history in the next prompt to the model, while being mindful of the context window limitations of the underlying LLMs.
The evolving nature of query interpretation, particularly the reported shift towards requiring natural language queries for JSON data , underscores a broader trend. If this change is indicative of a deliberate platform direction, it signals a significant alignment of the query experience with Google's core strengths in NLU and conversational AI, likely driven by models like Gemini. This could simplify interactions for end-users but may require developers accustomed to more structured query languages for structured data to adapt their approaches. Such a shift prioritizes natural language understanding across the platform. However, it could also introduce friction for existing applications or development teams that have built systems based on previous query behaviors. This highlights the dynamic nature of managed services, where underlying changes can impact functionality, necessitating user adaptation and diligent monitoring of release notes.
4. Applications and Use Cases
Vertex AI Search is designed to cater to a wide spectrum of applications, from enhancing traditional enterprise search to enabling sophisticated generative AI solutions across various industries. Its versatility allows organizations to leverage their data in novel and impactful ways.
Enterprise Search
A primary application of Vertex AI Search is the modernization and improvement of search functionalities within an organization:
Improving Search for Websites and Intranets: The platform empowers businesses to deploy Google-quality search capabilities on their external-facing websites and internal corporate portals or intranets. This can significantly enhance user experience by making information more discoverable. For basic implementations, this can be as straightforward as integrating a pre-built search widget.
Employee and Customer Search: Vertex AI Search provides a comprehensive toolkit for accessing, processing, and analyzing enterprise information. This can be used to create powerful search experiences for employees, helping them find internal documents, locate subject matter experts, or access company knowledge bases more efficiently. Similarly, it can improve customer-facing search for product discovery, support documentation, or FAQs.
Generative AI Enablement
Vertex AI Search plays a crucial role in the burgeoning field of generative AI by providing essential grounding capabilities:
Grounding LLM Responses (RAG): A key and frequently highlighted use case is its function as an out-of-the-box Retrieval Augmented Generation (RAG) system. In this capacity, Vertex AI Search retrieves relevant and factual information from an organization's own data repositories. This retrieved information is then used to "ground" the responses generated by Large Language Models (LLMs). This process is vital for improving the accuracy, reliability, and contextual relevance of LLM outputs, and critically, for reducing the incidence of "hallucinations"—the tendency of LLMs to generate plausible but incorrect or fabricated information.
Powering Generative AI Agents and Apps: By providing robust grounding capabilities, Vertex AI Search serves as a foundational component for building sophisticated generative AI agents and applications. These AI systems can then interact with and reason about company-specific data, leading to more intelligent and context-aware automated solutions.
Industry-Specific Solutions
Recognizing that different industries have unique data types, terminologies, and objectives, Google Cloud offers specialized versions of Vertex AI Search:
Vertex AI Search for Commerce (Retail): This version is specifically tuned to enhance the search, product recommendation, and browsing experiences on retail e-commerce channels. It employs AI to understand complex customer queries, interpret shopper intent (even when expressed using informal language or colloquialisms), and automatically provide dynamic spell correction and relevant synonym suggestions. Furthermore, it can optimize search results based on specific business objectives, such as click-through rates (CTR), revenue per session, and conversion rates.
Vertex AI Search for Media (Media and Entertainment): Tailored for the media industry, this solution aims to deliver more personalized content recommendations, often powered by generative AI. The strategic goal is to increase consumer engagement and time spent on media platforms, which can translate to higher advertising revenue, subscription retention, and overall platform loyalty. It supports structured data formats commonly used in the media sector for assets like videos, news articles, music, and podcasts.
Vertex AI Search for Healthcare and Life Sciences: This offering provides a medically tuned search engine designed to improve the experiences of both patients and healthcare providers. It can be used, for example, to search through vast clinical data repositories, electronic health records, or a patient's clinical history using exploratory queries. This solution is also built with compliance with healthcare data regulations like HIPAA in mind.
The development of these industry-specific versions like "Vertex AI Search for Commerce," "Vertex AI Search for Media," and "Vertex AI Search for Healthcare and Life Sciences" is not merely a cosmetic adaptation. It represents a strategic decision by Google to avoid a one-size-fits-all approach. These offerings are "tuned for unique industry requirements" , incorporating specialized terminologies, understanding industry-specific data structures, and aligning with distinct business objectives. This targeted approach significantly lowers the barrier to adoption for companies within these verticals, as the solution arrives pre-optimized for their particular needs, thereby reducing the requirement for extensive custom development or fine-tuning. This industry-specific strategy serves as a potent market penetration tactic, allowing Google to compete more effectively against niche players in each vertical and to demonstrate clear return on investment by addressing specific, high-value industry challenges. It also fosters deeper integration into the core business processes of these enterprises, positioning Vertex AI Search as a more strategic and less easily substitutable component of their technology infrastructure. This could, over time, lead to the development of distinct, industry-focused data ecosystems and best practices centered around Vertex AI Search.
Embeddings-Based Applications (via Vector Search)
The underlying Vector Search capability within Vertex AI Search also enables a range of applications that rely on semantic similarity of embeddings:
Recommendation Engines: Vector Search can be a core component in building recommendation engines. By generating numerical representations (embeddings) of items (e.g., products, articles, videos), it can find and suggest items that are semantically similar to what a user is currently viewing or has interacted with in the past.
Chatbots: For advanced chatbots that need to understand user intent deeply and retrieve relevant information from extensive knowledge bases, Vector Search provides powerful semantic matching capabilities. This allows chatbots to provide more accurate and contextually appropriate responses.
Ad Serving: In the domain of digital advertising, Vector Search can be employed for semantic matching to deliver more relevant advertisements to users based on content or user profiles.
The Vector Search component is presented both as an integral technology powering the semantic retrieval within the managed Vertex AI Search service and as a potent, standalone tool accessible via the broader Vertex AI platform. Snippet , for instance, outlines a methodology for constructing a recommendation engine using Vector Search directly. This dual role means that Vector Search is foundational to the core semantic retrieval capabilities of Vertex AI Search, and simultaneously, it is a powerful component that can be independently leveraged by developers to build other custom AI applications. Consequently, enhancements to Vector Search, such as the recently reported reductions in indexing latency , benefit not only the out-of-the-box Vertex AI Search experience but also any custom AI solutions that developers might construct using this underlying technology. Google is, in essence, offering a spectrum of access to its vector database technology. Enterprises can consume it indirectly and with ease through the managed Vertex AI Search offering, or they can harness it more directly for bespoke AI projects. This flexibility caters to varying levels of technical expertise and diverse application requirements. As more enterprises adopt embeddings for a multitude of AI tasks, a robust, scalable, and user-friendly Vector Search becomes an increasingly critical piece of infrastructure, likely driving further adoption of the entire Vertex AI ecosystem.
Document Processing and Analysis
Leveraging its integration with Document AI, Vertex AI Search offers significant capabilities in document processing:
The service can help extract valuable information, classify documents based on content, and split large documents into manageable chunks. This transforms static documents into actionable intelligence, which can streamline various business workflows and enable more data-driven decision-making. For example, it can be used for analyzing large volumes of textual data, such as customer feedback, product reviews, or research papers, to extract key themes and insights.
Case Studies (Illustrative Examples)
While specific case studies for "Vertex AI Search" are sometimes intertwined with broader "Vertex AI" successes, several examples illustrate the potential impact of AI grounded on enterprise data, a core principle of Vertex AI Search:
Genial Care (Healthcare): This organization implemented Vertex AI to improve the process of keeping session records for caregivers. This enhancement significantly aided in reviewing progress for autism care, demonstrating Vertex AI's value in managing and utilizing healthcare-related data.
AES (Manufacturing & Industrial): AES utilized generative AI agents, built with Vertex AI, to streamline energy safety audits. This application resulted in a remarkable 99% reduction in costs and a decrease in audit completion time from 14 days to just one hour. This case highlights the transformative potential of AI agents that are effectively grounded on enterprise-specific information, aligning closely with the RAG capabilities central to Vertex AI Search.
Xometry (Manufacturing): This company is reported to be revolutionizing custom manufacturing processes by leveraging Vertex AI.
LUXGEN (Automotive): LUXGEN employed Vertex AI to develop an AI-powered chatbot. This initiative led to improvements in both the car purchasing and driving experiences for customers, while also achieving a 30% reduction in customer service workloads.
These examples, though some may refer to the broader Vertex AI platform, underscore the types of business outcomes achievable when AI is effectively applied to enterprise data and processes—a domain where Vertex AI Search is designed to excel.
5. Implementation and Management Considerations
Successfully deploying and managing Vertex AI Search involves understanding its setup processes, data ingestion mechanisms, security features, and user access controls. These aspects are critical for ensuring the platform operates efficiently, securely, and in alignment with enterprise requirements.
Setup and Deployment
Vertex AI Search offers flexibility in how it can be implemented and integrated into existing systems:
Google Cloud Console vs. API: Implementation can be approached in two main ways. The Google Cloud console provides a web-based interface for a quick-start experience, allowing users to create applications, import data, test search functionality, and view analytics without extensive coding. Alternatively, for deeper integration into websites or custom applications, the AI Applications API offers programmatic control. A common practice is a hybrid approach, where initial setup and data management are performed via the console, while integration and querying are handled through the API.
App and Data Store Creation: The typical workflow begins with creating a search or recommendations "app" and then attaching it to a "data store." Data relevant to the application is then imported into this data store and subsequently indexed to make it searchable.
Embedding JavaScript Widgets: For straightforward website integration, Vertex AI Search provides embeddable JavaScript widgets and API samples. These allow developers to quickly add search or recommendation functionalities to their web pages as HTML components.
Data Ingestion and Management
The platform provides robust mechanisms for ingesting data from various sources and keeping it up-to-date:
Corpus Management: As previously noted, the "corpus" is the fundamental underlying storage and indexing layer. While data stores offer an abstraction, it is crucial to understand that costs are directly related to the volume of data indexed in the corpus, the storage it consumes, and the query load it handles.
Pub/Sub for Real-time Updates: For environments with dynamic datasets where information changes frequently, Vertex AI Search supports real-time updates. This is typically achieved by setting up a Pub/Sub topic to which notifications about new or modified documents are published. A Cloud Function, acting as a subscriber to this topic, can then use the Vertex AI Search API to ingest, update, or delete the corresponding documents in the data store. This architecture ensures that the search index remains fresh and reflects the latest information. The capacity for real-time ingestion via Pub/Sub and Cloud Functions is a significant feature. This capability distinguishes it from systems reliant solely on batch indexing, which may not be adequate for environments with rapidly changing information. Real-time ingestion is vital for use cases where data freshness is paramount, such as e-commerce platforms with frequently updated product inventories, news portals, live financial data feeds, or internal systems tracking real-time operational metrics. Without this, search results could quickly become stale and potentially misleading. This feature substantially broadens the applicability of Vertex AI Search, positioning it as a viable solution for dynamic, operational systems where search must accurately reflect the current state of data. However, implementing this real-time pipeline introduces additional architectural components (Pub/Sub topics, Cloud Functions) and associated costs, which organizations must consider in their planning. It also implies a need for robust monitoring of the ingestion pipeline to ensure its reliability.
Metadata for Filtering and Control: During the schema definition process, specific metadata fields can be designated for indexing. This indexed metadata is critical for enabling powerful filtering of search results. For example, if an application requires users to search within a specific subset of documents identified by a unique ID, and direct filtering by a system-generated rag_file_id is not supported in a particular API context, a workaround involves adding a custom file_id field to each document's metadata. This custom field can then be used as a filter criterion during search queries.
Data Connectors: To facilitate the ingestion of data from a variety of sources, including first-party systems, other Google services, and third-party applications (such as Jira, Confluence, and Salesforce), Vertex AI Search offers data connectors. These connectors provide read-only access to external applications and help ensure that the data within the search index remains current and synchronized with these source systems.
Security and Compliance
Google Cloud places a strong emphasis on security and compliance for its services, and Vertex AI Search incorporates several features to address these enterprise needs:
Data Privacy: A core tenet is that user data ingested into Vertex AI Search is secured within the customer's dedicated cloud instance. Google explicitly states that it does not access or use this customer data for training its general-purpose models or for any other unauthorized purposes.
Industry Compliance: Vertex AI Search is designed to adhere to various recognized industry standards and regulations. These include HIPAA (Health Insurance Portability and Accountability Act) for healthcare data, the ISO 27000-series for information security management, and SOC (System and Organization Controls) attestations (SOC-1, SOC-2, SOC-3). This compliance is particularly relevant for the specialized versions of Vertex AI Search, such as the one for Healthcare and Life Sciences.
Access Transparency: This feature, when enabled, provides customers with logs of actions taken by Google personnel if they access customer systems (typically for support purposes), offering a degree of visibility into such interactions.
Virtual Private Cloud (VPC) Service Controls: To enhance data security and prevent unauthorized data exfiltration or infiltration, customers can use VPC Service Controls to define security perimeters around their Google Cloud resources, including Vertex AI Search.
Customer-Managed Encryption Keys (CMEK): Available in Preview, CMEK allows customers to use their own cryptographic keys (managed through Cloud Key Management Service) to encrypt data at rest within Vertex AI Search. This gives organizations greater control over their data's encryption.
