#pipeline data management
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Total funding amounts to $125.3M.
Text

Enhancing Gas Pipeline Management with GIS: Key Benefits and Applications
In the energy and utilities sector, gas pipeline management is complex, requiring precision, safety, and a clear strategy for both existing infrastructure and future expansion. Geographic Information Systems (GIS) have revolutionized pipeline management by providing a spatially accurate, data-rich view of assets. From asset management and leak detection to route planning and demand forecasting, GIS is becoming indispensable for gas companies. This blog delves into the ways GIS transforms gas pipeline management, delivering benefits across safety, efficiency, cost-saving, and planning.
#benefits of using gis for gas pipelines#ensuring gas pipeline safety with gis tools#gas network analysis#gas pipeline asset management#gas pipeline gis mapping services#gas pipeline leak detection using gis#gas pipeline management in gis#gas pipeline mapping software#gas pipeline monitoring tools#gas pipeline risk assessment#gis applications in energy sector#gis for gas pipeline monitoring#gis for infrastructure management#gis in oil and gas industry#gis pipeline maintenance software#gis pipeline monitoring system#gis pipeline route planning#gis software for gas pipeline route optimization#victoryofgoodoverevil#gis solutions for pipeline maintenance and monitoring#gis-based pipeline integrity management#pipeline data management#pipeline geographic information systems#pipeline management solutions#remote sensing for gas pipelines#spatial analysis for gas pipelines#spatial data for gas pipelines
0 notes
Text
The Case Against One-Off Workflows

I've been in the data delivery business long enough to know a red flag when I see one. One-off workflows may be a convenient victory. I've constructed them, too—for that stressed-out client, that brand-new data spec, or an ad-hoc format change. They seem efficient at the time. Just do it and be gone.
But that's what occurred: weeks afterward, I found myself in that very same workflow, patching a path, mending a field, or describing why the logic failed when we brought on a comparable client. That's when the costs creep in quietly.
Fragmentation Creeps In Quietly
Every single one-off workflow introduces special logic. One can contain a bespoke transformation, another a client-specific validation, and another a brittle directory path. Do that across dozens of clients, hundreds of file formats, and constrained delivery windows—it's madness.
This fragmented configuration led to:
Mismatches in output between similar clients
Same business rules being duplicated in several locations
Global changes needing to be manually corrected in each workflow
Engineers wasting hours debugging small, preventable bugs
Quiet failures that were not discovered until clients complained
What was initially flexible became an operational hindrance gradually. And most infuriating of all, it wasn't clear until it became a crisis.
The Turning Point: Centralizing Logic
When we switched to a centralized methodology, it was a revelation. Rather than handling each request as an isolated problem, we began developing shared logic. One rule, one transform, one schema—deployed everywhere it was needed.
The outcome? A system that not only worked, but scaled.
Forge AI Data Operations enabled us to make that transition. In Forge's words, "Centralized logic eliminates the drag of repeated workflows and scales precision across the board."
With this approach, whenever one client altered specs, we ran the rule once. That change was automatically propagated to all relevant workflows. No tracking down scripts. No regression bugs.
The Real Payoffs of Centralization
This is what we observed:
40% less time spent on maintenance
Faster onboarding for new clients—sometimes in under a day
Consistent outputs regardless of source or format
Fewer late-night calls from ops when something failed
Better tracking, fewer bugs, and cleaner reporting
When logic lives in one place, your team doesn’t chase fixes. They improve the system.
Scaling Without Reinventing
Now, when a new request arrives, we don't panic. We fit it into what we already have. We don't restart pipelines—we just add to them.
Static one-off workflows worked when they first existed. But if you aim to expand, consistency wins over speed every time.
Curious about exploring this change further?
Download the white paper on how Forge AI Data Operations can assist your team in defining once and scaling infinitely—without workflow sprawl pain.
#Data Operations#Workflow Optimization#Centralized Systems#Data Engineering Best Practices#Process Automation#Workflow Management#Data Pipeline Efficiency
0 notes
Text
Understanding Core Components of the Data Engineering Ecosystem | Brilliqs

Explore the foundational components that power modern data engineering—from cloud computing and distributed platforms to data pipelines, Java-based workflows, and visual analytics. Learn more at www.brilliqs.com
#Data Engineering Ecosystem#Data Engineering Components#Cloud Data Infrastructure#Apache Spark#Amazon QuickSight#Data Pipelines#Data Management#Java for Data Engineering#Brilliqs
1 note
·
View note
Text
Investing in a great CRM/EMR but seeing messy results? Our latest post explains why consistent staff management is the key to unlocking your system's full potential. #MedspaCRM #BusinessEfficiency
#business#business consistency#clinic management#crm#customer relationship management#data accuracy#digital-marketing#electronic medical records#EMR#lead nurturing#marketing#Medspa Management#medspa operations#operational efficiency#patient experience#pipeline management#staff retention#Staff Training#technology
0 notes
Text
CRMLeaf Features Built to Improve Sales and Customer Relationships

In this blog, we’ll explore the key features of CRMLeaf that are designed to elevate your sales process and enhance customer relationships at every stage.
Read the full blog
#CRMLeaf#Sales CRM#Business CRM#CRM software#Lead management#Customer engagement#Project management#HR software#Payroll system#Billing CRM#Task tracking#Team collaboration#Pipeline management#Ticketing system#Employee tracking#Recruitment tool#Data security#Reports & insights#Role-based access
0 notes
Text

