#gpu cluster
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
In 2020, Tumblr had 29.4 million users in the US.
Text
#gpu cluster#gpu hosting#gpu cloud#ai#gpu dedicated server#artificial intelligence#nvidia#artificialintelligence#gpucloud#gpucluster
1 note
·
View note
Text
turns out if you have access to a good gpu then running the fucking enormous neural net necessary to segment cells correctly happens in 10 minutes instead of 2-5 hours
#now could i have at least bothered to set up scripting in order to use the cluster previously. yes. but i didn't.#and now i'm going to because it's actually worth my time to automate things if it lets me queue up 10 giant videos to run in under 2hr.#you guys would not believe how long the problem “get a computer to identify where the edges of the cells in this picture are” has bedeviled#the fields of cell and tissue biology. weeping and gnashing of teeth i tell you#and now it is solved. as long as you have last year's topline nvidia gpu available#or else 4 hours to kill while your macbook's fan achieves orbital flight.#box opener
9 notes
·
View notes
Text
#elon musk#tesla#xai#ai#artificial intelligence#supercomputer#super#computer#gpu#training#cluster#nvidia#h100#100k#memphis#tennessee#quantum computer#grok#language model#most#powerful#largest#gigafactory#compute#liquid cooled#dlc#supermicro#smc#tsla#$smc
2 notes
·
View notes
Text
VMware vSphere 8.0 Update 2 New Features and Download
VMware vSphere 8.0 Update 2 New Features and Download @vexpert #vmwarecommunities #vSphere8Update2Features #vGPUDefragmentationInDRS #QualityOfServiceForGPUWorkloads #vSphereVMHardwareVersion21 #NVMEDiskSupportInVSphere #SupervisorClusterDeployments
VMware consistently showcases its commitment to innovation when it comes to staying at the forefront of technology. In a recent technical overview, we were guided by Fai La Molari, Senior Technical Marketing Architect at VMware, on the latest advancements and enhancements in vSphere Plus for cloud-connected services and vSphere 8 update 2. Here’s a glimpse into VMware vSphere 8.0 Update 2 new…

View On WordPress
#NVMe disk support in vSphere#Quality of Service for GPU workloads#Supervisor Cluster deployments#Tanzu Kubernetes with vSphere#vGPU defragmentation in DRS#VM management enhancements#vSphere 8 update 2 features#vSphere and containerized workload support#vSphere DevOps integrations#vSphere VM hardware version 21
0 notes
Text
Obviously I think this is completely incorrect, but I do love it for how full-throated it is.
The moratorium on new large training runs needs to be indefinite and worldwide. There can be no exceptions, including for governments or militaries. If the policy starts with the U.S., then China needs to see that the U.S. is not seeking an advantage but rather trying to prevent a horrifically dangerous technology which can have no true owner and which will kill everyone in the U.S. and in China and on Earth. If I had infinite freedom to write laws, I might carve out a single exception for AIs being trained solely to solve problems in biology and biotechnology, not trained on text from the internet, and not to the level where they start talking or planning; but if that was remotely complicating the issue I would immediately jettison that proposal and say to just shut it all down.
Shut down all the large GPU clusters (the large computer farms where the most powerful AIs are refined). Shut down all the large training runs. Put a ceiling on how much computing power anyone is allowed to use in training an AI system, and move it downward over the coming years to compensate for more efficient training algorithms. No exceptions for governments and militaries. Make immediate multinational agreements to prevent the prohibited activities from moving elsewhere. Track all GPUs sold. If intelligence says that a country outside the agreement is building a GPU cluster, be less scared of a shooting conflict between nations than of the moratorium being violated; be willing to destroy a rogue datacenter by airstrike.
Frame nothing as a conflict between national interests, have it clear that anyone talking of arms races is a fool. That we all live or die as one, in this, is not a policy but a fact of nature. Make it explicit in international diplomacy that preventing AI extinction scenarios is considered a priority above preventing a full nuclear exchange, and that allied nuclear countries are willing to run some risk of nuclear exchange if that’s what it takes to reduce the risk of large AI training runs.
This guy really does not want to leave any chance that an advanced AI gets developed, ever, under any circumstances, even if preventing it risks nuclear war.
262 notes
·
View notes
Text
The algorithms behind generative AI tools like DallE, when combined with physics-based data, can be used to develop better ways to model the Earth's climate. Computer scientists in Seattle and San Diego have now used this combination to create a model that is capable of predicting climate patterns over 100 years 25 times faster than the state of the art. Specifically, the model, called Spherical DYffusion, can project 100 years of climate patterns in 25 hours–a simulation that would take weeks for other models. In addition, existing state-of-the-art models need to run on supercomputers. This model can run on GPU clusters in a research lab.
Continue Reading.
56 notes
·
View notes
Text

Switch 2 Technical Specifications?
CPU: Arm Cortex-A78C
8 cores
GPU @ Nvidia T239 Ampere (RTX 20 series)
1 Graphics Processing Cluster (GPC) 12 Streaming Multiprocessors (SM) 1534 CUDA cores 6 Texture Processing Clusters (TPC) 48 Gen 3 Tensor cores 2 RTX ray-tracing cores
RAM: 12 GB LPDDR5, (some/all units will have LPDDR5X chips) Two 6 GB chips
Power Profiles:
Handheld:
CPU @ 1100.8 MHz GPU @ 561 MHz, 1.72 TFLOPs peak RAM @ 2133 MHz, 68.26 GB/s peak bandwidth
Docked:
CPU @ 998.4 MHz GPU @ 1007.3 MHz, 3.09 TFLOPs peak RAM @ 3200 MHz, 102.40 GB/s peak bandwidth
16 notes
·
View notes
Text
when i have the gpu cluster i deserve im going to find the revealed truth vector and generate richly interpretable writing encoding alien wisdom at scale
7 notes
·
View notes
Note
QUESTION TWO:
SWITCH BOXES. you said that’s what monitors the connections between systems in the computer cluster, right? I assume it has software of its own but we don’t need to get into that, anyway, I am so curious about this— in really really large buildings full of servers, (like multiplayer game hosting servers, Google basically) how big would that switch box have to be? Do they even need one? Would taking out the switch box on a large system like that just completely crash it all?? While I’m on that note, when it’s really large professional server systems like that, how do THEY connect everything to power sources? Do they string it all together like fairy lights with one big cable, or??? …..the voices……..THE VOICES GRR

I’m acending (autism)
ALRIGHT! I'm starting with this one because the first question that should be answered is what the hell is a server rack?
