#concurrent programming
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
Mastering Thread Safety with the Synchronized Keyword in Java: A Comprehensive Guide
Synchronized Keyword in Java: Enhancing Thread Safety and Efficiency In the world of Java programming, ensuring thread safety and maintaining data integrity are critical aspects. One powerful tool that Java provides for achieving these goals is the synchronized keyword. By allowing concurrent access to shared resources in a controlled manner, the synchronized keyword plays a vital role in…
View On WordPress
#atomic variables#concurrent programming#data integrity#Java development#Java programming#multi-threading#resource sharing#synchronization techniques#synchronized blocks#synchronized keyword#synchronized methods#thread safety
0 notes
Text
Let's Talk Locks (and Chopsticks!): Diving into the Dining Philosophers Problem
Heyyyy,
So, I'm super excited to start diving into some classic computer science concepts here, especially those that pop up in the world of Linux and concurrent programming. And what better place to start than with the fascinating (and sometimes frustrating!) Dining Philosophers Problem (I learned it about two days ago so please be patient :P).

Think about it: a group of philosophers are sitting around a circular table. In front of each philosopher is a bowl of delicious spaghetti. To eat (somehow) a philosopher needs two chopsticks – one to their left and one to their right. However, there's only one chopstick between each pair of philosophers.
The philosophers have a simple life cycle: they think, they get hungry, they try to pick up their chopsticks, they eat, and then they put the chopsticks down and go back to thinking.
The tricky part arises when multiple philosophers get hungry at the same time. If everyone picks up their left chopstick simultaneously, no one can pick up their right chopstick! They all end up waiting indefinitely, holding one chopstick and starving. This, my friends, is a classic example of a deadlock (and I'm not talking about Valorant's agent ;) ).
Now, why is this relevant to Linux and programming?
Well, the Dining Philosophers Problem is a great analogy for common issues we face when dealing with concurrent processes or threads that need to access shared resources (like those chopsticks!). Chopsticks represent shared resources: Think of these as locks, mutexes, semaphores, or any other mechanism used to control access to critical sections of code (I'm going to talk about those in another posts). Philosophers represent processes or threads: These are the independent units of execution trying to use the shared resources.
The act of picking up chopsticks represents acquiring locks: A process needs to acquire the necessary locks before it can proceed with its task (eating). Deadlock in the problem mirrors deadlock in programs: Just like the philosophers can get stuck waiting for each other's chopsticks, threads can get stuck waiting for locks held by other threads, leading to a program freeze (don't try it at home).
