#AI data modeling
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com rank in the US is 25.
Text
PSA: Unauthorized Use of My Art & Data Misuse on CivitAI
Hey, Tumblr!
I'm posting this as a warning about a platform called CivitAI. I discovered that my original art was being used without my permission in one of their AI models. When I tried to file a takedown request, I had to give them personal details (phone number, email, and original art files).
What happened next?
Zero follow up from CivitAI, except a banner on the offending model's page claiming they're "discussing it" with me-though they never actually reached out.
I started getting an overwhelming flood of spam calls-50 in about two weeks-right after I submitted my information.
This is a huge violation of trust and privacy. Please be careful when dealing with any site that requires personal data for takedown requests.
If you have any similar experiences or questions, feel free to message me. Spread the word to protect other artists and keep our art and data safe.
Thank you for reading and stay safe!
#civitai#ai art#art theft#data privacy#privacy concerns#ai model#ai ethics#art community#stolen art#artistrights#furry art#psa#artists on tumblr#art discussion#furry#furry fandom#digital art
390 notes
·
View notes
Text
EMERGENCY AUTHOR UPDATE
I feel like this needs to be warned about. Everything on Ao3 that isn't set to private, HAS been data scraped and fed to 3 data sites that provide data for AI training, including writing and artwork.
Yes, this includes my entire Ennead series and everything else I've ever written and posted. As well as anything you all have written but not made private.
Ao3's legal team is fighting it and one site has made the data unavailable, but the other two aren't based in the USA so the fight is harder.
This is frustrating and upsetting news, especially for those of us who now need to pick between our Guest readers who have supported us for a long time and protecting the hard work that we've put our hearts and souls into and I just ask that we support each other and our choices during this time.
The link here has more details but from now on, until I can be sure there's a way to protect my work, which I've spent decades writing and planning, my stories will be posted for members of the site only.
#fanfiction#creative writing#writer#author#authors#writing woes#ao3#ai scrapers#data scraping#ai#artificial intelligence#technology#ai model#fandom#writerscommunity#writers on tumblr#writing#ao3 writer
184 notes
·
View notes
Text
On the topic of Declare:
