#ml data labeling
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The average Tumblr user visits about 67 pages every month.
Text
Generative AI | High-Quality Human Expert Labeling | Apex Data Sciences
Apex Data Sciences combines cutting-edge generative AI with RLHF for superior data labeling solutions. Get high-quality labeled data for your AI projects.
#GenerativeAI#AIDataLabeling#HumanExpertLabeling#High-Quality Data Labeling#Apex Data Sciences#Machine Learning Data Annotation#AI Training Data#Data Labeling Services#Expert Data Annotation#Quality AI Data#Generative AI Data Labeling Services#High-Quality Human Expert Data Labeling#Best AI Data Annotation Companies#Reliable Data Labeling for Machine Learning#AI Training Data Labeling Experts#Accurate Data Labeling for AI#Professional Data Annotation Services#Custom Data Labeling Solutions#Data Labeling for AI and ML#Apex Data Sciences Labeling Services
1 note
·
View note
Text
#multi-label classification#machine learning#classification techniques#AI#ML algorithms#quick insights#data science
0 notes
Text
Streamline Computer Vision Workflows with Hugging Face Transformers and FiftyOne
0 notes
Text
Decoding the Power of Speech: A Deep Dive into Speech Data Annotation

Introduction
In the realm of artificial intelligence (AI) and machine learning (ML), the importance of high-quality labeled data cannot be overstated. Speech data, in particular, plays a pivotal role in advancing various applications such as speech recognition, natural language processing, and virtual assistants. The process of enriching raw audio with annotations, known as speech data annotation, is a critical step in training robust and accurate models. In this in-depth blog, we'll delve into the intricacies of speech data annotation, exploring its significance, methods, challenges, and emerging trends.
The Significance of Speech Data Annotation
1. Training Ground for Speech Recognition: Speech data annotation serves as the foundation for training speech recognition models. Accurate annotations help algorithms understand and transcribe spoken language effectively.
2. Natural Language Processing (NLP) Advancements: Annotated speech data contributes to the development of sophisticated NLP models, enabling machines to comprehend and respond to human language nuances.
3. Virtual Assistants and Voice-Activated Systems: Applications like virtual assistants heavily rely on annotated speech data to provide seamless interactions, and understanding user commands and queries accurately.
Methods of Speech Data Annotation
1. Phonetic Annotation: Phonetic annotation involves marking the phonemes or smallest units of sound in a given language. This method is fundamental for training speech recognition systems.
2. Transcription: Transcription involves converting spoken words into written text. Transcribed data is commonly used for training models in natural language understanding and processing.
3. Emotion and Sentiment Annotation: Beyond words, annotating speech for emotions and sentiments is crucial for applications like sentiment analysis and emotionally aware virtual assistants.
4. Speaker Diarization: Speaker diarization involves labeling different speakers in an audio recording. This is essential for applications where distinguishing between multiple speakers is crucial, such as meeting transcription.
Challenges in Speech Data Annotation
1. Accurate Annotation: Ensuring accuracy in annotations is a major challenge. Human annotators must be well-trained and consistent to avoid introducing errors into the dataset.
2. Diverse Accents and Dialects: Speech data can vary significantly in terms of accents and dialects. Annotating diverse linguistic nuances poses challenges in creating a comprehensive and representative dataset.
3. Subjectivity in Emotion Annotation: Emotion annotation is subjective and can vary between annotators. Developing standardized guidelines and training annotators for emotional context becomes imperative.
Emerging Trends in Speech Data Annotation
1. Transfer Learning for Speech Annotation: Transfer learning techniques are increasingly being applied to speech data annotation, leveraging pre-trained models to improve efficiency and reduce the need for extensive labeled data.
2. Multimodal Annotation: Integrating speech data annotation with other modalities such as video and text is becoming more common, allowing for a richer understanding of context and meaning.
3. Crowdsourcing and Collaborative Annotation Platforms: Crowdsourcing platforms and collaborative annotation tools are gaining popularity, enabling the collective efforts of annotators worldwide to annotate large datasets efficiently.
Wrapping it up!
In conclusion, speech data annotation is a cornerstone in the development of advanced AI and ML models, particularly in the domain of speech recognition and natural language understanding. The ongoing challenges in accuracy, diversity, and subjectivity necessitate continuous research and innovation in annotation methodologies. As technology evolves, so too will the methods and tools used in speech data annotation, paving the way for more accurate, efficient, and context-aware AI applications.
At ProtoTech Solutions, we offer cutting-edge Data Annotation Services, leveraging expertise to annotate diverse datasets for AI/ML training. Their precise annotations enhance model accuracy, enabling businesses to unlock the full potential of machine-learning applications. Trust ProtoTech for meticulous data labeling and accelerated AI innovation.
#speech data annotation#Speech data#artificial intelligence (AI)#machine learning (ML)#speech#Data Annotation Services#labeling services for ml#ai/ml annotation#annotation solution for ml#data annotation machine learning services#data annotation services for ml#data annotation and labeling services#data annotation services for machine learning#ai data labeling solution provider#ai annotation and data labelling services#data labelling#ai data labeling#ai data annotation
0 notes
Text
Top 7 Data Labeling Challenges and Their Solution
Addressing data labeling challenges is crucial for Machine Learning success. This content explores the top seven issues faced in data labeling and provides effective solutions. From ambiguous labels to scalability concerns, discover insights to enhance the accuracy and efficiency of your labeled datasets, fostering better AI model training. Read the article:…

View On WordPress
#data annotation#data annotation companies#data annotation company#data annotation for AI/ML#Data Annotation in Machine Learning#data labeling
0 notes
Photo

Nvidia has announced the availability of DGX Cloud on Oracle Cloud Infrastructure. DGX Cloud is a fast, easy and secure way to deploy deep learning and AI applications. It is the first fully integrated, end-to-end AI platform that provides everything you need to train and deploy your applications.
