#how to delete wordpress site 2023
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
28.6 is the average number of monthly visits per US mobile user.
Text
How to Delete Wordpress Site
Deleting a WordPress site should be done with caution, as it permanently removes all of your site's content, settings, and data. Make sure you have a backup of any data you want to keep before proceeding. Here's a step-by-step guide on how to delete a WordPress site:
Before you begin:
Backup your site: Use a WordPress backup plugin or your hosting provider's backup feature to create a backup of your site's content and database. This is crucial in case you change your mind or need to restore your site later.
Export Content: If you want to save any posts, pages, or other content, export it using the WordPress export tool. This will create an XML file you can import into another WordPress site if needed.

#how to delete wordpress site#how to delete wordpress site and start over#how to delete wordpress site hostinger#how to delete wordpress site from cpanel#how to delete wordpress site 2022#how to delete wordpress site from localhost#how to delete wordpress site godaddy#how to delete wordpress site 2023#how to delete your wordpress site and start again#how to delete a wordpress site on bluehost
1 note
·
View note
Text
Full text of article as follows:
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
posts on deleted or suspended blogs
unanswered asks (normally these are not public until they’re answered)
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either. Instead of answering direct questions about these deals and the compiling of user data, Automattic sent a statement, which it posted publicly after this story was published, titled "Protecting User Choice." In it, Automattic promises that it's blocked AI crawlers from scraping its sites. The statement says, "We are also working directly with select AI companies as long as their plans align with what our community cares about: attribution, opt-outs, and control. Our partnerships will respect all opt-out settings. We also plan to take that a step further and regularly update any partners about people who newly opt out and ask that their content be removed from past sources and future training."
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believepartners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live postsays, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
Updated 4:05 p.m. EST with a statement from Automattic.
#It’s amazing how dishonest the staff post was#Original post#Posted for the convenience of users who are not currently subscribed to 404 media#But you absolutely should they’re great#10/10 highly recommended
162 notes
·
View notes
Text
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
posts on deleted or suspended blogs
unanswered asks (normally these are not public until they’re answered)
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI, but did not immediately hear back from the company. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either.
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live post says, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
45 notes
·
View notes
Text
Bro Your Taste....
12 Days of Aniblogging 2023, Day 5
Watching the Elitist Anime Superbowl play out earlier this year on Tumblr reawakened something in me. Seeing Evangelion lose to Mononoke like that in round two felt downright heretical. But why? I started but never finished NGE and I haven’t even seen Mononoke, so I shouldn’t have a dog in the fight. And yet, there’s an unspoken yet established hierarchy in my brain that tells me that Eva is better than Mononoke. These polls were a bit of a wake-up call for me that this isn't actually a common framework or approach anymore! So I thought it might be worthwhile to give an account of what anime elitism meant, and means, to me.

tldr (from KC Green's anime club)
Rather than going through all the shows in the bracket, it may be more useful to start by identifying which internet communities skew elitist in the first place. I started watching anime in the early 2010s, so Usenet and early forums and email discussion groups are lost on me. But I did my time on 4chan, for better or for worse. /a/ is perhaps the textbook example of an elitist community, and I would say that they’re responsible for establishing most of the modern weeb canon. The anime blogosphere, though diminished these days, is also a tastemaker, especially when you start seeking out “hidden gems” to make your taste seem cooler and more unique. I originally considered making Floating Catacombs a WordPress blog to try and link up with some of these folks, but ultimately determined that the baked-in audience of Tumblr would better serve my purposes (and they’re owned by the same damn guy now anyways). Lastly, as those previous communities declined, patchwork groups of elitists began to form on Twitter, where many still reside to this day arguing and ass-kissing amongst one another.
Elitism is, in part, an acknowledgement that the vast majority of anime is dogshit. Just look at any given season and count up the isekai shlock, blatant wish fulfillment high school romances, and mediocre shounens ripping off other mediocre shounens. At least 75% of anime is stuff you’d have to pay me to watch. Of course, this isn't unique to anime, being just as true of live-action TV. The difference is that prestige television doesn't have to compare itself to soap operas or reality TV, whereas anime is still commonly treated as a genre in of itself rather than as a medium. As long as that’s the case, anime elitism will always have a place, as a way to say “oh I like anime but not like that” so your taste doesn’t automatically get lumped in with the most low-quality and/or sexually dubious shows of the time.
And obviously, elitism can just as easily be framed as a reaction against the masses. There’s liking Mushishi for the sake of liking Mushishi, and there’s liking Mushishi because its serenity and thoughtfulness reflect well upon you for being able to appreciate it, unlike those dirty Redditors and MyAnimeList denizens who need fanservice in everything they watch. Unfortunately, this means elitists have a tendency to elevate some truly pretentious stuff that looks cool but just isn’t very compelling or deep under the surface. Ergo Proxy is my personal go-to example of this– how it beat out Stand Alone Complex in that Tumblr poll is a mystery to me. I’d argue that Lain is also overrated in this way, but I don’t want to hurt all the sad neurodivergent extremely online women who probably make up my entire audience.