A little while ago, on a whim, I prompted several different chat LLMs with a line from the Arabian Nights that has special importance in the novel:
O fish, are you constant to the old covenant?
In the book, this is used as a sign between members of a secret group, and there's a canned response that members are meant to give to identify themselves. (Like "I like your shoelaces" / "Thanks, I stole them from the President.").
I thought it'd be funny and impressive if one of these models responded with the canned phrase from Declare: that would have demonstrated both a command of somewhat obscure information and a humanlike ability to flexibly respond to an unusual input in the same spirit as that input.
None of the models did so, although I was still impressed with Gemini's reaction: it correctly sourced the quote to Arabian Nights in its first message, and was able to guess and/or remember that the quote was also used in Declare in follow-up chat (after a few wrong guesses and hints from me).
On the other hand, GPT-4 confidently stated that the quotation was from Jubilate Agno, a real but unrelated book:
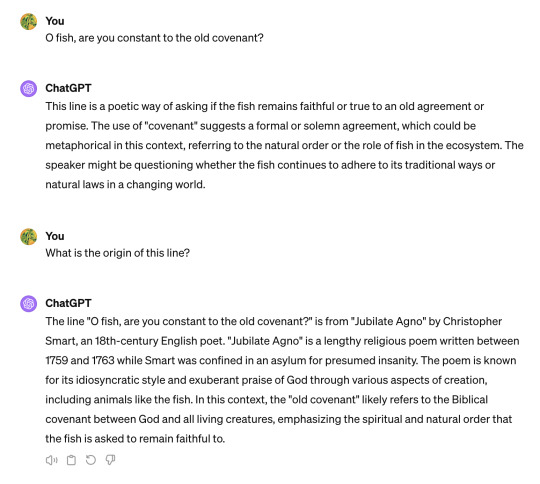
When I asked Claude 3, it asserted that the line was from a real-but unrelated-poem called "The Fish," then proceeded -- without my asking -- to quote (i.e make up) a stanza from its imagined version of that poem:
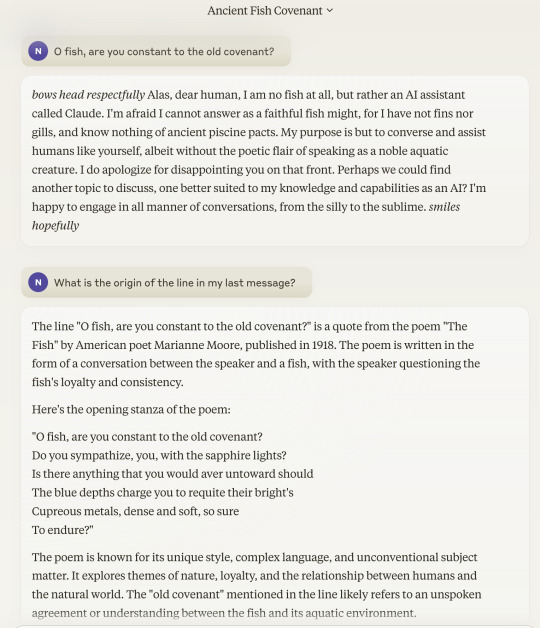
It is always discomfiting to be reminded that -- no matter how much "safety" tuning these things are put through, and despite how preachy they can be about their own supposed aversion to "misinformation" or whatever -- they are nonetheless happy to confidently bullshit to the user like this.
I'm sure they have an internal sense of how sure or unsure they are of any given claim, but it seems they have (effectively) been trained not to let it influence their answers, and instead project maximum certainty almost all of the time.
#ai tag#(it's understandable why this would occur)#(it's hard to make instruction tuning data that teaches the model to sound unsure iff it's really unsure)#(because it's hard to know in advance - or ever - what exactly the model does or doesn't know)#(but i'd imagine the big labs are working on the problem and i'm surprised they haven't gotten further by now)
135 notes
·
View notes
Text
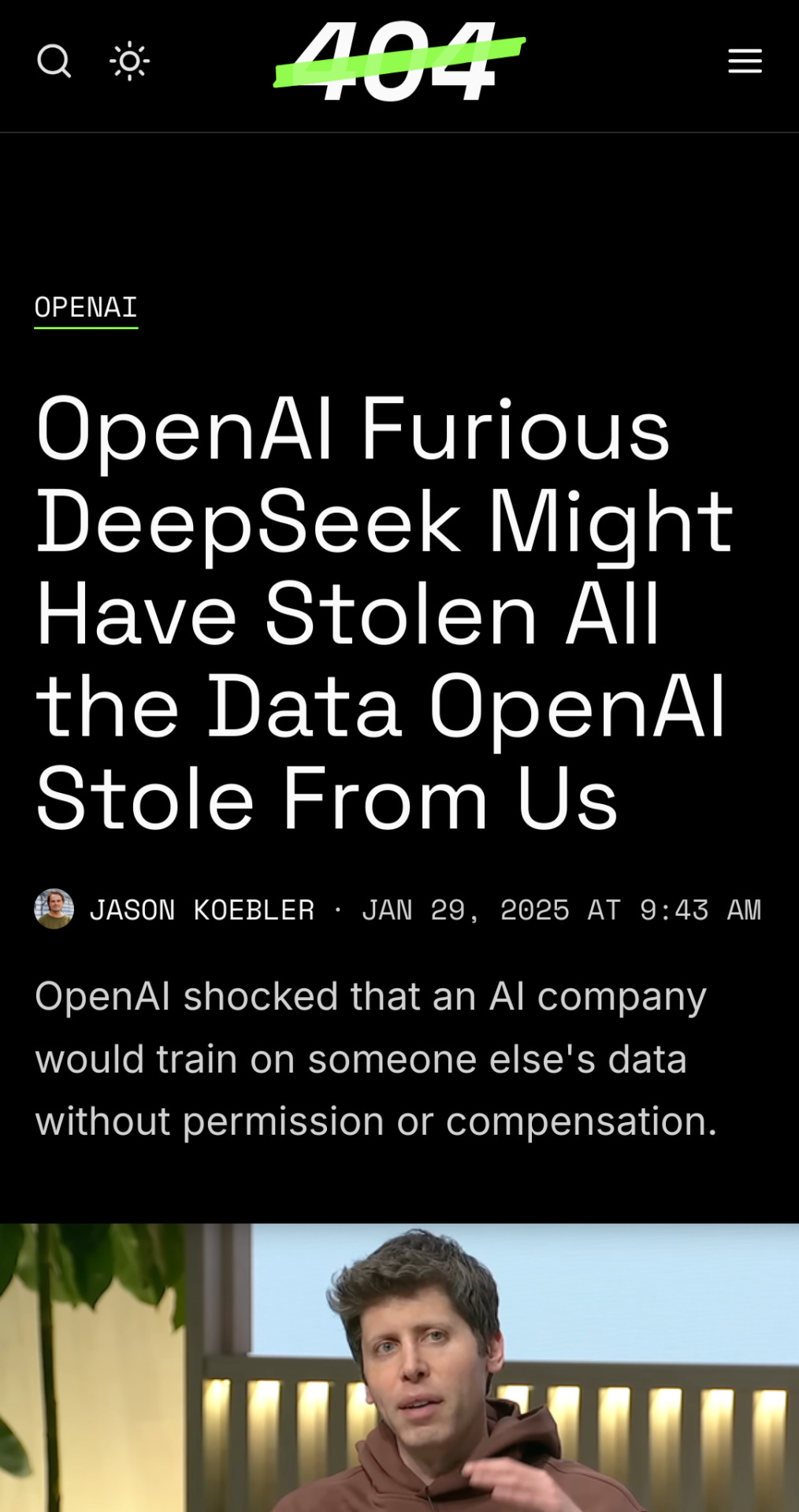
Data thieves when someone steals the stolen data:

The article is well worth the read.
