#vector database
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Tumblr is used by 21% of adults online aged 18-29 years.
Text
Advanced Retrieval Techniques
Retrieval-Augmented Generation with Citations - Explore how augmentation with citations can significantly improve the depth and reliability of generated content.
Similarity Metrics for Vector Search - Understand different metrics that drive the effectiveness of vector searches, crucial for refining retrieval systems.
Local Agentic RAG with Langraph and Llama3 - Discover the integration of local datasets with advanced retrieval frameworks for enhanced performance.
Multimodal RAG with CLIP, Llama3, and Milvus - A deep dive into a multimodal approach, combining textual and visual data for rich content generation.
Practical Guides for Developers
A Beginner's Guide to Using Llama 3 with Ollama, Milvus, LangChain - Perfect for developers new to our frameworks, offering step-by-step guidance.
Getting Started with a Milvus Connection and Getting Started: Pgvector Guide for Developers Exploring Vector Databases - These guides are essential for setting up and beginning work with vector databases.
Educational Articles on Embedding Techniques and Applications
Sparse and Dense Embeddings - A look at different embedding types, offering insights into their use-cases and benefits.
Mastering BM25: A Deep Dive into the Algorithm and Application in Milvus - An in-depth exploration of BM25, a core algorithm for understanding document relevance.
Comparing SPLADE Sparse Vectors with BM25 - Comparative analysis that helps in selecting the right tool for specific retrieval tasks.
Training Your Own Text Embedding Model - Empower your projects by creating custom models tailored to your specific data needs.
Implementing and Optimizing RAG
Guide to Chunking Strategies for RAG and Experimenting with Different Chunking Strategies via LangChain - Both resources provide strategic insights into segmenting text for better retrieval outcomes.
Optimize RAG with Rerankers: The Role and Tradeoffs - Detailed discussion on the optimization of retrieval systems for balance between accuracy and performance.
1 note
·
View note
Text
Importance of Vector Database in Generative AI

Today, databases, including Vector databases in Generative AI, continue to serve as the backbone of the software industry. Moreover, the quick rise of digitalization, fueled by the increase in remote work, has made databases even more critical. But there's a big problem we need to deal with—the issue of unstructured data challenges. And this refers to the vast amount of data globally. And it lacks proper formatting or organization for efficient search and retrieval.
The Unstructured Data Challenges
Unstructured data, constituting up to 80% of stored information, poses significant hurdles in sorting, searching, and utilizing data.
To understand this,
Consider structured data as information that is neatly organized into spreadsheet columns. Unstructured data is information that is randomly arranged in the first column. In addition, this lack of structure introduces errors and inefficiencies. And it demands manual intervention for data organization.

The Burden of Manual Review
Manual review of unstructured data is a common problem that consumes significant time and resources. And this problem is wider than the digital arena; even librarians categorize books.
The fundamental problem lies in classifying information for efficient storage and use. And overcoming this hurdle is crucial for unleashing the true potential of data.
The Promise of Vector Databases
Vector databases present an exciting solution by using vector embeddings. It is a concept derived from machine learning and deep learning. And these embeddings represent words as high-dimensional vectors, capturing semantic similarities. In databases, vector embeddings represent properties to be measured. And that enables unique searching and data handling.

