#how to delete wordpress site
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr has been banned in Indonesia for providing people with access to pornographic content.
Text
How to Delete a WordPress Site and Vanish From the Web
You’ve deleted the files—but your site still shows up on Google. Sound familiar? That’s because deletion isn’t just technical—it’s reputational. Learning how to delete WordPress site content thoroughly means knowing where your site lives beyond your server: cached in search engines, archived in public databases, and stored in metadata.

If your goal is full erasure, not digital limbo, it’s time to go beyond file deletion and explore the full lifecycle of content removal.
0 notes
Text
How to Delete Wordpress Site
Deleting a WordPress site should be done with caution, as it permanently removes all of your site's content, settings, and data. Make sure you have a backup of any data you want to keep before proceeding. Here's a step-by-step guide on how to delete a WordPress site:
Before you begin:
Backup your site: Use a WordPress backup plugin or your hosting provider's backup feature to create a backup of your site's content and database. This is crucial in case you change your mind or need to restore your site later.
Export Content: If you want to save any posts, pages, or other content, export it using the WordPress export tool. This will create an XML file you can import into another WordPress site if needed.

#how to delete wordpress site#how to delete wordpress site and start over#how to delete wordpress site hostinger#how to delete wordpress site from cpanel#how to delete wordpress site 2022#how to delete wordpress site from localhost#how to delete wordpress site godaddy#how to delete wordpress site 2023#how to delete your wordpress site and start again#how to delete a wordpress site on bluehost
1 note
·
View note
Text
yall, remind me so I don’t forget:
I am going to make a new side blog for my Flower Cows (since the old one’s a mess)
#random post#you don’t actually have to remind me I’m just typing this down so I myself don’t forget#But yeah I’m still gonna keep the old one up#(as a show of how far the species came)#but also because I don’t wanna risk deleting it & losing my whole Tumblr account XD#(cus if I remember correctly deleting a sideblog has a chance of deleting ur main too?)#But yeyeye I’m gonna work on remaking the account (hopefully before August ends & I have to go)#There will be more elaborate(?) lore#and hopefully more art!!#and I’m considering maybe trying Wordpress too?#since neither Neocities nor Google Sites worked for me#and Carrd worked but I couldn’t fit everything I want to#and the YouTuber that kinda enspired me to do make a Furry Original (Open) Species in the first place is using WordPress on their new speci#s#(their name is Sera Proto btw maybe check em out!! :3)#But yeyeye it’s gonna be all organized now :3#(…or at least I plan to try to.)
0 notes
Note
After Tumblr's backend migration to Wordpress, will the entire content of all half of billion blogs will be deleted??
Answer: Hi, @garotaviciada!
It’s important to note here that this is just the engine running the site, and there will be no changes to the front-end. So no—we’re not deleting content. All of Tumblr’s blogs, and the content on them, will continue to be served, both at the blog address and in the apps. There will just be different tech running under the hood.
Perhaps the simplest way to say so is that, besides a bug or two here or there, how you know and use Tumblr will not change at all. We hope this helps clarify things.
As it happens, we have answered similar questions here and here in the recent past—they also might be of interest. Thanks for getting in touch, and keep the questions coming, folks!
544 notes
·
View notes
Text
Full text of article as follows:
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
posts on deleted or suspended blogs
unanswered asks (normally these are not public until they’re answered)
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either. Instead of answering direct questions about these deals and the compiling of user data, Automattic sent a statement, which it posted publicly after this story was published, titled "Protecting User Choice." In it, Automattic promises that it's blocked AI crawlers from scraping its sites. The statement says, "We are also working directly with select AI companies as long as their plans align with what our community cares about: attribution, opt-outs, and control. Our partnerships will respect all opt-out settings. We also plan to take that a step further and regularly update any partners about people who newly opt out and ask that their content be removed from past sources and future training."
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believepartners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live postsays, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
Updated 4:05 p.m. EST with a statement from Automattic.
#It’s amazing how dishonest the staff post was#Original post#Posted for the convenience of users who are not currently subscribed to 404 media#But you absolutely should they’re great#10/10 highly recommended
162 notes
·
View notes
Text
I was at the library yesterday, which is now my go-to for distractionless work; I uploaded Dinner At The Palace with a few last edits so it's ready to go in print and epub, wrote all the sales copy, and updated my website with "coming soon" announcements. Wordpress really is just the worst; I can code what I want in about a third of the time it takes to tell Wordpress what I want and even then it fucks it up. It's like working with Word if it were designed by a toddler who hates me, personally. I'm building a new site on another platform, which is not much better but does allow me to copy, paste, or delete a block of text by selecting said text, something Wordpress's feeble grasp on structure is still grappling with. As we have daily proof. *gestures at Tumblr*
Anyway, I've been thinking about overhauling the older novels, standardizing them into the style guide I've developed. So I dug out all the upload files for Nameless, my first novel, and cracked them open just to see what kind of work it would take.