One thing I've noticed is that elitist communities don’t make a ton of art or fanfic or other creative works. For them, the primary way to participate in fandom is to argue over whether or not a show was good, or if a given part of a show was good (waifu wars, etc). This makes the output of these sites fairly ephemeral (in particular, imageboards automatically delete threads to make room for new ones), but it also means that people will constantly repeat themselves and get in the same arguments to make themselves persistently heard. We’re still arguing about Evangelion 25 years later, after all! After using shows as a cudgel against other shows for a long enough time, you can start to form a hierarchy of notable anime in ways that you can’t really with Tumblr or Reddit or any other community that largely hops from show to show as they come out.
The canon for anime elitism is mostly contained to the late 90s and 2000s, and I think there’s a few reasons for that. As I brought up in the Patlabor post, the 80s are something of a dark age for broadcast anime, while the 90s contain some of the last beautiful breaths of cel animation. The 2000s were when 4chan had an outsized presence online, so it makes sense that a lot of shows deemed elitist come from the era where their taste was king. By the mid-2010’s, after GamerGate, moot’s departure, and the blatant fascism on every board, 4chan’s cultural clout had effectively zeroed out.
There’s also the blunt argument that simply fewer cool artsy anime get made these days. Ping Pong is one of the last truly “elitist” shows I can point to, and that was nearly a decade ago. Due to the overlapping issues of anime overproduction, poor working conditions, and production committees seeking ever-safer investments, a lot of the stuff that comes out these days has a very workmanlike quality to it, competent but never targeting excellence.

OHHH YEAHHHHH
But my final reason for the decline of elitism is a wholly good one – more people are appreciating the good stuff these days! Watching anime has somehow become a normal hobby for the teens that grew up after me, no longer something that needs to be hidden and consigned to small school anime clubs. While battle shounen still reigns supreme, it’s probably leagues better than the comparable stuff from 10 or 20 years ago (though still pretty damn misogynist most of the time). More importantly, new fans and old-guard elitists actually agree on the good stuff! Works like Mob Psycho 100 and Trigun Stampede were huge hits and bridged the gap between these groups through their quality and style, and in Trigun’s case by re-adapting a classic. The breakthrough success of Bocchi the Rock demonstrates that people can vibe with more experimental animation now, and it doesn’t have to be relegated to its own sphere outside of the anime mainstream. And Oshi no Ko has a difficult “dude trust me” pitch but successfully synthesized the pretentious and the mass-market in terms of both its audience and its themes. (I would guess. I haven’t actually seen Oshi no Ko either. An important, unspoken part of anime elitism is lying about half the stuff you’ve seen and just going with the flow on how people around you felt about it). Combining an old-school 90’s-2000s feel with insane pacing and fights, Chainsaw Man similarly captured a wide audience. Even if people have qualms with the overall quality of the adaptation, that one episode shot like a movie won me over. It’s good that some of the most popular anime can be artsy as well, and if that’s what ultimately does elitism in, it will be a happy ending. May poptimism save us all.

In the meantime, elitism lives on in the manga world, where smug assholes can talk about how they liked a series before it got adapted. Manga is very popular these days, but that's mainly driven by people diving into the source material for anime that they enjoyed. This leaves fundamentally unadaptable manga as the last bastion of elitism, which makes sense when you consider how people talk about Berserk.
I’ll leave you with some rapid-fire hot takes of mine.
Steel Ball Run is not that good and its ranking on MyAnimeList as the second best manga of all time is nonsense. It will receive more proper crit in a few years once the inevitable David Production adaptation shines a light on its more troublesome bits.
After rewatching it this year, I can say with clarity that Everyone Is Sleeping On Concrete Revolutio
Goodnight Punpun kind of sucks! Might just be me.
As far as beloved 90’s psychological anime goes, 4chan and Reddit historically love Eva, while Tumblr overwhelmingly went for Utena in that poll. This whole thing smacks of gender.
The Gundam fandom historically has something of a reputation for misogyny, so it’s really funny and good that my exposure has instead been almost entirely trans women on tumblr. We will inherit the mecha genre.
Actually, screw manga, there is only one vector for anime elitism now, and it’s Thunderbolt Fantasy. You gotta get in on Gen Urobuchi’s Wild Puppet Show.

