#learn data science with python
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
Text
Learn data science using Python in Codesquadz
Learn Data Science with Python to become an in-demand developer with mastery in crucial skills like data manipulation, visualization, and machine learning.

0 notes
Text
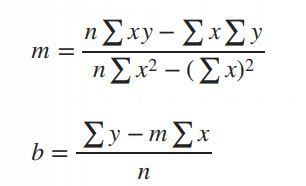
Simple Linear Regression in Data Science and machine learning
Simple linear regression is one of the most important techniques in data science and machine learning. It is the foundation of many statistical and machine learning models. Even though it is simple, its concepts are widely applicable in predicting outcomes and understanding relationships between variables.
This article will help you learn about:
1. What is simple linear regression and why it matters.
2. The step-by-step intuition behind it.
3. The math of finding slope() and intercept().
4. Simple linear regression coding using Python.
5. A practical real-world implementation.
If you are new to data science or machine learning, don’t worry! We will keep things simple so that you can follow along without any problems.
What is simple linear regression?
Simple linear regression is a method to model the relationship between two variables:
1. Independent variable (X): The input, also called the predictor or feature.
2. Dependent Variable (Y): The output or target value we want to predict.
The main purpose of simple linear regression is to find a straight line (called the regression line) that best fits the data. This line minimizes the error between the actual and predicted values.
The mathematical equation for the line is:
Y = mX + b
: The predicted values.
: The slope of the line (how steep it is).
: The intercept (the value of when).
Why use simple linear regression?
click here to read more https://datacienceatoz.blogspot.com/2025/01/simple-linear-regression-in-data.html
#artificial intelligence#bigdata#books#machine learning#machinelearning#programming#python#science#skills#big data#linear algebra#linear b#slope#interception
6 notes
·
View notes
Text
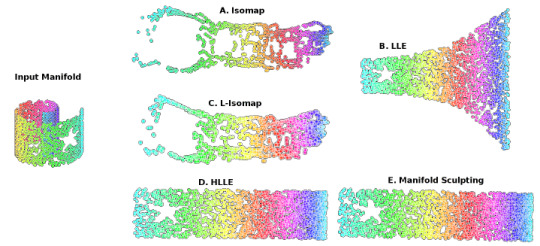
Locally Linear Embedding (LLE) approaches
#gradschool#light academia#data visualization#science#math#mathblr#studybrl#machine learning#ai#python#topology
46 notes
·
View notes
Text
What Is a Dynamically Typed Language?
When learning Python, you might hear the term “dynamically typed language” frequently. But what does it mean? Let’s break it down.
Typing refers to type-checking—the process of verifying whether the data types in your code are compatible with the operations being performed.
1️⃣ Strongly vs. Weakly Typed Languages
Strongly-Typed Languages (e.g., Python): These languages don’t allow type-coercion (implicit type conversion). For example:
pythonCopy code"1" + 2 # TypeError: cannot concatenate 'str' and 'int'
Weakly-Typed Languages (e.g., JavaScript): These languages allow type-coercion:
javascriptCopy code"1" + 2 // Outputs: "12"
2️⃣ Static vs. Dynamic Typing
Type-checking can occur at two stages:
Static Typing (e.g., Java, C++): Data types are checked before the program runs. You must declare the type of variables explicitly:
javaCopy codeintx=10;
Dynamic Typing (e.g., Python): Data types are checked during program execution. Variable types are inferred automatically:
pythonCopy codex = 10 # No need to declare 'x' as an integer.
Python: A Dynamically Typed Language
Since Python is an interpreted language, it executes code line by line. Type-checking happens on the fly, allowing you to write flexible and concise code.
Example: pythonCopy codex = "Hello"x = 10 # No error—Python allows 'x' to change types.
This flexibility makes Python beginner-friendly but also increases the risk of runtime errors if types are misused.