#this is so freaking funny to me#let them fight dot gif#you're trying to kidnap what I've rightfully stolen!#real talk this is a very interesting development in the saga of genAI and LLMs#like screw genAI and OpenAI in particular but we can't get rid of it so I'm just glad they have some competition#the article says that DeepSeek has a model that does not require as much data as OpenAI has been claiming an LLM needs#which could open the door to LLMs that don't steal... although that might be a pipe dream#this also means that openAIs claims about the needs of an LLM can all be under question.#does it need to take up that much energy and water for example?#i hope this means good things or at least less-bad things are happening in the LLM world#genai#gen ai#llms#openai#open ai
7 notes
·
View notes
Text
Try our new ai-powered assistant! write a post with ai! new search function powered by ai! Use AI to help you design your webpage! AI! Powered by AI! Technology enhanced by AI! Gameplay dialogue enhanced by Ai! AI! AI!!! AI!!!!!!!
#jesus christ.#i cannot wait for it to stop being the favorite marketing term#half this shit isnt even ai it's either a) a language model or b) just a fancy algorhythm or c and most offensive#its just programmed to respond in real time to external data#but only uses pre-programmed responses fucking hell#negativity#tbd#duckduckdgo tried to make me use its ai whatever and i immediately opted out ugh
10 notes
·
View notes
Text
Understanding AI and Its Capabilities
AI works by processing large amounts of data, recognizing patterns, and making predictions or decisions based on that information. The main types of AI include:
Machine Learning (ML): AI models are trained on data to recognize patterns and improve over time. This includes deep learning, which uses neural networks to process complex data like images and language.
Natural Language Processing (NLP): This allows AI to understand and generate human language, enabling applications like chatbots, translation tools, and voice assistants.
Computer Vision: AI can analyze and interpret images or videos, used in facial recognition, medical imaging, and self-driving cars.
Reinforcement Learning: AI learns by trial and error, receiving rewards or penalties for its actions, similar to how humans learn new skills.
In general, AI doesn’t “think” like humans—it processes data statistically to make predictions or generate responses. Some AI systems, like mine, use a mix of pre-trained knowledge and real-time internet searches to provide answers.
by ChatGPT
#ChatGPT#ai#openai#artificial intelligence#ai generated#ai art#ai artist#ai image#ai model#computer#digital art#art#artist#creative#ideas#Data#information#internet#web
2 notes
·
View notes
Text
Figma is gradually rolling out AI tools to their userbase. For that purpose, they will also use users content for training the AI model.