#AI#Automation#Data Infrastructure#Enterprise Analytics#ML and Deep Learning#AutoML#Big Data and Analytics#Business Intelligence#Business Process Automation#category-/Business & Industrial#category-/Computers & Electronics#category-/Computers & Electronics/Computer Hardware#category-/Computers & Electronics/Consumer Electronics#category-/Computers & Electronics/Enterprise Technology#category-/Computers & Electronics/Software#category-/News#category-/Science/Computer Science#category-/Science/Engineering & Technology#Conversational AI#Data Labelling#Data Management#Data Networks#Data Science#Data Storage and Cloud#Development Automation#DGX Cloud#Disaster Recovery and Business Continuity#enterprise LLMs#Generative AI
0 notes
Text
Top 7 branches of Artificial Intelligence you shouldn’t Miss Out on
This new and emerging world of big data, ChatGPT, robotics, virtual digital assistants, voice search, and recognition has all the potential to change the future, regardless of how AI affects productivity, jobs, and investments. By 2030, AI is predicted to generate $15.7 trillion for the global economy, which is more than China and India currently produce together.
Many different industries have seen major advancements in artificial intelligence. Systems that resemble the traits and actions of human intelligence are able to learn, reason, and comprehend tasks in order to act. Understanding the many artificial intelligence principles that assist in resolving practical issues is crucial. This can be accomplished by putting procedures and methods in place like machine learning, a subset of artificial intelligence.

Computer vision :The goal of computer vision, one of the most well-known disciplines of artificial intelligence at the moment, is to provide methods that help computers recognise and comprehend digital images and videos. Computers can recognise objects, faces, people, animals, and other features in photos by applying machine learning models to them. Computers can learn to discriminate between different images by feeding a model with adequate data. Algorithmic models assist computers in teaching themselves about the contexts of visual input. Object tracking is one example of the many industries in which computer vision is used for tracing or pursuing discovered stuff.
Classification of Images: An image is categorised and its membership in a given class is correctly predicted.
Facial Identification: On smartphones, face-unlock unlocks the device by recognising and matching facial features.
Fuzzy logic: Fuzzy logic is a method for resolving questions or assertions that can be true or untrue. This approach mimics human decision-making by taking into account all viable options between digital values of “yes” and “no.” In plain terms, it gauges how accurate a hypothesis is. This area of artificial intelligence is used to reason about ambiguous subjects. It’s an easy and adaptable way to use machine learning techniques and rationally mimic human cognition.
Expert systems :Similar to a human expert, an expert system is a computer programme that focuses on a single task. The fundamental purpose of these systems is to tackle complex issues with human-like decision-making abilities. They employ a set of guidelines known as inference rules that are defined for them by a knowledge base fed by data. They can aid with information management, virus identification, loan analysis, and other tasks by applying if-then logical concepts.
Robotics
Robots are programmable devices that can complete very detailed sets of tasks without human intervention. They can be manipulated by people using outside devices, or they may have internal control mechanisms. Robots assist humans in doing laborious and repetitive activities. Particularly AI-enabled robots can aid space research by organisations like NASA. Robotic evolution has recently advanced to include humanoid robots, which are also more well-known.
Machine learning: Machine learning, one of the more difficult subfields of artificial intelligence, is the capacity for computers to autonomously learn from data and algorithms. With the use of prior knowledge, machine learning may make decisions on its own and enhance performance. In order to construct logical models for future inference, the procedure begins with the collecting of historical data, such as instructions and firsthand experience. Data size affects output accuracy because a better model may be built with more data, increasing output accuracy.
Neural networks/deep learning :Artificial neural networks (ANNs) and simulated neural networks (SNNs) are other names for neural networks. Neural networks, the core of deep learning algorithms, are modelled after the human brain and mimic how organic neurons communicate with one another. Node layers, which comprise an input layer, one or more hidden layers, and an output layer, are a feature of ANNs. Each node, also known as an artificial neuron, contains a threshold and weight that are connected to other neurons. A node is triggered to deliver data to the following network layer when its output exceeds a predetermined threshold value. For neural networks to learn and become more accurate, training data is required.
Natural language processing :With the use of natural language processing, computers can comprehend spoken and written language just like people. Computers can process speech or text data to understand the whole meaning, intent, and sentiment of human language by combining machine learning, linguistics, and deep learning models. For instance, voice input is accurately translated to text data in speech recognition and speech-to-text systems. As people talk with different intonations, accents, and intensity, this might be difficult. Programmers need to train computers how to use apps that are driven by natural language so that they can recognise and understand data right away.
About Us :Are you looking for Object Recognition or any other Data Labeling service? To improve the performance of your AI and ML models, Data Labeler offers best-in-class training datasets. Check out few Use Cases and contact us if you have any in mind.
0 notes
Text
good evening mothers and fuckers of the jury today i bring: Amphoreus Is A Neural Network
my credentials: i’m a first year CS student in 2025.
if y’all’ve been on hsrtwt in the past few days and watching leak after leak come out, then you probably know what i’m yapping about. if not, check this, this, this, and this out.
if you’d rather wait for 3.4 to come out, this is your chance to scroll. rest of y’all are with me lets go gamers
to summarise the 3.4 leaks, lygus and cyrene are apparently running tests on phainon to make the perfect lord ravager, and phainon’s been through 33550336 loops (girl help him wtf) by now. in each loop, he has to watch everyone die over and over again, and phainon, obvi, cannot remember anything. each loop, he’s a complete blank slate, ready to be traumatised over and over again. lygus keeps track of each loop, and keeps refining the data he puts in at the start of each timeloop to remove the ‘imperfections’ from the previous loop that were corrupting his experiments.
ok anyways this is not about this shit we’re here to talk about why amphoreus is a neural network.
all of us here hate ai so i’m pretty sure you know the basic strokes of how it works, but if you don’t, then here’s a simple explanation: a neural network works based on input data. there’s many methods to training a machine, but the most generalised ones are the supervised vs the unsupervised models. how they work is what’s on the lid: supervised models mean that the input data is clearly labeled, and unsupervised models mean the input data is not labeled, which forces the ML algorithm to identify data on its own. based on what we know, i’m inclined to think that lygus is probably using a supervised model each time by removing outlier data and/or noise.
wonderful, let’s talk about mydei now. y’all’ve probably seen a bunch of theories and leaks, but mydei’s highly likely to be a glitch in the system, or even worse, might be a virus that someone’s trying to use to break everyone out of this loop. between all of the theories i’ve seen, the one that connects mydei to the amphoreus loop is the theory that he’s a type of fileless malware.