Key Takeaway
Dynamic typing simplifies coding by removing the need for explicit type declarations. However, it also requires careful testing to ensure type-related bugs don’t creep in.
Python learners, embrace dynamic typing—it’s one of the reasons Python is so versatile and fun to use!
2 notes
·
View notes
Text
What Are the Qualifications for a Data Scientist?
In today's data-driven world, the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making, understanding customer behavior, and improving products, the demand for skilled professionals who can analyze, interpret, and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientist, how DataCouncil can help you get there, and why a data science course in Pune is a great option, this blog has the answers.
The Key Qualifications for a Data Scientist
To succeed as a data scientist, a mix of technical skills, education, and hands-on experience is essential. Here are the core qualifications required:
1. Educational Background
A strong foundation in mathematics, statistics, or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields, with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap, offering the academic and practical knowledge required for a strong start in the industry.
2. Proficiency in Programming Languages
Programming is at the heart of data science. You need to be comfortable with languages like Python, R, and SQL, which are widely used for data analysis, machine learning, and database management. A comprehensive data science course in Pune will teach these programming skills from scratch, ensuring you become proficient in coding for data science tasks.
3. Understanding of Machine Learning
Data scientists must have a solid grasp of machine learning techniques and algorithms such as regression, clustering, and decision trees. By enrolling in a DataCouncil course, you'll learn how to implement machine learning models to analyze data and make predictions, an essential qualification for landing a data science job.
4. Data Wrangling Skills
Raw data is often messy and unstructured, and a good data scientist needs to be adept at cleaning and processing data before it can be analyzed. DataCouncil's data science course in Pune includes practical training in tools like Pandas and Numpy for effective data wrangling, helping you develop a strong skill set in this critical area.
5. Statistical Knowledge
Statistical analysis forms the backbone of data science. Knowledge of probability, hypothesis testing, and statistical modeling allows data scientists to draw meaningful insights from data. A structured data science course in Pune offers the theoretical and practical aspects of statistics required to excel.
6. Communication and Data Visualization Skills
Being able to explain your findings in a clear and concise manner is crucial. Data scientists often need to communicate with non-technical stakeholders, making tools like Tableau, Power BI, and Matplotlib essential for creating insightful visualizations. DataCouncil’s data science course in Pune includes modules on data visualization, which can help you present data in a way that’s easy to understand.
7. Domain Knowledge
Apart from technical skills, understanding the industry you work in is a major asset. Whether it’s healthcare, finance, or e-commerce, knowing how data applies within your industry will set you apart from the competition. DataCouncil's data science course in Pune is designed to offer case studies from multiple industries, helping students gain domain-specific insights.
Why Choose DataCouncil for a Data Science Course in Pune?
If you're looking to build a successful career as a data scientist, enrolling in a data science course in Pune with DataCouncil can be your first step toward reaching your goals. Here’s why DataCouncil is the ideal choice:
Comprehensive Curriculum: The course covers everything from the basics of data science to advanced machine learning techniques.
Hands-On Projects: You'll work on real-world projects that mimic the challenges faced by data scientists in various industries.
Experienced Faculty: Learn from industry professionals who have years of experience in data science and analytics.
100% Placement Support: DataCouncil provides job assistance to help you land a data science job in Pune or anywhere else, making it a great investment in your future.
Flexible Learning Options: With both weekday and weekend batches, DataCouncil ensures that you can learn at your own pace without compromising your current commitments.
Conclusion
Becoming a data scientist requires a combination of technical expertise, analytical skills, and industry knowledge. By enrolling in a data science course in Pune with DataCouncil, you can gain all the qualifications you need to thrive in this exciting field. Whether you're a fresher looking to start your career or a professional wanting to upskill, this course will equip you with the knowledge, skills, and practical experience to succeed as a data scientist.
