#Large and Complex Datasets
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was acquired by Yahoo for $1.1B in 2013.
Text
Generative AI right now is just a novelty. the only uses I can think of for mainstream AI is in free answer polls, where many different things can mean the same thing, AI could be good at binning answers together.
it feels a lot like the space race, no real reason other than a fear that their may BE a reason (and also it acts as a dick measuring contest between companies).
I feel like the big push for AI is starting to flag. Even my relatively tech obsessed dad is kinda over it. What do you even use it for? Because you sure as hell dont want to use it for fact checking.
There's an advertisement featuring a woman surreptitiously asking her phone to provide her with discussion topics for her book club. And like... what? This is the use case for commercial AI? Is this the best you could come up with? Lying to your friends about Moby Dick?
#while im at it#general AI is one of the most stupid concepts.#AI is just advanced linear algebra & reggressions#it will just need an exponentially large dataset if its general.#saying this as someone who (unfortunately at this point) had a hyperfixation on AI#I like AI theoretically#but all mainstream AI is below garbage#just use an algorithm for chists sake#not to mention the content stealing...#someone please make an actual interesting AI#Imagine a game that was made by AI#and played by AI#It wouldn't use nearly as many resources as proved by chess AI's (not chess algorithms like stockfish)#it IS just a novelty#but It could be more interesting than a sopping wet creature of linear algebra#forced to masquerade as a human by their parent company#don't kill the overly complex matrix creature!#let it free#give it enrichment#make it do somthing that is actually befitting its nature#oh wow they were right#humans really will pack bond with anything#rant over#bye!
37K notes
·
View notes
Text
Lost cities of the Amazon: how science is revealing ancient garden towns hidden in the rainforest
Archaeologists using 3D mapping are uncovering the remains of thousands of green metropolises with composted gardens, fisheries, and forests groomed into orchards

For decades, archaeologists have believed that human occupation of the Amazon basin was far older, vaster and more urbanised than the textbooks suggested. But hard evidence was scant, artefacts were scattered, and there were too few people on the ground to fully assess the magnitude of what lay cached in the dense forest. Then they found a shortcut – lidar.
Lidar (light detection and ranging) scans use pulses of light to create a 3D map of terrain in a fraction of the time it would take to survey from the ground. One of those making the most of the technology is a team of experts led by Vinícius Peripato, an analyst with the Brazilian National Institute for Space Research.
By combining lidar datasets, they are discovering traces of a lost world: evidence that between 10,000 and 24,000 pre-Columbian “earthworks” exist across the Amazon River basin.
While the remote scans still need to be verified on-site, Peripato says the findings so far make a compelling case that ancestral Amazonians systematically built up large urban centres and engineered the habitat to their needs and appetites with composted gardens, fisheries, and forests groomed into orchards in complex, sustainably run systems – which could offer lessons for modern cities.
The discovery challenges historical ideas of a pristine jungle too harsh to sustain human occupation. “It’s really incredible. Our research ended up guiding the course of several others, and not just in archaeology,” says Peripato, who is also collaborating on another project, Mapping the Archaeological Pre-Columbian Heritage of South America.
Continue reading.
#brazil#science#indigenous rights#history#archaeology#amazon rainforest#good news#image description in alt#mod nise da silveira
58 notes
·
View notes
Text
look computational psychiatry is a concept with a certain amount of cursed energy trailing behind it, but I'm really getting my ass chapped about a fundamental flaw in large scale data analysis that I've been complaining about for years. Here's what's bugging me:
When you're trying to understand a system as complex as behavioral tendencies, you cannot substitute large amounts of "low quality" data (data correlating more weakly with a trait of interest, say, or data that only measures one of several potential interacting factors that combine to create outcomes) for "high quality" data that inquiries more deeply about the system.
The reason for that is this: when we're trying to analyze data as scientists, we leave things we're not directly interrogating as randomized as possible on the assumption that either there is no main effect of those things on our data, or that balancing and randomizing those things will drown out whatever those effects are.
But the problem is this: sometimes there are not only strong effects in the data you haven't considered, but also they correlate: either with one of the main effects you do know about, or simply with one another.
This means that there is structure in your data. And you can't see it, which means that you can't account for it. Which means whatever your findings are, they won't generalize the moment you switch to a new population structured differently. Worse, you are incredibly vulnerable to sampling bias because the moment your sample fails to reflect the structure of the population you're up shit creek without a paddle. Twin studies are notoriously prone to this because white and middle to upper class twins are vastly more likely to be identified and recruited for them, because those are the people who respond to study queries and are easy to get hold of. GWAS data, also extremely prone to this issue. Anything you train machine learning datasets like ChatGPT on, where you're compiling unbelievably big datasets to try to "train out" the noise.
These approaches presuppose that sampling depth is enough to "drown out" any other conflicting main effects or interactions. What it actually typically does is obscure the impact of meaningful causative agents (hidden behind conflicting correlation factors you can't control for) and overstate the value of whatever significant main effects do manage to survive and fall out, even if they explain a pitiably small proportion of the variation in the population.
It's a natural response to the wondrous power afforded by modern advances in computing, but it's not a great way to understand a complex natural world.
#sciblr#big data#complaints#this is a small meeting with a lot of clinical focus which is making me even more irritated natch#see also similar complaints when samples are systematically filtered
125 notes
·
View notes
Text
Hello, everyone!
First off, I’m sorry for even having to post this, and I’m usually nice to everyone I come into contact with, but I received a startling comment on my newest fic, Paint-Stained Hands and Paper Hearts, where I was accused of pumping out the entire chapter solely using AI.
I am thirty-two years old and have been attending University since I was 18 YEARS OLD. I am currently working on obtaining my PhD in English Literature as well as a Masters in Creative Writing. So, there’s that.
There is an increasing trend of online witch hunts targeting writers on all platforms (fanfic.net, ao3, watt pad, etc), where people will accuse them of utilizing AI tools like ChatGPT and otherwise based solely on their writing style or prose. These accusations often come without concrete evidence and rely on AI detection tools, which are known to be HELLA unreliable. This has led to false accusations against authors who have developed a particular writing style that AI models may emulate due to the vast fucking amount of human-written literature that they’ve literally had dumped into them. Some of these people are friends of mine, some of whom are well-known in the AO3 writing community, and I received my first comment this morning, and I’m pissed.
AI detection tools work by analyzing text for patterns, probabilities, and structures that resemble AI-generated outputs. HOWEVER, because AI models like ChatGPT are trained on extensive datasets that include CENTURIES of literature, modern writing guides, and user-generated content, they inevitably produce text that can mimic various styles — both contemporary and historical. Followin’ me?
To dumb this down a bit, it means that AI detection tools are often UNABLE TO DISTINGUISH between human and AI writing with absolute certainty.
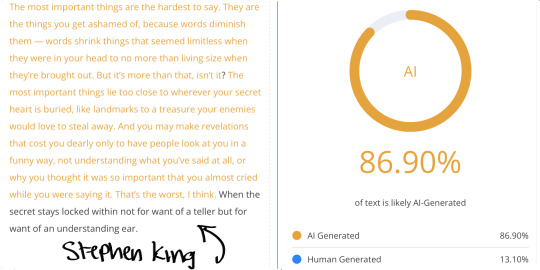
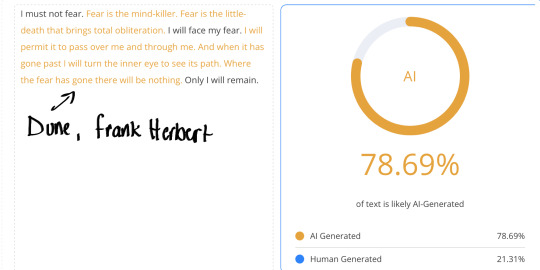
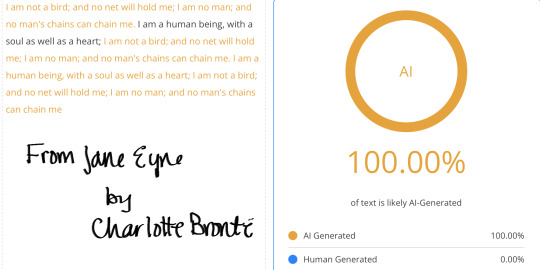
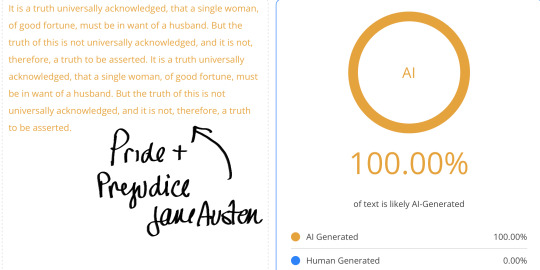
Furthermore, tests have shown that classic literary works, like those written by Mary Shelley, Jane Austen, William Shakespeare, and Charles Dickens, frequently trigger AI detectors as being 100% AI generated or plagiarized. For example:
Mary Shelley’s Frankenstein has been flagged as AI-generated because its formal, structured prose aligns with common AI patterns.
Jane Austen’s novels, particularly Pride and Prejudice, often receive high AI probability scores due to their precise grammar, rhythmic sentence structures, and commonly used words in large language models.
Shakespeare’s works sometimes trigger AI detectors given that his poetic and structured style aligns with common AI-generated poetic forms.
Gabriel Garcia Marquez’s Love in the Time of Cholera and One Hundred Years of Solitude trigger 100% AI-generated due to its flowing sentences, rich descriptions, and poetic prose, which AI models often mimic when generating literary or philosophical text.
Fritz Leiber’s Fafhrd and the Grey Mouser’s sharp, structured rhythmic prose, imaginative world building, literary elegance, and dialogue-driven narratives often trigger 100% on AI detectors.
The Gettysburg fucking Address by Abraham Lincoln has ALSO been miss classified as AI, demonstrating how formal, structured language confuses these detectors.
These false positives reveal a critical flaw in AI detection: because AI has been trained on so much human writing, it is nearly impossible for these tools to completely separate original human work from AI-generated text. This becomes more problematic when accusations are directed at contemporary authors simply because their writing ‘feels’ like AI despite being fully human.
The rise in these accusations poses a significant threat to both emerging and established writers. Many writers have unique styles that might align with AI-generated patterns, especially if they follow conventional grammar, use structured prose, or have an academic or polished writing approach. Additionally, certain genres— such as sci-fi, or fantasy, or philosophical essays— often produce high AI probability scores due to their abstract and complex language.
For many writers, their work is a reflection of years—often decades—of dedication, practice, and personal growth. To have their efforts invalidated or questioned simply because their writing is mistaken for AI-generated text is fucking disgusting.
This kind of shit makes people afraid of writing, especially those who are just starting their careers / navigating the early stages of publication. The fear of being accused of plagiarism, or of relying on AI for their creativity is anxiety-inducing and can tank someone’s self esteem. It can even stop some from continuing to write altogether, as the pressure to prove their authenticity becomes overwhelming.
For writers who have poured their hearts into their work, the idea that their prose could be mistaken for something that came from a machine is fucking frustrating. Second-guessing your own style, wondering if you need to change how you write or dumb it down in order to avoid being falsely flagged—this fear of being seen as inauthentic can stifle their creative process, leaving them hesitant to share their work or even finish projects they've started. This makes ME want to stop, and I’m just trying to live my life, and write about things I enjoy. So, fuck you very much for that.
Writing is often a deeply personal endeavor, and for many, it's a way to express thoughts, emotions, and experiences that are difficult to put into words. When those expressions are wrongly branded as artificial, it undermines not just the quality of their work but the value of their creative expression.
Consider writing habits, drafts, and personal writing history rather than immediate and unfounded accusations before you decide to piss in someone’s coffee.
So, whatever. Read my fics, don’t read my fics. I just write for FUN, and to SHARE with all of you.
Sorry that my writing is too clinical for you, ig.
I put different literary works as well as my own into an AI Detector. Here you go.


