#tensorflow python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Kazakhstan’s Minister of Communications and Informatics has blocked the Tumblr site because it contained 60 sites of terrorism, extremism, and pornography in 2015.
Text
youtube
Discover how to build a CNN model for skin melanoma classification using over 20,000 images of skin lesions
We'll begin by diving into data preparation, where we will organize, clean, and prepare the data form the classification model.
Next, we will walk you through the process of build and train convolutional neural network (CNN) model. We'll explain how to build the layers, and optimize the model.
Finally, we will test the model on a new fresh image and challenge our model.
Check out our tutorial here : https://youtu.be/RDgDVdLrmcs
Enjoy
Eran
#Python #Cnn #TensorFlow #deeplearning #neuralnetworks #imageclassification #convolutionalneuralnetworks #SkinMelanoma #melonomaclassification
#artificial intelligence#convolutional neural network#deep learning#python#tensorflow#machine learning#Youtube
3 notes
·
View notes
Text
The Best Open-Source Tools for Data Science in 2025

Data science in 2025 is thriving, driven by a robust ecosystem of open-source tools that empower professionals to extract insights, build predictive models, and deploy data-driven solutions at scale. This year, the landscape is more dynamic than ever, with established favorites and emerging contenders shaping how data scientists work. Here’s an in-depth look at the best open-source tools that are defining data science in 2025.
1. Python: The Universal Language of Data Science
Python remains the cornerstone of data science. Its intuitive syntax, extensive libraries, and active community make it the go-to language for everything from data wrangling to deep learning. Libraries such as NumPy and Pandas streamline numerical computations and data manipulation, while scikit-learn is the gold standard for classical machine learning tasks.
NumPy: Efficient array operations and mathematical functions.
Pandas: Powerful data structures (DataFrames) for cleaning, transforming, and analyzing structured data.
scikit-learn: Comprehensive suite for classification, regression, clustering, and model evaluation.
Python’s popularity is reflected in the 2025 Stack Overflow Developer Survey, with 53% of developers using it for data projects.
2. R and RStudio: Statistical Powerhouses
R continues to shine in academia and industries where statistical rigor is paramount. The RStudio IDE enhances productivity with features for scripting, debugging, and visualization. R’s package ecosystem��especially tidyverse for data manipulation and ggplot2 for visualization—remains unmatched for statistical analysis and custom plotting.
Shiny: Build interactive web applications directly from R.
CRAN: Over 18,000 packages for every conceivable statistical need.
R is favored by 36% of users, especially for advanced analytics and research.
3. Jupyter Notebooks and JupyterLab: Interactive Exploration
Jupyter Notebooks are indispensable for prototyping, sharing, and documenting data science workflows. They support live code (Python, R, Julia, and more), visualizations, and narrative text in a single document. JupyterLab, the next-generation interface, offers enhanced collaboration and modularity.
Over 15 million notebooks hosted as of 2025, with 80% of data analysts using them regularly.
4. Apache Spark: Big Data at Lightning Speed
As data volumes grow, Apache Spark stands out for its ability to process massive datasets rapidly, both in batch and real-time. Spark’s distributed architecture, support for SQL, machine learning (MLlib), and compatibility with Python, R, Scala, and Java make it a staple for big data analytics.
65% increase in Spark adoption since 2023, reflecting its scalability and performance.
5. TensorFlow and PyTorch: Deep Learning Titans
For machine learning and AI, TensorFlow and PyTorch dominate. Both offer flexible APIs for building and training neural networks, with strong community support and integration with cloud platforms.
TensorFlow: Preferred for production-grade models and scalability; used by over 33% of ML professionals.
PyTorch: Valued for its dynamic computation graph and ease of experimentation, especially in research settings.
6. Data Visualization: Plotly, D3.js, and Apache Superset
Effective data storytelling relies on compelling visualizations:
Plotly: Python-based, supports interactive and publication-quality charts; easy for both static and dynamic visualizations.