Starting Your Digital Transformation Journey
Small and medium-sized businesses (SMBs) can benefit greatly from digital transformation, which involves integrating digital technologies into all aspects of the business. This transformation isn't just about technology—it's about reshaping the way businesses operate and deliver value to customers.
Key Steps to help get you started on your journey.
1. Assess Your Needs
Begin by conducting a thorough analysis of your current business operations. Identify areas where digital technologies can bring the most benefits, such as customer service, sales, marketing, and internal processes. Consider the specific challenges your business faces and how digital solutions can address them.
2. Set Clear Goals
Define specific, measurable objectives for your digital transformation journey. Whether it's increasing customer satisfaction, improving operational efficiency, or boosting revenue, having clear goals will help guide your efforts and measure success. Make sure your goals align with your overall business strategy.
3. Choose the Right Tools
Select digital tools and technologies that align with your business needs and goals. This could include customer relationship management (CRM) systems, cloud computing, automation software, and data analytics tools. Ensure the chosen tools are scalable and can grow with your business.
4. Invest in Employee Training
Your employees play a crucial role in the success of your digital transformation. Provide comprehensive training and support to help them adapt to new technologies. Offer workshops, tutorials, and ongoing assistance to ensure everyone is comfortable and confident with the changes. Encourage a culture of continuous learning and innovation.
5. Implement Incrementally
Roll out digital transformation initiatives in stages to manage risks and ensure a smooth transition. Start with pilot projects to test new technologies and processes, gather feedback, and make necessary adjustments before scaling them across the entire organization. This approach allows you to learn from early experiences and refine your strategy as you go.
6. Monitor Progress and Adjust
Continuously track the progress of your digital transformation efforts. Use data and feedback to evaluate the effectiveness of your initiatives, identify areas for improvement, and make necessary adjustments. Regularly review your goals and strategy to ensure you're on track and adapt to changing market conditions.
7. Learn from Success Stories
Look to other businesses that have successfully undergone digital transformation for inspiration and insights. For example:
A local bakery integrated AI-driven inventory management to forecast sales and reduce food waste, leading to a 20% increase in sales within three months.
A boutique hotel used data analytics to offer personalized guest experiences, resulting in a 10% increase in guest satisfaction and repeat bookings.
These success stories highlight the potential benefits of digital transformation and can provide valuable lessons for your journey.
“A journey of a thousand miles begins with a single step. ”
— Lao Tzu