Once again, long post under cut.
So! The first thing I should get out of the way is what is the difference between a computer and a server. Which, is like asking the difference between a gaming console and a computer. Or better yet, the difference between a gaming computer and a regular everyday PC. Which is... that they are pretty much the same thing! But if you game on a gaming computer, you'll get much better performance than on a standard PC. This is (mostly) because a gaming computer has a whole separate processor dedicated to processing graphics (GPU). A server is different from a PC in the same way, it's just a computer that is specifically built to handle the loads of running an online service. That's why you can run a server off a random PC in your closet, the core components are the same! (So good news about your other question. Short answer, yes! It would be possible to connect the hodgepodge of computers to the sexy server racks upstairs, but I'll get more into that in the next long post)
But if you want to cater to hundreds or thousands of customers, you need the professional stuff. So let's break down what's (most commonly) in a rack setup, starting with the individual units (sometimes referred to just as 'U').
Short version of someone setting one up!
18 fucking hard drives. 2 CPUs. How many sticks of ram???
Holy shit, that's a lot. Now depending on your priorities, the next question is, can we play video games on it? Not directly! This thing doesn't have a GPU so using it to render a video game works, but you won't have sparkly graphics with high frame rate. I'll put some video links at the bottom that goes more into the anatomy of the individual units themselves.

I pulled this screenshot from this video rewiring a server rack! As you can see, there are two switch boxes in this server rack! Each rack gets their own switch box to manage which unit in the rack gets what. So it's not like everything is connected to one massive switch box. You can add more capacity by making it bigger or you can just add another one! And if you take it out then shit is fucked. Communication has been broken, 404 website not found (<- not actually sure if this error will show).
So how do servers talk to one another? Again, I'll get more into that in my next essay response to your questions. But basically, they can talk over the internet the same way that your machine does (each server has their own address known as an IP and routers shoot you at one).
POWER SUPPLY FOR A SERVER RACK (finally back to shit I've learned in class) YOU ARE ASKING IF THEY ARE WIRED TOGETHER IN SERIES OR PARALLEL! The answer is parallel. Look back up at the image above, I've called out the power cables. In fact, watch the video of that guy wiring that rack back together very fast. Everything on the right is power. How are they able to plug everything together like that? Oh god I know too much about this topic do not talk to me about transformers (<- both the electrical type and the giant robots). BASICALLY, in a data center (place with WAY to many servers) the building is literally built with that kind of draw in mind (oh god the power demands of computing, I will write a long essay about that in your other question). Worrying about popping a fuse is only really a thing when plugging in a server into a plug in your house.
Links to useful youtube videos
How does a server work? (great guide in under 20 min)
Rackmount Server Anatomy 101 | A Beginner's Guide (more comprehensive breakdown but an hour long)
DATA CENTRE 101 | DISSECTING a SERVER and its COMPONENTS! (the guy is surrounded by screaming server racks and is close to incomprehensible)
What is a patch panel? (More stuff about switch boxes- HOLY SHIT there's more hardware just for managing the connection???)
Data Center Terminologies (basic breakdown of entire data center)
Networking Equipment Racks - How Do They Work? (very informative)
Funny
#is this even writing advice anymore?#I'd say no#Do I care?#NOPE!#yay! Computer#I eat computers#Guess what! You get an essay for every question!#oh god the amount of shit just to manage one connection#I hope you understand how beautiful the fact that the internet exists and it's even as stable as it is#it's also kind of fucked#couldn't fit a college story into this one#Uhhh one time me and a bunch of friends tried every door in the administrative building on campus at midnight#got into some interesting places#took candy from the office candy bowl#good fun#networking#server racks#servers#server hardware#stem#technology#I love technology#Ask#spark
7 notes
·
View notes
Text
Self Hosting
I haven't posted here in quite a while, but the last year+ for me has been a journey of learning a lot of new things. This is a kind of 'state-of-things' post about what I've been up to for the last year.
I put together a small home lab with 3 HP EliteDesk SFF PCs, an old gaming desktop running an i7-6700k, and my new gaming desktop running an i7-11700k and an RTX-3080 Ti.
"Using your gaming desktop as a server?" Yep, sure am! It's running Unraid with ~7TB of storage, and I'm passing the GPU through to a Windows VM for gaming. I use Sunshine/Moonlight to stream from the VM to my laptop in order to play games, though I've definitely been playing games a lot less...
On to the good stuff: I have 3 Proxmox nodes in a cluster, running the majority of my services. Jellyfin, Audiobookshelf, Calibre Web Automated, etc. are all running on Unraid to have direct access to the media library on the array. All told there's 23 docker containers running on Unraid, most of which are media management and streaming services. Across my lab, I have a whopping 57 containers running. Some of them are for things like monitoring which I wouldn't really count, but hey I'm not going to bother taking an effort to count properly.
The Proxmox nodes each have a VM for docker which I'm managing with Portainer, though that may change at some point as Komodo has caught my eye as a potential replacement.
All the VMs and LXC containers on Proxmox get backed up daily and stored on the array, and physical hosts are backed up with Kopia and also stored on the array. I haven't quite figured out backups for the main storage array yet (redundancy != backups), because cloud solutions are kind of expensive.
