#docker apps
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is available in 18 languages.
Text
youtube
Dockge: A New Way To Manage Your Docker Containers
Dockge is a self-hosted Docker stack manager, designed to offer a simple and clean interface for managing multiple Docker compose files. It has been developed by the same individual responsible for creating Uptime Kuma, a popular software for monitoring uptime
Dockge is described as an easy-to-use, and reactive self-hosted manager that is focused on Docker compose.yaml stack orientation. It features an interactive editor for compose.yaml, an interactive web terminal, and a reactive UI where everything is responsive, including real-time progress and terminal output.
It allows for the management of compose.yaml files, including creating, editing, starting, stopping, restarting, and deleting, as well as updating Docker images. The user interface is designed to be easy to use and visually appealing, especially for those who appreciate the UI/UX of Uptime Kuma.
Additionally, Dockge can convert docker run … commands into compose.yaml and maintains a file-based structure, meaning that compose files are stored on the user's drive as usual and can be interacted with using normal docker compose commands.
The motivation behind Dockge's development includes dissatisfaction with existing solutions like Portainer, especially regarding stack management. Challenges with Portainer included issues like indefinite loading times when deploying stacks and unclear error messages. The developer initially planned to use Deno or Bun.js for Dockge's development but ultimately decided on Node.js due to lack of support for arm64 in the former technologies.
In summary, Dockge is a versatile and user-friendly tool for managing Docker stacks, offering a responsive and interactive environment for Docker compose file management. Its development was driven by a desire to improve upon existing tools in terms of usability and clarity.
Resource links:
Github: https://github.com/louislam/dockge
FAQ: https://github.com/louislam/dockge#faq
#youtube#education#free education#windows10#Docker Containers#docker course#docker tutorials#docker apps#Docker#github
0 notes
Link
看看網頁版全文 ⇨ 移除PDF上的註解:PDF Annotation Remover / Removing Annotations from PDFs: PDF Annotation Remover https://blog.pulipuli.info/2025/05/removing-annotations-from-pdfs-pdf-annotation-remover.html PDF的註解功能可以允許我們在原始檔案上添增額外的文字、標亮、線條、筆記。 而且這些註解還可以刪除、修改,讓原始檔案保持它原本的樣子。 不過如果有大量註解需要移除的話,手動操作其實非常繁瑣。 這時候你可以用我開發的PDF Annotation Remover,讓PDF檔案的註解全部移除吧。 PDF's annotation feature allows us to add additional text, highlights, lines, and notes directly onto the original file. These annotations can also be deleted or modified, preserving the original document's integrity. However, manually removing a large number of annotations can be quite tedious. For this, you can use my PDF Annotation Remover to remove all annotations from your PDF file.。 ---- # PDF註解功能 / PDF's Annotation Feature。 PDF 的註解功能讓使用者可以在 PDF 檔案上新增文字、標記和繪圖,如同在紙本文件上做筆記一樣。 您可以透過多種方式新增註解,例如:加入文字方塊、便條、使用鉛筆工具繪圖、螢光標示重點文字、為文字加上底線或刪除線,甚至插入形狀等。 這些註解能夠幫助您更有效率地審閱檔案、提供回饋意見或記錄個人想法。 許多 PDF 編輯軟體或線上工具都提供這些功能,例如我之前介紹過的PDF-XChange Editor,或是現在Microsoft Edge內建的PDF閱讀器,都能讓人輕鬆地在 PDF 檔案上進行註解。 不過新增註解是一回事,如果我們想要將PDF檔案傳給其他人、又不想讓其他人看到我們在PDF檔案上面的註解時,那就得要把註解移除掉了。 ---- # PDF註解移除器 / PDF Annotation Remover。 https://github.com/pulipulichen/docker-app-PDF-Annotation-Remover。 ---- 繼續閱讀 ⇨ 移除PDF上的註解:PDF Annotation Remover / Removing Annotations from PDFs: PDF Annotation Remover https://blog.pulipuli.info/2025/05/removing-annotations-from-pdfs-pdf-annotation-remover.html
0 notes
Text
Harnessing Containerization in Web Development: A Path to Scalability
Explore the transformative impact of containerization in web development. This article delves into the benefits of containerization, microservices architecture, and how Docker for web apps facilitates scalable and efficient applications in today’s cloud-native environment.
