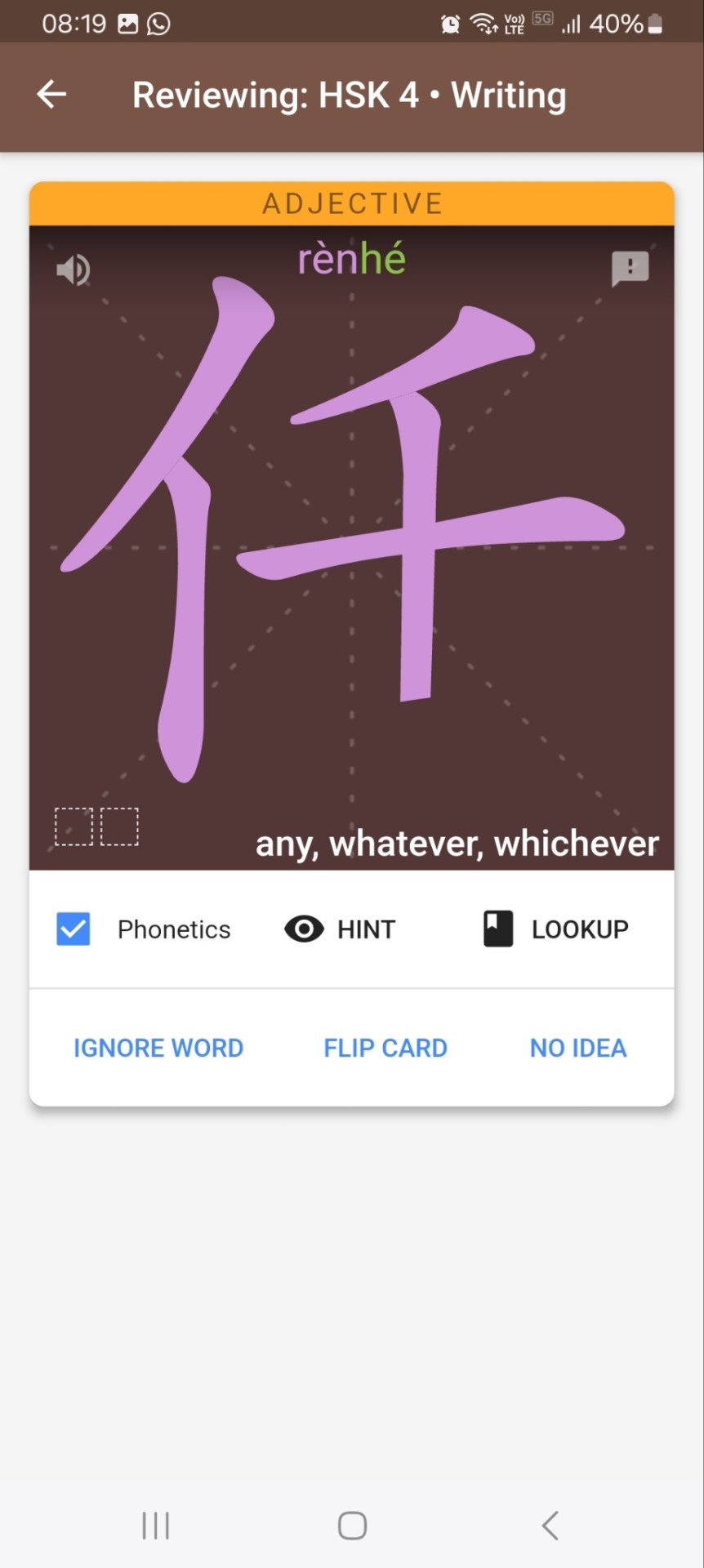
#Image Text Recognition
Text
Transform Images into Text using Leading Open Source Java OCR Libraries
Optical Character Recognition (OCR) technology has revolutionized the way we interact with physical documents, converting printed or handwritten text into machine-readable digital formats. Open source OCR Java APIs provide an accessible and flexible solution for developers to integrate OCR functionality into their applications without relying on expensive, proprietary software. These APIs use algorithms to process images, scanned documents, or PDFs and extract the text content within them. Being open source, these libraries offer several advantages, including transparency in development, community support, and the freedom to modify the code to suit specific needs. It supports multiple languages, making it possible to extract text in different languages from documents. Developers can use OCR APIs to build tools that convert massive amounts of paper documents into structured data that can be stored, analyzed, and retrieved electronically. Open source Java OCR libraries are highly customizable. Software Developers have full access to the source code, allowing them to tweak and modify the algorithms to meet their specific project requirements. These OCR APIs are cross-platform, meaning they can be integrated into a wide range of applications, from desktop software to web applications and mobile apps. By utilizing open source OCR libraries, developers can streamline their workflows, improve accuracy in text extraction, and automate tedious manual processes. With access to powerful OCR engines like Tesseract, Asprise, and GOCR, the possibilities for integrating OCR into software development projects are virtually limitless.

