#common crawl
Text
Ao3 and AI
They made a short blog post here and I dearly hope you read it, but the most important thing is:
1. Most AIs are trained off one dataset, the Common Crawl dataset.
2. Common Crawl can be be blocked in two lines of code.
3. Ao3 implemented that code in December 2022.
4. Fics that were already scraped will remain scraped and there's nothing we can do about it, but any fics posted after they put in that code will not be used to train AI unless the AI-makers make a new data-scraper.
5. Ao3 has also put code in place to slow down scrapers and they check their traffic for signs of abuse.
In short, you do not need to set your fic to members-only to stop it from being part of the Common Crawl dataset, though it will add another layer of protection for other scrapers if you feel really strongly about it. Please note that the blog post says locking your fic "will not block every potential scraper."
#ao3#archive of our own#ai#ao3 and ai#AI and ao3#important#psa#ao3 psa#fanfic#fanfiction#anti ai#fic#common crawl#fanfic being scraped by AI#locking ao3 fics#ao3 account#I said this
160 notes
·
View notes
Note
Hi helen, thanks for the explanations. Sorry for bothering you but can I ask,
Does locking fic next time I publish really help? Don't they have a way to breach Ao3's data since it's an AI? I also assume this isn't just sudowrites. Other AI writing services are probably doing so too, right? Like NovelAI
I'm afraid we're at about the limit of my knowledge here - I'm neither an industry expert on AI learning nor do I have the spoons for more research than I've done.
With that caveat, my understanding of the situation is this.
There is a "natural language" algorithm called GPT-3, which can be used by anyone to power their own apps (via subscription model) and has been trained on data from Common Crawl.
Common Crawl is a non-profit dedicated to archiving data from the internet and making it freely available to anyone. GPT-3 is the work of OpenAI, which also created the DALL-E visual art generator.
Sudowrite and other "novel generator" sites like it are using the GPT-3 base to generate "natural sounding" text. The stated goal of Sudowrite is to assist writers with their own work, by generating a couple more sentences when they're stuck, or new brainstorming ideas, or names for people and places.
One thing I do want to stress: this is NOT really an AI. There is no intelligence, decision-making, or independent action going on here. To explain it as simply as possible, what it does is a) look at what it's learned from ALL OF THE INTERNET, then b) look at a sentence you have given it (e.g. "it was a dark and stormy night"), then c) spit back out some content that, statistically, fits the patterns it has observed in all the other times someone has written "it was a dark and stormy night".
Given that you have to "train" GPT-3 towards whatever you specifically want it to do (fiction, news, chat bots, etc), and given that Sudowrite produces so much fandom-specific content so easily, I would guess that the Sudowrite version of GPT-3 has been given additional training using freely-available fanfiction, from AO3 or otherwise - but I do not know enough about the nuances of this technology to be sure.
So to answer your questions as best I can:
Locking your works on AO3 should protect them from being included in Common Crawl and similar datasets, I believe. This means they will also not be archived by the Internet Archive or appear on the Wayback Machine, will not appear in searches etc going forward, although anything that has already been archived will still be in those sets of data.
This may or may not do anything to keep them out of the pool for future generative algorithms.
This may or may not do anything to stop people specifically using fanfiction as additional training for creative writing AIs, depending on how they are obtaining that training data in the first place. (E.g. if everything on AO3 was locked tomorrow, someone could still just create an account and laboriously download a ton of random fic to use. Whether they would bother is another question.)
My personal take: we are long overdue a big conversation about data, and what is and should be freely available, and how content-creating AIs are being deployed and monetised. This is something that needs regulation and oversight, and we should be making a fuss about it.
(Not least because if you search the internet for "how to" articles on pretty much anything at this point, you will get a LOT of results written by this sort of AI generator. They look like real human text to start with, but as you read on you notice that there are weird little glitches, and then the instructions for making papier mache suddenly tell you to boil an egg, and you realise you can't actually trust anything you just read because it was auto-generated and may not work or be safe. True story.)
However. I am not myself concerned about the possibility that my writing has been used in this dataset. I don't like it or approve of it on a general level, but I don't believe it does me any harm or even meaningfully translates into "someone else profiting off my work". As far as I understand the technology, it will not be plagiarising any of my actual text. My biggest concern is with how readily it puts together context based on exisiting works. It's very obvious with something like Harry Potter, but if someone is looking for "names for magical items" and end up with three unique things I put in one of my stories and uses those in their work... yeah, that feels like a mess waiting to happen.
I'm also not concerned about AI "replacing" writers (or other artists). There is a lot more to creating art than putting words together or making brush-strokes. The AI can only spit out what was put into it, and it's always going to pick the most statistically likely option. That means in terms of storytelling, you will get cliche after cliche, empty dialogue that sounds good but doesn't mean anything, repeating the same themes with occasional nonsensical diversions for "variety", a general sense of hollowness and lack of actual human input...
... wait. Did anyone check whether Marvel's already using this thing?
46 notes
·
View notes
Text
Not to bring up "old" stuff, such as the OTW May Signal bit that was removed after some backlash, I wanted to see it. I threw the OTW into the Wayback Machine, went back to May 9th, and was able to see just what they pulled from the Signal after the community backlash to see what they regret adding to this month's Signal.
So I copy-pasted it, since I bet others who didn't read it wanted/want to, too. You can also read it directly from the OTW May Signal on the Wayback Machine here.
Quotes and etc are under the cut. All blue text is a link.
This is what they cut out of May 2023's Signal:
For Fair Use/Fair Dealing Week, the OTW’s Legal Chair, Betsy Rosenblatt, was interviewed about AI legal issues*. Betsy pointed out that having AIs learn from works such as fanfiction meant that they weren’t only using old works from the public domain to learn about the world. “That means that machines will learn how to describe and express a much more contemporary, broad, inclusive, and diverse set of ideas.” What’s more…
