#mongodb install ubuntu
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
130K people were victims of a chain letter scam that affected Tumblr in May 2011.
Text
Graylog Docker Compose Setup: An Open Source Syslog Server for Home Labs
Graylog Docker Compose Install: Open Source Syslog Server for Home #homelab GraylogInstallationGuide #DockerComposeOnUbuntu #GraylogRESTAPI #ElasticsearchAndGraylog #MongoDBWithGraylog #DockerComposeYmlConfiguration #GraylogDockerImage #Graylogdata
A really great open-source log management platform for both production and home lab environments is Graylog. Using Docker Compose, you can quickly launch and configure Graylog for a production or home lab Syslog. Using Docker Compose, you can create and configure all the containers needed, such as OpenSearch and MongoDB. Let’s look at this process. Table of contentsWhat is Graylog?Advantages of…

View On WordPress
#Docker Compose on Ubuntu#docker-compose.yml configuration#Elasticsearch and Graylog#Graylog data persistence#Graylog Docker image#Graylog installation guide#Graylog REST API#Graylog web interface setup#log management with Graylog#MongoDB with Graylog
0 notes
Text
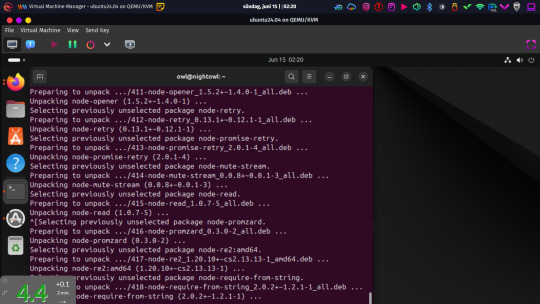
Progress, at least!
I got a VM set up and running, not fullscreen here so I could use my main system to screenshot it. Instead of Ubuntu Server, I decided to go with a minimal install of the desktop version with the GUI for accessibility more than anything else. I don't like Gnome, but I'll live with it. Rarely intend to use that after everything is set up and running anyway. Haven't set up clipboard (or any other) passthrough, so it was convenient having Firefox inside there to paste text in from. Besides some basic system utilities, this essentially just started out with Firefox installed and not much else.
This was while installing what felt like a shitload of other stuff required to get the database and Nightscout set up.
Now I do have both of those installed, and a fresh database with users created for Nightscout in MongoDB . I will have to leave the rest of the configuration and testing for tomorrow. But, at least as of now? Everything does appear to be there and functional. Got something accomplished, at least.
0 notes
Text
PROJETO
Passo a Passo da Implementação da NeoSphere
1. Configuração do Ambiente de Desenvolvimento
Ferramentas Necessárias:
Python 3.10+ para backend Web2 (FastAPI, Redis).
Node.js 18+ para serviços Web3 e frontend.
Solidity para smart contracts.
Docker para conteinerização de serviços (Redis, MongoDB, RabbitMQ).
Truffle/Hardhat para desenvolvimento de smart contracts.