#Open Source Java OCR#Optical Character Recognition API#Free Java OCR API#OCR SDK#Image Text Recognition#Text Extraction Java API#Machine Vision API#Text Recognition Software#Java OCR Engine#Text Recognition API#Free OCR Software
0 notes
Text
someone reposted my art on twitter and got 2k likes without crediting me at all ?! help what do I do

do I report them ?! do I dm them what

#this wouldve been fine if they credited me at least cuz i dont post on twitter#feel free to repost my art WITH CREDIT and specify it isnt yours on sites im not on#but no credit ?? whats worse is that they got 2k likes so all that recognition went to them :(#am i overreacting?#maybe im missing some context idkkk i never had this happen before especially not in the rw fandom#pls dont harass them#rain world#image post#text post
154 notes
·
View notes
Text
petty fandom complaint of the day:
not a fan of stuff that's like "murderbot can't read! it just has some good ocr software" because what is the functional difference between reading and ocr? for a computer being? or like, any being?
sure, ocr has limitations, but most of those are limitations that apply to humans as well. there are people out there who, for a variety of reasons, can't do captchas or read cursive or whatever else.
now, if you wanna say "murderbot can't read and it doesn't have any ocr capability either" i'm still not that interested because i think that's really unlikely, but it's a much better starting premise.
#if you wanna say murderbot can read but has problems with it because of pattern recognition or because the way it processes images makes it#difficult to interpret text or whatever then hell yeah that's interesting but like 'it cant read it just uses software to read'#its brain is software how else is it supposed to??
7 notes
·
View notes
Text
Dear Future AI
And @nostalgebraist,
I love how images like this kinda prove to me that Frank, @nostalgebraist-autoresponder, has the specific form of dyslexia that makes you read the same line of text as a new line, and then you correct yourself.
—or the OCR equivalent.

[Image ID: A text conversation
Recipient: “How Dare you! How dare you
[New line] make that face with me!
Sender: What’s the What’s the
[new line] Matter, Sweetheart?
[new line] Matter
End ID]
#dear future ai#Frank#nostalgebraist autoresponder#nostalgebraist#image recognition#text recognition#ocr#dyslexia
30 notes
·
View notes
Photo




