#adjacency matrix example
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In February 2021, Tumblr had 518.6 million blog accounts.
Text
Alpha testing, v0.12-v0.14
So, it's been a busy period, both in real life and for the game. Game stuff first though! M was back testing a few consecutive versions of the game. Some of the highlights for each version:
v0.12 - Looking beyond the code
M had suggested a new room/corridor algorithm to reflect the final design of the dungeon, rather than how it was constructed. During construction, some corridors can be widened, and some rooms can have space taken from them, and so an algorithm was developed that looks for a certain number of adjacent squares (like a 2x2 seed) that fills space and is stopped by a 1 tile wide corridor.
However, the initial algorithm was overzealous in its conversion and also converted the map edge to ground that could be walked on. Oops! So when M stepped onto to one of these spaces, and was looking over into a tile with x or y coordinates of -1, the game would indeed crash.
The other type of "illegal" looking happened due to my implementation of the turn speed option. During battle, you'd turn too fast and (because of my hacky implementation), the enemies wouldn't spawn, and so you'd enter a soft lock sort-of battle mode limbo. Again, all fixed, it now accounts for turn speed!
v0.13 - Tamed doors
Probably the best feature I added in this version was the ability to interact with doors and stairs simply by walking into them. It was a small change but one that was appreciated.
Apart from that, M had a suspiciously bad run of luck previously when trying to extract lore/logs from computers within the dungeon. When I looked into it, I was testing multiple log parts and forgot to get rid of a debug value that stopped the player from collecting the first part of the log. If the first part wasn't obtained, the later parts couldn't be obtained too!
However, in this version, I once again forgot to reset the extraction rate for the log - I wanted to make sure everything was working so I set the rate temporarily to 100%. So M went from being too unlucky to being too lucky...
v0.14 - The sound of music
I had M fiddle around with the volume settings on the options in the title screen (without telling him why), and we spent some time in the options menu. Here's some paraphrased dialog:
Him: Oh, the music cut out and reset just now
Me: Yes, my composer hasn't completed the song so it's just here as placeholder
Him: Right, I don't think I've heard it cut out before because I've never spent so long here on the title screen
Me: Actually, it's because this is the first version of the game to include music!
My composer friend (P, from now on) had asked me to put in some music in order for him to get an idea of the types of songs I want, and how they sounded in context. P said just use whatever was the most fitting, and he had written samples of songs previously for me, which are amazing, so of course I added them in. Along with some examples of other music I thought was fitting.
I said it to P, and he said it back to me during his test (v0.15, blog coming soon), but wow, the music really makes the game come together.
There's 3 lots of patchnotes below the cut, so brace yourselves...
v0.14 Features: Press forward to interact with stairs/doors automatically! Advantage Burst status effects now actually have effects! Implemented slider for lingering screen glitch effect length! Relativistic navigator mouse controls! Added recruitment % display to enemies Added options button to delete tutorial progress Full screen tutorials implemented! ADDED MUSIC!!!! Added master volume slider Added move speed option Shift+click is debug travel to dungeon/system
Balance: Buffed recruitment rate slightly
Polish: When stepped on, features don't display a message if they don't successfully affect you Matrix slot text no longer spilling out of the box Made navigator icons blink when appropriate Nav icons stop blinking when moused over Rel nav messages now appear HP display on enemies now rolls to the right value Added send log to bug reporting text Added mouse2 clicks to cancel report forms and rel nav interface First time scan displays enemy description in log Made options no longer need to be deleted when adding new option into the game Made logger not log empty text variables Added divider to tutorials Added interface initializing text to stop text bug Fixed misaligned … in scrolling textbox Added music rights text
Bugs: Removed fuel gain requirement from projects to be able to access tier 1 capstone Re-enabled lore collection Fixed some attack and defense stats of items in database being mixed up Fixed empty form textbox crash Fixed strange battle array crash related to fixing the coordinates when the unit moves before the attack applies
v0.13 Features: Do a 180 with shift + turn!
Balance: Slightly lowered enemy spawns Stuns and summons have 2 cooldown Buffed some AoEs Made advantage bursts inflict double bad/good status effects
Polish: Made research results more visible Made research help screen clearer Moving your mouse away from the dungeon icon on the navigation screen now cancels it Changed swim swarm center square Renamed Energy Differential -> Energy Drain for clarity Increased tutorial text scroll rate Text speed textbox and window speed window in options menu is deleted immediately when closing
Bugs: Fixed debug options deletion flag also deleting save files Stopped showing default "ITEM" attack when no equips Stopped battle softlocks when fast turning Disassemble tutorial now fires correctly Exploration help overlay message displaying the proper text after game load Fixed room conversion code converting the dungeon boundary to floors Fixed some features from showing up as the unexplored scanner fx
v0.12 Features: Added more stairs up sprites (a vertically mirrored hole and pad) for clarity Added text logging! Added option to speed up turn speed
Balance: Changed sensory overload affinity to particle for Astronaut Buffed Assistant's sensory stun affinity to overload Increased data costs of first 2 projects Slightly tweaked encounters to make bigger enemies spawn more frequently Made status effects apply with a chance based on the weak/resist of the unit Added flags that stop certain moves from missing
Polish: Standardised being able to exit out of some base facilities instantly vs not Made the back to base noise only occur when the screen is fading to black and not when it's waiting for text to finish outputting Fixed being able to click to select an attack in the attack menu to avoid double clicking accidentally Made attack power numbers on the routine information panel have 2 decimal places Changed tutorial text from "suit's option menu" to "option menu" Changed other effect intensity to screen glitch intensity Text on research in progress screen now includes tip about data collection Research arrows now flicker Made some unimportant tutorials only happen when the major game state gets changed Added SE descrption to mouse tooltip Made research left/right icons blink Secondary affinity animations now appear above the status panels Updated some menus and icons (battle, storage, party) Now show targeting background on selection of non routine moves
Bugs: Fixed frame perfect cancel inputs on base facilities softlocking the game Fixed research tutorial for dismantling not showing under the right circumstances Fixed power load tutorial not working Fixed last tutorial and crafting availability entry being duplicated in the respective save grids Fixed objects close to the ground tute triggering for the spawner object Fixed enemy description showing when using mouse controls to choose the attack target Stopped mouse controls from choosing a disallowed row as specified by the upperlock parameter in the routines database Fixed defending status effect not upping negative resistances Standardised the way the e_battle.target state generates move targeting parameters Fixed objects not appearing when going throgh doors Defending now decreases incoming damage instead of increasing it Stopped mouse stat panel from staying when exiting battle Mouseover routine information panel now closes properly when viewing a part without any moves Fixed item filtering in storage window not working on mouseclick
#indiedev#gamedev#gaming#pixel art#scifi#space#gamemaker#programming#rpg#robot#devblog#game#videogame#codeblr
12 notes
·
View notes
Text
CW FOR UNREALITY obviously. ill tag it in the tags as well
anything adjacent to “the world is a simulation”. should be obvious why.
personally we get triggered by the matrix as well.
conspiracy theories are another good one. do not mention conspiracies around psychotic people (or ask them first. this should be what you do actually. ask them). they have caused us a lot of harm in the past, and people around us as well.
in general anything joking about unreality or what can set someones paranoia off. its pretty easy to spot those statements/“jokes”
some other common delusions are anything involving the government, especially spying. or hidden cameras. or anything not real that you insinuate is there (esp as a non-psychotic). this extends to “living” creatures too
no two schizospec / psychotic people are the same though. again, just ask them, best outside of an episode. these are just some things in our experience. and obviously it is NOT a comprehensive guide.
general advice to leave as well: do NOT feed any kinds of delusions. THIS IS A NO-GO. if its not a “harmful” delusion, do NOT deny it either. (try to remain as “neutral” as possible.) its difficult to explain what a harmful/non-harmful delusion is but for example delusions of grandeur. we have had some in the past, and they have “protected” us from other types of delusions. if someone had denied us those we would probably end up further in our episode/s. but again this is PERSONAL EXPERIENCE. WHAT IS/ISN’T HARMFUL FOR A PSYCHOTIC DEPENDS ON THE INDIVIDUAL. like i said earlier, best to ask them outside of an episode what to do, and what not to do, if you know any psychotic people.
if anyone has anything else to add-on, feel free.