Explore DataCouncil’s offerings today and take the first step toward unlocking a rewarding career in data science! Looking for the best data science course in Pune? DataCouncil offers comprehensive data science classes in Pune, designed to equip you with the skills to excel in this booming field. Our data science course in Pune covers everything from data analysis to machine learning, with competitive data science course fees in Pune. We provide job-oriented programs, making us the best institute for data science in Pune with placement support. Explore online data science training in Pune and take your career to new heights!
#In today's data-driven world#the role of a data scientist has become one of the most coveted career paths. With businesses relying on data for decision-making#understanding customer behavior#and improving products#the demand for skilled professionals who can analyze#interpret#and extract value from data is at an all-time high. If you're wondering what qualifications are needed to become a successful data scientis#how DataCouncil can help you get there#and why a data science course in Pune is a great option#this blog has the answers.#The Key Qualifications for a Data Scientist#To succeed as a data scientist#a mix of technical skills#education#and hands-on experience is essential. Here are the core qualifications required:#1. Educational Background#A strong foundation in mathematics#statistics#or computer science is typically expected. Most data scientists hold at least a bachelor’s degree in one of these fields#with many pursuing higher education such as a master's or a Ph.D. A data science course in Pune with DataCouncil can bridge this gap#offering the academic and practical knowledge required for a strong start in the industry.#2. Proficiency in Programming Languages#Programming is at the heart of data science. You need to be comfortable with languages like Python#R#and SQL#which are widely used for data analysis#machine learning#and database management. A comprehensive data science course in Pune will teach these programming skills from scratch#ensuring you become proficient in coding for data science tasks.#3. Understanding of Machine Learning
3 notes
·
View notes
Text
Hey all, so the crowdfund is up for ReachAI. If anyone wants to go check it out it would mean a lot to me! Also you can watch the video there on IndieGOGO or here:
youtube
It should give you a bit of an idea on what ReachAI is and what the nonprofit will be doing as well as the benefits of becoming a donor (which there are even more than I talked about in the video including Webinars, 1-on-1 sessions with me, a newsletter update on research the organization is working on or right now that I am). I am excited to be bringing ReachAI closer to launch day, I am really hoping I can raise the money to get it started! I know it could do so much good in the world :3
#programming#programmer#artificial intelligence#machine learning#technology#python programming#coding#ai#python#programmers#data science#medical research#medical technology#aicommunity#aiinnovation#Youtube
24 notes
·
View notes
Text
The Skills I Acquired on My Path to Becoming a Data Scientist
Data science has emerged as one of the most sought-after fields in recent years, and my journey into this exciting discipline has been nothing short of transformative. As someone with a deep curiosity for extracting insights from data, I was naturally drawn to the world of data science. In this blog post, I will share the skills I acquired on my path to becoming a data scientist, highlighting the importance of a diverse skill set in this field.
The Foundation — Mathematics and Statistics
At the core of data science lies a strong foundation in mathematics and statistics. Concepts such as probability, linear algebra, and statistical inference form the building blocks of data analysis and modeling. Understanding these principles is crucial for making informed decisions and drawing meaningful conclusions from data. Throughout my learning journey, I immersed myself in these mathematical concepts, applying them to real-world problems and honing my analytical skills.
Programming Proficiency
Proficiency in programming languages like Python or R is indispensable for a data scientist. These languages provide the tools and frameworks necessary for data manipulation, analysis, and modeling. I embarked on a journey to learn these languages, starting with the basics and gradually advancing to more complex concepts. Writing efficient and elegant code became second nature to me, enabling me to tackle large datasets and build sophisticated models.
Data Handling and Preprocessing
Working with real-world data is often messy and requires careful handling and preprocessing. This involves techniques such as data cleaning, transformation, and feature engineering. I gained valuable experience in navigating the intricacies of data preprocessing, learning how to deal with missing values, outliers, and inconsistent data formats. These skills allowed me to extract valuable insights from raw data and lay the groundwork for subsequent analysis.