There are several interesting ways to approach solving the Dining Philosophers Problem (and preventing deadlocks in our programs!). Some common strategies include: Introducing a resource hierarchy: Making philosophers pick up chopsticks in a specific order. Allowing a philosopher to pick up both chopsticks only if both are available. Introducing a central coordinator. Limiting the number of philosophers trying to eat at the same time.
What are your initial thoughts on the Dining Philosophers Problem?
Have you encountered similar deadlock situations in your own programming projects? Let me know!
I'm planning on diving deeper into some of the solutions in future posts ;)
6 notes
·
View notes
Text
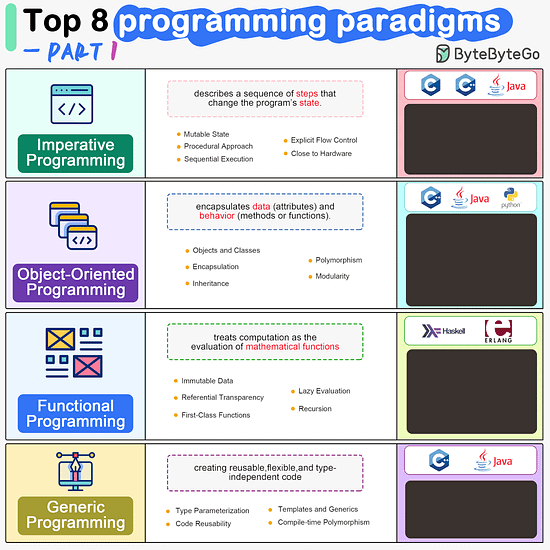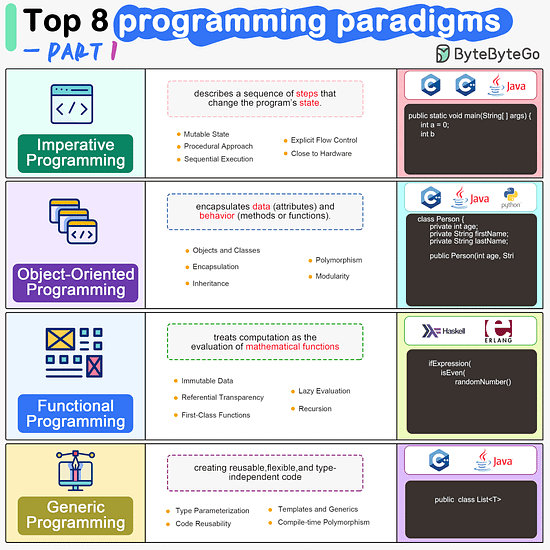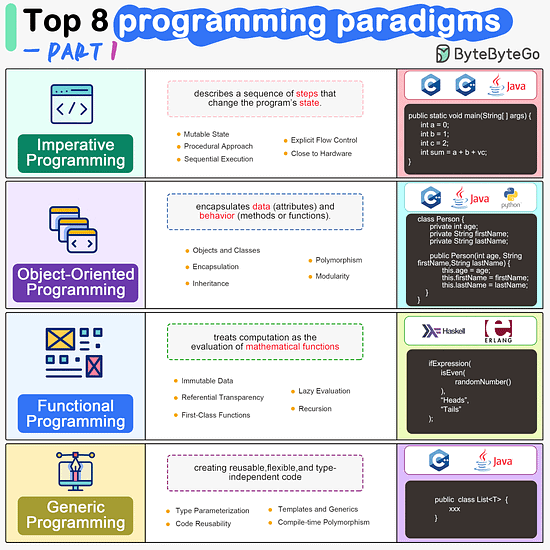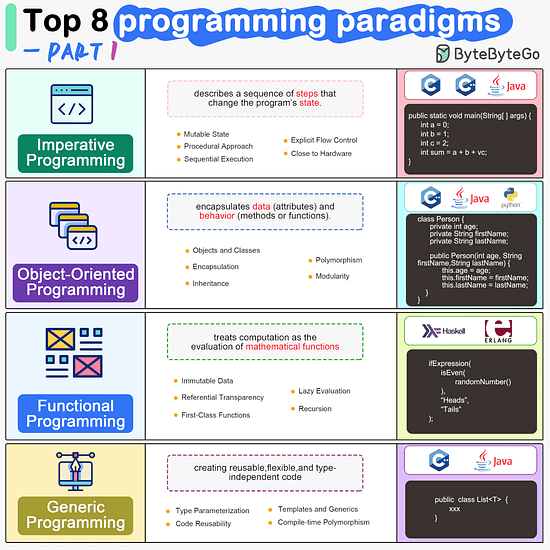
ByteByteGo | Newsletter/Blog
From the newsletter:
Imperative Programming Imperative programming describes a sequence of steps that change the program’s state. Languages like C, C++, Java, Python (to an extent), and many others support imperative programming styles.
Declarative Programming Declarative programming emphasizes expressing logic and functionalities without describing the control flow explicitly. Functional programming is a popular form of declarative programming.
Object-Oriented Programming (OOP) Object-oriented programming (OOP) revolves around the concept of objects, which encapsulate data (attributes) and behavior (methods or functions). Common object-oriented programming languages include Java, C++, Python, Ruby, and C#.
Aspect-Oriented Programming (AOP) Aspect-oriented programming (AOP) aims to modularize concerns that cut across multiple parts of a software system. AspectJ is one of the most well-known AOP frameworks that extends Java with AOP capabilities.
Functional Programming Functional Programming (FP) treats computation as the evaluation of mathematical functions and emphasizes the use of immutable data and declarative expressions. Languages like Haskell, Lisp, Erlang, and some features in languages like JavaScript, Python, and Scala support functional programming paradigms.
Reactive Programming Reactive Programming deals with asynchronous data streams and the propagation of changes. Event-driven applications, and streaming data processing applications benefit from reactive programming.
Generic Programming Generic Programming aims at creating reusable, flexible, and type-independent code by allowing algorithms and data structures to be written without specifying the types they will operate on. Generic programming is extensively used in libraries and frameworks to create data structures like lists, stacks, queues, and algorithms like sorting, searching.
Concurrent Programming Concurrent Programming deals with the execution of multiple tasks or processes simultaneously, improving performance and resource utilization. Concurrent programming is utilized in various applications, including multi-threaded servers, parallel processing, concurrent web servers, and high-performance computing.
