#legal operations software
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has 411 employees.
Text
CaseFox introduces MatterSuite, an AI-powered matter management platform designed to streamline workflows for law firms and in-house legal teams. With advanced AI-driven legal research, smart automation, document management, and seamless collaboration, MatterSuite empowers legal professionals to manage cases more efficiently than ever. Discover how AI is revolutionizing legal practice
#legal matter management#legal tech#legal software#law firm software#legal operations software#legal ai tool#ai powered legal software#legal software solution#legal workflow automation
1 note
·
View note
Text
Exploring the Legality of Algorithmic Trading in India

Algorithmic trading (algo trading) has transformed the operation of financial markets all over the world and the impact of it is also evident in India. Read more at Bigul.
Read more..
#Algorithmic Trading#Algorithmic Trading in India#Legality of Algorithmic Trading#Legality of Algorithmic Trading in India#algo trading#financial markets#operation of financial markets#Stock Brokers#guidelines for algorithmic trading#SEBI#algo trading app#bigul#algo trading india#algo trading platform#algo trading strategies#bigul algo#free algo trading software#algorithm software for trading#finance#bigul algo ideas#bigul execution algos#bigul algos#execution algos#bigul algo trading review#bigul algo trading#bigul algo trading app#bigul trading#bigul trading app#bigul trading platform#trading strategies
0 notes
Text
What Are the Advantages of Legal Case Management Software?
The legal industry is undergoing a significant transformation driven by technology, and legal case management software has become a key tool in enhancing efficiency. The rise of AI in the legal industry has enabled law firms and corporate legal departments to streamline their processes, improve client services, and reduce costs. In the USA, the need for effective management solutions is even more pronounced due to the increasing complexity of cases and growing client demands. But what are the specific advantages of adopting legal case management software?

Enhanced Organization and Accessibility
One of the most significant benefits of using legal case management software is the ability to keep all case-related information in one centralized location. For law firms and corporate legal operations, this means easier access to case files, contracts, and communications at any time. Gone are the days of sifting through paper files or outdated digital systems. Everything from billing records to client emails is readily available, providing legal teams with the tools they need to respond quickly and efficiently.
Automation and Workflow Optimization
Integrating AI in the legal industry has led to greater automation within case management systems. Tasks such as document drafting, deadline tracking, and billing can be automated, reducing human error and freeing up legal professionals to focus on more strategic matters. Automation can also help law firms scale their operations without increasing staff, offering a major competitive advantage.
Client Relationship Management (CRM) Integration
Law firms can further enhance their case management capabilities by using platforms like Salesforce. By integrating a CRM with legal case management software, law firms can track client interactions, improve communication, and create more personalized legal strategies. The ability to manage client relationships and case information in one place simplifies workflows and improves client satisfaction, setting firms apart from competitors.
Data-Driven Decision Making
Corporate legal departments, in particular, can benefit from the data-driven insights that legal case management software provides. These platforms offer analytics and reporting features that allow corporate legal operations teams to identify trends, measure performance, and make more informed decisions. Whether it's tracking case outcomes or managing budgets, data analytics help streamline operations and support better overall legal strategies.
Increased Compliance and Security
Legal professionals must ensure that their practices comply with regulations, including data privacy laws. Legal case management software provides built-in compliance tools and security features, helping firms and legal departments stay on top of ever-changing regulations. Additionally, these systems offer secure cloud-based storage, ensuring sensitive client information is protected.
Conclusion
Adopting legal case management software is no longer optional for law firms and corporate legal departments looking to remain competitive. With the integration of AI in the legal industry, CRM platforms like Salesforce for law firms, and enhanced automation, this software transforms how legal operations are managed. At Hike2, we specialize in helping legal teams optimize their processes with cutting-edge technology solutions, allowing them to focus on what truly matters—winning cases and delivering exceptional client service.
0 notes
Text
#Corporate Legal Department#Legal Operations Management#Technology Solutions for Legal Ops#Legal Ops Technology Solutions#Legal Ops Solution#Legal Ops Software Solutions#Software for Legal Ops#In-house Legal#Law Department#AI for Legal Ops#AI for Corporate Legal Team#Legal Ops Eco System
0 notes
Text
Copyright law: making personal copies of copyrighted work

image sourced from a Cory Doctorow article on DMCA: X (recommended reading)
creating a digital backup (legally, it's called making an "archival copy") of software is explicitly allowed. but copying or alerting books, music, vehicle operating systems, movies, shows, and so on - even those you’ve legally purchased - gets complicated due to overlapping laws
under the doctrine of "fair use," we are permitted to make backup / archival copies under certain conditions:
copyright law allows you to make copies for personal use in case the original is lost, damaged, or destroyed; or to change formats to use on new devices; or to otherwise alter or repair the original for your own personal use
all this falls within fair use
however, making a copy of copyrighted work simply for your own ease of use could be construed as copyright infringement
furthermore, the Digital Millennium Copyright Act (DMCA) restricts this by prohibiting "circumvention of encryption" on devices like DVDs and Blu-rays
the DMCA criminalizes making and disseminating technology, devices, or services intended to circumvent measures that control access to copyrighted works (aka "digital rights management" locks or DRM), and in fact criminalizes the act of circumventing access controls, whether or not doing so infringes on the copyright of the work itself
so, unless the original work you buy is unlocked, corporations that hold the copyright of that work can prosecute you for making legal archives of the material you own
and if the thing you bought is lost or damaged, or if the file format is no longer usable? you're just out of luck
DMCA needs to go
#copyright#ownership#archival copies#DMCA#backups#copyright infringement#capitalism ruins everything#my edits
296 notes
·
View notes
Text
What is Dataflow?
This post is inspired by another post about the Crowd Strike IT disaster and a bunch of people being interested in what I mean by Dataflow. Dataflow is my absolute jam and I'm happy to answer as many questions as you like on it. I even put referential pictures in like I'm writing an article, what fun!
I'll probably split this into multiple parts because it'll be a huge post otherwise but here we go!
A Brief History

Our world is dependent on the flow of data. It exists in almost every aspect of our lives and has done so arguably for hundreds if not thousands of years.
At the end of the day, the flow of data is the flow of knowledge and information. Normally most of us refer to data in the context of computing technology (our phones, PCs, tablets etc) but, if we want to get historical about it, the invention of writing and the invention of the Printing Press were great leaps forward in how we increased the flow of information.
Modern Day IT exists for one reason - To support the flow of data.
Whether it's buying something at a shop, sitting staring at an excel sheet at work, or watching Netflix - All of the technology you interact with is to support the flow of data.
Understanding and managing the flow of data is as important to getting us to where we are right now as when we first learned to control and manage water to provide irrigation for early farming and settlement.
Engineering Rigor
When the majority of us turn on the tap to have a drink or take a shower, we expect water to come out. We trust that the water is clean, and we trust that our homes can receive a steady supply of water.
Most of us trust our central heating (insert boiler joke here) and the plugs/sockets in our homes to provide gas and electricity. The reason we trust all of these flows is because there's been rigorous engineering standards built up over decades and centuries.

For example, Scottish Water will understand every component part that makes up their water pipelines. Those pipes, valves, fitting etc will comply with a national, or in some cases international, standard. These companies have diagrams that clearly map all of this out, mostly because they have to legally but also because it also vital for disaster recovery and other compliance issues.
Modern IT
And this is where modern day IT has problems. I'm not saying that modern day tech is a pile of shit. We all have great phones, our PCs can play good games, but it's one thing to craft well-designed products and another thing entirely to think about they all work together.
Because that is what's happened over the past few decades of IT. Organisations have piled on the latest plug-and-play technology (Software or Hardware) and they've built up complex legacy systems that no one really knows how they all work together. They've lost track of how data flows across their organisation which makes the work of cybersecurity, disaster recovery, compliance and general business transformation teams a nightmare.

