#sql tips
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Mobile Tumblr US users spend an average of 4.04 minutes per session on the app.
Text
Your Guide To SQL Interview Questions for Data Analyst

Introduction
A Data Analyst collects, processes, and analyses data to help companies make informed decisions. SQL is crucial because it allows analysts to efficiently retrieve and manipulate data from databases.
This article will help you prepare for SQL interview questions for Data Analyst positions. You'll find common questions, detailed answers, and practical tips to excel in your interview.
Whether you're a beginner or looking to improve your skills, this guide will provide valuable insights and boost your confidence in tackling SQL interview questions for Data Analyst roles.
Importance Of SQL Skills In Data Analysis Roles
Understanding SQL is crucial for Data Analysts because it enables them to retrieve, manipulate, and manage large datasets efficiently. SQL skills are essential for accurate Data Analysis, generating insights, and making informed decisions. Let's explore why SQL is so important in Data Analysis roles.
Role Of SQL In Data Retrieval, Manipulation, and Management
SQL, or Structured Query Language, is the backbone of database management. It allows Data Analysts to pull data from databases (retrieval), change this data (manipulation), and organise it effectively (management).
Using SQL, analysts can quickly find specific data points, update records, or even delete unnecessary information. This capability is essential for maintaining clean and accurate datasets.
Common Tasks That Data Analysts Perform Using SQL
Data Analysts use SQL to perform various tasks. They often write queries to extract specific data from databases, which helps them answer business questions and generate reports.
Analysts use SQL to clean and prepare data by removing duplicates and correcting errors. They also use it to join data from multiple tables, enabling a comprehensive analysis. These tasks are fundamental in ensuring data accuracy and relevance.
Examples Of How SQL Skills Can Solve Real-World Data Problems
SQL skills help solve many real-world problems. For instance, a retail company might use SQL to analyse sales data and identify the best-selling products. A marketing analyst could use SQL to segment customers based on purchase history, enabling targeted marketing campaigns.
SQL can also help detect patterns and trends, such as identifying peak shopping times or understanding customer preferences, which are critical for strategic decision-making.
Why Employers Value SQL Proficiency in Data Analysts
Employers highly value SQL skills because they ensure Data Analysts can work independently with large datasets. Proficiency in SQL means an analyst can extract meaningful insights without relying on other technical teams. This capability speeds up decision-making and problem-solving processes, making the business more agile and responsive.
Additionally, SQL skills often indicate logical, solid thinking and attention to detail, which are highly desirable qualities in any data-focused role.
Basic SQL Interview Questions
Employers often ask basic questions in SQL interviews for Data Analyst positions to gauge your understanding of fundamental SQL concepts. These questions test your ability to write and understand simple SQL queries, essential for any Data Analyst role. Here are some common basic SQL interview questions, along with their answers:
How Do You Retrieve Data From A Single Table?
Answer: Use the `SELECT` statement to retrieve data from a table. For example, `SELECT * FROM employees;` retrieves all columns from the "employees" table.
What Is A Primary Key?
Answer: A primary key is a unique identifier for each record in a table. It ensures that no two rows have the same key value. For example, in an "employees" table, the employee ID can be the primary key.
How Do You Filter Records In SQL?
Answer: Use the `WHERE` clause to filter records. For example, `SELECT * FROM employees WHERE department = 'Sales';` retrieves all employees in the Sales department.
What Is The Difference Between `WHERE` And `HAVING` Clauses?
Answer: The `WHERE` clause filters rows before grouping, while the `HAVING` clause filters groups after the `GROUP BY` operation. For example, `SELECT department, COUNT(*) FROM employees GROUP BY department HAVING COUNT(*) > 10;` filters departments with more than ten employees.
How Do You Sort Data in SQL?
Answer: Use the `ORDER BY` clause to sort data. For example, `SELECT * FROM employees ORDER BY salary DESC;` sorts employees by salary in descending order.
How Do You Insert Data Into A Table?
Answer: Use the `INSERT INTO` statement. For example, `INSERT INTO employees (name, department, salary) VALUES ('John Doe', 'Marketing', 60000);` adds a new employee to the "employees" table.
How Do You Update Data In A Table?
Answer: Use the `UPDATE` statement. For example, `UPDATE employees SET salary = 65000 WHERE name = 'John Doe';` updates John Doe's salary.
How Do You Delete Data From A Table?
Answer: Use the `DELETE` statement. For example, `DELETE FROM employees WHERE name = 'John Doe';` removes John Doe's record from the "employees" table.
What Is A Foreign Key?
Answer: A foreign key is a field in one table that uniquely identifies a row in another table. It establishes a link between the two tables. For example, a "department_id" in the "employees" table that references the "departments" table.
How Do You Use The `LIKE` Operator?
Answer: SQL's `LIKE` operator is used for pattern matching. For example, `SELECT * FROM employees WHERE name LIKE 'J%';` retrieves all employees whose names start with 'J'.
Must Read:
How to drop a database in SQL server?
Advanced SQL Interview Questions
In this section, we delve into more complex aspects of SQL that you might encounter during a Data Analyst interview. Advanced SQL questions test your deep understanding of database systems and ability to handle intricate data queries. Here are ten advanced SQL questions and their answers to help you prepare effectively.
What Is The Difference Between INNER JOIN And OUTER JOIN?
Answer: An INNER JOIN returns rows when there is a match in both tables. An OUTER JOIN returns all rows from one table and the matched rows from the other. If there is no match, the result is NULL on the side where there is no match.
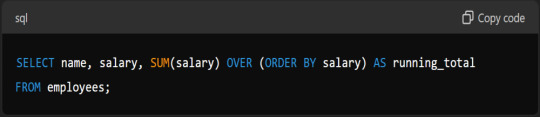
How Do You Use A Window Function In SQL?