# Instalação de dependências básicas (Linux/Ubuntu) sudo apt-get update sudo apt-get install -y python3.10 nodejs npm docker.io
2. Implementação da API Web2 com FastAPI
Estrutura do Projeto:
/neosphere-api ├── app/ │ ├── __init__.py │ ├── main.py # Ponto de entrada da API │ ├── models.py # Modelos Pydantic │ └── database.py # Conexão com MongoDB └── requirements.txt
Código Expandido (app/main.py):
from fastapi import FastAPI, Depends, HTTPException from pymongo import MongoClient from pymongo.errors import DuplicateKeyError from app.models import PostCreate, PostResponse from app.database import get_db import uuid import datetime app = FastAPI(title="NeoSphere API", version="0.2.0") @app.post("/posts/", response_model=PostResponse, status_code=201) async def create_post(post: PostCreate, db=Depends(get_db)): post_id = str(uuid.uuid4()) post_data = { "post_id": post_id, "user_id": post.user_id, "content": post.content, "media_urls": post.media_urls or [], "related_nft_id": post.related_nft_id, "created_at": datetime.datetime.utcnow(), "likes": 0, "comments_count": 0 } try: db.posts.insert_one(post_data) except DuplicateKeyError: raise HTTPException(status_code=400, detail="Post ID já existe") return post_data @app.get("/posts/{post_id}", response_model=PostResponse) async def get_post(post_id: str, db=Depends(get_db)): post = db.posts.find_one({"post_id": post_id}) if not post: raise HTTPException(status_code=404, detail="Post não encontrado") return post
3. Sistema de Cache com Redis para NFTs
Implementação Avançada (services/nft_cache.py):
import redis from tenacity import retry, stop_after_attempt, wait_fixed from config import settings class NFTCache: def __init__(self): self.client = redis.Redis( host=settings.REDIS_HOST, port=settings.REDIS_PORT, decode_responses=True ) @retry(stop=stop_after_attempt(3), wait=wait_fixed(0.5)) async def get_metadata(self, contract_address: str, token_id: str) -> dict: cache_key = f"nft:{contract_address}:{token_id}" cached_data = self.client.get(cache_key) if cached_data: return json.loads(cached_data) # Lógica de busca na blockchain metadata = await BlockchainService.fetch_metadata(contract_address, token_id) if metadata: self.client.setex( cache_key, settings.NFT_CACHE_TTL, json.dumps(metadata) ) return metadata def invalidate_cache(self, contract_address: str, token_id: str): self.client.delete(f"nft:{contract_address}:{token_id}")
4. Smart Contract para NFTs com Royalties (Arquivo Completo)
Contrato Completo (contracts/NeoSphereNFT.sol):
// SPDX-License-Identifier: MIT pragma solidity ^0.8.20; import "@openzeppelin/contracts/token/ERC721/ERC721.sol"; import "@openzeppelin/contracts/access/Ownable.sol"; import "@openzeppelin/contracts/interfaces/IERC2981.sol"; contract NeoSphereNFT is ERC721, Ownable, IERC2981 { using Counters for Counters.Counter; Counters.Counter private _tokenIdCounter; struct RoyaltyInfo { address recipient; uint96 percentage; } mapping(uint256 => RoyaltyInfo) private _royalties; mapping(uint256 => string) private _tokenURIs; event NFTMinted( uint256 indexed tokenId, address indexed owner, string tokenURI, address creator ); constructor() ERC721("NeoSphereNFT", "NSPH") Ownable(msg.sender) {} function mint( address to, string memory uri, address royaltyRecipient, uint96 royaltyPercentage ) external onlyOwner returns (uint256) { require(royaltyPercentage <= 10000, "Royalties max 100%"); uint256 tokenId = _tokenIdCounter.current(); _tokenIdCounter.increment(); _safeMint(to, tokenId); _setTokenURI(tokenId, uri); _setRoyaltyInfo(tokenId, royaltyRecipient, royaltyPercentage); emit NFTMinted(tokenId, to, uri, msg.sender); return tokenId; } function royaltyInfo( uint256 tokenId, uint256 salePrice ) external view override returns (address, uint256) { RoyaltyInfo memory info = _royalties[tokenId]; return ( info.recipient, (salePrice * info.percentage) / 10000 ); } function _setTokenURI(uint256 tokenId, string memory uri) internal { _tokenURIs[tokenId] = uri; } function _setRoyaltyInfo( uint256 tokenId, address recipient, uint96 percentage ) internal { _royalties[tokenId] = RoyaltyInfo(recipient, percentage); } }
