#data science with r
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
Here’s the third exciting installment in my series about backing up one Tumblr post that absolutely no one asked for. The previous updates are linked here.
Previously on Tumblr API Hell
Some blogs returned 404 errors. After investigating with Allie's help, it turns out it’s not a sideblog issue — it’s a privacy setting. It pleases me that Tumblr's rickety API respects the word no.
Also, shoutout to the one line of code in my loop that always broke when someone reblogged without tags. Fixed it.
What I got working:
Tags added during reblogs of the post
Any added commentary (what the blog actually wrote)
Full post metadata so I can extract other information later (ie. outside the loop)
New questions I’m trying to answer:
While flailing around in the JSON trying to figure out which blog added which text (because obviously Tumblr’s rickety API doesn’t just tell you), I found that all the good stuff lives in a deeply nested structure called trail. It splits content into HTML chunks — but there’s no guarantee about order, and you have to reconstruct it yourself.
Here’s a stylized diagram of what trail looks like in the JSON list (which gets parsed as a data frame in R):

I started wondering:
Can I use the trail to reconstruct a version tree to see which path through the reblog chain was the most influential for the post?
This would let me ask:
Which version of the post are people reblogging?
Does added commentary increase the chance it gets reblogged again?
Are some blogs “amplifiers” — their version spreads more than others?
It’s worth thinking about these questions now — so I can make sure I’m collecting the right information from Tumblr’s rickety API before I run my R code on a 272K-note post.
Summary
Still backing up one post. Just me, 600+ lines of R code, and Tumblr’s API fighting it out at a Waffle House parking lot. The code’s nearly ready — I’m almost finished testing it on an 800-note post before trying it on my 272K-note Blaze post. Stay tuned… Zero fucks given?
If you give zero fucks about my rickety API series, you can block my data science tag, #a rare data science post, or #tumblr's rickety API. But if we're mutuals then you know how it works here - you get what you get. It's up to you to curate your online experience. XD
#a rare data science post#tumblr's rickety API#fuck you API user#i'll probably make my R code available in github#there's a lot of profanity in the comments#just saying
24 notes
·
View notes
Text
always fun when physics problems randomly present themself before you