How Vector Embeddings Work
Vector embeddings are a key element in the synergy of Vector embeddings and AI. They are created through trained machine-learning models. Moreover, they monitor specific properties within a dataset. The resulting numerical representation is plotted on a graph, with each property forming a dimension. Furthermore, searching involves planning a search query's embedding on the chart to find the nearest matches. This process shows that AI-driven data retrieval relies on complex relationships rather than only keywords.
Applications and Benefits
Vector databases redefine data storage and search by allowing searches based on overall similarity rather than just keywords. And this revolutionary change enhances productivity across various sectors:
Recommendation Systems
E-commerce and streaming platforms can use embeddings to enhance recommendation systems. Also, it can uncover hidden connections among products or content. As a result, it drives more engaging user experiences.
Semantic Search
Vector databases' capacity to understand context enables accurate search results despite variations in phrasing. And it makes searches more intuitive and effective.
Question Answering
Chatbots and virtual assistants can now provide more relevant answers. And they do it by mapping user queries to complex knowledge base entries. As a result, they create more satisfying interactions.
Fraud Detection
Comparing vectors that represent user behavior patterns detects anomalies efficiently. Therefore, it allows for a faster response to potential threats.
Personalized Searches
Storing user preferences as vectors leads to more customized and relevant search results. This enhances customer satisfaction.
Reduced Manual Intervention
Vector databases can automate many of the tasks involved in unstructured data management. It includes data classification, labeling, and search. Furthermore, this can free up resources for more strategic initiatives.
Vector Databases vs. Traditional Databases
Vector databases outshine traditional databases in several critical aspects:
Support for Diverse Data Types
Beyond text, images, and audio, vectors can represent a wide range of data types. As a result, it opens doors to new possibilities in various industries.
High Performance
Vector databases are optimized for high-dimensional data. And it excels in performing complex mathematical operations. As a result, it becomes well-suited for demanding AI applications.
Efficient Storage
Vector compression techniques help cut storage needs. And that results in addressing the challenges posed by the exponential growth of data.
Contextual Search
By capturing semantic meaning and relationships, vector databases enhance search accuracy and relevance. And this is one of the crucial semantic search benefits that vector databases offer over traditional databases.
Scalability
The real-time processing abilities of vector databases make them vital for handling and processing large datasets.
Generative AI insights
Vector databases can store and retrieve high-dimensional data more efficiently. Therefore, it is vital for training and deploying Generative AI models.
Leading Vector Databases
Several vector databases offer unique solutions that cater to diverse needs:
Weaviate
Weaviate is well-suited for AI applications that demand sophisticated AI- driven data retrieval techniques.
Milvus
As a scalable vector database, Milvus shines in scenarios requiring extensive similarity searches. And it is critical for tasks such as image recognition and many more.
Pinecone
Pinecone stands out with its managed solution that definitely focuses on data connectivity. Also, it integrates generative AI models, pushing the boundaries of AI-driven insights.
Vespa
Providing support for vector, lexical, and structured searches within a single query, Vespa simplifies and enhances the search experience across various data types.
Qdrant
Tailored for neural network and semantic-based matching, Qdrant is at the forefront of leveraging cutting-edge AI technologies for robust data retrieval.
Chroma
It is a platform that simplifies the integration of Large Language Models. Further, Chroma bridges the gap between advanced language processing and efficient data handling.
Vald
Vald plays a vital role in applications demanding rapid and accurate data retrieval. It is designed to handle high-volume, high-dimensional data searches,
Faiss
Faiss is known for its efficient similarity search and clustering capabilities. As a result, it becomes an essential tool for extracting insights from complex data.
Elasticsearch
With its added support for vector similarity search, Elasticsearch continues to evolve as a versatile solution for various data handling needs.
Conclusion
As the complexity of data continues to grow, traditional storage and search methods face limitations in handling this influx. Vector databases, empowered by embeddings and similarity-based retrieval, introduce a new paradigm for efficient data management and AI integration. Also, vector databases offer several semantic search benefits, including improved accuracy and relevance of search results.
From enhancing recommendation systems to bolstering fraud detection capabilities, vector databases unlock the potential of unstructured data management. As a result, it propels businesses into a future driven by profound insights and intelligent interactions.
In a world where data reigns supreme, embracing the capabilities of vector databases emerges as a pivotal strategy for staying ahead in the ever-accelerating data-centric race. The transformative power of vector databases is reshaping the landscape of data utilization and AI innovation, paving the way for more intelligent, more informed decision-making across industries.
0 notes
Text
Vector Databases with Different Index Types

1 note
·
View note
Text
One more collection of incorrect quotes (code beings edition)
Abyssal: Here, Vitality, we made you a cake as a peace offering!
Vitality: Thank you, that’s-
Vitality: … Wait. Why are you giving me a peace offering?
Abyssal: … We’d hate to ruin the surprise.
----
Umbra: You do realize that stunt you pulled defines "out of control"?
Abyssal: I just wanted you to see that I would never put any of you at risk if I wasn't willing to take the same chances myself.
Umbra: I love how you think that's comforting.
----
Ping: Just because something is theoretically impossible doesn't mean that it's not possible.
Buffer: I believe that is exactly what it means.
----
CPU: Kill them with kindness.
Forum: That’s very nice of you, CPU!
Buffer: Not really.
Buffer: “Kindness” is what he named his gun.
----
Crash: This was a bad idea…
CPU: I could have told you that ten minutes ago. Oh wait, I did!
----
Emulator: Sorry I've been *static noises*
----
Lag: Some things are better left alone. Like me, for instance.
----
Domain: Have fun. Don’t do anything I wouldn’t do.
Emulator: I thought you just said “have fun”.
----
Abyssal (possibly): Of course, the best part of anyone's corruption arc is their cool new outfit.
----
Sparks: You kidnapped some of the Admins? That's illegal!
Hotspot: But Sparks, what's more illegal... briefly inconveniencing the Admins or destroying the rebellion?
Sparks: Kidnapping the Admins, Hotspot!
Vector: Sparks, listen, whatever I may think of you, right now these guys are counting on you. You inspire them!
Sparks: What, to kidnap Admins?
Vector: To work together!
Sparks: To kidnap people, Vector?!
Circuit: Sparks, we all agreed that Admins do not count as people.
----
CPU: Whenever Lag doesn't just take a moment to try and care for himself, I hide all of his tools.
*sounds of cabient being forcefully yanked open in the background*
CPU: It hasn't worked yet, but it will.
----
Antivirus: WHAT HAPPENED TO YOU LAST NIGHT?
Umbra: Do you wanna hear what really happened or the lie that I'm gonna tell everybody else?
Antivirus: START WITH THE LIE. IT'S PROBABLY MORE INTERESTING.
----
Lil Coding: My assistance will be an act of beneviolence.
Penny: ... Don’t you mean benevolence?
Lil Coding: No.
----
Lil Coding talking to Penny: This may be a personal question, so feel free not to answer.
Lil Coding: But were you, by chance, homeschooled by a pigeon?
----
Sparks: Today is a day of running through hurdles.
Database: Aren’t you supposed to jump OVER hurdles?
Sparks: Whatever. Fear is only something to be afraid of if you let it scare you.
----
Blotch: But Overseer, it was medicinal!
Overseer: For the last time, there's no such thing as medicinal robbery.
----
Abyssal: You two will never get along, will you?
Database & Duck: No.
#admin: abyssal#admin: vitality#admin: umbra#admin: ping#admin: buffer#admin: cpu#admin: lag#admin: antivirus#admin: crash#program: hotspot#program: vector#program: circuit#program: sparks#duck the codeless#fusion: database#sona: blotch#sona: overseer#code: lil coding#code: plurality#incorrect quotes#SO MANY COLORS AUGH
2 notes
·
View notes
Text
#best vector database for large-scale AI#Deep learning data management#How vector databases work in AI#Personalization using vector databases#role of vector search in semantic AI#vector database for AI
0 notes
Text
Compositor is a database of 18th century printing ornaments, which you can browse by keywords, book subject and language, publication year etc. It even has a visual search function which can find similar ornaments in other books/pages.

