#document indexing software
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr.com is the 103rd most visited website in the world.
Text
Unlock Efficiency with PDQ Docs: The Ultimate Document Management Software
In today’s fast-paced world, the way we manage and store documents has evolved dramatically. With businesses and individuals handling vast amounts of information daily, having an effective system for managing documents is no longer a luxury but a necessity. PDQ Docs, the ultimate document management software, offers a comprehensive solution to help you organize, secure, and access your documents effortlessly. This innovative software is designed to streamline document handling, saving time and enhancing productivity for businesses of all sizes.

The Power of PDQ Docs in Document Management
PDQ Docs stands out as the ultimate document management software because it offers an intuitive and user-friendly interface that makes it easy to store, retrieve, and share documents. Gone are the days of sifting through endless paper files or wasting time searching through disorganized digital folders. PDQ Docs allows users to create a centralized digital storage system where all documents can be safely stored and quickly accessed with just a few clicks.
This software is equipped with powerful search functionality, ensuring that finding the right document is a breeze. No more frustrating searches through a clutter of files—PDQ Docs’ advanced search options allow users to locate any document in seconds, boosting efficiency and reducing downtime.
Effortless Integration with Your Existing Workflow
Integrating a new software solution into your existing business processes can often be a challenging task. However, PDQ Docs makes this transition as seamless as possible. Designed to integrate easily with a variety of other tools, PDQ Docs can work in harmony with the systems you already use, such as project management software, CRM tools, and cloud storage platforms.
This level of integration means you don't have to completely overhaul your existing workflow to take advantage of PDQ Docs' powerful document management features. Instead, you can effortlessly incorporate the software into your current processes, enhancing efficiency without disrupting the way your business operates.
A Scalable Solution for Growing Businesses
Growing businesses witness different document management requirements. PDQ Docs is designed with scalability in mind, making it the ultimate document management software for businesses of all sizes. Whether you're a small startup or a large enterprise, PDQ Docs can grow with you, offering flexible storage options and additional features that cater to the evolving needs of your organization.
The software’s scalable design ensures that it remains a valuable asset as your document management requirements expand, allowing you to continue working efficiently without worrying about outgrowing the system.
Conclusion
PDQ Docs stands as the ultimate document management software, providing businesses and individuals with a robust, secure, and efficient solution for organizing and accessing documents. With features like secure storage, advanced search functionality, seamless collaboration, and easy integration with existing systems, PDQ Docs is the key to unlocking greater productivity and simplifying document management. Whether you're looking to streamline your business operations or enhance team collaboration, PDQ Docs is the answer to managing your documents with ease and confidence.
#ultimate document management software#cloud based document management#enterprise document management software#file organization software#document collaboration tools#document scanning software#document indexing software#paperless office solutions#template management#document generation#workflow optimization
1 note
·
View note
Note
Hi, random q. I saw in your tags that you swear by Scrivener for original fic. I’m still plugging away in ye olde Word and now I’m intrigued to know what about Scrivener you like so much. I’ve def heard about it but never used it, so I’m curious :)
YES I would love to tell you about my lord and savior software Scrivener. I hope you don't mind I published this long, long answer publicly.
So. The main issue I have with Word and Google Docs is that you hit a certain length/word count, and it starts to lag and load kind of jerkily. You know? Also, navigating chapter to chapter or scene to scene is awkward for me--you either have to have a whole bunch of individual documents and multiple windows open, or you have to use headers and the table of contents...which is fine for quickly finding chapters but less so for scenes within those chapters.
Messy, basically. Does not spark joy for me.
Enter Scrivener.
Now, before I evangelize a bit, I will say that Windows Scrivener and Mac Scrivener are not 100% created equal. They are both better, I think, than Word or Google docs, but the Mac version is a bit slicker and a little nicer to look at. I only say that for if you're using Windows, because if so my screencaps below won't exactly match what you see if/when you download the program.
ONWARD.
So, the #1 thing that Scrivener has over Word is that it's a one time fee, not a subscription. So while it is a little pricey (Just went and looked, $59.99 USD), it's only the one payment. All updates and such are covered and available as free downloads. I will also say that Scrivener gives you a 30 day free trial. That's not 30 consecutive days, but 30 days of use--if you only use it every other day, you'll have the trial for 60 days. They make it really easy to figure out if it's for you or not.
This is also going to feel like a lot, but there are built in tutorials and it's actually pretty intuitive, depending on how your brain works. Anyway! The basic gist of Scrivener is that it's a digital binder. You can keep all your book stuff in one place:

As you can see, there's the manuscript (aka my book), notes, research, more. Tbh, I mostly just use notes and Manuscript, but if it floats your boat, you can store maps, place names, worldbuilding, playlist links, moodboards, a whole ton of stuff, all in one menu that's easy to access and in a single window. You can organize it however itches your brain the best way.
But like I said, for me, the best is that Manuscript part, which I'm going to go into now. I use a three act structure for books (but break the big ol' middle act into two pieces because it makes my brain happy), so each act gets a folder.
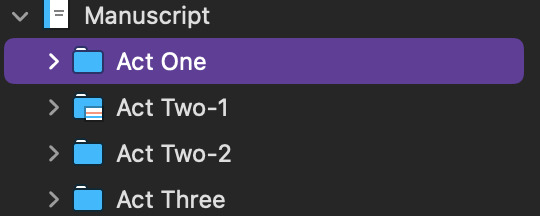
When I click and expand that act, each chapter has it's own folder. However, it also shows quick-reference index cards, so I can have an at-a-glance at what's going down in each chapter. (I'm using a outline system called Save the Cat for this book, which is why all my chapters have titles like 'Catalyst', feel free to ignore those...I also have a very compact timeline, so to help me stay organized, I labeled each chapter with when it happens.)

You can do the same with each individual chapter and the scenes, where when you click on the chapter folder, each scene gets a card. If you don't type in a summary, it'll just auto-populate the start of whatever content you were writing. You can see this in the 'Copper's Candids NEW' card.
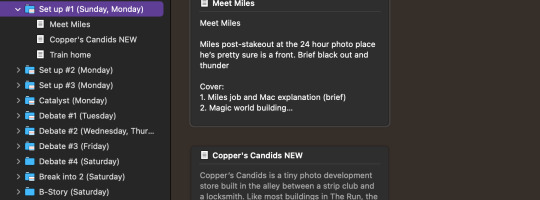
And, of course, it is writing software. When you click on the individual scene, it opens the blank document, and you can get cracking.
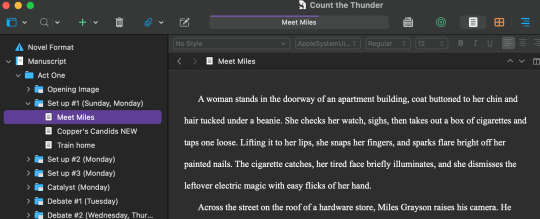
So. This system is nice for a few reasons. My favorite is that it makes navigating, reorganizing, and/or rewriting scenes extremely easy. It's just point and click, drag and drop. You can also open two docs in the same window at once, like this:
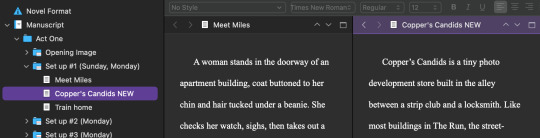
Which is a nice feature for several reasons--you can work on a new version of a scene with the old one pulled up next to it, or if there's something you wrote earlier or that comes later that's important to what you're working on now, you can have them both up for quick referencing.
Another slick thing is each doc has a notes section off to the right side of the screen--which is optional! I use it for future revision notes/descriptions of how I want the scene to go:
My other favorite part of Scrivener is that it makes it very easy to hoard your deleted scenes like a deranged dragon in case you want them later. My garbage looks like this:

There are SO MANY FILES hanging out in my trash, and you know what? I so rarely actually need them, but my god am I glad they're there on the rare occasion that I do. Word, again, can make it more difficult. I always had a massive 'cut' document that was longer than the actual project and again, awful to navigate. This just makes it easier.
Scrivener also makes it easy to compile the manuscript into other doc types--pdf, doc, docx, etc--for easy printing and sharing.
ANYWAY. I'm sure there are approximately 1 million other things I'm missing, but basically Scrivener takes all your book/long project bits, puts them in one centralized file, and makes it super easy to navigate. I've also found that outlining is easier, because I can just make the folders and scenes and drag them around while I noodle through the plot.
10/10, would recommend to any long-form writer. If you have any other questions, please let me know! If anyone has read this far and has a thing about Scrivener to add, please do! I love Scrivener, and a lot of my writing buddies love Scrivener, and it really kinda has revolutionized the way I write original fiction. I'm always happy to yell about how great it is.
#mail#story-monger#long post#Scrivener#free yourselves from the shackles of Word and Google Docs my long-form-writing friends#there is a Better Way#writing
101 notes
·
View notes
Text
i am trying to play this

but the process of installing it. mein gott
commodore emulation on a handheld is possible but i can't find a comprehensive tutorial for my situation (anbernic 40 running muOS). i am engaged in mortal fucking combat with retroarch which keeps saying FEED ME KICKSTART ROMS BOY. kickstarts from what i can tell are little bonus files that tell the emulator how to process big deal software. so i was like Fine. you can have those. but the muOS file structure is uniquely odd (especially compared to windows) and the folder where the kickstarts should live does not exist. i think the solution here is to fiddle around with another OS or use an emulator that doesn’t rely on retroarch
ONTO OTHER PROBLEMS! mind walker is only available in .adf. the reddit jury’s general consensus seems to be that .adf is the most annoying commodore rom format due to the load times (long) and emulator compatibility (variable). i have no idea if some brave angel with a neocities site has created an adf -> hdf converter. worst case scenario if the adf rom doesn't work would involve nixing the handheld plan entirely and pivoting to windows emu (more documentation and much easier to troubleshoot). there is a way to screenshare from PC but it wouldn't feel true to the vision. i am desperate to make this work on handheld if at all possible. dunno why. the idea of a portable geometric mad scientist game is just supremely appealing to me on so many levels. if i manage to get this thang up and running i will be so happy. ONWARDS!
35 notes
·
View notes
Note
I have to ask what did your notes look like for Echo Garden? I am such a horrible organizer it’s very hard for me to take notes on anything. So I’m just curious to see what they looked like/what they were like if you’d rather not provide an image :)
hahaha ohhhhhhh... oh. notes. notes EVERYWHERE
ok ok first! I've been asked how I organize writing before (and there are pictures) so please go give this a read: "Writing Program?"
that link answers your question, but I can give a lil more detail.
cut for TEG spoilers
here's a shortened version of the link above. for TEG I had notes in all these places:
-one doc was my "working document" where I was working on the current chapter, but towards the end I would put timelines and ch breakdowns and tons of notes at the top of it. here's what the very beginning looks like. when I finished the fic I noted it at the top cuz this was the doc I worked in 99% of the time :)

-one doc where I tried to keep things like worldbuilding and timelines organized. here's a pic of the top of the doc and also of the index


-one doc where I put all the future scenes that were written but we hadn't gotten there yet in the story
-one doc for notes/scenes I didn't need anymore aka the graveyard. it's always good to have a graveyard! that way you don't delete anything. you just move it to here and can cannibalize from it occasionally
-scattered notes done in other programs (all the above were done in OpenOffice), like Photoshop, where I was trying desperately to work out timelines. here's an RTF file lol

here's what the beginning of that RTF file looks like:

-handwritten notes (usually done on scraps of paper at work and brought home to be typed up). I taped them all into a notebook and then later separated them out and taped them to acid-free paper cuz, idk, what if they're historically relevant someday??? I'll probably never be that important but what if?? I had some pics of this but idk where they went
-notes on phone (usually written late at night when I was in bed and too tired to write them any other way). this is my absolute least favorite place/way to take notes. I haaaaaaaate using my phone for anything, let alone writing out things. but I imagine most people use this, and totally do use it if you like it!
ok I wanted to put more pics in here for you but I'm writing this at 5am and I need to get going to work. but yeah. it's a MESS haha. and I really wish it weren't. notes just come and go. I do have a novel writing software that should help with this, but I haven't started using it yet.
tl;dr if you are messy with notes, you are not alone
13 notes
·
View notes
Text
holy shit axure sucks so much i want to murder people bc of that how can a software, presumably made for coders and software engineers, be designed in a way that is so counter intuitive and annoying for coders. why can i not access a row on a table using its index. this is the simplest thing to do in any coding language ever designed on this planet. but this software, made to prototype uis, makes this so convoluted and obscure that i dont even know if its possible.
and the fuckin documentation on this piece of shit software is not like "here is how you can make this and then it can be used like this and this and this!". It's "here is a thing you can do! i will not explain what it does and how its useful ever!"
god i hade this software so much
2 notes
·
View notes
Note
BREAKING NEWS: Atlas Vanserra Creates Jobs, Fulfils Campaign Promise Ahead of Polls
Prythian: ‘The People’s Prince’ and crowd favourite contender for the 2024 Presidential Elections, Atlas Vanserra (02), the youngest presidential nominee has already begun fulfilling his campaign promise of solving the unemployment crisis. Vanserra, pictured below conferring with his future VP Pumpkin Vanserra (02) between public appearances, has brought a whole slew of previously unemployed or underemployed people into the workforce for their expertise in “baby talk.”A panel of linguists, speech specialists, and parents have been added to virtually every news outlet in town (with the exception of Fox and co, who already had them) and everyone from cat owners to older siblings have been hired as consultants. “I never thought I’d be able to do this,” said a young mother who wishes to remain anonymous, “I got married so young - right after I learned to read and write too - I had no experience or references, no understanding of the job market - and I love being a mother so I’m glad I’m getting paid to do just that.” Many parents of young children, who may have been struggling with the cost of living crisis, income insecurity, rent hikes etc, have found a saviour in Vanserra. “I was a little sceptical at first,” says Tom, a software engineering graduate from Stanford, “I was like, I got the employable degree and still got replaced by AI, what’s a baby gonna do, babble? Turns out, yeah!” Tom has had to move in with his long time girlfriend’s parents to better provide for their infant son as rent prices go up and home ownership remains a pipe dream. “We saved up to get married, we saved up to buy a house. We planned for our baby - we knew it was a big undertaking - but then I lost my job and I was working any minimum wage job I could find so my girl didn’t have to worry about nothing… at one point we considered other options but we had none, and prenatal care is so expensive… it was a nightmare. I’m glad that the public have started caring for mothers and babies postpartum though.”
So how has Vanserra helped? The vested interest in translating the nominee’s speeches has not only employed parents, but secured parents of young children stipends for their cooperation in helping researchers study child behaviour in a non invasive environment. “It’s not just videos or observations,” says a lead scientist with the Babble Initiative, “parents spend all of their time watching children, their wealth of knowledge is priceless. Given how often other animals mimic babies - like cats - we’ve been able to decentralise our input sources. We’re not looking at languages or fiction alone, but trying to ascertain if there are commonalities in these vocalisations. Essentially, if there is a baby language.” Fields like anthropology, archaeology, primatology etc have also received much attention and funding as fascinated patrons realise just how much goes into “understanding what we should but don’t.” “I thought it was just digging,” an anonymous donor remarks “but these guys are tracing language back centuries, connecting history with the present - I was thinking how I used to be a baby once and should understand one, you know? That’s what got me hooked.”
Many wonder if the arts will finally get the respect they deserve as more and more people recognise the important work critics, historians, and especially students do in interpreting, indexing, and interacting with media and information of all kinds. Atlas Vanserra’s manifesto, a 17 page document of artistic impressions, was deciphered by a team of artists - including writers, literary critics, art hostorians etc - after three months of rigorous study. “Several independent readings exist in the mainstream and experts disagree on exactly what each blob means, but that’s part of the work - and I hope it’s at least become clear to all that it is - as a matter of fact - a lot of work!” said a graduate student when asked why Project Demanifest is important today. “Media literacy is dead and intellectualism is dying. I didn’t know what change would look like but it definitely wasn’t an adorable ginger baby, but I’m so glad it’s not another tangerine.”
The People’s Prince has not yet secured the Presidency, and it is unclear at this stage if he will. Though a fan favourite, many have wondered if Atlas is just a fresh new fad the public is obsessed with than a valid contender. “I don’t think it matters,” said an ‘Atlas Truther’ “A democracy is only valid insofar as the people believe the ones in power will act in their best interests. I can’t say that with a good conscience right now, and I’m sure that’s true for a lot of others. When a toddler has a record of fewer tantrums than other contenders - shouldn’t that be a wake up call? People like to call us baby brained anarchists for wanting Atlas to win. I disagree. If a baby can win an election that’s a problem. If the baby has you thinking he should win the election, that’s also a problem. At least Atlas is cute and apathetic to monetary bribes.” Regardless of if we are set to have the youngest president to date, one cannot ignore how easily the youngling was able to affect and enact changes that the last several presidencies have been unable to do - before even coming into power. Atlas has raised the bar, let’s hope this becomes the standard. •
I am 100% invested in this political thriller of a baby becoming president
This ask is why ask boxes were invented
10 notes
·
View notes
Text






