#Data pipelines
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr was the first site to host the blog for President Barack Obama in 2011.
Text
Unlock the other 99% of your data - now ready for AI
New Post has been published on https://thedigitalinsider.com/unlock-the-other-99-of-your-data-now-ready-for-ai/
Unlock the other 99% of your data - now ready for AI
For decades, companies of all sizes have recognized that the data available to them holds significant value, for improving user and customer experiences and for developing strategic plans based on empirical evidence.
As AI becomes increasingly accessible and practical for real-world business applications, the potential value of available data has grown exponentially. Successfully adopting AI requires significant effort in data collection, curation, and preprocessing. Moreover, important aspects such as data governance, privacy, anonymization, regulatory compliance, and security must be addressed carefully from the outset.
In a conversation with Henrique Lemes, Americas Data Platform Leader at IBM, we explored the challenges enterprises face in implementing practical AI in a range of use cases. We began by examining the nature of data itself, its various types, and its role in enabling effective AI-powered applications.
Henrique highlighted that referring to all enterprise information simply as ‘data’ understates its complexity. The modern enterprise navigates a fragmented landscape of diverse data types and inconsistent quality, particularly between structured and unstructured sources.
In simple terms, structured data refers to information that is organized in a standardized and easily searchable format, one that enables efficient processing and analysis by software systems.
Unstructured data is information that does not follow a predefined format nor organizational model, making it more complex to process and analyze. Unlike structured data, it includes diverse formats like emails, social media posts, videos, images, documents, and audio files. While it lacks the clear organization of structured data, unstructured data holds valuable insights that, when effectively managed through advanced analytics and AI, can drive innovation and inform strategic business decisions.
Henrique stated, “Currently, less than 1% of enterprise data is utilized by generative AI, and over 90% of that data is unstructured, which directly affects trust and quality”.
The element of trust in terms of data is an important one. Decision-makers in an organization need firm belief (trust) that the information at their fingertips is complete, reliable, and properly obtained. But there is evidence that states less than half of data available to businesses is used for AI, with unstructured data often going ignored or sidelined due to the complexity of processing it and examining it for compliance – especially at scale.
To open the way to better decisions that are based on a fuller set of empirical data, the trickle of easily consumed information needs to be turned into a firehose. Automated ingestion is the answer in this respect, Henrique said, but the governance rules and data policies still must be applied – to unstructured and structured data alike.
Henrique set out the three processes that let enterprises leverage the inherent value of their data. “Firstly, ingestion at scale. It’s important to automate this process. Second, curation and data governance. And the third [is when] you make this available for generative AI. We achieve over 40% of ROI over any conventional RAG use-case.”
IBM provides a unified strategy, rooted in a deep understanding of the enterprise’s AI journey, combined with advanced software solutions and domain expertise. This enables organizations to efficiently and securely transform both structured and unstructured data into AI-ready assets, all within the boundaries of existing governance and compliance frameworks.
“We bring together the people, processes, and tools. It’s not inherently simple, but we simplify it by aligning all the essential resources,” he said.
As businesses scale and transform, the diversity and volume of their data increase. To keep up, AI data ingestion process must be both scalable and flexible.
“[Companies] encounter difficulties when scaling because their AI solutions were initially built for specific tasks. When they attempt to broaden their scope, they often aren’t ready, the data pipelines grow more complex, and managing unstructured data becomes essential. This drives an increased demand for effective data governance,” he said.
IBM’s approach is to thoroughly understand each client’s AI journey, creating a clear roadmap to achieve ROI through effective AI implementation. “We prioritize data accuracy, whether structured or unstructured, along with data ingestion, lineage, governance, compliance with industry-specific regulations, and the necessary observability. These capabilities enable our clients to scale across multiple use cases and fully capitalize on the value of their data,” Henrique said.
Like anything worthwhile in technology implementation, it takes time to put the right processes in place, gravitate to the right tools, and have the necessary vision of how any data solution might need to evolve.
IBM offers enterprises a range of options and tooling to enable AI workloads in even the most regulated industries, at any scale. With international banks, finance houses, and global multinationals among its client roster, there are few substitutes for Big Blue in this context.
To find out more about enabling data pipelines for AI that drive business and offer fast, significant ROI, head over to this page.