The document file for Nameless is so old that Windows wasn't sure how to open it. I mean it was just a .doc file and Windows likes to give you options when it's not a .docx, but I was still amused that I had to tell it how to get into the Ancient Tome. This was also before ebooks were as big as they are now, especially in indy publishing; these days you can just upload a word document and Lulu will convert it, but back in 2009 I had to create an HTML file of my novel to get it converted to ePub. Wild.
The bad news is that my early documents for my first few novels are a brutal mess, but the good news is that because I was less sophisticated in terms of how to typeset, they're also very simple and easy to upgrade, and even back then I was saving the covers as psd files, so it's all editable. I'd rather finish Royals/Ramblers than work over all my old manuscripts, but they're a nice break when I'm tired of other work.
Now I just have to determine if I have the emotional stability to re-read Nameless. It was a very personal novel to me, but it was also published almost 15 years ago, and I'm a little concerned about being able to read my deathless 2009 prose without wincing. I tell myself we all learn and grow, and Christopher and Lucas aren't real and won't suffer if I wrote them poorly, but I'm still bracing myself for all that.
125 notes
·
View notes
Text
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
posts on deleted or suspended blogs
unanswered asks (normally these are not public until they’re answered)
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI, but did not immediately hear back from the company. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either.
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live post says, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
45 notes
·
View notes
Text
Why Irish Businesses Should Always Maintain Their Websites
Since so much is pulled up online, your website may be the first interaction a customer has with you. Having a good-looking website can separate businesses in Limerick, Galway and even Dublin from rivals, allowing them to attract new customers.
We have assisted many Irish businesses and what we notice most is that keeping your website up to date helps maintain your online reputation and promotes growth in the future.
In the following sections, we will focus on why maintaining your website is important for your business.
1. First Impressions Matter
You would make sure the area near your store was tidy, fresh and not damaged. What is the point of doing it again in the cyber world?
Most of the time, a potential customer’s first contact with you happens when they visit your site. If the site takes a long time to open, links do not work, the information is old or the appearance is outdated, it gives a feeling that nobody cares. This scares off visitors and weakens your reputation.
If you regularly look after your website, it will continue to be fresh and serve its purpose, making people trust it and enjoy it.
2. Security Should Always Be Considered from the Beginning
More organizations are under cyber attacks and even small businesses are being targeted. Almost all the time, WordPress, Joomla, Magento and other content management systems make security updates to guard against new risks.
If you do not maintaining of your site:
Your customer details could be taken by fraudsters.
A search engine may blacklist your website.
Our maintenance services at Flo Web Design include regular security audits, updates for plugins and malware scans to give you a worry-free website and protect your visitors.
3. SEO depends on regular website maintenance
Google and other search engines prefer websites that get updated and maintained frequently. If a site is slow, features old information or isn’t accessible on mobile, it will be given a lower ranking by search engines.
Keeping your website updated makes it better:
How fast web pages are loading
Mobile responsiveness
Metadata and organized data
Dealing with broken links
Content freshness
As a result, your website becomes more visible to search engines, it gains higher positions and gets more traffic.
4. Improve the way users interact with the application
Website users today want sites that are easy to use and quick to respond. Anything that makes the site slow such as images that don’t load or ancient navigation, will lead them to leave.
Maintaining the website often helps keep:
All the links and pages are accessible.
Pictures and videos are displayed without any errors.
Checkout, buttons and forms work efficiently.
Updates are made to give the program a new look.
A seamless experience for users will make them more likely to stay and possibly become paying customers.
5. Making Sure Your Content is Up-to-Date
Information about companies can vary—such as their prices, services, working hours, contact details, special deals, employees and similar elements. If the changes aren’t reflected on your website, it confuses your customers and decreases trust.
If your site is updated, you demonstrate that your business is lively and interested in its customers.
Our team at Flo Web Design ensures that Irish companies update their content, update their blogs and remove any old materials from their website.
6. This involves backing up and recovering your data
Website crashes can happen for reasons such as plugin conflicts, issues with the server, hacking or making a mistake while deleting something important. If you don’t back up your files often, you could lose everything you have worked on for a long time.
With our maintenance package, your site is backed up automatically, making it easy and quick to restore it and continue your business.
7. The standards of both Compliance and Performance
All Irish businesses should follow the rules set out by GDPR. Failing to keep your contact forms and cookie policies current could result in serious fines and legal issues.
Maintenance done regularly will help your website:
Follows the necessary regulations for data protection.
The website is fast to load on every type of device.
Still works properly after OS and browser updates.
It’s more important to establish trust and eliminate risks than just fulfilling the requirements.
