#install and configure ADDS
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
Users from the US are the majority of Tumblr visitors.
Text
Setup a Domain Controller as Recommended by Microsoft
A Domain Controller (DC) responds to authentication requests. It has an hierarchical structure called domains. In this article, I will be discussing how to Setup a Domain Controller as Recommended by Microsoft in HyperV. Please see Pleasant User Group Permission and User Access, Domain Name System Protocol: Client Registration Issue, Domain Name System: How to create a DNS record, and how to fix…

View On WordPress
#Active Directory#Active Directory Accounts#ADDS#DC#Domain#Domain Controller#Domain Controller Setup#Domain Join#install and configure ADDS#Promote DC#Set up DC#Windows#Windows Server#Windows Server 2012#Windows Server 2016#Windows Server 2022#Windows Server 2025
0 notes
Text
I had a straight up delightful moment at work yesterday when a new member of the management team asked me how we were tracking warranties and I explained that we kind of aren't and he asked why we aren't and that meant he got a 30-minute rundown of how top-to-bottom fucked the procurement process is here.
First I explained the process for sending a quote (i am assigned a ticket in system A1, I create an opportunity in system A2, from the opportunity i can generate a quote in system B - if I start with the quote I can't associate it back to the opportunity or the ticket, if we need to change the quote after it was approved we need to generate a new quote from the opportunity to overwrite the old one - and send the quote from system B.)
Then I explained the process of getting approval (system B sends the quote and receives the approvals but does not communicate that to system A, so until it is manually updated system A sends a daily reminder about the quote to the client and after three days with no response will close the ticket even if the client approved the quote in system B. System B will send an email if a quote is approved but it comes from our generic support email so to make sure that I don't miss approvals I have filtering rules set up and a folder I check twice a day. Because there are 4 people who use this system I also check twice daily in system B to see if anyone else's quotes were approved).
Then I explained how I place the orders (easy! I'm a pro! We have a standardized PO pattern that tracks date, vendor and client, it's handy)
Then I explained how I document the orders (neither system A nor B has a way of storing information about orders in progress, only orders that are complete; as such I have created a PO Documentation spreadsheet that lists the PO number, vendor, line of business, client, items ordered, order total, order date, ETA, tracking numbers, serial numbers, delivery confirmation, ticket number for install, ticket title for install, shippong cost, and close confirmation, which all have to be entered individually and which require a minimum of three visits to the spreadsheet per order: entering initial info, entering tracking and SN info, then once more to get that info to close the opportunity)
Then I explained how we close an order (confirm hardware delivery or activate software, use system A2 to code hardware/software/non-taxable products appropriately, run wizard to add charges from A2 to ticket in A1; because the A2 charges were locked by approval in system B, use system A3 to add shipping or other fees or to remove any parts that were approved but not actually needed or ordered - THIS WEEK I got permission to do this bit on my initial A1 procurement ticket instead of generating an A1 post-procurement ticket for fees and shipping. Once all of that is done it's moved into system A4 and is no longer my problem).
If there is a warranty involved it *should* automatically have the expiration tracked in system C, but system C doesn't have any way to pull order info so there's no way it can track warranty *start* dates without somebody manually entering it or without using API data from the manufacturer, which some manufacturers don't provide (fuck you, Apple).
But me and my trainee are happy to add the start date to the configuration once a tech tells us that the device is enrolled in system C. If the techs will tell us that we can add that info no problem.
Until then, I have unfortunately been forced to start a spreadsheet.
The manager was appalled, it was great. I got to say the words "part of the reason things sometimes fall through the cracks is because we have so many cracks" and his response was "no shit." I'm talking to vendors about a procurement system now :) :) :) :)
579 notes
·
View notes
Text
How I ditched streaming services and learned to love Linux: A step-by-step guide to building your very own personal media streaming server (V2.0: REVISED AND EXPANDED EDITION)
This is a revised, corrected and expanded version of my tutorial on setting up a personal media server that previously appeared on my old blog (donjuan-auxenfers). I expect that that post is still making the rounds (hopefully with my addendum on modifying group share permissions in Ubuntu to circumvent 0x8007003B "Unexpected Network Error" messages in Windows 10/11 when transferring files) but I have no way of checking. Anyway this new revised version of the tutorial corrects one or two small errors I discovered when rereading what I wrote, adds links to all products mentioned and is just more polished generally. I also expanded it a bit, pointing more adventurous users toward programs such as Sonarr/Radarr/Lidarr and Overseerr which can be used for automating user requests and media collection.
So then, what is this tutorial? This is a tutorial on how to build and set up your own personal media server using Ubuntu as an operating system and Plex (or Jellyfin) to not only manage your media, but to also stream that media to your devices both at home and abroad anywhere in the world where you have an internet connection. Its intent is to show you how building a personal media server and stuffing it full of films, TV, and music that you acquired through indiscriminate and voracious media piracy various legal methods will free you to completely ditch paid streaming services. No more will you have to pay for Disney+, Netflix, HBOMAX, Hulu, Amazon Prime, Peacock, CBS All Access, Paramount+, Crave or any other streaming service that is not named Criterion Channel. Instead whenever you want to watch your favourite films and television shows, you’ll have your own personal service that only features things that you want to see, with files that you have control over. And for music fans out there, both Jellyfin and Plex support music streaming, meaning you can even ditch music streaming services. Goodbye Spotify, Youtube Music, Tidal and Apple Music, welcome back unreasonably large MP3 (or FLAC) collections.
On the hardware front, I’m going to offer a few options catered towards different budgets and media library sizes. The cost of getting a media server up and running using this guide will cost you anywhere from $450 CAD/$325 USD at the low end to $1500 CAD/$1100 USD at the high end (it could go higher). My server was priced closer to the higher figure, but I went and got a lot more storage than most people need. If that seems like a little much, consider for a moment, do you have a roommate, a close friend, or a family member who would be willing to chip in a few bucks towards your little project provided they get access? Well that's how I funded my server. It might also be worth thinking about the cost over time, i.e. how much you spend yearly on subscriptions vs. a one time cost of setting up a server. Additionally there's just the joy of being able to scream "fuck you" at all those show cancelling, library deleting, hedge fund vampire CEOs who run the studios through denying them your money. Drive a stake through David Zaslav's heart.
On the software side I will walk you step-by-step through installing Ubuntu as your server's operating system, configuring your storage as a RAIDz array with ZFS, sharing your zpool to Windows with Samba, running a remote connection between your server and your Windows PC, and then a little about started with Plex/Jellyfin. Every terminal command you will need to input will be provided, and I even share a custom #bash script that will make used vs. available drive space on your server display correctly in Windows.
If you have a different preferred flavour of Linux (Arch, Manjaro, Redhat, Fedora, Mint, OpenSUSE, CentOS, Slackware etc. et. al.) and are aching to tell me off for being basic and using Ubuntu, this tutorial is not for you. The sort of person with a preferred Linux distro is the sort of person who can do this sort of thing in their sleep. Also I don't care. This tutorial is intended for the average home computer user. This is also why we’re not using a more exotic home server solution like running everything through Docker Containers and managing it through a dashboard like Homarr or Heimdall. While such solutions are fantastic and can be very easy to maintain once you have it all set up, wrapping your brain around Docker is a whole thing in and of itself. If you do follow this tutorial and had fun putting everything together, then I would encourage you to return in a year’s time, do your research and set up everything with Docker Containers.
Lastly, this is a tutorial aimed at Windows users. Although I was a daily user of OS X for many years (roughly 2008-2023) and I've dabbled quite a bit with various Linux distributions (mostly Ubuntu and Manjaro), my primary OS these days is Windows 11. Many things in this tutorial will still be applicable to Mac users, but others (e.g. setting up shares) you will have to look up for yourself. I doubt it would be difficult to do so.
Nothing in this tutorial will require feats of computing expertise. All you will need is a basic computer literacy (i.e. an understanding of what a filesystem and directory are, and a degree of comfort in the settings menu) and a willingness to learn a thing or two. While this guide may look overwhelming at first glance, it is only because I want to be as thorough as possible. I want you to understand exactly what it is you're doing, I don't want you to just blindly follow steps. If you half-way know what you’re doing, you will be much better prepared if you ever need to troubleshoot.
Honestly, once you have all the hardware ready it shouldn't take more than an afternoon or two to get everything up and running.
(This tutorial is just shy of seven thousand words long so the rest is under the cut.)
Step One: Choosing Your Hardware
Linux is a light weight operating system, depending on the distribution there's close to no bloat. There are recent distributions available at this very moment that will run perfectly fine on a fourteen year old i3 with 4GB of RAM. Moreover, running Plex or Jellyfin isn’t resource intensive in 90% of use cases. All this is to say, we don’t require an expensive or powerful computer. This means that there are several options available: 1) use an old computer you already have sitting around but aren't using 2) buy a used workstation from eBay, or what I believe to be the best option, 3) order an N100 Mini-PC from AliExpress or Amazon.
Note: If you already have an old PC sitting around that you’ve decided to use, fantastic, move on to the next step.
When weighing your options, keep a few things in mind: the number of people you expect to be streaming simultaneously at any one time, the resolution and bitrate of your media library (4k video takes a lot more processing power than 1080p) and most importantly, how many of those clients are going to be transcoding at any one time. Transcoding is what happens when the playback device does not natively support direct playback of the source file. This can happen for a number of reasons, such as the playback device's native resolution being lower than the file's internal resolution, or because the source file was encoded in a video codec unsupported by the playback device.
Ideally we want any transcoding to be performed by hardware. This means we should be looking for a computer with an Intel processor with Quick Sync. Quick Sync is a dedicated core on the CPU die designed specifically for video encoding and decoding. This specialized hardware makes for highly efficient transcoding both in terms of processing overhead and power draw. Without these Quick Sync cores, transcoding must be brute forced through software. This takes up much more of a CPU’s processing power and requires much more energy. But not all Quick Sync cores are created equal and you need to keep this in mind if you've decided either to use an old computer or to shop for a used workstation on eBay
Any Intel processor from second generation Core (Sandy Bridge circa 2011) onward has Quick Sync cores. It's not until 6th gen (Skylake), however, that the cores support the H.265 HEVC codec. Intel’s 10th gen (Comet Lake) processors introduce support for 10bit HEVC and HDR tone mapping. And the recent 12th gen (Alder Lake) processors brought with them hardware AV1 decoding. As an example, while an 8th gen (Kaby Lake) i5-8500 will be able to hardware transcode a H.265 encoded file, it will fall back to software transcoding if given a 10bit H.265 file. If you’ve decided to use that old PC or to look on eBay for an old Dell Optiplex keep this in mind.
Note 1: The price of old workstations varies wildly and fluctuates frequently. If you get lucky and go shopping shortly after a workplace has liquidated a large number of their workstations you can find deals for as low as $100 on a barebones system, but generally an i5-8500 workstation with 16gb RAM will cost you somewhere in the area of $260 CAD/$200 USD.
Note 2: The AMD equivalent to Quick Sync is called Video Core Next, and while it's fine, it's not as efficient and not as mature a technology. It was only introduced with the first generation Ryzen CPUs and it only got decent with their newest CPUs, we want something cheap.
Alternatively you could forgo having to keep track of what generation of CPU is equipped with Quick Sync cores that feature support for which codecs, and just buy an N100 mini-PC. For around the same price or less of a used workstation you can pick up a mini-PC with an Intel N100 processor. The N100 is a four-core processor based on the 12th gen Alder Lake architecture and comes equipped with the latest revision of the Quick Sync cores. These little processors offer astounding hardware transcoding capabilities for their size and power draw. Otherwise they perform equivalent to an i5-6500, which isn't a terrible CPU. A friend of mine uses an N100 machine as a dedicated retro emulation gaming system and it does everything up to 6th generation consoles just fine. The N100 is also a remarkably efficient chip, it sips power. In fact, the difference between running one of these and an old workstation could work out to hundreds of dollars a year in energy bills depending on where you live.
You can find these Mini-PCs all over Amazon or for a little cheaper on AliExpress. They range in price from $170 CAD/$125 USD for a no name N100 with 8GB RAM to $280 CAD/$200 USD for a Beelink S12 Pro with 16GB RAM. The brand doesn't really matter, they're all coming from the same three factories in Shenzen, go for whichever one fits your budget or has features you want. 8GB RAM should be enough, Linux is lightweight and Plex only calls for 2GB RAM. 16GB RAM might result in a slightly snappier experience, especially with ZFS. A 256GB SSD is more than enough for what we need as a boot drive, but going for a bigger drive might allow you to get away with things like creating preview thumbnails for Plex, but it’s up to you and your budget.
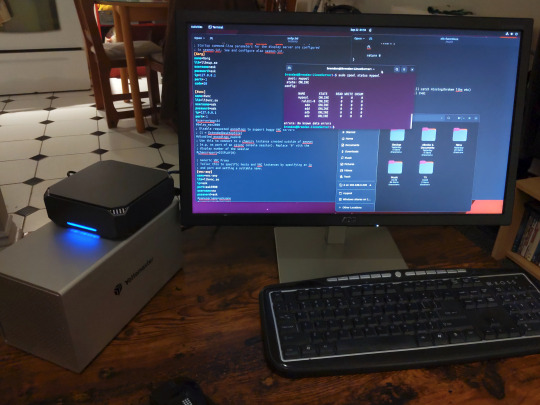
The Mini-PC I wound up buying was a Firebat AK2 Plus with 8GB RAM and a 256GB SSD. It looks like this:

Note: Be forewarned that if you decide to order a Mini-PC from AliExpress, note the type of power adapter it ships with. The mini-PC I bought came with an EU power adapter and I had to supply my own North American power supply. Thankfully this is a minor issue as barrel plug 30W/12V/2.5A power adapters are easy to find and can be had for $10.
Step Two: Choosing Your Storage
Storage is the most important part of our build. It is also the most expensive. Thankfully it’s also the most easily upgrade-able down the line.
For people with a smaller media collection (4TB to 8TB), a more limited budget, or who will only ever have two simultaneous streams running, I would say that the most economical course of action would be to buy a USB 3.0 8TB external HDD. Something like this one from Western Digital or this one from Seagate. One of these external drives will cost you in the area of $200 CAD/$140 USD. Down the line you could add a second external drive or replace it with a multi-drive RAIDz set up such as detailed below.
If a single external drive the path for you, move on to step three.
For people with larger media libraries (12TB+), who prefer media in 4k, or care who about data redundancy, the answer is a RAID array featuring multiple HDDs in an enclosure.
Note: If you are using an old PC or used workstatiom as your server and have the room for at least three 3.5" drives, and as many open SATA ports on your mother board you won't need an enclosure, just install the drives into the case. If your old computer is a laptop or doesn’t have room for more internal drives, then I would suggest an enclosure.
The minimum number of drives needed to run a RAIDz array is three, and seeing as RAIDz is what we will be using, you should be looking for an enclosure with three to five bays. I think that four disks makes for a good compromise for a home server. Regardless of whether you go for a three, four, or five bay enclosure, do be aware that in a RAIDz array the space equivalent of one of the drives will be dedicated to parity at a ratio expressed by the equation 1 − 1/n i.e. in a four bay enclosure equipped with four 12TB drives, if we configured our drives in a RAIDz1 array we would be left with a total of 36TB of usable space (48TB raw size). The reason for why we might sacrifice storage space in such a manner will be explained in the next section.
A four bay enclosure will cost somewhere in the area of $200 CDN/$140 USD. You don't need anything fancy, we don't need anything with hardware RAID controls (RAIDz is done entirely in software) or even USB-C. An enclosure with USB 3.0 will perform perfectly fine. Don’t worry too much about USB speed bottlenecks. A mechanical HDD will be limited by the speed of its mechanism long before before it will be limited by the speed of a USB connection. I've seen decent looking enclosures from TerraMaster, Yottamaster, Mediasonic and Sabrent.
When it comes to selecting the drives, as of this writing, the best value (dollar per gigabyte) are those in the range of 12TB to 20TB. I settled on 12TB drives myself. If 12TB to 20TB drives are out of your budget, go with what you can afford, or look into refurbished drives. I'm not sold on the idea of refurbished drives but many people swear by them.
When shopping for harddrives, search for drives designed specifically for NAS use. Drives designed for NAS use typically have better vibration dampening and are designed to be active 24/7. They will also often make use of CMR (conventional magnetic recording) as opposed to SMR (shingled magnetic recording). This nets them a sizable read/write performance bump over typical desktop drives. Seagate Ironwolf and Toshiba NAS are both well regarded brands when it comes to NAS drives. I would avoid Western Digital Red drives at this time. WD Reds were a go to recommendation up until earlier this year when it was revealed that they feature firmware that will throw up false SMART warnings telling you to replace the drive at the three year mark quite often when there is nothing at all wrong with that drive. It will likely even be good for another six, seven, or more years.