for the actual maths
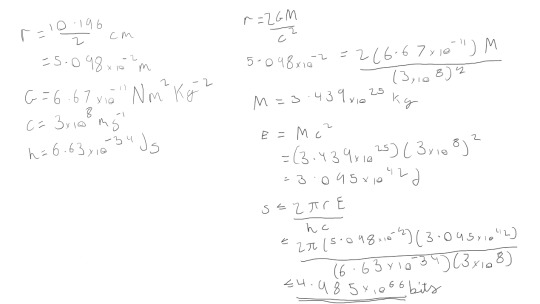
#196#r/196#/r/196#r196#rule#shitpost#ruleposting#shitposting#mathematics#mathblr#math#maths#maths posting#physics#science#black holes#information#data
40 notes
·
View notes
Text
wanted to learn some r so i started doing the cs50 r course. i was on a godawful school chromebook, and they've made it so you can't install linux, so i can't use vs code. rstudio cloud to the rescue, i sign up to rstudio cloud with my school email, write my first little program and save it in rstudio cloud.
i go back today. i want to carry on with my thing. i try to sign in to rstudio cloud.
"Your administrator has not approved access for this app."
WHAT THE FUCK DO YOU MEAN!!!!!! I WAS USING IT ON WEDNESDAY!!!!!!!!! LET ME SEE MY TINY PROGRAM PLEASEEE OH MY FUCKING GOD
#siph speaks#im SO salty about the school chromebook#im now on my normal laptop at home#so now i am gonna use vs code#but im not gonna be able to work on it at school >:(((#GRRRRRRRRRRRRRRRRRRRRRRRR#i pressed the “request access” button extremely forcefully but idk if the it team sees these things#fucking blocking access to my ide :(#so now i have to go set up vs code to work with r. or download rstudio desktop.#but if i do that then i can't work on it at school...#you'd think it's in their best interests to have me learning random data science as well#like do they not want their students going Above and Beyond and Exploring Around The Subject????#this is a very solvable problem tbf im just pissed about it#my approximately 5 lines of code... locked away from me...
16 notes
·
View notes
Text
#personally im voting data science ngl bc there still r like 3 ppl in thw world who study aerospace bc they like stars but if u#study data science u have forsaken your soul#comment if u think another major shld be included in the poll
8 notes
·
View notes
Text
...
#shout out to me for being an insufferable loud mouth in my group therapy class for over controlled losers#which is funny bc 1) i used to b extremely extremely shy and afraid of speaking to ppl and 2) bc im probably a normal amount of talkative#now lol. but in this class. its a class setting but im not getting a grade and the material isnt beyond my compression and psychology is a#soft science so i can argue back on things and not b objectivly wrong. so im like fuck it im gonna b annoying bc there r no consequences#except ppl thinking im annoying and like why tf would i care. i only see these ppl in this specific setting#and they have no authority over me and also they're annoying too bc they have similar issues to me but different. and there r archetypes.#like some ppl get real caught up on the rules and terminology of the material and im like ugh ur missing the point. the details dont fucking#matter. just think abt how u can use the idea. or some ppl r like really judgy and think theyre right abt things and im like. ugh. u sound#so insufferable. shut the fuck up. or some ppl r just extremely quiet and blank faced and just giving u nothing u have to carry the whole#conversation to make up for their lack of input. and i dont mean that in a bad way. i think everyone has the right to b annoying. i still#like them. so im like. well fuck it. i can b annoying too. so my annoying things r that im very padantic about the examples that our#instructors give. like: that doesn't fit with what u just said. or this is why i disagree with the idea. or actually i already do this thing#were learning today. which like. if i was an instructor. at least id b glad me as a student was engaging seriously with the materials#and is hopefully clarifying aspects of things. im told im good at conceptualizing things into metaphor.#whatever. i dont care. i mean. i feel intolerable but like also im not gonna stop bc who gives a fuck#also everytime they talk abt evolution stuff or data from studies im very suspicious. like show me how the fuck they quantified the number#of expressions the human face can make. show me the fucking data bc u cant fucking tell me its not an infinite number if u consider every#varied muscle movement in every combination. and its apparently very obvious when im disagreeing bc i make a face#which one of the instructors tried to prement my comments today but i was critical from a different perspective than she thought lol#anyway. shout of to being insufferable. as fucking lyrics from jc superstar wrattle endlessly through the empty caverns of my mind#i fucking love that musical. its rocketed up to like number 3 position. i lov musicals so much#bc im cringe and i don't give a fuck#unrelated
11 notes
·
View notes
Text
Ty for responding <3
#r/196#r/196archive#196#/r/196#rule#meme#memes#shitpost#shitposting#poll#tumblr polls#science#data#data science
50 notes
·
View notes
Text
>nothing to do for like 3 days
>starts teaching myself a new programming language out of boredom
#it's Julia and it will replace R for data science in the next like... decade or so#however long it takes for university profs and tutors to catch on and learn it#which could be pretty slow#p
8 notes
·
View notes
Text
What Are the Qualifications for a Data Scientist?
In today's data-driven world, the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making, understanding customer behavior, and improving products, the demand for skilled professionals who can analyze, interpret, and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientist, how DataCouncil can help you get there, and why a data science course in Pune is a great option, this blog has the answers.
The Key Qualifications for a Data Scientist
To succeed as a data scientist, a mix of technical skills, education, and hands-on experience is essential. Here are the core qualifications required:
1. Educational Background
A strong foundation in mathematics, statistics, or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields, with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap, offering the academic and practical knowledge required for a strong start in the industry.
2. Proficiency in Programming Languages
Programming is at the heart of data science. You need to be comfortable with languages like Python, R, and SQL, which are widely used for data analysis, machine learning, and database management. A comprehensive data science course in Pune will teach these programming skills from scratch, ensuring you become proficient in coding for data science tasks.
3. Understanding of Machine Learning
Data scientists must have a solid grasp of machine learning techniques and algorithms such as regression, clustering, and decision trees. By enrolling in a DataCouncil course, you'll learn how to implement machine learning models to analyze data and make predictions, an essential qualification for landing a data science job.