#ai#AI-powered#Americas#Analysis#Analytics#applications#approach#assets#audio#banks#Blue#Business#business applications#Companies#complexity#compliance#customer experiences#data#data collection#Data Governance#data ingestion#data pipelines#data platform#decision-makers#diversity#documents#emails#enterprise#Enterprises#finance
2 notes
·
View notes
Text
Understanding Core Components of the Data Engineering Ecosystem | Brilliqs

Explore the foundational components that power modern data engineering—from cloud computing and distributed platforms to data pipelines, Java-based workflows, and visual analytics. Learn more at www.brilliqs.com
#Data Engineering Ecosystem#Data Engineering Components#Cloud Data Infrastructure#Apache Spark#Amazon QuickSight#Data Pipelines#Data Management#Java for Data Engineering#Brilliqs
1 note
·
View note
Text
BigQuery Data Engineering Agent Set Ups Your Data Pipelines

BigQuery has powered analytics and business insights for data teams for years. However, developing, maintaining, and debugging data pipelines that provide such insights takes time and expertise. Google Cloud's shared vision advances BigQuery data engineering agent use to speed up data engineering.
Not just useful tools, these agents are agentic solutions that work as informed partners in your data processes. They collaborate with your team, automate tough tasks, and continually learn and adapt so you can focus on data value.
Value of data engineering agents
The data landscape changes. Organisations produce more data from more sources and formats than before. Companies must move quicker and use data to compete.
This is problematic. Common data engineering methods include:
Manual coding: Writing and updating lengthy SQL queries when establishing and upgrading pipelines can be tedious and error-prone.
Schema struggles: Mapping data from various sources to the right format is difficult, especially as schemas change.
Hard troubleshooting: Sorting through logs and code to diagnose and fix pipeline issues takes time, delaying critical insights.
Pipeline construction and maintenance need specialised skills, which limits participation and generates bottlenecks.
The BigQuery data engineering agent addresses these difficulties to speed up data pipeline construction and management.
Introduce your AI-powered data engineers
Imagine having a team of expert data engineers to design, manage, and debug pipelines 24/7 so your data team can focus on higher-value projects. Data engineering agent is experimental.
The BigQuery data engineering agent will change the game:
Automated pipeline construction and alteration
Do data intake, convert, and validate need a new pipeline? Just say what you need in normal English, and the agent will handle it. For instance:
Create a pipeline to extract data from the ‘customer_orders’ bucket, standardise date formats, eliminate duplicate entries by order ID, and dump it into a BigQuery table named ‘clean_orders’.”
Using data engineering best practices and your particular environment and context, the agent creates the pipeline, generates SQL code, and writes basic unit tests. Intelligent, context-aware automation trumps basic automation.
Should an outdated pipeline be upgraded? Tell the representative what you want changed. It analysed the code, suggested improvements, and suggested consequences on downstream activities. You review and approve modifications while the agent performs the tough lifting.
Proactive optimisation and troubleshooting
Problems with pipeline? The agent monitors pipelines, detects data drift and schema issues, and offers fixes. Like having a dedicated specialist defend your data infrastructure 24/7.
Bulk draft pipelines
Data engineers can expand pipeline production or modification by using previously taught context and information. The command line and API for automation at scale allow companies to quickly expand pipelines for different departments or use cases and customise them. After receiving command line instructions, the agent below builds bulk pipelines using domain-specific agent instructions.
How it works: Hidden intelligence
The agents employ many basic concepts to manage the complexity most businesses face:
Hierarchical context: Agents employ several knowledge sources:
Standard SQL, data formats, etc. are understood by everybody.
Understanding vertical-specific industry conventions (e.g., healthcare or banking data formats)
Knowledge of your department or firm's business environment, data architecture, naming conventions, and security laws
Information about data pipeline source and target schemas, transformations, and dependencies
Continuous learning: Agents learn from user interactions and workflows rather than following orders. As agents work in your environment, their skills grow.
Collective, multi-agent environment
BigQuery data engineering agents work in a multi-agent environment to achieve complex goals by sharing tasks and cooperating:
Ingestion agents efficiently process data from several sources.
A transformation agent builds reliable, effective data pipelines.
Validation agents ensure data quality and consistency.
Troubleshooters aggressively find and repair issues.
Dataplex metadata powers a data quality agent that monitors data and alerts of abnormalities.
Google Cloud is focussing on intake, transformation, and debugging for now, but it plans to expand these early capabilities to other important data engineering tasks.