6 notes
·
View notes
Text
Found this while looking for Wordpress user responses to the AI scraping situation:
And I agree wholeheartedly. On top of that, I know AI firms are desperate for more input, anything to keep the machine churning, but I just don't see how Tumblr and Reddit and so forth benefit them as inputs. GIGO, as they say, which is not to say that Tumblr is garbage, but that Midjourney et al are already being sued by everyone left and right for copyright infringement! And these aren't preemtive theoreticals or anything:
Not to mention (from the 404 Media coverage):
the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included: - private posts on public blogs - posts on deleted or suspended blogs - unanswered asks (normally these are not public until they’re answered) - private answers (these only show up to the receiver and are not public) - posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know) - content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.
(bolding mine)
Those are all DIFFERENT grounds for lawsuits. Class action privacy lawsuits. Class action data lawsuits. Nonconsenual porn distribution. Taking in copyright-owned material directly, not to mention I remain convinced that scraping the website full of fan gifs — i.e. TV AND MOVIE CLIPS — is a recipe for getting your ass handed to you by thirty thousand media companies.
And they are desperate for input so there's no way they're going to have the ability to filter all of this accurately; not to mention, Tumblr seems to have either tested a data set or given them a data set already? So that shit's ALL JUST IN THERE ALREADY? BOIIIIIIIIIIIIII
It's one thing to pay to suck down, say, Shutterstock's database, which has creators uploading their work and only their work for reuse and distribution. Tumblr blog data is not clean like Shutterstock data. Tumblr is full of users sharing information and links with eachother, and fan blogs sharing things within fair use law, and that is not the same fucking thing AT ALL.
Tumblr the company may be getting money out of this deal but you KNOW (and Tumblr corporate: if you don't see this coming, you're fucking dipshits) Midjourney/OpenAI is going to use them as an excuse and rope them into any lawsuits regarding the matter. So that's probably a net loss for you, Tumblr? You know? Have you considered that?
You COULD just say, hey. The website is constantly in debt and we need to raise $30M in user sponsorships or else the site is going down at the end of the year. But instead you're like, "actually, I think I'd prefer to take a cattleprod up my ass"
2 notes
·
View notes
Text
Full Article Under Cut
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
unanswered asks (normally these are not public until they’re answered)
posts on deleted or suspended blogs
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI, but did not immediately hear back from the company. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either.
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live post says, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
3 notes
·
View notes
Text

Ta-Da! List: Saturday - 12/16
I have decided to make a “Ta-Da! List” every day! There won’t be TMI.
Don’t know what a “Ta-Da! List” is? To learn more, check out @adhdjesse's book Extra Focus here.
– (throughout the day) made emails more manageable by deleting some while unsubscribing from email lists no longer necessary/wanted and added songs to the “Reading” playlist via Amazon Music – gave a human artist, L Finch, a shout-out on the WGS Instagram and the WGS FB page, created a Featured Image for it, then added it to the ASO ArtStation Collection and to the ASOs Album in December 2023 and 2023 ASOs Album in December Pinterest Sections, then shared it to The Titans’ Discord, O&T, Tumblr, the O&T FB page, and the ASOs of 2023 BMAC Album, the BMAC Gallery, the WGS Threads, Hive, the ASO and the December 2023 ASO Ko-fi Albums, Bluesky, Minds, the December 2023 ASO BMAC Album, the Google Sheet, Doc, and Slide, & updated the ASO announcement on the O&T & Tumblr SITE MAPs, the Minds “Announcements” post, and the Hive bio, & updated the list of most recent ASOs in the ASO Criteria O&T & Tumblr pages and the ASO Twitch panel – made an update to the description in BMAC – downloaded the demos to be played for tomorrow’s LPSD stream – shared “How to Communicate with the Neurodivergent: A Quick Guide” to the O&T Instagram and FB page, created a Feature Image for it, then shared it to O&T, Tumblr, Pinterest, the O&T Threads, Hive, Bluesky, and Minds – managed tags in O&T
Well, these are all the updates I had for today! Thank you for reading!
May every decision you make be *in the spirit of fairness* and may the rest of your day *NOT go to $#!7*!
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Please consider supporting through Buy Me a Coffee or the tip page! Like what you see? Click here to subscribe for updates! For more about MonriaTitans, click here! Watch MonriaTitans on Twitch and YouTube! The image was made in Canva!
View On WordPress
#achievement#adhdjesse#affiliatelink#Announcement#Announcements#ArtistShoutOuts#BecomEmpowered#BecomeSmarterEveryday#BEmpowering#blog#Bookshoporg#Canva#dailyachievements#designedwithcanva#extrafocus#learnsomethingneweveryday#Minds#Mindscom#MonriaTitans#MonriaTitansWGS#MT#news#OaT#referrallink#TaDaList#TaDaLists#TMA#WGS
0 notes
Text

