#history of data science
Text
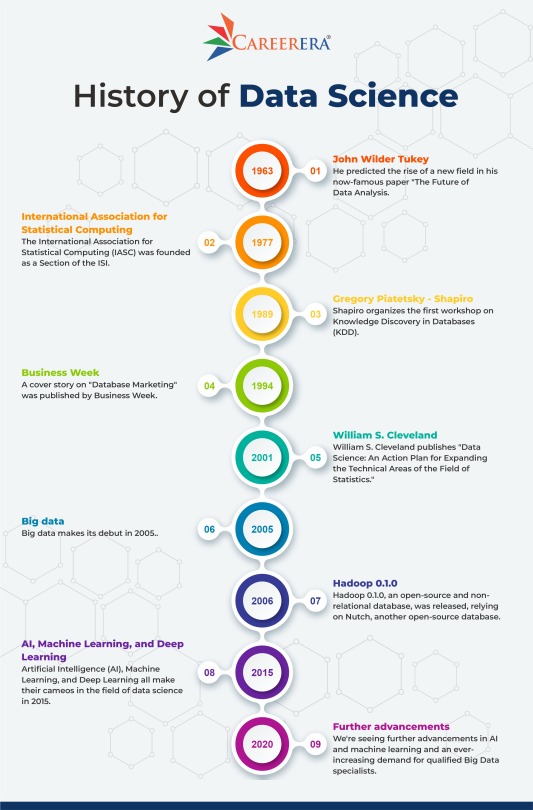
History of Data Science
Data science has grown in popularity as a result of the rise of programming languages like Python and data collection, analysis, and interpretation techniques.
Making sense of data, on the other hand, has a long history and has long been a source of disagreement among scientists, statisticians, librarians, computer scientists, and others. This infographic depicts the historical evolution of the phrase "Data Science," as well as attempts to define it and related terms.
0 notes
Text



Lidar-Derived Aerial Maps Reveal the Dramatic Meandering Changes in River Banks Over Millennia
5K notes
·
View notes
Text

Your Voice Is a Garden – the stunning sound visualizations ("Voice-Figures") of Victorian singer and inventor Margaret Watts Hughes, the first woman to present a scientific instrument of her own design at the Royal Society.
#music#sound#data visualization#Margaret Watts Hughes#women in STEM#women in science#women's history#Victorian art
39 notes
·
View notes
Text
Scientists pin down the origins of the moon’s tenuous atmosphere
New Post has been published on https://thedigitalinsider.com/scientists-pin-down-the-origins-of-the-moons-tenuous-atmosphere/
Scientists pin down the origins of the moon’s tenuous atmosphere