Workflow your way
Whether you prefer the BigQuery Studio UI, your chosen IDE for code authoring, or the command line for pipeline management, it wants to meet you there. The data engineering agent is now only available in BigQuery Studio's pipeline editor and API/CLI. It wants to make it available elsewhere.
Your data engineer and workers
Artificial Intelligent-powered bots are only beginning to change how data professionals interact with and value their data. The BigQuery data engineering agent allows data scientists, engineers, and analysts to do more, faster, and more reliably. These agents are intelligent coworkers that automate tedious tasks, optimise processes, and boost productivity. Google Cloud starts with shifting data from Bronze to Silver in a data lake and grows from there.
With Dataplex, BigQuery ML, and Vertex AI, the BigQuery data engineering agent can transform how organisations handle, analyse, and value their data. By empowering data workers of all skill levels, promoting collaboration, and automating challenging tasks, these agents are ushering in a new era of data-driven creativity.
Ready to start?
Google Cloud is only starting to build an intelligent, self-sufficient data platform. It regularly trains data engineering bots to be more effective and observant collaborators for all your data needs.
The BigQuery data engineering agent will soon be available. It looks forward to helping you maximise your data and integrating it into your data engineering processes.
#technology#technews#govindhtech#news#technologynews#Data engineering agent#multi-agent environment#data engineering team#BigQuery Data Engineering Agent#BigQuery#Data Pipelines
0 notes
Text
0 notes
Text
How Databricks Unity Catalog and Datagaps Automate Governance and Validation

Data quality is the backbone of accurate analytics, regulatory compliance, and efficient business operations. As organizations scale their data ecosystems, maintaining high data integrity becomes more challenging.
The seamless integration between Databricks Unity Catalog and Datagaps DataOps Suite provides a powerful framework for automated governance and validation, ensuring that data remains accurate, complete, and compliant at all times.
In our previous discussion, we highlighted how Datagaps enhances metadata management, lineage tracking, and automation within Unity Catalog. This article takes the next step by diving into data quality assurance – a crucial component of enterprise-wide data governance.
By leveraging Datagaps Data Quality Monitor, organizations can implement automated validation strategies, reduce manual effort, and integrate real-time data quality scores into Unity Catalog for proactive governance. Let’s explore how these technologies work together to ensure high-quality, reliable data that drives better decision-making and compliance.
The Growing Need for Automated Data Quality Assurance
Modern enterprises manage vast amounts of structured and unstructured data across multiple platforms. Ensuring data accuracy, completeness, and consistency is no longer just a best practice – it’s a necessity for regulatory compliance and business intelligence.
Databricks Unity Catalog provides a centralized governance framework for managing metadata, access controls, and data lineage across an organization. By integrating with Datagaps Data Quality Monitor, enterprises can automate data validation, reduce errors, and gain deeper insights into data health and integrity.
6 Key Data Quality Dimensions

Effective data quality management revolves around six fundamental dimensions:
Accuracy – Ensuring data reflects real-world values without discrepancies.
Completeness – Verifying that all required fields and records are present.
Consistency – Maintaining uniformity across multiple data sources and systems.
Timeliness – Ensuring data is up-to-date and available when needed.
Uniqueness – Eliminating duplicate records and redundant data entries.
Validity – Enforcing compliance with defined formats, business rules, and constraints.
By addressing these dimensions, organizations can improve the trustworthiness of their data assets, enhance AI/ML outcomes, and comply with industry regulations.
Automating Data Quality Validation with White-Box and Black-Box Testing
Ensuring data integrity at scale requires a systematic approach to validation. Two widely used methodologies are:
1. White-Box Testing
Examines internal data transformations, lineage, and business rules.
Ensures that every step in the ETL (Extract, Transform, Load) process adheres to defined standards.
Provides deeper insights into data processing logic to catch issues at the source.
2. Black-Box Testing
Focuses on output validation by comparing actual results against expected benchmarks.
Useful for detecting anomalies, missing records, and schema mismatches.
Works well for regulatory compliance and end-to-end data pipeline testing.
A hybrid approach combining both techniques ensures robust validation and proactive anomaly detection.
How Unity Catalog and Datagaps Data Quality Monitor Work Together
1. Unified Governance and Automated Validation
Databricks Unity Catalog centralizes metadata management, access control, and lineage tracking.