Common Challenges and How to Overcome Them
One of the common challenges businesses face during digital transformation is resistance to change. Employees may fear the unknown or worry about job security. To overcome this, communicate the benefits of digital transformation clearly and involve employees in the planning process. As stated in the steps above, provide comprehensive training and ongoing support to help them adapt confidently to new technologies.
Budget constraints can also be a significant hurdle. Start with small, impactful changes that offer a high return on investment. Explore funding options such as grants, subsidies, or flexible payment plans from technology providers. Emphasize the long-term cost savings and efficiencies gained through digital transformation to justify the initial investment.
Lastly, a lack of technical expertise can pose challenges for SMBs. Consider hiring consultants or partnering with technology providers who specialize in digital transformation. Invest in training and upskilling your current workforce to develop the necessary technical skills. Leverage industry networks, forums, and communities to share knowledge and gain insights from other businesses that have successfully implemented digital transformation.
By addressing these common challenges with strategic solutions, businesses can navigate their digital transformation journey successfully and unlock new opportunities for growth and innovation.
The 3 Top Industry Trends in Digital Transformation
1. AI-Powered Automation: AI continues to revolutionize industries by automating routine tasks and providing advanced insights. From customer service chatbots to supply chain optimization, AI-powered automation leads to faster decision-making, lower operational costs, and improved customer satisfaction.
2. Rise of Low-Code and No-Code Platforms: These platforms allow organizations to create and deploy custom applications without writing code, democratizing software development and enabling non-technical employees to build tools that fit their specific needs. This trend is expected to become even more widespread in 2025, empowering small businesses to innovate quickly and stay agile in a competitive market.
3. 5G Connectivity: The rollout of 5G networks will enable faster and more reliable internet connections, supporting the growth of IoT devices and real-time data processing. 5G connectivity enhances the capabilities of digital transformation initiatives across various industries, enabling businesses to leverage advanced technologies like augmented reality, virtual reality, and smart cities to deliver better customer experiences and improve operational efficiency.
Embarking on a digital transformation journey can seem daunting, but with careful planning and a strategic approach, SMBs can unlock new opportunities for growth and success. By assessing your needs, setting clear goals, choosing the right tools, investing in employee training, implementing incrementally, and continuously monitoring progress, you can position your business for long-term success in an increasingly digital world.
Learn more about DataPeak:
#technology#saas#machine learning#artificial intelligence#agentic ai#ai#digital transformation#cloud computing#cybersecurity#chatbots#SMBs#smbsuccess#DataPeak#FactR#streamline data management with AI#predictive analytics tools#ai solutions for data driven decision making#AI driven data workflow automation#best AI tools for data pipeline automation#reduce data processing time with AI#AI-driven business solutions#machine learning for workflow
0 notes
Text
Unveiling the Power of Delta Lake in Microsoft Fabric
Discover how Microsoft Fabric and Delta Lake can revolutionize your data management and analytics. Learn to optimize data ingestion with Spark and unlock the full potential of your data for smarter decision-making.
In today’s digital era, data is the new gold. Companies are constantly searching for ways to efficiently manage and analyze vast amounts of information to drive decision-making and innovation. However, with the growing volume and variety of data, traditional data processing methods often fall short. This is where Microsoft Fabric, Apache Spark and Delta Lake come into play. These powerful…
#ACID Transactions#Apache Spark#Big Data#Data Analytics#data engineering#Data Governance#Data Ingestion#Data Integration#Data Lakehouse#Data management#Data Pipelines#Data Processing#Data Science#Data Warehousing#Delta Lake#machine learning#Microsoft Fabric#Real-Time Analytics#Unified Data Platform
0 notes
Text
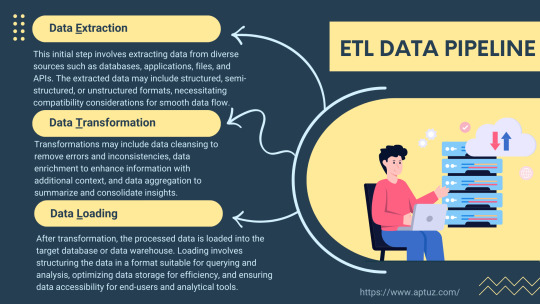
Explore the fundamentals of ETL pipelines, focusing on data extraction, transformation, and loading processes. Understand how these stages work together to streamline data integration and enhance organisational insights.
Know more at: https://bit.ly/3xOGX5u
#fintech#etl#Data pipeline#ETL Pipeline#Data Extraction#Data Transformation#Data Loading#data management#data analytics#redshift#technology#aws#Zero ETL
0 notes
Text
for everyone asking me "what do we do??!??!"
The Care We Dream Of: Liberatory and Transformative Approaches to LGBTQ+ Health by Zena Sharman
Mutual Aid: Building Solidarity During This Crisis (And the Next) by Dean Spade
Cop Watch 101 - Training Guide
The Do-It Yourself Occupation Guide
DIY HRT Wiki
The Innocence Project - helps take inmates off of death row
Food Not Bombs
Transfeminine Science - collection of articles and data about transfem HRT
Anti-Doxxing Guide for Activists
Mass Defense Program - National Lawyers Guild
How to be part of a CERT (Community Emergency Response Team)
Understanding and Advocating for Self Managed Abortion
The Basics of Organizing
Building Online Power
Build Your Own Solidarity Network
Organizing 101
How to Start a Non-Hierarchical Direct Action Group
A Short and Incomplete Guide for New Activists
Eight Things You Can Do to Get Active
Palestine Action Underground Manual
How to Blow Up a Pipeline by Andreas Malm
Spreadsheet of gynecologists that will tie your tubes without bothering you about it
COVID Resource Guide
Mask Bloc NJ (find one near you, these are international!)
Long Covid Justice
Donate to Palestinian campaigns (2, 3, 4)
Donate to Congolese campaigns (2, 3)
Donate to Sudanese campaigns (2, 3)
3K notes
·
View notes
Text
Why Data Teams Waste 70% of Their Week—and How to Fix It

Commercial data providers vow speed and scale. Behind the scenes, data teams find themselves drowning in work they never volunteered for. Rather than creating systems or enhancing strategy, they're re-processing files, debugging workflows, and babysitting fragile pipelines. Week after week, 70% of their time vanishes into operational black holes.
The actual problem is not so much the amount of data—it's the friction. Patching and manual processes consume the workday, with barely enough bandwidth for innovation or strategic initiatives.
Where the Week Disappears
Having worked with dozens of data-oriented companies, one trend is unmistakable: most time is consumed making data ready, rather than actually providing it. These include:
Reprocessing files because of small upstream adjustments
Reformatting outputs to satisfy many partner formats
Bailing out busted logic in ad-hoc pipelines
Manually checking or enhancing datasets
Responding to internal queries that depend on flawlessly clean data
Even as pipelines themselves seem to work, analysts and engineers tend to end up manually pushing tasks over the goal line. Over time, this continuous backstop role spirals out into a full-time job.
The Hidden Labor of Every Pipeline
Most teams underappreciate how much coordination and elbow grease lies buried in every workflow. Data doesn't simply move. It needs to be interpreted, cleansed, validated, standardized, and made available—usually by hand.
They're not fundamental technical issues. They're operational inefficiencies. Lacking automation over the entire data lifecycle, engineers are relegated to responding rather than creating. Time is spent patching scripts, fixing schema mismatches, and speeding toward internal SLAs.
The outcome? A team overwhelmed with low-value work under unrealistic timelines.
Solving the Problem with Automation
Forge AI Data Operations was designed for this very problem. Its purpose is to take the friction out of slowing down delivery and burning out teams. It automates each phase of the data life cycle—from ingestion and transformation to validation, enrichment, and eventual delivery.
Here's what it does automatically:
Standardizes diverse inputs
Applies schema mapping and formatting rules in real time
Validates, deduplicates, and enriches datasets on the fly
Packages and delivers clean data where it needs to go
Tracks each step for full transparency and compliance
This is not about speed. It's about providing data teams with time and mental room to concentrate on what counts.
Why This Matters
A data team's real value comes from architecture, systems design, and facilitating fast, data-driven decision-making. Not from massaging inputs or hunting down mistakes.
When 70% of the workweek is spent on grunt work, growth is stunted. Recruitment becomes a band-aid, not a solution. Innovation grinds to a halt. Automation is never about reducing jobs—it's about freeing up space for high-impact work.
Reclaim the Workweek
Your team's most precious resource is time. Forge AI enables you to free yourself from wasting it on repetitive tasks. The reward? Quicker turnaround, less error, happier clients, and space to expand—without expanding headcount.
Witness how Forge AI Data Operations can return your team's week back—and at last prioritize what actually moves your business ahead.
#Data Operations#Data Automation#Data Engineering#Workflow Optimization#Commercial Data Providers#Data Pipeline Management#Time Management for Data Teams
1 note
·
View note
Text
What is Dataflow?
This post is inspired by another post about the Crowd Strike IT disaster and a bunch of people being interested in what I mean by Dataflow. Dataflow is my absolute jam and I'm happy to answer as many questions as you like on it. I even put referential pictures in like I'm writing an article, what fun!
I'll probably split this into multiple parts because it'll be a huge post otherwise but here we go!
A Brief History