#Containerization in Web Development#Microservices architecture#Benefits of containerization#Docker for web apps#Scalable web applications#DevOps practices#Cloud-native development
0 notes
Text
📝 Guest Post: Local Agentic RAG with LangGraph and Llama 3*
New Post has been published on https://thedigitalinsider.com/guest-post-local-agentic-rag-with-langgraph-and-llama-3/
📝 Guest Post: Local Agentic RAG with LangGraph and Llama 3*
In this guest post, Stephen Batifol from Zilliz discusses how to build agents capable of tool-calling using LangGraph with Llama 3 and Milvus. Let’s dive in.
LLM agents use planning, memory, and tools to accomplish tasks. Here, we show how to build agents capable of tool-calling using LangGraph with Llama 3 and Milvus.
Agents can empower Llama 3 with important new capabilities. In particular, we will show how to give Llama 3 the ability to perform a web search, call custom user-defined functions
Tool-calling agents with LangGraph use two nodes: an LLM node decides which tool to invoke based on the user input. It outputs the tool name and tool arguments based on the input. The tool name and arguments are passed to a tool node, which calls the tool with the specified arguments and returns the result to the LLM.
Milvus Lite allows you to use Milvus locally without using Docker or Kubernetes. It will store the vectors you generate from the different websites we will navigate to.
Introduction to Agentic RAG
Language models can’t take actions themselves—they just output text. Agents are systems that use LLMs as reasoning engines to determine which actions to take and the inputs to pass them. After executing actions, the results can be transmitted back into the LLM to determine whether more actions are needed or if it is okay to finish.
They can be used to perform actions such as Searching the web, browsing your emails, correcting RAG to add self-reflection or self-grading on retrieved documents, and many more.
Setting things up
LangGraph – An extension of Langchain aimed at building robust and stateful multi-actor applications with LLMs by modeling steps as edges and nodes in a graph.
Ollama & Llama 3 – With Ollama you can run open-source large language models locally, such as Llama 3. This allows you to work with these models on your own terms, without the need for constant internet connectivity or reliance on external servers.
Milvus Lite – Local version of Milvus that can run on your laptop, Jupyter Notebook or Google Colab. Use this vector database we use to store and retrieve your data efficiently.
Using LangGraph and Milvus
We use LangGraph to build a custom local Llama 3-powered RAG agent that uses different approaches:
We implement each approach as a control flow in LangGraph:
Routing (Adaptive RAG) – Allows the agent to intelligently route user queries to the most suitable retrieval method based on the question itself. The LLM node analyzes the query, and based on keywords or question structure, it can route it to specific retrieval nodes.
Example 1: Questions requiring factual answers might be routed to a document retrieval node searching a pre-indexed knowledge base (powered by Milvus).
Example 2: Open-ended, creative prompts might be directed to the LLM for generation tasks.
Fallback (Corrective RAG) – Ensures the agent has a backup plan if its initial retrieval methods fail to provide relevant results. Suppose the initial retrieval nodes (e.g., document retrieval from the knowledge base) don’t return satisfactory answers (based on relevance score or confidence thresholds). In that case, the agent falls back to a web search node.
The web search node can utilize external search APIs.
Self-correction (Self-RAG) – Enables the agent to identify and fix its own errors or misleading outputs. The LLM node generates an answer, and then it’s routed to another node for evaluation. This evaluation node can use various techniques:
Reflection: The agent can check its answer against the original query to see if it addresses all aspects.
Confidence Score Analysis: The LLM can assign a confidence score to its answer. If the score is below a certain threshold, the answer is routed back to the LLM for revision.
General ideas for Agents
Reflection – The self-correction mechanism is a form of reflection where the LangGraph agent reflects on its retrieval and generations. It loops information back for evaluation and allows the agent to exhibit a form of rudimentary reflection, improving its output quality over time.
Planning – The control flow laid out in the graph is a form of planning, the agent doesn’t just react to the query; it lays out a step-by-step process to retrieve or generate the best answer.
Tool use – The LangGraph agent’s control flow incorporates specific nodes for various tools. These can include retrieval nodes for the knowledge base (e.g., Milvus), demonstrating its ability to tap into a vast pool of information, and web search nodes for external information.