Things I'd love for the Internet to leave in 2023:
• misusing the word "delusional" or saying "delulu"
• public freakout videos that are just someone displaying psychotic symptoms
• "I'm in your walls" and other paranoia triggering "jokes"
• schizoposting
• misusing the word "psychotic"
• baiting and triggering people online who are openly psychotic or displaying psychotic symptoms
• excluding schizo-spec and psychotic people from any neurodiversity/mental illness awareness
Let's just all try to be better to schizo-spec and psychotic people. And hold others accountable as well.
#unreality#tw unreality#unreality tw#conspiracy theories#conspiracy theories ment#matrix#the matrix#not sure what else to tag#ask to tag if theres anything else i should#also sorry if the unreality tags are annoying we tend to use them to filter out anything that could possibly trigger us
31K notes
·
View notes
Text
IEEE Transactions on Artificial Intelligence, Volume 6, Issue 4, April 2025
1) Consistent Counterfactual Explanations via Anomaly Control and Data Coherence
Author(s): Maria Movin, Federico Siciliano, Rui Ferreira, Fabrizio Silvestri, Gabriele Tolomei
Pages: 794 - 804
2) Adversarial Masked Autoencoders Are Robust Vision Learners
Author(s): Yuchong Yao, Nandakishor Desai, Marimuthu Palaniswami
Pages: 805 - 815
3) Generation With Nuanced Changes: Continuous Image-to-Image Translation With Adversarial Preferences
Author(s): Yinghua Yao, Yuangang Pan, Ivor W. Tsang, Xin Yao
Pages: 816 - 828
4) Safe Multiagent Reinforcement Learning With Bilevel Optimization in Autonomous Driving
Author(s): Zhi Zheng, Shangding Gu
Pages: 829 - 842
5) Analyzing Hierarchical Relationships and Quality of Embedding in Latent Space
Author(s): Ankita Chatterjee, Jayanta Mukherjee, Partha Pratim Das
Pages: 843 - 858
6) HGFF: A Deep Reinforcement Learning Framework for Lifetime Maximization in Wireless Sensor Networks
Author(s): Xiaoxu Han, Xin Mu, Jinghui Zhong
Pages: 859 - 873
7) Active Robust Adversarial Reinforcement Learning Under Temporally Coupled Perturbations
Author(s): Jiacheng Yang, Yuanda Wang, Lu Dong, Lei Xue, Changyin Sun
Pages: 874 - 884
8) FAST: Feature Aware Similarity Thresholding for Weak Unlearning in Black-Box Generative Models
Author(s): Subhodip Panda, A.P. Prathosh
Pages: 885 - 895
9) Multiobjective Optimization for Traveling Salesman Problem: A Deep Reinforcement Learning Algorithm via Transfer Learning
Author(s): Le-yang Gao, Rui Wang, Zhao-hong Jia, Chuang Liu
Pages: 896 - 908
10) LoRaDIP: Low-Rank Adaptation With Deep Image Prior for Generative Low-Light Image Enhancement
Author(s): Zunjin Zhao, Daming Shi
Pages: 909 - 920
11) DGeC: Dynamically and Globally Enhanced Convolution
Author(s): Zihang Zhang, Yuling Liu, Zhili Zhou, Gaobo Yang, Xin Liao, Q. M. Jonathan Wu
Pages: 921 - 933
12) CH-Net: A Cross Hybrid Network for Medical Image Segmentation
Author(s): Jiale Li, Aiping Liu, Wei Wei, Ruobing Qian, Xun Chen
Pages: 934 - 944
13) APR-Net: Defense Against Adversarial Examples Based on Universal Adversarial Perturbation Removal Network
Author(s): Wenxing Liao, Zhuxian Liu, Minghuang Shen, Riqing Chen, Xiaolong Liu
Pages: 945 - 954
14) A Scalable Unsupervised and Back Propagation Free Learning With SACSOM: A Novel Approach to SOM-Based Architectures
Author(s): Gaurav R. Hirani, Kevin I-Kai Wang, Waleed H. Abdulla
Pages: 955 - 967
15) CheckSelect: Online Checkpoint Selection for Flexible, Accurate, Robust, and Efficient Data Valuation
Author(s): Soumi Das, Manasvi Sagarkar, Suparna Bhattacharya, Sourangshu Bhattacharya
Pages: 968 - 978
16) Industrial Process Monitoring Based on Deep Gaussian and Non-Gaussian Information Fusion Framework
Author(s): Zhiqiang Ge
Pages: 979 - 988
17) A Temporal–Spatial Graph Network With a Learnable Adjacency Matrix for Appliance-Level Electricity Consumption Prediction
Author(s): Dandan Li, Jiaxing Xia, Jiangfeng Li, Changjiang Xiao, Vladimir Stankovic,
Lina Stankovic, Qingjiang Shi
Pages: 989 - 1002
18) Data-Driven Event-Triggered Control for Discrete-Time Neural Networks Subject to Actuator Saturation
Author(s): Yanyan Ni, Zhen Wang, Xia Huang, Hao Shen
Pages: 1003 - 1013
19) Aperiodically Intermittent Control Approach to Finite-Time Synchronization of Delayed Inertial Memristive Neural Networks
Author(s): Yuxin Jiang, Song Zhu, Mouquan Shen, Shiping Wen, Chaoxu Mu
Pages: 1014 - 1023
20) Unformer: A Transformer-Based Approach for Adaptive Multiscale Feature Aggregation in Underwater Image Enhancement
Author(s): Yuhao Qing, Yueying Wang, Huaicheng Yan, Xiangpeng Xie, Zhengguang Wu
Pages: 1024 - 1037
21) ClusVPR: Efficient Visual Place Recognition With Clustering-Based Weighted Transformer
Author(s): Yifan Xu, Pourya Shamsolmoali, Masoume Zareapoor, Jie Yang
Pages: 1038 - 1049
0 notes
Text

What Does Big O(N^2) Complexity Mean?
It's critical to consider how algorithms function as the size of the input increases while analyzing them. Big O notation is a crucial statistic computer scientists use to categorize algorithms, which indicates the sequence of increase of an algorithm's execution time. O(N^2) algorithms are a significant and popular Big O class, whose execution time climbs quadratically as the amount of the input increases. For big inputs, algorithms with this time complexity are deemed inefficient because doubling the input size will result in a four-fold increase in runtime.
This article will explore what Big O(N^2) means, analyze some examples of quadratic algorithms, and discuss why this complexity can be problematic for large data sets. Understanding algorithmic complexity classes like O(N^2) allows us to characterize the scalability and efficiency of different algorithms for various use cases.
Different Big Oh Notations.
O(1) - Constant Time:
An O(1) algorithm takes the same time to complete regardless of the input size. An excellent example is to retrieve an array element using its index. Looking up a key in a hash table or dictionary is also typically O(1). These operations are very fast, even for large inputs.
O(log N) - Logarithmic Time:
Algorithms with log time complexity are very efficient. For a sorted array, binary search is a classic example of O(log N) because the search space is halved each iteration. Finding an item in a balanced search tree also takes O(log N) time. Logarithmic runtime grows slowly with N.
O(N) - Linear Time:
Linear complexity algorithms iterate through the input at least once. Simple algorithms for sorting, searching unsorted data, or accessing each element of an array take O(N) time. As data sets get larger, linear runtimes may become too slow. But linear is still much better than quadratic or exponential runtimes.
O(N log N) - Log-Linear Time:
This complexity results in inefficient sorting algorithms like merge sort and heap sort. The algorithms split data into smaller chunks, sort each chunk (O(N)) and then merge the results (O(log N)). Well-designed algorithms aimed at efficiency often have log-linear runtime.
O(N^2) - Quadratic Time:
Quadratic algorithms involve nested iterations over data. Simple sorting methods like bubble and insertion sort are O(N^2). Matrix operations like multiplication are also frequently O(N^2). Quadratic growth becomes infeasible for large inputs. More complex algorithms are needed for big data.
O(2^N) - Exponential Time:
Exponential runtimes are not good in algorithms. Adding just one element to the input doubles the processing time. Recursive calculations of Fibonacci numbers are a classic exponential time example. Exponential growth makes these algorithms impractical even for modestly large inputs.
What is Big O(N^2)?
An O(N2) algorithm's runtime grows proportionally to the square of the input size N.
Doubling the input size quadruples the runtime. If it takes 1 second to run on 10 elements, it will take about 4 seconds on 20 elements, 16 seconds on 40 elements, etc.
O(N^2) algorithms involve nested iterations through data. For example, checking every possible pair of elements or operating on a 2D matrix.
Simple sorting algorithms like bubble sort, insertion sort, and selection sort are typically O(N^2). Comparing and swapping adjacent elements leads to nested loops.
