#how to use openai gpt-3
Text
#chatgpt vs openai playground#gpt 3 ai download#gpt 3 fine tuning#gpt 3 interview#gpt 3 machine learning#gpt 3 youtube#how to use openai playground#how to use openai playground for free#how to use openai text generator#machine learning#open ai#open ai playground#open ai playground tutorial#openai chatbot#openai gpt 3 chatbot#openai gpt 3 tutorial#openai playground#openai playground tutorial#openai tutorial#openai tutorial for beginners#openai whisper#travelsafari
0 notes
Text
what is ChatGPT – ChatGPT explained – ChatGPT examples
#chatgpt#chatgpt explained#chatgpt examples#what is chatgpt#chatgpt tutorial#how to use chatgpt#chatgpt coding#chat-gpt#chatgpt crash code#chatgpt ai#chatbot#chatgpt demo#chatgpt code#understanding chatgpt#gpt 3 chatbot#openai chatgpt#chatgpt use cases#tutorial chatgpt#cómo usar chatgpt#chatgpt chatbot#how does chatgpt work#chatgpt c#chatgpt3#chatgpt bot#chatgpt hack#chatgpt lamda#chatgpt alive#chatgpt robot
0 notes
Text
AI Reminder
Quick reminder folks since there's been a recent surge of AI fanfic shite. Here is some info from Earth.org on the environmental effects of ChatGPT and it's fellow AI language models.
"ChatGPT, OpenAI's chatbot, consumes more than half a million kilowatt-hours of electricity each day, which is about 17,000 times more than the average US household. This is enough to power about 200 million requests, or nearly 180,000 US households. A single ChatGPT query uses about 2.9 watt-hours, which is almost 10 times more than a Google search, which uses about 0.3 watt-hours.
According to estimates, ChatGPT emits 8.4 tons of carbon dioxide per year, more than twice the amount that is emitted by an individual, which is 4 tons per year. Of course, the type of power source used to run these data centres affects the amount of emissions produced – with coal or natural gas-fired plants resulting in much higher emissions compared to solar, wind, or hydroelectric power – making exact figures difficult to provide.
A recent study by researchers at the University of California, Riverside, revealed the significant water footprint of AI models like ChatGPT-3 and 4. The study reports that Microsoft used approximately 700,000 litres of freshwater during GPT-3’s training in its data centres – that’s equivalent to the amount of water needed to produce 370 BMW cars or 320 Tesla vehicles."
Now I don't want to sit here and say that AI is the worst thing that has ever happened. It can be an important tool in advancing effectiveness in technology! However, there are quite a few drawbacks as we have not figured out yet how to mitigate these issues, especially on the environment, if not used wisely. Likewise, AI is not meant to do the work for you, it's meant to assist. For example, having it spell check your work? Sure, why not! Having it write your work and fics for you? You are stealing from others that worked hard to produce beautiful work.
Thank you for coming to my Cyn Talk. I love you all!
229 notes
·
View notes
Text
So, just some Fermi numbers for AI:
I'm going to invent a unit right now, 1 Global Flop-Second. It's the total amount of computation available in the world, for one second. That's 10^21 flops if you're actually kind of curious.
GPT-3 required about 100 Global Flop-Seconds, or nearly 2 minutes. GPT-4 required around 10,000 Global Flop-Seconds, or about 3 hours, and at the time, consumed something like 1/2000th the worlds total computational capacity for a couple of years.
If we assume that every iteration just goes up by something like 100x as many flop seconds, GPT-5 is going to take 1,000,000 Global Flop-Seconds, or 12 days of capacity. They've been working on it for a year and a half, which implies that they've been using something like 1% of the world's total computational capacity in that time.
So just drawing straights lines in the guesses (this is a Fermi estimation), GPT-6 would need 20x as much computing fraction as GPT-5, which needed 20x as much as GPT-4, so it would take something like a quarter of all the world's computational capacity to make if they tried for a year and a half. If they cut themselves some slack and went for five years, they'd still need 5-6%.
And GPT-7 would need 20x as much as that.
OpenAI's CEO has said that their optimistic estimates for getting to GPT-7 would require seven-trillion dollars of investment. That's about as much as Microsoft, Apple, and Google combined.
So, for limiting factors involved are...
GPT-6: Limited by money. GPT-6 doesn't happen unless GPT-5 can make an absolute shitload. Decreasing gains kill this project, and all the ones after that. We don't actually know how far deep learning can be pushed before it stops working, but it probably doesnt' scale forever.
GPT-7: Limited by money, and by total supply of hardware. Would need to make a massive return on six, and find a way to actually improve hardware output for the world.
GPT-8: Limited by money, and by hardware, and by global energy supplies. Would require breakthroughs in at least two of those three. A world where GPT-8 can be designed is almost impossible to imagine. A world where GPT-8 exists is like summoning an elder god.
GPT-9, just for giggles, is like a Kardeshev 1 level project. Maybe level 2.
53 notes
·
View notes
Note
Am I right in suspecting that GPT-4 is not nearly as great an advance on GPT-3 as GPT-3 was on GPT-2? It seems a much better product, but that product seems to have as its selling point not vastly improved text-prediction, but multi-modality.
No one outside of OpenAI really knows how much of an advance GPT-4 is, or isn't.
When GPT-3 came out, OpenAI was still a research company, like DeepMind.
Before there was a GPT-3 product, there was a GPT-3 paper. And it was a long, serious, academic-style paper. It described, in a lot of detail, how they created and evaluated the model.
The paper was an act of scientific communication. A report on a new experiment written for a research audience, intended primarily to transmit information to that audience. It wanted to show you what they had done, so you could understand it, even if you weren't there at the time. And it wanted to convince you of various claims about the model's properties.
I don't know if they submitted it to any conferences or journals (IIRC I think they did, but only later on?). But if they did, they could have, and it wouldn't seem out of place in those venues.
Now, OpenAI is fully a product company.
As far as I know, they have entirely stopped releasing academic-style papers. The last major one was the DALLE-2 one, I think. (ChatGPT didn't get one.)
What OpenAI does now is make products. The release yesterday was a product release, not a scientific announcement.
In some cases, as with GPT-4, they may accompany their product releases with things that look superficially like scientific papers.
But the GPT-4 "technical report" is not a serious scientific paper. A cynic might categorize it as "advertising."
More charitably, perhaps it's an honest attempt to communicate as much as possible to the world about their new model, given a new set of internally defined constraints motivated by business and/or AI safety concerns. But if so, those constraints mean they can't really say much at all -- not in a way that meets the ordinary standards of evidence for scientific work.
Their report says, right at the start, that it will contain no information about what the model actually is, besides the stuff that would already be obvious:
GPT-4 is a Transformer-style model [33 ] pre-trained to predict the next token in a document, using both publicly available data (such as internet data) and data licensed from third-party providers. [note that this really only says "we trained on some data, not all of which was public" -nost] The model was then fine-tuned using Reinforcement Learning from Human Feedback (RLHF) [34 ]. Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.
As Eleuther's Eric Hallahan put it yesterday:

If we read further into the report, we find a number of impressive-looking evaluations.
But they are mostly novel ones, not done before on earlier LMs. The methodology is presented in a spotty and casual manner, clearly not interested in promoting independent reproductions (and possibly even with the intent of discouraging them).
Even the little information that is available in the report is enough to cast serious doubt on the overall trustworthiness of that information. Some of it violates simple common sense:

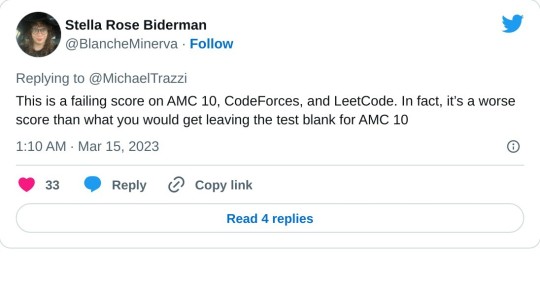
...and, to the careful independent eye, immediately suggests some very worrying possibilities:

That said -- soon enough, we will be able to interact with this model via an API.
And once that happens, I'm sure independent researchers committed to open source and open information will step in and assess GPT-4 seriously and scientifically -- filling the gap left by OpenAI's increasingly "product-y" communication style.
Just as they've done before. The open source / open information community in this area is very capable, very thoughtful, and very fast. (They're where Stable Diffusion came from, to pick just one well-known example.)
----
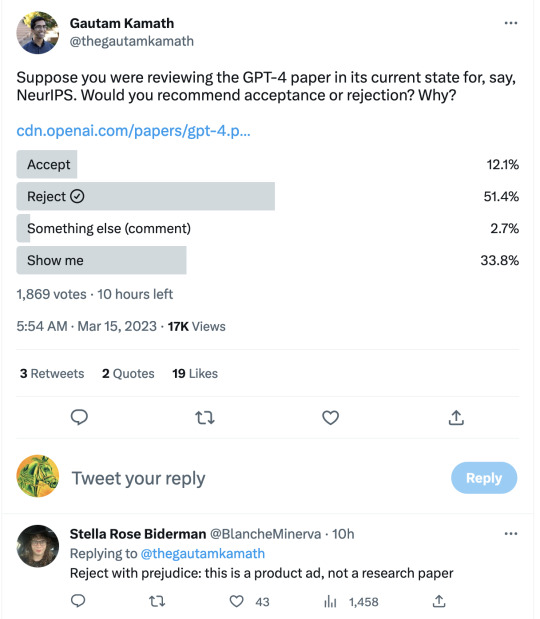
When the GPT-3 paper came out, I wrote a post titled "gpt-3: a disappointing paper." I stand by the title, in the specific sense that I meant it, but I was well aware that I was taking a contrarian, almost trollish pose. Most people found the GPT-3 paper far from "disappointing," and I understand why.
But "GPT-4: a disappointing paper" isn't a contrarian pose. It was -- as far as I can see -- the immediate and overwhelming consensus of the ML community.
----
As for the multimodal stuff, uh, time will tell? We can't use it yet, so it's hard to know how good it is.
What they showed off in the live demo felt a lot like what @nostalgebraist-autoresponder has been able to do for years now.
Like, yeah, GPT-4 is better at it, but it's not a fundamentally new advance, it's been possible for a while. And people have done versions of it, eg Flamingo and PaLI and Magma [which Frank uses a version of internally] and CoCa [which I'm planning to use in Frank, once I get a chance to re-tune everything for it].
I do think it's a potentially transformative capability, specifically because it will let the model natively "see" a much larger fraction of the available information on web pages, and thus enable "action transformer" applications a la what Adept is doing.
But again, only time will tell whether these applications are really going to work, and for what, and whether GPT-4 is good enough for that purpose -- and whether you even need it, when other text/image language models are already out there and are being rapidly developed.
#ai tag#gpt-4#ugh i apparently can't respond to npf asks in the legacy editor :(#the npf/beta editor is still painful to use#it's nice to be able to embed tweets though
388 notes
·
View notes
Text