Step Three: Installing Linux
For this step you will need a USB thumbdrive of at least 6GB in capacity, an .ISO of Ubuntu, and a way to make that thumbdrive bootable media.
First download a copy of Ubuntu desktop (for best performance we could download the Server release, but for new Linux users I would recommend against the server release. The server release is strictly command line interface only, and having a GUI is very helpful for most people. Not many people are wholly comfortable doing everything through the command line, I'm certainly not one of them, and I grew up with DOS 6.0. 22.04.3 Jammy Jellyfish is the current Long Term Service release, this is the one to get.
Download the .ISO and then download and install balenaEtcher on your Windows PC. BalenaEtcher is an easy to use program for creating bootable media, you simply insert your thumbdrive, select the .ISO you just downloaded, and it will create a bootable installation media for you.
Once you've made a bootable media and you've got your Mini-PC (or you old PC/used workstation) in front of you, hook it directly into your router with an ethernet cable, and then plug in the HDD enclosure, a monitor, a mouse and a keyboard. Now turn that sucker on and hit whatever key gets you into the BIOS (typically ESC, DEL or F2). If you’re using a Mini-PC check to make sure that the P1 and P2 power limits are set correctly, my N100's P1 limit was set at 10W, a full 20W under the chip's power limit. Also make sure that the RAM is running at the advertised speed. My Mini-PC’s RAM was set at 2333Mhz out of the box when it should have been 3200Mhz. Once you’ve done that, key over to the boot order and place the USB drive first in the boot order. Then save the BIOS settings and restart.
After you restart you’ll be greeted by Ubuntu's installation screen. Installing Ubuntu is really straight forward, select the "minimal" installation option, as we won't need anything on this computer except for a browser (Ubuntu comes preinstalled with Firefox) and Plex Media Server/Jellyfin Media Server. Also remember to delete and reformat that Windows partition! We don't need it.
Step Four: Installing ZFS and Setting Up the RAIDz Array
Note: If you opted for just a single external HDD skip this step and move onto setting up a Samba share.
Once Ubuntu is installed it's time to configure our storage by installing ZFS to build our RAIDz array. ZFS is a "next-gen" file system that is both massively flexible and massively complex. It's capable of snapshot backup, self healing error correction, ZFS pools can be configured with drives operating in a supplemental manner alongside the storage vdev (e.g. fast cache, dedicated secondary intent log, hot swap spares etc.). It's also a file system very amenable to fine tuning. Block and sector size are adjustable to use case and you're afforded the option of different methods of inline compression. If you'd like a very detailed overview and explanation of its various features and tips on tuning a ZFS array check out these articles from Ars Technica. For now we're going to ignore all these features and keep it simple, we're going to pull our drives together into a single vdev running in RAIDz which will be the entirety of our zpool, no fancy cache drive or SLOG.
Open up the terminal and type the following commands:
sudo apt update
then
sudo apt install zfsutils-linux
This will install the ZFS utility. Verify that it's installed with the following command:
zfs --version
Now, it's time to check that the HDDs we have in the enclosure are healthy, running, and recognized. We also want to find out their device IDs and take note of them:
sudo fdisk -1
Note: You might be wondering why some of these commands require "sudo" in front of them while others don't. "Sudo" is short for "super user do”. When and where "sudo" is used has to do with the way permissions are set up in Linux. Only the "root" user has the access level to perform certain tasks in Linux. As a matter of security and safety regular user accounts are kept separate from the "root" user. It's not advised (or even possible) to boot into Linux as "root" with most modern distributions. Instead by using "sudo" our regular user account is temporarily given the power to do otherwise forbidden things. Don't worry about it too much at this stage, but if you want to know more check out this introduction.
If everything is working you should get a list of the various drives detected along with their device IDs which will look like this: /dev/sdc. You can also check the device IDs of the drives by opening the disk utility app. Jot these IDs down as we'll need them for our next step, creating our RAIDz array.
RAIDz is similar to RAID-5 in that instead of striping your data over multiple disks, exchanging redundancy for speed and available space (RAID-0), or mirroring your data writing by two copies of every piece (RAID-1), it instead writes parity blocks across the disks in addition to striping, this provides a balance of speed, redundancy and available space. If a single drive fails, the parity blocks on the working drives can be used to reconstruct the entire array as soon as a replacement drive is added.
Additionally, RAIDz improves over some of the common RAID-5 flaws. It's more resilient and capable of self healing, as it is capable of automatically checking for errors against a checksum. It's more forgiving in this way, and it's likely that you'll be able to detect when a drive is dying well before it fails. A RAIDz array can survive the loss of any one drive.
Note: While RAIDz is indeed resilient, if a second drive fails during the rebuild, you're fucked. Always keep backups of things you can't afford to lose. This tutorial, however, is not about proper data safety.
To create the pool, use the following command:
sudo zpool create "zpoolnamehere" raidz "device IDs of drives we're putting in the pool"
For example, let's creatively name our zpool "mypool". This poil will consist of four drives which have the device IDs: sdb, sdc, sdd, and sde. The resulting command will look like this:
sudo zpool create mypool raidz /dev/sdb /dev/sdc /dev/sdd /dev/sde
If as an example you bought five HDDs and decided you wanted more redundancy dedicating two drive to this purpose, we would modify the command to "raidz2" and the command would look something like the following:
sudo zpool create mypool raidz2 /dev/sdb /dev/sdc /dev/sdd /dev/sde /dev/sdf
An array configured like this is known as RAIDz2 and is able to survive two disk failures.
Once the zpool has been created, we can check its status with the command:
zpool status
Or more concisely with:
zpool list
The nice thing about ZFS as a file system is that a pool is ready to go immediately after creation. If we were to set up a traditional RAID-5 array using mbam, we'd have to sit through a potentially hours long process of reformatting and partitioning the drives. Instead we're ready to go right out the gates.
The zpool should be automatically mounted to the filesystem after creation, check on that with the following:
df -hT | grep zfs
Note: If your computer ever loses power suddenly, say in event of a power outage, you may have to re-import your pool. In most cases, ZFS will automatically import and mount your pool, but if it doesn’t and you can't see your array, simply open the terminal and type sudo zpool import -a.
By default a zpool is mounted at /"zpoolname". The pool should be under our ownership but let's make sure with the following command:
sudo chown -R "yourlinuxusername" /"zpoolname"
Note: Changing file and folder ownership with "chown" and file and folder permissions with "chmod" are essential commands for much of the admin work in Linux, but we won't be dealing with them extensively in this guide. If you'd like a deeper tutorial and explanation you can check out these two guides: chown and chmod.
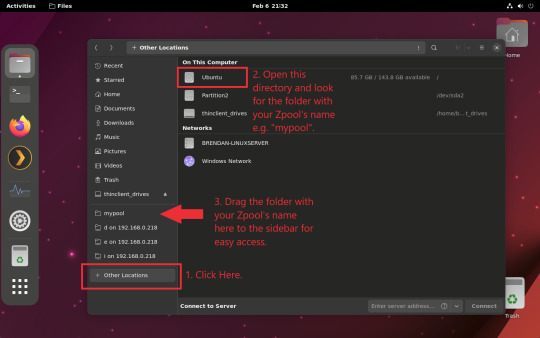
You can access the zpool file system through the GUI by opening the file manager (the Ubuntu default file manager is called Nautilus) and clicking on "Other Locations" on the sidebar, then entering the Ubuntu file system and looking for a folder with your pool's name. Bookmark the folder on the sidebar for easy access.
Your storage pool is now ready to go. Assuming that we already have some files on our Windows PC we want to copy to over, we're going to need to install and configure Samba to make the pool accessible in Windows.
Step Five: Setting Up Samba/Sharing
Samba is what's going to let us share the zpool with Windows and allow us to write to it from our Windows machine. First let's install Samba with the following commands:
sudo apt-get update
then
sudo apt-get install samba
Next create a password for Samba.
sudo smbpswd -a "yourlinuxusername"
It will then prompt you to create a password. Just reuse your Ubuntu user password for simplicity's sake.
Note: if you're using just a single external drive replace the zpool location in the following commands with wherever it is your external drive is mounted, for more information see this guide on mounting an external drive in Ubuntu.
After you've created a password we're going to create a shareable folder in our pool with this command
mkdir /"zpoolname"/"foldername"
Now we're going to open the smb.conf file and make that folder shareable. Enter the following command.
sudo nano /etc/samba/smb.conf
This will open the .conf file in nano, the terminal text editor program. Now at the end of smb.conf add the following entry:
["foldername"]
path = /"zpoolname"/"foldername"
available = yes
valid users = "yourlinuxusername"
read only = no
writable = yes
browseable = yes
guest ok = no
Ensure that there are no line breaks between the lines and that there's a space on both sides of the equals sign. Our next step is to allow Samba traffic through the firewall:
sudo ufw allow samba
Finally restart the Samba service:
sudo systemctl restart smbd
At this point we'll be able to access to the pool, browse its contents, and read and write to it from Windows. But there's one more thing left to do, Windows doesn't natively support the ZFS file systems and will read the used/available/total space in the pool incorrectly. Windows will read available space as total drive space, and all used space as null. This leads to Windows only displaying a dwindling amount of "available" space as the drives are filled. We can fix this! Functionally this doesn't actually matter, we can still write and read to and from the disk, it just makes it difficult to tell at a glance the proportion of used/available space, so this is an optional step but one I recommend (this step is also unnecessary if you're just using a single external drive). What we're going to do is write a little shell script in #bash. Open nano with the terminal with the command:
nano
Now insert the following code:
#!/bin/bash CUR_PATH=`pwd` ZFS_CHECK_OUTPUT=$(zfs get type $CUR_PATH 2>&1 > /dev/null) > /dev/null if [[ $ZFS_CHECK_OUTPUT == *not\ a\ ZFS* ]] then IS_ZFS=false else IS_ZFS=true fi if [[ $IS_ZFS = false ]] then df $CUR_PATH | tail -1 | awk '{print $2" "$4}' else USED=$((`zfs get -o value -Hp used $CUR_PATH` / 1024)) > /dev/null AVAIL=$((`zfs get -o value -Hp available $CUR_PATH` / 1024)) > /dev/null TOTAL=$(($USED+$AVAIL)) > /dev/null echo $TOTAL $AVAIL fi
Save the script as "dfree.sh" to /home/"yourlinuxusername" then change the ownership of the file to make it executable with this command:
sudo chmod 774 dfree.sh
Now open smb.conf with sudo again:
sudo nano /etc/samba/smb.conf
Now add this entry to the top of the configuration file to direct Samba to use the results of our script when Windows asks for a reading on the pool's used/available/total drive space:
[global]
dfree command = /home/"yourlinuxusername"/dfree.sh
Save the changes to smb.conf and then restart Samba again with the terminal:
sudo systemctl restart smbd
Now there’s one more thing we need to do to fully set up the Samba share, and that’s to modify a hidden group permission. In the terminal window type the following command:
usermod -a -G sambashare “yourlinuxusername”
Then restart samba again:
sudo systemctl restart smbd
If we don’t do this last step, everything will appear to work fine, and you will even be able to see and map the drive from Windows and even begin transferring files, but you'd soon run into a lot of frustration. As every ten minutes or so a file would fail to transfer and you would get a window announcing “0x8007003B Unexpected Network Error”. This window would require your manual input to continue the transfer with the file next in the queue. And at the end it would reattempt to transfer whichever files failed the first time around. 99% of the time they’ll go through that second try, but this is still all a major pain in the ass. Especially if you’ve got a lot of data to transfer or you want to step away from the computer for a while.
It turns out samba can act a little weirdly with the higher read/write speeds of RAIDz arrays and transfers from Windows, and will intermittently crash and restart itself if this group option isn’t changed. Inputting the above command will prevent you from ever seeing that window.
The last thing we're going to do before switching over to our Windows PC is grab the IP address of our Linux machine. Enter the following command:
hostname -I
This will spit out this computer's IP address on the local network (it will look something like 192.168.0.x), write it down. It might be a good idea once you're done here to go into your router settings and reserving that IP for your Linux system in the DHCP settings. Check the manual for your specific model router on how to access its settings, typically it can be accessed by opening a browser and typing http:\\192.168.0.1 in the address bar, but your router may be different.
Okay we’re done with our Linux computer for now. Get on over to your Windows PC, open File Explorer, right click on Network and click "Map network drive". Select Z: as the drive letter (you don't want to map the network drive to a letter you could conceivably be using for other purposes) and enter the IP of your Linux machine and location of the share like so: \\"LINUXCOMPUTERLOCALIPADDRESSGOESHERE"\"zpoolnamegoeshere"\. Windows will then ask you for your username and password, enter the ones you set earlier in Samba and you're good. If you've done everything right it should look something like this:

You can now start moving media over from Windows to the share folder. It's a good idea to have a hard line running to all machines. Moving files over Wi-Fi is going to be tortuously slow, the only thing that’s going to make the transfer time tolerable (hours instead of days) is a solid wired connection between both machines and your router.
Step Six: Setting Up Remote Desktop Access to Your Server
After the server is up and going, you’ll want to be able to access it remotely from Windows. Barring serious maintenance/updates, this is how you'll access it most of the time. On your Linux system open the terminal and enter:
sudo apt install xrdp
Then:
sudo systemctl enable xrdp
Once it's finished installing, open “Settings” on the sidebar and turn off "automatic login" in the User category. Then log out of your account. Attempting to remotely connect to your Linux computer while you’re logged in will result in a black screen!
Now get back on your Windows PC, open search and look for "RDP". A program called "Remote Desktop Connection" should pop up, open this program as an administrator by right-clicking and selecting “run as an administrator”. You’ll be greeted with a window. In the field marked “Computer” type in the IP address of your Linux computer. Press connect and you'll be greeted with a new window and prompt asking for your username and password. Enter your Ubuntu username and password here.
If everything went right, you’ll be logged into your Linux computer. If the performance is sluggish, adjust the display options. Lowering the resolution and colour depth do a lot to make the interface feel snappier.
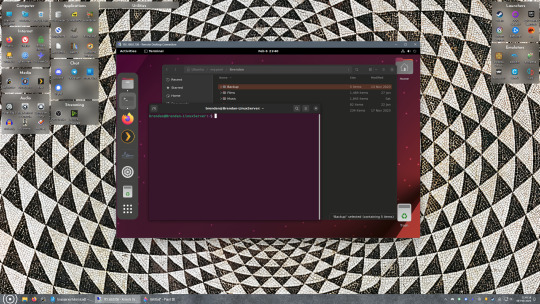
Remote access is how we're going to be using our Linux system from now, barring edge cases like needing to get into the BIOS or upgrading to a new version of Ubuntu. Everything else from performing maintenance like a monthly zpool scrub to checking zpool status and updating software can all be done remotely.

This is how my server lives its life now, happily humming and chirping away on the floor next to the couch in a corner of the living room.
Step Seven: Plex Media Server/Jellyfin
Okay we’ve got all the ground work finished and our server is almost up and running. We’ve got Ubuntu up and running, our storage array is primed, we’ve set up remote connections and sharing, and maybe we’ve moved over some of favourite movies and TV shows.
Now we need to decide on the media server software to use which will stream our media to us and organize our library. For most people I’d recommend Plex. It just works 99% of the time. That said, Jellyfin has a lot to recommend it by too, even if it is rougher around the edges. Some people run both simultaneously, it’s not that big of an extra strain. I do recommend doing a little bit of your own research into the features each platform offers, but as a quick run down, consider some of the following points:
Plex is closed source and is funded through PlexPass purchases while Jellyfin is open source and entirely user driven. This means a number of things: for one, Plex requires you to purchase a “PlexPass” (purchased as a one time lifetime fee $159.99 CDN/$120 USD or paid for on a monthly or yearly subscription basis) in order to access to certain features, like hardware transcoding (and we want hardware transcoding) or automated intro/credits detection and skipping, Jellyfin offers some of these features for free through plugins. Plex supports a lot more devices than Jellyfin and updates more frequently. That said, Jellyfin's Android and iOS apps are completely free, while the Plex Android and iOS apps must be activated for a one time cost of $6 CDN/$5 USD. But that $6 fee gets you a mobile app that is much more functional and features a unified UI across platforms, the Plex mobile apps are simply a more polished experience. The Jellyfin apps are a bit of a mess and the iOS and Android versions are very different from each other.
Jellyfin’s actual media player is more fully featured than Plex's, but on the other hand Jellyfin's UI, library customization and automatic media tagging really pale in comparison to Plex. Streaming your music library is free through both Jellyfin and Plex, but Plex offers the PlexAmp app for dedicated music streaming which boasts a number of fantastic features, unfortunately some of those fantastic features require a PlexPass. If your internet is down, Jellyfin can still do local streaming, while Plex can fail to play files unless you've got it set up a certain way. Jellyfin has a slew of neat niche features like support for Comic Book libraries with the .cbz/.cbt file types, but then Plex offers some free ad-supported TV and films, they even have a free channel that plays nothing but Classic Doctor Who.
Ultimately it's up to you, I settled on Plex because although some features are pay-walled, it just works. It's more reliable and easier to use, and a one-time fee is much easier to swallow than a subscription. I had a pretty easy time getting my boomer parents and tech illiterate brother introduced to and using Plex and I don't know if I would've had as easy a time doing that with Jellyfin. I do also need to mention that Jellyfin does take a little extra bit of tinkering to get going in Ubuntu, you’ll have to set up process permissions, so if you're more tolerant to tinkering, Jellyfin might be up your alley and I’ll trust that you can follow their installation and configuration guide. For everyone else, I recommend Plex.
So pick your poison: Plex or Jellyfin.
Note: The easiest way to download and install either of these packages in Ubuntu is through Snap Store.
After you've installed one (or both), opening either app will launch a browser window into the browser version of the app allowing you to set all the options server side.
The process of adding creating media libraries is essentially the same in both Plex and Jellyfin. You create a separate libraries for Television, Movies, and Music and add the folders which contain the respective types of media to their respective libraries. The only difficult or time consuming aspect is ensuring that your files and folders follow the appropriate naming conventions:
Plex naming guide for Movies
Plex naming guide for Television
Jellyfin follows the same naming rules but I find their media scanner to be a lot less accurate and forgiving than Plex. Once you've selected the folders to be scanned the service will scan your files, tagging everything and adding metadata. Although I find do find Plex more accurate, it can still erroneously tag some things and you might have to manually clean up some tags in a large library. (When I initially created my library it tagged the 1963-1989 Doctor Who as some Korean soap opera and I needed to manually select the correct match after which everything was tagged normally.) It can also be a bit testy with anime (especially OVAs) be sure to check TVDB to ensure that you have your files and folders structured and named correctly. If something is not showing up at all, double check the name.
Once that's done, organizing and customizing your library is easy. You can set up collections, grouping items together to fit a theme or collect together all the entries in a franchise. You can make playlists, and add custom artwork to entries. It's fun setting up collections with posters to match, there are even several websites dedicated to help you do this like PosterDB. As an example, below are two collections in my library, one collecting all the entries in a franchise, the other follows a theme.