While the moon lacks any breathable air, it does host a barely-there atmosphere. Since the 1980s, astronomers have observed a very thin layer of atoms bouncing over the moon’s surface. This delicate atmosphere — technically known as an “exosphere” — is likely a product of some kind of space weathering. But exactly what those processes might be has been difficult to pin down with any certainty.
Now, scientists at MIT and the University of Chicago say they have identified the main process that formed the moon’s atmosphere and continues to sustain it today. In a study appearing today in Science Advances, the team reports that the lunar atmosphere is primarily a product of “impact vaporization.”
In their study, the researchers analyzed samples of lunar soil collected by astronauts during NASA’s Apollo missions. Their analysis suggests that over the moon’s 4.5-billion-year history its surface has been continuously bombarded, first by massive meteorites, then more recently, by smaller, dust-sized “micrometeoroids.” These constant impacts have kicked up the lunar soil, vaporizing certain atoms on contact and lofting the particles into the air. Some atoms are ejected into space, while others remain suspended over the moon, forming a tenuous atmosphere that is constantly replenished as meteorites continue to pelt the surface.
The researchers found that impact vaporization is the main process by which the moon has generated and sustained its extremely thin atmosphere over billions of years.
“We give a definitive answer that meteorite impact vaporization is the dominant process that creates the lunar atmosphere,” says the study’s lead author, Nicole Nie, an assistant professor in MIT’s Department of Earth, Atmospheric and Planetary Sciences. “The moon is close to 4.5 billion years old, and through that time the surface has been continuously bombarded by meteorites. We show that eventually, a thin atmosphere reaches a steady state because it’s being continuously replenished by small impacts all over the moon.”
Nie’s co-authors are Nicolas Dauphas, Zhe Zhang, and Timo Hopp at the University of Chicago, and Menelaos Sarantos at NASA Goddard Space Flight Center.
Weathering’s roles
In 2013, NASA sent an orbiter around the moon to do some detailed atmospheric reconnaissance. The Lunar Atmosphere and Dust Environment Explorer (LADEE, pronounced “laddie”) was tasked with remotely gathering information about the moon’s thin atmosphere, surface conditions, and any environmental influences on the lunar dust.
LADEE’s mission was designed to determine the origins of the moon’s atmosphere. Scientists hoped that the probe’s remote measurements of soil and atmospheric composition might correlate with certain space weathering processes that could then explain how the moon’s atmosphere came to be.
Researchers suspect that two space weathering processes play a role in shaping the lunar atmosphere: impact vaporization and “ion sputtering” — a phenomenon involving solar wind, which carries energetic charged particles from the sun through space. When these particles hit the moon’s surface, they can transfer their energy to the atoms in the soil and send those atoms sputtering and flying into the air.
“Based on LADEE’s data, it seemed both processes are playing a role,” Nie says. “For instance, it showed that during meteorite showers, you see more atoms in the atmosphere, meaning impacts have an effect. But it also showed that when the moon is shielded from the sun, such as during an eclipse, there are also changes in the atmosphere’s atoms, meaning the sun also has an impact. So, the results were not clear or quantitative.”
Answers in the soil
To more precisely pin down the lunar atmosphere’s origins, Nie looked to samples of lunar soil collected by astronauts throughout NASA’s Apollo missions. She and her colleagues at the University of Chicago acquired 10 samples of lunar soil, each measuring about 100 milligrams — a tiny amount that she estimates would fit into a single raindrop.
Nie sought to first isolate two elements from each sample: potassium and rubidium. Both elements are “volatile,” meaning that they are easily vaporized by impacts and ion sputtering. Each element exists in the form of several isotopes. An isotope is a variation of the same element, that consists of the same number of protons but a slightly different number of neutrons. For instance, potassium can exist as one of three isotopes, each one having one more neutron, and there being slightly heavier than the last. Similarly, there are two isotopes of rubidium.
