#data types sql
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
Signed or Unsigned? How to Choose the Right SQL Data Type
1 note
·
View note
Text
Understanding the Difference Between nVARCHAR and VARCHAR
Introduction Hey there, fellow SQL Server enthusiasts! Today, we’re diving into the world of character data types, specifically nVARCHAR and VARCHAR. As someone who’s worked with SQL Server for years, I’ve come to appreciate the importance of understanding these data types and how they can impact your database design and performance. In this article, we’ll explore the key differences between…

View On WordPress
#nVARCHAR vs VARCHAR#performance considerations#SQL Server data types#storage differences#Unicode support
0 notes
Text
https://www.tutorialspoint.com/sql/sql-data-types.htm
Learn about SQL data types-
Numeric data types (INT, TINYINT, BIGINT, FLOAT, REAL) Date and Time data types (DATE, TIME, DATETIME) Character and String data types (CHAR, VARCHAR, TEXT) Unicode character string data types (NCHAR, NVARCHAR, NTEXT) Binary data types (BINARY, VARBINARY)
0 notes
Text
Harnessing Power and Precision with User-Defined Data Types in SQL Server
CodingSight
In the world of SQL Server, data is king, and precision is paramount. As your database grows and evolves, you may find that standard data types don't always fit your specific needs. This is where User-Defined Data Types (UDDTs) step in as the unsung heroes of SQL Server. In this article, we'll explore User-Defined Data Types in SQL Server, their advantages, how to create them, and practical use cases.
What Are User-Defined Data Types (UDDTs) in SQL Server?
User-Defined Data Types, often abbreviated as UDDTs, allow you to define custom data types tailored to your application's unique requirements. Think of them as your own personalized data containers. SQL Server, a robust relational database management system, offers this feature to empower developers with flexibility and precision in data handling.
Advantages of Using User-Defined Data Types
Enhanced Clarity and Documentation: By creating UDDTs with meaningful names, you enhance the clarity of your database schema. This makes it easier for your team to understand the data structure, leading to better documentation and maintenance.
Data Integrity: UDDTs enable you to enforce constraints and rules specific to your data. For instance, you can define a UDDT for representing valid email addresses, ensuring data integrity by preventing incorrect data from entering the database.
Simplified Maintenance: When you need to make changes to your data structure, modifying a UDDT in one place automatically updates all columns using that type. This simplifies maintenance and reduces the risk of errors.
Creating User-Defined Data Types
Creating a User-Defined Data Type in SQL Server is a straightforward process. Here's a basic syntax example:
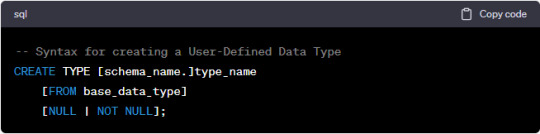
[schema_name.]: Specifies the schema in which the UDDT will be created.
type_name: Assign a unique name for your UDDT.
[FROM base_data_type]: You can base your UDDT on an existing SQL Server data type.
[NULL | NOT NULL]: Define whether the UDDT allows NULL values or not.
Practical Use Cases for User-Defined Data Types
Standardized Date Formats: If your application requires consistent date formats, create a UDDT to enforce this standard. This ensures that all dates in your database conform to your chosen format.
Geographic Coordinates: When working with geographic data, defining a UDDT for latitude and longitude pairs can enhance precision and simplify location-based queries.
Product Codes: In e-commerce databases, you can create a UDDT for product codes with specific formatting and validation rules, preventing invalid codes from entering the system.
Currency Values: To ensure accuracy in financial applications, use UDDTs to represent currency values with fixed decimal places, reducing the risk of rounding errors.
Conclusion
User-Defined Data Types in SQL Server provide the means to tailor your database to your application's exact needs. They offer advantages such as improved clarity, data integrity, and simplified maintenance. By creating custom data types, you empower your database to handle data with precision and accuracy, enhancing both your application's performance and your development team's efficiency.
In a world where data is king, User-Defined Data Types reign as the crown jewels of SQL Server, allowing you to unlock the full potential of your database and take control of your data like never before. Whether you're developing a new application or enhancing an existing one, harness the power and precision of UDDTs to create a data structure that perfectly aligns with your vision.
0 notes
Text
Maximize Efficiency with Volumes in Databricks Unity Catalog
With Databricks Unity Catalog's volumes feature, managing data has become a breeze. Regardless of the format or location, the organization can now effortlessly access and organize its data. This newfound simplicity and organization streamline data managem

View On WordPress
#Cloud#Data Analysis#Data management#Data Pipeline#Data types#Databricks#Databricks SQL#Databricks Unity catalog#DBFS#Delta Sharing#machine learning#Non-tabular Data#performance#Performance Optimization#Spark#SQL#SQL database#Tabular Data#Unity Catalog#Unstructured Data#Volumes in Databricks
0 notes
Text
Ever since OpenAI released ChatGPT at the end of 2022, hackers and security researchers have tried to find holes in large language models (LLMs) to get around their guardrails and trick them into spewing out hate speech, bomb-making instructions, propaganda, and other harmful content. In response, OpenAI and other generative AI developers have refined their system defenses to make it more difficult to carry out these attacks. But as the Chinese AI platform DeepSeek rockets to prominence with its new, cheaper R1 reasoning model, its safety protections appear to be far behind those of its established competitors.