Examples of Agents
To showcase the capabilities of our LLM agents, let’s look into two key components: the Hallucination Grader and the Answer Grader. While the full code is available at the bottom of this post, these snippets will provide a better understanding of how these agents work within the LangChain framework.
Hallucination Grader
The Hallucination Grader tries to fix a common challenge with LLMs: hallucinations, where the model generates answers that sound plausible but lack factual grounding. This agent acts as a fact-checker, assessing if the LLM’s answer aligns with a provided set of documents retrieved from Milvus.
```
### Hallucination Grader
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Prompt
prompt = PromptTemplate(
template="""You are a grader assessing whether
an answer is grounded in / supported by a set of facts. Give a binary score 'yes' or 'no' score to indicate
whether the answer is grounded in / supported by a set of facts. Provide the binary score as a JSON with a
single key 'score' and no preamble or explanation.
Here are the facts:
documents
Here is the answer:
generation
""",
input_variables=["generation", "documents"],
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke("documents": docs, "generation": generation)
```
Answer Grader
Following the Hallucination Grader, another agent steps in. This agent checks another crucial aspect: ensuring the LLM’s answer directly addresses the user’s original question. It utilizes the same LLM but with a different prompt, specifically designed to evaluate the answer’s relevance to the question.
```
def grade_generation_v_documents_and_question(state):
"""
Determines whether the generation is grounded in the document and answers questions.
Args:
state (dict): The current graph state
Returns:
str: Decision for next node to call
"""
print("---CHECK HALLUCINATIONS---")
question = state["question"]
documents = state["documents"]
generation = state["generation"]
score = hallucination_grader.invoke("documents": documents, "generation": generation)
grade = score['score']
# Check hallucination
if grade == "yes":
print("---DECISION: GENERATION IS GROUNDED IN DOCUMENTS---")
# Check question-answering
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke("question": question,"generation": generation)
grade = score['score']
if grade == "yes":
print("---DECISION: GENERATION ADDRESSES QUESTION---")
return "useful"
else:
print("---DECISION: GENERATION DOES NOT ADDRESS QUESTION---")
return "not useful"
else:
pprint("---DECISION: GENERATION IS NOT GROUNDED IN DOCUMENTS, RE-TRY---")
return "not supported"
```
You can see in the code above that we are checking the predictions by the LLM that we use as a classifier.
Compiling the LangGraph graph.
This will compile all the agents that we defined and will make it possible to use different tools for your RAG system.
```
# Compile
app = workflow.compile()
# Test
from pprint import pprint
inputs = "question": "Who are the Bears expected to draft first in the NFL draft?"
for output in app.stream(inputs):
for key, value in output.items():
pprint(f"Finished running: key:")
pprint(value["generation"])
```
Conclusion
In this blog post, we showed how to build a RAG system using agents with LangChain/ LangGraph, Llama 3, and Milvus. These agents make it possible for LLMs to have planning, memory, and different tool use capabilities, which can lead to more robust and informative responses.
Feel free to check out the code available in the Milvus Bootcamp repository.
If you enjoyed this blog post, consider giving us a star on Github, and share your experiences with the community by joining our Discord.
This is inspired by the Github Repository from Meta with recipes for using Llama 3
*This post was written by Stephen Batifol and originally published on Zilliz.com here. We thank Zilliz for their insights and ongoing support of TheSequence.
#ADD#agent#agents#amp#Analysis#APIs#app#applications#approach#backup#bears#binary#Blog#bootcamp#Building#challenge#code#CoLab#Community#connectivity#data#Database#Docker#emails#engines#explanation#extension#Facts#form#framework
0 notes
Text





🤝Hand holding support is available with 100% passing assurance🎯 📣Please let me know if you or any of your contacts need any certificate📣 📝or training to get better job opportunities or promotion in current job📝 📲𝗖𝗼𝗻𝘁𝗮𝗰𝘁 𝗨𝘀 : Interested people can whatsapp me directly ✅WhatsApp :- https://wa.link/8le28q 💯Proxy available with 100% passing guarantee.📌 🎀 FIRST PASS AND THAN PAY 🎀 ISC2 : CISSP & CCSP Cisco- CCNA, CCNP, Specialty ITILv4 CompTIA - All exams Google-Google Cloud Associate & Google Cloud Professional People Cert- ITILv4 PMI-PMP, PMI-ACP, PMI-PBA, PMI-CAPM, PMI-RMP, etc. EC Counsil-CEH,CHFI AWS- Associate, Professional, Specialty Juniper- Associate, Professional, Specialty Oracle - All exams Microsoft - All exams SAFe- All exams Scrum- All Exams Azure & many more… 📲𝗖𝗼𝗻𝘁𝗮𝗰𝘁 𝗨𝘀 : Interested people can whatsapp me directly ✅WhatsApp :- https://wa.link/8le28q
Thanks & Regards,… Krishna Sinha (Subnetting Guru) Intact Technology & Consultant Contact : +1-8176686697 (USA) & +91-9674277941 (India)
0 notes
Text

With older systems the more data stored, the slower the systems performed. This is because historically Relational Databases are not infinitely horizontally scalable, leading to data warehousing. This is a fully working example.