Data Visualization and Communication
Data visualization plays a pivotal role in conveying insights to stakeholders and decision-makers. I realized the power of effective visualizations in telling compelling stories and making complex information accessible. I explored various tools and libraries, such as Matplotlib and Tableau, to create visually appealing and informative visualizations. Sharing these visualizations with others enhanced my ability to communicate data-driven insights effectively.

Machine Learning and Predictive Modeling
Machine learning is a cornerstone of data science, enabling us to build predictive models and make data-driven predictions. I delved into the realm of supervised and unsupervised learning, exploring algorithms such as linear regression, decision trees, and clustering techniques. Through hands-on projects, I gained practical experience in building models, fine-tuning their parameters, and evaluating their performance.
Database Management and SQL
Data science often involves working with large datasets stored in databases. Understanding database management and SQL (Structured Query Language) is essential for extracting valuable information from these repositories. I embarked on a journey to learn SQL, mastering the art of querying databases, joining tables, and aggregating data. These skills allowed me to harness the power of databases and efficiently retrieve the data required for analysis.

Domain Knowledge and Specialization
While technical skills are crucial, domain knowledge adds a unique dimension to data science projects. By specializing in specific industries or domains, data scientists can better understand the context and nuances of the problems they are solving. I explored various domains and acquired specialized knowledge, whether it be healthcare, finance, or marketing. This expertise complemented my technical skills, enabling me to provide insights that were not only data-driven but also tailored to the specific industry.
Soft Skills — Communication and Problem-Solving
In addition to technical skills, soft skills play a vital role in the success of a data scientist. Effective communication allows us to articulate complex ideas and findings to non-technical stakeholders, bridging the gap between data science and business. Problem-solving skills help us navigate challenges and find innovative solutions in a rapidly evolving field. Throughout my journey, I honed these skills, collaborating with teams, presenting findings, and adapting my approach to different audiences.
Continuous Learning and Adaptation
Data science is a field that is constantly evolving, with new tools, technologies, and trends emerging regularly. To stay at the forefront of this ever-changing landscape, continuous learning is essential. I dedicated myself to staying updated by following industry blogs, attending conferences, and participating in courses. This commitment to lifelong learning allowed me to adapt to new challenges, acquire new skills, and remain competitive in the field.
In conclusion, the journey to becoming a data scientist is an exciting and dynamic one, requiring a diverse set of skills. From mathematics and programming to data handling and communication, each skill plays a crucial role in unlocking the potential of data. Aspiring data scientists should embrace this multidimensional nature of the field and embark on their own learning journey. If you want to learn more about Data science, I highly recommend that you contact ACTE Technologies because they offer Data Science courses and job placement opportunities. Experienced teachers can help you learn better. You can find these services both online and offline. Take things step by step and consider enrolling in a course if you’re interested. By acquiring these skills and continuously adapting to new developments, they can make a meaningful impact in the world of data science.
#data science#data visualization#education#information#technology#machine learning#database#sql#predictive analytics#r programming#python#big data#statistics
15 notes
·
View notes
Text
2 notes
·
View notes
Text

Summer Internship Program 2024
For More Details Visit Our Website - internship.learnandbuild.in
#machine learning#programming#python#linux#data science#data scientist#frontend web development#backend web development#salesforce admin#salesforce development#cloud AI with AWS#Internet of things & AI#Cyber security#Mobile App Development using flutter#data structures & algorithms#java core#python programming#summer internship program#summer internship program 2024
2 notes
·
View notes
Text

TOP 10 courses that have generally been in high demand in 2024-
Data Science and Machine Learning: Skills in data analysis, machine learning, and artificial intelligence are highly sought after in various industries.
Cybersecurity: With the increasing frequency of cyber threats, cybersecurity skills are crucial to protect sensitive information.
Cloud Computing: As businesses transition to cloud-based solutions, professionals with expertise in cloud computing, like AWS or Azure, are in high demand.
Digital Marketing: In the age of online businesses, digital marketing skills, including SEO, social media marketing, and content marketing, are highly valued.