Our world is dependent on the flow of data. It exists in almost every aspect of our lives and has done so arguably for hundreds if not thousands of years.
At the end of the day, the flow of data is the flow of knowledge and information. Normally most of us refer to data in the context of computing technology (our phones, PCs, tablets etc) but, if we want to get historical about it, the invention of writing and the invention of the Printing Press were great leaps forward in how we increased the flow of information.
Modern Day IT exists for one reason - To support the flow of data.
Whether it's buying something at a shop, sitting staring at an excel sheet at work, or watching Netflix - All of the technology you interact with is to support the flow of data.
Understanding and managing the flow of data is as important to getting us to where we are right now as when we first learned to control and manage water to provide irrigation for early farming and settlement.
Engineering Rigor
When the majority of us turn on the tap to have a drink or take a shower, we expect water to come out. We trust that the water is clean, and we trust that our homes can receive a steady supply of water.
Most of us trust our central heating (insert boiler joke here) and the plugs/sockets in our homes to provide gas and electricity. The reason we trust all of these flows is because there's been rigorous engineering standards built up over decades and centuries.

For example, Scottish Water will understand every component part that makes up their water pipelines. Those pipes, valves, fitting etc will comply with a national, or in some cases international, standard. These companies have diagrams that clearly map all of this out, mostly because they have to legally but also because it also vital for disaster recovery and other compliance issues.
Modern IT
And this is where modern day IT has problems. I'm not saying that modern day tech is a pile of shit. We all have great phones, our PCs can play good games, but it's one thing to craft well-designed products and another thing entirely to think about they all work together.
Because that is what's happened over the past few decades of IT. Organisations have piled on the latest plug-and-play technology (Software or Hardware) and they've built up complex legacy systems that no one really knows how they all work together. They've lost track of how data flows across their organisation which makes the work of cybersecurity, disaster recovery, compliance and general business transformation teams a nightmare.

Some of these systems are entirely dependent on other systems to operate. But that dependency isn't documented. The vast majority of digital transformation projects fail because they get halfway through and realise they hadn't factored in a system that they thought was nothing but was vital to the organisation running.
And this isn't just for-profit organisations, this is the health services, this is national infrastructure, it's everyone.
There's not yet a single standard that says "This is how organisations should control, manage and govern their flows of data."
Why is that relevant to the companies that were affected by Crowd Strike? Would it have stopped it?
Maybe, maybe not. But considering the global impact, it doesn't look like many organisations were prepared for the possibility of a huge chunk of their IT infrastructure going down.
Understanding dataflows help with the preparation for events like this, so organisations can move to mitigate them, and also the recovery side when they do happen. Organisations need to understand which systems are a priority to get back operational and which can be left.
The problem I'm seeing from a lot of organisations at the moment is that they don't know which systems to recover first, and are losing money and reputation while they fight to get things back online. A lot of them are just winging it.
Conclusion of Part 1
Next time I can totally go into diagramming if any of you are interested in that.
How can any organisation actually map their dataflow and what things need to be considered to do so. It'll come across like common sense, but that's why an actual standard is so desperately needed!
789 notes
·
View notes
Text
I am really glad Ko brought up about the Sharks being neurotic about image and cultivating a specific brand bc I do think fans broadly and willmack fans coming from the tknp -> jdtz pipeline specifically do not think about the fact that the Sharks are majority owned by a man who founded and remains the majority stakeholder of the largest PEOPLE AND DATA MANAGEMENT company in the world. Even I forget that. But this is an org that knows how to manipulate data and people, because they are owned by the guy who invented doing that. In addition to the org being pathologically neurotic about their image, I feel very confident Sharks PR & Marketing have marketing resources at their disposal that most team's PR departments can only dream of, both due to Hasso AND their proximity to Silicon Valley.
There is a reason none of our beat reporters have pressed Mike Grier on the Zetterlund trade. There is a reason JD Young does not get prospect interviews anymore. There is a reason they keep Brodie Brazil on a very short leash now they employ him directly. The Sharks are obsessively concerned with their image and operate on a hair trigger. If Macklin says one word about being annoyed, if Becher decides he doesn't like it anymore, if Hasso thinks it's devaluing the brand &tc &tc, it's over.
#they are protective and possessive of macklin in ways i don't think any of us realize#like hockey twt does not realize they are on a collision course#even a regular team would hit their limit at some point#but the sharks are notably and INTENSELY neurotic about image#hockey for ts
51 notes
·
View notes
Text
Development Update - December 2024