#bytebytego#resource#programming#concurrent#generic#reactive#funtional#aspect#oriented#aop#fp#object#oop#declarative#imperative
8 notes
·
View notes
Text
very busy and stressed, submitted application today to Become Busier, good idea
#one of the main reasons i chose this adn program over the other i got accepted into was bc of bridge programs#so i can earn my adn and bsn concurrently#which in two years i know ill be so thankful#but UGH !#personal
2 notes
·
View notes
Text
Unlike 99% of human languages, computer languages are designed. Many of them never catch on for real applications. So what makes a computer language successful? Here's one case study...
#software development#software engineering#golang#coding#artificial language#concurrency#google#programming languages#compiler#computing history#mascot#gophers
5 notes
·
View notes
Text
Virtual Threads and Structured Concurrency in Java
So I was curious about virtual threads and the structured concurrency API that is being introduced to Java so I did some research and wrote some things about it on my Dev.to blog. Check it out!
#java#development#web development#webdev#coding#programming#java programming#structured concurrency#concurrency#codeblr
2 notes
·
View notes
Text
Asynchronous LLM API Calls in Python: A Comprehensive Guide
New Post has been published on https://thedigitalinsider.com/asynchronous-llm-api-calls-in-python-a-comprehensive-guide/
Asynchronous LLM API Calls in Python: A Comprehensive Guide
As developers and dta scientists, we often find ourselves needing to interact with these powerful models through APIs. However, as our applications grow in complexity and scale, the need for efficient and performant API interactions becomes crucial. This is where asynchronous programming shines, allowing us to maximize throughput and minimize latency when working with LLM APIs.
In this comprehensive guide, we’ll explore the world of asynchronous LLM API calls in Python. We’ll cover everything from the basics of asynchronous programming to advanced techniques for handling complex workflows. By the end of this article, you’ll have a solid understanding of how to leverage asynchronous programming to supercharge your LLM-powered applications.
Before we dive into the specifics of async LLM API calls, let’s establish a solid foundation in asynchronous programming concepts.
Asynchronous programming allows multiple operations to be executed concurrently without blocking the main thread of execution. In Python, this is primarily achieved through the asyncio module, which provides a framework for writing concurrent code using coroutines, event loops, and futures.
Key concepts:
Coroutines: Functions defined with async def that can be paused and resumed.
Event Loop: The central execution mechanism that manages and runs asynchronous tasks.
Awaitables: Objects that can be used with the await keyword (coroutines, tasks, futures).
Here’s a simple example to illustrate these concepts:
import asyncio async def greet(name): await asyncio.sleep(1) # Simulate an I/O operation print(f"Hello, name!") async def main(): await asyncio.gather( greet("Alice"), greet("Bob"), greet("Charlie") ) asyncio.run(main())
In this example, we define an asynchronous function greet that simulates an I/O operation with asyncio.sleep(). The main function uses asyncio.gather() to run multiple greetings concurrently. Despite the sleep delay, all three greetings will be printed after approximately 1 second, demonstrating the power of asynchronous execution.
The Need for Async in LLM API Calls
When working with LLM APIs, we often encounter scenarios where we need to make multiple API calls, either in sequence or parallel. Traditional synchronous code can lead to significant performance bottlenecks, especially when dealing with high-latency operations like network requests to LLM services.
Consider a scenario where we need to generate summaries for 100 different articles using an LLM API. With a synchronous approach, each API call would block until it receives a response, potentially taking several minutes to complete all requests. An asynchronous approach, on the other hand, allows us to initiate multiple API calls concurrently, dramatically reducing the overall execution time.
Setting Up Your Environment
To get started with async LLM API calls, you’ll need to set up your Python environment with the necessary libraries. Here’s what you’ll need:
Python 3.7 or higher (for native asyncio support)
aiohttp: An asynchronous HTTP client library
openai: The official OpenAI Python client (if you’re using OpenAI’s GPT models)
langchain: A framework for building applications with LLMs (optional, but recommended for complex workflows)
You can install these dependencies using pip:
pip install aiohttp openai langchain <div class="relative flex flex-col rounded-lg">
Basic Async LLM API Calls with asyncio and aiohttp
Let’s start by making a simple asynchronous call to an LLM API using aiohttp. We’ll use OpenAI’s GPT-3.5 API as an example, but the concepts apply to other LLM APIs as well.
import asyncio import aiohttp from openai import AsyncOpenAI async def generate_text(prompt, client): response = await client.chat.completions.create( model="gpt-3.5-turbo", messages=["role": "user", "content": prompt] ) return response.choices[0].message.content async def main(): prompts = [ "Explain quantum computing in simple terms.", "Write a haiku about artificial intelligence.", "Describe the process of photosynthesis." ] async with AsyncOpenAI() as client: tasks = [generate_text(prompt, client) for prompt in prompts] results = await asyncio.gather(*tasks) for prompt, result in zip(prompts, results): print(f"Prompt: promptnResponse: resultn") asyncio.run(main())
In this example, we define an asynchronous function generate_text that makes a call to the OpenAI API using the AsyncOpenAI client. The main function creates multiple tasks for different prompts and uses asyncio.gather() to run them concurrently.