Some of these systems are entirely dependent on other systems to operate. But that dependency isn't documented. The vast majority of digital transformation projects fail because they get halfway through and realise they hadn't factored in a system that they thought was nothing but was vital to the organisation running.
And this isn't just for-profit organisations, this is the health services, this is national infrastructure, it's everyone.
There's not yet a single standard that says "This is how organisations should control, manage and govern their flows of data."
Why is that relevant to the companies that were affected by Crowd Strike? Would it have stopped it?
Maybe, maybe not. But considering the global impact, it doesn't look like many organisations were prepared for the possibility of a huge chunk of their IT infrastructure going down.
Understanding dataflows help with the preparation for events like this, so organisations can move to mitigate them, and also the recovery side when they do happen. Organisations need to understand which systems are a priority to get back operational and which can be left.
The problem I'm seeing from a lot of organisations at the moment is that they don't know which systems to recover first, and are losing money and reputation while they fight to get things back online. A lot of them are just winging it.
Conclusion of Part 1
Next time I can totally go into diagramming if any of you are interested in that.
How can any organisation actually map their dataflow and what things need to be considered to do so. It'll come across like common sense, but that's why an actual standard is so desperately needed!
789 notes
·
View notes
Text
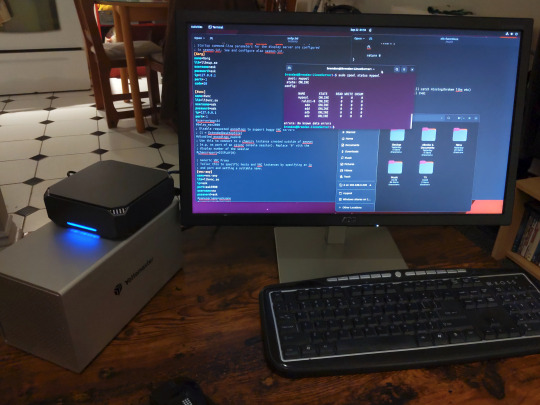
How I ditched streaming services and learned to love Linux: A step-by-step guide to building your very own personal media streaming server (V2.0: REVISED AND EXPANDED EDITION)
This is a revised, corrected and expanded version of my tutorial on setting up a personal media server that previously appeared on my old blog (donjuan-auxenfers). I expect that that post is still making the rounds (hopefully with my addendum on modifying group share permissions in Ubuntu to circumvent 0x8007003B "Unexpected Network Error" messages in Windows 10/11 when transferring files) but I have no way of checking. Anyway this new revised version of the tutorial corrects one or two small errors I discovered when rereading what I wrote, adds links to all products mentioned and is just more polished generally. I also expanded it a bit, pointing more adventurous users toward programs such as Sonarr/Radarr/Lidarr and Overseerr which can be used for automating user requests and media collection.
So then, what is this tutorial? This is a tutorial on how to build and set up your own personal media server using Ubuntu as an operating system and Plex (or Jellyfin) to not only manage your media, but to also stream that media to your devices both at home and abroad anywhere in the world where you have an internet connection. Its intent is to show you how building a personal media server and stuffing it full of films, TV, and music that you acquired through indiscriminate and voracious media piracy various legal methods will free you to completely ditch paid streaming services. No more will you have to pay for Disney+, Netflix, HBOMAX, Hulu, Amazon Prime, Peacock, CBS All Access, Paramount+, Crave or any other streaming service that is not named Criterion Channel. Instead whenever you want to watch your favourite films and television shows, you’ll have your own personal service that only features things that you want to see, with files that you have control over. And for music fans out there, both Jellyfin and Plex support music streaming, meaning you can even ditch music streaming services. Goodbye Spotify, Youtube Music, Tidal and Apple Music, welcome back unreasonably large MP3 (or FLAC) collections.
On the hardware front, I’m going to offer a few options catered towards different budgets and media library sizes. The cost of getting a media server up and running using this guide will cost you anywhere from $450 CAD/$325 USD at the low end to $1500 CAD/$1100 USD at the high end (it could go higher). My server was priced closer to the higher figure, but I went and got a lot more storage than most people need. If that seems like a little much, consider for a moment, do you have a roommate, a close friend, or a family member who would be willing to chip in a few bucks towards your little project provided they get access? Well that's how I funded my server. It might also be worth thinking about the cost over time, i.e. how much you spend yearly on subscriptions vs. a one time cost of setting up a server. Additionally there's just the joy of being able to scream "fuck you" at all those show cancelling, library deleting, hedge fund vampire CEOs who run the studios through denying them your money. Drive a stake through David Zaslav's heart.
On the software side I will walk you step-by-step through installing Ubuntu as your server's operating system, configuring your storage as a RAIDz array with ZFS, sharing your zpool to Windows with Samba, running a remote connection between your server and your Windows PC, and then a little about started with Plex/Jellyfin. Every terminal command you will need to input will be provided, and I even share a custom #bash script that will make used vs. available drive space on your server display correctly in Windows.
If you have a different preferred flavour of Linux (Arch, Manjaro, Redhat, Fedora, Mint, OpenSUSE, CentOS, Slackware etc. et. al.) and are aching to tell me off for being basic and using Ubuntu, this tutorial is not for you. The sort of person with a preferred Linux distro is the sort of person who can do this sort of thing in their sleep. Also I don't care. This tutorial is intended for the average home computer user. This is also why we’re not using a more exotic home server solution like running everything through Docker Containers and managing it through a dashboard like Homarr or Heimdall. While such solutions are fantastic and can be very easy to maintain once you have it all set up, wrapping your brain around Docker is a whole thing in and of itself. If you do follow this tutorial and had fun putting everything together, then I would encourage you to return in a year’s time, do your research and set up everything with Docker Containers.
Lastly, this is a tutorial aimed at Windows users. Although I was a daily user of OS X for many years (roughly 2008-2023) and I've dabbled quite a bit with various Linux distributions (mostly Ubuntu and Manjaro), my primary OS these days is Windows 11. Many things in this tutorial will still be applicable to Mac users, but others (e.g. setting up shares) you will have to look up for yourself. I doubt it would be difficult to do so.
Nothing in this tutorial will require feats of computing expertise. All you will need is a basic computer literacy (i.e. an understanding of what a filesystem and directory are, and a degree of comfort in the settings menu) and a willingness to learn a thing or two. While this guide may look overwhelming at first glance, it is only because I want to be as thorough as possible. I want you to understand exactly what it is you're doing, I don't want you to just blindly follow steps. If you half-way know what you’re doing, you will be much better prepared if you ever need to troubleshoot.
Honestly, once you have all the hardware ready it shouldn't take more than an afternoon or two to get everything up and running.
(This tutorial is just shy of seven thousand words long so the rest is under the cut.)
Step One: Choosing Your Hardware
Linux is a light weight operating system, depending on the distribution there's close to no bloat. There are recent distributions available at this very moment that will run perfectly fine on a fourteen year old i3 with 4GB of RAM. Moreover, running Plex or Jellyfin isn’t resource intensive in 90% of use cases. All this is to say, we don’t require an expensive or powerful computer. This means that there are several options available: 1) use an old computer you already have sitting around but aren't using 2) buy a used workstation from eBay, or what I believe to be the best option, 3) order an N100 Mini-PC from AliExpress or Amazon.
Note: If you already have an old PC sitting around that you’ve decided to use, fantastic, move on to the next step.
When weighing your options, keep a few things in mind: the number of people you expect to be streaming simultaneously at any one time, the resolution and bitrate of your media library (4k video takes a lot more processing power than 1080p) and most importantly, how many of those clients are going to be transcoding at any one time. Transcoding is what happens when the playback device does not natively support direct playback of the source file. This can happen for a number of reasons, such as the playback device's native resolution being lower than the file's internal resolution, or because the source file was encoded in a video codec unsupported by the playback device.
Ideally we want any transcoding to be performed by hardware. This means we should be looking for a computer with an Intel processor with Quick Sync. Quick Sync is a dedicated core on the CPU die designed specifically for video encoding and decoding. This specialized hardware makes for highly efficient transcoding both in terms of processing overhead and power draw. Without these Quick Sync cores, transcoding must be brute forced through software. This takes up much more of a CPU’s processing power and requires much more energy. But not all Quick Sync cores are created equal and you need to keep this in mind if you've decided either to use an old computer or to shop for a used workstation on eBay
Any Intel processor from second generation Core (Sandy Bridge circa 2011) onward has Quick Sync cores. It's not until 6th gen (Skylake), however, that the cores support the H.265 HEVC codec. Intel’s 10th gen (Comet Lake) processors introduce support for 10bit HEVC and HDR tone mapping. And the recent 12th gen (Alder Lake) processors brought with them hardware AV1 decoding. As an example, while an 8th gen (Kaby Lake) i5-8500 will be able to hardware transcode a H.265 encoded file, it will fall back to software transcoding if given a 10bit H.265 file. If you’ve decided to use that old PC or to look on eBay for an old Dell Optiplex keep this in mind.
Note 1: The price of old workstations varies wildly and fluctuates frequently. If you get lucky and go shopping shortly after a workplace has liquidated a large number of their workstations you can find deals for as low as $100 on a barebones system, but generally an i5-8500 workstation with 16gb RAM will cost you somewhere in the area of $260 CAD/$200 USD.
Note 2: The AMD equivalent to Quick Sync is called Video Core Next, and while it's fine, it's not as efficient and not as mature a technology. It was only introduced with the first generation Ryzen CPUs and it only got decent with their newest CPUs, we want something cheap.
Alternatively you could forgo having to keep track of what generation of CPU is equipped with Quick Sync cores that feature support for which codecs, and just buy an N100 mini-PC. For around the same price or less of a used workstation you can pick up a mini-PC with an Intel N100 processor. The N100 is a four-core processor based on the 12th gen Alder Lake architecture and comes equipped with the latest revision of the Quick Sync cores. These little processors offer astounding hardware transcoding capabilities for their size and power draw. Otherwise they perform equivalent to an i5-6500, which isn't a terrible CPU. A friend of mine uses an N100 machine as a dedicated retro emulation gaming system and it does everything up to 6th generation consoles just fine. The N100 is also a remarkably efficient chip, it sips power. In fact, the difference between running one of these and an old workstation could work out to hundreds of dollars a year in energy bills depending on where you live.
You can find these Mini-PCs all over Amazon or for a little cheaper on AliExpress. They range in price from $170 CAD/$125 USD for a no name N100 with 8GB RAM to $280 CAD/$200 USD for a Beelink S12 Pro with 16GB RAM. The brand doesn't really matter, they're all coming from the same three factories in Shenzen, go for whichever one fits your budget or has features you want. 8GB RAM should be enough, Linux is lightweight and Plex only calls for 2GB RAM. 16GB RAM might result in a slightly snappier experience, especially with ZFS. A 256GB SSD is more than enough for what we need as a boot drive, but going for a bigger drive might allow you to get away with things like creating preview thumbnails for Plex, but it’s up to you and your budget.
The Mini-PC I wound up buying was a Firebat AK2 Plus with 8GB RAM and a 256GB SSD. It looks like this:

Note: Be forewarned that if you decide to order a Mini-PC from AliExpress, note the type of power adapter it ships with. The mini-PC I bought came with an EU power adapter and I had to supply my own North American power supply. Thankfully this is a minor issue as barrel plug 30W/12V/2.5A power adapters are easy to find and can be had for $10.
Step Two: Choosing Your Storage
Storage is the most important part of our build. It is also the most expensive. Thankfully it’s also the most easily upgrade-able down the line.
For people with a smaller media collection (4TB to 8TB), a more limited budget, or who will only ever have two simultaneous streams running, I would say that the most economical course of action would be to buy a USB 3.0 8TB external HDD. Something like this one from Western Digital or this one from Seagate. One of these external drives will cost you in the area of $200 CAD/$140 USD. Down the line you could add a second external drive or replace it with a multi-drive RAIDz set up such as detailed below.
If a single external drive the path for you, move on to step three.
For people with larger media libraries (12TB+), who prefer media in 4k, or care who about data redundancy, the answer is a RAID array featuring multiple HDDs in an enclosure.
Note: If you are using an old PC or used workstatiom as your server and have the room for at least three 3.5" drives, and as many open SATA ports on your mother board you won't need an enclosure, just install the drives into the case. If your old computer is a laptop or doesn’t have room for more internal drives, then I would suggest an enclosure.
The minimum number of drives needed to run a RAIDz array is three, and seeing as RAIDz is what we will be using, you should be looking for an enclosure with three to five bays. I think that four disks makes for a good compromise for a home server. Regardless of whether you go for a three, four, or five bay enclosure, do be aware that in a RAIDz array the space equivalent of one of the drives will be dedicated to parity at a ratio expressed by the equation 1 − 1/n i.e. in a four bay enclosure equipped with four 12TB drives, if we configured our drives in a RAIDz1 array we would be left with a total of 36TB of usable space (48TB raw size). The reason for why we might sacrifice storage space in such a manner will be explained in the next section.
A four bay enclosure will cost somewhere in the area of $200 CDN/$140 USD. You don't need anything fancy, we don't need anything with hardware RAID controls (RAIDz is done entirely in software) or even USB-C. An enclosure with USB 3.0 will perform perfectly fine. Don’t worry too much about USB speed bottlenecks. A mechanical HDD will be limited by the speed of its mechanism long before before it will be limited by the speed of a USB connection. I've seen decent looking enclosures from TerraMaster, Yottamaster, Mediasonic and Sabrent.
When it comes to selecting the drives, as of this writing, the best value (dollar per gigabyte) are those in the range of 12TB to 20TB. I settled on 12TB drives myself. If 12TB to 20TB drives are out of your budget, go with what you can afford, or look into refurbished drives. I'm not sold on the idea of refurbished drives but many people swear by them.
When shopping for harddrives, search for drives designed specifically for NAS use. Drives designed for NAS use typically have better vibration dampening and are designed to be active 24/7. They will also often make use of CMR (conventional magnetic recording) as opposed to SMR (shingled magnetic recording). This nets them a sizable read/write performance bump over typical desktop drives. Seagate Ironwolf and Toshiba NAS are both well regarded brands when it comes to NAS drives. I would avoid Western Digital Red drives at this time. WD Reds were a go to recommendation up until earlier this year when it was revealed that they feature firmware that will throw up false SMART warnings telling you to replace the drive at the three year mark quite often when there is nothing at all wrong with that drive. It will likely even be good for another six, seven, or more years.

