#AI data scraping author concerns
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Post activity is at the highest at 4:00 pm EDT; notes peak at 10:00 pm EDT.
Text
AI: Pandora's Box for Authors, or an Unexpected Ally? Navigating the Fear and Finding the Opportunity
Hey y’all, Sumo Sized Ginger here. Let’s talk about the giant, algorithm-powered elephant in the room: Artificial Intelligence. If you’re a writer, author, or any kind of content creator, chances are you’ve got some strong feelings about it. And frankly, you have every right to. The Elephant: Training Data and the Feeling of Invasion I want to tackle the big issue head-on. The way many AI…
#affordable editing for authors#AI animation from text#AI content creation#AI copyright issues creative writing#AI data scraping author concerns#AI editing partner#AI editing software#AI ethics writing community#AI for authors#AI for novelists#AI for sensitive content creation#AI image generation authors#AI manuscript editing#AI productivity tools writers#AI story generation platforms#AI workflow for authors#AI writing assistant#AI writing tools#artificial intelligence writing#author tech tools#copy editing AI#cost-effective author tools#create video from text#developmental editing AI#Gemini for writers comparison#generative AI authors#horror writing AI assistance#Imagen 3 prompts#improve writing with AI#independent author tools
1 note
·
View note
Text

Ellipsus Digest: March 18
Each week (or so), we'll highlight the relevant (and sometimes rage-inducing) news adjacent to writing and freedom of expression.
This week: AI continues its hostile takeover of creative labor, Spain takes a stand against digital sludge, and the usual suspects in the U.S. are hard at work memory-holing reality in ways both dystopian and deeply unserious.
ChatGPT firm reveals AI model that is “good at creative writing” (The Guardian)
... Those quotes are working hard.
OpenAI (ChatGPT) announced a new AI model trained to emulate creative writing—at least, according to founder Sam Altman: “This is the first time i have been really struck by something written by AI.” But with growing concerns over unethically scraped training data and the continued dilution of human voices, writers are asking… why?
Spoiler: the result is yet another model that mimics the aesthetics of creativity while replacing the act of creation with something that exists primarily to generate profit for OpenAI and its (many) partners—at the expense of authors whose work has been chewed up, swallowed, and regurgitated into Silicon Valley slop.
Spain to impose massive fines for not labeling AI-generated content (Reuters)
But while big tech continues to accelerate AI’s encroachment on creative industries, Spain (in stark contrast to the U.S.) has drawn a line: In an attempt to curb misinformation and protect human labor, all AI-generated content must be labeled, or companies will face massive fines. As the internet is flooded with AI-written text and AI-generated art, the bill could be the first of many attempts to curb the unchecked spread of slop.
Besos, España 💋
These words are disappearing in the new Trump administration (NYT)
Project 2025 is moving right along—alongside dismantling policies and purging government employees, the stage is set for a systemic erasure of language (and reality). Reports show that officials plan to wipe government websites of references to LGBTQ+, BIPOC, women, and other communities—words like minority, gender, Black, racism, victim, sexuality, climate crisis, discrimination, and women have been flagged, alongside resources for marginalized groups and DEI initiatives, for removal.
It’s a concentrated effort at creating an infrastructure where discrimination becomes easier… because the words to fight it no longer officially exist. (Federally funded educational institutions, research grants, and historical archives will continue to be affected—a broader, more insidious continuation of book bans, but at the level of national record-keeping, reflective of reality.) Doubleplusungood, indeed.
Pete Hegseth’s banned images of “Enola Gay” plane in DEI crackdown (The Daily Beast)
Fox News pundit-turned-Secretary of Defense-slash-perpetual-drunk-uncle Pete Hegseth has a new target: banning educational materials featuring the Enola Gay, the plane that dropped the atomic bomb on Hiroshima. His reasoning: that its inclusion in DEI programs constitutes "woke revisionism." If a nuke isn’t safe from censorship, what is?
The data hoarders resisting Trump’s purge (The New Yorker)
Things are a little shit, sure. But even in the ungoodest of times, there are people unwilling to go down without a fight.
Archivists, librarians, and internet people are bracing for the widespread censorship of government records and content. With the Trump admin aiming to erase documentation of progressive policies and minority protections, a decentralized network is working to preserve at-risk information in a galvanized push against erasure, refusing to let silence win.
Let us know if you find something other writers should know about, (or join our Discord and share it there!) Until next week, - The Ellipsus Team xo

619 notes
·
View notes
Note
what is (was?) lore fm 😭 any why's everyone talking about it
omg i didn’t expect so many people to actually care about my tags and send me asks about this lmao. i have to run some errands so i’ll respond to them in detail re: the gift economy of fandom when i get back home, but in answer to your question, anon:
lore.fm was an app for mobile, in beta, being advertised on tiktok as “audible for ao3” which has just shut down due to fannish-author backlash. the spokesperson for lore.fm was presented as a small fannish creator running a passion project to improve accessibility of fanfic, but reddit sleuths discovered that she was/is backed by a larger tech startup with a history of releasing and developing apps which leverage generative ai.
ao3 artists were/are understandably upset about the idea of having their works hosted outside of ao3 (despite lore.fm’s spokesperson claiming that the app would not host their works—which she called “content”—publicly) without their permission. they were also upset about the idea of their works being scraped for ai training data. some writers were also upset about the idea that their fics being made available outside of ao3 would reduce their number of hits/kudos/comments (personally, i think this is the least of our concerns, but i understand why people would be distressed).
there was a general lack of transparency around the development and release of the app, and the spokesperson on tiktok basically responded to all criticism by calling detractors “ableist” and “classist”, and then a few hours later announced that the app (which she called a “product” – which, why was she calling it that when she claimed it was supposed to be a free access tool?) was shutting down due to author backlash—backlash which she then reduced to butthurt authors being thirsty and selfish for kudos/comments/hits.
now people on tumblr and reddit are celebrating its shutdown and people on tiktok are upset that this accessibility tool is no longer in development/slated for release. but personally, i’m sure that there were plans for monetization down the line so i’m glad it’s gone.