D3.js: JavaScript library for highly customizable, web-based visualizations; ideal for specialists seeking full control.
Apache Superset: Open-source dashboarding platform for interactive, scalable visual analytics; increasingly adopted for enterprise BI.
Tableau Public, though not fully open-source, is also popular for sharing interactive visualizations with a broad audience.
7. Pandas: The Data Wrangling Workhorse
Pandas remains the backbone of data manipulation in Python, powering up to 90% of data wrangling tasks. Its DataFrame structure simplifies complex operations, making it essential for cleaning, transforming, and analyzing large datasets.
8. Scikit-learn: Machine Learning Made Simple
scikit-learn is the default choice for classical machine learning. Its consistent API, extensive documentation, and wide range of algorithms make it ideal for tasks such as classification, regression, clustering, and model validation.
9. Apache Airflow: Workflow Orchestration
As data pipelines become more complex, Apache Airflow has emerged as the go-to tool for workflow automation and orchestration. Its user-friendly interface and scalability have driven a 35% surge in adoption among data engineers in the past year.
10. MLflow: Model Management and Experiment Tracking
MLflow streamlines the machine learning lifecycle, offering tools for experiment tracking, model packaging, and deployment. Over 60% of ML engineers use MLflow for its integration capabilities and ease of use in production environments.
11. Docker and Kubernetes: Reproducibility and Scalability
Containerization with Docker and orchestration via Kubernetes ensure that data science applications run consistently across environments. These tools are now standard for deploying models and scaling data-driven services in production.
12. Emerging Contenders: Streamlit and More
Streamlit: Rapidly build and deploy interactive data apps with minimal code, gaining popularity for internal dashboards and quick prototypes.
Redash: SQL-based visualization and dashboarding tool, ideal for teams needing quick insights from databases.
Kibana: Real-time data exploration and monitoring, especially for log analytics and anomaly detection.
Conclusion: The Open-Source Advantage in 2025
Open-source tools continue to drive innovation in data science, making advanced analytics accessible, scalable, and collaborative. Mastery of these tools is not just a technical advantage—it’s essential for staying competitive in a rapidly evolving field. Whether you’re a beginner or a seasoned professional, leveraging this ecosystem will unlock new possibilities and accelerate your journey from raw data to actionable insight.
The future of data science is open, and in 2025, these tools are your ticket to building smarter, faster, and more impactful solutions.
#python#r#rstudio#jupyternotebook#jupyterlab#apachespark#tensorflow#pytorch#plotly#d3js#apachesuperset#pandas#scikitlearn#apacheairflow#mlflow#docker#kubernetes#streamlit#redash#kibana#nschool academy#datascience
0 notes
Text
🔷Project Title: Multimodal Data Fusion for Enhanced Patient Risk Stratification using Deep Learning and Bayesian Survival Modeling.🟦
ai-ml-ds-healthcare-multimodal-survival-019 Filename: multimodal_patient_risk_stratification.py Timestamp: Mon Jun 02 2025 19:39:35 GMT+0000 (Coordinated Universal Time) Problem Domain:Healthcare Analytics, Clinical Decision Support, Predictive Medicine, Survival Analysis, Multimodal Machine Learning, Deep Learning, Bayesian Statistics. Project Description:This project aims to develop an…
#Bayesian#ClinicalDecisionSupport#DeepLearning#DigitalHealth#HealthcareAI#MultimodalAI#pandas#PyMC#python#RiskStratification#SurvivalAnalysis#TensorFlow
