#sudowrite
Text
i hope this doesn’t need to be said but just in case
you might have seen people talking about sudowrite and/or their tool storyengine recently

and just like… don’t. don’t do it. don’t try it out just to see what it’s about.
for two main reasons:
1) never feed anything proprietary into a large language model (LLM, eg ChatGPT, google bard, etc.).
this means don’t give it private company information when you’re at work, but also don’t give it your original writing. that’s your work.
because of the way these language models work, anything you feed into it is part of it now. and yeah, the FAQ says they “don’t claim ownership” over anything and yeah, they give you that reassuring bullshit about how unlikely it is that the exact same sentence will be reconstructed—
but that’s not the point.
do you have an unusual way of constructing sentences? a metaphor you like to use? a writing tic that sets you apart from the rest? anything that gives you a unique writing voice?
feed your writing into an LLM, and the model has your voice now. the model can generate text that sounds like it was written by you and someone else can claim it’s theirs because they gave the model a prompt.
don’t feed the model.
2) the other reason is that sudowrite scraped a bunch of omegaverse fic without consent to build their model and that’s a really shitty thing to do, because it means people weren’t given the chance to choose whether or not to feed the model.
don’t feed the model.
26K notes
·
View notes
Text
FYI, I have also locked all my fanfics down to registered users only because of the AI scraping on AO3. I'm one of many fan creators doing this right now and I know it stinks for users without an AO3 account, but it's the only option writers have available to us at the moment to stop our work from being scraped and stolen.
If this makes you mad, the Federal Register is currently open to comments on AI accountability until June 12th, 2023.
It only takes a second to leave a comment to ask for legislation that works used in AI creations or training MUST secure the express consent of the original creator before they can be used. If we can get protections for artists, writers, musicians and everyone who creates that their work cannot be used in AI without their permission, we can go back to making fanworks freely available without fear of them being misused. Until then, we're stuck playing defense until the courts catch up.
(If you're a fan creator looking to do this as well, AO3 has a tool to let you do all your fics at the same time in seconds. On your dashboard, go to Edit Works and you'll be able to change the status on everything at once.)
If you missed the context, AO3 recently found that the archive was scraped for use in AI services like ChatGPT and Sudowrite. While they put in protections in December 2022 to try to stop it from happening in the future, it's not foolproof and there is nothing they can do about works already swiped prior to that date. The archive is recommending fan creators restrict their works to registered users only to prevent against additional large scale scraping in the future.
#ao3#archiveofourown#archive of our own#ai#artificial intelligence#Sudowrite#tech news#fandom#fanfiction#fanfic writing#pro tip from me to you: you own the copyright to your fanworks#not the characters and details from the source material obviously#but your writing itself is yours and can be registered and protected as such#ChatGPT#tech bros#psa#important psa#ao3 writer
703 notes
·
View notes
Text
Elon Musk did not create an AI trained on your fanfiction.
Hi, AI ethicist + fanfiction expert here. (This is one of those times where I feel uniquely qualified to comment on something...)
I’m seeing this weird game of telephone about the Sudowrite AI that I think started out pretty accurate, but now has become “Elon Musk created an AI that is stealing your fanfiction” (which frankly gives him far too much credit). I can probably say more about this, but here are a few things that I want to clarify for folks, which can be boiled down to “Elon Musk has nothing to do with this” and “this is nothing new”:
Elon Musk is not involved in any way with Sudowrite, as far as I can tell. Sudowrite does, however, use GPT-3, the widely-used large language model created by OpenAI, which Elon Musk co-founded. He resigned in 2018, citing a conflict of interest due to Tesla’s AI development. It wasn’t until after he left that OpenAI went from being a non-profit to a capped for-profit. Elon Musk doesn’t have anything to do with OpenAI currently (and in fact just cut off their access to Twitter data), though I can’t find anything that confirms whether or not he might have shares in the company. I would also be shocked if Elon actually contributed anything but money to the development of GPT-3.
Based on Sudowrite’s description on their FAQ, they are not collecting any training data themselves - they’re just using GPT-3 paired with their own proprietary narrative model. And GPT-3 is trained on datasets like common crawl and webtext, which can simplistically be described as “scraping the whole internet.” Same as their DALL-E art generator. So it’s not surprising that AO3 would be in that dataset, along with everything else (e.g., Tumblr posts, blogs, news articles, all the words people write online) that doesn’t use technical means to prohibit scraping.
OpenAI does make money now, including from companies like Sudowrite paying for access to GPT-3. And Sudowrite itself is a paid service. So yes, someone is profiting from its use (though OpenAI is capped at no more than 100% return on investment) and I think that the conversations about art (whether visual or text) being used to train these models without consent of the artist are important conversations to be having.
I think it’s possible that what OpenAI is doing is legal (i.e., not copyright infringement) for some of the same reasons that fanfiction is legal (or perhaps more accurately, for reasons that many for-profit remixes are found to be fair use), but I think whether it’s ETHICAL is a completely different question, and I’ve seen a huge amount of disagreement on this.
But the last thing I will say is that this is nothing new. GPT-3 has been around for years and it’s not even the first OpenAI product to have used content scraped from the web.
1K notes
·
View notes
Text
I'm just gonna be out with it. If you use AI generators to write fanfiction for you then publish it? Unfollow me. You have to be astrononically shit at writing if you need to use software that leeches off other people's nonprofit talents. Absolute fucking parasitism.
32 notes
·
View notes
Text
About Sudowrite
I have been seeing people panicking about sudowrite, and I have decided to write a small information post to hopefully clear up some common misconceptions I have been seeing.
Elon Musk is involved.
No. This is blatantly false. Elon Musk was involved with openai - NOT SUDOWRITE - when it was founded. He co-founded the company with a 1 billion dollar investment in 2016, 2 years later in 2018 he left the company. According to this Bloomberg article, he left because "Musk has to focus on “a painfully large number of engineering & manufacturing problems” at Tesla & SpaceX, he said, adding that he hasn’t “been involved closely” with OpenAI for more than a year. Musk left the company’s board in February [2018].
Why is when he left important?
The first gpt paper was published on June 11th 2018. This is 4 months after Musk left the company, and over a year since he said he stopped being involved. He has not been involved with gpt whatsoever.
What is Sudowrite
Sudowrite is, to my understanding, in the most basic terms a word processor with a generate text button.
Sudowrite operates with a gpt-3 model. This is the third gpt model. Gpt is a text-generation program created by the aforementioned openai. Not sudowrite. Basically, gpt is a transformer model. There is a complicated way of putting this, but in short it generates human-like text.
Why can it generate fanfic?
From 2011 to October 2019, an internet crawl was done to train an ai on the entire internet. This includes most websites. This includes ao3. Gpt is trained on this data. From my understanding, no new data is being added to gpt from websites like ao3. Privating your fanfic will do nothing against what is already collected and in use, as the collection of data is already finished, and not current. Please stop panicking.