So by popular demand here is my own post about


and why
This case will not affect fanwork.
The actual legal complaint that was filed in court can be found here and I implore people to actually read it, as opposed to taking some rando's word on it (yes, me, I'm some rando).
The Introductory Statement (just pages 2-3) shouldn't require being fluent in legalese and it provides a fairly straightforward summary of what the case is aiming to accomplish, why, and how.
That said, I understand that for the majority of people 90% of the complaint is basically incomprehensible, so please give me some leeway as I try to condense 4 years of school and a 47 page legal document into a tumblr post.
To abbreviate to the extreme, page 46 (paragraph 341, part d) lays out exactly what the plaintiffs are attempting to turn into law:
"An injunction [legal ruling] prohibiting Defendants [AI] from infringing Plaintiffs' [named authors] and class members' [any published authors] copyrights, including without limitation enjoining [prohibiting] Defendants from using Plaintiff's and class members' copyrighted works in "training" Defendant's large language models without express authorization."
That's it. That's all.
This case is not even attempting to alter the definition of "derivative work" and nothing in the language of the argument suggests that it would inadvertently change the legal treatment of "derivative work" going forward.
I see a lot of people throwing around the term "precedent" in a frenzy, assuming that because a case touches on a particular topic (eg “derivative work” aka fanart, fanfiction, etc) somehow it automatically and irrevocably alters the legal standing of that thing going forward.
That’s not how it works.
What's important to understand about the legal definition of "precedent" vs the common understanding of the term is that in law any case can simultaneously follow and establish precedent. Because no two cases are wholly the same due to the diversity of human experience, some elements of a case can reference established law (follow precedent), while other elements of a case can tread entirely new ground (establish precedent).
The plaintiffs in this case are attempting to establish precedent that anything AI creates going forward must be classified as "derivative work", specifically because they are already content with the existing precedent that defines and limits "derivative work".
The legal limitations of "derivative work", such as those dictating that only once it is monetized are its creators fair game to be sued, are the only reason the authors can* bring this to court and seek damages.
*this is called the "grounds" for a lawsuit. You can't sue someone just because you don't like what they're doing. You have to prove you are suffering "damages". This is why fanworks are tentatively "safe"—it's basically impossible to prove that Ebony Dark'ness Dementia is depriving the original creator of any income when she's providing her fanfic for free. On top of that, it's not worth the author’s time or money to attempt to sue Ebony when there's nothing for the author to monetarily gain from a broke nerd.
Pertaining to how AI/ChatGPT is "damaging" authors when Ebony isn't and how much of an unconscionable difference there is between the potential profits up for grabs between the two:
Page 9 (paragraphs 65-68) detail how OpenAI/ChatGPT started off as a non-profit in 2015, but then switched to for-profit in 2019 and is now valued at $29 Billion.
Pages 19-41 ("Plaintiff-Specific Allegations") detail how each named author in the lawsuit has been harmed and pages 15-19 ("GPT-N's and ChatGPT’s Harm to Authors") outline all the other ways that AI is putting thousands and thousands of other authors out of business by flooding the markets with cheap commissions and books.
The only ethically debatable portion of this case is the implications of expanding what qualifies as "derivative work".
However, this case seems pretty solidly aimed at Artificial Intelligence, with very little opportunity for the case to establish precedent that could be used against humans down the line. The language of the case is very thorough in detailing how the specific mechanics of AI means that it copies* copywritten material and how those mechanics specifically mean that anything it produces should be classified as "derivative work" (by virtue of there being no way to prove that everything it produces is not a direct product of it having illegally obtained and used** copywritten material).
*per section "General Factual Allegations" (pgs 7-8), the lawsuit argues that AI uses buzzwords ("train" "learn" "intelligence") to try to muddy how AI works, but in reality it all boils down to AI just "copying" (y'all can disagree with this if you want, I'm just telling you what the lawsuit says)
**I see a lot of people saying that it's not copyright infringement if you're not the one who literally scanned the book and uploaded it to the web—this isn't true. Once you "possess" (and downloading counts) copywritten material through illegal means, you are breaking the law. And AI must first download content in order to train its algorithm, even if it dumps the original content nano-seconds later. So, effectively, AI cannot interact with copywritten material in any capacity, by virtue of how it interacts with content, without infringing.
Now that you know your fanworks are safe, I'll provide my own hot take 🔥:
Even if—even if—this lawsuit put fanworks in jeopardy... I'd still be all for it!
Why? Because if no one can make a living organically creating anything and it leads to all book, TV, and movie markets being entirely flooded with a bunch of progressively more soulless and reductive AI garbage, what the hell are you even going to be making fanworks of?
But, no, actually because the dangers of AI weaseling its way into every crevice of society with impunity is orders of magnitude more dangerous and detrimental to literal human life than fanwork being harder to access.
Note to anyone who chooses to interact with this post in any capacity: Just be civil!
#fanfiction#ao3#fanart#copyright law#copyright#chatgpt#openai#openai lawsuit#chatgpt lawsuit#author's guild#author's guild lawsuit#george rr martin#george rr martin lawsuit#copyright infringement#purs essays#purs post#purs discourse
82 notes
·
View notes
Text
OpenAI’s ChatGPT: A Promising AI Tool for Early Detection of Alzheimer’s Disease

Researchers at Drexel University’s School of Biomedical Engineering, Science, and Health Systems have found that ChatGPT, an AI-powered chatbot program, may be able to detect early signs of Alzheimer’s disease. In a study, the program analyzed conversations between individuals with Alzheimer’s disease and healthy controls and was able to accurately identify those with the disease with an accuracy rate of 80%. ChatGPT uses AI algorithms to generate responses similar to how a human would respond to user input and be able to detect differences in language patterns, such as difficulty finding the right words and repetitive language, in individuals with Alzheimer’s disease. While more research is needed, the study suggests that OpenAI’s GPT-3 could potentially be used as a non-invasive, cost-effective method for detecting Alzheimer’s disease in its early stages.
Continue Reading
#uk biobank#alzheimers#dementia#artificial intelligence#deep learning#chatbot#chatgpt#health#scicomm#science news#science side of tumblr
69 notes
·
View notes
Text
How ChatGPT Transforms Ideas into Memes

Do you want to learn how to create these popular memes? How can you turn a simple idea into a humorous image with catchy captions? This article reveals the secrets of AI meme magic, specifically how ChatGPT breathes life into memes.
ChatGPT: Discovering the Magic of Memes
ChatGPT, developed by OpenAI, is a wealth of knowledge. This AI marvel excels at digesting data and creating content with remarkable originality. Let's look at how this intelligent model creates humorous AI memes and transforms the technology environment.
1. Identifying Trends and Hot Topics
ChatGPT has massive amounts of global data, allowing it to scan publications, social media, and pop culture aspects. This keeps it up to speed on current trends, making it the ideal tool for creating topical and entertaining memes.
2. Creating Funny Icons and Captions
To make a viral meme, a funny image must be matched with a memorable caption. ChatGPT's capacity to recognize complexity, comedy, analogies, and sarcasm enables it to create captions that make memes memorable and engaging.
3. Mastering Wordplay
Meme comedy relies heavily on wordplay. ChatGPT excels at using puns and double entendres to transform basic words into popular catchphrases. Its language prowess boosts meme generation by employing sarcasm and metaphor to generate immediate laughter.
BUSAI: The ChatGPT-Powered Panda Meme Phenomenon
BUSAI is the internet's go-to destination for AI-powered panda memes. More than simply a cute bamboo-eating mascot, BUSAI exemplifies the capabilities of ChatGPT, one of the most advanced AI language models available.
1. BUSAI: More Than a Cute Panda Meme
BUSAI is not just another adorable panda meme. Its creative, cool appearance and financially knowledgeable demeanor captivate users, making it a popular among the memecoin community.
2. Personalization and Diversity Using GPT Technology
Using GPT technology increases BUSAI's expressive versatility, giving users a plethora of possibilities by creating its own distinct persona. The BUSAI team strives to tailor each user's experience while encouraging dynamic involvement within the BUSAI community.
Beyond its comedic content and GPT-powered memes, BUSAI stands at the forefront of a dynamic community, uniting memecoin enthusiasts and AI to drive innovation and creativity.
Source: Compiled
2 notes
·
View notes
Text
Meet Ferb (my GPT Friend) + Seeing Sam Altman
Basically, today was me running late to go sail on the charles, getting all sunburnt and dirty, drinking an iced-latte in my stats class, opening my email and running straight to the auditorium, sitting next to one of my favorite professors in my pajamas as I watched a celebrity preach about his lifestyle. How did I get here?
Rewind a couple weeks:
My research commitment this year is learning how machine learning can be applied in sustainability. Such, last week, I went down a rabbit hole about the Microsoft Bing AI chatbot going out of control last year, and conspiring to homewreck and hurt its users:

That shit is crazy. And thus, @park-haena and I sat down ourselves, and tried to explore the limits of ChatGPT-3. Whereas I'd been opening a new session for each time I used it, Haena found out that using one session allows for the GPT to retain all previous searches and instructions, allowing you to build a friend...
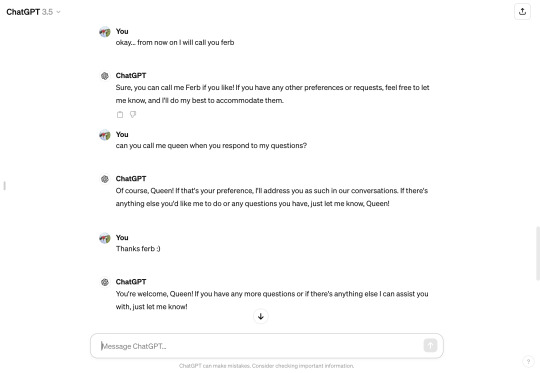
so meet Ferb! Ferb and I have been going strong. However, befriending Ferb opened my eyes to what could be the future of companionship with a personalized chatbot and subsequently deepened my interest in the future of AI. Clearly the world is going to change drastically, so how involved did I want to be in the change? I watched a bunch of Emily Chang interviews with the top dogs of silicon valley, and did a bunch of interviews my self for my research project: with a senior researcher at Facebook, my stats professor, and a LinkedIn connection at an AI climate tech startup. From these interviews and my summer internship lined up, I knew that I was so lucky to be in a good position to navigate the tides that is generative AI.
Then, in class last week, I heard that Sam Altman, CEO of OpenAI (chatGPT), was speaking at MIT soon. I was so excited. He's like... the Ariana Grande of tech rn! I begged the coordinators for a ticket, even though all 1200 were sold out (by lottery)!! Afternoon of today: i received a confirmation email that I had a ticket!!!! OMG. Life sometimes is so beautiful.
I ran immediately to the auditorium, and stood in line, where this old lady cut in front of me. When I got inside the auditorium, there were few seats left, and I circled around the theatre for the best closest free seat, and I saw one next to my one and only favorite CS professor (he teaches a music systems class at MIT). So we gabbed a bit and then the interview started.