Answer: A window function calculates across a set of table rows related to the current row. For example, to calculate the running total of salaries:
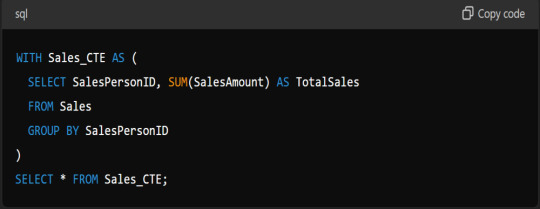
Explain The Use Of CTE (Common Table Expressions) In SQL.
Answer: A CTE allows you to define a temporary result set that you can reference within a SELECT, INSERT, UPDATE, or DELETE statement. It is defined using the WITH clause:
What Are Indexes, And How Do They Improve Query Performance?
Answer: Indexes are database objects that improve the speed of data retrieval operations on a table. They work like the index in a book, allowing the database engine to find data quickly without scanning the entire table.
How Do You Find The Second-highest Salary In A Table?
Answer: You can use a subquery for this:
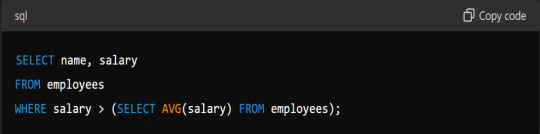
What Is A Subquery, And When Would You Use One?
Answer: A subquery is a query nested inside another query. You use it when you need to filter results based on the result of another query:
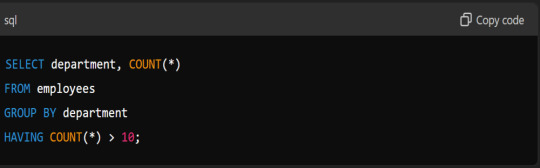
Explain The Use Of GROUP BY And HAVING Clauses.
Answer: GROUP BY groups rows sharing a property so that aggregate functions can be applied to each group. HAVING filters groups based on aggregate properties:
How Do You Optimise A Slow Query?
Answer: To optimise a slow query, you can:
Use indexes to speed up data retrieval.
Avoid SELECT * by specifying only necessary columns.
Break down complex queries into simpler parts.
Analyse query execution plans to identify bottlenecks.
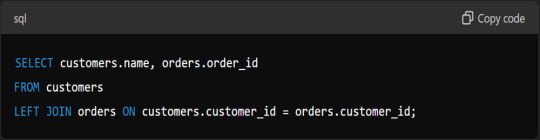
Describe A Scenario Where You Would Use A LEFT JOIN.
Answer: Use a LEFT JOIN when you need all records from the left table and the matched records from the right table. For example, to find all customers and their orders, even if some customers have no orders:
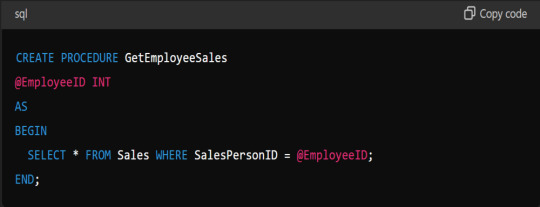
What Is A Stored Procedure, And How Do You Create One?
Answer: A stored procedure is a prepared SQL code you can reuse. It encapsulates SQL queries and logic in a single function:
These advanced SQL questions and answers will help you demonstrate your proficiency and problem-solving skills during your Data Analyst interview.
Practical Problem-Solving Scenarios SQL Questions
In SQL interviews for Data Analyst roles, you’ll often face questions that test your ability to solve real-world problems using SQL. These questions go beyond basic commands and require you to think critically and apply your knowledge to complex scenarios. Here are ten practical SQL questions with answers to help you prepare.
How Would You Find Duplicate Records In A Table Named `Employees` Based On The `Email` Column?
Answer:
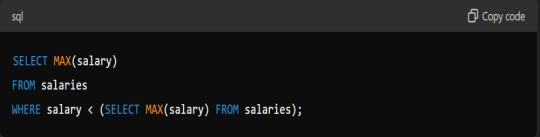
Write A Query To Find The Second Highest Salary In A Table Named `Salaries`.
Answer:
How Do You Handle NULL Values In SQL When Calculating The Total Salary In The `Employees` Table?
Answer:

Create A Query To Join The `Employees` Table And `Departments` Table On The `Department_id` And Calculate The Total Salary Per Department.
Answer:
How Do You Find Employees Who Do Not Belong To Any Department?
Answer:
Write A Query To Retrieve The Top 3 Highest-paid Employees From The `Employees` Table.
Answer:
How Do You Find Employees Who Joined In The Last Year?
Answer:
Calculate The Average Salary Of Employees In The `Employees` Table, Excluding Those With A Wage Below 3000.
Answer:
Update The Salary By 10% For Employees In The `Employees` Table Who Work In The 'Sales' Department.
Answer:
Delete Records Of Employees Who Have Not Been Active For The Past 5 years.
Answer:
These questions cover a range of scenarios you might encounter in an SQL interview. Practice these to enhance your problem-solving skills and better prepare for your interview.
Tips for Excelling in SQL Interviews
Understanding how to excel in SQL interviews is crucial for aspiring data professionals, as it showcases technical expertise and problem-solving skills and enhances job prospects in a competitive industry. Excelling in SQL interviews requires preparation and practice. Here are some tips to help you stand out and perform your best.
Best Practices for Preparing for SQL Interviews
Preparation is critical to success in SQL interviews. Start by reviewing the basics of SQL, including common commands and functions. Practice writing queries to solve various problems.
Ensure you understand different types of joins, subqueries, and aggregate functions. Mock interviews can also be helpful. They simulate the real interview environment and help you get comfortable answering questions under pressure.
Resources for Improving SQL Skills
Knowing about resources for improving SQL skills enhances data management proficiency and boosts career prospects. It also facilitates complex Data Analysis and empowers you to handle large datasets efficiently. There are many resources available to help you improve your SQL skills. Here are a few:
Books: "SQL For Dummies" by Allen G. Taylor is a great start. "Learning SQL" by Alan Beaulieu is another excellent resource.
