#Tumblr API
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Average visit duration of Tumblr.com is 10 mins and 25 secs.
Text
Tumblr.js is back!
Hello Tumblr—your friendly neighborhood Tumblr web developers here. It’s been a while!
Remember the official JavaScript client library for the Tumblr API? tumblr.js? Well, we’ve picked it up, brushed it off, and released a new version of tumblr.js for you.
Having an official JavaScript client library for the Tumblr API means that you can interact with Tumblr in wild and wonderful ways. And we know as well as anybody how important it is to foster that kind of creativity.
Moving forward, this kind of creativity is something we’re committed to supporting. We’d love to hear about how you’re using it to build cool stuff here on Tumblr!
Some highlights:
NPF post creation is now supported via the createPost method.
The bundled TypeScript type declarations have been vastly improved and are generated from source.
Some deprecated dependencies with known vulnerabilities have been removed.
Intrigued? Have a look at the changelog or read on for more details.
Migrating
v4 includes breaking changes, so if you’re ready to upgrade to from a previous release, there are a few things to keep in mind:
The callback API has been deprecated and is expected to be removed in a future version. Please migrate to the promise API.
There is no need to use returnPromises (the method or the option). A promise will be returned when no callback is provided.
createPost is a new method for NPF posts.
Legacy post creation methods have been deprecated.
createLegacyPost is a new method with the same behavior as createPost in previous versions (rename createPost to createLegacyPost to maintain existing behavior).
The legacy post creation helpers like createPhotoPost have been removed. Use createLegacyPost(blogName, { type: 'photo' }).
See the changelog for detailed release notes.
What’s in store for the future?
We'll continue to maintain tumblr.js, but we’d like to hear from you. What do you want? How can we provide the tools for you to continue making cool stuff that makes Tumblr great?
Let us know right here or file an issue on GitHub.
Some questions for you:
We’d like to improve types to make API methods easier to use. What methods are most important to you?
Are there API methods that you miss?
Tumblr.js is a Node.js library, would you use it in the browser to build web applications?
228 notes
·
View notes
Text
boop = function(blog, type="normal"){ return window.tumblr.apiFetch('/v2/boop',{method:"POST",credentials:"include",body:{context:"blog_view",receiver:blog,type:type}});} boop("irradiate-space","normal");
28 notes
·
View notes
Note
hi! research question I'd love your input on:
do you know how to generate size-of-fandom stats? I'm researching the Ghost fandom and while I know from the This Week in Tumblr posts about what their size is *now,* I'd like to try to compare it to past years, and be able to make statements like "x% of the fandom is reblogging explicit content."
I'm also looking for deeper info on how tumblr works if someone deactivates - do their notes vanish too?
It sounds like you want to gather Tumblr information only -- is that right? I don't have a lot of expertise with Tumblr data (I think I last gathered some over a decade ago), but it looks like their API still lets you retrieve posts with a certain tag and specify a timestamp, if you're willing to do a bit of programming. So you could, e.g., retrieve the last N posts of each month that use a particular fandom tag. And then you can compare those samples of posts to see how the content has changed over time. If you want to do that, there are libraries in Python and probably other languages that can make it easier to work with the Tumblr API.
I believe the posts retrieved this way don't include reblogs, so you'd also have to look at the post notes to get info about how many reblogs different types of posts are getting. As to your question of deactivated accounts within those notes, I'm not certain of the answer. I frequently see reblog chains where some accounts in the chain have deactivated, so those notes are not entirely gone. But I don't know if the replies/likes from deactivated accounts disappear from post notes. Anyone else know?
12 notes
·
View notes
Text
Working with the Tumblr API is like nothing else
63 notes
·
View notes
Text
does anyone know what the rules are for tumblr's api?
Don't re-implement the Dashboard, and don't recreate complete Tumblr functions or clients on a platform where Tumblr already has an official client (like web, iPhone, Android, or Windows Phone 8).
i read this and was wondering if making a sort of "port" of tumblr to a game console (that doesnt already have an official client or a way to access tumblr) would be allowed
5 notes
·
View notes
Text