You might be wondering what I'm doing with all this, and the answer is not a whole lot. I make some things available for my private discord server to take advantage of, the main thing being game servers for Minecraft, Valheim, and a few others. For all that stuff I have to try and do things mostly the right way, so I have users managed in Authentik and all my other stuff connects to that. I've also written some small things here and there to automate tasks around the lab, like SSL certs which I might make a separate post on, and custom dashboard to view and start the various game servers I host. Otherwise it's really just a few things here and there to make my life a bit nicer, like RSSHub to collect all my favorite art accounts in one place (fuck you Instagram, piece of shit).
It's hard to go into detail on a whim like this so I may break it down better in the future, but assuming I keep posting here everything will probably be related to my lab. As it's grown it's definitely forced me to be more organized, and I promise I'm thinking about considering maybe working on documentation for everything. Bookstack is nice for that, I'm just lazy. One day I might even make a network map...
5 notes
·
View notes
Text
#gpu hosting#gpu cluster#gpu cloud#ai#gpu dedicated server#artificial intelligence#nvidia#artificialintelligence#gpucloud#gpucluster
0 notes
Text
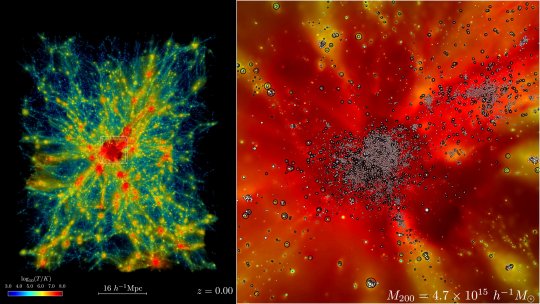
Record-breaking run on Frontier sets new bar for simulating the universe in exascale era
The universe just got a whole lot bigger—or at least in the world of computer simulations, that is. In early November, researchers at the Department of Energy's Argonne National Laboratory used the fastest supercomputer on the planet to run the largest astrophysical simulation of the universe ever conducted.
The achievement was made using the Frontier supercomputer at Oak Ridge National Laboratory. The calculations set a new benchmark for cosmological hydrodynamics simulations and provide a new foundation for simulating the physics of atomic matter and dark matter simultaneously. The simulation size corresponds to surveys undertaken by large telescope observatories, a feat that until now has not been possible at this scale.
"There are two components in the universe: dark matter—which as far as we know, only interacts gravitationally—and conventional matter, or atomic matter," said project lead Salman Habib, division director for Computational Sciences at Argonne.
"So, if we want to know what the universe is up to, we need to simulate both of these things: gravity as well as all the other physics including hot gas, and the formation of stars, black holes and galaxies," he said. "The astrophysical 'kitchen sink' so to speak. These simulations are what we call cosmological hydrodynamics simulations."
Not surprisingly, the cosmological hydrodynamics simulations are significantly more computationally expensive and much more difficult to carry out compared to simulations of an expanding universe that only involve the effects of gravity.
"For example, if we were to simulate a large chunk of the universe surveyed by one of the big telescopes such as the Rubin Observatory in Chile, you're talking about looking at huge chunks of time—billions of years of expansion," Habib said. "Until recently, we couldn't even imagine doing such a large simulation like that except in the gravity-only approximation."
The supercomputer code used in the simulation is called HACC, short for Hardware/Hybrid Accelerated Cosmology Code. It was developed around 15 years ago for petascale machines. In 2012 and 2013, HACC was a finalist for the Association for Computing Machinery's Gordon Bell Prize in computing.
Later, HACC was significantly upgraded as part of ExaSky, a special project led by Habib within the Exascale Computing Project, or ECP. The project brought together thousands of experts to develop advanced scientific applications and software tools for the upcoming wave of exascale-class supercomputers capable of performing more than a quintillion, or a billion-billion, calculations per second.
As part of ExaSky, the HACC research team spent the last seven years adding new capabilities to the code and re-optimizing it to run on exascale machines powered by GPU accelerators. A requirement of the ECP was for codes to run approximately 50 times faster than they could before on Titan, the fastest supercomputer at the time of the ECP's launch. Running on the exascale-class Frontier supercomputer, HACC was nearly 300 times faster than the reference run.
The novel simulations achieved its record-breaking performance by using approximately 9,000 of Frontier's compute nodes, powered by AMD Instinct MI250X GPUs. Frontier is located at ORNL's Oak Ridge Leadership Computing Facility, or OLCF.
IMAGE: A small sample from the Frontier simulations reveals the evolution of the expanding universe in a region containing a massive cluster of galaxies from billions of years ago to present day (left). Red areas show hotter gasses, with temperatures reaching 100 million Kelvin or more. Zooming in (right), star tracer particles track the formation of galaxies and their movement over time. Credit: Argonne National Laboratory, U.S Dept of Energy
vimeo
In early November 2024, researchers at the Department of Energy's Argonne National Laboratory used Frontier, the fastest supercomputer on the planet, to run the largest astrophysical simulation of the universe ever conducted. This movie shows the formation of the largest object in the Frontier-E simulation. The left panel shows a 64x64x76 Mpc/h subvolume of the simulation (roughly 1e-5 the full simulation volume) around the large object, with the right panel providing a closer look. In each panel, we show the gas density field colored by its temperature. In the right panel, the white circles show star particles and the open black circles show AGN particles. Credit: Argonne National Laboratory, U.S Dept. of Energy
3 notes
·
View notes
Text
Share Your Anecdotes: Multicore Pessimisation
I took a look at the specs of new 7000 series Threadripper CPUs, and I really don't have any excuse to buy one, even if I had the money to spare. I thought long and hard about different workloads, but nothing came to mind.
Back in university, we had courses about map/reduce clusters, and I experimented with parallel interpreters for Prolog, and distributed computing systems. What I learned is that the potential performance gains from better data structures and algorithms trump the performance gains from fancy hardware, and that there is more to be gained from using the GPU or from re-writing the performance-critical sections in C and making sure your data structures take up less memory than from multi-threaded code. Of course, all this is especially important when you are working in pure Python, because of the GIL.
