#git rebase
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
69% of Tumblr users are millennials.
Text
do you ever think about killing yourself
1 note
·
View note
Text

Use Git if: ✅ You need speed and distributed development ✅ You want better branching and merging ✅ You work offline frequently
#git tutorial#git commands#git basics#git workflow#git repository#git commit#git push#git pull#git merge#git branch#git rebase#git clone#git fetch#git vs svn#git version control#git best practices#git for beginners#git advanced commands#git vs github#git stash#git log#git diff#git reset#git revert#gitignore#git troubleshooting#git workflow strategies#git for developers#cloudcusp.com#cloudcusp
1 note
·
View note
Text
ma'am sorry. your robot girl backed up her memories, hit her head, forgot stuff, and immediately backed up their memories again. the surgeon is helping her git rebase but you should be prepared for the worst (sorting every file manually)
#robot girl#robot#tw amnesia#tw git rebase#don't ask why she's using git to store backups#she's a little silly
20 notes
·
View notes
Text

I know having so many base pairs makes rebasing complicated, but you're in Bilateria, so shouldn't you at LEAST be better at using git head?
Lungfish [Explained]
Transcript Under the Cut
[Cueball is standing on the end of a wooden dock looking down at a Lungfish sticking its head out of the water.]
Lungfish: It turns out I've been editing both Copy of Copy of Gene v3(Newest)(2) and Copy of Copy of Gene v3(Final)(2), so now I can't delete either one.Cueball: You have got to stop doing this. Lungfish: It's fine, I'll just buy more storage.
[Caption below comic:] Why Lungfish have such enormous genomes.
1K notes
·
View notes
Text
So I came across this recently.
It's funny, because I think I exactly half agree with it. I do rebase-heavy workflows in Git mostly because every single Git client makes merge-based workflows ugly and hard to use. If GitHub simply displayed merges the way it displayed squash-merges, that would eliminate so much of the need for squash-merges.
But I don't think this covers everything. So let me go through every use-case for rebase separately:
git merge --squash
The squash-merge is one of the most popular ways to merge pull requests on GitHub, and it's an abject failure of the Git ecosystem that it's so popular.
When you do a regular merge on a pull request, you are essentially taking a bundle of commits from somewhere else, and putting it on top of your own main branch. It's an extremely linear thing to do.
But if you do that, GitHub's commit log just gets a bunch of commits interspersed throughout, with zero indication where they're from. And the nicer clients, if they do, visualize it as a tree (pronounced "DAG") (pronounced "a huge tangle of curvy lines"):

This pic is from an article telling you to rebase, and, like, sure, rebasing sure is one way to work around a UI that displays your merges as a huge tangle. But Fossil makes a really good point. Why not instead display your merges as, like, not a huge tangle? git log --first-parent does this (and that's clearly an option in that Git UI), but it should be the default everywhere. And even when expanding the "bundle", the bundled commits should still be grouped together, not interspersed with other commits at essentially random.
The other issue is that, when showing the "tangle of commits", the reason it's so tangled is because it's showing the commits in chronological order of when the commits were made. Which is a completely useless sort order, compared to, say, chronological order of when they arrived in the current branch (i.e. grouping the merged-in commits together). This is why GitHub's rebase-merge is also such a popular alternative to merges.
git pull --rebase
Okay, so. Now you've fixed commit log visualization of merged pull requests. But that's not the only use of rebase! Here's another one: if you're working on some code, and constantly keeping it synced with remote, you'll generate tons of merges that are complete useless noise. Unlike a merged PR, these should ideally be hidden completely, or at least nearly-completely.
Anti-rebase people say that these merges serve the functionality of, like, preserving history. You made one commit when the remote was in this state, and another commit when the remote was in that state, and this is sometimes important history to preserve.
I think they are way overestimating how important that history is (judging by how many people use pull-rebase). I'm fine preserving that history if you can declutter the UIs, but it does require your UI to be able to distinguish between "important" merges (of new features from feature branches) and "unimportant" merges (keeping branches in sync with remotes).