Datagaps Data Quality Monitor extends these capabilities with automated quality checks, reducing manual efforts.
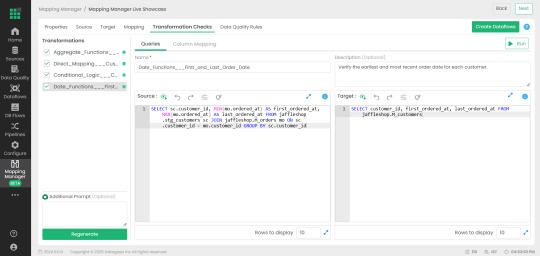
2. Mapping Manager Utility: Simplifying Test Case Automation
One of the standout features of Datagaps Data Quality Monitor is the Mapping Manager Utility, which:
Extracts mapping configurations from Databricks Unity Catalog.
Automatically generates white-box and black-box test cases.
Reduces the need for manual intervention, increasing efficiency and scalability.
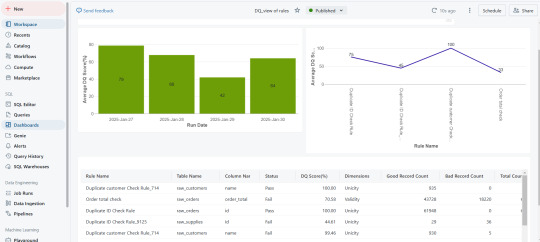
3. Real-Time Data Quality Scores for Proactive Governance
After test execution, a data quality score is generated.
These scores are seamlessly integrated into Databricks Unity Catalog, allowing real-time monitoring.
Organizations can visualize data quality insights through dashboards and take corrective actions before issues impact business operations.
Key Use Cases
ETL and Data Pipeline Validation – Ensuring data transformations adhere to defined business rules.
Regulatory Compliance and Audit Readiness – Mitigating risks associated with inaccurate reporting.
Enterprise Data Lakehouse Governance – Enhancing consistency across distributed datasets.
AI/ML Data Preprocessing – Ensuring clean, high-quality data for better model performance.
Automated Data Quality Checks – Reducing manual data validation efforts for faster, more reliable insights.
Scalability for Large Datasets – Efficiently managing high-volume, high-velocity enterprise data.
Faster QA Cycles – Automating test case execution for rapid turnaround.
Lower Operational Resources – Reducing human intervention, saving time and resources.
The Business Impact: Why This Integration Matters
Enhanced Automation – Eliminates manual quality checks and increases efficiency.
Real-Time Monitoring – Provides instant visibility into data quality metrics.
Stronger Compliance – Supports industry standards and regulations effortlessly.
Scalability – Designed for large-scale, complex data ecosystems.
Cost Efficiency – Reduces operational overhead and improves ROI on data management initiatives.
Ensuring data quality at scale requires a combination of automated governance, real-time monitoring, and seamless integration. The connection between Databricks Unity Catalog and Datagaps Data Quality Monitor provides a comprehensive solution to achieve this goal.
With automated test case generation, continuous data validation, and integrated governance, organizations can ensure their data is always accurate, complete, and compliant—laying the foundation for data-driven decision-making and regulatory confidence.
0 notes
Text
Unlock Scalable & AI-Powered Data Engineering Solutions In today’s fast-paced, data-driven world, businesses require scalable, efficient, and secure data pipelines to unlock their full potential. Hitech Analytics delivers end-to-end Data Engineering Services, enabling seamless data integration, management, and optimization for real-time insights, enhanced decision-making, and sustained business growth. Our expertise in ETL processes, cloud solutions, and AI-driven frameworks ensures that your data works smarter, faster, and more efficiently. Explore our Data Engineering Services: https://www.hitechanalytics.com/data-engineering-services/

#AI & Machine Learning#Data Lakes#Data Pipelines#Data Processing#Business Intelligence#Cloud Computing
1 note
·
View note
Text
The Importance of Data Engineering in Today’s Data-Driven World

In today’s fast-paced, technology-driven world, data has emerged as a critical asset for businesses across all sectors. It serves as the foundation for strategic decisions, drives innovation, and shapes competitive advantage. However, extracting meaningful insights from data requires more than just access to information; it necessitates well-designed systems and processes for efficient data management and analysis. This is where data engineering steps in. A vital aspect of data science and analytics, data engineering is responsible for building, optimizing, and maintaining the systems that collect, store, and process data, ensuring it is accessible and actionable for organizations.