Happy New Year, everyone! We're so excited to be able to start off 2025 with our biggest news yet: we have a planned closed beta launch window of Q1 2026 for Mythaura!
Read on for a recap of 2024, more information about our closed beta period, Ryu expressions, January astrology, and Ko-fi Winter Quarter reward concepts!
2024 Year in Review
Creative
This year, the creative team worked on adding new features, introducing imaginative designs, and refining lore/worldbuilding to enrich the overall experience.
New Beasts and Expressions: All 9 beast expression bases completed for both young and adult with finalized specials for Dragons, Unicorns, Griffins, Hippogriffs, and Ryu.
Mutations, Supers and Specials: Introduced the Celestial mutation as well as new Specials Banding & Merle, and the Super Prismatic.
New Artist: Welcomed Sourdeer to the creative team.
Collaboration and Sponsorship: Sponsored several new companions from our Ko-Fi sponsors—Amaru, Inkminks, Somnowl, Torchlight Python, Belligerent Capygora, and the Fruit-Footeded Gecko.
New Colors: Revealed two eye-catching colors, Canyon (a contest winner) and Porphyry (a surprise bonus), giving players even more variety for their Beasts.
Classes and Gear: Unveiled distinct classes, each with its own themed equipment and companions, to provide deeper roleplay and strategic depth.
Items and Worldbuilding: Created a range of new items—from soulshift coins to potions, rations, and over a dozen fishable species—enriching Mythaura’s economy and interactions.
Star Signs & Astrology: Continued to elaborate on the zodiac-like system, connecting each Beast’s fate to celestial alignments.
Questing & Story Outline: Laid the groundwork for the intro quest pipeline and overarching narrative, ensuring that players’ journey unfolds with purposeful progression.

Code
This year, the development team worked diligently on refining and expanding the codebase to support new features, enhance performance, and improve gameplay experiences. A total 429,000 lines of code changed across both the backend and frontend, reflecting:
New Features: Implementation of systems like skill trees, inventory management, community forums, elite enemies, npc & quest systems, and advanced customization options for Beasts.
Optimizations and Refactoring: Significant cleanup and streamlining of backend systems, such as game state management, passive effects, damage algorithms, and map data structures, ensuring better performance and maintainability.
Map Builder: a tool that allows us to build bespoke maps
Regular updates to ensure compatibility with modern tools and frameworks.
It’s worth noting that line changes alone don’t capture the complexity of programming work. For example:
A single line of efficient code can replace multiple lines of legacy logic.
Optimizing backend systems often involves removing redundant or outdated code without adding new functionality.
Things like added dependencies can add many lines of code without adding much bespoke functionality.

Mythaura Closed Beta

We are so beyond excited to share this information with you here first: Mythaura closed beta is targeted for Q1 2026!
On behalf of the whole team, thank you all so, so much for all of the support for Mythaura over the years. Whether you’ve been around since the Patreon days or joined us after Koa and Sark took over…it’s your support that has gotten this project to where it is. We are so grateful for the faith and trust placed in us, and the opportunity to create something we hope people will truly love and enjoy. This has truly been a collaborative effort with you and we are constantly humbled by all of the thoughtful insights, engaging discussions, and great ideas to come out of this amazing community of supporters.
So: thank you again, it’s been an emotional and amazing journey for the dev team and we’re delighted to join you on your journeys through Mythaura.
Miyazaki Full-Time
Hey everyone, Koa here!
We’re thrilled to share some news about Mythaura’s development! Starting in 2025, Miya will be officially dedicating herself full-time to Mythaura. Her focus will be on bringing even more depth and wonder to the world of Mythaura through content creation, worldbuilding, and building up the brand. It’s a huge step forward, and we’re so excited for the impact her passion and creativity will have on the project!
In addition, I’ve secured 4-day weeks and will be working full-time each Friday to dive deeper into development. This extra push is going to allow us to keep moving steadily forward on both the art and code fronts, and with Miya’s expanded role, the next year of development is looking really promising.
Thank you all for being here and supporting Mythaura every step of the way. We can’t wait to share more as things progress!
Closed Beta FAQ
In the interest of keeping all of the information about our Closed Beta in one place and update as needed, we have added as much information as possible to the FAQ page.
If you have any questions that you can think of, please feel free to reach out to us through our contact form or on Discord!
Winter Quarter (2025) Concepts
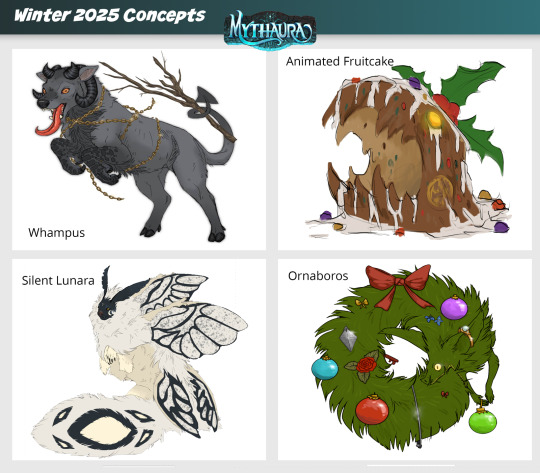