0 notes
Text
🔷Project Title: Multimodal Data Fusion for Enhanced Patient Risk Stratification using Deep Learning and Bayesian Survival Modeling.🟦
ai-ml-ds-healthcare-multimodal-survival-019 Filename: multimodal_patient_risk_stratification.py Timestamp: Mon Jun 02 2025 19:39:35 GMT+0000 (Coordinated Universal Time) Problem Domain:Healthcare Analytics, Clinical Decision Support, Predictive Medicine, Survival Analysis, Multimodal Machine Learning, Deep Learning, Bayesian Statistics. Project Description:This project aims to develop an…
#Bayesian#ClinicalDecisionSupport#DeepLearning#DigitalHealth#HealthcareAI#MultimodalAI#pandas#PyMC#python#RiskStratification#SurvivalAnalysis#TensorFlow
0 notes
Text
🔷Project Title: Multimodal Data Fusion for Enhanced Patient Risk Stratification using Deep Learning and Bayesian Survival Modeling.🟦
ai-ml-ds-healthcare-multimodal-survival-019 Filename: multimodal_patient_risk_stratification.py Timestamp: Mon Jun 02 2025 19:39:35 GMT+0000 (Coordinated Universal Time) Problem Domain:Healthcare Analytics, Clinical Decision Support, Predictive Medicine, Survival Analysis, Multimodal Machine Learning, Deep Learning, Bayesian Statistics. Project Description:This project aims to develop an…
#Bayesian#ClinicalDecisionSupport#DeepLearning#DigitalHealth#HealthcareAI#MultimodalAI#pandas#PyMC#python#RiskStratification#SurvivalAnalysis#TensorFlow
0 notes
Text
🔷Project Title: Multimodal Data Fusion for Enhanced Patient Risk Stratification using Deep Learning and Bayesian Survival Modeling.🟦
ai-ml-ds-healthcare-multimodal-survival-019 Filename: multimodal_patient_risk_stratification.py Timestamp: Mon Jun 02 2025 19:39:35 GMT+0000 (Coordinated Universal Time) Problem Domain:Healthcare Analytics, Clinical Decision Support, Predictive Medicine, Survival Analysis, Multimodal Machine Learning, Deep Learning, Bayesian Statistics. Project Description:This project aims to develop an…
#Bayesian#ClinicalDecisionSupport#DeepLearning#DigitalHealth#HealthcareAI#MultimodalAI#pandas#PyMC#python#RiskStratification#SurvivalAnalysis#TensorFlow
0 notes
Text
🔷Project Title: Multimodal Data Fusion for Enhanced Patient Risk Stratification using Deep Learning and Bayesian Survival Modeling.🟦
ai-ml-ds-healthcare-multimodal-survival-019 Filename: multimodal_patient_risk_stratification.py Timestamp: Mon Jun 02 2025 19:39:35 GMT+0000 (Coordinated Universal Time) Problem Domain:Healthcare Analytics, Clinical Decision Support, Predictive Medicine, Survival Analysis, Multimodal Machine Learning, Deep Learning, Bayesian Statistics. Project Description:This project aims to develop an…
#Bayesian#ClinicalDecisionSupport#DeepLearning#DigitalHealth#HealthcareAI#MultimodalAI#pandas#PyMC#python#RiskStratification#SurvivalAnalysis#TensorFlow
0 notes
Text
#AI Career#BCA to AI#Machine Learning for Beginners#Python for AI#AI Projects Portfolio#Data Science Fundamentals#TensorFlow Tutorials#Deep Learning Essentials#AI Internships#Building AI Resume#AI Communities & Networking#Math for AI#NLP Projects#Image Recognition Guide
0 notes
Text
🎣 Classify Fish Images Using MobileNetV2 & TensorFlow 🧠
In this hands-on video, I’ll show you how I built a deep learning model that can classify 9 different species of fish using MobileNetV2 and TensorFlow 2.10 — all trained on a real Kaggle dataset! From dataset splitting to live predictions with OpenCV, this tutorial covers the entire image classification pipeline step-by-step.
🚀 What you’ll learn:
How to preprocess & split image datasets
How to use ImageDataGenerator for clean input pipelines
How to customize MobileNetV2 for your own dataset
How to freeze layers, fine-tune, and save your model
How to run predictions with OpenCV overlays!
