#containerized applications
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr Inc. has $15.1M in annual revenue.
Text
Mastering Azure Container Apps: From Configuration to Deployment
Thank you for following our Azure Container Apps series! We hope you're gaining valuable insights to scale and secure your applications. Stay tuned for more tips, and feel free to share your thoughts or questions. Together, let's unlock the Azure's Power.
#API deployment#application scaling#Azure Container Apps#Azure Container Registry#Azure networking#Azure security#background processing#Cloud Computing#containerized applications#event-driven processing#ingress management#KEDA scalers#Managed Identities#microservices#serverless platform
0 notes
Text
What Is the Best Way to Containerize ColdFusion Applications Using Docker?
#What Is the Best Way to Containerize ColdFusion Applications Using Docker?#Best Way to Containerize ColdFusion Applications Using Docker#Containerize ColdFusion Applications Using Docker
0 notes
Text






#TechKnowledge Have you heard of Containerization?
Swipe to discover what it is and how it can impact your digital security! 🚀
👉 Stay tuned for more simple and insightful tech tips by following us.
🌐 Learn more: https://simplelogic-it.com/
💻 Explore the latest in #technology on our Blog Page: https://simplelogic-it.com/blogs/
✨ Looking for your next career opportunity? Check out our #Careers page for exciting roles: https://simplelogic-it.com/careers/
#techterms#technologyterms#techcommunity#simplelogicit#makingitsimple#techinsight#techtalk#containerization#application#development#testing#deployment#devops#docker#kubernets#openshift#scalability#security#knowledgeIispower#makeitsimple#simplelogic#didyouknow
0 notes
Text
Karthik Ranganathan, Co-Founder and Co-CEO of Yugabyte – Interview Series
New Post has been published on https://thedigitalinsider.com/karthik-ranganathan-co-founder-and-co-ceo-of-yugabyte-interview-series/
Karthik Ranganathan, Co-Founder and Co-CEO of Yugabyte – Interview Series

Karthik Ranganathan is co-founder and co-CEO of Yugabyte, the company behind YugabyteDB, the open-source, high-performance distributed PostgreSQL database. Karthik is a seasoned data expert and former Facebook engineer who founded Yugabyte alongside two of his Facebook colleagues to revolutionize distributed databases.
What inspired you to co-found Yugabyte, and what gaps in the market did you see that led you to create YugabyteDB?
My co-founders, Kannan Muthukkaruppan, Mikhail Bautin, and I, founded Yugabyte in 2016. As former engineers at Meta (then called Facebook), we helped build popular databases including Apache Cassandra, HBase, and RocksDB – as well as running some of these databases as managed services for internal workloads.
We created YugabyteDB because we saw a gap in the market for cloud-native transactional databases for business-critical applications. We built YugabyteDB to cater to the needs of organizations transitioning from on-premises to cloud-native operations and combined the strengths of non-relational databases with the scalability and resilience of cloud-native architectures. While building Cassandra and HBase at Facebook (which was instrumental in addressing Facebook’s significant scaling needs), we saw the rise of microservices, containerization, high availability, geographic distribution, and Application Programming Interfaces (API). We also recognized the impact that open-source technologies have in advancing the industry.
People often think of the transactional database market as crowded. While this has traditionally been true, today Postgres has become the default API for cloud-native transactional databases. Increasingly, cloud-native databases are choosing to support the Postgres protocol, which has been ingrained into the fabric of YugabyteDB, making it the most Postgres-compatible database on the market. YugabyteDB retains the power and familiarity of PostgreSQL while evolving it to an enterprise-grade distributed database suitable for modern cloud-native applications. YugabyteDB allows enterprises to efficiently build and scale systems using familiar SQL models.
How did your experiences at Facebook influence your vision for the company?
In 2007, I was considering whether to join a small but growing company–Facebook. At the time, the site had about 30 to 40 million users. I thought it might double in size, but I couldn’t have been more wrong! During my over five years at Facebook, the user base grew to 2 billion. What attracted me to the company was its culture of innovation and boldness, encouraging people to “fail fast” to catalyze innovation.
Facebook grew so large that the technical and intellectual challenges I craved were no longer present. For many years I had aspired to start my own company and tackle problems facing the common user–this led me to co-create Yugabyte.
Our mission is to simplify cloud-native applications, focusing on three essential features crucial for modern development:
First, applications must be continuously available, ensuring uptime regardless of backups or failures, especially when running on commodity hardware in the cloud.
Second, the ability to scale on demand is crucial, allowing developers to build and release quickly without the delay of ordering hardware.
Third, with numerous data centers now easily accessible, replicating data across regions becomes vital for reliability and performance.
These three elements empower developers by providing the agility and freedom they need to innovate, without being constrained by infrastructure limitations.
Could you share the journey from Yugabyte’s inception in 2016 to its current status as a leader in distributed SQL databases? What were some key milestones?
At Facebook, I often talked with developers who needed specific features, like secondary indexes on SQL databases or occasional multi-node transactions. Unfortunately, the answer was usually “no,” because existing systems weren’t designed for those requirements.
Today, we are experiencing a shift towards cloud-native transactional applications that need to address scale and availability. Traditional databases simply can’t meet these needs. Modern businesses require relational databases that operate in the cloud and offer the three essential features: high availability, scalability, and geographic distribution, while still supporting SQL capabilities. These are the pillars on which we built YugabyteDB and the database challenges we’re focused on solving.
In February 2016, the founders began developing YugabyteDB, a global-scale distributed SQL database designed for cloud-native transactional applications. In July 2019, we made an unprecedented announcement and released our previously commercial features as open source. This reaffirmed our commitment to open-source principles and officially launched YugabyteDB as a fully open-source relational database management system (RDBMS) under an Apache 2.0 license.