"I’m also intrigued by some of the expressive possibilities that AI may create. Will DALL·E or ChatGPT become characters in fan fiction? Surely they will. I want to read the fan-created stories where DALL·E and ChatGPT fall in love with each other (or don’t), get into arguments (or don’t), buy a house together (or don’t), team up to solve (or perpetrate!) crimes….
Will fans will take up this challenge?"
Thought it might be worth noting that the OTW did add this about AI and Data Scraping on the Archive on May 13th.
*The interview is still up, but just in case, I'll be pulling the link from the Wayback Machine instead of the actual link.
I will be highlighting a few important points (imo) in case people don't want to read the entire interview. For longer highlights, I will be adding bold/italics/underline to help people keep from jumping around the text and read out of order (I know I do, and that tends to help me).
Because I'm having Thoughts about AI scraping, I might make a Tumblr-esque essay and put my English major to use looking into some of this interview (If I ever do, I might add a link to this post). Highlighting things and reading through this interview makes me want to pull my stuff from AO3, and I've only just started posting there a year ago.
Highlighting phrases and sentences does not mean I agree with them. It means I think they are important to see and consider.
Here's the interview that Signal links to:
...Betsy Rosenblatt is the legal chair for the Organization for Transformative Works (OTW), a nonprofit dedicated to preserving fan works.... The interview with Betsy follows.
Katherine: When you think about AI technology, fan works, and copyright, what excites you? And, what keeps you up at night?
Betsy: One of the things that excites me—which is probably a bit off to the side of what most people are talking about with AI and copyright—is that AIs are reading fan fiction now. For a long time, machine learning relied almost exclusively on data sources that were known to be in the copyright public domain, such as works published prior to 1927 and public records. The result of that was that machines were often learning archaic ideas—learning to associate certain professions with certain races and genders, for example. Now, machine learning is turning to broader sources from across the internet, including fan works. That means that machines will learn how to describe and express a much more contemporary, broad, inclusive, and diverse set of ideas.
I’m also intrigued by some of the expressive possibilities that AI may create. Will DALL·E or ChatGPT become characters in fan fiction? Surely they will. I want to read the fan-created stories where DALL·E and ChatGPT fall in love with each other (or don’t), get into arguments (or don’t), buy a house together (or don’t), team up to solve (or perpetrate!) crimes….
As for what keeps me up at night, I remain mostly optimistic. I think it would be a very sad turn of events if some of the newly begun litigation about data crawling and scraping ended up preventing machines from building contemporary, inclusive, broad-based data pools to draw on. I think it would be very sad if people turned to AI-created works instead of finding, exploring, and making fan works of their own. But I don’t think either of those things is very likely to happen. Fans make fan works because they love doing it. They feel compelled to tell the stories they imagine, and they want to share those with communities of other fans. They use fan work creation to build skills and find their own voices. I don’t think that the emergence of new technologies will stop them from doing that.
Katherine: Artists have filed a class-action lawsuit alleging that AI companies violate copyright law when they create databases of copyrighted images to “train” their AI image products. At least one of the companies in the suit, Stability AI, says that this is a fair use: “Anyone that believes that this isn’t fair use does not understand the technology and misunderstands the law.” What questions would you like to see a court ask when analyzing whether ingesting copyrighted works to create AI-training databases is a fair use?
Betsy: I tend to agree with Stability AI’s statement. I would like to see courts consider the “training” process separately from the process of generating works. It is, of course, possible that a machine could generate an infringing work. But the process of training that machine involves something very different—turning expressive works into data and creating relationships based on that data collection. We call it machine “learning” for a reason. A well-trained machine won’t generate an infringing work, but it needs as large a pool of data to work from as possible to do that. The mere fact that an AI can create something infringing doesn’t determine whether the gathering of information is infringement. Consider the classic Sony v. Betamax case: The VCR can be used to infringe, but it has noninfringing (fair) uses, and therefore the VCR does not inherently infringe. I recognize that the analogy isn’t perfect, but I find it persuasive. In general, courts have found that “interim” copying isn’t infringement—that is, copying isn’t infringement when it occurs inside a machine and does not, itself, make copyrighted works perceptible to people—and I think courts should continue to follow that logic.
Katherine: Will the Supreme Court’s 2021 Google v. Oracle decision have any bearing on this case?
Betsy: I hope so. That case highlighted that we shouldn’t be locked into one definition of “transformative” work, and that copying for the purpose of engaging in a different technological use can be transformative copying.
Katherine: What would you say to online creators who might be discouraged by AI technology?
Betsy: You will always make your work better than an AI can. What matters about your work is that it comes from you. That makes your work irreplaceable, and it will always remain so.
#OTW Signal#OTW Signal May 2023#betsy rosenblatt#ao3 works#archiveofourown#ChatGPT#ai art is theft#ai writing is theft#we write fanfiction because we want to share#but if AI will be scanning/scraping/copying our words#we won't want to share our stories anymore#and let me tell you#while you shouldn't write for an audience#you always like knowing that someone is reading your hard work#scraping ao3#common crawl#anti ai#mel-the-pirate post
8 notes
·
View notes
Text
youtube
The Truth About AI Getting "Creative"
#generative ai#generative art#generative text#dall-e 2#stable diffusion#lensa ai#chatgpt#common crawl#technology#mkbhd
3 notes
·
View notes
Text
Gen AI Doom Loop
Since the rise of ChatGPT, the tech industry has been obsessed with the power of generative AI. While coverage has focused on the impact of generative AI on creative work, little has been written about its long-term impact on itself.
How AI works
At their core, tools like ChatGPT, Google Bard, and Llama are advanced auto-complete systems. Looking at what is being typed, the AI systems guesses…