8. Making Your Website Resistant to Future Changes
Technology keeps advancing all the time. Plugins become old, browsers are updated and people’s needs change.
When you maintain your website regularly, it grows with your business. If you add new features, boost e-commerce or update the design, frequent upgrades help you not have to begin again.
How a Retailer in Ireland Benefited from Website Maintenance
A shop in Cork contacted us for help because their site was down for two days. Since the developers failed to update the site’s plugins or security measures for more than a year, the site was breached.
We recovered the site from our backup, removed the malware, updated the plugins and applied the best security measures. By opting for a monthly service package, they haven’t experienced any downtime and now get 35% more online inquiries due to faster performance.
Take action before a problem arises. Keeping your computer well-maintained is like having insurance.
So, What Services Are Part of Website Maintenance with Flo Web Design?
Our services include packages that are customized for businesses in Ireland.
Keeping an eye on security
Ensuring a fast website
Links on your website are checked for breaks
Backup & recovery
Updates on GDPR compliance
Updates to the content (upon request)
We’ll take care of your website’s back end, helping it run as efficiently as you run your business.
Conclusion
Just as you maintain a car regularly, you should keep your website up to date. This rule also applies to the internet. A secure, effective and successful website depends on regular upkeep.
Your website’s updates, security and page issues are all taken care of by Flo Web Design. We handle all the necessary jobs, allowing you to focus on your business.
Want to Maintain Your Site in the Best Way Possible?
We will make sure your website is kept safe, fast and performing at its peak each and every month.
2 notes
·
View notes
Text
So I've been looking through photomatt's responses to the situation (which he's since deleted but you can see them here https://www.dropbox.com/scl/fo/pyh4ca4v4mc0ggrklgd0i/h?rlkey=2se1p4911irku3mw42sp8htrz&e=2&dl=0) and I saw this:

Seriously? You're on the hook for nuking a trans person's account for no reason and the last thing you're thinking about is how the site's design handles posts with high popularity? YOU'RE BEING ACCUSED OF TRANSPHOBIC BEHAVIOR AND YOU'RE WORRIED ABOUT THE SITE'S FUCKING UX DESIGN?!
This is beyond pathetic. I'm starting to run out of words for how piss poor he's handling this situation.
[ID: A post from photomatt that reads "I'm continuing to get harassment and death threats here, in a way that is overwhelming the account. If it's hard for me to deal with this, with the team behind me, if nothing else this has given me a lot of empathy for how pile-ons must be totally unmanageable for users with the interface of Tumblr, especially the lack of basic things like bulk actions that have been in WordPress for a decade-plus." /end ID]
#justice for predstrogen#trans rights#car hammer explosion#sorry if I messed up the photo ID I haven't done it before
10 notes
·
View notes
Text
After privating all of my posts here (I am never deleting anything, not completely, that is), I have chanced upon the capital C graphic design Community here on Tumblr, which I have instantly joined to built rapport and connection with other graphic designers and graphic design students here on Tumblr (at least with the ones who are also interested in building together and in public, lol).
You can find the community here: https://www.tumblr.com/communities/graphic-design
And since I have said before that I want to do weekly round‑ups to look at what I was doing the last seven days, this post doubles (or triples?) as that, as a fauxrst post (false first post, I like those), as well as creating something (a)new.
The last week I was building an’ changing a few things on my website, drawing inspiration from all sorts of people, all sorts of places, all sorts of nets.
I have added a couple of new pages to my WordPress‑based website, and moved around navigational links.
There is of course the page with the design links to websites and podcasts you can use in your RSS feed readers of choice, provided you do a little bit of digging (if you need some help with that, you can write me any way you like, and we’ll look into it together)

The new stuff I put in the footer, following inspiration from Scott Boms website.
I have a page for friends now (currently made up of my teachers, tutors, and professors, mostly), a page for what I am doing now, called Now (which is a really cool idea, and it fits neatly between the very thin substance of a status post, and a long form post like this one, both in size, as well as now‑ness; you can find out more about that here: https://nownownow.com/about)

But what I think is the most important addition to my website, is the page about tools, “Werkzeuge” in German.
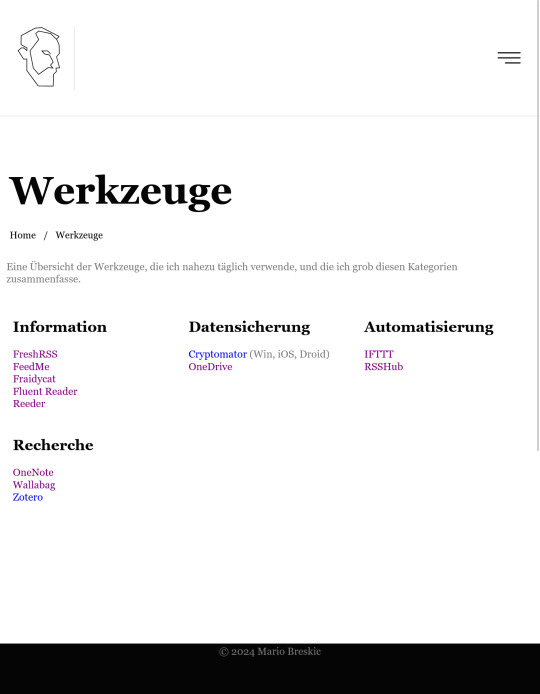
Here I could finally dump all of my graphic design hacker tools, at least that is how I think of them.