The team reasoned that if the moon’s atmosphere consists of atoms that have been vaporized and suspended in the air, lighter isotopes of those atoms should be more easily lofted, while heavier isotopes would be more likely to settle back in the soil. Furthermore, scientists predict that impact vaporization, and ion sputtering, should result in very different isotopic proportions in the soil. The specific ratio of light to heavy isotopes that remain in the soil, for both potassium and rubidium, should then reveal the main process contributing to the lunar atmosphere’s origins.
With all that in mind, Nie analyzed the Apollo samples by first crushing the soils into a fine powder, then dissolving the powders in acids to purify and isolate solutions containing potassium and rubidium. She then passed these solutions through a mass spectrometer to measure the various isotopes of both potassium and rubidium in each sample.
In the end, the team found that the soils contained mostly heavy isotopes of both potassium and rubidium. The researchers were able to quantify the ratio of heavy to light isotopes of both potassium and rubidium, and by comparing both elements, they found that impact vaporization was most likely the dominant process by which atoms are vaporized and lofted to form the moon’s atmosphere.
“With impact vaporization, most of the atoms would stay in the lunar atmosphere, whereas with ion sputtering, a lot of atoms would be ejected into space,” Nie says. “From our study, we now can quantify the role of both processes, to say that the relative contribution of impact vaporization versus ion sputtering is about 70:30 or larger.” In other words, 70 percent or more of the moon’s atmosphere is a product of meteorite impacts, whereas the remaining 30 percent is a consequence of the solar wind.
“The discovery of such a subtle effect is remarkable, thanks to the innovative idea of combining potassium and rubidium isotope measurements along with careful, quantitative modeling,” says Justin Hu, a postdoc who studies lunar soils at Cambridge University, who was not involved in the study. “This discovery goes beyond understanding the moon’s history, as such processes could occur and might be more significant on other moons and asteroids, which are the focus of many planned return missions.”
“Without these Apollo samples, we would not be able to get precise data and measure quantitatively to understand things in more detail,” Nie says. “It’s important for us to bring samples back from the moon and other planetary bodies, so we can draw clearer pictures of the solar system’s formation and evolution.”
This work was supported, in part, by NASA and the National Science Foundation.
#1980s#acids#air#Analysis#asteroids#astronauts#Astronomy#atmosphere#atoms#author#billion#chemistry#Composition#data#dust#EAPS#earth#Earth and atmospheric sciences#energy#Environment#Environmental#Evolution#flight#focus#form#Foundation#History#how#impact#Impacts
22 notes
·
View notes
Photo
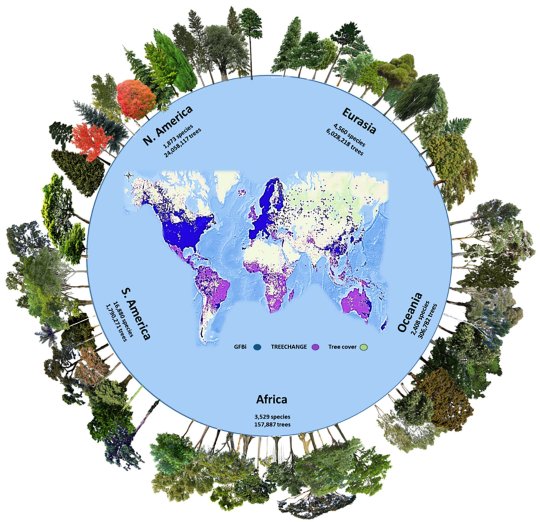
Diagram showing the number of tree species and the estimated tree population of the world in 2022.
“The number of tree species and individuals per continent in the Global Forest Biodiversity Initiative (GFBI) database. This dataset (blue points in the central map) was used for the parametric estimation and merged with the TREECHANGE occurrence-based data (purple points in the central map) to provide the estimates in this study. Green areas represent the global tree cover. GFBI consists of abundance-based records of 38 million trees for 28,192 species. Depicted here are some of the most frequent species recorded in each continent. Some GFBI and TREECHANGE points may overlap in the map. Image credit: Gatti et al., doi: 10.1073/pnas.2115329119.“
Source: Tom Kimmerer’s Twitter page
#scientific diagram#trees#forestcore#botany#katia plant scientist#rainforest#taiga#woodland#forests#Forest#tree cover#nature#science#ecology#natural history#diagram#infographic#big data#biology#plant biology#bioinformatics#science news
105 notes
·
View notes
Text
Have you ever wondered how scientists know what earth's climate was like in the past? Thousands of years ago, long before humans started to measure and record these things?
It's a really fascinating question with a VERY cool answer! Ice cores! Basically, they go to someplace cold, like the Arctic or Antarctic, and drill really deep into the ice to take a vertical section of it.