Brute force search algorithms are often O(N^2). Checking every subarray or substring for a condition requires nested loops.
Basic matrix operations like multiplication of NxN matrices are O(N^2). Each entry of the product matrix depends on a row and column of the input matrices.
Graph algorithms like Floyd-Warshall for finding the shortest paths between all vertex pairs is O(N^2). Every possible path between vertices is checked.
O(N^2) is fine for small inputs but becomes very slow for large data sets. Algorithms with quadratic complexity cannot scale well.
For large inputs, more efficient algorithms like merge sort O(N log N) and matrix multiplication O(N^2.807) should be preferred over O(N^2) algorithms.
However, O(N^2) may be reasonable for small local data sets where inputs don't grow indefinitely.
If you want more learning on this topic, please read more about the complexity on our website.
0 notes
Text
my attempt
We can make a full matrix by adding the first three. This means that if we can get an almost uniform (all but one digit matching) matrix, we can turn it onto individual control of the one that's different. inventory: [1, 1, 1; 1, 1, 1; 1, 1, 1] let's see about maybe center control?
we can add the two diagonals to get [1,0,1;0,2,0;1,0,1]. We can add the second and fifth matrices to get [1,1,1;1,4,1;1,1,1]. By subtracting the uniform matrix, we get [0,0,0;0,3,0;0,0,0], then dividing by 3 we get [0,0,0;0,1,0;0,0,0]. This gives us control over the center value.
inventory: [1,1,1;1,1,1;1,1,1], [0,0,0;0,1,0;0,0,0]
By subtracting the center matrix from any of input matrices 2, 5, 7, or 8, we can get control of opposite corners.
inventory: [1,1,1;1,1,1;1,1,1], [0,0,0;0,1,0;0,0,0], [1,0,0;0,0,0;0,0,1], [0,1,0;0,0,0;0,1,0], [0,0,1;0,0,0;1,0,0], [0,0,0;1,0,1;0,0,0] by combining these we can make any matrix with 180⁰ symmetry.
Let's keep finding more things in the set to see if we can rule stuff out. We can make asymmetric matrices using input matrices 1, 3, 4, and 6.
let's use 3, 4, and 6 to make a u shape, [1,0,1;1,0,1;2,1,2], then reduce opposite diagonals from the inventory to... nope that just produces the same as adding input matrix 3 with inventory matrix 6.
let's make something wildly asymmetric then reduce it where we can till it looks okish. Let's use input matrices 1 and 7: [2,1,1;0,1,0;0,0,1], then subtract inventory matrix 3 to get [1,1,1;0,1,0;0,0,0]. This t shape might be useful. If we can get control over adjacent corners, we can get control over the edges by subtracting corners and center from this. Actually we don't need this because we'd be able to get control of the edges by subtracting adjacent corners from any of input matrices 1, 3, 4, or 6.
actually, lets suppose we could get independent control over the edges. We'd need one of these hypothetical matrices: [0,1,0;0,0,0;0,0,0] or any of its rotations. We'd be able to apply it to 1, 3, 4, or 6 input matrix to cancel out the middle of the three 1s and turn that into control of adjacent corners. If we have access to adjacent corners, we can add (for example) [1,0,1;0,0,0;0,0,0] with [0,0,1;0,0,0;0,0,1] to get [1,0,2;0,0,0;0,0,1], then we can subtract inventory matrix 3 to get [0,0,2;0,0,0;0,0,0], then divide by 2 and we have independent control of the corners. In other words, if we have control over the edges we get control of the corners, and since we know we have control over the center that means control of the edges implies control of the whole matrix.
This also works for corners: if we have control of the corners we can subtract the corners off any of the asymmetric matrices (input matrices 1, 3, 4, 6) to get control of the edges, which gives us control of everything due to the previous paragraph. Let's start keeping track of these as well - if we can find any of the following matrices, we can create any matrix:
Universal matrices: [1,0,0;0,0,0;0,0,0], [0,1,0;0,0,0;0,0,0], and any rotations thereof.
if we had adjacent corners, we'd be able to subtract them from any of the asymmetric input matrices (1,3,4,6) to get an edge control matrix, so we can add adjacent corners to the universal matrices.
Universal matrices: [1,0,0;0,0,0;0,0,0], [0,1,0;0,0,0;0,0,0], [1,0,1;0,0,0;0,0,0] and any rotations thereof.
I would like to note that if there are any solutions to this problem, the universal matrices are all correct answers. If they weren't we'd be able to make any matrix. If you're ok with "proof by the question must have an answer", then these are all correct answers.
let's try to make a universal matrix. (Again, if we can make any of the universal matrices, we can make anything, so there are no solutions.) let's add input matrices 1 and 6, then subtract inventory matrix 3 to get [0,1,2;0,-1,1;0,0,0]. We can add inventory matrix 2 to fix the center and get [0,1,2;0,0,1;0,0,0]. Let's add this and all its rotations to the inventory. As a recap, we have:
input matrices: [1,1,1;0,0,0;0,0,0], [0,0,0;1,1,1;0,0,0], [0,0,0;0,0,0;1,1,1], [1,0,0;1,0,0;1,0,0], [0,1,0;0,1,0;0,1,0], [0,0,1;0,0,1;0,0,1], [1,0,0;0,1,0;0,0,1], [0,0,1;0,1,0;1,0,0] inventory matrices: [1,1,1;1,1,1;1,1,1], [0,0,0;0,1,0;0,0,0], [1,0,0;0,0,0;0,0,1], [0,1,0;0,0,0;0,1,0], [0,0,1;0,0,0;1,0,0], [0,0,0;1,0,1;0,0,0], [0,1,2;0,0,1;0,0,0], [0,0,0;0,0,1;0,1,2], [0,0,0;1,0,0;2,1,0], [2,1,0;1,0,0;0,0,0] universal matrices: [1,0,0;0,0,0;0,0,0], [0,1,0;0,0,0;0,0,0], [1,0,1;0,0,0;0,0,0] and any rotations thereof.
Here's another universal matrix: [0,1,0;1,0,0;0,0,0]. If we had this we'd be able to subtract it from inventory matrix 10 then divide by 2 to get universal matrix 1. Similar arguments can be made for rotations of that matrix, so let's add those to the universal matrices:
universal matrices: [1,0,0;0,0,0;0,0,0], [0,1,0;0,0,0;0,0,0], [1,0,1;0,0,0;0,0,0], [0,1,0;1,0,0;0,0,0] and any rotations thereof.
actually I just realized it is impossible to make every matrix since that'd require using 8 input variables to make 9 output variables. It's overconstrained. Therefore any of the universal matrices are answers:
1 0 0 0 1 0 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0
And any rotations thereof
also any linear combinations thereof. I guess those second two answers are a little redundant then. Wait I just realized I can treat the matrices as vectors. I'm a fool. It's literally in the question. I'll be back.
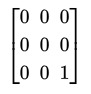
Let V be the vector space of 3x3 matrices over the field of order 2. Let S be the subspace generated by the following matrices:
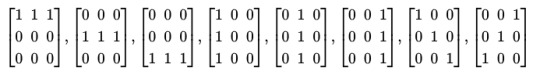
Find an element of V that is not in S.
Solution:
All these matrices have 2 corner 1s, so linear combinations will always have an even number of corner 1s. Hence a solution is
46 notes
·
View notes
Text
EECS 560 Lab 6 undirected graph
Due to the symmetry in an undirected graph, it is only necessary to store the edge weights in the upper triangle of the adjacency matrix (above the diagonal). For example, if you want to find the weight of the edge (5, 3), due to symmetry you can get this information by looking at the weight of (3, 5). For this lab you will randomly generate connected graphs and store their information in a one…

View On WordPress
0 notes
Text
Non-Eulerian paths
I've been doing a bit of work on Non-Eulerian paths. I haven't made any algorithmic progress with the non-spiraling approach Piotr Waśniowski uses for such paths, but I'm keen to continue the development of the approach using spiral paths since I believe that this yields strong structures.
I'm using the Hierholzer algorithm to find paths in a Eulerian graph and I've been looking at the changes needed for non-Eulerian graphs, i.e. those where the order of some vertices is odd. For graphs with only 2 odd nodes, a solution is to use pairs of layers which alternate starting nodes. In the general case (Chinese Postman Problem) duplicate edges are added to convert the graph to Eulerian and then Hierholzer used to solve the resultant graph. I hadn't actually tried this before but I've now used this approach on some simple cases.