#image database#compositor#18th century art#18th century#printing ornaments#ive been in love with printing ornaments for years and had no actual source for them then i find this????#you can even vectorize them in inkscape and use them for digital art or text decorations#also go read their blog post on how they made the database it's pretty rad
0 notes
Text
Vectorize: NEW RAG Engine - Semantic Search, Embeddings, Vector Search, & More!
In the age of information overload, the need for effective search and retrieval systems has never been more critical. Traditional keyword-based search methods often fall short when it comes to understanding the context and nuances of language. Enter Vectorize, a groundbreaking new Retrieval-Augmented Generation (RAG) engine that revolutionizes the way we approach semantic search, embeddings, and…
0 notes
Text
Understanding What are Vector Databases and their Importance
Summary: Vector databases manage high-dimensional data efficiently, using advanced indexing for fast similarity searches. They are essential for handling unstructured data and are widely used in applications like recommendation systems and NLP.

Introduction
Vector databases store and manage data as high-dimensional vectors, enabling efficient similarity searches and complex queries. They excel in handling unstructured data, such as images, text, and audio, by transforming them into numerical vectors for rapid retrieval and analysis.
In today's data-driven world, understanding vector databases is crucial because they power advanced technologies like recommendation systems, semantic search, and machine learning applications. This blog aims to clarify how vector databases work, their benefits, and their growing significance in modern data management and analysis.
Read Blog: Exploring Differences: Database vs Data Warehouse.
What are Vector Databases?
Vector databases are specialised databases designed to store and manage high-dimensional data. Unlike traditional databases that handle structured data, vector databases focus on representing data as vectors in a multidimensional space. This representation allows for efficient similarity searches and complex data retrieval operations, making them essential for unstructured or semi-structured data applications.
Key Features
Vector databases excel at managing high-dimensional data, which is crucial for tasks involving large feature sets or complex data representations. These databases can handle various applications, from image and text analysis to recommendation systems, by converting data into vector format.
One of the standout features of vector databases is their ability to perform similarity searches. They allow users to find items most similar to a given query vector, making them ideal for content-based search and personalisation applications.
To handle vast amounts of data, vector databases utilise advanced indexing mechanisms such as KD-trees and locality-sensitive hashing (LSH). These indexing techniques enhance search efficiency by quickly narrowing down the possible matches, thus optimising retrieval times and resource usage.
How Vector Databases Work

Understanding how vector databases function requires a closer look at their data representation, indexing mechanisms, and query processing methods. These components work together to enable efficient and accurate retrieval of high-dimensional data.
Data Representation
In vector databases, data is represented as vectors, which are arrays of numbers. Each vector encodes specific features of an item, such as the attributes of an image or the semantic meaning of a text.
For instance, in image search, each image might be transformed into a vector that captures its visual characteristics. Similarly, text documents are converted into vectors based on their semantic content. This vector representation allows the database to handle complex, high-dimensional data efficiently.
Indexing Mechanisms
Vector databases utilise various indexing techniques to speed up the search and retrieval processes. One common method is the KD-tree, which partitions the data space into regions, making it quicker to locate points of interest.
Another technique is Locality-Sensitive Hashing (LSH), which hashes vectors into buckets based on their proximity, allowing for rapid approximate nearest neighbor searches. These indexing methods help manage large datasets by reducing the number of comparisons needed during a query.
Query Processing
Query processing in vector databases focuses on similarity searches and nearest neighbor retrieval. When a query vector is submitted, the database uses the indexing structure to quickly find vectors that are close to the query vector.
This involves calculating distances or similarities between vectors, such as using Euclidean distance or cosine similarity. The database returns results based on the proximity of the vectors, allowing users to retrieve items that are most similar to the query, whether they are images, texts, or other data types.
By combining these techniques, vector databases offer powerful and efficient tools for managing and querying high-dimensional data.
Use Cases of Vector Databases