My Star Trek collection, featuring all eleven television series, and thirteen films.
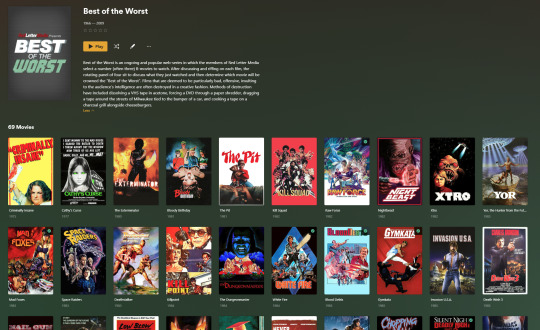
My Best of the Worst collection, featuring sixty-nine films previously showcased on RedLetterMedia’s Best of the Worst. They’re all absolutely terrible and I love them.
As for settings, ensure you've got Remote Access going, it should work automatically and be sure to set your upload speed after running a speed test. In the library settings set the database cache to 2000MB to ensure a snappier and more responsive browsing experience, and then check that playback quality is set to original/maximum. If you’re severely bandwidth limited on your upload and have remote users, you might want to limit the remote stream bitrate to something more reasonable, just as a note of comparison Netflix’s 1080p bitrate is approximately 5Mbps, although almost anyone watching through a chromium based browser is streaming at 720p and 3mbps. Other than that you should be good to go. For actually playing your files, there's a Plex app for just about every platform imaginable. I mostly watch television and films on my laptop using the Windows Plex app, but I also use the Android app which can broadcast to the chromecast connected to the TV in the office and the Android TV app for our smart TV. Both are fully functional and easy to navigate, and I can also attest to the OS X version being equally functional.
Part Eight: Finding Media
Now, this is not really a piracy tutorial, there are plenty of those out there. But if you’re unaware, BitTorrent is free and pretty easy to use, just pick a client (qBittorrent is the best) and go find some public trackers to peruse. Just know now that all the best trackers are private and invite only, and that they can be exceptionally difficult to get into. I’m already on a few, and even then, some of the best ones are wholly out of my reach.
If you decide to take the left hand path and turn to Usenet you’ll have to pay. First you’ll need to sign up with a provider like Newshosting or EasyNews for access to Usenet itself, and then to actually find anything you’re going to need to sign up with an indexer like NZBGeek or NZBFinder. There are dozens of indexers, and many people cross post between them, but for more obscure media it’s worth checking multiple. You’ll also need a binary downloader like SABnzbd. That caveat aside, Usenet is faster, bigger, older, less traceable than BitTorrent, and altogether slicker. I honestly prefer it, and I'm kicking myself for taking this long to start using it because I was scared off by the price. I’ve found so many things on Usenet that I had sought in vain elsewhere for years, like a 2010 Italian film about a massacre perpetrated by the SS that played the festival circuit but never received a home media release; some absolute hero uploaded a rip of a festival screener DVD to Usenet. Anyway, figure out the rest of this shit on your own and remember to use protection, get yourself behind a VPN, use a SOCKS5 proxy with your BitTorrent client, etc.
On the legal side of things, if you’re around my age, you (or your family) probably have a big pile of DVDs and Blu-Rays sitting around unwatched and half forgotten. Why not do a bit of amateur media preservation, rip them and upload them to your server for easier access? (Your tools for this are going to be Handbrake to do the ripping and AnyDVD to break any encryption.) I went to the trouble of ripping all my SCTV DVDs (five box sets worth) because none of it is on streaming nor could it be found on any pirate source I tried. I’m glad I did, forty years on it’s still one of the funniest shows to ever be on TV.
Part Nine/Epilogue: Sonarr/Radarr/Lidarr and Overseerr
There are a lot of ways to automate your server for better functionality or to add features you and other users might find useful. Sonarr, Radarr, and Lidarr are a part of a suite of “Servarr” services (there’s also Readarr for books and Whisparr for adult content) that allow you to automate the collection of new episodes of TV shows (Sonarr), new movie releases (Radarr) and music releases (Lidarr). They hook in to your BitTorrent client or Usenet binary newsgroup downloader and crawl your preferred Torrent trackers and Usenet indexers, alerting you to new releases and automatically grabbing them. You can also use these services to manually search for new media, and even replace/upgrade your existing media with better quality uploads. They’re really a little tricky to set up on a bare metal Ubuntu install (ideally you should be running them in Docker Containers), and I won’t be providing a step by step on installing and running them, I’m simply making you aware of their existence.
The other bit of kit I want to make you aware of is Overseerr which is a program that scans your Plex media library and will serve recommendations based on what you like. It also allows you and your users to request specific media. It can even be integrated with Sonarr/Radarr/Lidarr so that fulfilling those requests is fully automated.
And you're done. It really wasn't all that hard. Enjoy your media. Enjoy the control you have over that media. And be safe in the knowledge that no hedgefund CEO motherfucker who hates the movies but who is somehow in control of a major studio will be able to disappear anything in your library as a tax write-off.
1K notes
·
View notes
Text
Using Sims2Pack Clean Installer with The Sims 2: Legacy Collection (and Ultimate too!)
Bringing over a simple (and previously documented) tutorial on how to make Sims2Pack Clean Installer work with Sims 2 Legacy and UC. This is just an adapated version of SimsWiki's UC FAQ, so all credit goes to them. If you want a written step-by-step, please go to their website! STEP 1: Download Sims2Pack Clean Installer

Download (and install) Sims2Pack Clean Installer. This tutorial will be covering the installable version, but the NoInstall one probably works the same. STEP 2: Open the Sims2Pack Clean Installer configuration file

You will now go into the directory where you selected and installed Sims2Pack Clean Installer on. By default, it installs on the C:/ drive, so it is probably located at C:\Program Files (x86)\Sims2Pack Clean Installer. That may vary if you changed the directory.
Open the file called "S2PCI.ini". That is the configuration file that we will be altering. PS: You can use your computer's default Notepad for this, but software like Notepad++ can be easier to manage/edit.
STEP 3: Edit your Sims2Pack Clean Installer configuration to detect Sims 2 Legacy/UC

Where it says SaveGamePath="", you will add the directory where your game's Documents folder is in between the "", just like shown in the photo. - For The Sims 2: Legacy Collection, it is usually C:\Users\YourUserName\Documents\EA Games\The Sims 2 Legacy - For The Sims 2: Ultimate Collection, it is usually C:\Users\YourUserName\Documents\EA Games\The Sims 2™ Ultimate Collection
After that, simply save and replace the file. Depending on your computer settings, it might say it is not able to save. If this happens to you, simply save the edited S2PCI.ini on your desktop, then copy and paste the file inside the Sims2Pack Clean Installer folder and replace the original file (and it should always ask for you to replace the original file! check the tips below for clarification). It might ask for administrator permission, just click yes and proceed until the file is replaced with the one you just edited.

TIP: Not sure what your username is? Simple: on your File Explorer, go to Documents > EA Games > The Sims 2 Legacy (or Ultimate Collection) and click the bar. It will show the full path to the folder. Copy that path and follow the rest of this step. TIP 2: Make sure to save it as a .ini file and NOT a .txt one! If you are having difficulties with that, go to File > Save as on Notepad and select "All Files (*)" as file type. Make sure to also name it exactly as S2PCI.ini (it SHOULD ask you to replace the original file, if it did not, something is wrong. Try following the steps again making sure everything was properly followed!)
STEP 4: Install your Custom Content

The last step is to install your custom content. To make sure that Sims2Pack Clean Installer is working properly with the configuration file you edited, make sure that it shows the path written in the file when you press install. It should point to the game's Documents folder like the image above. Now that you showed the program where your Sims 2 Documents folder is, it should auto-detect where to put the files. Ta-da! Your Sims2Pack Clean Installer is done and working. Enjoy your Custom Content and Sims2Pack installing galore all you want <3
#ts2#sims2#ts2legacy#legacycollection#thesims2#the sims 2#the sims 2 legacy#sims 2#sims 2 legacy#ts2cc#sims2cc#s2cc
288 notes
·
View notes
Text