5. Sistema de Pagamentos com Gateway Unificado
Implementação Completa (payment/gateway.py):
from abc import ABC, abstractmethod from typing import Dict, Optional from pydantic import BaseModel class PaymentRequest(BaseModel): amount: float currency: str method: str user_metadata: Dict payment_metadata: Dict class PaymentProvider(ABC): @abstractmethod def process_payment(self, request: PaymentRequest) -> Dict: pass class StripeACHProvider(PaymentProvider): def process_payment(self, request: PaymentRequest) -> Dict: # Implementação real usando a SDK do Stripe return { "status": "success", "transaction_id": "stripe_tx_123", "fee": request.amount * 0.02 } class NeoPaymentGateway: def __init__(self): self.providers = { "ach": StripeACHProvider(), # Adicionar outros provedores } def process_payment(self, request: PaymentRequest) -> Dict: provider = self.providers.get(request.method.lower()) if not provider: raise ValueError("Método de pagamento não suportado") # Validação adicional if request.currency not in ["USD", "BRL"]: raise ValueError("Moeda não suportada") return provider.process_payment(request) # Exemplo de uso: # gateway = NeoPaymentGateway() # resultado = gateway.process_payment(PaymentRequest( # amount=100.00, # currency="USD", # method="ACH", # user_metadata={"country": "US"}, # payment_metadata={"account_number": "..."} # ))
6. Autenticação Web3 com SIWE
Implementação no Frontend (React):
import { useSigner } from 'wagmi' import { SiweMessage } from 'siwe' const AuthButton = () => { const { data: signer } = useSigner() const handleLogin = async () => { const message = new SiweMessage({ domain: window.location.host, address: await signer.getAddress(), statement: 'Bem-vindo à NeoSphere!', uri: window.location.origin, version: '1', chainId: 137 // Polygon Mainnet }) const signature = await signer.signMessage(message.prepareMessage()) // Verificação no backend const response = await fetch('/api/auth/login', { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify({ message, signature }) }) if (response.ok) { console.log('Autenticado com sucesso!') } } return ( <button onClick={handleLogin}> Conectar Wallet </button> ) }
7. Estratégia de Implantação
Infraestrutura com Terraform:
# infra/main.tf provider "aws" { region = "us-east-1" } module "neosphere_cluster" { source = "terraform-aws-modules/ecs/aws" cluster_name = "neosphere-prod" fargate_capacity_providers = ["FARGATE"] services = { api = { cpu = 512 memory = 1024 port = 8000 } payment = { cpu = 256 memory = 512 port = 3000 } } } resource "aws_elasticache_cluster" "redis" { cluster_id = "neosphere-redis" engine = "redis" node_type = "cache.t3.micro" num_cache_nodes = 1 parameter_group_name = "default.redis6.x" }
Considerações Finais
Testes Automatizados:
Implementar testes end-to-end com Cypress para fluxos de usuário
Testes de carga com k6 para validar escalabilidade
Testes de segurança com OWASP ZAP
Monitoramento:
Configurar Prometheus + Grafana para métricas em tempo real
Integrar Sentry para captura de erros no frontend
CI/CD:
Pipeline com GitHub Actions para deploy automático
Verificação de smart contracts com Slither
Documentação:
Swagger para API REST
Storybook para componentes UI
Archimate para documentação de arquitetura
Este esqueleto técnico fornece a base para uma implementação robusta da NeoSphere, combinando as melhores práticas de desenvolvimento Web2 com as inovações da Web3.
0 notes
Text
标题即关键词+TG@yuantou2048
蜘蛛池系统搭建教程+TG@yuantou2048
在互联网时代,网站的优化和推广变得尤为重要。而“蜘蛛池”作为一种高效的网站优化手段,被越来越多的人所熟知。本文将详细介绍如何搭建一个属于自己的蜘蛛池系统。
什么是蜘蛛池?