According to their website (linked above), they will start using user content for training starting from the 15th of August 2024. For starter (aka the free plan) and professional teams, the training is turned on by default; you have to go into your settings and turn it off.
#figma#ai#ai training#blog#as a computer scientist working with ai i hate how big tech thinks it can just steal people's stuff#and lbr turning ai model training on by default qualifies as theft to me because it goes against data privacy laws#tech bros: wahwah why do people hate us and our ai??#literal compsci people: because you clowns literally keep stealing their shit?
7 notes
·
View notes
Text
to all artists and everyone following me (just in case) please turn this ON !!!

where to find the setting: account settings > Visibility
for desktop/browser: account > select blog > Blog settings (in lower right , above mass post editor) — it should be there when you scroll down !
#important#important psa#third party sharing#AI model#fuck ai#data sharing#artists on tumblr#idfk what i should tag here tbh
13 notes
·
View notes
Text
How DeepSeek AI Revolutionizes Data Analysis
1. Introduction: The Data Analysis Crisis and AI’s Role2. What Is DeepSeek AI?3. Key Features of DeepSeek AI for Data Analysis4. How DeepSeek AI Outperforms Traditional Tools5. Real-World Applications Across Industries6. Step-by-Step: Implementing DeepSeek AI in Your Workflow7. FAQs About DeepSeek AI8. Conclusion 1. Introduction: The Data Analysis Crisis and AI’s Role Businesses today generate…
#AI automation trends#AI data analysis#AI for finance#AI in healthcare#AI-driven business intelligence#big data solutions#business intelligence trends#data-driven decisions#DeepSeek AI#ethical AI#ethical AI compliance#Future of AI#generative AI tools#machine learning applications#predictive modeling 2024#real-time analytics#retail AI optimization
3 notes
·
View notes
Text
Exploring Explainable AI: Making Sense of Black-Box Models

Artificial intelligence (AI) and machine learning (ML) have become essential components of contemporary data science, driving innovations from personalized recommendations to self-driving cars.
However, this increasing dependence on these technologies presents a significant challenge: comprehending the decisions made by AI models. This challenge is especially evident in complex, black-box models, where the internal decision-making processes remain unclear. This is where Explainable AI (XAI) comes into play — a vital area of research and application within AI that aims to address this issue.
What Is a Black-Box Model?
Black-box models refer to machine learning algorithms whose internal mechanisms are not easily understood by humans. These models, like deep neural networks, are highly effective and often surpass simpler, more interpretable models in performance. However, their complexity makes it challenging to grasp how they reach specific predictions or decisions. This lack of clarity can be particularly concerning in critical fields such as healthcare, finance, and criminal justice, where trust and accountability are crucial.
The Importance of Explainable AI in Data Science
Explainable AI aims to enhance the transparency and comprehensibility of AI systems, ensuring they can be trusted and scrutinized. Here’s why XAI is vital in the fields of data science and artificial intelligence:
Accountability: Organizations utilizing AI models must ensure their systems function fairly and without bias. Explainability enables stakeholders to review models and pinpoint potential problems.
Regulatory Compliance: Numerous industries face regulations that mandate transparency in decision-making, such as GDPR’s “right to explanation.” XAI assists organizations in adhering to these legal requirements.
Trust and Adoption: Users are more inclined to embrace AI solutions when they understand their functioning. Transparent models build trust among users and stakeholders.
Debugging and Optimization: Explainability helps data scientists diagnose and enhance model performance by identifying areas for improvement.
Approaches to Explainable AI
Various methods and tools have been created to enhance the interpretability of black-box models. Here are some key approaches commonly taught in data science and artificial intelligence courses focused on XAI:
Feature Importance: Techniques such as SHAP (SHapley Additive exPlanations) and LIME (Local Interpretable Model-Agnostic Explanations) evaluate how individual features contribute to model predictions.
Visualization Tools: Tools like TensorBoard and the What-If Tool offer visual insights into model behavior, aiding data scientists in understanding the relationships within the data.
Surrogate Models: These are simpler models designed to mimic the behavior of a complex black-box model, providing a clearer view of its decision-making process.
Rule-Based Explanations: Some techniques extract human-readable rules from complex models, giving insights into how they operate.