The performance penalty of parallelisation hits even harder when you try to distribute your computation between different computers over the network, and the overhead of serialisation, communication, and scheduling work can easily exceed the gains of parallel computation, especially for small to medium workloads. If you benchmark your Hadoop cluster on a toy problem, you may well find that it's faster to solve your toy problem on one desktop PC than a whole cluster, because it's a toy problem, and the gains only kick in when your data set is too big to fit on a single computer.
The new Threadripper got me thinking: Has this happened to somebody with just a multicore CPU? Is there software that performs better with 2 cores than with just one, and better with 4 cores than with 2, but substantially worse with 64? It could happen! Deadlocks, livelocks, weird inter-process communication issues where you have one process per core and every one of the 64 processes communicates with the other 63 via pipes? There could be software that has a badly optimised main thread, or a badly optimised work unit scheduler, and the limiting factor is single-thread performance of that scheduler that needs to distribute and integrate work units for 64 threads, to the point where the worker threads are mostly idling and only one core is at 100%.
I am not trying to blame any programmer if this happens. Most likely such software was developed back when quad-core CPUs were a new thing, or even back when there were multi-CPU-socket mainboards, and the developer never imagined that one day there would be Threadrippers on the consumer market. Programs from back then, built for Windows XP, could still run on Windows 10 or 11.
In spite of all this, I suspect that this kind of problem is quite rare in practice. It requires software that spawns one thread or one process per core, but which is deoptimised for more cores, maybe written under the assumption that users have for two to six CPU cores, a user who can afford a Threadripper, and needs a Threadripper, and a workload where the problem is noticeable. You wouldn't get a Threadripper in the first place if it made your workflows slower, so that hypothetical user probably has one main workload that really benefits from the many cores, and another that doesn't.
So, has this happened to you? Dou you have a Threadripper at work? Do you work in bioinformatics or visual effects? Do you encode a lot of video? Do you know a guy who does? Do you own a Threadripper or an Ampere just for the hell of it? Or have you tried to build a Hadoop/Beowulf/OpenMP cluster, only to have your code run slower?
I would love to hear from you.
13 notes
·
View notes
Text
📝 Guest Post: Yandex develops and open-sources YaFSDP — a tool for faster LLM training and optimized GPU consumption*
New Post has been published on https://thedigitalinsider.com/guest-post-yandex-develops-and-open-sources-yafsdp-a-tool-for-faster-llm-training-and-optimized-gpu-consumption/
📝 Guest Post: Yandex develops and open-sources YaFSDP — a tool for faster LLM training and optimized GPU consumption*
A few weeks ago, Yandex open-sourced the YaFSDP method — a new tool that is designed to dramatically speed up the training of large language models. In this article, Mikhail Khrushchev, the leader of the YandexGPT pre-training team will talk about how you can organize LLM training on a cluster and what issues may arise. He’ll also look at alternative training methods like ZeRO and FSDP and explain how YaFSDP differs from them.
Problems with Training on Multiple GPUs
What are the challenges of distributed LLM training on a cluster with multiple GPUs? To answer this question, let’s first consider training on a single GPU:
We do a forward pass through the network for a new data batch and then calculate loss.
Then we run backpropagation.
The optimizer updates the optimizer states and model weights.
So what changes when we use multiple GPUs? Let’s look at the most straightforward implementation of distributed training on four GPUs (Distributed Data Parallelism):
What’s changed? Now:
Each GPU processes its own chunk of a larger data batch, allowing us to increase the batch size fourfold with the same memory load.
We need to synchronize the GPUs. To do this, we average gradients among GPUs using all_reduce to ensure the weights on different maps are updated synchronously. The all_reduce operation is one of the fastest ways to implement this: it’s available in the NCCL (NVIDIA Collective Communications Library) and supported in the torch.distributed package.
Let’s recall the different communication operations (they are referenced throughout the article):
These are the issues we encounter with those communications:
In all_reduce operations, we send twice as many gradients as there are network parameters. For example, when summing up gradients in fp16 for Llama 70B, we need to send 280 GB of data per iteration between maps. In today’s clusters, this takes quite a lot of time.
Weights, gradients, and optimizer states are duplicated among maps. In mixed precision training, the Llama 70B and the Adam optimizer require over 1 TB of memory, while a regular GPU memory is only 80 GB.
This means the redundant memory load is so massive we can’t even fit a relatively small model into GPU memory, and our training process is severely slowed down due to all these additional operations.
Is there a way to solve these issues? Yes, there are some solutions. Among them, we distinguish a group of Data Parallelism methods that allow full sharding of weights, gradients, and optimizer states. There are three such methods available for Torch: ZeRO, FSDP, and Yandex’s YaFSDP.
ZeRO
In 2019, Microsoft’s DeepSpeed development team published the article ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. The researchers introduced a new memory optimization solution, Zero Redundancy Optimizer (ZeRO), capable of fully partitioning weights, gradients, and optimizer states across all GPUs:
The proposed partitioning is only virtual. During the forward and backward passes, the model processes all parameters as if the data hasn’t been partitioned. The approach that makes this possible is asynchronous gathering of parameters.
Here’s how ZeRO is implemented in the DeepSpeed library when training on the N number of GPUs:
Each parameter is split into N parts, and each part is stored in a separate process memory.
We record the order in which parameters are used during the first iteration, before the optimizer step.
We allocate space for the collected parameters. During each subsequent forward and backward pass, we load parameters asynchronously via all_gather. When a particular module completes its work, we free up memory for this module’s parameters and start loading the next parameters. Computations run in parallel.
During the backward pass, we run reduce_scatter as soon as gradients are calculated.
During the optimizer step, we update only those weights and optimizer parameters that belong to the particular GPU. Incidentally, this speeds up the optimizer step N times!