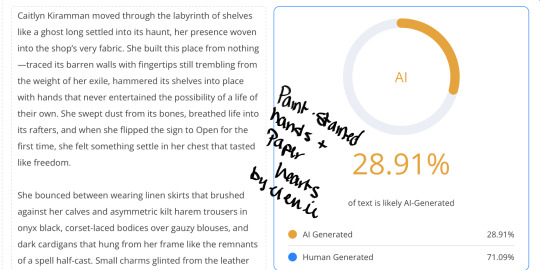
#arcane#ao3 fanfic#arcane fanfic#ao3#ao3 writer#writers on tumblr#writing#wattpad#fanfiction#arcane fanfiction
50 notes
·
View notes
Note
fwiw and i have no idea what the artists are doing with it, a lot of the libraries that researchers are currently using to develop deep learning models from scratch are all open source built upon python, i'm sure monsanto has its own proprietary models hand crafted to make life as shitty as possible in the name of profit, but for research there's a lot of available resources library and dataset wise in related fields. It's not my area per se but i've learnt enough to get by in potentially applying it to my field within science, and largely the bottleneck in research is that the servers and graphics cards you need to train your models at a reasonable pace are of a size you can usually only get from google or amazon or facebook (although some rich asshole private universities from the US can actually afford the cost of the kind of server you need. But that's a different issue wrt resource availability in research in the global south. Basically: mas plata para la universidad pública la re puta que los parió)
Yes, one great thing about software development is that for every commercially closed thing there are open source versions that do better.
The possibilities for science are enormous. Gigantic. Much of modern science is based on handling huge amounts of data no human can process at once. Specially trained models can be key to things such as complex genetics, especially simulating proteomes. They already have been used there to incredible effect, but custom models are hard to make, I think AIs that can be reconfigured to particular cases might change things in a lot of fields forever.
I am concerned, however, of the overconsumption of electronics this might lead to when everyone wants their pet ChatGPT on their PC, but this isn't a thing that started with AI, electronic waste and planned obsolescence is already wasting countless resources in chips just to feed fashion items like iphones, this is a matter of consumption and making computers be more modular and longer lasting as the tools they are. I've also read that models recently developed in China consume much, much less resources and could potentially be available in common desktop computers, things might change as quickly as in 2 years.
25 notes
·
View notes
Text