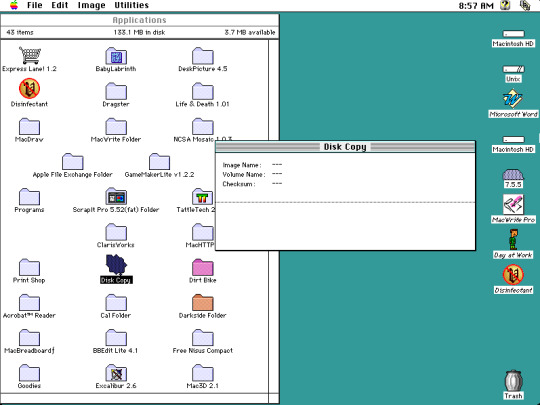

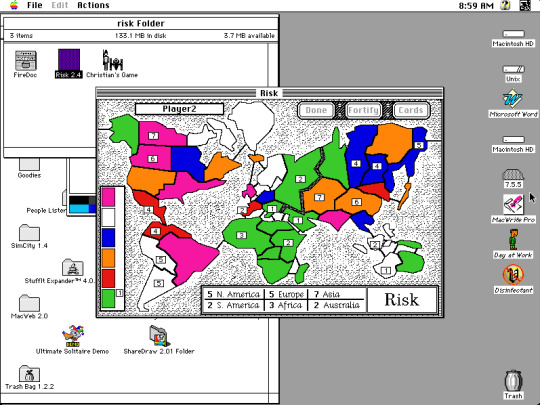

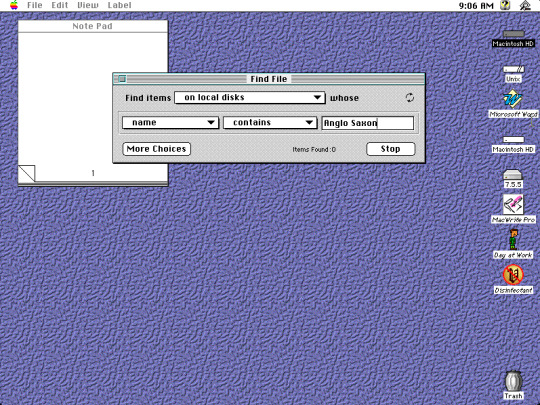
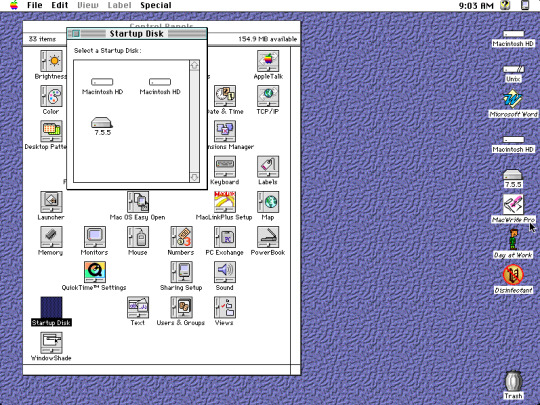
Alright! So here's Part 2 of my Classic Macintosh Screencap series! Beginning in order of left to right beginning from top to bottom:
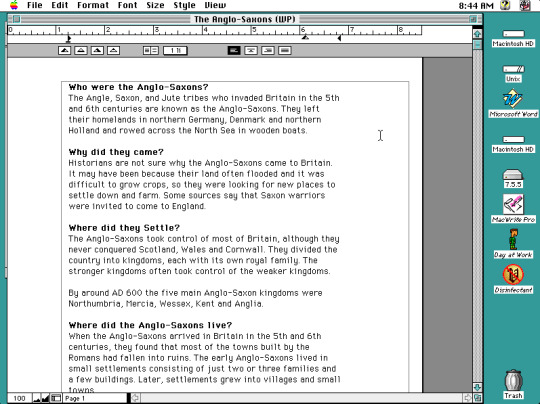
The contents of a report about the Anglo Saxons that I wrote.
I wrote this back in 2008! I refuse to believe that 2008 was almost 16 years ago. I was in high school at the time, so please excuse my atrocious writing. Honestly, doing my schoolwork in this emulator (full-screen) was actually quite nice, it served as a pleasant environment for some distraction-free writing.
Artwork by my niece who was around 8 at the time. I'd let her use the emulator environment from time to time to play games or in this case, draw. Crazy that she's in college now, time sure flies.
The Stickies application that we've known and loved in macOS is a lot older than you think. It debuted in Macintosh System 7.5 in 1994!
The contents of the main drive and also the System Folder where the System Software resides. A neat thing about the System Folder: You can move it anywhere even while the system is running, you can stuff it in a folder elsewhere, and the Mac will still find the System Folder and be able to boot from it! It is no longer possible to do this trick starting with the first release of Mac OS X/macOS back in 2001 and the folder is simply called 'System' ever since.
System related settings were in the form of Control Panels, they were essentially little program snippets and you can freely move them in and out of the Control Panels folder. Third party applications would sometimes include their own Control Panels for better system integration. An example would be a Control Panel for your graphics card. Starting with Mac OS X the Control Panels were replaced by System Preferences/System Settings and the panels are fixed. They cannot be removed or moved around.
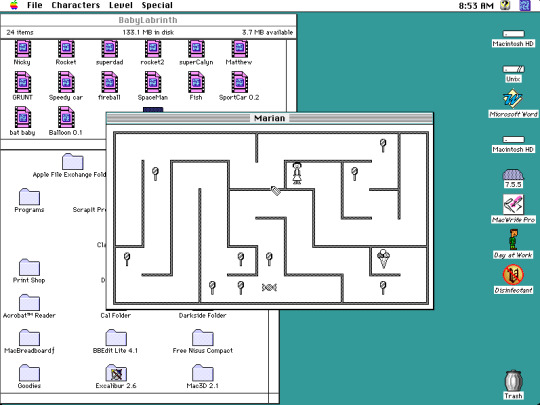
A simple maze game called Baby Labyrinth.
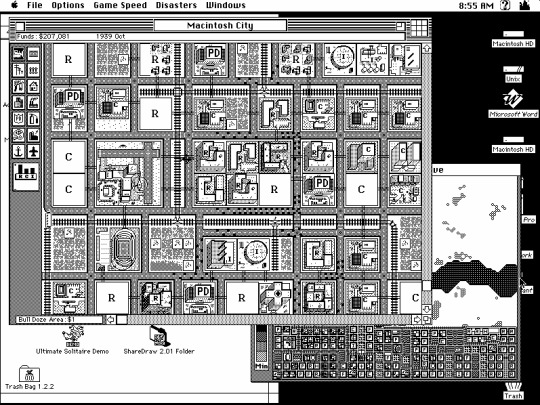
SimCity Classic is one of my favorite vintage games to play. It doesn't like running on any color setting other than black & white, even telling you to set it to this color setting, then quits. Much older software that was written without color displays in mind might not work and might even crash until you change the color settings. However not all vintage Macs supported setting the color to black and white.
Ok so the disk image is actually a tad bit older than I thought. This saved game was from 2007!
The disk image format style of installing applications by opening a DMG file, and dragging it into an Applications icon in the present day? It's been around since the early days of Macs. It was originally used to preserve the resource fork of files as it couldn't be easily transferred and preserved over networks. Even though resource forks aren't really being used any longer, this method of software distribution has been standard and preferred ever since.
An error message. Nothing serious, the application just couldn't find a particular piece of software.
A game of Risk!
Some wallpapers that came bundled with the system. Hmm... yes purple.
Before Spotlight, this is what you'd use to look for files. Since indexing wasn't a thing that was built into the system, it would take a considerable amount of time to find a document. I tried searching for that Anglo Saxon document that I wrote and about 5 mins later it was still searching. I gave up.
Another feature that has existed for quite a while: The ability to select a startup disk in the Control Panel. Drives that contain a valid System Folder will show up in this panel. Once you select a drive, the system will then boot up from that drive moving forward, until you return to the same Startup Disk control panel then specify a different drive.
I have an actual Mac stashed away in storage that I'd like to share more pics and screen caps, but sadly I'm out of state at the moment and not sure when I'll have a chance to revisit it.
#macintosh#System 7#1990s#1990s aesthetic#90s aesthetic#90s nostalgia#old computers#technology#computing#vintage#vintage electronics#retro aesthetic#retro computing#vintage computing#apple#apple computers#abandonware#vaporwave#software#old software#vintage mac#BasiliskII#classic mac#microsoft word#old web#old internet#nostalgiacore#old games#old programs
3 notes
·
View notes
Text
Thesis Writing

Realistic Goal Setting
One of the most critical aspects of thesis writing is setting realistic goals. Simply stating, “I’ll have my thesis written in 4 months,” can be overwhelming and counterproductive. Instead, break down this over arching aim into manageable goals. Setting smaller milestones, like completing specific sections or chapters within shorter time frames, provides a sense of achievement and maintains motivation.
Initial goals should be realistic, based on your personal working habits and prior experience. Many underestimate the time required, especially without prior experience in writing such extensive documents. Different tasks, like experiments, lab presentations, or conferences, will also compete for your time. Setting achievable goals and securing “easy wins” early on, such as completing a subsection of the Methods chapter, can build confidence and create a sense of accomplishment. As you progress, gradually set more challenging goals to push yourself further.
Organization