#WordPress site deletion#Delete WordPress website#Removing WordPress site#Uninstall WordPress from cPanel#Backup WordPress website#WordPress database deletion#Website platform migration#WordPress site management#cPanel tutorial#WordPress site backup#WordPress website security#Data backup and recovery#Website content management#WordPress maintenance#WordPress database management#Website data protection#Deleting WordPress files#Secure data storage#WordPress site removal process#WordPress website best practices
0 notes
Text
Full article text below read more
Tumblr and Wordpress are preparing to sell user data to Midjourney and OpenAI, according to a source with internal knowledge about the deals and internal documentation referring to the deals.
The exact types of data from each platform going to each company are not spelled out in documentation we’ve reviewed, but internal communications reviewed by 404 Media make clear that deals between Automattic, the platforms’ parent company, and OpenAI and Midjourney are imminent.
The internal documentation details a messy and controversial process within Tumblr itself. One internal post made by Cyle Gage, a product manager at Tumblr, states that a query made to prepare data for OpenAI and Midjourney compiled a huge number of user posts that it wasn’t supposed to. It is not clear from Gage’s post whether this data has already been sent to OpenAI and Midjourney, or whether Gage was detailing a process for scrubbing the data before it was to be sent.
Gage wrote:
“the way the data was queried for the initial data dump to Midjourney/OpenAI means we compiled a list of all tumblr’s public post content between 2014 and 2023, but also unfortunately it included, and should not have included:
private posts on public blogs
posts on deleted or suspended blogs
unanswered asks (normally these are not public until they’re answered)
private answers (these only show up to the receiver and are not public)
posts that are marked ‘explicit’ / NSFW / ‘mature’ by our more modern standards (this may not be a big deal, I don’t know)
content from premium partner blogs (special brand blogs like Apple’s former music blog, for example, who spent money with us on an ad campaign) that may have creative that doesn’t belong to us, and we don’t have the rights to share with this-parties; this one is kinda unknown to me, what deals are in place historically and what they should prevent us from doing.”
Gage’s post makes clear that engineers are working on compiling a list of post IDs that should not have been included, and that password-protected posts, DMs, and media flagged as CSAM and other community guidelines violations were not included.
Automattic plans to launch a new setting on Wednesday that will allow users to opt-out of data sharing with third parties, including AI companies, according to the source, who spoke on the condition of anonymity, and internal documents. A new FAQ section we reviewed is titled “What happens when you opt out?” states that “If you opt out from the start, we will block crawlers from accessing your content by adding your site on a disallowed list. If you change your mind later, we also plan to update any partners about people who newly opt-out and ask that their content be removed from past sources and future training.”
404 Media has asked Automattic how it accidentally compiled data that it shouldn’t share, and whether any of that content was shared with OpenAI, but did not immediately hear back from the company. 404 Media asked Automattic about an imminent deal with Midjourney last week but did not hear back then, either.
Another internal document shows that, on February 23, an employee asked in a staff-only thread, “Do we have assurances that if a user opts out of their data being shared with third parties that our existing data partners will be notified of such a change and remove their data?”
Andrew Spittle, Automattic’s head of AI replied: “We will notify existing partners on a regular basis about anyone who's opted out since the last time we provided a list. I want this to be an ongoing process where we regularly advocate for past content to be excluded based on current preferences. We will ask that content be deleted and removed from any future training runs. I believe partners will honor this based on our conversations with them to this point. I don't think they gain much overall by retaining it.” Automattic did not respond to a question from 404 Media about whether it could guarantee that people who opt out will have their data deleted retroactively.
News about a deal between Tumblr and Midjourney has been rumored and speculated about on Tumblr for the last week. Someone claiming to be a former Tumblr employee announced in a Tumblr blog post that the platform was working on a deal with Midjourney, and the rumor made it onto Blind, an app for verified employees of companies to anonymously discuss their jobs. 404 Media has seen the Blind posts, in which what seems like an Automattic employee says, “I'm not sure why some of you are getting worked up or worried about this. It's totally legal, and sharing it publicly is perfectly fine since it's right there in the terms & conditions. So, go ahead and spread the word as much as you can with your friends and tech journalists, it's totally fine.”
Separately, 404 Media viewed a public, now-deleted post by Gage, the product manager, where he said that he was deleting all of his images off of Tumblr, and would be putting them on his personal website. A still-live post says, “i've deleted my photography from tumblr and will be moving it slowly but surely over to cylegage.com, which i'm building into a photography portfolio that i can control end-to-end.” At one point last week, his personal website had a specific note stating that he did not consent to AI scraping of his images. Gage’s original post has been deleted, and his website is now a blank page that just reads “Cyle.” Gage did not respond to a request for comment from 404 Media.
Several online platforms have made similar deals with AI companies recently, including Reddit, which entered into an AI content licensing deal with Google and said in its SEC filing last week that it’s “in the early stages of monetizing [its] user base” by training AI on users’ posts. Last year, Shutterstock signed a six year deal with OpenAI to provide training data.
OpenAI and Midjourney did not respond to requests for comment.
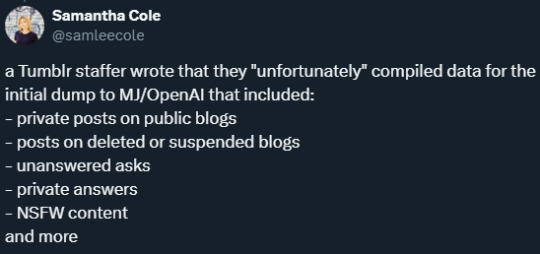
Behind a paywall (or at least you need an account) but if true fuuuckk
#took one for the team on this#important info about our data being shared is behind a subscribe wall lolol#pretty sure this is illegal in the EU and California#possibly elsewhere#the fuckening of tumblr
825 notes
·
View notes
Video
youtube
How To Delete A WordPress Site From cPanel (2023) 🔥 | FAST & Easy!
1 note
·
View note
Photo