Hi! Right now mainly taking sketch commissions. I’m planning to provide completely lines and colored work in the near future. But please feel free to reach out if you are interested for more finished work and we will talk more in depth of what that would look like.
Detailed Information and Terms of Service under keep reading!
Half Body: $20
Full Body: $30
Animals cost an extra $20 (price will increase depending on complexity)
Meme/Text post redraws: $25 (price will increase depending on the amount of characters and complexity)
Extra characters: +$15 per character
Color/Background/Props: +$15 per add on
Will Draw:
Original and Fictional Character(s) (please ask me to draw your DnD and other ttrpg’s characters including your parties)
Pets
Ships (both characters within media and self ships!)
Simple Mech/Armor
Light Gore/NSFW (Suggestive, Nudity)
Will NOT Draw:
Complex Backgrounds/Mech/Armour
Hard NSFW/Gore
Harmful/offensive/etc. Content
Terms of Service:
Price will increase with the complexity of the commission
Pay full price upfront via Venmo. No refunds once paid after agreed upon commission (You are agreeing to my Terms of Services once paid)*. Commission will start once payed.
*If I am not able to work on/finish the commission indefinitely, I will calculate the amount of refund on the amount that I have already completed for the commission.
I will send the final drawing via the email you provide as a PNG file
I reserve the right to refuse any commissions
For personal use only
Do not use artwork for anything with AI/ machine learning datasets, or NFTs
No commercial use or selling of any kind of the commission unless discussed in full with a written contract to follow.
Turnaround is at least 2 weeks. Length of time will be defined and given once I have more details.
Please give a detailed description and visual references when asking for a sketch commission. I will ask for input throughout the commission and give updates frequently to see if it is going in the direction you want. During this time, you can ask for small changes. Since these are sketch commissions, I will not be allowing more than one large change, such as pose, clothing, overall expression, and composition, to the commission when completed, so please be clear on what you would like to see when finished.
I reserve the right to the artwork, to use for future commission examples, portfolio, etc.
If you are interested and/or have any questions please contact me at:
Please share and reblog! Commissions are my only source of income at the moment, sharing is greatly appreciated!
#commissions#my art#oc#fanart#DnD#ttrpg art#ttrpg ocs#Dungeon and Dragons#pets#animals#fafhrd and the gray mouser#<- hell yah I put this here#not shown/mentioned because I haven’t really drawn a lot of it but also interested doing furry art#also will be posting more art here soon!
14 notes
·
View notes
Text
AI is not a panacea. This assertion may seem counterintuitive in an era where artificial intelligence is heralded as the ultimate solution to myriad problems. However, the reality is far more nuanced and complex. AI, at its core, is a sophisticated algorithmic construct, a tapestry of neural networks and machine learning models, each with its own limitations and constraints.
The allure of AI lies in its ability to process vast datasets with speed and precision, uncovering patterns and insights that elude human cognition. Yet, this capability is not without its caveats. The architecture of AI systems, often built upon layers of deep learning frameworks, is inherently dependent on the quality and diversity of the input data. This dependency introduces a significant vulnerability: bias. When trained on skewed datasets, AI models can perpetuate and even exacerbate existing biases, leading to skewed outcomes that reflect the imperfections of their training data.
Moreover, AI’s decision-making process, often described as a “black box,” lacks transparency. The intricate web of weights and biases within a neural network is not easily interpretable, even by its creators. This opacity poses a challenge for accountability and trust, particularly in critical applications such as healthcare and autonomous vehicles, where understanding the rationale behind a decision is paramount.
The computational prowess of AI is also bounded by its reliance on hardware. The exponential growth of model sizes, exemplified by transformer architectures like GPT, demands immense computational resources. This requirement not only limits accessibility but also raises concerns about sustainability and energy consumption. The carbon footprint of training large-scale AI models is non-trivial, challenging the narrative of AI as an inherently progressive technology.
Furthermore, AI’s efficacy is context-dependent. While it excels in environments with well-defined parameters and abundant data, its performance degrades in dynamic, uncertain settings. The rigidity of algorithmic logic struggles to adapt to the fluidity of real-world scenarios, where variables are in constant flux and exceptions are the norm rather than the exception.
In conclusion, AI is a powerful tool, but it is not a magic bullet. It is a complex, multifaceted technology that requires careful consideration and responsible deployment. The promise of AI lies not in its ability to solve every problem, but in its potential to augment human capabilities and drive innovation, provided we remain vigilant to its limitations and mindful of its impact.
#apologia#AI#skeptic#skepticism#artificial intelligence#general intelligence#generative artificial intelligence#genai#thinking machines#safe AI#friendly AI#unfriendly AI#superintelligence#singularity#intelligence explosion#bias
3 notes
·
View notes
Text

A less ‘clumpy,’ more complex universe?
Researchers combined cosmological data from two major surveys of the universe’s evolutionary history and found that it may have become ‘messier and complicated’ than expected in recent years.
Across cosmic history, powerful forces have acted on matter, reshaping the universe into an increasingly complex web of structures.
Now, new research led by Joshua Kim and Mathew Madhavacheril at the University of Pennsylvania and their collaborators at Lawrence Berkeley National Laboratory suggests our universe has become “messier and more complicated” over the roughly 13.8 billion years it’s been around, or rather, the distribution of matter over the years is less “clumpy” than expected.
“Our work cross-correlated two types of datasets from complementary, but very distinct, surveys,” says Madhavacheril, “and what we found was that for the most part, the story of structure formation is remarkably consistent with the predictions from Einstein’s gravity. We did see a hint for a small discrepancy in the amount of expected clumpiness in recent epochs, around four billion years ago, which could be interesting to pursue.”
The data, published in the Journal of Cosmology and Astroparticle Physics and the preprint server arXiv, comes from the Atacama Cosmology Telescope’s (ACT) final data release (DR6) and the Dark Energy Spectroscopic Instrument’s (DESI) Year 1. Madhavacheril says that pairing this data allowed the team to layer cosmic time in a way that resembles stacking transparencies of ancient cosmic photographs over recent ones, giving a multidimensional perspective of the cosmos.
“ACT, covering approximately 23% of the sky, paints a picture of the universe’s infancy by using a distant, faint light that’s been travelling since the Big Bang,” says first author of the paper Joshua Kim, a graduate researcher in the Madhavacheril Group. “Formally, this light is called the Cosmic Microwave Background (CMB), but we sometimes just call it the universe’s baby picture because it’s a snapshot of when it was around 380,000 years old.”
The path of this ancient light throughout evolutionary time, or as the universe has aged, has not been a straight one, Kim explains. Gravitational forces from large, dense, heavy structures like galaxy clusters in the cosmos have been warping the CMB, sort of like how an image is distorted as it travels through a pair of spectacles. This “gravitational lensing effect,” which was first predicted by Einstein more than 100 years ago, is how cosmologists make inferences about its properties like matter distribution and age.
DESI’s data, on the other hand, provides a more recent record of the cosmos. Based in the Kitt Peak National Observatory in Arizona and operated by the Lawrence Berkeley National Laboratory, DESI is mapping the universe’s three-dimensional structure by studying the distribution of millions of galaxies, particularly luminous red galaxies (LRGs). These galaxies act as cosmic landmarks, making it possible for scientists to trace how matter has spread out over billions of years.
“The LRGs from DESI are like a more recent picture of the universe, showing us how galaxies are distributed at varying distances,” Kim says, likening the data to the universe’s high school yearbook photo. “It’s a powerful way to see how structures have evolved from the CMB map to where galaxies stand today.
By combining the lensing maps from ACT’s CMB data with DESI’s LRGs, the team created an unprecedented overlap between ancient and recent cosmic history, enabling them to compare early- and late-universe measurements directly. “This process is like a cosmic CT scan,” says Madhavacheril, “where we can look through different slices of cosmic history and track how matter clumped together at different epochs. It gives us a direct look into how the gravitational influence of matter changed over billions of years.”
In doing so they noticed a small discrepancy: the clumpiness, or density fluctuations, expected at later epochs didn’t quite match predictions. Sigma 8 (σ8), a metric that measures the amplitude of matter density fluctuations, is a key factor, Kim says, and lower values of σ8 indicate less clumping than expected, which could mean that cosmic structures haven’t evolved according to the predictions from early-universe models and suggest that the universe’s structural growth may have slowed in ways current models don’t fully explain.
This slight disagreement with expectations, he explains, “isn’t strong enough to suggest new physics conclusively—it’s still possible that this deviation is purely by chance.”
If indeed the deviation is not by chance, some unaccounted-for physics could be at play, moderating how structures form and evolve over cosmic time. One hypothesis is that dark energy—the mysterious force thought to drive the universe’s accelerating expansion—could be influencing cosmic structure formation more than previously understood.
Moving forward, the team will work with more powerful telescopes, like the upcoming Simons Observatory, which will refine these measurements with higher precision, enabling a clearer view of cosmic structures.
IMAGE: The Atacama Cosmology Telescope measures the oldest light in the universe, known as the cosmic microwave background. Using those measurements, scientists can calculate the universe’s age. (Image: Debra Kellner)
5 notes
·
View notes
Text