Effective thesis writing necessitates thorough preparation and organization. Before starting, ensure you have all the necessary information and materials. This includes:
Drafts of figures for each chapter, especially the Results.
Collated and analyzed raw data with clear statistical analysis descriptions.
Knowledge of the sources of equipment, chemicals, and composition of solutions.
A comprehensive bibliography using a reference database.
Having all this information at your fingertips prevents disruptions and ensures a smooth writing process. Understanding your data is crucial; conclusions cannot be drawn without knowing the outcomes of your experiments. Hence, organized data collection and analysis are essential to avoid any surprises during the write-up.
Thesis Content and Writing Process

A typical thesis includes the following sections: General Introduction, Methods, Results (with several sub-chapters), Overall Discussion, Bibliography, Acknowledgements, and Indexes. The suggested order for writing these sections is:
Methods: This chapter should be straight forward, detailing what you did and how. Be careful to avoid plagiarism, even in standard protocols, and ensure the inclusion of all methodologies used, especially for final experiments.
2. Results: Start with the easiest chapters or those that may form the basis of a manuscript. Results chapters do not have to follow the chronological order of experiments or the order they will appear in the final thesis.
3. General Introduction: This is often the most challenging part to write. It should provide a historical and contemporary assessment of the literature in your research field and outline the thesis focus. Creating an outline early in the process can help manage this chapter, breaking it into subsections for manageable writing and frequent revision.
4. Overall Discussion: This chapter should synthesize your findings, placing them in the context of your research field. Avoid repeating discussions from individual Results chapters.
Illustrating Your Thesis

Effective illustration of your data through figures is crucial. Good figures tell a story and provide a lasting legacy of your work. Tips for creating effective figures include:
Legibility: Use readable font sizes.
Consistency: Maintain consistency in data presentation.
Separation of panels: Use separate figures when possible to avoid clutter.
Color usage: Be mindful of color use, ensuring accessibility for color-blind individuals and black-and-white print versions.
Figures should be intensively revised and adapted, allowing time to master your figure-making software. Informative figure legends are essential, conveying the “take-home” message clearly.
Communication and Feedback
Maintaining communication with your supervisor throughout the writing process is crucial. Early feedback can prevent extensive revisions later. Schedule regular meetings to discuss drafts and incorporate feedback aimed at improving your work. This collaborative approach ensures your thesis aligns with academic standards and expectations.
Rewards and Relaxation
The thesis writing process can be exhausting and frustrating. Realistic goal setting should include rewarding yourself for completing tasks. Balance work and relaxation to maintain productivity and avoid burnout. Remember, completing your thesis is a significant step toward your career advancement.
Preparing a Manuscript for Publication