View On WordPress
#AI#ChatGPT#Common Crawl#Data Sets#Generative AI#Google Bard#Large Language Model#Llama#LLM#LLMs#Mistatins in AI#OpenAI#Training AI#Truthiness
0 notes
Text

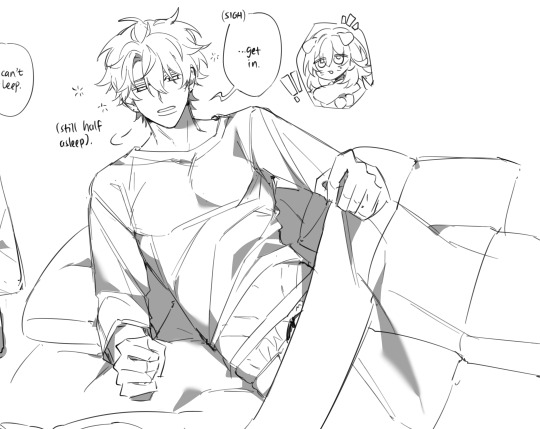
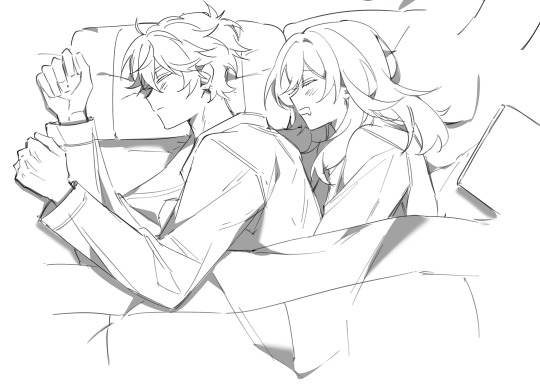
#honkai star rail#dewdles#it becomes such a common occurrence that he jst no longer questions it and lets her crawl into bed w him
3K notes
·
View notes
Text