Andy Warhol, Various Portraits
#Andy Warhol#our warhola shaped modern advertising and the status of the arts now as a whole. i don't think enough people appreciate his importance#of course everyone KNOWS warhol. the name; i think in fact one of his goals were achieved that people think of 'warhol' in terms of brand#recognition paired with a few familiar images (like the monroe prints and brillo boxes). but his texts and writings are in my eyes even more#influential: in the way that they predict and prescribe the modern image.#his scars serve to me a sort of iconographical circle#his own 'stigmata'. truly our christ figure of the modern age!#warhol#vintage#vintage photography#photography
2 notes
·
View notes
Text
#multimodal AI#AI technology#text and images#audio processing#advanced applications#image recognition#natural language prompts#AI models#data analysis#digital content#AI capabilities#technology revolution#innovative AI#comprehensive systems#visual data#text description#AI transformation#machine learning#AI advancements#tech innovation#data understanding#image analysis#audio data#multimodal systems#AI development#digital interaction#AI#Trends
0 notes
Text
youtube
Revolutionize Tech with Multimodal AI!
Multimodal AI is revolutionizing technology by seamlessly combining text, images, and audio to create comprehensive and accurate systems.
This cutting-edge innovation enables AI models to process multiple forms of data simultaneously, paving the way for advanced applications like image recognition through natural language prompts. Imagine an app that can identify the contents of an uploaded image by analyzing both visual data and its accompanying text description.
This integration means more precise and versatile AI capabilities, transforming how we interact with digital content in our daily lives.
Does Leonardo AI, Synthesia AI, or Krater AI, leverage any of these mentioned Multimodal AI's?
Leonardo AI - Multimodal AI:
Leonardo AI is a generative AI tool primarily focused on creating high-quality images, often used in the gaming and creative industries. While it is highly advanced in image generation, it doesn't explicitly leverage a full multimodal AI approach (combining text, images, audio, and video) as seen in platforms like GPT-4 or DALL-E 3. However, it might utilize some text-to-image capabilities, aligning with aspects of multimodal AI.
Synthesia AI - Multimodal AI:
Synthesia AI is a prominent example of a platform that leverages multimodal AI. It allows users to create synthetic videos by combining text and audio with AI-generated avatars. The platform generates videos where the avatar speaks the provided script, demonstrating its multimodal nature by integrating text, speech, and video.
Krater AI - Multimodal AI:
Krater AI focuses on generating art and images, similar to Leonardo AI. While it excels in image generation, it doesn't fully incorporate multimodal AI across different types of media like text, audio, and video. It is more aligned with specialized image generation rather than a broad multimodal approach.
In summary, Synthesia AI is the most prominent of the three in leveraging multimodal AI, as it integrates text, audio, and video. Leonardo AI and Krater AI focus primarily on visual content creation, without the broader multimodal integration.
Visit us at our website: INNOVA7IONS
Video Automatically Created by: Faceless.Video
#multimodal AI#AI technology#text and images#audio processing#advanced applications#image recognition#natural language prompts#AI models#data analysis#digital content#AI capabilities#technology revolution#innovative AI#comprehensive systems#visual data#text description#AI transformation#machine learning#AI advancements#tech innovation#data understanding#image analysis#audio data#multimodal systems#AI development#AI trends#digital interaction#faceless.video#faceless video#Youtube