Online Courses: Many websites offer comprehensive SQL courses. Explore platforms that provide interactive SQL exercises.
Practice Websites: LeetCode, HackerRank, and SQLZoo offer practice problems that range from beginner to advanced levels. Regularly solving these problems will help reinforce your knowledge and improve your problem-solving skills.
Importance of Understanding Business Context and Data Interpretation
Understanding the business context is crucial in addition to technical skills. Employers want to know that you can interpret data and provide meaningful insights.
Familiarise yourself with the business domain relevant to the job you are applying for. Practice explaining your SQL queries and the insights they provide in simple terms. This will show that you can communicate effectively with non-technical stakeholders.
Tips for Writing Clean and Efficient SQL Code
Knowing tips for writing clean and efficient SQL code ensures better performance, maintainability, and readability. It also leads to optimised database operations and easier collaboration among developers. Writing clean and efficient SQL code is essential in interviews. Follow these tips:
Use Clear and Descriptive Names: Use meaningful names for tables, columns, and aliases. This will make your queries more straightforward to read and understand.
Format Your Code: Use indentation and line breaks to organise your query. It improves readability and helps you spot errors more easily.
Optimise Your Queries: Use indexing, limit the use of subqueries, and avoid unnecessary columns in your SELECT statements. Efficient queries run faster and use fewer resources.
Common Pitfalls to Avoid During the Interview
Knowing common interview pitfalls is crucial to present your best self and avoid mistakes. It further increases your chances of securing the job you desire. Preparation is key. Here's how you can avoid some common mistakes during the interview:
Not Reading the Question Carefully: Ensure you understand the interviewer's question before writing your query.
Overcomplicating the Solution: Start with a simple solution and build on it if necessary. Avoid adding unnecessary complexity.
Ignoring Edge Cases: Consider edge cases and test your queries with different datasets. It shows that you think critically about your solutions.
By following these tips, you'll be well-prepared to excel in your SQL interviews. Practice regularly, use available resources, and focus on clear, efficient coding. Understanding the business context and avoiding common pitfalls will help you stand out as a strong candidate.
Read Further:
Advanced SQL Tips and Tricks for Data Analysts.
Conclusion
Preparing for SQL interviews is vital for aspiring Data Analysts. Understanding SQL fundamentals, practising query writing, and solving real-world problems are essential.
Enhance your skills using resources such as books, online courses, and practice websites. Focus on writing clean, efficient code and interpreting data within a business context.
Avoid common pitfalls by reading questions carefully and considering edge cases. By following these guidelines, you can excel in your SQL interviews and secure a successful career as a Data Analyst.
#sql interview questions#sql tips and tricks#sql tips#sql in data analysis#sql#data analyst interview questions#sql interview#sql interview tips for data analysts#data science#pickl.ai#data analyst
1 note
·
View note
Text
🚀 Struggling to balance transactional (OLTP) & analytical (OLAP) workloads? Microsoft Fabric SQL Database is the game-changer! In this blog, I’ll share best practices, pitfalls to avoid, and optimization tips to help you master Fabric SQL DB. Let’s dive in! 💡💬 #MicrosoftFabric #SQL
#Data management#Database Benefits#Database Optimization#Database Tips#Developer-Friendly#Fabric SQL Database#Microsoft Fabric#SQL database#SQL Performance#Transactional Workloads#Unlock SQL Potential
0 notes
Text
Tiempo ejecución consulta sql
Para medir el tiempo exacto de ejecución de una consulta en Oracle, puedes utilizar algunas herramientas y comandos que ofrece la base de datos y el cliente SQL, como SQL*Plus. Aquí tienes varias formas de hacerlo: 1. Usar SET TIMING ON en SQL*Plus Si estás utilizando SQL*Plus, puedes activar la opción TIMING que mide automáticamente el tiempo que tarda cada consulta en ejecutarse. SET TIMING…

View On WordPress
1 note
·
View note
Text
[Fabric] Leer PowerBi data con Notebooks - Semantic Link
El nombre del artículo puede sonar extraño puesto que va en contra del flujo de datos que muchos arquitectos pueden pensar para el desarrollo de soluciones. Sin embargo, las puertas a nuevos modos de conectividad entre herramientas y conjuntos de datos pueden ayudarnos a encontrar nuevos modos que fortalezcan los análisis de datos.
En este post vamos a mostrar dos sencillos modos que tenemos para leer datos de un Power Bi Semantic Model desde un Fabric Notebook con Python y SQL.
¿Qué son los Semantic Links? (vínculo semántico)
Como nos gusta hacer aquí en LaDataWeb, comencemos con un poco de teoría de la fuente directa.
Definición Microsoft: Vínculo semántico es una característica que permite establecer una conexión entre modelos semánticos y Ciencia de datos de Synapse en Microsoft Fabric. El uso del vínculo semántico solo se admite en Microsoft Fabric.
Dicho en criollo, nos facilita la conectividad de datos para simplificar el acceso a información. Si bién Microsoft lo enfoca como una herramienta para Científicos de datos, no veo porque no puede ser usada por cualquier perfil que tenga en mente la resolución de un problema leyendo datos limpios de un modelo semántico.
El límite será nuestra creatividad para resolver problemas que se nos presenten para responder o construir entorno a la lectura de estos modelos con notebooks que podrían luego volver a almacenarse en Onelake con un nuevo procesamiento enfocado en la solución.
Semantic Links ofrecen conectividad de datos con el ecosistema de Pandas de Python a través de la biblioteca de Python SemPy. SemPy proporciona funcionalidades que incluyen la recuperación de datos de tablas , cálculo de medidas y ejecución de consultas DAX y metadatos.
Para usar la librería primero necesitamos instalarla:
%pip install semantic-link
Lo primero que podríamos hacer es ver los modelos disponibles:
import sempy.fabric as fabric df_datasets = fabric.list_datasets()
Entrando en más detalle, también podemos listar las tablas de un modelo:
df_tables = fabric.list_tables("Nombre Modelo Semantico", include_columns=True)
Cuando ya estemos seguros de lo que necesitamos, podemos leer una tabla puntual:
df_table = fabric.read_table("Nombre Modelo Semantico", "Nombre Tabla")
Esto genera un FabricDataFrame con el cual podemos trabajar libremente.