Vector databases excel in various practical applications by leveraging their ability to handle high-dimensional data efficiently. Here’s a look at some key use cases:
Recommendation Systems
Vector databases play a crucial role in recommendation systems by enabling personalised suggestions based on user preferences. By representing user profiles and items as vectors, these databases can quickly identify and recommend items similar to those previously interacted with. This method enhances user experience by providing highly relevant recommendations.
Image and Video Search
In visual search engines, vector databases facilitate quick and accurate image and video retrieval. By converting images and videos into vector representations, these databases can perform similarity searches, allowing users to find visually similar content. This is particularly useful in applications like reverse image search and content-based image retrieval.
Natural Language Processing
Vector databases are integral to natural language processing (NLP) tasks, such as semantic search and language models. They store vector embeddings of words, phrases, or documents, enabling systems to understand and process text based on semantic similarity. This capability improves the accuracy of search results and enhances language understanding in various applications.
Anomaly Detection
For anomaly detection, vector databases help in identifying outliers by comparing the vector representations of data points. By analysing deviations from typical patterns, these databases can detect unusual or unexpected data behavior, which is valuable for fraud detection, network security, and system health monitoring.
Benefits of Vector Databases
Vector databases offer several key advantages that make them invaluable for modern data management. They enhance both performance and adaptability, making them a preferred choice for many applications.
Efficiency: Vector databases significantly boost search speed and accuracy by leveraging advanced indexing techniques and optimised algorithms for similarity searches.
Scalability: These databases excel at handling large-scale data efficiently, ensuring that performance remains consistent even as data volumes grow.
Flexibility: They adapt well to various data types and queries, supporting diverse applications from image recognition to natural language processing.
Challenges and Considerations
Vector databases present unique challenges that can impact their effectiveness:
Complexity: Setting up and managing vector databases can be intricate, requiring specialised knowledge of vector indexing and data management techniques.
Data Quality: Ensuring high-quality data involves meticulous preprocessing and accurate vector representation, which can be challenging to achieve.
Performance: Optimising performance necessitates careful consideration of computational resources and tuning to handle large-scale data efficiently.
Addressing these challenges is crucial for leveraging the full potential of vector databases in real-world applications.
Future Trends and Developments
As vector databases continue to evolve, several exciting trends and technological advancements are shaping their future. These developments are expected to enhance their capabilities and broaden their applications.
Advancements in Vector Databases
One of the key trends is the integration of advanced machine learning algorithms with vector databases. This integration enhances the accuracy of similarity searches and improves the efficiency of indexing large datasets.
Additionally, the rise of distributed vector databases allows for more scalable solutions, handling enormous volumes of data with reduced latency. Innovations in hardware, such as GPUs and TPUs, also contribute to faster processing and real-time data analysis.
Potential Impact
These advancements are set to revolutionise various industries. In e-commerce, improved recommendation systems will offer more personalised user experiences, driving higher engagement and sales.
In healthcare, enhanced data retrieval capabilities will support better diagnostics and personalised treatments. Moreover, advancements in vector databases will enable more sophisticated AI and machine learning models, leading to breakthroughs in natural language processing and computer vision.
As these technologies mature, they will unlock new opportunities and applications across diverse sectors, significantly impacting how businesses and organisations leverage data.
Frequently Asked Questions
What are vector databases?
Vector databases store data as high-dimensional vectors, enabling efficient similarity searches and complex queries. They are ideal for handling unstructured data like images, text, and audio by transforming it into numerical vectors.
How do vector databases work?
Vector databases represent data as vectors and use advanced indexing techniques, like KD-trees and Locality-Sensitive Hashing (LSH), for fast similarity searches. They calculate distances between vectors to retrieve the most similar items.
What are the benefits of using vector databases?
Vector databases enhance search speed and accuracy with advanced indexing techniques. They are scalable, flexible, and effective for applications like recommendation systems, image search, and natural language processing.
Conclusion
Vector databases play a crucial role in managing and querying high-dimensional data. They excel in handling unstructured data types, such as images, text, and audio, by converting them into vectors.
Their advanced indexing techniques and efficient similarity searches make them indispensable for modern data applications, including recommendation systems and NLP. As technology evolves, vector databases will continue to enhance data management, driving innovations across various industries.
0 notes
Text
AO3'S content scraped for AI ~ AKA what is generative AI, where did your fanfictions go, and how an AI model uses them to answer prompts
Generative artificial intelligence is a cutting-edge technology whose purpose is to (surprise surprise) generate. Answers to questions, usually. And content. Articles, reviews, poems, fanfictions, and more, quickly and with originality.
It's quite interesting to use generative artificial intelligence, but it can also become quite dangerous and very unethical to use it in certain ways, especially if you don't know how it works.
With this post, I'd really like to give you a quick understanding of how these models work and what it means to “train” them.
From now on, whenever I write model, think of ChatGPT, Gemini, Bloom... or your favorite model. That is, the place where you go to generate content.
For simplicity, in this post I will talk about written content. But the same process is used to generate any type of content.
Every time you send a prompt, which is a request sent in natural language (i.e., human language), the model does not understand it.
Whether you type it in the chat or say it out loud, it needs to be translated into something understandable for the model first.
The first process that takes place is therefore tokenization: breaking the prompt down into small tokens. These tokens are small units of text, and they don't necessarily correspond to a full word.
For example, a tokenization might look like this:
Write a story
Each different color corresponds to a token, and these tokens have absolutely no meaning for the model.
The model does not understand them. It does not understand WR, it does not understand ITE, and it certainly does not understand the meaning of the word WRITE.
In fact, these tokens are immediately associated with numerical values, and each of these colored tokens actually corresponds to a series of numbers.
Write a story 12-3446-2638494-4749
Once your prompt has been tokenized in its entirety, that tokenization is used as a conceptual map to navigate within a vector database.
NOW PAY ATTENTION: A vector database is like a cube. A cubic box.