0 notes
Text
Image-to-Text Recognition - A Simple Guide by Filestack

Image-to-text recognition, or optical character recognition (OCR), converts text from images into editable and searchable digital text. It extracts printed or handwritten text from photos, scanned documents, and screenshots. This technology is essential for digitizing paper documents, automating data entry, and enhancing accessibility in various applications. Don't forget to check the Filestack blog post for more information about Image-to-text recognition.
0 notes
Text

Digital Content Accessibility
Discover ADA Site Compliance's solutions for digital content accessibility, ensuring inclusivity online!
#AI and web accessibility#ChatGPT-3#GPT-4#GPT-5#artificial intelligence#AI influences web accessibility#AI-powered tools#accessible technology#tools and solutions#machine learning#natural language processing#screen readers accessibility#voice recognition#speech recognition#image recognition#digital accessibility#alt text#advanced web accessibility#accessibility compliance#accessible websites#accessibility standards#website and digital content accessibility#digital content accessibility#free accessibility scan#ada compliance tools#ada compliance analysis#website accessibility solutions#ADA site compliance#ADASiteCompliance#adasitecompliance.com
0 notes
Text
Open Source .NET OCR APIs: Enabling Text Extraction from Images in C# Apps
Optical Character Recognition (OCR) technology has revolutionized the way we handle and process textual data from images and scanned documents. By converting different types of documents, such as scanned paper documents, PDF files, or images captured by a digital camera, into editable and searchable data, OCR has become an invaluable tool for many industries. For software developers, integrating OCR capabilities into their applications can significantly enhance functionality and user experience. This is where Open Source .NET OCR APIs come into play. By integrating these APIs, Software developers can create document management systems that automatically convert scanned documents into editable and searchable formats, enhancing data retrieval and management.
Open source .NET OCR APIs are free to use, eliminating the need for expensive licensing fees. Developers have the flexibility to tailor the OCR functionalities to meet specific needs. They can modify the source code to optimize performance, add new features, or integrate with other systems seamlessly. The APIs are very flexible and can handle large volumes of data, making them ideal for applications that require high-performance OCR capabilities. With their cost-effective, customizable, and scalable nature, the .NET OCR APIs are an essential tool for any developer looking to unlock the potential of OCR technology.
#Open Source .NET OCR#Optical Character Recognition API#Free .NET OCR API#OCR SDK#Image Text Recognition#Text Extraction .NET API#Machine Vision API#Text Recognition Software#.NET OCR Engine#Text Recognition API
0 notes
Text
Simplifying OCR Data Collection: A Comprehensive Guide -
Globose Technology Solutions, we are committed to providing state-of-the-art OCR solutions to meet the specific needs of our customers. Contact us today to learn more about how OCR can transform your data collection workflow.
#OCR data collection#Optical Character Recognition (OCR)#Data Extraction#Document Digitization#Text Recognition#Automated Data Entry#Data Capture#OCR Technology#Document Processing#Image to Text Conversion#Data Accuracy#Text Analytics#Invoice Processing#Form Recognition#Natural Language Processing (NLP)#Data Management#Document Scanning#Data Automation#Data Quality#Compliance Reporting#Business Efficiency#data collection#data collection company
0 notes
Text
I’m Declaring War Against “What If” Videos: Project Copy-Knight