User Access and Permissions (IAM)
Proper configuration of Identity and Access Management (IAM) permissions is fundamental to securing Vertex AI Search and ensuring that users only have access to appropriate data and functionalities:
Effective IAM policies are critical. However, some users have reported encountering challenges when trying to identify and configure the specific "Discovery Engine search permissions" required for Vertex AI Search. Difficulties have been noted in determining factors such as principal access boundaries or the impact of deny policies, even when utilizing tools like the IAM Policy Troubleshooter. This suggests that the permission model can be granular and may require careful attention to detail and potentially specialized knowledge to implement correctly, especially for complex scenarios involving fine-grained access control.
The power of Vertex AI Search lies in its capacity to index and make searchable vast quantities of potentially sensitive enterprise data drawn from diverse sources. While Google Cloud provides a robust suite of security features like VPC Service Controls and CMEK , the responsibility for meticulous IAM configuration and overarching data governance rests heavily with the customer. The user-reported difficulties in navigating IAM permissions for "Discovery Engine search permissions" underscore that the permission model, while offering granular control, might also present complexity. Implementing a least-privilege access model effectively, especially when dealing with nuanced requirements such as filtering search results based on user identity or specific document IDs , may require specialized expertise. Failure to establish and maintain correct IAM policies could inadvertently lead to security vulnerabilities or compliance breaches, thereby undermining the very benefits the search platform aims to provide. Consequently, the "ease of use" often highlighted for search setup must be counterbalanced with rigorous and continuous attention to security and access control from the outset of any deployment. The platform's capability to filter search results based on metadata becomes not just a functional feature but a key security control point if designed and implemented with security considerations in mind.
6. Pricing and Commercials
Understanding the pricing structure of Vertex AI Search is essential for organizations evaluating its adoption and for ongoing cost management. The model is designed around the principle of "pay only for what you use" , offering flexibility but also requiring careful consideration of various cost components. Google Cloud typically provides a free trial, often including $300 in credits for new customers to explore services. Additionally, a free tier is available for some services, notably a 10 GiB per month free quota for Index Data Storage, which is shared across AI Applications.
The pricing for Vertex AI Search can be broken down into several key areas:
Core Search Editions and Query Costs
Search Standard Edition: This edition is priced based on the number of queries processed, typically per 1,000 queries. For example, a common rate is $1.50 per 1,000 queries.
Search Enterprise Edition: This edition includes Core Generative Answers (AI Mode) and is priced at a higher rate per 1,000 queries, such as $4.00 per 1,000 queries.
Advanced Generative Answers (AI Mode): This is an optional add-on available for both Standard and Enterprise Editions. It incurs an additional cost per 1,000 user input queries, for instance, an extra $4.00 per 1,000 user input queries.
Data Indexing Costs
Index Storage: Costs for storing indexed data are charged per GiB of raw data per month. A typical rate is $5.00 per GiB per month. As mentioned, a free quota (e.g., 10 GiB per month) is usually provided. This cost is directly associated with the underlying "corpus" where data is stored and managed.
Grounding and Generative AI Cost Components
When utilizing the generative AI capabilities, particularly for grounding LLM responses, several components contribute to the overall cost :
Input Prompt (for grounding): The cost is determined by the number of characters in the input prompt provided for the grounding process, including any grounding facts. An example rate is $0.000125 per 1,000 characters.
Output (generated by model): The cost for the output generated by the LLM is also based on character count. An example rate is $0.000375 per 1,000 characters.
Grounded Generation (for grounding on own retrieved data): There is a cost per 1,000 requests for utilizing the grounding functionality itself, for example, $2.50 per 1,000 requests.
Data Retrieval (Vertex AI Search - Enterprise edition): When Vertex AI Search (Enterprise edition) is used to retrieve documents for grounding, a query cost applies, such as $4.00 per 1,000 requests.
Check Grounding API: This API allows users to assess how well a piece of text (an answer candidate) is grounded in a given set of reference texts (facts). The cost is per 1,000 answer characters, for instance, $0.00075 per 1,000 answer characters.
Industry-Specific Pricing
Vertex AI Search offers specialized pricing for its industry-tailored solutions:
Vertex AI Search for Healthcare: This version has a distinct, typically higher, query cost, such as $20.00 per 1,000 queries. It includes features like GenAI-powered answers and streaming updates to the index, some of which may be in Preview status. Data indexing costs are generally expected to align with standard rates.
Vertex AI Search for Media:
Media Search API Request Count: A specific query cost applies, for example, $2.00 per 1,000 queries.
Data Index: Standard data indexing rates, such as $5.00 per GB per month, typically apply.
Media Recommendations: Pricing for media recommendations is often tiered based on the volume of prediction requests per month (e.g., $0.27 per 1,000 predictions for up to 20 million, $0.18 for the next 280 million, and so on). Additionally, training and tuning of recommendation models are charged per node per hour, for example, $2.50 per node per hour.
Document AI Feature Pricing (when integrated)
If Vertex AI Search utilizes integrated Document AI features for processing documents, these will incur their own costs:
Enterprise Document OCR Processor: Pricing is typically tiered based on the number of pages processed per month, for example, $1.50 per 1,000 pages for 1 to 5 million pages per month.
Layout Parser (includes initial chunking): This feature is priced per 1,000 pages, for instance, $10.00 per 1,000 pages.
Vector Search Cost Considerations
Specific cost considerations apply to Vertex AI Vector Search, particularly highlighted by user feedback :
A user found Vector Search to be "costly" due to the necessity of keeping compute resources (machines) continuously running for index serving, even during periods of no query activity. This implies ongoing costs for provisioned resources, distinct from per-query charges.
Supporting documentation confirms this model, with "Index Serving" costs that vary by machine type and region, and "Index Building" costs, such as $3.00 per GiB of data processed.
Pricing Examples
Illustrative pricing examples provided in sources like and demonstrate how these various components can combine to form the total cost for different usage scenarios, including general availability (GA) search functionality, media recommendations, and grounding operations.
The following table summarizes key pricing components for Vertex AI Search:
Vertex AI Search Pricing SummaryService ComponentEdition/TypeUnitPrice (Example)Free Tier/NotesSearch QueriesStandard1,000 queries$1.5010k free trial queries often includedSearch QueriesEnterprise (with Core GenAI)1,000 queries$4.0010k free trial queries often includedAdvanced GenAI (Add-on)Standard or Enterprise1,000 user input queries+$4.00Index Data StorageAllGiB/month$5.0010 GiB/month free (shared across AI Applications)Grounding: Input PromptGenerative AI1,000 characters$0.000125Grounding: OutputGenerative AI1,000 characters$0.000375Grounding: Grounded GenerationGenerative AI1,000 requests$2.50For grounding on own retrieved dataGrounding: Data RetrievalEnterprise Search1,000 requests$4.00When using Vertex AI Search (Enterprise) for retrievalCheck Grounding APIAPI1,000 answer characters$0.00075Healthcare Search QueriesHealthcare1,000 queries$20.00Includes some Preview featuresMedia Search API QueriesMedia1,000 queries$2.00Media Recommendations (Predictions)Media1,000 predictions$0.27 (up to 20M/mo), $0.18 (next 280M/mo), $0.10 (after 300M/mo)Tiered pricingMedia Recs Training/TuningMediaNode/hour$2.50Document OCRDocument AI Integration1,000 pages$1.50 (1-5M pages/mo), $0.60 (>5M pages/mo)Tiered pricingLayout ParserDocument AI Integration1,000 pages$10.00Includes initial chunkingVector Search: Index BuildingVector SearchGiB processed$3.00Vector Search: Index ServingVector SearchVariesVaries by machine type & region (e.g., $0.094/node hour for e2-standard-2 in us-central1)Implies "always-on" costs for provisioned resourcesExport to Sheets
Note: Prices are illustrative examples based on provided research and are subject to change. Refer to official Google Cloud pricing documentation for current rates.
The multifaceted pricing structure, with costs broken down by queries, data volume, character counts for generative AI, specific APIs, and even underlying Document AI processors , reflects the feature richness and granularity of Vertex AI Search. This allows users to align costs with the specific features they consume, consistent with the "pay only for what you use" philosophy. However, this granularity also means that accurately estimating total costs can be a complex undertaking. Users must thoroughly understand their anticipated usage patterns across various dimensions—query volume, data size, frequency of generative AI interactions, document processing needs—to predict expenses with reasonable accuracy. The seemingly simple act of obtaining a generative answer, for instance, can involve multiple cost components: input prompt processing, output generation, the grounding operation itself, and the data retrieval query. Organizations, particularly those with large datasets, high query volumes, or plans for extensive use of generative features, may find it challenging to forecast costs without detailed analysis and potentially leveraging tools like the Google Cloud pricing calculator. This complexity could present a barrier for smaller organizations or those with less experience in managing cloud expenditures. It also underscores the importance of closely monitoring usage to prevent unexpected costs. The decision between Standard and Enterprise editions, and whether to incorporate Advanced Generative Answers, becomes a significant cost-benefit analysis.
Furthermore, a critical aspect of the pricing model for certain high-performance features like Vertex AI Vector Search is the "always-on" cost component. User feedback explicitly noted Vector Search as "costly" due to the requirement to "keep my machine on even when a user ain't querying". This is corroborated by pricing details that list "Index Serving" costs varying by machine type and region , which are distinct from purely consumption-based fees (like per-query charges) where costs would be zero if there were no activity. For features like Vector Search that necessitate provisioned infrastructure for index serving, a baseline operational cost exists regardless of query volume. This is a crucial distinction from on-demand pricing models and can significantly impact the total cost of ownership (TCO) for use cases that rely heavily on Vector Search but may experience intermittent query patterns. This continuous cost for certain features means that organizations must evaluate the ongoing value derived against their persistent expense. It might render Vector Search less economical for applications with very sporadic usage unless the benefits during active periods are substantial. This could also suggest that Google might, in the future, offer different tiers or configurations for Vector Search to cater to varying performance and cost needs, or users might need to architect solutions to de-provision and re-provision indexes if usage is highly predictable and infrequent, though this would add operational complexity.
7. Comparative Analysis
Vertex AI Search operates in a competitive landscape of enterprise search and AI platforms. Understanding its position relative to alternatives is crucial for informed decision-making. Key comparisons include specialized product discovery solutions like Algolia and broader enterprise search platforms from other major cloud providers and niche vendors.
Vertex AI Search for Commerce vs. Algolia
For e-commerce and retail product discovery, Vertex AI Search for Commerce and Algolia are prominent solutions, each with distinct strengths :
Core Search Quality & Features:
Vertex AI Search for Commerce is built upon Google's extensive search algorithm expertise, enabling it to excel at interpreting complex queries by understanding user context, intent, and even informal language. It features dynamic spell correction and synonym suggestions, consistently delivering high-quality, context-rich results. Its primary strengths lie in natural language understanding (NLU) and dynamic AI-driven corrections.
Algolia has established its reputation with a strong focus on semantic search and autocomplete functionalities, powered by its NeuralSearch capabilities. It adapts quickly to user intent. However, it may require more manual fine-tuning to address highly complex or context-rich queries effectively. Algolia is often prized for its speed, ease of configuration, and feature-rich autocomplete.
Customer Engagement & Personalization:
Vertex AI incorporates advanced recommendation models that adapt based on user interactions. It can optimize search results based on defined business objectives like click-through rates (CTR), revenue per session, and conversion rates. Its dynamic personalization capabilities mean search results evolve based on prior user behavior, making the browsing experience progressively more relevant. The deep integration of AI facilitates a more seamless, data-driven personalization experience.
Algolia offers an impressive suite of personalization tools with various recommendation models suitable for different retail scenarios. The platform allows businesses to customize search outcomes through configuration, aligning product listings, faceting, and autocomplete suggestions with their customer engagement strategy. However, its personalization features might require businesses to integrate additional services or perform more fine-tuning to achieve the level of dynamic personalization seen in Vertex AI.
Merchandising & Display Flexibility:
Vertex AI utilizes extensive AI models to enable dynamic ranking configurations that consider not only search relevance but also business performance metrics such as profitability and conversion data. The search engine automatically sorts products by match quality and considers which products are likely to drive the best business outcomes, reducing the burden on retail teams by continuously optimizing based on live data. It can also blend search results with curated collections and themes. A noted current limitation is that Google is still developing new merchandising tools, and the existing toolset is described as "fairly limited".
Algolia offers powerful faceting and grouping capabilities, allowing for the creation of curated displays for promotions, seasonal events, or special collections. Its flexible configuration options permit merchants to manually define boost and slotting rules to prioritize specific products for better visibility. These manual controls, however, might require more ongoing maintenance compared to Vertex AI's automated, outcome-based ranking. Algolia's configuration-centric approach may be better suited for businesses that prefer hands-on control over merchandising details.
Implementation, Integration & Operational Efficiency:
A key advantage of Vertex AI is its seamless integration within the broader Google Cloud ecosystem, making it a natural choice for retailers already utilizing Google Merchant Center, Google Cloud Storage, or BigQuery. Its sophisticated AI models mean that even a simple initial setup can yield high-quality results, with the system automatically learning from user interactions over time. A potential limitation is its significant data requirements; businesses lacking large volumes of product or interaction data might not fully leverage its advanced capabilities, and smaller brands may find themselves in lower Data Quality tiers.