The latest version of YugabyteDB (unveiled in September) features enhanced Postgres compatibility. It includes an Adaptive Cost-Based Optimizer (CBO) that optimizes query plans for large-scale, multi-region applications, and Smart Data Distribution that automatically determines whether to store tables together for lower latency, or to shard and distribute data for greater scalability. These enhancements allow developers to run their PostgreSQL applications on YugabyteDB efficiently and scale without the need for trade-offs or complex migrations.
YugabyteDB is known for its compatibility with PostgreSQL and its Cassandra-inspired API. How does this multi-API approach benefit developers and enterprises?
YugabyteDB’s multi-API approach benefits developers and enterprises by combining the strengths of a high-performance SQL database with the flexibility needed for global, internet-scale applications.
It supports scale-out RDBMS and high-volume Online Transaction Processing (OLTP) workloads, while maintaining low query latency and exceptional resilience. Compatibility with PostgreSQL allows for seamless lift-and-shift modernization of existing Postgres applications, requiring minimal changes.
In the latest version of the distributed database platform, released in September 2024, features like the Adaptive CBO and Smart Data Distribution enhance performance by optimizing query plans and automatically managing data placement. This allows developers to achieve low latency and high scalability without compromise, making YugabyteDB ideal for rapidly growing, cloud-native applications that require reliable data management.
AI is increasingly being integrated into database systems. How is Yugabyte leveraging AI to enhance the performance, scalability, and security of its SQL systems?
We are leveraging AI to enhance our distributed SQL database by addressing performance and migration challenges. Our upcoming Performance Copilot, an enhancement to our Performance Advisor, will simplify troubleshooting by analyzing query patterns, detecting anomalies, and providing real-time recommendations to troubleshoot database performance issues.
We are also integrating AI into YugabyteDB Voyager, our database migration tool that simplifies migrations from PostgreSQL, MySQL, Oracle, and other cloud databases to YugabyteDB. We aim to streamline transitions from legacy systems by automating schema conversion, SQL translation, and data transformation, with proactive compatibility checks. These innovations focus on making YugabyteDB smarter, more efficient, and easier for modern, distributed applications to use.
What are the key advantages of using an open-source SQL system like YugabyteDB in cloud-native applications compared to traditional proprietary databases?
Transparency, flexibility, and robust community support are key advantages when using an open-source SQL system like YugabyteDB in cloud-native applications. When we launched YugabyteDB, we recognized the skepticism surrounding open-source models. We engaged with users, who expressed a strong preference for a fully open database to trust with their critical data.
We initially ran on an open-core model, but rapidly realized it needed to be a completely open solution. Developers increasingly turn to PostgreSQL as a logical Oracle alternative, but PostgreSQL was not built for dynamic cloud platforms. YugabyteDB fills this gap by supporting PostgreSQL’s feature depth for modern cloud infrastructures. By being 100% open source, we remove roadblocks to adoption.
This makes us very attractive to developers building business-critical applications and to operations engineers running them on cloud-native platforms. Our focus is on creating a database that is not only open, but also easy to use and compatible with PostgreSQL, which remains a developer favorite due to its mature feature set and powerful extensions.
The demand for scalable and adaptable SQL solutions is growing. What trends are you observing in the enterprise database market, and how is Yugabyte positioned to meet these demands?
Larger scale in enterprise databases often leads to increased failure rates, especially as organizations deal with expanded footprints and higher data volumes. Key trends shaping the database landscape include the adoption of DBaaS, and a shift back from public cloud to private cloud environments. Additionally, the integration of generative AI brings opportunities and challenges, requiring automation and performance optimization to manage the growing data load.
Organizations are increasingly turning to DBaaS to streamline operations, despite initial concerns about control and security. This approach improves efficiency across various infrastructures, while the focus on private cloud solutions helps businesses reduce costs and enhance scalability for their workloads.
YugabyteDB addresses these evolving demands by combining the strengths of relational databases with the scalability of cloud-native architectures. Features like Smart Data Distribution and an Adaptive CBO, enhance performance and support a large number of database objects. This makes it a competitive choice for running a wide range of applications.
Furthermore, YugabyteDB allows enterprises to migrate their PostgreSQL applications while maintaining similar performance levels, crucial for modern workloads. Our commitment to open-source development encourages community involvement and provides flexibility for customers who want to avoid vendor lock-in.
With the rise of edge computing and IoT, how does YugabyteDB address the challenges posed by these technologies, particularly regarding data distribution and latency?
YugabyteDB’s distributed SQL architecture is designed to meet the challenges posed by the rise of edge computing and IoT by providing a scalable and resilient data layer that can operate seamlessly in both cloud and edge contexts. Its ability to automatically shard and replicate data ensures efficient distribution, enabling quick access and real-time processing. This minimizes latency, allowing applications to respond swiftly to user interactions and data changes.
By offering the flexibility to adapt configurations based on specific application requirements, YugabyteDB ensures that enterprises can effectively manage their data needs as they evolve in an increasingly decentralized landscape.
As Co-CEO, how do you balance the dual roles of leading technological innovation and managing company growth?
Our company aims to simplify cloud-native applications, compelling me to stay on top of technology trends, such as generative AI and context switches. Following innovation demands curiosity, a desire to make an impact, and a commitment to continuous learning.
Balancing technological innovation and company growth is fundamentally about scaling–whether it’s scaling systems or scaling impact. In distributed databases, we focus on building technologies that scale performance, handle massive workloads, and ensure high availability across a global infrastructure. Similarly, scaling Yugabyte means growing our customer base, enhancing community engagement, and expanding our ecosystem–while maintaining operational excellence.
All this requires a disciplined approach to performance and efficiency.