4. Data Wrangling Skills
Raw data is often messy and unstructured, and a good data scientist needs to be adept at cleaning and processing data before it can be analyzed. DataCouncil's data science course in Pune includes practical training in tools like Pandas and Numpy for effective data wrangling, helping you develop a strong skill set in this critical area.
5. Statistical Knowledge
Statistical analysis forms the backbone of data science. Knowledge of probability, hypothesis testing, and statistical modeling allows data scientists to draw meaningful insights from data. A structured data science course in Pune offers the theoretical and practical aspects of statistics required to excel.
6. Communication and Data Visualization Skills
Being able to explain your findings in a clear and concise manner is crucial. Data scientists often need to communicate with non-technical stakeholders, making tools like Tableau, Power BI, and Matplotlib essential for creating insightful visualizations. DataCouncil’s data science course in Pune includes modules on data visualization, which can help you present data in a way that’s easy to understand.
7. Domain Knowledge
Apart from technical skills, understanding the industry you work in is a major asset. Whether it’s healthcare, finance, or e-commerce, knowing how data applies within your industry will set you apart from the competition. DataCouncil's data science course in Pune is designed to offer case studies from multiple industries, helping students gain domain-specific insights.
Why Choose DataCouncil for a Data Science Course in Pune?
If you're looking to build a successful career as a data scientist, enrolling in a data science course in Pune with DataCouncil can be your first step toward reaching your goals. Here’s why DataCouncil is the ideal choice:
Comprehensive Curriculum: The course covers everything from the basics of data science to advanced machine learning techniques.
Hands-On Projects: You'll work on real-world projects that mimic the challenges faced by data scientists in various industries.
Experienced Faculty: Learn from industry professionals who have years of experience in data science and analytics.
100% Placement Support: DataCouncil provides job assistance to help you land a data science job in Pune or anywhere else, making it a great investment in your future.
Flexible Learning Options: With both weekday and weekend batches, DataCouncil ensures that you can learn at your own pace without compromising your current commitments.
Conclusion
Becoming a data scientist requires a combination of technical expertise, analytical skills, and industry knowledge. By enrolling in a data science course in Pune with DataCouncil, you can gain all the qualifications you need to thrive in this exciting field. Whether you're a fresher looking to start your career or a professional wanting to upskill, this course will equip you with the knowledge, skills, and practical experience to succeed as a data scientist.
Explore DataCouncil’s offerings today and take the first step toward unlocking a rewarding career in data science! Looking for the best data science course in Pune? DataCouncil offers comprehensive data science classes in Pune, designed to equip you with the skills to excel in this booming field. Our data science course in Pune covers everything from data analysis to machine learning, with competitive data science course fees in Pune. We provide job-oriented programs, making us the best institute for data science in Pune with placement support. Explore online data science training in Pune and take your career to new heights!
#In today's data-driven world#the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making#understanding customer behavior#and improving products#the demand for skilled professionals who can analyze#interpret#and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientis#how DataCouncil can help you get there#and why a data science course in Pune is a great option#this blog has the answers.#The Key Qualifications for a Data Scientist#To succeed as a data scientist#a mix of technical skills#education#and hands-on experience is essential. Here are the core qualifications required:#1. Educational Background#A strong foundation in mathematics#statistics#or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields#with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap#offering the academic and practical knowledge required for a strong start in the industry.#2. Proficiency in Programming Languages#Programming is at the heart of data science. You need to be comfortable with languages like Python#R#and SQL#which are widely used for data analysis#machine learning#and database management. A comprehensive data science course in Pune will teach these programming skills from scratch#ensuring you become proficient in coding for data science tasks.#3. Understanding of Machine Learning
3 notes
·
View notes
Text
Exploring Data Science Tools: My Adventures with Python, R, and More
Welcome to my data science journey! In this blog post, I'm excited to take you on a captivating adventure through the world of data science tools. We'll explore the significance of choosing the right tools and how they've shaped my path in this thrilling field.
Choosing the right tools in data science is akin to a chef selecting the finest ingredients for a culinary masterpiece. Each tool has its unique flavor and purpose, and understanding their nuances is key to becoming a proficient data scientist.
I. The Quest for the Right Tool
My journey began with confusion and curiosity. The world of data science tools was vast and intimidating. I questioned which programming language would be my trusted companion on this expedition. The importance of selecting the right tool soon became evident.
I embarked on a research quest, delving deep into the features and capabilities of various tools. Python and R emerged as the frontrunners, each with its strengths and applications. These two contenders became the focus of my data science adventures.
II. Python: The Swiss Army Knife of Data Science
Python, often hailed as the Swiss Army Knife of data science, stood out for its versatility and widespread popularity. Its extensive library ecosystem, including NumPy for numerical computing, pandas for data manipulation, and Matplotlib for data visualization, made it a compelling choice.
My first experiences with Python were both thrilling and challenging. I dove into coding, faced syntax errors, and wrestled with data structures. But with each obstacle, I discovered new capabilities and expanded my skill set.