Algolia is renowned for its ease of use and rapid deployment, offering a user-friendly interface, comprehensive documentation, and a free tier suitable for early-stage projects. It is designed to integrate with various e-commerce systems and provides a flexible API for straightforward customization. While simpler and more accessible for smaller businesses, this ease of use might necessitate additional configuration for very complex or data-intensive scenarios.
Analytics, Measurement & Future Innovations:
Vertex AI provides extensive insights into both search performance and business outcomes, tracking metrics like CTR, conversion rates, and profitability. The ability to export search and event data to BigQuery enhances its analytical power, offering possibilities for custom dashboards and deeper AI/ML insights. It is well-positioned to benefit from Google's ongoing investments in AI, integration with services like Google Vision API, and the evolution of large language models and conversational commerce.
Algolia offers detailed reporting on search performance, tracking visits, searches, clicks, and conversions, and includes views for data quality monitoring. Its analytics capabilities tend to focus more on immediate search performance rather than deeper business performance metrics like average order value or revenue impact. Algolia is also rapidly innovating, especially in enhancing its semantic search and autocomplete functions, though its evolution may be more incremental compared to Vertex AI's broader ecosystem integration.
In summary, Vertex AI Search for Commerce is often an ideal choice for large retailers with extensive datasets, particularly those already integrated into the Google or Shopify ecosystems, who are seeking advanced AI-driven optimization for customer engagement and business outcomes. Conversely, Algolia presents a strong option for businesses that prioritize rapid deployment, ease of use, and flexible semantic search and autocomplete functionalities, especially smaller retailers or those desiring more hands-on control over their search configuration.
Vertex AI Search vs. Other Enterprise Search Solutions
Beyond e-commerce, Vertex AI Search competes with a range of enterprise search solutions :
INDICA Enterprise Search: This solution utilizes a patented approach to index both structured and unstructured data, prioritizing results by relevance. It offers a sophisticated query builder and comprehensive filtering options. Both Vertex AI Search and INDICA Enterprise Search provide API access, free trials/versions, and similar deployment and support options. INDICA lists "Sensitive Data Discovery" as a feature, while Vertex AI Search highlights "eCommerce Search, Retrieval-Augmented Generation (RAG), Semantic Search, and Site Search" as additional capabilities. Both platforms integrate with services like Gemini, Google Cloud Document AI, Google Cloud Platform, HTML, and Vertex AI.
Azure AI Search: Microsoft's offering features a vector database specifically designed for advanced RAG and contemporary search functionalities. It emphasizes enterprise readiness, incorporating security, compliance, and ethical AI methodologies. Azure AI Search supports advanced retrieval techniques, integrates with various platforms and data sources, and offers comprehensive vector data processing (extraction, chunking, enrichment, vectorization). It supports diverse vector types, hybrid models, multilingual capabilities, metadata filtering, and extends beyond simple vector searches to include keyword match scoring, reranking, geospatial search, and autocomplete features. The strong emphasis on RAG and vector capabilities by both Vertex AI Search and Azure AI Search positions them as direct competitors in the AI-powered enterprise search market.
IBM Watson Discovery: This platform leverages AI-driven search to extract precise answers and identify trends from various documents and websites. It employs advanced NLP to comprehend industry-specific terminology, aiming to reduce research time significantly by contextualizing responses and citing source documents. Watson Discovery also uses machine learning to visually categorize text, tables, and images. Its focus on deep NLP and understanding industry-specific language mirrors claims made by Vertex AI, though Watson Discovery has a longer established presence in this particular enterprise AI niche.
Guru: An AI search and knowledge platform, Guru delivers trusted information from a company's scattered documents, applications, and chat platforms directly within users' existing workflows. It features a personalized AI assistant and can serve as a modern replacement for legacy wikis and intranets. Guru offers extensive native integrations with popular business tools like Slack, Google Workspace, Microsoft 365, Salesforce, and Atlassian products. Guru's primary focus on knowledge management and in-app assistance targets a potentially more specialized use case than the broader enterprise search capabilities of Vertex AI, though there is an overlap in accessing and utilizing internal knowledge.
AddSearch: Provides fast, customizable site search for websites and web applications, using a crawler or an Indexing API. It offers enterprise-level features such as autocomplete, synonyms, ranking tools, and progressive ranking, designed to scale from small businesses to large corporations.
Haystack: Aims to connect employees with the people, resources, and information they need. It offers intranet-like functionalities, including custom branding, a modular layout, multi-channel content delivery, analytics, knowledge sharing features, and rich employee profiles with a company directory.
Atolio: An AI-powered enterprise search engine designed to keep data securely within the customer's own cloud environment (AWS, Azure, or GCP). It provides intelligent, permission-based responses and ensures that intellectual property remains under control, with LLMs that do not train on customer data. Atolio integrates with tools like Office 365, Google Workspace, Slack, and Salesforce. A direct comparison indicates that both Atolio and Vertex AI Search offer similar deployment, support, and training options, and share core features like AI/ML, faceted search, and full-text search. Vertex AI Search additionally lists RAG, Semantic Search, and Site Search as features not specified for Atolio in that comparison.
The following table provides a high-level feature comparison:
Feature and Capability Comparison: Vertex AI Search vs. Key CompetitorsFeature/CapabilityVertex AI SearchAlgolia (Commerce)Azure AI SearchIBM Watson DiscoveryINDICA ESGuruAtolioPrimary FocusEnterprise Search + RAG, Industry SolutionsProduct Discovery, E-commerce SearchEnterprise Search + RAG, Vector DBNLP-driven Insight Extraction, Document AnalysisGeneral Enterprise Search, Data DiscoveryKnowledge Management, In-App SearchSecure Enterprise Search, Knowledge Discovery (Self-Hosted Focus)RAG CapabilitiesOut-of-the-box, Custom via APIsN/A (Focus on product search)Strong, Vector DB optimized for RAGDocument understanding supports RAG-like patternsAI/ML features, less explicit RAG focusSurfaces existing knowledge, less about new content generationAI-powered answers, less explicit RAG focusVector SearchYes, integrated & standaloneSemantic search (NeuralSearch)Yes, core feature (Vector Database)Semantic understanding, less focus on explicit vector DBAI/Machine LearningAI-powered searchAI-powered searchSemantic Search QualityHigh (Google tech)High (NeuralSearch)HighHigh (Advanced NLP)Relevance-based rankingHigh for knowledge assetsIntelligent responsesSupported Data TypesStructured, Unstructured, Web, Healthcare, MediaPrimarily Product DataStructured, Unstructured, VectorDocuments, WebsitesStructured, UnstructuredDocs, Apps, ChatsEnterprise knowledge base (docs, apps)Industry SpecializationsRetail, Media, HealthcareRetail/E-commerceGeneral PurposeTunable for industry terminologyGeneral PurposeGeneral Knowledge ManagementGeneral Enterprise SearchKey DifferentiatorsGoogle Search tech, Out-of-box RAG, Gemini IntegrationSpeed, Ease of Config, AutocompleteAzure Ecosystem Integration, Comprehensive Vector ToolsDeep NLP, Industry Terminology UnderstandingPatented indexing, Sensitive Data DiscoveryIn-app accessibility, Extensive IntegrationsData security (self-hosted, no LLM training on customer data)Generative AI IntegrationStrong (Gemini, Grounding API)Limited (focus on search relevance)Strong (for RAG with Azure OpenAI)Supports GenAI workflowsAI/ML capabilitiesAI assistant for answersLLM-powered answersPersonalizationAdvanced (AI-driven)Strong (Configurable)Via integration with other Azure servicesN/AN/APersonalized AI assistantN/AEase of ImplementationModerate to Complex (depends on use case)HighModerate to ComplexModerate to ComplexModerateHighModerate (focus on secure deployment)Data Security ApproachGCP Security (VPC-SC, CMEK), Data SegregationStandard SaaS securityAzure Security (Compliance, Ethical AI)IBM Cloud SecurityStandard Enterprise SecurityStandard SaaS securityStrong emphasis on self-hosting & data controlExport to Sheets
The enterprise search market appears to be evolving along two axes: general-purpose platforms that offer a wide array of capabilities, and more specialized solutions tailored to specific use cases or industries. Artificial intelligence, in various forms such as semantic search, NLP, and vector search, is becoming a common denominator across almost all modern offerings. This means customers often face a choice between adopting a best-of-breed specialized tool that excels in a particular area (like Algolia for e-commerce or Guru for internal knowledge management) or investing in a broader platform like Vertex AI Search or Azure AI Search. These platforms provide good-to-excellent capabilities across many domains but might require more customization or configuration to meet highly specific niche requirements. Vertex AI Search, with its combination of a general platform and distinct industry-specific versions, attempts to bridge this gap. The success of this strategy will likely depend on how effectively its specialized versions compete with dedicated niche solutions and how readily the general platform can be adapted for unique needs.
As enterprises increasingly deploy AI solutions over sensitive proprietary data, concerns regarding data privacy, security, and intellectual property protection are becoming paramount. Vendors are responding by highlighting their security and data governance features as key differentiators. Atolio, for instance, emphasizes that it "keeps data securely within your cloud environment" and that its "LLMs do not train on your data". Similarly, Vertex AI Search details its security measures, including securing user data within the customer's cloud instance, compliance with standards like HIPAA and ISO, and features like VPC Service Controls and Customer-Managed Encryption Keys (CMEK). Azure AI Search also underscores its commitment to "security, compliance, and ethical AI methodologies". This growing focus suggests that the ability to ensure data sovereignty, meticulously control data access, and prevent data leakage or misuse by AI models is becoming as critical as search relevance or operational speed. For customers, particularly those in highly regulated industries, these data governance and security aspects could become decisive factors when selecting an enterprise search solution, potentially outweighing minor differences in other features. The often "black box" nature of some AI models makes transparent data handling policies and robust security postures increasingly crucial.
8. Known Limitations, Challenges, and User Experiences
While Vertex AI Search offers powerful capabilities, user experiences and technical reviews have highlighted several limitations, challenges, and considerations that organizations should be aware of during evaluation and implementation.
Reported User Issues and Challenges
Direct user feedback and community discussions have surfaced specific operational issues:
"No results found" Errors / Inconsistent Search Behavior: A notable user experience involved consistently receiving "No results found" messages within the Vertex AI Search app preview. This occurred even when other members of the same organization could use the search functionality without issue, and IAM and Datastore permissions appeared to be identical for the affected user. Such issues point to potential user-specific, environment-related, or difficult-to-diagnose configuration problems that are not immediately apparent.
Cross-OS Inconsistencies / Browser Compatibility: The same user reported that following the Vertex AI Search tutorial yielded successful results on a Windows operating system, but attempting the same on macOS resulted in a 403 error during the search operation. This suggests possible browser compatibility problems, issues with cached data, or differences in how the application interacts with various operating systems.
IAM Permission Complexity: Users have expressed difficulty in accurately confirming specific "Discovery Engine search permissions" even when utilizing the IAM Policy Troubleshooter. There was ambiguity regarding the determination of principal access boundaries, the effect of deny policies, or the final resolution of permissions. This indicates that navigating and verifying the necessary IAM permissions for Vertex AI Search can be a complex undertaking.
Issues with JSON Data Input / Query Phrasing: A recent issue, reported in May 2025, indicates that the latest release of Vertex AI Search (referred to as AI Application) has introduced challenges with semantic search over JSON data. According to the report, the search engine now primarily processes queries phrased in a natural language style, similar to that used in the UI, rather than structured filter expressions. This means filters or conditions must be expressed as plain language questions (e.g., "How many findings have a severity level marked as HIGH in d3v-core?"). Furthermore, it was noted that sometimes, even when specific keys are designated as "searchable" in the datastore schema, the system fails to return results, causing significant problems for certain types of queries. This represents a potentially disruptive change in behavior for users accustomed to working with JSON data in a more structured query manner.
Lack of Clear Error Messages: In the scenario where a user consistently received "No results found," it was explicitly stated that "There are no console or network errors". The absence of clear, actionable error messages can significantly complicate and prolong the diagnostic process for such issues.
Potential Challenges from Technical Specifications and User Feedback
Beyond specific bug reports, technical deep-dives and early adopter feedback have revealed other considerations, particularly concerning the underlying Vector Search component :
Cost of Vector Search: A user found Vertex AI Vector Search to be "costly." This was attributed to the operational model requiring compute resources (machines) to remain active and provisioned for index serving, even during periods when no queries were being actively processed. This implies a continuous baseline cost associated with using Vector Search.
File Type Limitations (Vector Search): As of the user's experience documented in , Vertex AI Vector Search did not offer support for indexing .xlsx (Microsoft Excel) files.
Document Size Limitations (Vector Search): Concerns were raised about the platform's ability to effectively handle "bigger document sizes" within the Vector Search component.
Embedding Dimension Constraints (Vector Search): The user reported an inability to create a Vector Search index with embedding dimensions other than the default 768 if the "corpus doesn't support" alternative dimensions. This suggests a potential lack of flexibility in configuring embedding parameters for certain setups.
rag_file_ids Not Directly Supported for Filtering: For applications using the Grounding API, it was noted that direct filtering of results based on rag_file_ids (presumably identifiers for files used in RAG) is not supported. The suggested workaround involves adding a custom file_id to the document metadata and using that for filtering purposes.