0 notes
Text
youtube
#youtube#video#codeonedigest#microservices#aws#microservice#docker#awscloud#nodejs module#nodejs#nodejs express#node js#node js training#node js express#node js development company#node js development services#app runner#aws app runner#docker image#docker container#docker tutorial#docker course
0 notes
Text
Best Self-hosted Apps in 2023
Best Self-hosted Apps in 2023 #homelab #selfhosting #BestSelfHostedApps2023 #ComprehensiveGuideToSelfHosting #TopMediaServersForPersonalUse #SecurePasswordManagersForSelfHost #EssentialToolsForSelfHostedSetup #RaspberryPiCompatibleHostingApps
You can run many great self-hosted apps in your home lab or on your media server with only a small amount of tinkering. Let’s look at the best self-hosted apps in 2023 and a list of apps you should check out. Table of contentsWhy Self-hosting?Plex: The Media Server KingJellyfin: Open Source Media FreedomEmby: A Balanced Media ContenderNextcloud: Your Personal Cloud ServiceHome Assistant:…

View On WordPress
#Best self-hosted apps 2023#Comprehensive guide to self-hosting#Docker containers for easy app deployment#Essential tools for self-hosted setup#In-depth analysis of self-hosted platforms#Manage sensitive data with self-host#Raspberry Pi compatible hosting apps#Secure password managers for self-host#Self-host vs. cloud services comparison#Top media servers for personal use
1 note
·
View note
Text
Activepieces:10 Best Reasons to Choose This No-Code Wonder
Activepieces: The no-code Zapier alternative. It helps you do tasks, and make content without any code. It improves your work better. Try it right now! Are you sick of running your business like rocket science? You probably feel bad when you need someone who knows computer code to fix your computers. Hiring someone who has complete knowledge of computer coding for your website or business, is a…
View On WordPress
#activepieces#activepieces 10 best reasons choose this no code wonder#activepieces best appsumo lifetime deal#activepieces create automations 100 apps#activepieces docker#activepieces funding#activepieces github#activepieces open source no code#activepieces price#activepieces pricing plans#activepieces review#building workflow activepieces#connecting with multiple apps activepieces#integration Chatgpt activepieces#why should I choose activepieces?
0 notes
Text
0 notes
Text
I'm a big fan of extensive reading apps for language learning, and even collaborated on such an app some 10 years ago. It eventually had to be shut down, sadly enough.
Right now, the biggest one in the market is the paywalled LingQ, which is pretty good, but well, requires money.
There's also the OG programs, LWT (Learning With Texts) and FLTR (Foreign Language Text Reader), which are so cumbersome to set up and use that I'm not going to bother with them.
I presently use Vocab Tracker as my daily driver, but I took a spin around GitHub to see what fresh new stuff is being developed. Here's an overview of what I found, as well as VT itself.
(There were a few more, like Aprelendo and TextLingo, which did not have end-user-friendly installations, so I'm not counting them).