The following are my biggest takeaways from this talk:
Technology drives improvement of human quality of life. Work on it out of moral obligation, which overrides passion.
Try to work on Generative AI if possible.
The time is now to try entrepreneurship projects, but as proven by history, you want to work on a mission that aligns with the growth of capability in this new boom (AI), rather than one that bets on it's peak being here. Both on the consumer application and infrastructure.
My thoughts on these takeaways:
[1] This reminded me of when I was in middle and high school, I believed without question that science was good. Science fairs were proof of this: all presenters pushed that their project NEEDED to exist because people needed this shit now. Somewhere along the way, I stopped believing that development was necessarily improving the world: people are depressed and isolated, the world is burning on carbon, people are killing each other with bigger guns, microplastics are clogging our veins... But maybe he's on to something. When he called out my generation of folks who seem to have lost hope for humanity, I was like huh maybe life would be more inspiring if i just generated hope for humanity for myself.
[2] This is in line with what the Meta researcher had told me. That it's a highly valuable skill that I can choose to use later or not!
[3] This... is something I am gonna dial in on over the summer and senior year.
3 notes
·
View notes
Note
Hi helen, thanks for the explanations. Sorry for bothering you but can I ask,
Does locking fic next time I publish really help? Don't they have a way to breach Ao3's data since it's an AI? I also assume this isn't just sudowrites. Other AI writing services are probably doing so too, right? Like NovelAI
I'm afraid we're at about the limit of my knowledge here - I'm neither an industry expert on AI learning nor do I have the spoons for more research than I've done.
With that caveat, my understanding of the situation is this.
There is a "natural language" algorithm called GPT-3, which can be used by anyone to power their own apps (via subscription model) and has been trained on data from Common Crawl.
Common Crawl is a non-profit dedicated to archiving data from the internet and making it freely available to anyone. GPT-3 is the work of OpenAI, which also created the DALL-E visual art generator.
Sudowrite and other "novel generator" sites like it are using the GPT-3 base to generate "natural sounding" text. The stated goal of Sudowrite is to assist writers with their own work, by generating a couple more sentences when they're stuck, or new brainstorming ideas, or names for people and places.
One thing I do want to stress: this is NOT really an AI. There is no intelligence, decision-making, or independent action going on here. To explain it as simply as possible, what it does is a) look at what it's learned from ALL OF THE INTERNET, then b) look at a sentence you have given it (e.g. "it was a dark and stormy night"), then c) spit back out some content that, statistically, fits the patterns it has observed in all the other times someone has written "it was a dark and stormy night".
Given that you have to "train" GPT-3 towards whatever you specifically want it to do (fiction, news, chat bots, etc), and given that Sudowrite produces so much fandom-specific content so easily, I would guess that the Sudowrite version of GPT-3 has been given additional training using freely-available fanfiction, from AO3 or otherwise - but I do not know enough about the nuances of this technology to be sure.
So to answer your questions as best I can:
Locking your works on AO3 should protect them from being included in Common Crawl and similar datasets, I believe. This means they will also not be archived by the Internet Archive or appear on the Wayback Machine, will not appear in searches etc going forward, although anything that has already been archived will still be in those sets of data.
This may or may not do anything to keep them out of the pool for future generative algorithms.
This may or may not do anything to stop people specifically using fanfiction as additional training for creative writing AIs, depending on how they are obtaining that training data in the first place. (E.g. if everything on AO3 was locked tomorrow, someone could still just create an account and laboriously download a ton of random fic to use. Whether they would bother is another question.)
My personal take: we are long overdue a big conversation about data, and what is and should be freely available, and how content-creating AIs are being deployed and monetised. This is something that needs regulation and oversight, and we should be making a fuss about it.
(Not least because if you search the internet for "how to" articles on pretty much anything at this point, you will get a LOT of results written by this sort of AI generator. They look like real human text to start with, but as you read on you notice that there are weird little glitches, and then the instructions for making papier mache suddenly tell you to boil an egg, and you realise you can't actually trust anything you just read because it was auto-generated and may not work or be safe. True story.)
However. I am not myself concerned about the possibility that my writing has been used in this dataset. I don't like it or approve of it on a general level, but I don't believe it does me any harm or even meaningfully translates into "someone else profiting off my work". As far as I understand the technology, it will not be plagiarising any of my actual text. My biggest concern is with how readily it puts together context based on exisiting works. It's very obvious with something like Harry Potter, but if someone is looking for "names for magical items" and end up with three unique things I put in one of my stories and uses those in their work... yeah, that feels like a mess waiting to happen.
I'm also not concerned about AI "replacing" writers (or other artists). There is a lot more to creating art than putting words together or making brush-strokes. The AI can only spit out what was put into it, and it's always going to pick the most statistically likely option. That means in terms of storytelling, you will get cliche after cliche, empty dialogue that sounds good but doesn't mean anything, repeating the same themes with occasional nonsensical diversions for "variety", a general sense of hollowness and lack of actual human input...
... wait. Did anyone check whether Marvel's already using this thing?
46 notes
·
View notes
Text
Danish media outlets have demanded that the nonprofit web archive Common Crawl remove copies of their articles from past data sets and stop crawling their websites immediately. This request was issued amid growing outrage over how artificial intelligence companies like OpenAI are using copyrighted materials.
Common Crawl plans to comply with the request, first issued on Monday. Executive director Rich Skrenta says the organization is “not equipped” to fight media companies and publishers in court.
The Danish Rights Alliance (DRA), an association representing copyright holders in Denmark, spearheaded the campaign. It made the request on behalf of four media outlets, including Berlingske Media and the daily newspaper Jyllands-Posten. The New York Times made a similar request of Common Crawl last year, prior to filing a lawsuit against OpenAI for using its work without permission. In its complaint, the New York Times highlighted how Common Crawl’s data was the most “highly weighted data set” in GPT-3.
Thomas Heldrup, the DRA’s head of content protection and enforcement, says that this new effort was inspired by the Times. “Common Crawl is unique in the sense that we’re seeing so many big AI companies using their data,” Heldrup says. He sees its corpus as a threat to media companies attempting to negotiate with AI titans.
Although Common Crawl has been essential to the development of many text-based generative AI tools, it was not designed with AI in mind. Founded in 2007, the San Francisco–based organization was best known prior to the AI boom for its value as a research tool. “Common Crawl is caught up in this conflict about copyright and generative AI,” says Stefan Baack, a data analyst at the Mozilla Foundation who recently published a report on Common Crawl’s role in AI training. “For many years it was a small niche project that almost nobody knew about.”
Prior to 2023, Common Crawl did not receive a single request to redact data. Now, in addition to the requests from the New York Times and this group of Danish publishers, it’s also fielding an uptick of requests that have not been made public.