How to use DXVK with The Sims 3
Have you seen this post about using DXVK by Criisolate? But felt intimidated by the sheer mass of facts and information?
@desiree-uk and I compiled a guide and the configuration file to make your life easier. It focuses on players not using the EA App, but it might work for those just the same. It’s definitely worth a try.
Adding this to your game installation will result in a better RAM usage. So your game is less likely to give you Error 12 or crash due to RAM issues. It does NOT give a huge performance boost, but more stability and allows for higher graphics settings in game.
The full guide behind the cut. Let me know if you also would like it as PDF.
Happy simming!
Disclaimer and Credits
Desiree and I are no tech experts and just wrote down how we did this. Our ability to help if you run into trouble is limited. So use at your own risk and back up your files!
We both are on Windows 10 and start the game via TS3W.exe, not the EA App. So your experience may differ.
This guide is based on our own experiments and of course criisolate’s post on tumblr: https://www.tumblr.com/criisolate/749374223346286592/ill-explain-what-i-did-below-before-making-any
This guide is brought to you by Desiree-UK and Norn.
Compatibility
Note: This will conflict with other programs that “inject” functionality into your game so they may stop working. Notably
Reshade
GShade
Nvidia Experience/Nvidia Inspector/Nvidia Shaders
RivaTuner Statistics Server
It does work seamlessly with LazyDuchess’ Smooth Patch.
LazyDuchess’ Launcher: unknown
Alder Lake patch: does conflict. One user got it working by starting the game by launching TS3.exe (also with admin rights) instead of TS3W.exe. This seemed to create the cache file for DXVK. After that, the game could be started from TS3W.exe again. That might not work for everyone though.
A word on FPS and V-Sync
With such an old game it’s crucial to cap framerate (FPS). This is done in the DXVK.conf file. Same with V-Sync.
You need
a text editor (easiest to use is Windows Notepad)
to download DXVK, version 2.3.1 from here: https://github.com/doitsujin/DXVK/releases/tag/v2.3.1 Extract the archive, you are going to need the file d3d9.dll from the x32 folder
the configuration file DXVK.conf from here: https://github.com/doitsujin/DXVK/blob/master/DXVK.conf. Optional: download the edited version with the required changes here.
administrator rights on your PC
to know your game’s installation path (bin folder) and where to find the user folder
a tiny bit of patience :)
First Step: Backup
Backup your original Bin folder in your Sims 3 installation path! The DXVK file may overwrite some files! The path should be something like this (for retail): \Program Files (x86)\Electronic Arts\The Sims 3\Game\Bin (This is the folder where also GraphicsRule.sgr and the TS3W.exe and TS3.exe are located.)
Backup your options.ini in your game’s user folder! Making the game use the DXVK file will count as a change in GPU driver, so the options.ini will reset once you start your game after installation. The path should be something like this: \Documents\Electronic Arts\The Sims 3 (This is the folder where your Mods folder is located).
Preparations
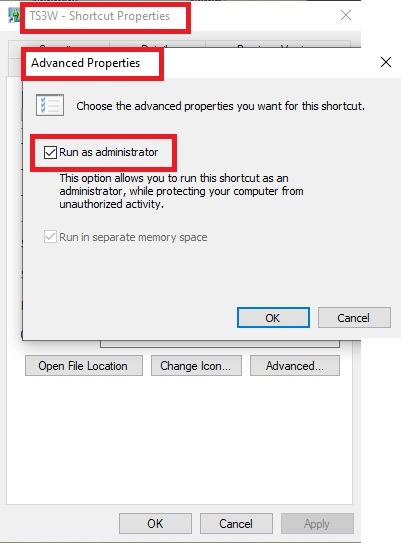
Make sure you run the game as administrator. You can check that by right-clicking on the icon that starts your game. Go to Properties > Advanced and check the box “Run as administrator”. Note: This will result in a prompt each time you start your game, if you want to allow this application to make modifications to your system. Click “Yes” and the game will load.
2. Make sure you have the DEP settings from Windows applied to your game.
Open the Windows Control Panel.
Click System and Security > System > Advanced System Settings.
On the Advanced tab, next to the Performance heading, click Settings.
Click the Data Execution Prevention tab.
Select 'Turn on DEP for all programs and services except these”:
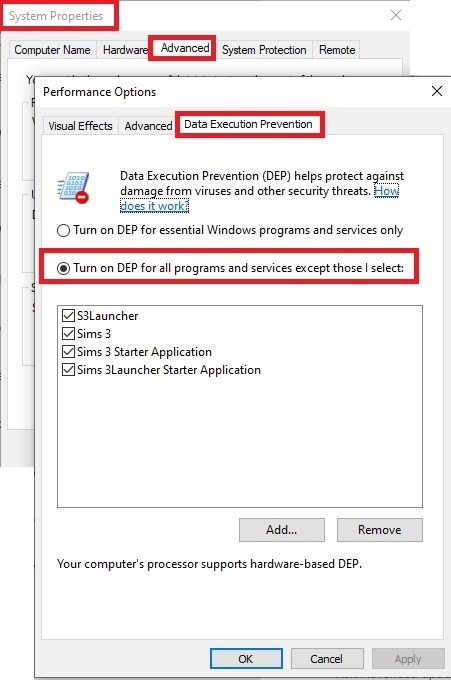
Click the Add button, a window to the file explorer opens. Navigate to your Sims 3 installation folder (the bin folder once again) and add TS3W.exe and TS3.exe.
Click OK. Then you can close all those dialog windows again.
Setting up the DXVK.conf file
Open the file with a text editor and delete everything in it. Then add these values:
d3d9.textureMemory = 1
d3d9.presentInterval = 1
d3d9.maxFrameRate = 60
d3d9.presentInterval enables V-Sync,d3d9.maxFrameRate sets the FrameRate. You can edit those values, but never change the first line (d3d9.textureMemory)!
The original DXVK.conf contains many more options in case you would like to add more settings.

A. no Reshade/GShade
Setting up DXVK
Copy the two files d3d9.dll and DXVK.conf into the Bin folder in your Sims 3 installation path. This is the folder where also GraphicsRule.sgr and the TS3W.exe and TS3.exe are located. If you are prompted to overwrite files, please choose yes (you DID backup your folder, right?)
And that’s basically all that is required to install.
Start your game now and let it run for a short while. Click around, open Buy mode or CAS, move the camera.
Now quit without saving. Once the game is closed fully, open your bin folder again and double check if a file “TS3W.DXVK-cache” was generated. If so – congrats! All done!
Things to note
Heads up, the game options will reset! So it will give you a “vanilla” start screen and options.
Don’t worry if the game seems to be frozen during loading. It may take a few minutes longer to load but it will load eventually.
The TS3W.DXVK-cache file is the actual cache DXVK is using. So don’t delete this! Just ignore it and leave it alone. When someone tells to clear cache files – this is not one of them!
Update Options.ini
Go to your user folder and open the options.ini file with a text editor like Notepad.
Find the line “lastdevice = “. It will have several values, separated by semicolons. Copy the last one, after the last semicolon, the digits only. Close the file.
Now go to your backup version of the Options.ini file, open it and find that line “lastdevice” again. Replace the last value with the one you just copied. Make sure to only replace those digits!
Save and close the file.
Copy this version of the file into your user folder, replacing the one that is there.
Things to note:
If your GPU driver is updated, you might have to do these steps again as it might reset your device ID again. Though it seems that the DXVK ID overrides the GPU ID, so it might not happen.
How do I know it’s working?
Open the task manager and look at RAM usage. Remember the game can only use 4 GB of RAM at maximum and starts crashing when usage goes up to somewhere between 3.2 – 3.8 GB (it’s a bit different for everybody).
So if you see values like 2.1456 for RAM usage in a large world and an ongoing save, it’s working. Generally the lower the value, the better for stability.
Also, DXVK will have generated its cache file called TS3W.DXVK-cache in the bin folder. The file size will grow with time as DXVK is adding stuff to it, e.g. from different worlds or savegames. Initially it might be something like 46 KB or 58 KB, so it’s really small.
Optional: changing MemCacheBudgetValue
MemCacheBudgetValue determines the size of the game's VRAM Cache. You can edit those values but the difference might not be noticeable in game. It also depends on your computer’s hardware how much you can allow here.
The two lines of seti MemCacheBudgetValue correspond to the high RAM level and low RAM level situations. Therefore, theoretically, the first line MemCacheBudgetValue should be set to a larger value, while the second line should be set to a value less than or equal to the first line.
The original values represent 200MB (209715200) and 160MB (167772160) respectively. They are calculated as 200x1024x1024=209175200 and 160x1024x1024=167772160.
Back up your GraphicsRules.sgr file! If you make a mistake here, your game won’t work anymore.
Go to your bin folder and open your GraphicsRules.sgr with a text editor.
Search and find two lines that set the variables for MemCacheBudgetValue.
Modify these two values to larger numbers. Make sure the value in the first line is higher or equals the value in the second line. Examples for values: 1073741824, which means 1GB 2147483648 which means 2 GB. -1 (minus 1) means no limit (but is highly experimental, use at own risk)
Save and close the file. It might prompt you to save the file to a different place and not allow you to save in the Bin folder. Just save it someplace else in this case and copy/paste it to the Bin folder afterwards. If asked to overwrite the existing file, click yes.
Now start your game and see if it makes a difference in smoothness or texture loading. Make sure to check RAM and VRAM usage to see how it works.
You might need to change the values back and forth to find the “sweet spot” for your game. Mine seems to work best with setting the first value to 2147483648 and the second to 1073741824.
Uninstallation
Delete these files from your bin folder (installation path):
d3d9.dll
DXVK.conf
TS3W.DXVK-cache
And if you have it, also TS3W_d3d9.log
if you changed the values in your GraphicsRule.sgr file, too, don’t forget to change them back or to replace the file with your backed up version.
OR
delete the bin folder and add it from your backup again.
B. with Reshade/GShade
Follow the steps from part A. no Reshade/Gshade to set up DXVK.
If you are already using Reshade (RS) or GShade (GS), you will be prompted to overwrite files, so choose YES. RS and GS may stop working, so you will need to reinstall them.
Whatever version you are using, the interface shows similar options of which API you can choose from (these screenshots are from the latest versions of RS and GS).
Please note:
Each time you install and uninstall DXVK, switching the game between Vulkan and d3d9, is essentially changing the graphics card ID again, which results in the settings in your options.ini file being repeatedly reset.
ReShade interface
Choose – Vulcan

Click next and choose your preferred shaders.
Hopefully this install method works and it won't install its own d3d9.dll file.
If it doesn't work, then choose DirectX9 in RS, but you must make sure to replace the d3d9.dll file with DXVK's d3d9.dll (the one from its 32bit folder, checking its size is 3.86mb.)
GShade interface
Choose –
Executable Architecture: 32bit
Graphics API: DXVK
Hooking: Normal Mode
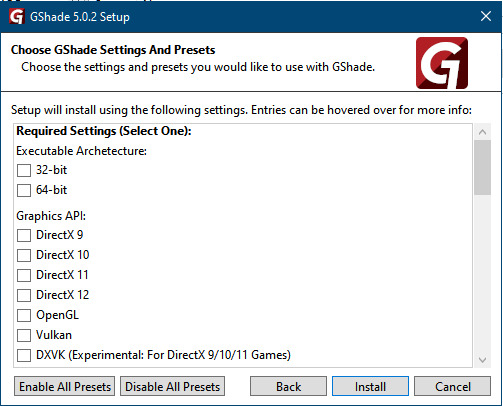
GShade is very problematic, it won't work straight out of the box and the overlay doesn't show up, which defeats the purpose of using it if you can't add or edit the shaders you want to use.
Check the game's bin folder, making sure the d3d9.dll is still there and its size is 3.86mb - that is DXVK's dll file.
If installing using the DXVK method doesn't work, you can choose the DirectX method, but there is no guarantee it works either.
The game will not run with these files in the folder:
d3d10core.dll
d3d11.dll
dxgi.dll
If you delete them, the game will start but you can't access GShade! It might be better to use ReShade.
Some Vulcan and DirectX information, if you’re interested:
Vulcan is for rather high end graphic cards but is backward compatible with some older cards. Try this method with ReShade or GShade first.
DirectX is more stable and works best with older cards and systems. Try this method if Vulcan doesn't work with ReShade/GShade in your game – remember to replace the d3d9.dll with DXVK's d3d9.dll.
For more information on the difference between Vulcan and DirectX, see this article:
https://www.howtogeek.com/884042/vulkan-vs-DirectX-12/
748 notes
·
View notes
Text
Cozybug Mod Recs: Ranching
Something about those cute little farm animals always hooks me!! I'm always on the lookout for new animal skins/retextures, or cute animals to add into the roster. Here are a few that I've played with before, all 1.6 compatible and available on Nexusmods.
Mizu's Quail

This mod has become a staple in my last three playthroughs! The quail themselves are absolutely adorable, come in up to 4 different variations, and make the cutest sounds. I especially love that they're a little cheaper than chickens, so they make a great starter coop animal when you're still pinching pennies! This mod also has compat with Animal Husbandry, if that's something you play with.
Ice Cream Cows

Who can resist a cute lil ice cream cow?? Certainly not me. These little guys come in 7 "flavors", each producing their own milk. You can either turn it into ice cream using the included machine recipe, or just make regular cheese out of it. Taste implications aside, I like the flexibility there lol. There's a whole layer of recipes, gift tastes, and buffs to explore as well once you get deeper into the mod!
Otter's Barn + Coop Animals