199 notes
·
View notes
Note
I've noticed some book covers recently have AI art included in them. Why does it feel like publishing is giving less effort to ensure AI art is not being used? What can other authors do to ensure AI art is not being used for their covers?
I have seen a couple of controversies about this -- one, a Sarah J Maas cover, one a Christopher Paolini cover.
On the one hand, the fact is that MANY covers are made using at least in part stock images -- artists and photographers upload their images to the stock site, the publisher pays whatever licensing fees and uses the image/photo/whatever as part of the design. This is totally normal.
In these two cases, at least, it looks like these images were obtained from stock image sites. I can see a designer searching the stock sites for images (just like they have for years and years), seeing a dope-looking wolf or spaceman or whatever that somebody uploaded, and being like, "cool image!" and paying the fee and using it, just as they have done a thousand times before, and not even thinking anything of it. Which like -- is a LITTLE less scary to me than the publisher, idk, firing the designers and then just having some intern go on an AI bot and say "make me a cover with a wolf on it!"
The problem of course is that (most? all??? much of??) AI-generated "art" is scraping other images/artwork off the internet and, to use the technical term, mish-moshing it, which means that somebody somewhere's intellectual property is being used/altered/god-knows-what, unbeknownst to them. I strongly suspect that, nine or even six months ago or whenever these covers were being designed, the designers and other folks at the publisher didn't even KNOW to be concerned about what was on the stock sites -- like this technology is moving at SUCH a rapid pace, it's head-spinning.
I can tell you what agents are concerned about at the moment, and it's three-pronged:
-- we don't want our authors or artists work to be data-mined / scraped to "train" AI learning models/bots
-- we don't want covers or other imagery created by AI
-- we don't want AI generated narration for audiobooks
Agents are working to get this kind of language into contracts currently -- this is literally one of the top topics at all of our agency meetings, and I'm sure is a top topic at publishers as well. However different publishers are at different stages here -- some are including it, some are still working on the language, etc -- but I suspect/hope that these kinds of clauses will be standard in publishing contracts across the board by the end of the year. (Though of course it might be evolving as the technology evolves.)
281 notes
·
View notes
Text
Been thinking about the ao3 scrape. Looked into it, and I feel its important to acknowledge, first, the fact that every website that was scraped has had their datasets either disabled (temporarily, though it's highly unlikely that nyuuzyou will win any of their cases) or deleted. AI programs on HuggingFace cannot be trained on any of the data that was scraped. This specific iteration of the problem is, from what I can tell, solved.
But it's still incredibly concerning.
Someone could just... do that. Steal millions of works, both writing and art, and then have the audacity to fight against the DMCAs they've recieved.
Now, as idiotic as it sounds, I don't plan on restricting my fics. I've had a good number of guests leave kudos and comments, and I respect their decision to do so anonymously.
As much as I'd hate to have my words reused in a generator, I have to remember that I have faults.
If my fics were fed into a robot, it wouldn't stop talking about the character's eyes and eyebrows. It would have those random typos I keep making in Fish in a Birdcage. If left unflitered, it would curse randomly and rather excessively. Would it know what to do with page breaks? Would it be able to learn my exact usage of italics, or would it just guess randomly, if at all? If it were trying to replicate my QSMP fics with other languages scattered throughout them, would it be able to recognize that and just start throwing in random spanish or french without reason? Or would it start making shit up, not having a translator built in because the laziest person alive didn't consider that because the fic was labeled as English?
There are a large number of chatfics on ao3. If every single piece of fanfiction was thrown into a robot, I wouldn't be surprised for a piece of narration to be randomly interrupted by a youtube comment esque diologue. And maybe the shorthand typing would end up in the normal narration, too. Even if a person filtered out tags to reduce faults, there are still so many untagged fics. Not to mention, AI fics being fed into an AI generator will fuck up so much shit.
Authors make formatting mistakes. Authors forget punctuation. Authors may learn some CCS code to throw into a fic that would be incredibly hard to interperet. Authors throw headcanons onto characters that may change their gender, appearance, etc. The best thing about fandom is that each person experiences it differently. Trying to mix all of these into one will, with enough work I suppose, create a product that some people find to be acceptable. But it will be so harrowingly inconsistent and confusing that no one could ever fully enjoy it.
Ao3 is, quite possibly, one of the most diverse websites out there. Which makes it also a horrible training ground for AI, which has the sole capability of being able to follow directions consistently.
Yes, your works have been stolen. Yes, my works will probably continue to get stolen. Yes, it will suck ass, and some lonely bitch will manage to make a few cheap bucks off of it.
But all that matters to me right now is that AI never has the life, the ideas, the experiences, nor the expression that a human does.
#reminder that adding -ai to the end of google searches or swearing somewhere in the search gets rid of the ai summaries#ao3#archive of our own#ao3 author#ao3 scrape#anti ai#fuck ai#idk if this will reach anyone but it was on my mind and i couldnt get out of bed before i typed it all out
14 notes
·
View notes
Text
Are there generative AI tools I can use that are perhaps slightly more ethical than others? —Better Choices
No, I don't think any one generative AI tool from the major players is more ethical than any other. Here’s why.
For me, the ethics of generative AI use can be broken down to issues with how the models are developed—specifically, how the data used to train them was accessed—as well as ongoing concerns about their environmental impact. In order to power a chatbot or image generator, an obscene amount of data is required, and the decisions developers have made in the past—and continue to make—to obtain this repository of data are questionable and shrouded in secrecy. Even what people in Silicon Valley call “open source” models hide the training datasets inside.
Despite complaints from authors, artists, filmmakers, YouTube creators, and even just social media users who don’t want their posts scraped and turned into chatbot sludge, AI companies have typically behaved as if consent from those creators isn’t necessary for their output to be used as training data. One familiar claim from AI proponents is that to obtain this vast amount of data with the consent of the humans who crafted it would be too unwieldy and would impede innovation. Even for companies that have struck licensing deals with major publishers, that “clean” data is an infinitesimal part of the colossal machine.
Although some devs are working on approaches to fairly compensate people when their work is used to train AI models, these projects remain fairly niche alternatives to the mainstream behemoths.