This approach allows us to send multiple requests to the LLM API simultaneously, significantly reducing the total time required to process all prompts.
Advanced Techniques: Batching and Concurrency Control
While the previous example demonstrates the basics of async LLM API calls, real-world applications often require more sophisticated approaches. Let’s explore two important techniques: batching requests and controlling concurrency.
Batching Requests: When dealing with a large number of prompts, it’s often more efficient to batch them into groups rather than sending individual requests for each prompt. This reduces the overhead of multiple API calls and can lead to better performance.
import asyncio from openai import AsyncOpenAI async def process_batch(batch, client): responses = await asyncio.gather(*[ client.chat.completions.create( model="gpt-3.5-turbo", messages=["role": "user", "content": prompt] ) for prompt in batch ]) return [response.choices[0].message.content for response in responses] async def main(): prompts = [f"Tell me a fact about number i" for i in range(100)] batch_size = 10 async with AsyncOpenAI() as client: results = [] for i in range(0, len(prompts), batch_size): batch = prompts[i:i+batch_size] batch_results = await process_batch(batch, client) results.extend(batch_results) for prompt, result in zip(prompts, results): print(f"Prompt: promptnResponse: resultn") asyncio.run(main())
Concurrency Control: While asynchronous programming allows for concurrent execution, it’s important to control the level of concurrency to avoid overwhelming the API server or exceeding rate limits. We can use asyncio.Semaphore for this purpose.
import asyncio from openai import AsyncOpenAI async def generate_text(prompt, client, semaphore): async with semaphore: response = await client.chat.completions.create( model="gpt-3.5-turbo", messages=["role": "user", "content": prompt] ) return response.choices[0].message.content async def main(): prompts = [f"Tell me a fact about number i" for i in range(100)] max_concurrent_requests = 5 semaphore = asyncio.Semaphore(max_concurrent_requests) async with AsyncOpenAI() as client: tasks = [generate_text(prompt, client, semaphore) for prompt in prompts] results = await asyncio.gather(*tasks) for prompt, result in zip(prompts, results): print(f"Prompt: promptnResponse: resultn") asyncio.run(main())
In this example, we use a semaphore to limit the number of concurrent requests to 5, ensuring we don’t overwhelm the API server.
Error Handling and Retries in Async LLM Calls
When working with external APIs, it’s crucial to implement robust error handling and retry mechanisms. Let’s enhance our code to handle common errors and implement exponential backoff for retries.
import asyncio import random from openai import AsyncOpenAI from tenacity import retry, stop_after_attempt, wait_exponential class APIError(Exception): pass @retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=4, max=10)) async def generate_text_with_retry(prompt, client): try: response = await client.chat.completions.create( model="gpt-3.5-turbo", messages=["role": "user", "content": prompt] ) return response.choices[0].message.content except Exception as e: print(f"Error occurred: e") raise APIError("Failed to generate text") async def process_prompt(prompt, client, semaphore): async with semaphore: try: result = await generate_text_with_retry(prompt, client) return prompt, result except APIError: return prompt, "Failed to generate response after multiple attempts." async def main(): prompts = [f"Tell me a fact about number i" for i in range(20)] max_concurrent_requests = 5 semaphore = asyncio.Semaphore(max_concurrent_requests) async with AsyncOpenAI() as client: tasks = [process_prompt(prompt, client, semaphore) for prompt in prompts] results = await asyncio.gather(*tasks) for prompt, result in results: print(f"Prompt: promptnResponse: resultn") asyncio.run(main())
This enhanced version includes:
A custom APIError exception for API-related errors.
A generate_text_with_retry function decorated with @retry from the tenacity library, implementing exponential backoff.
Error handling in the process_prompt function to catch and report failures.