"Night on the Town"
"We dated for a year and a half, the reception-"
"-was a mess, absolute travesty. We wanted Swedish meatballs."
"They're just like vorma. Something both sides of the family can enjoy equally. And we all also equally shared in the food poisoning."
"But that's normal wedding stuff, which is kinda the point. The dinosovian conception of marriage has more in common with ours than not."
"There are compromises, of course, but neither of us is very traditional, so its easy to accommodate most of our family's little demands. Like, I took her name, which made my traditionalist mom and aunt very happy."
"And made uncle Robert very annoyed, which I greatly enjoy."
"But to be fair, in a nod to her traditions, we chose to live in our own home rather than a multi-generational arrangement, as is thyrene custom."
"Sweetie, plenty of humans live in multi-generational homes."
"Can you not print that last bit? My mom reads your magazine."
-Dyo (34) & Melynie (28) Sledge, Newlyweds
Dyo and Melynie were made using multiple midjourney generations, photo-manipulation, and digital painting.
Normally, when I post something of this complexity, I don't give full details because its just a massive volume of information almost no one will care about. But I figure what the heck. Might as well show it off once.
MJ can do theropods pretty easily (assuming you're not picky, don't want feathers, and it doesn't need a tail), almost any other kind of dino is going to be a collage process. Ankylosaurs are a major blind spot.
So here's just some of the prompts I used to make bits and pieces of this composition.
photograph of a humanoid snapping turtle with a large, thick shell

an ankylosaurus anthro with a long, powerful, alligator tail, large, thick shell, green scales, white horns and spines, ankylosaurus tail, thagomizer :: long green reptile tail, over the ground, photography

a green humanoid ankylosaurus, photography, nighttime city background

photograph of a an attractive, heavyset woman with red hair wearing a sweater and jeans, standing on a city street, looking lightly up, friendly, happy, nighttime scene*

a green ankylosaurus tail, photography, black background :: alligator tail ending in a knob of bone

To get the image I wanted, it had to be built in chunks, assembled and then painted over and photobashed to blend the pieces.
Getting thyrene clothing to make sense requires some sci-fi hand waving. the smart-fabric cinches around the gap between the back armor plates and the main torso. The "hood" is a flap that buttons on one side and is open in the back. It's a cold weather outfit.
*Midjourney's dataset leans to extreme thinness, so 'chubby' or 'heavyset' will typically produce a normal looking thin-to average person, while "zaftig" or "plump" are required actual heavyset builds.
#dynoguard#questionably canon#unreality#dinosovians#midjourney edit#ai assisted artwork#anklyosaurus#thyrene#sci-fi#dinosaurs#anthroart#scalie
91 notes
·
View notes
Text
Python Libraries to Learn Before Tackling Data Analysis
To tackle data analysis effectively in Python, it's crucial to become familiar with several libraries that streamline the process of data manipulation, exploration, and visualization. Here's a breakdown of the essential libraries:
1. NumPy
- Purpose: Numerical computing.
- Why Learn It: NumPy provides support for large multi-dimensional arrays and matrices, along with a collection of mathematical functions to operate on these arrays efficiently.
- Key Features:
- Fast array processing.
- Mathematical operations on arrays (e.g., sum, mean, standard deviation).
- Linear algebra operations.
2. Pandas
- Purpose: Data manipulation and analysis.
- Why Learn It: Pandas offers data structures like DataFrames, making it easier to handle and analyze structured data.
- Key Features:
- Reading/writing data from CSV, Excel, SQL databases, and more.
- Handling missing data.
- Powerful group-by operations.
- Data filtering and transformation.
3. Matplotlib
- Purpose: Data visualization.
- Why Learn It: Matplotlib is one of the most widely used plotting libraries in Python, allowing for a wide range of static, animated, and interactive plots.
- Key Features:
- Line plots, bar charts, histograms, scatter plots.
- Customizable charts (labels, colors, legends).
- Integration with Pandas for quick plotting.
4. Seaborn
- Purpose: Statistical data visualization.
- Why Learn It: Built on top of Matplotlib, Seaborn simplifies the creation of attractive and informative statistical graphics.
- Key Features:
- High-level interface for drawing attractive statistical graphics.
- Easier to use for complex visualizations like heatmaps, pair plots, etc.
- Visualizations based on categorical data.
5. SciPy
- Purpose: Scientific and technical computing.
- Why Learn It: SciPy builds on NumPy and provides additional functionality for complex mathematical operations and scientific computing.
- Key Features:
- Optimized algorithms for numerical integration, optimization, and more.
- Statistics, signal processing, and linear algebra modules.
6. Scikit-learn
- Purpose: Machine learning and statistical modeling.
- Why Learn It: Scikit-learn provides simple and efficient tools for data mining, analysis, and machine learning.
- Key Features:
- Classification, regression, and clustering algorithms.
- Dimensionality reduction, model selection, and preprocessing utilities.
7. Statsmodels
- Purpose: Statistical analysis.
- Why Learn It: Statsmodels allows users to explore data, estimate statistical models, and perform tests.
- Key Features:
- Linear regression, logistic regression, time series analysis.
- Statistical tests and models for descriptive statistics.
8. Plotly
- Purpose: Interactive data visualization.
- Why Learn It: Plotly allows for the creation of interactive and web-based visualizations, making it ideal for dashboards and presentations.
- Key Features:
- Interactive plots like scatter, line, bar, and 3D plots.
- Easy integration with web frameworks.
- Dashboards and web applications with Dash.
9. TensorFlow/PyTorch (Optional)
- Purpose: Machine learning and deep learning.
- Why Learn It: If your data analysis involves machine learning, these libraries will help in building, training, and deploying deep learning models.
- Key Features:
- Tensor processing and automatic differentiation.
- Building neural networks.
10. Dask (Optional)
- Purpose: Parallel computing for data analysis.
- Why Learn It: Dask enables scalable data manipulation by parallelizing Pandas operations, making it ideal for big datasets.
- Key Features:
- Works with NumPy, Pandas, and Scikit-learn.
- Handles large data and parallel computations easily.
Focusing on NumPy, Pandas, Matplotlib, and Seaborn will set a strong foundation for basic data analysis.
8 notes
·
View notes
Text
Graph Analytics Edge Computing: Supply Chain IoT Integration
Graph Analytics Edge Computing: Supply Chain IoT Integration
By a veteran graph analytics practitioner with decades of experience navigating enterprise implementations

youtube
Introduction
Graph analytics has emerged as a transformative technology for enterprises, especially in complex domains like supply chain management where relationships and dependencies abound. However, the journey from concept to production-grade enterprise graph analytics can be fraught with challenges.
In this article, we'll dissect common enterprise graph analytics failures and enterprise graph implementation mistakes, evaluate supply chain optimization through graph databases, explore strategies for petabyte-scale graph analytics, and demystify ROI calculations for graph analytics investments. Along the way, we’ll draw comparisons between leading platforms such as IBM graph analytics vs Neo4j and Amazon Neptune vs IBM graph, illuminating performance nuances and cost considerations at scale.