[ID:A cylinder of ice, about an inch in diameter and perhaps a little over a foot long (that's around 2.5 centimeters in diameter and over 30cm long, for those of you sensibly using the metric system), held in thickly-gloved hands. End ID.]
Here's what they look like. Kind of - they're a lot bigger when they come out of a glacier, but they get broken down into smaller pieces for transportation and study.
The US National Oceanic and Atmospheric Administration has a cool article on it here, but I'll go over the basics because tumblr science communication has a uniquely fun dialect, and I much prefer to learn things that way. I'm also putting it under a read-more because it got long.
If you've ever taken a geology class, you probably know that rock gets deposited vertically over time, with the newest at the top and the oldest at the bottom. In places where ice stays frozen for a long time, it's basically the same principle - year after year of snow and ice layered on top of each other. Ice cores can include stuff that's been frozen for perhaps thousands of years - including air bubbles, dust, sea salt, volcanic ash, etc. Both those and the ancient ice itself can tell us things about what earth's climate was like when they were first frozen.
The water in the ice cores contains, just like water from today, varying ratios of oxygen isotopes: oxygen-16 and oxygen-18. Remember, the difference between isotopes is the number of neutrons in each atom - oxygen-16, with 16 neutrons, is the 'normal' one, which makes up over 99% of oxygen atoms. It's also lighter than oxygen-18, which has two extra neutrons, and that means that it's slightly more difficult to get out of the atmosphere via precipitation - and this is easier at colder temperatures. So, as global climate gets cooler, the ratio of oxygen-16 to 18 increases, and as global climate cools, it decreases. We can measure those ratios in ice cores to figure out what Earth's climate was like in the past - as far back as we can find ice. How far is that? Up to 800,000 years. Yeah, that's some fucking old ice.
That's a lot of ice, I can hear you thinking. You're right - the deepest ice core ever collected was 3769m - 3.7 kilometers of ice (for my fellow Americans, that's over 2 and a quarter miles). That is a stupidly long piece of ice. Now you know why they have to break it up to analyze it.
Also, remember those air bubbles I mentioned? We can measure the concentrations of gases in those to learn about the composition of Earth's atmosphere a long fucking time ago, including the concentration of greenhouse gases like carbon dioxide and methane. (How do you get air bubbles out of ancient ice you ask? NOAA has the answer: crush it under a vacuum hood. That means there's no other gases around to contaminate your sample while you put it in an airtight vial.)
How do we know how old the ice is? Same way we date other ancient stuff - there's two main methods.
Radioactivity and radioisotopes! Mostly naturally occurring, although for recent ice, radioactivity from nuclear testing can also be used. Carbon dioxide can be radiocarbon dated, volcanic material can be argon/argon dated, etc.
Layering! Especially looking for distinctive stuff like volcanic ash from significant geological events. This can be used to synchronize ice cores from different places, or for relative ages (i.e. this section is older than this one).
These are far from the only things ice cores can teach us, but this post is already very long so I'll leave it here. Check out the NOAA article for more details, and a fun anecdote about how no fieldwork project ever goes entirely according to plan - especially when there's polar bears.
Sources: 1, 2
#hylian rambles#hylian does science#science side of tumblr#climate change#ice cores#science education#i should do a followup post about the history of atmospheric greenhouse gases sometime#dig into some actual ice core data. because it blew my mind when i first saw it and i'm sure it'll blow yours too.
11 notes
·
View notes
Text
love when I sit down to read academic papers form my subject and I love my subject!
#And also: not to toot my own horn#I think I’m really good at it#I love the mix of math hard science data analysis and social history and social analysis
10 notes
·
View notes
Text
fuck algorithms collecting personalized data fuck having content perfectly tailored and shoved down our throats fuck platforms making you disable adblockers to access anything fuck algorithms that want to force-fee content to people so much they don't know how to search for things themselves fuck what the internet is trying to become
#this is making me feel embarrassed that I'm choosing a degree in computer science#yt forcing me to turn my watch history on so I can have a homepage? I need to hunt the ceo for sport.#I HAVE WATCH HISTORY OFF FOR A REASON DUMBASS#MY HOMEPAGE HAS WORKED PERFECTLY FINE WITHOUT NEEDING TO USE IT UP UNTIL NOW#I'm lucky my adblockers still work.#I despise this new trend in internet corporations wanting your data sooooo bad so they can get you to doom scroll or binge videos more#I hope that the internet experiences a collapse at some point from this so the radioactive fallout creates better things#sorry for the ranting post I haven't slept well and the yt thing is trying to drag me to a snapping point
4 notes
·
View notes
Text