The linked post doesn't talk about this problem at all, so I don't know how well Fossil handles this.
git commit --fixup
That leaves the amend/fixup commit. The link does mention that Fossil supports editing past metadata (e.g. commit message). But sometimes you want to edit the actual changes of a commit.
Now, for a sufficiently published commit, this is a bad idea. But if you have a habit of "commit early, commit often", having 50 bugfix commits makes a commit log really cluttered.
I frequently, like, have to weigh stuff like "is it worth cluttering the commit log to fix one typo in one comment?" for old code. And it would really suck to also have to do that for unpublished code, instead of going in with my trusty rebase scalpel.
git that's all I wanted to say
In conclusion. git rebase is a solution to a number of things that could also be viewed as UI problems, and fixed in other, better ways, and Fossil sure sounds like it's fixed some of them. But some of those UI problems are legitimately hard, and I'm not convinced Fossil fixes all of them, and GitHub extremely has not, so I'm gonna keep rebasing.
41 notes
·
View notes
Text
81k in a conversation about what size of change a single git commit should encapsulate: I don't have strong opinions about this, though. The one git thing I do have strong feelings about is merge vs rebase. I always rebase if I can.
me: Yeah, I find rebases easier to reason about even though I know the two are really similar.
me: Merging… it's like eukaryotic sex. You shouldn't do it unless you have to.
18 notes
·
View notes
Text
GitHub and Git Commands: From Beginner to Advanced Level

Git and GitHub are essential tools for every developer, whether you're just starting or deep into professional software development. In this blog, we'll break down what Git and GitHub are, why they matter, and walk you through the most essential commands, from beginner to advanced. This guide is tailored for learners who want to master version control and collaborate more effectively on projects.
GitHub and Git Commands
What Is Git?
Git is a distributed version control system created by Linus Torvalds. It allows you to track changes in your code, collaborate with others, and manage your project history.
What Is GitHub?
GitHub is a cloud-based platform built on Git. It allows developers to host repositories online, share code, contribute to open-source projects, and manage collaboration through pull requests, issues, and branches
Why Learn Git and GitHub?
Manage and track code changes efficiently
Collaborate with teams
Roll back to the previous versions of the code
Host and contribute to open-source projects
Improve workflow through automation and branching
Git Installation (Quick Start)
Before using Git commands, install Git from git-scm.com.
Check if Git is installed:
bash
git --version
Beginner-Level Git Commands
These commands are essential for every new user of Git:
1. git init
Initialises a new Git repository.
bash
git init
2. git clone
Clones an existing repository from GitHub.
bash
git clone https://github.com/user/repo.git
3. git status
Checks the current status of files (modified, staged, untracked).
bash
git status
4. git add
Stage changes for commit.
bash
git add filename # stage a specific file git add . # stage all changes
5. git commit
Records changes to the repository.
bash
git commit -m "Your commit message"
6. git push
Pushes changes to the remote repository.
bash
git push origin main # pushes to the main branch
7. git pull
Fetches and merges changes from the remote repository.
bash
git pull origin main
Intermediate Git Commands
Once you’re comfortable with the basics, start using these:
1. git branch
Lists, creates, or deletes branches.
bash
git branch # list branches git branch new-branch # create a new branch
2. git checkout
Switches branches or restores files.
bash
git checkout new-branch
3. git merge
Merges a branch into the current one.
bash
git merge feature-branch
4. git log
Shows the commit history.
bash
git log
5. .gitignore
Used to ignore specific files or folders in your project.
Example .gitignore file:
bash
node_modules/ .env *.log
Advanced Git Commands
Level up your Git skills with these powerful commands:
1. git stash
Temporarily shelves changes not ready for commit.
bash
git stash git stash apply
2. git rebase
Reapplies commits on top of another base tip.
bash
git checkout feature-branch git rebase main
3. git cherry-pick
Apply the changes introduced by an existing commit.
bash
git cherry-pick <commit-hash>
4. git revert
Reverts a commit by creating a new one.
bash
git revert <commit-hash>
5. git reset
Unstages or removes commits.
bash
git reset --soft HEAD~1 # keep changes git reset --hard HEAD~1 # remove changes
GitHub Tips for Projects
Use Readme.md to document your project
Leverage issues and pull requests for collaboration
Add contributors for team-based work
Use GitHub Actions to automate workflows
Final Thoughts
Mastering Git and GitHub is an investment in your future as a developer. Whether you're working on solo projects or collaborating in a team, these tools will save you time and help you maintain cleaner, safer code. Practice regularly and try contributing to open-source projects to strengthen your skills.