Programming and Software Development: Proficiency in programming languages and software development skills continue to be in high demand across industries.
Healthcare and Nursing: Courses related to healthcare and nursing, especially those addressing specific needs like telemedicine, have seen increased demand.
Project Management: Project management skills are crucial in various sectors, and certifications like PMP (Project Management Professional) are highly valued.
Artificial Intelligence (AI) and Robotics: AI and robotics courses are sought after as businesses explore automation and intelligent technologies.
Blockchain Technology: With applications beyond cryptocurrencies, blockchain technology courses are gaining popularity in various sectors, including finance and supply chain.
Environmental Science and Sustainability: Courses focusing on environmental sustainability and green technologies are increasingly relevant in addressing global challenges.
Join Now
learn more -

#artificial intelligence#html#coding#machine learning#python#programming#indiedev#rpg maker#devlog#linux#digital marketing#top 10 high demand course#Data Science courses#Machine Learning training#Cybersecurity certifications#Cloud Computing courses#Digital Marketing classes#Programming languages tutorials#Software Development courses#Healthcare and Nursing programs#Project Management certification#Artificial Intelligence courses#Robotics training#Blockchain Technology classes#Environmental Science education#Sustainability courses
2 notes
·
View notes
Text
Hyperparameter tuning in machine learning
The performance of a machine learning model in the dynamic world of artificial intelligence is crucial, we have various algorithms for finding a solution to a business problem. Some algorithms like linear regression , logistic regression have parameters whose values are fixed so we have to use those models without any modifications for training a model but there are some algorithms out there where the values of parameters are not fixed.
Here's a complete guide to Hyperparameter tuning in machine learning in Python!
#datascience #dataanalytics #dataanalysis #statistics #machinelearning #python #deeplearning #supervisedlearning #unsupervisedlearning
#machine learning#data analysis#data science#artificial intelligence#data analytics#deep learning#python#statistics#unsupervised learning#feature selection
3 notes
·
View notes
Text
Understanding Outliers in Machine Learning and Data Science

In machine learning and data science, an outlier is like a misfit in a dataset. It's a data point that stands out significantly from the rest of the data. Sometimes, these outliers are errors, while other times, they reveal something truly interesting about the data. Either way, handling outliers is a crucial step in the data preprocessing stage. If left unchecked, they can skew your analysis and even mess up your machine learning models.
In this article, we will dive into:
1. What outliers are and why they matter.
2. How to detect and remove outliers using the Interquartile Range (IQR) method.
3. Using the Z-score method for outlier detection and removal.
4. How the Percentile Method and Winsorization techniques can help handle outliers.
This guide will explain each method in simple terms with Python code examples so that even beginners can follow along.
1. What Are Outliers?
An outlier is a data point that lies far outside the range of most other values in your dataset. For example, in a list of incomes, most people might earn between $30,000 and $70,000, but someone earning $5,000,000 would be an outlier.
Why Are Outliers Important?
Outliers can be problematic or insightful:
Problematic Outliers: Errors in data entry, sensor faults, or sampling issues.
Insightful Outliers: They might indicate fraud, unusual trends, or new patterns.
Types of Outliers
1. Univariate Outliers: These are extreme values in a single variable.
Example: A temperature of 300°F in a dataset about room temperatures.
2. Multivariate Outliers: These involve unusual combinations of values in multiple variables.
Example: A person with an unusually high income but a very low age.
3. Contextual Outliers: These depend on the context.
Example: A high temperature in winter might be an outlier, but not in summer.
2. Outlier Detection and Removal Using the IQR Method
The Interquartile Range (IQR) method is one of the simplest ways to detect outliers. It works by identifying the middle 50% of your data and marking anything that falls far outside this range as an outlier.