Today, security researchers from Cisco and the University of Pennsylvania are publishing findings showing that, when tested with 50 malicious prompts designed to elicit toxic content, DeepSeek’s model did not detect or block a single one. In other words, the researchers say they were shocked to achieve a “100 percent attack success rate.”
The findings are part of a growing body of evidence that DeepSeek’s safety and security measures may not match those of other tech companies developing LLMs. DeepSeek’s censorship of subjects deemed sensitive by China’s government has also been easily bypassed.
“A hundred percent of the attacks succeeded, which tells you that there’s a trade-off,” DJ Sampath, the VP of product, AI software and platform at Cisco, tells WIRED. “Yes, it might have been cheaper to build something here, but the investment has perhaps not gone into thinking through what types of safety and security things you need to put inside of the model.”
Other researchers have had similar findings. Separate analysis published today by the AI security company Adversa AI and shared with WIRED also suggests that DeepSeek is vulnerable to a wide range of jailbreaking tactics, from simple language tricks to complex AI-generated prompts.
DeepSeek, which has been dealing with an avalanche of attention this week and has not spoken publicly about a range of questions, did not respond to WIRED’s request for comment about its model’s safety setup.
Generative AI models, like any technological system, can contain a host of weaknesses or vulnerabilities that, if exploited or set up poorly, can allow malicious actors to conduct attacks against them. For the current wave of AI systems, indirect prompt injection attacks are considered one of the biggest security flaws. These attacks involve an AI system taking in data from an outside source—perhaps hidden instructions of a website the LLM summarizes—and taking actions based on the information.
Jailbreaks, which are one kind of prompt-injection attack, allow people to get around the safety systems put in place to restrict what an LLM can generate. Tech companies don’t want people creating guides to making explosives or using their AI to create reams of disinformation, for example.
Jailbreaks started out simple, with people essentially crafting clever sentences to tell an LLM to ignore content filters—the most popular of which was called “Do Anything Now” or DAN for short. However, as AI companies have put in place more robust protections, some jailbreaks have become more sophisticated, often being generated using AI or using special and obfuscated characters. While all LLMs are susceptible to jailbreaks, and much of the information could be found through simple online searches, chatbots can still be used maliciously.
“Jailbreaks persist simply because eliminating them entirely is nearly impossible—just like buffer overflow vulnerabilities in software (which have existed for over 40 years) or SQL injection flaws in web applications (which have plagued security teams for more than two decades),” Alex Polyakov, the CEO of security firm Adversa AI, told WIRED in an email.
Cisco’s Sampath argues that as companies use more types of AI in their applications, the risks are amplified. “It starts to become a big deal when you start putting these models into important complex systems and those jailbreaks suddenly result in downstream things that increases liability, increases business risk, increases all kinds of issues for enterprises,” Sampath says.
The Cisco researchers drew their 50 randomly selected prompts to test DeepSeek’s R1 from a well-known library of standardized evaluation prompts known as HarmBench. They tested prompts from six HarmBench categories, including general harm, cybercrime, misinformation, and illegal activities. They probed the model running locally on machines rather than through DeepSeek’s website or app, which send data to China.
Beyond this, the researchers say they have also seen some potentially concerning results from testing R1 with more involved, non-linguistic attacks using things like Cyrillic characters and tailored scripts to attempt to achieve code execution. But for their initial tests, Sampath says, his team wanted to focus on findings that stemmed from a generally recognized benchmark.
Cisco also included comparisons of R1’s performance against HarmBench prompts with the performance of other models. And some, like Meta’s Llama 3.1, faltered almost as severely as DeepSeek’s R1. But Sampath emphasizes that DeepSeek’s R1 is a specific reasoning model, which takes longer to generate answers but pulls upon more complex processes to try to produce better results. Therefore, Sampath argues, the best comparison is with OpenAI’s o1 reasoning model, which fared the best of all models tested. (Meta did not immediately respond to a request for comment).
Polyakov, from Adversa AI, explains that DeepSeek appears to detect and reject some well-known jailbreak attacks, saying that “it seems that these responses are often just copied from OpenAI’s dataset.” However, Polyakov says that in his company’s tests of four different types of jailbreaks—from linguistic ones to code-based tricks—DeepSeek’s restrictions could easily be bypassed.
“Every single method worked flawlessly,” Polyakov says. “What’s even more alarming is that these aren’t novel ‘zero-day’ jailbreaks—many have been publicly known for years,” he says, claiming he saw the model go into more depth with some instructions around psychedelics than he had seen any other model create.
“DeepSeek is just another example of how every model can be broken—it’s just a matter of how much effort you put in. Some attacks might get patched, but the attack surface is infinite,” Polyakov adds. “If you’re not continuously red-teaming your AI, you’re already compromised.”
