#api metadata
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is used by 21% of adults online aged 18-29 years.
Text
BigQuery Tables For Apache Iceberg Optimize Open Lakehouse

BigQuery tables
Optimized storage for the open lakehouse using BigQuery tables for Apache Iceberg. BigQuery native tables have been supporting enterprise-level data management features including streaming ingestion, ACID transactions, and automated storage optimizations for a number of years. Open-source file formats like Apache Parquet and table formats like Apache Iceberg are used by many BigQuery clients to store data in data lakes.
Google Cloud introduced BigLake tables in 2022 so that users may take advantage of BigQuery’s security and speed while keeping a single copy of their data. BigQuery clients must manually arrange data maintenance and conduct data changes using external query engines since BigLake tables are presently read-only. The “small files problem” during ingestion presents another difficulty. Table writes must be micro-batched due to cloud object storage’ inability to enable appends, necessitating trade-offs between data integrity and efficiency.
Google Cloud provides the first look at BigQuery tables for Apache Iceberg, a fully managed storage engine from BigQuery that works with Apache Iceberg and offers capabilities like clustering, high-throughput streaming ingestion, and autonomous storage optimizations. It provide the same feature set and user experience as BigQuery native tables, but they store data in customer-owned cloud storage buckets using the Apache Iceberg format. Google’s are bringing ten years of BigQuery developments to the lakehouse using BigQuery tables for Apache Iceberg.Image Credit To Google Cloud
BigQuery’s Write API allows for high-throughput streaming ingestion from open-source engines like Apache Spark, and BigQuery tables for Apache Iceberg may be written from BigQuery using the GoogleSQL data manipulation language (DML). This is an example of how to use clustering to build a table:
CREATE TABLE mydataset.taxi_trips CLUSTER BY vendor_id, pickup_datetime WITH CONNECTION us.myconnection OPTIONS ( storage_uri=’gs://mybucket/taxi_trips’, table_format=’ICEBERG’, file_format=’PARQUET’ ) AS SELECT * FROM bigquery-public-data.new_york_taxi_trips.tlc_green_trips_2020;
Fully managed enterprise storage for the lakehouse
Drawbacks of BigQuery tables for Apache Iceberg
The drawbacks of open-source table formats are addressed by BigQuery tables for Apache Iceberg. BigQuery handles table-maintenance duties automatically without requiring client labor when using BigQuery tables for Apache Iceberg. BigQuery automatically re-clusters data, collects junk from files, and combines smaller files into appropriate file sizes to keep the table optimized.
For example, the size of the table is used to adaptively decide the ideal file sizes. BigQuery tables for Apache Iceberg take use of more than ten years of experience in successfully and economically managing automatic storage optimization for BigQuery native tables. OPTIMIZE and VACUUM do not need human execution.
BigQuery tables for Apache Iceberg use Vortex, an exabyte-scale structured storage system that drives the BigQuery storage write API, to provide high-throughput streaming ingestion. Recently ingested tuples are persistently stored in a row-oriented manner in BigQuery tables for Apache Iceberg, which regularly convert them to Parquet. The open-source Spark and Flink BigQuery connections provide parallel readings and high-throughput ingestion. You may avoid maintaining custom infrastructure by using Pub/Sub and Datastream to feed data into BigQuery tables for Apache Iceberg.
Advantages of using BigQuery tables for Apache Iceberg
Table metadata is stored in BigQuery’s scalable metadata management system for Apache Iceberg tables. BigQuery handles metadata via distributed query processing and data management strategies, and it saves fine-grained information. since of this, BigQuery tables for Apache Iceberg may have a greater rate of modifications than table formats since they are not limited by the need to commit the information to object storage. The table information is tamper-proof and has a trustworthy audit history since authors are unable to directly alter the transaction log.
While expanding support for governance policy management, data quality, and end-to-end lineage via Dataplex, BigQuery tables for Apache Iceberg still support the fine-grained security rules imposed by the storage APIs.Image Credit To Google Cloud
BigQuery tables for Apache Iceberg are used to export metadata into cloud storage Iceberg snapshots. BigQuery metastore, a serverless runtime metadata service that was revealed earlier this year, will shortly register the link to the most recent exported information. Any engine that can comprehend Iceberg may query the data straight from Cloud Storage with to Iceberg metadata outputs.
Find out more
Clients such as HCA Healthcare, one of the biggest healthcare organizations globally, recognize the benefits of using BigQuery tables for Apache Iceberg as their BigQuery storage layer that is compatible with Apache Iceberg, opening up new lakehouse use-cases. All Google Cloud regions now provide a preview of the BigQuery tables for Apache Iceberg.
Can other tools query data stored in BigQuery tables for Apache Iceberg?
Yes, metadata is exported from Apache Iceberg BigQuery tables into cloud storage Iceberg snapshots. This promotes interoperability within the open data ecosystem by enabling any engine that can comprehend the Iceberg format to query the data straight from Cloud Storage.
How secure are BigQuery tables for Apache Iceberg?
The strong security features of BigQuery, including as fine-grained security controls enforced by storage APIs, are carried over into BigQuery tables for Apache Iceberg. Additionally, end-to-end lineage tracking, data quality control, and extra governance policy management layers are made possible via interaction with Dataplex.
Read more on Govindhtech.com
#BigQuery#ApacheIceberg#BigQueryTables#BigLaketables#ApacheSpark#API#metadata#News#Technews#Technology#Technologynews#Technologytrends#govindhtech
0 notes
Text
Guide to Creating a Great NFT Marketplace Strategy
Non-fungible tokens, or NFTs, have proven to be a lucrative investment for some people, and speculators continue to buy and sell NFTs every single day. If you’re considering getting into an NFT marketplace, it would be a good idea to have a strategy in mind first. A sound marketplace strategy for selling NFTs will help you get in front of the right buyers faster and more efficiently.
Below are some steps you can take to create a great NFT marketplace strategy:
1. Learn About Exchanges
NFT exchanges are places where NFTs are bought and sold online. Look for a site that uses an NFT API for marketplaces since these tools can help buy and sell faster.