Ok, posting this here, too, because maybe there's a little genius amongst you folks over here gdhfhf
9 notes
·
View notes
Text
It really is very frustrating to try to use Tumblr through the API, because:
First you have to Register An App, even though I am a user, I am trying to just automate some workflows, I am not an App Developer making a third-party integration for others.
Then you must use OAuth. Having an API where the only authentication mechanism is OAuth should be a crime. OAuth is an okay solution for letting third-party code get credentials on behalf of users with user consent. But I am not third-party code!!! I am me, the user; my code is an extension of me, it is me, alkfsdafklsdalfsalf!
Randomly things will just fail to post. You will be told the profoundly helpful status 400, code 8001, which if we go by observation alone are the only possible numbers, and mean any possible error. "Posting failed. Please try again." Incidentally, if you are ever responsible for a "Please try again" error message for something that is not a transient error but will persistently reliably fail, we need to break out the medieval corporal punishments. Flogging. Stocks. Those little cages on street posts. And responsibility goes up the chain of command - the higher the position, the longer the punishment.
This. This will be the thing that finally drives me off Tumblr. No amount of adoring Tumblr fans will keep me if I can't reliably publish posts from the comfort of my text editor.
31 notes
·
View notes
Text
If blocking both popular blogs and blogs that leave a lot of replies to popular posts has the ability to cause backend slowdowns, and that's not currently fixable, there desperately needs to be a client-side means of filtering these people out. How many database queries is Tumblr currently expending JUST on three specific blogs with cartoon character icons?
16 notes
·
View notes
Text
i dont think ive complained enough about how absolutely shitty the tumblr api is. the documentation is like. mediocre, to begin with. the actual api? the /blocks route gives you the blogs a blog has blocked if you GET it, but POST it? well now youre blocking a blog. dont be deceived by the plural though - to block multiple blogs you need /blocks/bulk. oh also using the... DELETE method (??) you can remove a block, still via /blocks. the /post route is the legacy post format. /posts is what youre looking for, but dont GET it, because then youre fetching a blogs posts. again, dont be deceived by the plural, but this time there is no bulk route. oh and of course /posts/{post id} gets a post... but with POST it edits the post. now with this theme of incorrect plurals, youd at least expect them to have correct plurals, but no! in order to retrieve drafts you use... /posts/draft. there are some communities routes, but guess what? theyre listed in a different format in the documentation to everything else! to be honest, its a better format, but i guess they couldnt be bothered to update their docs.
and then, the /user/dashboard route. heres what the docs say:

(this the ONLY way to get random posts btw)
simple enough... naturally you would scroll down for more info but... thats it. after that tiny description, there is a horribly layed out list of arguments and their descriptions, info on the response format, and nothing else. what dashboard is it getting? who knows! it doesnt seem to be the Following tab - which is in order of recency - so i can only assume its For You. it also, by default, returns posts in the legacy format, which is much less convenient than their Neue Post Format (??). posts are also returned without blog info and instead with just a blog name, and, for whatever reason, there is no argument to change this. i dont remember what i did to get around this, but it was probably taking that blog name and running it through the /info route or getting the posts and then getting them again with the /posts/... route (which does return blog info).
ok.. so its badly documented and inconvenient to use. big deal! except... theres more. if youre going through dashboard posts individually, like i do for my bot, youll probably use the offset argument parameter - the offset from the first post on the dash - to specify which post to get. however at somewhere around an offset of 250, it stops returning new posts. just the same one over and over. probably a rate limit right?