How can I backup, restore and recover my WordPress site?
Backing up, restoring, and recovering your WordPress site is crucial in case of any unforeseen events, such as site crashes, hacks, or even accidental deletion of content. It is always a good practice to have a backup system in place to ensure that you can restore your site quickly and easily. Too know more visit here: https://wordpresswebdevelopmentsolution.blogspot.com/2023/03/how-can-i-backup-restore-and-recover-my.html
0 notes
Text
Tips to Secure Your WordPress Site in 2023

The increasing incidences of cyberattacks make cybersecurity more critical than ever. Perhaps because it’s the most popular content management system, hackers love to break into WordPress sites. Busy business owners and blog managers often forget to update plugins and keep their databases secure. Small business owners may believe there is little threat of a cybercriminal taking over their sites until it happens to them. The number of people doing business online increased during the COVID-19 pandemic. With heightened activity came even more hackers ready to steal information or create chaos just for fun.
What Are Some Cybersecurity Trends in 2023 for WordPress?
W3Techs tracks the usage of various popular online software and recently estimated about 43.1% of all websites utilize WordPress as a CMS. Some of the trends you’re seeing heading into 2023 for cybersecurity for WordPress are what you’d expect. WordPress.org currently lists over 60,000 plugins in its directory. However, plugins and themes may open the door to SQL injection attacks. Brute force attacks will continue to remain a popular way to gain entry into WordPress websites. The hacker tries different combinations, hoping to hit on your password. Brute force attacks can shut a site down due to increased bandwidth use and strain on the system. A recent survey by BakerHostetler found around 24% of cyber attacks on U.S. businesses were phishing-related. Disgruntled former employees, people being careless with passwords or lack of knowledge all contributed to hacking due to phishing attacks. The report also showed a sharp rise in ransomware, at 37% of hacking attempts.
How Do I Make My WordPress Site More Secure?
Some of the extreme breaches in recent years impacted millions of consumers. In 2018, hackers gained access to the information of 500 million guest accounts via Marriott International's databases, costing the company $28 million. Securing your website is crucial to your online presence, no matter what platform you utilize. Laws such as the General Data Protection Regulation (GDPR) act and California Consumer Privacy Act (CCPA) require you to collect only the information you need, delete what you no longer require and take steps to keep it safe from criminals. GDPR and CCPA come with hefty fines if you ignore your responsibilities. What can you do to ensure your WordPress site is more secure? Fortunately, there are simple steps to keep hackers out and data protected. 1. Update Your Site Every time you log in to your WordPress dashboard, you’ll see a counter across the top bar telling you if you need to update anything. You can set your site to accept updates automatically or manually, but make it a habit to check the counter. An un-updated website is vulnerable to various attacks from outside forces. SQL injection attacks often seek the most vulnerable entry points into the open source software. When WP releases an update, it tends to address any security concerns and shore up your site’s cybersecurity. 2. Choose a Trusted HostHire Penetration Testing Your hosting company is only a good value if their cheap practices don’t put your website at risk. Hackers enter sites via their accounts on a shared server. While all businesses would ideally have a dedicated server, the costs are sometimes prohibitive for small companies. However, you can avoid many issues by going with a hosting provider with an excellent track record. Ask questions about the hours IT staff are on hand — the answer should be 24/7. Do they monitor for and stop attacks as they occur? Such proactive measures are essential to work against brute force and SQL injection attacks. 3. Hire Penetration Testing One way to ensure you close up any open doors to hackers is to hire a company to test for system vulnerabilities. For example, you might conduct a firewall penetration test to see how well it blocks someone trying to gain entry without permission. Does the system lock them out after a certain number of attempts? Is the website owner notified? Think of the various ways cybercriminals access WordPress websites and test each entry point to see their weaknesses. Once you understand where an attack might occur, you can take steps to prevent a potential event. Plugins such as Security Ninja can scan for vulnerabilities and save you the cost of hiring an outside provider. 4. Train Employees Train everyone who logs into your CMS to protect their passwords. Each machine should have antivirus and malware protections installed. Writers and editors should avoid clicking on any links to log in and always go directly to the site. Teach your staff what phishing is and how to avoid it. Change passwords frequently and remove access for former employees immediately and not months later. Taking basic steps to educate workers and protect your site may save you thousands of dollars in cleanup costs. 5. Choose a Secure Theme Not all themes are created equal, so make sure the WordPress community respects a theme or plugin’s creator. The person should have experience developing software that isn’t vulnerable to attacks. Sadly, some people create software to trick sites into sharing sensitive information and then use what they collect to dox your customers, sharing things online they wouldn’t want anyone else to know.
Create a Checklist
The best way to secure your WordPress site in 2023 is to create a checklist of things you should tend to regularly for your website. Make it a habit to update outdated plugins and themes, remind employees to protect their login credentials and test frequently to find the holes and fill them before a hacker stumbles across your vulnerabilities. Read the full article
0 notes
Text
Find a Grave - It's About Time
I know this post is from back in March, but this an effort which everyone should support. Find A Grave should change their name!
Reprinted from my History Hermann WordPress blog and Wayback Machine. This was originally posted on August 13, 2020.
© 2020-2023 Burkely Hermann. All rights reserved.
The Hipster Historian [original post from there is here]