If you're looking for super cute reskins of the barn and coop animals, Otter has you covered! As a CP enthusiast, these are the two I've used, and they allow you to customize which skins appear in Marnie's shop when you purchase animals. There are also AT versions available though, if that's more your jam! Otter also has a collection of other animal retextures/additions, so you could make your whole farm match if you want.
Elle's Coop + Barn Animals


I would be absolutely nuts not the mention the ✨classics✨ that are "Elle's Cuter" mods. There is something just oh so satisfying about how these little guys look, especially when they're laying down for a little rest!! Absolutely adorable CP mod with tons of configurability for skins - in fact, my only criticism is that it took me AGES to decide which skins I wanted to turn on in my game from the pages and pages of options.
Livestock Bazaar

This mod 100% revolutionized Marnie's store for me, and now I won't play without it! Not only does it organize the front page for better scrolling/locating animals if you have a bunch of custom ones installed, it also has a super nice UI for choosing skins. I've been burned too often by the "random" choice that always gives me the same brown cow, so being able to preview and pick is a game changer.
70 notes
·
View notes
Text

Welcome back, coding enthusiasts! Today we'll talk about Git & Github , the must-know duo for any modern developer. Whether you're just starting out or need a refresher, this guide will walk you through everything from setup to intermediate-level use. Let’s jump in!
What is Git?
Git is a version control system. It helps you as a developer:
Track changes in your codebase, so if anything breaks, you can go back to a previous version. (Trust me, this happens more often than you’d think!)
Collaborate with others : whether you're working on a team project or contributing to an open-source repo, Git helps manage multiple versions of a project.
In short, Git allows you to work smarter, not harder. Developers who aren't familiar with the basics of Git? Let’s just say they’re missing a key tool in their toolkit.
What is Github ?
GitHub is a web-based platform that uses Git for version control and collaboration. It provides an interface to manage your repositories, track bugs, request new features, and much more. Think of it as a place where your Git repositories live, and where real teamwork happens. You can collaborate, share your code, and contribute to other projects, all while keeping everything well-organized.
Git & Github : not the same thing !
Git is the tool you use to create repositories and manage code on your local machine while GitHub is the platform where you host those repositories and collaborate with others. You can also host Git repositories on other platforms like GitLab and BitBucket, but GitHub is the most popular.
Installing Git (Windows, Linux, and macOS Users)
You can go ahead and download Git for your platform from (git-scm.com)
Using Git
You can use Git either through the command line (Terminal) or through a GUI. However, as a developer, it’s highly recommended to learn the terminal approach. Why? Because it’s more efficient, and understanding the commands will give you a better grasp of how Git works under the hood.
GitWorkflow
Git operates in several key areas:
Working directory (on your local machine)
Staging area (where changes are prepared to be committed)
Local repository (stored in the hidden .git directory in your project)
Remote repository (the version of the project stored on GitHub or other hosting platforms)
Let’s look at the basic commands that move code between these areas:
git init: Initializes a Git repository in your project directory, creating the .git folder.
git add: Adds your files to the staging area, where they’re prepared for committing.
git commit: Commits your staged files to your local repository.
git log: Shows the history of commits.
git push: Pushes your changes to the remote repository (like GitHub).
git pull: Pulls changes from the remote repository into your working directory.
git clone: Clones a remote repository to your local machine, maintaining the connection to the remote repo.
Branching and merging
When working in a team, it’s important to never mess up the main branch (often called master or main). This is the core of your project, and it's essential to keep it stable.
To do this, we branch out for new features or bug fixes. This way, you can make changes without affecting the main project until you’re ready to merge. Only merge your work back into the main branch once you're confident that it’s ready to go.
Getting Started: From Installation to Intermediate
Now, let’s go step-by-step through the process of using Git and GitHub from installation to pushing your first project.
Configuring Git
After installing Git, you’ll need to tell Git your name and email. This helps Git keep track of who made each change. To do this, run:

Master vs. Main Branch
By default, Git used to name the default branch master, but GitHub switched it to main for inclusivity reasons. To avoid confusion, check your default branch:

Pushing Changes to GitHub
Let’s go through an example of pushing your changes to GitHub.
First, initialize Git in your project directory:

Then to get the ‘untracked files’ , the files that we haven’t added yet to our staging area , we run the command

Now that you’ve guessed it we’re gonna run the git add command , you can add your files individually by running git add name or all at once like I did here

And finally it's time to commit our file to the local repository

Now, create a new repository on GitHub (it’s easy , just follow these instructions along with me)
Assuming you already created your github account you’ll go to this link and change username by your actual username : https://github.com/username?tab=repositories , then follow these instructions :


You can add a name and choose wether you repo can be public or private for now and forget about everything else for now.

Once your repository created on github , you’ll get this :

As you might’ve noticed, we’ve already run all these commands , all what’s left for us to do is to push our files from our local repository to our remote repository , so let’s go ahead and do that

And just like this we have successfully pushed our files to the remote repository
Here, you can see the default branch main, the total number of branches, your latest commit message along with how long ago it was made, and the number of commits you've made on that branch.

Now what is a Readme file ?
A README file is a markdown file where you can add any relevant information about your code or the specific functionality in a particular branch—since each branch can have its own README.
It also serves as a guide for anyone who clones your repository, showing them exactly how to use it.
You can add a README from this button:

Or, you can create it using a command and push it manually:

But for the sake of demonstrating how to pull content from a remote repository, we’re going with the first option:

Once that’s done, it gets added to the repository just like any other file—with a commit message and timestamp.
However, the README file isn’t on my local machine yet, so I’ll run the git pull command:

Now everything is up to date. And this is just the tiniest example of how you can pull content from your remote repository.
What is .gitignore file ?
Sometimes, you don’t want to push everything to GitHub—especially sensitive files like environment variables or API keys. These shouldn’t be shared publicly. In fact, GitHub might even send you a warning email if you do:

To avoid this, you should create a .gitignore file, like this:

Any file listed in .gitignore will not be pushed to GitHub. So you’re all set!
Cloning
When you want to copy a GitHub repository to your local machine (aka "clone" it), you have two main options:
Clone using HTTPS: This is the most straightforward method. You just copy the HTTPS link from GitHub and run:

It's simple, doesn’t require extra setup, and works well for most users. But each time you push or pull, GitHub may ask for your username and password (or personal access token if you've enabled 2FA).
But if you wanna clone using ssh , you’ll need to know a bit more about ssh keys , so let’s talk about that.
Clone using SSH (Secure Shell): This method uses SSH keys for authentication. Once set up, it’s more secure and doesn't prompt you for credentials every time. Here's how it works:
So what is an SSH key, actually?
Think of SSH keys as a digital handshake between your computer and GitHub.
Your computer generates a key pair:
A private key (stored safely on your machine)
A public key (shared with GitHub)
When you try to access GitHub via SSH, GitHub checks if the public key you've registered matches the private key on your machine.
If they match, you're in — no password prompts needed.
Steps to set up SSH with GitHub:
Generate your SSH key:

2. Start the SSH agent and add your key:

3. Copy your public key:

Then copy the output to your clipboard.
Add it to your GitHub account:
Go to GitHub → Settings → SSH and GPG keys
Click New SSH key
Paste your public key and save.
5. Now you'll be able to clone using SSH like this:

From now on, any interaction with GitHub over SSH will just work — no password typing, just smooth encrypted magic.
And there you have it ! Until next time — happy coding, and may your merges always be conflict-free! ✨👩💻👨💻
#code#codeblr#css#html#javascript#java development company#python#studyblr#progblr#programming#comp sci#web design#web developers#web development#website design#webdev#website#tech#html css#learn to code#github
93 notes
·
View notes
Text


MINIMALIST CAS SCREEN V2
This is a redux of my old minimalist CAS screen from a few years back, but with the lighting mod changes I did, problems started cropping up, so I decided to overhaul it.
More information and installation instructions under the cut.
Changes since V1
new wallpaper for both YACAS and CAS versions
now includes lighting configurations for the CAS rooms themselves. (Note: Both Maxis Match Lighting Mod and Cinema Secrets lighting mods have custom CAS lighting configurations built in, so unless you're using the vanilla lighting, you don't need to add in the lighting configuration changes)
Two versions available: Soft Light and Hard Light.
The differences are more obvious for those on lighting mods than vanilla (see below - soft light on the left, hard light on the right)


With lighting mods, It looks something more like this. Both are taken with MM Lighting Mod (soft light on the left, hard light on the right)


REQUIRED CC:
Invisible Floor Lamps by @nixedsims (NOT included as per their TOU since I didn't modify anything to her work)
Invisible CAS and YACAS objects by Windkeeper (NOT included - link in the text)
Keep CAS Clean - to fix the freezing sims and wandering strays problems with custom CAS screens done with Pets and Seasons installed
For the invisible objects, kindly use the following
wind_CASinvisibleroundpodium
wind_CASinvisibleobjects_nomirror
wind_CASinvisibleobjects_familypart
wind_YACASinvisibleobjects_nomirror
wind_YACASinvisibleobjects_familypart
INSTALLATION INSTRUCTIONS:
Part 1: Installing the CAS Screens
Download the required CC and drop them both in the Downloads folder.
Choose one CAS room and one YACAS room from each folder (depending on the lighting type) and drop them both in the Downloads folder. Make sure not to rename the CAS! and YACAS! packages otherwise they will not work.
Part 2: Installing the Lighting Configuration
If you're either a Maxis Match Lighting Mod or Cinema Secrets Lighting Mod user, no need to do anything else, as the configuration changes, customized to each mod, are included in the main files for each lighting mod. Just make sure you're on the latest version of either mod.
If you're a vanilla lighting user, copy both lighting configuration files in the VANILLA_LIGHTING_CONFIG folder into your Base Game Lights folder.
If you're a Radiance Lighting System 2.4 user (NOT my Radiance 2.5 mod, that is unsupported and I suggest any existing users to jump over to Cinema Secrets), copy both lighting configuration files in the RADIANCE_2.4_LIGHTING_CONFIG in the Base Game Lights folder (Note: I used @bugjartimedecayoff's edit as base as this is the most stable RLS 2.4 lighting config available currently)
Paths would depend on what installation you're running on
Ultimate Collection (Origin, Starter Pack, MagiPack repack: "Double Deluxe/Base/TSData/Res/Lights"
Disc version: "The Sims 2/TSData/Res/Lights"
Legacy Collection: "Base/TSData/Res/Lights"
NOTE: Radiance fixes are untested as I don't really use this lighting mod.
DOWNLOAD
65 notes
·
View notes
Text
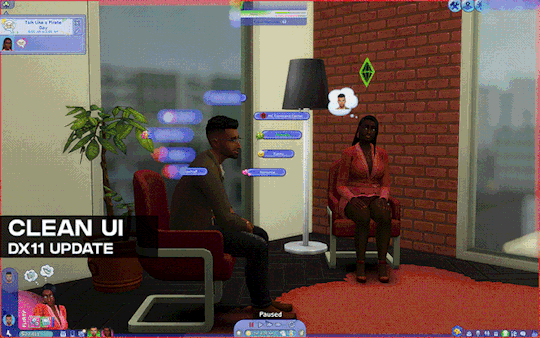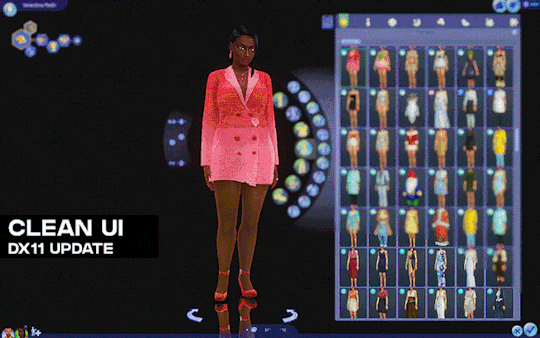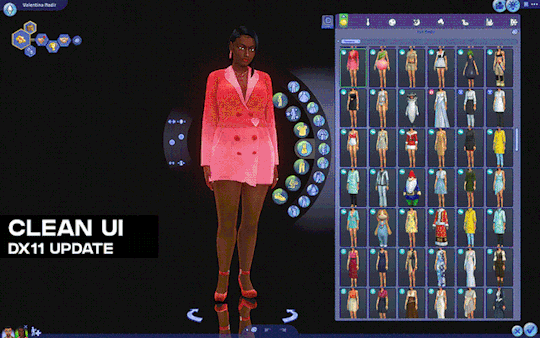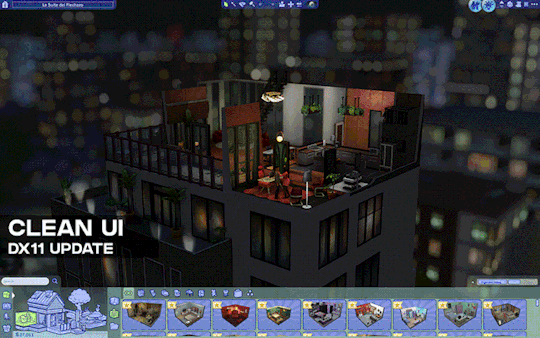
[Reshade add-on] Clean UI for DX11
After so so sooooo many crashes later, I finally managed to create a working setting for this add-on for DX11 games by using an older REST version 🫠
You can read the whole post on Patreon here, or below the cut for those who can't access the site.