?????
you might be thinking "its probably that 300 api calls limit and youre just using a few extra calls" but thats wrong. for starters around 50 extra calls just doesnt sound accurate for what im doing. it would most likely be way more than that or way less. and even if im wrong, it doesnt reset after a minute. i have no idea when it resets, in fact. sometimes it feels like more than an hour, but i havent timed it. i also havent tested what happens if i go straight to 250, which i probably should do. on top of all that, i dont think this is what would actually happen if i got rate limited, its just the only remotely possible explanation i can think of.
another thing is that you cant get the full text of a post natively, only the content of the reblog. i had to write my own method for that. also - this is kinda nitpicky - you cant easily get the blog that last contributed in the thread, only whoever last reblogged it (who might have reblogged it without saying anything). by that i mean 5 people might have reblogged it without saying anything since anyone added anything to the thread, but you can only find that 5th person (easily). the workaround is to check if the person who last reblogged it said anything, if not get the last person in the 'trail', which is a list of reblogs in the thread that said something that doesnt include the last reblog. this also... doesnt work sometimes i guess? i didnt bother figuring out why, but one time out of the blue it gave me an error when trying to get the name of the last person in the trail.
i hate the tumblr api
#tumblr api#my ramblings#programming#i bet you cant guess what my bot is#although BECAUSE I CAN ONLY USE MY DASH#and im too far in to make a new account#it *does* reblog a lot of my mutuals posts#and people im following#so they might be able to guess
2 notes
·
View notes
Text
Do You Want Some Cookies?
Doing the project-extrovert is being an interesting challenge. Since the scope of this project shrunk down a lot since the first idea, one of the main things I dropped is the use of a database, mostly to reduce any cost I would have with hosting one. So things like authentication needs to be fully client-side and/or client-stored. However, this is an application that doesn't rely on JavaScript, so how I can store in the client without it? Well, do you want some cookies?
Why Cookies
I never actually used cookies in one of my projects before, mostly because all of them used JavaScript (and a JS framework), so I could just store everything using the Web Storage API (mainly localstorage). But now, everything is server-driven, and any JavaScript that I will add to this project, is to enhance the experience, and shouldn't be necessary to use the application. So the only way to store something in the client, using the server, are Cookies.
TL;DR Of How Cookies Work
A cookie, in some sense or another, is just an HTTP Header that is sent every time the browser/client makes a request to the server. The server sends a Set-Cookie header on the first response, containing the value and optional "rules" for the cookie(s), which then the browser stores locally. After the cookie(s) is stored in the browser, on every subsequent request to the server, a Cookie header will be sent together, which then the server can read the values from.
Pretty much all websites use cookies some way or another, they're one of the first implementations of state/storage on the web, and every browser supports them pretty much. Also, fun note, because it was one of the first ways to know what user is accessing the website, it was also heavy abused by companies to track you on any website, the term "third-party cookie" comes from the fact that a cookie, without the proper rules or browser protection, can be [in summary] read from any server that the current websites calls. So things like advertising networks can set cookies on your browser to know and track your profile on the internet, without you even knowing or acknowledging. Nowadays, there are some regulations, primarily in Europe with the General Data Privacy Regulation (GDPR), that's why nowadays you always see the "We use Cookies" pop-up in websites you visit, which I beg you to actually click "Decline" or "More options" and remove any cookie labeled "Non-essential".
Small Challenges and Workarounds
But returning to the topic, using this simple standard wasn't so easy as I thought. The code itself isn't that difficult, and thankfully Go has an incredible standard library for handling HTTP requests and responses. The most difficult part was working around limitations and some security concerns.
Cookie Limitations
The main limitation that I stumbled was trying to have structured data in a cookie. JSON is pretty much the standard for storing and transferring structured data on the web, so that was my first go-to. However, as you may know, cookies can't use any of these characters: ( ) < > @ , ; : \ " / [ ] ? = { }. And well, when a JSON file looks {"like":"this"}, you can think that using JSON is pretty much impossible. Go's http.SetCookie function automatically strips " from the cookie's value, and the other characters can go in the Set-Cookie header, but can cause problems.
On my first try, I just noticed about the stripping of the " character (and not the other characters), so I needed to find a workaround. And after some thinking, I started to try implementing my own data structure format, I'm learning Go, and this could be an opportunity to also understand how Go's JSON parsing and how mostly struct tags works and try to implement something similar.
My idea was to make something similar to JSON in one way or another, and I ended up with:
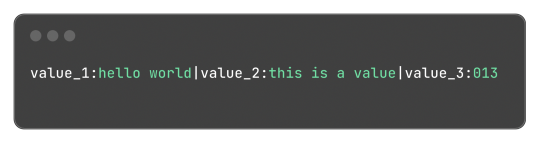
Which, for reference, in JSON would be:
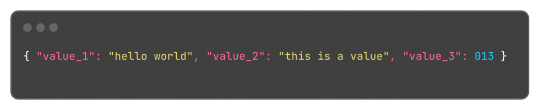
This format is something very easy to implement, just using strings.Split does most of the job of extracting the values and strings.Join to "encode" the values back. Yes, this isn't a "production ready" format or anything like that, but it is hacky and just a small fix for small amounts of structured data.
Go's Struct Tags
Go has an interesting and, to be honest, very clever feature called Struct Tags, which are a simple way to add metadata to Structs. They are simple strings that are added to each field and can contain key-value data:

Said metadata can be used by things such the encoding/json package to transform said struct into a JSON object with the correct field names:

Without said tags, the output JSON would be:

This works both for encoding and decoding the data, so the package can correctly map the JSON field "access_token" to the struct field "Token".
And well, these tokens aren't limited or some sort of special syntax, any key-value pair can be added and accessed by the reflect package, something like this:
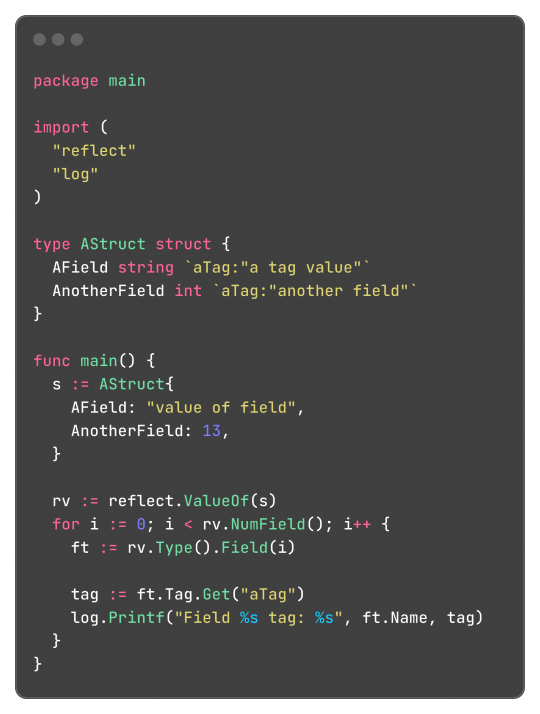
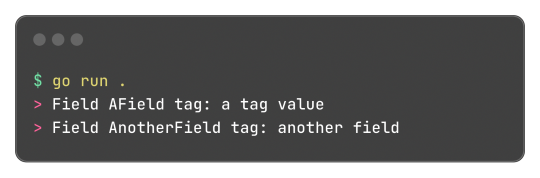
Learning this feature and the reflect package itself, empowered me to do a very simple encoding and decoding of the format where:

Can be transformed into:

And that's what I did, and the [basic] implementation source code just has 150 lines of code, not counting the test file to be sure it worked. It works, and now I can store structured data in cookies.
Legacy in Less Than 3 Weeks
And today, I found that I can just use url.PathEscape, and it escapes all ( ) < > @ , ; : \ " / [ ] ? = { } characters, so it can be used both in URLs and, surprise, cookie values. Not only that, but something like base64.URLEncoding would also work just fine. You live, and you learn y'know, that's what I love about engineering.
Security Concerns and Refactoring Everything
Another thing that was a limitation and mostly worry about me, is storing access tokens on cookies. A cookie by default isn't that secure, and can be easily accessed by JavaScript and browser extensions, there are ways to block and secure cookies, but even then, you can just open the developer tools of the browser and see them easily. Even though the only way to something malicious end up happening with these tokens are if the actual client end up being compromised, which means the user has bigger problems than just a social media token being leaked, it's better to try preventing these issues nonetheless (and learn something new as always).
The encryption and decryption part isn't so difficult, Go already provides packages for encryption under the crypto module. So I just implemented an encryption that cyphers a string based on a key environment variable, which I will change every month or so to improve security even more.
Doing this encryption on every endpoint would be repetitive, so adding a middleware would be a solution. I already made a small abstraction over the default Go's router (the DefaultMuxServer struct), which I'm going to be honest, wasn't the best abstraction, since it deviated a lot from Go's default HTTP package conventions. This deviation also would difficult the implementation of a generic middleware that I could use in any route or even any function that handles HTTP requests, a refactor was needed. Refactoring made me end up rewriting a lot of code and simplifying a lot of the code from the project. All routes now are structs that implement the http.Handler interface, so I can use them outside the application router and test them if needed; The router ends up being just a helper for having all routes in a struct, instead of multiple mux.HandleFunc calls in a function, and also handles adding middlewares to all routes; Middlewares end up being just a struct that can return a wrapped HandlerFunc function, which the router calls using a custom/wrapped implementation of the http.ResponseWriter interface, so middlewares can actually modify the content and headers of the response. The refactor had 1148 lines added, and 524 removed, and simplified a lot of the code.
For the encryption middleware, it encrypts all cookie values that are set in the Set-Cookie header, and decrypts any incoming cookie. Also, the encrypted result is encoded to base64, so it can safely be set in the Set-Cookie header after being cyphered.
---
And that's what I worked in around these last three days, today being the one where I actually used all this functionality and actually implemented the OAuth2 process, using an interface and a default implementation that I can easily reimplement for some special cases like Mastodon's OAuth process (since the token and OAuth application needs to be created on each instance separately). It's being interesting learning Go and trying to be more effective and implement things the way the language wants. Everything is being very simple nonetheless, just needing to align my mind with the language mostly.
It has been a while since I wrote one of these long posts, and I remembered why, it takes hours to do, but it's worth the work I would say. Unfortunately I can't write these every day, but hopefully they will become more common, so I can log better the process of working on the projects. Also, for the 2 persons that read this blog, give me some feedback! I really would like to know if there's anything I could improve in the writing, anything that ended up being confusing, or even how I could write the image description for the code snippets, I'm not sure how to make them more accessible for screen reader users.
Nevertheless, completing this project will also help to make these post, since the conversion for Markdown to Tumblr's NPF in the web editor sucks ass, and I know I can do it better.
2 notes
·
View notes
Text
A [somewhat humble] success
Day 149 - Apr 2nd, 12.024
As you can see here, I was somewhat able to convert Markdown to the Tumblr's Neue Post format successfully. It is not a perfect conversion, but it is a start, and a proof of concept, which hopefully I can mature and improve this week to be something more useful and stable.
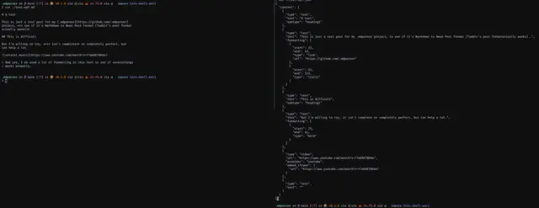
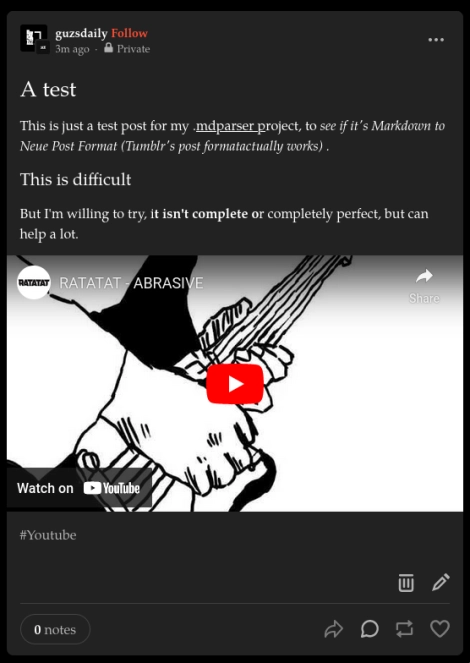
And since there isn't any public library or utility for this type of conversion, maybe create a actual thing for other people to use. Who knows, I'm kinda tired to be honest, but I'm happy with the results.
Today's artists & creative things Music: ABRASIVE - by ratatat
© 2024 Gustavo "Guz" L. de Mello. Licensed under CC BY-SA 4.0
2 notes
·
View notes
Text
I had been looking for a new coding project lately... and I just realized the Tumblr API is a thing that exists (and isn't paywalled to hell and back)
Y'know, maybe what I need to finally learn to love this site is to tear it open and poke around its insides with a stick. A rusty stick. Because I code in Rust. Please laugh.
9 notes
·
View notes
Note
hi ! im curious , you made all these post or isome kind of program generates them ?
Hi! and thanks for taking an interest!
I reblog some stuff and manually post some others, but the majority of my posts are generated through php pages I run from the command line on my Windows machine using the Oath protocol and Tumbr's API. My foobar musicplayer is connected to the last FM scrobbler, and I access their API, get my feed, and alter it with my saved commentary and images, then automatically post it to tumblr. I'm also hooked up to Spotify (and they use curl not Oauth) so I can post music links as well. For a while I was doing YouTube videos as well, but pulled it down, as I need to increase the accuracy of their search.
90% of the code I wrote myself, though I'll admit I don't really understand the actual OAuth transfer that well, those sections are straight copied and pasted :-)
4 notes
·
View notes
Text
Anyway, lets entertain ourselves reading the tumblr's api documentation

I mean, what is that for
4 notes
·
View notes
Text
having fun with the tumblr api, looking for conversations!
This elisp function in emacs lets me retrieve conversations from tumblr! The api doesn't have any documentation about /conversations.
The sid cookie was edited of course. I don't want my private conversations to show up here.
(let ((url-request-method "GET") (url-request-extra-headers `(("authorization" . "bearer") ("cookie" . "sid=aWX8ldphBKnKvrnStFz0jHRttkdfmvNhlfKHJnrdyxgl.a"))) (url-request-data "fields%5Bblogs%5D=avatar%2Cname%2Cseconds_since_last_activity%2Curl%2Cblog_view_url%2Cuuid%2Ctheme%2Cdescription_npf%2Cis_adult%2C%3Fprimary&participant=t%3Y-T8aKdASPs_51V8TQ")) (with-current-buffer (url-retrieve-synchronously "https://www.tumblr.com/api/v2/conversations") (buffer-string)))
Have fun exploring!
4 notes
·
View notes
Text
i really wish there was a route to batch follow and unfollower users. my regular pruning script bumps its head every time i change up my follow list
2 notes
·
View notes