Step Three: Installing Linux
For this step you will need a USB thumbdrive of at least 6GB in capacity, an .ISO of Ubuntu, and a way to make that thumbdrive bootable media.
First download a copy of Ubuntu desktop (for best performance we could download the Server release, but for new Linux users I would recommend against the server release. The server release is strictly command line interface only, and having a GUI is very helpful for most people. Not many people are wholly comfortable doing everything through the command line, I'm certainly not one of them, and I grew up with DOS 6.0. 22.04.3 Jammy Jellyfish is the current Long Term Service release, this is the one to get.
Download the .ISO and then download and install balenaEtcher on your Windows PC. BalenaEtcher is an easy to use program for creating bootable media, you simply insert your thumbdrive, select the .ISO you just downloaded, and it will create a bootable installation media for you.
Once you've made a bootable media and you've got your Mini-PC (or you old PC/used workstation) in front of you, hook it directly into your router with an ethernet cable, and then plug in the HDD enclosure, a monitor, a mouse and a keyboard. Now turn that sucker on and hit whatever key gets you into the BIOS (typically ESC, DEL or F2). If you’re using a Mini-PC check to make sure that the P1 and P2 power limits are set correctly, my N100's P1 limit was set at 10W, a full 20W under the chip's power limit. Also make sure that the RAM is running at the advertised speed. My Mini-PC’s RAM was set at 2333Mhz out of the box when it should have been 3200Mhz. Once you’ve done that, key over to the boot order and place the USB drive first in the boot order. Then save the BIOS settings and restart.
After you restart you’ll be greeted by Ubuntu's installation screen. Installing Ubuntu is really straight forward, select the "minimal" installation option, as we won't need anything on this computer except for a browser (Ubuntu comes preinstalled with Firefox) and Plex Media Server/Jellyfin Media Server. Also remember to delete and reformat that Windows partition! We don't need it.
Step Four: Installing ZFS and Setting Up the RAIDz Array
Note: If you opted for just a single external HDD skip this step and move onto setting up a Samba share.
Once Ubuntu is installed it's time to configure our storage by installing ZFS to build our RAIDz array. ZFS is a "next-gen" file system that is both massively flexible and massively complex. It's capable of snapshot backup, self healing error correction, ZFS pools can be configured with drives operating in a supplemental manner alongside the storage vdev (e.g. fast cache, dedicated secondary intent log, hot swap spares etc.). It's also a file system very amenable to fine tuning. Block and sector size are adjustable to use case and you're afforded the option of different methods of inline compression. If you'd like a very detailed overview and explanation of its various features and tips on tuning a ZFS array check out these articles from Ars Technica. For now we're going to ignore all these features and keep it simple, we're going to pull our drives together into a single vdev running in RAIDz which will be the entirety of our zpool, no fancy cache drive or SLOG.
Open up the terminal and type the following commands:
sudo apt update
then
sudo apt install zfsutils-linux
This will install the ZFS utility. Verify that it's installed with the following command:
zfs --version
Now, it's time to check that the HDDs we have in the enclosure are healthy, running, and recognized. We also want to find out their device IDs and take note of them:
sudo fdisk -1
Note: You might be wondering why some of these commands require "sudo" in front of them while others don't. "Sudo" is short for "super user do”. When and where "sudo" is used has to do with the way permissions are set up in Linux. Only the "root" user has the access level to perform certain tasks in Linux. As a matter of security and safety regular user accounts are kept separate from the "root" user. It's not advised (or even possible) to boot into Linux as "root" with most modern distributions. Instead by using "sudo" our regular user account is temporarily given the power to do otherwise forbidden things. Don't worry about it too much at this stage, but if you want to know more check out this introduction.
If everything is working you should get a list of the various drives detected along with their device IDs which will look like this: /dev/sdc. You can also check the device IDs of the drives by opening the disk utility app. Jot these IDs down as we'll need them for our next step, creating our RAIDz array.
RAIDz is similar to RAID-5 in that instead of striping your data over multiple disks, exchanging redundancy for speed and available space (RAID-0), or mirroring your data writing by two copies of every piece (RAID-1), it instead writes parity blocks across the disks in addition to striping, this provides a balance of speed, redundancy and available space. If a single drive fails, the parity blocks on the working drives can be used to reconstruct the entire array as soon as a replacement drive is added.
Additionally, RAIDz improves over some of the common RAID-5 flaws. It's more resilient and capable of self healing, as it is capable of automatically checking for errors against a checksum. It's more forgiving in this way, and it's likely that you'll be able to detect when a drive is dying well before it fails. A RAIDz array can survive the loss of any one drive.
Note: While RAIDz is indeed resilient, if a second drive fails during the rebuild, you're fucked. Always keep backups of things you can't afford to lose. This tutorial, however, is not about proper data safety.
To create the pool, use the following command:
sudo zpool create "zpoolnamehere" raidz "device IDs of drives we're putting in the pool"
For example, let's creatively name our zpool "mypool". This poil will consist of four drives which have the device IDs: sdb, sdc, sdd, and sde. The resulting command will look like this:
sudo zpool create mypool raidz /dev/sdb /dev/sdc /dev/sdd /dev/sde
If as an example you bought five HDDs and decided you wanted more redundancy dedicating two drive to this purpose, we would modify the command to "raidz2" and the command would look something like the following:
sudo zpool create mypool raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
An array configured like this is known as RAIDz2 and is able to survive two disk failures.
Once the zpool has been created, we can check its status with the command:
zpool status
Or more concisely with:
zpool list
The nice thing about ZFS as a file system is that a pool is ready to go immediately after creation. If we were to set up a traditional RAID-5 array using mbam, we'd have to sit through a potentially hours long process of reformatting and partitioning the drives. Instead we're ready to go right out the gates.
The zpool should be automatically mounted to the filesystem after creation, check on that with the following:
df -hT | grep zfs
Note: If your computer ever loses power suddenly, say in event of a power outage, you may have to re-import your pool. In most cases, ZFS will automatically import and mount your pool, but if it doesn’t and you can't see your array, simply open the terminal and type sudo zpool import -a.
By default a zpool is mounted at /"zpoolname". The pool should be under our ownership but let's make sure with the following command:
sudo chown -R "yourlinuxusername" /"zpoolname"
Note: Changing file and folder ownership with "chown" and file and folder permissions with "chmod" are essential commands for much of the admin work in Linux, but we won't be dealing with them extensively in this guide. If you'd like a deeper tutorial and explanation you can check out these two guides: chown and chmod.
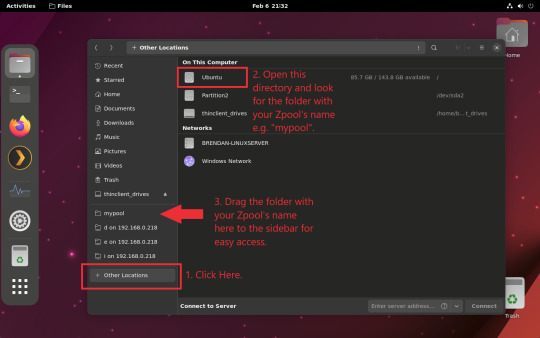
You can access the zpool file system through the GUI by opening the file manager (the Ubuntu default file manager is called Nautilus) and clicking on "Other Locations" on the sidebar, then entering the Ubuntu file system and looking for a folder with your pool's name. Bookmark the folder on the sidebar for easy access.
Your storage pool is now ready to go. Assuming that we already have some files on our Windows PC we want to copy to over, we're going to need to install and configure Samba to make the pool accessible in Windows.
Step Five: Setting Up Samba/Sharing
Samba is what's going to let us share the zpool with Windows and allow us to write to it from our Windows machine. First let's install Samba with the following commands:
sudo apt-get update
then
sudo apt-get install samba
Next create a password for Samba.
sudo smbpswd -a "yourlinuxusername"
It will then prompt you to create a password. Just reuse your Ubuntu user password for simplicity's sake.
Note: if you're using just a single external drive replace the zpool location in the following commands with wherever it is your external drive is mounted, for more information see this guide on mounting an external drive in Ubuntu.
After you've created a password we're going to create a shareable folder in our pool with this command
mkdir /"zpoolname"/"foldername"
Now we're going to open the smb.conf file and make that folder shareable. Enter the following command.
sudo nano /etc/samba/smb.conf
This will open the .conf file in nano, the terminal text editor program. Now at the end of smb.conf add the following entry:
["foldername"]
path = /"zpoolname"/"foldername"
available = yes
valid users = "yourlinuxusername"
read only = no
writable = yes
browseable = yes
guest ok = no
Ensure that there are no line breaks between the lines and that there's a space on both sides of the equals sign. Our next step is to allow Samba traffic through the firewall:
sudo ufw allow samba
Finally restart the Samba service:
sudo systemctl restart smbd
At this point we'll be able to access to the pool, browse its contents, and read and write to it from Windows. But there's one more thing left to do, Windows doesn't natively support the ZFS file systems and will read the used/available/total space in the pool incorrectly. Windows will read available space as total drive space, and all used space as null. This leads to Windows only displaying a dwindling amount of "available" space as the drives are filled. We can fix this! Functionally this doesn't actually matter, we can still write and read to and from the disk, it just makes it difficult to tell at a glance the proportion of used/available space, so this is an optional step but one I recommend (this step is also unnecessary if you're just using a single external drive). What we're going to do is write a little shell script in #bash. Open nano with the terminal with the command:
nano
Now insert the following code:
#!/bin/bash CUR_PATH=`pwd` ZFS_CHECK_OUTPUT=$(zfs get type $CUR_PATH 2>&1 > /dev/null) > /dev/null if [[ $ZFS_CHECK_OUTPUT == *not\ a\ ZFS* ]] then IS_ZFS=false else IS_ZFS=true fi if [[ $IS_ZFS = false ]] then df $CUR_PATH | tail -1 | awk '{print $2" "$4}' else USED=$((`zfs get -o value -Hp used $CUR_PATH` / 1024)) > /dev/null AVAIL=$((`zfs get -o value -Hp available $CUR_PATH` / 1024)) > /dev/null TOTAL=$(($USED+$AVAIL)) > /dev/null echo $TOTAL $AVAIL fi
Save the script as "dfree.sh" to /home/"yourlinuxusername" then change the ownership of the file to make it executable with this command:
sudo chmod 774 dfree.sh
Now open smb.conf with sudo again:
sudo nano /etc/samba/smb.conf
Now add this entry to the top of the configuration file to direct Samba to use the results of our script when Windows asks for a reading on the pool's used/available/total drive space:
[global]
dfree command = /home/"yourlinuxusername"/dfree.sh
Save the changes to smb.conf and then restart Samba again with the terminal:
sudo systemctl restart smbd
Now there’s one more thing we need to do to fully set up the Samba share, and that’s to modify a hidden group permission. In the terminal window type the following command:
usermod -a -G sambashare “yourlinuxusername”
Then restart samba again:
sudo systemctl restart smbd
If we don’t do this last step, everything will appear to work fine, and you will even be able to see and map the drive from Windows and even begin transferring files, but you'd soon run into a lot of frustration. As every ten minutes or so a file would fail to transfer and you would get a window announcing “0x8007003B Unexpected Network Error”. This window would require your manual input to continue the transfer with the file next in the queue. And at the end it would reattempt to transfer whichever files failed the first time around. 99% of the time they’ll go through that second try, but this is still all a major pain in the ass. Especially if you’ve got a lot of data to transfer or you want to step away from the computer for a while.
It turns out samba can act a little weirdly with the higher read/write speeds of RAIDz arrays and transfers from Windows, and will intermittently crash and restart itself if this group option isn’t changed. Inputting the above command will prevent you from ever seeing that window.
The last thing we're going to do before switching over to our Windows PC is grab the IP address of our Linux machine. Enter the following command:
hostname -I
This will spit out this computer's IP address on the local network (it will look something like 192.168.0.x), write it down. It might be a good idea once you're done here to go into your router settings and reserving that IP for your Linux system in the DHCP settings. Check the manual for your specific model router on how to access its settings, typically it can be accessed by opening a browser and typing http:\\192.168.0.1 in the address bar, but your router may be different.
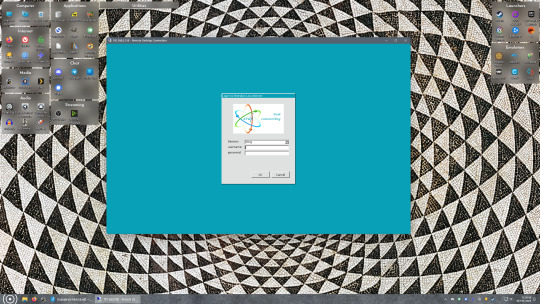
Okay we’re done with our Linux computer for now. Get on over to your Windows PC, open File Explorer, right click on Network and click "Map network drive". Select Z: as the drive letter (you don't want to map the network drive to a letter you could conceivably be using for other purposes) and enter the IP of your Linux machine and location of the share like so: \\"LINUXCOMPUTERLOCALIPADDRESSGOESHERE"\"zpoolnamegoeshere"\. Windows will then ask you for your username and password, enter the ones you set earlier in Samba and you're good. If you've done everything right it should look something like this:

You can now start moving media over from Windows to the share folder. It's a good idea to have a hard line running to all machines. Moving files over Wi-Fi is going to be tortuously slow, the only thing that’s going to make the transfer time tolerable (hours instead of days) is a solid wired connection between both machines and your router.
Step Six: Setting Up Remote Desktop Access to Your Server
After the server is up and going, you’ll want to be able to access it remotely from Windows. Barring serious maintenance/updates, this is how you'll access it most of the time. On your Linux system open the terminal and enter:
sudo apt install xrdp
Then:
sudo systemctl enable xrdp
Once it's finished installing, open “Settings” on the sidebar and turn off "automatic login" in the User category. Then log out of your account. Attempting to remotely connect to your Linux computer while you’re logged in will result in a black screen!
Now get back on your Windows PC, open search and look for "RDP". A program called "Remote Desktop Connection" should pop up, open this program as an administrator by right-clicking and selecting “run as an administrator”. You’ll be greeted with a window. In the field marked “Computer” type in the IP address of your Linux computer. Press connect and you'll be greeted with a new window and prompt asking for your username and password. Enter your Ubuntu username and password here.
If everything went right, you’ll be logged into your Linux computer. If the performance is sluggish, adjust the display options. Lowering the resolution and colour depth do a lot to make the interface feel snappier.
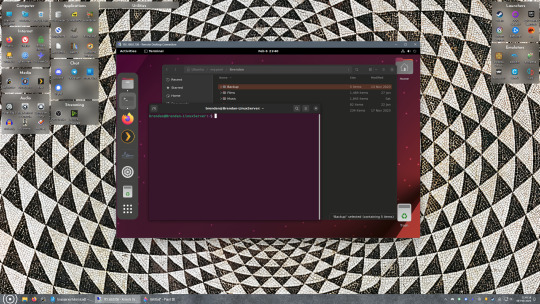
Remote access is how we're going to be using our Linux system from now, barring edge cases like needing to get into the BIOS or upgrading to a new version of Ubuntu. Everything else from performing maintenance like a monthly zpool scrub to checking zpool status and updating software can all be done remotely.

This is how my server lives its life now, happily humming and chirping away on the floor next to the couch in a corner of the living room.
Step Seven: Plex Media Server/Jellyfin
Okay we’ve got all the ground work finished and our server is almost up and running. We’ve got Ubuntu up and running, our storage array is primed, we’ve set up remote connections and sharing, and maybe we’ve moved over some of favourite movies and TV shows.
Now we need to decide on the media server software to use which will stream our media to us and organize our library. For most people I’d recommend Plex. It just works 99% of the time. That said, Jellyfin has a lot to recommend it by too, even if it is rougher around the edges. Some people run both simultaneously, it’s not that big of an extra strain. I do recommend doing a little bit of your own research into the features each platform offers, but as a quick run down, consider some of the following points:
Plex is closed source and is funded through PlexPass purchases while Jellyfin is open source and entirely user driven. This means a number of things: for one, Plex requires you to purchase a “PlexPass” (purchased as a one time lifetime fee $159.99 CDN/$120 USD or paid for on a monthly or yearly subscription basis) in order to access to certain features, like hardware transcoding (and we want hardware transcoding) or automated intro/credits detection and skipping, Jellyfin offers some of these features for free through plugins. Plex supports a lot more devices than Jellyfin and updates more frequently. That said, Jellyfin's Android and iOS apps are completely free, while the Plex Android and iOS apps must be activated for a one time cost of $6 CDN/$5 USD. But that $6 fee gets you a mobile app that is much more functional and features a unified UI across platforms, the Plex mobile apps are simply a more polished experience. The Jellyfin apps are a bit of a mess and the iOS and Android versions are very different from each other.
Jellyfin’s actual media player is more fully featured than Plex's, but on the other hand Jellyfin's UI, library customization and automatic media tagging really pale in comparison to Plex. Streaming your music library is free through both Jellyfin and Plex, but Plex offers the PlexAmp app for dedicated music streaming which boasts a number of fantastic features, unfortunately some of those fantastic features require a PlexPass. If your internet is down, Jellyfin can still do local streaming, while Plex can fail to play files unless you've got it set up a certain way. Jellyfin has a slew of neat niche features like support for Comic Book libraries with the .cbz/.cbt file types, but then Plex offers some free ad-supported TV and films, they even have a free channel that plays nothing but Classic Doctor Who.
Ultimately it's up to you, I settled on Plex because although some features are pay-walled, it just works. It's more reliable and easier to use, and a one-time fee is much easier to swallow than a subscription. I had a pretty easy time getting my boomer parents and tech illiterate brother introduced to and using Plex and I don't know if I would've had as easy a time doing that with Jellyfin. I do also need to mention that Jellyfin does take a little extra bit of tinkering to get going in Ubuntu, you’ll have to set up process permissions, so if you're more tolerant to tinkering, Jellyfin might be up your alley and I’ll trust that you can follow their installation and configuration guide. For everyone else, I recommend Plex.
So pick your poison: Plex or Jellyfin.
Note: The easiest way to download and install either of these packages in Ubuntu is through Snap Store.
After you've installed one (or both), opening either app will launch a browser window into the browser version of the app allowing you to set all the options server side.
The process of adding creating media libraries is essentially the same in both Plex and Jellyfin. You create a separate libraries for Television, Movies, and Music and add the folders which contain the respective types of media to their respective libraries. The only difficult or time consuming aspect is ensuring that your files and folders follow the appropriate naming conventions:
Plex naming guide for Movies
Plex naming guide for Television
Jellyfin follows the same naming rules but I find their media scanner to be a lot less accurate and forgiving than Plex. Once you've selected the folders to be scanned the service will scan your files, tagging everything and adding metadata. Although I find do find Plex more accurate, it can still erroneously tag some things and you might have to manually clean up some tags in a large library. (When I initially created my library it tagged the 1963-1989 Doctor Who as some Korean soap opera and I needed to manually select the correct match after which everything was tagged normally.) It can also be a bit testy with anime (especially OVAs) be sure to check TVDB to ensure that you have your files and folders structured and named correctly. If something is not showing up at all, double check the name.
Once that's done, organizing and customizing your library is easy. You can set up collections, grouping items together to fit a theme or collect together all the entries in a franchise. You can make playlists, and add custom artwork to entries. It's fun setting up collections with posters to match, there are even several websites dedicated to help you do this like PosterDB. As an example, below are two collections in my library, one collecting all the entries in a franchise, the other follows a theme.

My Star Trek collection, featuring all eleven television series, and thirteen films.
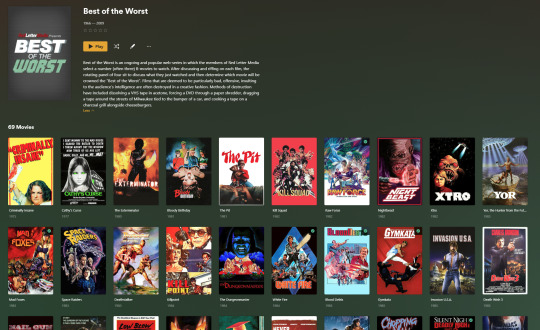
My Best of the Worst collection, featuring sixty-nine films previously showcased on RedLetterMedia’s Best of the Worst. They’re all absolutely terrible and I love them.
As for settings, ensure you've got Remote Access going, it should work automatically and be sure to set your upload speed after running a speed test. In the library settings set the database cache to 2000MB to ensure a snappier and more responsive browsing experience, and then check that playback quality is set to original/maximum. If you’re severely bandwidth limited on your upload and have remote users, you might want to limit the remote stream bitrate to something more reasonable, just as a note of comparison Netflix’s 1080p bitrate is approximately 5Mbps, although almost anyone watching through a chromium based browser is streaming at 720p and 3mbps. Other than that you should be good to go. For actually playing your files, there's a Plex app for just about every platform imaginable. I mostly watch television and films on my laptop using the Windows Plex app, but I also use the Android app which can broadcast to the chromecast connected to the TV in the office and the Android TV app for our smart TV. Both are fully functional and easy to navigate, and I can also attest to the OS X version being equally functional.
Part Eight: Finding Media
Now, this is not really a piracy tutorial, there are plenty of those out there. But if you’re unaware, BitTorrent is free and pretty easy to use, just pick a client (qBittorrent is the best) and go find some public trackers to peruse. Just know now that all the best trackers are private and invite only, and that they can be exceptionally difficult to get into. I’m already on a few, and even then, some of the best ones are wholly out of my reach.
If you decide to take the left hand path and turn to Usenet you’ll have to pay. First you’ll need to sign up with a provider like Newshosting or EasyNews for access to Usenet itself, and then to actually find anything you’re going to need to sign up with an indexer like NZBGeek or NZBFinder. There are dozens of indexers, and many people cross post between them, but for more obscure media it’s worth checking multiple. You’ll also need a binary downloader like SABnzbd. That caveat aside, Usenet is faster, bigger, older, less traceable than BitTorrent, and altogether slicker. I honestly prefer it, and I'm kicking myself for taking this long to start using it because I was scared off by the price. I’ve found so many things on Usenet that I had sought in vain elsewhere for years, like a 2010 Italian film about a massacre perpetrated by the SS that played the festival circuit but never received a home media release; some absolute hero uploaded a rip of a festival screener DVD to Usenet. Anyway, figure out the rest of this shit on your own and remember to use protection, get yourself behind a VPN, use a SOCKS5 proxy with your BitTorrent client, etc.
On the legal side of things, if you’re around my age, you (or your family) probably have a big pile of DVDs and Blu-Rays sitting around unwatched and half forgotten. Why not do a bit of amateur media preservation, rip them and upload them to your server for easier access? (Your tools for this are going to be Handbrake to do the ripping and AnyDVD to break any encryption.) I went to the trouble of ripping all my SCTV DVDs (five box sets worth) because none of it is on streaming nor could it be found on any pirate source I tried. I’m glad I did, forty years on it’s still one of the funniest shows to ever be on TV.
Part Nine/Epilogue: Sonarr/Radarr/Lidarr and Overseerr
There are a lot of ways to automate your server for better functionality or to add features you and other users might find useful. Sonarr, Radarr, and Lidarr are a part of a suite of “Servarr” services (there’s also Readarr for books and Whisparr for adult content) that allow you to automate the collection of new episodes of TV shows (Sonarr), new movie releases (Radarr) and music releases (Lidarr). They hook in to your BitTorrent client or Usenet binary newsgroup downloader and crawl your preferred Torrent trackers and Usenet indexers, alerting you to new releases and automatically grabbing them. You can also use these services to manually search for new media, and even replace/upgrade your existing media with better quality uploads. They’re really a little tricky to set up on a bare metal Ubuntu install (ideally you should be running them in Docker Containers), and I won’t be providing a step by step on installing and running them, I’m simply making you aware of their existence.
The other bit of kit I want to make you aware of is Overseerr which is a program that scans your Plex media library and will serve recommendations based on what you like. It also allows you and your users to request specific media. It can even be integrated with Sonarr/Radarr/Lidarr so that fulfilling those requests is fully automated.
And you're done. It really wasn't all that hard. Enjoy your media. Enjoy the control you have over that media. And be safe in the knowledge that no hedgefund CEO motherfucker who hates the movies but who is somehow in control of a major studio will be able to disappear anything in your library as a tax write-off.
1K notes
·
View notes
Text
The Dow is on track for its worst April since 1932—the bleakest year of the Great Depression. Nearly a century later, markets are once again facing economic turbulence on a historic scale.
Trump's approval rating drops to 42%, the lowest it's been since he became president, according to a Reuters/Ipsos poll.
A cutting-edge microscope at Harvard Medical School could pave the way for major breakthroughs in cancer detection and aging research—but its progress is now at risk. The scientist who created the software to analyze its images, 30-year-old Russian-born Kseniia Petrova, has been held in immigration detention for two months. Arrested in February at a Boston airport, Petrova is now detained in Louisiana, facing possible deportation to Russia, where she says she fears imprisonment for protesting the war in Ukraine. Her case highlights the tension between immigration policy and the U.S.'s reliance on global scientific talent.
The Department of Homeland Security denied Mahmoud Khalil permission to be present for the birth of his first child, which took place Monday at a hospital in New York. Instead, Khalil had to experience the moment over the phone from Jena, Louisiana—more than 1,000 miles away from his wife, Dr. Noor Abdalla, who delivered their baby boy. The case has sparked criticism over DHS's handling of family and humanitarian considerations.
The White House is considering policies to encourage more Americans to marry and have children, including a potential $5,000 “baby bonus,” according to The New York Times. The proposals align with a broader conservative push to address falling birth rates and promote traditional family values. Other ideas on the table include reserving 30% of Fulbright scholarships for applicants who are married or have children, and funding educational programs that teach women about fertility and ovulation.
A group of Venezuelan migrants facing removal under a broad wartime authority challenged the Trump administration’s deportation process at the Supreme Court, arguing the notices they received don’t meet legal standards. The ACLU, representing the migrants, said the English-only notices—often given less than 24 hours before deportation—violate a recent Supreme Court ruling requiring enough time for individuals to seek habeas review.
The Education Department announced it will start collecting student loan payments from over 5 million borrowers who are in default. This means it will begin taking money from federal wages, Social Security checks, and tax refunds. This move comes as pandemic-era protections for student loan borrowers continue to wind down.
Tensions are rising within the Arizona Democratic Party as the state party chair is at odds with the governor and U.S. senators. In response, officials are considering shifting 2026 campaign funds to local county Democrats.
The U.S. Department of Commerce has announced substantial tariffs on solar panel imports from four Southeast Asian countries—Cambodia, Vietnam, Thailand, and Malaysia—following a year-long investigation into alleged trade violations by Chinese-owned manufacturers operating in these nations. The tariffs, which vary by country and company, are as follows:
Cambodia: Facing the steepest duties, with tariffs reaching up to 3,521%, due to non-cooperation with the investigation.
Vietnam: Companies may face duties up to 395.9%.
Thailand: Tariffs could be as high as 375.2%.
Malaysia: Duties are set at 34.4%.
Senator Adam Schiff is urging the National Archives to investigate the Trump administration's use of Signal and similar messaging apps. He emphasized the need for NARA to reach out to every federal agency involved to make sure all relevant records are preserved. This comes amid growing concerns over transparency and potential violations of federal recordkeeping laws.
#aaron parnas#current events#news#america#politics#political#us politics#donald trump#american politics#president trump#elon musk#jd vance#law#trump administration#trump#trump admin
99 notes
·
View notes
Text
Humans are not perfectly vigilant