My system consists of two pillars: new information, and how it is being stored. I believe that everyone rolls their own tools after a while. I would just love it if somebody would find some use for mine, if only to build something better from that.
The two RSS feeds linked to from the footer are neat: you have the usual feed for the whole site, but I also provided an RSS feed of my custom status updates, which you can see on Home.
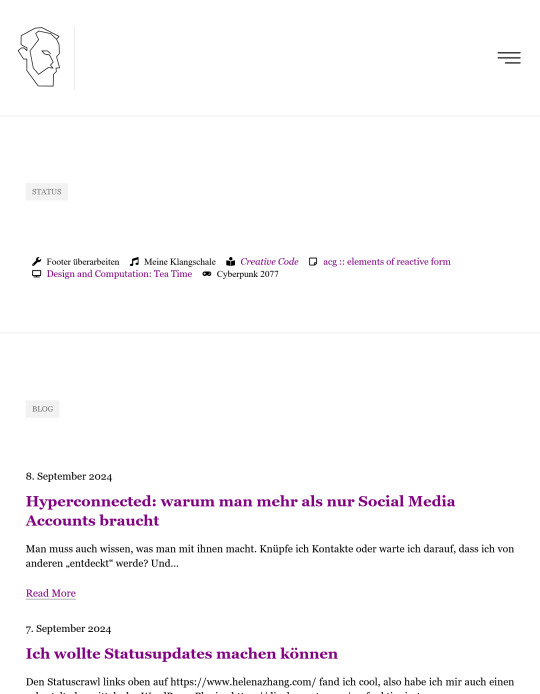
These status updates are my own, most recent solution to my issues with posting, well, status updates on my socials:
you know, issues like
am I posting the same status update to every net I have an account for,
will I automate and schedule the same content everywhere and be a boring, cold machine, and
do I want to burn myself out coming up thesaurus’d variants of the same post for every net?
So now there are two ways to check (three, really) in what mess I’ve gotten myself into recently: you can check my Now page, you can look at my Statuses, or you can check it out using your own, third way.
As for my study schedule, I am glad that summer is over, because I clearly cannot function during summer. I hope with cooler days ahead, I can keep a cooler head while practicing the art of not judging what I do or don’t do. I might have gotten my degree, but I want to learn so much more.
Started reading Creative Code by John Maeda and sort of forensically/archeologically recreating the years during which it was written and printed, because these past twenty years have basically muddied the tracks quite a bit, so to speak. It is a good read.
And I think I have covered the whole week now, broadly enough.
I need to figure out which hashtags should go with this post. I need to look at the top posts for each tag I think could fit, and then consider what being in the top means for each tag I am looking at.
Eh, let’s go through this together:
huge tags first (>1 million followers)
#drawing
6.1M followers
1.3K recent posts
#artwork
3M followers
1.3K recent posts
#illustration
16M followers
962 recent posts
#digital painting
1.6M followers
157 recent posts
#digital art
5.5M followers
3.5K recent posts
#sketch
4.8M followers
662 recent posts
#traditional art
1.2M followers
448 recent posts
#graphic design
5.8M followers
this one doesn’t even show a recent posts count at all? But it feels extremely dead if you look at recent posts under that tag.
We’ll figure this out together. If it is graphic design, then I will tag it as such. If it is something else, then I will not tag it as graphic design. I think that this is a solid foundation towards connecting.
So, what is this post?
It is about my website, it is about studying, about me being a graphic designer, and about software I use. Also, it is about creative coding, generative art, a book, and that I use WordPress.
So I wonder which tags I will use? I prefer low counts when it comes to hashtags. Five sounds reasonable, nice for chunking, too,
So there. I might not be a student anymore, but that means that I have just proven to have the discipline to get my degree, so studyblr fits.
Hi everyone! Hello world.
4 notes
·
View notes
Text
Bro Your Taste....