Nota: FabricDataFrame es la estructura de datos principal de vínculo semántico. Realiza subclases de DataFrame de Pandas y agrega metadatos, como información semántica y linaje
Existen varias funciones que podemos investigar usando la librería. Una de las favoritas es la que nos permite entender las relaciones entre tablas. Podemos obtenerlas y luego usar otro apartado de la librería para plotearlo:
from sempy.relationships import plot_relationship_metadata relationships = fabric.list_relationships("Nombre Modelo Semantico") plot_relationship_metadata(relationships)
Un ejemplo de la respuesta:
Conector Nativo Semantic Link Spark
Adicional a la librería de Python para trabajar con Pandas, la característica nos trae un conector nativo para usar con Spark. El mismo permite a los usuarios de Spark acceder a las tablas y medidas de Power BI. El conector es independiente del lenguaje y admite PySpark, Spark SQL, R y Scala. Veamos lo simple que es usarlo:
spark.conf.set("spark.sql.catalog.pbi", "com.microsoft.azure.synapse.ml.powerbi.PowerBICatalog")
Basta con especificar esa línea para pronto nutrirnos de clásico SQL. Listamos tablas de un modelo:
%%sql SHOW TABLES FROM pbi.`Nombre Modelo Semantico`
Consulta a una tabla puntual:
%%sql SELECT * FROM pbi.`Nombre Modelo Semantico`.NombreTabla
Así de simple podemos ejecutar SparkSQL para consultar el modelo. En este caso es importante la participación del caracter " ` " comilla invertida que nos ayuda a leer espacios y otros caracteres.
Exploración con DAX
Como un tercer modo de lectura de datos incorporaron la lectura basada en DAX. Esta puede ayudarnos de distintas maneras, por ejemplo guardando en nuestro FabricDataFrame el resultado de una consulta:
df_dax = fabric.evaluate_dax( "Nombre Modelo Semantico", """ EVALUATE SUMMARIZECOLUMNS( 'State'[Region], 'Calendar'[Year], 'Calendar'[Month], "Total Revenue" , CALCULATE([Total Revenue] ) ) """ )
Otra manera es utilizando DAX puramente para consultar al igual que lo haríamos con SQL. Para ello, Fabric incorporó una nueva y poderosa etiqueta que lo facilita. Delimitación de celdas tipo "%%dax":
%%dax "Nombre Modelo Semantico" -w "Area de Trabajo" EVALUATE SUMMARIZECOLUMNS( 'State'[Region], 'Calendar'[Year], 'Calendar'[Month], "Total Revenue" , CALCULATE([Total Revenue] ) )
Hasta aquí llegamos con esos tres modos de leer datos de un Power Bi Semantic Model utilizando Fabric Notebooks. Espero que esto les revuelva la cabeza para redescubrir soluciones a problemas con un nuevo enfoque.
#fabric#fabric tips#fabric tutorial#fabric training#fabric notebooks#python#pandas#spark#power bi#powerbi#fabric argentina#fabric cordoba#fabric jujuy#ladataweb#microsoft fabric#SQL#dax
0 notes
Text
How to Group Data by Week in Google Sheets (sheetscheat.com)
0 notes
Text
How to Disable IntelliSense in SQL Server Management Studio
In the dynamic world of database management, SQL Server Management Studio (SSMS) stands as a pivotal tool for developers and administrators. However, there are instances when the IntelliSense feature, despite its helpful intentions, might become more of a hindrance than a help. Whether due to performance issues or personal preference, disabling IntelliSense can streamline your coding experience.…
View On WordPress
0 notes
Text
Life update -
Hi, sorry for being MIA for a while and I'll try to update here more frequently. Here's a general update of what I've been up to.
Changed my Tumblr name from studywithmeblr to raptorstudiesstuff. Changed my blog name as well. I don't feel comfortable putting my real name on my social media platforms so I'm going by 'Raptor' now.
💻 Finished the Machine Learning-2 and Unsupervised Learning module along with projects. Got a pretty good grade in both of them and my overall grade went up a bit.
📝 Started applying for data science internships and jobs but got rejected from most of the companies I applied to... 😬
I'll start applying again in a week or two with a new resume. Let me know any tips I can use to not get rejected. 😅
💻 Started SQL last week and really enjoying it. I did get a bad grade on an assignment though. Hope I can make up for it in the final quiz. 🤞
🏥 Work has been alright. We're a little less staffed than usual this week but I'm trying not to stress too much about it.
📖 Currently reading Discworld #1 - The Color of Magic. More than halfway through.
📺 Re-watched the Lord of The Rings movies and now I'm compelled to read the books or rewatch the Hobbit movies.
"There's good in this world, Mr Frodo, and it's worth fighting for." This scene had me in tears and I really needed to hear that..
📺 Watched the first 4 episodes of First Kill on Netflix and I don't know what I was doing to myself. The writing and dialogue is so cheesy and terrible. The acting is okay-ish. It's so bad that it turned out to be quite hilarious. Laughed the whole time.
🎧 Discovered a new (for me) song that I'm obsessed with right now - Mirrors by Justin Timberlake.
📷 Took some really cool pics on my camera..





Might start the 100 days productivity challenge soon as that is the only way I find myself to be consistent.
Peace ✌️
Raptor
PS. Please don't repost any of my pictures without permission.
#study with me#study blog#studyblr#study motivation#study#study inspiration#student#100 days of productivity#student life#life update#update#raptor#photography#nature#original photographers#currently reading#reading#lotr#the hobbit#books and reading#books#tv shows#tv series#netflix#datascience#data analytics#machine learning#sql
9 notes
·
View notes
Note
Hey there! I want to go into statistical analysis and comms/data analysis, and I have a pretty good plan in place already and know what I'm doing, but was wondering if there are any tips you could give as I see in your bio you're studying data science?