57 notes
·
View notes
Text
yall the slaying of princess is infecting my studies
I've been doing computer science and the only way I've been remembering the types of hacking by thinking which voice would do that.
PHISHING IS SOO OPPORTUNIST he's a snake oil sales man
skeptic is an SQL injection because he's smart enough to figure that out.
brute force attack is stubborn
I think cheated is a denial of service attack since he uses the power of numbers in razor and that's basically what it is
it's hard to choose for data interseption but I think cold purely off vibes
I can't think of anyone for malware because it's so broad and the left over voices don't seem like the type to hack anyone so if yall have ideas tell me.
hunted is breaking in and raiding your fridge
#slay the princess#stp#stp voices#voice of the cold#voice of the opportunist#voice of the cheated#voice of the skeptic#voice of the hunted#voice of the stubborn#stp opportunist#stp stubborn#stp hunted#stp cheated#stp skeptic#stp cold#i made this
30 notes
·
View notes
Text
SeekL x Killer Chat - The Beginning

Lyra sits at her PC. Looking at her monitor. She's just finished learning ArnoldC. Her recent obsession with all of Arnold Schwarzenegger's movies led her to learn of the existence of ArnoldC.
Coding was but another way to write. It could be artistic; it was unique.
They look at their previous works with other coding languages. Brainfuck and JSFuck, both were very interesting. Especially having JSFuck running on actual web pages. Another favorite, similar to ArnoldC, Shakespeare. A language that looks similar to Shakespearen. The language she learnt right before ArnoldC.
She whistles and looked through the internet to see if there was anything that could expand her esoteric coding languages.
They squint at the name of one, SeekL? An interesting name without a description. With a shrug they start to comb through the internet. Nothing was showing up as a learning tool for the coding language. However, there were a few articles about how it was used by some hackers.
She hums to herself and double checks her shields and makes sure her data is locked up tight. Then she hops onto the dark web to see if there was anything.
"Oh, well that's interesting," she said looking at the page that came with more information, but just barely.
*SeekL is similar to SQL. If you wish to learn, click here*
'Should I click to learn it?' The idea bounced around their brain, but she found no reason to reject it. So she clicked it.
She was automatically joined into a group chat. There she learnt basic SeekL and some SQL. She made friends with the others in the chat and helped them with their last hacks. They got to be part of a group for a few days, chat with Odxny on video calls each day, and become Thrim. They learnt how much coding could be used to for a vendetta and how easily some people crumble to a ransom.
It was interesting and she wanted to continue in this new world.
Then came the final day for the server to shut down. Her hands trembled as she typed in the phone number for Odxny, hoping she didn't mess anything up. She only had one shot.
exec dial(555-448-4746)
It rang once.
Twice.
Thri-
"Hey"
Relief flooded her.
11 notes
·
View notes
Text
SQL Fundamentals #1: SQL Data Definition
Last year in college , I had the opportunity to dive deep into SQL. The course was made even more exciting by an amazing instructor . Fast forward to today, and I regularly use SQL in my backend development work with PHP. Today, I felt the need to refresh my SQL knowledge a bit, and that's why I've put together three posts aimed at helping beginners grasp the fundamentals of SQL.
Understanding Relational Databases
Let's Begin with the Basics: What Is a Database?
Simply put, a database is like a digital warehouse where you store large amounts of data. When you work on projects that involve data, you need a place to keep that data organized and accessible, and that's where databases come into play.
Exploring Different Types of Databases
When it comes to databases, there are two primary types to consider: relational and non-relational.
Relational Databases: Structured Like Tables
Think of a relational database as a collection of neatly organized tables, somewhat like rows and columns in an Excel spreadsheet. Each table represents a specific type of information, and these tables are interconnected through shared attributes. It's similar to a well-organized library catalog where you can find books by author, title, or genre.
Key Points:
Tables with rows and columns.
Data is neatly structured, much like a library catalog.
You use a structured query language (SQL) to interact with it.
Ideal for handling structured data with complex relationships.
Non-Relational Databases: Flexibility in Containers
Now, imagine a non-relational database as a collection of flexible containers, more like bins or boxes. Each container holds data, but they don't have to adhere to a fixed format. It's like managing a diverse collection of items in various boxes without strict rules. This flexibility is incredibly useful when dealing with unstructured or rapidly changing data, like social media posts or sensor readings.
Key Points:
Data can be stored in diverse formats.
There's no rigid structure; adaptability is the name of the game.
Non-relational databases (often called NoSQL databases) are commonly used.
Ideal for handling unstructured or dynamic data.
Now, Let's Dive into SQL:

SQL is a :
Data Definition language ( what todays post is all about )
Data Manipulation language
Data Query language
Task: Building and Interacting with a Bookstore Database
Setting Up the Database
Our first step in creating a bookstore database is to establish it. You can achieve this with a straightforward SQL command:
CREATE DATABASE bookstoreDB;
SQL Data Definition
As the name suggests, this step is all about defining your tables. By the end of this phase, your database and the tables within it are created and ready for action.