oh he's goin places alright!!
#ava#animation vs animator#alan becker#eemiesketch#ava the second coming#tsc#i finished all my finals!!! here i come crawling back to tumblr :3#also i have never in my LIFE taken a physics class... curse you common core.
275 notes
·
View notes
Text
my house is radioactive apparently.... i'm just like her

#edit: SORRY I SHOULD SPECIFY THAT ITS FINE LOL#we're getting a guy to fix it. it's in the air so we just need to get a ventilation system#it's radon gas btw which is common apparently#psa test your basement/attic/crawl space for radon gas if you haven't before#radon tag
183 notes
·
View notes
Text
this is super random but if dick grayson was dean winchester, would jason or tim be sam? like i could argue both so idk!
#dc#dcu#dc comics#jason todd#tim drake#supernatural#spn#sam winchester#dick grayson#dean winchester#random poll#this is for an au that has been gnawing at my brain#‘but jason should be dean!’ false.#just bc jackles played both of them doesn’t make them similar characters#like all they have in common aside from jensen#is guns leather jacket and literally crawling out of their grave#i could talk abt the similarities b/w dick and dean for hours yall
65 notes
·
View notes
Text
Everyone starts as a level 0 commoner, when they reach level one they can choose a class.
#Tick here to allow us to use in the podcast#Fantasy#rule idea#submission#so fun fact this is how dungeon crawl classic (dcc) works#you get normally 4 commoners each and whoever survives the initial adventure aka funnel gets to become a level 1 character
626 notes
·
View notes
Text
genuinely not trying to flex or anything but i have never understood how psmd is considered to be the hardest pmd game
#bwark#like the water continent's economy isn't in shambles like mist's is in gates so items are very affordable#especially when you sell the fresh apples and buy old ones from kecleon as your hunger item#oran berries are even more op than they already were. blast seeds got the biggest buff ever#tiny reviver seeds are plentiful and cheap and make the much more expensive full ones kinda useless for most of the game#this game was the debut of wands. unbelievably overpowered for how much they stack#some dungeons allow you to have up to 8 team members (before dx made this common)#you can have salamence dragonite all of team act and victini as early recruits#emeras (barrage) are very powerful (barrage) when you can find the right ones (barrage)#this game doesn't even have a proper ultimate dungeon#the hardest challenge i had on my previous 100% run were the post game bosses that had other forms to fight like mewtwo kyogre and groudon#and i don't mean any of this as a criticsm because idc that much it's just a take that ive seen a lot (especially when the game was released#) and i just never understood it even back then#i find the original rt harder because of jt lacking the qol of later games (and by later games i mean. the very next one. explorers)#and also gates. not because the gane is actually hard but because the heavily zoomed in camera and awful dungeon layout make dungeon#crawling in that game a goddamm nightmare
21 notes
·
View notes
Text
Do you ever think how Sebek is 16. And how Malleus and Lilia have said that 16 is the age of a newborn (fae). But Sebek looks like hes (more than, honestly) 16 in human years. So it's not hard to asume that he inherited the human lifespan, which makes his disdain of humans and his dad more explainable, and mostly about hating his own weaknesses. So Silver AND Sebek have to suffer :)
Lilia and Malleus will outlive them. Sebek's mom and even grandpa will outlive them. And what impact they had on the lives of the people they love most, amounts timewise to the same as a dog to a human if not less.
#death mention#sebek zigvolt#source is riddles suitor vignette where malleus calls riddle a newborn (in age)#and lilia has a voiceline that says like youve just crawled out of the craddle and you can walk??? to yuu so around 16 = newborn#and like in general lilia is 500+ i doubt a full fae would develop THAT fast for 16 years#sebek get along with silver u hav so much in common i BEG OF YOU#watch me give twst way more credit than it deserves on its themes#this sideblog is so i can cry abt sebek off main#text#this is technicallyyyy a headcanon but come on no way he has the fae lifespan#and yea he propably thinks of his dad as cursing him with weakness and a short life#and i have no idea what the deal with his sibs is we need more info twst come ON#and yea we keep seeing malleus perspective on this but silvers... sebeks... im putting them under a microscope#well silver has kinda given up honestly#the tags are just extra writing space wym#i stop
73 notes
·
View notes
Text
I just realized here in the early morning hours that in a straight couple, you are indubitably getting some kind of power struggle where both the man and the woman assume, maybe even subconsciously, that they’re respectively going to be the winners. You could say This is probably why 99% of non-marriage relationships end and 50% of all marriages end in straight folk. It isn’t that most couples HaTe EaCh OtHeR, it is that they have some competition going on in their minds that there exists no rules to.
#I could go on but it is 6 in the morning#in me and hims case#I am paranoid he wants me to forget things so he can paint himself an image of being my compassionate helper#somebody who makes a sacrifice for their lover to help them#as if that isn’t the norm and I’m not completely inept or disabled anyways#in my case I am competing with him in what I believe is a fight to be more genuine somehow I feel he is a liar because I can’t possibly be#in love with somebody who does some of the things he does#all of it is evil and if I said all of this to him he would stare at me#like I have lobsters crawling out of my ears#it’s too late comma we have a child comma and we must microdose psilocybin to find our common ground and fuck on it
11 notes
·
View notes
Text

