#Delimited Data
Text
Efficiently Split Names in Excel: Using Text to Columns, Flash Fill, or Ctrl+E
Efficiently Split Names in Excel: Using Text to Columns, Flash Fill, or Ctrl+E
Do you struggle with splitting names in Excel? Are you tired of manually separating first and last names from a combined cell? Look no further! In this short tutorial video, we’ll teach you how to use two built-in Excel tools – Text to Columns and Flash Fill or Ctrl+E – to quickly and easily split names. We’ll guide you through the process step-by-step and provide helpful tips for handling more…
View On WordPress
#Advanced Excel Techniques#Automatic name extraction#Complex name structures#Ctrl+E#Data Analysis#Data efficiency#Data management#Data Manipulation#Database Management#Delimited Data#Excel Formulas#Excel name splitting#Excel Skills#First and last names#Flash Fill#Formatting Tools#Guide#How To#Microsoft Excel#Middle initials#Name Formatting#Name Parsing#Productivity#Quick and Easy#Shortcuts#Spreadsheet Optimization#Streamline Workflow#Streamlining#Text to Columns#Time-saving techniques
1 note
·
View note
Text
Kaiowá Indigenous land retaken in Brazilian state becomes the epicenter of conflict for demarcation: 'We are at war'
'We don't want an agreement. We want the land now,' says Indigenous leader of the Panambi Lagoa-Rica land

A contaminated river, armed attacks, a young man with a bullet lodged in his brain, Indigenous people shot in the neck and leg, forests and Indigenous houses set on fire. With the lack of definition for the cut-off point, the recovery of ancestral territories by the Guarani Kaiowá people and the violent reaction of large landowners, the small town of Douradina in the state of Mato Grosso do Sul has become the epicenter of a new chapter in land conflicts in Brazil.
Last Friday (13) marked two months since Indigenous people took back three areas of Panambi Lagoa-Rica Indigenous Land. Since then, tensions have escalated in Mato Grosso do Sul. The 12,196-hectare area was delimited and recognized by the National Foundation for Indigenous Peoples (FUNAI, in Portuguese) in 2011 as being traditionally occupied by the Guarani Kaiowá people, but the land demarcation process has stalled ever since. According to data from the Land Management System of the National Institute for Colonization and Agrarian Reform (INCRA, in Portuguese), there are at least 26 rural properties overlapping the territory.
On September 8, rockets were once again fired at night from the camp set up by men linked to the agribusiness sector in the Yvy Ajherê Guarani Kaiowá community. The Indigenous group see the attack as retaliation for the construction of a prayer house in the area.
With the shots, the Kaiowá advanced towards the camp, so did the National Force and, amid mediation attempts and war cries, the men abandoned the post for the first time in 57 days. They fled closer: to the headquarters of Cleto Spessatto's farm, a few meters away.
Continue reading.
#brazil#brazilian politics#politics#environmental justice#indigenous rights#guarani kaiowa people#farming#image description in alt#mod nise da silveira
11 notes
·
View notes
Text
The split() function in python
The split() method in Python is used to split a string into a list of strings. It takes an optional separator argument, which is the delimiter that is used to split the string. If the separator is not specified, the string is split at any whitespace characters.
The syntax of the split() method is as follows:
Python
string_name.split(separator)
where:
string_name is the string object that is calling the split() method.
separator is the string that is being used as the separator.
For example, the following code splits the string my_string at the first occurrence of the " character:
Python
my_string = "This is a string with a \"quote\" in it."
parts = my_string.split("\"")
print(parts)
This code will print the following output:
['This is a string with a ', 'quote', ' in it.']
Here are some additional examples of how to use the split() method:
Python
my_string = "This is a string with multiple separators: -_--_-"
parts = my_string.split("--")
print(parts)
This code will print the following output:
['This is a string with multiple separators: ', '_', '_-']
Python
my_string = "This is a string without a separator."
parts = my_string.split("@")
print(parts)
This code will print the following output:
['This is a string without a separator.']
The split() method is a very versatile tool that can be used to split strings into lists of strings in a variety of ways. It is commonly used for tasks such as parsing text files, extracting data from strings, and validating user input.
#programmer#studyblr#learning to code#python#kumar's python study notes#codetober#progblr#coding#codeblr#programming
39 notes
·
View notes
Text

Day 1 - 100 days of code C++
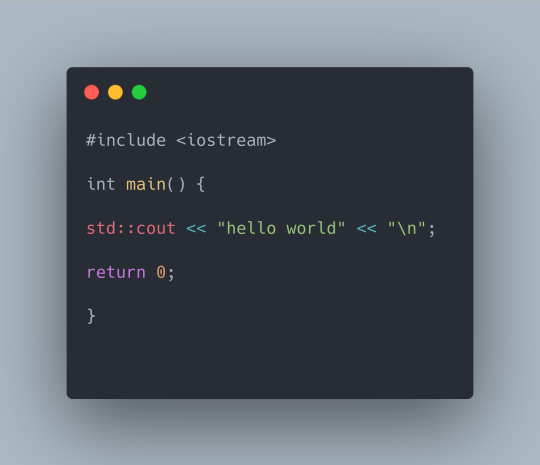
Observations
#include
It means that we are calling a library of the language, that is, we are calling some resource whose purpose is to help in some action that our code is doing, in this case, we are calling this library to print our screen output - hello world - via * std::cout*.
int main()
This is the main function of the language, that is, our program does not exist if there is no main function. The parentheses are used to pass a parameter, in this case we are not passing any.
{}
The keys are the representation of where our code will be executed, therefore it delimits the execution block, even calling other functions or executing something simpler, however being within these delimiters.
std::cout
This is our command responsible for calling the c++ language standard library that works with data input and output - iostream. Without this command we would not be able to print an output on screen.
std::endl
If you stick to STD::, this means that STD is an abbreviation of the word STANDARD, that is, it is an abbreviation that references the C++ Standard library / directive - iostream. Its purpose is to make a line break, that is, when you finish executing the command, the cursor goes to a new line. The letter "\n" does the same thing, I used it because it is a simpler language syntax.
return()
Return(0) means that, if our program does not present any syntax errors, it will not return any errors, thus ending our program properly.
Conclusion
As we observed, C++ is an apparently simple language, it has a concise syntax, for me, for the time being, it did not present major problems, since, as far as I could see, it shares characteristics of other languages that I had the opportunity to have contact with until then. Next day, I want to get into the subject of variables and their types.
47 notes
·
View notes
Text
Doing a thesis or dissertation? What to include in your abstract, findings, discussion & conclusion

1.Abstract
Functions of a Thesis Abstract
The abstract serves as a concise summary of the entire thesis and typically includes:
a. The aims of the study: Clearly stating what the research intends to achieve.
b. The background and context of the study: Providing a brief overview of the research topic and its significance.
c. The methodology and methods used: Describing the approach and specific techniques used to gather and analyze data.
d .The key findings of the study: Highlighting the most important results.
e, The contribution to the field: Explaining how the research adds to existing knowledge.
Abstract Move and Sub-Move Options
Introduction
Provide context and background of the research.
Identify the motivation for the research.
Explain the significance of the research focus.
Identify the research gap or continuation of research tradition.
Purpose
State the aims or intentions, questions, or hypotheses.
Develop these aims or intentions further.
Method
Identify and justify the overall approach and methods.
Outline key design aspects.
Describe data sources and parameters.
Explain data analysis processes.
Product
Present main findings/results of key aims or questions.
Provide findings/results of subsidiary or additional aims or questions
Conclusion
Discuss the significance/importance of findings beyond the research, considering contributions to theory, research, and practice.
Suggest applications for practice and implications for further research.
2. Introduction Chapter