You can find link for the code in the blog: https://eranfeit.net/how-to-actually-fine-tune-mobilenetv2-classify-9-fish-species/
You can find more tutorials, and join my newsletter here : https://eranfeit.net/
👉 Watch the full tutorial here: https://youtu.be/9FMVlhOGDoo
Enjoy
Eran
#Python #ImageClassification #MobileNetV2
#artificial intelligence#convolutional neural network#deep learning#tensorflow#python#machine learning
0 notes
Text







#DidYouKnow This AI Tool? TensorFlow
Swipe left to explore!
💻 Explore insights on the latest in #technology on our Blog Page 👉 https://simplelogic-it.com/blogs/
🚀 Ready for your next career move? Check out our #careers page for exciting opportunities 👉 https://simplelogic-it.com/careers/
#didyouknowfacts#knowledgedrop#interestingfacts#factoftheday#learnsomethingneweveryday#mindblown#tensorflow#ai#scalable#flexible#python#javascript#swift#automation#developers#didyouknowthat#triviatime#makingitsimple#learnsomethingnew#simplelogicit#simplelogic#makeitsimple
1 note
·
View note
Text
Unlock Your Career Potential with a Data Science Certificate Program
What Can I Do with a Certificate in Data Science?
Data science is a broad field that includes activities like data analysis, statistical analysis, machine learning, and fundamental computer science. It might be a lucrative and exciting career path if you are up to speed on the latest technology and are competent with numbers and data. Depending on the type of work you want, you can take a variety of paths. Some will use your strengths more than others, so it is always a good idea to assess your options and select your course. Let’s look at what you may acquire with a graduate certificate in data science.
Data Scientist Salary
Potential compensation is one of the most critical factors for many people when considering a career. According to the Bureau of Labor Statistics (BLS), computer and information research scientists may expect a median annual pay of $111,840, albeit that amount requires a Ph.D. degree. The BLS predicts 19 percent growth in this industry over the next ten years, which is much faster than the general average.
Future data scientists can make impressive incomes if they are willing to acquire a Ph.D. degree. Data scientists that work for software publishers and R&D organizations often earn the most, with top earners making between $123,180 and $125,860 per year. On average, the lowest-paid data scientists work for schools and institutions, but their pay of $72,030 is still much higher than the national average of $37,040.
Role of statistics in research
At first appearance, a statistician’s job may appear comparable to that of a data analyst or data scientist. After all, this job necessitates regular engagement with data. On the other hand, statistical analysts are primarily concerned with mathematics, whereas data scientists and data analysts focus on extracting meaningful information from data. To excel in their field, statisticians must be experienced and confident mathematicians.
Statisticians may work in various industries since most organizations require some statistical analysis. Statisticians frequently specialize in fields such as agriculture or education. A statistician, on the other hand, can only be attained with a graduate diploma in data science due to the strong math talents necessary.
Machine Learning Engineer
Several firms’ principal product is data. Even a small group of engineers or data scientists might need help with data processing. Many workers must sift through vast data to provide a data service. Many companies are looking to artificial intelligence to assist them in managing extensive data. Machine learning, a kind of artificial intelligence, is a vital tool for handling vast amounts of data.
Machine learning, on the other hand, is designed by machine learning engineers to analyze data automatically and change it into something useful. However, the recommendation algorithm accumulates more data points when you watch more videos. As more data is collected, the algorithm “learns,” and its suggestions become more accurate. Furthermore, because the algorithm runs itself after construction, it speeds up the data collection.
Data Analyst
A data scientist and a data analyst are similar, and the terms can be used interchangeably depending on the company. You may be requested to access data from a database, master Excel spreadsheets, or build data visualizations for your company’s personnel. Although some coding or programming knowledge is advantageous, data analysts rarely use these skills to the extent that data scientists do.