And then there are the ecological consequences. The current environmental impact of generative AI usage is similarly outsized across the major options. While generative AI still represents a small slice of humanity's aggregate stress on the environment, gen-AI software tools require vastly more energy to create and run than their non-generative counterparts. Using a chatbot for research assistance is contributing much more to the climate crisis than just searching the web in Google.
It’s possible the amount of energy required to run the tools could be lowered—new approaches like DeepSeek’s latest model sip precious energy resources rather than chug them—but the big AI companies appear more interested in accelerating development than pausing to consider approaches less harmful to the planet.
How do we make AI wiser and more ethical rather than smarter and more powerful? —Galaxy Brain
Thank you for your wise question, fellow human. This predicament may be more of a common topic of discussion among those building generative AI tools than you might expect. For example, Anthropic’s “constitutional” approach to its Claude chatbot attempts to instill a sense of core values into the machine.
The confusion at the heart of your question traces back to how we talk about the software. Recently, multiple companies have released models focused on “reasoning” and “chain-of-thought” approaches to perform research. Describing what the AI tools do with humanlike terms and phrases makes the line between human and machine unnecessarily hazy. I mean, if the model can truly reason and have chains of thoughts, why wouldn’t we be able to send the software down some path of self-enlightenment?
Because it doesn’t think. Words like reasoning, deep thought, understanding—those are all just ways to describe how the algorithm processes information. When I take pause at the ethics of how these models are trained and the environmental impact, my stance isn’t based on an amalgamation of predictive patterns or text, but rather the sum of my individual experiences and closely held beliefs.
The ethical aspects of AI outputs will always circle back to our human inputs. What are the intentions of the user’s prompts when interacting with a chatbot? What were the biases in the training data? How did the devs teach the bot to respond to controversial queries? Rather than focusing on making the AI itself wiser, the real task at hand is cultivating more ethical development practices and user interactions.
12 notes
·
View notes
Text
ok i've done some light research. if you want a software engineer/fic writer's inital take on lore.fm, i'll keep it short and sweet.
my general understanding of lore.fm functionality:
they use OpenAI's public API. they take in the text from the URL provided and use it to spit out your AI-read fic. their API uses HTTP requests, meaning a connection is made to an OpenAI server over HTTP to do as lore.fm asks and then give back the audio. my concern is that i wasn't able to find out what exactly that means. does OpenAI just parse the data and spit out a response? is that data then stored somewhere to better their model (probably yes)? does OpenAI do anything to ensure that the data is being used the way it was intended (we know this probably isn't true because lore.fm exists)?
lore.fm stores the generated audio (i am almost certain of this because of the features described in this reddit post). meaning that someone's fic is sitting in a lore.fm database. what are they doing with that data? what can they do with it? how is it being stored? what is being stored, the text and the audio, or just the audio?
i find transparency a very difficult thing to ask for in tech. people are concerned with technological trade secrets and stifling innovation (hilarious when i think about lore.fm, because it doesn't take a genius to feed text into AI and display the response somewhere, sorry to say). and while i find the idea of AI being used to help further accessibility on apps that don't yet provide it promising, i find the method that lore.fm (and OpenAI) chooses to do this to be dangerous and pave a path for a harmful integration of AI (and also fanfiction in general -- we write to interact, and lore.fm removes that aspect of it entirely).
we already know that AI companies have been paying to scrape data from different sources for the purposes of bettering their models, and we already know that they've only started asking for permission to do this because users found out (and not from the goodness of their hearts, because more data means better models, and asking for permission adds overhead). but this way of using it allows AI to backdoor-scrape data that the original sources of the data didn't give consent to. maybe the author declined to have their fic scraped by AI on the site they posted it onto (if the site asked at all), but they didn't know a third-party app like lore.fm would feed it into an AI model anyways.
what's the point of writing fics if i have no control over my own content?
#i could talk about harmful integrations of AI for days#but this way of using it definitely sets a bad precedent#and i think ao3 unfortunately didn't anticipate this kind of thing when it was created#and so i don't want to blame ao3 entirely because they are a group of independent devs that are volunteering to do this#but i also think they either need to make an effort to protect text from being scraped this way#or they need to lockdown the site altogether#we call it fail-closed in cs terms#and right now it's fail-open#the problem with that is that there are probably people posting to ao3 right now that have no idea this is going on#and they don't know they should lockdown their fics#and now their fics are being fed into this model and they have no idea#idk#lore.fm#fanfiction#ao3
23 notes
·
View notes
Note
i mean. whats the moral ground on gen ai if it 100% IS genuinely home programmed as claimed?
i admittedly am not a programmer, i don't know how much work it'd realistically take to create something like that on your own or what other stuff it might be referencinging & take from but i remember hearing that the program being used for the smp took like. 7 yearsish to develop as a passion project?? which at least would predate chatgpt's public release in 2022 by about 4.
i guess the real question for me personally would then be what was the AIs training material. if its all original or public domain, then (beyond ecological impact lol) i dont..... see an ethical issue ig? idk, whats your take?
okayyyy okay hang on i'll pull out my notes on ethical concerns with AI and put that all below the cut, it got a bit long (but TLDR for whats under there: i don't think the ethical concerns are as significant in this case if the one source we have is true. it is just one source tho)
but honestly my main gripe with it right now is just that i dont like it 😭 i think watching a streamer talk to NPCs that sound like AI isnt interesting. i think NPCs immediately forgetting relationships theyre building with characters is predictable as hell and frustrating to watch. i think the similar tones and mannerisms with every NPC is boring. i respect the difficulty of making that on one's own but that doesn't really make me like it any better im afraid!