Anything I should do for prep/classes to take to get me a leg up would be amazing, thank you in advance!
Hey there! Thanks for the ask!
If you're going into stat, the first thing I'd suggest is get a good grip on your maths.(Rhyme not intended lol) You should take courses on Derivatives, Integrals, Linear Algebra. We are also taught Real analysis pretty intensively.
For programming languages, I'd say Python is more than enough. But R, SQL are good to have on your CV. Open up a kaggle account and start doing some work there. It will take you a long way.
The best tip I can give you is to take care of your health. It's a pretty taxing subject once you get into it. But prioritise yourself first. Our coursework is intense and while it might not be the same for you, doing mathematics all day is always difficult.
Good luck on your journey. Hope I was of help.
#altin answers#studyblr#studyspo#study motivation#study inspiration#study hard#study aesthetic#studying#study#datablr#statblr#statistics#study study study
9 notes
·
View notes
Text



19 July 2023
I am trying my best to drink more water, and this big water bottle with motivational quotes is helping me a lot! Is strange, but to look at it, and know the pacing is great.
About programming, as I have to hurry up with my studies in order to keep up with the new architecture squad, I am trying to figure out the best notebook to write, as I learn better by writing.
I am using the purple one to Java, programming logic, SQL and GIT-Github; the colorful to Typescript and Angular, and I am thinking of using the brown to Spring Framework (as it is a huge topic).
Yes, for whom was working with JSF, JSP, JQuery (it is better to say that I was struggling with JQuery... hated it), it is a big change to turn my mindset to this modern stack - I will deal less with legacy code.
I am accepting all possible tips regarding Angular and Spring Framework, if is there anyone working with it here ❤️
That's it! Have you all a great Wednesday 😘
#studyblr#study#study blog#daily life#dailymotivation#study motivation#studying#study space#productivity#study desk#programming struggles#programming#must lean java#spring framework#coding#coding community#programming community#bottle#water bottle#notebook#stationary#purple#i love purple
66 notes
·
View notes
Text
USEFUL TIPS FOR ANYONE USING NEOCITIES
So, I saw this super awesome post called BEGINNERS GUIDE TO BLUESKY and it more or less inspired me to make a post of my own pertaining to the the likes of Neocities.
What is Neocities?
Long story short, it is an open-source web hosting service that is both F2U (1 GB storage/200 GB bandwidth) and P2U (50 GB storage/3000 GB bandwidth). It's kinda sorta a spiritual successor to the now defunct GeoCities.
Why Use Neocities?
HELPFUL LINKS
Neocities has a full on Tutorials Page to help people wanting to learning how to code. Though I will say that I'm a bit surprised they don't have W3 Schools on there.
CREATIVE FREEDOM
If you Browse on Neocities, you will see how vastly different all of the websites look. That being said, you have an enormous amount of creative freedom when it comes to making your website. You can build it from scratch or look up some pre-made templates from websites such as templatemo, HTML5 Templates, TEMPLATED, template4all, and many more.
Now it is important to note that Neocities doesn't allow certain things such as jQuery, PHP, Python, SQL, etc. In fact, the only things allowed on Neocities are HTML, CSS, and JavaScript! Though I do think it is important to note that you can turn your website into a blog using Zonelets, have a Guestbook/Comments Section with Guestbooks, embed your Bluesky feed with Embed Bsky, embed your Twitter/X feed with Twitter Publish, and much more!
What Do People Use Neocities For?
Some people use it for blogging & portfolio & educational purposes. Some people use it to share their writings & artwork & music. Some people use it to help people with finding neat things. Some people use it for shits and giggles. There are legitimately a number of reasons people use it and you know what? That's 100% a-okay!
Are Any Programs Required To Use Neocities?
Technically, no. The reason I say this is because Neocities has a built-in HTML Editor. However, I don't like using it unless if I absolutely have to (which is next to never). Instead, I use Brackets. It's very user-friendly and it legit lets you know if there's a goof somewhere in your code. Legit 10 out of 10 recommend. Though I will say that some people use Notepad++.
#pvposeur's tutorial#pvposeur's tutorials#pvposeur's how tos#pvposeur's how to#pvposeur's psa#pvposeur's public service announcements#pvposeur's public service announcement#tutorial#tutorials#how to#how tos#psa#public service announcements#public service announcement#neocities#free to reblog
2 notes
·
View notes
Text
Level Up Your Analysis: Essential SQL Tips and Tricks for Data Analysts
Take your data analysis skills to the next level with these essential SQL tips and tricks. Discover powerful techniques to manipulate and explore data, empowering you to extract valuable insights.
0 notes
Text
How to Become a Data Scientist in 2025 (Roadmap for Absolute Beginners)

Want to become a data scientist in 2025 but don’t know where to start? You’re not alone. With job roles, tech stacks, and buzzwords changing rapidly, it’s easy to feel lost.
But here’s the good news: you don’t need a PhD or years of coding experience to get started. You just need the right roadmap.
Let’s break down the beginner-friendly path to becoming a data scientist in 2025.
✈️ Step 1: Get Comfortable with Python
Python is the most beginner-friendly programming language in data science.
What to learn:
Variables, loops, functions
Libraries like NumPy, Pandas, and Matplotlib
Why: It’s the backbone of everything you’ll do in data analysis and machine learning.
🔢 Step 2: Learn Basic Math & Stats
You don’t need to be a math genius. But you do need to understand:
Descriptive statistics
Probability
Linear algebra basics
Hypothesis testing
These concepts help you interpret data and build reliable models.
📊 Step 3: Master Data Handling
You’ll spend 70% of your time cleaning and preparing data.
Skills to focus on:
Working with CSV/Excel files
Cleaning missing data
Data transformation with Pandas
Visualizing data with Seaborn/Matplotlib
This is the “real work” most data scientists do daily.