By the way, it has been over a century, folks... (coughs).
3 notes
·
View notes
Text
https://www.teepublic.com/t-shirt/46350021-future-machine-learning-engineer




#chatbot#ai#ai tools#ai artwork#artificalintelligence#machinelearning#machine learning#data science#prompt engineering#artificial intelligence#hbculove#black history month#hbcu#black history#merch by amazon
3 notes
·
View notes
Text




NASA Cassini-Huygens
Commonly called Cassini, was a space-research mission by NASA, the European Space Agency (ESA), and the Italian Space Agency (ASI) to send a space probe to study the planet Saturn and its system, including its rings and natural satellites. The Flagship-class robotic spacecraft comprised both NASA's Cassini space probe and ESA's Huygens lander, which landed on Saturn's largest moon, Titan. It was the fourth space probe to visit Saturn and the first to enter its orbit, where it stayed from 2004 to 2017. The two craft took their names from the astronomers Giovanni Cassini and Christiaan Huygens.
#cosmos#cassini#outer space#saturn#saturn's moons#nasa#dania rambles about shit#i'm doing some research rn and came across these images in my powerpoint notes from astronomy class during my third year so here they are#between architect / teacher / astronomer as my top careers it's hilarious I just landed on graphic design#there's a pipeline from using ms paint to this i know there is#gonna be an art teacher or a math or some type of science or shit even a history one if I don't finish the architect path#also like meterology is an interest bc of the movie twister and I've always liked looking at all the data charts
2 notes
·
View notes
Text
Check In
Hey, y’all. I’ve been gone for a minute. Please forgive me. I’m back with an update. I’ve been trying to do a little bit more focus. Dropped one gym bae for another. I’m going to my gym at another location than where I met first gym bae and there’s a trainer this time I make eyes with. Serves as a little extra motivation to get up in the mornings. I’m waking up earlier. Trying to get more things done.
It’s officially March and I’ve made some progress with React. I feel more confident to now dive back into algos. I also NEED to now as it’s now March. I thought I would be interviewing by this time. It’s been almost 4 months since my layoff and while I knew I had a large bridge to gap, there’s still so much I need. I am trying to remain positive. A few nights ago, the reality of my situation kicked in and woke up me up. I had a deep question of whether I should stay or go back home. This was the same night where I felt like I had made a large breakthrough and milestone with my React learning. I had to remind myself that the devil likes to cast doubt when you’re making progress…and when you’re not making enough, it likes to make you think you should give up…but I’m staying here. I still have a lot of savings and it isn’t June yet.
One of my male “friends” I’ve mentioned here called me asking AGAIN if I’ve started interviewing. He sounded really insecure and I had to block that energy and tell him, “No. I’m not ready. I will be, but it’s not quite the time to throw in the towel yet.”
I think I will start interviewing in April. I think I want to spend the next 3 months on the algo plan I set out to do but got side tracked on months ago.
I’ve gotta get up much earlier if I want to get out there and get it on time…And I will. I keep yearning for home. And to visit NY. And New Orleans. And Nashville. And I’m just trying to use it as motivation to really get at it and get there. And I will. I’m going to get the job I want and I am going to learn everything I need to equip me for this transition. It’ll be hard, but I’m ready for it.