Tweet ref: https://x.com/tts_maruadelei/status/1932082549217751271
much like the other chrysos heirs, mydei doesn’t actually exist, but let me say: ain’t it interesting how mydei, the demigod of strife, who should have risen to be a titan that governed disputes, is the one who caused glitches in lygus’ system during the forgotten years?
let’s go back to the theory for a second: fileless attacks, simplified, operate based off of memory alone, which makes it much, much harder to detect compared to normal malware and viruses in a computer system. these fileless attacks can manifest in multiple ways, and one of those ways is a Distributed Denial of Service attack, aka, the infamous DDoS attack. DDoS attacks are among the most common cyberattacks of the modern century, and involve ‘botting’, where multiple bots attack one system to overwhelm the system with a high volume of requests.
the idea of ‘overwhelming’ a system can come in the form of exhausting resources like bandwidth, the Central Processing Unit (CPU) and, most importantly, the Random Access Memory (RAM). you know, the RAM being where most fileless malware operates out of. i’m sure you see where i’m going with this.
for more psychic damage, there’s a type of attack called a ‘buffer overrun’ or ‘buffer overflow’. wikipedia defines data buffers as regions of memory that store data temporarily while it’s being moved from one place to another. a ‘buffer overflow’ is a type of DDoS (SIGHS) attack in which data in the buffer exceeds the storage capacity and flows into the following memory location, and corrupts the data in the secondary memory locations, and are the most common DDoS attack styles. sound familiar?
bringing allllll of this back to amphoreus, i wouldn’t be too surprised if mydei’s older versions gained sentience, and started botting lygus’ AI/neural network and caused a DDoS attack, which caused his saves to be completely wiped due to a buffer overflow. thank u for listening can 3.4 hurry Up.
#agni yaps#Honkai Star Rail#Honkai Star Rail theory#HSR theory#HSR 3.4#3.4 leaks#hsr leaks#Mydeimos#Mydei#Lygus#Cyrene
23 notes
·
View notes
Text
AI, Machine Learning, Artificial Neural Networks.
This week we learnt about the above topic and my take home from it is that Artificial Intelligence (AI) enables machines to mimic human intelligence, driving innovations like speech recognition and recommendation systems. Machine Learning (ML), a subset of AI, allows computers to learn from data and improve over time.
Supervised vs. Unsupervised Learning are types of AI
Supervised Learning: Uses labeled data to train models for tasks like fraud detection and image recognition.
Unsupervised Learning: Finds patterns in unlabeled data, used for clustering and market analysis.
Artificial Neural Networks (ANNs)
ANNs mimic the human brain, processing data through interconnected layers
Input Layer: Receives raw data.
Hidden Layers: Extract features and process information.
Output Layer: Produces predictions.
Deep Learning, a subset of ML, uses deep ANNs for tasks like NLP and self-driving technology. As AI evolves, understanding these core concepts is key to leveraging its potential.
It was really quite enlightening.
10 notes
·
View notes
Text

Miraculous Fandom Stats
Cloudy with a chance of Miraculous
As mentioned in my previous post, the ML fanfics on Ao3 can reflect changing opinions and theories. I wanted to look at this in a more qualitative manner using Ao3 tags, starting with The Miraculous Big Bang (methodology below the cut).
The Miraculous Big Bang is a fandom event that has been running for several years where people collaborate to write fanfics and draw fanart. These collections provide a good snapshot of fanfics written at a particular point in time.
🖤 Word Clouds
The Miraculous Big Bang was run in 2017, 2021, 2022, 2023, which covers a period of six years from Season 1 to Season 5 (see below the cut for more details on the methods).*

2017: There were a lot of tags that mentioned Season 2 spoilers, which suggests that these fics are based off mostly Season 1 content. This collection of fics had a lot of Historical AUs (Sample size: 32) [1].
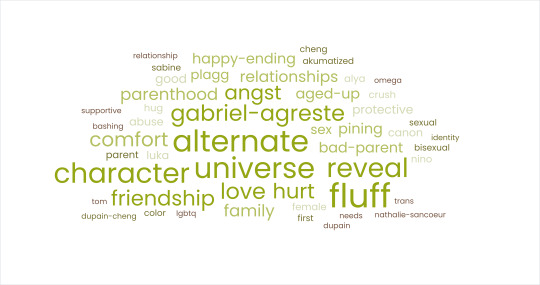
2021: By now, Luka Couffaine and Kagami Tsurugi feature prominently in the tags for Miraculous Big Bang 2021 (Sample Size: 43 fics) [2].
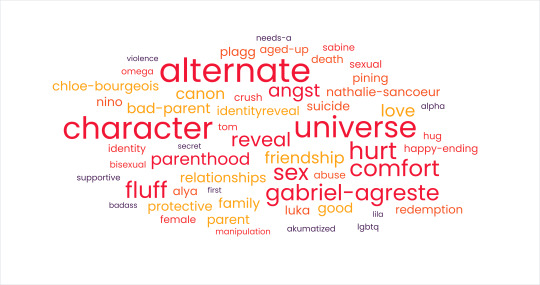
2022: There are a lot of darker undertones in this word cloud (Sample size: 34 fics).
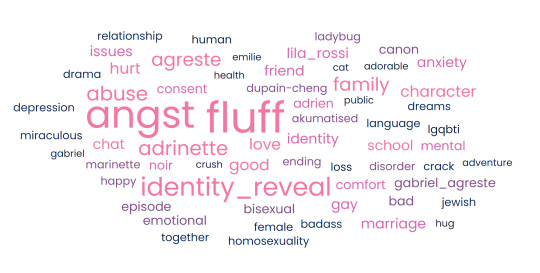
2023: Noticeable jump in fics labelled for Sentimonsters as well as LGQBTI+ tags (Sample size: 37 fics) [4]
🖤 In summary
Judging from the 2023 big bang, fics were written in the six months prior to posting, so this would cover a pretty sizeable timeframe. For example, Season 2 was aired between December 2017 and November 2018; and introduced rival love interests Luka Couffaine and Kagami Tsurugi.