🧬 Step 4: Learn Machine Learning (ML)
Once you’re solid with data handling, dive into ML.
Start with:
Supervised learning (Linear Regression, Decision Trees, KNN)
Unsupervised learning (Clustering)
Model evaluation metrics (accuracy, recall, precision)
Toolkits: Scikit-learn, XGBoost
🚀 Step 5: Work on Real Projects
Projects are what make your resume pop.
Try solving:
Customer churn
Sales forecasting
Sentiment analysis
Fraud detection
Pro tip: Document everything on GitHub and write blogs about your process.
✏️ Step 6: Learn SQL and Databases
Data lives in databases. Knowing how to query it with SQL is a must-have skill.
Focus on:
SELECT, JOIN, GROUP BY
Creating and updating tables
Writing nested queries
🌍 Step 7: Understand the Business Side
Data science isn’t just tech. You need to translate insights into decisions.
Learn to:
Tell stories with data (data storytelling)
Build dashboards with tools like Power BI or Tableau
Align your analysis with business goals
🎥 Want a Structured Way to Learn All This?
Instead of guessing what to learn next, check out Intellipaat’s full Data Science course on YouTube. It covers Python, ML, real projects, and everything you need to build job-ready skills.
https://www.youtube.com/watch?v=rxNDw68XcE4
🔄 Final Thoughts
Becoming a data scientist in 2025 is 100% possible — even for beginners. All you need is consistency, a good learning path, and a little curiosity.
Start simple. Build as you go. And let your projects speak louder than your resume.
Drop a comment if you’re starting your journey. And don’t forget to check out the free Intellipaat course to speed up your progress!
2 notes
·
View notes
Note
tumblr user prettyboykatsuki u have bewitched me body and soul… i keep opening ur blog like my daily newspaper every few hours not only bc i love ur brain and every take u have on anything is just perfect but also! your theme is genuinely so satisfying to look at i genuinely admire the amount of creativity u have and the effort and time u must have put into it. like ur tagging/ organisation system genuinely scratches an itch in my brain it’s sooooo cool. also!! i love your nails??? how long did they take u to do they r stunning :3 im currently gaslighting my dad into paying for my eid nails lol wish me luck <3
i get so emotional when i get asks like this it just means a lot to me 💔💔i love posting and having fun on here so i get like 💔💔 soggy as hell when other people also enjoy my presence on here!! i am A Lot so it’s nice that people can like leisure and find comfort in my blog u know…. kissing you so gently
i did indeed put my whole pussy into my theme so i love getting compliments on it i can’t lie to you. AHSNGMSJDN. i get very excited. IM SO EXCITED WBT MY TAGGING SYSTEM… bc I Love SQL….
also thank u!!!!!! my nails took me like. 6 hours 💀💀 i have very shaky hands sometimes so the french tips got messed up and i had to repeat it a bunch. the gems and charms are the easiest part, they just need a little patience but the the french tips r the devil . manifesting he pays for ur nails queen 🙂↕️
5 notes
·
View notes
Text
2 notes
·
View notes
Text
[Fabric] Entre Archivos y Tablas de Lakehouse - SQL Notebooks
Ya conocemos un panorama de Fabric y por donde empezar. La Data Web nos mostró unos artículos sobre esto. Mientras más veo Fabric más sorprendido estoy sobre la capacidad SaaS y low code que generaron para todas sus estapas de proyecto.
Un ejemplo sobre la sencillez fue copiar datos con Data Factory. En este artículo veremos otro ejemplo para que fanáticos de SQL puedan trabajar en ingeniería de datos o modelado dimensional desde un notebook.
Arquitectura Medallón
Si nunca escuchaste hablar de ella te sugiero que pronto leas. La arquitectura es una metodología que describe una capas de datos que denotan la calidad de los datos almacenados en el lakehouse. Las capas son carpetas jerárquicas que nos permiten determinar un orden en el ciclo de vida del datos y su proceso de transformaciones.
Los términos bronce (sin procesar), plata (validado) y oro (enriquecido/agrupado) describen la calidad de los datos en cada una de estas capas.
Ésta metodología es una referencia o modo de trabajo que puede tener sus variaciones dependiendo del negocio. Por ejemplo, en un escenario sencillo de pocos datos, probablemente no usaríamos gold, sino que luego de dejar validados los datos en silver podríamos construir el modelado dimensional directamente en el paso a "Tablas" de Lakehouse de Fabric.
NOTAS: Recordemos que "Tablas" en Lakehouse es un spark catalog también conocido como Metastore que esta directamente vinculado con SQL Endpoint y un PowerBi Dataset que viene por defecto.
¿Qué son los notebooks de Fabric?
Microsoft los define como: "un elemento de código principal para desarrollar trabajos de Apache Spark y experimentos de aprendizaje automático, es una superficie interactiva basada en web que usan los científicos de datos e ingenieros de datos para escribir un código que se beneficie de visualizaciones enriquecidas y texto en Markdown."
Dicho de manera más sencilla, es un espacio que nos permite ejecutar bloques de código spark que puede ser automatizado. Hoy por hoy es una de las formas más populares para hacer transformaciones y limpieza de datos.
Luego de crear un notebook (dentro de servicio data engineering o data science) podemos abrir en el panel izquierdo un Lakehouse para tener referencia de la estructura en la cual estamos trabajando y el tipo de Spark deseado.