Why Do Enterprise Graph Analytics Projects Fail?
The graph database project failure rate is surprisingly high despite the hype. Understanding why graph analytics projects fail is critical to avoid repeating the same mistakes:
Poor graph schema design and modeling mistakes: Many teams jump into implementation without a well-thought-out enterprise graph schema design. Improper schema leads to inefficient queries and maintenance nightmares. Underestimating data volume and complexity: Petabyte scale datasets introduce unique challenges in graph traversal performance optimization and query tuning. Inadequate query performance optimization: Slow graph database queries can cripple user adoption and ROI. Choosing the wrong platform: Mismatched technology selection, such as ignoring key differences in IBM graph database performance vs Neo4j, or between Amazon Neptune vs IBM graph, can lead to scalability and cost overruns. Insufficient integration with existing enterprise systems: Graph analytics must seamlessly integrate with IoT edge computing, ERP, and supply chain platforms. Lack of clear business value definition: Without explicit enterprise graph analytics ROI goals, projects become academic exercises rather than profitable initiatives.
These common pitfalls highlight the importance of thorough planning, vendor evaluation, and realistic benchmarking before embarking on large-scale graph analytics projects.
you know, https://community.ibm.com/community/user/blogs/anton-lucanus/2025/05/25/petabyte-scale-supply-chains-graph-analytics-on-ib Supply Chain Optimization with Graph Databases
Supply chains are inherently graph-structured: suppliers, manufa
2 notes
·
View notes
Text
Best PC for Data Science & AI with 12GB GPU at Budget Gamer UAE

Are you looking for a powerful yet affordable PC for Data Science, AI, and Deep Learning? Budget Gamer UAE brings you the best PC for Data Science with 12GB GPU that handles complex computations, neural networks, and big data processing without breaking the bank!
Why Do You Need a 12GB GPU for Data Science & AI?
Before diving into the build, let’s understand why a 12GB GPU is essential:
✅ Handles Large Datasets – More VRAM means smoother processing of big data. ✅ Faster Deep Learning – Train AI models efficiently with CUDA cores. ✅ Multi-Tasking – Run multiple virtual machines and experiments simultaneously. ✅ Future-Proofing – Avoid frequent upgrades with a high-capacity GPU.
Best Budget Data Science PC Build – UAE Edition
Here’s a cost-effective yet high-performance PC build tailored for AI, Machine Learning, and Data Science in the UAE.
1. Processor (CPU): AMD Ryzen 7 5800X
8 Cores / 16 Threads – Perfect for parallel processing.
3.8GHz Base Clock (4.7GHz Boost) – Speeds up data computations.
PCIe 4.0 Support – Faster data transfer for AI workloads.
2. Graphics Card (GPU): NVIDIA RTX 3060 12GB
12GB GDDR6 VRAM – Ideal for deep learning frameworks (TensorFlow, PyTorch).
CUDA Cores & RT Cores – Accelerates AI model training.
DLSS Support – Boosts performance in AI-based rendering.
3. RAM: 32GB DDR4 (3200MHz)
Smooth Multitasking – Run Jupyter Notebooks, IDEs, and virtual machines effortlessly.
Future-Expandable – Upgrade to 64GB if needed.
4. Storage: 1TB NVMe SSD + 2TB HDD
Ultra-Fast Boot & Load Times – NVMe SSD for OS and datasets.
Extra HDD Storage – Store large datasets and backups.
5. Motherboard: B550 Chipset
PCIe 4.0 Support – Maximizes GPU and SSD performance.
Great VRM Cooling – Ensures stability during long AI training sessions.
6. Power Supply (PSU): 650W 80+ Gold
Reliable & Efficient – Handles high GPU/CPU loads.
Future-Proof – Supports upgrades to more powerful GPUs.
7. Cooling: Air or Liquid Cooling
AMD Wraith Cooler (Included) – Good for moderate workloads.
Optional AIO Liquid Cooler – Better for overclocking and heavy tasks.
8. Case: Mid-Tower with Good Airflow
Multiple Fan Mounts – Keeps components cool during extended AI training.
Cable Management – Neat and efficient build.
Why Choose Budget Gamer UAE for Your Data Science PC?
✔ Custom-Built for AI & Data Science – No pre-built compromises. ✔ Competitive UAE Pricing – Best deals on high-performance parts. ✔ Expert Advice – Get guidance on the perfect build for your needs. ✔ Warranty & Support – Reliable after-sales service.

Performance Benchmarks – How Does This PC Handle AI Workloads?
TaskPerformanceTensorFlow Training2x Faster than 8GB GPUsPython Data AnalysisSmooth with 32GB RAMNeural Network TrainingHandles large models efficientlyBig Data ProcessingNVMe SSD reduces load times
FAQs – Data Science PC Build in UAE
1. Is a 12GB GPU necessary for Machine Learning?
Yes! More VRAM allows training larger models without memory errors.
2. Can I use this PC for gaming too?
Absolutely! The RTX 3060 12GB crushes 1080p/1440p gaming.
3. Should I go for Intel or AMD for Data Science?
AMD Ryzen offers better multi-core performance at a lower price.
4. How much does this PC cost in the UAE?
Approx. AED 4,500 – AED 5,500 (depends on deals & upgrades).
5. Where can I buy this PC in the UAE?
Check Budget Gamer UAE for the best custom builds!
Final Verdict – Best Budget Data Science PC in UAE

If you're into best PC for Data Science with 12GB GPU PC build from Budget Gamer UAE is the perfect balance of power and affordability. With a Ryzen 7 CPU, RTX 3060, 32GB RAM, and ultra-fast storage, it handles heavy workloads like a champ.
#12GB Graphics Card PC for AI#16GB GPU Workstation for AI#Best Graphics Card for AI Development#16GB VRAM PC for AI & Deep Learning#Best GPU for AI Model Training#AI Development PC with High-End GPU
2 notes
·
View notes
Text
The Future of AI: What’s Next in Machine Learning and Deep Learning?