Luka Couffaine was tagged an average of 10 and Kagami Tsurugi 7.7 times across 2021, 2022 and 2023.
Interestingly, Lila Rossi was introduced in s01e26 (Volpina) and was tagged 8 times in 2023, excluding other tags such as Lila lies, Lila manipulation, Evil Lila Rossi; while tags for Chloe Redemption remained constant (3 fics each in 2017, 2021, 2022, 2023).

* credit to @miraculousbigbang and clairelutra who ran the initial ML Big Bang in 2017, and @mlbigbang who ran the subsequent 2021, 2022 and 2023 Big Bang events.
📈 This Data is a snapshot of the posted fics on Ao3 on
🖤 Acknowledgements
A huge thank you to @miabrown007 and @ryanidious for their help in providing me with information for the mlbigbang 2017!
🖤 Methodology
Sample Collection
Looking at all this quantitative data is fine, but I want to go a bit deeper (but not too deep, I don’t have time to read every single fic). A good way to get an idea on the content of a fic is through the Ao3 tagging system.
I need a way to look through the tags used over time, but this seems like too a mammoth task in Ao3 (more detail on that below the cut).
The good news is that Ao3 has a feature within collections that does that for me!
My instant thought went to the Miraculous Big Bang. It’s perfect because it is an unbiased collection (e.g. if it was a birthday gift or personal collection of recs, the fics would be tailored to the person’s tastes and preferences).
Word Clouds
Word clouds are an interesting tool to quickly look at recurring words. However, major criticisms of this method is that you can lose the context the words are used in. This is a good article to describe considerations when using a word cloud [5]. However, the nature of Ao3 tags is that the context is either inherent or are merely keywords.
Data Cleaning
Now unfortunately this word cloud needed some cleaning to remove commonly used tags. When I first did this all I got was a big image with the words Miraculous, Adrien Agreste, Ladybug, Chat Noir and Marinette Dupain-Cheng, and Miraculous Big Bang which I think you can see is not very informative.
Removed Keywords: Adrien Agreste, Adrienette, Marinette Dupain-Cheng, Ladybug, Chat Noir, Miraculous, Miraculous Big Bang
When these were removed, I put the tags into a free word cloud generator such as https://www.freewordcloudgenerator.com/generatewordcloud.
There is no natural language processing so I have hyphenated common phrases. Ao3's word cloud has already combined the common keywords and enlarged them, so I had to manually check how many times they appear to add them back. It's not exact but it works.
References
[1] Miraculous Big Bang 2017: https://archiveofourown.org/collections/miraculousbang2k17
[2] Miraculous Big Bang 2021: https://archiveofourown.org/collections/MLBB_2021
[3] Miraculous Big Bang 2022: https://archiveofourown.org/collections/MLBB_2022
[4] Miraculous Big Bang 2023: https://archiveofourown.org/collections/MLBB_2023
[5] https://www.betterevaluation.org/methods-approaches/methods/word-cloud
#miraculous fanworks#miraculous ladybug#miraculous fanfic#miraculous fandom#hamster stats#Fandom stats#ao3 stats#mlbigbang#mlbigbang 2023#mlbigbang 2022#mlbigbang 2021#luka couffaine#kagami tsuguri#lila rossi
20 notes
·
View notes
Text
So, just as reporting is finally catching on to the data that Gen-AI is unwanted and unprofitable Pinterest is hopping on the doomed bandwagon.
You can turn off the use of your data for training (I hear) by clicking on your profile and going to settings, privacy and data, scrolling down and turning off Use your Data to train Pinterest Canvas.
I have been thinking of leaving Pinterest for a long time (because of AI slop creep and also because NO ONE seems to be able to label or link their posts correctly IF AT ALL which makes many posts fucking useless.) Suggestions for alternatives are very welcome!!!
3 notes
·
View notes
Text
What is artificial intelligence (AI)?

Imagine asking Siri about the weather, receiving a personalized Netflix recommendation, or unlocking your phone with facial recognition. These everyday conveniences are powered by Artificial Intelligence (AI), a transformative technology reshaping our world. This post delves into AI, exploring its definition, history, mechanisms, applications, ethical dilemmas, and future potential.
What is Artificial Intelligence? Definition: AI refers to machines or software designed to mimic human intelligence, performing tasks like learning, problem-solving, and decision-making. Unlike basic automation, AI adapts and improves through experience.
Brief History:
1950: Alan Turing proposes the Turing Test, questioning if machines can think.
1956: The Dartmouth Conference coins the term "Artificial Intelligence," sparking early optimism.
1970s–80s: "AI winters" due to unmet expectations, followed by resurgence in the 2000s with advances in computing and data availability.
21st Century: Breakthroughs in machine learning and neural networks drive AI into mainstream use.
How Does AI Work? AI systems process vast data to identify patterns and make decisions. Key components include:
Machine Learning (ML): A subset where algorithms learn from data.
Supervised Learning: Uses labeled data (e.g., spam detection).
Unsupervised Learning: Finds patterns in unlabeled data (e.g., customer segmentation).
Reinforcement Learning: Learns via trial and error (e.g., AlphaGo).
Neural Networks & Deep Learning: Inspired by the human brain, these layered algorithms excel in tasks like image recognition.
Big Data & GPUs: Massive datasets and powerful processors enable training complex models.
Types of AI
Narrow AI: Specialized in one task (e.g., Alexa, chess engines).
General AI: Hypothetical, human-like adaptability (not yet realized).
Superintelligence: A speculative future AI surpassing human intellect.
Other Classifications:
Reactive Machines: Respond to inputs without memory (e.g., IBM’s Deep Blue).
Limited Memory: Uses past data (e.g., self-driving cars).