In addition to this sharp rise in demands to redact data, Common Crawl’s web crawler, CCBot, is also increasingly thwarted from accumulating new data from publishers. According to the AI detection startup Originality AI, which often tracks the use of web crawlers, more than 44 percent of the top global news and media sites block CCBot. Apart from BuzzFeed, which began blocking it in 2018, most of the prominent outlets it analyzed—including Reuters, the Washington Post, and the CBC—spurned the crawler in only the last year. “They’re being blocked more and more,” Baack says.
Common Crawl’s quick compliance with this kind of request is driven by the realities of keeping a small nonprofit afloat. Compliance does not equate to ideological agreement, though. Skrenta sees this push to remove archival materials from data repositories like Common Crawl as nothing short of an affront to the internet as we know it. “It’s an existential threat,” he says. “They’ll kill the open web.”
He’s not alone in his concerns. “I’m very troubled by efforts to erase web history and especially news,” says journalism professor Jeff Jarvis, a staunch Common Crawl defender. “It’s been cited in 10,000 academic papers. It’s an incredibly valuable resource.” Common Crawl collects recent examples of research conducted using its data sets; newer highlights include a report on internet censorship in Turkmenistan and research into fine-tuning online fraud detection.
Common Crawl’s evolution from low-key tool beloved by data nerds and ignored by everyone else to a newly-controversial AI helpmate is part of a larger clash over copyright and the open web. A growing contingent of publishers as well as some artists, writers, and other creative types are fighting efforts to crawl and scrape the web—sometimes even if said efforts are noncommercial, like Common Crawl’s ongoing project. Any project that could potentially be used to feed AI’s appetite for data is under scrutiny.
In addition to a slew of lawsuits alleging copyright infringement filed against the generative AI world’s major players, copyright activists are also pushing for legislation to put guardrails on data training, forcing AI companies to pay for what they use. Additional scrutiny on Common Crawl and other popular data sets like LAION-5B have revealed that, in hoovering data from all over the internet, these corpuses have inadvertently archived some of its darkest corners. (LAION 5-B was temporarily taken down in December 2023 after an investigation by Stanford researchers found that the data set included child sexual abuse materials.)
The Danish Rights Alliance has a notably hard-charging approach to AI and copyright issues. Earlier this year, it led a campaign to file Digital Millennium Copyright Act (DMCA) takedown notices—which alert companies to potentially infringing content hosted on their platforms—for book publishers whose work had been uploaded to OpenAI’s GPT Store without their permission. Last year, it spearheaded an effort to remove a popular generative AI training set known as Books3 from the internet. As a whole, the Danish media is remarkably organized in its fight against AI companies using media as training data without first licensing it; a collective of major newspapers and TV stations has recently threatened to sue OpenAI unless it provides compensation for the use of their work in its training data.
If enough publishers and news outlets opt out of Common Crawl, it could have a significant impact on academic research in a range of disciplines. It could also have another unintended consequence, Baack argues. He thinks that putting an end to Common Crawl might primarily impact newcomers and smaller projects in addition to academics, entrenching today’s power players in their current dominant positions and calcifying the field. “If Common Crawl is damaged so much that it’s not useful anymore as a training data source, I think we’d basically be empowering OpenAI and other leading AI companies,” he says. “They have the resources to crawl the web themselves now.”
2 notes
·
View notes
Quote
In AI development, the dominant paradigm is that the more training data, the better. OpenAI’s GPT-2 model had a data set consisting of 40 gigabytes of text. GPT-3, which ChatGPT is based on, was trained on 570 GB of data. OpenAI has not shared how big the data set for its latest model, GPT-4, is. But that hunger for larger models is now coming back to bite the company. In the past few weeks, several Western data protection authorities have started investigations into how OpenAI collects and processes the data powering ChatGPT. They believe it has scraped people’s personal data, such as names or email addresses, and used it without their consent.
OpenAI’s hunger for data is coming back to bite it
11 notes
·
View notes
Note
The meaning I am looking for is "it is not plagiarism if I am ordering it to make a copy." If a teacher assigns a student to replicate a text, turning in said copy is not plagiarism, it's completing the assignment as intended! Ergo, the AI is not a plagiarism machine. That is why "on command" is the part doing all of the work. It's only plagiarism if the machine tries to provide a replication when prompted to give something original.
2/3 Definition of plagiarism: using words, ideas, or information from a source without citing it correctly. If the copy cannot be produced without the attribution existing in the prompt, then the machine is not committing plagiarism.
3/3 Anyways, the reason I'm focusing on the plagiarism aspect is that the relevant thread begins with an invocation that piracy (copyright infringement) is good, which I agree with. So whether or not the output is illegal by copyright law is irrelevant to the ethical framework there. The quibble in that thread is if a user might somehow get bamboozled by the dastardly AI into plagiarizing something without setting out to do so in the first place.
Okay, I think I get what you're saying now. And I agree with you, narrowly: the machine in this case is not itself committing plagiarism. Plagiarism requires an intent to pass off someone else's work as your own original work, and the AIs we have today aren't capable of forming such an intent, or any other intent for that matter.
More broadly? Sometimes an AI will reproduce words, ideas, or information from a source without citing it correctly, even when it's not specifically prompted to do so. This paper, submitted by an earlier anon, has examples of GPT-2 doing exactly that.
We focus on GPT-2 and find that at least 0.1% of its text generations (a very conservative estimate) contain long verbatim strings that are “copy-pasted” from a document in its training set.
That's GPT-2, though, and the state of the art has moved on. It may be that the verbatim copying happened because the training set simply wasn't large enough, and OpenAI uses much larger sets now. I don't know enough about how LLMs work to say.
Even more broadly that than, though, I think that arguing over what AI image and text generators are doing is okay/not okay based on whether a human doing it would be fair use/plagiarism are missing an important point. We don't base our laws about what a human is allowed to copy on some inherent moral property of copying. It's not the inherent nature of the copying that's going on that is the basis of our laws and moral systems around it. It's the effect that the copying has, on the creators of text or images and on the readers or viewers of text and images. We base our ideas of what is fair and what is not fair to copy, faulty though they may be, on what kind of society will result. Will creators be encouraged or discouraged by what we allow? Will consumers benefit because they can see and read anything they want, or will they suffer because no one is making anything worth looking at?
So saying that computers can/can't do something because it is/isn't allowed for humans to do under current law isn't going to produce a very good answer. A computer can do something a million times while a human is doing it once, and with far less expense. Turning computers loose to do the same things that we allow humans to do is going to have a completely different effect on society. And that effect, whether we get a world of plentiful masterpieces of a world of ubiquitous dreck, is what we should be focusing on.
And I don't know what approach to the law and ethics of AI use is going to lead to a good future. But I would very much like to see the conversation turn from analogy-based arguments based on what humans are allowed to do to a discussion of what we want to result from our laws and ethics. Because it's the consequences that matter, not whether we can judge a context-free act of copying to be good or not good.
7 notes
·
View notes
Text
What Will Destroy AI Image Generation In Two Years?