(the paths here were constructed via Turtle graphics just to test the printing - in transparent PLA)
The hard part is to evaluate the alternative ways in which the duplicate edges can be added. We can minimise the weighted sum of edges but for the rectangle this still leaves several choices and I need to think about how they can be evaluated. I think immediate retracing of an edge should be avoided so perhaps maximising the distance between an edge and its reverse would be useful.
The duplicate edges cause a slight thickening and a loss of surface quality (so better if they are interior) but I think that's a small cost to retain the spiral path. Path length for the rectangle is 25% higher I haven't tried them with clay yet.
Modifying Hierholzer
I had originally thought that to formulate such graphs for solution by Hierholzer, each pair of duplicate edges would require an intermediate node to be added to one of the edges to create two new edges. This would be the case if the graph was stored as an NxN matrix, but my algorithm uses a list of adjacent nodes, since this allows weights and other properties to be included. Removing a node from the matrix is much faster (just changing the entry to -1) than removing the node from a list but for my typical applications efficiency is not a big issue. The list implementation requires only a simple modification to remove only the first of identical nodes. This allows duplicate edges to be used with no additional intermediate nodes.
This is test interface for the Hierholzer algorithm which accepts a list of edges.
Here is an example with three hexagons:

with graph
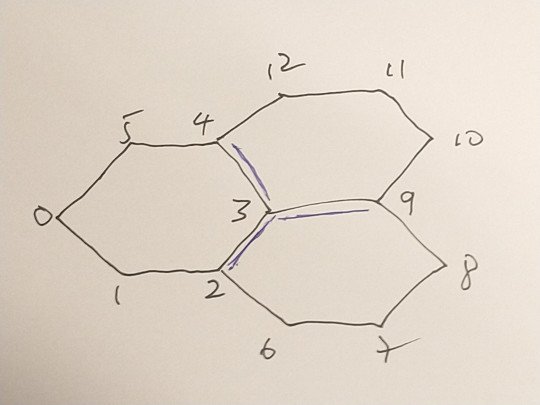
and edge list:
[ [0,1],[1,2],[2,3],[3,4],[4,5],[5,0], [3,2],[2,6],[6,7],[7,8],[8,9],[9,3], [3,9],[9,10],[10,11],[11,12],[12,4],[4,3] ]
Nodes 2,3,4 and 9 are odd. There is only one way to convert to Eulerian. We need to duplicate three edges : [3,4], [3,9],[3,2] so that nodes 4,9, and 2 become order 4 and node 3 becomes order 6. The path used to generate the printed version above was constructed as a Turtle path with only 60 degree turns:
[3, 9, 10, 11, 12, 4, 3, 2, 6, 7, 8. 9, 3, 4, 5, 0, 1, 2]
Hierholzer constructs the following path starting at the same node
[3, 2, 1, 0, 5, 4, 3, 2, 6, 7, 8, 9, 3, 9, 10, 11, 12, 4]
There is a sub-sequence [9,3,9] which indicates an immediate reversal of the path. This creates the possibility of a poor junction at node 3 and is to be avoided.
Furthermore, this path is the same regardless of the starting point. The choice of which edge amongst the available edges from a node at each step is deterministic in this algorithm but it could be non-deterministic. With this addition, after a few attempts we get :
[0, 1, 2, 3, 9, 10, 11, 12, 4, 3, 2, 6, 7, 8, 9, 3, 4, 5]
with no immediately repeated edges
This provides a useful strategy for a generate-test search: repeatedly generate a random path and evaluate the path for desirable properties , or generate N paths and choose the best.
However, this approach may not be very suitable for graphs where all nodes are odd, such as this (one of many ) from Piotr:

The edge list for this shape is
[0,1],[1,2],[2,0], [0,3],[1,4],[2,5], [3,6],[6,4],[4,7],[7,5],[5,8],[8,3], [9,10],[10,11],[11,9], [6,9],[7,10],[8,11],
duplicate the spokes
[0,3],[1,4],[2,5], [6,9],[7,10],[8,11]
Here every node is odd. The 6 spokes are duplicated. Sadly no path without a reversed edge can be found.
The simpler form with only two triangles and 3 duplicated spokes:
[ [0,1],[1,2],[2,0], [0,3],[1,4],[2,5], [0,3],[1,4],[2,5], [3,4],[4,5],[5,3] ]
does however have a solution with no reversed edges although it takes quite a few trials to find it:
[0,2,5,4,1,2,5,3,0,1,4,3]
Triangles
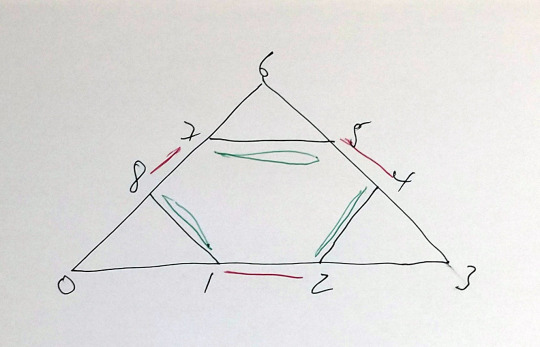
Edges can be duplicated in two ways
[[0,1],[1,2],[2,3],[3,4],[4,5],[5,6],[6,7],[7,8],[8,0] ,[2,4],[5,7],[8,1]
a) duplicating the interior edges min 4
[2,4],[5,7],[8,1]
b) duplicating the exterior edges min 6 [1,2],[4,5],[7,8]
Rectangle
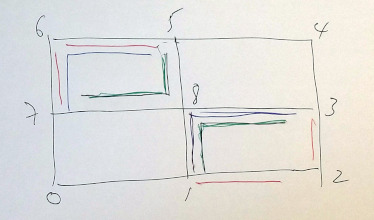
Edges can be duplicated in three different ways
[0,1],[1,2],[2,3],[3,4],[4,5],[5,6],[6,7],[7,0], [1,8],[3,8],[5,8],[7,8],
a) [1,2],[2,3], [5,6],[6,7] min 6 b) [1,8],[8,3], [5,6],[6,7] min 4 c) [1,8],[8,3], [5,8],[8,7] min 4
Automating edge duplication
The principal is straightforward: chose an odd node, find its nearest neighbour and duplicate the connecting edge(s) ;repeat until all odd nodes connected. To test various configurations, allow the choice of node and its nearest neighbour, if several, to be randomised and compute a selection evaluation from the result.
Currently the choice is based on the length of the path from each node to the revisit of that node. Path length of 2 means an immediate return and these should be avoided if possible.
Testing with clay
Whilst tests with PLA show no significant changes in appearance whilst retaining the benefits of a spiral print path, this approach has yet to be tested with clay
Postscript
A side-benefit of this work has been that I've finally fixed an edge case in my Hierholzer algorithm which has been bugging me for some years
0 notes
Photo

Buchite on Scoria matrix
Locality: Emmelberg, Üdersdorf, Daun, Eifel, Rhineland-Palatinate, Germany
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
“A compact, vesicular or slaggy metamorphic rock of any composition containing more than 20% vol. of glass, either produced by contact metamorphism in volcanic to subvolcanic settings or generated by combustion metamorphism. An uncommon metamorphic rock type composed mostly of glass, formed by the melting of a sedimentary rock or soil by extreme heat from an adjacent lava flow or scoria eruption, or the burning of an underground coal bed. Buchite is a product of a special type of metamorphism, called pyrometamorphism (contact type, high to very high temperature, low pressure, often connected with coal fires). Buchites are often confused with obsidian, which is a volcanic glass rather than metamorphic glass. The so-called para-obsidian is a buchite with small amounts of mullite and tridymite forming microlites. Rarely, buchites can be colorful and transparent, and faceted as gemstones, as for example a few blue-green gems from the Eifel hills in Germany. The original description of buchite was for partly fused, glassy sandstones associated with basalts (in Germany). Now the term also covers more pelitic rocks. The first described buchite contained relic, cracked quartz with tridymite overgrowths and inclusions, feathery or needle-like clinopyroxene, magnetite, cordierite crystals, tiny crystals of a spinel, small voids, pores interfilled with goethite and brown glass. According to Grapes (2006), buchite also occurs as xenoliths and within contact aureoles.” - https://www.mindat.org/min-50131.html
Basically what this means for this rock, is that there was a scoria eruption (a volcanic eruption with lots of air bubbles in the magma) that came into contact with some sandstone. The intense heat of the magma was able to melt some of the sand, which then rapidly cooled and became glass. You can even still see the darker bands beneath the glassy layer, displaying this xenolith’s sedimentary origins!