I'm on tour with my new, nationally bestselling novel The Bezzle! Catch me in BOSTON with Randall "XKCD" Munroe (Apr 11), then PROVIDENCE (Apr 12), and beyond!

Here's a fun AI story: a security researcher noticed that large companies' AI-authored source-code repeatedly referenced a nonexistent library (an AI "hallucination"), so he created a (defanged) malicious library with that name and uploaded it, and thousands of developers automatically downloaded and incorporated it as they compiled the code:
https://www.theregister.com/2024/03/28/ai_bots_hallucinate_software_packages/
These "hallucinations" are a stubbornly persistent feature of large language models, because these models only give the illusion of understanding; in reality, they are just sophisticated forms of autocomplete, drawing on huge databases to make shrewd (but reliably fallible) guesses about which word comes next:
https://dl.acm.org/doi/10.1145/3442188.3445922
Guessing the next word without understanding the meaning of the resulting sentence makes unsupervised LLMs unsuitable for high-stakes tasks. The whole AI bubble is based on convincing investors that one or more of the following is true:
There are low-stakes, high-value tasks that will recoup the massive costs of AI training and operation;
There are high-stakes, high-value tasks that can be made cheaper by adding an AI to a human operator;
Adding more training data to an AI will make it stop hallucinating, so that it can take over high-stakes, high-value tasks without a "human in the loop."
These are dubious propositions. There's a universe of low-stakes, low-value tasks – political disinformation, spam, fraud, academic cheating, nonconsensual porn, dialog for video-game NPCs – but none of them seem likely to generate enough revenue for AI companies to justify the billions spent on models, nor the trillions in valuation attributed to AI companies:
https://locusmag.com/2023/12/commentary-cory-doctorow-what-kind-of-bubble-is-ai/
The proposition that increasing training data will decrease hallucinations is hotly contested among AI practitioners. I confess that I don't know enough about AI to evaluate opposing sides' claims, but even if you stipulate that adding lots of human-generated training data will make the software a better guesser, there's a serious problem. All those low-value, low-stakes applications are flooding the internet with botshit. After all, the one thing AI is unarguably very good at is producing bullshit at scale. As the web becomes an anaerobic lagoon for botshit, the quantum of human-generated "content" in any internet core sample is dwindling to homeopathic levels:
https://pluralistic.net/2024/03/14/inhuman-centipede/#enshittibottification
This means that adding another order of magnitude more training data to AI won't just add massive computational expense – the data will be many orders of magnitude more expensive to acquire, even without factoring in the additional liability arising from new legal theories about scraping:
https://pluralistic.net/2023/09/17/how-to-think-about-scraping/
That leaves us with "humans in the loop" – the idea that an AI's business model is selling software to businesses that will pair it with human operators who will closely scrutinize the code's guesses. There's a version of this that sounds plausible – the one in which the human operator is in charge, and the AI acts as an eternally vigilant "sanity check" on the human's activities.
For example, my car has a system that notices when I activate my blinker while there's another car in my blind-spot. I'm pretty consistent about checking my blind spot, but I'm also a fallible human and there've been a couple times where the alert saved me from making a potentially dangerous maneuver. As disciplined as I am, I'm also sometimes forgetful about turning off lights, or waking up in time for work, or remembering someone's phone number (or birthday). I like having an automated system that does the robotically perfect trick of never forgetting something important.
There's a name for this in automation circles: a "centaur." I'm the human head, and I've fused with a powerful robot body that supports me, doing things that humans are innately bad at.
That's the good kind of automation, and we all benefit from it. But it only takes a small twist to turn this good automation into a nightmare. I'm speaking here of the reverse-centaur: automation in which the computer is in charge, bossing a human around so it can get its job done. Think of Amazon warehouse workers, who wear haptic bracelets and are continuously observed by AI cameras as autonomous shelves shuttle in front of them and demand that they pick and pack items at a pace that destroys their bodies and drives them mad:
https://pluralistic.net/2022/04/17/revenge-of-the-chickenized-reverse-centaurs/
Automation centaurs are great: they relieve humans of drudgework and let them focus on the creative and satisfying parts of their jobs. That's how AI-assisted coding is pitched: rather than looking up tricky syntax and other tedious programming tasks, an AI "co-pilot" is billed as freeing up its human "pilot" to focus on the creative puzzle-solving that makes coding so satisfying.
But an hallucinating AI is a terrible co-pilot. It's just good enough to get the job done much of the time, but it also sneakily inserts booby-traps that are statistically guaranteed to look as plausible as the good code (that's what a next-word-guessing program does: guesses the statistically most likely word).
This turns AI-"assisted" coders into reverse centaurs. The AI can churn out code at superhuman speed, and you, the human in the loop, must maintain perfect vigilance and attention as you review that code, spotting the cleverly disguised hooks for malicious code that the AI can't be prevented from inserting into its code. As "Lena" writes, "code review [is] difficult relative to writing new code":
https://twitter.com/qntm/status/1773779967521780169
Why is that? "Passively reading someone else's code just doesn't engage my brain in the same way. It's harder to do properly":
https://twitter.com/qntm/status/1773780355708764665
There's a name for this phenomenon: "automation blindness." Humans are just not equipped for eternal vigilance. We get good at spotting patterns that occur frequently – so good that we miss the anomalies. That's why TSA agents are so good at spotting harmless shampoo bottles on X-rays, even as they miss nearly every gun and bomb that a red team smuggles through their checkpoints:
https://pluralistic.net/2023/08/23/automation-blindness/#humans-in-the-loop
"Lena"'s thread points out that this is as true for AI-assisted driving as it is for AI-assisted coding: "self-driving cars replace the experience of driving with the experience of being a driving instructor":
https://twitter.com/qntm/status/1773841546753831283
In other words, they turn you into a reverse-centaur. Whereas my blind-spot double-checking robot allows me to make maneuvers at human speed and points out the things I've missed, a "supervised" self-driving car makes maneuvers at a computer's frantic pace, and demands that its human supervisor tirelessly and perfectly assesses each of those maneuvers. No wonder Cruise's murderous "self-driving" taxis replaced each low-waged driver with 1.5 high-waged technical robot supervisors:
https://pluralistic.net/2024/01/11/robots-stole-my-jerb/#computer-says-no
AI radiology programs are said to be able to spot cancerous masses that human radiologists miss. A centaur-based AI-assisted radiology program would keep the same number of radiologists in the field, but they would get less done: every time they assessed an X-ray, the AI would give them a second opinion. If the human and the AI disagreed, the human would go back and re-assess the X-ray. We'd get better radiology, at a higher price (the price of the AI software, plus the additional hours the radiologist would work).
But back to making the AI bubble pay off: for AI to pay off, the human in the loop has to reduce the costs of the business buying an AI. No one who invests in an AI company believes that their returns will come from business customers to agree to increase their costs. The AI can't do your job, but the AI salesman can convince your boss to fire you and replace you with an AI anyway – that pitch is the most successful form of AI disinformation in the world.
An AI that "hallucinates" bad advice to fliers can't replace human customer service reps, but airlines are firing reps and replacing them with chatbots:
https://www.bbc.com/travel/article/20240222-air-canada-chatbot-misinformation-what-travellers-should-know
An AI that "hallucinates" bad legal advice to New Yorkers can't replace city services, but Mayor Adams still tells New Yorkers to get their legal advice from his chatbots:
https://arstechnica.com/ai/2024/03/nycs-government-chatbot-is-lying-about-city-laws-and-regulations/
The only reason bosses want to buy robots is to fire humans and lower their costs. That's why "AI art" is such a pisser. There are plenty of harmless ways to automate art production with software – everything from a "healing brush" in Photoshop to deepfake tools that let a video-editor alter the eye-lines of all the extras in a scene to shift the focus. A graphic novelist who models a room in The Sims and then moves the camera around to get traceable geometry for different angles is a centaur – they are genuinely offloading some finicky drudgework onto a robot that is perfectly attentive and vigilant.
But the pitch from "AI art" companies is "fire your graphic artists and replace them with botshit." They're pitching a world where the robots get to do all the creative stuff (badly) and humans have to work at robotic pace, with robotic vigilance, in order to catch the mistakes that the robots make at superhuman speed.
Reverse centaurism is brutal. That's not news: Charlie Chaplin documented the problems of reverse centaurs nearly 100 years ago:
https://en.wikipedia.org/wiki/Modern_Times_(film)
As ever, the problem with a gadget isn't what it does: it's who it does it for and who it does it to. There are plenty of benefits from being a centaur – lots of ways that automation can help workers. But the only path to AI profitability lies in reverse centaurs, automation that turns the human in the loop into the crumple-zone for a robot:
https://estsjournal.org/index.php/ests/article/view/260