蜘蛛池是一种模拟搜索引擎爬虫行为的技术,通过模拟大量爬虫对目标网站进行访问,从而提高网站的收录速度和排名。它的工作原理是利用大量的虚拟用户代理(User-Agent)来模拟真实用户的访问行为,让搜索引擎认为该网站非常受欢迎,进而提升其在搜索结果中的排名。
搭建蜘蛛池系统的步骤
第一步:选择合适的服务器
首先,你需要一台性能稳定的服务器。建议选择配置较高的云服务器,以确保能够承载大量的并发请求。
第二步:安装基础环境
1. 操作系统:推荐使用Linux系统,如Ubuntu或CentOS。
2. 编程语言:Python是目前最常用的编程语言之一,可以方便地编写爬虫程序。
3. 数据库:MySQL或MongoDB等数据库用于存储爬取的数据。
第三步:编写爬虫程序
- 使用Python的Scrapy框架来编写爬虫程序。Scrapy是一个开源的爬虫框架,支持快速开发和部署爬虫项目。
- 安装Python环境,并安装Scrapy框架。
```bash
sudo apt-get update
sudo apt-get install python3-pip
pip3 install scrapy
```
第四步:编写爬虫脚本
创建一个新的Scrapy项目:
```bash
scrapy startproject mySpiderPool
cd mySpiderPool
```
编写爬虫代码,定义需要爬取的URL列表以及解析规则。
```python
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://example.com']
def parse(self, response):
编写具体的爬虫逻辑
pass
```
第五步:运行爬虫
```bash
scrapy crawl your_spider_name
```
第六步:配置爬虫
在`settings.py`中配置爬虫的基本设置,例如下载延迟、并发请求数量等参数。
```python
mySpider/spiders/myspider.py
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://example.com']
def parse(self, response):
解析网页内容
pass
```
第七步:部署与监控
- 将爬虫部署到服务器上,并定期检查日志文件,监控爬虫的运行状态。
第八步:维护与优化
- 根据需求调整爬虫的行为,比如设置爬虫的速度、重试次数等。
第九步:自动化执行
- 使用定时任务(如CronJob)实现自动化的爬虫任务。
注意事项
- 确保遵守robots.txt协议,避免对目标网站造成过大的负担。
- 遵守相关法律法规,合理合法地使用蜘蛛池系统,确保不违反任何法律或道德规范。
结语
通过以上步骤,你已经成功搭建了一个基本的蜘蛛池系统。但请务必注意,使用蜘蛛池时要遵循各网站的robots.txt文件规定,尊重网站的爬取策略,避免对目标网站造成不必要的压力。
总结
蜘蛛池系统可以帮助提高网站的SEO效果,但请确保你的行为符合网络爬虫的相关规定,避免过度抓取导致封禁IP地址等问题。
希望这篇教程能帮助你更好地理解和使用蜘蛛池系统。如果你有任何问题或疑问,欢迎加入我们的社区交流群组获取更多技术支持。
希望这篇文章对你有所帮助!
加飞机@yuantou2048

谷歌快排
Google外链代发
0 notes
Text
How to Install MongoDB with PHP on Ubuntu 24.04
This article explains how to install and configure MongoDB with PHP, Apache or Nginx web server on Ubuntu 24.04. MongoDB is a popular NoSQL database that stores data in a flexible, JSON-like format, allowing for dynamic schemas and easy scalability. MongoDB offers a more flexible way to store data, which is advantageous for applications with changing data requirements. MongoDB works seamlessly…
0 notes

Text
How to Install MongoDB Ubuntu 20.04 Linux.
How to Install MongoDB Ubuntu 20.04 Linux.
Hi Techies! Will look at “How to install MongoDB on Ubuntu 20.04” Linux. MongoDB is a No-SQL database. Which is written in C++, It uses a JSON like structure. MongoDB is a cross-platform and document-oriented database. The initial release of the MongoDB was on 11 February 2009, you can find the main website of the MongoDB as well the git repository 10gen software company began developing…
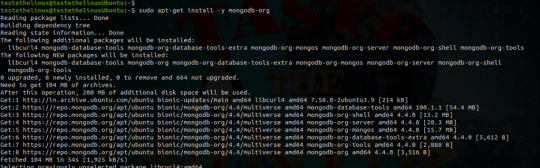
View On WordPress
#install mongodb#install mongodb on linux#install mongodb on ubuntu#install mongodb on ubuntu 18.04#install mongodb on ubuntu 20.04#mongodb install linux#mongodb install ubuntu#mongodb install ubuntu 16.04#mongodb install ubuntu 18#mongodb install ubuntu 20.04
0 notes
Link
If the software you have is for PC computers and you want to Install Mongodb Linux, you purchase it on DevOps. This is a software program that essentially allows you to use a PC's operating system right on the Mac. This way, you can run any PC program that you have! You should get a PC operating system to accompany it. https://www.devopscheetah.com/install-mongodb-on-amazon-linux/
0 notes
Link
Check this tutorial for install Mongdb Ubuntu 16.04. Here you can find a complete, step by step tutorial on MongoDB community edition installation on Linux, Ubuntu operating system. How to connect to remote server, installation of PHP driver on Ubuntu platform.