Find A Grave.
What a site. It landed on the genealogy scene in 1995 when Salt Lake City resident Jim Timpton built a genealogical database with his hobby of visiting celebrity gravestones. Since then, it has grown into a global database for many of the millions of dead from around the world.

Anna N Daniloff — Evergreen-Washelli Memorial Park, Seattle, Washington, USA.
Members and non-members alike can sift through the multitudes of data and find information on their ancestors and view their finals resting places. Due to the interest in genealogy, per the increase in awareness of family history through companies like Ancestry and 23 & Me, more and more people are getting interested in their past and finding their ancestors.
With this increase in popularity, there are some parts of the genealogy world that haven’t moved into the future.

I’ve always loved Find a Grave, I’ve used it since my earliest days in researching my family as a teen, and have appreciated the community base of genealogists who dedicate their time to photographing not just their families, but thousands of others as well.
But there is one thing that has always bothered me about the site, it’s acronymic name that genealogists commonly use, FAG.
FAG
It may not be quickly apparent to some, but the word fag is one of a turbulent history in the LGBTQIA community. It has been used to harass, threaten, abuse and in many cases murder.
youtube
In the past few years, genealogy and the research into one’s family history have blossomed significantly with companies like Ancestry, 23 and Ancestry putting out genetic genealogy test commercials for the general public to see. With this, we as a community have introduced a great variety of people to our much loved and passionate field.
As we continue to evolve and change into an inclusive community of genealogists and death positive folks that range to your Great-Aunt Mary and your Harley-riding younger brother Zac — we all love this field.
Note: As of today, I received a comment on my blog that said the following
“There is a new RAOGK -Random Acts of Genealogical Kindness that was started and we will not tolerate the use of that acronym. We have a photo of the National archives building The old Please if you could make that distinction in the post, so the new group doesn’t get lambasted. “
The problem is, there are some that are refusing to acknowledge this issue. Earlier this week, noted genetic genealogist Blaine Bettinger asked the Facebook genealogy group RAOGK (Random Acts of Genealogical Kindness) to stop using the term as shorthand. This one post has garnered over 247 comments and 8 shares.
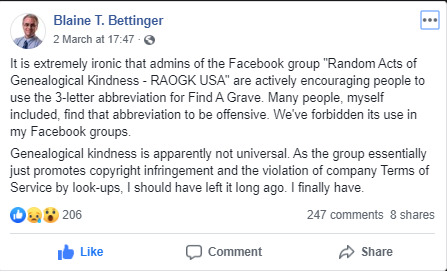
I even posted something in the group this morning and it was swiftly deleted and within minutes of it being deleted, a member of the group ‘reached out’ (I use this word with several grains of salt) to me with the following:

This individual then proceeded to tell me that gay people aren’t offended by this acronym (hey, so, I’m gay, and I am) and that “It’s not being used in a derogatory way so I just don’t understand why it’s such an issue,” followed by “I think you’re a wee too sensitive.”
I’m just going to put it out there — that is privilege speaking. The term fag is a loaded term that comes with decades of violence, ignorance, and harassment. But, if I have to drag y’all kicking and screaming into the future — I will. This needs to change now.