Read MORE: https://yasirinsights.com/github-and-git-commands/
2 notes
·
View notes
Text
this is, obviously, the kind of thing you ideally never use, and thus probably shouldn't really know?
however: I finally bothered to figure out how to use git rebase --onto to sync changes between multiple git branches that depend on one another.
normally, one runs git rebase [new base branch] to change the base of the the currently checked out branch to the target. typically this is git rebase main or git rebase master. there's a second argument that can go after the new base branch that defaults to the currently checked out branch; that argument makes following the documentation/examples I could find confusing and I always check out the branch I'm working on so I'm going to ignore it.
the --onto argument takes two inputs: the first is the same as the regular argument; the second is the last commit on the current checked out feature branch we want to drop because it is now obsolete.
I think the way git diagrams usually show branches is unhelpful here; here's mine. say I have this:
A---B---C---D feature1 A---B---C---D---E---F feature2
I realize that I have a bug in commit C in feature1, and the fix will merge conflict with D. I rewrite history on feature1 to fix it:
A---B---C*--D* feature1 A---B---C---D---E---F feature2
now I check out feature2, wanting to update it. I can't just do git rebase feature1, because git will try to make A---B---C*--D*--C---D---E---F. I can make a temporary branch based on feature1, cherry pick E and F onto it, then hard reset feature2 to the temporary branch, but that's silly. (I could probably do a number of other things; there are like eleven billion git commands. please comment if you know an even better way to do this.)
what I want to do here is git rebase --onto feature1 D (where D is the sha of commit D, the last commit I do not want to keep on feature2 because I am replacing it with the new base branch).
I have no idea why this command is not git rebase feature1 --onto D or something. replacing the first argument you would normally use with a flag and then the argument you would normally use and then another different argument makes precisely zero sense? but, whatever, fine. sure wasted me a lot of time in between the first time I read that manpage, gave up, did temporary branches for years, then finally figured it out, but you do you, git devs.
edit: oh, this probably goes without saying if you know enough git to read this, but this is only necessary if one does rewrite history on feature1. if you just commit a fix on it normally, git rebase feature1 (and then handling any merge conflicts in E and F) will work fine. that's why you generally don't need to know this; it's only necessary if you're manipulating your commit history because you think it'll provide useful clarity and think that's worth the complexity in your git workflow. I do it a fair amount because I tend to juggle multiple potential changes to the same code at once more than is probably wise, but I definitely lean toward not doing it, particularly in a codebase that uses squash merging for PRs and discards all of this history in the end anyway.
3 notes
·
View notes
Text
not me having to finally learn git rebase because i accidentally uploaded an API auth token to the repo and i need that commit gone 😬😬😬 rebase of shame
2 notes
·
View notes
Text
I really love to git rebase on one hour of sleep
5 notes
·
View notes
Text
omg two kinda big things
1. I just booked my laser consultation so i’m finally working towards getting this awful hair off my face which is a big win for dysphoria and sensory issues
2. I just realized that since the big feature I’ve been working on since starting got delayed (after I figured out that the work that had been done before I started completely missed the point of what we were doing) that if I can come out by sometime next week my deadname pretty much won’t be in the version control without any rebasing needed (except some projects from my old team but most of those were rewritten and archived recently anyway, and if i don’t do it by early next week I’ll have just modified like every single test file in two huge projects so that git blame is gonna haunt me…)
only thing holding me back right now is i’m (90% sure i’m) planning on changing my last name and idk that work would let me do that without the legal name change? (and then that 10% unsure…)
2 notes
·
View notes
Text
okay I knoooooow there are benefits to working in a monorepo or else no one would do it, but. I just had the scariest git moment of my career where I was trying to fix a merge conflict in a PR and rebase wasn't working for some reason so I followed github's little instructions (bad idea) and ended up doing like a merge merge into my feature branch that pulled in changes from basically every folder in our repo. which means literally every single person in our codeowners file got pinged. I'm mortified
#closed the PR in shame and starting fresh with a new one from my last non-fucked commit#and you know how I fixed it in the new branch? a goddamn rebase lol. idk what I was doing the first time that didn't work
4 notes
·
View notes
Text
A beginners guide to GIT: Part 2 - Concepts and terms
Table of content: Part 1: What is GIT? Why should I care?