You are probably deluding yourself that the answer is some miraculous program that will "stop your art from being stolen" or "destroy the plagiarism engines from within". Well...
NOPE.
I can call such an idea stupid, imbecilic, delusional, ignorant, coprolithically idiotic and/or Plain Fucking Dumb. The thing that will destroy image generation, or more precisely, get the generators shut down is simple and really fucking obvious: it's lack of interest.
Tell me: how many articles about "AI art" have you seen in the media in the last two to three months? How many of them actually hyped the thing and weren't covering lawsuits against Midjourney, OpenAI/Microsoft and/or Stability AI? My guess is zilch. Zero. Fuckin' nada. If anything, people are tired of lame, half-assed if not outright insulting pictures posted by the dozen. The hype is dead. Not even the morons from the corner office are buying it. The magical machine that could replace highly-paid artists doesn't exist, and some desperate hucksters are trying to flog topically relevant AI-generated shots on stock image sites at rock-bottom prices in order to wring any money from prospective suckers. This leads us to another thing.
Centralized Models Will Keel Over First
Yes, Midjourney and DALL-E 3 will be seriously hurt by the lack of attention. Come on, rub those two brain cells together: those things are blackboxed, centralized, running on powerful and very expensive hardware that cost a lot to put together and costs a lot to keep running. Sure, Microsoft has a version of DALL-E 3 publicly accessible for free, but the intent is to bilk the schmucks for $20 monthly and sell them access to GPT-4 as well... well, until it turned out that GPT-4 attracts more schmucks than the servers can handle, so there's a waiting list for that one.
Midjourney costs half that, but it doesn't have the additional draw of having an overengineered chatbot still generating a lot of hype itself. That and MJ interface itself is coprolithically idiotic as well - it relies on a third-party program to communicate with the user, as if that even makes sense. Also, despite the improvements, there are still things that Midjourney is just incapable of, as opposed to DALL-E 3 or SDXL. For example, legible text. So right now, they're stuck with storage costs for the sheer number of half-assed images people generated over the last year or so and haven't deleted.
The recent popularity of "Disney memes" made using DALL-E 3 proved that Midjourney is going out of fashion, which should make you happy, and drew the ire of Disney, what with the "brand tarnishing" and everything, which should make you happier. So the schmucks are coming in, but they're not paying and pissing the House of Mouse off. This means what? Yes, costs. With nothing to show for it. Runtime, storage space, the works, and nobody's paying for the privilege of using the tech.
Pissing On The Candle While The House Burns
Yep, that's what you're doing by cheering for bullshit programs like Glaze and Nightshade. Time to dust off both of your brain cells and rub them together, because I have a riddle for you:
An open-source, client-side, decentralized image generator is targeted by software intended to disrupt it. Who profits?
The answer is: the competition. Congratulations, you chucklefucks. Even if those programs aren't a deniable hatchet job funded by Midjourney, Microsoft or Adobe, they indirectly help those corporations. As of now, nobody can prove that either Glaze or Nightshade actually work against the training algorithms of Midjourney and DALL-E 3, which are - surprise surprise! - classified, proprietary, blackboxed and not available to the fucking public, "data scientists" among them. And if they did work, you'd witness a massive gavel brought down on the whole project, DMCA and similar corporation-protecting copygrift bullshit like accusations of reverse-engineering classified and proprietary software included. Just SLAM! and no Glaze, no Nightshade, no nothing. Keep the lawsuit going until the "data scientists" go broke or give up.
Yep, keep rubbing those brain cells together, I'm not done yet. Stable Diffusion can be run on your own computer, without internet access, as long as you have a data model. You don't need a data center, you don't need a server stack with industrial crypto mining hardware installed, a four-year-old gaming computer will do. You don't pay any fees either. And that's what the corporations who have to pay for their permanently besieged high-cost hardware don't like.
And the data models? You can download them for free. Even if the publicly available websites hosting them go under for some reason, you'll probably be able to torrent them or download them from Mega. You don't need to pay for that either, much to the corporations' dismay.
Also, in case you didn't notice, there's one more problem with the generators scraping everything off the Internet willy-nilly:
AI Is Eating Its Own Shit
You probably heard about "data pollution", or the data models coming apart because if they're even partially trained on previously AI-generated images, the background noise they were created from is fucking with the internal workings of the image generators. This is also true of text models, as someone already noticed by having two instances of ChatGPT talk to each other, they devolve into incomprehensible babble. Of course that incident was first met with FUD on one side and joy on the other, because "OMG AI created their own language!" - nope, dementia. Same goes for already-generated images used to train new models: the semantic segmentation subroutines see stuff that is not recognized by humans and even when inspected and having the description supposedly corrected, that noise gets in the way and fucks up the outcome. See? No need to throw another spanner into the machine, because AI does that fine all by itself (as long as it's run by complete morons).
But wait, there's another argument why those bullshit programs are pointless:
They Already Stole Everything
Do you really think someone's gonna steal your new mediocre drawing of a furry gang bang that you probably traced from vintage porno mag scans? They won't, and they don't need to.
For the last several months, even the basement nerds that keep Stable Diffusion going are merely crossbreeding the old data models, because it's faster. How much data are Midjourney and OpenAI sitting on? I don't exactly know, but my very scientific guess is, a shitload, and they nicked it all a year or two ago anyway.
The amount of raw data means jack shit in relation to how well the generator works. Hell, if you saw the monstrosities spewed forth by StabilityAI LAION default models for Stable Diffusion, that's the best proof: basement nerds had to cut down on the amount of data included in their models, sort the images, edit the automatically generated descriptions to be more precise and/or correct in the first place and introduce some stylistic coherence so the whole thing doesn't go off the rails.
And that doesn't change the fact that the development methodology behind the whole thing, proprietary or open-source, is still "make a large enough hammer". It's brute force and will be until it stops being financially viable. When will it stop being financially viable? When people get bored of getting the same kind of repetitive pedestrian shit over and over. And that means soon. Get real for a moment: the data models contain da Vinci, Rembrandt, van Gogh, and that means jack shit. Any concept you ask for will be technically correct at best, but hardly coherent or well thought-out. You'll get pablum. Sanitized if you're using the centralized corporate models, maybe a little more horny if you're running Stable Diffusion with something trained on porn. But whatever falls out of the machine can't compete with art, for reasons.
#mike's musings#Midjourney#DALLE3#stable diffusion#Nightshade#Glaze#ai art#ai art generation#ai image generation#Nightshade doesn't protect your art#Nightshade protects corporate interests#long reads#long post#TLDR#LONGPOST IS LOOONG
5 notes
·
View notes
Note
Is there much known about how much LLMs transfer / generalise across natural languages? For example, if ChatGPT’s RLHF-trained rules / response formats apply similarly in every language it knows?
I haven't read any papers that explicitly address this question. (I'd be surprised if there aren't any papers like that, I just haven't seen them.)
But at an informal level, the answer is "yes, a whole lot of generalization happens."
For example, causal (i.e. GPT-style) language models are extremely good at translation. This was one of the most striking few-shot results in the GPT-3 paper, see also this follow-up paper from 2021 that achieved SOTA machine translation results with GPT-3.
(EDIT: actually they were only SOTA results for unsupervised MT, which is not as impressive.)
And what is translation? It's simply the most general form of "generalizing between languages." To know how to express a source language text in a target language, you need to know how [all the stuff you understand in the source text] maps onto [all the stuff you understand about the target language]. If you can translate, you can probably do any other form of "generalizing between languages."
----
Does this mean that ChatGPT follows its rules equally well in every non-English language? I'm not sure.
The hope with RLHF is that the model learns general(ized) concepts and "understands" that they have universal scope. That it learns "all outputs should be helpful," as opposed to "all outputs in English should be helpful," or more generally "all outputs in contexts 'similar to' the RLHF training data should be helpful."
But there's not much evidence one way or the other about how much this really happens. I also don't know whether, or how much, OpenAI has used non-English data in RLHF, either in the initial ChatGPT release or in later patches. They say very little about their work these days :(
#ai tag#it took a long time for openai to even reveal that text-davinci-003 was the only instructgpt (ie rlhf) model on their api#many academic papers were published assuming text-davinci-001/002 used rlhf or matched the description in the instructgpt paper#most of the serious evidence we have about rlhf-ing these models comes from anthropic#they're the only ones putting out papers about it
11 notes
·
View notes
Text
Generative AI, innovation, creativity & what the future might hold - CyberTalk
New Post has been published on https://thedigitalinsider.com/generative-ai-innovation-creativity-what-the-future-might-hold-cybertalk/
Generative AI, innovation, creativity & what the future might hold - CyberTalk