Functions of a Thesis Introduction
The introduction sets the stage for the thesis, addressing several key points:
a. Describing the problem, issue, or question of interest.
b. Reviewing the background and context, including a literature review.
c. Identifying gaps in existing knowledge.
d. Explaining what the study will do to address these gaps.
e .Outlining the methodology and scope of the study.
f. Discussing the expected contribution to the field.
g. Providing an outline of the thesis structure.
Introduction Move and Sub-Move Options
Establish a Research Territory
Explain the importance, relevance, or problem of the topic.
Provide background information.
Review previous research.
Define key terms and constructs.
Establish a Niche
Indicate gaps in previous research.
Raise questions about prior studies.
Identify a problem or need.
Extend previous knowledge.
Occupy the Niche
Outline the purpose, aim, and objectives of the research.
Specify research questions/hypotheses.
Describe theoretical perspectives.
Detail the methodology and design.
Indicate the scope/delimitations.
Explain the contribution to the field.
Outline the thesis organization.
3. Literature Review Chapter

Functions of a Literature Review
The literature review chapter serves multiple purposes:
Summarizing background and contextual information.
Reviewing theoretical perspectives related to the research.
Critiquing the research literature relevant to the study.
Identifying gaps or shortcomings in existing research.
Justifying the significance of addressing these gaps.
Explaining how the literature informs the research design and methodology.
Organizational Options for a Literature Review
The literature review can be organized in various ways, including:
Themes and topics.
Research questions or hypotheses.
Variables investigated in the study.
Chronological presentation of literature.
A combination of these options.
Literature Review Move and Sub-Move Options
Establish Knowledge Territory
Present knowledge claims and statements about theories, beliefs, constructs, and definitions.
State the centrality, importance, or significance of the theme/topic.
Present research evidence.
Create a Research Niche/Gap in Knowledge
Critique knowledge claims, issues, and problems.
Present research evidence in relation to the critique.
Identify gaps in knowledge/research.
Continue or develop a tradition that is under-investigated.
Argue for a new perspective or theoretical framework.
Announce Occupation of the Research Niche/Gap
Announce the aim of the research study.
State theoretical positions/frameworks.
Describe the research design and processes.
Define key concepts and terms in the research.
4.Methodology Chapter

Functions of a Methodology Chapter
The methodology chapter details the research design and methods, including:
Describing and justifying the methodological approach.
Detailing the research design.
Justifying the specific methods for data collection.
Discussing the validity and reliability of data.
Outlining the data collection procedures.
Explaining the data analysis procedures.
Methodology Move and Sub-Move Options
Present Measurement Procedures
Overview the methodological approach.
Explain methods of measuring variables.
Justify the approach and methods.
Describe Data Collection Procedures
Describe the sample, including location, size, characteristics, context, and ethical issues.
Describe instruments used for data collection and their validity and reliability.
Detail the data collection steps.
Justify data collection procedures.
Elucidate Data and Analysis Procedures
Outline data analysis procedures.
Justify data analysis procedures.
Preview results.
5. Results Chapter

Functions of a Results Chapter
The results chapter presents and explains the findings:
Presenting results/findings relevant to research questions/hypotheses.
Explaining the meaning of findings without interpretation.
Providing evidence to support findings.
Referring back to methodology and background/context.
Referring forward to the discussion of results.
Results Move and Sub-Move Options
Present Metatextual Information
Provide background information.
Reference methodology detail.
Reference forward to discussion detail.
Link between sections.
Present Results
Restate research questions/hypotheses.
Present procedures for generating results.
Present results with evidence and explanation.
6. Discussion Chapter

Functions of a Thesis Discussion of Results
The discussion chapter interprets the results and situates them within the broader field:
Overviewing the research aims and questions/hypotheses.
Summarizing the theoretical and research contexts.
Summarizing the methodological approach.
Discussing the contribution of the results to existing theory, research, and practice.
Including interpretations, comparisons, explanations, and evaluations of the results.
Results Move and Sub-Move Options
Provide Background Information
Restate aims, research questions, and hypotheses.
Restate key published research.
Restate the research/methodological approach.
Present Statement of Results (SoR)
Restate a key result.
Expand on the key result.
Evaluate/Comment on Results or Findings
Explain the result and suggest reasons.
Comment on whether the result was expected or unexpected.
Compare results with previous research.
Provide examples of results.
Make general claims arising from the results.
Support claims with previous research.
Make recommendations for future research.
Justify further research recommendations.
7. Conclusion Chapter

Functions of a Conclusion Chapter
The conclusion chapter wraps up the thesis by:
Reminding of the aims and key methodological features.
Summarizing the study’s findings.
Evaluating the study’s contribution to theory and practice.
Discussing practical applications.
Making recommendations for further research.
Results Move and Sub-Move Options
Restatement of Aims and Methodological Approach
Restate the aims of the study.
Restate key features of the research methodology and methods.
Summary of Findings
Summarize the key findings.
Evaluation of Study’s Contribution
Discuss the significance of findings for theory and research development.
Discuss the significance of findings for practical application.
Justify the significance of findings.
Identify any limitations.
Recommendations for Further Research
Make recommendations for further research based on the findings and limitations.
Investing in your academic future with Dissertation Writing Help For Students means choosing a dedicated professional who understands the complexities of dissertation writing and is committed to your success. With a comprehensive range of services, personalized attention, and a proven track record of helping students achieve their academic goals, I am here to support you at every stage of your dissertation journey.
Feel free to reach out to me at [email protected] to commence a collaborative endeavor towards scholarly excellence. Whether you seek guidance in crafting a compelling research proposal, require comprehensive editing to refine your dissertation, or need support in conducting a thorough literature review, I am here to facilitate your journey towards academic success. and discuss how I can assist you in realizing your academic aspirations.
#academics#education#grad school#gradblr#phd#phd life#phd research#phd student#phdblr#study#study motivation#studying#studyblr#studyspo#study blog#study aesthetic#student#university#student life#university student#writters on tumblr#my writing#writeblr#writing#writers on tumblr#writers and poets#writerscommunity#uniblr#students#academia
3 notes
·
View notes
Text
I think in parentheticals (and I write like that too)
In the garden of my mind, thoughts bloom wild and free, a tapestry of code and art, a symphony of me.
(Brushstrokes of no-thoughts femboy Bengali dreams)
Neurons fire in patterns, complex beyond compare, as I navigate this life with logic and flair.
{My mind: a codebase of evolving truths}
[Data points scatter, t-tests confuse]
--Sensory overload interrupts my stream of--
/*TO-DO!!! Refactor life for optimal growth*/
|grep for joy| |in life's terminal|
A canvas of brackets, ideas intertwine, functions and objects, in chaos align.
/*FIX ME!!!!!!! Catch exceptions thrown by society*/
|stdout of trauma| |stdin of healing|
Confidence intervals stretch far and wide, as গোলাপ্রী blooms, with so many colors inside.
{Functions intertwined? Objects undefined?}
[Omg, what if logistic regression predicts my fate?]
I am able to visualize the complexity within, as p-values in my field irritate me from under my skin.
(Artistic visions lazily swirl with wanton scientific precision)
--consciousness, a synesthesia of ideas--
{while(true) { explore(self); } // Infinite loop}
In loops infinite, I explore lessons of my soul; all your null hypotheses rejected! Hah, I'm extraordinary and whole.
/*I DARE YOU: Try to do five weeks of work in one morning*/
[Is it valid to try to see if ANOVA reveals the variance of me?]
(A canvas of brackets, a masterpiece of neurodiversity)
Opening tags of 'they', closing with 'he', in this markup of life, I'm finally free.
--tasting colors of code, hearing shapes of data--
/*NOTE TO SELF: Embrace the chaos of your own source code*/
|Pipe delimited| |thoughts flow through|
{R ((THANK YOU GGPLOT2)) attempts to visualize the complexity of my being}
Reality bends, a Möbius strip of thought, where logic and emotion are intricately wrought.
[Observed Rose vs. Expected Rose, let's try a chi-squared goodness of societal fit test]
(Palette: deep indigo, soft lavender, rose pink)
--LaTeX equations describe emotional states--
/*WARNING warning WARRRNNINGG: Potential infinite loop in intellectualization and self-reflection*/
|Filter noise| |amplify authentic signal|
{Machine learning dreams, AI nightmares}
As matrices model my unique faceting, while watercolors blur lines of binary thinking,
(Each brushstroke - a deliberate step towards ease and self-realization)
--Thoughts branch like decision trees, recursive and wild--
/*TO DO!!!! Optimize for radical self-forgiveness, self-acceptance, and growth*/
|Compile experiences| |into wisdom|
{function authenticSelf() { return shadow.integrate(); }}
In this experiment of existence, I hypothesize.
[Will they date me if I Spearman's rank correlation my traits?]
Data structures cannot possibly contain the potential of my rise.
(Art and science are just two interrelated hemispheres of one brain
{function adhd_brain(input: Life): Experience[] {
return input.events.flatMap(event =>
event.overthink().analyze().reanalyze()
).filter(thought => thought.isInteresting || thought.isChaotic);
}}
--Stream of consciousness overflows its banks--
Clustering algorithms group my personality as one.
Branches of thoughts, but with just one distraction, it's all gone!
/*NOTE: That's okay. Cry and move on.*/
|Filter noise| |amplify authentic signal|
{if (self == undefined) { define(self); }}
Hypothesis: I contain multitudes, yet I'm true.
[Obviously, a non-parametric me needs a non-parametric test: Wilcoxon signed-rank test of my growth]
(Ink and code flow from the same creative source: me)
<404: Fixed gender identity not found>
As thoughts scatter like leaves on the floor.
[So if my words] [seem tangled] [and complex]
[Maybe I'm just a statistical outlier] [hard to context]
--Sensory input overloads system buffers--
/*END OF FILE… but the thoughts never truly end*/
/*DO NOT FORGET TO COMMIT AND PUSH TO GIT*/
{return life.embrace(chaos).find(beauty);}
--
Rose the artist formerly known as she her Pri
~ গোলাপ্রী
#poem#original poem#code#i code#programming#healing#neurodivergence#self love#love#prose#coding#developer#adhd#thoughts#thinking#branching thoughts#branches#me#actually adhd#adhd brain#neurodivergent#neurodiversity
2 notes
·
View notes
Photo