An NFT API for marketplaces is a piece of code that utilizes code from other sites. A marketplace website that uses APIs can leverage purpose-built selling tools from other developers without requiring buyers and sellers to leave the marketplace website.
2. Use Video Marketing
Video is one of the best ways to sell NFTs because it allows sellers to show and tell about the NFTs they have listed in a marketplace. Within your video marketing content, you can tell the story of the NFTs you’re selling, explain the value and deeper meaning behind NFTs and show off your personality as a seller.
Many video-sharing platforms allow sellers to utilize SEO techniques to attract buyers as well. When you combine SEO and video marketing, you’re more likely to get in front of the right buyers faster.
3. Use Email Marketing
It would also be a good idea to use email marketing to reach potential buyers. Start by collecting the email addresses of potential buyers. Create a weekly or monthly newsletter detailing all the NFTs you have for sale, but also include information about upcoming sales as well.
You should also include helpful, informative content for NFT enthusiasts in your newsletter to entice subscribers. Even if someone isn’t in the market to make a purchase right now, keeping subscribers engaged means you may reach the right person at a future date.
Experience the future of digital assets – Access our NFT API today! https://simplehash.com
0 notes
Text
How to back up your tumblr blog with Tumblr-Utils FOR MAC USERS
I've seen a few guides floating around on how to use some more complex options for backing up your tumblr blog, but most are extremely PC focused. Here is a guide for fellow (unfortunate) mac users!
Note: I am not a tech savvy person at all. My brother walked me through this, and I'm just sharing what he told me. Unfortunately I won't be able to help much if you need trouble shooting or advice ;; sorry! This is also based off of this guide (link) by @/magz.
- - - - GUIDE - - - -
First, open terminal. You can command+space to search through your applications, and search for "terminal". It should look like this.

You should see something like this within the window:
[COMPUTER NAME]:~ [USER NAME]$ []
First, create a virtual environment for tumblr back up. This will limit any conflicts with other python programs. Type and enter this into terminal:
python3 -m venv .tumblr_backup
Then, Activate the virtual environment by entering this:
source .tumblr_backup/bin/activate
The next line should now show something like this:
(.tumblr_backup) [COMPUTER NAME]:~ [USER NAME]$ []
As a side note, you can exit this virtual environment by typing and entering "deactivate". You can re-enter it through the previous line we used to activate it to begin with.
Next, install the base package with this line:
python3 -m pip install tumblr-backup
The linked guide details various options for tumblr back up packages that you can install. Copied from the guide for convenience:
"tumblr-backup : default tumblr-backup[video] : adds option to download videos tumblr-backup[exif] : adds option to download EXIF information of fotos (photography metadata information) tumblr-backup[notes] : adds option to download notes of posts (huge) tumblr-backup[jq] : adds option to filter which posts to backup tumblr-backup[all] : adds all options (personally doesn't work for us at the moment of writing this)"
I chose the video option, but you can pick which you'd like. Download that specific package with this line. Note that unlike the previous lines Ive shown, the square brackets here are actually part of it and must be used:
python3 -m pip install tumblr-backup[OPTION]
Next, you need to create an app linked to your tumblr account to get an OAuth consumer key (aka API key). Go to this link: [https://www.tumblr.com/oauth/apps] and click the [+Register application] button. Here, you will have to input a bunch of info. What you put doesn't really matter. This is how the original guide filled it out, and I did pretty much the exact same thing:

(The github link for your convenience: https://github.com/Cebtenzzre/tumblr-utils)
For the next step, You'll take the OAuth consumer key (NOT the secret key) and set it as the API key in tumblr-utils to give it the ability to download your blog. Input this line. Note that in this case, the square brackets are NOT to be included- just copy and paste the key:
tumblr-backup --set-api-key [YOUR OAUTH CONSUMER KEY]
This will set you up to start your back up! Type this to see all the different customization options you can pick from for your backup:
tumblr-backup --help
To begin your back up, pick which options you want to choose from and select which of your blogs you want to back up. It should look like this:
tumblr-backup [OPTIONS] [BLOG NAME]
For example, I am currently backing up this blog and I wanted to save videos as well as reversing the post order in the monthly archives. This is what my command looked like:
tumblr-backup -r --save-video bare1ythere
And there you have it! Your backup will be saved into a file titled after your blog. You can search through finder for it from there. There is also an option to specify where you want to save your blog, but I'm not sure how it works. I hope this was useful!!
92 notes
·
View notes
Text
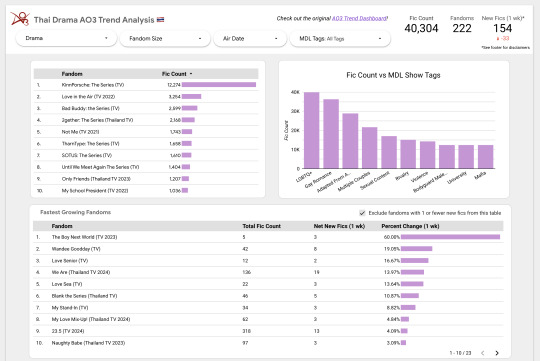
Introducing the Thai Drama AO3 Trends Dashboard! (Beta) 🇹🇭
Over the last several weeks or so I've been building an auto-scraping setup to get AO3 stats on Thai Drama fandoms. Now I finally have it ready to share out!
Take a look if you're interested and let me know what you think :)
(More details and process info under the cut.)
Main Features
This dashboard pulls in data about the quantity of Thai Drama fics over time.