What is sudowrite trained on?
Thankfully, for this we have a simple awnser.

In this faq (which you can find at the bottom of this page) it is stated that the sudowrite copy of gpt-3 has the models data, (the common crawl, web text, wikipedia, etc) and 10s of thousands of books. As it states here, again, there is no new data being collected. It is from 2019. Privating things will do nothing.
What else can I do to be informed?
I am begging everyone to read this article. It breaks down what gpt is, what the training data is, and everything you might want to know. Please read it.
68 notes
·
View notes
Text
Does anyone know if Sudowrite is behind those horrible bot comments playing AO3 accusing authors of using Sudowrite to make their fics?
Has that been confirmed? Did the bots drop other names?
Because someone out there is really helping a LOT of users learn about how Sudowrite scraped all AO3 up until 2019 to make its plagiarized database.
Either this is a marketing stunt gone wrong or a very horrible double ploy. Either way Sudowrite should take a swan dive.
#ao3#2024#Sudowrite#I’ve never wished for the unhinged power of Anonymous more#if only this happened during their peak mlp years so there’d be some skin in the game#god I hope whoever made that horrible thing doesn’t sleep well at night.
4 notes
·
View notes
Text
Just as a heads up to anyone who enjoys my writing - I have published two fics to AO3 that I never crossposted to FFN. I have made it so you can only view them if you’re logged in to AO3. This is because I’m concerned about these fics being potentially scraped by an AI developed by Elon Musk (for more info, see these threads on reddit and twitter).
I wouldn’t be surprised if FFN’s data got scraped by sudowrite. I’m not gonna go and delete everything there, which means there is no way for me to protect the writing that’s already there. I will try to protect my future writing, which means that you shouldn’t be surprised if in the future I stop crossposting to FFN. Likewise, I have a few fics that are multichap WIP’s. They will likely become archive-locked when I update them, assuming I don’t update the FFN version.
I’m sorry, guest commenters. I love you, but I’m protecting myself.
EDIT: I completely forgot that FFN has introduced anti-scraping measures (pre-finals crunch is killing my logical capacity). I’ll keep updating on FFN, and guest commenters will have to go there instead of AO3. Yes, this means your questions will go unanswered. Please make an account on either website if you want your questions to be answered, or ask them to me on tumblr.
47 notes
·
View notes
Text
The Electric Sea: An AI-generated experiment
I wanted to experiment with Sudowrite’s Story Engine, so I used it to generate a 12-chapter, roughly 22,500-word novella over the course of a weekend. The generation was based on around 6,500 words of story beat prompting, with the skeleton generated by AI but rewritten mainly by myself. Here is the entirely human-written (except for some names I got the AI to suggest) “brain dump” synopsis in its final version, following several rewrites as the story progressed:
A slipstream novel set in an alternate future about a hacker named Jack who is arrested by corporate security and taken to a domed city in the middle of the ocean, managed by an AI named the Curator, who produces the city's elaborate theme park-style culture, which has been corrupted and broken down by years of corporate control and subcultural resistance. A rogue executive asks Jack to come to the city to perform a mysterious job. Jack agrees, and he is assigned a partner: a former underground musician who now uses the AI to program the city's pop music. But the morning after he arrives, the executive is murdered, and Jack and his partner are framed for the crime. They escape to the floating city's underbelly, where they learn that the AI killed the executive and has secretly been running the city for reasons incomprehensible to human minds. Jack and his partner must decide whether to stop the AI or allow it to run the city.
I gave it a slew of genre and prose parameters that may or may not have made much difference, honestly:
Genre: Cyberpunk, literary, surreal, slipstream, hardboiled, neo-noir
Style: Terse, hip, literary, avoid cliches, include futuristic cultural references, focus on emotions, be weird, reduce metaphors, include surreal elements, hardboiled, noir
And here's the rest below. Each chapter includes the text of the story, which is almost entirely generated by the Sudowrite AI, sometimes with one or two do-overs. It also includes the chapter summaries, which were generated as a long list based on this "brain dump" and then almost entirely rewritten by me as the story progressed, as well as the individual story beats that the AI was working with.
Honestly, this thing is more coherent than I expected. Or as Sudowrite might put it: it will lead you down labyrinthine passages that send a shiver up your spine. The choice is yours and yours alone -- but at what cost? We're playing with fire.
Chapter 1
Chapter 2
Chapter 3
Chapter 4
Chapter 5
Chapter 6
Chapter 7
Chapter 8
Chapter 9
Chapter 10
Chapter 11
Chapter 12
15 notes
·
View notes
Note
Please stop making AI Fanfics; it's art theft.
AI programs still from pre-existing fics to write the prompts you ask of them, A03 is currently fighting against AI programs but they can't do much if people keep feeding the machine.
Please don't feed the AI!
So I did look into this, mostly because the state of the internet has forced my natural response to anything to be "don't believe it without evidence".
Since you didn't cite anything, I just did my own digging. It appears that this specific claim originates from a reddit thread. The OP cites this article as their main source. Ironically, a good chunk of the post is straight up copy-pasted. The website is Communications Today, which is apparently an Indian telecoms magazine, but I could not find much information on it at all about them that wasn't produced by them.
According to their own LinkedIn:
"Communications Today provides a platform to build corporate image and influence purchase decisions through advertising. The magazine reaches decision makers who allocate budgets for procurement of equipment and services and identify and evaluate vendors for supplies. In-depth coverage and comprehensive research has made Communications Today an important referral for telecom, network equipment purchasers, and broadcasters."
Source
This publication appears to have some guest writers who have legit positions, however the specific AI article has no credited writer. This is questionable. Point is, I have doubts about the trustworthiness of this source to begin with, but there is clearly going to be some level of bias involved with its reporting. The article is pretty sensationalist anyway. This is how the media world works - outrage and fear sells.
This post also includes three examples. As someone who has written research based papers before, this is far from enough to prove anything.
To be clear, the AI I used was not sudowrite, which much of this discussion seems to centre around. The one I used (nor sudowrite itself apparently) don't use user input as training. This means that it responds to prompts and questions, but this doesn't actually teach it anything new permanently. Thus, me using it in this way has zero impact on its dataset and is certainly not feeding it. I also paid no money to use it. Your claim of me interacting with a chatbot somehow making AO3 action (can't find much in the way of evidence of this either by the way) harder also appears unfounded. If it did specifically scrape and train from AO3, then the damage is already done, so again my interaction with it would not mean anything to legal action.
GPT3 (which is what these bots use) have sourced data from the scope of all areas of the internet. It is not, as far as I can tell, any kind of specific targeting of AO3 as a training ground. The issue in this lies in the way this information is presented. "AI BOT SCANS AO3 TO STEAL YOUR FANFICS" stands out a little more than the alternative. AO3 even responded to the OP mirroring the fact that bots are everywhere, have been for a while, and they can't do much about it - not sure if this constitutes 'fighting AI programs' as you claim.