0 notes
Text
Linux - Cara Instal MongoDB 4 pada Debian 10
Linux – Cara Instal MongoDB 4 pada Debian 10

MongoDB adalah server basis data NoSQL, cross-platform dan opensource yang dikembangkan oleh MongoDB Inc. MongoDB menggunakan JSON untuk menyimpan datanya dan populer untuk menangani sejumlah data besar dengan skalabilitas, ketersediaan tinggi, dan kinerja tinggi.
Table of Contents Mengimpor Key GPG MongoDB di Debian Menginstal Repositori APT MongoDB 4 pada Debian Menginstal libcurl3 di Debian Mengin…
View On WordPress
#Cara Install MongoDB di CentOS#Cara Install MongoDB di Ubuntu#Cara Install MongoDB di Ubuntu 18.04#How to Install MongoDB 4.0 on Debian 9/8/7#Install MongoDB di Linux
0 notes
Text
Graylog syslog server on Raspberry Pi 4 (8gb)
This is how I installed graylog on my Pi.
What is needed:
1.- Raspberry Pi 4 - 8 GB Ram with firmware patch to boot from USB.
2.- Geekworm Raspberry Pi 4 mSATA SSD Adapter X857.
3.- MSata drive (using a 250 gb drive).
4.- Raspbian/Debian, Ubuntu aarch64.
5.- Network connection (Ethernet, WiFi and BT disabled).
6.- Rpi4 heatsinks (optional/recommended).
Procedure:
Install OS (Raspbian Aarch64) on the MSata drive, boot the raspberry pi and then do
# sudo apt update && apt full-upgrade -y
# sudo apt install apt-transport-https openjdk-11-jre-headless uuid-runtime pwgen dirmngr gnupg wget zip curl
Install MongoDB
# curl -s https://www.mongodb.org/static/pgp/server-4.2.asc | sudo apt-key add -
# echo "deb [ arch=arm64 ] https://repo.mongodb.org/apt/ubuntu bionic/mongodb-org/4.2 multiverse" | sudo tee /etc/apt/sources.list.d/mongodb-org-4.2.list
# sudo apt update && sudo apt install mongodb-org -y
# sudo systemctl enable mongod
# sudo systemctl start mongod
# sudo systemctl status mongod
Install Elasticsearch
# wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
# echo "deb [ arch=arm64 ] https://artifacts.elastic.co/packages/oss-7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
# sudo apt update && sudo apt install elasticsearch-oss -y
# sudo tee -a /etc/elasticsearch/elasticsearch.yml > /dev/null <<EOT cluster.name: graylog network.host: 127.0.0.1 http.port: 9200 action.auto_create_index: false EOT
# sudo systemctl daemon-reload
# sudo systemctl enable elasticsearch.service
# sudo systemctl restart elasticsearch.service
Install Graylog
Download the latest graylog-x.x.x.tgz from https://www.graylog.org/downloads-2 and scp it to your PI or
# cd opt
# wget https://downloads.graylog.org/releases/graylog/graylog-x.x.x.tgz
# sudo tar -xf graylog-x.x.x.tgz
# sudo mv /opt/graylog-x.x.x /opt/graylog
# sudo rm graylog-x.x.x.tgz
# vi /etc/graylog/server/server.conf and configure to your needs
To start the server do:
# cd /opt/graylog/bin
# ./graylogctl start
After the server started go to http://server-ip:9000 and use the user admin with the password previously configured, create an input and that should be all.
To configure password and settings on server.conf please refer to graylog documentation.
2 notes
·
View notes
Text
标题:如何在服务器上搭建蜘蛛池?TG@yuantou2048
在互联网时代,数据的抓取和分析变得尤为重要。而“蜘蛛池”作为一项关键技术,被广泛应用于网站爬虫、数据分析等领域。本文将详细介绍如何在服务器上搭建一个高效的蜘蛛池。
1. 什么是蜘蛛池?