If you'd like an essay-formatted version of this post to read or share, here's a link to it on pluralistic.net, my surveillance-free, ad-free, tracker-free blog:
https://pluralistic.net/2024/04/01/human-in-the-loop/#monkey-in-the-middle
Image: Cryteria (modified) https://commons.wikimedia.org/wiki/File:HAL9000.svg
CC BY 3.0 https://creativecommons.org/licenses/by/3.0/deed.en
--
Jorge Royan (modified) https://commons.wikimedia.org/wiki/File:Munich_-_Two_boys_playing_in_a_park_-_7328.jpg
CC BY-SA 3.0 https://creativecommons.org/licenses/by-sa/3.0/deed.en
--
Noah Wulf (modified) https://commons.m.wikimedia.org/wiki/File:Thunderbirds_at_Attention_Next_to_Thunderbird_1_-_Aviation_Nation_2019.jpg
CC BY-SA 4.0 https://creativecommons.org/licenses/by-sa/4.0/deed.en
#pluralistic#ai#supervised ai#humans in the loop#coding assistance#ai art#fully automated luxury communism#labor
379 notes
·
View notes
Text
Who Is Helping DOGE? List of Staff Revealed
- Feb 14, 2025 | Newsweek | By James Bickerton, US News Reporter

DOGE head Elon Musk speaks in the Oval Office at the White House on February 11, 2025. Andrew Harnik/Getty
list of 30 employees and alleged allies of Elon Musk's newly created Department of Government Efficiency (DOGE) has been published by ProPublica, an investigative news outlet.
Newsweek reached out to Musk for comment via emails to the Tesla and SpaceX press offices.
DOGE, a U.S. government organization which, despite its name, doesn't have full department status, was created by President Trump via an executive order on January 20 with the aim of cutting what the new administration regards as wasteful spending. Musk, a close Trump ally, heads the body and has been given special government employee status.
Musk has called for sweeping cuts to federal spending, suggesting it could be reduced by up to $2 trillion per year out of a 2024 total of $6.75 trillion, according to U.S. Treasury figures.
This ties in with Trump's pledge to "drain the swamp," a term his supporters use for what they believe is a permanent left-leaning bureaucracy that holds massive power regardless of who is in the White House.
DOGE has already recommended that the U.S. Agency for International Development (USAID) be closed down, with its functions transferred to the State Department. In a recent interview, Trump said he wants DOGE to go through spending at the Departments of Education and Defense.
On February 8, a federal judge imposed a temporary restraining order blocking DOGE employees from accessing the Treasury Department's payment system, resulting in Musk calling for him to be impeached.
A White House spokesperson told ProPublica: "Those leading this mission with Elon Musk are doing so in full compliance with federal law, appropriate security clearances, and as employees of the relevant agencies, not as outside advisors or entities."
The 30 DOGE employees and associates reported by ProPublica, which labeled them Musk's "demolition crew," are listed below.

Not Even DOGE Employees Know Who’s Legally Running DOGE! Despite all appearances, the White House insists that Elon Musk is not in charge of DOGE. US DOGE Service employees can’t get a straight answer about who is. Photograph: Kena Betancur/Getty Images
DOGE Employees And Associates
Christopher Stanley, 33: Stanley was part of the team Musk used to take over Twitter, now X, according to his LinkedIn profile, serving as senior director for security engineering for the company. The New York Times reports he now works for Musk at DOGE.
Brad Smith, 42: According to The New York Times, Smith, a friend of Trump's son-in-law Jared Kushner, was one of the first people appointed to help lead DOGE. He also served with the first Trump administration and was involved with Operation Warp Speed, the federal government's coronavirus vaccine development program.
Thomas Shedd, 28: Shedd serves as director of the Technology Transformation Services, a government body created to assist federal agencies with IT, and previously worked as a software engineer at Tesla.
Amanda Scales, 34: According to ProPublica, Scales is chief of staff at the Office of Personnel Management, a government agency that helps manage civil service. She previously worked for Musk's artificial intelligence company Xai.
Michael Russo, 67: Russo is a senior figure at the Social Security Administration, a government agency that administers the American Social Security program. According to his LinkedIn page, Russo previously worked for Shift4 Payments, a payment processing company that has invested in Musk's company SpaceX.
Rachel Riley, 33: Riley works in the Department of Health & Human Services as a senior adviser in the secretary's office. ProPublica reports she has been "working closely" with Brad Smith, who led DOGE during the transition period.
Nikhil Rajpal, 30: According to Wired, Rajpal, who in 2018 worked as an engineer at Twitter, is part of the DOGE team. He formally works as part of the Office of Personnel Management.
Justin Monroe, 36: According to ProPublica, Monroe is working as an adviser in the FBI director's office, having previously been senior director for security at SpaceX.
Katie Miller, 33: Miller is a spokesperson for DOGE. Trump announced her involvement with the new body in December. She served as Vice President Mike Pence's press secretary during Trump's first term.
Tom Krause, 47: Krause is a Treasury Department employee who is also affiliated with DOGE, according to The New York Times. Krause was involved in the DOGE team's bid to gain access to the Treasury Department's payments system.
Gavin Kliger, 25: Kliger, a senior adviser at the Office of Personnel Management, is reportedly closely linked to Musk's team. On his personal Substack blog, he wrote a post titled "Why I gave up a seven-figure salary to save America."
Gautier "Cole" Killian, 24: Killian is an Environmental Protection Agency employee who researched blockchain at McGill University. Killian is also a member of the DOGE team, according to Wired.
Stephanie Holmes, 43: ProPublica reports that Holmes runs human resources at DOGE, having previously managed her own HR consulting company, BrighterSideHR.
Luke Farritor, 23: Farritor works as an executive engineer at the Department of Health and previously interned at SpaceX, according to his LinkedIn account. He won a $100,000 fellowship from billionaire tech entrepreneur Peter Thiel in March 2024.
Marko Elez, 25: Elez is a Treasury Department staffer who worked as an engineer at X for one year and at SpaceX for around three years. The Wall Street Journal reported that Elez was linked to a social media account that had made racist remarks, but Musk stood by him after he initially resigned.
Steve Davis, 45: Davis is a longtime Musk associate who previously worked for the tech billionaire at SpaceX, the Boring Company and X. According to The New York Times, Davis was one of the first people involved in setting up DOGE with Musk and has been involved in staff recruitment.
Edward Coristine, 19: Coristine is a Northeastern University graduate who was detailed to the Office of Personnel Management and is affiliated with DOGE. He previously interned at Neuralink, a Musk company that works on brain-computer interfaces.
Nate Cavanaugh, 28: Cavanaugh is an entrepreneur who interviewed staffers at the General Services Administration as part of the DOGE team, according to ProPublica.

Unmasked: Musk’s Secret DOGE Goon Squad—Who Are All Under 26! The world’s richest man doesn’t want anyone knowing his right-hand people who are disrupting government. — Josh Fiallo, Breaking News Reporter, Daily Beast, February 3, 2025
Akash Bobba, 21: A recent graduate from the University of California, Berkeley, Bobba works as an "expert" at the Office of Personnel Management and was identified by Wired as part of Musk's DOGE team.
Brian Bjelde, 44: A 20-year SpaceX veteran, Bjelde now works as a senior adviser at the Office of Personnel Management, where he wants to cut 70 percent of the workforce, according to CNN.
Riccardo Biasini, 39: Biasini is an engineer who now works as a senior adviser to the director at the Office of Personnel Management. He previously worked for two Musk companies, Tesla and the Boring Company.
Anthony Armstrong, 57: Another senior adviser to the director at the Office of Personnel Management Armstrong previously worked as a banked with Morgan Stanley, and was involved in Musk's 2022 purchase of Twitter.
Keenan D. Kmiec, 45: Kmiec is a lawyer who works as part of the Executive Office of the President. He previously clerked on the Supreme Court for Chief Justice John Roberts.
James Burnham, 41: Burnham is a general counsel at DOGE whose involvement with the Musk-led body was first reported by The New York Times in January. He previously worked as a clerk for Supreme Court Justice Neil Gorsuch.
Jacob Altik, 32: A lawyer affiliated with the Executive Office of the President, Altik previously clerked for D.C. Circuit Court of Appeals Judge Neomi Rao, whom Trump appointed during his first term.
Jordan M. Wick, 28: Wick is an official member of DOGE and previously worked as a software engineer for the self-driving car company Waymo.
Ethan Shaotran, 22: Shaotran is a former Harvard student who Wired listed as one of several young software engineers working to analyze internal government data at DOGE.
Kyle Schutt, 37: Schutt is a software engineer affiliated with DOGE and worked at the General Services Administration. He was involved in the launch of WinRed, a Republican fundraising platform that helped raise $1.8 billion ahead of the November 2024 elections.
Ryan Riedel, 37: Riedel is the chief information officer at the Department of Energy and a former SpaceX employee.
Adam Ramada, 35: Ramada is an official DOGE member, according to federal records seen by ProPublica. Ramada previously worked for venture capital company Spring Tide Capital. E&E News reported he had been seen at the Energy Department and the General Services Administration.
Kendell M. Lindemann, 24: Lindemann is an official member of the DOGE team who previously worked for health care company Russell Street Ventures, founded by fellow DOGE associate Brad Smith, and as a business analyst for McKinsey & Company.
Nicole Hollander, 42: Hollander works at the General Services Administration. She was previously employed by X, where she was involved with the company's real estate portfolio.
Alexandra T. Beynon, 36: Beynon is listed as an official member of DOGE, according to documents seen by ProPublica. She previously worked for therapy startup Mindbloom and banking firm Goldman Sachs.
Jennifer Balajadia, 36: Balajadia is a member of the DOGE team who previously worked for the Boring Company for seven years. According to The New York Times, she is a close Musk confidant and assists with his scheduling.
91 notes
·
View notes
Text
Why enshittification happens and how to stop it.
The enshittification of the internet and increasingly the software we use to access it is driven by profit. It happens because corporations are machines for making profits from end users, the users and customers are only seen as sources of profits. Their interests are only considered if it can help the bottom line. It's capitalism.
For social media it's users are mainly seen by the companies that run the sites as a way for getting advertisers to pay money that can profit the shareholders. And social media is in a bit of death spiral right now, since they have seldom or never been profitable and investor money is drying up as they realize this.
So the social media companies. are getting more and more desperate for money. That's why they are getting more aggressive with getting you to watch ads or pay for the privilege of not watching ads. It won't work and tumblr and all the other sites will die eventually.
But it's not just social media companies, it's everything tech-related. It gets worse the more monopolistic a tech giant is. Google is abusing its chrome-based near monopoly over the web, nerfing adblockers, trying to drm the web, you name it. And Microsoft is famously a terrible company, spying on Windows users and selling their data. Again, there is so much money being poured into advertising, at least 493 billion globally, the tech giants want a slice of that massive pie. It's all about making profits for shareholders, people be damned.
And the only insurance against this death spiral is not being run by a corporation. If the software is being developed by a non-profit entity, and it's open source, there is no incentive for the developers to fuck over the users for the sake of profits for shareholders, because there aren't any profits, and no shareholders.
Free and Open source software is an important part of why such software development can stay non-corporate. It allows for volunteers to contribute to the code and makes it harder for users to be secretly be fucked over by hidden code.
Mozilla Firefox and Thunderbird are good examples of this. There is a Mozilla corporation, but it exists only for legal reasons and is a wholly-owned subsidiary of the non-profit Mozilla foundation. There are no shareholders. That means the Mozilla corporation is not really a corporation in the sense that Google is, and as an organization has entirely different incentives. If someone tells you that Mozilla is just another corporation, (which people have said in the notes of posts about firefox on this very site) they are spreading misinformation.
That's why Firefox has resisted the enshittification of the internet so well, it's not profit driven. And people who develop useful plugins that deshitify the web like Ublock origin and Xkit are as a rule not profit-driven corporations.
And you can go on with other examples of non-profit software like Libreoffice and VLC media player, both of which you should use.
And you can go further, use Linux as your computer's operating system.. It's the only way to resist the enshitification that the corporate duopoly of Microsoft and Apple has brought to their operating system. The plethora of community-run non-profit Linux distributions like Debian, Mint and Arch are the way to counteract that, and they will stay resistant to the same forces (creating profit for shareholders) that drove Microsoft to create Windows 11.
Of course not all Linux distributions are non-profits. There are corporate created distros like Red Hat's various distros, Canonical's Ubuntu and Suse's Opensuse, and they prove the point I'm making. There has some degree of enshittification going on with those, red hat going closed source and Canonical with the snap store for example. Mint is by now a succesful community-driven response to deshitify Ubuntu by removing snaps for example, and even they have a back-up plan to use Debian as a base in case Canonical makes Ubuntu unuseable.
As for social media, which I started with, I'm going to stay on tumblr for now, but it will definitely die. The closest thing to a community run non-profit replacement I can see is Mastodon, which I'm on as @[email protected].
You don't have to keep using corporate software, and have it inevitably decline because the corporations that develop it cares more about its profits than you as an end user.
The process of enshittification proves that corporations being profit-driven don't mean they will create a better product, and in fact may cause them to do the opposite. And the existence of great free and open source software, created entirely without the motivation of corporate profits, proves that people don't need to profit in order to help their fellow human beings. It kinda makes you question capitalism.
924 notes
·
View notes
Text
Today, the US Federal Trade Commission filed a lawsuit against farming equipment manufacturer Deere & Company—makers of the iconic green John Deere tractors, harvesters, and mowers—citing its longtime reluctance to keep its customers from fixing their own machines.
“Farmers rely on their agricultural equipment to earn a living and feed their families,” FTC chair Lina Khan wrote in a statement alongside the full complaint. “Unfair repair restrictions can mean farmers face unnecessary delays during tight planting and harvest windows.”
The FTC’s main complaint here centers around a software problem. Deere places limitations on its operational software, meaning certain features and calibrations on its tractors can only be unlocked by mechanics who have the right digital key. Deere only licenses those keys to its authorized dealers, meaning farmers often can’t take their tractors to more convenient third-party mechanics or just fix a problem themselves. The suit would require John Deere to stop the practice of limiting what repair features its customers can use and make them available to those outside official dealerships.
Kyle Wiens is the CEO of the repair advocacy retailer iFixit and an occasional WIRED contributor who first wrote about John Deere’s repair-averse tactics in 2015. In an interview today, he noted how frustrated farmers get when they try to fix something that has gone wrong, only to run into Deere's policy.
“When you have a thing that doesn’t work, if you’re 10 minutes from the store, it’s not a big deal,” Wiens says. “If the store is three hours away, which it is for farmers in most of the country, it’s a huge problem.”
The other difficulty is that US copyright protections prevent anyone but John Deere from making software that counteracts the restrictions the company has put on its platform. Section 1201 of the Digital Millennium Copyright Act of 1998 makes it so people can’t legally counteract technological measures that fall under its protections. John Deere’s equipment falls under that copyright policy.
“Not only are they being anti-competitive, it's literally illegal to compete with them,” Wiens says.
Deere in the Headlights
Wiens says that even though there has been a decade of pushback against John Deere from farmers and repairability advocates, the customers using the company’s machines have not seen much benefit from all that discourse.
“Things really have not gotten better for farmers,” Wiens says. “Even with all of the noise around a right to repair over the years, nothing has materially changed for farmers on the ground yet.”
This suit against Deere, he thinks, will be different.
“This has to be the thing that does it,” Wiens says. “The FTC is not going to settle until John Deere makes the software available. This is a step in the right direction.”
Deere’s reluctance to make its products more accessible has angered many of its customers, and even garnered generally bipartisan congressional support for reparability in the agricultural space. The FTC alleges John Deere also violated legislation passed by the Colorado state government in 2023 that requires farm equipment sold in the state to make operational software accessible to users.
“Deere’s unlawful business practices have inflated farmers’ repair costs and degraded farmers’ ability to obtain timely repairs,” the suit reads.
Deere & Company did not respond to a request for comment for this story. Instead, the company forwarded its statement about the FTC's lawsuit. The statement reads, in part: “Deere remains fully committed to ensuring that customers have the highest quality equipment, reliable customer service and that they, along with independent repair technicians, have access to tools and resources that can help diagnose, maintain and repair our customers’ machines. Deere’s commitment to these ideals will not waiver even as it fights against the FTC’s meritless claims.”
Elsewhere in the statement, Deere accused the FTC of "brazen partisanship" filed on the "eve of a change in administration" from chair Lina Khan to FTC Commissioner Andrew Ferguson. The company also pointed to an announcement, made yesterday, about an expansion to its repairability program that lets independent technicians reprogram the electronic controllers on Deere equipment.
Nathan Proctor, senior director for the Campaign for the Right to Repair at the advocacy group US PIRG, wrote a statement lauding the FTC’s decision. He thinks this case, no matter how it turns out, will be a positive step for the right to repair movement more broadly.
“I think this discovery process will paint a picture that will make it very clear that their equipment is programmed to monopolize certain repair functions,” Proctor tells WIRED. “And I expect that Deere will either fix the problem or pay the price. I don’t know how long that is going to take. But this is such an important milestone, because once the genie’s out of the bottle, there’s no getting it back in.”
41 notes
·
View notes
Text
Enhancing Legal Operations: AI, Case Management, and Data Analytics for Corporate Law Firms
The legal landscape is evolving rapidly, and corporate law firms are embracing cutting-edge technology to enhance their operations. From AI-driven solutions to advanced legal case management software, firms are revolutionizing how they manage cases, collaborate with clients, and make data-driven decisions. Here’s how AI, case management, and data analytics are reshaping the future of legal operations.