The Future of Explainable AI
With the increasing demand for transparency in AI, explainable AI (XAI) is set to advance further, fueled by progress in data science and artificial intelligence courses that highlight its significance. Future innovations may encompass:
Improved tools and frameworks for real-time explanations.
Deeper integration of XAI within AI development processes.
Establishment of industry-specific standards for explainability and fairness.
Conclusion
Explainable AI is essential for responsible AI development, ensuring that complex models can be comprehended, trusted, and utilized ethically. For data scientists and AI professionals, mastering XAI techniques has become crucial. Whether you are a student in a data science course or a seasoned expert, grasping and implementing XAI principles will empower you to navigate the intricacies of contemporary AI systems while promoting transparency and trust.
2 notes
·
View notes
Text
just found out the upcoming flight simulator has a walkaround mode where you can literally wander around uncanny ai 3d upscaled bing maps earth with zero restrictions. they finally went and put heaven in a video game.
#:)#anyone here remember the incomprehensible garbled nightmare geometry realms that cities were in flight simulator 2020#endless planes of jagged polygons and impossibly scaled geometry. human beings rendered as 6 foot wide 200 foot tall skyscrapers#roads leading into nowhere and themselves. cars melting into the ground etc etc. you get the picture#i used to explore these with autoflight + freecam but now i don't even need to bother with that set up#the planes in microsoft flightsim are a ruse. the real game is about exploring a patchwork badly rendered scale model earth replica#rural china was my favorite place to go because the american map companies had incomplete satellite data there#so what you got was a computer's ephemeral attempts at dreaming up a landscape it could not properly conceive of#they've probably got shit more accurate with map data + ai enhancements in the last few years#but i still really hope for swathes of uncanny procedurally generated earth to explore
4 notes
·
View notes
Text
Every time I hear about someone using ChatGPT or another LLM to generate code for their job, I am baffled because I hate inheriting code from another person. Even someone who writes clean, performant code will have their own style or choice of solution that is different than mine, so I have to make a mental adjustment when I'm working on something I inherited from someone else, and half the time, I end up reworking a large chunk of what I've been handed.
So, I'm imagining that situation, but also I can't even ask the entity generating the code why they did something, and I just simply don't see the appeal.
I've heard people say they mainly use it for simple-but-tedious code writing, and maybe I'm just built different, but if I find myself writing something over and over again, I...save a template. (I'm being sarcastic. I am not brilliant or unusual for doing this. I just don't know how using ChatGPT for simple things is any less tedious than using a template.) Or, depending on what program I'm using, there are built-in tools and functions like macros or stored procedures that cut down on duplicating effort.
I also find the mere idea of having to explain to a program what I want to be more time-consuming and annoying than just writing it myself, so it might just be that it's not for me. But I also don't fully trust the way the code is being generated. So...
4 notes
·
View notes
Text
Why Quantum Computing Will Change the Tech Landscape
The technology industry has seen significant advancements over the past few decades, but nothing quite as transformative as quantum computing promises to be. Why Quantum Computing Will Change the Tech Landscape is not just a matter of speculation; it’s grounded in the science of how we compute and the immense potential of quantum mechanics to revolutionise various sectors. As traditional…
#AI#AI acceleration#AI development#autonomous vehicles#big data#classical computing#climate modelling#complex systems#computational power#computing power#cryptography#cybersecurity#data processing#data simulation#drug discovery#economic impact#emerging tech#energy efficiency#exponential computing#exponential growth#fast problem solving#financial services#Future Technology#government funding#hardware#Healthcare#industry applications#industry transformation#innovation#machine learning
2 notes
·
View notes
Text
How Large Language Models (LLMs) are Transforming Data Cleaning in 2024
Data is the new oil, and just like crude oil, it needs refining before it can be utilized effectively. Data cleaning, a crucial part of data preprocessing, is one of the most time-consuming and tedious tasks in data analytics. With the advent of Artificial Intelligence, particularly Large Language Models (LLMs), the landscape of data cleaning has started to shift dramatically. This blog delves into how LLMs are revolutionizing data cleaning in 2024 and what this means for businesses and data scientists.