12 Days of Aniblogging 2023, Day 5
Watching the Elitist Anime Superbowl play out earlier this year on Tumblr reawakened something in me. Seeing Evangelion lose to Mononoke like that in round two felt downright heretical. But why? I started but never finished NGE and I haven’t even seen Mononoke, so I shouldn’t have a dog in the fight. And yet, there’s an unspoken yet established hierarchy in my brain that tells me that Eva is better than Mononoke. These polls were a bit of a wake-up call for me that this isn't actually a common framework or approach anymore! So I thought it might be worthwhile to give an account of what anime elitism meant, and means, to me.

tldr (from KC Green's anime club)
Rather than going through all the shows in the bracket, it may be more useful to start by identifying which internet communities skew elitist in the first place. I started watching anime in the early 2010s, so Usenet and early forums and email discussion groups are lost on me. But I did my time on 4chan, for better or for worse. /a/ is perhaps the textbook example of an elitist community, and I would say that they’re responsible for establishing most of the modern weeb canon. The anime blogosphere, though diminished these days, is also a tastemaker, especially when you start seeking out “hidden gems” to make your taste seem cooler and more unique. I originally considered making Floating Catacombs a WordPress blog to try and link up with some of these folks, but ultimately determined that the baked-in audience of Tumblr would better serve my purposes (and they’re owned by the same damn guy now anyways). Lastly, as those previous communities declined, patchwork groups of elitists began to form on Twitter, where many still reside to this day arguing and ass-kissing amongst one another.
Elitism is, in part, an acknowledgement that the vast majority of anime is dogshit. Just look at any given season and count up the isekai shlock, blatant wish fulfillment high school romances, and mediocre shounens ripping off other mediocre shounens. At least 75% of anime is stuff you’d have to pay me to watch. Of course, this isn't unique to anime, being just as true of live-action TV. The difference is that prestige television doesn't have to compare itself to soap operas or reality TV, whereas anime is still commonly treated as a genre in of itself rather than as a medium. As long as that’s the case, anime elitism will always have a place, as a way to say “oh I like anime but not like that” so your taste doesn’t automatically get lumped in with the most low-quality and/or sexually dubious shows of the time.
And obviously, elitism can just as easily be framed as a reaction against the masses. There’s liking Mushishi for the sake of liking Mushishi, and there’s liking Mushishi because its serenity and thoughtfulness reflect well upon you for being able to appreciate it, unlike those dirty Redditors and MyAnimeList denizens who need fanservice in everything they watch. Unfortunately, this means elitists have a tendency to elevate some truly pretentious stuff that looks cool but just isn’t very compelling or deep under the surface. Ergo Proxy is my personal go-to example of this– how it beat out Stand Alone Complex in that Tumblr poll is a mystery to me. I’d argue that Lain is also overrated in this way, but I don’t want to hurt all the sad neurodivergent extremely online women who probably make up my entire audience.

One thing I've noticed is that elitist communities don’t make a ton of art or fanfic or other creative works. For them, the primary way to participate in fandom is to argue over whether or not a show was good, or if a given part of a show was good (waifu wars, etc). This makes the output of these sites fairly ephemeral (in particular, imageboards automatically delete threads to make room for new ones), but it also means that people will constantly repeat themselves and get in the same arguments to make themselves persistently heard. We’re still arguing about Evangelion 25 years later, after all! After using shows as a cudgel against other shows for a long enough time, you can start to form a hierarchy of notable anime in ways that you can’t really with Tumblr or Reddit or any other community that largely hops from show to show as they come out.
The canon for anime elitism is mostly contained to the late 90s and 2000s, and I think there’s a few reasons for that. As I brought up in the Patlabor post, the 80s are something of a dark age for broadcast anime, while the 90s contain some of the last beautiful breaths of cel animation. The 2000s were when 4chan had an outsized presence online, so it makes sense that a lot of shows deemed elitist come from the era where their taste was king. By the mid-2010’s, after GamerGate, moot’s departure, and the blatant fascism on every board, 4chan’s cultural clout had effectively zeroed out.
There’s also the blunt argument that simply fewer cool artsy anime get made these days. Ping Pong is one of the last truly “elitist” shows I can point to, and that was nearly a decade ago. Due to the overlapping issues of anime overproduction, poor working conditions, and production committees seeking ever-safer investments, a lot of the stuff that comes out these days has a very workmanlike quality to it, competent but never targeting excellence.