(and ye, ik, if i don't like it i can just not engage. which is what im doing! i closed stream and im just going to tune into other things LMAO im just complaining on my own little blog away from maintags)
welcome to Under The Cut sorry this is so long
i want to disclaim i'm not an authority on this at all, i don't know what theyre using over on misadventures smp, my knowledge on this is limited to what i've been studying at uni
anyway over my notes. the key ethical issues we're usually looking at with genAI and LLMs in general:
the data being input into the model can really affect the results. we've seen genai have preference towards male, white people in many cases, as well as other privileged groups, that's not rlly news. with this smp, if the data was all prewritten or at least checked by the programmers, this shouldnt turn up as an issue and - tmk - it doesn't really have scope to in this smp
data privacy is a pretty big issue, as well as scraping data without consent. re: the previous point tho, that would theoretically not be an issue here, awesome stuff
this isn't something brought up a lot in online discussions, but there is a social impact to using ai that's aiming to be convincingly human. i don't reallllly think the npcs are very convincing, so it's unlikely to affect the streamers and probably most of the audience and therefore i really dont think this should be a huge issue. like, here i'm talking the effects of anthropomorphising machines and the unintentional spread of misinformation, but the NPCs seem solidly . fake. if that makes sense. and im assuming here that the audience is mature enough to understand that (tho idk? does a youtube audience skew younger than a twitch chat? in that case it might be different)
misuse of ai for the purpose of misinfo doesn't rlly apply here i think, they're just doing minecraft, so i'm ruling that out
these models are usually a black box in terms of how they work, so it's hard to see if there Are issues. i genuinely have no idea how this specific program works because it seems the only source is one of martyn's streams, and i don't really expect him to get into the details of how it was programmed or whether the model functions as a black box like most genai. idk on this one
environmental impact.. i mean this one is pretty frequently talked about LMAO and this post (which i received from a reply, ty o7) about what martyn said claims that the data pool isnt large enough to cause environmental concern. with such a small userbase (aka just the server members) im willing to believe both the training + use dont have such a massive impact on the environment, especially when we're already looking at an industry thats based on streaming video in high quality over the internet, like that's already an significant environmental impact in itself is it not?
i guess there's an element of replacing humans with AI here. uh - this is a tricky one to speak on, because in the end i'm not qualified to decide if an smp is unethical because they're using genai (or similar) rather than employing people to play NPCs. goodness knows hiring people for non-streamed roles hasn't always worked out (qsmp had a lot of issues with this, and that's well-documented on this site). this one's beyond my scope a bit tho, i do computer ethics more than workplace ethics, but i do think that's a conversation worth having too
finally, the question of "hey, is this stealing from artists/writers?". if what's been said by martyn is true, it doesn't sound like it! in which case, fantastic!
okay now i've gone through all my notes, theyre not rlly comprehensive for every genai issue but that's all im willing to get into atp. idk i do want to go back and watch this martyn stream since it's The Only Source rn so im turning off rbs on this post bc i dont want this post going anywhere until i actually have facts LMAO i just wanted to answer this ask for now
quick note on it taking 7 years: i think that doesn't rule out the possibility that this is still a form of generative AI. 7 years is an interesting length of time, and i say that because that's literally when they started making GPTs! i rlly want to hear more on the devlopment of that one, but 7 years ago is when the foundations for the current LLM stuff came about (tmk? correct me if im wrong here) so i wouldn't be surprised if the end product has a lot in common. idk im just guessing about here tho bc again i really really dont know any of the technical details of their program, take that all with a grain of salt, 7 years is just a rlly specific number and i wanted to draw that connection because i dont think predating chatgpt prevents it from being pretty similar!
my whole point isn't really potentially ethical issues tho, i'm just deeply tired of seeing genai such as chatgpt or similarly trained models everywhere. if nothing else, it feels distasteful, and i dont really like it LOL simple as that
3 notes
·
View notes
Note
When you say no to ai, does that include me using Chatgtp for my assignments unethical
Yes. All AI requires the theft of copyrighted and private material from everyday people, to artists and authors and hobbyists. That includes the scraping of fanfiction on this site and others. Giving chatgpt one prompt uses up 13 ml of water, one of our most crucial finite resources. Chatgpt and others of its kind use up 10x more power than a normal google search. It also means that by outsourcing your work to a bot, you are depriving yourself of the learning you're paying for, and its making all of us stupider as a result. There is literally no up side or longevity for AI. It is unethical, and is destroying our environment in the middle of a climate crisis and everyone who uses it should not only stop, but feel ashamed for participating in the theft of people's work.
6 notes
·
View notes
Text
How I'm Tracking My Manga Reading Backlog
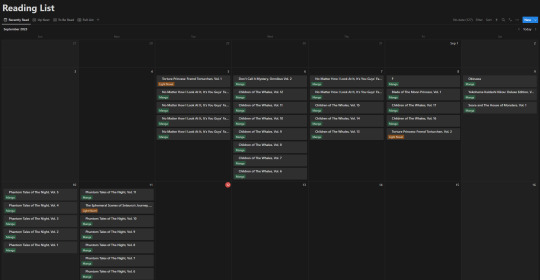
I'm bad at keeping up with reading sometimes. I'll read newer releases while still forgetting about some, want to re-read something even though I haven't started on another series, and leave droves of titles sitting on my shelves staring at me.
I got tired of that, and also tired of all these different tracking websites and apps that don't do what I want. So, with Notion and a few other tools, I've set out to make my own, and I like it! So I thought, hey, why not share how I'm doing it and see how other people keep track of their lists, so that's why I'm here. Enough rambling though, let me lead you through why I decided to make my own.
So, the number 1 challenge: Automation. In truth, it's far from perfect and is the price I pay for being lazy. But, I can automate a significant chunk of the adding process. I've yet to find a proper way to go from barcode scanning on my phone to my reading list, but I can go pretty easily from an amazon listing to the reading list. With it I grab: title, author, publisher, page count, and cover image.
So what do I use?
Well, it's a funky and interesting thing called 'Bardeen' that allows you to scrape webpages (among other things), collect and properly structure the desired information, and then feed it right into your Notion database. It's a little odd to try and figure out at first, but it's surprisingly intuitive in how it works! Once you have your template setup, you just head to the webpage (I've found Amazon the best option) and hit the button for the scraper you've built, and it puts it into Notion.
It saves an inordinate amount of time in populating fields by hand, and with the help of templates from Notion, means that the only fields left "empty" are the dated fields for tracking reading.

Thanks to Bardeen, the hardest (and really only) challenge is basically solved. Not "as" simple as a barcode, but still impressively close. Now, since the challenge is out of the way, how about some fun stuff?