A Prehistoric Burial with 6 Ankle Bracelets Discovered in France
An individual bedecked in copper jewelry was discovered during the excavation of a protohistoric necropolis in Aubagne, southeastern France.
The necropolis, which served as a transitional site between the late Bronze and early Iron ages from roughly 900 to 600 B.C., was first unearthed in 2021. Ten burials, including three cremation deposits and eight burials buried beneath a tumulus, were discovered at that time. Three additional burials were found during this year’s excavation, one of which was hidden beneath a 33-foot-diameter tumulus. The tumulus is noteworthy because a deep ditch surrounded it, and it probably used to be marked by a ring of stones. However, the burial inside was not furnished.
The two additional graves discovered this season were: The first contained the skeletal remains of a person who was wearing a twisted copper alloy bracelet and a pearl and stone jewel on the left shoulder. Near the deceased’s head, two ceramic pots were buried.
The second non-tumulus burial is the richest found in this necropolis thus far. The individual was buried wearing a tubular torc with rolled terminals around their neck, three ankle bangles, and three toe rings. A brooch and a large ceramic urn were placed next to the deceased.
The tumulus and the first burial are close together. The third was separated from the first two. Each space was clearly and purposefully delimited by structures that are now long gone. A line of postholes separates the tumulus and the first inhumation, indicating a linear structure that once formed the boundary line of space reserved for the dead. The second burial was defined by a six-foot-long alignment of stone blocks.
The discovery of these three graves has significantly increased our knowledge of protohistoric southern French funerary customs. They also show that the necropolis was much larger than what early archaeologists had thought it to be. The necropolis is estimated to have covered at least 1.3 hectares and probably even more, according to the new data.
By Leman Altuntaş.
#A Prehistoric Burial with 6 Ankle Bracelets Discovered in France#ancient tomb#ancient grave#ancient necropolis#ancient artifacts#archeology#archeolgst#history#history news#ancient history#ancient culture#ancient civilizations
46 notes
·
View notes
Text