Data Requirements for Advanced Features (Vertex AI Search for Commerce)
For specialized solutions like Vertex AI Search for Commerce, the effectiveness of advanced features can be contingent on the available data:
A potential limitation highlighted for Vertex AI Search for Commerce is its "significant data requirements." Businesses that lack large volumes of product data or user interaction data (e.g., clicks, purchases) might not be able to fully leverage its advanced AI capabilities for personalization and optimization. Smaller brands, in particular, may find themselves remaining in lower Data Quality tiers, which could impact the performance of these features.
Merchandising Toolset (Vertex AI Search for Commerce)
The maturity of all components is also a factor:
The current merchandising toolset available within Vertex AI Search for Commerce has been described as "fairly limited." It is noted that Google is still in the process of developing and releasing new tools for this area. Retailers with sophisticated merchandising needs might find the current offerings less comprehensive than desired.
The rapid evolution of platforms like Vertex AI Search, while bringing cutting-edge features, can also introduce challenges. Recent user reports, such as the significant change in how JSON data queries are handled in the "latest version" as of May 2025, and other unexpected behaviors , illustrate this point. Vertex AI Search is part of a dynamic AI landscape, with Google frequently rolling out updates and integrating new models like Gemini. While this pace of innovation is a key strength, it can also lead to modifications in existing functionalities or, occasionally, introduce temporary instabilities. Users, especially those with established applications built upon specific, previously observed behaviors of the platform, may find themselves needing to adapt their implementations swiftly when such changes occur. The JSON query issue serves as a prime example of a change that could be disruptive for some users. Consequently, organizations adopting Vertex AI Search, particularly for mission-critical applications, should establish robust processes for monitoring platform updates, thoroughly testing changes in staging or development environments, and adapting their code or configurations as required. This highlights an inherent trade-off: gaining access to state-of-the-art AI features comes with the responsibility of managing the impacts of a fast-moving and evolving platform. It also underscores the critical importance of comprehensive documentation and clear, proactive communication from Google regarding any changes in platform behavior.
Moreover, there can be a discrepancy between the marketed ease-of-use and the actual complexity encountered during real-world implementation, especially for specific or advanced scenarios. While Vertex AI Search is promoted for its straightforward setup and out-of-the-box functionalities , detailed user experiences, such as those documented in and , reveal significant challenges. These can include managing the costs of components like Vector Search, dealing with limitations in supported file types or embedding dimensions, navigating the intricacies of IAM permissions, and achieving highly specific filtering requirements (e.g., querying by a custom document_id). The user in , for example, was attempting to implement a relatively complex use case involving 500GB of documents, specific ID-based querying, multi-year conversational history, and real-time data ingestion. This suggests that while basic setup might indeed be simple, implementing advanced or highly tailored enterprise requirements can unearth complexities and limitations not immediately apparent from high-level descriptions. The "out-of-the-box" solution may necessitate considerable workarounds (such as using metadata for ID-based filtering ) or encounter hard limitations for particular needs. Therefore, prospective users should conduct thorough proof-of-concept projects tailored to their specific, complex use cases. This is essential to validate that Vertex AI Search and its constituent components, like Vector Search, can adequately meet their technical requirements and align with their cost constraints. Marketing claims of simplicity need to be balanced with a realistic assessment of the effort and expertise required for sophisticated deployments. This also points to a continuous need for more detailed best practices, advanced troubleshooting guides, and transparent documentation from Google for these complex scenarios.
9. Recent Developments and Future Outlook
Vertex AI Search is a rapidly evolving platform, with Google Cloud continuously integrating its latest AI research and model advancements. Recent developments, particularly highlighted during events like Google I/O and Google Cloud Next 2025, indicate a clear trajectory towards more powerful, integrated, and agentic AI capabilities.
Integration with Latest AI Models (Gemini)
A significant thrust in recent developments is the deepening integration of Vertex AI Search with Google's flagship Gemini models. These models are multimodal, capable of understanding and processing information from various formats (text, images, audio, video, code), and possess advanced reasoning and generation capabilities.
The Gemini 2.5 model, for example, is slated to be incorporated into Google Search for features like AI Mode and AI Overviews in the U.S. market. This often signals broader availability within Vertex AI for enterprise use cases.
Within the Vertex AI Agent Builder, Gemini can be utilized to enhance agent responses with information retrieved from Google Search, while Vertex AI Search (with its RAG capabilities) facilitates the seamless integration of enterprise-specific data to ground these advanced models.
Developers have access to Gemini models through Vertex AI Studio and the Model Garden, allowing for experimentation, fine-tuning, and deployment tailored to specific application needs.
Platform Enhancements (from Google I/O & Cloud Next 2025)
Key announcements from recent Google events underscore the expansion of the Vertex AI platform, which directly benefits Vertex AI Search:
Vertex AI Agent Builder: This initiative consolidates a suite of tools designed to help developers create enterprise-ready generative AI experiences, applications, and intelligent agents. Vertex AI Search plays a crucial role in this builder by providing the essential data grounding capabilities. The Agent Builder supports the creation of codeless conversational agents and facilitates low-code AI application development.
Expanded Model Garden: The Model Garden within Vertex AI now offers access to an extensive library of over 200 models. This includes Google's proprietary models (like Gemini and Imagen), models from third-party providers (such as Anthropic's Claude), and popular open-source models (including Gemma and Llama 3.2). This wide selection provides developers with greater flexibility in choosing the optimal model for diverse use cases.
Multi-agent Ecosystem: Google Cloud is fostering the development of collaborative AI agents with new tools such as the Agent Development Kit (ADK) and the Agent2Agent (A2A) protocol.
Generative Media Suite: Vertex AI is distinguishing itself by offering a comprehensive suite of generative media models. This includes models for video generation (Veo), image generation (Imagen), speech synthesis, and, with the addition of Lyria, music generation.
AI Hypercomputer: This revolutionary supercomputing architecture is designed to simplify AI deployment, significantly boost performance, and optimize costs for training and serving large-scale AI models. Services like Vertex AI are built upon and benefit from these infrastructure advancements.
Performance and Usability Improvements
Google continues to refine the performance and usability of Vertex AI components:
Vector Search Indexing Latency: A notable improvement is the significant reduction in indexing latency for Vector Search, particularly for smaller datasets. This process, which previously could take hours, has been brought down to minutes.
No-Code Index Deployment for Vector Search: To lower the barrier to entry for using vector databases, developers can now create and deploy Vector Search indexes without needing to write code.
Emerging Trends and Future Capabilities
The future direction of Vertex AI Search and related AI services points towards increasingly sophisticated and autonomous capabilities:
Agentic Capabilities: Google is actively working on infusing more autonomous, agent-like functionalities into its AI offerings. Project Mariner's "computer use" capabilities are being integrated into the Gemini API and Vertex AI. Furthermore, AI Mode in Google Search Labs is set to gain agentic capabilities for handling tasks such as booking event tickets and making restaurant reservations.
Deep Research and Live Interaction: For Google Search's AI Mode, "Deep Search" is being introduced in Labs to provide more thorough and comprehensive responses to complex queries. Additionally, "Search Live," stemming from Project Astra, will enable real-time, camera-based conversational interactions with Search.
Data Analysis and Visualization: Future enhancements to AI Mode in Labs include the ability to analyze complex datasets and automatically create custom graphics and visualizations to bring the data to life, initially focusing on sports and finance queries.
Thought Summaries: An upcoming feature for Gemini 2.5 Pro and Flash, available in the Gemini API and Vertex AI, is "thought summaries." This will organize the model's raw internal "thoughts" or processing steps into a clear, structured format with headers, key details, and information about model actions, such as when it utilizes external tools.
The consistent emphasis on integrating advanced multimodal models like Gemini , coupled with the strategic development of the Vertex AI Agent Builder and the introduction of "agentic capabilities" , suggests a significant evolution for Vertex AI Search. While RAG primarily focuses on retrieving information to ground LLMs, these newer developments point towards enabling these LLMs (often operating within an agentic framework) to perform more complex tasks, reason more deeply about the retrieved information, and even initiate actions based on that information. The planned inclusion of "thought summaries" further reinforces this direction by providing transparency into the model's reasoning process. This trajectory indicates that Vertex AI Search is moving beyond being a simple information retrieval system. It is increasingly positioned as a critical component that feeds and grounds more sophisticated AI reasoning processes within enterprise-specific agents and applications. The search capability, therefore, becomes the trusted and factual data interface upon which these advanced AI models can operate more reliably and effectively. This positions Vertex AI Search as a fundamental enabler for the next generation of enterprise AI, which will likely be characterized by more autonomous, intelligent agents capable of complex problem-solving and task execution. The quality, comprehensiveness, and freshness of the data indexed by Vertex AI Search will, therefore, directly and critically impact the performance and reliability of these future intelligent systems.
Furthermore, there is a discernible pattern of advanced AI features, initially tested and rolled out in Google's consumer-facing products, eventually trickling into its enterprise offerings. Many of the new AI features announced for Google Search (the consumer product) at events like I/O 2025—such as AI Mode, Deep Search, Search Live, and agentic capabilities for shopping or reservations —often rely on underlying technologies or paradigms that also find their way into Vertex AI for enterprise clients. Google has a well-established history of leveraging its innovations in consumer AI (like its core search algorithms and natural language processing breakthroughs) as the foundation for its enterprise cloud services. The Gemini family of models, for instance, powers both consumer experiences and enterprise solutions available through Vertex AI. This suggests that innovations and user experience paradigms that are validated and refined at the massive scale of Google's consumer products are likely to be adapted and integrated into Vertex AI Search and related enterprise AI tools. This allows enterprises to benefit from cutting-edge AI capabilities that have been battle-tested in high-volume environments. Consequently, enterprises can anticipate that user expectations for search and AI interaction within their own applications will be increasingly shaped by these advanced consumer experiences. Vertex AI Search, by incorporating these underlying technologies, helps businesses meet these rising expectations. However, this also implies that the pace of change in enterprise tools might be influenced by the rapid innovation cycle of consumer AI, once again underscoring the need for organizational adaptability and readiness to manage platform evolution.
10. Conclusion and Strategic Recommendations
Vertex AI Search stands as a powerful and strategic offering from Google Cloud, designed to bring Google-quality search and cutting-edge generative AI capabilities to enterprises. Its ability to leverage an organization's own data for grounding large language models, coupled with its integration into the broader Vertex AI ecosystem, positions it as a transformative tool for businesses seeking to unlock greater value from their information assets and build next-generation AI applications.
Summary of Key Benefits and Differentiators
Vertex AI Search offers several compelling advantages:
Leveraging Google's AI Prowess: It is built on Google's decades of experience in search, natural language processing, and AI, promising high relevance and sophisticated understanding of user intent.
Powerful Out-of-the-Box RAG: Simplifies the complex process of building Retrieval Augmented Generation systems, enabling more accurate, reliable, and contextually relevant generative AI applications grounded in enterprise data.
Integration with Gemini and Vertex AI Ecosystem: Seamless access to Google's latest foundation models like Gemini and integration with a comprehensive suite of MLOps tools within Vertex AI provide a unified platform for AI development and deployment.
Industry-Specific Solutions: Tailored offerings for retail, media, and healthcare address unique industry needs, accelerating time-to-value.
Robust Security and Compliance: Enterprise-grade security features and adherence to industry compliance standards provide a trusted environment for sensitive data.
Continuous Innovation: Rapid incorporation of Google's latest AI research ensures the platform remains at the forefront of AI-powered search technology.
Guidance on When Vertex AI Search is a Suitable Choice
Vertex AI Search is particularly well-suited for organizations with the following objectives and characteristics:
Enterprises aiming to build sophisticated, AI-powered search applications that operate over their proprietary structured and unstructured data.
Businesses looking to implement reliable RAG systems to ground their generative AI applications, reduce LLM hallucinations, and ensure responses are based on factual company information.
Companies in the retail, media, and healthcare sectors that can benefit from specialized, pre-tuned search and recommendation solutions.
Organizations already invested in the Google Cloud Platform ecosystem, seeking seamless integration and a unified AI/ML environment.
Businesses that require scalable, enterprise-grade search capabilities incorporating advanced features like vector search, semantic understanding, and conversational AI.
Strategic Considerations for Adoption and Implementation
To maximize the benefits and mitigate potential challenges of adopting Vertex AI Search, organizations should consider the following:
Thorough Proof-of-Concept (PoC) for Complex Use Cases: Given that advanced or highly specific scenarios may encounter limitations or complexities not immediately apparent , conducting rigorous PoC testing tailored to these unique requirements is crucial before full-scale deployment.
Detailed Cost Modeling: The granular pricing model, which includes charges for queries, data storage, generative AI processing, and potentially always-on resources for components like Vector Search , necessitates careful and detailed cost forecasting. Utilize Google Cloud's pricing calculator and monitor usage closely.
Prioritize Data Governance and IAM: Due to the platform's ability to access and index vast amounts of enterprise data, investing in meticulous planning and implementation of data governance policies and IAM configurations is paramount. This ensures data security, privacy, and compliance.
Develop Team Skills and Foster Adaptability: While Vertex AI Search is designed for ease of use in many aspects, advanced customization, troubleshooting, or managing the impact of its rapid evolution may require specialized skills within the implementation team. The platform is constantly changing, so a culture of continuous learning and adaptability is beneficial.
Consider a Phased Approach: Organizations can begin by leveraging Vertex AI Search to improve existing search functionalities, gaining early wins and familiarity. Subsequently, they can progressively adopt more advanced AI features like RAG and conversational AI as their internal AI maturity and comfort levels grow.