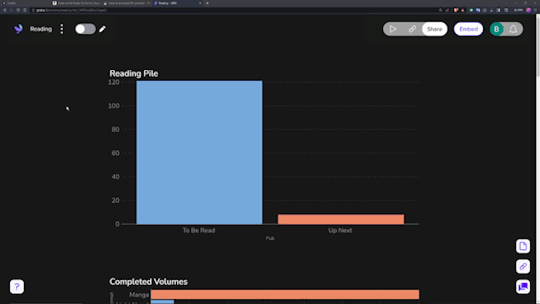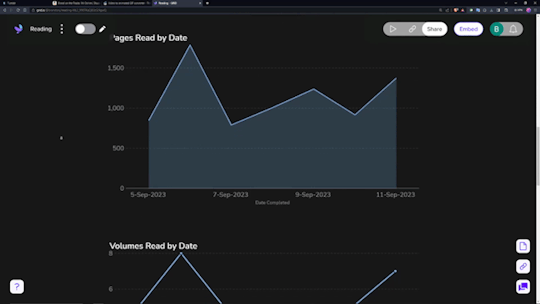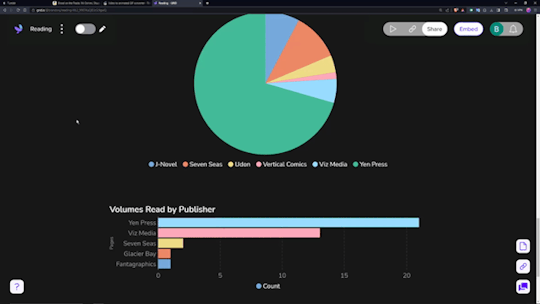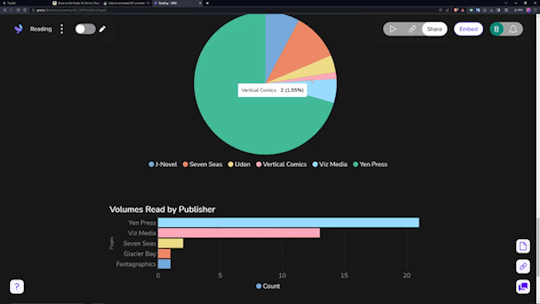
Data visualization is incredibly fun for all sorts of people. Getting to see a breakdown of all the little pieces that make up your reading habits is very interesting. Sadly, Notion doesn't have the ability to build charts from your own databases, so you need a tool.
The one I ended up settling on was 'Grid.is', as it has a "direct" integration/embed with Notion.
Sure, it has its own "limitations", but they pose absolutely zero concern as to how I want to set up my own data visualization. You can have (as far as I know) an unlimited number of graphs/charts on a single page, and you can choose to embed that page as a single entity, or go along and embed them as independent links. Either way, the graphs are really great and there's a lot of customization and options in regards to them. Also, incredibly thankful for the fact that there's an AI assistant to create the charts for you. The way that Notion data's read in is horrendous, so the AI makes it infinitely easier than what it appears as at first.
And yes, all those little popups and hover behaviors are preserved in the embeds.
Well, I suppose rather than talking about the tertiary tools, I should talk about what I'm doing with Notion itself, no?
Alright, so, like all Notion pages it starts with a database. It's the central core to keeping track of data and you can't do without it. Of course, data is no good if you can't have it properly organized, so how do I organize it?
With tags, of course! I don't have a massive amount of tags in place for the database, but I am considering adding more in terms of genre and whatnot. Regardless, what I have for the entries currently is: Title, Reading Status (TBR, Reading, Read, etc.), Author, Format (manga or LN), Date Started, Date Completed, Pages, and Publisher.
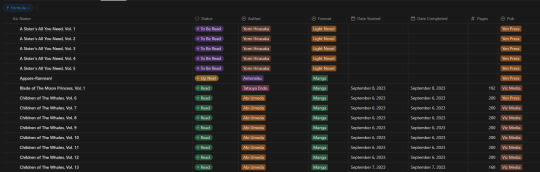
In addition to those "displayed" tags, I have two tertiary fields. The first is an image link so that entries can display an image in the appropriate view. The second, and a bit more of a pain, is a formula field used to create a proper "title" field so that Notion can sort effectively (they use lexicographic, so numbers end up sorted as letters instead). This is the poorly optimized Notion formula I used, as I don't have much experience with how they approach stuff like this. It just adds a leading zero to numbers less than 10 so that it can be properly sorted.

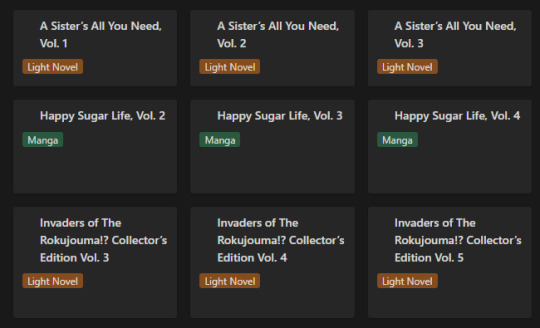
Of course this list view isn't my default view though, the calendar from the top of this post is. Most of the time though, I don't have it set to the monthly view, but rather weekly. Following up that view though, I've got my "up next" tab. This tab's meant to track all the titles/entries that I'm about to read. Things I'm planning to read today, tomorrow, or the day after. Sorta a three day sliding window to help me keep on top of the larger backlog and avoid being paralyzed by choice. It's also the only view that uses images currently.

Following that, I've got my "To Be Read" gallery. I wanted to use a kanban board but notion will only display each category as a single column, so I chose this view instead, which makes it much easier to get a better grasp of what's in the list. I've been considering adding images to this view, but I need to toy around with it some more. Either way, the point is to be able to take a wider look at what I've got left in my TBR and where I might go next.
So overall, I've ordered these views (though the list view I touch on "first" is actually the last of the views) in order from "most recent" to "least recent", if that makes any sense. Starting with where I've finished, moving to where I go next, what I have left, and then a grouping of everything for just in case.
It's certainly far from a perfect execution on a reading list/catalogue, but I think personally speaking that it checks off basically all of the boxes I required it to, and it gives me all the freedom that I could ever want - even if it means I have to put in a bit of elbow grease to make things work.