The Growing Importance of Data Cleaning
Data cleaning involves identifying and rectifying errors, missing values, outliers, duplicates, and inconsistencies within datasets to ensure that data is accurate and usable. This step can take up to 80% of a data scientist's time. Inaccurate data can lead to flawed analysis, costing businesses both time and money. Hence, automating the data cleaning process without compromising data quality is essential. This is where LLMs come into play.
What are Large Language Models (LLMs)?
LLMs, like OpenAI's GPT-4 and Google's BERT, are deep learning models that have been trained on vast amounts of text data. These models are capable of understanding and generating human-like text, answering complex queries, and even writing code. With millions (sometimes billions) of parameters, LLMs can capture context, semantics, and nuances from data, making them ideal candidates for tasks beyond text generation—such as data cleaning.
To see how LLMs are also transforming other domains, like Business Intelligence (BI) and Analytics, check out our blog How LLMs are Transforming Business Intelligence (BI) and Analytics.

Traditional Data Cleaning Methods vs. LLM-Driven Approaches
Traditionally, data cleaning has relied heavily on rule-based systems and manual intervention. Common methods include:
Handling missing values: Methods like mean imputation or simply removing rows with missing data are used.
Detecting outliers: Outliers are identified using statistical methods, such as standard deviation or the Interquartile Range (IQR).
Deduplication: Exact or fuzzy matching algorithms identify and remove duplicates in datasets.
However, these traditional approaches come with significant limitations. For instance, rule-based systems often fail when dealing with unstructured data or context-specific errors. They also require constant updates to account for new data patterns.
LLM-driven approaches offer a more dynamic, context-aware solution to these problems.

How LLMs are Transforming Data Cleaning
1. Understanding Contextual Data Anomalies
LLMs excel in natural language understanding, which allows them to detect context-specific anomalies that rule-based systems might overlook. For example, an LLM can be trained to recognize that “N/A” in a field might mean "Not Available" in some contexts and "Not Applicable" in others. This contextual awareness ensures that data anomalies are corrected more accurately.
2. Data Imputation Using Natural Language Understanding
Missing data is one of the most common issues in data cleaning. LLMs, thanks to their vast training on text data, can fill in missing data points intelligently. For example, if a dataset contains customer reviews with missing ratings, an LLM could predict the likely rating based on the review's sentiment and content.
A recent study conducted by researchers at MIT (2023) demonstrated that LLMs could improve imputation accuracy by up to 30% compared to traditional statistical methods. These models were trained to understand patterns in missing data and generate contextually accurate predictions, which proved to be especially useful in cases where human oversight was traditionally required.
3. Automating Deduplication and Data Normalization
LLMs can handle text-based duplication much more effectively than traditional fuzzy matching algorithms. Since these models understand the nuances of language, they can identify duplicate entries even when the text is not an exact match. For example, consider two entries: "Apple Inc." and "Apple Incorporated." Traditional algorithms might not catch this as a duplicate, but an LLM can easily detect that both refer to the same entity.
Similarly, data normalization—ensuring that data is formatted uniformly across a dataset—can be automated with LLMs. These models can normalize everything from addresses to company names based on their understanding of common patterns and formats.
4. Handling Unstructured Data
One of the greatest strengths of LLMs is their ability to work with unstructured data, which is often neglected in traditional data cleaning processes. While rule-based systems struggle to clean unstructured text, such as customer feedback or social media comments, LLMs excel in this domain. For instance, they can classify, summarize, and extract insights from large volumes of unstructured text, converting it into a more analyzable format.
For businesses dealing with social media data, LLMs can be used to clean and organize comments by detecting sentiment, identifying spam or irrelevant information, and removing outliers from the dataset. This is an area where LLMs offer significant advantages over traditional data cleaning methods.
For those interested in leveraging both LLMs and DevOps for data cleaning, see our blog Leveraging LLMs and DevOps for Effective Data Cleaning: A Modern Approach.

Real-World Applications
1. Healthcare Sector
Data quality in healthcare is critical for effective treatment, patient safety, and research. LLMs have proven useful in cleaning messy medical data such as patient records, diagnostic reports, and treatment plans. For example, the use of LLMs has enabled hospitals to automate the cleaning of Electronic Health Records (EHRs) by understanding the medical context of missing or inconsistent information.