OHHH YEAHHHHH
But my final reason for the decline of elitism is a wholly good one – more people are appreciating the good stuff these days! Watching anime has somehow become a normal hobby for the teens that grew up after me, no longer something that needs to be hidden and consigned to small school anime clubs. While battle shounen still reigns supreme, it’s probably leagues better than the comparable stuff from 10 or 20 years ago (though still pretty damn misogynist most of the time). More importantly, new fans and old-guard elitists actually agree on the good stuff! Works like Mob Psycho 100 and Trigun Stampede were huge hits and bridged the gap between these groups through their quality and style, and in Trigun’s case by re-adapting a classic. The breakthrough success of Bocchi the Rock demonstrates that people can vibe with more experimental animation now, and it doesn’t have to be relegated to its own sphere outside of the anime mainstream. And Oshi no Ko has a difficult “dude trust me” pitch but successfully synthesized the pretentious and the mass-market in terms of both its audience and its themes. (I would guess. I haven’t actually seen Oshi no Ko either. An important, unspoken part of anime elitism is lying about half the stuff you’ve seen and just going with the flow on how people around you felt about it). Combining an old-school 90’s-2000s feel with insane pacing and fights, Chainsaw Man similarly captured a wide audience. Even if people have qualms with the overall quality of the adaptation, that one episode shot like a movie won me over. It’s good that some of the most popular anime can be artsy as well, and if that’s what ultimately does elitism in, it will be a happy ending. May poptimism save us all.

In the meantime, elitism lives on in the manga world, where smug assholes can talk about how they liked a series before it got adapted. Manga is very popular these days, but that's mainly driven by people diving into the source material for anime that they enjoyed. This leaves fundamentally unadaptable manga as the last bastion of elitism, which makes sense when you consider how people talk about Berserk.
I’ll leave you with some rapid-fire hot takes of mine.
Steel Ball Run is not that good and its ranking on MyAnimeList as the second best manga of all time is nonsense. It will receive more proper crit in a few years once the inevitable David Production adaptation shines a light on its more troublesome bits.
After rewatching it this year, I can say with clarity that Everyone Is Sleeping On Concrete Revolutio
Goodnight Punpun kind of sucks! Might just be me.
As far as beloved 90’s psychological anime goes, 4chan and Reddit historically love Eva, while Tumblr overwhelmingly went for Utena in that poll. This whole thing smacks of gender.
The Gundam fandom historically has something of a reputation for misogyny, so it’s really funny and good that my exposure has instead been almost entirely trans women on tumblr. We will inherit the mecha genre.
Actually, screw manga, there is only one vector for anime elitism now, and it’s Thunderbolt Fantasy. You gotta get in on Gen Urobuchi’s Wild Puppet Show.

6 notes
·
View notes
Text
SO WHAT IS TUMBLR'S SURVEY?
I'm not sure if this is something people are seeing site-wide, but the Tumblr staff is asking users to sign up and complete a survey regarding feedback, prototype-testing, and such. You may have seen this banner at the top of your dashboard:

I recognize, after giving them my blog information, that it is very unlikely they will reach out to me for such matters despite giving my consent...
But seemingly unlike Tumblr's staff, I value transparency! So, I'm going to talk about what's on there, and what I personally responded with.
Some quick disclaimers:
I am not asking for people to copy/paste or use my answers to influence their own survey responses. In fact, I discourage directly copying answers or "spamming"/"overloading" the survey. If you, as an individual, agree with the points I have brought up, please voice them in your own words and in your own survey response.
I am not violating any known terms by discussing this survey, as there is no confidentiality agreement present upon beginning the survey.
Everything I mention in this post, as well as in my response, are alleged (excluding details surrounding Tumblr's NYCCHR Settlement, which is publicly accessible information -> Summary of NYC Gov. Settlements [ LINK ] and NYCCHR Settlement Documentation [ LINK ].
With that out of the way, let's get started.
The survey itself is pretty standard in terms of engagement and feedback. It is hosted by Crowdsignal, which is Automatic's own platform hosted under Wordpress (re: you use a Wordpress account, or it is highly encouraged to use said account, to create a Crowdsignal account). It features type-box responses, as well as a few typical Likert-scale questions.
As for the content, it begins standard. As the company states they wish to gain a wide array of responses, the first group of questions is pretty straightforward: When did you first join Tumblr, when is the last time you used Tumblr, how often do you use Tumblr, etc.
There is an interesting question, Question 4, asking users to rank their average activity on Tumblr. The activities are things such as reblogging posts, liking posts, sending direct messages, etc etc., and has a ranking system from "Never" to "Always", with a "Not Sure" option for those who aren't sure how to rank.
Then, we start to get into the meat of the survey a little. At least, for vocal little assholes like me. The next question is "Which of the following purchases have you made on Tumblr?"
And questions structured like this one, with multiple choice boxes and an "Other" type-box… Allow for feedback. So I gave some.
In response to being asked about my purchase history, I selected "None", then used the type-box to respond with the following:
I refuse to financially support Tumblr until the company and its employees uphold the promises made by themselves, and in accordance with the NYCCHR Settlement regarding blatant discrimination against its userbase on the basis of sexual orientation and gender identity, as well as their less-investigated biases against BIPOC bloggers, particularly those that are Black.