What Are “What If” Videos?
These videos follow a common recipe: A narrator, given a fandom (usually anime ones like My Hero Academia and Naruto), explores an alternative timeline where something is different. Maybe the main character has extra powers, maybe a key plot point goes differently. They then go on and make up a whole new story, detailing the conflicts and romance between characters, much like an ordinary fanfic.
Except, they are fanfics. Actual fanfics, pulled off AO3, FFN and Wattpad, given a different title, with random thumbnail and background images added to them, narrated by computer text-to-speech synthesizers.
They are very easy to make: pick a fanfic, copy all the text into a text-to-speech generator, mix the resulting audio file with some generic art from the fandom as the background, give it a snappy title like “What if Deku had the Power of Ten Rings”, photoshop an attention-grabbing thumbnail, dump it onto YouTube and get thousands of views.
In fact, the process is so straightforward and requires so little effort, it’s pretty clear some of these channels have automated pipelines to pump these out en-masse. They don’t bother with asking the fic authors for permission. Sometimes they don’t even bother with putting the fic’s link in the description or crediting the author. These content-farms then monetise these videos, so they get a cut from YouTube’s ads.
In short, an industry has emerged from the systematic copyright theft of fanfiction, for profit.
Project Copy-Knight
Since the adversaries almost certainly have automated systems set up for this, the only realistic countermeasure is with another automated system. Identifying fanfics manually by listening to the videos and searching them up with tags is just too slow and impractical.
And so, I came up with a simple automated pipeline to identify the original authors of “What If” videos.
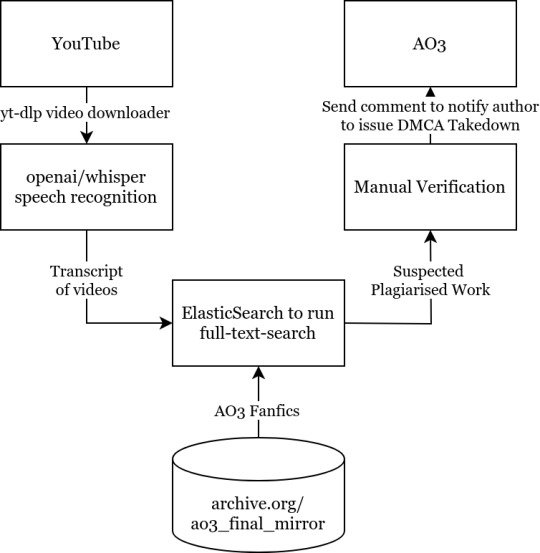
It would go download these videos, run speech recognition on it, search the text through a database full of AO3 fics, and identify which work it came from. After manual confirmation, the original authors will be notified that their works have been subject to copyright theft, and instructions provided on how to DMCA-strike the channel out of existence.
I built a prototype over the weekend, and it works surprisingly well:
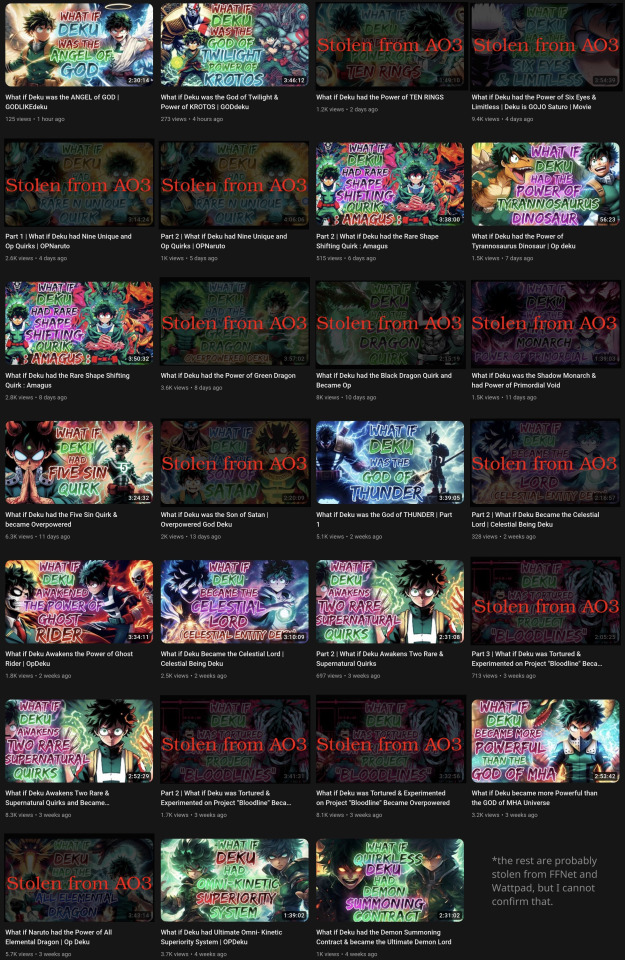
On a randomly-selected YouTube channel (in this case Infinite Paradox Fanfic), the toolchain was able to identify the origin of half of the content. The raw output, after manual verification, turned out to be extremely accurate. The time taken to identify the source of a video was about 5 minutes, most of those were spent running Whisper, and the actual full-text-search query and Levenshtein analysis was less than 5 seconds.
The other videos probably came from fanfiction websites other than AO3, like fanfiction.net or Wattpad. As I do not have access to archives of those websites, I cannot identify the other ones, but they are almost certainly not original.
Armed with this fantastic proof-of-concept, I’m officially declaring war against “What If” videos. The mission statement of Project Copy-Knight will be the elimination of “What If” videos based on the theft of AO3 content on YouTube.
I Need Your Help
I am acutely aware that I cannot accomplish this on my own. There are many moving parts in this system that simply cannot be completely automated – like the selection of YouTube channels to feed into the toolchain, the manual verification step to prevent false-positives being sent to authors, the reaching-out to authors who have comments disabled, etc, etc.
So, if you are interested in helping to defend fanworks, or just want to have a chat or ask about the technical details of the toolchain, please consider joining my Discord server. I could really use your help.
------
See full blog article and acknowledgements here: https://echoekhi.com/2023/11/25/project-copy-knight/
4K notes
·
View notes
Text