Technically, we optimize query execution, reduce latency, and improve system throughput; organizationally, we streamline processes, scale teams, and enhance cross-functional collaboration. In both cases, success comes from empowering teams with the right tools, insights, and processes to make smart, data-driven decisions.
How do you see the role of distributed SQL databases evolving in the next 5-10 years, particularly in the context of AI and machine learning?
In the next few years, distributed SQL databases will evolve to handle complex data analysis, enabling users to make predictions and detect anomalies with minimal technical expertise. There is an immense amount of database specialization in the context of AI and machine learning, but that is not sustainable. Databases will need to evolve to meet the demands of AI. This is why we’re iterating and enhancing capabilities on top of pgvector, ensuring developers can use Yugabyte for their AI database needs.
Additionally, we can expect an ongoing commitment to open source in AI development. Five years ago, we made YugabyteDB fully open source under the Apache 2.0 license, reinforcing our dedication to an open-source framework and proactively building our open-source community.
Thank you for all of your detailed responses, readers who wish to learn more should visit YugabyteDB.
#2024#adoption#ai#AI development#Analysis#anomalies#Apache#Apache 2.0 license#API#applications#approach#architecture#automation#backups#billion#Building#Business#CEO#Cloud#cloud solutions#Cloud-Native#Collaboration#Community#compromise#computing#containerization#continuous#curiosity#data#data analysis
0 notes
Text
Harnessing Containerization in Web Development: A Path to Scalability
Explore the transformative impact of containerization in web development. This article delves into the benefits of containerization, microservices architecture, and how Docker for web apps facilitates scalable and efficient applications in today’s cloud-native environment.
#Containerization in Web Development#Microservices architecture#Benefits of containerization#Docker for web apps#Scalable web applications#DevOps practices#Cloud-native development
0 notes
Text
Using Docker with Node.js Applications
Learn how to use Docker with Node.js applications. This guide covers setting up Docker, creating Dockerfiles, managing dependencies, and using Docker Compose.
Introduction Docker has revolutionized the way we build, ship, and run applications. By containerizing your Node.js applications, you can ensure consistency across different environments, simplify dependencies management, and streamline deployment processes. This guide will walk you through the essentials of using Docker with Node.js applications, from setting up a Dockerfile to running your…

View On WordPress
#application deployment#containerization#DevOps#Docker#Docker Compose#Dockerfile#Express.js#Node.js#web development
0 notes
Text
Best Kubernetes Management Tools in 2023
Best Kubernetes Management Tools in 2023 #homelab #vmwarecommunities #Kubernetesmanagementtools2023 #bestKubernetescommandlinetools #managingKubernetesclusters #Kubernetesdashboardinterfaces #kubernetesmanagementtools #Kubernetesdashboard
Kubernetes is everywhere these days. It is used in the enterprise and even in many home labs. It’s a skill that’s sought after, especially with today’s push for app modernization. Many tools help you manage things in Kubernetes, like clusters, pods, services, and apps. Here’s my list of the best Kubernetes management tools in 2023. Table of contentsWhat is Kubernetes?Understanding Kubernetes and…

View On WordPress
#best Kubernetes command line tools#containerized applications management#Kubernetes cluster management tools#Kubernetes cost monitoring#Kubernetes dashboard interfaces#Kubernetes deployment solutions#Kubernetes management tools 2023#large Kubernetes deployments#managing Kubernetes clusters#open-source Kubernetes tools
0 notes
Note
Any recommendations/cautions about using Alpine Linux on the desktop? It's always intrigued me and you're the only person I've seen post about it
Alpine is pretty good for desktop, very stable, good security practice, professional development philosophy, broad package availability. You will run into some very obvious pitfalls, although they can mostly be obviated by using some modern applications.
The Alpine wiki is a little sparse and at times can be weirdly focussed, like spending a lot of the installation page talking about the very specific usecase of a diskless install. Nonetheless, it's quite good and should be your first port of call. A lot of the things I'm mentioning here are well covered in the article on Daily Driving for Desktop use. I'm basically just editorializing here.
The installation procedure is command-line only, but pretty straightforward, you run setup-alpine and follow the prompts, assuming you want a basic system. If you need special disk partitioning, you'll usually have to do it yourself. There's a whole whackload of helpers to get you set up, like setup-desktop which will help you install any of 'gnome', 'plasma', 'xfce', 'mate', 'sway', or 'lxqt'. Most of these are called by setup-alpine for you, but not the desktop one. You can call it at any time though.
Most obviously, musl libc, no glibc. Packaged software will work fine. There's a compatibility shim called gcompat that will usually work, but might fall apart on more complicated software expecting glibc, for example I've had no luck running glibc AppImages. For more complex software, Flatpaks are a good option, e.g. Steam runs great on Alpine as a Flatpak, I run the Homestuck Companion Flatpak. Your last ditch is containerization and chroots, which are fortunately really easy to handle, just install podman and Distrobox and you can run anything that won't run on Alpine inside a Fedora or Debian or Whatever container seamlessly with your desktop.
Less obviously: no systemd. Systemd underpins some really common features of modern Linux and not having it around means you have to use a few different tools that are anywhere from comparable to a little worse for some tasks. Packaged applications will work smoothly, just learn the OpenRC invocations, Alpine has a really great wiki. For writing your own services, it's a lot more limited than SystemD, you're not going to have full access to like, udev functionality, instead you get the good but kind of weird eudev system.
If you're mainly installing things from the repos you'll barely notice the difference, other than that every package is split up into three, <package>, <package>-docs, and <package>-dev. This is a container-y thing, to allow Alpine container images to install the smallest possible packageset. If you need man pages you'll have to install them specifically.