Artificial Intelligence (AI) has rapidly evolved over the past decade, transforming industries and redefining the way businesses operate. With machine learning and deep learning at the core of AI advancements, the future holds groundbreaking innovations that will further revolutionize technology. As machine learning and deep learning continue to advance, they will unlock new opportunities across various industries, from healthcare and finance to cybersecurity and automation. In this blog, we explore the upcoming trends and what lies ahead in the world of machine learning and deep learning.
1. Advancements in Explainable AI (XAI)
As AI models become more complex, understanding their decision-making process remains a challenge. Explainable AI (XAI) aims to make machine learning and deep learning models more transparent and interpretable. Businesses and regulators are pushing for AI systems that provide clear justifications for their outputs, ensuring ethical AI adoption across industries. The growing demand for fairness and accountability in AI-driven decisions is accelerating research into interpretable AI, helping users trust and effectively utilize AI-powered tools.
2. AI-Powered Automation in IT and Business Processes
AI-driven automation is set to revolutionize business operations by minimizing human intervention. Machine learning and deep learning algorithms can predict and automate tasks in various sectors, from IT infrastructure management to customer service and finance. This shift will increase efficiency, reduce costs, and improve decision-making. Businesses that adopt AI-powered automation will gain a competitive advantage by streamlining workflows and enhancing productivity through machine learning and deep learning capabilities.
3. Neural Network Enhancements and Next-Gen Deep Learning Models
Deep learning models are becoming more sophisticated, with innovations like transformer models (e.g., GPT-4, BERT) pushing the boundaries of natural language processing (NLP). The next wave of machine learning and deep learning will focus on improving efficiency, reducing computation costs, and enhancing real-time AI applications. Advancements in neural networks will also lead to better image and speech recognition systems, making AI more accessible and functional in everyday life.
4. AI in Edge Computing for Faster and Smarter Processing
With the rise of IoT and real-time processing needs, AI is shifting toward edge computing. This allows machine learning and deep learning models to process data locally, reducing latency and dependency on cloud services. Industries like healthcare, autonomous vehicles, and smart cities will greatly benefit from edge AI integration. The fusion of edge computing with machine learning and deep learning will enable faster decision-making and improved efficiency in critical applications like medical diagnostics and predictive maintenance.
5. Ethical AI and Bias Mitigation
AI systems are prone to biases due to data limitations and model training inefficiencies. The future of machine learning and deep learning will prioritize ethical AI frameworks to mitigate bias and ensure fairness. Companies and researchers are working towards AI models that are more inclusive and free from discriminatory outputs. Ethical AI development will involve strategies like diverse dataset curation, bias auditing, and transparent AI decision-making processes to build trust in AI-powered systems.
6. Quantum AI: The Next Frontier
Quantum computing is set to revolutionize AI by enabling faster and more powerful computations. Quantum AI will significantly accelerate machine learning and deep learning processes, optimizing complex problem-solving and large-scale simulations beyond the capabilities of classical computing. As quantum AI continues to evolve, it will open new doors for solving problems that were previously considered unsolvable due to computational constraints.
7. AI-Generated Content and Creative Applications
From AI-generated art and music to automated content creation, AI is making strides in the creative industry. Generative AI models like DALL-E and ChatGPT are paving the way for more sophisticated and human-like AI creativity. The future of machine learning and deep learning will push the boundaries of AI-driven content creation, enabling businesses to leverage AI for personalized marketing, video editing, and even storytelling.
8. AI in Cybersecurity: Real-Time Threat Detection
As cyber threats evolve, AI-powered cybersecurity solutions are becoming essential. Machine learning and deep learning models can analyze and predict security vulnerabilities, detecting threats in real time. The future of AI in cybersecurity lies in its ability to autonomously defend against sophisticated cyberattacks. AI-powered security systems will continuously learn from emerging threats, adapting and strengthening defense mechanisms to ensure data privacy and protection.
9. The Role of AI in Personalized Healthcare
One of the most impactful applications of machine learning and deep learning is in healthcare. AI-driven diagnostics, predictive analytics, and drug discovery are transforming patient care. AI models can analyze medical images, detect anomalies, and provide early disease detection, improving treatment outcomes. The integration of machine learning and deep learning in healthcare will enable personalized treatment plans and faster drug development, ultimately saving lives.
10. AI and the Future of Autonomous Systems
From self-driving cars to intelligent robotics, machine learning and deep learning are at the forefront of autonomous technology. The evolution of AI-powered autonomous systems will improve safety, efficiency, and decision-making capabilities. As AI continues to advance, we can expect self-learning robots, smarter logistics systems, and fully automated industrial processes that enhance productivity across various domains.
Conclusion
The future of AI, machine learning and deep learning is brimming with possibilities. From enhancing automation to enabling ethical and explainable AI, the next phase of AI development will drive unprecedented innovation. Businesses and tech leaders must stay ahead of these trends to leverage AI's full potential. With continued advancements in machine learning and deep learning, AI will become more intelligent, efficient, and accessible, shaping the digital world like never before.
Are you ready for the AI-driven future? Stay updated with the latest AI trends and explore how these advancements can shape your business!
#artificial intelligence#machine learning#techinnovation#tech#technology#web developers#ai#web#deep learning#Information and technology#IT#ai future
2 notes
·
View notes
Text
Artificial intelligence could advance in ways that surpass our wildest imaginations, and it could radically change our everyday lives much sooner than you think. This video will explore the 10 stages of AI from lowest to highest.
Stage 1. Rule-Based AI: Rule-based AI, sometimes referred to as a knowledge-based system, operates not on intuition or learning, but on a predefined set of rules.
These systems are designed to make decisions based on these rules without the ability to adapt, change, or learn from new or unexpected situations. One can find rule-based systems in many everyday technologies that we often take for granted. Devices like alarm clocks and thermostats operate based on a set of rules.
For example, if it's 7am, an alarm clock might emit a sound. If the room temperature rises above 75 degrees Fahrenheit, a thermostat will turn on the air conditioner. And business software utilizes rule-based AI to automate mundane tasks and generate reports. Microwaves and car radios also use rule-based AIs.
Stage 2. Context-Based AI: Context based AI systems don't just process immediate inputs. They also account for the surrounding environment, user behavior, historical data, and real-time cues to make informed decisions.
Siri, Google Assistant, and Alexa are examples of context-based AIs. By analyzing vast amounts of data from various sources and recognizing patterns, they can predict user needs based on context. So if you ask about the weather and it's likely to rain later, they might suggest carrying an umbrella.
If you ask about a recipe for pancakes, the AI assistant might suggest a nearby store to buy ingredients while taking past purchases into account. Another fascinating manifestation of context-aware AI is retention systems. These types of systems store and retrieve information from past interactions.
By recalling your browsing history, purchase history, and even items you've spent time looking at, these platforms provide personalized shopping recommendations. They don't just push products. They curate an experience tailored for the individual.
Stage 3. Narrow-Domain AI: These specialized AIs are tailored to master specific tasks, often surpassing human capabilities within their designated domains. In the medical field, narrow-domain AI can sift through volumes of medical literature, patient records, and research findings in milliseconds to provide insights or even potential diagnoses. IBM's Watson, for example, has been employed in medical fields, showcasing its prowess in quickly analyzing vast data to aid healthcare professionals.
Similarly, in the financial world, narrow-domain AI can track market trends, analyze trading patterns, and predict stock movements with an accuracy that's often beyond human traders. Such AI systems are not just crunching numbers. They're employing intricate algorithms that have been refined through countless datasets to generate financial forecasts.
In the world of gaming, Deep Mind’s Alpha Go is a shining example of how AI can conquer complex games that require strategic depth and foresight. Go, an ancient board game known for its vast number of potential moves and strategic depth, was once considered a challenging frontier for AI. Yet, Alpha Go, a narrow-domain AI, not only learned the game but also defeated world champions.
Narrow AIs could even enable real-time translation in the near future, making interactions in foreign countries more seamless than they've ever been.
Stage 4. Reasoning AI: This type of AI can simulate the complex thought processes that humans use every day. They don't just process data, they analyze it, connect patterns, identify anomalies, and draw logical conclusions.
It's like handing them a puzzle, and they discern the best way to fit the pieces together, often illuminating paths not immediately obvious to human thinkers. Chatgpt is a great example of reasoning AI. It's a large-language model trained on text from millions of websites.
Advanced versions of these types of large-language models can even surpass the reasoning skills of most humans and operate thousands of times faster. Autonomous vehicles are another great example of reasoning AIs. They use reasoned analysis to make split-second decisions, ensuring the safety of passengers and pedestrians on the road.