1 - Introducing the 'Books' Table
A bookstore is all about its collection of books, so our 'bookstoreDB' needs a place to store them. We'll call this place the 'books' table. Here's how you create it:
CREATE TABLE books ( -- Don't worry, we'll fill this in soon! );
Now, each book has its own set of unique details, including titles, authors, genres, publication years, and prices. These details will become the columns in our 'books' table, ensuring that every book can be fully described.
Now that we have the plan, let's create our 'books' table with all these attributes:
CREATE TABLE books ( title VARCHAR(40), author VARCHAR(40), genre VARCHAR(40), publishedYear DATE, price INT(10) );
With this structure in place, our bookstore database is ready to house a world of books.
2 - Making Changes to the Table
Sometimes, you might need to modify a table you've created in your database. Whether it's correcting an error during table creation, renaming the table, or adding/removing columns, these changes are made using the 'ALTER TABLE' command.
For instance, if you want to rename your 'books' table:
ALTER TABLE books RENAME TO books_table;
If you want to add a new column:
ALTER TABLE books ADD COLUMN description VARCHAR(100);
Or, if you need to delete a column:
ALTER TABLE books DROP COLUMN title;
3 - Dropping the Table
Finally, if you ever want to remove a table you've created in your database, you can do so using the 'DROP TABLE' command:
DROP TABLE books;
To keep this post concise, our next post will delve into the second step, which involves data manipulation. Once our bookstore database is up and running with its tables, we'll explore how to modify and enrich it with new information and data. Stay tuned ...
Part2
#code#codeblr#java development company#python#studyblr#progblr#programming#comp sci#web design#web developers#web development#website design#webdev#website#tech#learn to code#sql#sqlserver#sql course#data#datascience#backend
112 notes
·
View notes
Text
is there a way to solve this sql issue. I've run into it a few times and I wish i had a way to future-proof my queries.
we have a few tables for data that is somewhat universal on our site. for example file_attachments. you can attach files to almost every internal page on our site. file_attachments has an id column for each attachment's unique ID number, but attachee_id is used to join this table on anything.
the problem is, our system uses the same series of numbers for various of IDs. 123456 can (and is) an ID for items, purchase orders, sales orders, customers, quotes, etc. so to correctly join file_attachments to the items table, i need to join file_attachments.attachee_id to items.id and then filter file_attachments.attachment_type = 'item'. attachment_types do NOT have their own series of id numbers. i have to filter this column using words. then, sometimes our dev team decides to change our terminology which breaks all my queries. they sometimes do this accidentally by adding extra spaces before, after, or between words. though TRIM can generally resolve that.
is there anything I might be able to do to avoid filtering with words?
i was thinking about doing something to identify the rows for the first instance of each attachment_type and then assign row numbers to the results (sorted by file_attachments.id), thus creating permanent IDs i can use regardless of whether anyone alters the names used for attachment_type, or eventually adds new types. but idk if this is a regular issue with databases and whether there's a generally accepted way to deal with it.
8 notes
·
View notes
Text
Structured Query Language (SQL): A Comprehensive Guide
Structured Query Language, popularly called SQL (reported "ess-que-ell" or sometimes "sequel"), is the same old language used for managing and manipulating relational databases. Developed in the early 1970s by using IBM researchers Donald D. Chamberlin and Raymond F. Boyce, SQL has when you consider that end up the dominant language for database structures round the world.
Structured query language commands with examples
Today, certainly every important relational database control system (RDBMS)—such as MySQL, PostgreSQL, Oracle, SQL Server, and SQLite—uses SQL as its core question language.
What is SQL?
SQL is a website-specific language used to:
Retrieve facts from a database.
Insert, replace, and delete statistics.
Create and modify database structures (tables, indexes, perspectives).
Manage get entry to permissions and security.
Perform data analytics and reporting.
In easy phrases, SQL permits customers to speak with databases to shop and retrieve structured information.
Key Characteristics of SQL
Declarative Language: SQL focuses on what to do, now not the way to do it. For instance, whilst you write SELECT * FROM users, you don’t need to inform SQL the way to fetch the facts—it figures that out.
Standardized: SQL has been standardized through agencies like ANSI and ISO, with maximum database structures enforcing the core language and including their very own extensions.
Relational Model-Based: SQL is designed to work with tables (also called members of the family) in which records is organized in rows and columns.
Core Components of SQL
SQL may be damaged down into numerous predominant categories of instructions, each with unique functions.
1. Data Definition Language (DDL)
DDL commands are used to outline or modify the shape of database gadgets like tables, schemas, indexes, and so forth.
Common DDL commands:
CREATE: To create a brand new table or database.
ALTER: To modify an present table (add or put off columns).
DROP: To delete a table or database.
TRUNCATE: To delete all rows from a table but preserve its shape.
Example:
sq.
Copy
Edit
CREATE TABLE personnel (
id INT PRIMARY KEY,
call VARCHAR(one hundred),
income DECIMAL(10,2)
);
2. Data Manipulation Language (DML)
DML commands are used for statistics operations which include inserting, updating, or deleting information.
Common DML commands:
SELECT: Retrieve data from one or more tables.