Let's explore how Data Engineering is important in today's world:
1. What is Data Engineering
2. Why is Data Engineering Important
3. Key Components of Data Engineering
4. Trends in Data Engineering
5. The Future of Data Engineering
Let’s examine each one in detail below.
What is Data Engineering?
Data engineering involves creating systems that help collect, store, and process data effectively.It involves creating data pipelines that transport data from its source to storage and analysis systems, implementing ETL processes (Extract, Transform, Load), and maintaining data management systems to ensure data is accessible and secure. It enables organizations to make better use of their data resources for data-driven decision-making.
Why is Data Engineering Important?
Supports Data-Driven Decision-Making: In a competitive world, decisions need to be based on facts and insights. Data engineering ensures that clean, reliable, and up-to-date data is available to decision-makers. From forecasting market trends to optimizing operations, data engineering helps businesses stay ahead.
Manages Big Data Effectively: Big data engineering focuses on handling large and complex datasets, making it possible to process and analyze them efficiently. Industries like finance, healthcare, and e-commerce rely heavily on big data solutions to deliver better results.
Enables Modern Technologies: Technologies like machine learning, artificial intelligence, and predictive analytics depend on well-prepared data. Without a solid modern data infrastructure, these advanced technologies cannot function effectively. Data engineering ensures these systems have the data they need to perform accurately.
Key Components of Data Engineering:
Data Pipelines: Data pipelines move data automatically between systems.They take data from one source, change it into a useful format, and then store it or prepare it for analysis.
ETL Processes: ETL (Extract, Transform, Load) processes are crucial in preparing raw data for analysis. They clean, organize, and format data, ensuring it is ready for use.
Data Management Systems:
These systems keep data organized and make it easy to access. Examples of these systems are databases, data warehouses, and data lakes.
Data Engineering Tools: From tools like Apache Kafka for real-time data streaming to cloud platforms like AWS and Azure, data engineering tools are essential for managing large-scale data workflows.
Trends in Data Engineering:
The field of data engineering is changing quickly, and many trends are shaping its future:
Cloud-Based Infrastructure: More businesses are moving to the cloud for scalable and flexible data storage.
Real-Time Data Processing: The need for instant insights is driving the adoption of real-time data systems.
Automation in ETL: Automating repetitive ETL tasks is becoming a standard practice to improve efficiency.
Focus on Data Security: With increasing concerns about data privacy, data engineering emphasizes building secure systems.
Sustainability: Energy-efficient systems are gaining popularity as companies look for greener solutions.
The Future of Data Engineering:
The future of data engineering looks bright. As data grows in size and complexity, more skilled data engineers will be needed.Innovations in artificial intelligence and machine learning will further integrate with data engineering, making it a critical part of technological progress. Additionally, advancements in data engineering tools and methods will continue to simplify and enhance workflows.
Conclusion:
Data engineering is the backbone of contemporary data management and analytics. It provides the essential infrastructure and frameworks that allow organizations to efficiently process and manage large volumes of data. By focusing on data quality, scalability, and system performance, data engineers ensure that businesses can unlock the full potential of their data, empowering them to make informed decisions and drive innovation in an increasingly data-driven world.
Tudip Technologies has been a pioneering force in the tech industry for over a decade, specializing in AI-driven solutions. Our innovative solutions leverage GenAI capabilities to enhance real-time decision-making, identify opportunities, and minimize costs through seamless processes and maintenance.
If you're interested in learning more about the Data Engineering related courses offered by Tudip Learning please visit: https://tudiplearning.com/course/essentials-of-data-engineering/.
#Data engineering trends#Importance of data engineering#Data-driven decision-making#Big data engineering#Modern data infrastructure#Data pipelines#ETL processes#Data engineering tools#Future of data engineering#Data Engineering
1 note
·
View note
Text
Unveiling the Power of Delta Lake in Microsoft Fabric
Discover how Microsoft Fabric and Delta Lake can revolutionize your data management and analytics. Learn to optimize data ingestion with Spark and unlock the full potential of your data for smarter decision-making.