As using REST 1.2.0 and above cause crashes whenever I create a setting or attempt to use it for a brief amount of time, I decided to use a much older version of REST (1.1.0), which turns out to be more stable to configure and use. While this means being able to use the add-on for the DX11 game, it has its own set of problems, which may/may not be a dealbreaker for some.
I decided to make a new post since the original one is quite lengthy and I want to keep DX9 and DX11 versions separate due to the different information each version has.
➡️ For the DX9 version, find it here. And here for the Patreon post.
In short, with the help of REST (an add-on for reshade/gshade), you can block/prevent shaders from affecting the UI.
// Things to know if using this version ⚠️
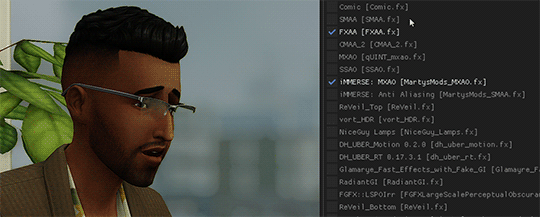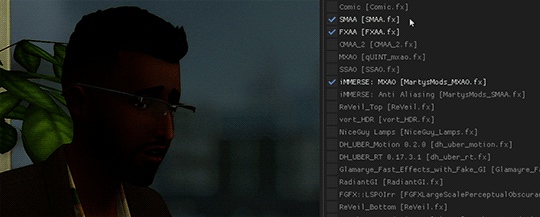
Some shaders will not work properly and will cause some gamma issues. If your preset look different than how it normally is (a lot darker/brighter), enable/disable your active shaders and see which one is causing it. It's easily fixed by using an alternative shader that achieve a similar look.
Shaders affected (ones I've known so far): SMAA & MartysMods_SMAA (FMAA is not affected, use this instead), FilmicAnamorphSharpen, ArcaneBloom & NeoBloom, Glamarye_Fast_Effects, MagicHDR, CRT_Lotte.
You will not be able to change your window resolution, either via graphic settings or by using SRWE. This will cause your game to stop and eventually having to force stop it with the task manager. It is recommended that you have your game in Windowed Fullscreen to avoid issues and have the add-on disabled if you want to change the resolution in-game.
// Required Files
REST add-on v 1.1.0 (testing)
REST config for v 1.1.0 (simfileshare only)
// Installation
Have ReShade with full add-on support installed for this to work.
Download the REST_ x64_1.1.0 add-on from the github linked in the requirements section as well as the config.
Extract the ReshadeEffectShaderToggler.addon file into the game's \Bin folder where your TS4_64.exe is (where you had also installed ReShade).
If you use GShade: place the .addon file in the gshade-addons folder.
Still in the \Bin folder, drop the x.x_ReshadeEffectShaderToggler_DX11.ini file you downloaded.
If you use GShade: place the .ini file in the gshade-addons folder along with the .addon file. If my config doesn't show up in the add-on menu, move it back to the \Bin folder.
Rename the file and remove the prefix and suffix. Both .addon and .ini file should share the same name for the add-on to recognize my settings = [ ReshadeEffectShaderToggler.ini ]
Open up your game. If you see the same menu as below then you’ve successfully installed the add-on & settings! Restart if needed.
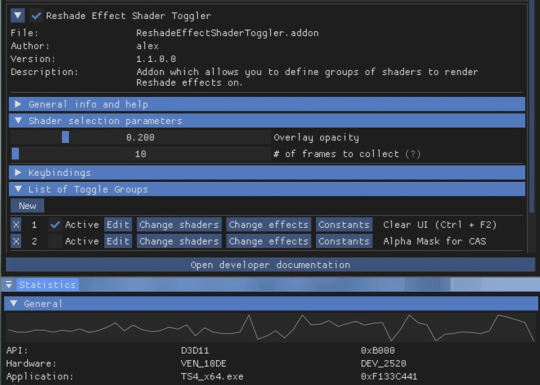
I've set the shortcuts for Clear UI to match with my Effect toggle key, which is Ctrl + F2. If yours are set differently, match the shortcut of this toggle group with your effect toggle key:
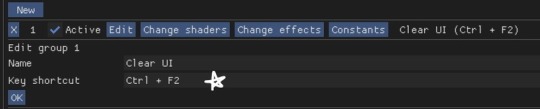
Reason being, having the toggle group active will prevent you from enabling/disabling your preset. Changing the shortcut will allow you to disable & enable your preset and toggle group at the same time.
To avoid the add-on from not working, make sure to do the following:
Enable post processing effects
Disable laptop mode & edge smoothing
Set 3d scene resolution to high
As long as all of the above are met, you should not encounter any problems. This has been tested to work on all graphics settings from low to ultra. External modifications (like Simp4Settings) may/may not have an effect, but from the testing I've done it has shown no problems so far.
215 notes
·
View notes
Text
Downloading fanfic from AO3
I've been downloading a lot of fanfic lately for personal archival purposes, and I figured I'd share how I do it in case it's useful to anyone else (and so I have it written down in case I forget!).
There are lots of different ways to save fic, including the file download built into AO3, but I find that this gives me the nicest ebooks in the most efficient way.
(Under a cut cause long.)
Download Calibre: https://calibre-ebook.com/ or (clickable link).
Calibre is about the best ebook management and control program around and it's free. You can get it for windows, mac, and linux or download and run it from a portable storage device (I'm using a windows PC).
Install it and run it. It's gonna ask you where you want to put your library. Dealer's choice on this one. I recommend your internal drive (and then back up to external/cloud), but YMMV.
If you want to keep fanfic separate from the rest of your ebooks, you can create multiple libraries. I do, and my libraries are creatively named 'Books' and 'Fic'.
Customise Calibre
Now you're gonna install some plugins. Go to Preferences on the menu bar (far right), click its little side arrow, then choose 'Get plugins to enhance Calibre'.
At the top right of the box that pops up is 'Filter by name'. The plugins you want to get are:
EpubMerge
FanFicFare
Install them one at a time. It will ask you where you want them. I recommend 'the main bar' and 'the main bar when device is attached' (should be selected by default). When you're done, close and reopen Calibre.
The plugins you just installed should appear on the far right of the toolbar, but if you can't see one or both of them, fear not! Just click Preferences (the button, not the side arrow), then Toolbars and Menus (in the 'Interface' section) then choose the main toolbar from the drop down menu. That will let you add and remove things - I suggest getting rid of Donate, Connect Share, and News. That'll leave you room to add your new plugins to the menu bar.
(Do donate, though, if you can afford it. This is a hell of a program.)
Now you're ready to start saving your fave fanfic!
Saving fanfic
I'll go through both methods I use, but pick whatever makes you happy (and/or works best for what you're downloading).
ETA: if the fics are locked you can't easily use FanFicFare. Skip down to the next section. (It does ask for a username/password if you try and get a locked fic, but it's never worked for me - I had to edit the personal.ini in the configuration options, and even then it skips locked fics in a series.)
Calibre and FanFicFare
You can work from entirely within Calibre using the FanFicFare plugin. Just click its side arrow and pick from the menu. The three main options I use are download from URL, make anthology from a webpage, and update story/anthology.
Download from URL: pick Download from URL (or just click the FanFicFare button) and paste the fic's URL into the box (if you've copied it to your clipboard, it will be there automatically). You can do more than one fic at a time - just paste the URLs in one after the other (each on a new line). When you're done, make sure you have the output format you want and then go.
Make Anthology Epub From Web Page: if you want a whole series as a single ebook, pick Anthology Options, then Make Anthology Epub From Webpage. Paste the series URL into the box (if you've copied it to your clipboard, it will be there automatically), click okay when it displays the story URLs, check your output format and go.
Update series/anthology: if you downloaded an unfinished fic or series and the author updates, you can automatically add the update to your ebook. Just click on the ebook in Calibre, open the FanFicFare menu using its side arrow, and select either Update Existing FanFic Books or Anthology Options, Update Anthology epub. Okay the URLs and/or the output format, then go.
Any fic downloaded using FanFicFare will be given an automatically generated Calibre cover. You can change the cover and the metadata by right clicking on the title and picking edit metadata. You can do it individually, to change the cover or anything else specific to that ebook, or in bulk, which is great for adding a tag or series name to multiple fics. Make sure you generate a new cover if you change the metadata.
Browser plugins, Calibre, and EpubMerge
You can also use a browser addon/plugin to download from AO3. I use FicLab (Firefox/Chrome), but I believe there's others. FicLab: https://www.ficlab.com/ (clickable link).
FicLab puts a 'Save' button next to fic when you're looking at a list of fics, eg search results, series page, author's work list etc. Just click the 'Save' button, adjust the settings, and download the fic. You can also use it from within the fic by clicking the toolbar icon and running it.
FicLab is great if you're reading and come across a fic you want to save. It also generates a much nicer (IMO) cover than Calibre.
You can add the downloaded fic to Calibre (just drag and drop) or save it wherever. The advantage to dropping it into Calibre is that all your fic stays nicely organised, you can adjust the metadata, and you can easily combine fics.
Combining fics
You can combine multiple fics into an anthology using EpubMerge. This is great if you want a single ebook of an author's short fics, or their AUs, or their fics in a specific ship that aren't part of a series. (It only works on epubs, so if you've saved as some other format, you'll need to convert using Calibre's Convert books button.)
Select the ones you want to combine, click EpubMerge, adjust the order if necessary, and go.
The cover of the merged epubs will be the cover of the first fic in the merge list. You can add a new cover by editing the metadata and generating a new cover.
Combing with FanFicFare
You can also combine nonseries fics using FanFicFare's Make Anthology ePub from URLs option by pasting the individual fic URLs into the box.
Where there's more than a few fics, I find it easier to download them with FicLab and combine them with EpubMerge, and I prefer keeping both the combined and the individual versions of fic, but again YMMV.
Reconverting and Converting
Once I'm done fussing, I reconvert the ebook to the same format, to ensure everything is embedded in the file. Is this necessary? YMMV, but it's a quick and easy step that does zero harm.
If you don't want your final ebook to be an epub, just convert it to whatever format you like.
Disclaimers
Save fanfic for your own personal enjoyment/offline reading/safeguarding against the future. If it's not your fic, don't distribute it, or upload it to other sites, or otherwise be a dick. Especially if the author deletes it. Respect their wishes and their rights.
This may work on other fanfic sites, eg FFN, but I've never tried so I don't know.
If you download a fic, do leave the author a kudo or a comment; you'll make them so happy.
This is how I save fic. I'm not pretending it's the only way, or even the best way! This is just the way that works for me.
#fanfic#fic#ao3#ficlab#calibre#fanficfare#epubmerge#downloading fanfic#adding the my fic tag so I can find this again#my fic
1K notes
·
View notes
Text
Fix PXE Boot Stuck or No Boot Image was found for HyperV VM
In this article, we shall discuss how to “fix PXE Boot Stuck or No Boot Image was found for HyperV VM. The bootloader did not find any operating system”. This means that the bootloader could not find a bootable image from the network to boot the VM. Please see Linux Boot Process Explained Step by Step for Beginners, and how to Fix Windows Stuck on System Restore. Here is how to Fix Hyper-V VM…
#Add CD/DVD Drive drive on Hyper-V#Hyper V#hyperV#HyperV tutorial#HyperV VM#Microsoft Windows#Post VM Installation Configuration#PXE Boot Stuck#PXE Server Setup#Virtual Machine#Virtual Machine Failed#Virtual Machines#VM#VMs#Windows#Windows 10#Windows 11#Windows Server#Windows Server 2012#Windows Server 2016#Windows Server 2019#Windows Server 2022
0 notes
Note
Amy tips for getting 30 prebuilt pcs for 1500$ each
We're going to play a game where I show tumblr what I do at work by doing it on tumblr. You can answer my questions in successive anonymous asks. My responses to you will be bracketed by dashed lines, with instructions and commentary before and after.
---------------------------
Hi Anon!
I can definitely help you with your desktop needs. Can you tell me whether you're looking minimize your costs, or get the maximum amount of computer that I can get you for a per-unit price of $1500?
Here are some details that will help me narrow down options that are a good fit for your situation:
Very generally, what will these be for? Basic office use (browsing, office suite)? Video Production? CAD? Finance? Medical providers? Educators?
What date are you looking to have these machines in place?
Is there a specific type of software that you know will be installed on these devices, and if so can you get me the hardware specs required by the software vendor?
Please let me know if you've got any questions, or if there is anything that I can do for you.
Thanks! - Ms-D
-----------------------------
The average cost of business desktops that I sell at work is $700-$900; these are devices that I would give an anticipated lifespan of 7 years, with hardware upgrades planned at 5 years. This is for a mid-range desktop with a 3-year next business day onsite warranty, no software, and does not include the cost of tax, shipping, or configuration. The cost of labor can come close to the cost of the machine for configuration. If I were *PERSONALLY* deploying these machines (pulling them out of the box, debloating, creating profiles, installing software, reboxing, transporting to the site, installing and connecting to peripherals) I'd probably charge around $200-300 per device. My work charges a lot more. Because of that, a 1500 computer is quite likely to be a 700 computer with three hours of estimated labor. If you've got an in-house IT department and aren't going to be paying through the nose for setup, you can get *a lot* of business-class computer for $1500.
If someone at work asked me for a $1500 computer, I would assume that was the cost of the machine ONLY, no peripherals, no configuration, no installation, no software, though I would try to consider both tax and our markup and would look for devices that would maximize performance while under-but-close-to the mark. If I found something that was slightly over (say by up to $70), I would drop our markup to get closer to the client's budget.
What this means for YOU, the computer consumer, is that when you're looking at a computer you need to consider the following in your budget, NOT just the sticker price.
Computer Cost
Software Cost
Setup Cost (if you're not doing it yourself)
Shipping Cost
Tax
Peripherals (computers almost all come with a mouse and a keyboard, these are usually inexpensive but very sturdy; if you want a nice keyboard and an ergonomic mouse you have to buy your own)
Whether you will LOSE peripherals when you replace your current device - do you need to buy an external optical disk drive if your old machine had a CD drive but the new machine doesn't?
Those things can add hundreds of dollars to your total cost, so figure out how much that will be so that you can figure out what your ACTUAL budget for your computer is.
(Also your computer shouldn't be plugged directly into the wall; if you're getting ready to replace a machine and you don't already own a desktop UPS, a desktop UPS should be part of the cost of your next machine!)
118 notes
·
View notes
Text
Mod Updates
As always delete old Mods Files and the localthumbcache, when updating my Mods!
---
More Servings Options - Cakes In Baking Menu Part Added some more Recipes to Baking Menu from the Cupcake Factory like Chocolate Biscotti, Cream Tarts, Glazed Doughnuts etc.
Foster Family Foster Kids should be able to autonomously sleep again, instead of just napping.
Live in Services Live in Service NPCs should be able to autonomously sleep again, instead of just napping.
Roommates Roommates should be able to autonomously sleep again, instead of just napping.
Send Sims to Bed Fixed an Issue with Sims trying to use a Bed as a Sleeping Bag and complaining before finally using it as a Bed. When using the "Bedtime" Addon Interaction Sims should be able to autonomously sleep again, instead of just napping.
Random Bug Fix
Change Diaper via Changing Table Fix Added a few more "change Diaper" Interactions to be considered by the Fix.
---
Mod Manifests Info
The Mods above got manifested for the new PlumbBuddy App (https://plumbbuddy.app/).
What is PlumbBuddy and what does Manifest mean?
PlumbBuddy is a new App for Sims 4 Players created by Sims 4 Players, which helps with Mod Installation Issues & Game Configuration Issues. When Modders add Manifests to their Mods, PlumbBuddy knows what Files are required for the Mod to work correctly, and will tell you if those are missing, or when you installed all Versions of a Mod, where you should have chosen one. Since a lot of my Mods do actually require Files (XML Injector) I will add step by step Manifests to them either when I update them for other Updates or in an extra "Manifest" Update.
Do I need PlumbBuddy for your Mods to work? No. PlumbBuddy is an external App and is not required, but when you do use it, my Mods with Manifests will be shown in it's Catalog, and PlumbBuddy can help you with Installation Issues.
---
My Site with all possible Download Links: lms-mods.com
Support Questions via Discord only please!
107 notes
·
View notes
Text
Lot Previews and Build/Buy Mode Mods I use
Finally! Pretty much everything I had on my old Simblr has been reposted here! Thank you for your interest in these homes. I hope they continue to bring a smile to your face as you play with them. 😊
Here are some previews of the lots I've been polishing up recently. Fun fact: 90% of these lots started out as houses I built for my kids' sims families when they were young (ah how the years fly by!).
These will eventually get uploaded at least that's the plan as I have more time.
Here's where I could use your feedback though:
I love to build and landscape, but decorating the insides...not quite as much.😅
I'd be able to put these lots up faster if you're ok with furnishing and decorating them yourself. I'd add things like kitchens and bathrooms and place beds in the bedrooms.
What do you think? Scroll through and let me know!