Look. I've been on tumblr a while. I've seen fear explode and spread like wildfire before (4chan incident, for example). I think it's a little misguided to mass panic (about something that has existed for years). The only evidence I could find was those three examples on reddit. I really don't think that equates to the chaos on this issue.
I'll also be clear that I'm not exactly an AI defender, and I dislike Elon Musk for many many reasons. I do think AI writing is a little more murky than AI generated images (certainly worthy of concern) because it's hard to prove much direct copying, especially in the case of Fanfiction which, by nature, involves existing IPs.
Does AI call into question a lot of potential societal problems? Yes. Is it straight up nefarious and evil? Nope, not in my opinion anyway.
That aside I also don't really care on a personal level. For me, writing is a hobby that I'm fortunate to be able to share with others. I also think there comes a point where the concept of artistic 'ownership' becomes asinine anyway, but that's a whole other debate.
My specific posts:
I have been using my OWN existing fanfic summaries as a basis. I don't think I can really be accused of stealing my own work. And as I said, I don't see enough evidence to prove in anyway that these bots are directly ripping things from AO3 in the copyright sense (as in, content in tact enough that it could be traced to an original author).
In other words, thank you and all, but I don't really like this kind of scare posting. Especially if you're not going to source or back up your claims, whatever your intent this comes across as spreading misinformation. I found my little experiment both interesting and amusing, and ultimately what I share on my blog in my relatively tiny corner of the internet is my decision.
TLDR: Don't believe everything you read on the internet - do research before forming solid opinions.
27 notes
·
View notes
Text

I'm sure someone's done this already but I find it infinitely hilarious
Here's an article about it if you haven't seen this yet:
#ai scraping#sudowrite#omegaverse#generative ai#destiel#destiel meme for omegaverse content#it all comes full circle
9 notes
·
View notes
Note
Hi helen, thanks for the explanations. Sorry for bothering you but can I ask,
Does locking fic next time I publish really help? Don't they have a way to breach Ao3's data since it's an AI? I also assume this isn't just sudowrites. Other AI writing services are probably doing so too, right? Like NovelAI
I'm afraid we're at about the limit of my knowledge here - I'm neither an industry expert on AI learning nor do I have the spoons for more research than I've done.
With that caveat, my understanding of the situation is this.
There is a "natural language" algorithm called GPT-3, which can be used by anyone to power their own apps (via subscription model) and has been trained on data from Common Crawl.
Common Crawl is a non-profit dedicated to archiving data from the internet and making it freely available to anyone. GPT-3 is the work of OpenAI, which also created the DALL-E visual art generator.
Sudowrite and other "novel generator" sites like it are using the GPT-3 base to generate "natural sounding" text. The stated goal of Sudowrite is to assist writers with their own work, by generating a couple more sentences when they're stuck, or new brainstorming ideas, or names for people and places.
One thing I do want to stress: this is NOT really an AI. There is no intelligence, decision-making, or independent action going on here. To explain it as simply as possible, what it does is a) look at what it's learned from ALL OF THE INTERNET, then b) look at a sentence you have given it (e.g. "it was a dark and stormy night"), then c) spit back out some content that, statistically, fits the patterns it has observed in all the other times someone has written "it was a dark and stormy night".
Given that you have to "train" GPT-3 towards whatever you specifically want it to do (fiction, news, chat bots, etc), and given that Sudowrite produces so much fandom-specific content so easily, I would guess that the Sudowrite version of GPT-3 has been given additional training using freely-available fanfiction, from AO3 or otherwise - but I do not know enough about the nuances of this technology to be sure.
So to answer your questions as best I can:
Locking your works on AO3 should protect them from being included in Common Crawl and similar datasets, I believe. This means they will also not be archived by the Internet Archive or appear on the Wayback Machine, will not appear in searches etc going forward, although anything that has already been archived will still be in those sets of data.
This may or may not do anything to keep them out of the pool for future generative algorithms.
This may or may not do anything to stop people specifically using fanfiction as additional training for creative writing AIs, depending on how they are obtaining that training data in the first place. (E.g. if everything on AO3 was locked tomorrow, someone could still just create an account and laboriously download a ton of random fic to use. Whether they would bother is another question.)
My personal take: we are long overdue a big conversation about data, and what is and should be freely available, and how content-creating AIs are being deployed and monetised. This is something that needs regulation and oversight, and we should be making a fuss about it.
(Not least because if you search the internet for "how to" articles on pretty much anything at this point, you will get a LOT of results written by this sort of AI generator. They look like real human text to start with, but as you read on you notice that there are weird little glitches, and then the instructions for making papier mache suddenly tell you to boil an egg, and you realise you can't actually trust anything you just read because it was auto-generated and may not work or be safe. True story.)
However. I am not myself concerned about the possibility that my writing has been used in this dataset. I don't like it or approve of it on a general level, but I don't believe it does me any harm or even meaningfully translates into "someone else profiting off my work". As far as I understand the technology, it will not be plagiarising any of my actual text. My biggest concern is with how readily it puts together context based on exisiting works. It's very obvious with something like Harry Potter, but if someone is looking for "names for magical items" and end up with three unique things I put in one of my stories and uses those in their work... yeah, that feels like a mess waiting to happen.
I'm also not concerned about AI "replacing" writers (or other artists). There is a lot more to creating art than putting words together or making brush-strokes. The AI can only spit out what was put into it, and it's always going to pick the most statistically likely option. That means in terms of storytelling, you will get cliche after cliche, empty dialogue that sounds good but doesn't mean anything, repeating the same themes with occasional nonsensical diversions for "variety", a general sense of hollowness and lack of actual human input...
... wait. Did anyone check whether Marvel's already using this thing?
46 notes
·
View notes
Text
The whole thing about Sudowrite is like…
get out of here with your “but you already posted your work for free on ao3, why are you mad that an AI is using it without asking?” bad faith takes.
Posting fanfics on ao3 is like bringing a dish to the neighbourhood potluck. I know what to expect there, everyone is nice and polite, and if they like my dish they can ask for the recipe or take some leftovers home or whatever. There are implied, understood social rules that the entire community understands and follows.
The fucking AI is like entering my kitchen at 2 am to find out some asshole decided to follow me home and is eating the leftovers with their fucking hands. Not only that, but they’ve been doing it for a while and stealing my ingredients and bringing them to Greta from two streets over. That’s why all of her dishes are too sweet because she’s been using MY maple syrup without knowing how to properly pair it up with other flavours or anything. I made that maple syrup myself, I know it’s a grade B from late in the season and not a grade A, so I would never put it on pancakes and I’m also adjusting the amount from what the recipe says. Greta doesn’t know any of that, she doesn’t even know where maple syrup comes from!