Vocab Tracker

++ Available on web ++ 1-5 word-marking hotkeys and instant meanings makes using it a breeze ++ Supports websites
-- Default meaning/translation is not always reliable -- No custom languages -- Ugliest interface by far -- Does not always recognise user-selected phrases -- Virtually unusable on mobile -- Most likely no longer maintained/developed
Lute

++ Supports virtually all languages (custom language support), including Hindi and Sanskrit ++ Per-language, customisable dictionary settings ++ Excellent, customisable hotkey support
-- No instant meaning look-up makes it cumbersome to use, as you have to load an external dictionary for each word -- Docker installation
LinguaCafe

++ Instant meanings thanks to pre-loaded dictionaries ++ Supports ebooks, YouTube, subtitles, and websites ++ Customisable fonts ++ Best interface of the bunch
== Has 7 word learning levels, which may be too many for some
-- Hotkeys are not customisable (yet) and existing ones are a bit cumbersome (0 for known, for eg.) -- No online dictionary look-up other than DeepL, which requires an API key (not an intuitive process) -- No custom languages -- Supports a maximum of 15,000 characters per "chapter", making organising longer texts cumbersome -- Docker installation
Dzelda

++ Supports pdf and epub ++ Available on web
-- Requires confirming meaning for each word to mark that word, making it less efficient to read through -- No custom languages, supports only some Latin-script languages -- No user-customisable dictionaries (has a Google Form to suggest more dictionaries)
#langblr#languages#language learning#language immersion#fltr#lwt#lingq#vocab tracker#language learning apps
458 notes
·
View notes
Link
看看網頁版全文 ⇨ 將PDF轉換成模仿成掃描檔:ScanSim PDF / Converting PDF to Simulated Scanned Document: ScanSim PDF https://blog.pulipuli.info/2025/05/converting-pdf-to-simulated-scanned-document-scansim-pdf.html 列印、簽名、拍照、轉換成PDF、上傳,這是現在很多證明文件的處理手續。 處理後的PDF檔案只是圖片的封裝,不能直接選取與複製,只能作為證明文件留存,這已經是最基本的資安防護手段。 然而,如果可以將數位文件直接轉換成彷彿掃描檔一樣的檔案,那不就可以省下列印與掃描的繁雜手續了嗎?也許這時候Docker APP ScanSim PDF就能夠派上用場了。 Printing, signing, taking a photo, converting it to PDF, and uploading it—this is the procedure for processing many verification documents nowadays. The processed PDF file is merely a container for the image; the text cannot be directly selected or copied. It can only serve as an archive of the verification document, which is a basic security measure. However, if digital documents could be directly converted into files that resemble scanned documents, wouldn't that eliminate the tedious printing and scanning steps? Perhaps the Docker APP ScanSim PDF could be useful in this situation.。 ---- # 包含文字的PDF檔案 / A PDF File Containing Text。 - 範例檔案:緊急聯絡通訊錄 上圖是一個常見的緊急聯絡通訊錄PDF檔案。 通常我們會將此PDF列印,拿去給大家簽名,簽完名後再掃描歸檔。 由於這個檔案是由Word直接轉換成PDF的關係,上面的文字是可以直接選取、複製,也可以直接用搜尋找出來。 如果是要當成資料庫來查詢的話,這當然是很不錯。 但也有人會覺得這樣填完的資料可能會被有心人士複製,會有資安疑慮。 ---- 繼續閱讀 ⇨ 將PDF轉換成模仿成掃描檔:ScanSim PDF / Converting PDF to Simulated Scanned Document: ScanSim PDF https://blog.pulipuli.info/2025/05/converting-pdf-to-simulated-scanned-document-scansim-pdf.html
0 notes
Text
I made it easier to back up your blog with tumblr-utils
Hey friends! I've seen a few posts going around about how to back up your blog in case tumblr disappears. Unfortunately the best backup approach I've seen is not the built-in backup option from tumblr itself, but a python app called tumblr-utils. tumblr-utils is a very, very cool project that deserves a lot of credit, but it can be tough to get working. So I've put together something to make it a bit easier for myself that hopefully might help others as well.
If you've ever used Docker, you know how much of a game-changer it is to have a pre-packaged setup for running code that someone else got working for you, rather than having to cobble together a working environment yourself. Well, I just published a tumblr-utils Docker container! If you can get Docker running on your system - whether Windows, Linux, or Mac - you can tell it to pull this container from dockerhub and run it to get a full backup of your tumblr blog that you can actually open in a web browser and navigate just like the real thing!
This is still going to be more complicated than grabbing a zip file from the tumblr menu, but hopefully it lowers the barrier a little bit by avoiding things like python dependency errors and troubleshooting for your specific operating system.
If you happen to have an Unraid server, I'm planning to submit it to the community apps repository there to make it even easier.
Drop me a message or open an issue on github if you run into problems!