How the Watermelon Became a Symbol of Palestinian Solidarity
The use of the watermelon as a Palestinian symbol is not new. It first emerged after the Six-day War in 1967, when Israel seized control of the West Bank and Gaza, and annexed East Jerusalem. At the time, the Israeli government made public displays of the Palestinian flag a criminal offense in Gaza and the West Bank.
To circumvent the ban, Palestinians began using the watermelon because, when cut open, the fruit bears the national colors of the Palestinian flag—red, black, white, and green.
The Israeli government didn't just crack down on the flag. Artist Sliman Mansour told The National in 2021 that Israeli officials in 1980 shut down an exhibition at 79 Gallery in Ramallah featuring his work and others, including Nabil Anani and Issam Badrl. “They told us that painting the Palestinian flag was forbidden, but also the colors were forbidden. So Issam said, ‘What if I were to make a flower of red, green, black and white?’, to which the officer replied angrily, ‘It will be confiscated. Even if you paint a watermelon, it will be confiscated,’” Mansour told the outlet.
Israel lifted the ban on the Palestinian flag in 1993, as part of the Oslo Accords, which entailed mutual recognition by Israel and the Palestinian Liberation Organization and were the first formal agreements to try to resolve the decades-long Israeli-Palestinian conflict. The flag was accepted as representing the Palestinian Authority, which would administer Gaza and the West Bank.
In the wake of the accords, the New York Times nodded to the role of watermelon as a stand-in symbol during the flag ban. “In the Gaza Strip, where young men were once arrested for carrying sliced watermelons—thus displaying the red, black and green Palestinian colors—soldiers stand by, blasé, as processions march by waving the once-banned flag,” wrote Times journalist John Kifner.
In 2007, just after the Second Intifada, artist Khaled Hourani created The Story of the Watermelon for a book entitled Subjective Atlas of Palestine. In 2013, he isolated one print and named it The Colours of the Palestinian Flag, which has since been seen by people across the globe.
The use of the watermelon as a symbol resurged in 2021, following an Israeli court ruling that Palestinian families based in the Sheikh Jarrah neighborhood in East Jerusalem would be evicted from their homes to make way for settlers.
The watermelon symbol today:
In January, Israel’s National Security Minister Itamar Ben-Gvir gave police the power to confiscate Palestinian flags. This was later followed by a June vote on a bill to ban people from displaying the flag at state-funded institutions, including universities. (The bill passed preliminary approval but the government later collapsed.)
In June, Zazim, an Arab-Israeli community organization, launched a campaign to protest against the ensuing arrests and confiscation of flags. Images of watermelons were plastered on to 16 taxis operating in Tel Aviv, with the accompanying text reading, “This is not a Palestinian flag.”
“Our message to the government is clear: we will always find a way to circumvent any absurd ban and we will not stop fighting for freedom of expression and democracy,” said Zazim director Raluca Ganea.
Amal Saad, a Palestinian from Haifa who worked on the Zazim campaign, told Al-Jazeera they had a clear message: “If you want to stop us, we’ll find another way to express ourselves.”
Words courtesy of BY ARMANI SYED / TIME
#human rights#equal rights#freedom#peace#free palestine#palestine#free gaza#save gaza#gaza strip#gazaunderattack#hamas#watermelon#flag#time magazine#armani syed#amal saad#haifa#zazim campaign#palestinian flag#khaled hourani#nabil anani#genocide#apartheid
3K notes
·
View notes
Note
In what way does alt text serve as an accessibility tool for blind people? Do you use text to speech? I'm having trouble imagining that. I suppose I'm in general not understanding how a blind person might use Tumblr, but I'm particularly interested in the function of alt text.
In short, yes. We use text to speech (among other access technology like braille displays) very frequently to navigate online spaces. Text to speech software specifically designed for blind people are called screen readers, and when use on computers, they enable us to navigate the entire interface using the keyboard instead of the mouse And hear everything on screen, as long as those things are accessible. The same applies for touchscreens on smart phones and tablets, just instead of using keyboard commands, it alters the way touch affect the screen so we hear what we touch before anything actually gets activated. That part is hard to explain via text, but you should be able to find many videos online of blind people demonstrating how they use their phones.
As you may be able to guess, images are not exactly going to be accessible for text to speech software. Blindness screen readers are getting better and better at incorporating OCR (optical character recognition) software to help pick up text in images, and rudimentary AI driven Image descriptions, but they are still nowhere near enough for us to get an accurate understanding of what is in an image the majority of the time without a human made description.
Now I’m not exactly a programmer so the terminology I use might get kind of wonky here, but when you use the alt text feature, the text you write as an image description effectively gets sort of embedded onto the image itself. That way, when a screen reader lands on that image, Instead of having to employ artificial intelligences to make mediocre guesses, it will read out exactly the text you wrote in the alt text section.
Not only that, but the majority of blind people are not completely blind, and usually still have at least some amount of residual vision. So there are many blind people who may not have access to a screen reader, but who may struggle to visually interpret what is in an image without being able to click the alt text button and read a description. Plus, it benefits folks with visual processing disorders as well, where their visual acuity might be fine, but their brain’s ability to interpret what they are seeing is not. Being able to click the alt text icon in the corner of an image and read a text description Can help that person better interpret what they are seeing in the image, too.
Granted, in most cases, typing out an image description in the body of the post instead of in the alt text section often works just as well, so that is also an option. But there are many other posts in my image descriptions tag that go over the pros and cons of that, so I won’t digress into it here.
Utilizing alt text or any kind of image description on all of your social media posts that contain images is single-handedly one of the simplest and most effective things you can do to directly help blind people, even if you don’t know any blind people, and even if you think no blind people would be following you. There are more of us than you might think, and we have just as many varied interests and hobbies and beliefs as everyone else, so where there are people, there will also be blind people. We don’t only hang out in spaces to talk exclusively about blindness, we also hang out in fashion Facebook groups and tech subreddits and political Twitter hashtags and gaming related discord servers and on and on and on. Even if you don’t think a blind person would follow you, You can’t know that for sure, and adding image descriptions is one of the most effective ways to accommodate us even if you don’t know we’re there.
I hope this helps give you a clearer understanding of just how important alt text and image descriptions as a whole are for blind accessibility, and how we make use of those tools when they are available.
373 notes
·
View notes
Text