Analysts evaluate a company’s data and draw meaningful conclusions from it. Analysts generate reports based on their findings to help the organization develop and improve over time. For example, a store analyst may use purchase data to identify the most common client demographics. The company might then utilize the data to create targeted marketing campaigns to reach those segments. Writing reports that explain data in a way that people outside the data field can understand is part of the intricacy of this career.
Data scientists
Data scientists and data analysts frequently share responsibilities. The direct contrast between the two is that a data scientist has a more substantial background in computer science. A data scientist may also take on more commonly associated duties with data analysts, particularly in smaller organizations with fewer employees. To be a competent data scientist, you must be skilled in math and statistics. To analyze data more successfully, you’ll also need to be able to write code. Most data scientists examine data trends before making forecasts. They typically develop algorithms that model data well.
Data Engineer
A data engineer and a data scientist are the same people. On the other hand, data engineers frequently have solid technological backgrounds, and data scientists usually have mathematical experience. Data scientists may develop software and understand how it works, but data engineers in the data science sector must be able to build, manage, and troubleshoot complex software.
A data engineer is essential as a company grows since it will create the basic data architecture necessary to move forward. Analytics may also discover areas that need to be addressed and those that are doing effectively. This profession requires solid software engineering skills rather than understanding how to interpret statistics correctly.
Important Data Scientist Skills
Data scientist abilities are further divided into two types.
Their mastery of sophisticated mathematical methods, statistics, and technologically oriented abilities is significantly tied to their technical expertise.
Excellent interpersonal skills, communication, and collaboration abilities are examples of non-technical attributes.
Technical Data Science Skills
While data scientists only need a lifetime of information stored in their heads to start a successful career in this field, a few basic technical skills that may be developed are required. These are detailed below Technical Data Science Skills
An Understanding of Basic Statistics
An Understanding of Basic Tools Used
A Good Understanding of Calculus and Algebra
Data Visualization Skills
Correcting Dirty Data
An Understanding of Basic Statistics
Regardless of whether an organization eventually hires a data science specialist, this person must know some of the most prevalent programming tools and the language used to use these programs. Understanding statistical programming languages such as R or Python and database querying languages such as SQL is required. Data scientists must understand maximum likelihood estimators, statistical tests, distributions, and other concepts. It is also vital that these experts understand how to identify which method will work best in a given situation. Depending on the company, data-driven tactics for interpreting and calculating statistics may be prioritized more or less.
A Good Understanding of Calculus and Algebra
It may appear unusual that a data science specialist would need to know how to perform calculus and algebra when many apps and software available today can manage all of that and more. Valid, not all businesses place the same importance on this knowledge. However, modern organizations whose products are characterized by data and incremental advances will benefit employees who possess these skills and do not rely just on software to accomplish their goals.
Data Visualization Skills & Correcting Dirty Data
This skill subset is crucial for newer firms beginning to make decisions based on this type of data and future projections. While robots solve this issue in many cases, the ability to detect and correct erroneous data may be a crucial skill that differentiates one in data science. Smaller firms significantly appreciate this skill since incorrect data can substantially impact their bottom line. These skills include locating and restoring missing data, correcting formatting problems, and changing timestamps.
Non-Technical Data Science Skills
It may be puzzling that data scientists would require non-technical skills. However, several essential skills must be had that fall under this category of Non-Technical Data Science Skills.
Excellent Communication Skills
A Keen Sense of Curiosity
Career Mapping and Goal Setting Skills
Excellent Communication Skills
Data science practitioners must be able to correctly communicate their work’s outcomes to technically sophisticated folks and those who are not. To do so, they must have exceptional interpersonal and communication abilities.
A Keen Sense of Curiosity
Data science specialists must maintain a level of interest to recognize current trends in their business and use them to make future projections based on the data they collect and analyze. This natural curiosity will drive them to pursue their education at the top of their game.
Career Mapping and Goal Setting Skills
A data scientist’s talents will transfer from one sub-specialty to another. Professionals in this business may specialize in different fields than their careers. As a result, they need to understand what additional skills they could need in the future if they choose to work in another area of data science.