Thesis writing often leads to the preparation of manuscripts for peer-reviewed journals. This process involves:
Ensuring your study has a clear hypothesis and contributes significantly to the field.
Drafting Methods and Results sections first to highlight any missing data or additional analyses needed.
Writing a concise Discussion that places your findings in the context of existing research without recapitulating the Results section.
Finalizing Key points summary, Abstract, and Introduction after drafting the main content to ensure focus and clarity.
Following ethical and statistical reporting policies, including providing detailed Methods and ensuring data reproducibility.
Conclusion
The process of writing a thesis and preparing manuscripts is iterative and requires careful planning, organization, and communication. By setting realistic goals, staying organized, and seeking continuous feedback, you can navigate this challenging task effectively. Remember, your thesis is a significant milestone in your academic journey, paving the way for future research contributions and career advancements.
Investing in your academic future with Dissertation Writing Help For Students means choosing a dedicated professional who understands the complexities of dissertation writing and is committed to your success. With a comprehensive range of services, personalized attention, and a proven track record of helping students achieve their academic goals, I am here to support you at every stage of your dissertation journey.
Feel free to reach out to me at [email protected] to commence a collaborative endeavor towards scholarly excellence. Whether you seek guidance in crafting a compelling research proposal, require comprehensive editing to refine your dissertation, or need support in conducting a thorough literature review, I am here to facilitate your journey towards academic success. and discuss how I can assist you in realizing your academic aspirations.
#academics#education#grad school#gradblr#phd#phd life#phd research#phd student#phdblr#study#studyspo#students#studyblr#studying#student#study motivation#study blog#writters on tumblr#my writing#writeblr#writing#writers on tumblr#university student#university#uniblr#stanford university#princeton university#harvad university#essay writing#research
3 notes
·
View notes
Text
This Week in Rust 518
Hello and welcome to another issue of This Week in Rust! Rust is a programming language empowering everyone to build reliable and efficient software. This is a weekly summary of its progress and community. Want something mentioned? Tag us at @ThisWeekInRust on Twitter or @ThisWeekinRust on mastodon.social, or send us a pull request. Want to get involved? We love contributions.
This Week in Rust is openly developed on GitHub and archives can be viewed at this-week-in-rust.org. If you find any errors in this week's issue, please submit a PR.
Updates from Rust Community
Project/Tooling Updates
Strobe Crate
System dependencies are hard (so we made them easier)
Observations/Thoughts
Trying to invent a better substring search algorithm
Improving Node.js with Rust-Wasm Library
Mixing C# and Rust - Interop
A fresh look on incremental zero copy serialization
Make the Rust compiler 5% faster with this one weird trick
Part 3: Rowing Afloat Datatype Boats
Recreating concurrent futures combinators in smol
Unpacking some Rust ergonomics: getting a single Result from an iterator of them
Idea: "Using Rust", a living document
Object Soup is Made of Indexes
Analyzing Data 180,000x Faster with Rust
Issue #10: Serving HTML
Rust vs C on an ATTiny85; an embedded war story
Rust Walkthroughs
Analyzing Data /,000x Faster with Rust
Fully Automated Releases for Rust Projects
Make your Rust code unit testable with dependency inversion
Nine Rules to Formally Validate Rust Algorithms with Dafny (Part 2): Lessons from Verifying the range-set-blaze Crate
[video] Let's write a message broker using QUIC - Broke But Quick Episode 1
[video] Publishing Messages over QUIC Streams!! - Broke But Quick episode 2
Miscellaneous
[video] Associated types in Iterator bounds
[video] Rust and the Age of High-Integrity Languages
[video] Implementing (part of) a BitTorrent client in Rust
Crate of the Week
This week's crate is cargo-show-asm, a cargo subcommand to show the optimized assembly of any function.
Thanks to Kornel for the suggestion!
Please submit your suggestions and votes for next week!
Call for Participation
Always wanted to contribute to open-source projects but did not know where to start? Every week we highlight some tasks from the Rust community for you to pick and get started!
Some of these tasks may also have mentors available, visit the task page for more information.
* Hyperswitch (Hacktoberfest)- [FEATURE] separate payments_session from payments core * Hyperswitch (Hacktoberfest)- [NMI] Use connector_response_reference_id as reference to merchant * Hyperswitch (Hacktoberfest)- [Airwallex] Use connector_response_reference_id as reference to merchant * Hyperswitch (Hacktoberfest)- [Worldline] Use connector_response_reference_id as reference to merchant * Ockam - Make ockam project delete (no args) interactive by asking the user to choose from a list of space and project names to delete (tuify) * Ockam - Validate CBOR structs according to the cddl schema for authenticator/direct/types * Ockam - Slim down the NodeManagerWorker for node / node status
If you are a Rust project owner and are looking for contributors, please submit tasks here.
Updates from the Rust Project
397 pull requests were merged in the last week
rewrite gdb pretty-printer registration
add FileCheck annotations to mir-opt tests
add MonoItems and Instance to stable_mir
add a csky-unknown-linux-gnuabiv2hf target
add a test showing failing closure signature inference in new solver
add new simpler and more explicit syntax for check-cfg
add stable Instance::body() and RustcInternal trait
automatically enable cross-crate inlining for small functions
avoid a track_errors by bubbling up most errors from check_well_formed
avoid having rustc_smir depend on rustc_interface or rustc_driver
coverage: emit mappings for unused functions without generating stubs
coverage: emit the filenames section before encoding per-function mappings
coverage: fix inconsistent handling of function signature spans
coverage: move most per-function coverage info into mir::Body
coverage: simplify the injection of coverage statements
disable missing_copy_implementations lint on non_exhaustive types
do not bold main message in --error-format=short
don't ICE when encountering unresolved regions in fully_resolve
don't compare host param by name
don't crash on empty match in the nonexhaustive_omitted_patterns lint
duplicate ~const bounds with a non-const one in effects desugaring
eliminate rustc_attrs::builtin::handle_errors in favor of emitting errors directly
fix a performance regression in obligation deduplication
fix implied outlives check for GAT in RPITIT
fix spans for removing .await on for expressions
fix suggestion for renamed coroutines feature
implement an internal lint encouraging use of Span::eq_ctxt
implement jump threading MIR opt
implement rustc part of RFC 3127 trim-paths
improve display of parallel jobs in rustdoc-gui tester script
initiate the inner usage of cfg_match (Compiler)
lint non_exhaustive_omitted_patterns by columns
location-insensitive polonius: consider a loan escaping if an SCC has member constraints applied only
make #[repr(Rust)] incompatible with other (non-modifier) representation hints like C and simd
make rustc_onunimplemented export path agnostic
mention into_iter on borrow errors suggestions when appropriate
mention the syntax for use on mod foo; if foo doesn't exist
panic when the global allocator tries to register a TLS destructor
point at assoc fn definition on type param divergence
preserve unicode escapes in format string literals when pretty-printing AST
properly account for self ty in method disambiguation suggestion
report unused_import for empty reexports even it is pub
special case iterator chain checks for suggestion
strict provenance unwind
suggest ; after bare match expression E0308
suggest constraining assoc types in more cases
suggest relaxing implicit type Assoc: Sized; bound
suggest removing redundant arguments in format!()
uplift movability and mutability, the simple way
miri: avoid a linear scan over the entire int_to_ptr_map on each deallocation
miri: fix rounding mode check in SSE4.1 round functions
miri: intptrcast: remove information about dead allocations
disable effects in libcore again
add #[track_caller] to Option::unwrap_or_else
specialize Bytes<R>::next when R is a BufReader
make TCP connect handle EINTR correctly
on Windows make read_dir error on the empty path
hashbrown: add low-level HashTable API
codegen_gcc: add support for NonNull function attribute
codegen_gcc: fix #[inline(always)] attribute and support unsigned comparison for signed integers
codegen_gcc: fix endianness
codegen_gcc: fix int types alignment
codegen_gcc: optimize popcount implementation
codegen_gcc: optimize u128/i128 popcounts further
cargo add: Preserve more comments
cargo remove: Preserve feature comments
cargo replace: Partial-version spec support
cargo: Provide next steps for bad -Z flag
cargo: Suggest cargo-search on bad commands
cargo: adjust -Zcheck-cfg for new rustc syntax and behavior
cargo: if there's a version in the lock file only use that exact version
cargo: make the precise field of a source an Enum
cargo: print environment variables for build script executions with -vv
cargo: warn about crate name's format when creating new crate
rustdoc: align stability badge to baseline instead of bottom
rustdoc: avoid allocating strings primitive link printing
clippy: map_identity: allow closure with type annotations
clippy: map_identity: recognize tuple identity function
clippy: add lint for struct field names
clippy: don't emit needless_pass_by_ref_mut if the variable is used in an unsafe block or function
clippy: make multiple_unsafe_ops_per_block ignore await desugaring
clippy: needless pass by ref mut closure non async fn
clippy: now declare_interior_mutable_const and borrow_interior_mutable_const respect the ignore-interior-mutability configuration entry
clippy: skip if_not_else lint for '!= 0'-style checks
clippy: suggest passing function instead of calling it in closure for option_if_let_else
clippy: warn missing_enforced_import_renames by default
rust-analyzer: generate descriptors for all unstable features
rust-analyzer: add command for only opening external docs and attempt to fix vscode-remote issue
rust-analyzer: add incorrect case diagnostics for module names
rust-analyzer: fix VS Code detection for Insiders version
rust-analyzer: import trait if needed for unqualify_method_call assist
rust-analyzer: pick a better name for variables introduced by replace_is_some_with_if_let_some
rust-analyzer: store binding mode for each instance of a binding independently
perf: add NES emulation runtime benchmark
Rust Compiler Performance Triage
Approved RFCs
Changes to Rust follow the Rust RFC (request for comments) process. These are the RFCs that were approved for implementation this week:
Add f16 and f128 float types
Unicode and escape codes in literals
Final Comment Period
Every week, the team announces the 'final comment period' for RFCs and key PRs which are reaching a decision. Express your opinions now.
RFCs
No RFCs entered Final Comment Period this week.
Tracking Issues & PRs
[disposition: merge] Consider alias bounds when computing liveness in NLL (but this time sound hopefully)
[disposition: close] regression: parameter type may not live long enough
[disposition: merge] Remove support for compiler plugins.
[disposition: merge] rustdoc: Document lack of object safety on affected traits
[disposition: merge] Stabilize Ratified RISC-V Target Features
[disposition: merge] Tracking Issue for const mem::discriminant
New and Updated RFCs
[new] eRFC: #[should_move] attribute for per-function opting out of Copy semantics
Call for Testing
An important step for RFC implementation is for people to experiment with the implementation and give feedback, especially before stabilization. The following RFCs would benefit from user testing before moving forward:
No RFCs issued a call for testing this week.
If you are a feature implementer and would like your RFC to appear on the above list, add the new call-for-testing label to your RFC along with a comment providing testing instructions and/or guidance on which aspect(s) of the feature need testing.
Upcoming Events
Rusty Events between 2023-10-25 - 2023-11-22 🦀
Virtual
2023-10-30 | Virtual (Melbourne, VIC, AU) | Rust Melbourne
(Hybrid - online & in person) October 2023 Rust Melbourne Meetup
2023-10-31 | Virtual (Europe / Africa) | Rust for Lunch
Rust Meet-up
2023-11-01 | Virtual (Cardiff, UK)| Rust and C++ Cardiff
ECS with Bevy Game Engine
2023-11-01 | Virtual (Indianapolis, IN, US) | Indy Rust
Indy.rs - with Social Distancing
2023-11-02 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-11-07 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn | Mirror
2023-11-07 | Virtual (Buffalo, NY, US) | Buffalo Rust Meetup
Buffalo Rust User Group, First Tuesdays
2023-11-09 | Virtual (Nuremberg, DE) | Rust Nuremberg
Rust Nürnberg online
2023-11-14 | Virtual (Dallas, TX, US) | Dallas Rust
Second Tuesday
2023-11-15 | Virtual (Cardiff, UK)| Rust and C++ Cardiff
Building Our Own Locks (Atomics & Locks Chapter 9)
2023-11-15 | Virtual (Richmond, VA, US) | Linux Plumbers Conference
Rust Microconference in LPC 2023 (Nov 13-16)
2023-11-15 | Virtual (Vancouver, BC, CA) | Vancouver Rust
Rust Study/Hack/Hang-out
2023-11-16 | Virtual (Charlottesville, NC, US) | Charlottesville Rust Meetup
Crafting Interpreters in Rust Collaboratively
2023-11-07 | Virtual (Berlin, DE) | OpenTechSchool Berlin
Rust Hack and Learn | Mirror
2023-11-21 | Virtual (Washington, DC, US) | Rust DC
Mid-month Rustful
Europe
2023-10-25 | Dublin, IE | Rust Dublin
Biome, web development tooling with Rust
2023-10-25 | Paris, FR | Rust Paris
Rust for the web - Paris meetup #61
2023-10-25 | Zagreb, HR | impl Zagreb for Rust
Rust Meetup 2023/10: Lunatic
2023-10-26 | Augsburg, DE | Rust - Modern Systems Programming in Leipzig
Augsburg Rust Meetup #3
2023-10-26 | Copenhagen, DK | Copenhagen Rust Community
Rust metup #41 sponsored by Factbird
2023-10-26 | Delft, NL | Rust Nederland
Rust at TU Delft
2023-10-26 | Lille, FR | Rust Lille
Rust Lille #4 at SFEIR
2022-10-30 | Stockholm, SE | Stockholm Rust
Rust Meetup @Aira + Netlight
2023-11-01 | Cologne, DE | Rust Cologne
Web-applications with axum: Hello CRUD!
2023-11-07 | Bratislava, SK | Bratislava Rust Meetup Group
Rust Meetup by Sonalake
2023-11-07 | Brussels, BE | Rust Aarhus
Rust Aarhus - Rust and Talk beginners edition
2023-11-07 | Lyon, FR | Rust Lyon
Rust Lyon Meetup #7
2023-11-09 | Barcelona, ES | BcnRust
11th BcnRust Meetup
2023-11-09 | Reading, UK | Reading Rust Workshop
Reading Rust Meetup at Browns
2023-11-21 | Augsburg, DE | Rust - Modern Systems Programming in Leipzig
GPU processing in Rust
2023-11-23 | Biel/Bienne, CH | Rust Bern
Rust Talks Bern @ Biel: Embedded Edition
North America
2023-10-25 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
2023-10-25 | Chicago, IL, US | Deep Dish Rust
Rust Happy Hour
2023-11-01 | Brookline, MA, US | Boston Rust Meetup
Boston Common Rust Lunch
2023-11-08 | Boulder, CO, US | Boulder Rust Meetup
Let's make a Discord bot!
2023-11-14 | New York, NY, US | Rust NYC
Rust NYC Monthly Mixer: Share, Show, & Tell! 🦀
2023-11-14 | Seattle, WA, US | Cap Hill Rust Coding/Hacking/Learning
Rusty Coding/Hacking/Learning Night
2023-11-15 | Richmond, VA, US + Virtual | Linux Plumbers Conference
Rust Microconference in LPC 2023 (Nov 13-16)
2023-11-16 | Nashville, TN, US | Music City Rust Developers
Python loves Rust!
2023-11-16 | Seattle, WA, US | Seattle Rust User Group
Seattle Rust User Group Meetup
2023-11-21 | San Francisco, CA, US | San Francisco Rust Study Group
Rust Hacking in Person
2023-11-22 | Austin, TX, US | Rust ATX
Rust Lunch - Fareground
Oceania
2023-10-26 | Brisbane, QLD, AU | Rust Brisbane
October Meetup
2023-10-30 | Melbourne, VIC, AU + Virtual | Rust Melbourne
(Hybrid - in person & online) October 2023 Rust Melbourne Meetup
2023-11-21 | Christchurch, NZ | Christchurch Rust Meetup Group
Christchurch Rust meetup meeting
If you are running a Rust event please add it to the calendar to get it mentioned here. Please remember to add a link to the event too. Email the Rust Community Team for access.
Jobs
Please see the latest Who's Hiring thread on r/rust
Quote of the Week
When your Rust build times get slower after adding some procedural macros:
We call that the syn tax :ferris:
– Janet on Fosstodon
Thanks to Jacob Pratt for the suggestion!
Please submit quotes and vote for next week!
This Week in Rust is edited by: nellshamrell, llogiq, cdmistman, ericseppanen, extrawurst, andrewpollack, U007D, kolharsam, joelmarcey, mariannegoldin, bennyvasquez.
Email list hosting is sponsored by The Rust Foundation
Discuss on r/rust
9 notes
·
View notes
Text
Streamlining Your Workflow with PDQ Docs: The Best Document Management Software
In today’s fast-paced business environment, efficient document management is crucial for maintaining productivity and organization. With the growing volume of digital documents, businesses need a robust solution to store, organize, and retrieve information quickly. This is where document management software like PDQ Docs comes in, offering a comprehensive system that streamlines workflows, reduces paper clutter, and improves collaboration across teams.
What is Document Management Software?
Document management software (DMS) is designed to manage, track, and store digital documents. It allows organizations to store files in an easily accessible central repository, providing users with the ability to retrieve, share, and manage documents with ease. This software typically includes features like version control, access permissions, and secure storage to ensure that documents are safely stored and can be accessed when needed. PDQ Docs is a powerful document management tool that makes managing your business documents more efficient and effective.