It’s the first day of Winter Quarter 2025, which means we’ve got new Quarterly Rewards for Sponsors to vote on on our Ko-fi page!
Which concepts would you like to see made into official site items? Sponsors of Bronze level or higher have a vote in deciding. Please check out the Companion post and the Glamour post on Ko-fi to cast your vote for the winning concepts!
Votes must be posted by January 29, 2025 at 11:59pm PDT in order to be considered.
All Fall 2024 Rewards are now listed in our Ko-fi Shop for individual purchase for all Sponsor levels at $5 USD flat rate per unit. As a reminder, please remember that no more than 3 units of any given item can be purchased. If you purchase more than 3 units of any given item, your entire purchase will be refunded and you will need to place your order again, this time with no more than 3 units of any given item.
Fall 2024 Glamour: Diaphonized Ryu
Fall 2024 Companion: Inhabited Skull
Fall 2024 Solid Gold Glamour: Hippogriff (Young)
NOTE: As covered in the FAQ, the Ko-fi shop will be closing at the end of the year. These will be the last Winter Quarter rewards for Mythaura!
New Super: Zebra

We've added our first new Super to the site since last year's Prismatic: Zebra, which has a chance to occur when parents have the Wildebeest and Banding Specials!
Zebra is now live in our Beast Creator--we're excited to see what you all create with it!
New Expressions: Ryu