Conclusion:
Data Science is about finding hidden data insights regarding patterns, behavior, interpretation, and assumptions to make informed business decisions. Data Scientists / Science professionals are the people who carry out these responsibilities. According to Harvard, data science is the world’s most in-demand and sought-after occupation. Nsccool Academy offers classroom self-paced learning certification courses and the most comprehensive Data Science certification training in Coimbatore.
#nschoolacademy#DataScience#DataScientist#MachineLearning#AI (Artificial Intelligence)#BigData#DeepLearning#Analytics#DataAnalysis#DataEngineering#DataVisualization#Python#RStats#TensorFlow#PyTorch#SQL#Tableau#PowerBI#JupyterNotebooks#ScikitLearn#Pandas#100DaysOfCode#WomenInTech#DataScienceCommunity#DataScienceJobs#LearnDataScience#AIForEveryone#DataDriven#DataLiteracy
1 note
·
View note
Text
#LinearRegression#MachineLearning#DataScience#AI#DataAnalysis#StatisticalModeling#PredictiveAnalytics#RegressionAnalysis#MLAlgorithms#DataMining#Python#R#MATLAB#ScikitLearn#Statsmodels#TensorFlow#PyTorch
1 note
·
View note
Text
instagram
🚀Motivation comes from the sense of longing something or someone. May it be in terms of money, affluence or to woo someone 😇
🌟Start asking yourself Questions like:
📍Are you happy with your current situation? Is this the best that you can do?
Question this to yourself whenever you are weary.
If the answer to the above question is yes, then set new goals. Raise your bar.
But if you have the answer as No, then here are some things that you can do.
1. Focus on what you want more. There has to be something that you would want far more than others. Set that as your target.
2. Make it fun. Believe me you don’t want to do what you dont like.
3. Treat yourself with every step closer to your goal.
4. Fill yourself with a positive attitude. Always hope for better for that is one thing that gives us strength to move forward.
5. Once achieved your goal, set a new target.
The most important thing in life is moving forward; doing things that we haven’t. The thrill of the unknown and variety of possibilities of life that you can uncover will always keep you motivated. 🙏🏻✨🥰
#programming#programmers#developers#datascientist#machinelearning#deeplearning#tensorflow#PyTorch#codingchallenge#machinelearningtools#python#machinelearningalgorithm#machinelearningmodel#machinelearningmodels#datasciencecourse#datasciencebootcamp#dataanalyst#datavisualization#machinelearningengineer#artificialintelligence#mobiledeveloper#softwaredeveloper#devlife#coding#setup#1w#Instagram
0 notes
Text
Explorando o TensorFlow: O Framework que Revolucionou o Machine Learning
Introdução ao TensorFlow O avanço da inteligência artificial (IA) e do aprendizado de máquina (Machine Learning) revolucionou diversas indústrias, como saúde, finanças, transporte e entretenimento. Nesse cenário, o TensorFlow, um framework de código aberto desenvolvido pelo Google, emerge como uma das ferramentas mais poderosas e amplamente utilizadas por desenvolvedores e pesquisadores para…
#aprendizado de máquina#aprendizado por reforço#deep learning#inteligência artificial#Keras#machine learn#machine learning#modelos preditivos#NLP#processamento de linguagem natural#Python#redes neurais#TensorFlow#TensorFlow em produção#TensorFlow exemplos#TensorFlow frameworks#TensorFlow GPU#TensorFlow instalação#TensorFlow para iniciantes#TensorFlow tutorial#treinamento de modelos#visão computacional
0 notes
Text
Apache Beam For Beginners: Building Scalable Data Pipelines
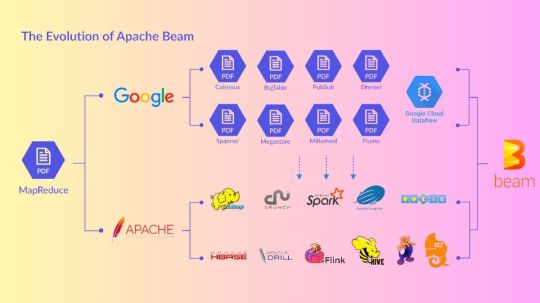
Apache Beam
Apache Beam, the simplest method for streaming and batch data processing. Data processing for mission-critical production workloads can be written once and executed anywhere.