Optimizing Performance: Streaming Responses
For long-form content generation, streaming responses can significantly improve the perceived performance of your application. Instead of waiting for the entire response, you can process and display chunks of text as they become available.
import asyncio from openai import AsyncOpenAI async def stream_text(prompt, client): stream = await client.chat.completions.create( model="gpt-3.5-turbo", messages=["role": "user", "content": prompt], stream=True ) full_response = "" async for chunk in stream: if chunk.choices[0].delta.content is not None: content = chunk.choices[0].delta.content full_response += content print(content, end='', flush=True) print("n") return full_response async def main(): prompt = "Write a short story about a time-traveling scientist." async with AsyncOpenAI() as client: result = await stream_text(prompt, client) print(f"Full response:nresult") asyncio.run(main())
This example demonstrates how to stream the response from the API, printing each chunk as it arrives. This approach is particularly useful for chat applications or any scenario where you want to provide real-time feedback to the user.
Building Async Workflows with LangChain
For more complex LLM-powered applications, the LangChain framework provides a high-level abstraction that simplifies the process of chaining multiple LLM calls and integrating other tools. Let’s look at an example of using LangChain with async capabilities:
This example shows how LangChain can be used to create more complex workflows with streaming and asynchronous execution. The AsyncCallbackManager and StreamingStdOutCallbackHandler enable real-time streaming of the generated content.
import asyncio from langchain.llms import OpenAI from langchain.prompts import PromptTemplate from langchain.chains import LLMChain from langchain.callbacks.manager import AsyncCallbackManager from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler async def generate_story(topic): llm = OpenAI(temperature=0.7, streaming=True, callback_manager=AsyncCallbackManager([StreamingStdOutCallbackHandler()])) prompt = PromptTemplate( input_variables=["topic"], template="Write a short story about topic." ) chain = LLMChain(llm=llm, prompt=prompt) return await chain.arun(topic=topic) async def main(): topics = ["a magical forest", "a futuristic city", "an underwater civilization"] tasks = [generate_story(topic) for topic in topics] stories = await asyncio.gather(*tasks) for topic, story in zip(topics, stories): print(f"nTopic: topicnStory: storyn'='*50n") asyncio.run(main())
Serving Async LLM Applications with FastAPI
To make your async LLM application available as a web service, FastAPI is an great choice due to its native support for asynchronous operations. Here’s an example of how to create a simple API endpoint for text generation:
from fastapi import FastAPI, BackgroundTasks from pydantic import BaseModel from openai import AsyncOpenAI app = FastAPI() client = AsyncOpenAI() class GenerationRequest(BaseModel): prompt: str class GenerationResponse(BaseModel): generated_text: str @app.post("/generate", response_model=GenerationResponse) async def generate_text(request: GenerationRequest, background_tasks: BackgroundTasks): response = await client.chat.completions.create( model="gpt-3.5-turbo", messages=["role": "user", "content": request.prompt] ) generated_text = response.choices[0].message.content # Simulate some post-processing in the background background_tasks.add_task(log_generation, request.prompt, generated_text) return GenerationResponse(generated_text=generated_text) async def log_generation(prompt: str, generated_text: str): # Simulate logging or additional processing await asyncio.sleep(2) print(f"Logged: Prompt 'prompt' generated text of length len(generated_text)") if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8000)
This FastAPI application creates an endpoint /generate that accepts a prompt and returns generated text. It also demonstrates how to use background tasks for additional processing without blocking the response.
Best Practices and Common Pitfalls
As you work with async LLM APIs, keep these best practices in mind:
Use connection pooling: When making multiple requests, reuse connections to reduce overhead.
Implement proper error handling: Always account for network issues, API errors, and unexpected responses.
Respect rate limits: Use semaphores or other concurrency control mechanisms to avoid overwhelming the API.
Monitor and log: Implement comprehensive logging to track performance and identify issues.
Use streaming for long-form content: It improves user experience and allows for early processing of partial results.
#API#APIs#app#applications#approach#Article#Articles#artificial#Artificial Intelligence#asynchronous programming#asyncio#background#Building#code#col#complexity#comprehensive#computing#Concurrency#concurrency control#content#Delay#developers#display#endpoint#Environment#error handling#event#FastAPI#forest
0 notes
Text
All the concurrency in the world will not fix crummy algorithms.