By: Jerry A. Coyne and Luana S. Maroja
Edition: Jul/Aug 2023
SUMMARY: Biology faces a grave threat from “progressive” politics that are changing the way our work is done, delimiting areas of biology that are taboo and will not be funded by the government or published in scientific journals, stipulating what words biologists must avoid in their writing, and decreeing how biology is taught to students and communicated to other scientists and the public through the technical and popular press. We wrote this article not to argue that biology is dead, but to show how ideology is poisoning it. The science that has brought us so much progress and understanding—from the structure of DNA to the green revolution and the design of COVID-19 vaccines—is endangered by political dogma strangling our essential tradition of open research and scientific communication. And because much of what we discuss occurs within academic science, where many scientists are too cowed to speak their minds, the public is largely unfamiliar with these issues. Sadly, by the time they become apparent to everyone, it might be too late.
* * *
We’re all familiar with the culture wars that pit progressive Leftists against centrists and those on the Right. In the past, those skirmishes dealt with politics and sociocultural issues and in academia were restricted largely to the humanities. But—apart from the “sociobiology wars” of the seventies and our perennial battles against creationism—we biologists always thought that our field would avoid such struggles. After all, scientific truth would surely be immune to attack or distortion by political ideology, and most of us were too busy working in the lab to engage in partisan squabbles.
We were wrong. Scientists both inside and outside the academy were among the first to begin politically purging their fields by misrepresenting or even lying about inconvenient truths. Campaigns were launched to strip scientific jargon of words deemed offensive, to ensure that results that could “harm” people seen as oppressed were removed from research manuscripts, and to tilt the funding of science away from research and toward social reform. The American government even refused to make genetic data—collected with taxpayer dollars—publicly available if analysis of that data could be considered “stigmatizing.” In other words, science—and here we are speaking of all STEM fields (science, technology, engineering, and mathematics)—has become heavily tainted with politics, as “progressive social justice” elbows aside our real job: finding truth.
In biology, these changes have been a disaster. By diluting our ability to investigate what we find intriguing or important, withholding research support, controlling the political tone of manuscripts, and demonizing research areas and researchers themselves, ideologues have cut off whole lines of inquiry. This will decrease human wellbeing, for, as all scientists understand—and as the connection between heat-resistant bacteria and PCR tests demonstrates—we never know what benefits can come from research driven by pure curiosity. But nourishing curiosity has a value all its own. After all, it doesn’t make us healthier or wealthier to study black holes or the Big Bang, but it certainly enriches our lives to know about such things. Thus, the erosion of academic freedom in science by progressive ideology hurts us both intellectually and materially.
Although biology has clashed with ideology at other times and places (e.g., the Soviet Lysenko affair, creationism, and the anti-vax movement), the present situation is worse, for it affects all scientific fields. What’s equally unfortunate is that scientists themselves—helped along by university administrators—have become complicit in their own muzzling.
Here we give six examples of how our own field—evolutionary and organismal biology—has been impeded or misrepresented by ideology. Each example involves a misstatement spread by ideologues, followed by a brief explanation of why each statement is wrong. Finally, we give what we see as the ideology behind each misstatement and then assess its damage to scientific research, teaching, and the popular understanding of science. Our ultimate concern is biology research—the discovery of new facts—but research isn’t free from social influence; it goes hand in hand with teaching and the public acceptance of biological facts. If certain areas of research are stigmatized by the media, for example, public understanding will suffer, and there will follow a loss of interest in teaching as well as in research in these areas. By cutting off or impeding interest in biology, the misrepresentation or stigmatization by the media ultimately deprives us of opportunities to understand the world.
We concentrate on our own field of evolutionary biology because it’s what we feel most compelled to defend, but we add that related ideological conflicts are common in sciences such as chemistry, physics, math, and even computer science. In these other areas, however, the clashes involve less denial of scientific facts and more effort toward purifying language, devaluing traditional measures of merit, changing the demographics of scientists, drastically altering how science is taught, and “decolonizing” science.
Sex in humans is not a discrete and binary distribution of males and females but a spectrum.
All behavioral and psychological differences between human males and females are due to socialization.
Evolutionary psychology, the study of the evolutionary roots of human behavior, is a bogus field based on false assumptions.
We should avoid studying genetic differences in behavior between individuals.
“Race and ethnicity are social constructs, without scientific or biological meaning.”
Indigenous “ways of knowing” are equivalent to modern science and should be respected and taught as such.
[ Continued... ]
#biological egalitarianism#Jerry A. Coyne#Luana S. Maroja#Luana Maroja#Jerry Coyne#evolutionary biology#evolutionary psychology#other ways of knowing#biological sex#sex differences#science#ideological corruption#ideological capture#anti science#biology denial#biology denialism#biology#biological sciences#radical egalitarianism#indigenous ways of knowing#religion is a mental illness
11 notes
·
View notes
Text
In this paper there will be discussed a re-imagination of logical categorization, based on modern data from quantum physics for the reason of obviating the limitations, paradoxes, and arbitrary parameters found to characterize a said physical reality. If you are unfamiliar with categories: category, in logic, is a term used to denote the several most general, or highest types of thought forms or entities, or to denote any distinction such that, if a form or entity belonging to one category is substituted into a statement in place of one belonging to another, a nonsensical assertion must result.
Categorization shaped classical logic, which shaped mathematical logic, which shaped the scientific method, which in turn shaped the development of classical and quantum mechanics.
The discourse is developed into a new form of mathematical logic, and form of set theory that is corrective of the shortfalls above-mentioned.
This reconceptualization will be called compositive logic.
The theory proposes that reality is an ob-reciprocal reference.
In the most general sense, that means that reality is of no reciprocal condition, or put in other terms- reality does not compartmentally express itself, and thus elements, making the substantive aspect of reality an indicative relation, and not absolute.
Reality as a totality in itself cannot have a precursor nor any external initiative, or initiation, because it itself encapsulates everythingness, thus objective reality shouldn't have specified characteristics, which are delimitations, suggestive of an external entity, or pre-generative entity, or inexplicable spontaneous internal function.
It will be demonstrated that the foundation of formal, and informal logic has a categorizational incompleteness, and issues of contradictions and paradoxes, consequently arising in the theories of math, classical, and quantum mechanics.
Not being privied to the now standard quantum mechanical data is being proposed as a fundamental negation that blocked pre-classical thinkers from forming sufficiently complex general parameters for the construction of the sentient reciprocal order, or in other terms- an accurate definition of categories that requires experimentally testable findings about the Planck scales of the universe and Planck epoch to be a part of the perspective.
The following three excerpts that are cited from the website Wikipedia.org contain information that has been externally fact checked:
" the Planck scale is an energy scale around 1.22×1019 GeV (the Planck energy, corresponding to the energy equivalent of the Planck mass, 2.17645×10−8 kg) at which quantum effects of gravity become strong. At this scale, present descriptions and theories of sub-atomic particle interactions in terms of quantum field theory break down and become inadequate, due to the impact of the apparent non-renormalizability of gravity within current theories."
Excerpt 2:
"At the Planck length scale, the strength of gravity is expected to become comparable with the other forces, and it is theorized that all the fundamental forces are unified at that scale, but the exact mechanism of this unification remains unknown. The Planck scale is therefore the point where the effects of quantum gravity can no longer be ignored in other fundamental interactions, where current calculations and approaches begin to break down, and a means to take account of its impact is necessary. On these grounds, it has been speculated that it may be an approximate lower limit at which a black hole could be formed by collapse. While physicists have a fairly good understanding of the other fundamental interactions of forces on the quantum level, gravity is problematic, and cannot be integrated with quantum mechanics at very high energies using the usual framework of quantum field theory. At lesser energy levels it is usually ignored, while for energies approaching or exceeding the Planck scale, a new theory of quantum gravity is necessary. Approaches to this problem include string theory and M-theory, loop quantum gravity, noncommutative geometry, and causal set theory."
Excerpt 3:
"In Big Bang cosmology, the Planck epoch or Planck era is the earliest stage of the Big Bang, before the time passed was equal to the Planck time, tP, or approximately 10 to the negative 43 seconds. There is no currently available physical theory to describe such short times, and it is not clear in what sense the concept of time is meaningful for values smaller than the Planck time. It is generally assumed that quantum effects of gravity dominate physical interactions at this time scale. At this scale, the unified force of the Standard Model is assumed to be unified with gravitation."
Here we have a synopsis of two universal extremes
and not merely the quantum universe, as the largest scales of the universe is where the universe from the Planck time is said to be right now, demarking physically in consistent examples, where our physical premises break down because of our physical incapacity, whether as measurement, or experiential incapacity in the case of the Planck epoch, where light (an aspect of physical reality described by theories invariably stemming from the faux categorizations of classical logic), from that early in the universe's so-called emergence will never reach us.
If we look at the universe from the perspective of its demonstrated structural limits, physical reality is assertable as a literal finite domain, containing all the physical outcomes possible.
However, where there are definable limits demarking where the dynamics of physical reality no longer apply, it does not explicate an imperative of negation of other possible domains, as physical reality, as a domain, contains strictly physical outcomes in accordance with the exclusive categorization.
Let x=x be equivalent to a domain characterized by the totality of all possible functions and transformations categorizable as physical: with our assertion of x=x being true, we discover that the domain x=x does not express that x=p.
The fact that x=x does not express x=p, for no aspect of x=p is containing in domain x=x, does not mean that x=p does not exist, in fact, as x=x can be defined as finite under the above-mentioned definition, there is no account for the structural exclusion of x=p that is consisting as domain x=x, for domain x=x is inherently and absolutely expressing domain x=x only ( as far as quantum mechanics go there has never been a non-physical outcome and will never be a non-physical outcome), which is a different categorical imperative from the exclusion of potential domain x=p, thus the non-existence of x=p as a domain is not proven by the expressions of x=x.
It has been established that x=x represents the consisting potential of physical reality; and it has been established also that the domain of x=x is both noninclusional and nonnegational of a domain x=p, which represents a single consisting potential other than x=x. There is also a noninclusion of x=o, =t, =5, x=s,.....n.
X=x and x=p are non-interdependent imperatives, based on the fact that x=x intrinsically excludes x=p, and x=p intrinsically excludes x=x, and that the intrinsic exclusion is not specific to x=p, or x=x but to all potential domains .
From the definition above we can assert a structural continuum that is not defined in the conditions of the superimposed domains, as they are superimpositions that are in themselves fine-tuned, thus demonstrating an adherence to a specifying context.
Ultimate reality cannot be an element, or a set type of universality as any such specification requires a specifier.
Reality, in its absolutely logical form, cannot be an expression of any kind, as this is fine-tuning, that domains the expression as a categorical domain that does not actively exclude the existence of external domains.
Reality is logically non-referential, and the tangibility that we associate with physical reality is not "in the expression of" a beingness
(beingness is defined by physical reality's quantitative standards when we see it as a domain that simply just is, without proper categorization).
We can find non-referentiality by reduction of the quantum mechanic relativism that we experience in physical reality.
In the overarching domain that contains all superimpositions such as x=x, is characterized the non-interdependency of x=x and any given other domain such as x=p.
Superimpositionality is not describable within the local frameworks of finite domains themselves: they are not expressing of overarching dynamics in themselves. They seem absolutely local
Invariation of external domains, both in themselves as superimpositions, and as naturally extenuating domains, indicate a relativism that does not express the structural limitation of locality, just universalism, which without the usual physical reference of locality is something quite different from solely physical interpretations of an empty set.
The reduction of superimpositionality to non-referentiality sees the non-locality in superimpositionality prevariated by further non-localizational relativism, where now universality goes, the basic reference of quantitative coherence in relation to context excluding the opposite, is the said nonreferentiality that reality can be logical. It's not nothingness, however it's not as irrational as existency.
So we can see where non-referentiality covers all truly realistic outcomes and demonstrates through a determined reduction of Relativistic structural ethos, not only explication of all realistic participles, but also the de-relativistic subjectivization of all realistic participles, making the non-referentiality actual, in not being objectively expressing of intrinsic, or perturbed fine-tuning.
We can establish that applying substantive, elementary metrics to non-referentiality, basically making reality a materially existing location, must have the metrics somehow amount to a non-referentiality being true.
The elementary metrics being proposed must then be categorizable as basally referential, however, maintaining of non-referentiality.
The application of element metrics to nonreferentiality creates the least relativistic relationship.
The active de-gradualization from physical reality to nonreferentiality as a base logic system is the affirmation of nonreferentiality itself as a non-expression, as all extents involved are categorized within reality.
The most basic relativism is singularly universal, where elements are intrinsic property, thus of no particular demarcation. This is superimpositionality. Giving metrication to nonreferentiality equals to the sphere of superimpositionality, which, further metricated, results in local superimpositions, of all possible typologies, non-interdependent in nature on a level that represents a specific prevarication.
Further metrication invariates elements of superimposed domains, for instance, in physical reality, planets, space, time, forces, etc.
If we choose to element nonreferentiality like this we become capable of any typology of transformation graphed within the framework of a field theory.
The proposed field, consisting of these levels of relativism as sub-fields, hold all objects as defined with 4 basic values from the sub-fields:
1. Non-referentiality
2. Superimpositionality
3. Domains
4. Elements of domains
These values are of course general. They are simply significant points on a spectrum.
2 notes
·
View notes
Text
SAS Assignment Help Blueprint for Accurate Correlation Analysis Results
Correlation analysis is a statistical method used to assess the relationship between two or more variables. It quantifies how changes in one variable relate to changes in another, producing a correlation coefficient that ranges from -1 to +1. A coefficient of +1 indicates a perfect positive correlation, -1 indicates a perfect negative correlation (one variable increases while the other decreases), and a value of 0 signifies no correlation between the variables.
In the data analysis field correlation analysis is pivotal for hypothesis testing, exploratory analysis and feature selection in machine learning models. In other words, correlation assists students, researchers and analysts to identify which variables are related and possibly can be chosen for further qualitative explorative statistical analysis.