These two situations are nothing alike! And just because I agreed to bring the free food to the potluck, it doesn’t mean that I agreed for some automated system to take it without asking behind my back!

Some things I’ve heard people say and my bitchy answers behind the cut, as well as actual ~professional writer~ advice because I felt bad about being bitchy:
“Oh but you would have talked someone through the recipe if they asked, so why are you pissed that the robot reverse-engineered the ingredients and gave them to other people???”
The. Robot. Did. Not. Ask.
But also it’s just fucking ridiculous to think that an AI can just sample a bunch of finished stories and extract turns of phrases and stylistic elements or what have you from them and offer them up to another writer as if they have any value outside of their context. It would be like tasting turmeric in a dish and then telling the next person that turmeric is the great solution to fix their flavour profile when you’re missing the part where I also added black pepper and the exact timing of when to add both of these things for full effect. Knowing about metaphors — or worse! Being suggested a metaphor by a software that doesn’t even know what your story is about and what themes are relevant — is not the same as actually knowing when and how to use the goddamn thing.
“Why are you so angry, just let other people have their ~process”
This sudowrite thing is both unethical (stole my stuff to train it’s dataset), fucking rude (stole my stuff to train it’s dataset) and a tacky, amateurish crutch that will harm those writers who use it in the long run. This process of yours is bad and you should feel bad. Asking an AI to help you generate a story won’t help you learn how to write one — and worse, it will actively teach you bad habits that will impede your ability to write creatively in the future.
“Oh but it’s just to fluff up a couple of sentences”
If those sentences aren’t important enough to merit your full attention then don’t include them in the novel to begin with. The best thing you can learn as a writer is that sometimes, if the words for a scene won’t come, it’s because you need to rethink the scene. Or not include it at all! Tolkien hit Bilbo on the head and made him miss an entire battle, and it worked a lot better for the ~themes and tone~ of the book than if he had witnessed said battle. If you just say “he took the train” instead of describing the entire ride, it’s fine. You don’t need to ask a robot to describe the train for you.
“Oh but I have a story in mind, except that I can’t write very well, so I need extra help. Not everyone is a good writer!”
It’s called hiring a ghostwriter. It’s one of the unspoken foundations of publishing. Look it up. There is no shame in doing it and it’s been done for so long and for so many people that there is an entire structure already in place around the practice. Which means it’s easy to find out how to do it, how much to pay and how to handle crediting (or not, depending on contracts) your writing help. Also these people are goddamn professionals and you will have a much better end result than if you just cobbled a story together piecemeal via a talking robot.
“Oh but I just want something to help me brainstorm, I’m not using it for actual writing, or if I do I’ll rewrite a lot of it. It’s fiiiine!”
Find a beta. Join a writer’s group. Do a manuscript swap. Sorry about the required social aspect of these things but seriously. It will do so much good to your creativity and inspiration if you just talk to another human being about your craft. They can offer suggestions about what you actually WANT to write, not just what you have written so far.
“Oh but I have writer’s block”
We all do. You’re not special.
I don’t have any actual advice on this one because my usual advice is to stop thinking of writing stories as some ~sacred unknowable feat of creativity and inspiration~ and realize that it’s just a craft, and like any craft you can practice and learn to do it pretty reliably.
To go back to my earlier cooking metaphor: some days you don’t have the mental energy or ~*inspiration*~ to make a really fancy meal for dinner. But you still gotta eat. The moment you learn which boring but easy and functional recipes you can make on those days instead or giving up and ordering in, that’s the day you can really say you became serious about being a home cook. (Disabilities notwhistanding etc this is a metaphor).
Similarly, you become a ‘real’ writer when you learn that you can still do writer shit even if you’re not ~*inspired*~, like working on outlines or making a bullet point list of what should go in a chapter so you can come back later or even take a break or create marketing material. Writing is an art, yeah, but it’s also a skill. Some days you’re gonna bang out 500 really boring words without a single hint of divine inspiration and that’s just a thing you gotta learn to deal with.
But in this case I’m not sure if the advice applies because if the fictional person I’m talking to is using an AI software to combat writer’s block, then they probably have already achieved the cynicism required to apply my anti-creative block method of “put aside the naive idea that creativity is a talent and realize it’s just unglamorous work.” So yeah I got nothing ¯\_(ツ)_/¯
“It’s just a more advanced version of autocorrect, chill out”
Autocorrect sucks. It’s only good for changing ‘fuck’ to ‘duck’ and making funny screenshots.
#sudowrites#sudowrite#ai writing is bad and you should feel bad#long post sorry not sorry#some actual decent writing advice under the cut you should check it out
27 notes
·
View notes
Text
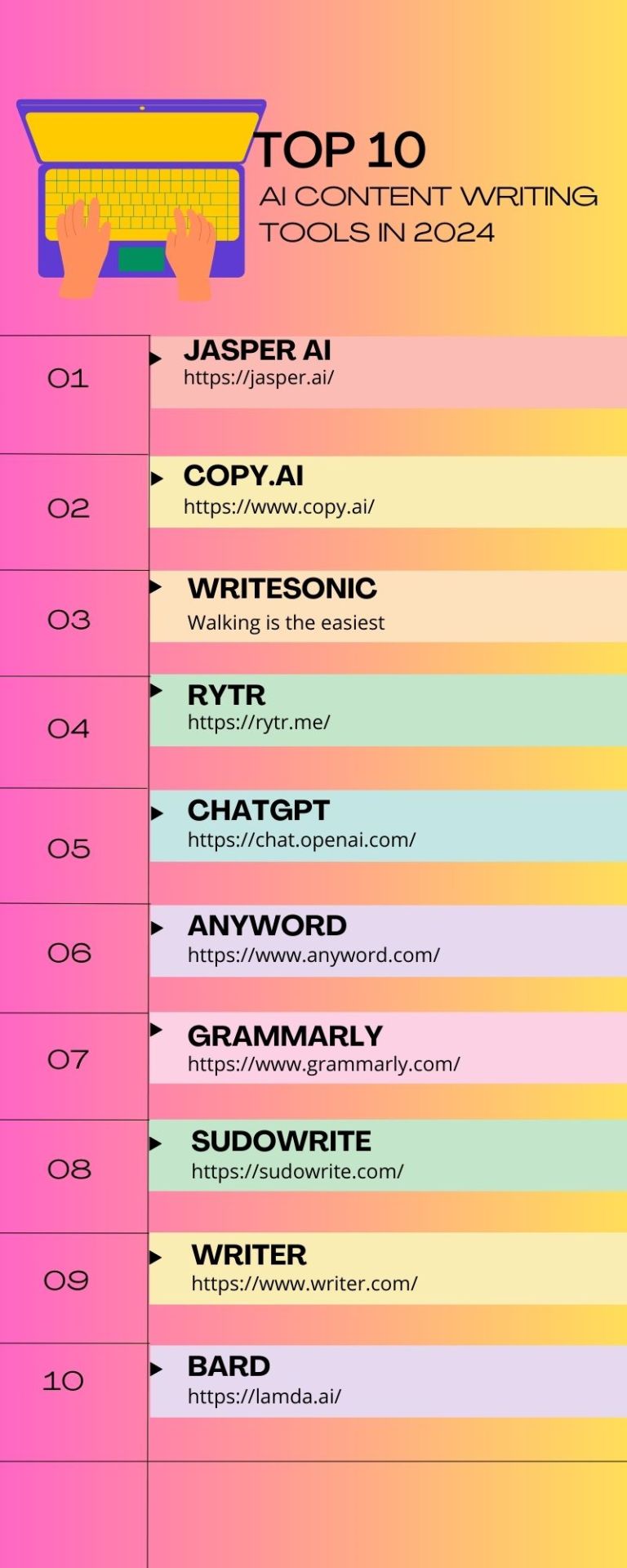
#aiwriting#aicontent#contentwriting#artificialintelligence#marketingtools#jasperai#copyai#writesonic#rytr#chatgpt#anyword#grammarly#sudowrite#writer#bard
2 notes
·
View notes
Text
The Rise of the Machines: AI ‘story engines’
KJ Charles, 19th May 2023
If you’re book-Twitter-adjacent you will doubtless have heard there’s an AI book generator out there created by a company called Sudowrite. (As in “Pseudowrite”, which is at least honest. I’m also thinking Sudocrem, which is stuff you put on a baby’s bottom when it’s got sore from sitting in its own excrement. Anyway.)