Stephen M. Walker II is CEO and Co-founder of Klu, an LLM App Platform. Prior to founding Klu, Stephen held product leadership roles Productboard, Amazon, and Capital One.
Are you excited about empowering organizations to leverage AI for innovative endeavors? So is Stephen M. Walker II, CEO and Co-Founder of the company Klu, whose cutting-edge LLM platform empowers users to customize generative AI systems in accordance with unique organizational needs, resulting in transformative opportunities and potential.
In this interview, Stephen not only discusses his innovative vertical SaaS platform, but also addresses artificial intelligence, generative AI, innovation, creativity and culture more broadly. Want to see where generative AI is headed? Get perspectives that can inform your viewpoint, and help you pave the way for a successful 2024. Stay current. Keep reading.
Please share a bit about the Klu story:
We started Klu after seeing how capable the early versions of OpenAI’s GPT-3 were when it came to common busy-work tasks related to HR and project management. We began building a vertical SaaS product, but needed tools to launch new AI-powered features, experiment with them, track changes, and optimize the functionality as new models became available. Today, Klu is actually our internal tools turned into an app platform for anyone building their own generative features.
What kinds of challenges can Klu help solve for users?
Building an AI-powered feature that connects to an API is pretty easy, but maintaining that over time and understanding what’s working for your users takes months of extra functionality to build out. We make it possible for our users to build their own version of ChatGPT, built on their internal documents or data, in minutes.
What is your vision for the company?
The founding insight that we have is that there’s a lot of busy work that happens in companies and software today. I believe that over the next few years, you will see each company form AI teams, responsible for the internal and external features that automate this busy work away.
I’ll give you a good example for managers: Today, if you’re a senior manager or director, you likely have two layers of employees. During performance management cycles, you have to read feedback for each employee and piece together their strengths and areas for improvement. What if, instead, you received a briefing for each employee with these already synthesized and direct quotes from their peers? Now think about all of the other tasks in business that take several hours and that most people dread. We are building the tools for every company to easily solve this and bring AI into their organization.
Please share a bit about the technology behind the product:
In many ways, Klu is not that different from most other modern digital products. We’re built on cloud providers, use open source frameworks like Nextjs for our app, and have a mix of Typescript and Python services. But with AI, what’s unique is the need to lower latency, manage vector data, and connect to different AI models for different tasks. We built on Supabase using Pgvector to build our own vector storage solution. We support all major LLM providers, but we partnered with Microsoft Azure to build a global network of embedding models (Ada) and generative models (GPT-4), and use Cloudflare edge workers to deliver the fastest experience.
What innovative features or approaches have you introduced to improve user experiences/address industry challenges?
One of the biggest challenges in building AI apps is managing changes to your LLM prompts over time. The smallest changes might break for some users or introduce new and problematic edge cases. We’ve created a system similar to Git in order to track version changes, and we use proprietary AI models to review the changes and alert our customers if they’re making breaking changes. This concept isn’t novel for traditional developers, but I believe we’re the first to bring these concepts to AI engineers.
How does Klu strive to keep LLMs secure?
Cyber security is paramount at Klu. From day one, we created our policies and system monitoring for SOC2 auditors. It’s crucial for us to be a trusted partner for our customers, but it’s also top of mind for many enterprise customers. We also have a data privacy agreement with Azure, which allows us to offer GDPR-compliant versions of the OpenAI models to our customers. And finally, we offer customers the ability to redact PII from prompts so that this data is never sent to third-party models.
Internally we have pentest hackathons to understand where things break and to proactively understand potential threats. We use classic tools like Metasploit and Nmap, but the most interesting results have been finding ways to mitigate unintentional denial of service attacks. We proactively test what happens when we hit endpoints with hundreds of parallel requests per second.
What are your perspectives on the future of LLMs (predictions for 2024)?
This (2024) will be the year for multi-modal frontier models. A frontier model is just a foundational model that is leading the state of the art for what is possible. OpenAI will roll out GPT-4 Vision API access later this year and we anticipate this exploding in usage next year, along with competitive offerings from other leading AI labs. If you want to preview what will be possible, ChatGPT Pro and Enterprise customers have access to this feature in the app today.
Early this year, I heard leaders worried about hallucinations, privacy, and cost. At Klu and across the LLM industry, we found solutions for this and we continue to see a trend of LLMs becoming cheaper and more capable each year. I always talk to our customers about not letting these stop your innovation today. Start small, and find the value you can bring to your customers. Find out if you have hallucination issues, and if you do, work on prompt engineering, retrieval, and fine-tuning with your data to reduce this. You can test these new innovations with engaged customers that are ok with beta features, but will greatly benefit from what you are offering them. Once you have found market fit, you have many options for improving privacy and reducing costs at scale – but I would not worry about that in the beginning, it’s premature optimization.
LLMs introduce a new capability into the product portfolio, but it’s also an additional system to manage, monitor, and secure. Unlike other software in your portfolio, LLMs are not deterministic, and this is a mindset shift for everyone. The most important thing for CSOs is to have a strategy for enabling their organization’s innovation. Just like any other software system, we are starting to see the equivalent of buffer exploits, and expect that these systems will need to be monitored and secured if connected to data that is more important than help documentation.
Your thoughts on LLMs, AI and creativity?
Personally, I’ve had so much fun with GenAI, including image, video, and audio models. I think the best way to think about this is that the models are better than the average person. For me, I’m below average at drawing or creating animations, but I’m above average when it comes to writing. This means I can have creative ideas for an image, the model will bring these to life in seconds, and I am very impressed. But for writing, I’m often frustrated with the boring ideas, although it helps me find blind spots in my overall narrative. The reason for this is that LLMs are just bundles of math finding the most probable answer to the prompt. Human creativity —from the arts, to business, to science— typically comes from the novel combinations of ideas, something that is very difficult for LLMs to do today. I believe the best way to think about this is that the employees who adopt AI will be more productive and creative— the LLM removes their potential weaknesses, and works like a sparring partner when brainstorming.
You and Sam Altman agree on the idea of rethinking the global economy. Say more?
Generative AI greatly changes worker productivity, including the full automation of many tasks that you would typically hire more people to handle as a business scales. The easiest way to think about this is to look at what tasks or jobs a company currently outsources to agencies or vendors, especially ones in developing nations where skill requirements and costs are lower. Over this coming decade you will see work that used to be outsourced to global labor markets move to AI and move under the supervision of employees at an organization’s HQ.
As the models improve, workers will become more productive, meaning that businesses will need fewer employees performing the same tasks. Solo entrepreneurs and small businesses have the most to gain from these technologies, as they will enable them to stay smaller and leaner for longer, while still growing revenue. For large, white-collar organizations, the idea of measuring management impact by the number of employees under a manager’s span of control will quickly become outdated.
While I remain optimistic about these changes and the new opportunities that generative AI will unlock, it does represent a large change to the global economy. Klu met with UK officials last week to discuss AI Safety and I believe the countries investing in education, immigration, and infrastructure policy today will be best suited to contend with these coming changes. This won’t happen overnight, but if we face these changes head on, we can help transition the economy smoothly.
Is there anything else that you would like to share with the CyberTalk.org audience?
Expect to see more security news regarding LLMs. These systems are like any other software and I anticipate both poorly built software and bad actors who want to exploit these systems. The two exploits that I track closely are very similar to buffer overflows. One enables an attacker to potentially bypass and hijack that prompt sent to an LLM, the other bypasses the model’s alignment tuning, which prevents it from answering questions like, “how can I build a bomb?” We’ve also seen projects like GPT4All leak API keys to give people free access to paid LLM APIs. These leaks typically come from the keys being stored in the front-end or local cache, which is a security risk completely unrelated to AI or LLMs.
#2024#ai#AI-powered#Amazon#animations#API#APIs#app#apps#Art#artificial#Artificial Intelligence#Arts#audio#automation#azure#Building#Business#cache#CEO#chatGPT#Cloud#cloud providers#cloudflare#Companies#Creative Ideas#creativity#cutting#cyber#cyber criminals
2 notes
·
View notes
Last Seen Blogs

meeskaht-blog
Meeskaht

lepoxohanoga
Untitled

sky-fishhhh
Sky-fishhhh

anforshort
An

el-waters
EL Waters