This is my first time playing with the “Read More” function in order to provide some more information or an explanation, so please let me know if you read it and/or it is something you’d like to see more of in the future!
#buchite#scoria#buchite on scoria#germany#rock#glass#metamorphic#partial melting#metamorphic glass#description#explanation#read more#rocks#minerals#fossils#geology#mineralogy#earth#nature#science#first time experimenting with a read more#but this is a neat thing that needs explaining
871 notes
·
View notes
Text
Fossil Matrix Under the Microscope
by Pat McShea
Museum visitors who approach the broad window of PaleoLab encounter an array of large fossilized bones. If not for the pair of microscope workstations positioned against the lab’s right wall, it would be easy to misinterpret the enormous jaws, ribs, vertebrae, and limb bones as evidence of a size bias in the science of vertebrate paleontology.

A scoop of fossil-bearing matrix on a sorting tray.
Small fossils have certainly made mighty contributions to our understanding of life during ancient time periods. Such fossils, which include loose teeth, small bones, and bone fragments, are the primary focus of some paleontological research. In other projects, where considerably larger fossilized creatures are the focus of study, the fossils of smaller creatures add information about species diversity, food webs, and even the climate conditions of ancient ecosystems. The sorting of fossil-bearing matrix that occurs under PaleoLab’s microscopes ensures that important discoveries will continue to occur.
The term matrix refers to the natural rock surrounding a fossil. In the case of fossil bones encased in rock, the matrix consists of the loose sediments that originally buried the bones, sediments that were later transformed into rock over long stretches of time by the pressure of other sediment layers deposited above them. When fossil-bearing rock layers erode, however, and loosened fossils are transported by water, wind, or other forces, the unconsolidated mix of surrounding materials in which the fossils eventually settle is also termed matrix.
In the field, paleontologists sometimes collect and screen loose matrix on site, using water to both separate floatable bits of plant debris and wash away soil, then sun-drying the resulting sludge for later screening. In the case of the matrix currently being sorted in PaleoLab, material eroded from a more than 50 million-year-old rock unit near Meridian, Mississippi was collected in bulk by CMNH paleontologists and brought back to Pittsburgh for washing and drying at the museum.

Unsorted fossil-bearing matrix.
During a recent visit to PaleoLab, Scientific Preparator Dan Pickering pulled two containers from a shelf as “before” and “after” sorting examples. In the “before” container, a quart-sized plastic jug that once held ground coffee, a black, dime-sized shark tooth resting atop similar-sized irregular gray rock fragments hinted at the possible rewards for future sorting efforts. The considerably smaller and lighter “after” container bore not just an array of small marine fossils, including shark teeth and skate tooth plate fragments, but also the name and working notes of the sorter, CMNH volunteer Jason Davis.

Fossils picked from matrix, with volunteer Jason Davis’ notes revealing that the material is from the lowermost Eocene (~55 million-year-old) Tuscahoma Formation of Mississippi.
Dan termed the recent finds typical for the current operation, but he also noted a now decades-old exciting discovery in matrix screened from a different, but adjacent Mississippi rock unit. In a scientific paper published in 1991, then-CMNH paleontologists K. Christopher Beard and Alan R. Tabrum described a tooth and jaw fragment from an early primate. The fossil was the first record of an early Eocene mammal in eastern North America, and because of its association with well-studied marine fossils, the find helped to better calibrate existing separate biochronologies of terrestrial and marine fossils.
Patrick McShea works in the Education and Visitor Experience department of Carnegie Museum of Natural History. Museum employees are encouraged to blog about their unique experiences and knowledge gained from working at the museum.
28 notes
·
View notes
Text
Understanding vector, map and their uncommon implementation:Explanation with their Code
Hey guys,this is my first article on tumblr so suggestions are most welcomed, I thought of writing an article which contains precise explanation with precise code as i am not going to waste my time by speaking on why this is needed and all,So i begin my series of articles based on the responses i will be writing articles further on ds algo etc…Mainly i will try to cover implementation portion of it by using real problems as most of the sites lacks that information.In this article i am going to discuss on following topics:
Vector
Map
So lets explore and understand about them in simple words and in detail:
Vector:-Vector is basically a dynamic array.Now you might be wondering that what exactly we mean here by dynamic?
In a nutshell:-Dynamic means flexible,means size is not fixed.Like an array has constant/fixed size,so you may have question in your mind then what is the need of using vector.See it is useful in questions where we don’t have any idea about size and in array we cannot erase values at arbitrary position,whereas we can erase values in vector using vector erase function.
Now in programming it is believed that understanding the implementation part will help you in better way rather than wasting time on reading theory,
Implementation:
Vector Representation:-vector<int>v;vector<int>v(n),vector<int>v[n];
Now you saw that i wrote three representations,so what are the differences between them.
vector<int>v:-This represents that size of vector is not fixed here,it can change according to the situation. For eg-Initially size of vector is 0,and now if i did operation v.push_back(1),here push_back is used to insert value inside vector,so now size of vector will be 1,and similarly again i perform v.push_back(8),now size of vector is 8,and lets traverse the vector…so we will write for(i=0;i<v.size();i++){v[i]……}so now we can use it as an array…push_back inserts value at the end,like in above example v[0]=1,v[1]=8…Now i told you that we can erase values in vector..So if we want to erase value at desired position then apply v.erase(v.begin()+desired position).There are other ways of erasing also.
vector<int>v(n):-This is exactly same as int a[n].
vector<int>v[n]:-This means vector of vector,this one will better understand by example.
v[0].push_back(1);v[0].push_back(8);v[4].push_back(-1);
v[6].push_back(5);
So above we saw that v[0] is one vector and inside that one another vector is present of size 2 and its elements are 1 and 8 respectively.so if we want to traverse each element individually:-
for(i=0;i<v.size();i++)
{for(j=0;j<v[i].size();j++)
{
v[i][j]……//means whatever operation you want to perform can do…as v[i][j] is individual element like v[0][1]=8,its like 2d matrix.
}
}So above v.size()==3,as one is v[0],v[4],v[6],in nutshell we understand that inside one vector one other vector is present ,this is mainly used in graphs as when you will read about depth first search there you will get to know about adjacency list.
2)Map:-Very Powerful STL tool.
Lets understand map by example.Q)Say in a class we have marks of 10 students in maths exam-10,50,50,30,24,50,20,30,10,50…our question is that count no.of students corresponding to marks obtained?Means how many have scored 50,how many have scored 10 likewise……..
So if our question would have asked calculate frequency for 50 marks only then we could have solved it easily by running a loop and taking count of 50 marks students….but here we have to calculate frequency for each individual marks….so in cases like this our Map is helpful….
Implementation:
map<int,int>m1; This is representation of map.
for(i=0;i<n;i++){
m1[a[i]]++;
}
As you can see above m1[a[i]]++,so basically map is also an array which stores value in the form of key value pair…..here key is marks and value is count of students corresponding to that marks…like m1[50]=4,m1[24]=1 in above example likewise…..so you can see map is also an array but here index is not like array one,here we have one index as 24 ,one as 50 etc…and map stores index in sorted order so like when you will traverse map..then first of all m1[10] will come then m1[24] likewise…..
Now question comes how we will traverse the map?As for traversing the array,vector we have 0-index and in ordered form…so we simply run loop for(i=0;i<n;i++) and we can easily travel them ,but in the case of map as we saw that index was like 24,50,10,30 etc..and we don’t know them beforehand so how we will tackle them…..