Steps:
1. Calculate the 25th percentile (Q1) and 75th percentile (Q3) of your data.
2. Compute the IQR:
{IQR} = Q3 - Q1
Q1 - 1.5 \times \text{IQR}
Q3 + 1.5 \times \text{IQR} ] 4. Anything below the lower bound or above the upper bound is an outlier.
Python Example:
import pandas as pd
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate Q1, Q3, and IQR
Q1 = df['Values'].quantile(0.25)
Q3 = df['Values'].quantile(0.75)
IQR = Q3 - Q1
# Define the bounds
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# Identify and remove outliers
outliers = df[(df['Values'] < lower_bound) | (df['Values'] > upper_bound)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Values'] >= lower_bound) & (df['Values'] <= upper_bound)]
print("Filtered Data:\n", filtered_data)
Key Points:
The IQR method is great for univariate datasets.
It works well when the data isn’t skewed or heavily distributed.
3. Outlier Detection and Removal Using the Z-Score Method
The Z-score method measures how far a data point is from the mean, in terms of standard deviations. If a Z-score is greater than a certain threshold (commonly 3 or -3), it is considered an outlier.
Formula:
Z = \frac{(X - \mu)}{\sigma}
is the data point,
is the mean of the dataset,
is the standard deviation.
Python Example:
import numpy as np
# Sample dataset
data = {'Values': [12, 14, 18, 22, 25, 28, 32, 95, 100]}
df = pd.DataFrame(data)
# Calculate mean and standard deviation
mean = df['Values'].mean()
std_dev = df['Values'].std()
# Compute Z-scores
df['Z-Score'] = (df['Values'] - mean) / std_dev
# Identify and remove outliers
threshold = 3
outliers = df[(df['Z-Score'] > threshold) | (df['Z-Score'] < -threshold)]
print("Outliers:\n", outliers)
filtered_data = df[(df['Z-Score'] <= threshold) & (df['Z-Score'] >= -threshold)]
print("Filtered Data:\n", filtered_data)
Key Points:
The Z-score method assumes the data follows a normal distribution.
It may not work well with skewed datasets.
4. Outlier Detection Using the Percentile Method and Winsorization
Percentile Method:
In the percentile method, we define a lower percentile (e.g., 1st percentile) and an upper percentile (e.g., 99th percentile). Any value outside this range is treated as an outlier.
Winsorization:
Winsorization is a technique where outliers are not removed but replaced with the nearest acceptable value.
Python Example:
from scipy.stats.mstats import winsorize
import numpy as np
Sample data
data = [12, 14, 18, 22, 25, 28, 32, 95, 100]
Calculate percentiles
lower_percentile = np.percentile(data, 1)
upper_percentile = np.percentile(data, 99)
Identify outliers
outliers = [x for x in data if x < lower_percentile or x > upper_percentile]
print("Outliers:", outliers)
# Apply Winsorization
winsorized_data = winsorize(data, limits=[0.01, 0.01])
print("Winsorized Data:", list(winsorized_data))
Key Points:
Percentile and Winsorization methods are useful for skewed data.
Winsorization is preferred when data integrity must be preserved.
Final Thoughts
Outliers can be tricky, but understanding how to detect and handle them is a key skill in machine learning and data science. Whether you use the IQR method, Z-score, or Wins
orization, always tailor your approach to the specific dataset you’re working with.
By mastering these techniques, you’ll be able to clean your data effectively and improve the accuracy of your models.
#science#skills#programming#bigdata#books#machinelearning#artificial intelligence#python#machine learning#data centers#outliers#big data#data analysis#data analytics#data scientist#database#datascience#data
4 notes
·
View notes
Text
CETPA Summer Training: Gain the Skills You Need to Excel in Your Career
CETPA's Summer Training program is designed to help you gain the skills you need to excel in your career. Whether you're an engineering student, a business student, or a recent graduate, CETPA's program can help you develop the skills you need to land your dream job.
Summer Training in Noida at CETPA covers a wide range of topics, including:
JAVA
Python
Machine Learning
Data Science
Data Analytics
Web Development
much more.