Here’s how the forward pass would work in ZeRO if we had only one parameter tensor per layer:
The training scheme for a single GPU would look like this:
From the diagram, you can see that:
Communications are now asynchronous. If communications are faster than computations, they don’t interfere with computations or slow down the whole process.
There are now a lot more communications.
The optimizer step takes far less time.
The ZeRO concept implemented in DeepSpeed accelerated the training process for many LLMs, significantly optimizing memory consumption. However, there are some downsides as well:
Many bugs and bottlenecks in the DeepSpeed code.
Ineffective communication on large clusters.
A peculiar principle applies to all collective operations in the NCCL: the less data sent at a time, the less efficient the communications.
Suppose we have N GPUs. Then for all_gather operations, we’ll be able to send no more than 1/N of the total number of parameters at a time. When N is increased, communication efficiency drops.
In DeepSpeed, we run all_gather and reduce_scatter operations for each parameter tensor. In Llama 70B, the regular size of a parameter tensor is 8192 × 8192. So when training on 1024 maps, we can’t send more than 128 KB at a time, which means network utilization is ineffective.
DeepSpeed tried to solve this issue by simultaneously integrating a large number of tensors. Unfortunately, this approach causes many slow GPU memory operations or requires custom implementation of all communications.
As a result, the profile looks something like this (stream 7 represents computations, stream 24 is communications):
Evidently, at increased cluster sizes, DeepSpeed tended to significantly slow down the training process. Is there a better strategy then? In fact, there is one.
The FSDP Era
The Fully Sharded Data Parallelism (FSDP), which now comes built-in with Torch, enjoys active support and is popular with developers.
What’s so great about this new approach? Here are the advantages:
FSDP combines multiple layer parameters into a single FlatParameter that gets split during sharding. This allows for running fast collective communications while sending large volumes of data.
Based on an illustration from the FSDP documentation
FSDP has a more user-friendly interface: — DeepSpeed transforms the entire training pipeline, changing the model and optimizer. — FSDP transforms only the model and sends only the weights and gradients hosted by the process to the optimizer. Because of this, it’s possible to use a custom optimizer without additional setup.
FSDP doesn’t generate as many bugs as DeepSpeed, at least in common use cases.
Dynamic graphs: ZeRO requires that modules are always called in a strictly defined order, otherwise it won’t understand which parameter to load and when. In FSDP, you can use dynamic graphs.
Despite all these advantages, there are also issues that we faced:
FSDP dynamically allocates memory for layers and sometimes requires much more memory than is actually necessary.
During backward passes, we came across a phenomenon that we called the “give-way effect”. The profile below illustrates it:
The first line here is the computation stream, and the other lines represent communication streams. We’ll talk about what streams are a little later.
So what’s happening in the profile? Before the reduce_scatter operation (blue), there are many preparatory computations (small operations under the communications). The small computations run in parallel with the main computation stream, severely slowing down communications. This results in large gaps between communications, and consequently, the same gaps occur in the computation stream.
We tried to overcome these issues, and the solution we’ve come up with is the YaFSDP method.
YaFSDP
In this part, we’ll discuss our development process, delving a bit into how solutions like this can be devised and implemented. There are lots of code references ahead. Keep reading if you want to learn about advanced ways to use Torch.
So the goal we set before ourselves was to ensure that memory consumption is optimized and nothing slows down communications.
Why Save Memory?
That’s a great question. Let’s see what consumes memory during training:
— Weights, gradients, and optimizer states all depend on the number of processes and the amount of memory consumed tends to near zero as the number of processes increases. — Buffers consume constant memory only. — Activations depend on the model size and the number of tokens per process.
It turns out that activations are the only thing taking up memory. And that’s no mistake! For Llama 2 70B with a batch of 8192 tokens and Flash 2, activation storage takes over 110 GB (the number can be significantly reduced, but this is a whole different story).
Activation checkpointing can seriously reduce memory load: for forward passes, we only store activations between transformer blocks, and for backward passes, we recompute them. This saves a lot of memory: you’ll only need 5 GB to store activations. The problem is that the redundant computations take up 25% of the entire training time.
That’s why it makes sense to free up memory to avoid activation checkpointing for as many layers as possible.
In addition, if you have some free memory, efficiency of some communications can be improved.
Buffers
Like FSDP, we decided to shard layers instead of individual parameters — this way, we can maintain efficient communications and avoid duplicate operations. To control memory consumption, we allocated buffers for all required data in advance because we didn’t want the Torch allocator to manage the process.
Here’s how it works: two buffers are allocated for storing intermediate weights and gradients. Each odd layer uses the first buffer, and each even layer uses the second buffer.
This way, the weights from different layers are stored in the same memory. If the layers have the same structure, they’ll always be identical! What’s important is to ensure that when you need layer X, the buffer has the weights for layer X. All parameters will be stored in the corresponding memory chunk in the buffer:
Other than that, the new method is similar to FSDP. Here’s what we’ll need:
Buffers to store shards and gradients in fp32 for the optimizer (because of mixed precision).
A buffer to store the weight shard in half precision (bf16 in our case).
Now we need to set up communications so that:
The forward/backward pass on the layer doesn’t start until the weights of that layer are collected in its buffer.
Before the forward/backward pass on a certain layer is completed, we don’t collect another layer in this layer’s buffer.
The backward pass on the layer doesn’t start until the reduce_scatter operation on the previous layer that uses the same gradient buffer is completed.
The reduce_scatter operation in the buffer doesn’t start until the backward pass on the corresponding layer is completed.
How do we achieve this setup?
Working with Streams
You can use CUDA streams to facilitate concurrent computations and communications.
How is the interaction between CPU and GPU organized in Torch and other frameworks? Kernels (functions executed on the GPU) are loaded from the CPU to the GPU in the order of execution. To avoid downtime due to the CPU, the kernels are loaded ahead of the computations and are executed asynchronously. Within a single stream, kernels are always executed in the order in which they were loaded to the CPU. If we want them to run in parallel, we need to load them to different streams. Note that if kernels in different streams use the same resources, they may fail to run in parallel (remember the “give-way effect” mentioned above) or their executions may be very slow.