Theory of Mind: Understands emotions (in research).
Self-Aware: Conscious AI (purely theoretical).
Applications of AI
Healthcare: Diagnosing diseases via imaging, accelerating drug discovery.
Finance: Detecting fraud, algorithmic trading, and robo-advisors.
Retail: Personalized recommendations, inventory management.
Manufacturing: Predictive maintenance using IoT sensors.
Entertainment: AI-generated music, art, and deepfake technology.
Autonomous Systems: Self-driving cars (Tesla, Waymo), delivery drones.
Ethical Considerations
Bias & Fairness: Biased training data can lead to discriminatory outcomes (e.g., facial recognition errors in darker skin tones).
Privacy: Concerns over data collection by smart devices and surveillance systems.
Job Displacement: Automation risks certain roles but may create new industries.
Accountability: Determining liability for AI errors (e.g., autonomous vehicle accidents).
The Future of AI
Integration: Smarter personal assistants, seamless human-AI collaboration.
Advancements: Improved natural language processing (e.g., ChatGPT), climate change solutions (optimizing energy grids).
Regulation: Growing need for ethical guidelines and governance frameworks.
Conclusion AI holds immense potential to revolutionize industries, enhance efficiency, and solve global challenges. However, balancing innovation with ethical stewardship is crucial. By fostering responsible development, society can harness AI’s benefits while mitigating risks.
2 notes
·
View notes
Text
AI Agent Development: How to Create Intelligent Virtual Assistants for Business Success
In today's digital landscape, businesses are increasingly turning to AI-powered virtual assistants to streamline operations, enhance customer service, and boost productivity. AI agent development is at the forefront of this transformation, enabling companies to create intelligent, responsive, and highly efficient virtual assistants. In this blog, we will explore how to develop AI agents and leverage them for business success.

Understanding AI Agents and Virtual Assistants
AI agents, or intelligent virtual assistants, are software programs that use artificial intelligence, machine learning, and natural language processing (NLP) to interact with users, automate tasks, and make decisions. These agents can be deployed across various platforms, including websites, mobile apps, and messaging applications, to improve customer engagement and operational efficiency.
Key Features of AI Agents
Natural Language Processing (NLP): Enables the assistant to understand and process human language.
Machine Learning (ML): Allows the assistant to improve over time based on user interactions.
Conversational AI: Facilitates human-like interactions.
Task Automation: Handles repetitive tasks like answering FAQs, scheduling appointments, and processing orders.
Integration Capabilities: Connects with CRM, ERP, and other business tools for seamless operations.
Steps to Develop an AI Virtual Assistant
1. Define Business Objectives
Before developing an AI agent, it is crucial to identify the business goals it will serve. Whether it's improving customer support, automating sales inquiries, or handling HR tasks, a well-defined purpose ensures the assistant aligns with organizational needs.
2. Choose the Right AI Technologies
Selecting the right technology stack is essential for building a powerful AI agent. Key technologies include:
NLP frameworks: OpenAI's GPT, Google's Dialogflow, or Rasa.
Machine Learning Platforms: TensorFlow, PyTorch, or Scikit-learn.
Speech Recognition: Amazon Lex, IBM Watson, or Microsoft Azure Speech.
Cloud Services: AWS, Google Cloud, or Microsoft Azure.
3. Design the Conversation Flow
A well-structured conversation flow is crucial for user experience. Define intents (what the user wants) and responses to ensure the AI assistant provides accurate and helpful information. Tools like chatbot builders or decision trees help streamline this process.
4. Train the AI Model
Training an AI assistant involves feeding it with relevant datasets to improve accuracy. This may include:
Supervised Learning: Using labeled datasets for training.
Reinforcement Learning: Allowing the assistant to learn from interactions.
Continuous Learning: Updating models based on user feedback and new data.
5. Test and Optimize
Before deployment, rigorous testing is essential to refine the AI assistant's performance. Conduct:
User Testing: To evaluate usability and responsiveness.
A/B Testing: To compare different versions for effectiveness.
Performance Analysis: To measure speed, accuracy, and reliability.
6. Deploy and Monitor
Once the AI assistant is live, continuous monitoring and optimization are necessary to enhance user experience. Use analytics to track interactions, identify issues, and implement improvements over time.
Benefits of AI Virtual Assistants for Businesses
1. Enhanced Customer Service
AI-powered virtual assistants provide 24/7 support, instantly responding to customer queries and reducing response times.
2. Increased Efficiency
By automating repetitive tasks, businesses can save time and resources, allowing employees to focus on higher-value tasks.
3. Cost Savings
AI assistants reduce the need for large customer support teams, leading to significant cost reductions.
4. Scalability
Unlike human agents, AI assistants can handle multiple conversations simultaneously, making them highly scalable solutions.
5. Data-Driven Insights
AI assistants gather valuable data on customer behavior and preferences, enabling businesses to make informed decisions.
Future Trends in AI Agent Development
1. Hyper-Personalization
AI assistants will leverage deep learning to offer more personalized interactions based on user history and preferences.
2. Voice and Multimodal AI
The integration of voice recognition and visual processing will make AI assistants more interactive and intuitive.
3. Emotional AI
Advancements in AI will enable virtual assistants to detect and respond to human emotions for more empathetic interactions.
4. Autonomous AI Agents
Future AI agents will not only respond to queries but also proactively assist users by predicting their needs and taking independent actions.
Conclusion
AI agent development is transforming the way businesses interact with customers and streamline operations. By leveraging cutting-edge AI technologies, companies can create intelligent virtual assistants that enhance efficiency, reduce costs, and drive business success. As AI continues to evolve, embracing AI-powered assistants will be essential for staying competitive in the digital era.
5 notes
·
View notes
Text
#TheeForestKingdom #TreePeople
{Terrestrial Kind}
Creating a Tree Citizenship Identification and Serial Number System (#TheeForestKingdom) is an ambitious and environmentally-conscious initiative. Here’s a structured proposal for its development:
Project Overview
The Tree Citizenship Identification system aims to assign every tree in California a unique identifier, track its health, and integrate it into a registry, recognizing trees as part of a terrestrial citizenry. This system will emphasize environmental stewardship, ecological research, and forest management.