1 note
·
View note
Text
0 notes
Text
Java Interview Questions on Multithreading and Concurrency for Experienced Developers
Java Interview Questions on Multithreading and Concurrency. Here are some advanced interview questions on multithreading and concurrency suitable for candidates with 10 years of Java experience. Can you explain the difference between parallelism and concurrency in the context of multithreading? In the context of multithreading, parallelism, and concurrency are related but distinct…
View On WordPress
#Best Practices#concurrency#interview#interview questions#Interview Success Tips#Interview Tips#Java#Microservices#multithreading#programming#Senior Developer#Software Architects
0 notes
Text
Unveiling the Future of JVM Technology: Innovations and Directions
Are you curious about the future of Java Virtual Machine (JVM) technology and the exciting innovations it holds? As the backbone of Java-based applications, the JVM continues to evolve, paving the way for groundbreaking advancements in the world of programming. In this article, we'll delve into the future directions and innovations in JVM technology that are poised to shape the landscape of software development.
The Evolution of JVM Technology
Since its inception, the JVM has undergone significant evolution, enabling developers to write platform-independent code and execute it seamlessly across diverse environments. From performance enhancements to advanced garbage collection algorithms, each iteration of the JVM has brought forth new capabilities and optimizations, empowering developers to build robust, scalable, and efficient applications.
Future Directions in JVM Technology
Looking ahead, several key trends and innovations are set to redefine the future of JVM technology:
Project Loom: Project Loom aims to revolutionize concurrency in Java by introducing lightweight, user-mode threads known as fibers. By reducing the overhead associated with traditional threads, fibers promise to improve the scalability and responsiveness of Java applications, particularly in highly concurrent scenarios such as microservices and reactive programming.
GraalVM: GraalVM represents a groundbreaking initiative that offers high-performance, polyglot execution capabilities on the JVM. With support for multiple programming languages, including Java, JavaScript, Python, and Ruby, GraalVM enables developers to seamlessly integrate different language runtimes within a single application, unlocking new possibilities for interoperability and productivity.
Project Panama: Project Panama aims to enhance the interoperability between Java and native code, enabling seamless integration with libraries and frameworks written in languages such as C and C++. By providing efficient access to native data structures and functions, Project Panama facilitates the development of high-performance, low-level components within Java applications, such as multimedia processing and system-level programming.
Ahead-of-Time (AOT) Compilation: AOT compilation is gaining traction as a promising approach to improving startup times and reducing memory footprint in Java applications. By precompiling Java bytecode into native machine code, AOT compilation eliminates the need for just-in-time (JIT) compilation at runtime, resulting in faster startup times and improved overall performance, particularly in resource-constrained environments such as cloud-based deployments.
Embracing the Future of JVM Technology with The Tech Tutor
At The Tech Tutor, we're committed to empowering developers with the knowledge and skills they need to thrive in a rapidly evolving technological landscape. Our comprehensive courses and tutorials cover a wide range of topics, including JVM internals, performance optimization, and the latest advancements in Java ecosystem.
Whether you're a seasoned Java developer looking to stay ahead of the curve or a newcomer eager to explore the exciting world of JVM technology, The Tech Tutor has you covered. Join our community today and embark on a journey of continuous learning and innovation in JVM technology.
Conclusion
As JVM technology continues to evolve, developers can expect to see a myriad of innovations that enhance performance, scalability, and interoperability in Java-based applications. From Project Loom's revolutionization of concurrency to GraalVM's polyglot execution capabilities, the future of JVM technology is brimming with possibilities.
Stay ahead of the curve and embrace the future of JVM technology with The Tech Tutor. Explore our comprehensive courses and tutorials to unlock your full potential as a Java developer and shape the future of software development.
#JVMTechnology#Java#FutureInnovations#ProjectLoom#GraalVM#ProjectPanama#AOTCompilation#Programming#SoftwareDevelopment#TechTrends#TheTechTutor#JavaDevelopers#Concurrency#PolyglotExecution#ContinuousLearning#DeveloperCommunity
1 note
·
View note
Text
Are you a student or aspiring developer eager to unlock the secrets of modern C++ for efficient and error-free code? 🤖 Look no further!
In our latest blog post, we delve into the dynamic world of concurrency, introducing you to the powerful tools of latches and barriers in C++20. Discover how these synchronization mechanisms can streamline your code and help you create software that runs smoothly.