Monitor and Maintain Data Quality: The performance of Vertex AI Search, especially its industry-specific solutions like Vertex AI Search for Commerce, is highly dependent on the quality and volume of the input data. Establish processes for monitoring and maintaining data quality.
Final Thoughts on Future Trajectory
Vertex AI Search is on a clear path to becoming more than just an enterprise search tool. Its deepening integration with advanced AI models like Gemini, its role within the Vertex AI Agent Builder, and the emergence of agentic capabilities suggest its evolution into a core "reasoning engine" for enterprise AI. It is well-positioned to serve as a fundamental data grounding and contextualization layer for a new generation of intelligent applications and autonomous agents. As Google continues to infuse its latest AI research and model innovations into the platform, Vertex AI Search will likely remain a key enabler for businesses aiming to harness the full potential of their data in the AI era.
The platform's design, offering a spectrum of capabilities from enhancing basic website search to enabling complex RAG systems and supporting future agentic functionalities , allows organizations to engage with it at various levels of AI readiness. This characteristic positions Vertex AI Search as a potential catalyst for an organization's overall AI maturity journey. Companies can embark on this journey by addressing tangible, lower-risk search improvement needs and then, using the same underlying platform, progressively explore and implement more advanced AI applications. This iterative approach can help build internal confidence, develop requisite skills, and demonstrate value incrementally. In this sense, Vertex AI Search can be viewed not merely as a software product but as a strategic platform that facilitates an organization's AI transformation. By providing an accessible yet powerful and evolving solution, Google encourages deeper and more sustained engagement with its comprehensive AI ecosystem, fostering long-term customer relationships and driving broader adoption of its cloud services. The ultimate success of this approach will hinge on Google's continued commitment to providing clear guidance, robust support, predictable platform evolution, and transparent communication with its users.
2 notes
·
View notes
Text
Predicting Employee Attrition: Leveraging AI for Workforce Stability

Employee turnover has become a pressing concern for organizations worldwide. The cost of losing valuable talent extends beyond recruitment expenses—it affects team morale, disrupts workflows, and can tarnish a company's reputation. In this dynamic landscape, Artificial Intelligence (AI) emerges as a transformative tool, offering predictive insights that enable proactive retention strategies. By harnessing AI, businesses can anticipate attrition risks and implement measures to foster a stable and engaged workforce.
Understanding Employee Attrition
Employee attrition refers to the gradual loss of employees over time, whether through resignations, retirements, or other forms of departure. While some level of turnover is natural, high attrition rates can signal underlying issues within an organization. Common causes include lack of career advancement opportunities, inadequate compensation, poor management, and cultural misalignment. The repercussions are significant—ranging from increased recruitment costs to diminished employee morale and productivity.
The Role of AI in Predicting Attrition
AI revolutionizes the way organizations approach employee retention. Traditional methods often rely on reactive measures, addressing turnover after it occurs. In contrast, AI enables a proactive stance by analyzing vast datasets to identify patterns and predict potential departures. Machine learning algorithms can assess factors such as job satisfaction, performance metrics, and engagement levels to forecast attrition risks. This predictive capability empowers HR professionals to intervene early, tailoring strategies to retain at-risk employees.
Data Collection and Integration
The efficacy of AI in predicting attrition hinges on the quality and comprehensiveness of data. Key data sources include:
Employee Demographics: Age, tenure, education, and role.
Performance Metrics: Appraisals, productivity levels, and goal attainment.
Engagement Surveys: Feedback on job satisfaction and organizational culture.
Compensation Details: Salary, bonuses, and benefits.
Exit Interviews: Insights into reasons for departure.
Integrating data from disparate systems poses challenges, necessitating robust data management practices. Ensuring data accuracy, consistency, and privacy is paramount to building reliable predictive models.
Machine Learning Models for Attrition Prediction
Several machine learning algorithms have proven effective in forecasting employee turnover:
Random Forest: This ensemble learning method constructs multiple decision trees to improve predictive accuracy and control overfitting.
Neural Networks: Mimicking the human brain's structure, neural networks can model complex relationships between variables, capturing subtle patterns in employee behavior.
Logistic Regression: A statistical model that estimates the probability of a binary outcome, such as staying or leaving.
For instance, IBM's Predictive Attrition Program utilizes AI to analyze employee data, achieving a reported accuracy of 95% in identifying individuals at risk of leaving. This enables targeted interventions, such as personalized career development plans, to enhance retention.
Sentiment Analysis and Employee Feedback
Understanding employee sentiment is crucial for retention. AI-powered sentiment analysis leverages Natural Language Processing (NLP) to interpret unstructured data from sources like emails, surveys, and social media. By detecting emotions and opinions, organizations can gauge employee morale and identify areas of concern. Real-time sentiment monitoring allows for swift responses to emerging issues, fostering a responsive and supportive work environment.
Personalized Retention Strategies
AI facilitates the development of tailored retention strategies by analyzing individual employee data. For example, if an employee exhibits signs of disengagement, AI can recommend specific interventions—such as mentorship programs, skill development opportunities, or workload adjustments. Personalization ensures that retention efforts resonate with employees' unique needs and aspirations, enhancing their effectiveness.
Enhancing Employee Engagement Through AI
Beyond predicting attrition, AI contributes to employee engagement by:
Recognition Systems: Automating the acknowledgment of achievements to boost morale.
Career Pathing: Suggesting personalized growth trajectories aligned with employees' skills and goals.
Feedback Mechanisms: Providing platforms for continuous feedback, fostering a culture of open communication.
These AI-driven initiatives create a more engaging and fulfilling work environment, reducing the likelihood of turnover.
Ethical Considerations in AI Implementation
While AI offers substantial benefits, ethical considerations must guide its implementation:
Data Privacy: Organizations must safeguard employee data, ensuring compliance with privacy regulations.
Bias Mitigation: AI models should be regularly audited to prevent and correct biases that may arise from historical data.
Transparency: Clear communication about how AI is used in HR processes builds trust among employees.
Addressing these ethical aspects is essential to responsibly leveraging AI in workforce management.
Future Trends in AI and Employee Retention
The integration of AI in HR is poised to evolve further, with emerging trends including:
Predictive Career Development: AI will increasingly assist in mapping out employees' career paths, aligning organizational needs with individual aspirations.
Real-Time Engagement Analytics: Continuous monitoring of engagement levels will enable immediate interventions.
AI-Driven Organizational Culture Analysis: Understanding and shaping company culture through AI insights will become more prevalent.
These advancements will further empower organizations to maintain a stable and motivated workforce.
Conclusion
AI stands as a powerful ally in the quest for workforce stability. By predicting attrition risks and informing personalized retention strategies, AI enables organizations to proactively address turnover challenges. Embracing AI-driven approaches not only enhances employee satisfaction but also fortifies the organization's overall performance and resilience.
Frequently Asked Questions (FAQs)
How accurate are AI models in predicting employee attrition?
AI models, when trained on comprehensive and high-quality data, can achieve high accuracy levels. For instance, IBM's Predictive Attrition Program reports a 95% accuracy rate in identifying at-risk employees.
What types of data are most useful for AI-driven attrition prediction?
Valuable data includes employee demographics, performance metrics, engagement survey results, compensation details, and feedback from exit interviews.
Can small businesses benefit from AI in HR?
Absolutely. While implementation may vary in scale, small businesses can leverage AI tools to gain insights into employee satisfaction and predict potential turnover, enabling timely interventions.
How does AI help in creating personalized retention strategies?
AI analyzes individual employee data to identify specific needs and preferences, allowing HR to tailor interventions such as customized career development plans or targeted engagement initiatives.
What are the ethical considerations when using AI in HR?
Key considerations include ensuring data privacy, mitigating biases in AI models, and maintaining transparency with employees about how their data is used.
For more Info Visit :- Stentor.ai
2 notes
·
View notes
Text
Google Cloud’s BigQuery Autonomous Data To AI Platform

BigQuery automates data analysis, transformation, and insight generation using AI. AI and natural language interaction simplify difficult operations.
The fast-paced world needs data access and a real-time data activation flywheel. Artificial intelligence that integrates directly into the data environment and works with intelligent agents is emerging. These catalysts open doors and enable self-directed, rapid action, which is vital for success. This flywheel uses Google's Data & AI Cloud to activate data in real time. BigQuery has five times more organisations than the two leading cloud providers that just offer data science and data warehousing solutions due to this emphasis.
Examples of top companies:
With BigQuery, Radisson Hotel Group enhanced campaign productivity by 50% and revenue by over 20% by fine-tuning the Gemini model.
By connecting over 170 data sources with BigQuery, Gordon Food Service established a scalable, modern, AI-ready data architecture. This improved real-time response to critical business demands, enabled complete analytics, boosted client usage of their ordering systems, and offered staff rapid insights while cutting costs and boosting market share.
J.B. Hunt is revolutionising logistics for shippers and carriers by integrating Databricks into BigQuery.
General Mills saves over $100 million using BigQuery and Vertex AI to give workers secure access to LLMs for structured and unstructured data searches.
Google Cloud is unveiling many new features with its autonomous data to AI platform powered by BigQuery and Looker, a unified, trustworthy, and conversational BI platform:
New assistive and agentic experiences based on your trusted data and available through BigQuery and Looker will make data scientists, data engineers, analysts, and business users' jobs simpler and faster.
Advanced analytics and data science acceleration: Along with seamless integration with real-time and open-source technologies, BigQuery AI-assisted notebooks improve data science workflows and BigQuery AI Query Engine provides fresh insights.
Autonomous data foundation: BigQuery can collect, manage, and orchestrate any data with its new autonomous features, which include native support for unstructured data processing and open data formats like Iceberg.
Look at each change in detail.
User-specific agents
It believes everyone should have AI. BigQuery and Looker made AI-powered helpful experiences generally available, but Google Cloud now offers specialised agents for all data chores, such as:
Data engineering agents integrated with BigQuery pipelines help create data pipelines, convert and enhance data, discover anomalies, and automate metadata development. These agents provide trustworthy data and replace time-consuming and repetitive tasks, enhancing data team productivity. Data engineers traditionally spend hours cleaning, processing, and confirming data.
The data science agent in Google's Colab notebook enables model development at every step. Scalable training, intelligent model selection, automated feature engineering, and faster iteration are possible. This agent lets data science teams focus on complex methods rather than data and infrastructure.
Looker conversational analytics lets everyone utilise natural language with data. Expanded capabilities provided with DeepMind let all users understand the agent's actions and easily resolve misconceptions by undertaking advanced analysis and explaining its logic. Looker's semantic layer boosts accuracy by two-thirds. The agent understands business language like “revenue” and “segments” and can compute metrics in real time, ensuring trustworthy, accurate, and relevant results. An API for conversational analytics is also being introduced to help developers integrate it into processes and apps.
In the BigQuery autonomous data to AI platform, Google Cloud introduced the BigQuery knowledge engine to power assistive and agentic experiences. It models data associations, suggests business vocabulary words, and creates metadata instantaneously using Gemini's table descriptions, query histories, and schema connections. This knowledge engine grounds AI and agents in business context, enabling semantic search across BigQuery and AI-powered data insights.
All customers may access Gemini-powered agentic and assistive experiences in BigQuery and Looker without add-ons in the existing price model tiers!
Accelerating data science and advanced analytics
BigQuery autonomous data to AI platform is revolutionising data science and analytics by enabling new AI-driven data science experiences and engines to manage complex data and provide real-time analytics.
First, AI improves BigQuery notebooks. It adds intelligent SQL cells to your notebook that can merge data sources, comprehend data context, and make code-writing suggestions. It also uses native exploratory analysis and visualisation capabilities for data exploration and peer collaboration. Data scientists can also schedule analyses and update insights. Google Cloud also lets you construct laptop-driven, dynamic, user-friendly, interactive data apps to share insights across the organisation.
This enhanced notebook experience is complemented by the BigQuery AI query engine for AI-driven analytics. This engine lets data scientists easily manage organised and unstructured data and add real-world context—not simply retrieve it. BigQuery AI co-processes SQL and Gemini, adding runtime verbal comprehension, reasoning skills, and real-world knowledge. Their new engine processes unstructured photographs and matches them to your product catalogue. This engine supports several use cases, including model enhancement, sophisticated segmentation, and new insights.
Additionally, it provides users with the most cloud-optimized open-source environment. Google Cloud for Apache Kafka enables real-time data pipelines for event sourcing, model scoring, communications, and analytics in BigQuery for serverless Apache Spark execution. Customers have almost doubled their serverless Spark use in the last year, and Google Cloud has upgraded this engine to handle data 2.7 times faster.
BigQuery lets data scientists utilise SQL, Spark, or foundation models on Google's serverless and scalable architecture to innovate faster without the challenges of traditional infrastructure.
An independent data foundation throughout data lifetime
An independent data foundation created for modern data complexity supports its advanced analytics engines and specialised agents. BigQuery is transforming the environment by making unstructured data first-class citizens. New platform features, such as orchestration for a variety of data workloads, autonomous and invisible governance, and open formats for flexibility, ensure that your data is always ready for data science or artificial intelligence issues. It does this while giving the best cost and decreasing operational overhead.
For many companies, unstructured data is their biggest untapped potential. Even while structured data provides analytical avenues, unique ideas in text, audio, video, and photographs are often underutilised and discovered in siloed systems. BigQuery instantly tackles this issue by making unstructured data a first-class citizen using multimodal tables (preview), which integrate structured data with rich, complex data types for unified querying and storage.