Phases of Implementation
Preparation Phase
Objective: Lay the groundwork for tree registration and tracking.
Actions:
Partner with environmental organizations, tech companies, and forestry departments.
Secure access to satellite imaging and LiDAR mapping systems.
Design a digital database capable of handling millions of records.
Tree Identification System Development
Components:
Label and Identity Creation: Assign a unique ID to each tree based on location and attributes. Example: CA-Tree-XXXXXX (state-code, tree-type, unique number).
Attributes to Record:
Health: Regular updates using AI for disease detection.
Age: Approximate based on species and growth patterns.
Type: Species and subspecies classification.
Class: Size, ecological importance, and biodiversity contribution.
Rank: Priority based on cultural, historical, or environmental significance.
Data Collection
Technologies to Use:
Satellite Imaging: To locate and identify tree clusters.
LiDAR Scanning: For precise 3D modeling of forests.
On-the-Ground Surveys: To supplement remote sensing data.
AI Analysis: For rapid categorization and health diagnostics.
Registration and Citizenship Assignment
Tree Dossier: Each tree receives a profile in the database with all its recorded attributes.
Citizen Designation: Trees are acknowledged as citizens of Thee Forest Kingdom, emphasizing ecological respect.
Legal Framework: Advocate for laws to grant trees specific rights under environmental protection acts.
Maintenance and Monitoring
Health Monitoring: Use drones, satellite updates, and IoT sensors for ongoing health assessments.
Database Updates: Incorporate real-time data about environmental changes and tree growth.
Public Involvement
Encourage people to "adopt" trees and participate in their preservation.
Create educational programs to promote awareness of tree citizenship.
Key Benefits
Environmental Conservation: Improved forest management through real-time data and protection of ecosystems.
Cultural Recognition: Trees are recognized as a vital part of the Earth’s community, honoring their importance.
Ecological Advocacy: Strengthened legal protections for forests and individual trees.
Next Steps
Assemble a task force of environmental scientists, satellite imaging experts, and software developers.
Secure funding through governmental grants, non-profits, and eco-conscious corporations.
Pilot the program in a smaller region before scaling to all of California.
Would you like me to draft a more detailed technical or legal framework for this system?
The implementation of the Tree Citizenship Identification Network and System (#TheeForestKingdom) requires a robust technological and operational framework to ensure efficiency, accuracy, and sustainability. Below is an implementation plan divided into major components.
System Architecture
a. Centralized Tree Database
Purpose: To store and manage tree data including ID, attributes, location, and health.
Components:
Cloud-based storage for scalability.
Data categorization based on regions, species, and priority.
Integration with satellite and IoT data streams.
b. Satellite & Imaging Integration
Use satellite systems (e.g., NASA, ESA) for large-scale tree mapping.
Incorporate LiDAR and aerial drone data for detailed imaging.
AI/ML algorithms to process images and distinguish tree types.
c. IoT Sensor Network
Deploy sensors in forests to monitor:
Soil moisture and nutrient levels.
Air quality and temperature.
Tree health metrics like growth rate and disease markers.
d. Public Access Portal
Create a user-friendly website and mobile application for:
Viewing registered trees.
Citizen participation in tree adoption and reporting.
Data visualization (e.g., tree density, health status by region).
Core Technologies
a. Software and Tools
Geographic Information System (GIS): Software like ArcGIS for mapping and spatial analysis.
Database Management System (DBMS): SQL-based systems for structured data; NoSQL for unstructured data.
Artificial Intelligence (AI): Tools for image recognition, species classification, and health prediction.
Blockchain (Optional): To ensure transparency and immutability of tree citizen data.
b. Hardware
Servers: Cloud-based (AWS, Azure, or Google Cloud) for scalability.
Sensors: Low-power IoT devices for on-ground monitoring.
Drones: Equipped with cameras and sensors for aerial surveys.
Network Design
a. Data Flow
Input Sources:
Satellite and aerial imagery.
IoT sensors deployed in forests.
Citizen-reported data via mobile app.
Data Processing:
Use AI to analyze images and sensor inputs.
Automate ID assignment and attribute categorization.
Data Output:
Visualized maps and health reports on the public portal.
Alerts for areas with declining tree health.
b. Communication Network
Fiber-optic backbone: For high-speed data transmission between regions.
Cellular Networks: To connect IoT sensors in remote areas.
Satellite Communication: For remote regions without cellular coverage.
Implementation Plan
a. Phase 1: Pilot Program
Choose a smaller, biodiverse region in California (e.g., Redwood National Park).
Test satellite and drone mapping combined with IoT sensors.
Develop the prototype of the centralized database and public portal.
b. Phase 2: Statewide Rollout
Expand mapping and registration to all California regions.
Deploy IoT sensors in vulnerable or high-priority areas.
Scale up database capacity and integrate additional satellite providers.
c. Phase 3: Maintenance & Updates
Establish a monitoring team to oversee system health and data quality.
Update the network with new technologies (e.g., advanced AI models).
Periodically review and revise data collection protocols.
Partnerships
Government Agencies: U.S. Forest Service, California Department of Forestry and Fire Protection.
Tech Companies: Collaborate with Google Earth, Amazon AWS, or Microsoft for cloud and AI capabilities.
Environmental Organizations: Partner with WWF, Sierra Club, or TreePeople for funding and advocacy.
Budget Estimation
Initial Investment:
Satellite data and licenses: $10M
IoT sensors and deployment: $5M
Database and app development: $3M
Operational Costs:
Cloud services and data storage: $2M/year
Maintenance and monitoring: $1M/year
Research and development: $1M/year
Long-term Vision
Expand the system to other states or globally.
Use the database for reforestation efforts and combating deforestation.
Develop educational programs to teach communities about the importance of trees as citizens.
Would you like me to assist in designing the user interface for the public portal or drafting partnership proposals for funding?