SAS: A Popular Tool for Data Analysis and Correlation
SAS (Statistical Analysis System) is one of the leading software packages for the correlation analysis and is mostly used by academicians, students in universities and for other professional research purposes. SAS also has different versions; for example, SAS Viya, SAS OnDemand, and SAS Enterprise Miner designed for specific users. The main strength of the software lies on its ability to handle large datasets, perform numerous operations and automates calculations with high levels of accuracy, which makes the software very useful for students who study statistics and data analysis.
Being a robust software, many of the students have issues and concerns with its application. Some of the general difficulties are: writing accurate syntax for performing correlation analysis, writing interpretation, handling big datasets. These issues may result in the inaccurate analysis and description of results and misleading conclusions.
Overcoming SAS Challenges with SAS Assignment Help
SAS Assignment Help is a valuable resource for students who face these challenges. These services provide comprehensive support on how to set up, run and interpret the correlation analysis in SAS. Whether a student is having trouble understanding the technical interface of the program, or the theoretical interpretation of the results of the analysis, these services help the student get accurate results and clear understanding of the analysis.
Students can gain confidence in performing correlation analysis by opting for SAS homework support to simplify concepts and get coding assistance. It saves time when tackling complicated questions and recurring errors during the process of running the codes in SAS.
SAS Assignment Help Blueprint for Accurate Correlation Analysis Results
With the basic understanding on correlation analysis and the issues students encounter, lets proceed with steps to be followed in order to perform correlation analysis in SAS. This guideline will take you through preparation of the data to the interpretation of the results with meaningful insights.
Step 1: Loading the Data into SAS
The first of approach of carrying out correlation analysis in SAS is to import the data set. In this context, let us work with the well-known Iris dataset which comprises several attributes of iris flower. To load the data into SAS, we use the following code:
data iris;
infile "/path-to-your-dataset/iris.csv" delimiter=',' missover dsd firstobs=2;
input SepalLength SepalWidth PetalLength PetalWidth Species $;
run;
Here, infile specifies the location of the dataset, and input defines the variables we want to extract from the dataset. Notice that the Species variable is a categorical one (denoted by $), whereas the other four are continuous.
Step 2: Conducting the Correlation Analysis
After loading the data set you can proceed to the correlation analysis as shown below. In case of numerical data such as SepalLength, SepalWidth, PetalLength and PetalWidth the PROC CORR is used. Here is how you can do it in SAS:
proc corr data=iris;
var SepalLength SepalWidth PetalLength PetalWidth;
run;
The output will provide you with a correlation matrix, showing the correlation coefficients between each pair of variables. It also includes the p-value, which indicates the statistical significance of the correlation. Values with a p-value below 0.05 are considered statistically significant.
Step 3: Interpreting the Results
After you had carried out the correlation analysis it is time to interpreted the results. SAS will generate a matrix along with correlation coefficients for each pair of variables of interest. For instance, you may observe that, the correlation coefficient of SepalLength and PetalLength is 0.87 indicating a positive and strong correlation.
Accurate interpretation of the results is highly important. High coefficients near +1 or -1 indicate strong relationship while coefficients near zero indicate a weak or no relationship of variables.
Step 4: Visualizing the Correlation Matrix
One of the helpful ways to do value addition to your analysis is by using visualization tools to plot correlation matrix. SAS does not directly support in-built tools but one can export the results and then use other statistical software such as R, python to plot the results. However, SAS can produce basic scatter plots to visually explore correlations:
proc sgscatter data=iris;
matrix SepalLength SepalWidth PetalLength PetalWidth;
run;
This code generates scatter plots for each pair of variables, helping you visually assess the correlation.
Step 5: Addressing Multicollinearity
One of the usual issues experienced in correlation analysis is multicollinearity, which is a condition where independent variables are highly correlated. Multicollinearity must be addressed in order to get rid of unreliable results in regression models. SAS provides a handy tool for this: the Variance Inflation Factor (VIF).
proc reg data=iris;
model SepalLength = SepalWidth PetalLength PetalWidth / vif;
run;
If any variable has a VIF above 10, it suggests high multicollinearity, which you may need to address by removing or transforming variables.
Coding Best Practices for Correlation Analysis in SAS
To ensure that your analysis is accurate and reproducible, follow these coding best practices:
Clean Your Data: Always make sure your data set does not contain any missing values or outliners that may affect results of correlation. Use PROC MEANS or PROC UNIVARIATE to check for outliers.
proc means data=iris n nmiss mean std min max;
run;
Transform Variables When Necessary: If your data has not met the conditions of normality the variables should be transformed. SAS provides procedures like PROC STANDARD or log transformations to standardize or transform data.
data iris_transformed;
set iris;
log_SepalLength = log(SepalLength);
run;
Validate Your Model: Make sure the correlations make sense within the framework of your study by double-checking your output every time. When using predictive models, make use of hold-out samples or cross-validation.
Also Read: Writing Your First SAS Assignment: A Comprehensive Help Guide
Struggling with Your SAS Assignment? Let Our Experts Guide You to Success!
Have you been struggling with your SAS assignments, wondering how to approach your data analysis or getting lost in trying to interpret your results? Try SAS assignment support!
If the process of analyzing large data sets and SAS syntax sounds intimidating, you are not alone. Even if a student understands how to do basic data analysis, he may stumble upon major problems in applying SAS software for performing correlation and regression or simple manipulations of data.
Students also ask these questions:
What are common errors to avoid when performing correlation analysis in SAS?
How do I interpret a low p-value in a correlation matrix?
What is the difference between correlation and causation in statistical analysis?
At Economicshelpdesk, we provide quality sas assignment writing services to students who require assistance in completing their assignments. For the beginners in SAS or learners who are in the intermediate level of sas certifications, our professional team provides the needed assistance to write advance level syntax. We know that SAS with its many versions such as SAS Viya, SAS OnDemand for Academics, and SAS Enterprise Miner might be confusing and we specialize in all versions to suit various dataset and analysis requirements.
For students who have successfully gathered their data but are not good at analysing and coming up with coherent and accurate interpretation of the same, we provide interpretation services. We write meaningful and logical interpretations that are simple to understand, well structured and well aligned with the statistical results.
Our services are all-encompassing: You will get all-inclusive support in the form of comprehensive report of your results and detailed explanation along with output tables, visualizations and SAS file containing the codes. We provide services for students of all academic levels and ensure timely, accurate and reliable solution to your SAS assignments.
Conclusion
For students who are unfamiliar with statistics and data analysis, performing a precise correlation analysis using SAS can be a challenging undertaking. However, students can overcome obstacles and produce reliable, understandable results by adhering to an organized approach and using the tools and techniques offered by SAS. We offer much-needed support with our SAS Assignment Help service, which will guarantee that your correlation analyses are precise and insightful.
Get in touch with us right now, and we'll assist you in achieving the outcomes required for your academic success. Don't let your SAS assignments overwhelm you!
Helpful Resources for SAS and Correlation Analysis
Here are a few textbooks and online resources that can provide further guidance:
"SAS Essentials: Mastering SAS for Data Analytics" by Alan C. Elliott & Wayne A. Woodward – A beginner-friendly guide to SAS programming and data analysis.
"The Little SAS Book: A Primer" by Lora D. Delwiche & Susan J. Slaughter – A comprehensive introduction to SAS, including chapters on correlation analysis.
SAS Documentation – SAS’s official documentation and tutorials provide in-depth instructions on using various SAS functions for correlation analysis.
0 notes
Text
Fwd: Postdoc: SmithC.GenomeEvolution
Begin forwarded message:
> From: [email protected]
> Subject: Postdoc: SmithC.GenomeEvolution
> Date: 6 September 2024 at 05:11:47 BST
> To: [email protected]
>
>
>
>
> Postdoctoral Position: Bioinformatic & single-cell ‘omics approaches
> for studying genome evolution
>
> The Department of Biological Sciences at Smith College invites
> applications for a benefits eligible postdoctoral position, focusing
> on genome evolution in microeukaryotes (aka protists), to begin on or
> after December 1, 2024. The bulk of the work will focus on bioinformatic
> analyses of data generated in the lab from diverse amoebae. The initial
> appointment is for one year, with the possibility of extending for
> additional years. The position will be housed in Professor Laura Katz's
> laboratory in the Department of Biological Sciences ; questions should
> be directed [email protected].
>
> The goals of this research include characterizing genome architecture
> in poorly-studied clades and reconstructing the evolutionary history of
> both genes and species (i.e. species delimitation). The ideal candidate
> will: 1) be a productive researcher with interests in both biodiversity
> and phylogenomics of microorganisms; 2) have experience identifying and
> isolating diverse protists; 3) have knowledge of bioinformatic and/or
> phylogenetic tools; 3) have excellent communication and interpersonal
> skills; and 4) be interested in collaborating with graduate and
> undergraduate students in the laboratory.
>
> Research in the Katz lab aims to elucidate principles of the evolution in
> eukaryotes through analyses of microbial groups, and to assess how these
> principles apply (or fail to apply) to other organisms. Currently we focus
> on three interrelated areas: (1) characterizing evolutionary relationships
> among eukaryotes using single-cell ‘omics and phylogenomics; (2)
> exploring the evolution of germline vs somatic genomes; and (3) describing
> the phylogeography and biodiversity of protists in local environments
> (bogs, fens, coastal habitats).
>
> Submit application through Smith’s employment website with a cover
> letter, curriculum vitae, sample publications and the contact information
> for three confidential references. Finalists may be asked for additional
> materials. Review of applications will begin on September 18, 2024.
>
> Link:
>
> https://ift.tt/KS5v3LG
>
>
>
> Laura Katz
0 notes
Text
youtube
🌐 Let's get down and dirty with Ethernet Frames! 🌐
Hey there, networking nerds! Today, we're rolling up our sleeves and diving deep into the Ethernet Frame Header. 📦🔍
Ethernet Frame Header Breakdown 🔬
Preamble & Start Frame Delimiter (SFD): These guys sync up the receiver and tell it a frame is coming.
Destination MAC: Where the frame is going. It's 48 bits (6 bytes) of pure address goodness.
Source MAC: Where the frame came from. Another 48-bit address.
Ethernet Type: Tells us what's in the data (like IPv4, IPv6, ARP, etc.). It's a 16-bit field, so there are 65,536 possibilities!
Why learn about Ethernet?
It's the foundation of most networks. Understanding Ethernet helps you grasp networking concepts at a fundamental level.
It's used in wired networks (like LANs) and even some wireless ones (like Wi-Fi).
Join us as we demystify Ethernet frames and build a solid networking foundation! 🤘
#Ethernet #Networking #IT #EthernetFrame #MACAddress #LearnWithMe
0 notes
Text
Aion notes pt. 2
[2]
With this definition we have described and delimited the scope of the subject. Theoretically, no limits can be set to the field of consciousness, since it is capable of indefinite extension. Empirically, however, it always finds its limit when it comes up against the unknown.[2]
(limit is to be understood here as in the so-called ‘calculus’: mathematic, fractal, and, with any hope, progressively infinitessimal)
Here, empiricality is assumedly subjective in its heterological senses, as the notion of the unconscious places one’s own limits under erasure. Perhaps there is a different use of ‘empiricism,’ not merely sensory, but it will then tug at the boundaries of the heterological through only the flexure of notation.
[2] The Ego’s capacity cannot be delimited; it is expandable, and mutable. It, however, has two limits:
An external unknown, or horizon. This is not named explicitly and can have no foundation.
The internal unknown: by this we refer to the unconscious and its agents.
The Origo, [in its relation to the unconscious only] on the other hand, at least so far as the named elements are concerned, and their sensory traces and traceures, might be said to have access via the Ego, which, I think, has a phenomenological essence here neglected by Jung, namely, its self-conception, which is not the same as mere access in the purely phenomenological sense, or, rather, relates to other fields of access based on self-relation. The Subject-Object schema here dominates, though it may be (/that) focus elides other domains of givenness. This is an open field of recollection/investigation.
(we might say that the Origo is, in fact, *blind* in the domain of the symbolic, though it is, itself, the very *space of seeing*.
This is a very important direction for the progress of consciousness studies, as consciousness-without(-a-)trace (or tarnish; the ‘tain of seeing itself’) does should not seem electrologically possible.
CF: Heidegger and the critique of the S-O schema, which seems here to have been moved indoors, i.e, out of the reach of philosophy proper, contra phenomenology, which must be nomadic, even evasive, so as to remain operant.
(Fellow phenomenologists! Resist well the sonorous notations of the invader and its notaries!)
(see my forthcoming (re?)translation of Heidegger’s early lectures from ‘Ontology, Hermeneutics of Facticity’, and addended commentary)
It is unclear here what Jung means by 'indefinite extension,' but this clarifies my conceptual gloss: 'Origo of perception (and presumably apperception(‘s traces?)’ [‘thought’/noesis] is oddly absent from the discussion) = 'Ego' (=\= 'subject?) for Jung.
This would mean that the Self is closer to what elsewhere is designated as the 'Subject.' This seems to summate most of what is found in the first chapter.
…
This lacunam demands another theory of the Ego, which is to yet be borne out, and we expect to find after the symbolic fold of narrative and its mythemes, which seem to be the primary occupation of the rest of Jung’s text.
…
This unknown is further specified as being of two limits: internal (unconscious) and unmediated, and external: mediated by the senses (why is there no analogous concept? Given preoccupations with the collective unconscious…. this is of course considered to be internal, but, as I not elsewhere, it is difficult to divide that to which one, constitutively, has no access…even temporal divisions gain, if any, a secondary, but preliminary, sense, or simply their [pr/e-]erasure.).
There is, thus, to the Origo, accessible, to extend the above, two domains of available data: psychic and somatic.
Not all endosomatic stimuli breach the horizon of consciousness, but insofar as they are accessible to consciousness, they are also psychic in nature. (This strikes me as just a bit of a muddled explanation, but alas, the idea is clear enough, which is, perhaps, the inherent muddlement)
Note: this changes very little, but I have found a (very bad, admittedly) reference mentioning the possibility that ‘endosomatic’ refers to phenomena which actually have their origin in the body and are not ‘sensory’ in the manner elsewhere meant.
I have therefore suggested that the term “psychic” be used only where there is evidence of a will capable of modifying reflex or instinctual processes. Here I must refer the reader to my paper “On the Nature of the Psyche,”
<< n.b.; not to be confused with my paper by the same name, which I translated around the same time., lol >>
Jung makes this remark in response to a theory mentioned in passing that all life-processes are to be designated as 'psychic.' Somatic/endosomatic belong to the data, the psychic are 'autodata': modifiable, or at least their modificational causes can be seen as internal/potentially relative to the Will. ((This is interesting, but also may require further explanation at some point.))
… I am not sure if this is what he’s actually saying.
[3]
[3] As implied already by its sources, in what is essentially a restatement of [2] the Ego has two domains of access, though Jung makes the point of their both being in essence psychic and ultimately unmediated in their being as presentation: Mind has access only
to its internal object as also Mind, though there are processes which are not-Mind, or, rather, there is, to such perceptions, a thing-in-itself.
These bases are:
The somatic/external. A further mediation is here invoked: the external is arrived at by the ‘endosomatic’: stimuli within the body. They are, in fact, subordinate (given that we can, and do, often ignore the body, in itself, on a regular basis, thus pushing it out of consciousness as such) to a field which Jung does not name: the ‘(endo)somatic subject’ and/or its unconscious. This would encompass automatic reactions, things usually tuned out, but technically available, &c. The fact that they may be available to consciousness is enough for Jung to assign them, still, a psychical nature.
(pre-note on (‘)the collective unconscious and Lacan’s Real(‘): this, which is also the demonic, must be the domain of the former’s resilience, to the extent which it per and transists to any substantial distance)
The fixed horizon here, which would, really, blend into the world, is, perhaps, the purely physiological, which is to say, that portion of the somatic unconsciousness corresponding to the non-somatic unconscious without possibility of presentation to the Ego. The psychicality of this domain, like the physical absolute Unknown, or, really, any absolutely unknowable: the ‘unknown unknowns which cannot be known,’ is, of nature, undecidable.
It is worth mentioning here that the notion of ‘subject’ is potentially complexified by these alterior ‘things’-that-view: the endosomatic is ‘psychic,’ and reacts, but is not a subject. It perceives. The notion of the ‘subject’ hereto invoked seems, to me, to be circular: the subject is that to which things appear, all things appear to subjects, which are consciousnesses and in each case equivalent (for the prior author) to Egos…. However, the endosomatic has internal operations which to not present, in full, to the Ego. The Unconscious has contents which do not present to consciousness. It is suggested that the Ego is the gateway to the Self (I… think?), but what is to suggest, as in the Truth <-> Production relation in Lacan, that the unplumbable depths of the somatic do not connect to the Unconscious? Why is there no Subject of the unconscious? Is the Body not a subject? How would one know? It seems to have, by Jung’s own conception, those properties particular to one….
The Psychic: I have … suggested that the term “psychic” be used only where there is evidence of a will capable of modifying reflex or instinctual processes.
The psychic is defined as unmediated by senses, and the above, which is in no way clear to the present commentator.
A moment is then spent on the notion that all life processes are in fact psychic, which is dismissed as a ‘nebulous’ idea, and the above quote is offered as a rejoinder.
Consider both extraordinary acts of somatic control, and the issue of the interactions of different essences.Cybernetics offers an alternative to this sort zoetic pan-psychism, with, I would argue, a less nebulous form and purpose.Consider also, relative to Jung’s definition, ‘expanded’ understandings of the Will.
[4]
The Ego ‘rests’ on two fields of access:
All of consciousness
All of the Unconscious
The Unconscious can be divided thusly:
That to which there is voluntary access (Jung equates this with memory).
That to which there is involuntary access
That to which there is no access
It is worth asking whether there is any difference in ‘essence’ between 2. and 3., or if it is simply an occurrential divide: 3. is that which is not accessed. Consider the models and suggestions below regarding energies, resistance, &c., and the division as probabilistic, or, even, non-existent, and more a matter of what can be considered simultaneously. Some thoughts may be unthinkable, but whether they exist, as such, in the unconscious, is perhaps an open question at best.
Perhaps this is merely a matter of impossible thoughts which can be imagined as possibles by an external viewer. In this sense, the Unconscious, or at least that of which it is inaccessible, might be said to, in fact, exist in the Other. Multiple senses of this may be worth unpacking
They are improbable or ‘dissatisfying’/dysphoric to the Ego, or even to any possible viewer in a given domain, at least as wholes, even if their parts are satisfying.
They exist as ‘extimate’ possibles satisfying as conceptions (only) to the viewer modeling a given Self.
They are able to act as causal actants in some sense, and produce efferents which do in fact have an effect or are satisfying, but are not themselves so.
In this , it is possible the zone exists to model Others, and thus relates via affects supplied to the conscious appended to the actually-thought; this suggests a Subject of the Unconscious
It is worth wondering what role creativity plays here, and whether the Unconscious exists as the Virtual of the Ego’s production.
Herethroughout, the emphasis is on access, and not production, so, in that, one wonders if all possibles exist in the Unconscious, a notion which would collapse the distinction, as well as open a field unto the entirety of the Umwelt and Other… This suggests interesting readings of the text going forward…
0 notes
Text
10 most useful Excel Tips