Overview of Apache Beam
An open source, consistent approach for specifying batch and streaming data-parallel processing pipelines is called Apache Beam. To define the pipeline, you create a program using one of the open source Beam SDKs. One of Beam’s supported distributed processing back-ends, such as Google Cloud Dataflow, Apache Flink, or Apache Spark, then runs the pipeline.
Beam is especially helpful for situations involving embarrassingly parallel data processing, where the issue may be broken down into numerous smaller data bundles that can be handled separately and concurrently. Beam can also be used for pure data integration and Extract, Transform, and Load (ETL) activities. These operations are helpful for loading data onto a new system, converting data into a more suitable format, and transferring data between various storage media and data sources.Image credit to Apache Beam
How Does It Operate?
Sources of Data
Whether your data is on-premises or in the cloud, Beam reads it from a wide range of supported sources.
Processing Data
Your business logic is carried out by Beam for both batch and streaming usage cases.
Writing Data
The most widely used data sinks on the market receive the output of your data processing algorithms from Beam.
Features of Apache Beams
Combined
For each member of your data and application teams, a streamlined, unified programming model for batch and streaming use cases.
Transportable
Run pipelines across several execution contexts (runners) to avoid lock-in and provide flexibility.
Wide-ranging
Projects like TensorFlow Extended and Apache Hop are built on top of Apache Beam, demonstrating its extensibility.
Open Source
Open, community-based support and development to help your application grow and adapt to your unique use cases.
Apache Beam Pipeline Runners
The data processing pipeline you specify with your Beam program is converted by the Beam Pipeline Runners into an API that works with the distributed processing back-end of your choosing. You must designate a suitable runner for the back-end where you wish to run your pipeline when you run your Beam program.
Beam currently supports the following runners:
The Direct Runner
Runner for Apache Flink Apache Flink
Nemo Runner for Apache
Samza the Apache A runner Samza the Apache
Spark Runner for Apache Spark by Apache
Dataflow Runner for Google Cloud Dataflow on Google Cloud
Jet Runner Hazelcast Jet Hazelcast
Runner Twister 2
Get Started
Get Beam started on your data processing projects.
Visit our Getting started from Apache Spark page if you are already familiar with Apache Spark.
As an interactive online learning tool, try the Tour of Beam.
For the Go SDK, Python SDK, or Java SDK, follow the Quickstart instructions.
For examples that demonstrate different SDK features, see the WordCount Examples Walkthrough.
Explore our Learning Resources at your own speed.
on detailed explanations and reference materials on the Beam model, SDKs, and runners, explore the Documentation area.
Learn how to run Beam on Dataflow by exploring the cookbook examples.
Contribute
The Apache v2 license governs Beam, a project of the Apache Software Foundation. Contributions are highly valued in the open source community of Beam! Please refer to the Contribute section if you would want to contribute.
Apache Beam SDKs
Whether the input is an infinite data set from a streaming data source or a finite data set from a batch data source, the Beam SDKs offer a uniform programming model that can represent and alter data sets of any size. Both bounded and unbounded data are represented by the same classes in the Beam SDKs, and operations on the data are performed using the same transformations. You create a program that specifies your data processing pipeline using the Beam SDK of your choice.
As of right now, Beam supports the following SDKs for specific languages:
Java SDK for Apache Beam Java
Python’s Apache Beam SDK
SDK Go for Apache Beam Go
Apache Beam Python SDK
A straightforward yet effective API for creating batch and streaming data processing pipelines is offered by the Python SDK for Apache Beam.