I am using Reshade 4.91 for the images that you see. That link will take you to Reshade's official repository folder for Reshade 4.0 series downloads.
Other than cropping and resizing, this is how they look in my game. I'm blessed enough to have a machine that will let me play with this beautiful custom LUT I configured. It helps to see bright, happy colors, especially in winter. 😎
So now a few words about the mods or hacks I use to make building a whole lot more fun, considering I play with very little CC in my game.
I use a number of building cheats such as 'allow45degreeangleofrotation true', 'boolprop snapobjectstogrid false', "setquartertileplacement on", and of course, "moveobjects". If you notice an object blocking something feel free to move/remove it. Grab this mod to allow your sims to sit in chairs placed at 45 degree angles.
I use a lot of shiftable decor mods: shiftable wall lamps, ceiling deco made shiftable, shiftable wall decor. The other day I ran across this mod that allows you to shift just about anything up or down, so I may switch to this in the future. Today I came across Fway's Object Freedom mod which I'm going to start testing out since it includes the "Shiftable Everything" mod. If you've been frustrated by the limits of where things can be placed in order to be used, this might be the answer!
I also use a few default replacements (head over here for a more complete list):
CuriousB's Lush Terrain
Peppermint & Ginger's Shrub defaults
TVickie's Phlox default replacement
PineappleForest's Spiderlily texture default (along with a number of other defaulted things).
Fway's Default Garden Plot
Less saturated BG flowers (I can use the poppies finally!)
Lunatech Lighten Up Ceiling Light Placement Fix
I do use a few other things but these are the primary ones.
And as far as CC goes, these are the only items you'll have to deal with (Use Sims 2 Pack Clean Installer to remove any of these things if you don't want them in your game):
Anything Maxis "Lost and Found", preorder "Bonus" items, or items that were offered on the Sims 2 website. I'll label this in the lot post.
Functional Washer/dryer
Maxis Match Wall Cabinets by CTNutmegger at ModtheSims
Maxis Match Chimney Recolors: Brick, Stucco, Southwestern Style Stucco, Masonry
So there you have a short list of things I have in my game that you may already have in yours, but if not, you now know where to find them. :) I'm looking forward to hearing your feedback on what I should do with the lots (since my time is pretty limited by real life responsibilities). 🎉😄
#ts2 build#sims 2 lots#residential lots#ts2 screenshots#sims 2 build#sims 2 house#lot#sims 2 mods#ts2 mods#ts2 resources#resources
68 notes
·
View notes
Text
I present to your attention the finished version of the modified Sims Medieval launcher :
⭐TSM+ ⭐
What is it and what is it for?
This is a simplified way to install mods and cc. Add content to the game:
The Mods folder, Packages and the Resource file are fully configured correctly, lying in their places. All you need to do is put them in your The Sims Medieval folder, and you can use the mods without any unnecessary movements. No more modding failures due to accidentally incorrect location or spelling!
A new program to launch TSM to quickly change the appearance of the kingdom.

How is that?
📍 Inside the Mods folder there are several ready-made EMPTY subfolders (Winter - winter, Summer - summer, Fall - autumn, Spring - spring, Dark_world - gloomy world, Rural_life - rural life), which should be filled with default substitutions of worlds on the appropriate themes (or wait for our filling using special kits 💜) 📍After launch After selecting the desired option with a number, the current type of kingdom will be automatically replaced and the game will start. 📍You can change the appearance of the kingdom with one click at least every time you log into the game (which we are doing ourselves now, creating a set of seasons - we need a different season for the screenshots each time) 📍Make yourself a shortcut to the new launcher on your desktop and forget about the native version of the game
UPD: I changed the encoding (because the old one didn't work for many) and added automatic cache deletion before starting the game.
32 notes
·
View notes
Text
idk why but microsoft is adding text formatting and shit into notepad completely killing the "just a text editor" part of it. but they made wordpad! which is just "notepad but rich text editing" already!
and then! they made "Edit" WHICH IS JUST NOTEPAD but runs in your terminal, no extra features or anything just like old pre-windows 11 notepad but with some features like line endings proper indentation configuration and shit. im happy it exists but why did we do this. wordpad and notepad already existed why did we move them around and add another one.
anyway if you're a windows user download Edit (winget install -e --id Microsoft.Edit) and play around with the terminal, by changing directories and opening and editing files. its a good skill to have
21 notes
·
View notes