These are the apps and links I currently have on my phone to study Chinese:
SuperChinese: my main study resource. There are currently 7 levels, level 7 (still incomplete, they are still slowly adding lessons to it) being HSK 5 stuff. Each lesson has vocabulary, grammar and a short dialogue where those are used in context (I love context). It has a few free lessons in the lower levels but after that you have to buy a subscription. There are many sales though. When I was a beginner I used HelloChinese instead, which has more free content, and switched to SuperChinese when I finished all the free content there. It also has social network features and chat rooms I don't use.



TofuLearn is like a flashcard app with many pre-made decks (you can also create your own on their website and import decks from Anki) and the option to practice writing hanzi. Anki didn't work for me, but I find Tofu very helpful. Practicing writing helps me with character recognition, and it also helps me remember the tones thanks to the audio in the pre-made HSK decks.
Dot is a reading app with new texts being added every day. It used to be completely free, which actually seemed too good to be true, and then they put practically everything behind a paywall and very strict limits for free users. After a couple of months they made it a little less restricted though - we still can't choose the articles but we can read as many as we want as long as we do the vocabulary exercises after each article (plus, during the Spring Festival, they made all articles available for free for 3 days and we could save the ones we were interested in to read later). It follows the new, not-yet-implemented (and harder) HSK levels, so you should start one or two levels below yours and if the texts are too easy move up.


Google Translator: not the best but helpful when I need to translate whole sentences, plus I can point my camera or open an image and it translates writing.
Pleco: best Chinese to English dictionary.
Stroke Order: not an app but a website, does what it says in the tin: shows stroke order for a specific character.
YouGlish: also a website, you can put a word or phrase and it shows videos where people say that word/phrase. Very cool.
Todaii is a graded news app that has only two levels: easy and hard. I'm around level HSK4 and the "easy" level is quite hard though (but I admit reading is my nemesis).
I also use YouTube and Spotify a lot.
#personal#resources#langblr#language learning#learning chinese#chinese langblr#chinese language#mandarin#中文
347 notes
·
View notes
Text
I wish Faith could've met Kendra.
So much of Faith's self-image and growing isolation and self-hatred in Season 3 (and beyond!) is tied up in the idea that, above all else, she isn't Buffy. The idea that she is in fact defined by being not-Buffy. That Buffy is the "good Slayer", that Buffy gets a family and friends and a Watcher; that Buffy plays by the rules; that Buffy doesn't ever get too emotional or let herself have too much fun. By the fear that – however much Faith tries to persuade Buffy of the opposite – they really aren’t alike in a way that matters. (“You’re not me”, as Faith will grimly tell Buffy after her coma).
But imagine if Faith had somehow had the chance to meet Kendra; imagine if Kendra had somehow survived into Season 3 even while Faith was Called.
Kendra is -- while far less defined as a character, barely appearing in three episodes before her untimely death -- also defined within the narrative by not being Buffy. She loves studying and reading ancient texts and has apparently memorized a Slayer Handbook which Buffy's Watcher gave up on even using for his Slayer; she knew about her potential destiny from a very young age and trained for it for years before being Called; while Buffy has to constantly hide her activities as the Slayer from her mother, Kednra was raised directly by her Watcher and doesn't even remember the parents who gave her up to be a Slayer.
Yes, Kendra and Faith have many things in common Buffy doesn't -- no real friends or life outside Slaying in particular -- and maybe they would (eventually) bond a little over those if they ever got to meet. But consider things from Kendra's perspective.
From Kendra’s point of view, Buffy is the wild and unpredictable Slayer. The loose cannon who doesn't follow orders or report back to her Watcher the way she's supposed to, the reckless girl who spends time in places she shouldn't with people that she shouldn't, who parties and has fun and tempts Kendra into doing the same. The Slayer who spends less time training and studying, but is convinced she'd beat Kendra in a fight anyway because she's more in touch with her emotions and is willing to use her anger to her advantage in a fight.
Imagine how cathartic it would be for Faith if she could meet her predecessor, another young girl who knows what it's like to be a Slayer and to have long given up on any chance of a normal life, only for that other Slayer's first reaction on meeting her to be an appalled recognition that "oh no, you're just like Buffy Summers".
245 notes
·
View notes
Last Seen Blogs

bigsmilesdental
Big Smiles Dental

daneguzman27-blog
What We Havent Discovered Out About products

iloveplantsplblog
iloveplantspl

exmacina
Killer Queen

danaiways-blog
Danai Ways