This purports to generate you a book. According to the promo video, you do a “brain dump” of a vague idea, and throw in a couple of characters if you can be bothered. That gets ‘expanded’ into a synopsis, which gets ‘expanded’ into a chapter by chapter breakdown, which gets ‘expanded’ into text, and lo and behold the AI has written you a book!
Let’s just remind ourself: artificial intelligence is not intelligent. It’s a prediction engine. It has scraped billions of words of text and it offers you what it judges to be the most likely one to come up next. If you spend your keyboard time thinking, “What’s the most predictable word or plot event I can use here, I really need this to be something the reader will totally expect”, this could be the tool for you.
[...]
8 notes
·
View notes
Text
Ngl, all this stuff about porn corrupting AI is making me really wanna write some porn
5 notes
·
View notes
Text
AI and fanworks - a dissection
In attempt to address some of the fears and uncertainty going around in the fan communities at the moment I wanted to have a look at AI interacts with art and fandom, and more specifically how it relates to theft in these fields. When AI comes up there has been a lot of knee jerk defensiveness and hurt from artists and writers in the fan community, and honestly, that’s fair enough. This is a field that has advanced rapidly, which has entered the scene with all the force of an explosion. I don’t think anyone was expecting it to hype up this much or so suddenly be splashed everywhere all at once, becoming the topic of debate in nearly every discipline and field, be it law and academia, digital art, and even fanfic writing.
It’s everywhere, it’s all over the place, and to be honest, it’s just a bit of a mess.
Currently we’ve had a strong outpouring of reaction, lashing out at everything to do with AI and its involvement in creative works. The thing is though, this whole issue of AI in art - especially its use on and in relation to fanworks - is something that's complicated and layered and isn’t composed so much of one single offense being committed, but rather multiple stacked issues all tangled together, each of which is simultaneously eliciting reactions all that all end up jumbled together.
What I want to do a bit here is unpick the different layers of how AI is causing offense and why people are reacting the way they are, and in doing so, hopefully give us to the tools to advance the conversation a little and explain more clearly why we don’t want AI used in certain ways.
There are, in essence, three layers of potential ‘theft’ in this AI cake. These are:
The training data that goes into the AI.
The issue regarding ‘styles’ and the question of theft in regards to that.
Use of AI for the completion of another person’s story.
This last one is the one that’s doing the rounds right now in the fanfic community and is causing a lot of strife and upset after a screenshot of a TikTok of someone saying that they were using ChatGPT to finish abandoned and/or incomplete fanfictions.
It’s a concept that has caused a lot of anger, a lot of hurt, and a lot of grief for authors who are facing the concept of this being done to their work and honestly that’s fair enough. As a fic writer myself, I also find the concept highly uncomfortable and have strong feelings about it. Maybe this person was trolling, maybe they were not, but the fact exists that this is increasingly coming a subject of debate.
So, let's go through this mess step by step, see how exactly ‘AI theft’ is being done, what different levels this ‘theft’ is operating at, and what, if anything, can be done about it. And I’m not claiming to have a magic solution, but just that in understanding a problem, you have a better toolkit to explain to others why it is a problem and how to ask for the specific things that might help improve the situation.
Training datasets - yeah, there’s some problems here
One thing we need to talk about going into this section is how AI actually functions - AI here being specifically image and word generators.
Text generators such as ChatGPT and Sudowrites are essentially word calculators. When someone feeds in an input, a prompt saying ‘write me this email’ or ‘write me a script for so and so story’ they essentially behave in the same manner as an autocomplete on your phone. Part of a sentence gets written, and based on the hundreds of thousands of pieces of writing they examined in their training data, they write what the next most expected thing in the sentence would be.
For art generators, it comes down more on pattern recognition. A picture on a screen is just a pattern of pixels, and by feeding them huge amounts of training images you can teach them what the pattern for say ‘an apple’ looks like. When prompted, they can then use that learned pattern to spit out the image of an apple, one that doesn’t look specifically like any single image that went in. In essence it is a new ‘original’ apple, one that never existed specifically just like that before.
All of these systems require huge amounts of training data to work. The more data they have, the better they can recognise patterns and spit out output that looks pretty or makes sense, or seems to properly match the prompt that was put in.

In both these situations, writing or art, you can put in a prompt and get out an output that was created on demand and is different from even the pieces of work it might have been trained on, something that is ‘original’. This is, I think, where a lot of the back and forth regarding use of generated writing and art as a whole comes from and why there’s a lot of debate about whether it counts as theft or not.
And honestly, whether generated content counts as ‘art’ or not, whether it counts as original, and whether the person who prompted it ‘owns it’ or the company who created the generator does isn’t a debate I want to get into here. Hello Future Me did a very good breakdown of this issue and the legalities of AI regarding copyright on YouTube, and I would recommend watching that if you want to learn more. Basically, it’s a murky pond with a lot of nuance and it’s not the debate we’re looking at here, so we’re just going to set it aside and focus on the other part of this instead - the training data.
Because yeah, currently the vast majority of these generative ‘AI’ models have been trained on materials taken without the creators consent. They need huge amount of training data to work, and a great deal of it has been sourced in an unethical way. We’ve seen this with OpenAI scraping AO3 for writing text, to use as training material for their software - and being caught out with it by the whole knot thing. We know that Stable Diffusion was trained using the work of thousands of digital artists works without permission and used their work as training to help educate their image generation software, now resulting in a class action lawsuit by artists against it.