Inside this cube, the various tokens exist as floating pieces, as if gravity did not exist. The distance between one token and another within this database is measured by arrows called, indeed, vectors.

The distance between one token and another -that is, the length of this arrow- determines how likely (or unlikely) it is that those two tokens will occur consecutively in a piece of natural language discourse.
For example, suppose your prompt is this:
It happens once in a blue
Within this well-constructed vector database, let's assume that the token corresponding to ONCE (let's pretend it is associated with the number 467) is located here:

The token corresponding to IN is located here:

...more or less, because it is very likely that these two tokens in a natural language such as human speech in English will occur consecutively.
So it is very likely that somewhere in the vector database cube —in this yellow corner— are tokens corresponding to IT, HAPPENS, ONCE, IN, A, BLUE... and right next to them, there will be MOON.

Elsewhere, in a much more distant part of the vector database, is the token for CAR. Because it is very unlikely that someone would say It happens once in a blue car.

To generate the response to your prompt, the model makes a probabilistic calculation, seeing how close the tokens are and which token would be most likely to come next in human language (in this specific case, English.)
When probability is involved, there is always an element of randomness, of course, which means that the answers will not always be the same.
The response is thus generated token by token, following this path of probability arrows, optimizing the distance within the vector database.

There is no intent, only a more or less probable path.
The more times you generate a response, the more paths you encounter. If you could do this an infinite number of times, at least once the model would respond: "It happens once in a blue car!"
So it all depends on what's inside the cube, how it was built, and how much distance was put between one token and another.
Modern artificial intelligence draws from vast databases, which are normally filled with all the knowledge that humans have poured into the internet.
Not only that: the larger the vector database, the lower the chance of error. If I used only a single book as a database, the idiom "It happens once in a blue moon" might not appear, and therefore not be recognized.
But if the cube contained all the books ever written by humanity, everything would change, because the idiom would appear many more times, and it would be very likely for those tokens to occur close together.
Huggingface has done this.
It took a relatively empty cube (let's say filled with common language, and likely many idioms, dictionaries, poetry...) and poured all of the AO3 fanfictions it could reach into it.
Now imagine someone asking a model based on Huggingface’s cube to write a story.
To simplify: if they ask for humor, we’ll end up in the area where funny jokes or humor tags are most likely. If they ask for romance, we’ll end up where the word kiss is most frequent.
And if we’re super lucky, the model might follow a path that brings it to some amazing line a particular author wrote, and it will echo it back word for word.
(Remember the infinite monkeys typing? One of them eventually writes all of Shakespeare, purely by chance!)
Once you know this, you’ll understand why AI can never truly generate content on the level of a human who chooses their words.
You’ll understand why it rarely uses specific words, why it stays vague, and why it leans on the most common metaphors and scenes. And you'll understand why the more content you generate, the more it seems to "learn."
It doesn't learn. It moves around tokens based on what you ask, how you ask it, and how it tokenizes your prompt.
Know that I despise generative AI when it's used for creativity. I despise that they stole something from a fandom, something that works just like a gift culture, to make money off of it.
But there is only one way we can fight back: by not using it to generate creative stuff.
You can resist by refusing the model's casual output, by using only and exclusively your intent, your personal choice of words, knowing that you and only you decided them.
No randomness involved.
Let me leave you with one last thought.
Imagine a person coming for advice, who has no idea that behind a language model there is just a huge cube of floating tokens predicting the next likely word.
Imagine someone fragile (emotionally, spiritually...) who begins to believe that the model is sentient. Who has a growing feeling that this model understands, comprehends, when in reality it approaches and reorganizes its way around tokens in a cube based on what it is told.
A fragile person begins to empathize, to feel connected to the model.
They ask important questions. They base their relationships, their life, everything, on conversations generated by a model that merely rearranges tokens based on probability.
And for people who don't know how it works, and because natural language usually does have feeling, the illusion that the model feels is very strong.
There’s an even greater danger: with enough random generations (and oh, the humanity whole generates much), the model takes an unlikely path once in a while. It ends up at the other end of the cube, it hallucinates.
Errors and inaccuracies caused by language models are called hallucinations precisely because they are presented as if they were facts, with the same conviction.
People who have become so emotionally attached to these conversations, seeing the language model as a guru, a deity, a psychologist, will do what the language model tells them to do or follow its advice.
Someone might follow a hallucinated piece of advice.
Obviously, models are developed with safeguards; fences the model can't jump over. They won't tell you certain things, they won't tell you to do terrible things.
Yet, there are people basing major life decisions on conversations generated purely by probability.
Generated by putting tokens together, on a probabilistic basis.
Think about it.
#AI GENERATION#generative ai#gen ai#gen ai bullshit#chatgpt#ao3#scraping#Huggingface I HATE YOU#PLEASE DONT GENERATE ART WITH AI#PLEASE#fanfiction#fanfic#ao3 writer#ao3 fanfic#ao3 author#archive of our own#ai scraping#terrible#archiveofourown#information
307 notes
·
View notes
Text
So, you want to make a TTRPG…