0 notes
Text
youtube
Insights Sequential and Concurrent Statements - No More Confusion [Beginner’s Guide] - Part ii
Subscribe to "Learn And Grow Community"
YouTube : https://www.youtube.com/@LearnAndGrowCommunity
LinkedIn Group : https://www.linkedin.com/groups/7478922/
Blog : https://LearnAndGrowCommunity.blogspot.com/
Facebook : https://www.facebook.com/JoinLearnAndGrowCommunity/
Twitter Handle : https://twitter.com/LNG_Community
DailyMotion : https://www.dailymotion.com/LearnAndGrowCommunity
Instagram Handle : https://www.instagram.com/LearnAndGrowCommunity/
Follow #LearnAndGrowCommunity
This is the Part ii of last Video "VHDL Basics : Insights Sequential and Concurrent Statements - No More Confusion [Beginner’s Guide]", for deeper understanding, and it is very important to have deeper insights on Sequential and Concurrent statement, if you are designing anything in VHDL or Verilog HDL. In this comprehensive tutorial, we will cover everything you need to know about VHDL sequential and concurrent statements. Sequential statements allow us to execute code in a step-by-step manner, while concurrent statements offer a more parallel execution approach. Welcome to this beginner's guide on VHDL basics, where we will dive into the concepts of sequential and concurrent statements in VHDL. If you've ever been confused about these fundamental aspects of VHDL programming, this video is perfect for you. We will start by explaining the differences between sequential and concurrent statements, providing clear examples and illustrations to eliminate any confusion. By the end of this video, you will have a solid understanding of how to effectively utilize sequential and concurrent statements in your VHDL designs. This guide is suitable for beginners who have some basic knowledge of VHDL. We will go step-by-step and explain each concept thoroughly, ensuring that you grasp the fundamentals before moving on to more advanced topics. Make sure to subscribe to our channel for more informative videos on VHDL programming and digital design. Don't forget to hit the notification bell to stay updated with our latest uploads. If you have any questions or suggestions, feel free to leave them in the comments section below.
#VHDL basics#VHDL programming#VHDL tutorial#VHDL sequential statements#VHDL concurrent statements#VHDL beginner's guide#VHDL programming guide#VHDL insights#VHDL concepts#VHDL design#digital design#beginner's tutorial#coding tutorial#VHDL for beginners#VHDL learning#VHDL syntax#VHDL examples#VHDL video tutorial#VHDL step-by-step#VHDL Examples#VHDL Coding#VHDL Course#VHDL#Xilinx ISE#FPGA#Altera#Xilinx Vivado#VHDL Simulation#VHDL Synthesis#Youtube
1 note
·
View note
Text


It was never a common species, the blue-grey warbler that locals called the jack pine bird. A belated discovery among American birds, it was undescribed by science until the mid 19th century—and then, known only on the basis of a single specimen. The bird's wintering grounds in the Caribbean would eventually fulfill the demands of collectors and museums, but the intricacies of its lifecycle remained a mystery for decades, the first nest only found in 1903. As the already-rare bird became rarer, people could only guess at why. There were just so few birds to look for, their breeding habitat inscrutable amidst the dense, impassable woodland of their Midwestern home. The one clue was the most apparent thing about the bird: its affinity with the jack pine (Pinus banksiana).
Over time, more nests were found—not in the eponymous trees, as might be expected for a songbird, but on the ground at their feet. Data points converged, leading to the realization that not only did the bird nest almost exclusively in proximity to the scrubby pines, but only utilized trees that fell within a specific range: new growth, between five and fifteen feet tall, with branches that swept shelteringly close to the ground. Subsequently, it would be noticed that the greatest volume of specimen collection for the bird had corresponded with years in which historically significant wildfires had impacted the Midwest—fires that, for decades afterwards, had been staunchly suppressed. The pieces fell into place, like jack pine seeds, whose cones open only under the heat of a blaze.
With the bird's total population having dwindled to the low hundreds, a program of prescribed burns, clearcutting, and replanting was instituted, with many acres of land purchased and devoted to the preservation and maintenance of suitable breeding habitat. Concurrently, efforts were made to protect the vulnerable bird against brood parasitism by the brown-headed cowbird.
When the first federal list of protected species was put forward in 1966, the name of the small grey warbler was inscribed beside birds such as the Kauai ʻōʻō and the Dusky Seaside Sparrow.
The ʻōʻō, last of the genus Moho, would be removed from the list in 2023 due to extinction, after thirty-six years without a sighting.
The endling Dusky Seaside Sparrow, a male named Orange Band, would die of old age in captivity in 1987, with his species being delisted three years later.
in 2019, fifty-two years after the creation of the Endangered Species Protection Act, the name of Kirtland's warbler, too, was removed from the list: it had been determined that, with a population now numbering nearly 5000, the jack pine bird could be considered safely stable.