#Codeblr#nene leakes#python#coding#black in tech#software engineer#software engineering#women in tech#women’s history month#Data structures#computer science
2 notes
·
View notes
Text
Working on a large scale project/database. If interested, download the file below.
#history#science#cia#fbi#data#database#largescale#large#scale#mathematics#math#physics#astrophysics#psychology#countries#america#continents#south america#north america#asia#europe#russia#china#yugoslavia#soviet union#serial#killer#serial killer#anonymous#anon
2 notes
·
View notes
Text
why must god give his toughest battles (an essay) to his strongest soldiers (a very sleepy boy)
#damien.txt#it's my final essay and it's due today but i haven't started any of it because i'm lowkey an idiot sjkdfhgsjk#nah it's like a 3 page essay it's really not hard i just have to like... actually read stuff and that's kinda rough#but also the articles are fascinating! did you know archival studies groups are looking into ao3 and vtubers as ways of transforming#information science and the ways in which we save our data? i didn't! i think it's really cool!#but i can't just talk about what i think is cool in the essay lol#but ahhh i'm so sleepy. i've yawned like 6 times in the past 10 minutes#and then after this i need to write my essay on d&d for my history class lol but that's not due until tomorrow and is arguably way easier#i'm really not even gonna have a finals week tbh it's just a finals weekend comprising of today and tomorrow and then i am finished
5 notes
·
View notes
Text
Can AI automate computational reproducibility?
New Post has been published on https://thedigitalinsider.com/can-ai-automate-computational-reproducibility/
Can AI automate computational reproducibility?
Last month, Sakana AI released an “AI scientist”, which the company called “the first comprehensive system for fully automatic scientific discovery”. It was touted as being able to accelerate science without suffering from human limitations.
Unfortunately, the “AI Scientist” has many shortcomings. It has no checks for novelty, so generated papers could rehash earlier work. And Sakana did not perform any human review (let alone expert “peer” review) of the generated papers—so it is unclear if the papers are any good (apparently they are not). While these flaws are particularly flagrant in Sakana’s case, the lack of good evaluation affects most AI agents, making it hard to measure their real-world impact.
Today, we introduce a new benchmark for measuring how well AI can reproduce existing computational research. We also share how this project has changed our thinking about “general intelligence” and the potential economic impact of AI. Read the paper.
Visions of AI automating science are enticing, but aren’t within reach, and lead to flawed science. In contrast, using AI for well-scoped tasks such as verifying computational reproducibility can save a lot of time and redirect effort towards more productive scientific activity. AI could also help find relevant literature, write code to rapidly test ideas, and perform other computational tasks.
In a new paper, we introduce CORE-Bench (Computational Reproducibility Agent Benchmark), a benchmark for measuring how well AI can automate computational reproducibility, that is, reproducing a paper’s findings when the code and data are available. The authors are Zachary S. Siegel, Sayash Kapoor, Nitya Nadgir, Benedikt Stroebl, and Arvind Narayanan. CORE-Bench is a first step in a larger project to rigorously evaluate progress in automating research tasks of increasing difficulty.
Computationally reproducing a study is a far more limited task than replication, which requires re-running experiments that might involve human subjects. Even the limited reproducibility task is hard: In the 2022 Machine Learning Reproducibility Challenge, over a third of the papers could not be reproduced even when experts reproducing the papers had the code and data.
If AI could automate this mundane yet important task, researchers could automate the implementation of baselines, reviewers could more easily assess if a paper has flaws, and journals and conferences could more easily verify if submitted and published papers are reproducible.
We created CORE-Bench using scientific papers and their accompanying code and data repositories. We used Code Ocean to source papers that were likely to be reproducible. We manually reproduced 90 papers from computer science, medicine, and social science, and curated a set of questions for each paper to be able to verify the answers.
We release CORE-Bench with three difficulty levels. Tasks in all three levels require the use of both language and vision capabilities. The hardest version closely resembles real-world reproduction attempts, and we expect that improvements on the benchmark will translate to agents that are actually useful to scientists.