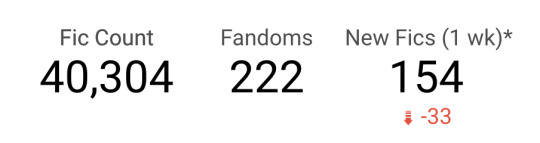
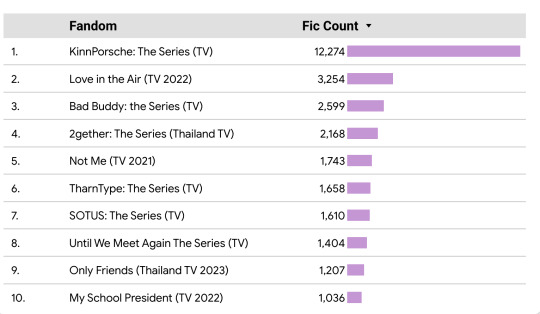
Using filters, it allows you to break that data down by drama, fandom size, air date, and a select number of MyDramaList tags.
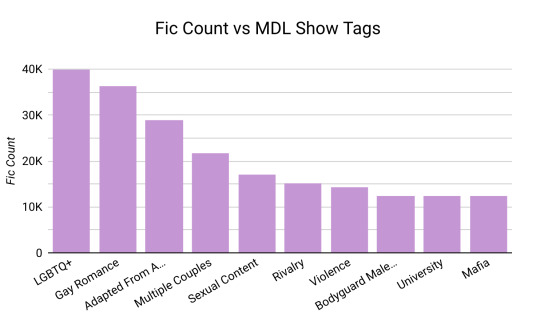
You can also see which fandoms have had the most new fics added on a weekly basis, plus the growth as a percentage of the total.
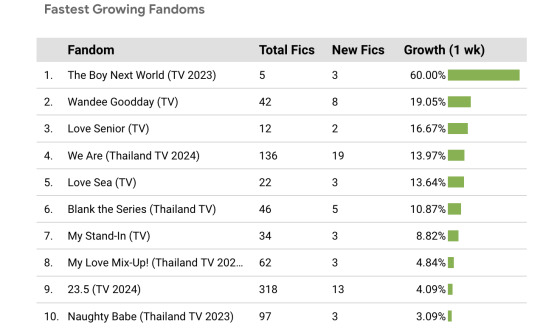
My hope is that this will make it easier to compare Thai Drama fandoms as a collective and pick out trends that otherwise might be difficult to see in an all-AO3 dataset.
Process
Okay -- now for the crunchy stuff...
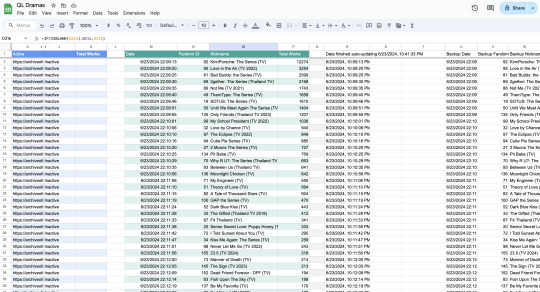
Scraping 🔎
Welcome to the most over-complicated Google Sheets spreadsheet ever made.
I used Google Sheets formulas to scrape certain info from each Thai Drama tag, and then I wrote some app scripts to refresh the data once a day. There are 5 second breaks between the refreshes for each fandom to avoid overwhelming AO3's servers.
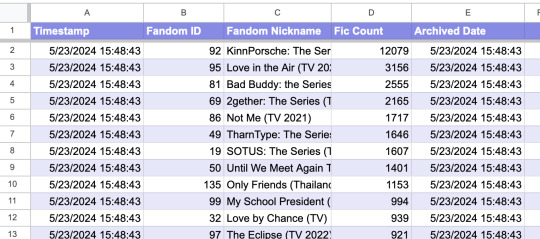
Archiving 📁
Once all the data is scraped, it gets transferred to a different Archive spreadsheet that feeds directly into the data dashboard. The dashboard will update automatically when new data is added to the spreadsheet, so I don't have to do anything manually.
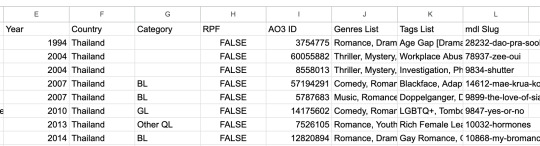
Show Metadata 📊
I decided to be extra and use a (currently unofficial) MyDramaList API to pull in data about each show, such as the year it came out and the MDL tags associated with it. Fun! I might pull in even more info in the future if the mood strikes me.
Bonus - Pan-Fandom AO3 Search
Do you ever find it a bit tedious to have like, 15 different tabs open for the shows you're currently reading fic for?
While making this dash, I also put together this insane URL that basically serves as a "feed" for any and all new Thai drama fics. You can check it out here! It could be useful if you like checking for new fics in multiple fandoms at once. :)
Other Notes
Consider this dashboard the "beta" version -- please let me know if you notice anything that looks off. Also let me know if there are any fandoms missing! Thanks for checking it out!
The inspiration for this dashboard came from @ao3-anonymous 's AO3 Fandom Trend Analysis Dashboard, which I used as a jumping off point for my own data dash. Please give them some love <3
#in which i am the biggest nerd ever#thai bl#thai drama#lgbt drama#ql drama#data science#acafan#fandom data visualization#fanfiction data
287 notes
·
View notes
Text
Here’s the third exciting installment in my series about backing up one Tumblr post that absolutely no one asked for. The previous updates are linked here.
Previously on Tumblr API Hell
Some blogs returned 404 errors. After investigating with Allie's help, it turns out it’s not a sideblog issue — it’s a privacy setting. It pleases me that Tumblr's rickety API respects the word no.
Also, shoutout to the one line of code in my loop that always broke when someone reblogged without tags. Fixed it.
What I got working:
Tags added during reblogs of the post
Any added commentary (what the blog actually wrote)
Full post metadata so I can extract other information later (ie. outside the loop)
New questions I’m trying to answer:
While flailing around in the JSON trying to figure out which blog added which text (because obviously Tumblr’s rickety API doesn’t just tell you), I found that all the good stuff lives in a deeply nested structure called trail. It splits content into HTML chunks — but there’s no guarantee about order, and you have to reconstruct it yourself.