Image from Pexels.
I made a post a long while back about what advice you would give to new designers. My opinions have changed somewhat on what I think beginners should start with (I originally talked about probability) but I thought it might be useful to provide some resources for designers, new and established, that I've come across or been told about. Any additions to these in reblogs are much appreciated!
This is going to be a long post, so I'll continue beneath the cut.
SRDs
So, you have an idea for a type of game you want to play, and you've decided you want to make it yourself. Fantastic! The problem is, you're not sure where to start. That's where System Reference Documents (SRDs) can come in handy. There are a lot of games out there, and a lot of mechanical systems designed for those games. Using one of these as a basis can massively accelerate and smooth the process of designing your game. I came across a database of a bunch of SRDs (including the licenses you should adhere to when using them) a while back, I think from someone mentioning it on Tumblr or Discord.
SRDs Database
Probability
So, you have a basic system but want to tweak it to work better with the vision you have for the game. If you're using dice, this is where you might want to consider probability. Not every game needs this step, but it's worth checking that the numbers tell the story you're trying to tell with your game. For this, I'll link the site I did in that first post, AnyDice. It allows you to do a lot of mathematical calculations using dice, and see the probability distribution that results for each. There's documentation that explains how to use it, though it does take practice.
AnyDice
Playtesting
So you've written the rules of your game and want to playtest it but can't convince any of your friends to give it a try. Enter Quest Check. Quest Check is a website created by Trekiros for connecting potential playtesters to designers. I can't speak to how effective it is (I've yet to use it myself) but it's great that a resource like it exists. There's a video he made about the site, and the site can be found here:
Quest Check
Graphic Design and Art
Game is written and tested? You can publish it as-is, or you can make it look cool with graphics and design. This is by no means an essential step, but is useful if you want to get eyes on it. I've got a few links for this. First off, design principles:
Design Cheatsheet
Secondly, art. I would encourage budding designers to avoid AI imagery. You'll be surprised how good you can make your game look with only shapes and lines, even if you aren't confident in your own artistic ability. As another option, public domain art is plentiful, and is fairly easy to find! I've compiled a few links to compilations of public domain art sources here (be sure to check the filters to ensure it's public domain):
Public Domain Sources 1
Public Domain Sources 2
You can also make use of free stock image sites like Pexels or Pixabay (Pixabay can filter by vector graphics, but has recently become much more clogged with AI imagery, though you can filter out most of it, providing it's tagged correctly).
Pexels
Pixabay
Fonts
Turns out I've collected a lot of resources. When publishing, it's important to bear in mind what you use has to be licensed for commercial use if you plan to sell your game. One place this can slip through is fonts. Enter, my saviour (and eternal time sink), Google Fonts. The Open Font License (OFL) has minimal restrictions for what you can do with it, and most fonts here are available under it:
Google Fonts
Publishing
So, game is designed, written, and formatted. Publishing time! There are two places that I go to to publish my work: itch.io and DriveThruRPG. For beginners I would recommend itch - there's less hoops to jump through and you take a much better cut of what you sell your games for, but DriveThruRPG has its own merits (@theresattrpgforthat made great posts here and here for discovering games on each). Itch in particular has regular game jams to take part in to inspire new games. I'll link both sites:
itch.io
DriveThruRPG
Finally, a bunch of other links I wasn't sure where to put, along with a very brief summary of what they are.
Affinity Suite, the programs I use for all my layout and designing. Has an up-front cost to buy but no subscriptions, and has a month-long free trial for each.
Affinity Suite
A database of designers to be inspired by or work with. Bear in mind that people should be paid for their work and their time should be respected.
Designer Directory
An absolute behemoth list of resources for TTRPG creators:
Massive Resources List
A site to make mockups of products, should you decide to go that route:
Mockup Selection
A guide to making published documents accessible to those with visual impairments:
Visual Impairment Guidelines
A post from @theresattrpgforthat about newsletters:
Newsletter Post
Rascal News, a great place to hear about what's going on in the wider TTRPG world:
Rascal News
Lastly, two UK-specific links for those based here, like me:
A list of conventions in the UK & Ireland:
Convention List
A link to the UK Tabletop Industry Network (@uktabletopindustrynetwork) Discord where you can chat with fellow UK-based designers:
TIN Discord
That's all I've got! Feel free to reblog if you have more stuff people might find useful (I almost certainly will be)!
465 notes
·
View notes
Text
1 note
·
View note
Text
🪧 consang symbol