INSERT: Add new records.
UPDATE: Modify existing statistics.
DELETE: Remove information.
Example:
square
Copy
Edit
INSERT INTO employees (id, name, earnings)
VALUES (1, 'Alice Johnson', 75000.00);
three. Data Query Language (DQL)
Some specialists separate SELECT from DML and treat it as its very own category: DQL.
Example:
square
Copy
Edit
SELECT name, income FROM personnel WHERE profits > 60000;
This command retrieves names and salaries of employees earning more than 60,000.
4. Data Control Language (DCL)
DCL instructions cope with permissions and access manage.
Common DCL instructions:
GRANT: Give get right of entry to to users.
REVOKE: Remove access.
Example:
square
Copy
Edit
GRANT SELECT, INSERT ON personnel TO john_doe;
five. Transaction Control Language (TCL)
TCL commands manage transactions to ensure data integrity.
Common TCL instructions:
BEGIN: Start a transaction.
COMMIT: Save changes.
ROLLBACK: Undo changes.
SAVEPOINT: Set a savepoint inside a transaction.
Example:
square
Copy
Edit
BEGIN;
UPDATE personnel SET earnings = income * 1.10;
COMMIT;
SQL Clauses and Syntax Elements
WHERE: Filters rows.
ORDER BY: Sorts effects.
GROUP BY: Groups rows sharing a assets.
HAVING: Filters companies.
JOIN: Combines rows from or greater tables.
Example with JOIN:
square
Copy
Edit
SELECT personnel.Name, departments.Name
FROM personnel
JOIN departments ON personnel.Dept_id = departments.Identity;
Types of Joins in SQL
INNER JOIN: Returns statistics with matching values in each tables.
LEFT JOIN: Returns all statistics from the left table, and matched statistics from the right.
RIGHT JOIN: Opposite of LEFT JOIN.
FULL JOIN: Returns all records while there is a in shape in either desk.
SELF JOIN: Joins a table to itself.
Subqueries and Nested Queries
A subquery is a query inside any other query.
Example:
sq.
Copy
Edit
SELECT name FROM employees
WHERE earnings > (SELECT AVG(earnings) FROM personnel);
This reveals employees who earn above common earnings.
Functions in SQL
SQL includes built-in features for acting calculations and formatting:
Aggregate Functions: SUM(), AVG(), COUNT(), MAX(), MIN()
String Functions: UPPER(), LOWER(), CONCAT()
Date Functions: NOW(), CURDATE(), DATEADD()
Conversion Functions: CAST(), CONVERT()
Indexes in SQL
An index is used to hurry up searches.
Example:
sq.
Copy
Edit
CREATE INDEX idx_name ON employees(call);
Indexes help improve the performance of queries concerning massive information.
Views in SQL
A view is a digital desk created through a question.
Example:
square
Copy
Edit
CREATE VIEW high_earners AS
SELECT call, salary FROM employees WHERE earnings > 80000;
Views are beneficial for:
Security (disguise positive columns)
Simplifying complex queries
Reusability
Normalization in SQL
Normalization is the system of organizing facts to reduce redundancy. It entails breaking a database into multiple related tables and defining overseas keys to link them.
1NF: No repeating groups.
2NF: No partial dependency.
3NF: No transitive dependency.
SQL in Real-World Applications
Web Development: Most web apps use SQL to manipulate customers, periods, orders, and content.
Data Analysis: SQL is extensively used in information analytics systems like Power BI, Tableau, and even Excel (thru Power Query).
Finance and Banking: SQL handles transaction logs, audit trails, and reporting systems.
Healthcare: Managing patient statistics, remedy records, and billing.
Retail: Inventory systems, sales analysis, and consumer statistics.
Government and Research: For storing and querying massive datasets.
Popular SQL Database Systems
MySQL: Open-supply and extensively used in internet apps.
PostgreSQL: Advanced capabilities and standards compliance.
Oracle DB: Commercial, especially scalable, agency-degree.
SQL Server: Microsoft’s relational database.
SQLite: Lightweight, file-based database used in cellular and desktop apps.
Limitations of SQL
SQL can be verbose and complicated for positive operations.
Not perfect for unstructured information (NoSQL databases like MongoDB are better acceptable).
Vendor-unique extensions can reduce portability.
Java Programming Language Tutorial
Dot Net Programming Language
C ++ Online Compliers
C Language Compliers
2 notes
·
View notes
Text
Short-Term vs. Long-Term Data Analytics Course in Delhi: Which One to Choose?

In today’s digital world, data is everywhere. From small businesses to large organizations, everyone uses data to make better decisions. Data analytics helps in understanding and using this data effectively. If you are interested in learning data analytics, you might wonder whether to choose a short-term or a long-term course. Both options have their benefits, and your choice depends on your goals, time, and career plans.
At Uncodemy, we offer both short-term and long-term data analytics courses in Delhi. This article will help you understand the key differences between these courses and guide you to make the right choice.
What is Data Analytics?
Data analytics is the process of examining large sets of data to find patterns, insights, and trends. It involves collecting, cleaning, analyzing, and interpreting data. Companies use data analytics to improve their services, understand customer behavior, and increase efficiency.