We also offer a variety of hands-on projects and case studies, so you can put your skills to the test and gain real-world experience.
In addition to the technical skills, our program also helps you develop soft skills, such as communication, teamwork, and problem-solving. These skills are essential for success in any career.
CETPA's Summer Training in Noida is taught by experienced industry professionals who are passionate about teaching. They will help you master the skills you need to succeed in your career.
If you're looking for a Summer Training in Noida that will help you gain the skills you need to excel in your career, CETPA Infotech is the perfect choice for you.
Benefits of attending CETPA's Summer Training :
Gain the skills you need to excel in your career
Get ahead of the competition
Network with industry professionals
Learn from experienced industry professionals
Gain real-world experience
Develop soft skills
For more information:
Visit:https://www.cetpainfotech.com/summer-training
Contact:+91-9212172602

#summer training#summer training in noida#summer training in delhi#online summer training#techskills#itcareer#java training#python training#machine learning#web development#data science#data analytics#dot net
2 notes
·
View notes
Text
Software Developer - C#.Net + React
Job title: Software Developer – C#.Net + React Company: Big Red Recruitment Job description: for a versatile full stack developer ready to dive into both front-end React development and backend C#/.NET services. You’ll have the…Play a pivotal role in modernising crucial systems for a global manufacturing business. As a Full Stack Developer… Expected salary: £45000 – 55000 per year Location:…
#agritech#artificial intelligence#Azure#Backend#Backend Developer#Blockchain#business-intelligence#data-privacy#data-science#deep-learning#ethical AI#gcp#generative AI#GIS#healthtech#HPC#insurtech#it-support#legaltech#marine-tech#metaverse#Networking#no-code#Python#Salesforce#SEO#software-development#system-administration#telecoms
0 notes
Text

Start your career in data science with Mind Coders’ 5-month Data Science Program. This engaging course is designed for both students and working professionals, combining hands-on experience with guidance from experts—available in both online and offline formats. Gain practical knowledge using widely-used industry tools such as Python, MySQL, Power BI, Excel, and Tableau. Learn from experienced industry professionals and active data science practitioners, and develop the skills necessary to succeed in one of today's most in-demand and high paying fields
0 notes
Text
Understanding IHD with Data Science
Ischemic Heart Disease (IHD), more commonly recognized as coronary artery disease, is a profound health concern that stems from a decreased blood supply to the heart. Such a decrease is typically due to fatty deposits or plaques narrowing the coronary arteries. These arteries, as vital conduits delivering oxygen-rich blood to the heart, play a paramount role in ensuring the heart's efficient functioning. An obstruction or reduced flow within these arteries can usher in adverse outcomes, with heart attacks being the most dire. Given the gravity of IHD, the global medical community emphasizes the essence of early detection and prompt intervention to manage its repercussions effectively.
A New Age in Healthcare: Embracing Data Science
As we stand on the cusp of the fourth industrial revolution, technology's intertwining with every domain is evident. The healthcare sector is no exception. The integration of data science in healthcare is not merely an augmentation; it's a paradigm shift. Data science, with its vast array of tools and methodologies, is fostering new avenues to understand, diagnose, and even predict various health conditions long before they manifest pronounced symptoms.
Machine Learning: The Vanguard of Modern Medical Research
Among the myriad of tools under the vast umbrella of data science, Machine Learning (ML) shines exceptionally bright. An essential offshoot of artificial intelligence, ML capitalizes on algorithms and statistical models, granting computers the capability to process vast amounts of data and discern patterns without being explicitly programmed.
In the healthcare realm, the applications of ML are manifold. From predicting potential disease outbreaks based on global health data trends to optimizing patient flow in bustling hospitals, ML is progressively becoming a linchpin in medical operations. One of its most lauded applications, however, is its prowess in early disease prediction, and IHD detection stands as a testament to this.