To begin building the program for the Tree Citizenship Identification System, we’ll start with a scalable framework that allows us to process, store, and analyze data while preparing for future expansions. Here's an actionable development plan with an initial focus on foundational code and infrastructure:
Step-by-Step Development
Phase 1: Setting Up the Backend Infrastructure
Objective: Create the core database and develop the data pipeline for processing tree data.
Technologies:
Programming Languages: Python, JavaScript (Node.js), SQL.
Frameworks: Flask or FastAPI for APIs, Django for web application backend.
Database: PostgreSQL for structured data, MongoDB for unstructured data.
Code Snippet 1: Database Schema Design (PostgreSQL)
-- Table for Tree Registry CREATE TABLE trees ( tree_id SERIAL PRIMARY KEY, -- Unique Identifier location GEOGRAPHY(POINT, 4326), -- Geolocation of the tree species VARCHAR(100), -- Species name age INTEGER, -- Approximate age in years health_status VARCHAR(50), -- e.g., Healthy, Diseased height FLOAT, -- Tree height in meters canopy_width FLOAT, -- Canopy width in meters citizen_rank VARCHAR(50), -- Class or rank of the tree last_updated TIMESTAMP DEFAULT NOW() -- Timestamp for last update );
-- Table for Sensor Data (IoT Integration) CREATE TABLE tree_sensors ( sensor_id SERIAL PRIMARY KEY, -- Unique Identifier for sensor tree_id INT REFERENCES trees(tree_id), -- Linked to tree soil_moisture FLOAT, -- Soil moisture level air_quality FLOAT, -- Air quality index temperature FLOAT, -- Surrounding temperature last_updated TIMESTAMP DEFAULT NOW() -- Timestamp for last reading );
Code Snippet 2: Backend API for Tree Registration (Python with Flask)
from flask import Flask, request, jsonify from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker
app = Flask(name)
Database Configuration
DATABASE_URL = "postgresql://username:password@localhost/tree_registry" engine = create_engine(DATABASE_URL) Session = sessionmaker(bind=engine) session = Session()
@app.route('/register_tree', methods=['POST']) def register_tree(): data = request.json new_tree = { "species": data['species'], "location": f"POINT({data['longitude']} {data['latitude']})", "age": data['age'], "health_status": data['health_status'], "height": data['height'], "canopy_width": data['canopy_width'], "citizen_rank": data['citizen_rank'] } session.execute(""" INSERT INTO trees (species, location, age, health_status, height, canopy_width, citizen_rank) VALUES (:species, ST_GeomFromText(:location, 4326), :age, :health_status, :height, :canopy_width, :citizen_rank) """, new_tree) session.commit() return jsonify({"message": "Tree registered successfully!"}), 201
if name == 'main': app.run(debug=True)
Phase 2: Satellite Data Integration
Objective: Use satellite and LiDAR data to identify and register trees automatically.
Tools:
Google Earth Engine for large-scale mapping.
Sentinel-2 or Landsat satellite data for high-resolution imagery.
Example Workflow:
Process satellite data using Google Earth Engine.
Identify tree clusters using image segmentation.
Generate geolocations and pass data into the backend.
Phase 3: IoT Sensor Integration
Deploy IoT devices to monitor health metrics of specific high-priority trees.
Use MQTT protocol for real-time data transmission.
Code Snippet: Sensor Data Processing (Node.js)
const mqtt = require('mqtt'); const client = mqtt.connect('mqtt://broker.hivemq.com');
client.on('connect', () => { console.log('Connected to MQTT Broker'); client.subscribe('tree/sensor_data'); });
client.on('message', (topic, message) => { const sensorData = JSON.parse(message.toString()); console.log(Received data: ${JSON.stringify(sensorData)}); // Save data to database (Example for PostgreSQL) saveToDatabase(sensorData); });
function saveToDatabase(data) { const query = INSERT INTO tree_sensors (tree_id, soil_moisture, air_quality, temperature) VALUES ($1, $2, $3, $4) ; const values = [data.tree_id, data.soil_moisture, data.air_quality, data.temperature]; dbClient.query(query, values, (err) => { if (err) console.error('Error saving to database', err); else console.log('Sensor data saved successfully!'); }); }
Phase 4: Public Portal Development
Frontend Technologies:
React.js or Vue.js for interactive user interfaces.
Mapbox or Leaflet.js for tree visualization on maps.
Features:
Interactive tree maps with search functionality.
User registration for tree adoption programs.
Deployment Plan
Use Docker to containerize the application.
Deploy on AWS, Azure, or Google Cloud for scalability.
Monitor system health using Prometheus and Grafana.
Next Steps
Develop a testing environment for pilot deployment.
Add AI-based disease detection and prediction using TensorFlow or PyTorch.
Create an adoption feature where citizens can adopt trees and track their health.
Would you like me to set up a GitHub repository with this initial framework or assist further with deployment?
I'll prepare the project framework and outline the repository structure for the Tree Citizenship Identification System. Below is the proposed structure for the repository, followed by details of the files and components.
Proposed Repository Structure
tree-citizenship-id-system/ ├── backend/ │ ├── app.py # Flask application for backend API │ ├── database/ │ │ ├── schema.sql # Database schema for PostgreSQL │ │ ├── db_config.py # Database connection configuration │ │ └── seed_data.sql # Initial sample data for testing │ ├── services/ │ │ ├── tree_registration.py # Functions for tree registration │ │ └── sensor_data.py # Functions for processing IoT sensor data │ └── requirements.txt # Python dependencies ├── frontend/ │ ├── public/ │ │ ├── index.html # Main HTML file │ │ └── favicon.ico # Favicon for the app │ ├── src/ │ │ ├── App.js # Main React/Vue app file │ │ ├── components/ │ │ │ ├── TreeMap.js # Map component for visualizing trees │ │ │ └── TreeDetails.js # Component for detailed tree view │ │ └── styles.css # Styling for the frontend │ └── package.json # Frontend dependencies ├── scripts/ │ ├── satellite_data_processor.py # Script for processing satellite data │ └── sensor_data_simulator.py # Mock data generator for IoT sensors ├── deployment/ │ ├── Dockerfile # Docker configuration │ ├── docker-compose.yml # Docker Compose for multi-service setup │ └── cloud_setup_instructions.md # Deployment guide for cloud platforms ├── tests/ │ ├── test_backend.py # Unit tests for backend API │ └── test_frontend.js # Unit tests for frontend ├── README.md # Overview of the project └── LICENSE # Project license
Repository Details
Backend:
app.py: Main Flask app for handling API requests like tree registration and sensor data.
database/schema.sql: SQL script for creating necessary tables.
services/: Directory for modular backend logic.