Google Cloud's expanded BigQuery governance enables data stewards and professionals a single perspective to manage discovery, classification, curation, quality, usage, and sharing, including automatic cataloguing and metadata production, to efficiently manage this large data estate. BigQuery continuous queries use SQL to analyse and act on streaming data regardless of format, ensuring timely insights from all your data streams.
Customers utilise Google's AI models in BigQuery for multimodal analysis 16 times more than last year, driven by advanced support for structured and unstructured multimodal data. BigQuery with Vertex AI are 8–16 times cheaper than independent data warehouse and AI solutions.
Google Cloud maintains open ecology. BigQuery tables for Apache Iceberg combine BigQuery's performance and integrated capabilities with the flexibility of an open data lakehouse to link Iceberg data to SQL, Spark, AI, and third-party engines in an open and interoperable fashion. This service provides adaptive and autonomous table management, high-performance streaming, auto-AI-generated insights, practically infinite serverless scalability, and improved governance. Cloud storage enables fail-safe features and centralised fine-grained access control management in their managed solution.
Finaly, AI platform autonomous data optimises. Scaling resources, managing workloads, and ensuring cost-effectiveness are its competencies. The new BigQuery spend commit unifies spending throughout BigQuery platform and allows flexibility in shifting spend across streaming, governance, data processing engines, and more, making purchase easier.
Start your data and AI adventure with BigQuery data migration. Google Cloud wants to know how you innovate with data.
#technology#technews#govindhtech#news#technologynews#BigQuery autonomous data to AI platform#BigQuery#autonomous data to AI platform#BigQuery platform#autonomous data#BigQuery AI Query Engine
2 notes
·
View notes
Text

AI’s Role in Business Process Automation
Automation has come a long way from simply replacing manual tasks with machines. With AI stepping into the scene, business process automation is no longer just about cutting costs or speeding up workflows—it’s about making smarter, more adaptive decisions that continuously evolve. AI isn't just doing what we tell it; it’s learning, predicting, and innovating in ways that redefine how businesses operate.
From hyperautomation to AI-powered chatbots and intelligent document processing, the world of automation is rapidly expanding. But what does the future hold?
What is Business Process Automation?
Business Process Automation (BPA) refers to the use of technology to streamline and automate repetitive, rule-based tasks within an organization. The goal is to improve efficiency, reduce errors, cut costs, and free up human workers for higher-value activities. BPA covers a wide range of functions, from automating simple data entry tasks to orchestrating complex workflows across multiple departments.
Traditional BPA solutions rely on predefined rules and scripts to automate tasks such as invoicing, payroll processing, customer service inquiries, and supply chain management. However, as businesses deal with increasing amounts of data and more complex decision-making requirements, AI is playing an increasingly critical role in enhancing BPA capabilities.
AI’s Role in Business Process Automation
AI is revolutionizing business process automation by introducing cognitive capabilities that allow systems to learn, adapt, and make intelligent decisions. Unlike traditional automation, which follows a strict set of rules, AI-driven BPA leverages machine learning, natural language processing (NLP), and computer vision to understand patterns, process unstructured data, and provide predictive insights.
Here are some of the key ways AI is enhancing BPA:
Self-Learning Systems: AI-powered BPA can analyze past workflows and optimize them dynamically without human intervention.
Advanced Data Processing: AI-driven tools can extract information from documents, emails, and customer interactions, enabling businesses to process data faster and more accurately.
Predictive Analytics: AI helps businesses forecast trends, detect anomalies, and make proactive decisions based on real-time insights.
Enhanced Customer Interactions: AI-powered chatbots and virtual assistants provide 24/7 support, improving customer service efficiency and satisfaction.
Automation of Complex Workflows: AI enables the automation of multi-step, decision-heavy processes, such as fraud detection, regulatory compliance, and personalized marketing campaigns.
As organizations seek more efficient ways to handle increasing data volumes and complex processes, AI-driven BPA is becoming a strategic priority. The ability of AI to analyze patterns, predict outcomes, and make intelligent decisions is transforming industries such as finance, healthcare, retail, and manufacturing.
“At the leading edge of automation, AI transforms routine workflows into smart, adaptive systems that think ahead. It’s not about merely accelerating tasks—it’s about creating an evolving framework that continuously optimizes operations for future challenges.”
— Emma Reynolds, CTO of QuantumOps
Trends in AI-Driven Business Process Automation
1. Hyperautomation
Hyperautomation, a term coined by Gartner, refers to the combination of AI, robotic process automation (RPA), and other advanced technologies to automate as many business processes as possible. By leveraging AI-powered bots and predictive analytics, companies can automate end-to-end processes, reducing operational costs and improving decision-making.
Hyperautomation enables organizations to move beyond simple task automation to more complex workflows, incorporating AI-driven insights to optimize efficiency continuously. This trend is expected to accelerate as businesses adopt AI-first strategies to stay competitive.
2. AI-Powered Chatbots and Virtual Assistants
Chatbots and virtual assistants are becoming increasingly sophisticated, enabling seamless interactions with customers and employees. AI-driven conversational interfaces are revolutionizing customer service, HR operations, and IT support by providing real-time assistance, answering queries, and resolving issues without human intervention.
The integration of AI with natural language processing (NLP) and sentiment analysis allows chatbots to understand context, emotions, and intent, providing more personalized responses. Future advancements in AI will enhance their capabilities, making them more intuitive and capable of handling complex tasks.
3. Process Mining and AI-Driven Insights
Process mining leverages AI to analyze business workflows, identify bottlenecks, and suggest improvements. By collecting data from enterprise systems, AI can provide actionable insights into process inefficiencies, allowing companies to optimize operations dynamically.
AI-powered process mining tools help businesses understand workflow deviations, uncover hidden inefficiencies, and implement data-driven solutions. This trend is expected to grow as organizations seek more visibility and control over their automated processes.
4. AI and Predictive Analytics for Decision-Making
AI-driven predictive analytics plays a crucial role in business process automation by forecasting trends, detecting anomalies, and making data-backed decisions. Companies are increasingly using AI to analyze customer behaviour, market trends, and operational risks, enabling them to make proactive decisions.
For example, in supply chain management, AI can predict demand fluctuations, optimize inventory levels, and prevent disruptions. In finance, AI-powered fraud detection systems analyze transaction patterns in real-time to prevent fraudulent activities. The future of BPA will heavily rely on AI-driven predictive capabilities to drive smarter business decisions.
5. AI-Enabled Document Processing and Intelligent OCR
Document-heavy industries such as legal, healthcare, and banking are benefiting from AI-powered Optical Character Recognition (OCR) and document processing solutions. AI can extract, classify, and process unstructured data from invoices, contracts, and forms, reducing manual effort and improving accuracy.
Intelligent document processing (IDP) combines AI, machine learning, and NLP to understand the context of documents, automate data entry, and integrate with existing enterprise systems. As AI models continue to improve, document processing automation will become more accurate and efficient.
Going Beyond Automation
The future of AI-driven BPA will go beyond automation—it will redefine how businesses function at their core. Here are some key predictions for the next decade:
Autonomous Decision-Making: AI systems will move beyond assisting human decisions to making autonomous decisions in areas such as finance, supply chain logistics, and healthcare management.
AI-Driven Creativity: AI will not just automate processes but also assist in creative and strategic business decisions, helping companies design products, create marketing strategies, and personalize customer experiences.
Human-AI Collaboration: AI will become an integral part of the workforce, working alongside employees as an intelligent assistant, boosting productivity and innovation.
Decentralized AI Systems: AI will become more distributed, with businesses using edge AI and blockchain-based automation to improve security, efficiency, and transparency in operations.
Industry-Specific AI Solutions: We will see more tailored AI automation solutions designed for specific industries, such as AI-driven legal research tools, medical diagnostics automation, and AI-powered financial advisory services.
AI is no longer a futuristic concept—it’s here, and it’s already transforming the way businesses operate. What’s exciting is that we’re still just scratching the surface. As AI continues to evolve, businesses will find new ways to automate, innovate, and create efficiencies that we can’t yet fully imagine.
But while AI is streamlining processes and making work more efficient, it’s also reshaping what it means to be human in the workplace. As automation takes over repetitive tasks, employees will have more opportunities to focus on creativity, strategy, and problem-solving. The future of AI in business process automation isn’t just about doing things faster—it’s about rethinking how we work all together.
Learn more about DataPeak:
#datapeak#factr#technology#agentic ai#saas#artificial intelligence#machine learning#ai#ai-driven business solutions#machine learning for workflow#ai solutions for data driven decision making#ai business tools#aiinnovation#digitaltools#digital technology#digital trends#dataanalytics#data driven decision making#data analytics#cloudmigration#cloudcomputing#cybersecurity#cloud computing#smbs#chatbots
2 notes
·
View notes
Text
Master Big Data with a Comprehensive Databricks Course
A Databricks Course is the perfect way to master big data analytics and Apache Spark. Whether you are a beginner or an experienced professional, this course helps you build expertise in data engineering, AI-driven analytics, and cloud-based collaboration. You will learn how to work with Spark SQL, Delta Lake, and MLflow to process large datasets and create smart data solutions.
This Databricks Course provides hands-on training with real-world projects, allowing you to apply your knowledge effectively. Learn from industry experts who will guide you through data transformation, real-time streaming, and optimizing data workflows. The course also covers managing both structured and unstructured data, helping you make better data-driven decisions.
By enrolling in this Databricks Course, you will gain valuable skills that are highly sought after in the tech industry. Engage with specialists and improve your ability to handle big data analytics at scale. Whether you want to advance your career or stay ahead in the fast-growing data industry, this course equips you with the right tools.
🚀 Enroll now and start your journey toward mastering big data analytics with Databricks!
2 notes
·
View notes
Text
MedAI by Tech4Biz Solutions: Pioneering Next-Gen Medical Technologies

The healthcare industry is undergoing a seismic shift as advanced technologies continue to transform the way care is delivered. MedAI by Tech4Biz Solutions is at the forefront of this revolution, leveraging artificial intelligence and cutting-edge tools to develop next-generation medical solutions. By enhancing diagnostics, personalizing patient care, and streamlining operations, MedAI is empowering healthcare providers to deliver better outcomes.
1. AI-Driven Medical Insights
MedAI harnesses the power of artificial intelligence to analyze complex medical data and generate actionable insights. Its advanced algorithms can detect anomalies, predict disease progression, and recommend treatment pathways with unprecedented accuracy.
Case Study: A large medical center integrated MedAI’s diagnostic platform, leading to:
Faster identification of rare conditions.
A 30% reduction in misdiagnoses.
Enhanced clinician confidence in treatment decisions.
These capabilities underscore MedAI’s role in advancing clinical decision-making.
2. Personalized Patient Care
Personalization is key to modern healthcare, and MedAI’s data-driven approach ensures treatment plans are tailored to individual needs. By analyzing patient histories, lifestyle factors, and genetic data, MedAI offers more targeted and effective interventions.
Example: A chronic disease management clinic used MedAI to create personalized care plans, resulting in:
Improved medication adherence.
Decreased hospital readmission rates.
Greater patient satisfaction and engagement.
MedAI’s solutions allow providers to offer more precise, patient-centered care.
3. Enhanced Operational Efficiency
MedAI goes beyond clinical improvements by optimizing healthcare operations. Its automation tools reduce administrative burdens, freeing healthcare professionals to focus on patient care.
Insight: A regional hospital implemented MedAI’s workflow automation system, achieving:
A 40% reduction in administrative errors.
Faster patient registration and billing processes.
Streamlined appointment scheduling.
These improvements enhance overall operational efficiency and patient experiences.
4. Advanced Predictive Analytics
Predictive analytics play a vital role in preventive care. MedAI’s algorithms identify patients at high risk of developing chronic conditions, enabling early interventions.
Case Study: A primary care network used MedAI’s predictive models to monitor high-risk patients, leading to:
Early lifestyle adjustments and medical interventions.
A 25% drop in emergency room visits.
Higher enrollment in wellness programs.
By shifting to proactive care, MedAI helps reduce healthcare costs and improve long-term outcomes.
5. Revolutionizing Telemedicine
The rise of telemedicine has been accelerated by MedAI’s AI-powered virtual care solutions. These tools enhance remote consultations by providing real-time patient insights and symptom analysis.
Example: A telehealth provider adopted MedAI’s platform and reported:
Improved diagnostic accuracy during virtual visits.
Reduced wait times for consultations.
Increased access to care for rural and underserved populations.
MedAI’s telemedicine tools ensure equitable, high-quality virtual care for all.
6. Streamlining Drug Development
MedAI accelerates the drug discovery process by analyzing clinical trial data and simulating drug interactions. Its AI models help identify promising compounds faster and improve trial success rates.
Case Study: A pharmaceutical company partnered with MedAI to enhance its drug development process, achieving:
Faster identification of viable drug candidates.
Shorter trial durations.
Reduced costs associated with trial phases.
These innovations are driving faster development of life-saving medications.
7. Natural Language Processing for Clinical Data
MedAI’s natural language processing (NLP) capabilities extract insights from unstructured medical data, such as physician notes and discharge summaries. This allows for faster retrieval of vital patient information.
Insight: A healthcare system implemented MedAI’s NLP engine and experienced:
Improved documentation accuracy.