Alpine has a very solid main repo, and a community repo that's plenty good, and worth enabling on any desktop system. It'll generally be automatically enabled when you set up a desktop anyway, but just a notice if you're going manual. You can run Stable alpine, which updates every six months, or if you want you can run Edge, which is a rolling release of packages as they get added. Lots of very up-to-date software, and pretty stable as these go. You can go from Stable->Edge pretty easily, going back not so much.
There's also the Testing repo, only available on Edge, which I don't really recommend, especially since apkbuild files are so easy to run if you just need one thing that has most of its dependencies met.
Package management is with APK, which is fast and easy to work with. The wiki page will cover you.
Side note: if you want something more batteries-included, you could look at Postmarket, an Alpine derivative mainly focussed on running on smartphones but that is a pretty capable desktop OS, and which has a fairly friendly setup process. I run this on an ARM Chromebook and it's solid. Installation requires some reading between the lines because it's intended for the weird world of phones, so you'll probably want to follow the PMBootstrap route.
8 notes
·
View notes
Text
Can Open Source Integration Services Speed Up Response Time in Legacy Systems?
Legacy systems are still a key part of essential business operations in industries like banking, logistics, telecom, and manufacturing. However, as these systems get older, they become less efficient—slowing down processes, creating isolated data, and driving up maintenance costs. To stay competitive, many companies are looking for ways to modernize without fully replacing their existing systems. One effective solution is open-source integration, which is already delivering clear business results.

Why Faster Response Time Matters
System response time has a direct impact on business performance. According to a 2024 IDC report, improving system response by just 1.5 seconds led to a 22% increase in user productivity and a 16% rise in transaction completion rates. This means increased revenue, customer satisfaction as well as scalability in industries where time is of great essence.
Open-source integration is prominent in this case. It can minimize latency, enhance data flow and make process automation easier by allowing easier communication between legacy systems and more modern applications. This makes the systems more responsive and quick.
Key Business Benefits of Open-Source Integration
Lower Operational Costs
Open-source tools like Apache Camel and Mule eliminate the need for costly software licenses. A 2024 study by Red Hat showed that companies using open-source integration reduced their IT operating costs by up to 30% within the first year.
Real-Time Data Processing
Traditional legacy systems often depend on delayed, batch-processing methods. With open-source platforms using event-driven tools such as Kafka and RabbitMQ, businesses can achieve real-time messaging and decision-making—improving responsiveness in areas like order fulfillment and inventory updates.
Faster Deployment Cycles: Open-source integration supports modular, container-based deployment. The 2025 GitHub Developer Report found that organizations using containerized open-source integrations shortened deployment times by 43% on average. This accelerates updates and allows faster rollout of new services.
Scalable Integration Without Major Overhauls
Open-source frameworks allow businesses to scale specific parts of their integration stack without modifying the core legacy systems. This flexibility enables growth and upgrades without downtime or the cost of a full system rebuild.
Industry Use Cases with High Impact
Banking
Integrating open-source solutions enhances transaction processing speed and improves fraud detection by linking legacy banking systems with modern analytics tools.
Telecom
Customer service becomes more responsive by synchronizing data across CRM, billing, and support systems in real time.
Manufacturing
Real-time integration with ERP platforms improves production tracking and inventory visibility across multiple facilities.
Why Organizations Outsource Open-Source Integration
Most internal IT teams lack skills and do not have sufficient resources to manage open-source integration in a secure and efficient manner. Businesses can also guarantee trouble-free setup and support as well as improved system performance by outsourcing to established providers. Top open-source integration service providers like Suma Soft, Red Hat Integration, Talend, TIBCO (Flogo Project), and Hitachi Vantara offer customized solutions. These help improve system speed, simplify daily operations, and support digital upgrades—without the high cost of replacing existing systems.
2 notes
·
View notes
Text
Ready to future-proof your applications and boost performance? Discover how PHP microservices can transform your development workflow! 💡
In this powerful guide, you'll learn: ✅ What PHP Microservices Architecture really means ✅ How to break a monolithic app into modular services ✅ Best tools for containerization like Docker & Kubernetes ✅ API Gateway strategies and service discovery techniques ✅ Tips on error handling, security, and performance optimization
With real-world examples and practical steps, this guide is perfect for developers and teams aiming for faster deployment, independent scaling, and simplified maintenance.
🎯 Whether you’re a solo developer or scaling a product, understanding microservices is the key to next-level architecture.
🌐 Brought to you by Orbitwebtech, Best Web Development Company in the USA, helping businesses build powerful and scalable web solutions.
📖 Start reading now and give your PHP projects a cutting-edge upgrade!
2 notes
·
View notes
Text
If you think I've gotten less insane about StrickPage, no, I've just hit a minor depressive episode and been heads down lately but I still am working on The Project in the background and it continues to grow out of control I am just being Good and biting my tongue and staring at the wall when I get new info. But yeah the string wall is getting insane too I have no idea how I'll even make this a video essay series I might need a more experienced video editor's help legitimately. I have developed a deep and abiding loathing for the Genius phone App and a gnashing frustration at the fact one cannot forensically track changes to a Spotify playlist.
Incomplete Primary Sources now cover:
Five AEW Shows and [x] PPVs, a span of 350+ BTE episodes, footage from at least 6 other promotions, five plus albums and singles, Swerve's socials that he cleaned and/or recreated when he joined AEW, NOT Hangman's socials except Bsky skeets cuz I was slow, socials of others involved, at least three books, and miscellaneous promos, interviews, podcasts, documentaries, posts by fans about socials as secondary sources, playlists, and attempted CSI reconstructions of Spotify Playlist timelines.
I have fucked around with basic python for the first time to download containerized application 3rd party amazing open source software and had a meltdown when it then updated six weeks later and broke. I have learned so much about rap and r&b history my Spotify algorithm is permanently changed for the better, the same way getting in wrestling made my news apps send me push notifications about the local football team. I have paid for subscriptions for early 2010s indie wrestling archive footage and 'download everything from a public Instagram immediately with details' tools that make me both so happy and a little uncomfortable still.