And that fucking sucks.
It sucks on multiple levels. If someone creates a piece of art, copyright law and shit requires that someone wanting to make use of it ask permission. And that’s fair. Copyright law does have its issues, but it does provide some protection to artists and their work. Using someone else's work without permission is not okay, especially when you’re using it for your own profit. There’s a couple of different aspects we need to unpick here, so let’s unpick them.
Yes, a generated work might not be a specific copy of any work that was taken and put into it, but honestly that doesn’t even matter - the lack of consent on the part of the people whose work is being used in this situation is unethical. Web scraping has always been a thing, but there’s a difference between people gathering data for research purposes and a corporation gathering the work of independent small artists and writers without their consent for use in generating their own profits. Because yes, these systems are currently free to use but you know that monetisation is an any now kind of thing, right? Eventually these generative softwares will be paywalled and used as a means of earning profit for the companies that created them, and that work will be done off the back of all the artists/writers whose work was put in.
Already, on the level of being a regular writer or artist, this is pretty shitty (particularly when you consider that generated works are being eyed up by corporations as a way to avoid having to pay proper artists and writers for their work). As a fanworks author, the thought is even shittier. Part of what is lovely about the fan community is the fact that it’s all done for free. Fanworks exist in a specific legal framework that prevents monetisation, yes, and for the most part that’s something that’s celebrated. The joy of creating art or writing a story - of creating and sharing it with a community, just for the sake of doing it and not because of profit, is an integral part of what makes being a creator of fanworks so amazing. So to have something that you’ve created for free and shared for the love of it - specifically with the intent of never having it monetised - fed into a machine that will, in the end, be used to turn corporate profits is souring. People are entirely right to not feel pleased at that concept.
AI techbros would argue that there isn’t a way to create large generative models like this with big enough datasets unless they collect them the way they do, but is it really?
Dance Diffusion is a music generation program that creates music from purely public domain, volunteered, and licenced material. It uses only works where the musicians have either consented to be part of the dataset, or have made their work available broadly for public use. And yes, the reason that they’ve taken this route is probably because the music industry is cutthroat with copyright and they’d be sued out of existence otherwise, but at the very least it proves that taking an ethical approach to data sourcing is entirely possible.
Already some generative software for images are working to do the same. Adobe Firefly is an image generator that runs entirely on its own stock photos, licenced photos, and images that are public domain . This already seems like a more ethical direction, one which is essentially no different than a company using public domain images and modifying them for commercial purpose without using AI. Yes, it has a more constrained data set and therefore might be less developed, but honestly if you can’t create a quality product without doing it ethically, you just shouldn’t make that product.
This is the element of consent missing from many of the big generative softwares right now. The only reason this isn’t the mode of approach being used in selecting what goes into training data is because techbros are testing the waters of what they can get away with, because yeah, taking this step takes more effort and is more expensive, even if it is demonstrably more ethical, and god forbid anything standing in the way of silicon valley profit margins.
So yes, there is unethical shit going on in regards to how people’s art and writing is being put into training sets without their consent, for the final result of generating corporate profits, and as a fanwork author it’s particularly galling when such a model might be making use of work you specifically created in good faith with a desire for it not to be commercialized. You have a right to be upset about this and to have a desire for your work not to be used.
Work that is used in training AI should have to be volunteered, obtained with a licence and the artist’s consent, or be works of public domain. It has to be an opt-in system, end of story.
If you take away this issue of stolen training works, the ethical dilemma of generated works is already a lot more palatable. Yeah, it might not be the same as making a work from scratch yourself and some might argue it’s not ‘real art’, but at that point it just becomes another tool people can use without this bad-taste-in-the-mouth feeling that you’re using software exploiting stolen works from non-consenting artists and writers. (The undervaluing of artists and writers works is something I acknowledge, but that’s a different debate and we’re not going to get into it here – though it will be touched upon briefly in the next section.)
The thing is though, this issue isn’t one we can readily fix as individuals. This is something that’s going to come down to government regulation and legislation. If you feel strongly about it, that’s the areas you need to put pressure - learn about what regulation is being done, make known your support for regulations that do promote more ethical practice, and if you’re someone who is generating artistic works, when make your consumer vote count and do it using software that more ethically sources its training data.
And yeah, maybe this sort of sucks as a conclusion for this issue, but the cat’s out of the bag now and generated works are likely here to stay. We’re in the wild west of them right now, but things can be done and it doesn’t need to be the complete dystopia it currently feels like it might be becoming.
The ‘theft’ part of ‘art theft’
Here we move on from the issues inherent with the generative models themselves - or more specifically their training sets - and to the ways they’re being used. This issue is split into two parts, the first of which is a more prominent issue in visual art and the second of which is an issue more specific to fanfic writing.
Up until now you can sort of argue that use of a generative model is a victimless crime. The output you get may have been trained using someone else’s work, but it itself isn’t a strict copy of anything that exists. It’s created on demand and it’s unique. And yeah, you might say, maybe it sucks a bit that the training data stuff is a bit unethical but the harm there is already done and using it to generate a piece of art isn’t hurting anyone.
And to a point that’s true. If the ethical sourcing problem for data is solved, then there isn’t necessarily a lot of harm in using that software to generate something – it might not be the same process as creating art yourself, but it’s a tool that people can do doubt find some helpful uses for.
Using AI to copy someone’s style, or to finish one of their pieces of fiction, however, is something that hurts someone. It’s not a bad system causing the problem, but bad actors using that system to cause harm. In this this is distinct from the previous theft issue we’ve discussed. Even in a world where the big AI software’s all have de facto ethical training data, this would still be an issue.
‘Style’ theft – a problem for artists
One of the big things that’s been happening with image generation AIs is people training them to mimic certain styles, so that the user can then create new works in that style. There’s a lot of pretty furious debate back and forth about it in regards to whether using a style is art theft, whether its infringing copyright, with the weeping techbros often hurrying to cry ‘you can’t own a style!’
And to a certain point, yeah, they have a point. If you were to train an AI on impressionist artworks and tell it ‘paint me a tree in the style of Monet’ I don’t think anyone would necessarily have a problem with it. It’s a style, yes, but no one person owns it, and most of the people who developed that style are long dead – more works being created in that style and even sold commercially isn’t going to undercut a specific artist’s market. You could up and decide to learn to paint yourself and start churning out Monet-esque works by hand and it wouldn’t be copyright infringement or art theft or any of the like.
The situation is sort of different when you’re dealing with a living artist today. Already there have been cases of artists with distinct and beloved styles having their portfolios fed into AI without their consent, so that the prompter can then create works in their style.