III. R: The Statistical Powerhouse
In the world of statistics, R shines as a powerhouse. Its statistical packages like dplyr for data manipulation and ggplot2 for data visualization are renowned for their efficacy. As I ventured into R, I found myself immersed in a world of statistical analysis and data exploration.
My journey with R included memorable encounters with data sets, where I unearthed hidden insights and crafted beautiful visualizations. The statistical prowess of R truly left an indelible mark on my data science adventure.
IV. Beyond Python and R: Exploring Specialized Tools
While Python and R were my primary companions, I couldn't resist exploring specialized tools and programming languages that catered to specific niches in data science. These tools offered unique features and advantages that added depth to my skill set.

For instance, tools like SQL allowed me to delve into database management and querying, while Scala opened doors to big data analytics. Each tool found its place in my toolkit, serving as a valuable asset in different scenarios.
V. The Learning Curve: Challenges and Rewards
The path I took wasn't without its share of difficulties. Learning Python, R, and specialized tools presented a steep learning curve. Debugging code, grasping complex algorithms, and troubleshooting errors were all part of the process.
However, these challenges brought about incredible rewards. With persistence and dedication, I overcame obstacles, gained a profound understanding of data science, and felt a growing sense of achievement and empowerment.
VI. Leveraging Python and R Together
One of the most exciting revelations in my journey was discovering the synergy between Python and R. These two languages, once considered competitors, complemented each other beautifully.

I began integrating Python and R seamlessly into my data science workflow. Python's data manipulation capabilities combined with R's statistical prowess proved to be a winning combination. Together, they enabled me to tackle diverse data science tasks effectively.
VII. Tips for Beginners
For fellow data science enthusiasts beginning their own journeys, I offer some valuable tips:
Embrace curiosity and stay open to learning.
Work on practical projects while engaging in frequent coding practice.
Explore data science courses and resources to enhance your skills.
Seek guidance from mentors and engage with the data science community.
Remember that the journey is continuous—there's always more to learn and discover.
My adventures with Python, R, and various data science tools have been transformative. I've learned that choosing the right tool for the job is crucial, but versatility and adaptability are equally important traits for a data scientist.
As I summarize my expedition, I emphasize the significance of selecting tools that align with your project requirements and objectives. Each tool has a unique role to play, and mastering them unlocks endless possibilities in the world of data science.
I encourage you to embark on your own tool exploration journey in data science. Embrace the challenges, relish the rewards, and remember that the adventure is ongoing. May your path in data science be as exhilarating and fulfilling as mine has been.
Happy data exploring!
22 notes
·
View notes
Text
Recall: My original goal was to write R code to back up my Blaze post in case Tumblr disappears.
Here’s what I learned about Tumblr’s rickety API based on a test post with ~800 notes.
What I thought I would see:
A beautiful reblog tree, clearly showing how my post spread across Tumblr — every reblog linked to the one it came from.
Posts with tags would show up as blue dots in my version tree. (Tags interest me because they represent people who more deeply engaged with my post. And I'm nosy. XD)
What Tumblr’s rickety API actually gave me:
Orphaned nodes. Reblogs that definitely happened but aren’t connected to anything.
I expected to get a clean version history: Original Post (Blog A) → Blog B → Blog C
But the API fucker just shrugs and tells you C reblogged A. What the fuck happened to Blog B?
The result is that whole branches of the tree vanish. And that’s in addition to the reblogs that are missing because of the API respecting blog privacy settings (as it definitely should).
Conclusion:
As always, I feel disappointed but not surprised by Tumblr’s inability to fully function. The data doesn’t reflect what I know Tumblr users actually did; it just reflects what the API is willing to share.
I am so tired.
TL;DR: Nope. I cannot fully back up my Blaze post using the rickety API.
A quick rendering of the reblog version tree from the test post — a visual representation of my disappointment.
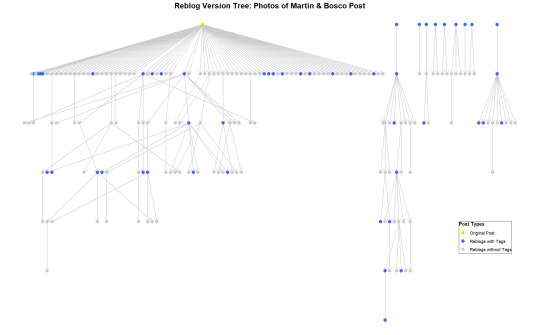
#a rare data science post#tumblr's rickety api#tumblr’s API is chaotic undocumented and inconsistent#this project is now complete#i never want to see the R script ever again
21 notes
·
View notes
Text