Get started with the Python SDK
Set up your Python development environment, download the Beam SDK for Python, and execute an example pipeline by using the Beam Python SDK quickstart. Next, learn the fundamental ideas that are applicable to all of Beam’s SDKs by reading the Beam programming handbook.
For additional details on specific APIs, consult the Python API reference.
Python streaming pipelines
With Beam SDK version 2.5.0, the Python streaming pipeline execution is possible (although with certain restrictions).
Python type safety
Python lacks static type checking and is a dynamically typed language. In an attempt to mimic the consistency assurances provided by real static typing, the Beam SDK for Python makes use of type hints both during pipeline creation and runtime. In order to help you identify possible issues with the Direct Runner early on, Ensuring Python Type Safety explains how to use type hints.
Managing Python pipeline dependencies
Because the packages your pipeline requires are installed on your local computer, they are accessible when you execute your pipeline locally. You must, however, confirm that these requirements are present on the distant computers if you wish to run your pipeline remotely. Managing Python Pipeline Dependencies demonstrates how to enable remote workers to access your dependencies.
Developing new I/O connectors for Python
You can develop new I/O connectors using the flexible API offered by the Beam SDK for Python. For details on creating new I/O connectors and links to implementation guidelines unique to a certain language, see the Developing I/O connectors overview.
Making machine learning inferences with Python
Use the RunInference API for PyTorch and Scikit-learn models to incorporate machine learning models into your inference processes. You can use the tfx_bsl library if you’re working with TensorFlow models.
The RunInference API allows you to generate several kinds of transforms since it accepts different kinds of setup parameters from model handlers, and the type of parameter dictates how the model is implemented.
An end-to-end platform for implementing production machine learning pipelines is called TensorFlow Extended (TFX). Beam has been integrated with TFX. Refer to the TFX user handbook for additional details.
Python multi-language pipelines quickstart
Transforms developed in any supported SDK language can be combined and used in a single multi-language pipeline with Apache Beam. Check out the Python multi-language pipelines quickstart to find out how to build a multi-language pipeline with the Python SDK.
Unrecoverable Errors in Beam Python
During worker startup, a few typical mistakes might happen and stop jobs from commencing. See Unrecoverable faults in Beam Python for more information on these faults and how to fix them in the Python SDK.
Apache Beam Java SDK
A straightforward yet effective API for creating batch and streaming parallel data processing pipelines in Java is offered by the Java SDK for Apache Beam.
Get Started with the Java SDK
Learn the fundamental ideas that apply to all of Beam’s SDKs by beginning with the Beam Programming Model.
Further details on specific APIs can be found in the Java API Reference.
Supported Features
Every feature that the Beam model currently supports is supported by the Java SDK.
Extensions
A list of available I/O transforms may be found on the Beam-provided I/O Transforms page.
The following extensions are included in the Java SDK:
Inner join, outer left join, and outer right join operations are provided by the join-library.
For big iterables, sorter is a scalable and effective sorter.
The benchmark suite Nexmark operates in both batch and streaming modes.
A batch-mode SQL benchmark suite is called TPC-DS.
Euphoria’s Java 8 DSL for BEAM is user-friendly.
There are also a number of third-party Java libraries.
Java multi-language pipelines quickstart
Transforms developed in any supported SDK language can be combined and used in a single multi-language pipeline with Apache Beam. Check out the Java multi-language pipelines quickstart to find out how to build a multi-language pipeline with the Java SDK.
Read more on govindhtech.com
#ApacheBeam#BuildingScalableData#Pipelines#Beginners#ApacheFlink#SourcesData#ProcessingData#WritingData#TensorFlow#OpenSource#GoogleCloud#ApacheSpark#ApacheBeamSDK#technology#technews#Python#machinelearning#news#govindhtech
0 notes