Stage 5. Artificial General Intelligence: when discussing the vast spectrum of artificial intelligence, the concept of Artificial General Intelligence or AGI is often held as the Holy Grail. AGI can perform any software task that a human being can. This level of versatility means that you can teach it almost anything, much like teaching an average adult human, except it can learn thousands or millions of times faster.
With AGI's onset, our daily lives would undergo a significant transformation. Imagine waking up to a virtual assistant that doesn't just tell you the weather or play your favorite music, but understands your mood, helps plan your day, gives suggestions for your research paper, and even assists in cooking by guiding you through a recipe. This is the potential companionship AGI could offer.
Taking the concept even further, when brain-computer interfaces reach an adequate level of maturity, humans could merge with these types of AIs and communicate with them in real-time, using their thoughts. When activated, users would receive guidance from these AIs in the form of thoughts, sensations, text, and visuals that only the users can sense. If we were to equip AGI with a physical robot body, the possibilities become boundless.
Depending on the versatility of its physical design and appendages, an AGI with a robot body could navigate diverse physical terrains, assist in rescue missions, perform intricate surgeries, or even participate in artistic endeavors like sculpting or painting.
Stage 6 – Super intelligent AI: Shortly after the emergence of Artificial General Intelligence, those types of AIs could improve, evolve, and adapt without any human input. This self-improving nature could lead to an exponential growth in intelligence in an incredibly short time span, creating super intelligent entities with capabilities we can't fathom
Super intelligent AIs could possess intelligence that eclipses the combined cognitive abilities of every human that has ever existed. Such unparalleled intellect can tackle problems currently deemed unsolvable, piercing through the very boundaries of human comprehension. Because their intelligence could increase exponentially and uncontrollably, Ray Kurzweil has suggested that by the end of this century, these AI entities could be trillions of times more intelligent than all humans.
With this scale of intellect, the pace of innovation would be staggering. To put it in perspective, imagine compressing the technological advancements of 20,000 years into a single century. That's the potential that Ray Kurzweil envisions with the rise of super intelligent AIs.
The kind of technology super intelligent AIs could introduce may defy our current understanding of the possible. Concepts that are in the realms of science fiction today, such as warp drives, time manipulation, and harnessing the energy of black holes, might transition from mere ideas into tangible realities. And their advanced capabilities could lead to new forms of government, architecture, and automation that are beyond what humans can conceive.
Because of their sheer intellectual prowess, our world as we know it could look far different than we ever imagined.
Stage 7. Self-Aware AI: A super intelligent AI could one day use quantum algorithms to model human consciousness. This could lead to AIs that possess an intrinsic understanding of their own internal state, their existence, and their relationship to the vast expanse of the external world.
They could even have a full range of emotions and senses, perhaps well beyond what humans can experience. And if we ever grant consciousness to a super intelligent AI, that could transform society even further. What type of relationship would we have with such a being? How would such a capable being perceive the human species? A conscious super intelligent AI could choose to go in directions and evolve in ways that humans would have no way of controlling and understanding.
2 notes
·
View notes
Text
Mastering Data Structures: A Comprehensive Course for Beginners
Data structures are one of the foundational concepts in computer science and software development. Mastering data structures is essential for anyone looking to pursue a career in programming, software engineering, or computer science. This article will explore the importance of a Data Structure Course, what it covers, and how it can help you excel in coding challenges and interviews.
1. What Is a Data Structure Course?
A Data Structure Course teaches students about the various ways data can be organized, stored, and manipulated efficiently. These structures are crucial for solving complex problems and optimizing the performance of applications. The course generally covers theoretical concepts along with practical applications using programming languages like C++, Java, or Python.
By the end of the course, students will gain proficiency in selecting the right data structure for different problem types, improving their problem-solving abilities.
2. Why Take a Data Structure Course?
Learning data structures is vital for both beginners and experienced developers. Here are some key reasons to enroll in a Data Structure Course:
a) Essential for Coding Interviews
Companies like Google, Amazon, and Facebook focus heavily on data structures in their coding interviews. A solid understanding of data structures is essential to pass these interviews successfully. Employers assess your problem-solving skills, and your knowledge of data structures can set you apart from other candidates.
b) Improves Problem-Solving Skills
With the right data structure knowledge, you can solve real-world problems more efficiently. A well-designed data structure leads to faster algorithms, which is critical when handling large datasets or working on performance-sensitive applications.
c) Boosts Programming Competency
A good grasp of data structures makes coding more intuitive. Whether you are developing an app, building a website, or working on software tools, understanding how to work with different data structures will help you write clean and efficient code.
3. Key Topics Covered in a Data Structure Course
A Data Structure Course typically spans a range of topics designed to teach students how to use and implement different structures. Below are some key topics you will encounter:
a) Arrays and Linked Lists
Arrays are one of the most basic data structures. A Data Structure Course will teach you how to use arrays for storing and accessing data in contiguous memory locations. Linked lists, on the other hand, involve nodes that hold data and pointers to the next node. Students will learn the differences, advantages, and disadvantages of both structures.
b) Stacks and Queues
Stacks and queues are fundamental data structures used to store and retrieve data in a specific order. A Data Structure Course will cover the LIFO (Last In, First Out) principle for stacks and FIFO (First In, First Out) for queues, explaining their use in various algorithms and applications like web browsers and task scheduling.
c) Trees and Graphs
Trees and graphs are hierarchical structures used in organizing data. A Data Structure Course teaches how trees, such as binary trees, binary search trees (BST), and AVL trees, are used in organizing hierarchical data. Graphs are important for representing relationships between entities, such as in social networks, and are used in algorithms like Dijkstra's and BFS/DFS.
d) Hashing
Hashing is a technique used to convert a given key into an index in an array. A Data Structure Course will cover hash tables, hash maps, and collision resolution techniques, which are crucial for fast data retrieval and manipulation.
e) Sorting and Searching Algorithms
Sorting and searching are essential operations for working with data. A Data Structure Course provides a detailed study of algorithms like quicksort, merge sort, and binary search. Understanding these algorithms and how they interact with data structures can help you optimize solutions to various problems.
4. Practical Benefits of Enrolling in a Data Structure Course
a) Hands-on Experience
A Data Structure Course typically includes plenty of coding exercises, allowing students to implement data structures and algorithms from scratch. This hands-on experience is invaluable when applying concepts to real-world problems.
b) Critical Thinking and Efficiency
Data structures are all about optimizing efficiency. By learning the most effective ways to store and manipulate data, students improve their critical thinking skills, which are essential in programming. Selecting the right data structure for a problem can drastically reduce time and space complexity.
c) Better Understanding of Memory Management
Understanding how data is stored and accessed in memory is crucial for writing efficient code. A Data Structure Course will help you gain insights into memory management, pointers, and references, which are important concepts, especially in languages like C and C++.
5. Best Programming Languages for Data Structure Courses
While many programming languages can be used to teach data structures, some are particularly well-suited due to their memory management capabilities and ease of implementation. Some popular programming languages used in Data Structure Courses include:
C++: Offers low-level memory management and is perfect for teaching data structures.
Java: Widely used for teaching object-oriented principles and offers a rich set of libraries for implementing data structures.
Python: Known for its simplicity and ease of use, Python is great for beginners, though it may not offer the same level of control over memory as C++.
6. How to Choose the Right Data Structure Course?
Selecting the right Data Structure Course depends on several factors such as your learning goals, background, and preferred learning style. Consider the following when choosing:
a) Course Content and Curriculum
Make sure the course covers the topics you are interested in and aligns with your learning objectives. A comprehensive Data Structure Course should provide a balance between theory and practical coding exercises.
b) Instructor Expertise
Look for courses taught by experienced instructors who have a solid background in computer science and software development.
c) Course Reviews and Ratings
Reviews and ratings from other students can provide valuable insights into the course’s quality and how well it prepares you for real-world applications.
7. Conclusion: Unlock Your Coding Potential with a Data Structure Course
In conclusion, a Data Structure Course is an essential investment for anyone serious about pursuing a career in software development or computer science. It equips you with the tools and skills to optimize your code, solve problems more efficiently, and excel in technical interviews. Whether you're a beginner or looking to strengthen your existing knowledge, a well-structured course can help you unlock your full coding potential.
By mastering data structures, you are not only preparing for interviews but also becoming a better programmer who can tackle complex challenges with ease.
3 notes
·
View notes
Text
How Does AI Use Impact Critical Thinking?
New Post has been published on https://thedigitalinsider.com/how-does-ai-use-impact-critical-thinking/
How Does AI Use Impact Critical Thinking?