Key Features of PDQ Docs
PDQ Docs offers a wide range of features that make it stand out as one of the leading document management software solutions available today. One of its most impressive features is its intuitive user interface, which simplifies document organization and retrieval. With PDQ Docs, you can easily categorize documents into folders and tag them with relevant keywords, making it easy to locate any file with just a few clicks.
Another significant advantage of using PDQ Docs is its version control functionality. This feature allows businesses to track changes made to documents over time, ensuring that the latest version is always available to users. Additionally, PDQ Docs provides secure access controls, allowing you to assign permissions to different team members based on their roles. This helps ensure that sensitive documents are only accessible to those with the proper authorization.
Benefits of Using PDQ Docs
The primary benefit of using PDQ Docs is the improved efficiency it offers businesses. With everything stored in one centralized system, there is no need to sift through piles of paper or search through multiple locations for important documents. The software’s robust search functionality ensures that you can find any document within seconds.
Why PDQ Docs is the Right Choice for Your Business
When it comes to document management software, PDQ Docs is a top choice for businesses looking for a reliable, scalable, and user-friendly solution. The software’s flexibility allows it to cater to businesses of all sizes, whether you are a small startup or a large enterprise. PDQ Docs’ cloud-based nature ensures that your documents are accessible from anywhere, allowing for remote work and mobile access.
Conclusion
In conclusion, if you are looking for a reliable document management software that enhances your business operations, improves productivity, and ensures document security, PDQ Docs is the ideal solution. With its user-friendly interface, powerful features, and numerous benefits, PDQ Docs helps businesses organize, store, and retrieve documents efficiently. By adopting PDQ Docs, your business can streamline its workflow, improve team collaboration, and ensure that your documents are always accessible and secure.
#document management software#document storage#centralized document management#electronic document management#paperless office#workflow automation#document indexing#compliance management#business process management#user friendly document generation software#unlimited documents generation#unlimited templates
0 notes
Text
A Confession of Digital Mess
I’m looking for citations to back up a post I made, and I am having just a bit of a problem. This is kind of boring, but since @deepfriedinfant deserves some kind of update, here it is (hidden because it’s long).
Google is rather notoriously starting to get bad at finding things. And the thing I’m looking for is something which… well, unless I already had the specific details which I’m looking for, there are way too many things out there which basically share all the possible search terms.
That’s not the problem; that’s a thing that everyone online encounters these days. If that were all, we’d be done; it would just be a matter of me either admitting defeat or doing a search and examining every single one of hundreds of results.
The problem is searching my own stuff.
I keep files. When I see an image I may want later, I drag it to the desktop. (For those using other OSes/browsers which don’t behave the same way as the Mac: this saves the file to your account’s Desktop folder.) When I see text I like, if it’s just part of a page I select it and drag the selection to the desktop. (A feature Apple created years ago and kind of seems not to like any more — this creates a .textClipping file containing the text in rich text format, unfortunately using an archaic storage mechanism that is otherwise almost completely abandoned for the last 2 decades.) If it’s an entire document, I save the document to the desktop.
Every so often, I go through the huge mass of files on my desktop (right at this moment: 516 items — I’m overdue), get rid of anything which has outlived its usefulness, and throw all the remains into a folder named “To Be Filed”.
Which is all well and good, but:
I very seldom go into the “To Be Filed” folder and actually file things. It contains many, many thousands of items, some of them dating back to the GWB administration. (And many of them now completely lacking context — I’m now, IIRC, two computers on from what I was using back then, and when you copy files from one computer to another, the modification date is changed and some of the filesystem metadata is lost.) And I actually have an even older “To Be Filed” folder which I thought I had lost, causing me to create the current one, which also contains vast numbers of files.
Many years ago, I did do a bunch of filing, at least in the sense of separating text and images out a bit. I have a folder named “Random Text” which really ought to have subfolders already and will absolutely need them if I ever get around to adding more stuff to it, and an “Images” folder containing subfolders with the names of topics and/or sources. So not everything that I might want to search is even in the “To Be Filed” folder(s), some of it is elsewhere.
Much to my delight, a while back Apple added OCR software to the Mac OS. This is very useful, and the last time I used OCR software, which was at least a decade and a half ago, it was ludicrously bad, so the accuracy they have in their freebie version surprises me. But this does mean that any image sitting around which has identifiable text in it is indexed for searching, so now I get huge numbers of results for practically everything by default. (And while you can restrict search results by type, you can’t do a negative restriction — you can’t search for “not images”, and there are multiple types of files which contain text so you can’t do a single search for all text types.)
I have periodically downloaded big collections of things. I have complete runs of comics. I have that archive of game walkthroughs that somebody compiled from GameFAQs a while back. All kinds of stuff. Now that Apple indexes images, all of it can pop up in search results — and none of it is typically what I want. (Okay, yes, every once in a while I end up looking for a walkthrough of an old game or a specific comic strip. But that’s genuinely a rare thing.)
Just to make things even better, it turns out that Apple’s text indexing system does not index .textClipping files. This is something which has been true all along — Google shows that people were complaining about this all the way back in 2008 — but recently it has begun to dawn on me that, given the number of clipping files I have around, many of which are exactly the kind of thing I might want to use as a citation, this is very specifically my problem. These have to be searched manually every time I want to find something, unless I can remember the location of the file and the name (which is automatically created from the first few words of the text). Ouch.
So right now I am taking some steps to ameliorate the problem while I keep looking. First, I’m looking for things which are giving me large numbers of results I don’t want, like the aforementioned GameFAQs archive, and changing them from folders into compressed read-only disk image files, the contents of which are not part of the general search index. (If space was an issue, it would be better to use compressed archives files like 7Zip, which get somewhat better compression levels, but that obviously isn’t a problem if I’m already holding on to the uncompressed files — and a disk image file can be mounted, searched, and used directly without any hassle if I do want to find something in that specific collection, whereas archives can be problematic no matter how much effort is put into making them act like they’re just a special type of folder.) I’m also looking into some kind of scheme to convert all my .textClipping files into an indexable format, but this turns out to be a more convoluted operation than you would assume.
This may take a while. It will speed me up in future searches, but it may take a while.
2 notes
·
View notes
Text
Inform Basics (#17: your project)
I've said it before: we've covered enough material for you to start your own Inform 7 project, even if you are a beginner like me. Let's take a break from coding to talk a bit about development environments.
Have you downloaded an Inform 7 Integrated Developemnt Environment (IDE for short) yet? If you've been clicking on my code snippets, you've already encountered Borogove, an online IDE for not only Inform 7 but several other IF development platforms. Its ability to share live snippets of code that are fully functional in many forum softwares is rather amazing and makes it easer to assist other developers in need.
Nevertheless, I don't recommend it for creating a full-fledged game. Why is that?
No external file support for features like images, sound, and other shared documents.
The Index is not fully functional, as it does not contain links to either default or custom actions.
Borogove does not support Inform 7's table of contents feature (more on this in a minute).
My understanding is that it does support external files for Inkle and others, but not Inform 7. While I encourage using the snippets as a great way to share and demonstrate code, Borogove falls short of the standard Inform 7 IDEs. Windows, MacOS, and Linux are supported. You can find and download the latest versions here:
Note that Windows Defender and other antivirus softwares tend to mistakenly flag the interpreter executables--git, frotz, and glulxe--as malicious. This has been reported to Microsoft repeatedly, but the files have yet to be whitelisted. If you get an error about these files, you can consider it a false positive.
After installing the IDE, you'll find a two-panel layout. By default, the left pane is for entering and reading source code, while the right pane contains a playable instance of your compiled code. You can compile and recompile by clicking "go" at the top-left of the application window.
My practice is to create a backup of a project every couple of days, while compiling frequently as I work. In informal polling, Inform 7 authors of varying levels of skill tend to do the same.
On to the main purpose of this post: using Inform 7's built-in features to organize your program. Let's look at an automatically generated table of contents for Repeat the Ending, which is among the larger (code-wise) Inform 7 games. The left-hand pane of the IDE shows tabs at the right and top edges. The top tabs are "source" and "contents." This is a screenshot of the contents tab.