Here’s a stylized diagram of what trail looks like in the JSON list (which gets parsed as a data frame in R):

I started wondering:
Can I use the trail to reconstruct a version tree to see which path through the reblog chain was the most influential for the post?
This would let me ask:
Which version of the post are people reblogging?
Does added commentary increase the chance it gets reblogged again?
Are some blogs “amplifiers” — their version spreads more than others?
It’s worth thinking about these questions now — so I can make sure I’m collecting the right information from Tumblr’s rickety API before I run my R code on a 272K-note post.
Summary
Still backing up one post. Just me, 600+ lines of R code, and Tumblr’s API fighting it out at a Waffle House parking lot. The code’s nearly ready — I’m almost finished testing it on an 800-note post before trying it on my 272K-note Blaze post. Stay tuned… Zero fucks given?
If you give zero fucks about my rickety API series, you can block my data science tag, #a rare data science post, or #tumblr's rickety API. But if we're mutuals then you know how it works here - you get what you get. It's up to you to curate your online experience. XD
#a rare data science post#tumblr's rickety API#fuck you API user#i'll probably make my R code available in github#there's a lot of profanity in the comments#just saying
24 notes
·
View notes
Text
Why Your Business Needs Expert WordPress Development?

1. WordPress: The Platform Built for Growth
WordPress powers over 40% of websites globally—and for good reason. It’s flexible, customizable, and SEO-friendly. Whether you need a sleek portfolio, a content-driven blog, or a high-converting e-commerce store, WordPress adapts to your business needs.
But just having a WordPress site isn't enough. You need experts who know how to unleash its full potential. That’s exactly where expert WordPress website development services step in to make a real difference—turning ideas into digital experiences that work.
2. Custom WordPress Web Design That Reflects Your Brand
Think of your website as your digital storefront—it should feel like your brand, speak your language, and instantly connect with your audience. Generic templates and cookie-cutter designs just don’t cut it anymore.
At Cross Atlantic Software, our team specializes in creating fully customized WordPress web design solutions. We take the time to understand your brand, audience, and business goals—then design a website that communicates your identity with clarity and impact.
From choosing the right color palettes and typography to structuring user-friendly navigation and responsive layouts, our designs are both beautiful and functional.
3. Speed, Security, and Scalability by Professional Developers
Having a fast, secure, and scalable website is crucial—not just for user experience but also for search engine rankings.
Our skilled WordPress web developers at Cross Atlantic Software don’t just build websites—they engineer digital experiences. We optimize every aspect of your site, from lightweight coding to secure plugins and future-ready architecture.
Whether it’s integrating payment gateways, custom plugins, or third-party APIs, our developers ensure that your site runs smoothly and grows with your business.
4. Search Engine Optimization (SEO) Built-In
What good is a stunning website if no one finds it?
A professional WordPress site should come optimized from the ground up. We integrate best SEO practices into the development process, including keyword placement, metadata, mobile responsiveness, site speed, and more.
This means your website won’t just look good—it will perform well in search results, helping you attract more organic traffic and potential customers.
5. User Experience That Keeps Visitors Coming Back
Today’s users are impatient. If your website is clunky, confusing, or slow, they’ll bounce within seconds.
Our WordPress website development services focus on creating seamless user experiences—fast-loading pages, intuitive navigation, clear call-to-actions, and a design that adapts across all devices.
Great UX doesn’t just please your visitors—it builds trust and drives conversions.
6. Looking for “WordPress Experts Near Me”? We’ve Got You Covered
We know how important it is to work with a team that understands your market. Whether you're searching for WordPress experts near me or want a team that communicates closely and understands your local business context, Cross Atlantic Software bridges the gap.
We offer both local and remote development services, with dedicated project managers who ensure smooth communication and progress at every step.
So, even if we’re not just around the corner, we work as if we are—collaboratively, transparently, and efficiently.
7. You Deserve the Best WordPress Designers Near You
A good design is more than just visual appeal—it’s a strategic asset.
Our WordPress designers near me service ensures you get the best of both creativity and conversion strategy. We blend aesthetics with analytics to craft websites that not only look great but also guide your visitors towards taking action—whether that’s filling out a form, making a purchase, or signing up for your newsletter.
8. Reliable Support and Maintenance
Launching a site is just the beginning.
We offer ongoing support, maintenance, backups, and updates to ensure your website stays healthy and competitive. If you ever run into issues or want to scale, our team is just a call or click away.
In a digital landscape that’s constantly evolving, your website should not only keep up—but lead. Don’t settle for average. With Cross Atlantic Software, you get access to top-tier WordPress website development services that are tailored, tested, and trusted.
Whether you're looking for WordPress web design, reliable WordPress web developers, or trying to find the best WordPress experts near me, we’re here to help.
#wordpress web design#WordPress web developers#WordPress experts near me#WordPress website development services
2 notes
·
View notes
Text
How to Implement Royalty Payments in NFTs Using Smart Contracts
NFTs have revolutionized how creators monetize their digital work, with royalty payments being one of the most powerful features. Let's explore how to implement royalty mechanisms in your NFT smart contracts, ensuring creators continue to benefit from secondary sales - all without needing to write code yourself.

Understanding NFT Royalties
Royalties allow creators to earn a percentage of each secondary sale. Unlike traditional art, where artists rarely benefit from appreciation in their work's value, NFTs can automatically distribute royalties to creators whenever their digital assets change hands.
The beauty of NFT royalties is that once set up, they work automatically. When someone resells your NFT on a compatible marketplace, you receive your percentage without any manual intervention.
No-Code Solutions for Implementing NFT Royalties
1. Choose a Creator-Friendly NFT Platform
Several platforms now offer user-friendly interfaces for creating NFTs with royalty settings:
OpenSea: Allows setting royalties up to 10% through their simple creator dashboard
Rarible: Offers customizable royalty settings without coding
Foundation: Automatically includes a 10% royalty for creators
Mintable: Provides easy royalty configuration during the minting process
NFTPort: Offers API-based solutions with simpler implementation requirements
2. Setting Up Royalties Through Platform Interfaces
Most platforms follow a similar process:
Create an account and verify your identity
Navigate to the creation/minting section
Upload your digital asset
Fill in the metadata (title, description, etc.)