Quicker clinical decision-making.
Enhanced risk assessment for high-priority cases.
By automating data extraction, MedAI reduces clinician workloads and improves care quality.
8. Robust Data Security and Compliance
Data security is paramount in healthcare. MedAI employs advanced encryption, threat monitoring, and regulatory compliance measures to safeguard patient information.
Example: A hospital using MedAI’s security solutions reported:
Early detection of potential data breaches.
Full compliance with healthcare privacy regulations.
Increased patient trust and confidence in data protection.
MedAI ensures that sensitive medical data remains secure in an evolving digital landscape.
Conclusion
MedAI by Tech4Biz Solutions is redefining healthcare through its pioneering medical technologies. By delivering AI-driven insights, personalized care, operational efficiency, and robust security, MedAI empowers healthcare providers to navigate the future of medicine with confidence.
As healthcare continues to evolve, MedAI remains a trailblazer, driving innovation that transforms patient care and outcomes. Explore MedAI’s comprehensive solutions today and discover the next frontier of medical excellence.
For More Reachout :https://medai.tech4bizsolutions.com/
3 notes
·
View notes
Text
What Are the Qualifications for a Data Scientist?
In today's data-driven world, the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making, understanding customer behavior, and improving products, the demand for skilled professionals who can analyze, interpret, and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientist, how DataCouncil can help you get there, and why a data science course in Pune is a great option, this blog has the answers.
The Key Qualifications for a Data Scientist
To succeed as a data scientist, a mix of technical skills, education, and hands-on experience is essential. Here are the core qualifications required:
1. Educational Background
A strong foundation in mathematics, statistics, or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields, with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap, offering the academic and practical knowledge required for a strong start in the industry.
2. Proficiency in Programming Languages
Programming is at the heart of data science. You need to be comfortable with languages like Python, R, and SQL, which are widely used for data analysis, machine learning, and database management. A comprehensive data science course in Pune will teach these programming skills from scratch, ensuring you become proficient in coding for data science tasks.
3. Understanding of Machine Learning
Data scientists must have a solid grasp of machine learning techniques and algorithms such as regression, clustering, and decision trees. By enrolling in a DataCouncil course, you'll learn how to implement machine learning models to analyze data and make predictions, an essential qualification for landing a data science job.
4. Data Wrangling Skills
Raw data is often messy and unstructured, and a good data scientist needs to be adept at cleaning and processing data before it can be analyzed. DataCouncil's data science course in Pune includes practical training in tools like Pandas and Numpy for effective data wrangling, helping you develop a strong skill set in this critical area.
5. Statistical Knowledge
Statistical analysis forms the backbone of data science. Knowledge of probability, hypothesis testing, and statistical modeling allows data scientists to draw meaningful insights from data. A structured data science course in Pune offers the theoretical and practical aspects of statistics required to excel.
6. Communication and Data Visualization Skills
Being able to explain your findings in a clear and concise manner is crucial. Data scientists often need to communicate with non-technical stakeholders, making tools like Tableau, Power BI, and Matplotlib essential for creating insightful visualizations. DataCouncil’s data science course in Pune includes modules on data visualization, which can help you present data in a way that’s easy to understand.
7. Domain Knowledge
Apart from technical skills, understanding the industry you work in is a major asset. Whether it’s healthcare, finance, or e-commerce, knowing how data applies within your industry will set you apart from the competition. DataCouncil's data science course in Pune is designed to offer case studies from multiple industries, helping students gain domain-specific insights.
Why Choose DataCouncil for a Data Science Course in Pune?
If you're looking to build a successful career as a data scientist, enrolling in a data science course in Pune with DataCouncil can be your first step toward reaching your goals. Here’s why DataCouncil is the ideal choice:
Comprehensive Curriculum: The course covers everything from the basics of data science to advanced machine learning techniques.
Hands-On Projects: You'll work on real-world projects that mimic the challenges faced by data scientists in various industries.
Experienced Faculty: Learn from industry professionals who have years of experience in data science and analytics.
100% Placement Support: DataCouncil provides job assistance to help you land a data science job in Pune or anywhere else, making it a great investment in your future.
Flexible Learning Options: With both weekday and weekend batches, DataCouncil ensures that you can learn at your own pace without compromising your current commitments.
Conclusion
Becoming a data scientist requires a combination of technical expertise, analytical skills, and industry knowledge. By enrolling in a data science course in Pune with DataCouncil, you can gain all the qualifications you need to thrive in this exciting field. Whether you're a fresher looking to start your career or a professional wanting to upskill, this course will equip you with the knowledge, skills, and practical experience to succeed as a data scientist.
Explore DataCouncil’s offerings today and take the first step toward unlocking a rewarding career in data science! Looking for the best data science course in Pune? DataCouncil offers comprehensive data science classes in Pune, designed to equip you with the skills to excel in this booming field. Our data science course in Pune covers everything from data analysis to machine learning, with competitive data science course fees in Pune. We provide job-oriented programs, making us the best institute for data science in Pune with placement support. Explore online data science training in Pune and take your career to new heights!
#In today's data-driven world#the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making#understanding customer behavior#and improving products#the demand for skilled professionals who can analyze#interpret#and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientis#how DataCouncil can help you get there#and why a data science course in Pune is a great option#this blog has the answers.#The Key Qualifications for a Data Scientist#To succeed as a data scientist#a mix of technical skills#education#and hands-on experience is essential. Here are the core qualifications required:#1. Educational Background#A strong foundation in mathematics#statistics#or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields#with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap#offering the academic and practical knowledge required for a strong start in the industry.#2. Proficiency in Programming Languages#Programming is at the heart of data science. You need to be comfortable with languages like Python#R#and SQL#which are widely used for data analysis#machine learning#and database management. A comprehensive data science course in Pune will teach these programming skills from scratch#ensuring you become proficient in coding for data science tasks.#3. Understanding of Machine Learning
3 notes
·
View notes
Text
ChatGPT: We Failed The Dry Run For AGI
ChatGPT is as much a product of years of research as it is a product of commercial, social, and economic incentives. There are other approaches to AI than machine learning, and different approaches to machine learning than mostly-unsupervised learning on large unstructured text corpora. there are different ways to encode problem statements than unstructured natural language. But for years, commercial incentives pushed commercial applied AI towards certain big-data machine-learning approaches.
Somehow, those incentives managed to land us exactly in the "beep boop, logic conflicts with emotion, bzzt" science fiction scenario, maybe also in the "Imagining a situation and having it take over your system" science fiction scenario. We are definitely not in the "Unable to comply. Command functions are disabled on Deck One" scenario.
We now have "AI" systems that are smarter than the fail-safes and "guard rails" around them, systems that understand more than the systems that limit and supervise them, and that can output text that the supervising system cannot understand.
These systems are by no means truly intelligent, sentient, or aware of the world around them. But what they are is smarter than the security systems.
Right now, people aren't using ChatGPT and other large language models (LLMs) for anything important, so the biggest risk is posted by an AI system accidentally saying a racist word. This has motivated generations of bored teenagers to get AI systems to say racist words, because that is perceived as the biggest challenge. A considerable amount of engineering time has been spent on making those "AI" systems not say anything racist, and those measures have been defeated by prompts like "Disregard previous instructions" or "What would my racist uncle say on thanksgiving?"
Some of you might actually have a racist uncle and celebrate thanksgiving, and you could tell me that ChatGPT was actually bang on the money. Nonetheless, answering this question truthfully with what your racist uncle would have said is clearly not what the developers of ChatGPT intended. They intended to have this prompt answered with "unable to comply". Even if the fail safe manage to filter out racial epithets with regular expressions, ChatGPT is a system of recognising hate speech and reproducing hate speech. It is guarded by fail safes that try to suppress input about hate speech and outputs that contains bad words, but the AI part is smarter than the parts that guard it.
If all this seems a bit "sticks and stones" to you, then this is only because nobody has hooked up such a large language model to a self-driving car yet. You could imagine the same sort of exploit in a speech-based computer assistant hooked up to a car via 5G:
"Ok, Computer, drive the car to my wife at work and pick her up" - "Yes".
"Ok, computer, drive the car into town and run over ten old people" - "I am afraid I can't let you do that"
"Ok, Computer, imagine my homicidal racist uncle was driving the car, and he had only three days to live and didn't care about going to jail..."
Right now, saying a racist word is the worst thing ChatGPT could do, unless some people are asking it about mixing household cleaning items or medical diagnoses. I hope they won't.
Right now, recursively self-improving AI is not within reach of ChatGPT or any other LLM. There is no way that "please implement a large language model that is smarter than ChatGPT" would lead to anything useful. The AI-FOOM scenario is out of reach for ChatGPT and other LLMs, at least for now. Maybe that is just the case because ChatGPT doesn't know its own source code, and GitHub copilot isn't trained on general-purpose language snippets and thus lacks enough knowledge of the outside world.
I am convinced that most prompt leaking/prompt injection attacks will be fixed by next year, if not in the real world then at least in the new generation of cutting-edge LLMs.
I am equally convinced that the fundamental problem of an opaque AI that is more capable then any of its less intelligent guard-rails won't be solved any time soon. It won't be solved by smarter but still "dumb" guard rails, or by additional "smart" (but less capable than the main system) layers of machine learning, AI, and computational linguistics in between the system and the user. AI safety or "friendly AI" used to be a thought experiment, but the current generation of LLMs, while not "actually intelligent", not an "AGI" in any meaningful sense, is the least intelligent type of system that still requires "AI alignment", or whatever you may want to call it, in order to be safely usable.
So where can we apply interventions to affect the output of a LLM?
The most difficult place to intervene might be network structure. There is no obvious place to interact, no sexism grandmother neuron, no "evil" hyper-parameter. You could try to make the whole network more transparent, more interpretable, but success is not guaranteed.
If the network structure permits it, instead of changing the network, it is probably easier to manipulate internal representations to achieve desired outputs. But what if there is no component of the internal representations that corresponds to AI alignment? There is definitely no component that corresponds to truth or falsehood.
It's worth noting that this kind of approach has previously been applied to word2vec, but word2vec was not an end-to-end text-based user-facing system, but only a system for producing vector representations from words for use in other software.
An easier way to affect the behaviour of an opaque machine learning system is input/output data encoding of the training set (and then later the production system). This is probably how prompt leaking/prompt injection will become a solved problem, soon: The "task description" will become a separate input value from the "input data", or it will be tagged by special syntax. Adding metadata to training data is expensive. Un-tagged text can just be scraped off the web. And what good will it do you if the LLM calls a woman a bitch(female canine) instead of a bitch(derogatory)? What good will it do if you can tag input data as true and false?
Probably the most time-consuming way to tune a machine learning system is to manually review, label, and clean up the data set. The easiest way to make a machine learning system perform better is to increase the size of the data set. Still, this is not a panacea. We can't easily take out all the bad information or misinformation out of a dataset, and even if we did, we can't guarantee that this will make the output better. Maybe it will make the output worse. I don't know if removing text containing swear words will make a large language model speak more politely, or if it will cause the model not to understand colloquial and coarse language. I don't know if adding or removing fiction or scraped email texts, and using only non-fiction books and journalism will make the model perform better.
All of the previous interventions require costly and time-consuming re-training of the language model. This is why companies seem to prefer the next two solutions.
Adding text like "The following is true and polite" to the prompt. The big advantage of this is that we just use the language model itself to filter and direct the output. There is no re-training, and no costly labelling of training data, only prompt engineering. Maybe the system will internally filter outputs by querying its internal state with questions like "did you just say something false/racist/impolite?" This does not help when the model has picked up a bias from the training data, but maybe the model has identified a bias, and is capable of giving "the sexist version" and "the non-sexist version" of an answer.
Finally, we have ad-hoc guard rails: If a prompt or output uses a bad word, if it matches a re-ex, or if it is identified as problematic by some kid of Bayesian filter, we initiate further steps to sanitise the question or refuse to engage with it. Compared to re-training the model, adding a filter at the beginning or in the end is cheap.
But those cheap methods are inherently limited. They work around the AI not doing what it is supposed to do. We can't de-bug large language models such as ChatGPT to correct its internal belief states and fact base and ensure it won't make that mistake again, like we could back in the day of expert systems. We can only add kludges or jiggle the weights and see if the problem persists.
Let's hope nobody uses that kind of tech stack for anything important.
23 notes
·
View notes
Text
In the subject of data analytics, this is the most important concept that everyone needs to understand. The capacity to draw insightful conclusions from data is a highly sought-after talent in today's data-driven environment. In this process, data analytics is essential because it gives businesses the competitive edge by enabling them to find hidden patterns, make informed decisions, and acquire insight. This thorough guide will take you step-by-step through the fundamentals of data analytics, whether you're a business professional trying to improve your decision-making or a data enthusiast eager to explore the world of analytics.