There's a few more standard selection questions regarding the method(s) one uses to visit Tumblr, as well as what interest areas (e.g., fandom, gaming) you interact with. They also ask about how many primary accounts and sideblogs you have…
Then they strike again. The first question asking for a solely written response is summarizing the typical activities one does on Tumblr. The second, however, is much more intriguing:
"If you could change one thing about Tumblr, what would it be and why? If you would not change anything, please explain why."
There are… many things. But they asked for one, so I gave them one:
If I could change one thing about Tumblr, it would be the site moderation. Users have brought the seeming lack of moderation to attention time and time again, only to be met with waves of discriminatory moderation application. Appropriately filtered content gets deleted, or a blog banned, whilst hate speech and active harassment campaigns (particularly against LGBTQ+ and BIPOC individuals) are not only allowed to remain on the site, but often allowed/approved to be Blazed. Time and time again, too, the website's staff has promised that things would be fixed. Time and time again, including in the window following the NYCCHR Settlement, the site staff has not only not made any notable work on fixing these rampant issues, but has doubled-down and blamed its userbase for a lack of financial support.
In short, the moderation system. And this should be a surprise to nobody that follows me, as I've posted time and time again about how… poor, this system is. Whether it was my own experiences, or the experiences of those who have since had to rebuild their platforms, or who have had to outright leave the site due to the incessant harassment campaigns.
And then there's another small lull in questioning, which asks about the search functionality. Personally, if I were one to design this survey, I would have swapped Questions 12 and 13… But I acknowledge that 1) I have recency bias in discussing the moderation system and 2) it's possible that whoever is on the metrics team creating this survey simply is unaware that this may be (or is, depending on the crowd) the hottest issue on Tumblr. But I digress, let's jump to Question 13:
"How satisfied are you with the current system for reporting harassment on Tumblr?"
Now… If you've read this far, you know my answer. If you've followed me for more than a day, you know my answer. So I will let the survey response speak for itself:
The current system for reporting harassment is comical at best, and adversarial at worst. There have been many times that I have reported hate speech, graphic depictions of violence, and similarly harmful content, only to receive no follow-up / to see that the content is allowed to remain. This includes things found in tags, on the dashboard, and through the site's Blaze campaign. Yet, I too have seen posts about queerness (posts not sexual in nature, nor depicting anything else violating the ToS) be censored, removed, and flagged for being "inappropriate" for the userbase. At the VERY LEAST, I believe the system could be better if there were actual communication between the staff and the user, and if the report form were easier to locate. Reddit's moderation system, for example, works effectively not only in properly removing harmful content, but in communicating that these reports are being received and acknowledged.
From here, there aren't many options for feedback. The survey's focus shifts into the prototype-testing side of things. Determining what devices the user has access to, if they've been involved in prior research interviews/focus groups, if there's interest in these programs, etc etc.
So I fill it out accordingly (showing interest in providing feedback via virtual tests and sharing screens), give them my preferred email (not the one I use for Tumblr, but the story behind that is long and boring, and I'd rather forget it), age range, and my blog name.
Hello poor staffer who has to vet me! I'm not mad at you, I'm mad at your CEO.
And then you can receive a copy via email, if you provide it again. As someone who values transparency (and receipts), I would recommend doing this regardless of if you give in-depth feedback or not.
It's just nice to have a copy of the information you provided, as you may be asked to recall it upon being selected for any future communications.
In short, Tumblr has opened a channel for feedback and I do encourage people to give that feedback, regardless of if you're interested in the prototypes and interviews and whatever. You are a user of the platform. You have a voice; let it be heard!
2 notes
·
View notes
Text
A little Glazed...
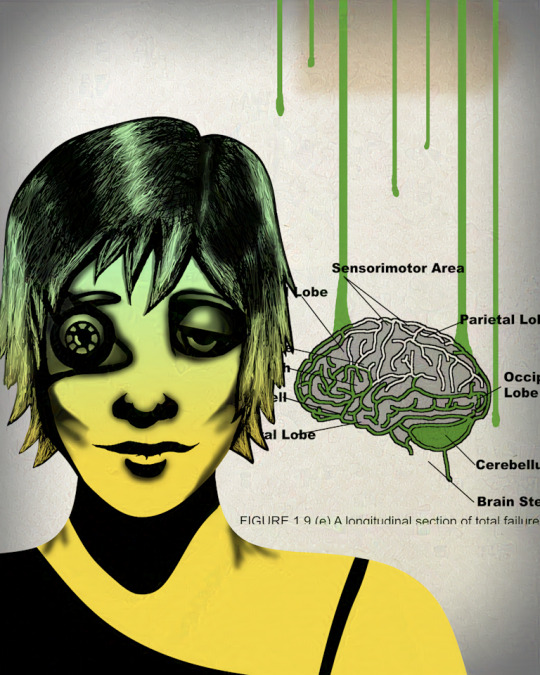
Ya know, there are some artifacts, but I'll take it! You'll put up with this art quality at the site, won't you, my few readers? More info under the cut!