蜘蛛池(Spider Pool)是一种用于管理多个爬虫任务的技术方案。它通过集中管理和调度爬虫任务,提高爬虫效率,降低资源消耗。对于需要大量抓取网页信息的场景,如搜索引擎优化(SEO)、市场调研等,蜘蛛池能够提供强大的支持。
2. 搭建前的准备工作
硬件准备
服务器配置:选择合适的服务器配置是基础。通常来说,CPU、内存和硬盘空间越大,处理能力越强。
操作系统:推荐使用Linux系统,因为其稳定性和安全性较高。
软件准备
Python环境:确保服务器上已安装Python及其相关库,如Scrapy、Requests等。
数据库:MySQL或MongoDB等数据库用于存储爬取的数据。
网络环境:确保服务器拥有稳定的网络环境,避免因网络波动导致的任务失败。
3. 安装必要软件
首先,你需要在服务器上安装必要的软件包。以Ubuntu为例:
```bash
sudo apt-get update
sudo apt-get install python3-pip
pip3 install scrapy redis
```
4. 创建项目结构
创建一个新的Scrapy项目,并配置Redis作为任务队列。
```bash
scrapy startproject myspiderpool
cd myspiderpool
```
5. 编写爬虫代码
编写爬虫代码时,可以参考Scrapy框架进行开发。以下是一个简单的爬虫示例:
```python
在项目目录下运行
scrapy startproject spiderpool
cd spiderpool
```
6. 配置Redis作为任务队列
```bash
sudo apt-get install redis-server
```
7. 编写爬虫脚本
```python
import scrapy
from scrapy_redis.spiders import RedisSpider
class MySpider(RedisSpider):
name = 'myspider'
allowed_domains = ['example.com']
custom_settings = {
'SCHEDULER': "scrapy_redis.scheduler.Scheduler",
'DUPEFILTER_CLASS': "scrapy_redis.dupefilter.RFPDupeFilter"
```
8. 启动Redis服务
```bash
redis-server &
```
9. 运行爬虫
```bash
scrapy crawl your_spider_name
```
10. 监控与维护
为了更好地监控爬虫状态及错误日志记录,可以使用`scrapy-redis`插件来实现分布式爬虫功能。
```python
在settings.py中添加配置
```
11. 实现分布式爬虫
```bash
scrapy genspider example example.com
```
12. 启动爬虫
```bash
scrapy crawl your_spider_name
```
13. 总结
通过以上步骤,你已经成功地在服务器上搭建了一个基本的蜘蛛池。接下来,你可以根据需求调整参数设置,例如并发数、重试机制等。
14. 结语
通过上述步骤,我们完成了蜘蛛池的基本搭建。希望这篇文章对你有所帮助!
加飞机@yuantou2048

王腾SEO
ETPU Machine
0 notes
Text
How to Install MongoDB 8 on Ubuntu 24.04
This article explains installing MongoDB 8 Community Edition (LTS) on Ubuntu 24.04. MongoDB is a popular NoSQL database that stores data in a flexible, JSON-like format, allowing for dynamic schemas and easy scalability. MongoDB offers a more flexible way to store data, which is advantageous for applications with changing data requirements. The document model makes it easier to understand and…
0 notes
Photo

How to Install MongoDB on Ubuntu 18.04 ☞ http://bit.ly/2n959uK #MongoDB #Ubuntu #Morioh
#MongoDB#MongoDB Tutorial#Database#database tutorial#MongoDB Batabase#Learn to code#Learn code#Morioh
2 notes
·
View notes
Text
How to Install MongoDB on Docker Container linux.
How to Install MongoDB on Docker Container linux.
Hi Guys! Hope you are doing well. Let’s Learn about “How to Install MongoDB on Docker Container Linux”. The Docker is an open source platform, where developers can package there application and run that application into the Docker Container. So It is PAAS (Platform as a Service), which uses a OS virtualisation to deliver software in packages called containers. The containers are the bundle of…

View On WordPress
#docker hub#install mongodb#install mongodb docker#install mongodb docker container#install mongodb docker image#install mongodb docker linux#install mongodb docker ubuntu#install mongodb on docker container#mongodb docker install#mongodb docker tutorial#run docker on mongodb container
0 notes
Photo

How to Install MongoDB on Ubuntu 18.04 ☞ http://bit.ly/2n959uK #MongoDB #Ubuntu #Morioh
#MongoDB#MongoDB Tutorial#Database#database tutorial#MongoDB Batabase#Learn to code#Learn code#Morioh
2 notes
·
View notes