Conservationists continue to work to preserve the breeding habitat of Kirtland's Warbler in the midwestern US, as well as its winter roosts in the Bahamas and neighboring islands (though selective logging has replaced actual burning in recent years, due to the dangers posed by unpredictable fires). It's the kind of effort that it takes to undo the damage we've caused to the planet and its creatures—the kind of hope that we need, to not give up on them, or on ourselves.
-
The title of this piece is Prescribed Burn (Kirtland's Warbler). It is traditional gouache on 18x24" watercolor paper, and is part of my series Conservation Pieces, which focuses on efforts made to save critically endangered birds from extinction.
#kirtland's warbler#conservation#bird art#extinction stories#bird extinction#endangered species#series: conservation pieces
1K notes
·
View notes
Text

Charles Ponder·
Quit trashing Obama's accomplishments. He has done more than any other President before him. Here is a list of his impressive accomplishments:
1. First President to be photographed smoking a joint.
2. First President to apply for college aid as a foreign student, then deny he was a foreigner.
3. First President to have a social security number from a state he has never lived in.
4. First President to preside over a cut to the credit-rating of the United States.
5. First President to violate the War Powers Act.
6. First President to be held in contempt of court for illegally obstructing oil drilling in the Gulf of Mexico.
7. First President to require all Americans to purchase a product from a third party.
8. First President to spend a trillion dollars on "shovel-ready" jobs when there was no such thing as "shovel-ready" jobs.
9. First President to abrogate bankruptcy law to turn over control of companies to his union supporters.
10. First President to by-pass Congress and implement the Dream Act through executive fiat.
11. First President to order a secret amnesty program that stopped the deportation of illegal immigrants across the U.S., including those with criminal convictions.
12. First President to demand a company hand-over $20 billion to one of his political appointees.
13. First President to tell a CEO of a major corporation (Chrysler) to resign.
14. First President to terminate America’s ability to put a man in space.
15. First President to cancel the National Day of Prayer and to say that America is no longer a Christian nation.
16. First President to have a law signed by an auto-pen without being present.
17. First President to arbitrarily declare an existing law unconstitutional and refuse to enforce it.
18. First President to threaten insurance companies if they publicly spoke out on the reasons for their rate increases.
19. First President to tell a major manufacturing company in which state it is allowed to locate a factory.
20. First President to file lawsuits against the states he swore an oath to protect (AZ, WI, OH, IN).
21. First President to withdraw an existing coal permit that had been properly issued years ago.
22. First President to actively try to bankrupt an American industry (coal).
23. First President to fire an inspector general of AmeriCorps for catching one of his friends in a corruption case.
24. First President to appoint 45 czars to replace elected officials in his office.
25. First President to surround himself with radical left wing anarchists.
26. First President to golf more than 150 separate times in his five years in office.
27. First President to hide his birth, medical, educational and travel records.
28. First President to win a Nobel Peace Prize for doing NOTHING to earn it.
29. First President to go on multiple "global apology tours" and concurrent "insult our friends" tours.
30. First President to go on over 17 lavish vacations, in addition to date nights and Wednesday evening White House parties for his friends paid for by the taxpayers.
31. First President to have personal servants (taxpayer funded) for his wife.
32. First President to keep a dog trainer on retainer for $102,000 a year at taxpayer expense.
33. First President to fly in a personal trainer from Chicago at least once a week at taxpayer expense.
34. First President to repeat the Quran and tell us the early morning call of the Azan (Islamic call to worship) is the most beautiful sound on earth.
35. First President to side with a foreign nation over one of the American 50 states (Mexico vs Arizona).
36. First President to tell the military men and women that they should pay for their own private insurance because they "volunteered to go to war and knew the consequences."
37. Then he was the First President to tell the members of the military that THEY were UNPATRIOTIC for balking at the last suggestion.
I feel much better now. I had been under the impression he hadn't been doing ANYTHING... Such an accomplished individual... in the eyes of the ignorant maybe.!.
201 notes
·
View notes
Text
I love finding ways to circumvent ads. 3rd party programs and per-app internet blockers and one million different ad blocks. I will find a new website and be like 'damn this shit is great why is no one talking abt this' only to pull it up on someone else's device months later and realize it's a dumpster fire of banner ads and autoplay popups. I can watch twitch with no ads. My life is bliss, a lake of beautiful crystalline water completely undisturbed, the sounds of war and death so far away they do not even cause the slightest ripple across the surface.
Until I try to listen to music on the computer at work and immediately explode into a fountain of bloody viscera via 27 concurrent shotgun blasts to the head. And one sledgehammer
165 notes
·
View notes