The spouse says he feels this image in his soul, and I think I do too!
Glaze on a CPU is slooooooooooow! I had time for two test images today, and this is the second. The other had way more artifacts. I can try the web version, and there are instructions for running it on the GPU, but either of those is more complicated. As it is, it's worth my while to baffle WordPress, but if/when Tumblr sells out to AI, I'm going to have to take a few days and just DELETE all my art from my old posts. Hell, it's not like I'm popular. No one's gonna miss it.
I do not know how to add Nightshade, if that's possible for me. Honestly, I think this looks screwy enough and I don't want to do more things to it that take more time and might make it look worse.
Now that I have a Ko-Fi store, I can offer you the real, print-quality (300 dpi at 8 by 10!) illustrations as downloads. If, for example, you want Erik as Natalie Bassingthwaighte on your desktop or wall.
Here's my reference image, screenshotted from Voodoo Child by Rogue Traders:

Not bad in comparison, huh? See what I was goin for? I can still do shading and copy a style! I'm just slooooooow like Glaze on a CPU!
The brain is based on Open Clip Art and I'd swear the heart in the video is too. They look really similar! Everything else is all me and the line tool.
I think I want this illustration for A Little Loopy, but I might want it for Black Box. The content of both is similar! I'll put it up when I decide, and I'll see what I can do with my store.
I really, really miss this level of complexity, but I can't do shading and everything every time and keep up with myself. Even with my new, simplified style, I already can't keep up with myself! I'd have to slow down way more to give you this kind of art on time with every instalment, and I don't wanna. I wanna tell stories!!!
But I also really like it when I can make something that looks cool. I want better eyes and better motor skills and I lost my antifouling glove somewhere and I think I'll wobble less if I can find it. Bleh.
More art is inevitable, it'll just take time! And days in a row of skipping my eye exercises and staring at pixels instead!
2 notes
·
View notes
Text
writer sites
i was wondering how many other writers here blog on their own personal site rather than a 'third-party' one (substack, medium, tumblr, etc)? do you find one beneficial over the other? or is it just based on preference?
recently, i've been thinking about deleting my wordpress site and going heavy on medium, but i'm not sure yet. what says you?
#rext#rex#wordpress#writers life#writer#queer writers#writers on tumblr#tumblr writers#creative writing#writers#writerscommunity#medium#substack
2 notes
·
View notes
Text
Found this while looking for Wordpress user responses to the AI scraping situation:
And I agree wholeheartedly. On top of that, I know AI firms are desperate for more input, anything to keep the machine churning, but I just don't see how Tumblr and Reddit and so forth benefit them as inputs. GIGO, as they say, which is not to say that Tumblr is garbage, but that Midjourney et al are already being sued by everyone left and right for copyright infringement! And these aren't preemtive theoreticals or anything:
Not to mention (from the 404 Media coverage):
the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included: - private posts on public blogs - posts on deleted or suspended blogs - unanswered asks (normally these are not public until they’re answered) - private answers (these only show up to the receiver and are not public) - posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know) - content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.
(bolding mine)
Those are all DIFFERENT grounds for lawsuits. Class action privacy lawsuits. Class action data lawsuits. Nonconsenual porn distribution. Taking in copyright-owned material directly, not to mention I remain convinced that scraping the website full of fan gifs — i.e. TV AND MOVIE CLIPS — is a recipe for getting your ass handed to you by thirty thousand media companies.
And they are desperate for input so there's no way they're going to have the ability to filter all of this accurately; not to mention, Tumblr seems to have either tested a data set or given them a data set already? So that shit's ALL JUST IN THERE ALREADY? BOIIIIIIIIIIIIII
It's one thing to pay to suck down, say, Shutterstock's database, which has creators uploading their work and only their work for reuse and distribution. Tumblr blog data is not clean like Shutterstock data. Tumblr is full of users sharing information and links with eachother, and fan blogs sharing things within fair use law, and that is not the same fucking thing AT ALL.
Tumblr the company may be getting money out of this deal but you KNOW (and Tumblr corporate: if you don't see this coming, you're fucking dipshits) Midjourney/OpenAI is going to use them as an excuse and rope them into any lawsuits regarding the matter. So that's probably a net loss for you, Tumblr? You know? Have you considered that?
You COULD just say, hey. The website is constantly in debt and we need to raise $30M in user sponsorships or else the site is going down at the end of the year. But instead you're like, "actually, I think I'd prefer to take a cattleprod up my ass"
2 notes
·
View notes
Text
Full Article Under Cut
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
unanswered asks (normally these are not public until they’re answered)
posts on deleted or suspended blogs
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI, but did not immediately hear back from the company. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either.
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live post says, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
3 notes
·
View notes