#anime and manga#manga#manga reader#manga list#reading list#reading backlog#light novel#notion#notion template
11 notes
·
View notes
Note
Hey, I just wanna say that, as a disabled person who at first vehemently disagreed with you, reading your pinned post really helped me understand your perspective and I can't, in good faith, say that I entirely disagree with you. AI art could be a very good creative resource for people, and I also disagree with a lot of art snobbery surrounding 'real Art' anyway. BUT if AI art programs were trained on datasets comprised of only the art of consenting artists, I don't think this would be as big of a debate. The only thing I have an issue with is you blaming the proliferation of data scraping on 'bad actors' when it feels like, at the moment, that 'bad actors' are intrinsically tied to what AI art is, and that those "bad actors" are controlling the entirety of neural network learning. Imo as of right now AI art is just data theft and if/when we reach the point where that isn't the case the conversation that you're trying to have can be expanded upon, but until then I don't see the majority of artists agreeing that copyright theft is a valid way to help the disabled community. And I personally disagree with stealing other people's art to further my own creative abilities.
First of all, thank you very much for being polite and presenting your thoughts in good faith.
I understand where you're coming from; the AI industry as a whole is deeply fraught with ethical issues. However, I don't think that art theft is one of them. You see, digital art only exists as abstract data. This means it could only be "owned" as intellectual property under copyright law. Intellectual property is purely a legal construct; it was invented for the purpose of incentivizing innovation, rather than to uphold the philosophical principles of ownership. I find that it makes very little sense that people should be able to own ideas—after all, it's seemingly human nature to adopt others' ideas into our own viewpoints, and to spread our ideas to others. In fact, there is an entire field of study, called memetics, dedicated to this phenomenon. So, I don't think that data scrapers are guilty of art theft. There is, however, an argument to be made that they are guilty of plagiarism. Scraped AI training databases generally do not credit the original authors of their contents, though they do disclose that the contents are scraped from the internet, so they aren't exactly being passed off as the curators' own work. Make of that what you will—I'm not really sure where I stand on the matter, other than that I find it questionable at best. Either way, though, I believe that training an AI makes transformative use of the training data. In other words, I don't think that training an AI can qualify as plagiarism, even though compiling its training dataset can. Rather than art theft or plagiarism, I think the biggest ethical problem with the AI industry's practices is their handling of data. As I mentioned in my pinned post, the low standard of accountability is putting the security of personal and sensitive information at risk.
Feel free to disagree with me on this. I acknowledge that my stances on IP certainly aren't universal, and I know that some people might not be as concerned about privacy as I am, but I hope my reasoning at least makes sense. One last thing: a lot of AI development is funded by investments and grants, so refusing to use AI may not be very impactful in terms of incentivizing better ethics, especially considering that ethics-indifferent businesses can be a fairly reliable source of revenue for them. That's why I think seeking regulation is the best course of action, but again, feel free to disagree. If you aren't comfortable with the idea of supporting the industry by using its products, that's perfectly valid.
7 notes
·
View notes
Note
Hi !
First of all, I am a huge fan of your works (so good)!
I just saw that most of your stories on Ao3 are now available to subscribers only, including Would it be a sin? (😭)
Was there a reason behind this change?
Anyway, I can't wait for the future chapters of Throne of Blood and Liberal Arts !!!
Thank you so much!
Restricting Work
I want to be thoughtful and transparent with the decision to restrict fics to registered users of AO3.
With the proliferation of AI in fandom, particularly art though its making its way to fics, I had concerns about my words being used to produce AI content. I am under no delusion that I am a prolific or popular writer. (I like to imagine that I sit in my little corner writing the stories I want to read and am delighted when they seem to spark joy in others.) But the idea of the work and effort I put into writer, the hours I spend doing this, being used to generate AI produced work makes me queasy.
Fandom should be generated by fans. It should take some kind of human effort.
So when OTW released this announcement, that queasy feeling got worse. I'm not a published author. I write derivative works for fun based on my love and enjoyment for an established property. But I feel like my words should still be my words. Plagiarism or data scraping should matter.
There is no easy answer and part of me feels hopeless in the face of AI. I still post most of my work on Fanfiction.net and I highly doubt there are any measurements in place to protect against data scraping. And what has happened has already happened and no one can go back in time to stop that.
Maybe my work wasn't used. Maybe it doesn't matter if I restrict or not. Maybe its just something that I needed in this moment to feel a little better. I don't really know if it matters that I did or not. I don't know if I'll change my mind and open up the visibility to my fics in the future. It's all so unknown.
Guests
The downside of this is the guest readers. I don't want to stop anyone from reading my works and I don't know how much of a barrier it might be to people to get a registered AO3 account. I don't know how many people reading my works it affects and I do want to be mindful of that. Perhaps foolishly, I was surprised to get this ask. I was surprised that anyone noticed. Maybe I don't have a good grasp of how many people are reading my fics that are guests and not registered users. It's hard to gauge. I primarily look to comments and asks to gauge "readership" or the interest in my fics and maybe that isn't the best way to try to do that.
If I find out that this does affect a lot of people, then it is something I would consider when thinking about whether to keep work restricted or not.
I don't want my words used to generate AI fic but I also don't want to stop people from reading. They are competing priorities that are difficult to balance.
The visibility may stay restricted or I might change my mind the more I think this over.
9 notes
·
View notes
Text
To the people asking why they shouldn't use chat gpt and/or calling op a bigot for "discriminating against neurodivergent people" (also, yes goblin tools uses gpt, I see some people confused about that) I am an autistic software engineer here to explain. Here are some of the main reasons people object to AI usage:
1) environmental impact. AI uses a frankly disgusting amount of power and water. It took almost 300,000 kwh to just train chat gpt 3, and enough water to fill a nuclear reactors cooling tower. Some people will argue that only the training is this resource intensive and once the model is trained the damage is already done. This is untrue, as every conversation with chat gpt you have is the equivalent of wasting a large bottle of water and leaving a light on for an hour. Even if it was true, these companies are constantly training and improving existing models, and justifying that cost to their shareholders partially with YOUR use of their tool. And yes, big tech had a water and energy problem long before LLMs, but LLMs are significantly worse and only worsening.