The Water-element Ryu has had expressions completed for both the adult and young models. Expressions have been a huge, time-intensive project for the art team to undertake, but the result is always worth it!
Mythauran Astrology: January
The month of January is referred to as Hearth's Embrace, representing the fireplaces kept lit for the entirety of the coldest month of the year. This month is also associated with the constellation of the Glassblower and the carnelian stone.
Mythaura v0.35
Refactored "Beast Parties" into "User Parties," allowing non-beast entities like NPCs to be added to your party. NPCs added to your party will follow you in the overworld, cannot be made your leader, and will make their own decisions in combat.
Checkpoint floor functionality ironed out, allowing pre-built maps to appear at specific floor intervals.
The ability to set spawn and end coordinates in the map builder was added to allow staff to build checkpoint floors.
Various cleanups and refactors to improve performance and reduce the number of queries needed to run certain operations.
Added location events, which power interactable objects in the overworld, such as a lootable chest or a pickable bush.
Thank You!
Thanks for sticking through to the end of the post, we always look forward to sharing our month's work with all of you--thank you for taking the time to read. We'll see you around the Discord.
#mythaura#indie game#indie game dev#game dev#dev update#unicorn#dragon#griffin#peryton#ryu#basilisk#quetzal#hippogriff#kirin#petsite#pet site#virtual pet site#closed beta launch#flight rising#neopets
93 notes
·
View notes
Text
Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
New Post has been published on https://thedigitalinsider.com/datasets-matter-the-battle-between-open-and-closed-generative-ai-is-not-only-about-models-anymore/
Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
Two major open source datasets were released this week.
Created Using DALL-E
Next Week in The Sequence:
Edge 403: Our series about autonomous agents continues covering memory-based planning methods. The research behind the TravelPlanner benchmark for planning in LLMs and the impressive MemGPT framework for autonomous agents.
The Sequence Chat: A super cool interview with one of the engineers behind Azure OpenAI Service and Microsoft CoPilot.
Edge 404: We dive into Meta AI’s amazing research for predicting multiple tokens at the same time in LLMs.
You can subscribe to The Sequence below:
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
📝 Editorial: Datasets Matter: The Battle Between Open and Closed Generative AI is Not Only About Models Anymore
The battle between open and closed generative AI has been at the center of industry developments. From the very beginning, the focus has been on open vs. closed models, such as Mistral and Llama vs. GPT-4 and Claude. Less attention has been paid to other foundational aspects of the model lifecycle, such as the datasets used for training and fine-tuning. In fact, one of the limitations of the so-called open weight models is that they don’t disclose the training datasets and pipeline. What if we had high-quality open source datasets that rival those used to pretrain massive foundation models?
Open source datasets are one of the key aspects to unlocking innovation in generative AI. The costs required to build multi-trillion token datasets are completely prohibitive to most organizations. Leading AI labs, such as the Allen AI Institute, have been at the forefront of this idea, regularly open sourcing high-quality datasets such as the ones used for the Olmo model. Now it seems that they are getting some help.
This week, we saw two major efforts related to open source generative AI datasets. Hugging Face open-sourced FineWeb, a 44TB dataset of 15 trillion tokens derived from 96 CommonCrawl snapshots. Hugging Face also released FineWeb-Edu, a subset of FineWeb focused on educational value. But Hugging Face was not the only company actively releasing open source datasets. Complementing the FineWeb release, AI startup Zyphra released Zyda, a 1.3 trillion token dataset for language modeling. The construction of Zyda seems to have focused on a very meticulous filtering and deduplication process and shows remarkable performance compared to other datasets such as Dolma or RedefinedWeb.
High-quality open source datasets are paramount to enabling innovation in open generative models. Researchers using these datasets can now focus on pretraining pipelines and optimizations, while teams using those models for fine-tuning or inference can have a clearer way to explain outputs based on the composition of the dataset. The battle between open and closed generative AI is not just about models anymore.
🔎 ML Research
Extracting Concepts from GPT-4
OpenAI published a paper proposing an interpretability technique to understanding neural activity within LLMs. Specifically, the method uses k-sparse autoencoders to control sparsity which leads to more interpretable models —> Read more.
Transformer are SSMs
Researchers from Princeton University and Carnegie Mellon University published a paper outlining theoretical connections between transformers and SSMs. The paper also proposes a framework called state space duality and a new architecture called Mamba-2 which improves the performance over its predecessors by 2-8x —> Read more.
Believe or Not Believe LLMs
Google DeepMind published a paper proposing a technique to quantify uncertainty in LLM responses. The paper explores different sources of uncertainty such as lack of knowledge and randomness in order to quantify the reliability of an LLM output —> Read more.
CodecLM
Google Research published a paper introducing CodecLM, a framework for using synthetic data for LLM alignment in downstream tasks. CodecLM leverages LLMs like Gemini to encode seed intrstructions into the metadata and then decodes it into synthetic intstructions —> Read more.
TinyAgent
Researchers from UC Berkeley published a detailed blog post about TinyAgent, a function calling tuning method for small language models. TinyAgent aims to enable function calling LLMs that can run on mobile or IoT devices —> Read more.
Parrot
Researchers from Shanghai Jiao Tong University and Microsoft Research published a paper introducing Parrot, a framework for correlating multiple LLM requests. Parrot uses the concept of a Semantic Variable to annotate input/output variables in LLMs to enable the creation of a data pipeline with LLMs —> Read more.
🤖 Cool AI Tech Releases
FineWeb
HuggingFace open sourced FineWeb, a 15 trillion token dataset for LLM training —> Read more.
Stable Audion Open
Stability AI open source Stable Audio Open, its new generative audio model —> Read more.
Mistral Fine-Tune
Mistral open sourced mistral-finetune SDK and services for fine-tuning models programmatically —> Read more.
Zyda
Zyphra Technologies open sourced Zyda, a 1.3 trillion token dataset that powers the version of its Zamba models —> Read more.
🛠 Real World AI
Salesforce discusses their use of Amazon SageMaker in their Einstein platform —> Read more.
📡AI Radar
Cisco announced a $1B AI investment fund with some major positions in companies like Cohere, Mistral and Scale AI.
Cloudera acquired AI startup Verta.
Databricks acquired data management company Tabular.
Tektonic, raised $10 million to build generative agents for business operations —> Read more.
AI task management startup Hoop raised $5 million.
Galileo announced Luna, a family of evaluation foundation models.
Browserbase raised $6.5 million for its LLM browser-based automation platform.
AI artwork platform Exactly.ai raised $4.3 million.
Sirion acquired AI document management platform Eigen Technologies.
Asana added AI teammates to complement task management capabilities.
Eyebot raised $6 million for its AI-powered vision exams.
AI code base platform Greptile raised a $4 million seed round.
TheSequence is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
#agents#ai#AI-powered#amazing#Amazon#architecture#Asana#attention#audio#automation#automation platform#autonomous agents#azure#azure openai#benchmark#Blog#browser#Business#Carnegie Mellon University#claude#code#Companies#Composition#construction#data#Data Management#data pipeline#databricks#datasets#DeepMind
0 notes
Text
Maximize Efficiency with Volumes in Databricks Unity Catalog
With Databricks Unity Catalog's volumes feature, managing data has become a breeze. Regardless of the format or location, the organization can now effortlessly access and organize its data. This newfound simplicity and organization streamline data managem