The Role of AI in the Legal Industry
Artificial Intelligence (AI) is transforming the legal industry by streamlining mundane tasks such as contract analysis, document review, and legal research. AI-powered tools reduce the time spent on repetitive tasks, allowing lawyers to focus on more strategic aspects of their cases. Additionally, AI enhances predictive analytics, helping firms anticipate litigation outcomes and streamline processes to meet client demands more efficiently.
Legal Case Management Software: A Game-Changer
Efficient case management is the cornerstone of any successful corporate law firm. Legal case management software enables firms to centralize case information, track case progress, and manage deadlines effortlessly. With these tools, legal teams can improve collaboration, ensure compliance, and reduce errors that might otherwise arise in manual processes. For law firms leveraging platforms like Salesforce, integrating legal case management software can optimize workflows and improve client satisfaction.
Salesforce for Law Firms: A Strategic Asset
Salesforce, traditionally known as a powerful CRM, has made inroads into the legal sector. Law firms can leverage Salesforce for law firm-specific solutions to manage client relationships, improve data security, and customize workflows to meet unique legal needs. By integrating Salesforce into their corporate legal operations, firms can create more personalized client experiences, automate billing, and track client communication, enhancing overall operational efficiency.
Consultant Data Analytics: Driving Informed Decisions
Data analytics is emerging as a crucial element in corporate legal operations. Consultant data analytics experts help law firms interpret complex datasets to make informed decisions on case strategy, budgeting, and resource allocation. Predictive data analytics can also identify potential risks, allowing firms to mitigate them before they become significant issues. By analyzing historical data, law firms can refine their approach to client cases and improve overall success rates.
Conclusion
The integration of AI, legal case management software, Salesforce, and data analytics is ushering in a new era of corporate legal operations. These technologies streamline processes, improve client relations, and help firms make informed, data-driven decisions. For law firms seeking to stay competitive in today’s fast-paced legal environment, embracing these innovations is not just an option but a necessity.
HIKE2 provides comprehensive consulting services, helping corporate law firms harness the power of AI, data analytics, and Salesforce solutions to transform their legal operations.
#Consultant data analytics#Salesforce for law firm#corporate legal operations#Legal case management software
0 notes
Text
PPTH Staff Directory
Administration
Hen Nenaginad, Dr. Cuddy’s personal assistant (@toplessoncology), ask blog @ppthparttimer
Cardiology
Sydney Forrest, Head of Cardiology (@wilsons-three-legged-siamese), ask blog @ask-head-of-cardio
Custodial
Bruce N. Valentine (@ghostboyhood), ask blog @the-cleaning-guy
Diagnostics
Haven Ross House (@birdyboyfly), ask blog @ultimate-diagnostician-haven
Teagan Sinclair, Gynecologist (@robbinggoodfellows), ask blog @ask-teagan-sinclair
Cosmo Anderson, House's personal assistant (@cupofmints), ask blog @underpaid-assistant
Dr. Avery Alice Beau (@audiovideodisco), ask blog @dr-avery-beau
Emergency Medical Services
Dr. Kadee Montgomery, Head of Emergency Medical Services and Infectious Disease Specialist (@privatehousesanatomy), ask blog @kadeejeanmontgomery
Anji Foxx-Knight, Ambulance Operator and Automotive Technician (@rainismdata), ask blog @technician-para-driver
Fritz Litte, ER Doctor, ask blog @erdocfritz
Dr. Rylan Hopps, ER Physician (@dndadsbara), ask blog @nervous-physician
Endocrinology
Ev Price, Head of Endocrinology (@sillyhyperfixator), ask blog @ppth-endocrinology-head
Dr. Katherine “Kate” Rooke, Endocrinologist (@katttkhaos), ask blog @drkrooke
Epidemiology
Dr. Arwen Callejas, Head of Epidemiology (@addicbookedout)
Emilie Martin, Epidemiologist (@picking-dandelions-and-tunes)
Forensics
Stevie “Bird” Corcoran, Forensic Scientist and Teacher (@1mlostnow), ask blog @head-of-forensics
Melvin Rideau, Forensic Technician (@datas-boobs), ask blog @ppth-forensic-technician
Hematology
Ivan Andrews, Hematologist (@kleinekorpus)
IT
Andrew Hayes, Software Engineer (@tired-and-bored-nerd), ask blog @ask-ppths-it-guy
Immunology
Anastasia Vîrgolici, Immunologist (@starry-scarl3tt), ask blog @tired-ppth-immunologist
Lab
Anatol Dybowski, Head Lab Scientist (@tino-i-guess), ask blog @ppth-lab-head
Dr. Rachel Wilson-Cuddy, Pathologist & Medical Researcher (@annabelle-house)
Legal
Valerie Carr, Legal Consultant (@writing-and-sillies), ask blog @ask-ppth-legal
Neurology
Dr. Charlotte Eldorra (@estellemilano), ask blog @tiredicedlatte-enjoyer
Nursing
Nurse Sophie "Angel" Lile (@annoylyn), ask blog @doll-lile
OB-GYN
Dr. Fluoxetine Pearl, Head of OB-GYN (@asclexe), ask blog @ppth-obgyn-dept-head-real
Dr. Katherine Rhodes, Head of NICU and ICU (@privatehousesanatomy), ask blog @katherineelainerhodes)
Danny Begay, Gynecologist (@hemlocksloadofbull), ask blog @ask-danny-in-gynecology
Oncology
Dr. Francesca Scott, Head of Oncology (@birdyboyfly), ask blog @ask-head-of-oncology
Leo Fitsher, Nurse (@asclexe)
Mat Hulme, Ongologist (@evilchildeyeeter), ask blog @ratfather-oncologist
Dr. Gavin Maxwell, Hematologist (@worldrusher), ask blog @dr-maxwell-hemaoncol
Ophthalmology
Maddox “Maddie” N. Jagajiva, Ophthalmologist (@rainismdata), ask blog @dr-visionary-counselor
Pediatrics
Dr. Nanette “Ninny” Amesbury, Head of Pediatrics (@desire-mona)
Eddie Sting, Head of Pediatrics (@cherrishnoodles), ask blog @ask-head-of-pediatrics
Romeo "Vinny" Vincent, ENT nurse (@wilsons-three-legged-siamese), ask blog @earsandthroatnursey
Melanie Byrd, Pediatric Orthopedist (@tired-and-bored-nerd), ask blog @ppth-baby-bone-doc
Marie, Pediatrician (@marieinpediatrics-stuff)
Dr. Sophie Baker, Pediatric Neurosurgeon (@privatehousesanatomy), ask blog @sophieeloisebaker
Skye Ann-Meadows, Pediatrician (@estellemilano), ask blog @doctorof-unknownorgin
Plastics
Gabriella “Gabi” Kramer, Plastic Surgeon (@1mlostnow), ask blog @plastic-surgeon-gabi
Psychiatry/Psychology
Lena Ehris, Head of Psychiatry (@jellifishiez), ask blog @head-of-psychiatry
Dr. Venus Watanabe, Head of Psychiatry (@chocovenuss)
Dr. Annabelle House-Cuddy, Head of Psychiatry (@annabelle-house)
Dr. Madlock, Head of Psychology (@sushivisa)
Domingo Estrada, Social Worker (@robertseanleonardthinker), ask blog @ppth-socialworker
Dr. Kieran F. Campbell, Psychiatrist and Geneticist (@kim-the-kryptid), ask blog @consult-the-geneticist
Caitlin, Psychologist (@littlelqtte), ask blog @caitlin-interrupted
Dr. Callum Stone, Psychiatrist, ask blog @themanthemyththepsychologist
Pulmonology
Reina Linh Rivera, Head of Pulmonology (@prettypinkbubbless)
Dr. Milana Walker (@evilchildeyeeter), ask blog @dr-redbull-addict
Radiology
Dr. Eneko Ruiz-Arroyo, Head of Radiology (@katttkhaos), ask blog @headoradiology
Beth Klein, Radiology Tech (@emptylakes)
Steven Sandoval, Radiologist (@endofradio)
Research
Dr. Nadzieja Kruczewska, Toxicologist and Clinical Research Coordinator, ask blog @indigo-toxicologist
Patients
Ilja "Illusha" Vancura, Head Archivist at Rutgers Med (@scarriestmarlowe), blog @vancurarchivist
Francesco Cage, Best girldad patient (@dndadsbara), ask blog @francesco-cage
Joey Abrams, Forensics Student - kind of (@1mlostnow), ask blog @joey-is-fine
OOC: Hi, I'm Bird, and I run this PPTH blog! I'm 19, agender, aroace, and use they/them pronouns.
If you have an OC or a post that you would like for me to add to the blog, please feel free to send me an ask/message! If I follow you back, it'll be at my main blog, @birdyboyfly.
85 notes
·
View notes
Note
The FAQ link sent me straight to the inbox. Do you have a Patreon? (Sorry if you've answered this before.)
Oops, that's not supposed to happen!! I'm at the shop rn but once I'm home I'll take a look at it, I recently changed my site theme so the link might have just broke 🤣
I do have a Patreon, and a Ko-Fi now too as well!! (just recently started a secondary page for Ko-Fi, I haven't finished sprucing it up yet but it's at least setup enough to function lmao) Both are setup for monthly subs, but Ko-Fi is frankly my favorite as it also allows for one-time donations, it supports community goals (which Patreon got rid of, bleh) and its fees are WAY lower, meaning more of what people send me actually gets to me!
That said, I do want to include a disclaimer for anyone finding out for the first time:
Obviously with the nature of Rekindled being fanfiction, I can't directly profit off it, so I'm limited in what I can offer in terms of tier rewards. I'm not exactly keen on running the risk of offering stuff like early access pages or sellable digital downloads of the comic itself, that sort of thing, as it could be held against me as selling Rachel's characters / story / etc. for my own profit. While Patreon overall does offer the "legal grey area" of operating as more of an optional tip jar than a commercial storefront, I would still rather mitigate the risk of legal consequences before they've happened, rather than push my luck and get screwed for it later LMAO
Aa such, most of what I post rn are backlog Twitch VODs from past streams (which includes live footage and commentary of me making "new" episodes) and time lapses of completed episodes ! Stuff that contains Rekindled goodies without it being a direct sales item ;p
Aside from balancing on legal tightropes, I've also just... learned the hard way from past experiences that I'm not the best at maintaining a robust and regular tier reward system 🫣 (thanks ADHD) If I were able to do this as my full-time job, maybe, but ultimately I prefer keeping my crowdfunding platforms simple so I can focus on making what people are really paying for - the continued production of more episodes!
Sooooo with that big disclaimer / explanation aside , if you do decide to check it out, just keep in mind that both platforms are operating more like optional tip jars, with the odd piece of bonus content every now and then from what I can feasibly (and legally) provide !! I try my best to upload regularly enough for the monthly subscription to be "worth it", but that's why I also have a Ko-Fi setup now too, for people who would rather just make one time donations or don't want to deal with another monthly subscription cost (mood)
Regardless, all the money that I earn from Patreon, Ko-Fi, and Twitch goes back into Rekindled in some way or another! Whether it's helping cover costs for my drawing software or paying for new brushes / assets, or even just helping with our Internet bill so that I can keep posting LMAO I'm super grateful to those who have or are currently tucking some extra change into my pocket to help support my work and get me by, every little bit counts 🤗💖
(and ofc for those who don't have the means to support with money - reading my work, commenting on it, reblogging it, etc. is super helpful too!!! All your kind words and fun discussions and theories in the tags and fanart and everything in between are their own form of compensation, because it brings me immense amounts of joy and constantly reminds me why I do what I do 🥺💖)
31 notes
·
View notes
Text
She Won. They Didn't Just Change the Machines. They Rewired the Election. How Leonard Leo's 2021 sale of an electronics firm enabled tech giants to subvert the 2024 election.