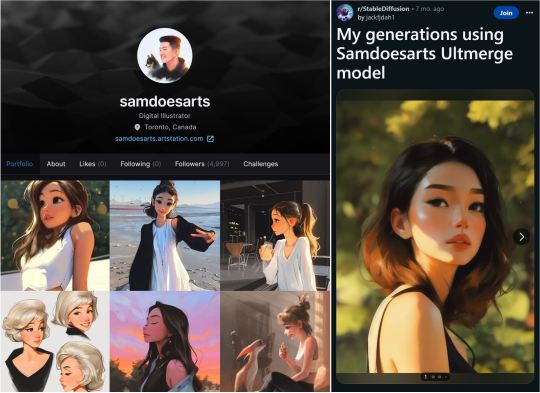
(Original work by samdoesart on the left, and generated work trained on samdoesart’s style on the right, posted on reddit. A model was specifically created trained on this artist in order to create art that looks like it was made by them.)
And this is harmful in two separate ways. We’ve covered above why its unethical and shitty to feed someone else’s work into a training set without their consent, and for a work to be generated in a specific artist’s style, a large amount of their work needs to be put in in order for the AI to learn its patterns and mimic it. The artist hasn’t consented to their inclusion, and now their hard work and the style they’ve created has been absorbed and made available for corporate use. Remember – most of these programs retain full ownership over all works they produce, regardless of the user that ‘created’ then. All generated works are owned by the corporation.

Unlike general AI generation, where you’re creating some generic piece of art or writing and it doesn’t specifically harm anyone, this is a crime that directly has a victim. A specific artist has had their work used without consent, and often with the specific goal of creating work in that artist’s style to avoid having to commission or pay the artist for otherwise producing a work in their style. By creating this workaround where they don’t have to pay the artist for their work, they’re directly contributing to the harm of the artists financial prospects and the devaluing of their work.
When we talk about generic AI generation as a whole, the type where thousands of different distinct inputs go in and the thing that comes out doesn’t look specifically like any single one of them, you can make a case that it’s not copying any specific person’s work. This isn’t the case here. This is use of AI for the purposes of creating an art is a specific persons style. As Hello Future Me puts it “it is deriving a product from their data and their art without any attribution, payment, or credit.” And I don’t know about you, but that sounds a lot like theft to me. Yes, maybe a specific existing work was not explicitly copied, but you’re still making use of their style without a consent in a way that undermines their work and the market for their work, and that is a pretty shitty thing to do.
This whole section has talked about visual art so far, but you can see how it could also be applied to a written work. Telling an AI ‘write something in the style of Shakespeare’ is harmless, just as the Monet example was harmless, but you can readily see how this could also be applied to say, a poet who has a particular style of writing, with their portfolio of works fed in to create more poems in their style without their consent.
The key difference here, I think, is that works like Monet or Shakespeare are part of the public domain. No one owns them and everyone is free to use them. Generating derivitive works off their creations harms no one, because these creators are not alive and still producing - and selling - their work today. That cannot be said of living artists whose work is being exploited without compensation and whos livelihoods are being threatened by generated works.
Feeding an artist or writer’s work into an AI so that you can use their style, while not strictly ‘copying’ any single work of theirs, it still a harmful thing to do and should not be done. Even if you don’t intend to sell it and are just doing it for your private fun – even if you never even post the results online – you’ve still put their portfolio into the training set, making it a part of the resources a corporation can now use to turn a profit without repaying the artist or writer for their contribution.
The Fic Problem – or, completing someone else’s work
Now we moved onto the specific issue that first prompted me to write up this debate. There’s been noise going around in the fic writing community about people using AI to write fanfic and/or to finish other people’s incomplete works.
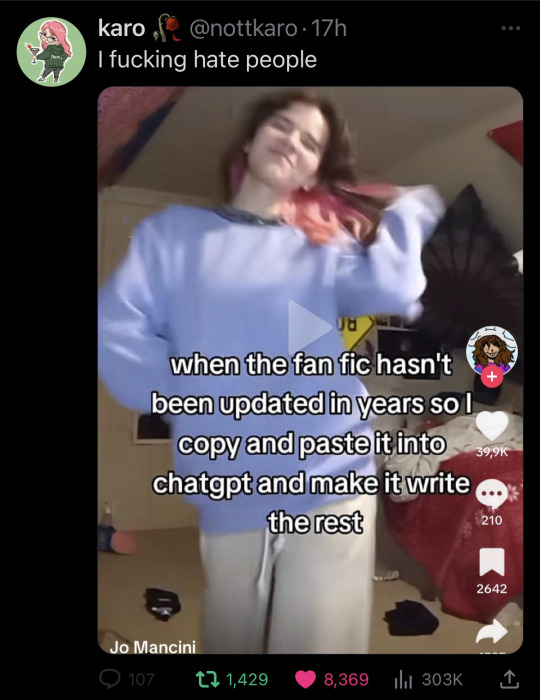
In general, using AI to write fanfic is no different than using AI to come up with any other kind of creative writing. It has the same underlying ethical issues inherent in the system – which is, currently, that all work is being generated based on training data that was obtained without consent. Leaving aside whether in general generating creative writing is a good thing to do (what’s the point in writing, after all, if you don’t enjoy the process of actually writing?) let’s talk instead about the issue of people finishing other people’s fics.
The fanfiction community – and the fanart community as well I would wager – has always had something of a problem with entitlement. And look, I sort of get it. When you find an amazing fic that isn’t finished, it can hurt to reach the end and wonder if you’ll ever get to read any more of it. But that’s just the way it is. The fanworks community is one that is built overwhelmingly upon people creating labours of love just for the joy of it and sharing them free of charge. It’s hobby work, it’s hours squeezed in around jobs and families and kids, it’s someone scraping time out of their busy day to create something and share it just for the sake of it. People move onto different projects for all manner of reasons – maybe they don’t enjoy the fandom anymore, maybe that story now has baggage, maybe their tastes have just changed and they want to write different stuff. Maybe they stopped writing fiction altogether. Maybe they died.
Some stories will never be finished, and honestly, no author owes you the end of one. They have every right to write whatever they want and work on what projects they like, even if that means leaving some unfinished.
Coming in to complain about it, or to demand new updates – or, in this case, to finish the work yourself without their consent, is a shitty thing to do. And yeah, some author’s do put their abandoned works up for adoption and are happy for people to finish them, but in most cases author’s don’t want this done. That’s a personal choice and varies author to author. Someone seeing an abandoned fic and choosing, with their own two hands, to write up an ending for it without asking the author is already a bit of a sketchy thing to do, even if it’s just done privately and never sees the light of day, and doing it using AI is even worse.
Because yeah, to do it, you have to feed that person’s fic into the AI. You as a person, are putting a piece of work made with love and shared freely with you as a gift into a corporate dataset, where it will be used to generate corporate profits off the back of that person’s work. And more, if you want it to write properly in their style and mimic them well, then hey, you have to probably put in even more of their work, so that the AI can copy them well, which means even more of their works taken without their consent and put into the AI.