Part 2: Definitions of terms and concepts
Part 3: How to learn GIT after (or instead of ) this guide.
Part 4: How to use GIT as 1 person
Part 5: How to use GIT as a group.
Now, a few (I PROMISE only a few!) concepts that are needed for being able to talk and read about GIT.
Just to be difficult, several of these have multiple names (Plø!)
GIT refers to its commands as "porcelain" commands (user friendly and clean) and "plumbing" commands (Not so user friendly, dirty). Yes. We are starting out with references to toilets :p
The workspace/working tree is all the files and folders you would have if you did not use GIT. It is folders, codefiles, headers, and build system files. All the good stuff we want to work on.
A repository is technically the hidden folder called “.git”. It is all the files GIT uses to keep track of your files and their history, and which enables you to do all the git things to the files in the working tree. You do NOT have to interact with these directly. Just know they are here ( Sometimes people refer to the working tree AND the repository together as “The repository”. Because we work hard on making life harder and more confusing than it needs to be)
The index/cache/staging area is a single, large, binary file in the .git. folder. It keeps track of the differences between last time you saved, and how the working tree is now. Every change, every new file, every file deleted.
Commit. To differentiate what GIT does from how you normally save files, we use the term “commit”. But it is just a save. Different commits are different saves. Easy peasy. Every commit, except the very first one is based on the commit before it. That is called the commits base.(This is the base that REBASE refers to).
The structure of GIT is actually very simple. It is a whole bunch of commits, and each commit knows the commit it came from (IE all commits except the first have a base). This makes a long chain. That's it. That is the entire idea
Staged files
So you now know that we can commit(save) and we have files that we change, but have not been committed. We need a name for files between those two. Files that we are getting ready to commit. All files that will be committed if you commit RIGHT NOW, are “staged for commit”.
HEAD. Because you can switch between different commits easily, we need a way to say “what commit are we looking at right now?”. That is HEAD.
HEAD can be “detached”. This basically means that the commit HEAD is pointing at, is NOT the latest commit. And while you CAN do work on a detached head, it gets messy and is not the smartest way to do it, so “detached head” also works as a bit of a warning.
(If you have ever worked with pointers, HEAD is simply a pointer to a commit)
If we make 3 commits, one after the other (which means HEAD is pointing at the last commit), then your commits could be represented like this:
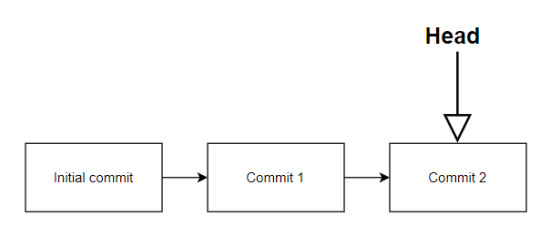
Branches. These are commits that are done one after the other. You always have at least your starting branch (Usually named master or main). If you create new branches, then they start from a specific commit and can be merged into the original branch whenever you are done.
If we expand the previous example, make a branch from the first commit, and then merge it before the third commit and delete the branch, it could look something like this:
Make the branch and add to it:

Then merge it into the main branch and delete the new feature branch:

origin/upstream. This refers to what commit and branch a branch came from. In our example, the "New feature branch" would have the upstream/origin "Main branch" , "Initial commit".