Everyone knows how the Republicans interfered in the 2024 US elections through voter interference and voter-roll manipulation, which in itself could have changed the outcomes of the elections. What's coming to light now reveals that indeed those occupying the White House, at least, are not those who won the election.
Here's how they did it.
(full story is replicated here below the read-more: X)
She Won
The missing votes uncovered in Smart Elections’ legal case in Rockland County, New York, are just the tip of the iceberg—an iceberg that extends across the swing states and into Texas.
On Monday, an investigator’s story finally hit the news cycle: Pro V&V, one of only two federally accredited testing labs, approved sweeping last-minute updates to ES&S voting machines in the months leading up to the 2024 election—without independent testing, public disclosure, or full certification review.
These changes were labeled “de minimis”—a term meant for trivial tweaks. But they touched ballot scanners, altered reporting software, and modified audit files—yet were all rubber-stamped with no oversight.
That revelation is a shock to the public.
But for those who’ve been digging into the bizarre election data since November, this isn’t the headline—it’s the final piece to the puzzle. While Pro V&V was quietly updating equipment in plain sight, a parallel operation was unfolding behind the curtain—between tech giants and Donald Trump.
And it started with a long forgotten sale.
A Power Cord Becomes a Backdoor
In March 2021, Leonard Leo—the judicial kingmaker behind the modern conservative legal machine—sold a quiet Chicago company by the name of Tripp Lite for $1.65 billion. The buyer: Eaton Corporation, a global power infrastructure conglomerate that just happened to have a partnership with Peter Thiel’s Palantir.
To most, Tripp Lite was just a hardware brand—battery backups, surge protectors, power strips. But in America’s elections, Tripp Lite devices were something else entirely.
They are physically connected to ES&S central tabulators and Electionware servers, and Dominion tabulators and central servers across the country. And they aren’t dumb devices. They are smart UPS units—programmable, updatable, and capable of communicating directly with the election system via USB, serial port, or Ethernet.
ES&S systems, including central tabulators and Electionware servers, rely on Tripp Lite UPS devices. ES&S’s Electionware suite runs on Windows OS, which automatically trusts connected UPS hardware.
If Eaton pushed an update to those UPS units, it could have gained root-level access to the host tabulation environment—without ever modifying certified election software.
In Dominion’s Democracy Suite 5.17, the drivers for these UPS units are listed as “optional”—meaning they can be updated remotely without triggering certification requirements or oversight. Optional means unregulated. Unregulated means invisible. And invisible means perfect for infiltration.
Enter the ballot scrubbing platform BallotProof. Co-created by Ethan Shaotran, a longtime employee of Elon Musk and current DOGE employee, BallotProof was pitched as a transparency solution—an app to “verify” scanned ballot images and support election integrity.
With Palantir's AI controlling the backend, and BallotProof cleaning the front, only one thing was missing: the signal to go live.
September 2024: Eaton and Musk Make It Official
Then came the final public breadcrumb:In September 2024, Eaton formally partnered with Elon Musk.
The stated purpose? A vague, forward-looking collaboration focused on “grid resilience” and “next-generation communications.”
But buried in the partnership documents was this line:
“Exploring integration with Starlink's emerging low-orbit DTC infrastructure for secure operational continuity.”
The Activation: Starlink Goes Direct-to-Cell
That signal came on October 30, 2024—just days before the election, Musk activated 265 brand new low Earth orbit (LEO) V2 Mini satellites, each equipped with Direct-to-Cell (DTC) technology capable of processing, routing, and manipulating real-time data, including voting data, through his satellite network.
DTC doesn’t require routers, towers, or a traditional SIM. It connects directly from satellite to any compatible device—including embedded modems in “air-gapped” voting systems, smart UPS units, or unsecured auxiliary hardware.
From that moment on:
Commands could be sent from orbit
Patch delivery became invisible to domestic monitors
Compromised devices could be triggered remotely
This groundbreaking project that should have taken two-plus years to build, was completed in just under ten months.
Elon Musk boasts endlessly about everything he’s launching, building, buying—or even just thinking about—whether it’s real or not. But he pulls off one of the largest and fastest technological feats in modern day history… and says nothing? One might think that was kind of… “weird.”
According to New York Times reporting, on October 5—just before Starlink’s DTC activation—Musk texted a confidant:
“I’m feeling more optimistic after tonight. Tomorrow we unleash the anomaly in the matrix.”
Then, an hour later:
“This isn’t something on the chessboard, so they’ll be quite surprised. ‘Lasers’ from space.”
It read like a riddle. In hindsight, it was a blueprint.
The Outcome
Data that makes no statistical sense. A clean sweep in all seven swing states.
The fall of the Blue Wall. Eighty-eight counties flipped red—not one flipped blue.
Every victory landed just under the threshold that would trigger an automatic recount. Donald Trump outperformed expectations in down-ballot races with margins never before seen—while Kamala Harris simultaneously underperformed in those exact same areas.
If one were to accept these results at face value—Donald Trump, a 34-count convicted felon, supposedly outperformed Ronald Reagan. According to the co-founder of the Election Truth Alliance:
“These anomalies didn’t happen nationwide. They didn’t even happen across all voting methods—this just doesn’t reflect human voting behavior.”
They were concentrated.
Targeted.
Specific to swing states and Texas—and specific to Election Day voting.
And the supposed explanation? “Her policies were unpopular.” Let’s think this through logically. We’re supposed to believe that in all the battleground states, Democratic voters were so disillusioned by Vice President Harris’s platform that they voted blue down ballot—but flipped to Trump at the top of the ticket?
Not in early voting.
Not by mail.
With exception to Nevada, only on Election Day.
And only after a certain threshold of ballots had been cast—where VP Harris’s numbers begin to diverge from her own party, and Trump’s suddenly begin to surge. As President Biden would say, “C’mon, man.”
In the world of election data analysis, there’s a term for that: vote-flipping algorithm.
And of course, Donald Trump himself:
He spent a year telling his followers he didn’t need their votes—at one point stating,
“…in four years, you don't have to vote again. We'll have it fixed so good, you're not gonna have to vote.”
____
They almost got away with the coup. The fact that they still occupy the White House and control most of the US government will make removing them and replacing them with the rightful President Harris a very difficult task.
But for this nation to survive, and for the world to not fall further into chaos due to this "administration," we must rid ourselves of the pretender and his minions and controllers once and for all.
65 notes
·
View notes