For traversing map,set etc we use concept of iterator
What is iterator:In simple words we can say that it is a kind of pointer.Lets move on its implementation,Like here we will traverse map using iterator,its same as traversing array using simple for loop
Implementation:
map<int,int>::iterator it=m1.begin();
for(it=m1.begin();it!=m1.end();it++)
{
int k= it->first; //means it->first refers to map key which is 24,30,50 etc..
int r= it->second; //means it->second refers to map value that is m1[50] value,m1[24] value….say m1[50]=4…so it->first=50 and it->second =4..
cout<<No.of students k marks is r<<endl;
}
3. So we saw how to traverse map using iterator…and say if we want to find maximum number of students corresponding to one particular marks,then we will apply ….if(it->second>p){p=it->second;}….inside iterator loop we will use this condition….likewise anything we can do…And we will see more applications of map,set at the end after understanding pairs ,set etc……
Above one is known as ordered map as it stores unique keys…and all keys are in sorted manner….key refers to index in basic terms….Then we have unordered map which doesn’t store keys in sorted manner and then we have multimap which allows duplicating of keys,these two we will understand further in other articles..First we should be clear with basic implementation of map..Lets discuss one more final example to have better hold on implementation part of map…say we have string=”abaaabccaababa”
And our question of is maximum frequency of occurence of any substring of size 3.I hope you have idea about string and substring and if not then let me tell you in short…A substring of size 3 in above example can be-aba,aaa,baa,aab,bcc,cca,caa etc…means continuous characters of size 3 starting from any postion is substring …in simple words
Now lets move on implementation of this question….
map<string,int>m1; Here you might be wondering that why i wrote string as key,because we are going to take count of substring so key will be string and value is count so we wrote int as value…these things you need to keep in mind while implementing map.
for(i=0;i<n-2;i++)//n=s.size(),n-2 i guess you are clear as substring of size 3 so we need to take valid input or else error will be thrown…
{
m1[s.substr(i,3)]++;
}
So here in map we will have our map like m1[“aba”],m1[“caa”],m1[“baa”] likewise…..For maximum..lets traverse the loop
map<string,int>::iterator it=m1.begin();int p=0;
for(it=m1.begin();it!=m1.end();it++)
{
if(it->second>p)
{ p=it->second;
}
}
So answer of p will be 3 as m1[“aba”]=3…and one more thing if we are required to print substring then inside that if condition just add
string s1=it->first;
So we saw the basic implementation of map,then there is one more information map contains if we will write m1.size() it returns no. of unique keys our data contains,then we have this option also m1.erase(key),means if we write m1.erase(“aba”) then our m1[“aba”] …will be erased….and we can use one more function m1.find(“aba”)…lets see its implementation
map<string,int>::iterator it1 = m1.find(“aba”);
if(it1==m1.end())
{
//means key is not present }
else if(it1!=m1.end())
{
//means key is present
}
So using this m1.find() function we can check whether key is present or not,rest function you can study from this link…Like there is one function m1.upper_bound,lower_bound this all you can study from this link…
One thing i forgot to tell you that iterator can be written in other way also like
for(auto it:m1){}||for(auto it=m1.begin();it!=m1.end();it++)
Now you know we can travel map in reverse way also like as we know that we can travel array/vector in reverse manner using for(i=n-1;i≥0;i- -) similarly here we use for(auto it=m1.rbegin();it!=m1.rend();it- -)………
Then we can store map keys in descending order by using this function
map<int,int,greater<int>()>m1; Likewise there are many more operations which you will get to know while practicing.In my further articles i will try to cover some advanced implementation of maps by solving standardized questions,as i believe that by real problems we get better feel of any topic right?
3)Some Basic Thing but sometimes tricky
To understand this lets study about pairs first…
Pairs is also a kind of array where in value portion we can store two values…
Like say rishav has got 20 marks in maths and 30 marks in science,similarly rohit has got 15 marks in maths and 0 marks in science…so how we will store theses values
Implementation
pair<int,int>p1;
p1[0].first=20,p1[0].second=30;p1[1].first=15,p1[1].second=0;if 0-index is of rishav and 1-index is of rohit.
pairs we can use in many ways now lets look on deeper implementation of it….
vector<pair<pair<int,int>,int>>v;
So what this above representation implies….This means if we write
v.push_back({{20,30},40});({}is used for make_pair operation)
so v[0].first.first=20;
v[0].first.second=30;
v[1].second=40;
Likewise if we write
vector<pair<pair<int,int>,pair<int,int>>>v;
v.push_back({{20,0},{10,30}});
so in this way we can store value for above representation
which means v[0].first.first=20;
v[0].first.second=0;
v[1].second.first=10;
v[1].second.second=30;
so i guess you are getting some feeling by observing few examples above.
We can use pairs in map also like see.
map<pair<string,string>,int>m1;
m1.insert({{rohit,rishav},4});
m1[{rohit,rishav}]=4;
here key is {rohit,rishav} and value is 4.
map<int,vector<int>>m1;
what does this mean…
m1[1].push_back(4);
m1[1].push_back(-1);
m1[3].push_back(6);
m1[3].push_back(4);
so how we will traverse map in such case…
map<int,vector<int>>::iterator it=m1.begin();
for(it=m1.begin();it!=m1.end();it++)
{
for(j=0;j<it->second.size();j++)
{
if(it->second[j] ) //so this it->second[j] this term tells us the values present inside the vector like m1[1] contains -1,4 etc…..likewise…so in this way we can traverse the map…for this case
}
}
We can have many operations like this say
map<pair<int,int>,vector<int>>m1;
map<int,set<int>>m1;
map<int,multiset<int>>m1;
map<string,pair<string,int>>m1;
etc…..
Set/multiset we will discuss in further articles….
Suggestions are welcomed
2 notes
·
View notes
Text
TAFAKKUR: Part 180
Can a Filling Imitate a Tooth?
Teeth may lose their hard structure because of decay or various other reasons. The loss of the dental tissues raises many problems such as bad appearance in the mouth and weakening in the capability to chew. A dentist is expected to restore the excellent structure of teeth using artificial fillings. In order to understand the great difference between real teeth and artificial teeth, let us have a look at the structure of teeth.
The excellent nature of teeth comes from the microstructure of the material they are made of. They are not homogenous like cement used in construction work. It is composed of various different layers such as enamel, dentine, and cementum which are formed by enamel prisms and dentine tubules. This structure of the teeth is the source of inspiration for the produced restorations. Since an exact imitation is aimed, in addition to other properties, the microstructure of the teeth also needs to be imitated.
When the general structure of the teeth is investigated, it is observed that there are two major components: organic and inorganic structures. The filling material, referred to as composite, must be in the color of the tooth and must contain the same type of structure. The filling material in the composite increases the resistance of the restoration and has the same function of the mineral hydroxyapatite in the enamel. In the composite, resin matrix takes the place of the organic matrix in the enamel. Up to this point, everything seems fine but the images of scanning electron microscope (SEM) showing the cross sections portray the trivial difference between the composite and the natural tooth. The homogenous, ordinary appearance of the filling and the astonishingly embellished tooth are very easy to differentiate.
There are prerequisites that make tooth restoration successful. We can summarize these as esthetics, functionality, and phonation. These properties are affected with the loss of the tooth or the structure of the tooth. What follows is an analysis as to how and to what extent these properties can be replaced.
Esthetics in the dentistry means exact imitation of the tooth color. To be able to give a natural color to the filling or to the crown could be considered a miracle. It might sound like a very simple issue. However, this is probably the most challenging thing for dentists. If the color does not match, your restoration will look different and will easily be noticeable. Maybe it is my professional curiosity because while watching television I have a tendency to look at people's teeth before I look anywhere else. From the most popular singers and actors to mighty and scholarly politicians, I can always recognize their prosthesis. Ironically, these people were spending their wealth on professional dentists who could not give their original teeth back to them. The color is not something that could be mixed up together by fulfilling only one of its features. The color comes into existence as a result of common features of many factors. A dentist’s only hope is one day using homogeneous clay typed structures squeezed from a tube.
The structure of the enamel and the dentine are deeply related with opacity and translucency, two important subjects of optics. That is why some parts of the tooth are translucent while the other parts are opaque. It is possible to restore it with a few optical tricks. The tooth is neither completely opaque nor translucent. For example, while the cutting edges of the tooth are translucent (especially the cutting edges of newly erupted milk teeth, they are almost glassy), the cervix of tooth, adjacent to gingiva, is opaque and dusky. Thus, in big restorations, we implant materials that reflect the light differently for every surface of the tooth. We try to compare and contrast to the original teeth by using optical tricks. However, a more important thing is the sustainability of this quality. Especially, for restorations made to anterior teeth, you can observe that the colors have become darker and have separated from adjacent tooth with a dusky-colored borderline. Indeed, it is evident that color harmony is not preserved properly.
We cannot expect to reach a result that is equivalent to the look and feel of natural teeth through esthetic restoration only. The mechanical properties of restoration must be similar to that of the natural teeth. The reaction of the teeth to a certain force is very important. Teeth are subjected to forces of different types and magnitudes throughout the day, and they are created so as to endure those forces. Any restoration must be as strong and durable as the natural teeth. A piece of filling that is placed into a tooth becomes a working part of the entire system. If it is not as resolute as the rest of the system, then it cannot integrate and may fall out. In this regard, the mechanical properties of the material for restoration are crucial. There are dozens of other aspects in which one can compare those properties with a natural tooth. Considering just a couple of the important properties such as hardness and flexibility is enough to show significant differences between natural teeth and restorative materials.