207 notes
·
View notes
Text
ended up having to go around the whole damn thing and use a different fuction altogether. then had to solve some dumb git error that took another dumb amount of time wiht a dumb workaround. 10:45 pm and hte interview is in 12 hours and 15 minutes maybe now i can actually get to checking the functionality of the goddamn program
trying to brush off code for an interview fukcign tomorrwo and i cannot solve this initial fucking erorr and i'm gonna fucking lose it oh my god
WHY is the html document not fukcing rendering when it has rendered for four years now jesus FUKC. someoen tell me how to use fukcing iframe in r shiny bc i am out of my whole entire mind
#me? competent? perish teh fucking thought#after i get through this app i have one mroe to check on and then ideally read up on docker with shiny#since i haven't touched docker in years and barely understood it even when i used it#and also claimed to have experience in it in my application for this job#tee fucking hee. shoutout to me for having not done anything all day. simply could not concentrate for the life of me. i swear to gd i trie#a;slkghoairho;izdrhgaoeirpaeitj
4 notes
·
View notes
Text
Man goes to the doctor. Says he's frustrated. Says his Python experience seems complicated and confusing. Says he feels there are too many environment and package management system options and he doesn't know what to do.
Doctor says, "Treatment is simple. Just use Poetry + pyenv, which combines the benefits of conda, venv, pip, and virtualenv. But remember, after setting up your environment, you'll need to install build essentials, which aren't included out-of-the-box. So, upgrade pip, setuptools, and wheel immediately. Then, you'll want to manage your dependencies with a pyproject.toml file.
"Of course, Poetry handles dependencies, but you may need to adjust your PATH and activate pyenv every time you start a new session. And don't forget about locking your versions to avoid conflicts! And for data science, you might still need conda for some specific packages.
"Also, make sure to use pipx for installing CLI tools globally, but isolate them from your project's environment. And if you're deploying, Dockerize your app to ensure consistency across different machines. Just be cautious about Docker’s compatibility with M1 chips.
"Oh, and when working with Jupyter Notebooks, remember to install ipykernel within your virtual environment to register your kernel. But for automated testing, you should...
76 notes
·
View notes
Note
so I saw that you work with Krita when it comes to your art. Do you have any tips when it comes the app? I have just started using it.
Sure!
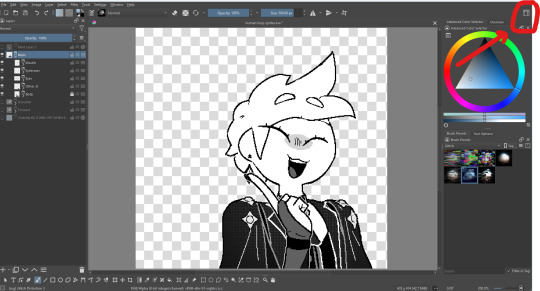
Up here is your workspaces tab where you can switch between different layouts. You can also adjust, make, and save your own layouts until you find the perfect orientation that you're most comfortable with.
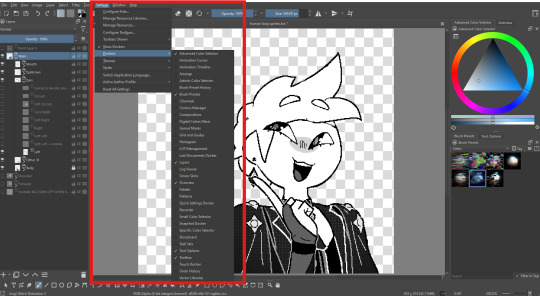
If you go to Settings -> Dockers, you can see all the different widgets (?) that you can add to your layout.

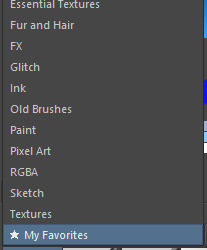
You can right click on brushes to add/remove them from tags to help you organize.
Here's a resource for adding and finding new brushes
If you want to use Krita to animate, I would recommend reading this beforehand because Krita is still working on implementing rendering and you need to download an extension to do that.
Since I don't know your familiarity with digital drawing programs in general I don't know what to explain, a lot of the things in Krita can be traced back and forth with other drawing programs, things are just in different places which poking around the program can help you find
if anyone has any other tips please feel free to add!
42 notes
·
View notes