2) it doesn't KNOW anything. This one is more philosophical, but chat gpt is advanced text prediction and arranging. Even researchers themselves are starting to accept that they will never be able to eliminate so called "hallucinations", which is when the model makes something plausible sounding up basically. It is not a "better search engine" because it is not retrieving any factual data, it is generating the most statistically probable results based on its training data, which will sometimes produce a desired output, but sometimes produces flat out nonsense. As well, you have to do your own fact checking. On Google, you can see the source of where something came from and who wrote, and gpt robs you of that context. There is no such thing as bias free, purely factual information unless we're talking incredibly basic questions and the info from chat gpt is basically worthless if it has no sources, no context, no author, and is made up by the model.
3) theft. This one is controversial, some people will argue that if you put something publicly on the Internet you are passively consenting to its use, but if I repost someones article without credit/claiming it as my own, they can still request that that article gets taken down. But the facts are that open AI used a dataset that scraped an absolutely massive amount of Internet data to train their model without asking, and you can get chat gpt to produce chunks of that text, especially in niche topics. For example, the software I work with is relatively niche and if you use chat gpt to get answers to questions about it, it will word for word reproduce some chunks of the actual documentation, mixed in with nonsense and with no accreditation. If you are using chat gpt for homework answers, you are potentially plagiarizing word for word chunks of other people's work.
4) this is one I don't see talked about often, but it's one that I feel is important. BIAS. GPT scraped the internet. Meaning, its word salads are entirely based on people who have internet access, and even more than that, people who post or post frequently on the Internet. That's a really small portion of the whole population. So, do you really want your word salads to have that kind of bias? Especially if you are using them for work or homework?? Wouldn't you rather put your unique, diverse, voice into the world?
Ultimately, using LLMs is an ethical decision you have to make and live with, but you should do it while understanding why people object to them, and also while understanding that the model doesn't know anything, it's like an advanced magic eight ball. Don't just play the victim and refuse to listen to concerns. Or call everyone taking issue with your use a bigot.

142K notes
·
View notes
Note
I have a question about your post regarding AI in which you detailed some agents' concerns. In particular you mentioned "we don't want our authors or artists work to be data-mined / scraped to "train" AI learning models/bots".
I completely agree, but what could be done to prevent this?
(I am no expert and clearly have NO idea what the terminology really is, but hopefully you will get it, sorry in advance?)
I mean, this is literally the thing we are all trying to figure out lol. But a start would be to have something in the contracts that SAYS Publishers do not have permission to license or otherwise permit companies to incorporate this copyrighted work into AI learning models, or to utilize this technology to mimic an author’s work.
The companies that are making AI bots or whatever are not shadowy guilds of hackers running around stealing things (despite how "web scraping" and "data mining" and all that sounds, which admittedly is v creepy and ominous!) -- web scraping, aka using robots to gather large amounts of publicly available data, is legal. That's like, a big part of how the internet works, it's how Google knows things when you google them, etc.
It's more dubious if scraping things that are protected under copyright is legal -- the companies would say that it is covered under fair use, that they are putting all this info in there to just teach the AI, and it isn't to COPY the author's work, etc etc. The people whose IP it is, though, probs don't feel that way -- and the law is sort of confused/non-existent. (There are loads of lawsuits literally RIGHT NOW that are aiming to sort some of this out, and the Writer's Guild strike which is ongoing and SAG-AFTRA strike which started this week is largely centered around some of the same issues when it comes to companies using AI for screenwriting, using actor's likeness and voice, etc.) Again, these are not shadowy organizations operating illegally off the coast of whatever -- these are regular-degular companies who can be sued, held to account, regulated, etc. The laws just haven’t caught up to the technology yet.
Point being, it's perhaps unethical to "feed" copyrighted work into an AI thing without permission of the copyright holder, but is it ILLEGAL? Uh -- yes??? but also ?????. US copyright law is pretty clear that works generated entirely by AI can't be protected under copyright -- and that works protected by copyright can't be, you know, copied by somebody else -- but there's a bit of a grey area here because of fair use? It’s confusing, for sure, and I'm betting all this is being hashed out in court cases and committee rooms and whatnot as I type.
Anywhoo, the first steps are clarifying these things contractually. Authors Guild (and agents) take the stance that this permission to "feed" info to AI learning models is something the Author automatically holds rights to, and only the author can decide if/when a book is "fed" into an AI... thing.
The Publishers kinda think this is something THEY hold the rights to, or both parties do, and that these rights should be frozen so NEITHER party can choose to "feed", or neither can choose to do so without the other's permission.
(BTW just to be clear, as I understand it -- which again is NOT MUCH lol -- this "permission" is not like, somebody calls each individual author and asks for permission -- it's part of the coding. Like how many e-books are DRM protected, so they are locked to a particular platform / device and you can't share them etc -- there are bits of code that basically say NOPE to scrapers. So (in my imagination, at least), the little spider-robot is Roomba-ing around the internet looking for things to scrape and it comes across this bit of code and NOPE, they have to turn around and try the next thing. Now – just like if an Etsy seller made mugs with pictures of Mickey Mouse on them, using somebody else’s IP is illegal – and those people CAN be sued if the copyright holder has the appetite to do that - but it’s also hard to stop entirely. So if some random person took your book and just copied it onto a blog -- the spider-robot wouldn't KNOW that info was under copyright, or they don't have permission to gobble it up, because it wouldn't have that bit of code to let them know -- so in that way it could be that nobody ever FULLY knows that the spider-robots won't steal their stuff, and publishers can't really be liable for that if third parties are involved mucking it up -- but they certainly CAN at least attempt to protect copyright!)
But also, you know how I don't even know what I'm talking about and don't know the words? Like in the previous paragraphs? The same goes for all the publishers and everyone else who isn't already a tech wizard, ALL of whom are suddenly learning a lot of very weird words and phrases and rules that nobody *exactly* understands, and it's all changing by the week (and by the day, even).