In today’s digital era, data is the new gold. Companies are constantly searching for ways to efficiently manage and analyze vast amounts of information to drive decision-making and innovation. However, with the growing volume and variety of data, traditional data processing methods often fall short. This is where Microsoft Fabric, Apache Spark and Delta Lake come into play. These powerful…
#ACID Transactions#Apache Spark#Big Data#Data Analytics#data engineering#Data Governance#Data Ingestion#Data Integration#Data Lakehouse#Data management#Data Pipelines#Data Processing#Data Science#Data Warehousing#Delta Lake#machine learning#Microsoft Fabric#Real-Time Analytics#Unified Data Platform
0 notes
Text
This blog showcase data pipeline automation and how it helps to boost your business to achieve its business goals.
0 notes
Text
Data Engineering is a crucial field within the tech industry that focuses on preparing and provisioning of data for analysis or operational uses. It comprises various tasks and responsibilities, from the initial collection of data to its deployment for business insights. Understanding the key terms relevant to data engineering is essential for professionals within the field to effectively communicate and execute their duties.
0 notes
Text
#Azure Data Factory#azure data factory interview questions#adf interview question#azure data engineer interview question#pyspark#sql#sql interview questions#pyspark interview questions#Data Integration#Cloud Data Warehousing#ETL#ELT#Data Pipelines#Data Orchestration#Data Engineering#Microsoft Azure#Big Data Integration#Data Transformation#Data Migration#Data Lakes#Azure Synapse Analytics#Data Processing#Data Modeling#Batch Processing#Data Governance
1 note
·
View note
Text
Explore the benefits of data pipelines. Uncover how these crucial tools can enhance data management and boost business performance.
0 notes
Text
#DataOps Platform#Data Collaboration#Data Security#Data Workflow Automation#Cross-Functional Collaboration#DataOps Tools#Data Insights#Data Quality#DevOps#Data Pipelines
1 note
·
View note
Text
Automating Tableau Reports Validation: The Easy Path to Trusted Insights

Automating Tableau Reports Validation is essential to ensure data accuracy, consistency, and reliability across multiple scenarios. Manual validation can be time-consuming and prone to human error, especially when dealing with complex dashboards and large datasets. By leveraging automation, organizations can streamline the validation process, quickly detect discrepancies, and enhance overall data integrity.
Going ahead, we’ll explore automation of Tableau reports validation and how it is done.
Importance of Automating Tableau Reports Validation
Automating Tableau report validation provides several benefits, ensuring accuracy, efficiency, and reliability in BI reporting.
Automating the reports validation reduces the time and effort, which allows analysts to focus on insights rather than troubleshooting the errors
Automation prevents data discrepancies and ensures all reports are pulling in consistent data
Many Organizations deal with high volumes of reports and dashboards. It is difficult to manually validate each report. Automating the reports validation becomes critical to maintain efficiency.
Organizations update their Tableau dashboards very frequently, sometimes daily. On automating the reports validation process, a direct comparison is made between the previous and current data to detect changes or discrepancies. This ensures metrics remain consistent after each data refresh.
BI Validator simplifies BI testing by providing a platform for automated BI report testing. It enables seamless regression, stress, and performance testing, making the process faster and more reliable.
Tableau reports to Database data comparison ensures that the records from the source data are reflected accurately in the visuals of Tableau reports.
This validation process extracts data from Tableau report visuals and compares it with SQL Server, Oracle, Snowflake, or other databases. Datagaps DataOps Suite BI Validator streamlines this by pulling report data, applying transformations, and verifying consistency through automated row-by-row and aggregate comparisons (e.g., counts, sums, averages).
The errors detected usually identify missing, duplicate or mismatched records.
Automation ensures these issues are caught early, reducing manual effort and improving trust in reporting.
Tableau Regression
In the DataOps suite, Regression testing is done by comparing the benchmarked version of tableau report with the live version of the report through Tableau Regression component.
This Tableau regression component can be very useful for automating the testing of Tableau reports or Dashboards during in-place upgrades or changes.
A diagram of a process AI-generated content may be incorrect.
Tableau Upgrade
Tableau Upgrade Component in BI validator helps in automated report testing by comparing the same or different reports of same or different Tableau sources.
The comparison is done in the same manner as regression testing where the differences between the reports can be pointed out both in terms of text as well as appearance.
Generate BI DataFlows is a handy and convenient feature provided by Datagaps DataOps suite to generate multiple dataflows at once for Business Intelligence components like Tableau.