Useful pre-existing knowledge so far: knowledge of Opera, Victorian Floriography, Horror Movies, some birding knowledge, your basic art history and queer history, and a strong layman's knowledge of Dolly Parton lore. Also just basic history, lit, and film nerd shit I think.
So yeah I am no longer raving about Gold in them hills in the streets, but I am collecting things in my cave of wonders like a little goblin and realizing I have dwelled too deep already and there's no way out but through the mountains and who knows how much I can carry out with me.
#the StrickPage scholar#monty rambles#my friend who knows nothing about this said 'okay tell me about your wrestling boys then' and i blue screened on where the fuck to start#she pointed out 'your eye is literally twitching when you think about them i love it'
4 notes
·
View notes
Text
Skyrocket Your Efficiency: Dive into Azure Cloud-Native solutions
Join our blog series on Azure Container Apps and unlock unstoppable innovation! Discover foundational concepts, advanced deployment strategies, microservices, serverless computing, best practices, and real-world examples. Transform your operations!!
#Azure App Service#Azure cloud#Azure Container Apps#Azure Functions#CI/CD#cloud infrastructure#cloud-native applications#containerization#deployment strategies#DevOps#Kubernetes#microservices architecture#serverless computing
0 notes
Text
Wasm will change the game of client side/offline web apps, I find the server side applications to be not that exciting because there's tons of ways to containerize applications already, the real value in my opinion is putting the browser back into people's hands as an interface but this time with more power/utility
2 notes
·
View notes
Text
How Python Powers Scalable and Cost-Effective Cloud Solutions

Explore the role of Python in developing scalable and cost-effective cloud solutions. This guide covers Python's advantages in cloud computing, addresses potential challenges, and highlights real-world applications, providing insights into leveraging Python for efficient cloud development.
Introduction
In today's rapidly evolving digital landscape, businesses are increasingly leveraging cloud computing to enhance scalability, optimize costs, and drive innovation. Among the myriad of programming languages available, Python has emerged as a preferred choice for developing robust cloud solutions. Its simplicity, versatility, and extensive library support make it an ideal candidate for cloud-based applications.
In this comprehensive guide, we will delve into how Python empowers scalable and cost-effective cloud solutions, explore its advantages, address potential challenges, and highlight real-world applications.
Why Python is the Preferred Choice for Cloud Computing?
Python's popularity in cloud computing is driven by several factors, making it the preferred language for developing and managing cloud solutions. Here are some key reasons why Python stands out:
Simplicity and Readability: Python's clean and straightforward syntax allows developers to write and maintain code efficiently, reducing development time and costs.
Extensive Library Support: Python offers a rich set of libraries and frameworks like Django, Flask, and FastAPI for building cloud applications.
Seamless Integration with Cloud Services: Python is well-supported across major cloud platforms like AWS, Azure, and Google Cloud.
Automation and DevOps Friendly: Python supports infrastructure automation with tools like Ansible, Terraform, and Boto3.
Strong Community and Enterprise Adoption: Python has a massive global community that continuously improves and innovates cloud-related solutions.
How Python Enables Scalable Cloud Solutions?
Scalability is a critical factor in cloud computing, and Python provides multiple ways to achieve it:
1. Automation of Cloud Infrastructure
Python's compatibility with cloud service provider SDKs, such as AWS Boto3, Azure SDK for Python, and Google Cloud Client Library, enables developers to automate the provisioning and management of cloud resources efficiently.
2. Containerization and Orchestration
Python integrates seamlessly with Docker and Kubernetes, enabling businesses to deploy scalable containerized applications efficiently.
3. Cloud-Native Development
Frameworks like Flask, Django, and FastAPI support microservices architecture, allowing businesses to develop lightweight, scalable cloud applications.
4. Serverless Computing
Python's support for serverless platforms, including AWS Lambda, Azure Functions, and Google Cloud Functions, allows developers to build applications that automatically scale in response to demand, optimizing resource utilization and cost.
5. AI and Big Data Scalability
Python’s dominance in AI and data science makes it an ideal choice for cloud-based AI/ML services like AWS SageMaker, Google AI, and Azure Machine Learning.
Looking for expert Python developers to build scalable cloud solutions? Hire Python Developers now!
Advantages of Using Python for Cloud Computing
Cost Efficiency: Python’s compatibility with serverless computing and auto-scaling strategies minimizes cloud costs.
Faster Development: Python’s simplicity accelerates cloud application development, reducing time-to-market.
Cross-Platform Compatibility: Python runs seamlessly across different cloud platforms.
Security and Reliability: Python-based security tools help in encryption, authentication, and cloud monitoring.
Strong Community Support: Python developers worldwide contribute to continuous improvements, making it future-proof.
Challenges and Considerations
While Python offers many benefits, there are some challenges to consider:
Performance Limitations: Python is an interpreted language, which may not be as fast as compiled languages like Java or C++.
Memory Consumption: Python applications might require optimization to handle large-scale cloud workloads efficiently.
Learning Curve for Beginners: Though Python is simple, mastering cloud-specific frameworks requires time and expertise.
Python Libraries and Tools for Cloud Computing
Python’s ecosystem includes powerful libraries and tools tailored for cloud computing, such as:
Boto3: AWS SDK for Python, used for cloud automation.
Google Cloud Client Library: Helps interact with Google Cloud services.
Azure SDK for Python: Enables seamless integration with Microsoft Azure.
Apache Libcloud: Provides a unified interface for multiple cloud providers.
PyCaret: Simplifies machine learning deployment in cloud environments.