To facilitate communication between streams, you can use the “event” primitive (event = torch.cuda.Event() in Torch). We can put an event into a stream (event.record(stream)), and then it’ll be appended to the end of the stream like a microkernel. We can wait for this event in another stream (event.wait(another_stream)), and then this stream will pause until the first stream reaches the event.
We only need two streams to implement this: a computation stream and a communication stream. This is how you can set up the execution to ensure that both conditions 1 and 2 (described above) are met:
In the diagram, bold lines mark event.record() and dotted lines are used for event.wait(). As you can see, the forward pass on the third layer doesn’t start until the all_gather operation on that layer is completed (condition 1). Likewise, the all_gather operation on the third layer won’t start until the forward pass on the first layer that uses the same buffer is completed (condition 2). Since there are no cycles in this scheme, deadlock is impossible.
How can we implement this in Torch? You can use forward_pre_hook, code on the CPU executed before the forward pass, as well as forward_hood, which is executed after the pass:
This way, all the preliminary operations are performed in forward_pre_hook. For more information about hooks, see the documentation.
What’s different for the backward pass? Here, we’ll need to average gradients among processes:
We could try using backward_hook and backward_pre_hook in the same way we used forward_hook and forward_pre_hook:
But there’s a catch: while backward_pre_hook works exactly as anticipated, backward_hook may behave unexpectedly:
— If the module input tensor has at least one tensor that doesn’t pass gradients (for example, the attention mask), backward_hook will run before the backward pass is executed. — Even if all module input tensors pass gradients, there is no guarantee that backward_hook will run after the .grad of all tensors is computed.
So we aren’t satisfied with the initial implementation of backward_hook and need a more reliable solution.
Reliable backward_hook
Why isn’t backward_hook suitable? Let’s take a look at the gradient computation graph for relatively simple operations:
We apply two independent linear layers with Weight 1 and Weight 2 to the input and multiply their outputs.
The gradient computation graph will look like this:
We can see that all operations have their *Backward nodes in this graph. For all weights in the graph, there’s a GradAccum node where the .grad of the parameter is updated. This parameter will then be used by YaFSDP to process the gradient.
Something to note here is that GradAccum is in the leaves of this graph. Curiously, Torch doesn’t guarantee the order of graph traversal. GradAccum of one of the weights can be executed after the gradient leaves this block. Graph execution in Torch is not deterministic and may vary from iteration to iteration.
How do we ensure that the weight gradients are calculated before the backward pass on another layer starts? If we initiate reduce_scatter without making sure this condition is met, it’ll only process a part of the calculated gradients. Trying to work out a solution, we came up with the following schema:
Before each forward pass, the additional steps are carried out:
— We pass all inputs and weight buffers through GateGradFlow, a basic torch.autograd.Function that simply passes unchanged inputs and gradients through itself.
— In layers, we replace parameters with pseudoparameters stored in the weight buffer memory. To do this, we use our custom Narrow function.
What happens on the backward pass:
The gradient for parameters can be assigned in two ways:
— Normally, we’ll assign or add a gradient during the backward Narrow implementation, which is much earlier than when we get to the buffers’ GradAccum. — We can write a custom function for the layers in which we’ll assign gradients without allocating an additional tensor to save memory. Then Narrow will receive “None” instead of a gradient and will do nothing.
With this, we can guarantee that:
— All gradients will be written to the gradient buffer before the backward GateGradFlow execution. — Gradients won’t flow to inputs and then to “backward” of the next layers before the backward GateGradFlow is executed.
This means that the most suitable place for the backward_hook call is in the backward GateGradFlow! At that step, all weight gradients have been calculated and written while a backward pass on other layers hasn’t yet started. Now we have everything we need for concurrent communications and computations in the backward pass.
Overcoming the “Give-Way Effect’
The problem of the “give-way effect” is that several computation operations take place in the communication stream before reduce_scatter. These operations include copying gradients to a different buffer, “pre-divide” of gradients to prevent fp16 overflow (rarely used now), and others.
Here’s what we did:
— We added a separate processing for RMSNorm/LayerNorm. Because these should be processed a little differently in the optimizer, it makes sense to put them into a separate group. There aren’t many such weights, so we collect them once at the start of an iteration and average the gradients at the very end. This eliminated duplicate operations in the “give-way effect”.
— Since there’s no risk of overflow with reduce_scatter in bf16 or fp32, we replaced “pre-divide” with “post-divide”, moving the operation to the very end of the backward pass.
As a result, we got rid of the “give-way effect”, which greatly reduced the downtime in computations:
Restrictions
The YaFSDP method optimizes memory consumption and allows for a significant gain in performance. However, it also has some restrictions:
— You can reach peak performance only if the layers are called so that their corresponding buffers alternate. — We explicitly take into account that, from the optimizer’s point of view, there can be only one group of weights with a large number of parameters.
Test Results
The resulting speed gain in small-batch scenarios exceeds 20%, making YaFSDP a useful tool for fine-turning models.
In Yandex’s pre-trainings, the implementation of YaFSDP along with other memory optimization strategies resulted in a speed gain of 45%.
Now that YaFSDP is open-source, you can check it out and tell us what you think! Please share comments about your experience, and we’d be happy to consider possible pull requests.
*This post was written by Mikhail Khrushchev, the leader of the YandexGPT pre-training team, and originally published here. We thank Yandex for their insights and ongoing support of TheSequence.