Since we love so much, don’t you think we should take care of it? Include all the members of the community, no matter how different we are? So here is my proposal, let’s call it Find a Memorial (FAM). Why FAM?
#1: It is not an offensive acronym or term and solves that problem hands down
#2: It incorporates family (FAM) into the term, which what this is all about
#3: Memorial is a much more applicable term as by definition, the graveyard has been used specifically for those graveyards near churches or as the definition of it says: “a burial ground, especially one beside a church.”Using the word memorial will incorporate not only graveyards and cemeteries but can also incorporate more non-traditional memorials such as cremations, at sea burials, etc.
If you support me, sign below with your name (i.e. Becky K., 34, Bellingham, WA) below and tweet at @FindAGrave and @Ancestry to make this happen.
---
We, the undersigned petition Ancestry (the parent company to Find a Grave) to change the name of Find a Grave to Find a Memorial for the following reasons:
The acronym represents our field in a much more appropriate way
The new acronym and name represents all types of departures from this earth, not just graves (cremations, scattered ashes, etc.)
Find a Grave has always been a community-centered database and we all contribute from all the corners of the world. People of every gender, color, background, religion, sexuality, and type. Why not keep everyone together on this journey with a more inclusive name.
Names of Signatories
Becky K., 34 – Bellingham, Washington, USA
Stephany B. – Georgia, USA
Chris F. – New Hampshire, USA
Kirsten Beyer – Illinois, USA
Hazel Scullin – Salt Lake City, Utah, USA
Elizabeth Ludwig – Utah, USA
Miranda Carter – Utah, USA
Megan Fincher – California, USA
Mary Rohrer Dexter
Linda Dupuy
Laura Napl
Tawna L. – Meridian, Idaho, USA
Betty Dees, 62 – Cape Canaveral, Florida, USA
Kelly Bembry – Midura, Virginia, USA
Casey F. – Long Beach, California, USA
Diane B.
Linda Fradelis – Chesapeake, Virginia, USA
Carolynn ni Lochlainn
Jenifer Kahn – Bakkala, Massachusetts
Jan Pennington – England
Leslie Rieger – Montana
Brenda Leyndyke – Battle Creek, Michigan, USA
Anna C. Matthews – Rockville Centre, New York, USA
Arlene F. – Michigan, USA
Deb
Sue J.
Erica Millar – Ontario, Canada
Geoff Mulholland
Robin G.
Anna
Raymond R Hawkins
Rich M., 62, – Medford, Oregon, USA
Charlotte N. – Utah, USA
Leah M. – Washington, USA
Dena R. – Visalia, California, USA
Jordan MacVay – Halifax, Nova Scotia, Canada
Victoria Kolakowski – Oakland, California, USA
Rebecca Campbell – Dallas, Texas
Miriam Robbins – Spokane, Washington, USA (Note left: User of FindAGrave for 18.5 yrs.)
Millicent Parsons – Indianapolis, Indiana, USA
Holly B. — Carnation, Washington, USA
Susan S.
Teresa Eckford – Sunshine Coast, Canada
Zoe Krainik – USA
Sarah Potter – Naperville, Illinois, USA
Kat Kellermeyer – Salt Lake City, Utah, USA
Joey De Luna – Bellingham, Washington, USA
Cindy Badger – Osan Air Base, S. Korea
Kolby LaBree – Bellingham, Washington, USA
Trish Riederer – California, USA
Heidi Pomerleau – Salt Lake City, Utah, USA
Valorie Cowan Zimmerman
Audra Searcy – Latrobe, Pennsylvania, USA
Emily Schroeder – Solon, Ohio, USA
Brooke W., 49 – Sydney, NSW, Australia
Chelsy Parrish, 28 – Mesa, Arizona, USA
Kassidy Price, 24 – St. George, Utah, USA
Diane Willey – Ontario, Canada
Andrea Weigel – Templeton, California, USA
#homophobia#genealogy#family history#find a grave#petitions#inclusive genealogy#hipster historian#Youtube
0 notes
Text
5 Big Web Design Predictions for 2022