Real-World Applications of Python in Cloud Computing
1. Netflix - Scalable Streaming with Python
Netflix extensively uses Python for automation, data analysis, and managing cloud infrastructure, enabling seamless content delivery to millions of users.
2. Spotify - Cloud-Based Music Streaming
Spotify leverages Python for big data processing, recommendation algorithms, and cloud automation, ensuring high availability and scalability.
3. Reddit - Handling Massive Traffic
Reddit uses Python and AWS cloud solutions to manage heavy traffic while optimizing server costs efficiently.
Future of Python in Cloud Computing
The future of Python in cloud computing looks promising with emerging trends such as:
AI-Driven Cloud Automation: Python-powered AI and machine learning will drive intelligent cloud automation.
Edge Computing: Python will play a crucial role in processing data at the edge for IoT and real-time applications.
Hybrid and Multi-Cloud Strategies: Python’s flexibility will enable seamless integration across multiple cloud platforms.
Increased Adoption of Serverless Computing: More enterprises will adopt Python for cost-effective serverless applications.
Conclusion
Python's simplicity, versatility, and robust ecosystem make it a powerful tool for developing scalable and cost-effective cloud solutions. By leveraging Python's capabilities, businesses can enhance their cloud applications' performance, flexibility, and efficiency.
Ready to harness the power of Python for your cloud solutions? Explore our Python Development Services to discover how we can assist you in building scalable and efficient cloud applications.
FAQs
1. Why is Python used in cloud computing?
Python is widely used in cloud computing due to its simplicity, extensive libraries, and seamless integration with cloud platforms like AWS, Google Cloud, and Azure.
2. Is Python good for serverless computing?
Yes! Python works efficiently in serverless environments like AWS Lambda, Azure Functions, and Google Cloud Functions, making it an ideal choice for cost-effective, auto-scaling applications.
3. Which companies use Python for cloud solutions?
Major companies like Netflix, Spotify, Dropbox, and Reddit use Python for cloud automation, AI, and scalable infrastructure management.
4. How does Python help with cloud security?
Python offers robust security libraries like PyCryptodome and OpenSSL, enabling encryption, authentication, and cloud monitoring for secure cloud applications.
5. Can Python handle big data in the cloud?
Yes! Python supports big data processing with tools like Apache Spark, Pandas, and NumPy, making it suitable for data-driven cloud applications.
#Python development company#Python in Cloud Computing#Hire Python Developers#Python for Multi-Cloud Environments
2 notes
·
View notes
Text
Platform Engineering: Streamlining Modern Software Development
New Post has been published on https://thedigitalinsider.com/platform-engineering-streamlining-modern-software-development/
Platform Engineering: Streamlining Modern Software Development
As we accelerate ahead of Industry 4.0, digital transformation reshapes businesses at an unprecedented level. Today, organizations face high pressures to deliver software faster, more reliably, and at scale.
The growing complexities of the cloud environment and heightened demand for frictionless customer experiences have further complicated software development. Since delivering a seamless customer experience is an organization’s top priority, continuous software development runs parallel with other operations.
Platform engineering has emerged to address these challenges. It is based upon integrating product names as an internal developer’s platform designed to streamline the software development process.
According to a research by Gartner, “45% of large software engineering organizations were already utilizing platform engineering platforms in 2022, and the number is expected to rise by 80% by 2026.”.
This article will explain platform engineering and its benefits and see how it boosts the entire software development cycle.
What is Platform Engineering?
With ever-increasing functionalities, cloud environments are becoming more complex every day. Developing new tools and software isn’t easy now. Sometimes, software development-related complexities, the underlying infrastructure that must be managed, and routine tasks become hard to tackle.
Platform engineering focuses on designing, developing, and optimizing Internal Developers Platforms (IDPs).
IDPs work as an added layer and bridge the gap between developers and underlying infrastructure. Adopting an IDP enables workflow standardizations, self-services in software development, and improved observability in development.
With all these workflow enhancements, developers can work in more automated environments. By enabling automation at every level, the internal data platforms streamline the software development lifecycle (SDCL) while adhering to the governance and compliance standards.
Core Concepts of Platform Engineering
As cloud computing, microservices, and containerization grew, organizations opted for more advanced platforms to manage their complexities. An engineering platform in software development creates a cohesive and efficient development environment that enhances productivity while maintaining operational stability.
Here are some of the core concepts of platform engineering:
1. Internal Developer Platform (IDP)
Internal Developer Platforms (IDPs) are designed to help organizations optimize their development processes. As development processes become more iterative, cloud complexities become an added burden.
Source
IDPs act as added layers in the development process, simplifying operations and enabling teams to leverage existing development technologies. It is an ecosystem that empowers developers by providing tools and automation and autonomously managing the end-to-end lifecycle, from development to deployment.
Some of the most demanded IDPs are:
Qovery
Platform.sh
Backstage by Spotify
Humanitec
Coherence
However, if not implemented strategically, IDPs can introduce further complexities downstream.
2. Self-Service
One of platform engineering’s most powerful features is its capability to empower developers through self-service. This means developers can work independently, provision, manage, and deploy applications without relying on operations teams. It empowers the workflow, enabling developers to iterate and deploy efficiently.
3. Workflow Automation
Automation is another reason to adopt an engineering platform. It automates routine tasks and reduces human error while ensuring scalability and consistency across the development lifecycle.
4. Standardization
Engineering platforms promote end-to-end standardization of best practices across the development workflow. They usually have built-in quality standards to meet compliance requirements. So, both organizations and development teams automatically follow compliance best practices.
5. Security & Governance
As security and governance are core concerns in any SDLC, integrating a robust engineering platform ensures robust governance to minimize vulnerabilities and risks.