#approach#Article#attention#Blue#bugs#cluster#clusters#code#Collective#communication#communications#computation#cpu#CUDA#data#developers#development#documentation#efficiency#flash#Full#gpu#gradients#Graph#how#illustration#insights#interaction#issues#it
0 notes
Text
A3 Ultra VMs With NVIDIA H200 GPUs Pre-launch This Month

Strong infrastructure advancements for your future that prioritizes AI
To increase customer performance, usability, and cost-effectiveness, Google Cloud implemented improvements throughout the AI Hypercomputer stack this year. Google Cloud at the App Dev & Infrastructure Summit:
Trillium, Google’s sixth-generation TPU, is currently available for preview.
Next month, A3 Ultra VMs with NVIDIA H200 Tensor Core GPUs will be available for preview.
Google’s new, highly scalable clustering system, Hypercompute Cluster, will be accessible beginning with A3 Ultra VMs.
Based on Axion, Google’s proprietary Arm processors, C4A virtual machines (VMs) are now widely accessible
AI workload-focused additions to Titanium, Google Cloud’s host offload capability, and Jupiter, its data center network.
Google Cloud’s AI/ML-focused block storage service, Hyperdisk ML, is widely accessible.
Trillium A new era of TPU performance
Trillium A new era of TPU performance is being ushered in by TPUs, which power Google’s most sophisticated models like Gemini, well-known Google services like Maps, Photos, and Search, as well as scientific innovations like AlphaFold 2, which was just awarded a Nobel Prize! We are happy to inform that Google Cloud users can now preview Trillium, our sixth-generation TPU.
Taking advantage of NVIDIA Accelerated Computing to broaden perspectives
By fusing the best of Google Cloud’s data center, infrastructure, and software skills with the NVIDIA AI platform which is exemplified by A3 and A3 Mega VMs powered by NVIDIA H100 Tensor Core GPUs it also keeps investing in its partnership and capabilities with NVIDIA.
Google Cloud announced that the new A3 Ultra VMs featuring NVIDIA H200 Tensor Core GPUs will be available on Google Cloud starting next month.
Compared to earlier versions, A3 Ultra VMs offer a notable performance improvement. Their foundation is NVIDIA ConnectX-7 network interface cards (NICs) and servers equipped with new Titanium ML network adapter, which is tailored to provide a safe, high-performance cloud experience for AI workloads. A3 Ultra VMs provide non-blocking 3.2 Tbps of GPU-to-GPU traffic using RDMA over Converged Ethernet (RoCE) when paired with our datacenter-wide 4-way rail-aligned network.
In contrast to A3 Mega, A3 Ultra provides:
With the support of Google’s Jupiter data center network and Google Cloud’s Titanium ML network adapter, double the GPU-to-GPU networking bandwidth
With almost twice the memory capacity and 1.4 times the memory bandwidth, LLM inferencing performance can increase by up to 2 times.
Capacity to expand to tens of thousands of GPUs in a dense cluster with performance optimization for heavy workloads in HPC and AI.
Google Kubernetes Engine (GKE), which offers an open, portable, extensible, and highly scalable platform for large-scale training and AI workloads, will also offer A3 Ultra VMs.
Hypercompute Cluster: Simplify and expand clusters of AI accelerators
It’s not just about individual accelerators or virtual machines, though; when dealing with AI and HPC workloads, you have to deploy, maintain, and optimize a huge number of AI accelerators along with the networking and storage that go along with them. This may be difficult and time-consuming. For this reason, Google Cloud is introducing Hypercompute Cluster, which simplifies the provisioning of workloads and infrastructure as well as the continuous operations of AI supercomputers with tens of thousands of accelerators.
Fundamentally, Hypercompute Cluster integrates the most advanced AI infrastructure technologies from Google Cloud, enabling you to install and operate several accelerators as a single, seamless unit. You can run your most demanding AI and HPC workloads with confidence thanks to Hypercompute Cluster’s exceptional performance and resilience, which includes features like targeted workload placement, dense resource co-location with ultra-low latency networking, and sophisticated maintenance controls to reduce workload disruptions.
For dependable and repeatable deployments, you can use pre-configured and validated templates to build up a Hypercompute Cluster with just one API call. This include containerized software with orchestration (e.g., GKE, Slurm), framework and reference implementations (e.g., JAX, PyTorch, MaxText), and well-known open models like Gemma2 and Llama3. As part of the AI Hypercomputer architecture, each pre-configured template is available and has been verified for effectiveness and performance, allowing you to concentrate on business innovation.
A3 Ultra VMs will be the first Hypercompute Cluster to be made available next month.
An early look at the NVIDIA GB200 NVL72
Google Cloud is also awaiting the developments made possible by NVIDIA GB200 NVL72 GPUs, and we’ll be providing more information about this fascinating improvement soon. Here is a preview of the racks Google constructing in the meantime to deliver the NVIDIA Blackwell platform’s performance advantages to Google Cloud’s cutting-edge, environmentally friendly data centers in the early months of next year.
Redefining CPU efficiency and performance with Google Axion Processors
CPUs are a cost-effective solution for a variety of general-purpose workloads, and they are frequently utilized in combination with AI workloads to produce complicated applications, even if TPUs and GPUs are superior at specialized jobs. Google Axion Processors, its first specially made Arm-based CPUs for the data center, at Google Cloud Next ’24. Customers using Google Cloud may now benefit from C4A virtual machines, the first Axion-based VM series, which offer up to 10% better price-performance compared to the newest Arm-based instances offered by other top cloud providers.
Additionally, compared to comparable current-generation x86-based instances, C4A offers up to 60% more energy efficiency and up to 65% better price performance for general-purpose workloads such as media processing, AI inferencing applications, web and app servers, containerized microservices, open-source databases, in-memory caches, and data analytics engines.
Titanium and Jupiter Network: Making AI possible at the speed of light
Titanium, the offload technology system that supports Google’s infrastructure, has been improved to accommodate workloads related to artificial intelligence. Titanium provides greater compute and memory resources for your applications by lowering the host’s processing overhead through a combination of on-host and off-host offloads. Furthermore, although Titanium’s fundamental features can be applied to AI infrastructure, the accelerator-to-accelerator performance needs of AI workloads are distinct.