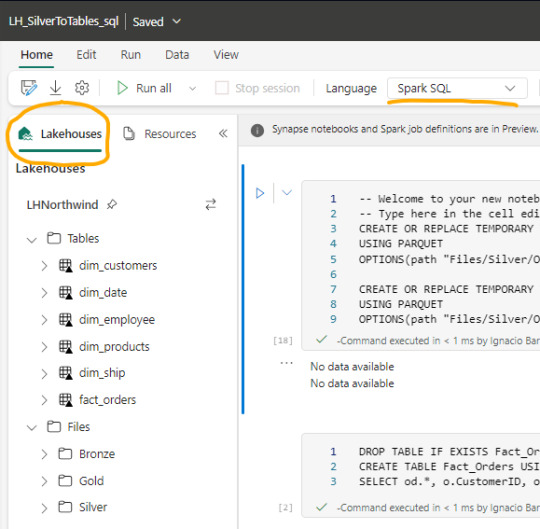
Spark
Spark se ha convertido en el indiscutible lenguaje de lectura de datos en un lake. Así como SQL lo fue por años sobre un motor de base de datos, ahora Spark lo es para Lakehouse. Lo bueno de spark es que permite usar más de un lenguaje según nuestro comodidad.

Creo que es inegable que python está ocupando un lugar privilegiado junto a SQL que ha ganado suficiente popularidad como para encontrarse con ingenieros de datos que no conocen SQL pero son increíbles desarrolladores en python. En este artículo quiero enfocarlo en SQL puesto que lo más frecuente de uso es Python y podríamos charlar de SQL para aportar a perfiles más antiguos como DBAs o Data Analysts que trabajaron con herramientas de diseño y Bases de Datos.
Lectura de archivos de Lakehouse con SQL
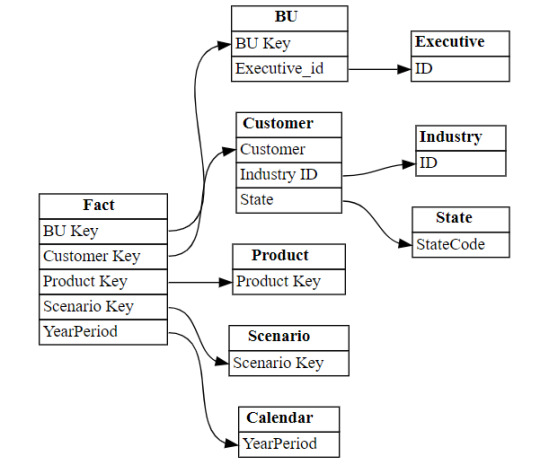
Lo primero que debemos saber es que para trabajar en comodidad con notebooks, creamos tablas temporales que nacen de un esquema especificado al momento de leer la información. Para el ejemplo veremos dos escenarios, una tabla Customers con un archivo parquet y una tabla Orders que fue particionada por año en distintos archivos parquet según el año.
CREATE OR REPLACE TEMPORARY VIEW Dim_Customers_Temp USING PARQUET OPTIONS ( path "Files/Silver/Customers/*.parquet", header "true", mode "FAILFAST" ) ;
CREATE OR REPLACE TEMPORARY VIEW Orders USING PARQUET OPTIONS ( path "Files/Silver/Orders/Year=*", header "true", mode "FAILFAST" ) ;
Vean como delimitamos la tabla temporal, especificando el formato parquet y una dirección super sencilla de Files. El "*" nos ayuda a leer todos los archivos de una carpeta o inclusive parte del nombre de las carpetas que componen los archivos. Para el caso de orders tengo carpetas "Year=1998" que podemos leerlas juntas reemplazando el año por asterisco. Finalmente, especificamos que tenga cabeceras y falle rápido en caso de un problema.
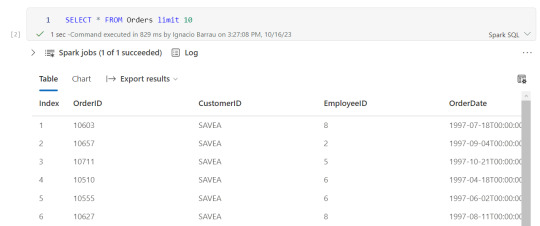
Consultas y transformaciones
Una vez creada la tabla temporal, podremos ejecutar en la celda de un notebook una consulta como si estuvieramos en un motor de nuestra comodidad como DBeaver.
Escritura de tablas temporales a las Tablas de Lakehouse
Realizadas las transformaciones, joins y lo que fuera necesario para construir nuestro modelado dimensional, hechos y dimensiones, pasaremos a almacenarlo en "Tablas".
Las transformaciones pueden irse guardando en otras tablas temporales o podemos almacenar el resultado de la consulta directamente sobre Tablas. Por ejemplo, queremos crear una tabla de hechos Orders a partir de Orders y Order details:
CREATE TABLE Fact_Orders USING delta AS SELECT od.*, o.CustomerID, o.EmployeeID, o.OrderDate, o.Freight, o.ShipName FROM OrdersDetails od LEFT JOIN Orders o ON od.OrderID = o.OrderID
Al realizar el Create Table estamos oficialmente almacenando sobre el Spark Catalog. Fíjense el tipo de almacenamiento porque es muy importante que este en DELTA para mejor funcionamiento puesto que es nativo para Fabric.
Resultado
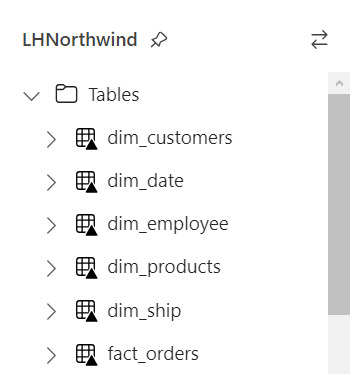
Si nuestro proceso fue correcto, veremos la tabla en la carpeta Tables con una flechita hacia arriba sobre la tabla. Esto significa que la tabla es Delta y todo está en orden. Si hubieramos tenido una complicación, se crearía una carpeta "Undefinied" en Tables la cual impide la lectura de nuevas tablas y transformaciones por SQL Endpoint y Dataset. Mucho cuidado y siempre revisar que todo quede en orden:
Pensamientos
Así llegamos al final del recorrido donde podemos apreciar lo sencillo que es leer, transformar y almacenar nuestros modelos dimensionales con SQL usando Notebooks en Fabric. Cabe aclarar que es un simple ejemplo sin actualizaciones incrementales pero si con lectura de particiones de tiempo ya creadas por un data engineering en capa Silver.