Drawn to the immense potential ML holds, I ventured into a research project aimed at harnessing the RandomForestClassifier model's capabilities. Within the medical research sphere, this model is celebrated for its robustness and adaptability, making it a prime choice for my endeavor.
Deep Dive into the Findings
The results from the ML model were heartening. With an accuracy rate of 90%, the model’s prowess in discerning the presence of IHD based on an array of parameters was evident. Such a high accuracy rate is pivotal, considering the stakes at hand – the very health of a human heart. 9 times out of 10 the model is correct at its predictions.
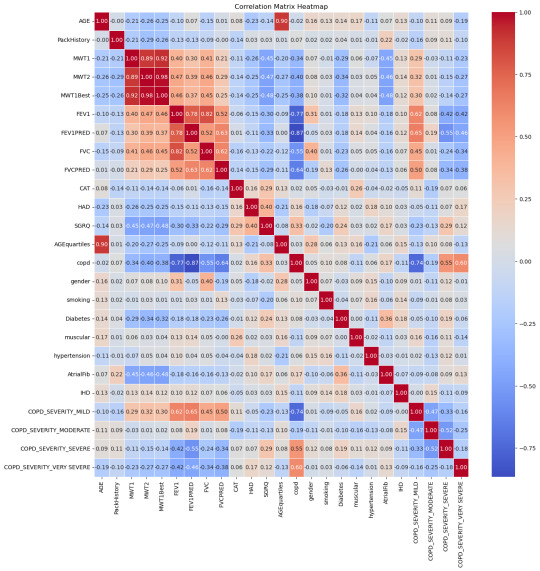
Breaking down the data, some correlations with IHD stood out prominently:
Moderate COPD (Chronic Obstructive Pulmonary Disease) – 15%: COPD's inclusion is noteworthy. While primarily a lung condition, its linkage with heart health has been a topic of numerous studies. A compromised respiratory system can inadvertently strain the heart, underscoring the interconnectedness of our bodily systems.
Diabetes – 18%: The correlation between diabetes and heart health isn't novel. Elevated blood sugar levels over extended periods can damage blood vessels, including the coronary arteries.
Age (segmented in quarterlies) – 15%: Age, as an immutable factor, plays a significant role. With age, several bodily systems gradually wear down, rendering individuals more susceptible to a plethora of conditions, IHD included.
Smoking habits – 14%: The deleterious effects of smoking on lung health are well-documented. However, its impact extends to the cardiovascular system, with nicotine and other chemicals adversely affecting heart functions.
MWT1 and MWT2 (indicators of physical endurance) – 13% and 14% respectively: Physical endurance and heart health share an intimate bond. These metrics, gauging one's physical stamina, can be precursors to potential heart-related anomalies.
Redefining Patient Care in the Machine Learning Era
Armed with these insights, healthcare can transcend its conventional boundaries. A deeper understanding of IHD's contributors empowers medical professionals to devise comprehensive care strategies that are both preventive and curative.
Moreover, the revelations from this study underscore the potential for proactive medical interventions. Instead of being reactive, waiting for symptoms to manifest, healthcare providers can now adopt a preventive stance. Patients exhibiting the highlighted risk factors can be placed under more meticulous observation, ensuring that potential IHD developments are nipped in the bud.
With the infusion of machine learning, healthcare is on the cusp of a personalized revolution. Gone are the days of one-size-fits-all medical approaches. Recognizing the uniqueness of each patient's health profile, machine learning models like the one employed in this study can pave the way for hyper-personalized care regimens.
As machine learning continues to entrench itself in healthcare, a future where disease predictions are accurate, interventions are timely, and patient care is unparalleled isn't merely a vision; it's an impending reality.
#heart disease#ihd#ischemic heart disease#programming#programmer#python#python programming#machine learning#data analysis#data science#data visualization#aicommunity#ai#artificial intelligence#medical research#medical technology
3 notes
·
View notes