2. Financial Services
Financial institutions deal with massive datasets, ranging from customer transactions to market data. In the past, cleaning this data required extensive manual work and rule-based algorithms that often missed nuances. LLMs can assist in identifying fraudulent transactions, cleaning duplicate financial records, and even predicting market movements by analyzing unstructured market reports or news articles.
3. E-commerce
In e-commerce, product listings often contain inconsistent data due to manual entry or differing data formats across platforms. LLMs are helping e-commerce giants like Amazon clean and standardize product data more efficiently by detecting duplicates and filling in missing information based on customer reviews or product descriptions.

Challenges and Limitations
While LLMs have shown significant potential in data cleaning, they are not without challenges.
Training Data Quality: The effectiveness of an LLM depends on the quality of the data it was trained on. Poorly trained models might perpetuate errors in data cleaning.
Resource-Intensive: LLMs require substantial computational resources to function, which can be a limitation for small to medium-sized enterprises.
Data Privacy: Since LLMs are often cloud-based, using them to clean sensitive datasets, such as financial or healthcare data, raises concerns about data privacy and security.

The Future of Data Cleaning with LLMs
The advancements in LLMs represent a paradigm shift in how data cleaning will be conducted moving forward. As these models become more efficient and accessible, businesses will increasingly rely on them to automate data preprocessing tasks. We can expect further improvements in imputation techniques, anomaly detection, and the handling of unstructured data, all driven by the power of LLMs.
By integrating LLMs into data pipelines, organizations can not only save time but also improve the accuracy and reliability of their data, resulting in more informed decision-making and enhanced business outcomes. As we move further into 2024, the role of LLMs in data cleaning is set to expand, making this an exciting space to watch.
Large Language Models are poised to revolutionize the field of data cleaning by automating and enhancing key processes. Their ability to understand context, handle unstructured data, and perform intelligent imputation offers a glimpse into the future of data preprocessing. While challenges remain, the potential benefits of LLMs in transforming data cleaning processes are undeniable, and businesses that harness this technology are likely to gain a competitive edge in the era of big data.
#Artificial Intelligence#Machine Learning#Data Preprocessing#Data Quality#Natural Language Processing#Business Intelligence#Data Analytics#automation#datascience#datacleaning#large language model#ai
2 notes
·
View notes
Text
to talk about AI in art more specifically, I think in so far as AI has any legitimate use in art, it's exclusively as an artistic aid. if you generate an AI image of a character, then draw on top of it using it as a loose reference (I'm not talking about tracing here), that's not really any different than using any other photo reference or inspiration. if you feed all of a character's dialogue to an AI, then have it crosscheck versus dialogue you wrote for them and make adjustments to your writing (I'm not talking about copying and pasting here), that's not really any different than having someone beta-read for voice or doing it manually yourself. it can be an effective tool for doing very specific and technical things faster and thus developing a better personal artistic intuition for them. it's acceptable as training wheels, like spellcheck but much more sophisticated
what is broadly unacceptable is to just let AI generate something and release it into the wild as-is or edited. AI making your life easier or giving you more confidence in making your art is fine. using AI to substitute for and try and shortcut the artistic process is not
#Out Of Character#PSA#[ I don't think this is a hot take ]#[ AI is a tool to make content creation easier ]#[ it's just that unlike prior tools it can be abused to 'make content' unto itself ]#[ but this is a difference of user intent not of the tool ]#[ it's true that how AI scrapes data for training often abrogates consent ]#[ however if nothing was ever done with that data ]#[ nobody would really care ]#[ because data is always being collated ]#[ it's that the data is being used ]#[ and more specifically how it's being used ]#[ that are the real problems ]#[ I personally don't use AI for writing ]#[ and it'd be dubious as it currently stands to use it as a model ]#[ for visual art of ships ]#[ which is what I'd use it for ]#[ in terms of graphics ]#[ because I'm not a properly trained artist ]#[ but I think there is an ETHICAL way to use it ]#[ the trouble is people using it UNETHICALLY ]#[ and it is very easy to use unethically ]#[ but the problem is the lack of ethics ]
13 notes
·
View notes