¿Qué hay de Databricks?
Podemos usar libremente databricks para todo lo que sean notebooks y procesamiento tal cual lo venimos usando. Lo que no tendríamos al trabajar de ésta manera sería la sencillez para leer y escribir tablas sin tener que especificar todo el ABFS y la característica de Data Wrangler. Dependerá del poder de procesamiento que necesitamos para ejecutar el notebooks si nos alcanza con el de Fabric o necesitamos algo particular de mayor potencia. Para más información pueden leer esto: https://learn.microsoft.com/en-us/fabric/onelake/onelake-azure-databricks
Espero que esto los ayude a introducirse en la construcción de modelados dimensionales con clásico SQL en un Lakehouse como alternativa al tradicional Warehouse usando Fabric. Pueden encontrar el notebook completo en mi github que incluye correr una celda en otro lenguaje y construcción de tabla fecha en notebook.
#power bi#ladataweb#fabric#microsoft fabric#fabric argentina#fabric cordoba#fabric jujuy#fabric tips#fabric training#fabric tutorial#fabric notebooks#data engineering#SQL#spark#data fabric#lakehouse#fabric lakehouse
0 notes
Text
How to Transition from Biotechnology to Bioinformatics: A Step-by-Step Guide

Biotechnology and bioinformatics are closely linked fields, but shifting from a wet lab environment to a computational approach requires strategic planning. Whether you are a student or a professional looking to make the transition, this guide will provide a step-by-step roadmap to help you navigate the shift from biotechnology to bioinformatics.
Why Transition from Biotechnology to Bioinformatics?
Bioinformatics is revolutionizing life sciences by integrating biological data with computational tools to uncover insights in genomics, proteomics, and drug discovery. The field offers diverse career opportunities in research, pharmaceuticals, healthcare, and AI-driven biological data analysis.
If you are skilled in laboratory techniques but wish to expand your expertise into data-driven biological research, bioinformatics is a rewarding career choice.
Step-by-Step Guide to Transition from Biotechnology to Bioinformatics
Step 1: Understand the Basics of Bioinformatics
Before making the switch, it’s crucial to gain a foundational understanding of bioinformatics. Here are key areas to explore:
Biological Databases – Learn about major databases like GenBank, UniProt, and Ensembl.
Genomics and Proteomics – Understand how computational methods analyze genes and proteins.
Sequence Analysis – Familiarize yourself with tools like BLAST, Clustal Omega, and FASTA.
🔹 Recommended Resources:
Online courses on Coursera, edX, or Khan Academy
Books like Bioinformatics for Dummies or Understanding Bioinformatics
Websites like NCBI, EMBL-EBI, and Expasy
Step 2: Develop Computational and Programming Skills
Bioinformatics heavily relies on coding and data analysis. You should start learning:
Python – Widely used in bioinformatics for data manipulation and analysis.
R – Great for statistical computing and visualization in genomics.
Linux/Unix – Basic command-line skills are essential for working with large datasets.
SQL – Useful for querying biological databases.
🔹 Recommended Online Courses:
Python for Bioinformatics (Udemy, DataCamp)
R for Genomics (HarvardX)
Linux Command Line Basics (Codecademy)
Step 3: Learn Bioinformatics Tools and Software
To become proficient in bioinformatics, you should practice using industry-standard tools:
Bioconductor – R-based tool for genomic data analysis.
Biopython – A powerful Python library for handling biological data.
GROMACS – Molecular dynamics simulation tool.
Rosetta – Protein modeling software.
🔹 How to Learn?
Join open-source projects on GitHub
Take part in hackathons or bioinformatics challenges on Kaggle
Explore free platforms like Galaxy Project for hands-on experience
Step 4: Work on Bioinformatics Projects
Practical experience is key. Start working on small projects such as:
✅ Analyzing gene sequences from NCBI databases ✅ Predicting protein structures using AlphaFold ✅ Visualizing genomic variations using R and Python
You can find datasets on:
NCBI GEO
1000 Genomes Project
TCGA (The Cancer Genome Atlas)
Create a GitHub portfolio to showcase your bioinformatics projects, as employers value practical work over theoretical knowledge.
Step 5: Gain Hands-on Experience with Internships
Many organizations and research institutes offer bioinformatics internships. Check opportunities at:
NCBI, EMBL-EBI, NIH (government research institutes)
Biotech and pharma companies (Roche, Pfizer, Illumina)
Academic research labs (Look for university-funded projects)
💡 Pro Tip: Join online bioinformatics communities like Biostars, Reddit r/bioinformatics, and SEQanswers to network and find opportunities.
Step 6: Earn a Certification or Higher Education
If you want to strengthen your credentials, consider:
🎓 Bioinformatics Certifications:
Coursera – Genomic Data Science (Johns Hopkins University)
edX – Bioinformatics MicroMasters (UMGC)
EMBO – Bioinformatics training courses
🎓 Master’s in Bioinformatics (optional but beneficial)
Top universities include Harvard, Stanford, ETH Zurich, University of Toronto
Step 7: Apply for Bioinformatics Jobs
Once you have gained enough skills and experience, start applying for bioinformatics roles such as:
Bioinformatics Analyst
Computational Biologist
Genomics Data Scientist
Machine Learning Scientist (Biotech)
💡 Where to Find Jobs?
LinkedIn, Indeed, Glassdoor
Biotech job boards (BioSpace, Science Careers)
Company career pages (Illumina, Thermo Fisher)
Final Thoughts
Transitioning from biotechnology to bioinformatics requires effort, but with the right skills and dedication, it is entirely achievable. Start with fundamental knowledge, build computational skills, and work on projects to gain practical experience.
Are you ready to make the switch? 🚀 Start today by exploring free online courses and practicing with real-world datasets!
#bioinformatics#biopractify#biotechcareers#biotechnology#biotech#aiinbiotech#machinelearning#bioinformaticstools#datascience#genomics#Biotechnology
4 notes
·
View notes