Feb 19, 2024
Day 1 of 100 days of productivity. Went to a local cafe, worked on the data cleaning for my side project in RStudio, got an iced coffee and poppyseed cake slice. Sent some emails, polished an old blog article and posted it. 7/10 productive vibes today.
#100 days of productivity#data science#side project#coding#r studio#coffee#emotional support iced coffee
14 notes
·
View notes
Text
I’ve long joked that Python is a slightly demonic programming language, but I just realized — Python, like the serpent of Eden! Python, like Crowley!
Anyway, my new headcanon is that Python is one of Crowley’s demonic innovations, designed to generate low-level discontent and petty bitterness among programmers and scientists around the globe. I cannot be convinced otherwise. (This is possibly the only way I can trick myself into actually appreciating its serpentine wiles.)
#every day is Take Your Fandom To Work Day if you’re committed enough to the bit#this has been your daily installment of Hot Takes From Local Biologist#(also for context i am an avid R and Java supporter and refuse to apologize for this)#good omens#crowley#data science#(ish)
22 notes
·
View notes
Text
Learning About Different Types of Functions in R Programming
Summary: Learn about the different types of functions in R programming, including built-in, user-defined, anonymous, recursive, S3, S4 methods, and higher-order functions. Understand their roles and best practices for efficient coding.
Introduction
Functions in R programming are fundamental building blocks that streamline code and enhance efficiency. They allow you to encapsulate code into reusable chunks, making your scripts more organised and manageable.
Understanding the various types of functions in R programming is crucial for leveraging their full potential, whether you're using built-in, user-defined, or advanced methods like recursive or higher-order functions.
This article aims to provide a comprehensive overview of these different types, their uses, and best practices for implementing them effectively. By the end, you'll have a solid grasp of how to utilise these functions to optimise your R programming projects.
What is a Function in R?
In R programming, a function is a reusable block of code designed to perform a specific task. Functions help organise and modularise code, making it more efficient and easier to manage.
By encapsulating a sequence of operations into a function, you can avoid redundancy, improve readability, and facilitate code maintenance. Functions take inputs, process them, and return outputs, allowing for complex operations to be performed with a simple call.
Basic Structure of a Function in R
The basic structure of a function in R includes several key components:
Function Name: A unique identifier for the function.
Parameters: Variables listed in the function definition that act as placeholders for the values (arguments) the function will receive.
Body: The block of code that executes when the function is called. It contains the operations and logic to process the inputs.
Return Statement: Specifies the output value of the function. If omitted, R returns the result of the last evaluated expression by default.
Here's the general syntax for defining a function in R:

Syntax and Example of a Simple Function
Consider a simple function that calculates the square of a number. This function takes one argument, processes it, and returns the squared value.