Publishers ARE starting to add some of this language, but I also would expect it to feel somewhat confused/wild-west-ish until some of the laws around this stuff are clearer. But really: We're all working on it!
87 notes
·
View notes
Text
Canadian News Outlets Sue OpenAI Over Copyright Infringement
A coalition of Canada’s largest news organizations has launched a groundbreaking lawsuit against OpenAI, the creator of ChatGPT, alleging unauthorized use of copyrighted news articles to train its artificial intelligence models. This legal action, the first of its kind in Canada, includes major publishers such as Toronto Star, Metroland Media, Postmedia, The Globe and Mail, The Canadian Press, and CBC.

Claims of Illegal Use of Journalism
In a unified statement, the media organizations emphasized the importance of journalism in serving the public interest, accusing OpenAI of exploiting their work for commercial gain without authorization.
“Journalism is in the public interest. OpenAI using other companies’ journalism for their own commercial gain is not. It’s illegal,” the coalition said.
The lawsuit highlights concerns over OpenAI's alleged bypassing of copyright protections like paywalls and disclaimers to scrape large amounts of content for developing its tools, including ChatGPT.
OpenAI’s Response
OpenAI maintains that its models are trained on publicly available data and adhere to "fair use" principles. The company claims to work with publishers by offering tools for attribution and allowing publishers to opt out of their systems if desired.
In response to the allegations, OpenAI stated: “Our software is grounded in fair use and related international copyright principles that are fair for creators and support innovation. We collaborate closely with news publishers in the display, attribution, and linking of their content.”
Legal Demands and Potential Impact
The Canadian media coalition seeks punitive damages of C$20,000 per article, which could amount to billions of dollars in compensation. The lawsuit also demands OpenAI share profits derived from the use of these articles and calls for an injunction to prevent future unauthorized use of their content.
This legal battle mirrors similar cases globally. For instance, the New York Times and other US publishers initiated legal proceedings against OpenAI last year, alleging copyright violations and obstruction of evidence. Similarly, renowned authors like John Grisham have joined lawsuits accusing the company of copyright infringement.
Implications for AI and Journalism
As AI continues to evolve, the case highlights the tension between technological innovation and the protection of intellectual property. With OpenAI recently valued at C$219bn after a significant round of fundraising, the stakes in this legal conflict are monumental.
The outcome of this lawsuit could reshape how AI companies interact with copyrighted material and set a precedent for the global use of journalism in AI training.
Conclusion
This landmark legal action by Canadian publishers not only underscores the value of journalism but also raises critical questions about ethical AI development. As the case unfolds, it will likely have far-reaching consequences for both the tech and media industries.
0 notes
Text
A musician in the US has been accused of using artificial intelligence (AI) tools and thousands of bots to fraudulently stream songs billions of times in order to claim millions of dollars of royalties.
Michael Smith, of North Carolina, has been charged with three counts of wire fraud, wire fraud conspiracy and money laundering conspiracy charges.
Prosecutors say it is the first criminal case of its kind they have handled.
"Through his brazen fraud scheme, Smith stole millions in royalties that should have been paid to musicians, songwriters, and other rights holders whose songs were legitimately streamed," said US attorney Damian Williams.
According to an unsealed indictment detailing the charges, the 52-year-old used hundreds of thousands of AI-generated songs to manipulate streams.
The tracks were streamed billions of times across multiple platforms by thousands of automated bot accounts to avoid detection.
Authorities say Mr Smith claimed more than $10m in royalty payments over the course of the scheme, which spanned several years.
What is AI and how does it work?
Prosecutors said Mr Smith was set to finally "face the music" following their investigation, which also involved the FBI.
"The FBI remains dedicated to plucking out those who manipulate advanced technology to receive illicit profits and infringe on the genuine artistic talent of others," said FBI acting assistant director Christie M. Curtis.
'Instant music ;)'
According to the indictment, Mr Smith was at points operating as many as 10,000 active bot accounts to stream his AI-generated tracks.
It is alleged that the tracks in question were provided to Mr Smith through a partnership with the chief executive of an unnamed AI music company, who he turned to in or around 2018.
The co-conspirator is said to have supplied him with thousands of tracks a month in exchange for track metadata, such as song and artist names, as well as a monthly cut of streaming revenue.
"Keep in mind what we're doing musically here... this is not 'music,' it's 'instant music' ;)," the executive wrote to Mr Smith in a March 2019 email, and disclosed in the indictment.
Citing further emails obtained from Mr Smith and fellow participants in the scheme, the indictment also states the technology used to create the tracks improved over time - making the scheme harder for platforms to detect.
In an email from February, Mr Smith claimed his "existing music has generated at this point over 4 billion streams and $12 million in royalties since 2019."
Mr Smith faces decades in prison if found guilty of the charges.
Earlier this year a man in Denmark was reportedly handed an 18-month sentence after being found guilty of fraudulently profiting from music streaming royalties.
Music streaming platforms such as Spotify, Apple Music and YouTube generally forbid users from artificially inflating their number of streams to gain royalties and have taken steps to clamp down on or advised users on how to avoid the practice.
Under changes to its royalties policies that took effect in April, Spotify said it would charge labels and distributors per track if it detected artificial streams of their material.
It also increased the number of streams a track needs in a 12 month period before royalties can be paid, and extended the minimum track length for noise recordings like white noise tracks.
Wider concerns
The wider rise of AI-generated music, and the increased availability of free tools to make tracks, have added to concerns for artists and record labels about getting their fair share of profits made on AI-created tracks.
Tools that can create text, images, video, audio in response to prompts are underpinned by systems that have been "trained" on vast quantities of data, such as online text and images scraped, often indiscriminately, from across the web.
Content that belongs to artists or is protected by copyright has been swept up to form part of some of the training data for such tools.
This has sparked outrage for artists across creative industries who feel their work is being used to generate seemingly novel material without due recognition or reward.
Platforms rushed to remove a track that cloned the voices of Drake and The Weeknd in 2023 after it went viral and made its way onto streaming services.
Earlier this year, artists including Billie Eilish, Chappell Roan, Elvis Costello and Aerosmith signed an open letter calling for the end to the "predatory" use of AI in the music industry.
1 note
·
View note