Every year, at this time, blogs like this one like to try and predict what’s going to happen in the year ahead. It’s a way of drawing a line under the archive and starting afresh. A rejuvenation that, as humans, we find life-affirming.
Ten years ago, I would have had high confidence in these predictions — after all I was eventually right about SVG adoption, even if it took a decade. But the last few years have shown that web design is tightly interwoven with the muggle world, and that world is anything but predictable.
So as we look at what might occur in the next year (or five), think of it less as a set of predictions and more as a wishlist.
Last Year’s Predictions
When I write this post every January, I like to keep myself honest by glancing back at the previous year’s predictions to gauge how accurate (or not) my predictions have been.
Last year I predicted the long-term trend for minimalism would end, WordPress would decline, cryptocurrency would go mainstream, and then hedged my bets by saying we’d make both more and fewer video calls.
Gradients, maximalism, and the nineties revival pulled us away from minimalism. It’s still popular, just not as dominant.
WordPress is still the biggest CMS in the world and will continue to be for some time. But the relentless grind of no-code site builders at the low end, and being outperformed by better CMS at the high end, mean that WordPress has passed its peak.
Over-inflated predictions for BitCoin reaching $100k by December 2021 turned out to be a damp squib. In the end, Bitcoin only tripled in value in 2021. However, with micro-tipping and major tech companies moving into the arena, it’s clear digital currency arrived in the public consciousness in 2021.
And how could I be wrong about more but also fewer video calls? So I’m calling that my first clean sweep ever. With that heady boast, let’s take a look at the next twelve months.
What Not to Expect in 2022
Do not expect the Metaverse to be significant in anything but marketing speak. Yes, the hardware is slowly becoming more available, but the Metaverse in 2022 is like playing an MMORPG on PS5: theoretically, great fun, until you discover that absolutely none of your friends can get their hands on a console.
Ignore the blog posts predicting a noughties-era retro trend. All those writers have done is looked at the nineties-era trend and added a decade. Fashions aren’t mathematical; they’re poetic. Retro happens when people find a period that rhymes with present-day hopes and fears. After the last couple of years, if we revisit a decade, it’s likely to be the late-forties.
Finally, don’t expect seismic change. Material design, parallax scrolling, and jQuery are still with us and are still valid choices under the right circumstances. Trends aren’t neat; they don’t start in January and conclude in December.
5 Web Design Predictions for 2022
Predictions tend to be self-fulfilling. So we’ve limited ourselves to five trends that we believe are either positive or, at worst harmless. Of course, there are no guarantees, but if these come to pass, we’ll be in good shape for 2023.
1. The Blockchain is Coming
Underpinning the cryptocurrency industry are blockchains. In simple terms, they’re a set of data that can be appended to but can’t be edited or deleted. Think of it as version control for data.
As with most technology, the first wave has been a way to make a fast buck. However, the exciting development is blockchain technology itself and the transformative nature of the approach. For example, Médecins Sans Frontières reportedly stores refugees’ medical records on the blockchain.
Imagine the Internet as a set of data, editable for a micro-fee, and freely accessed by anyone anywhere. Instead of millions of sites, a single, secure, autonomous source of truth. Someone somewhere’s working on it.
2. Positivity & Playfulness & A11y
Even before world events descended into an endless tirade of grim news, time was running out for dull, corporate, geometric sans-serif design.
We added gradients, we added personality, we embraced humor. And contrary to the established business logic, we still make money. Over the past few years, there have been extraordinary efforts by designers and developers to examine, test, and champion accessibility, and thanks to them, inclusive design is no longer reliant on the lowest common denominator.
In 2022 you can get experimental without obstructing 10%+ of your users.
3. Everything Green
Green is a fascinating color, the primary that isn’t (except in RGB, when it is).
Green has the same visual weight as blue, is substantially more flexible, and yet to date, has been radically underutilized in digital design.
Green has a prominent cultural association with the environment. At a time when tech companies are desperate to emphasize their ethical credentials, marketing companies will inevitably begin promoting a brand color shift to green as a quick fix for all those dumped chemicals, strip mines, and plastic-filled seas.
We’ve already seen earthy hues acquire popular appeal. At the other end of the vibrancy scale, neons are popular. Green spans both approaches with everything from calm sages to acidic neons.
In 2022, if you’re looking for a color to capture the moment, look to green.
4. Hero Text
A picture is supposed to be worth 1000 words, although I’m not sure anyone has actually tried to measure it. The problem is that sites increasingly rely on stock images, so the 1000 words that we’re getting may or may not accurately reflect 100% of our message.
In 2022, a handful of well-chosen words will be worth more than an image, with hero images taking a back seat to large hero text. This is aided by a number of minor trends, the most notable of which is the willingness of businesses to look beyond the geometric sans-serif to a more expressive form of typography.
Reading through the prediction posts on sites other than this, almost everyone agrees on large hero text replacing images, which virtually guarantees it won’t happen. Still, at the start of 2022, this seems to be the direction we’re taking.
5. Bring the Noise
One of the unexpected consequences of the past couple of years has been a renewed connection with nature. The effortless complexity in nature is endlessly engaging.
We’ve already begun to popularise gradients — there are no flat colors in nature — and the next logical step is the addition of noise.
In visual terms, noise is the grainy texture that sits so beautifully in vector illustrations. Noise has dipped in and out of trends for years, hampered a little by the leap in file size it creates. However, with WebP and Avif file types, noise is now usable on production sites.
Designing in 2022, when in doubt, throw some noise at it.
Featured image via Unsplash.
Source
The post 5 Big Web Design Predictions for 2022 first appeared on Webdesigner Depot.
via Webdesigner Depot https://ift.tt/gPuemDhTy
0 notes
Text
How can I backup, restore and recover my WordPress site?

Backing up, restoring, and recovering your WordPress site is crucial in case of any unforeseen events, such as site crashes, hacks, or even accidental deletion of content. It is always a good practice to have a backup system in place to ensure that you can restore your site quickly and easily. Too know more visit here: https://wordpresswebdevelopmentsolution.blogspot.com/2023/03/how-can-i-backup-restore-and-recover-my.html
1 note
·
View note