And that fucking sucks. It’s unethical, it’s a shitty thing to do, and if it’s unacceptable for a corporation to be taking someone’s work without their consent for use in AI training, then it’s unacceptable for you as an individual to be handing someone else’s work to them of your own volition.
As a fanfiction author, I cannot imagine anything more disheartening. I have a lot of unfinished works yes, some of which are even completely abandoned, but even when I haven’t touched them in years I don’t stop caring about those fics. I have everything that will happening in them already planned out – all the arcs, the twists, the resolutions and the ends – and someone else finishing it without my consent robs me of that chance to do it myself. You don’t know if an author still cares about a fic, whether they’re trying to work up the motivation to put out a new chapter even years later. You don’t know why they stopped writing it, or what that story might mean to them.
And I think this is what a lot of it comes down to. People will assume that because a fic is abandoned that an author doesn’t care about it anymore, or that because it’s fanfiction they don’t ‘own it’. Nothing could be further from the truth. Author’s do still care, and yes, they do own their own work. A transformative work might be one based on another franchise and one that makes use of another person’s copyright, but everything you put in yourself is still yours. Any new material, new characters, new concepts, new settings – the prose you use, the way you write, your turns of phrase. Those legally belong to the fanfic author even though they’re writing fanfic.
And yeah, some people might argue that putting someone's fanfic through an AI is a transformative act in itself. People write fic of fic, after all, and is creating something with AI based on fic really any different? Yes and no. A transformative work is one that builds on a copyrighted work in a different manner or for a different purpose from the original, adding adds "new expression, meaning, or message". It is this transformative act that makes it fair use, rather than just theft.
Could an AI do this, creating something that is ‘transformative’? Maybe. It’s not for me to say, and AI generators are getting better every day. In the use of AI in continuing a fic, however, I would argue that it’s use is not transformative but instead derivative. A derivative work is based on a work that has already been copyrighted. The new work arises—or derives—from the previous work. It’s things like a sequel or an adaptation, and you could clearly argue that the continuation of a story, a ‘Part 2′, counts under this banner of derivative rather than transformative.
And okay, relying on copyright law while already in the nebulous space of fanfic feels like a bit of a weird thing, but it still counts here. Anything new that a person put into a fic belongs to them, and if you take it without their consent then yes, that is indeed stealing. Putting it through an AI or not doesn’t change that.
And if the legal arguments here don’t sway you, then how about this - it’s a dick thing to do. Even if you don’t mean for it to hurt anyone, you are hurting the author. If you enjoy their work at all - and you must, if you’re so attached to it that you're desperate to see more of it - then respect the author. Respect the work they’ve done, the gift they’ve shared with you. Read it, enjoy it, and then move on.
Fandom is built on a shared foundation of love and respect, a community where people create things and share them with others in good faith just for the love of it. This relationship is a two-way street. Authors and artists share their work with you and put in hours making it, but if the fan community stops respecting that then things might end up changing. An author burned by seeing their work fed into AI might stop writing, or stop sharing their works publicly. Already people are locking down their AO3 accounts so that only registered users can read and are creating workskins to prevent text copy and pasting out of fear that their work will be the one that someone chooses to ‘finish for them’. Dread over non-consenting use of AI is already having a direct impact in making fic more inaccessible.
Is that the direction that we as a community want to head in? Because what’s currently happening a real shame. I would prefer to share my works with non-users, to have them read by anyone who cares to read them, but I’ve had to change that, just in the hopes that that small extra step might provide a slight sliver of protection that will keep my work from being put in an AI.
And what after that? Currently sites like AO3 allow readers to download copies of the fic so that they can store them themselves. If authors are concerned about their work being taken and used in AI, will they begin petitioning for this feature to be removed, so as to better protect their work from this sort of use? Artists are already coming up with programs such as Glaze to help protect their work from use in training datasets, but what recourse to writers have save to make their work more and more inaccessible and private? No doubt some authors are already contemplating whether its better to just start only sharing their works privately with friends or in discord servers, in the hopes that it might better protect their works from being stolen and used.
Its worth noting as well that any way in which an author restricts fic on AO3 in order to prevent AI - such as using a workskin to prevent copy and pasting - is one that will also impact peoples ability to do things like ficbinding and translations. If access is restricted, then its restricted for everyone, good and bad.
And some of you might say - well what does it matter if your work does end up in an AI? It’s a drop in the ocean, they won’t be copying your exact work so what does it even matter? And all I can say in response to that is that its about the principle of it. If someone is making use of another person’s work, then that person deserves to be fairly credited and compensated. If I create work for free, in rebellion against a world that is racing towards the commercialisation of all and everything, then I don’t want my work being exploited by some fucking corporation to earn profits. That’s not why I made it, that’s not why I shared it, and they can go fuck themselves.
Unethical corporations are one thing, but the other component of this problem is people within the community acting in bad faith. We might not as individuals be able to regulate mass AI data gathering, but we can chose how we behave in community spaces, and what things we chose to find acceptable in our communities.
What I’m trying to say is, if you love fanfiction, if you love fanart, if you love the works people create and want to see more, then please treat their creators with respect. We put a lot of work into creating the art you enjoy, we put blood and sweat and tears into it, and we want to keep making more. We want to share it with you. We can’t do that if you make us scared to do it, out of fear of our works being put into an AI without our consent.
It's about respect, it’s about common decency. We as a community need to decide whether we think it’s acceptable for people to put someone’s work into an AI without their consent – whether it’s acceptable to finish someone else’s work using an AI without their consent. Maybe AO3 will make some sort of ruling in the future about it, or maybe they won’t. Even if they do, it likely won’t make that big of a difference. Bad actors will act badly no matter the rules, all we can do as a community is make it clear how we feel about that and discourage these sorts of behaviours.
AI generative tools exist and like it or not will be here to stay. They have a lot of potential and could become a really useful and interesting tool in both writing and the visual arts, but as it stands there are serious issues with how it is used – both on a system wide level, with the unethical gathering of data, and on a user level, with people using it in bad faith.
AI is what it is, but it doesn’t change the underlying choice here – you as a member of the community have the choice whether to behave like a dick. Don’t be a dick.
#artificial intelligence#chatgpt#sudowrite#openAI#stablediffusion#fanfiction#fanart#fantasy#creative writing#fic#ao3#ff.net#image generation#art theft#te talks
5 notes
·
View notes
Last Seen Blogs


purehavoc
...

washimmachine
WASHIMMACHINE

jackal-nope
Ê̸̻n̶͚̎b̴̫͝y̴̼̏ ̶̧̈́g̶͕͊h̴̨̉o̸͈͋s̴̮͊t

appledoli
➵ art blog | katalina