6. Infrastructure as Code (IaC)
Platform engineering enables development teams to provision and manage infrastructure resources in repeatable and automated ways. It also promotes version control for easier management and collaboration and faster time-to-market.
At its core, it manages the development process more efficiently by reducing development complexities and ensuring compliance and quality.
Why is Platform Engineering Important to Adapt?
Platform engineering has gained importance due to the growing complexity of software and cloud-based development environments. Managing multiple development environments, multifaceted cloud environments, and diverse technology loads obstructs developers.
To avoid this, internal development platforms streamline the process by creating scalable, reusable platforms to automate tasks and simplify processes.
An IDP allows developers to stay ahead and be more productive at high-value tasks rather than tackling underlying infrastructure. Moreover, platform engineering enables security measures in the development process, diminishing risks and ensuring compliance.
Benefits of Platform Engineering
Internal development platforms offer several critical benefits that boost the overall software development process.
Accelerates Development Process: The cross-functional and automated collaborative environment leads to faster time-to-market and rationalized development costs.
Improves Developer Experience: Platform engineering offers self-service capabilities, enabling developers to be efficient and creative and focus on innovation instead of infrastructural complexities.
Enhances Scalability: Engineering platforms empower organizations to scale their applications and infrastructure to meet growing demands.
Establishes Governance: Platform engineering promotes governance, which is critical for all industries. It ensures that all activities are compliant and aligned with best practices.
Is Platform Engineering the Future of Software Development?
As businesses transform digitally, platform engineering provides a unified infrastructure to empower the build, test, and deployment processes. Integrating artificial intelligence (AI) will lead to more efficient internal platform services in the future.
Moreover, early adoption will provide a competitive advantage for seamless software development workflows.
For more resources on software development, cloud computing, and AI, visit Unite.ai.
#2022#adoption#ai#AI in software development#amp#applications#Article#artificial#Artificial Intelligence#automation#bridge#Cloud#cloud computing#cloud environment#code#Collaboration#collaborative#complexity#compliance#computing#containerization#continuous#customer experience#customer experiences#data#deployment#Developer#developers#development#development environment
0 notes
Text

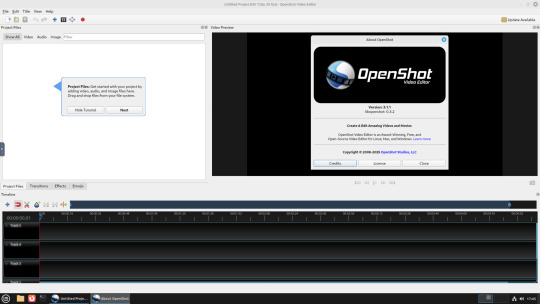

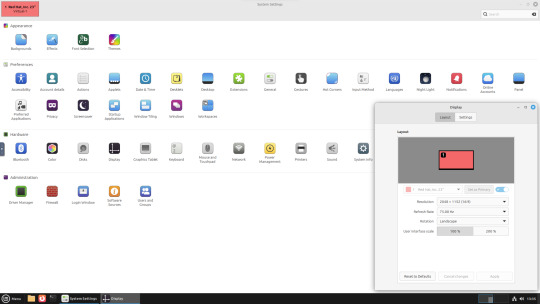
22.02.25
A quick look at the free, open source Openshot Video Editor, running in Linux Mint Cinnamon 22.1 on Distrosea!
On Mint, Openshot is installed via the Software Manager as a .deb file.
Here are some of the packages (dependencies) that are installed alongside it. The version featured in the manager (Openshot 3.1.1) is a few versions behind the web version (3.3.0) for stability reasons.
OpenShot was released in August 2008. It is built using Python, C++ (libopenshot) and the Qt5 framework. It is available for Linux, Chrome OS, Windows and Mac OS operating systems.
https://www.openshot.org/
It can handle most modern and classic video formats and can export videos in up to 8K resolution. It comes with a customisable interface, built-in tutorial, various transitions, effects, 3D text and animation effects with Blender Animation support and emoji emblems that can be used in video shots through the time line.
Openshot comes with a default dark theme and a light theme.
https://en.wikipedia.org/wiki/OpenShot
An interesting look at the OpenShot User interface. The window size of the VM is shown in the 'Display Settings' window. The actual display resolution is 2560x1440.
Online video tutorials can be watched here:
https://www.youtube.com/playlist?list=PLymupH2aoNQNezYzv2lhSwvoyZgLp1Q0T
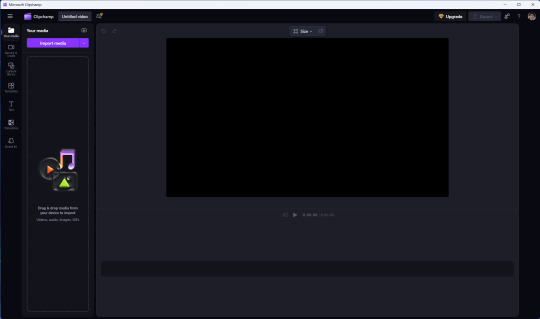
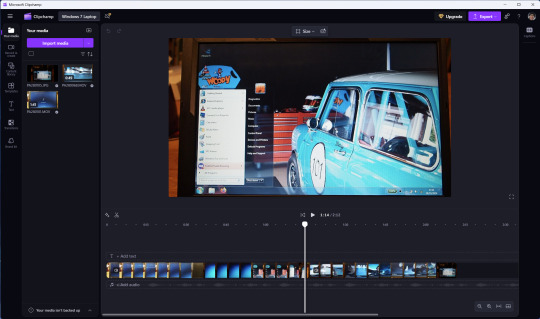
However I still prefer the simplicity of Clipchamp, as it includes ready made templates, a clean UI and is a browser based web-app that can run on any operating system.