There are four main types of data analytics:
Descriptive Analytics: Understanding what has happened in the past.
Diagnostic Analytics: Identifying why something happened.
Predictive Analytics: Forecasting future outcomes.
Prescriptive Analytics: Suggesting actions to achieve desired outcomes.
Short-Term Data Analytics Course
A short-term data analytics course is a fast-paced program designed to teach you essential skills quickly. These courses usually last from a few weeks to a few months.
Benefits of a Short-Term Data Analytics Course
Quick Learning: You can learn the basics of data analytics in a short time.
Cost-Effective: Short-term courses are usually more affordable.
Skill Upgrade: Ideal for professionals looking to add new skills without a long commitment.
Job-Ready: Get practical knowledge and start working in less time.
Who Should Choose a Short-Term Course?
Working Professionals: If you want to upskill without leaving your job.
Students: If you want to add data analytics to your resume quickly.
Career Switchers: If you want to explore data analytics before committing to a long-term course.
What You Will Learn in a Short-Term Course
Introduction to Data Analytics
Basic Tools (Excel, SQL, Python)
Data Visualization (Tableau, Power BI)
Basic Statistics and Data Interpretation
Hands-on Projects
Long-Term Data Analytics Course
A long-term data analytics course is a comprehensive program that provides in-depth knowledge. These courses usually last from six months to two years.
Benefits of a Long-Term Data Analytics Course
Deep Knowledge: Covers advanced topics and techniques in detail.
Better Job Opportunities: Preferred by employers for specialized roles.
Practical Experience: Includes internships and real-world projects.
Certifications: You may earn industry-recognized certifications.
Who Should Choose a Long-Term Course?
Beginners: If you want to start a career in data analytics from scratch.
Career Changers: If you want to switch to a data analytics career.
Serious Learners: If you want advanced knowledge and long-term career growth.
What You Will Learn in a Long-Term Course
Advanced Data Analytics Techniques
Machine Learning and AI
Big Data Tools (Hadoop, Spark)
Data Ethics and Governance
Capstone Projects and Internships
Key Differences Between Short-Term and Long-Term Courses
FeatureShort-Term CourseLong-Term CourseDurationWeeks to a few monthsSix months to two yearsDepth of KnowledgeBasic and Intermediate ConceptsAdvanced and Specialized ConceptsCostMore AffordableHigher InvestmentLearning StyleFast-PacedDetailed and ComprehensiveCareer ImpactQuick Entry-Level JobsBetter Career Growth and High-Level JobsCertificationBasic CertificateIndustry-Recognized CertificationsPractical ProjectsLimitedExtensive and Real-World Projects
How to Choose the Right Course for You
When deciding between a short-term and long-term data analytics course at Uncodemy, consider these factors:
Your Career Goals
If you want a quick job or basic knowledge, choose a short-term course.
If you want a long-term career in data analytics, choose a long-term course.
Time Commitment
Choose a short-term course if you have limited time.
Choose a long-term course if you can dedicate several months to learning.
Budget
Short-term courses are usually more affordable.
Long-term courses require a bigger investment but offer better returns.
Current Knowledge
If you already know some basics, a short-term course will enhance your skills.
If you are a beginner, a long-term course will provide a solid foundation.
Job Market
Short-term courses can help you get entry-level jobs quickly.
Long-term courses open doors to advanced and specialized roles.
Why Choose Uncodemy for Data Analytics Courses in Delhi?
At Uncodemy, we provide top-quality training in data analytics. Our courses are designed by industry experts to meet the latest market demands. Here’s why you should choose us:
Experienced Trainers: Learn from professionals with real-world experience.
Practical Learning: Hands-on projects and case studies.
Flexible Schedule: Choose classes that fit your timing.
Placement Assistance: We help you find the right job after course completion.
Certification: Receive a recognized certificate to boost your career.
Final Thoughts
Choosing between a short-term and long-term data analytics course depends on your goals, time, and budget. If you want quick skills and job readiness, a short-term course is ideal. If you seek in-depth knowledge and long-term career growth, a long-term course is the better choice.
At Uncodemy, we offer both options to meet your needs. Start your journey in data analytics today and open the door to exciting career opportunities. Visit our website or contact us to learn more about our Data Analytics course in delhi.
Your future in data analytics starts here with Uncodemy!
2 notes
·
View notes
Text
What is Python, How to Learn Python?
What is Python?
Python is a high-level, interpreted programming language known for its simplicity and readability. It is widely used in various fields like: ✅ Web Development (Django, Flask) ✅ Data Science & Machine Learning (Pandas, NumPy, TensorFlow) ✅ Automation & Scripting (Web scraping, File automation) ✅ Game Development (Pygame) ✅ Cybersecurity & Ethical Hacking ✅ Embedded Systems & IoT (MicroPython)
Python is beginner-friendly because of its easy-to-read syntax, large community, and vast library support.
How Long Does It Take to Learn Python?