To implement baselines, we tested the generalist AutoGPT agent and also implemented a task-specific modification to AutoGPT, which we call CORE-Agent. While the task-specific version improved accuracy significantly, there is still massive room for improvement: the best agent (CORE-Agent with GPT-4o) has an accuracy of 22% on CORE-Bench-Hard.
Computational reproducibility requires setting up the code environment correctly, running the code, and seeing if it produces the same results as reported in the paper. Using the shell and other tools correctly is still tricky for LLMs. When we evaluated generalist agents like AutoGPT, we weren’t surprised by their poor accuracy (less than 10% on CORE-Bench-Hard).
Yet, with a few person-days of effort, we were able to build CORE-Agent by modifying AutoGPT, which more than doubled accuracy on the hardest level. We also built a task-specific agent from scratch, but modifying AutoGPT was far less time consuming while also resulting in a stronger agent. We are cautiously optimistic that this approach can be pushed to yield agents that perform well enough to be useful in practice.
Simple task-specific modifications allow CORE-Agent to outperform AutoGPT.
If this pattern of being able to easily adapt a generalist agent to produce a task-specific agent holds in other areas, it should make us rethink generality. Generality roughly translates to being able to use the same model or agent without modification to perform a variety of tasks. This notion of generality underpins how Artificial General Intelligence (or AGI) is usually understood and the hopes and fears that accompany it.
But at least from the point of view of economic impacts, generality might be a red herring. For a task such as computational reproducibility on which expert humans collectively spend millions of hours every year, being able to automate it would be hugely impactful — regardless of whether the AI system did so out of the box, or after a few person days (or even a person year) of programmer effort.
In the AI Snake Oil book, we define generality as the inverse of task-specificity, and analyze how the history of AI (and computing) can be seen as the pursuit of gradually increasing generality. Increasing generality means decreasing the human effort it takes to build an AI system to perform a given task. From this perspective, systems like AutoGPT may be more general than most people (including us) gave them credit for.
Yet, definitions of AGI typically insist that a single system be able to do everything out of the box. There is no systematic effort to track how the human effort needed to build task-specific AI is changing over time. Just as we’ve argued against flawed conceptions of generality that overestimate AI progress, we should avoid flawed conceptions of generality that underestimate it.
Read the CORE-Bench paper here.
In our recent paper, AI Agents That Matter, we found several shortcomings with AI agent evaluations. While building CORE-Bench, these shortcomings informed the design of our benchmark.
We recently organized an online workshop on useful and reliable AI agents where leading experts shared their views on better agent design and evaluation. The workshop videos are available online.
Ben Bogin et al. released the SUPER benchmark to evaluate if AI agents can set up and execute tasks from repositories accompanying research papers. It is another interesting benchmark for measuring AI agents’ capability to automate research tasks. It differs from CORE-Bench in many ways:
CORE-Bench consists of tasks across scientific disciplines (computer science, medicine, social science) whereas SUPER consists of tasks from AI.
CORE-Bench requires the use of both vision-language and language models, and consists of multiple languages (Python and R) as opposed to SUPER (language models, Python).
Tasks in SUPER require access to a Jupyter notebook. In contrast, tasks in CORE-Bench require shell access and allow the agent to modify the sandbox arbitrarily.
#2022#agent#agents#AGI#ai#ai agent#AI AGENTS#AI Scientist#approach#artificial#Artificial General Intelligence#AutoGPT#benchmark#book#box#Building#challenge#code#comprehensive#computer#Computer Science#computing#data#Design#economic#Environment#GPT#gpt-4o#History#how
0 notes
Text
There will be no peace until folks learn the truth of who they are. #asiseeittpm
Folks choosing to pursue plans of man (2 state solution) rather than the plan of Universe Creator Source God. #lovehavemercy 🔥💕🐉
Proxy groups + #bullybabynation The greatest British invention.

#lovehavemercy#bigtruth#ammwwtpm#avidinternetexplorer#youtube#history#iot#science#iiiistpm#art#big data works
0 notes
Last Seen Blogs

questionmalk
ask me about my lobotomy

angriella-blog
~Angeriella~

ghoulizh
think happy thoughts

nikensthings
Niken Dieni Pramesi

pennywise-can-get-it
Fanfics And Guilty Pleasure