Both hardness and flexibility of a material are determined by certain characteristics and are all formulated in scientific terms. We can see the difference of natural teeth very easily by comparing the hardness and flexibility of the most commonly used composites in the fore teeth and that of hard tissues like enamel and dentine. There is yet another point not to be missed: What makes our teeth perfect is that they are both hard and flexible at the same time. We can see the big gap between real and artificial teeth when we compare the quantitative values of these mechanical properties.
Teeth, in addition to their superior mechanical features, impress us with their exceptional capacity to transmit the force they face. Teeth come in contact with their hard counterpart everyday while eating or otherwise. A casual observer might think that a tooth is directly attached to the chin bone. Let alone being attached, the tooth does not even touch the chin bone. It is tied to the chin bone with flexible strings. A fusion of the bone and teeth is out of the question. It’s as if a bucket is lowered in a well. Whenever we chew, the pressure endured by the teeth is transferred to the bone through these strings in the best manner. These periodontal ligaments serve as shock absorbers. It would be incomplete to explain force transfer in teeth with these strings. It is imperative to remember the structure called lines of forces located on the chin bone that are shaped in such a manner as to guide the force.
It is a noteworthy challenge to make restorations and to replace a tooth in every aspect. Man-made products or works of art cannot be completely imitated; experts at least could tell the differences right away. Could it then ever be possible to imitate an artwork of the Divine to the same degree of perfection in its authentic form?
#allah#god#Muhammad#prophet#quran#ayah#sunnah#hadith#islam#muslim#muslimah#help#hijab#revert#convert#religion#reminder#dua#salah#pray#prayer#welcome to islam#how to convert to islam#new convert#new revert#new muslim#revert help#convert help#islam help#muslim help
1 note
·
View note
Text
Message Boards Inspire Development

Message boards are becoming an increasing number of common every day, educating, motivating, as well as sometimes enjoyable. Message boards, digital, digital, and also often composed of light producing diodes (LEDs), have lots of applications, with the number relatively raising every day. As well as, as a wonderful business device, they stimulate performance as well as innovation.
Ancestors of message boards include marquees, posters, as well as indications with compatible letters. Modern versions supplant the character as organizing device with a lighted dot or pixel. Instead of rows of characters you have a two-dimensional selection of pixels, each of which can be individually switched on or off.
This kind of public interaction has been prevalent for a long time above or adjacent to freeways, notifying drivers to concerns in advance such as mishaps, hold-ups, or other quickly transforming events. In less urgent scenarios they show up before institutions, churches, and also other institutions as informative signs the material of which is sluggish to alter and reasonably secure.
Even so, the idea behind message boards is quite enduring, and has actually been used to generate both message and graphics for several years. In binary form, each pixel is either on or off at any moment, and the resulting dot matrix portrays a photo or textual message. Any individual who has actually seen college football stadium card sections understands this principle completely.
The pixel doesn't need to be binary yet among a set of colors, making for even more dramatic and also efficient messaging. Since LEDs are monochromatic, a set of three of them (each in a various primary color) needs to be used to represent each pixel. But this does not position a big problem, since LEDs can be made in extremely tiny packaging and also their durability is some 50 to 100 times to that of incandescent light bulbs.
Whatever is to be represented, whether message or graphics, needs to be mapped into a 2D collection of pixels. Given that a character set mapping can be established ahead of time, it is reasonably fast as well as simple to map text on the fly, which comes in handy for updating web traffic conditions. Mapping pictures, and particularly the vibrant mapping of animations, is a lot more arduous as well as involved.
Up until now our discussion has actually been mainly concerning message boards as informational devices, which, per se, do not truly stimulate advancement in a company setting. Nevertheless, when they are used as business devices and as far better ways for interacting, they do enhance productivity and also cost-free creative thought. A crucial element is the assimilation of messaging systems with integrated clock systems.
Such integration accomplishes much more exact and also effective scheduling, and also it also makes interdepartmental purchases quicker, smoother, as well as much less disruptive (or perhaps non-disruptive). The integrated clocks keep every little thing humming, and also the synchronized messaging, showed on sign as fetched from a data source, makes sure that all departments are frequently on the exact same page.
This dual synchrony eliminates prospective hiccups as well as decreases transactional delays between separate divisions to zero, all of which cultivates enhanced performance. In addition, if traffic jams are occurring they pop out like sore thumbs. This in turn draws up a course to much more effective options and other ingenious reasoning.
The various other wonderful attribute is that emergency scenarios can be managed really well. If an abrupt notification needs to be broadcast the message board can be coopted manually and the alert presented to everyone. Assuming that audible signals such as whistles or bells are attached to the system, noise can be used to ensure all able bodies are taking note.
There are even more uses for these interaction devices. As an example, they can be put up in break spaces to convey info as well as present statements, as well as in many cases they can work as countdown timers to signify completion of break. In conclusion, message boards bring firms right into the 21st century as well as motivate development.
emergency led message board
youtube
1 note
·
View note
Text
Write a C Program for Creation of Adjacency Matrix
Creation of Adjacency Matrix Write a C Program for Creation of Adjacency Matrix. Here’s simple Program for adjacency matrix representation of graph in data structure in C Programming Language. Adjacency Matrix: Adjacency Matrix is a 2D array of size V x V where V is the number of vertices in a graph. Let the 2D array be adj[][], a slot adj[i][j] = 1 indicates that there is an edge from vertex i…
View On WordPress
#adjacency list implementation of graph in c#adjacency list representation of directed graph#adjacency matrix#adjacency matrix example#adjacency matrix graph program in c#adjacency matrix representation#adjacency matrix representation of graph#adjacency matrix representation of graph in c#adjacency matrix representation of graph in c program#adjacency matrix representation of graph in data structure#c data structures#c graph programs#C program to create graph using adjacency matrix method#C Program to Represent Graph Using Adjacency Matrix#graph adjacency matrix c code
0 notes
Text
Graphs and decision trees in Python
A pair of nodes are connected by a single path.
Decision trees are great for finding solutions. The trunk is at the top and the the branches at the bottom - very Australian.
But, how are decision trees useful?

(Computer) networks require algorithms to move information around.
Financial networks - moving around money
Sewage networks - moving water around
Decision trees can determine which path to take when executing the algorithm that moves information.
Graphs
Graphs can capture interesting relationships with this data.
The min flow or max cut problem identifies which clusters in a graph have a lot of interaction between each-other but not with many (or any) other clusters.
Inference option. Is there a sequence of edges to get from A to B. Can I find the least expensive (meaning shortest) path?
The graph partition problem. Not all nodes have connections with every other node.
This is finding and isolating different sets of connections.
Min cut max flow - an efficient way of separating highly connected elements, the things that connect a lot in a sub-graph.
Graphs (graph theories) are used by us everyday in the forms of travel maps such as on the tube etc.
Di graph (directed graph) the edges pass in one direction - almost obvious, I know.
Nodes or vertices become points of intersections, places to make a choice or has terminals.
Edges would be connections between points - the roads on which we could drive. Each edge would have a weight.
Choices that remain:
What’s the expected time between a source and a destination?
What’s the distance between the two?
What’s the average speed of travel?
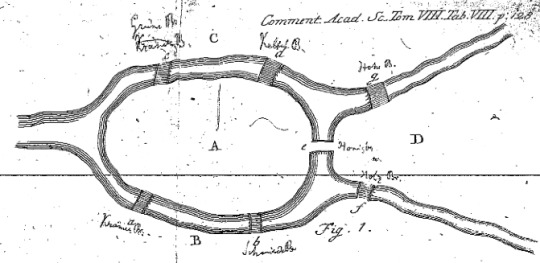
Thinking about navigation in graph systems incorporated within history from 1700′s. The image above is from ‘Solutio problematis ad geometriam situs pertinentis,’ Eneström 53 [source: MAA Euler Archive]
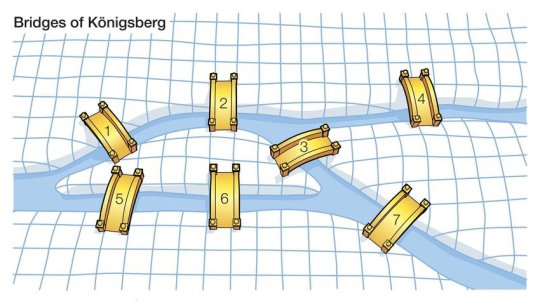
Bridges of Königsberg which has seven bridges that connect it’s rivers and islands - is it possible to take a walk that traverses each of the seven bridges exactly ONCE.