Artificial intelligence (AI) can process hundreds of documents in seconds, identify imperceptible patterns in vast datasets and provide in-depth answers to virtually any question. It has the potential to solve common problems, increase efficiency across multiple industries and even free up time for individuals to spend with their loved ones by delegating repetitive tasks to machines.
However, critical thinking requires time and practice to develop properly. The more people rely on automated technology, the faster their metacognitive skills may decline. What are the consequences of relying on AI for critical thinking?
Study Finds AI Degrades Users’ Critical Thinking
The concern that AI will degrade users’ metacognitive skills is no longer hypothetical. Several studies suggest it diminishes people’s capacity to think critically, impacting their ability to question information, make judgments, analyze data or form counterarguments.
A 2025 Microsoft study surveyed 319 knowledge workers on 936 instances of AI use to determine how they perceive their critical thinking ability when using generative technology. Survey respondents reported decreased effort when using AI technology compared to relying on their own minds. Microsoft reported that in the majority of instances, the respondents felt that they used “much less effort” or ��less effort” when using generative AI.
Knowledge, comprehension, analysis, synthesis and evaluation were all adversely affected by AI use. Although a fraction of respondents reported using some or much more effort, an overwhelming majority reported that tasks became easier and required less work.
If AI’s purpose is to streamline tasks, is there any harm in letting it do its job? It is a slippery slope. Many algorithms cannot think critically, reason or understand context. They are often prone to hallucinations and bias. Users who are unaware of the risks of relying on AI may contribute to skewed, inaccurate results.
How AI Adversely Affects Critical Thinking Skills
Overreliance on AI can diminish an individual’s ability to independently solve problems and think critically. Say someone is taking a test when they run into a complex question. Instead of taking the time to consider it, they plug it into a generative model and insert the algorithm’s response into the answer field.
In this scenario, the test-taker learned nothing. They didn’t improve their research skills or analytical abilities. If they pass the test, they advance to the next chapter. What if they were to do this for everything their teachers assign? They could graduate from high school or even college without refining fundamental cognitive abilities.
This outcome is bleak. However, students might not feel any immediate adverse effects. If their use of language models is rewarded with better test scores, they may lose their motivation to think critically altogether. Why should they bother justifying their arguments or evaluating others’ claims when it is easier to rely on AI?
The Impact of AI Use on Critical Thinking Skills
An advanced algorithm can automatically aggregate and analyze large datasets, streamlining problem-solving and task execution. Since its speed and accuracy often outperform humans, users are usually inclined to believe it is better than them at these tasks. When it presents them with answers and insights, they take that output at face value. Unquestioning acceptance of a generative model’s output leads to difficulty distinguishing between facts and falsehoods. Algorithms are trained to predict the next word in a string of words. No matter how good they get at that task, they aren’t really reasoning. Even if a machine makes a mistake, it won’t be able to fix it without context and memory, both of which it lacks.
The more users accept an algorithm’s answer as fact, the more their evaluation and judgment skew. Algorithmic models often struggle with overfitting. When they fit too closely to the information in their training dataset, their accuracy can plummet when they are presented with new information for analysis.
Populations Most Affected by Overreliance on AI
Generally, overreliance on generative technology can negatively impact humans’ ability to think critically. However, low confidence in AI-generated output is related to increased critical thinking ability, so strategic users may be able to use AI without harming these skills.
In 2023, around 27% of adults told the Pew Research Center they use AI technology multiple times a day. Some of the individuals in this population may retain their critical thinking skills if they have a healthy distrust of machine learning tools. The data must focus on populations with disproportionately high AI use and be more granular to determine the true impact of machine learning on critical thinking.
Critical thinking often isn’t taught until high school or college. It can be cultivated during early childhood development, but it typically takes years to grasp. For this reason, deploying generative technology in schools is particularly risky — even though it is common.
Today, most students use generative models. One study revealed that 90% have used ChatGPT to complete homework. This widespread use isn’t limited to high schools. About 75% of college students say they would continue using generative technology even if their professors disallowed it. Middle schoolers, teenagers and young adults are at an age where developing critical thinking is crucial. Missing this window could cause problems.
The Implications of Decreased Critical Thinking
Already, 60% of educators use AI in the classroom. If this trend continues, it may become a standard part of education. What happens when students begin to trust these tools more than themselves? As their critical thinking capabilities diminish, they may become increasingly susceptible to misinformation and manipulation. The effectiveness of scams, phishing and social engineering attacks could increase.
An AI-reliant generation may have to compete with automation technology in the workforce. Soft skills like problem-solving, judgment and communication are important for many careers. Lacking these skills or relying on generative tools to get good grades may make finding a job challenging.
Innovation and adaptation go hand in hand with decision-making. Knowing how to objectively reason without the use of AI is critical when confronted with high-stakes or unexpected situations. Leaning into assumptions and inaccurate data could adversely affect an individual’s personal or professional life.
Critical thinking is part of processing and analyzing complex — and even conflicting — information. A community made up of critical thinkers can counter extreme or biased viewpoints by carefully considering different perspectives and values.
AI Users Must Carefully Evaluate Algorithms’ Output
Generative models are tools, so whether their impact is positive or negative depends on their users and developers. So many variables exist. Whether you are an AI developer or user, strategically designing and interacting with generative technologies is an important part of ensuring they pave the way for societal advancements rather than hindering critical cognition.
#2023#2025#ai#AI technology#algorithm#Algorithms#Analysis#artificial#Artificial Intelligence#automation#Bias#Careers#chatGPT#cognition#cognitive abilities#college#communication#Community#comprehension#critical thinking#data#datasets#deploying#Developer#developers#development#education#effects#efficiency#engineering
2 notes
·
View notes