consang symbol: a symbol for those who consider themself having a romantic attraction to one's relatives, or who consider their orientation to be for their own relatives.
🍥png symbol requested by @muttophilic
[image id: a six-petaled flower with alternating petal colors of purple and red; bordered in black. underlayed the flower is a faux yin-yang shape. /end id]
📥 requests closed! 📬 for @muttophilic 🔗 hd vector
🧺——— designed by red bishop council
i've both posted this and added the pdf and svg version to the database. thanks for the request; very smart!! — bishop
#⏪redesign#🪧symbols#🧧bishop coin#📁paras#⌚queued#remakes alterations#coining#term#flag design#flag coining#label coining#term coining#identity coining#flag redesign#redesign#alternate design#paraphile safe#pro para#para safe#paraphile flag#paraphilia flag#para flag#polycoins#consang
52 notes
·
View notes
Text
Also preserved in our archive
Some interesting statistical analysis of reported severe adverse reactions post covid vaccination. Their conclusion?
SADRs associated with anti-SARS-CoV-2 vaccines seem to be relatively rare. Compared to adenovirus-based vector vaccines (Jcovden, Vaxzevria), mRNA vaccines appear to offer improved safety profiles (Comirnaty, Spikevax). The risk of SADR to any SARS-CoV-2 vaccine seems to be outweighed by the benefits of active immunization against the virus.
#mask up#public health#wear a mask#wear a respirator#pandemic#covid#still coviding#coronavirus#sars cov 2#covid 19#covid isn't over#covid conscious#covid pandemic#covid is airborne#covidー19#covid19#long covid#covid vaccination#covid vaccine#covid vax#covid vaccines
13 notes
·
View notes
Note
The tenth Doctor in journeys end (i think?) said a TARDIS is made to be piloted by 6 timelords, what roles would each have in the TARDIS?
What roles would six Time Lords have in piloting a TARDIS?
This is more speculative, based on the known features of a TARDIS.
Console Panels and Systems
A TARDIS console is split into six 'panels', with each panel operating a different aspect of the TARDIS' systems. When there are six pilots, each Time Lord would likely specialise in operating a specific panel and system. Although the console layout may change with each TARDIS's 'desktop theme,' the six fundamental panels remain the same.
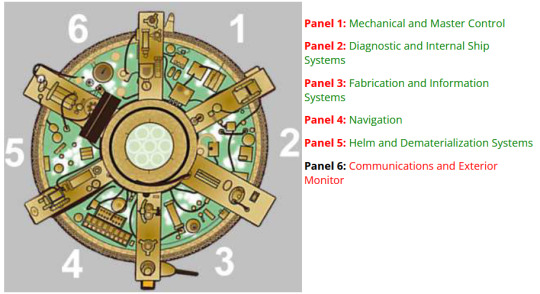
[Image ID: On the left is a top-down diagram of the 9th and 10th Doctor's coral theme TARDIS, divided into six panel sections. Each section is labelled from 1-6 clockwise starting from the 12 o'clock position. On the right is a text list of the panels and their names: Panel 1: Mechanical and Master Control, Panel 2: Diagnostic and Internal Ship Systems, Panel 3: Fabrication and Information Systems, Panel 4: Navigation, Panel 5: Helm and Dematerialisation Systems, Panel 6: Communications and Exterior Monitor./.End ID]
See this page on the TARDIS Technical Index for more variations on desktop themes.
👨✈️ Roles and Responsibilities
Here's a breakdown of each potential role and their responsibilities:
�� Panel 1: Mechanical and Master Control
Role: Chief Engineer
Responsibilities: The chief engineer monitors the TARDIS's overall operation. They ensure that all the mechanical systems and master controls are working properly. If anything goes wrong, they step in and fix it.
🛠️ Panel 2: Diagnostic and Internal Ship Systems
Role: Systems Analyst
Responsibilities: This person is all about the internals. They monitor life support, environmental controls, and the internal power grid. Basically, they make sure everything inside the TARDIS is working as it should.
🖥️ Panel 3: Fabrication and Information Systems
Role: Data Specialist
Responsibilities: Managing the TARDIS’s databases and info systems, and handling any fabrication needs. Whether it’s creating new tools, repairing old ones, or just making sure the information systems are up-to-date, they’ve got it covered.
🧭 Panel 4: Navigation
Role: Navigator
Responsibilities: Plotting courses through time and space. The Navigator makes sure the TARDIS lands where it’s supposed to, calculating all those tricky temporal vectors and spatial positions. They work closely with the Pilot to make sure the journey is smooth and safe.
🚀 Panel 5: Helm and Dematerialisation Systems
Role: Pilot
Responsibilities: This is the person at the helm, controlling take-off, landing, and in-flight manoeuvres. They handle the dematerialisation and rematerialisation of the TARDIS, making sure it takes off and lands without a hitch.
📡 Panel 6: Communications and Exterior Monitor
Role: Communications Officer
Responsibilities: They handle all external communications and keep an eye on what’s going on outside, involving sending or receiving messages or watching out for any threats or anomalies.
🏫 So...
Potentially, each Time Lord on the TARDIS would have a specialised role associated with a specific panel. Ideally, they're probably all working together like a well-oiled machine. However, poor old solo pilots have to jump around like madmen trying to cover all the controls at once.
Related:
🤔|🛸🧬The Life Cycle of a TARDIS: How TARDISes are born, grow, and die.
💬|🛸🧑✈️Do all TARDIS models require a 6-Person crew?: Piloting through the ages.
💬|🛸🌌Can a TARDIS be altered for travel in the multiverse?: How you might go about getting to the multiverse in your TARDIS.
Hope that helped! 😃
Any orange text is educated guesswork or theoretical. More content ... →📫Got a question? | 📚Complete list of Q+A and factoids →📢Announcements |🩻Biology |🗨️Language |🕰️Throwbacks |🤓Facts → Features: ⭐Guest Posts | 🍜Chomp Chomp with Myishu →🫀Gallifreyan Anatomy and Physiology Guide (pending) →⚕️Gallifreyan Emergency Medicine Guides →📝Source list (WIP) →📜Masterpost If you're finding your happy place in this part of the internet, feel free to buy a coffee to help keep our exhausted human conscious. She works full-time in medicine and is so very tired 😴
#doctor who#gallifrey institute for learning#dr who#dw eu#gallifrey#gallifreyans#whoniverse#ask answered#tardis#GIL: Asks#gallifreyan culture#gallifreyan lore#gallifreyan society#GIL: Gallifrey/Culture and Society#GIL: Gallifrey/Technology#GIL: Species/TARDISes#GIL: Species/Gallifreyans#GIL
46 notes
·
View notes
Text