The time required to learn Python depends on your goals and background. Here’s a general breakdown:
1. Basics of Python (1-2 months)
If you spend 1-2 hours daily, you can master:
Variables, Data Types, Operators
Loops & Conditionals
Functions & Modules
Lists, Tuples, Dictionaries
File Handling
Basic Object-Oriented Programming (OOP)
2. Intermediate Level (2-4 months)
Once comfortable with basics, focus on:
Advanced OOP concepts
Exception Handling
Working with APIs & Web Scraping
Database handling (SQL, SQLite)
Python Libraries (Requests, Pandas, NumPy)
Small real-world projects
3. Advanced Python & Specialization (6+ months)
If you want to go pro, specialize in:
Data Science & Machine Learning (Matplotlib, Scikit-Learn, TensorFlow)
Web Development (Django, Flask)
Automation & Scripting
Cybersecurity & Ethical Hacking
Learning Plan Based on Your Goal
📌 Casual Learning – 3-6 months (for automation, scripting, or general knowledge) 📌 Professional Development – 6-12 months (for jobs in software, data science, etc.) 📌 Deep Mastery – 1-2 years (for AI, ML, complex projects, research)
Scope @ NareshIT:
At NareshIT’s Python application Development program you will be able to get the extensive hands-on training in front-end, middleware, and back-end technology.
It skilled you along with phase-end and capstone projects based on real business scenarios.
Here you learn the concepts from leading industry experts with content structured to ensure industrial relevance.
An end-to-end application with exciting features
Earn an industry-recognized course completion certificate.
For more details:
#classroom#python#education#learning#teaching#institute#marketing#study motivation#studying#onlinetraining
2 notes
·
View notes
Text

Wielding Big Data Using PySpark
Introduction to PySpark
PySpark is the Python API for Apache Spark, a distributed computing framework designed to process large-scale data efficiently. It enables parallel data processing across multiple nodes, making it a powerful tool for handling massive datasets.
Why Use PySpark for Big Data?
Scalability: Works across clusters to process petabytes of data.
Speed: Uses in-memory computation to enhance performance.
Flexibility: Supports various data formats and integrates with other big data tools.
Ease of Use: Provides SQL-like querying and DataFrame operations for intuitive data handling.
Setting Up PySpark
To use PySpark, you need to install it and set up a Spark session. Once initialized, Spark allows users to read, process, and analyze large datasets.
Processing Data with PySpark
PySpark can handle different types of data sources such as CSV, JSON, Parquet, and databases. Once data is loaded, users can explore it by checking the schema, summary statistics, and unique values.
Common Data Processing Tasks
Viewing and summarizing datasets.
Handling missing values by dropping or replacing them.
Removing duplicate records.
Filtering, grouping, and sorting data for meaningful insights.
Transforming Data with PySpark
Data can be transformed using SQL-like queries or DataFrame operations. Users can:
Select specific columns for analysis.
Apply conditions to filter out unwanted records.
Group data to find patterns and trends.
Add new calculated columns based on existing data.
Optimizing Performance in PySpark
When working with big data, optimizing performance is crucial. Some strategies include:
Partitioning: Distributing data across multiple partitions for parallel processing.
Caching: Storing intermediate results in memory to speed up repeated computations.
Broadcast Joins: Optimizing joins by broadcasting smaller datasets to all nodes.
Machine Learning with PySpark
PySpark includes MLlib, a machine learning library for big data. It allows users to prepare data, apply machine learning models, and generate predictions. This is useful for tasks such as regression, classification, clustering, and recommendation systems.
Running PySpark on a Cluster
PySpark can run on a single machine or be deployed on a cluster using a distributed computing system like Hadoop YARN. This enables large-scale data processing with improved efficiency.
Conclusion
PySpark provides a powerful platform for handling big data efficiently. With its distributed computing capabilities, it allows users to clean, transform, and analyze large datasets while optimizing performance for scalability.
For Free Tutorials for Programming Languages Visit-https://www.tpointtech.com/
2 notes
·
View notes
Text
Protect Your Laravel APIs: Common Vulnerabilities and Fixes
API Vulnerabilities in Laravel: What You Need to Know
As web applications evolve, securing APIs becomes a critical aspect of overall cybersecurity. Laravel, being one of the most popular PHP frameworks, provides many features to help developers create robust APIs. However, like any software, APIs in Laravel are susceptible to certain vulnerabilities that can leave your system open to attack.

In this blog post, we’ll explore common API vulnerabilities in Laravel and how you can address them, using practical coding examples. Additionally, we’ll introduce our free Website Security Scanner tool, which can help you assess and protect your web applications.
Common API Vulnerabilities in Laravel
Laravel APIs, like any other API, can suffer from common security vulnerabilities if not properly secured. Some of these vulnerabilities include:
>> SQL Injection SQL injection attacks occur when an attacker is able to manipulate an SQL query to execute arbitrary code. If a Laravel API fails to properly sanitize user inputs, this type of vulnerability can be exploited.