See the slider at the bottom? Inform 7's automatically generated TOC features five tiers by default, and the slider can be used to dictate the level of detail displayed. Those tiers are as follows:
Volume (top level)
Book
Part
Chapter
Section (bottom level)
We can use these tiers in our code, and the IDE will detect them automatically. The practice looks like this:
Volume 1 - Global
It's as simple as that. We have a lot of freedom in what we say there. That isn't to say there aren't restrictions:
The heading must have a blank line above and below it.
The heading cannot contain characters that have specific functions in Inform 7 code. No periods, colons, semicolons, and the like.
The heading must begin with one of the five designations (volume, book, part, chapter, and section)
You have a lot of freedom in terms of how to order your code. I've gotten the impression that I do things differently, but I like the way my approach works.
For top-level headings, I used the following:
global: used to define verbs, data, kinds, variables, the player characters, and so forth. All things that apply to the game and its world generally.
the game: the actual geography, things, and specific action responses.
the companion text: the entirety of the Reader's Guide to Repeat the Ending.
the artwork: I chose to maintain the rules governing the display of artwork and alt descriptions separately.
mix and match: a true mixture of various late stage requirements.
Regarding mix and match: some rules in Inform 7 must follow related rules. For instance, a region (a group of individual rooms that can be dealt with as a collective) must follow the room definitions. For this reason I decided to define certain rules related to regions at the end, even if they seem to be global rules. This is the way that those late definitions were used:
The game world is a region. The eighties and the 90s are in the game world. Energy is a backdrop. Energy is in the game world. Instead of doing anything to the energy: say "It doesn't work that way. Entropic magic requires specificity.".
Sometimes, things just make sense at the end. I also kept all of my test scripts there.
How should you build your TOC? While you can see my example above, give equal or greater consideration to what will be easiest for you to read and update. The TOC is a tool to for you to manage your project. If it doesn't make intuitive sense to you, it's worthless. Think about the way you process information and build from there.
I hope this is helpful! Consider maintaining a test/scratch project where you can keep copies of useful code and test the cases we discuss here. Feel free to AMA!
Next: scenery and backdrops.
5 notes
·
View notes
Text
Pseudo-historical project about 1912 unit record equipment computation aka the "Symbolic Analyst Processor" full stack!



(above pictures emulate the looks of what this tech stack documentation and actual use may look like, still very early in the process though)
It is still coming together by my head as I write infodump notes and research various aspects of the whole time, (including the WIMP & MERN/MEAN stack) but yk, things are coming together nicely to give some milestone project mid-way between my current phase in life and the next where I go develop a fully alternative INTJ lively stack of tools. Explanations, history dives, lively reaction studies and a couple more content suggestions related to it are on the way.
Behold, the infodumps
"Top-bottom and back up workflow" 1910 / 1912 Unit Record Equipment Tabulator Computation "Bundle" Project (Pflaumen & Utalics' SymbolicAnalystProcessor)
Information Processing Language / LISP 1.5 / Bel, A-BASIC / DIBOL, Spreadsheets, Cellular Automaton, COS-310, magnetic tape storage too, TECO / VIM, Assembly, Wirebox, Tabulator, Alphanumeric Interpreter, Printer, RTTY device, Data Recording, Bulk Data Processing Indexed Cards, 60-64 entries Deque, 4K Direct-use RAM, 12K * 24 storage devices, Phonebook, Timeclock, DateTime Calendar, Programmable, Statistics, Demographics, Voting, Ledger, Journal, Logging, Rolodex, 12 Generic-use Registers & 4 Special Registers, Catalog, ~16 Keys Pad, Customized Hexadecimal Numeric Representation for "MachineCode" Hexdumps, 4*12 bits per page of data, Macros, Paracosm, may be useful for Military & Civilian Uses, Electrical Energy (and possibly incorporates some mechanical energy too), Nouns & Verbs, "Vector" XY plotter, Lambda Calculus / Panini Grammar / Universal Turing Machine Thesis, Rotors, Ural TriodeVaccumTube "Mainframe", Interactive-Use, Hypertext Interactive Video Terminal, Memex, Modem, Electric + Radio Telegraphy, Document-processing, Word-processing, Orange Plasma Touchscreen Terminal, Time-sharing, Cash Register, Bank, Automatic Teller Machine, Vending Machine, Oracle, Typewriter / Selectric, IBM 701, IBM 1440, IBM 403, IBM System/360, OpenPOWER, F#, IBM Tellum, MUD, TextWorld, solo text-adventures, Email, AIX, z/OS, Linux for IBM mainframes, Symbolic Processing System, Autocoder, modular, IBM Lotus Suite, interface with KDE or CDE, paper handling equipment, Addventure, 12-bit basic data unit as designated word, Distributed Interactive System, VeneraFS (cladogram Parade+DolDoc), GNU Hurd / MINIX3-style Microkernel, either permissive FLOSS license or public domain waiver, extensive documentation, printed illustrated booklets, music-playback, emulator / compiler / bytecode / interpreter, analog media-friendly, mostly for didactic tinkering educational uses, multilingual reconfigurable programming, HTML+CSS, Markdown, Argdown, DMA, hardware-friendly, software development environment for direct-access programmers and aesthetic designers, sub-version control system like Git, various hardware & software implementations, museum / observatory Toymaker story, constructed languages / imaginative paracosm influences around the immersive in-world lore of the "16^12" pseudo-historical setting…
Back to the point
The list is far from exhaustive or finished, as life is so much more than meets the eye. But this should be a good start to remind myself what I am working towards, a full revamp of the last ~120 years of history with much attention and care put into making it as satisfying to me as possible, despite the very probable scenario where people take the ideas and incorporate only some of such "modules" in their own workflows. Which is fine but not taking the whole package (and only specific modules) is eventually gonna be a major learning experience for me considering the reason I revamp it all beyond control freak stuff is literally to provide less exclusive / less invasive tools that anyone can learn and customize despite being very... idiosyncratic yk.
Still welcoming suggestions and constructive criticism for such big time, I hope those textual infodumps I do every so often don't bother you too much... Cya soon!
5 notes
·
View notes
Text
Haven't done a computer status update in a little bit. Raspberry Pi media server has been psuedo-retired. It's currently still functioning as a media server for a christmas display at my wife's work until the end of December.
It has been successfully replaced by the Dell Optiplex that I got from work. I was able to skip the process of building a migration script for the server (to allow files to be moved and refound via filename & hash), but only because I've been mapping storage outside the server's webroot via link files in the upload directory. So on the new HD the files are actually in the upload directory rather than linked to it. As far as the server knows they're in the same place.
I transferred the software between machines by making a new install of vogon on the optiplex and then importing a mysqldump of the existing install into it, bringing the user accounts, media data, and other configuration elements with it. I did end up changing the storage engine of the data and data_meta tables into innodb (from isam) and adding some additional indexing. There were some noticeable performance differences on the generated join queries between servers. We were looking at 7sec+ lookup times for searches in the audio module. I'm still not sure if it's a mariadb version difference between raspbian and ubuntu lts, if something got corrupted in the export/import process, or if it was some strange storage lookup difference between running the database off of a SETA Hard-Drive versus an SD card. I initially thought maybe it was a fragmentation issue, but the built in optimization processes didn't really impact it, but with the adjustments to the indexing we're regularly getting query times measured in microseconds versus seconds, so it's working pretty well now.
The x86 processor and the faster storage (without the power dropout issues) have really improved the experience. Especially with reading comic books.
If I haven't explained it before, the way the CBZ reader works is that it sends a file list from the archive to the browser, the browser requests an image, and the server extracts the image data into RAM, base64 encodes it, and sends it back to the browser. It's a process that is bottlenecked by both CPU and storage speeds, so it's noticeably snappier on the new machine, even if the CPU is over a decade old at this point.
I'm actually considering taking a crack at forking mozilla's pdf.js to work a similar way, sending a page of data at a time, to decrease transfer times and allow lower memory devices to open large PDFs without having to actually download the whole thing. I suspect that means I'm going to have to build smaller single page PDF files on the fly, which would mean coming up with some kind of solution for in document links. I'm still in the phase of deciding if it's enough of a problem to put effort into solving, so I haven't done enough research to know if it will be easy or difficult. It's always hard to tell in situations like this because just about every web reader project assumes downloading the whole file, and the question is do they do it this way because it's hard to sub-divide the format, or do they do it because full clientside logic can be demoed on github pages.
3 notes
·
View notes
Text
Control Structured Data with Intelligent Archiving