View On WordPress
#Cloud#Data Analysis#Data management#Data Pipeline#Data types#Databricks#Databricks SQL#Databricks Unity catalog#DBFS#Delta Sharing#machine learning#Non-tabular Data#performance#Performance Optimization#Spark#SQL#SQL database#Tabular Data#Unity Catalog#Unstructured Data#Volumes in Databricks
0 notes
Text
It's another busy week, so I'm gonna do one of these again because it genuinely helps me keep track. Today in a nutshell!
Worked on some e-mails over breakfast - mostly coordinating for dinner tonight (I 100% did not forget to make the reservation, I promise, I just uhhhhhhhhhhh definitely didn't forget, that's for sure, and thank goodness for no particular reason that they happened to have one table left at 6PM), happily agreeing to write some reference letters for my PhD student's postdoc applications, rescheduling some meetings, setting new meetings, meetings meetings meetings. Oh, and booking tables for a couple of card shows this month! Off to work!
I get in a little later than I'd like and rush downstairs to the lounge to make my mug of tea pre-class, where I run into a student who just defended his PhD last week. I'm on his reading committee, so we agree to set up a time to go over my (honestly quite minor) comments on his dissertation. I also run into our incredible facilities guy, who follows up on some technical issues my students ran into over the weekend, hopefully resolved - I have five groups of three undergraduate students running their own weather stations all across the metro area of our city!
No time to enjoy the tea, so I leave it to steep a hilariously long time and rush back downstairs to teach my class! This year's students are truly exceptional - apparently over the weekend they all discovered that the Mac version of the data collection software for their weather stations is no longer supported, and they all independently coordinated to get PCs into the hands of all 5 groups. Let me tell you, when you're expecting to have to spend the first 20 minutes of the class troubleshooting and are instead greeted by a quiet, expectant two rows of faces, it's a great feeling.
Today's lecture is a topic I'm really passionate about - teaching students the "why" behind a lot of the statistical methods they've learned in the past (these are college seniors) and working on building a pipeline for exploratory data analysis. This isn't explicitly part of the syllabus, but my gosh, the quality of the final reports has improved sharply once I introduced these lectures. The students participated a bunch and happily launched into think-pair-share groups without my having to coordinate them. This is my sixth time teaching this class, and these students are far and away the best I've encountered. I am also very, very bad with names (and have a lot of anxiety about calling someone by the wrong name) but managed to successfully use an example in class in which I rattled off four students' names in a row, no effort needed. Phew.
As a side note, this has always been far and away my least-favorite class to teach, and this was the year I was gonna change that - I brought it to a curriculum development workshop last year and even presented on it at an education conference last week. But... dang, having strong students truly makes it effortless to enjoy teaching this class.
Back to my office, which smells like the double-spiced chai that has been steeping so long it's probably quadruple-spiced by now. Delicious. I have an hour until my next commitment, so I try to get ahead on grading the homework assignment my students handed in on Friday (all 15 of them handed it in on time!!!!). I also realize that this is my last block of free time until dinner, so I run downstairs to heat up my soup for lunch.
After getting through four of the assignments, it's time for a weather briefing (we have a team for a national forecasting competition), which means it's mostly just time for technical difficulties, but we make it through in the end and wrap up a bit early - back to grading! Students are doing great on this assignment overall, which is gratifying, but I make a note of a topic some of them are struggling on so I can mention it during Wednesday's class.
Weekly hour-long meeting with one of my Master's students! He talked about how he's taking a course on pedagogy to help with his work as a teaching assistant this quarter (!!) and he's been working through my first round of revisions of his very first first-author scientific journal article and had a few clarifying questions. I recommended some off-the-wall papers in the communications literature that I think would dovetail well with some of the discussion in his paper, and he was really jazzed to get to explore those. We also decided to get him set up with a million core-hours on a supercomputer so he can start on the next phase of his research - he promised to have the paper ready for the next set of revisions by the end of the week, so while I'm working on that, he can get familiar with the new system. I am also reminded that I really need to come up with some more substantial funding for him - currently he's working on a fellowship, but that runs out after three years.
After he heads out (a few minutes early, more grading time!) I get an e-mail from a scientist in Switzerland - she and I are working on getting her out here for a two-year postdoc job studying lightning with me. She's made revisions on her application for funding, so that's another thing for me to read over this week. I'm also reminded that I have to get back to an Italian grad student who wants to come visit my group for a year. Still figuring out the logistics on that one...
I also need to get back to a forestry service colleague of mine about getting the university my share of the funds for our fast-approaching field work using brand-new radar tech to study wildfire smoke plumes. I really, really need to get back to him this week - I think we're planning on flying out in April to start.
ALSO also this week, I have some pretty intense revisions of my own to deal with - I've been given this opportunity to write a huge review article, and I finally got it done back in December... only to learn that they want it to be about half that length. I'm going to take a swing at carving 5,000 words out of that behemoth.
AND a colleague and I are working on a resubmission of a grant to study thunderstorms in really unusual places, and I promised her I'd have a complete draft for her to read by the 7th. Phew. Good thing my week is only front-loaded with meetings.
Whoops, no more time to grade/read e-mails and schedule in my head. We have someone here today interviewing for a job on our faculty, and I'm one of the search committee members! Better dash downstairs to catch the candidate's talk. We have five two-day interviews planned for the next four weeks. Ouch.
Awesome talk by the candidate (we're very lucky to be spoiled for choice even in our very specialized field - we've whittled 86 qualified candidates down to five), and I launch straight from that into a student's PhD entrance exam. At this stage I should mention how much I genuinely loathe our PhD entrance exam, which is a pedagogical and logistical nightmare all around. This was a very popular opinion, which is why we as the faculty voted unanimously to completely change the process last year. Why are there students still taking this horrible exam???? Fuck if I know, man. At this point, it's voluntary to opt into it, and I am baffled and deeply frustrated at how many faculty members apparently encouraged their students to take it. Anyway, the student does a great job and we muddle through somehow, and now it's back up to my office to do some cramming on small-talk topics before a colleague and I host the faculty candidate for dinner!
A delightful dinner all around - my colleague is someone I was initially intimidated by (she's a giant in the field) but with whom I have since bonded, so we had some fun banter in the car and I think it helped the job candidate relax a little. We had some fun big-picture talk (and some less-fun big picture talk about news that dropped as we were eating) but mostly just talked about how much we love this part of the world. Good food, drink, and conversation. On the car ride home, I managed to troubleshoot a problem my undergrad research assistant was having with getting access to the supercomputer he needs for his project. Phew.
That's a long day, but good stuff all around!
19 notes
·
View notes