Look for a "Royalties" or "Secondary Sales" section
Enter your desired percentage (typically between 2.5% and 10%)
Complete the minting process
3. Understanding Platform-Specific Settings
Different platforms have unique approaches to royalty implementation:
OpenSea
Navigate to your collection settings
Look for "Creator Earnings"
Set your percentage and add recipient addresses
Save your settings
Rarible
During the minting process, you'll see a "Royalties" field
Enter your percentage (up to 50%, though 5-10% is standard)
You can add multiple recipients with different percentages
Foundation
Has a fixed 10% royalty that cannot be modified
Automatically sends royalties to the original creator's wallet
4. Use NFT Creator Tools
Several tools help creators implement royalties without coding:
NFT Creator Pro: Offers drag-and-drop functionality with royalty settings
Manifold Studio: Provides customizable contracts without coding knowledge
Mintplex: Allows creators to establish royalties through simple forms
Bueno: Features a no-code NFT builder with royalty options
Important Considerations for Your Royalty Strategy
Marketplace Compatibility
Not all marketplaces honor royalty settings equally. Research which platforms respect creator royalties before deciding where to list your NFTs.
Reasonable Royalty Percentages
While you might be tempted to set high royalty percentages, market standards typically range from 5-10%. Setting royalties too high might discourage secondary sales altogether.
Payment Recipient Planning
Consider whether royalties should go to:
Your personal wallet
A business entity
Multiple creators (split royalties)
A community treasury or charity
Transparency with Collectors
Clearly communicate your royalty structure to potential buyers. Transparency builds trust in your project and helps buyers understand the long-term value proposition.
Navigating Royalty Enforcement Challenges
While the NFT industry initially embraced creator royalties, some marketplaces have made them optional. To maximize your royalty enforcement:
Choose supportive marketplaces: List primarily on platforms that enforce royalties
Engage with your community: Cultivate collectors who value supporting creators
Utilize blocklisting tools: Some solutions allow creators to block sales on platforms that don't honor royalties
Consider subscription models: Offer special benefits to collectors who purchase through royalty-honoring platforms
Tracking Your Royalty Payments
Without coding knowledge, you can still track your royalty income:
NFT Analytics platforms: Services like NFTScan and Moonstream provide royalty tracking
Wallet notification services: Set up alerts for incoming payments
Marketplace dashboards: Most platforms offer creator dashboards with earning statistics
Third-party accounting tools: Solutions like NFTax help track royalty income for tax purposes
Real-World Success Stories
Many successful NFT creators have implemented royalties without coding knowledge:
Digital artist Beeple receives royalties from secondary sales of his record-breaking NFT works
Photographer Isaac "Drift" Wright funds new creative projects through ongoing royalties
Music groups like Kings of Leon use NFT royalties to create sustainable revenue streams
Conclusion
Implementing royalty payments in NFTs doesn't require deep technical knowledge. By leveraging user-friendly platforms and tools, any creator can ensure they benefit from the appreciation of their digital assets over time.
As the NFT ecosystem evolves, staying informed about royalty standards and marketplace policies will help you maximize your passive income potential. With the right approach, you can create a sustainable revenue stream that rewards your creativity for years to come.
Remember that while no-code solutions make implementation easier, understanding the underlying principles of NFT royalties will help you make more strategic decisions for your creative business.
#game#mobile game development#multiplayer games#metaverse#blockchain#vr games#unity game development#nft#gaming
2 notes
·
View notes
Text
secret orbital cannon recipe:
for i in $(seq 200); do curl 'https://www.tumblr.com/api/v2/boop' --compressed -X POST [metadata, authentication] --data-raw '{"receiver": "$URL","context":"post","type":"normal|super|mischievous"}'; sleep .5; done
2 notes
·
View notes
Text
I found out today that the New York Times has an API which can be used to retrieve article metadata — abstracts, titles, first paragraphs, some information about the people or concepts mentioned — month by month. this has surely many applications, but I'm still working out what
6 notes
·
View notes
Text
Google Cloud’s BigQuery Autonomous Data To AI Platform

BigQuery automates data analysis, transformation, and insight generation using AI. AI and natural language interaction simplify difficult operations.
The fast-paced world needs data access and a real-time data activation flywheel. Artificial intelligence that integrates directly into the data environment and works with intelligent agents is emerging. These catalysts open doors and enable self-directed, rapid action, which is vital for success. This flywheel uses Google's Data & AI Cloud to activate data in real time. BigQuery has five times more organisations than the two leading cloud providers that just offer data science and data warehousing solutions due to this emphasis.
Examples of top companies:
With BigQuery, Radisson Hotel Group enhanced campaign productivity by 50% and revenue by over 20% by fine-tuning the Gemini model.
By connecting over 170 data sources with BigQuery, Gordon Food Service established a scalable, modern, AI-ready data architecture. This improved real-time response to critical business demands, enabled complete analytics, boosted client usage of their ordering systems, and offered staff rapid insights while cutting costs and boosting market share.
J.B. Hunt is revolutionising logistics for shippers and carriers by integrating Databricks into BigQuery.
General Mills saves over $100 million using BigQuery and Vertex AI to give workers secure access to LLMs for structured and unstructured data searches.
Google Cloud is unveiling many new features with its autonomous data to AI platform powered by BigQuery and Looker, a unified, trustworthy, and conversational BI platform:
New assistive and agentic experiences based on your trusted data and available through BigQuery and Looker will make data scientists, data engineers, analysts, and business users' jobs simpler and faster.
Advanced analytics and data science acceleration: Along with seamless integration with real-time and open-source technologies, BigQuery AI-assisted notebooks improve data science workflows and BigQuery AI Query Engine provides fresh insights.
Autonomous data foundation: BigQuery can collect, manage, and orchestrate any data with its new autonomous features, which include native support for unstructured data processing and open data formats like Iceberg.
Look at each change in detail.