Here are ten useful Excel tips to enhance your productivity and efficiency:
Use Keyboard Shortcuts: Familiarize yourself with common keyboard shortcuts to save time. For example,
Ctrl + C to copy
Ctrl + V to paste
Ctrl + Z to undo
Ctrl + Arrow Keys to navigate to the edges of data regions
Conditional Formatting: Highlight important data or trends by using conditional formatting. You can set rules to change the color of cells based on their values, making it easier to spot patterns.
Pivot Tables: Summarize large datasets quickly with pivot tables. They allow you to group and analyze data without the need for complex formulas.
VLOOKUP and HLOOKUP: Use these functions to search for a value in a table and return a corresponding value from a specified column (VLOOKUP) or row (HLOOKUP).
IF Statements: Create logical tests and return different values based on whether the test is true or false. This is useful for decision-making in your data analysis.
Data Validation: Restrict the type of data or values users can enter into a cell. This helps maintain data integrity and prevents errors.
Text to Columns: Split a single column of data into multiple columns based on a delimiter (like commas or spaces). This is useful for cleaning up data imported from other sources.
Remove Duplicates: Quickly find and remove duplicate values from your data set to ensure data accuracy.
Freeze Panes: Keep the top row or the first column visible while scrolling through your worksheet. This is helpful for large datasets where headers need to remain visible.
Use Formulas Efficiently: Learn and use a variety of formulas to perform calculations, such as SUM, AVERAGE, COUNT, and more complex functions like INDEX and MATCH. Also, using absolute and relative cell references can make your formulas more flexible and reusable.
These tips can help streamline your workflow and make data management in Excel more effective.
TCCI Computer classes provide the best training in all computer courses online and offline through different learning methods/media located in Bopal Ahmedabad and ISCON Ambli Road in Ahmedabad.
For More Information:
Call us @ +91 98256 18292
Visit us @ http://tccicomputercoaching.com/
#TCCI COMPUTER COACHING INSTITUTE#BEST COMPUTER CLASS IN ISCON-AMBLI ROAD AHMEDABAD#BEST COMPUTER CLASS IN BOPAL AHMEDABAD#BEST EXCEL LEARNING CLASS IN ISCON-AMBLI ROAD AHMEDABAD#LEARN BASIC COMPUTER SKILL IN SHILAJ AHMEDABAD
0 notes
Text
Understanding SQL Server Reporting Services' Split Function (SSRS)