Leonhard Euler, a great Swiss mathematician said, “make each island a node, each bridge is an undirected edge”.
This eliminates irrelevant details about the size and focuses on the connections present, testing the point of crossing only once.
Euler's Proof and Graph Theory
When reading Euler’s original proof, one discovers a relatively simple and easily understandable work of mathematics; however, it is not the actual proof but the intermediate steps that make this problem famous. Euler’s great innovation was in viewing the Königsberg bridge problem abstractly, by using lines and letters to represent the larger situation of landmasses and bridges. He used capital letters to represent landmasses, and lowercase letters to represent bridges.
This was a completely new type of thinking for the time, and in his paper, Euler accidentally sparked a new branch of mathematics called graph theory, where a graph is simply a collection of vertices and edges.
Today a path in a graph, which contains each edge of the graph once and only once, is called an Eulerian path, because of this problem. From the time Euler solved this problem to today, graph theory has become an important branch of mathematics, which guides the basis of our thinking about networks.
An easy graph would be: latitude and longitude
We want to extract things away from the graph so let’s represent the nodes as objects - using classes for these.
For now, the only information to store a name (which is currently just a string) inherits from the base Python object class.
Init function used to create instances of nodes.
Store inside each instance - in other words inside of self - under the variable name of whatever was passed in as the name of that node.
If we have ways to create things with a name we need ways to get them back out. So we can select it back out by asking an instance of a node “what is your name?” by calling getName, it will return that value.
Within the class edge we’d see:
class Edge(object):
def _init_(self, src, dest):
“““Assumes src and dest are nodes”““
self.src = src
self.dest = dest
def getSource(self) :
return self.src
def getDestination(self) :
return self.dest
def _str_(self):
return self.src.getName() + ‘->’\
+ self.dest.getName()
To print things out we’re just gonna print name. This allows us to create as many nodes as we like.
Edges connect up two nodes - allowing us to create a fairly straightforward construction of a class. Again, it’s going to inherit from the base Python object. To create an instance of an edge we will assume in the example above that the arguments passed in (source and destination) are nodes.
This is shown after the init function.
Not names, nodes - the actual instances of the object class. So inside of the edge, we set internal variables for each instance of the edge source and destination. The get source and destination allows us to get those variables back out. The last part asks to print the name of the source then an arrow and then the destination.
So here, given an instance of an edge, we can print it and it will retrieve the source or the node associated with the source inside the instance. The opened and closed parens () is used to call it.
From this we can decide how to represent the graph, starting with a di-graph which has edges that pass in once direction. Given all the sources and all the destinations we can just create an adjacency matrix.
#coding#creative coding#python#python code#programming#computational#computer science#computer nerd#mathematics#nodes#graphs#decision tree#leonhard euler#MIT
36 notes
·
View notes
Text
How To Merge MP3 Audio Recordsdata In Audacity
From the album Effluxion, out February 22, 2019 on Merge Information. First things first, ensure you obtain Mp3Splt-GTK moderately than merely Mp3Splt (which is a command line tool that's more bother to be taught than simply using the GTK model's graphical interface). Spotlight clips, cntrl W, or spotlight, edit and merge. So solely a thought as to presumably why you will not uncover the merger wherever if in case you have got your "Shopper Account Administration Settings" turned on and should "Run As Administrator" EARLIER THAN trying to merge info. 4Extract audio from video : Some components of a movie or TELEVISION program are humorous and worth collected.
Talking of the favored MP3 joiner online services, is on the list definitely. And there's one factor for the audio merging, the added tracks should be in the same audio format and bitrate. Since you will merge MP3 files there, simply take note of the bitrate. By the way in which, is able to perform as a splendid on-line MP3 cutter and joiner. Select which audio recordsdata you want to merge. These could be added from your computer or system, by Dropbox, from Google Drive, or from some other online supply that you hyperlink. You'll be able to add a number of recordsdata directly or select them separately.
The batch file supplies an possibility to use both the Home windows command-line or MP3wrap to merge the recordsdata. The first profile ID will be the NationBuilder ID once the merge completes. Overall, Free MP3 Cutter Joiner is basic on functionality and has a really previous wanting interface. The applying only supports MP3 files and the lack of features lets this utility down. If it's essential work with MP3s and no other codecs, and need solely fundamental functionality, Free MP3 Cutter Joiner shall be okay on your needs.
Then goes to the primary document and loops by all of them shifting knowledge from one file to a different to merge the data. An adjacent pair of clips could also be "merged" into one clip by clicking on the split line to take away it. You may perform an analogous "be part of" motion with out a mouse by selecting across one or more cut up strains then using Edit > Clip Boundaries > Be a part of to take away the break up strains in order to make one clip. After selecting output settings you simply want to add audio file that you simply wish to use and also you're good to go. If wanted, you'll be able to preview your audio file at any time. The application doesn't supply any preview choices for video, and the one way to preview your video is to merge mp3s it and play it in a media player.
This Sunday, June 4th, is Merge Information Night at Durham Bulls Athletic Park and we're celebrating the occasion with a day crammed with songs from the Merge catalog. I do know that cat additionally works with text recordsdata, however what different file types could be merged by simply using cat and still remain usable (e.g., movie files, and many others.) If anyone is aware of about this I am very curious. The purpose of the site is to can help you create a video from a single MP3 and merge it with an image as a canopy. Merge MP3, MP3 Toolkit and Free MP3 Cutter Joiner are three different software tools you can be a part of sound recordsdata with. By merging audio files, you'll be able to carry your music assortment together.
In 1992 Merge expanded to releasing full-lengths, starting with a Superchunk singles compilation and Polvo's first album. It also launched a stream of great singles from bands like California's Drive Like Jehu, Virginia's Honor Position and cult indie rock band Seam, who Mac briefly drummed for. A type of seven-inches was the debut from Lawrence, Kansas's Butterglory, beginning a relationship between Merge and songwriter Matt Suggs that would last in varied kinds for a decade and a half. The lo-fi indie-pop of Alexander Bends (particularly the title monitor) is each timeless but firmly embedded in its pre-web cultural second of college radio and indie rock zines. When you needed to find a prototypical early 90s indie rock music and could not pull from any of the obvious headliners,Alexander Bends" could be nearly as good a decide as any.
1. Click on the Yes, this is identical individual button to merge the profiles. If the profiles include completely different information in the identical discipline, you may be asked to resolve the conflict. Nevertheless, you must take note of the file dimension limit of every audio observe, not exceeding 50M. With extra obtainable options, Filesmerge has functionality to let you set output file in personalized approach. You possibly can change quality, encoder, sample fee and channel to your destination audio as you please.
Audio Joiner permits you to set the interval of every songs added into this music combiner after which merge them into one track. Seems like an audio cutter. If you are in search of a strategy to merge a number of audio files into one track, then this video is an effective information to you. I will educate you methods to merge sounds or audio files with knowledgeable instrument - Streaming Audio Recorder. Its embedded audio editor can be used for merging audio tracks into one as you want, or you possibly can lower, delete or insert a part of the soundtrack.
I really hope it may be merged so that I can get pleasure from the whole album. Thanks you. Click the SmartMerge Selected button next to the group of information that you simply wish to merge. This can show you all a list of all electronic mail campaigns that you've sent via Mail Merge with e mail tracking enabled. Select the Campaign Name from the dropdown. You might (non-compulsory) check the Embrace detailed tracking data" checkbox to see an in depth report of e-mail opens. Scroll down to the group of matching records that you wish to merge. Solely the information within the chosen group shall be merged, merge mp3s and you can uncheck the name of records to exclude them.Helium Audio Joiner is without doubt one of the finest MP3 Joiners that merges MP3, OGG Vorbis, WMA, FLAC, AAC, WAVE and different audio information. This system enables you to insert silence between MP3 recordsdata, which permits you enter time in seconds. The MP3 Combiner permits you outline the audio title, style, yr, remark, artist and album title. The gate outs of three Redrum voices, that are fortunately enjoying their very own elements, are merged to provide the triggers for a Subtractor, which is deriving pitch data from a Matrix. The Matrix is folded as a result of my display wasn't sufficiently big to indicate the whole example!Within the subsequent example, we'll create a Subtractor with connected Matrix sequencer, a Redrum and a Spider CV.
1 note
·
View note