7 notes
·
View notes
Text
100 days of code - day 11
Hi, today I didn't study rust, today I studied JavaScript. Well, I was thinking with myself, I need to finish that full stack course that I started a while ago. Because I never finish what I begin. So I'm going to focus on it a little more. To be honest, I should've taken this decision before. But I want to continue to study rust every day, a little at least.
So, I set my all the node development environment and started to code. I already know a little of JS, but I'm not too comfortable as I'm with C/C++, so I need to practice more.
Also, I was seeing that I know git, but only the basis, like commit, push, pull, and I'm not too used to use commands like branch, merge, rebase, checkout, etc. I've already used them, but since I'm not constantly branching, I have forgotten. So I'm practicing these git commands and git good practices as well.
That's it. Sometimes I feel a little lost, because programming has so many paths to choose from. It can give me a little anxiety, but, as long as I'm studying, progressing, and not paralyzed, I think it's ok.

#day 11#100 days of code#100daysofcode#codeblr#programming#progblr#studyblr#computer science#Rust#1000 hours#code#100 days of productivity#100 days of studying#100 days challenge#tech
7 notes
·
View notes
Text
You can learn Git easily, Here's all you need to get started:
1.Core:
• git init
• git clone
• git add
• git commit
• git status
• git diff
• git checkout
• git reset
• git log
• git show
• git tag
• git push
• git pull
2.Branching:
• git branch
• git checkout -b
• git merge
• git rebase
• git branch --set-upstream-to
• git branch --unset-upstream
• git cherry-pick
3.Merging:
• git merge
• git rebase
4.Stashing:
• git stash
• git stash pop
• git stash list
• git stash apply
• git stash drop
5.Remotes:
• git remote
• git remote
• add git
• remote remove
• git fetch
• git pull
• git push
• git clone --mirror
6.Configuration:
• git config
• git global config
• git reset config
7. Plumbing:
• git cat-file
• git checkout-index
• git commit-tree
• git diff-tree
• git for-each-ref
• git hash-object
• git Is-files
• git Is-remote
• git merge-tree
• git read-tree
• git rev-parse
• git show-branch
• git show-ref
• git symbolic-ref
• git tag --list
• git update-ref
8.Porcelain:
• git blame
• git bisect
• git checkout
• git commit
• git diff
• git fetch
• git grep
• git log
• git merge
• git push
• git rebase
• git reset
• git show
• git tag
9.Alias:
• git config --global alias.<alias> <command>
10.Hook:
• git config --local core.hooksPath <path>
11.Experimental: (May not be fully Supported)
• git annex
• git am
• git cherry-pick --upstream
• git describe
• git format-patch
• git fsck
• git gc
• git help
• git log --merges
• git log --oneline
• git log --pretty=
• git log --short-commit
• git log --stat
• git log --topo-order
• git merge-ours
• git merge-recursive
• git merge-subtree
• git mergetool
• git mktag
• git mv
• git patch-id
• git p4
• git prune
• git pull --rebase
• git push --mirror
• git push --tags
• git reflog
• git replace
• git reset --hard
• git reset --mixed
• git revert
• git rm
• git show-branch
• git show-ref
• git show-ref --heads
• git show-ref --tags
• git stash save
• git subtree
• git taq --delete
• git tag --force
• git tag --sign
• git tag -f
• git tag -I
• git tag --verify
• git unpack-file
• git update-index
• git verify-pack
• git worktree
3 notes
·
View notes
Note
I do agree that setting $EDITOR to vim regardless of popularit is... iffy, given that nano is a much better pick (having the controls in the bottom helps even if it takes a leap to figure out ^X means control+x) I just don't really get why $EDITOR is even used. I set it to mine just to avoid being dropped into vim like you said, but if I want my editor open I'd just open it. Is just reading a line not good enough for commit messages? It's really quite strange and something I'm just not a fan of.
(context: ranting about vim)
I like $EDITOR a lot for, like, commands that use it. "git commit" but also "git config --global -e" and "config nu" and "git rebase -i".
My commit messages tend to be several paragraphs, so having a text editor is good for that. And editing config files is of course best in a text editor.
3 notes
·
View notes