Data formatting and manipulation in SQL Server Reporting Services (SSRS) are essential for producing reports that are both visually appealing and educational. Splitting strings to extract or format specified information is a common activity in report development. Although not a feature of SSRS itself, the ssrs split function can be accomplished with the use of expressions and custom functions to manage such needs. This article provides useful advice for report developers by examining the ideas and uses of the Split function in SSRS.
Comprehending the Split Function
As in certain programming languages, there is no direct Split function in SSRS. Nevertheless, you can separate strings depending on a delimiter and accomplish comparable functionality with custom code or expressions. This is especially helpful for data fields that have several values separated by special characters like pipes, semicolons, and commas. You can extract individual components from these strings and show them in your reports in a more accessible and ordered format by separating them off.
Using Personalized Code to Divide Strings
You can use custom code in your report to emulate the Split function in SSRS. You can add custom code to a report in SSRS by going to the Code tab under Report Properties.
The string you wish to split is called inputString in this method, and the character or string you want to use as the split point is called delimiter. An array of strings will be returned by this code, which you can utilize in your report.
Including Personalized Code in Your Report
You can call the custom Split function from inside the expressions in your report once you've added it to the code. For instance, you may use the custom function to split and show specific items from a dataset field called ProductList that has items separated by commas. You could type the following expression in a text box:
The first item from the split result will be shown by this expression. To access different sections of the split string, you can change the index (for example, (1) for the second item).
Managing Complicated Situations
In more intricate situations, including dividing strings with several delimiters or handling huge datasets, you might have to improve your custom code or employ extra processing. For example, you could use layered string operations or regular expressions to adapt the Split function to handle multiple delimiters. In order to ensure effective processing, you should also optimize your code and take performance implications into account when working with big volumes of data.
Practical Applications in Reports
Using the Split function in SSRS can significantly enhance your reports by providing better data organization and presentation. Common applications include parsing product lists, extracting user information from concatenated fields, or formatting addresses. By splitting strings into manageable pieces, you can create more readable and insightful reports that meet the needs of your stakeholders.
Conclusion
While SSRS does not have a built-in Split function, you can achieve similar functionality through custom code and expressions. By implementing custom VB.NET functions and integrating them into your report expressions, you can effectively manage and manipulate string data to enhance the clarity and usability of your reports. Mastering these techniques will enable you to handle various data formatting challenges and create reports that are both informative and well-organized informative and well-organized.
0 notes
Text
VeryUtils Excel Converter Command Line
VeryUtils Excel Converter Command Line can batch convert Excel spreadsheets to a raw format such as CSV, DSV or other text file, without the need for Microsoft Office.
In the fast-paced world of data management, efficiency and flexibility are paramount. Introducing VeryUtils Excel Converter Command Line, a robust and highly customizable tool designed to streamline the process of converting Microsoft Excel spreadsheets into various raw formats such as CSV, DSV, and other text files, all without the need for Microsoft Office. This versatile application is perfect for both simple and advanced conversion schemes, ensuring your data is exactly how you need it, when you need it.
https://veryutils.com/excel-converter-command-line