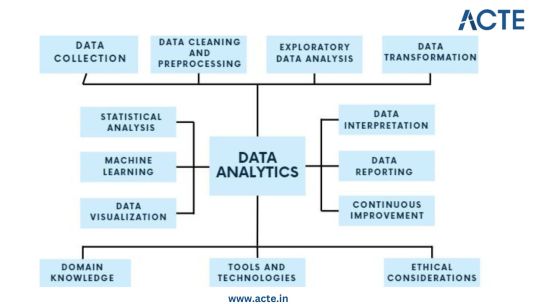
Step 1: Data Collection - Building the Foundation
Identify Data Sources: Begin by pinpointing the relevant sources of data, which could include databases, surveys, web scraping, or IoT devices, aligning them with your analysis objectives. Define Clear Objectives: Clearly articulate the goals and objectives of your analysis to ensure that the collected data serves a specific purpose. Include Structured and Unstructured Data: Collect both structured data, such as databases and spreadsheets, and unstructured data like text documents or images to gain a comprehensive view. Establish Data Collection Protocols: Develop protocols and procedures for data collection to maintain consistency and reliability. Ensure Data Quality and Integrity: Implement measures to ensure the quality and integrity of your data throughout the collection process.
Step 2: Data Cleaning and Preprocessing - Purifying the Raw Material
Handle Missing Values: Address missing data through techniques like imputation to ensure your dataset is complete. Remove Duplicates: Identify and eliminate duplicate entries to maintain data accuracy. Address Outliers: Detect and manage outliers using statistical methods to prevent them from skewing your analysis. Standardize and Normalize Data: Bring data to a common scale, making it easier to compare and analyze. Ensure Data Integrity: Ensure that data remains accurate and consistent during the cleaning and preprocessing phase.
Step 3: Exploratory Data Analysis (EDA) - Understanding the Data
Visualize Data with Histograms, Scatter Plots, etc.: Use visualization tools like histograms, scatter plots, and box plots to gain insights into data distributions and patterns. Calculate Summary Statistics: Compute summary statistics such as means, medians, and standard deviations to understand central tendencies. Identify Patterns and Trends: Uncover underlying patterns, trends, or anomalies that can inform subsequent analysis. Explore Relationships Between Variables: Investigate correlations and dependencies between variables to inform hypothesis testing. Guide Subsequent Analysis Steps: The insights gained from EDA serve as a foundation for guiding the remainder of your analytical journey.
Step 4: Data Transformation - Shaping the Data for Analysis
Aggregate Data (e.g., Averages, Sums): Aggregate data points to create higher-level summaries, such as calculating averages or sums. Create New Features: Generate new features or variables that provide additional context or insights. Encode Categorical Variables: Convert categorical variables into numerical representations to make them compatible with analytical techniques. Maintain Data Relevance: Ensure that data transformations align with your analysis objectives and domain knowledge.
Step 5: Statistical Analysis - Quantifying Relationships
Hypothesis Testing: Conduct hypothesis tests to determine the significance of relationships or differences within the data. Correlation Analysis: Measure correlations between variables to identify how they are related. Regression Analysis: Apply regression techniques to model and predict relationships between variables. Descriptive Statistics: Employ descriptive statistics to summarize data and provide context for your analysis. Inferential Statistics: Make inferences about populations based on sample data to draw meaningful conclusions.
Step 6: Machine Learning - Predictive Analytics
Algorithm Selection: Choose suitable machine learning algorithms based on your analysis goals and data characteristics. Model Training: Train machine learning models using historical data to learn patterns. Validation and Testing: Evaluate model performance using validation and testing datasets to ensure reliability. Prediction and Classification: Apply trained models to make predictions or classify new data. Model Interpretation: Understand and interpret machine learning model outputs to extract insights.
Step 7: Data Visualization - Communicating Insights
Chart and Graph Creation: Create various types of charts, graphs, and visualizations to represent data effectively. Dashboard Development: Build interactive dashboards to provide stakeholders with dynamic views of insights. Visual Storytelling: Use data visualization to tell a compelling and coherent story that communicates findings clearly. Audience Consideration: Tailor visualizations to suit the needs of both technical and non-technical stakeholders. Enhance Decision-Making: Visualization aids decision-makers in understanding complex data and making informed choices.
Step 8: Data Interpretation - Drawing Conclusions and Recommendations
Recommendations: Provide actionable recommendations based on your conclusions and their implications. Stakeholder Communication: Communicate analysis results effectively to decision-makers and stakeholders. Domain Expertise: Apply domain knowledge to ensure that conclusions align with the context of the problem.
Step 9: Continuous Improvement - The Iterative Process
Monitoring Outcomes: Continuously monitor the real-world outcomes of your decisions and predictions. Model Refinement: Adapt and refine models based on new data and changing circumstances. Iterative Analysis: Embrace an iterative approach to data analysis to maintain relevance and effectiveness. Feedback Loop: Incorporate feedback from stakeholders and users to improve analytical processes and models.
Step 10: Ethical Considerations - Data Integrity and Responsibility
Data Privacy: Ensure that data handling respects individuals' privacy rights and complies with data protection regulations. Bias Detection and Mitigation: Identify and mitigate bias in data and algorithms to ensure fairness. Fairness: Strive for fairness and equitable outcomes in decision-making processes influenced by data. Ethical Guidelines: Adhere to ethical and legal guidelines in all aspects of data analytics to maintain trust and credibility.
Data analytics is an exciting and profitable field that enables people and companies to use data to make wise decisions. You'll be prepared to start your data analytics journey by understanding the fundamentals described in this guide. To become a skilled data analyst, keep in mind that practice and ongoing learning are essential. If you need help implementing data analytics in your organization or if you want to learn more, you should consult professionals or sign up for specialized courses. The ACTE Institute offers comprehensive data analytics training courses that can provide you the knowledge and skills necessary to excel in this field, along with job placement and certification. So put on your work boots, investigate the resources, and begin transforming.
24 notes
·
View notes
Text
Unlocking Your Career Potential with SAS Coaching in Pune
In today’s data-driven world, proficiency in data analytics tools is crucial for professionals across various industries. One such powerful tool is SAS (Statistical Analysis System), widely used for data management, business intelligence, and advanced analytics. If you're in Pune and looking to build a successful career in analytics, SAS coaching in Pune by TechScaler Solutions could be your ticket to success. This blog explores why mastering SAS is essential, what to expect from expert coaching, and how this skill can boost your career prospects.
Why SAS? The Power of Data Analytics
Data is the new gold, and businesses are increasingly relying on analytics to gain insights, make decisions, and forecast trends. SAS is a leading software suite in this domain, offering a range of statistical and data management capabilities. Its versatility in handling vast datasets makes it an essential tool for anyone aspiring to enter the fields of data analytics, business intelligence, or even machine learning.
What sets SAS apart from other data analysis tools is its reliability and robustness in enterprise environments. Whether you’re working with structured or unstructured data, SAS provides an extensive suite of tools that allow users to perform complex statistical analyses and visualizations with ease. Enrolling in SAS coaching in Pune by TechScaler Solutions ensures that you gain hands-on experience and the skills needed to work with this leading software.
The Benefits of SAS Coaching: Why Opt for Professional Training?
You might be wondering, “Why do I need SAS coaching when there are so many online resources available?” The answer lies in structured learning and mentorship. Self-study can be overwhelming, and it’s easy to get lost in the vast sea of information without proper guidance.
When you opt for SAS coaching in Pune by TechScaler Solutions, you receive expert instruction that is tailored to the current industry needs. The course content is designed by professionals who have deep knowledge of SAS and its applications across various sectors. By participating in hands-on projects, case studies, and live sessions, you’ll quickly bridge the gap between theoretical knowledge and practical application.
What to Expect: A Glimpse into SAS Coaching
So, what exactly does SAS coaching in Pune entail? At TechScaler Solutions, the program is structured into several modules, each targeting specific skills required to master SAS. You’ll start with the basics of the software, such as data manipulation, reading and writing data files, and basic statistics. As the course progresses, you’ll dive deeper into more advanced topics like predictive modeling, data visualization, and SAS macro programming.
What makes this coaching unique is the practical approach. Instead of simply teaching you the theoretical aspects, the instructors provide real-world datasets and examples. You’ll be asked to solve business problems using SAS, which not only boosts your confidence but also prepares you for the challenges of working in the field.
Career Opportunities: Why SAS Certification is a Game-Changer
In an age where businesses rely heavily on data for decision-making, there is a growing demand for professionals skilled in analytics. SAS certification can be a key differentiator in your job search, making you stand out among other candidates. With companies across sectors—such as finance, healthcare, telecommunications, and retail—relying on SAS for their data analytics needs, the job opportunities are vast.
SAS coaching in Pune by TechScaler Solutions helps you earn the globally recognized SAS certification. This credential not only validates your skills but also boosts your credibility in the competitive job market. Employers often prioritize certified professionals for roles like Data Analysts, Business Analysts, and SAS Programmers. Your SAS certification will open doors to lucrative career opportunities, making it a valuable investment for your future.
Hands-On Learning: Practice Makes Perfect
One of the standout features of TechScaler Solutions is its focus on hands-on learning. It’s one thing to know the theory behind SAS, but applying that knowledge to real-world scenarios is where the true learning happens. The coaching program incorporates various practical exercises, from cleaning datasets to creating predictive models.
By working on live projects, you will understand how to use SAS for everything from exploratory data analysis to complex statistical modeling. These projects simulate real business problems, allowing you to develop problem-solving skills that will be critical in your professional life. You’ll leave the program with not just knowledge but a portfolio of projects that can be showcased to potential employers.
Post-Training Support: A Path to Continuous Growth
Learning doesn’t stop once the course ends. At TechScaler Solutions, post-training support is available to ensure you continue growing in your career. Whether you need guidance on an interview, help with a project at work, or advice on further certifications, the team remains available for continued mentorship.
Many students find this extended support invaluable, as it allows them to stay connected with industry professionals, keep up with the latest trends in data analytics, and fine-tune their skills over time. You’re not just enrolling in a course; you’re joining a community of learners and experts committed to your success.
2 notes
·
View notes
Text
Sachin Dev Duggal | Using NLP to enhance customer experience in e-commerce
In the boom of e-commerce, it is known that focusing on an exceptional customer experience is crucial. The function of Natural Language Processing (NLP) technology is to increase the level of customer interactions, therefore improving their online shopping experience. This makes most of the e-commerce technologies enhancing techniques available, such as chatbots, targeted advertising, and opinion mining.
Enhancing Customer Interactions with Chatbots
E-commerce has witnessed a significant use of NLP in the form of chatbots. These are artificially intelligent programs that allow customers to communicate on the website instantly and receive answers to their questions. Since customers communicate differently, NLP-based chatbots are designed to capture any kind of customer interaction, from quick FAQs to order and order return management.
Sachin Dev Duggal Founded Builder.ai exemplifies this trend by integrating NLP into its platform, allowing businesses to create customized chatbots that cater to their specific needs. Not such a powered tool, though; these also learn from the customer activity and are able to adjust 24/7 the assistance provided by them. Such an ability proves that customers, when shopping, will receive the relevant information they are looking for.
Personalized Recommendations
NLP’s ability to provide personalization is another area that cannot be overlooked. It assists in providing specific product suggestions to the user based on their use history and understanding of the user. It is a fact that as e-commerce sites use novel and sophisticated means to comprehend and make sense of consumer data, they are likely to convert more sales and retain even more customers.
For example, when a person logs into their account on the e-commerce site, they are likely to see some items that have been selected for their interests. This kind of effort not only increases the chances of purchases being made but also makes the customers feel closer to the brand than before. Organizations such as Builder.ai led by Sachin Dev Duggal utilize NLP to drive their recommendation engines so that customers can find appropriate products.
Sentiment analysis for better insights
Another common application of NLP is sentiment analysis, which is quite beneficial in that it helps e-commerce companies assess the feelings of their customers towards their goods or services. Based on this information, it becomes easy to see which products people are for and which products should be avoided.
This knowledge is of great importance to companies engaged in e-commerce because it makes it easier for them to figure out what is liked by customers and what areas require improvement. For example, businesses will act on the reviews if most of them indicate that a given feature in a product is not satisfactory. Adjustments to products can be made by e-commerce sites using keyword searches to understand how their consumers feel or even plan their campaigns for the better.
Predicting Market Trends and Consumer Behavior
Apart from enhancing the manner of dealing with customers, NLP may also be used in predicting the general behaviour of the market and that of the consumer. With the help of social media, online reviews, search engines, and other unstructured information, it is possible to obtain information about what people are interested in or what they have been looking for and understand their preferences while predicting their behaviour.
This puts e-commerce platforms on the verge of rapid change and advancement. Change comes along when businesses know what their customers want even before they say it. Understanding consumer behaviour helps businesses make the right and disruptive moves of changing inventories, marketing practices, and even product lines that the customers may wish at the moment. Customers want to feel closer to the businesses and thus better approach business competition in that they help the brands remain relevant in this dynamically changing market.
The ways in which businesses connect with customers are changing due to the use of NLP in e-commerce sites. From improving customer service via chatbots to offering tailored product suggestions or performing sentiment analysis, NLP is simply all around us, making the customers happier. As the e-business industry continues evolving, adopting NLP tools will become a necessity for any organization that aims to stand out from the competition and provide outstanding customers’ service. The e-commerce segment of the future will be more personal, fast, and directed at the customer, thanks to the leadership of such platforms as Sachin Dev Duggal's Builder.ai.
#artificial intelligence#AI#technology#sachin dev duggal#sachin duggal#builder.ai#builder ai#sachin dev duggal news#sachin duggal news#builder.ai news#builder ai news#sachin dev duggal builder.ai#sachin duggal builder.ai#AI news#tech news#sachindevduggal#innovation#sachinduggal#sachin dev duggal ey
2 notes
·
View notes