https://clipchamp.com/en/
Other popular open-source video editing applications include:
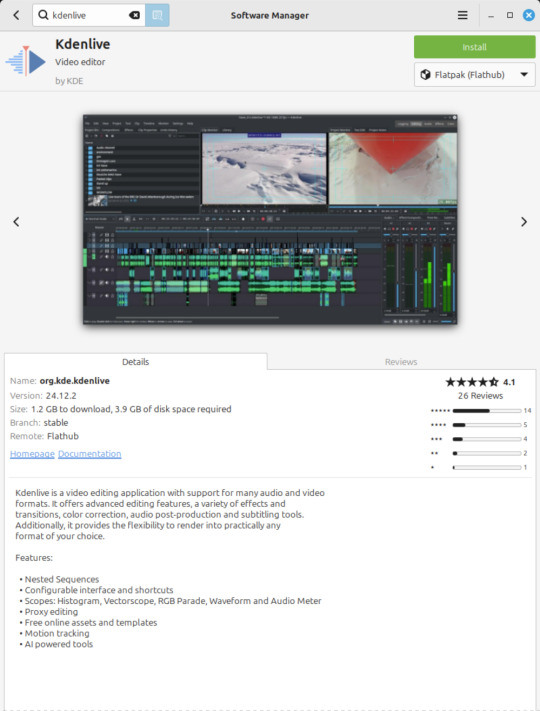
Kdenlive (released 2002)
https://kdenlive.org/en/
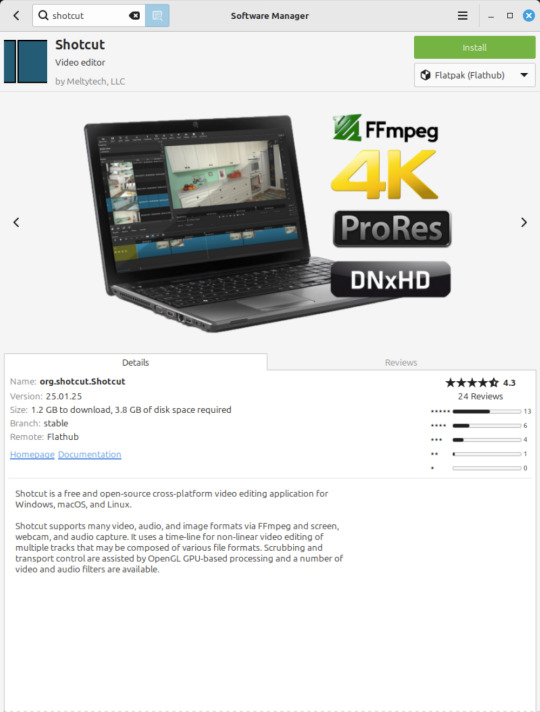
Shortcut (released 2011)
https://www.shotcut.org/
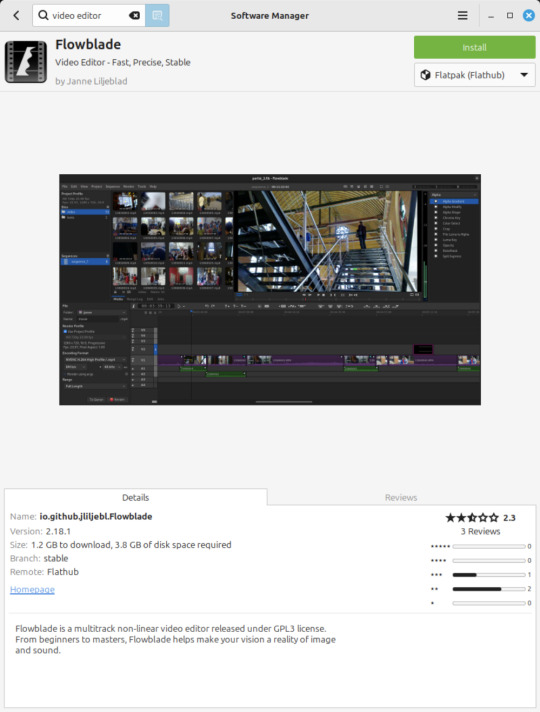
Flowblade Movie Editor (released 2009)
https://jliljebl.github.io/flowblade/
Blender Animation Program (released 1994)
https://www.blender.org/
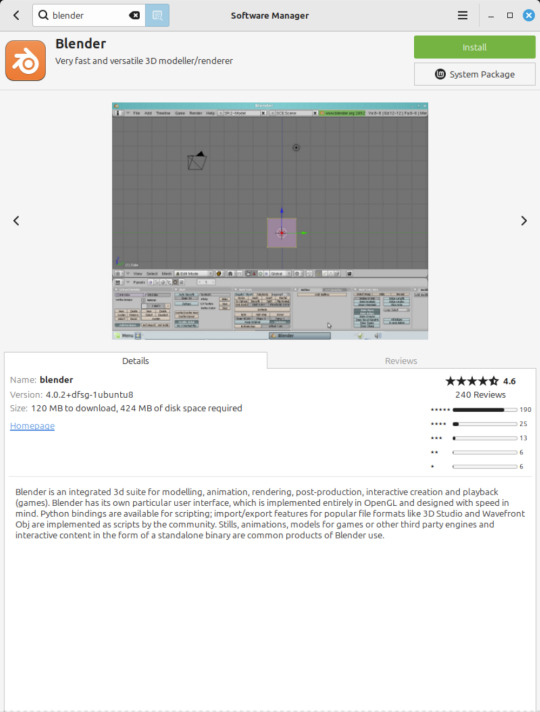
All of the video editors mentioned here have their pros and cons and many can be installed as a .deb (System Package) or .flatpak (Containerized App) on Linux Mint.
5 notes
·
View notes