Eric Barone continues to be THE video game creator of all time
(also fuck the YouTube copyright bots and their borderline illegal practices)
#concernedape#eric barone#YouTube#what happens is that creators license their music (sometimes for free) to companies to use in their own products or promotional content#and those companies register the entire package of content - including the non-exclusively licensed music - as copyright material#their copyright service employs shitty bots that don’t question their ownership of the content#and boom: even the original creator of the content can get their own Creative Commons music taken down#which is what happened to lofi girl#one of these days Youtube and/or these bot crawl firms is going to get SLAMMED with a class action lawsuit over this#and nobody will shed a single fucking tear for them#anyways eric barone continues to be the only valid game creator etc etc
60 notes
·
View notes
Photo






To be continued
#ts3#sims 3#sims 3 story#sims stories#tteot story#sims 3 simblr#erik zay#noah deville#emily golzine#gloria deville#they have a few things in common#starting with dick-measuring tendencies#i was waiting for them to interact because i though it would be fun!#anyway#see you later?#*crawls back into hole*#laurie arc
36 notes
·
View notes
Text
BABES WAKE UP. DUNGEON MESHI TRAILER DROPPED
come talk to me at anime north tomorrow about dungeon meshi im all caught up 🥹🫶
youtube

seeing this tankobon obi from a while back with the anime announcement on it feels so nostalgic now!!!
edit: Lines in Motion is so real for this one. love their video essays
#dm really is such a fun exploration of jrpg and dungeon crawling mechanics#and im so in love with how#the series asks questions about common rpg elements and spins them into true existential horror#the series really is a lot more than the episodic nature that people might find to be a challenge to trudge through at first#it honestly feels like im reading like. a manga version of hieronymus bosch's garden of earthly delights. a lot of the time#dungeon meshi#i love how it knows when to get serious and when to lighten the mood#i often don't like anime style comedy at all a lot of it is based on tired tropes and stuff#but kui really is a master at comedic timing#in the later chapters the story becomes serious without losing its core message: to share a meal with others
39 notes
·
View notes
Last Seen Blogs

yelenaswidow
Hawk’s Nest

supchristysparks
That One Hetalian Geek

ph-re-sch-pictures
Ph.Re.Sch. Pictures

mschirpych
Always Payless When Youare with Mschirpy

lyricstomb
Language address