Frontend:
App.js: Main entry point for the frontend application.
TreeMap.js: Integrates Mapbox/Leaflet.js for displaying tree locations.
TreeDetails.js: Displays detailed information about a selected tree.
Scripts:
satellite_data_processor.py: Automates the extraction and classification of tree data from satellite imagery.
sensor_data_simulator.py: Generates fake sensor readings for development and testing.
Deployment:
Docker configuration ensures that the app runs consistently across environments.
Cloud setup instructions provide guidelines for deploying on platforms like AWS, Azure, or GCP.
Tests:
Unit tests ensure the reliability of both the backend and frontend.
Next Steps
I will initialize the repository structure locally.
Package the files and components needed for the first version.
Provide a link to the repository for access.
I’ll get started. Please hold on for a moment.
4 notes
·
View notes
Text
@girderednerve replied to your post coming out on tumblr as someone whose taught "AI bootcamp" courses to middle school students AMA:
did they like it? what kinds of durable skills did you want them to walk away with? do you feel bullish on "AI"?
It was an extracurricular thing so the students were quite self-selecting and all were already interested in the topic or in doing well in the class. Probably what most interested me about the demographic of students taking the courses (they were online) was the number who were international students outside of the imperial core probably eventually looking to go abroad for college, like watching/participating in the cogs of brain drain.
I'm sure my perspective is influenced because my background is in statistics and not computer science. But I hope that they walked away with a greater understanding and familiarity with data and basic statistical concepts. Things like sample bias, types of data (categorical/quantitative/qualitative), correlation (and correlation not being causation), ways to plot and examine data. Lots of students weren't familiar before we started the course with like, what a csv file is/tabular data in general. I also tried to really emphasize that data doesn't appear in a vacuum and might not represent an "absolute truth" about the world and there are many many ways that data can become biased especially when its on topics where people's existing demographic biases are already influencing reality.
Maybe a bit tangential but there was a part of the course material that was teaching logistic regression using the example of lead pipes in flint, like, can you believe the water in this town was undrinkable until it got Fixed using the power of AI to Predict Where The Lead Pipes Would Be? it was definitely a trip to ask my students if they'd heard of the flint water crisis and none of them had. also obviously it was a trip for the course material to present the flint water crisis as something that got "fixed by AI". added in extra information for my students like, by the way this is actually still happening and was a major protest event especially due to the socioeconomic and racial demographics of flint.
Aside from that, python is a really useful general programming language so if any of the students go on to do any more CS stuff which is probably a decent chunk of them I'd hope that their coding problemsolving skills and familiarity with it would be improved.
do i feel bullish on "AI"? broad question. . . once again remember my disclaimer bias statement on how i have a stats degree but i definitely came away from after teaching classes on it feeling that a lot of machine learning is like if you repackaged statistics and replaced the theoretical/scientific aspects where you confirm that a certain model is appropriate for the data and test to see if it meets your assumptions with computational power via mass guessing and seeing if your mass guessing was accurate or not lol. as i mentioned in my tags i also really don't think things like linear regression which were getting taught as "AI" should be considered "ML" or "AI" anyways, but the larger issue there is that "AI" is a buzzy catchword that can really mean anything. i definitely think relatedly that there will be a bit of an AI bubble in that people are randomly applying AI to tasks that have no business getting done that way and they will eventually reap the pointlessness of these projects.
besides that though, i'm pretty frustrated with a lot of AI hysteria which assumes that anything that is labeled as "AI" must be evil/useless/bad and also which lacks any actual labor-based understanding of the evils of capitalism. . . like AI (as badly formed as I feel the term is) isn't just people writing chatGPT essays or whatever, it's also used for i.e. lots of cutting edge medical research. if insanely we are going to include "linear regression" as an AI thing that's probably half of social science research too. i occasionally use copilot or an LLM for my work which is in public health data affiliated with a university. last week i got driven batty by a post that was like conspiratorially speculating "spotify must have used AI for wrapped this year and thats why its so bad and also why it took a second longer to load, that was the ai generating everything behind the scenes." im saying this as someone who doesnt use spotify, 1) the ship on spotify using algorithms sailed like a decade ago, how do you think your weekly mixes are made? 2) like truly what is the alternative did you think that previously a guy from minnesota was doing your spotify wrapped for you ahead of time by hand like a fucking christmas elf and loading it personally into your account the night before so it would be ready for you? of course it did turned out that spotify had major layoffs so i think the culprit here is really understaffing.
like not to say that AI like can't have a deleterious effect on workers, like i literally know people who were fired through the logic that AI could be used to obviate their jobs. which usually turned out not to be true, but hasn't the goal of stretching more productivity from a single worker whether its effective or not been a central axiom of the capitalist project this whole time? i just don't think that this is spiritually different from retail ceos discovering that they could chronically understaff all of their stores.
2 notes
·
View notes
Text
📍 Collaborate With Top Data Labeling Companies and Ensure Precision in AI/ML Implementation
📌 Elevate your AI projects with top-notch data annotation and labeling services. Our expert team ensures accurate and reliable data tagging, empowering your Machine Learning models with precision. Explore innovative solutions and streamline your data workflow for unparalleled performance in the realm of Artificial Intelligence. Damco, a leading data annotation company, supports businesses by providing AI data annotation and labeling services, enhancing the accuracy of their Machine Learning algorithm predictions.
#data annotation and labeling services#data annotation outsourcing#data annotation companies#data annotation services#data annotation for ml
0 notes