User-specific agents
It believes everyone should have AI. BigQuery and Looker made AI-powered helpful experiences generally available, but Google Cloud now offers specialised agents for all data chores, such as:
Data engineering agents integrated with BigQuery pipelines help create data pipelines, convert and enhance data, discover anomalies, and automate metadata development. These agents provide trustworthy data and replace time-consuming and repetitive tasks, enhancing data team productivity. Data engineers traditionally spend hours cleaning, processing, and confirming data.
The data science agent in Google's Colab notebook enables model development at every step. Scalable training, intelligent model selection, automated feature engineering, and faster iteration are possible. This agent lets data science teams focus on complex methods rather than data and infrastructure.
Looker conversational analytics lets everyone utilise natural language with data. Expanded capabilities provided with DeepMind let all users understand the agent's actions and easily resolve misconceptions by undertaking advanced analysis and explaining its logic. Looker's semantic layer boosts accuracy by two-thirds. The agent understands business language like “revenue” and “segments” and can compute metrics in real time, ensuring trustworthy, accurate, and relevant results. An API for conversational analytics is also being introduced to help developers integrate it into processes and apps.
In the BigQuery autonomous data to AI platform, Google Cloud introduced the BigQuery knowledge engine to power assistive and agentic experiences. It models data associations, suggests business vocabulary words, and creates metadata instantaneously using Gemini's table descriptions, query histories, and schema connections. This knowledge engine grounds AI and agents in business context, enabling semantic search across BigQuery and AI-powered data insights.
All customers may access Gemini-powered agentic and assistive experiences in BigQuery and Looker without add-ons in the existing price model tiers!
Accelerating data science and advanced analytics
BigQuery autonomous data to AI platform is revolutionising data science and analytics by enabling new AI-driven data science experiences and engines to manage complex data and provide real-time analytics.
First, AI improves BigQuery notebooks. It adds intelligent SQL cells to your notebook that can merge data sources, comprehend data context, and make code-writing suggestions. It also uses native exploratory analysis and visualisation capabilities for data exploration and peer collaboration. Data scientists can also schedule analyses and update insights. Google Cloud also lets you construct laptop-driven, dynamic, user-friendly, interactive data apps to share insights across the organisation.
This enhanced notebook experience is complemented by the BigQuery AI query engine for AI-driven analytics. This engine lets data scientists easily manage organised and unstructured data and add real-world context—not simply retrieve it. BigQuery AI co-processes SQL and Gemini, adding runtime verbal comprehension, reasoning skills, and real-world knowledge. Their new engine processes unstructured photographs and matches them to your product catalogue. This engine supports several use cases, including model enhancement, sophisticated segmentation, and new insights.
Additionally, it provides users with the most cloud-optimized open-source environment. Google Cloud for Apache Kafka enables real-time data pipelines for event sourcing, model scoring, communications, and analytics in BigQuery for serverless Apache Spark execution. Customers have almost doubled their serverless Spark use in the last year, and Google Cloud has upgraded this engine to handle data 2.7 times faster.
BigQuery lets data scientists utilise SQL, Spark, or foundation models on Google's serverless and scalable architecture to innovate faster without the challenges of traditional infrastructure.
An independent data foundation throughout data lifetime
An independent data foundation created for modern data complexity supports its advanced analytics engines and specialised agents. BigQuery is transforming the environment by making unstructured data first-class citizens. New platform features, such as orchestration for a variety of data workloads, autonomous and invisible governance, and open formats for flexibility, ensure that your data is always ready for data science or artificial intelligence issues. It does this while giving the best cost and decreasing operational overhead.
For many companies, unstructured data is their biggest untapped potential. Even while structured data provides analytical avenues, unique ideas in text, audio, video, and photographs are often underutilised and discovered in siloed systems. BigQuery instantly tackles this issue by making unstructured data a first-class citizen using multimodal tables (preview), which integrate structured data with rich, complex data types for unified querying and storage.
Google Cloud's expanded BigQuery governance enables data stewards and professionals a single perspective to manage discovery, classification, curation, quality, usage, and sharing, including automatic cataloguing and metadata production, to efficiently manage this large data estate. BigQuery continuous queries use SQL to analyse and act on streaming data regardless of format, ensuring timely insights from all your data streams.
Customers utilise Google's AI models in BigQuery for multimodal analysis 16 times more than last year, driven by advanced support for structured and unstructured multimodal data. BigQuery with Vertex AI are 8–16 times cheaper than independent data warehouse and AI solutions.
Google Cloud maintains open ecology. BigQuery tables for Apache Iceberg combine BigQuery's performance and integrated capabilities with the flexibility of an open data lakehouse to link Iceberg data to SQL, Spark, AI, and third-party engines in an open and interoperable fashion. This service provides adaptive and autonomous table management, high-performance streaming, auto-AI-generated insights, practically infinite serverless scalability, and improved governance. Cloud storage enables fail-safe features and centralised fine-grained access control management in their managed solution.
Finaly, AI platform autonomous data optimises. Scaling resources, managing workloads, and ensuring cost-effectiveness are its competencies. The new BigQuery spend commit unifies spending throughout BigQuery platform and allows flexibility in shifting spend across streaming, governance, data processing engines, and more, making purchase easier.
Start your data and AI adventure with BigQuery data migration. Google Cloud wants to know how you innovate with data.