In this example:
square_number is the function name.
x is the parameter, representing the input value.
The body of the function calculates x^2 and stores it in the variable result.
The return(result) statement provides the output of the function.
You can call this function with an argument, like so:

This function is a simple yet effective example of how you can leverage functions in R to perform specific tasks efficiently.
Must Read: R Programming vs. Python: A Comparison for Data Science.
Types of Functions in R
In R programming, functions are essential building blocks that allow users to perform operations efficiently and effectively. Understanding the various types of functions available in R helps in leveraging the full power of the language.
This section explores different types of functions in R, including built-in functions, user-defined functions, anonymous functions, recursive functions, S3 and S4 methods, and higher-order functions.
Built-in Functions
R provides a rich set of built-in functions that cater to a wide range of tasks. These functions are pre-defined and come with R, eliminating the need for users to write code for common operations.
Examples include mathematical functions like mean(), median(), and sum(), which perform statistical calculations. For instance, mean(x) calculates the average of numeric values in vector x, while sum(x) returns the total sum of the elements in x.
These functions are highly optimised and offer a quick way to perform standard operations. Users can rely on built-in functions for tasks such as data manipulation, statistical analysis, and basic operations without having to reinvent the wheel. The extensive library of built-in functions streamlines coding and enhances productivity.
User-Defined Functions
User-defined functions are custom functions created by users to address specific needs that built-in functions may not cover. Creating user-defined functions allows for flexibility and reusability in code. To define a function, use the function() keyword. The syntax for creating a user-defined function is as follows:

In this example, my_function takes two arguments, arg1 and arg2, adds them, and returns the result. User-defined functions are particularly useful for encapsulating repetitive tasks or complex operations that require custom logic. They help in making code modular, easier to maintain, and more readable.
Anonymous Functions
Anonymous functions, also known as lambda functions, are functions without a name. They are often used for short, throwaway tasks where defining a full function might be unnecessary. In R, anonymous functions are created using the function() keyword without assigning them to a variable. Here is an example:

In this example, sapply() applies the anonymous function function(x) x^2 to each element in the vector 1:5. The result is a vector containing the squares of the numbers from 1 to 5.
Anonymous functions are useful for concise operations and can be utilised in functions like apply(), lapply(), and sapply() where temporary, one-off computations are needed.
Recursive Functions
Recursive functions are functions that call themselves in order to solve a problem. They are particularly useful for tasks that can be divided into smaller, similar sub-tasks. For example, calculating the factorial of a number can be accomplished using recursion. The following code demonstrates a recursive function for computing factorial:

Here, the factorial() function calls itself with n - 1 until it reaches the base case where n equals 1. Recursive functions can simplify complex problems but may also lead to performance issues if not implemented carefully. They require a clear base case to prevent infinite recursion and potential stack overflow errors.
S3 and S4 Methods
R supports object-oriented programming through the S3 and S4 systems, each offering different approaches to object-oriented design.
S3 Methods: S3 is a more informal and flexible system. Functions in S3 are used to define methods for different classes of objects. For instance:

In this example, print.my_class is a method that prints a custom message for objects of class my_class. S3 methods provide a simple way to extend functionality for different object types.
S4 Methods: S4 is a more formal and rigorous system with strict class definitions and method dispatch. It allows for detailed control over method behaviors. For example:

Here, setClass() defines a class with a numeric slot, and setMethod() defines a method for displaying objects of this class. S4 methods offer enhanced functionality and robustness, making them suitable for complex applications requiring precise object-oriented programming.
Higher-Order Functions
Higher-order functions are functions that take other functions as arguments or return functions as results. These functions enable functional programming techniques and can lead to concise and expressive code. Examples include apply(), lapply(), and sapply().
apply(): Used to apply a function to the rows or columns of a matrix.
lapply(): Applies a function to each element of a list and returns a list.
sapply(): Similar to lapply(), but returns a simplified result.
Higher-order functions enhance code readability and efficiency by abstracting repetitive tasks and leveraging functional programming paradigms.
Best Practices for Writing Functions in R
Writing efficient and readable functions in R is crucial for maintaining clean and effective code. By following best practices, you can ensure that your functions are not only functional but also easy to understand and maintain. Here are some key tips and common pitfalls to avoid.
Tips for Writing Efficient and Readable Functions
Keep Functions Focused: Design functions to perform a single task or operation. This makes your code more modular and easier to test. For example, instead of creating a function that processes data and generates a report, split it into separate functions for processing and reporting.
Use Descriptive Names: Choose function names that clearly indicate their purpose. For instance, use calculate_mean() rather than calc() to convey the function’s role more explicitly.
Avoid Hardcoding Values: Use parameters instead of hardcoded values within functions. This makes your functions more flexible and reusable. For example, instead of using a fixed threshold value within a function, pass it as a parameter.
Common Mistakes to Avoid
Overcomplicating Functions: Avoid writing overly complex functions. If a function becomes too long or convoluted, break it down into smaller, more manageable pieces. Complex functions can be harder to debug and understand.
Neglecting Error Handling: Failing to include error handling can lead to unexpected issues during function execution. Implement checks to handle invalid inputs or edge cases gracefully.
Ignoring Code Consistency: Consistency in coding style helps maintain readability. Follow a consistent format for indentation, naming conventions, and comment style.
Best Practices for Function Documentation
Document Function Purpose: Clearly describe what each function does, its parameters, and its return values. Use comments and documentation strings to provide context and usage examples.
Specify Parameter Types: Indicate the expected data types for each parameter. This helps users understand how to call the function correctly and prevents type-related errors.
Update Documentation Regularly: Keep function documentation up-to-date with any changes made to the function’s logic or parameters. Accurate documentation enhances the usability of your code.
By adhering to these practices, you’ll improve the quality and usability of your R functions, making your codebase more reliable and easier to maintain.
Read Blogs:
Pattern Programming in Python: A Beginner’s Guide.
Understanding the Functional Programming Paradigm.
Frequently Asked Questions
What are the main types of functions in R programming?
In R programming, the main types of functions include built-in functions, user-defined functions, anonymous functions, recursive functions, S3 methods, S4 methods, and higher-order functions. Each serves a specific purpose, from performing basic tasks to handling complex operations.
How do user-defined functions differ from built-in functions in R?
User-defined functions are custom functions created by users to address specific needs, whereas built-in functions come pre-defined with R and handle common tasks. User-defined functions offer flexibility, while built-in functions provide efficiency and convenience for standard operations.
What is a recursive function in R programming?
A recursive function in R calls itself to solve a problem by breaking it down into smaller, similar sub-tasks. It's useful for problems like calculating factorials but requires careful implementation to avoid infinite recursion and performance issues.
Conclusion
Understanding the types of functions in R programming is crucial for optimising your code. From built-in functions that simplify tasks to user-defined functions that offer customisation, each type plays a unique role.
Mastering recursive, anonymous, and higher-order functions further enhances your programming capabilities. Implementing best practices ensures efficient and maintainable code, leveraging R’s full potential for data analysis and complex problem-solving.
#Different Types of Functions in R Programming#Types of Functions in R Programming#r programming#data science
4 notes
·
View notes
Text
anyone have tips on learning the basics of linear algebra in approximately seven days. trying to take a datamining class and i might have dived directly into the ocean.
#math#linear algebra#programming help#data mining#data science#please help im just a little library sciene student PLEASE#at least the class seems to be R-based... i know r
2 notes
·
View notes
Text
2 notes
·
View notes
Text
Data Prep Day!
Finally fully back at work and in R/RStudio today. Today's goal was to set up some basic structural topic models using a dataframe of information about PubMed publications on post-acute COVID-19 sequalae.
No exciting results today, but if you're interested in topic modeling or wrangling data in R, I made a video so you can follow along with me while I code. Not a formal lesson, more of a "come to work with me" thing. Enjoy!
Highlights:
Full Video:
youtube
#come to work with me#postdoc life#postdoctoral research#public health#complex systems#pubmed#text as data#R#R studio#coding#data science#learn to code#code with me#research#academic research#science#phdblr#gradblr#studyblr#scienceblr#long covid#covid#covid research#Youtube
3 notes
·
View notes