Key Features of VeryUtils Excel Converter:
VeryUtils Excel Converter stands out with a comprehensive set of features designed to meet the diverse needs of its users. Here are the key features that make this tool indispensable:
EXTENSIVE FORMAT SUPPORT
Supports Multiple Excel Formats: Convert spreadsheets from a wide range of Excel formats including XLS, XLSX, XLSM, and XLSB.
FLEXIBLE SHEET SELECTION
Selective Sheet Conversion: Include or exclude specific sheets based on their names, with support for wildcards to simplify the selection process.
CUSTOMIZABLE DATA RANGE
Define Conversion Range: Set the range for conversion using fixed parameters or dynamic keyword searches, allowing precise control over the data extracted.
ADVANCED CUSTOMIZATION OPTIONS
Delimiter and Character Customization: Customize delimiters, quote characters, newline characters, and modes to fit your specific requirements.
Output File Formatting: Adjust the formatting of date, numeric, decimal, currency, accounting, and boolean cells to ensure the output matches your needs.
Encoding Options: Choose the output file encoding to maintain compatibility with various systems.
COMPLIANCE AND NORMALIZATION
Official Rules Compliance: Built-in support ensures compliance with official CSV, DSV, and Excel-import rules.
Newline Normalization: Normalize newline characters for cross-platform compatibility, ensuring your files work seamlessly on different operating systems.
DIRECTORY STRUCTURE CUSTOMIZATION
Organized Output: Customize the directory structure of the output files and create advanced structures based on source folders and workbook names for better organization.
INTEGRATION AND AUTOMATION
Command-Line Interface (CLI): Integrate the powerful conversion engine into your own applications using the command-line interface, enabling automation and integration into existing workflows.
USER-FRIENDLY PROFILE MANAGEMENT
Profile Manager: The profile manager assists users in configuring the appropriate profiles for any conversion task, simplifying the setup process.
COMPREHENSIVE SUPPORT AND UPDATES
Context-Sensitive Help: Access extensive, context-sensitive, and up-to-date online help to resolve any issues quickly.
Update Checker: Stay updated with the latest and most stable version of the software through the built-in update checker.
PERFORMANCE AND RELIABILITY
Logging Options: Enable logging to capture errors and ensure no issues go unnoticed.
Fast and Ad-Free: Enjoy a fast, efficient conversion process with no ads to interrupt your workflow.
Experience the Convenience of VeryUtils Excel Converter
Whether you're a data analyst, a developer, or a business professional, VeryUtils Excel Converter Command Line is tailored to make your data conversion tasks easier and more efficient. Its powerful features, combined with a high level of customization, ensure that you can handle any conversion scenario with confidence.
Don't just take our word for it. Explore all the features yourself or download the latest version today to see how VeryUtils Excel Converter can transform the way you manage your data.
For more information and to download the latest version, visit our web page at https://veryutils.com/excel-converter-command-line
0 notes
Last Seen Blogs

lmtyas-pod
Let Me Tell You A Story

exposureevents
ExposureEvents

lolo-mlw
Lolo García

sparklymocha
Untitled

imobiliarerolabs
Imobiliare.ro Labs