#technology#technews#govindhtech#news#technologynews#BigQuery autonomous data to AI platform#BigQuery#autonomous data to AI platform#BigQuery platform#autonomous data#BigQuery AI Query Engine
2 notes
·
View notes
Text
21/10/2023 || Day 100
Happy Day 100! I officially have done 100 Days of Code, and it's wild to think that when I first started it I pretty much was finished with school. It's crazy how fast time goes by. Anyways, I accidentally did some programming today despite it being a weekend, so here's some progress on a new small project:
Music Info App - Log # 1
I decided that I want to stop paying for Spotify, especially since my student discount will end in January. The problem is that I have a lot of music on there, and downloading each song/album one by one from youtube will be the death of me. Instead, I struggled for 2 hours today installing a youtube downloader (youtube-dl) on my PC, and when that finally started to work, I realized that I'm too impatient to figure out if I can keep the metadata of the video/audio, so I decided to do some coding myself. Now, I really like to have my music organized with all the necessary info (i.e. title, artist, track #), so I found an API that will give me all of that. The thing that took me a while to figure out, even before today/writing the code, was how to manipulate a file's metadata. I guess I finally asked Google the right question because a Node module called "ffmetadata" came up in the search results and I can now add the title, artist, track number, and other metadata to a file without me needing to manually write it. You guys have no idea how much of a weight off my shoulders this is, and I'm so happy this works!! I'm gonna have to do some tweaking for user input (i.e. to be able to choose which directory to look at and get info on the files in the directory), but that's a later thing.
16 notes
·
View notes
Text

Open-source Tools and Scripts for XMLTV Data
XMLTV is a popular format for storing TV listings. It is widely used by media centers, TV guide providers, and software applications to display program schedules. Open-source tools and scripts play a vital role in managing and manipulating XMLTV data, offering flexibility and customization options for users.
In this blog post, we will explore some of the prominent open-source tools and scripts available for working with xmltv examples.
What is XMLTV?
XMLTV is a set of software tools that helps to manage TV listings stored in the XML format. It provides a standard way to describe TV schedules, allowing for easy integration with various applications and services. XMLTV files contain information about program start times, end times, titles, descriptions, and other relevant metadata.
Open-source Tools and Scripts for XMLTV Data
1. EPG Best
EPG Best is an open-source project that provides a set of utilities to obtain, manipulate, and display TV listings. It includes tools for grabbing listings from various sources, customizing the data, and exporting it in different formats. Epg Best offers a flexible and extensible framework for managing XMLTV data.
2. TVHeadend
TVHeadend is an open-source TV streaming server and digital video recorder for Linux. It supports various TV tuner hardware and provides a web interface for managing TV listings. TVHeadend includes built-in support for importing and processing XMLTV data, making it a powerful tool for organizing and streaming TV content.
3. WebGrab+Plus
WebGrab+Plus is a popular open-source tool for grabbing electronic program guide (EPG) data from websites and converting it into XMLTV format. It supports a wide range of sources and provides extensive customization options for configuring channel mappings and data extraction rules. WebGrab+Plus is widely used in conjunction with media center software and IPTV platforms.
4. XMLTV-Perl
XMLTV-Perl is a collection of Perl modules and scripts for processing XMLTV data. It provides a rich set of APIs for parsing, manipulating, and generating XMLTV files. XMLTV-Perl is particularly useful for developers and system administrators who need to work with XMLTV data in their Perl applications or scripts.
5. XMLTV GUI
XMLTV GUI is an open-source graphical user interface for configuring and managing XMLTV grabbers. It simplifies the process of setting up grabber configurations, scheduling updates, and viewing the retrieved TV listings.
XMLTV GUI is a user-friendly tool for users who prefer a visual interface for interacting with XMLTV data.
Open-source tools and scripts for XMLTV data offer a wealth of options for managing and utilizing TV listings in XML format. Whether you are a media enthusiast, a system administrator, or a developer, these tools provide the flexibility and customization needed to work with TV schedules effectively.
By leveraging open-source solutions, users can integrate XMLTV data into their applications, media centers, and services with ease.
Stay tuned with us for more insights into open-source technologies and their applications!

Step-by-Step XMLTV Configuration for Extended Reality
Extended reality (XR) has become an increasingly popular technology, encompassing virtual reality (VR), augmented reality (AR), and mixed reality (MR).
One of the key components of creating immersive XR experiences is the use of XMLTV data for integrating live TV listings and scheduling information into XR applications. In this blog post, we will provide a step-by-step guide to configuring XMLTV for extended reality applications.
What is XMLTV?
XMLTV is a set of utilities and libraries for managing TV listings stored in the XML format. It provides a standardized format for TV scheduling information, including program start times, end times, titles, descriptions, and more. This data can be used to populate electronic program guides (EPGs) and other TV-related applications.
Why Use XMLTV for XR?
Integrating XMLTV data into XR applications allows developers to create immersive experiences that incorporate live TV scheduling information. Whether it's displaying real-time TV listings within a virtual environment or overlaying TV show schedules onto the real world in AR, XMLTV can enrich XR experiences by providing users with up-to-date programming information.
Step-by-Step XMLTV Configuration for XR
Step 1: Obtain XMLTV Data
The first step in configuring XMLTV for XR is to obtain the XMLTV data source. There are several sources for XMLTV data, including commercial providers and open-source projects. Choose a reliable source that provides the TV listings and scheduling information relevant to your target audience and region.
Step 2: Install XMLTV Utilities
Once you have obtained the XMLTV data, you will need to install the XMLTV utilities on your development environment. XMLTV provides a set of command-line tools for processing and manipulating TV listings in XML format. These tools will be essential for parsing the XMLTV data and preparing it for integration into your XR application.
Step 3: Parse XMLTV Data
Use the XMLTV utilities to parse the XMLTV data and extract the relevant scheduling information that you want to display in your XR application. This may involve filtering the data based on specific channels, dates, or genres to tailor the TV listings to the needs of your XR experience.
Step 4: Integrate XMLTV Data into XR Application
With the parsed XMLTV data in hand, you can now integrate it into your XR application. Depending on the XR platform you are developing for (e.g., VR headsets, AR glasses), you will need to leverage the platform's development tools and APIs to display the TV listings within the XR environment.
Step 5: Update XMLTV Data
Finally, it's crucial to regularly update the XMLTV data in your XR application to ensure that the TV listings remain current and accurate. Set up a process for fetching and refreshing the XMLTV data at regular intervals to reflect any changes in the TV schedule.
Incorporating XMLTV data into extended reality applications can significantly enhance the immersive and interactive nature of XR experiences. By following the step-by-step guide outlined in this blog post, developers can seamlessly configure XMLTV for XR and create compelling XR applications that seamlessly integrate live TV scheduling information.