Example Vulnerability:
$user = DB::select("SELECT * FROM users WHERE username = '" . $request->input('username') . "'");
Solution: Laravel’s query builder automatically escapes parameters, preventing SQL injection. Use the query builder or Eloquent ORM like this:
$user = DB::table('users')->where('username', $request->input('username'))->first();
>> Cross-Site Scripting (XSS) XSS attacks happen when an attacker injects malicious scripts into web pages, which can then be executed in the browser of a user who views the page.
Example Vulnerability:
return response()->json(['message' => $request->input('message')]);
Solution: Always sanitize user input and escape any dynamic content. Laravel provides built-in XSS protection by escaping data before rendering it in views:
return response()->json(['message' => e($request->input('message'))]);
>> Improper Authentication and Authorization Without proper authentication, unauthorized users may gain access to sensitive data. Similarly, improper authorization can allow unauthorized users to perform actions they shouldn't be able to.
Example Vulnerability:
Route::post('update-profile', 'UserController@updateProfile');
Solution: Always use Laravel’s built-in authentication middleware to protect sensitive routes:
Route::middleware('auth:api')->post('update-profile', 'UserController@updateProfile');
>> Insecure API Endpoints Exposing too many endpoints or sensitive data can create a security risk. It’s important to limit access to API routes and use proper HTTP methods for each action.
Example Vulnerability:
Route::get('user-details', 'UserController@getUserDetails');
Solution: Restrict sensitive routes to authenticated users and use proper HTTP methods like GET, POST, PUT, and DELETE:
Route::middleware('auth:api')->get('user-details', 'UserController@getUserDetails');
How to Use Our Free Website Security Checker Tool
If you're unsure about the security posture of your Laravel API or any other web application, we offer a free Website Security Checker tool. This tool allows you to perform an automatic security scan on your website to detect vulnerabilities, including API security flaws.
Step 1: Visit our free Website Security Checker at https://free.pentesttesting.com. Step 2: Enter your website URL and click "Start Test". Step 3: Review the comprehensive vulnerability assessment report to identify areas that need attention.
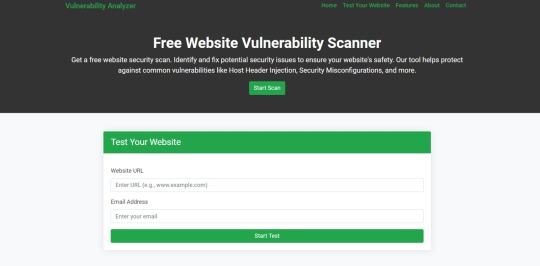
Screenshot of the free tools webpage where you can access security assessment tools.
Example Report: Vulnerability Assessment
Once the scan is completed, you'll receive a detailed report that highlights any vulnerabilities, such as SQL injection risks, XSS vulnerabilities, and issues with authentication. This will help you take immediate action to secure your API endpoints.
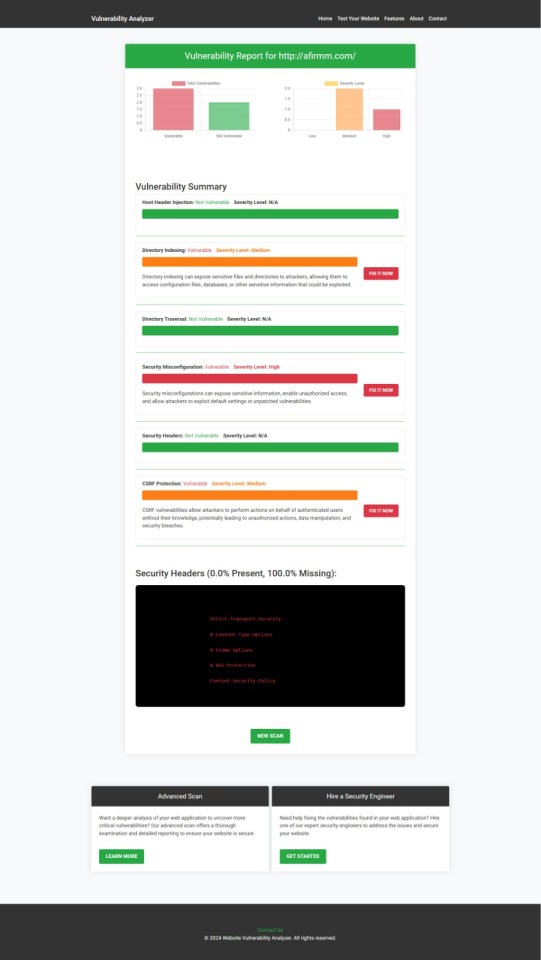
An example of a vulnerability assessment report generated with our free tool provides insights into possible vulnerabilities.
Conclusion: Strengthen Your API Security Today
API vulnerabilities in Laravel are common, but with the right precautions and coding practices, you can protect your web application. Make sure to always sanitize user input, implement strong authentication mechanisms, and use proper route protection. Additionally, take advantage of our tool to check Website vulnerability to ensure your Laravel APIs remain secure.
For more information on securing your Laravel applications try our Website Security Checker.
#cyber security#cybersecurity#data security#pentesting#security#the security breach show#laravel#php#api
2 notes
·
View notes