Generate BI DataFlows feature is beneficial in migration scenarios as it enables efficient data comparison between the original and migrated platforms and supports the validations like BI source, Regression and Upgrade. By generating multiple dataflows based on selected reports, users can quickly detect discrepancies or inconsistencies that may arise during the migration process, ensuring data integrity and accuracy while minimizing potential errors. Furthermore, when dealing with a large volume of reports, this feature speeds up the validation process, minimizes manual effort, and improves overall efficiency in detecting and resolving inconsistencies.
As seen from the image, the wizard starts by generating the Dataflow details. The connection details like the engine, validation type, Source-Data Source and Target-Data Source are to be provided by users.
Note: BI source validation and Regression validation types do not prompt for Target-Data source
Let’s take a closer look at the steps involved in “Generate BI Dataflows”
Reports
The Reports section prompts users to select pages from the required reports in the validation process. For Data Compare validation and Upgrade Validation, both source and target pages will be required. For other cases, only the source page will be needed.
Here is a sample screenshot of the extraction of source and target pages from the source and target report respectively
Visual Mapping and Column Mapping (only in Data Compare Validation)
The "Visual Mapping" section allows users to load and compare source and target pages and then establish connections between corresponding tables.
It consists of three sections namely Source Page, Target Page, and Mapping.
In the source page and target page, respective Tableau worksheets are loaded and on selecting the worksheets option, users can preview the data.
After loading the source and target pages, in the mapping section, the dataset columns of source and target will be automatically mapped for each mapping.
After Visual Mapping, the "Column Mapping" section displays the columns of the source dataset and target dataset that were selected for the data comparison. It provides a count of the number of dataset columns that are mapped and unmapped in the "Mapped" and "Unmapped" tabs respectively.
Filters (for the rest of the validation types)
The filters section enables users to apply the filters and parameters on the reports to help in validating them. These filters can either be applied and selected directly through reports or they can be parameterized as well.
Options section varies depending on the type of validation selected by the user. Options section is the pre final stage of generating the flows where some of the advanced options and comparison options are prompted to be selected as per the liking of the user to get the results as they like.
Here’s a sample screenshot of options section before generating the dataflows
This screenshot indicates report to report comparison options to be selected.
Generate section helps to generate multiple dataflows with the selected type of validation depending on the number of selected workbooks for tableau.
The above screenshot indicates that four dataflows are set to be generated on clicking the Generate BI Dataflows button. These dataflows are the same type of validation (Tableau Regression Validation in this case)
Stress Test Plan
To automate the stress testing and performance testing of Tableau Reports, Datagaps DataOps suite BI Validator comes with a component called Stress Test Plan to simulate the number of users actively accessing the reports to analyze how Tableau reports and dashboards perform under heavy load. Results of the stress test plan can be used to point out performance issues, optimize data models and queries to ensure the robustness of the Tableau environment to handle heavy usage patterns. Stress Test Plan allows users to perform the stress testing for multiple views from multiple workbooks at once enabling the flexibility and automation to check for performance bottlenecks of Tableau reports.
For more information on Stress Test Plan, check out “Tableau Performance Testing”.
Integration with CI/CD tools and Pipelines
In addition to these features, DataOps Suite comes with other interesting features like application in built pipelines where the set of Tableau BI dataflows can be run automatically in a certain order either in sequence or parallel.
Also, there’s an inbuilt scheduler in the application where the users can schedule the run of these pipelines involving these BI dataflows well in advance. The jobs can be scheduled to run once or repeatedly as well.
Achieve the seamless and automated Tableau report validation with the advanced capabilities of Datagaps DataOps Suite BI Validator.
0 notes
Text
What is the difference between Data Scientist and Data Engineers ?
In today’s data-driven world, organizations harness the power of data to gain valuable insights, make informed decisions, and drive innovation. Two key players in this data-centric landscape are data scientists and data engineers. Although their roles are closely related, each possesses unique skills and responsibilities that contribute to the successful extraction and utilization of data. In…
View On WordPress
#Big Data#Business Intelligence#Data Analytics#Data Architecture#Data Compliance#Data Engineering#Data Infrastructure#Data Insights#Data Integration#Data Mining#Data Pipelines#Data Science#data security#Data Visualization#Data Warehousing#Data-driven Decision Making#Exploratory Data Analysis (EDA)#Machine Learning#Predictive Analytics
1 note
·
View note