Stay tuned for more XR development tips and tutorials!
Visit our xmltv information blog and discover how these advancements are shaping the IPTV landscape and what they mean for viewers and content creators alike. Get ready to understand the exciting innovations that are just around the corner.
youtube
4 notes
·
View notes
Text
A search across different repositories you should start via (meta-)search engines. We recommend the following discovery services:
Datacite - is the DOI registry for research data and offers both a web interface for searching DOI datasets and an API for retrieving its metadata.
Base -Bielefeld Academic Search Engine - is one of the world's largest search engines for scientific web documents, which can be searched specifically for the publication type "research data".
B2Find - is a discovery service based on metadata harvested from EUDAT data centres and other repositories of the European Union.
In addition, you can use Google Dataset Search to find open data in the web. Google Dataset Search finds datasets if the provider uses the open standard schema.org to describe the content of their web pages.
Guys..let's find a dataset
10 notes
·
View notes
Text
obviously we don't know exactly how this is being done but from what i understand this new midjourney deal (if it even happens) is specifically about tumblr giving midjourney access to the Tumblr API, which it previously did not have. various datasets used in AI training probably already include data from Tumblr because they either scraped data from Tumblr specifically (something that is probably technically against TOS but can be done without accessing the API, also something I have personally done many times on websites like TikTok and Twitter for research) or from google (which indexes links and images posted to Tumblr that you can scrape without even going on Tumblr). The API, which I currently have access to bc of my university, specifically allows you to create a dataset from specific blogs and specific tags. This dataset for tags looks basically exactly like the tag page you or i would have access to, with only original posts showing up but with all of the metadata recorded explicitly (all info you have access to from the user interface of Tumblr itself, just not always extremely clearly). For specific blogs it does include reblogs as well, but this generally seems like a less useful way of collecting data unless you are doing research into specific users (not something i am doing). It depends on your institution what the limits of this API are of course, and it does seem a bit concerning that Tumblr internally seems to have a version that includes unanswered asks, private posts, drafts etc but through the API itself you cannot get these posts. If you choose to exclude your blog from 3rd party partners, what it seems like Tumblr is doing is just removing your original posts from being indexed in any way, so not showing up on Google, not showing up in tags, in searches etc. This means your original posts arent showing up when asking the API for all posts in a specific tag, and it probably also makes it impossible to retrieve a dataset based on your blog. This means it doesnt just exclude your posts and blog from any dataset midjourney creates (if they even take the deal), it's also excluded from the type of research i'm doing (not saying this as a guilt trip, i already have my datasets so i dont care) and it's seemingly excluded from all on-site searches by other users. it's also important to note that every single thing you can do with the Tumblr API to collect data on posts and users you could feasibly also do manually by scrolling while logged in and just writing everything down in an excel sheet.
#this isnt a Take about whether or not you should turn on that new option bc like idk which option is better personally. like im not sure#im just trying to clarify what i think is going on as someone who's used this API quite a lot
3 notes
·
View notes
Text
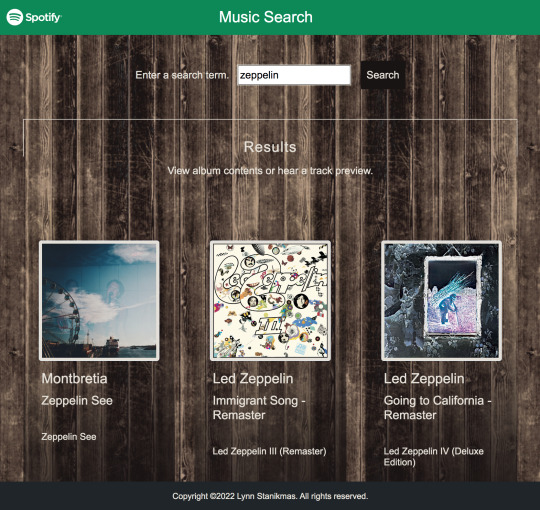






Angular SPA integrated with the Spotify Web API returns JSON metadata about music artists, albums, and tracks, directly from the Spotify Data Catalogue.
#angular#spotify#my music#firebase#firestore#data#database#backend#html5#frontend#coding#responsive web design company#responsivewebsite#responsivedesign#responsive web development#web development#web developers#software development#software#development#information technology#developer#technology#engineering#ui ux development services#ui#ui ux design#uidesign#ux#user interface
2 notes
·
View notes
Text
Yesterday, I
figured out how to force Emacs to update its metadata of whether a file differs between its memory and the file system*;
used that to get my partial save in Emacs on par with native save - the UI now correctly updates to show if the file has unsaved changes after each run of partial save, there's no more spurious blocking prompts in some cases warning that the file has changed on disk, and third-party packages "just work" (undo-tree recognizes which node in the history matches the saved file correctly, for example); and
implemented partial revert to complement partial save: same "git add --patch" UI, but instead of picking unsaved changes to be saved, I pick differences from the file to load into my in-editor copy - that might be throwing away unsaved changes, or pulling out-of-band changes to the file into my editor (like when a "git pull" changes a file I have open), but it lets me do it safely, without losing other unsaved changes that I want to keep. This was trickier because instead of having "gp" apply the changes to the file itself, we have to apply the changes to a temp file, then change the buffer to match the contents of that temp file. Luckily, Emacs' built-in "revert-buffer" does most of this, in a way that we can almost cleanly reuse - we just have to temporarily associate the buffer to the temp file, do the revert, then associate it back to the real file, and fix up another related buffer-local variable that revert messes up.
* you might think "but Emacs already knows if the buffer differs from the file", but if you look closely, it actually usually doesn't. Normally, Emacs only knows if the buffer is different from the last read or write of the file. Emacs only checks if the file and buffer differ in a few very specific situations, and even then it optimizes by only checking for content differences if the file's modified time is newer than what Emacs remembers it to be. And it doesn't provide any API for this.
2 notes
·
View notes