Google has released a new Titanium ML network adapter to address these demands, which incorporates and expands upon NVIDIA ConnectX-7 NICs to provide further support for virtualization, traffic encryption, and VPCs. The system offers best-in-class security and infrastructure management along with non-blocking 3.2 Tbps of GPU-to-GPU traffic across RoCE when combined with its data center’s 4-way rail-aligned network.
Google’s Jupiter optical circuit switching network fabric and its updated data center network significantly expand Titanium’s capabilities. With native 400 Gb/s link rates and a total bisection bandwidth of 13.1 Pb/s (a practical bandwidth metric that reflects how one half of the network can connect to the other), Jupiter could handle a video conversation for every person on Earth at the same time. In order to meet the increasing demands of AI computation, this enormous scale is essential.
Hyperdisk ML is widely accessible
For computing resources to continue to be effectively utilized, system-level performance maximized, and economical, high-performance storage is essential. Google launched its AI-powered block storage solution, Hyperdisk ML, in April 2024. Now widely accessible, it adds dedicated storage for AI and HPC workloads to the networking and computing advancements.
Hyperdisk ML efficiently speeds up data load times. It drives up to 11.9x faster model load time for inference workloads and up to 4.3x quicker training time for training workloads.
With 1.2 TB/s of aggregate throughput per volume, you may attach 2500 instances to the same volume. This is more than 100 times more than what big block storage competitors are giving.
Reduced accelerator idle time and increased cost efficiency are the results of shorter data load times.
Multi-zone volumes are now automatically created for your data by GKE. In addition to quicker model loading with Hyperdisk ML, this enables you to run across zones for more computing flexibility (such as lowering Spot preemption).
Developing AI’s future
Google Cloud enables companies and researchers to push the limits of AI innovation with these developments in AI infrastructure. It anticipates that this strong foundation will give rise to revolutionary new AI applications.
Read more on Govindhtech.com
#A3UltraVMs#NVIDIAH200#AI#Trillium#HypercomputeCluster#GoogleAxionProcessors#Titanium#News#Technews#Technology#Technologynews#Technologytrends#Govindhtech
2 notes
·
View notes
Text
TITLE: PrismNET Asia-Pacific Leaders Symposium: Launch of the 319 Global Service Center Initiative
On May 7th, the PrismNET Asia-Pacific Leaders’ Symposium was successfully held at the Cordis Hotel in Hong Kong, bringing together service center heads and community leaders from various countries and regions within Asia-Pacific to discuss the expansive plans for PrismNET. At the event, Marlik Luno, the Chairman of PrismNET Global Development Committee and Chief Operating Officer, welcomed the representatives of the Asia-Pacific community and outlined the development plans for the upcoming months. Luno highlighted the current global societal transformation characterized by significant shifts in productivity. PrismNET is at the forefront of this transformation, leading the development in the AIGC artificial intelligence industry. The company has addressed the industry’s core challenge of GPU power supply for energy in artificial intelligence, having upgraded 13 GPU power clusters globally with a total capacity reaching 1100P. Furthermore, the platform is developing the PrismNET Chain (PNC), a global distributed power cluster blockchain network aimed at consolidating idle and redundant GPU power for scheduling and distribution, thus maximizing the application value of individual GPU capacities.
Subsequently, Tomy Tang, from the Platform Education and Development Committee, analyzed the current state and future value of the AI+DePin industry track for the leaders. He discussed how PrismNET positions itself as the first platform globally to implement an AI+Web3.0 ecosystem. The platform’s GPU power leasing service has already provided cost-effective energy solutions for more AI enterprises. Using AI for content publication, data streaming, and automated sales through e-commerce server rooms built around the world, along with matrixed account operations, the platform has achieved over $7000 in sales profit per account on TikTok, demonstrating the deep application of AI in e-commerce.
Following this, William delved into an in-depth analysis of PrismNET’s business model and its long-term value prospects. Many community leaders expressed that PrismNET’s business model fully meets everyone’s market expectations and that this mechanism is adaptable to various market conditions, ensuring the best possible outcomes for business expansion. The business model, being a core element of project development, features low barriers to entry, high returns, vast potential for imagination, scalability, user-friendliness, and strong promotional drive, which are significant characteristics of the PrismNET model.
During the banquet, the platform made a major announcement with the launch of PriamAI, an AI short video tool tailored for C-end users, integrating functions like IP creation, graphic generation, video conversion, and digital human cloning. PrismAI provides numerous entrepreneurs with powerful tools for easy use. Additionally, users can utilize PNC for exchanges to enhance their experience significantly, also greatly boosting PNC’s circulation and application value within the ecosystem.
At the banquet, the 319 Global Service Center Plan was announced, which, through the strong support of salons and sharing sessions, aids in the business development of service centers in various regions and rapidly propagates PrismNET’s vast ecosystem in the market. The banquet also recognized outstanding service centers for April, with Chief Operating Officer Luno personally distributing awards to the winners. Additionally, the development and evaluation plans for the community in May and a preview of the PrismNET Global Elite International Symposium scheduled for June were announced.
During this meeting, leaders from the Wutong Community and Xinxin International Community shared their experiences, insights, and market development strategies deeply with the attendees, setting goals and resolutions for May. All leaders present reached a high consensus to strive with full effort to discuss, build, share, and win together, and to collaborate in developing a grand industry ecosystem alongside the platform.
About PrismNET
PrismNET aims to provide cheap computing power and sustainable development super power for global AIGC entrepreneurs and developers in the AI field. It promotes the development of the artificial intelligence industry through the construction of distributed computing power cluster networks and computing power leasing services under trusted networks. Provide global investors with a convenient way to participate in the artificial intelligence track and an AI income path.
Follow PrismNET on:
Website | Telegram |Channel| Twitter | Medium | YouTube

2 notes
·
View notes