Control Structured Data with Intelligent Archiving
You thought you had your data under control. Spreadsheets, databases, documents all neatly organized in folders and subfolders on the company server. Then the calls started coming in. Where are the 2015 sales figures for the Western region? Do we have the specs for the prototype from two years ago? What was the exact wording of that contract with the supplier who went out of business? Your neatly organized data has turned into a chaotic mess of fragmented information strewn across shared drives, email, file cabinets and the cloud. Before you drown in a sea of unstructured data, it’s time to consider an intelligent archiving solution. A system that can automatically organize, classify and retain your information so you can find what you need when you need it. Say goodbye to frantic searches and inefficiency and hello to the control and confidence of structured data.
The Need for Intelligent Archiving of Structured Data
You’ve got customer info, sales data, HR records – basically anything that can be neatly filed away into rows and columns. At first, it seemed so organized. Now, your databases are overloaded, queries are slow, and finding anything is like searching for a needle in a haystack. An intelligent archiving system can help you regain control of your structured data sprawl. It works by automatically analyzing your data to determine what’s most important to keep active and what can be safely archived. Say goodbye to rigid retention policies and manual data management. This smart system learns your data access patterns and adapts archiving plans accordingly. With less active data clogging up your production systems, queries will run faster, costs will decrease, and your data analysts can actually get work done without waiting hours for results. You’ll also reduce infrastructure demands and risks associated with oversized databases. Compliance and governance are also made easier. An intelligent archiving solution tracks all data movement, providing a clear chain of custody for any information that needs to be retained or deleted to meet regulations. Maybe it’s time to stop treading water and start sailing your data seas with an intelligent archiving solution. Your databases, data analysts and CFO will thank you. Smooth seas ahead, captain!
How Intelligent Archiving Improves Data Management
Intelligent archiving is like a meticulous assistant that helps tame your data chaos. How, you ask? Let’s explore:
Automated file organization
Intelligent archiving software automatically organizes your files into a logical folder structure so you don’t have to spend hours sorting through documents. It’s like having your own personal librarian categorize everything for easy retrieval later.
Efficient storage
This software compresses and deduplicates your data to free up storage space. Duplicate files hog valuable storage, so deduplication removes redundant copies and replaces them with pointers to a single master copy. Your storage costs decrease while data accessibility remains the same.
Compliance made simple
For companies in regulated industries, intelligent archiving simplifies compliance by automatically applying retention policies as data is ingested. There’s no danger of mistakenly deleting information subject to “legal hold” and avoiding potential fines or sanctions. Let the software handle the rules so you can avoid data jail.
Searchability
With intelligent archiving, your data is indexed and searchable, even archived data. You can quickly find that invoice from five years ago or the contract you signed last month. No more digging through piles of folders and boxes. Search and find — it’s that easy. In summary, intelligent archiving brings order to the chaos of your data through automated organization, optimization, compliance enforcement, and searchability. Tame the data beast once and for all!
Implementing an Effective Data Archiving Strategy
So you have a mind-boggling amount of data accumulating and you’re starting to feel like you’re drowning in a sea of unstructured information. Before you decide to throw in the towel, take a deep breath and consider implementing an intelligent archiving strategy.
Get Ruthless
Go through your data and purge anything that’s obsolete or irrelevant. Be brutally honest—if it’s not useful now or in the foreseeable future, delete it. Free up storage space and clear your mind by ditching the digital detritus.
Establish a Filing System
Come up with a logical taxonomy to categorize your data. Group similar types of info together for easy searching and access later on. If you have trouble classifying certain data points, you probably don’t need them. Toss ‘em!
Automate and Delegate
Use tools that can automatically archive data for you based on your taxonomy. Many solutions employ machine learning to categorize and file data accurately without human input. Let technology shoulder the burden so you can focus on more important tasks, like figuring out what to have for lunch.
Review and Refine
Revisit your archiving strategy regularly to make sure it’s still working for your needs. Make adjustments as required to optimize how data is organized and accessed. Get feedback from other users and incorporate their suggestions. An effective archiving approach is always a work in progress. With an intelligent data archiving solution in place, you’ll gain control over your information overload and find the freedom that comes from a decluttered digital space. Tame the data deluge and reclaim your sanity!
Conclusion
So there you have it. The future of data management and control through intelligent archiving is here. No longer do you have to grapple with endless spreadsheets, documents, files and manually track the relationships between them.With AI-powered archiving tools, your data is automatically organized, categorized and connected for you. All that structured data chaos becomes a thing of the past. Your time is freed up to focus on more meaningful work. The possibilities for data-driven insights and optimization seem endless. What are you waiting for? Take back control of your data and unleash its potential with intelligent archiving. The future is now, so hop to it! There’s a whole new world of data-driven opportunity out there waiting for you.
2 notes
·
View notes
Text
Some things I will add regarding the Tumblr Utils method:
If you have other python software installed, you might need to remove them lest your computer have an issue with which version of Python to run the script on, I had to remove a C++ emulator which was clashing with the python for some reason, though admittedly that program never actually worked for me.
Use the command window rather than trying to download and run the code yourself, the link in the document points to a version of the code that was incompatible with the current Python version I was using and I wasted close to two hours trying to force it to run before giving up.
The API key request appears to be automatic, so you don't have to wait for one of the few remaining staff members to personally authorize you.
This is the current line of code that works to backup your account:
tumblr-backup --save-audio --save-video --tag-index --incremental blog-name
Replace "blog-name" with your blog name.
save-audio and save-video are self explanatory, however I did encounter some issues with posts where videos couldn't be saved. The program will give you a post number pointing to which post couldn't be saved, so if you wish you can go and save those videos/audios through a different method. tag-index creates an index of every tag you've ever used, which is helpful but also note that it means every tag. incremental is perhaps the most useful one, as it allows you to keep updating the backup. The document uses --i, which according to the script I ran is no longer used.
Good wifi is absolutely recommended as this thing ate up most of my bandwidth and took nearly 3 days for about 91000 posts. Another important command, especially if you have wifi troubles, is
tumblr-backup --save-audio --save-video --tag-index --continue blog-name
If ever your command is interrupted, this allows the program to continue from where the last increment stopped. I made a notepad file containing these two lines and just copied + pasted them any time the program crashed.
You can use your computer while this runs, I set mine up with a power connection and disabled the auto shutdown feature. I do recommend doing this, it's not difficult as long as you don't have the world's most unique computer problems like I did.
Btw much as I love to make fun of twitter and reddit's business decisions, I have 0% trust in tumblr's management to not go a similar route so this is your gentle reminder that you should regularly go to your blog settings to export your blog. That's a fancy way of saying you can download a backup of your blog so if everything goes down you'll still have a backup of your posts & convos.
#tumblr#tumblr backup#it appears to save it all as html so it could in theory be exported to a new blog altogether#my favourite error was 'python does not have python installed'#that turned out to be an issue with the path
120K notes
·
View notes