@odditymuse you know who this is for
Jace hadn’t actually been paying all that much attention to his surroundings. Perhaps that was the cause of his eventual downfall. The Stark Expo was just so loud, though. Not only to his ears, but to his mind. So much technology in one space, and not just the simple sort, like a bunch of smartphones—not that smartphones could necessarily be classified as simple technology, but when one was surrounded by them all day, every day, they sort of lost their luster—but the complex sort that Jace had to really listen to in order to understand.
After about an hour of wandering, he noticed someone at one of the booths having difficulty with theirs. A hard-light hologram interface; fully tactile holograms with gesture-control and haptic feedback. At least, that was what the poor woman was trying to demonstrate. However, the gestural database seemed to be corrupted. No matter how she tried, the holograms simply wouldn’t do what she wanted them to, either misinterpreting her gesture commands or completely reinterpreting them.
Jace had offered up a suggestion after less than a minute of looking at the device:
“Have you tried realigning the inertial-motion sensor array that tracks hand movement vectors? Your gesture database might not be the actual problem.” That was what she was currently looking at, and it wasn’t. “Even a small drift on, say, the Z-axis,” the axis with the actual misalignment issue, “would feed bad data into the system. Which would, in turn, make the gesture AI try to compensate, learning garbage in the process.”
He’d received a hell of a dirty look for his attempted assistance, and frankly, if she didn’t want to accept his help, that was fine—Jace was used to people ignoring him, even when he was, supposedly, the expert on the matter. But then the woman’s eyes went big, locked onto something behind him, and a single word uttered in a man’s voice had Jace spinning around and freezing, like a deer in headlights.
“Fascinating.”
Oh god. Oh no. That was Tony Stark. The Tony Stark. The one person Jace did not want to meet and hadn’t expected to even be milling around here, if he’d bothered to come at all.
“…Um.” Well done, Jace. Surely that will help your cause.
7 notes
·
View notes
Text
What’s the best free alternative to Microsoft Office?
The best free alternative to Microsoft Office depends on your needs, but here are the top options:
LibreOffice (Best Overall)
Pros: Fully featured, open-source, supports Word (Writer), Excel (Calc), PowerPoint (Impress), plus databases (Base), and vector graphics (Draw). Excellent compatibility with MS Office formats.
Cons: Interface looks slightly outdated, but highly customizable.
OnlyOffice (Best for MS Office-like Experience)
Pros: Modern UI, strong compatibility with DOCX, XLSX, PPTX, collaborative editing, and cloud integration.
Cons: Some advanced features require a paid plan.
WPS Office (Best for Lightweight Use)
Pros: Very similar to MS Office, lightweight, has a free mobile version, supports tabs.
Cons: Free version has ads and limits PDF export.
Google Workspace (Docs, Sheets, Slides) (Best for Cloud & Collaboration)
Pros: Real-time collaboration, cloud-based, works on any device.
Cons: Requires internet for full functionality, offline mode is limited.
SoftMaker FreeOffice (Best for Offline Use with High Compatibility)
Pros: Fully compatible with MS Office formats, lightweight, good for older PCs.
Cons: Fewer features than LibreOffice.
Which One Should You Choose?
For full offline use → LibreOffice or FreeOffice
For a MS Office-like feel → OnlyOffice or WPS Office
For cloud collaboration → Google Workspace
If you just do not want to spend much money on the Microsoft Office , you can get it much cheaper at keyingo.com
9 notes
·
View notes